
Hesitant Fuzzy Linear Regression Model for Decision Making



Abstract
:1. Introduction
2. Preliminaries
3. Decision Making Based on Hesitant Fuzzy Linear Regression Model
3.1. Linear Regression Model
3.2. Fuzzy Linear Regression Model
3.3. Hesitant Fuzzy Linear Regression Model
3.4. Decision-Making Algorithm Based on HFLRM
- Step 1.
- Let be a connected input–output variable decision matrix provided by the DMs, where are HFEs.
- Step 2.
- For two finite HFEs, and , there are two opposite principles for normalization. The first one is -normalization in which we remove some elements of and which have more elements than the others. The second one is -normalization in which we add some elements to and which have fewer elements than the other. In this paper, we use the principle of -normalization [51] to make all HFEs equal in the matrix H. Let be the normalized matrix where are HFEs.
- Step 3.
- Again normalize the matrix by using the following equation:Let be a normalized decision matrix where are HFEs.
- Step 4.
- By estimating the parameters with the help of a linear programming model, the HFLRM is obtained using the normalized decision matrix .
- Step 5.
- Rank the alternatives using residual values obtained from the score values of and , i.e., , where are predicted values which are calculated by using Definitions 2, 3 and 6.
- Step 6.
- Finally, the alternatives are ranked according to the values of . The alternative with the least residual is identified as the best choice.
4. The TOPSIS Method under Hesitant Environment
- Step 1.
- Take the decision matrices H and , the same as mentioned in Steps 1 and 2 of Section 3.4.
- Step 2.
- Normalize the decision matrix with the help of the following formula:Let be the normalized decision matrix where, are HFEs.
- Step 3.
- Weighted normalized decision matrix is calculated by multiplying the normalized decision matrix with its associated weights, i.e., .
- Step 4.
- Determine the positive ideal solution and negative ideal solutionwhere and represent the set of benefit and cost criteria, respectively.
- Step 5.
- Calculate the Euclidean distance of each alternative from the positive ideal solution and negative ideal solution , respectively.
- Step 6.
- Calculate the relative closeness of each alternative to the ideal solution where
- Step 7.
- Rank the alternatives according to relative closeness values in the descending order.
Spearman’s Rank Correlation Coefficient
5. An Application Example
- Step 3.
- We further normalize the data of matrix to make all of its elements lie between 0 and 1 for a common scale. The normalized decision matrix is shown in Table 3.
- Step 4.
- Now, we estimate the parameters using the LP model by taking , and which is formulated as follows:ForSubject to the constraintsand
- Steps 5 and 6.
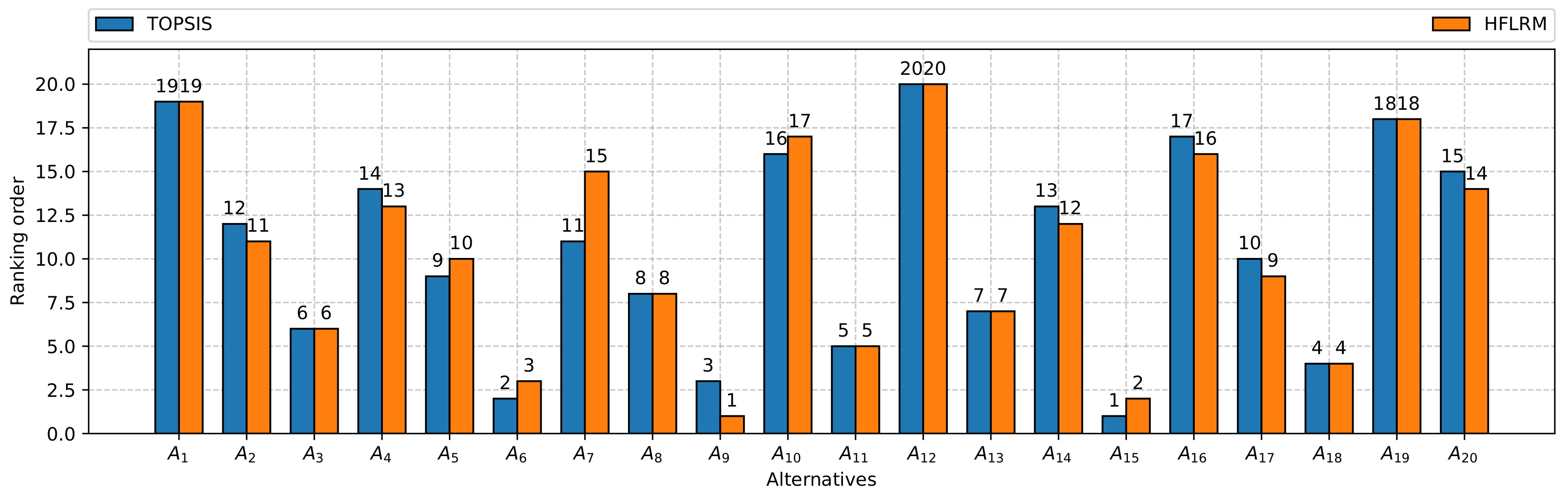
- Now, we will find the estimated values of all the alternatives in the form of HFEs with the help of HFLRM . For the sake of paper length, we omit the calculation of the estimated values of all alternatives and keep ourselves fixed to calculate the estimated value of the first alternative only. By using Definitions 3 and 6, the HFE corresponding to first alternative is computed as follows:0.2437, 0.2564, 0.2701, 0.2452, 0.2579, 0.2715, 0.2467, 0.2594, 0.2730, 0.2412, 0.2539, 0.2677, 0.2427, 0.2554, 0.2691, 0.2442, 0.2569, 0.2705, 0.2387, 0.2515, 0.2652, 0.2401, 0.2529, 0.2667, 0.2417, 0.2544, 0.2681}The score value of is then calculated by using Definition 2 which is . Similarly, we can find the score values of all which can be seen in Table 5. Finally, the alternatives are ranked with the help of residual values where are score values of HFEs corresponding to all alternatives in Table 1. The final ranking order of alternatives is shown in Table 5. We can see outlet 9 has the smallest residual value, i.e., while outlet 12 has the largest residual value, i.e., Therefore, is considered the best alternative and the worst alternative is
6. Results and Discussion
- The HFLRM can identify outliers (i.e., ) that may be included in the data set; if these are not identified, it may result in an inaccurate solution. However, the data presented in the application example of this paper have no outlier.
- The HFLRM provides results by solving a simple LP model to obtain the ranking for the decision-making problem which provides results quickly with less computational time as compared to TOPSIS.
- In comparison with TOPSIS, the complexity of the proposed methodology does not increase by inserting more criteria and alternatives to the given MCDM problem.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TOPSIS | Technique for Order of Preference by Similarity to Ideal Solution |
| FLRM | Fuzzy Linear Regression Model |
| HFS | Hesitant Fuzzy Set |
| HFLRM | Hesitant Fuzzy Linear Regression Model |
| MCDM | Multi-Criteria Decision Making |
| HFE | Hesitant Fuzzy Element |
References
- Zadeh, L. Fuzzy Sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- La Scalia, G.; Aiello, G.; Rastellini, C.; Micale, R.; Cicalese, L. Multi-criteria decision making support system for pancreatic islet transplantation. Expert Syst. Appl. 2011, 38, 3091–3097. [Google Scholar] [CrossRef]
- Sałabun, W.; Piegat, A. Comparative analysis of MCDM methods for the assessment of mortality in patients with acute coronary syndrome. Artif. Intell. Rev. 2017, 48, 557–571. [Google Scholar] [CrossRef]
- Dimić, S.; Pamučar, D.; Ljubojević, S.; Đorović, B. Strategic transport management models—The case study of an oil industry. Sustainability 2016, 8, 954. [Google Scholar] [CrossRef] [Green Version]
- Kizielewicz, B.; Więckowski, J.; Shekhovtsov, A.; Wątróbski, J.; Depczyński, R.; Sałabun, W. Study Towards The Time-based MCDA Ranking Analysis—A Supplier Selection Case Study. Facta Univ. Ser. Mech. Eng. 2021, 19, 381–399. [Google Scholar] [CrossRef]
- Bączkiewicz, A.; Kizielewicz, B.; Shekhovtsov, A.; Wątróbski, J.; Sałabun, W. Methodical Aspects of MCDM Based E-Commerce Recommender System. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 122. [Google Scholar] [CrossRef]
- Bączkiewicz, A.; Kizielewicz, B.; Shekhovtsov, A.; Yelmikheiev, M.; Kozlov, V.; Sałabun, W. Comparative Analysis of Solar Panels with Determination of Local Significance Levels of Criteria Using the MCDM Methods Resistant to the Rank Reversal Phenomenon. Energies 2021, 14, 5727. [Google Scholar] [CrossRef]
- Shekhovtsov, A.; Kizielewicz, B.; Sałabun, W. Intelligent Decision Making Using Fuzzy Logic: Comparative Analysis of Using Different Intersection and Union Operators. In Proceedings of the International Conference on Intelligent and Fuzzy Systems, Istanbul, Turkey, 24–26 August 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 192–199. [Google Scholar]
- Pamucar, D.; Ecer, F. Prioritizing the weights of the evaluation criteria under fuzziness: The fuzzy full consistency method–FUCOM-F. Facta Univ. Ser. Mech. Eng. 2020, 18, 419–437. [Google Scholar]
- Ye, J. Multicriteria group decision-making method using vector similarity measures for trapezoidal intuitionistic fuzzy numbers. Group Decis. Negot. 2012, 21, 519–530. [Google Scholar] [CrossRef]
- Sałabun, W.; Shekhovtsov, A.; Pamučar, D.; Wątróbski, J.; Kizielewicz, B.; Więckowski, J.; Bozanić, D.; Urbaniak, K.; Nyczaj, B. A Fuzzy Inference System for Players Evaluation in Multi-Player Sports: The Football Study Case. Symmetry 2020, 12, 2029. [Google Scholar] [CrossRef]
- Wątróbski, J.; Jankowski, J.; Ziemba, P.; Karczmarczyk, A.; Zioło, M. Generalised framework for multi-criteria method selection. Omega 2019, 86, 107–124. [Google Scholar] [CrossRef]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Faizi, S.; Rashid, T.; Sałabun, W.; Zafar, S.; Wątróbski, J. Decision making with uncertainty using hesitant fuzzy sets. Int. J. Fuzzy Syst. 2018, 20, 93–103. [Google Scholar] [CrossRef] [Green Version]
- Mardani, A.; Saraji, M.K.; Mishra, A.R.; Rani, P. A novel extended approach under hesitant fuzzy sets to design a framework for assessing the key challenges of digital health interventions adoption during the COVID-19 outbreak. Appl. Soft Comput. 2020, 96, 106613. [Google Scholar] [CrossRef]
- Narayanamoorthy, S.; Ramya, L.; Baleanu, D.; Kureethara, J.V.; Annapoorani, V. Application of normal wiggly dual hesitant fuzzy sets to site selection for hydrogen underground storage. Int. J. Hydrogen Energy 2019, 44, 28874–28892. [Google Scholar] [CrossRef]
- Dong, Q.; Ma, X. Enhanced fuzzy time series forecasting model based on hesitant differential fuzzy sets and error learning. Expert Syst. Appl. 2021, 166, 114056. [Google Scholar] [CrossRef]
- Tzeng, G.H.; Huang, J.J. Multiple Attribute Decision Making: Methods and Applications; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Rezaei, J. Best-worst multi-criteria decision-making method. Omega 2015, 53, 49–57. [Google Scholar] [CrossRef]
- Faizi, S.; Sałabun, W.; Nawaz, S.; ur Rehman, A.; Wątróbski, J. Best-Worst method and Hamacher aggregation operations for intuitionistic 2-tuple linguistic sets. Expert Syst. Appl. 2021, 181, 115088. [Google Scholar] [CrossRef]
- Keshavarz Ghorabaee, M.; Zavadskas, E.K.; Olfat, L.; Turskis, Z. Multi-criteria inventory classification using a new method of evaluation based on distance from average solution (EDAS). Informatica 2015, 26, 435–451. [Google Scholar] [CrossRef]
- Wang, J.; Ma, X.; Xu, Z.; Zhan, J. Three-way multi-attribute decision making under hesitant fuzzy environments. Inf. Sci. 2021, 552, 328–351. [Google Scholar] [CrossRef]
- Farhadinia, B.; Herrera-Viedma, E. Multiple criteria group decision making method based on extended hesitant fuzzy sets with unknown weight information. Appl. Soft Comput. 2019, 78, 310–323. [Google Scholar] [CrossRef]
- Asai, H.; Tanaka, S.; Uegima, K. Linear regression analysis with fuzzy model. IEEE Trans. Syst. Man Cybern 1982, 12, 903–907. [Google Scholar]
- Tanaka, H. Fuzzy data analysis by possibilistic linear models. Fuzzy Sets Syst. 1987, 24, 363–375. [Google Scholar] [CrossRef]
- Celmiņš, A. Least squares model fitting to fuzzy vector data. Fuzzy Sets Syst. 1987, 22, 245–269. [Google Scholar] [CrossRef]
- Diamond, P. Fuzzy least squares. Inf. Sci. 1988, 46, 141–157. [Google Scholar] [CrossRef]
- Tanaka, H.; Watada, J. Possibilistic linear systems and their application to the linear regression model. Fuzzy Sets Syst. 1988, 27, 275–289. [Google Scholar] [CrossRef]
- Tanaka, H.; Ishibuchi, H. Identification of possibilistic linear systems by quadratic membership functions of fuzzy parameters. Fuzzy Sets Syst. 1991, 41, 145–160. [Google Scholar] [CrossRef]
- Sakawa, M.; Yano, H. Multiobjective fuzzy linear regression analysis for fuzzy input-output data. Fuzzy Sets Syst. 1992, 47, 173–181. [Google Scholar] [CrossRef]
- Peters, G. Fuzzy linear regression with fuzzy intervals. Fuzzy Sets Syst. 1994, 63, 45–55. [Google Scholar] [CrossRef]
- Kim, K.J.; Chen, H.R. A comparison of fuzzy and nonparametric linear regression. Comput. Oper. Res. 1997, 24, 505–519. [Google Scholar] [CrossRef]
- Yen, K.K.; Ghoshray, S.; Roig, G. A linear regression model using triangular fuzzy number coefficients. Fuzzy Sets Syst. 1999, 106, 167–177. [Google Scholar] [CrossRef]
- Chen, Y.S. Outliers detection and confidence interval modification in fuzzy regression. Fuzzy Sets Syst. 2001, 119, 259–272. [Google Scholar] [CrossRef]
- Kocadağlı, O. A new approach for fuzzy multiple regression with fuzzy output. Int. J. Ind. Syst. Eng. 2011, 9, 49–66. [Google Scholar]
- Choi, S.H.; Buckley, J.J. Fuzzy regression using least absolute deviation estimators. Soft Comput. 2008, 12, 257–263. [Google Scholar] [CrossRef]
- Černỳ, M.; Rada, M. On the Possibilistic Approach to Linear Regression with Rounded or Interval-Censored Data. Meas. Sci. Rev. 2011, 11, 34–40. [Google Scholar] [CrossRef] [Green Version]
- Karsak, E.E.; Sener, Z.; Dursun, M. Robot selection using a fuzzy regression-based decision-making approach. Int. J. Prod. Res. 2012, 50, 6826–6834. [Google Scholar] [CrossRef]
- İçen, D.; Demirhan, H. Error measures for fuzzy linear regression: Monte Carlo simulation approach. Appl. Soft Comput. 2016, 46, 104–114. [Google Scholar] [CrossRef]
- Choi, S.H.; Jung, H.Y.; Kim, H. Ridge fuzzy regression model. Int. J. Fuzzy Syst. 2019, 21, 2077–2090. [Google Scholar] [CrossRef]
- Chakravarty, S.; Demirhan, H.; Baser, F. Fuzzy regression functions with a noise cluster and the impact of outliers on mainstream machine learning methods in the regression setting. Appl. Soft Comput. 2020, 96, 106535. [Google Scholar] [CrossRef]
- Wang, N.; Reformat, M.; Yao, W.; Zhao, Y.; Chen, X. Fuzzy Linear regression based on approximate Bayesian computation. Appl. Soft Comput. 2020, 97, 106763. [Google Scholar] [CrossRef]
- Hesamian, G.; Akbari, M.G. A fuzzy additive regression model with exact predictors and fuzzy responses. Appl. Soft Comput. 2020, 95, 106507. [Google Scholar] [CrossRef]
- Boukezzoula, R.; Coquin, D. Interval-valued fuzzy regression: Philosophical and methodological issues. Appl. Soft Comput. 2021, 103, 107145. [Google Scholar] [CrossRef]
- Xu, Z.; Xia, M. Distance and similarity measures for hesitant fuzzy sets. Inf. Sci. 2011, 181, 2128–2138. [Google Scholar] [CrossRef]
- Farhadinia, B. Information measures for hesitant fuzzy sets and interval-valued hesitant fuzzy sets. Inf. Sci. 2013, 240, 129–144. [Google Scholar] [CrossRef]
- Xia, M.; Xu, Z. Hesitant fuzzy information aggregation in decision making. Int. J. Approx. Reason. 2011, 52, 395–407. [Google Scholar] [CrossRef] [Green Version]
- Cheng, C.B. Group opinion aggregationbased on a grading process: A method for constructing triangular fuzzy numbers. Comput. Math. Appl. 2004, 48, 1619–1632. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.J.; Moskowitz, H.; Koksalan, M. Fuzzy versus statistical linear regression. Eur. J. Oper. Res. 1996, 92, 417–434. [Google Scholar] [CrossRef]
- Zimmermann, H.J. Fuzzy Sets, Decision Making, and Expert Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1987; Volume 10. [Google Scholar]
- Zhu, B.; Xu, Z. Consistency measures for hesitant fuzzy linguistic preference relations. IEEE Trans. Fuzzy Syst. 2013, 22, 35–45. [Google Scholar] [CrossRef]
- Kizielewicz, B.; Więckowski, J.; Wątrobski, J. A Study of Different Distance Metrics in the TOPSIS Method. In Intelligent Decision Technologies; Springer: Berlin/Heidelberg, Germany, 2021; pp. 275–284. [Google Scholar]
- Sałabun, W.; Urbaniak, K. A new coefficient of rankings similarity in decision-making problems. In Proceedings of the International Conference on Computational Science, Krakow, Poland, 16–18 June 2021; Springer: Berlin/Heidelberg, Germany, 2020; pp. 632–645. [Google Scholar]
- Sałabun, W.; Wątróbski, J.; Shekhovtsov, A. Are MCDA methods benchmarkable? A comparative study of TOPSIS, VIKOR, COPRAS, and PROMETHEE II methods. Symmetry 2020, 12, 1549. [Google Scholar] [CrossRef]
- Chowdhury, A.K.; Debsarkar, A.; Chakrabarty, S. Novel Methods for Assessing Urban Air Quality: Combined Air and Noise Pollution Approach. J. Atmos. Pollut. 2015, 3, 1–8. [Google Scholar] [CrossRef]


{kind=link}
| Y | ||||
|---|---|---|---|---|
| Y | ||||
|---|---|---|---|---|
| Y | ||||
|---|---|---|---|---|
| 19 | ||||
| 11 | ||||
| 6 | ||||
| 13 | ||||
| 10 | ||||
| 3 | ||||
| 15 | ||||
| 8 | ||||
| 1 | ||||
| 17 | ||||
| 5 | ||||
| 20 | ||||
| 7 | ||||
| 12 | ||||
| 2 | ||||
| 16 | ||||
| 9 | ||||
| 4 | ||||
| 18 | ||||
| 14 |
| 19 | ||||
| 12 | ||||
| 6 | ||||
| 14 | ||||
| 9 | ||||
| 2 | ||||
| 11 | ||||
| 8 | ||||
| 3 | ||||
| 16 | ||||
| 5 | ||||
| 20 | ||||
| 7 | ||||
| 13 | ||||
| 1 | ||||
| 17 | ||||
| 10 | ||||
| 4 | ||||
| 18 | ||||
| 15 |
| d | ||||
|---|---|---|---|---|
| 19 | 19 | 0 | 0 | |
| 11 | 12 | 1 | ||
| 6 | 6 | 0 | 0 | |
| 13 | 14 | 1 | ||
| 10 | 9 | 1 | 1 | |
| 3 | 2 | 1 | 1 | |
| 15 | 11 | 4 | 16 | |
| 8 | 8 | 0 | 0 | |
| 1 | 3 | 4 | ||
| 17 | 16 | 1 | 1 | |
| 5 | 5 | 0 | 0 | |
| 20 | 20 | 0 | 0 | |
| 7 | 7 | 0 | 0 | |
| 12 | 13 | 1 | ||
| 2 | 1 | 1 | 1 | |
| 16 | 17 | 1 | ||
| 9 | 10 | 1 | ||
| 4 | 4 | 0 | 0 | |
| 18 | 18 | 0 | 0 | |
| 14 | 15 | 1 |
| Range | Degree of Association |
|---|---|
| 0.8–1.00 | Very strong positive |
| 0.6–0.79 | Strong positive |
| 0.4–0.59 | Moderate positive |
| 0.2–0.39 | Weak positive |
| 0–0.19 | Very weak positive |
| 0– | Very weak positive |
| – | Weak negative |
| – | Moderate negative |
| – | Strong negative |
| – | Very strong negative |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sultan, A.; Sałabun, W.; Faizi, S.; Ismail, M. Hesitant Fuzzy Linear Regression Model for Decision Making. Symmetry 2021, 13, 1846. https://doi.org/10.3390/sym13101846
Sultan A, Sałabun W, Faizi S, Ismail M. Hesitant Fuzzy Linear Regression Model for Decision Making. Symmetry. 2021; 13(10):1846. https://doi.org/10.3390/sym13101846
Chicago/Turabian StyleSultan, Ayesha, Wojciech Sałabun, Shahzad Faizi, and Muhammad Ismail. 2021. "Hesitant Fuzzy Linear Regression Model for Decision Making" Symmetry 13, no. 10: 1846. https://doi.org/10.3390/sym13101846