1. Introduction
Citizen science—the involvement of volunteers in data collection, analysis, and interpretation—holds great promise for nature conservation [
1]. Species observation data collected through citizen science allows large-scale monitoring (spatial and temporal) that would be impossible or too expensive to carry out with only professional scientists [
2,
3,
4]. Citizen science (CS) has already made enormous contributions to conservation science, and this approach of harnessing the power of data, information and voluntary skills has the potential to do much more [
5]. For a review of studies which directly contribute to understanding of the role of CS in conservation sciences, see [
6].
Citizen sciences cover a large range of programs with a great diversity of methodological approaches. This diversity ranges from CS programs with standardized protocols intended for volunteers with good naturalist skills, to CS programs open to any observer which promote the collection of opportunistic data [
2,
7,
8].
Mass participation approaches, though a powerful means of raising awareness and educating about nature and its conservation [
9,
10], are most often associated with unstructured monitoring programs because data collection is more flexible. In addition to the many CS-related biases, the so-called “opportunistic” data that come from these unstructured programs are more susceptible to observer bias [
11]. It is well-known that researchers must exercise caution in the use of such data for modeling distributions [
12] and making predictions [
13].
These biases are often classified into three categories: spatial, temporal, and species-related [
14,
15]. It is now well-known that species presence data derived from opportunistic programs exhibit strong temporal and spatial bias. Data are not collected randomly either in time [
16,
17,
18] or in space [
19,
20] leading to unfortunate gaps and redundancies. In addition, although there have been substantial improvements [
21,
22] these biases also include observer errors and species detectability problems due to skill heterogeneity of volunteers [
23].
Among these biases, the study of spatial heterogeneity in recording intensity has a literature which can be classified into two relatively permeable categories: the first group studies that attempt to explain this heterogeneity from a geographical perspective, using landscape spatial variables; the second concerns studies that aim to explain it from a social and human perspective, using human behavior and observer engagement variables.
The first category of studies have shown that at least three landscape spatial variables can explain spatial heterogeneity in recording intensity. The first is the proximity of the “home base” [
24], of “previous records” [
25], of “large cities” [
15,
26], or of high “population density” areas [
19,
27]. The second is site accessibility or remoteness. It has been shown that records are more numerous in easily accessible areas [
28], such as along highways [
26] or in areas close to roads [
19,
27], than in areas remote from roads. Finally, the third often cited variable is the natural quality of the landscape. Protected areas [
25], high quality habitats [
12] or areas with high species richness [
24,
28], threatened species and habitats [
25] or particular taxonomic groups [
29] are more visited by observers. However, in these studies, all participants are considered to be equivalent, and no allowance is made for differences between observers.
Conversely, the other studies have sought to document the heterogeneity of participants in biodiversity CS, from social and human behavior viewpoints. The first source of participant heterogeneity noted is the type of CS program. During the past decade, CS programs have changed and diversified significantly [
2] and this has been accompanied by a notable change in participation due in part to the development of Internet tools which have led to massive recruitment [
30,
31]. The second source of participant heterogeneity, observed within individual CS programs, is the increase in non-specialist or beginner participants from the wider general public as opposed to naturalists with expert knowledge. Seen as providing valuable insights into observers’ recording behavior, this heterogeneity has been studied in particular from the angles of motivation, temporal behavior (also called “participant engagement”) [
28,
32,
33,
34], and spatial behavior. For example, with a “behavioral ecology approach”, ref. [
29] showed that local and tourist participants have different spatial recording habits. Spatial variables have also been used either to group participants (based on their spatial practices in addition to their temporal practices) [
7] or in very rare studies (one to our knowledge) to link peoples’ profiles (e.g., “Dabbler”, “Steady”, “Enthusiast”) to the spatial distribution of records [
28]. In the latter study, the authors showed that datasets from each of the three different programs had its own spatial and taxonomic signature depending on volunteer profile. They also found hotspots of recording intensity in sites containing open water.
A better understanding of these links could be used to better manage data biases in studies that use CS data in conservation, for example, by filtering certain groups of volunteers to obtain better spatial representativeness, as well as to reduce spatial bias by improving recommendations to participants, for example, by asking volunteers to give preference to recordings in sites that are unfamiliar to them or less attractive.
Our hypothesis was that differing observer profiles introduce spatial bias into bird recording, which can be related to landscape naturalness. Using an opportunistic bird observation dataset that includes more than 7 million data, collected over 15 years, by a wide and diverse range of people and covering an area of 32,000 km2, we:
Analyzed individual participants’ habits to identify observer profiles;
Used the landscape naturalness gradient approach to explain the spatial distribution of observations at regional level;
Explored the links between observer profiles and landscape naturalness in the neighborhood of their records.
2. Materials and Methods
2.1. Bird Dataset and Preprocessing
The CS bird dataset used in this study was collected by the French BirdLife International Partner (Ligue pour la Protection des Oiseaux, LPO). The data were considered as opportunistic because most came from participants who recorded whatever, wherever, and whenever they chose. Participants could contribute their records online after their outing or, since 2017, directly in the field using the smartphone application NaturaList to geolocate record. Observations may involve heard birdsongs or direct, visual observations. There is no minimum or maximum outing duration and observers are free to declare all or part of their observations. Moreover, observers do not need any prerequisites to register and they do not receive any training. The only obligation is to create an online account by specifying some mandatory personal information (e.g., identity, date of birth, address, contact number). After record declaration, a data validation procedure by a member of LPO is used to control and filter out unlikely records, which means that each record submitted must be validated to be added to the database. The dataset used in this study included more than 7 million records collected by nearly 10,000 participants. It covered a time span of 15 years (from 2005 to 2019) and a spatial extent of 32,000 km2, corresponding to the administrative region of Pays-de-la-Loire in western France.
The data were prepared as follows: first, data collected and managed by several local groups were aggregated so that each record was associated with a single observer identity. Second, the aggregated dataset was checked so as to include only those records for which the observed species, date and time, X, Y coordinates, as well as observer information were available. Finally, the unified database was cleaned of incomplete and erroneous records.
2.2. Observer Profiles
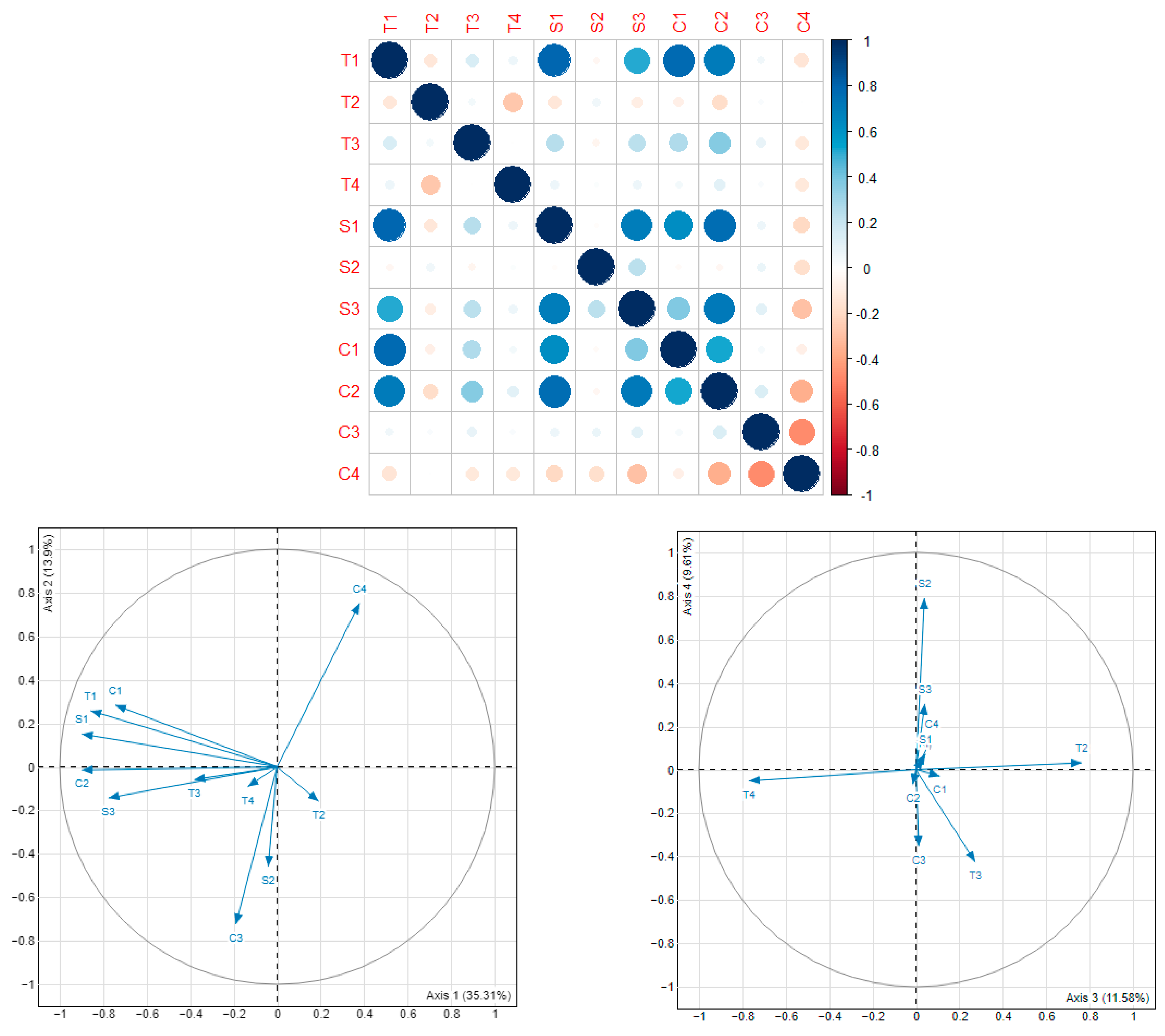
Our aim was to define observer profiles based on an original set of metrics integrating spatial, temporal, and content characteristics of recording. Since the dataset used covered a period of 15 years, during which the objectives, methods and data collection tools had greatly evolved, it was assumed that observer profiles had also evolved over time leading to a certain heterogeneity in recording behavior [
35]. We used the analysis of bird records to deduce observer habits using metrics inspired by previous work on “engagement characteristics” of participants in CS [
7,
28,
33,
34]. Initially 22 metrics were developed, of which 11 were retained after exploratory analyses, principal components analysis (PCA), and correlation tests. The table of the 22 metrics, the correlation matrix, and the PCA plots on axes 1–2 and 3–4 of the 11 metrics are given for information in
Appendix A. These metrics provided information on three aspects of observer behavior: temporal habits (T) (cumulative number of recording days, recording day frequency, recording effort, percentage of records made during the week (Monday to Friday)), spatial habits (S) (spatial amplitude, spatial density, minimum geometric extent), and record quality (C) (number of records, species richness, Species Generalization Index (SGI), Species Synanthropy Index (SSI)) (
Table 1).
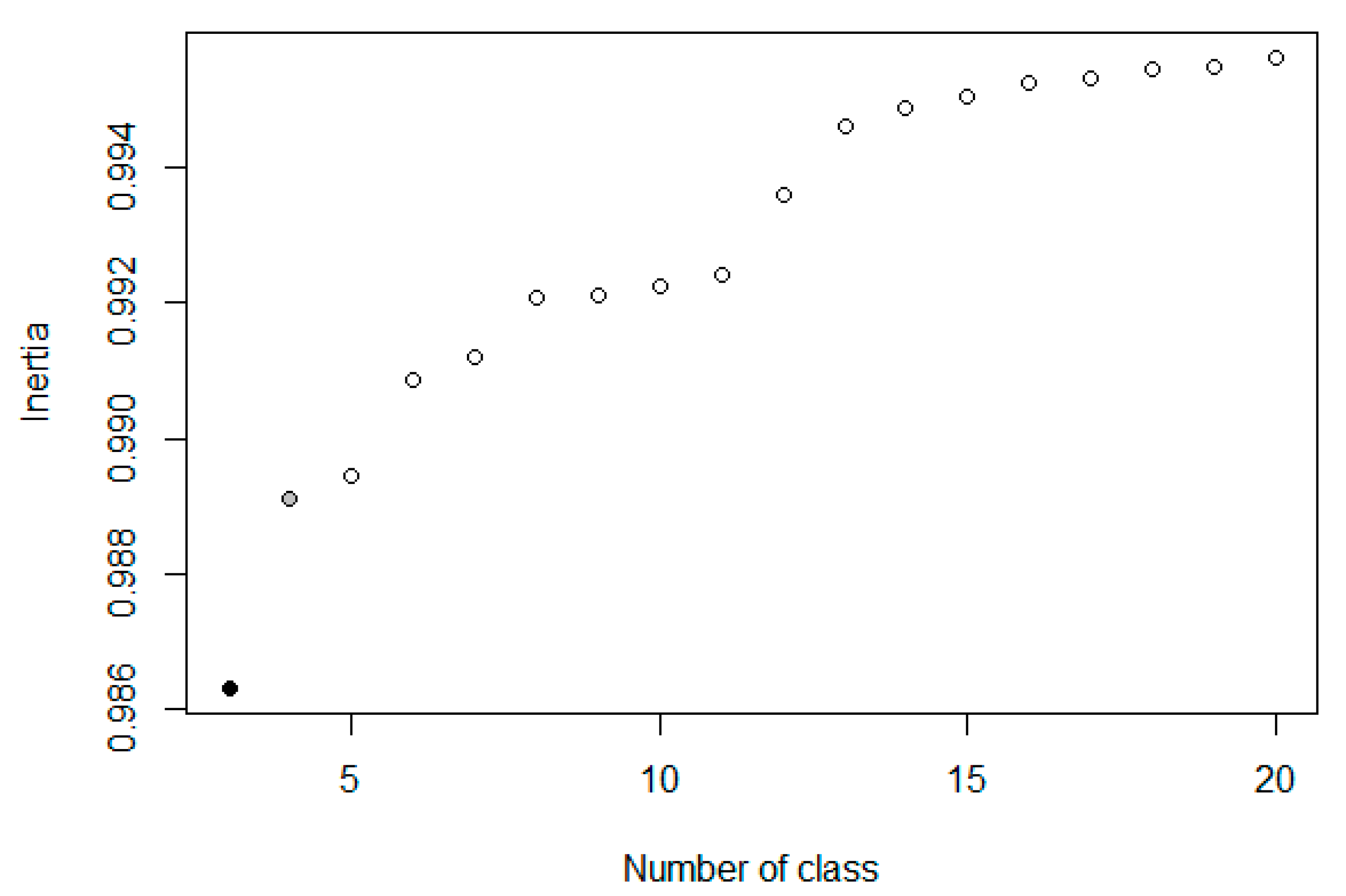
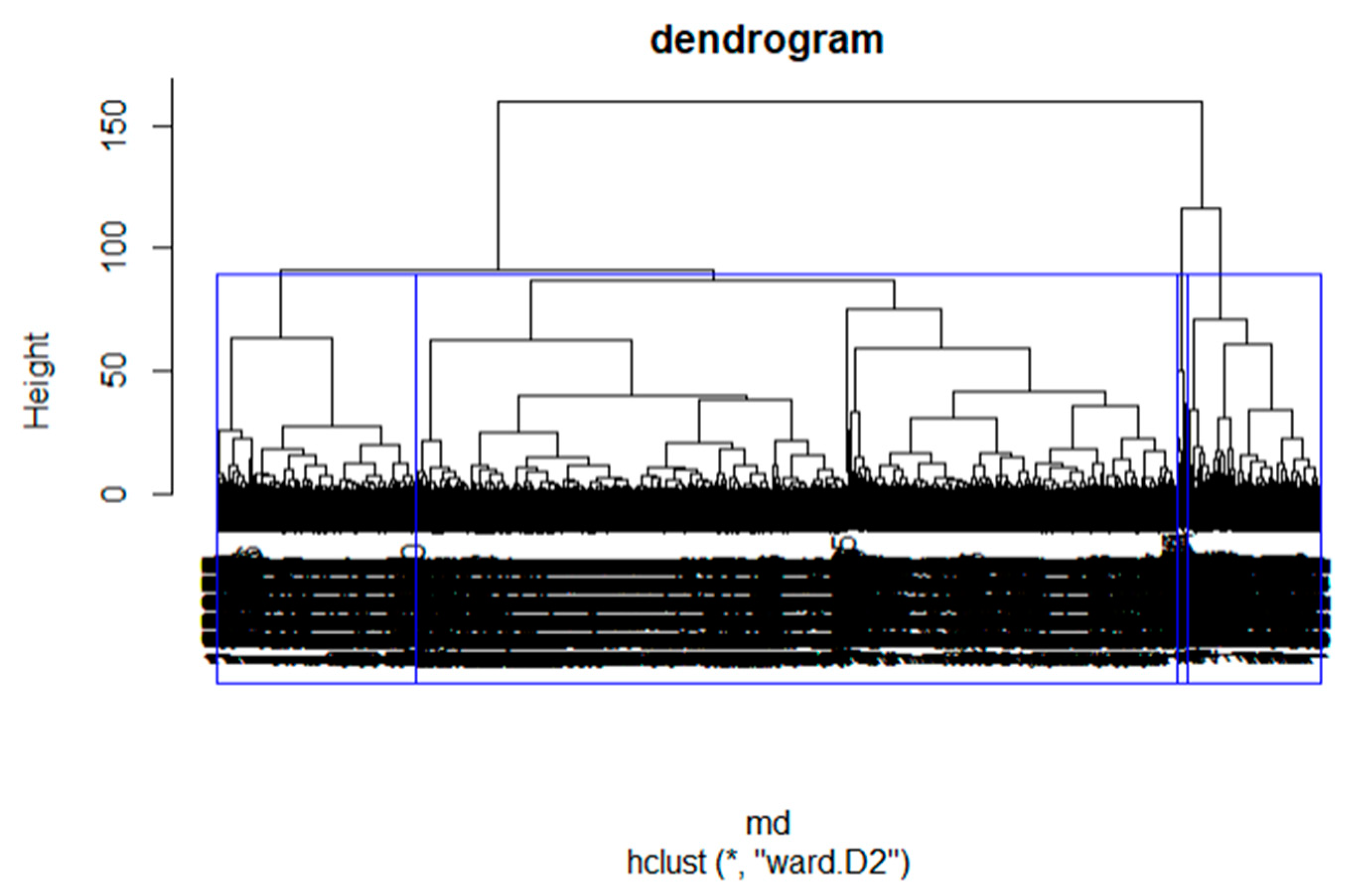
Only observers with at least two recording days and five observations were retained for analyses, i.e., 5896 observers out of a total of 9878. The objective of these thresholds was to retain only observers who had shown a certain commitment to the program. Following this, we explored similarities and differences in observation habits using hierarchical cluster analysis (HCA) and Ward’s minimum increase of sum-of-squares (of errors) method, without predefining a number of desired clusters. Observer profiles were identified from the dendrogram by analysis of inertia. We used the partitioning with the greatest relative inertia loss, identified with hierarchical clustering on principle components (HCPC).
2.3. Mapping the Naturalness Index (NI) of the Study Area
In order to interpret the spatial distribution of the recording, we chose to focus on the degree of naturalness of the landscape (naturalness index). This integrated method positions landscapes on a relative, quantitative scale ranging from “pristine” to “urban” [
36] or more simply from “wild” to “not wild” [
37]. This replicable method for assessing landscape quality has been used in numerous studies worldwide [
37,
38,
39,
40] and it includes most of the spatial variables already tested and cited in the introduction (proximity, accessibility/remoteness, habitat quality) facilitating comparisons with other work.
To quantify and map the naturalness index of the landscape, we adapted previous methodology [
37,
40,
41] to our regional context and to the available spatial data. Among the four attributes generally used, we retained three: hemeroby of landcover (also called naturalness of landcover), human impact on landscape, and remoteness from road access. The fourth attribute, ruggedness, was excluded from our study because it was not relevant for the landscapes of our study area which are generally low-lying (maximum 416 m above sea level).
2.3.1. Landscape Hemeroby
The hemeroby concept provides a measure of anthropogenic impact on landscapes and habitats using a scale, in which the highest values (ahemerob) correspond to “natural” or undisturbed landscapes while artificial landscapes obtain the lowest values (metahemerob) [
42,
43]. To use the most recent and accurate data, a composite land cover map from different thematic datasets related specifically to natural and semi-natural vegetation, agriculture, forests, rivers, and human infrastructure was created. The details of the data used are given in
Appendix B. To create the composite layer map, each dataset was first rasterized at 20 m then reclassified on a hemeroby scale and finally aggregated with the other data, giving priority to the most precise and recent data in cases of overlapping. For hemerobic reclassification, we applied a predefined hemeroby scale of landcover [
43,
44,
45] which we adapted to our landcover dataset. The hemeroby scale ranged from level 6 (“ahemerob”, i.e., no human impact) to level 1 (“metahemerob”, i.e., destroyed, originally biocenosis). For each hemerobic level (1–6), we applied a second level of precision (1.1, 1.2, …) in order to consider the precision of the dataset used. The second level of hemerobic classification was based on local, expert knowledge. The complete table of hemerobic reclassifications is given in
Appendix C. To account for the influence that the pattern of land cover immediately adjacent to the observer has upon hemeroby, the average hemeroby score of all cells within 250 m of the target cell was calculated as proposed by [
37]. The final hemeroby scale ranged from 1 to 255.
2.3.2. Human Influence on Landscape
The “human influence on the landscape” attribute was quantified and mapped by two human presence proxies: human population and modern human artefact density. Similarly to Müller et al. (2015), we first used human population density as a proxy for human influence on landscape. To measure the population density, we used “Filosofi” data, which are the most precise population data available in France, collected at household level. To guarantee personal confidentiality, the French national institute of statistics and economic studies (INSEE) makes the data available in aggregate form on a 200 m grid. We used the Filosofi dataset for 2016, rasterized at a resolution of 20 m. The modern human artefact indicator refers to the quantity of artificial structures within the visible landscape, including railways, pylons, buildings, and other built structures. Similarly to [
37], a number of modern human artefacts were extracted from the BD TOPO (IGN) and aggregated in a single dataset. The density calculation of the human modern artefacts area was performed with the focal statistic tool (ESRI, ArcGIS Pro 2.). For each cell, this tool calculates the location of a statistic in the neighborhood of a radius of 500 m circle (0.7854 km
2). The radius of the moving window was chosen by an empirical method and according to [
46]. We first tested three radial distances (500 m, 1 km, and 2 km) and kept the best compromise between visual representation and the normal distribution of the resulting data. The modern human artefacts map result is expressed in area of built-up land per square kilometer. The two layers were aggregated with equal weighting and reclassified on a relative scale from 1 to 255.
2.3.3. Remoteness from Roads and Paths
Remoteness from access is a very common indicator of naturalness maps (e.g., [
37,
38] and [
40]). Remote areas are important both for species sensitivity to human presence and disturbance [
47] and for the opportunity of solitude which some observers may seek [
48]. We calculated the Euclidean distance in meters from all roads and paths including a buffer of 1 km around our study site. Only motorways were not considered because we assumed that it was not possible to go walking from these fenced roads. The remoteness from access layer was reclassified on a relative scale from 1 to 255. To produce the final map of naturalness index, we computed the sum of the three layers (hemeroby of the landscape, human influence on landscape and remoteness from access) with equal weighting. The final map had a resolution of 20 m and the naturalness index ranged from 1 (minimum naturalness index) to 255 (maximum naturalness index). All spatial analyses were carried out with ESRI ArcGIS pro 2.7.
2.4. Statistical Analyses
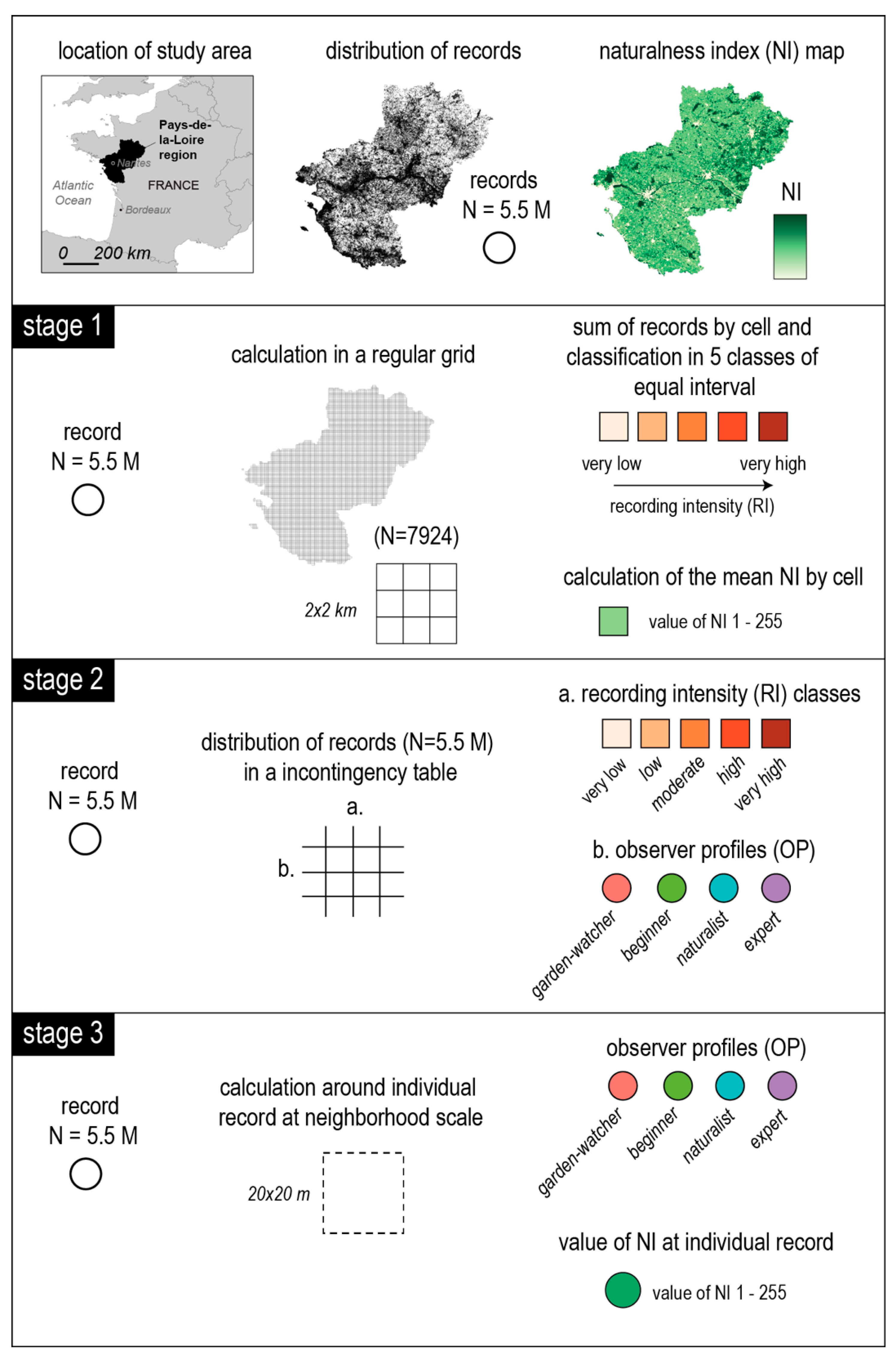
An illustrated workflow of the data analyses is given in
Figure 1.
2.4.1. Testing the Effects of Naturalness Index on the Spatial Distribution of Recordings, at Regional Scale
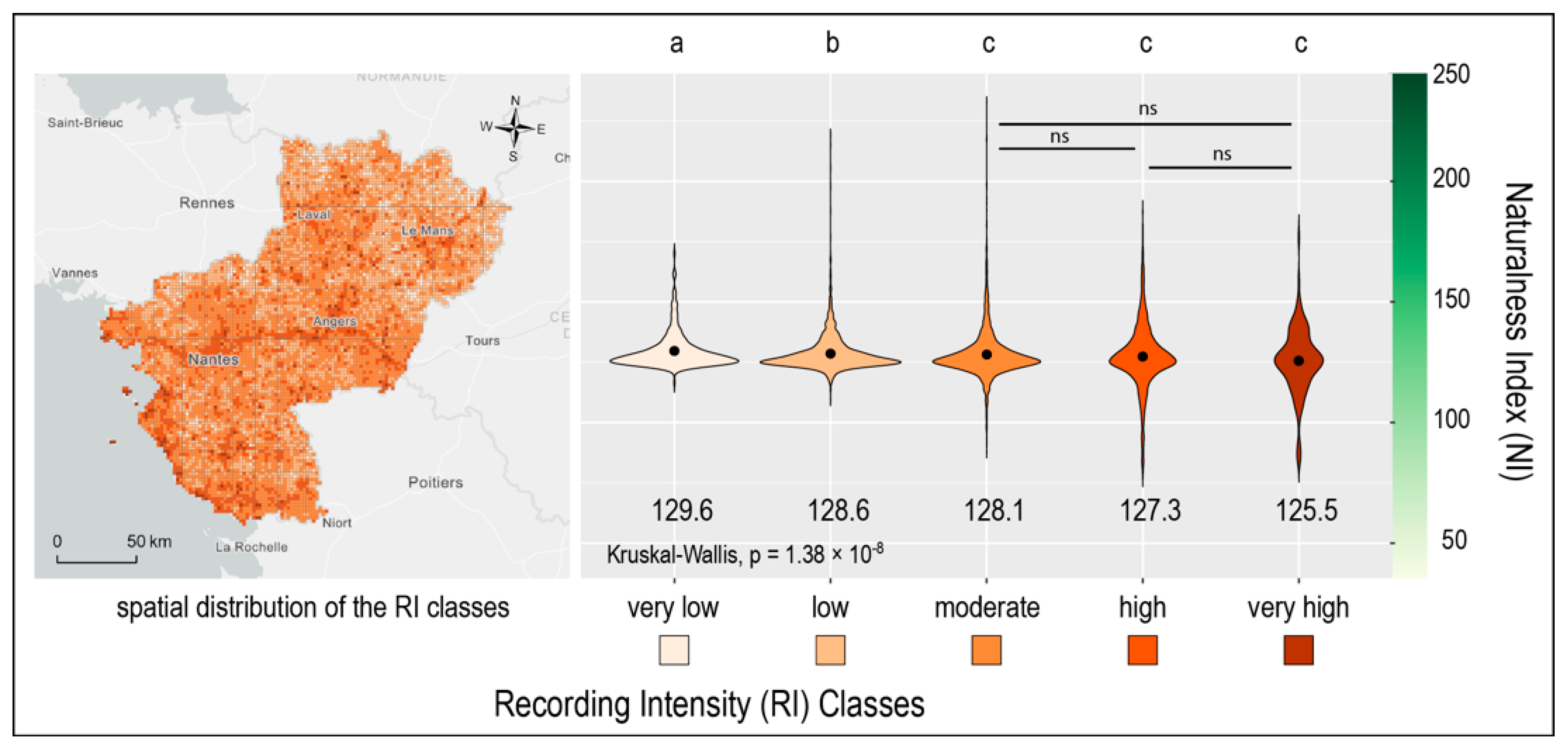
Using GIS, a pre-existing 2 × 2 km grid used for French bird atlases was retained for the analysis across the study area; cells encompassing less than 80% of regional land cover (mainly boundary cells) were removed, leading to a grid of 7924 cells. First, mean naturalness index (NI) was calculated for each cell. Second, the exact locations of bird records were intersected with the regular grid (
Figure 1). The number of records was calculated within each cell and all cells were then divided into five classes of recording intensity (RI) of equal intervals ranging from very low recording intensity to very high (
Figure 1). We retained five classes which corresponded to the best compromise between a sufficiently large number for the analysis but small enough to guarantee a good, visual mapped representation. Moreover, because only a few cells had a very large number of records, the RI were log transformed to perform the classification with a normalized data set. In order to test the effect of NI on RI classes, differences in mean NI between classes of log RI were tested using non-parametric Kruskal–Wallis (KW) tests because of heteroscedasticity of the data (
Figure 1). Differences in mean NI were tested between each combination of RI classes with Dunn’s post-hoc test of multiple comparisons using rank sums. We used Bonferroni method to adjust the
p-value for multiple comparisons.
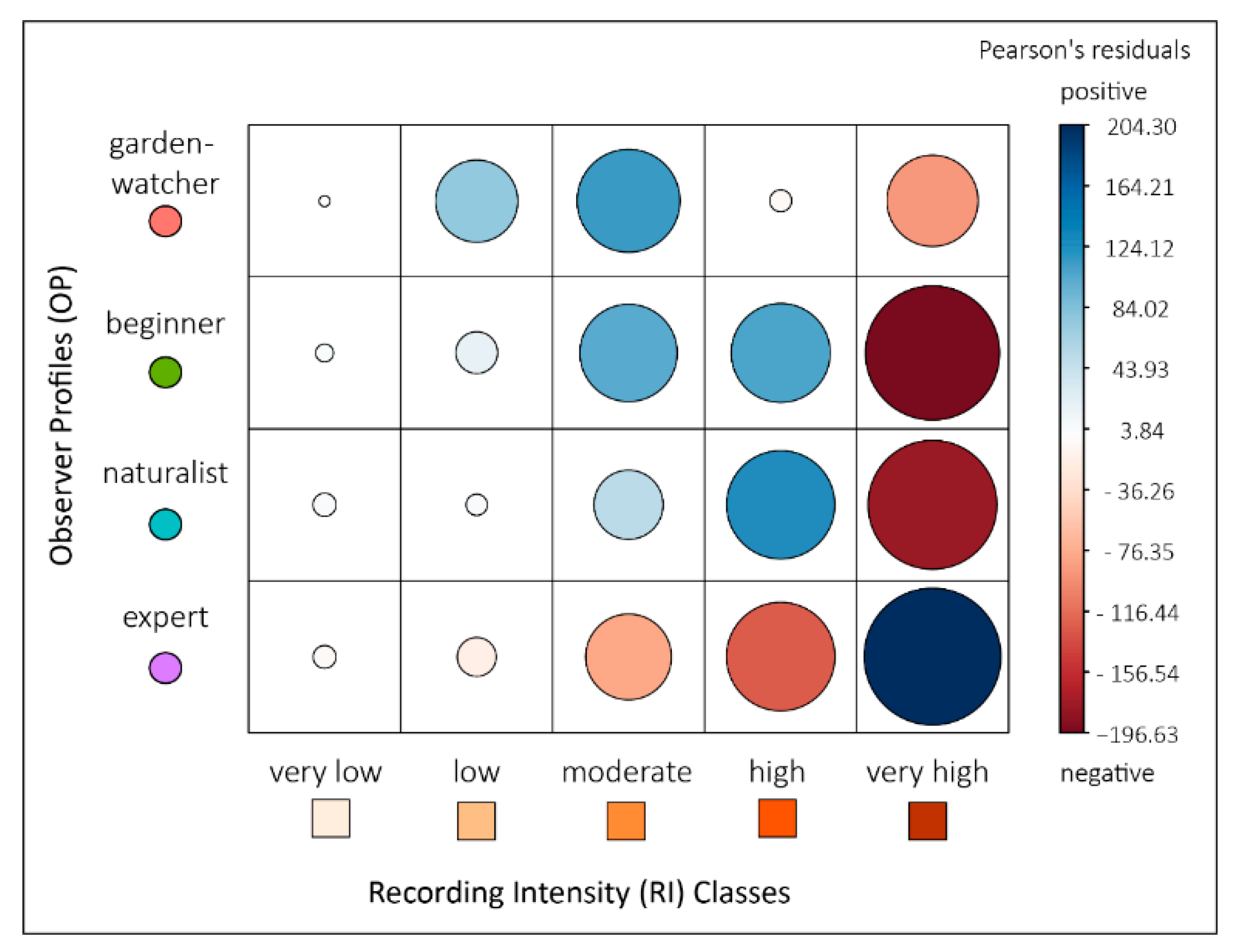
2.4.2. Testing the Hypothesis of a Homogeneous Distribution of the Records among Observer Profiles and Recording Intensity Classes
To test the hypothesis of a homogeneous distribution of the records according to observer profile and RI class, a Chi square test was applied on a contingency table. This table gathers the number of records of each observer profile in the different classes of RI. In order to interpret the intensity and the direction of each relationship (positive or negative), Pearson residuals were calculated and plotted.
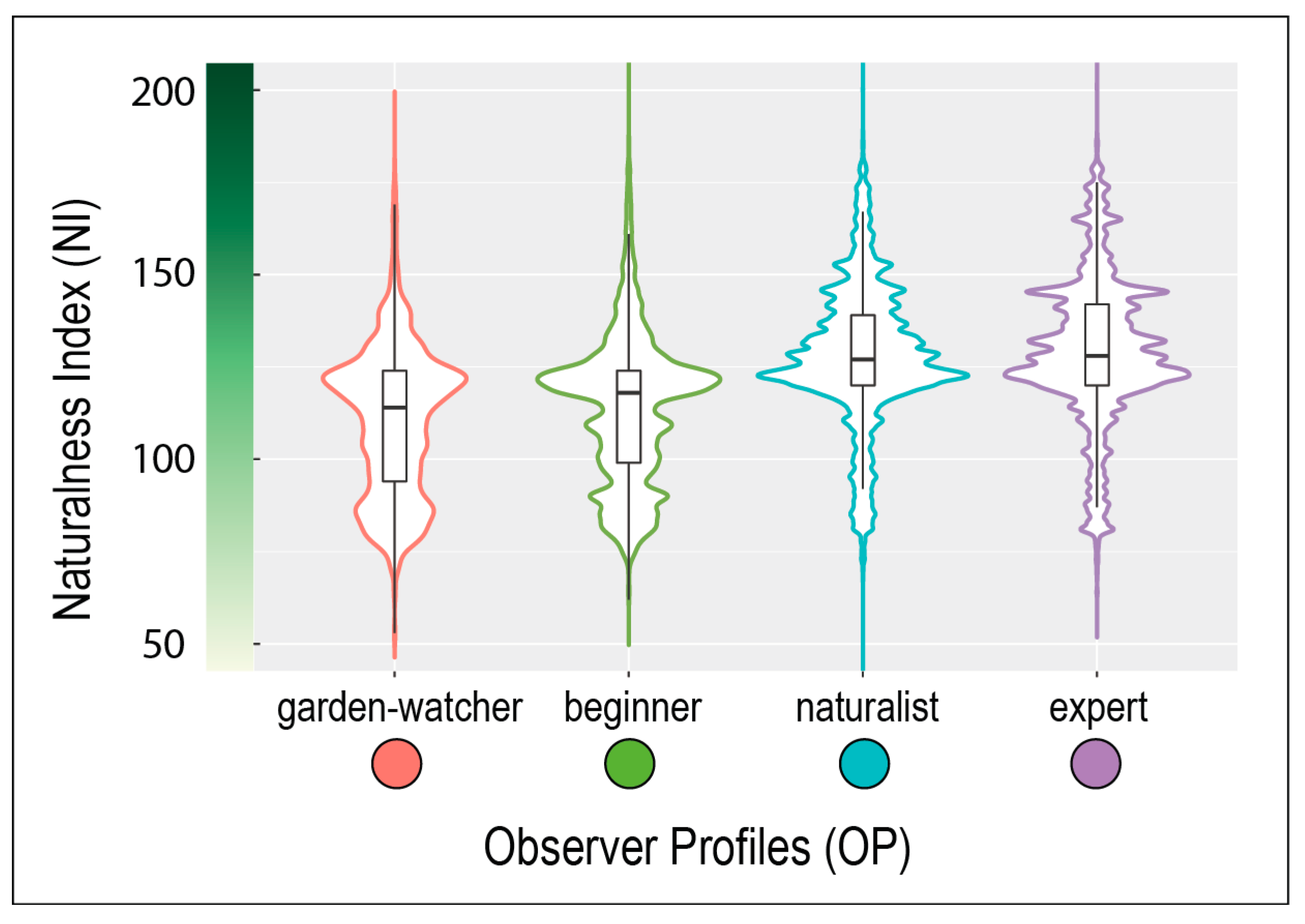
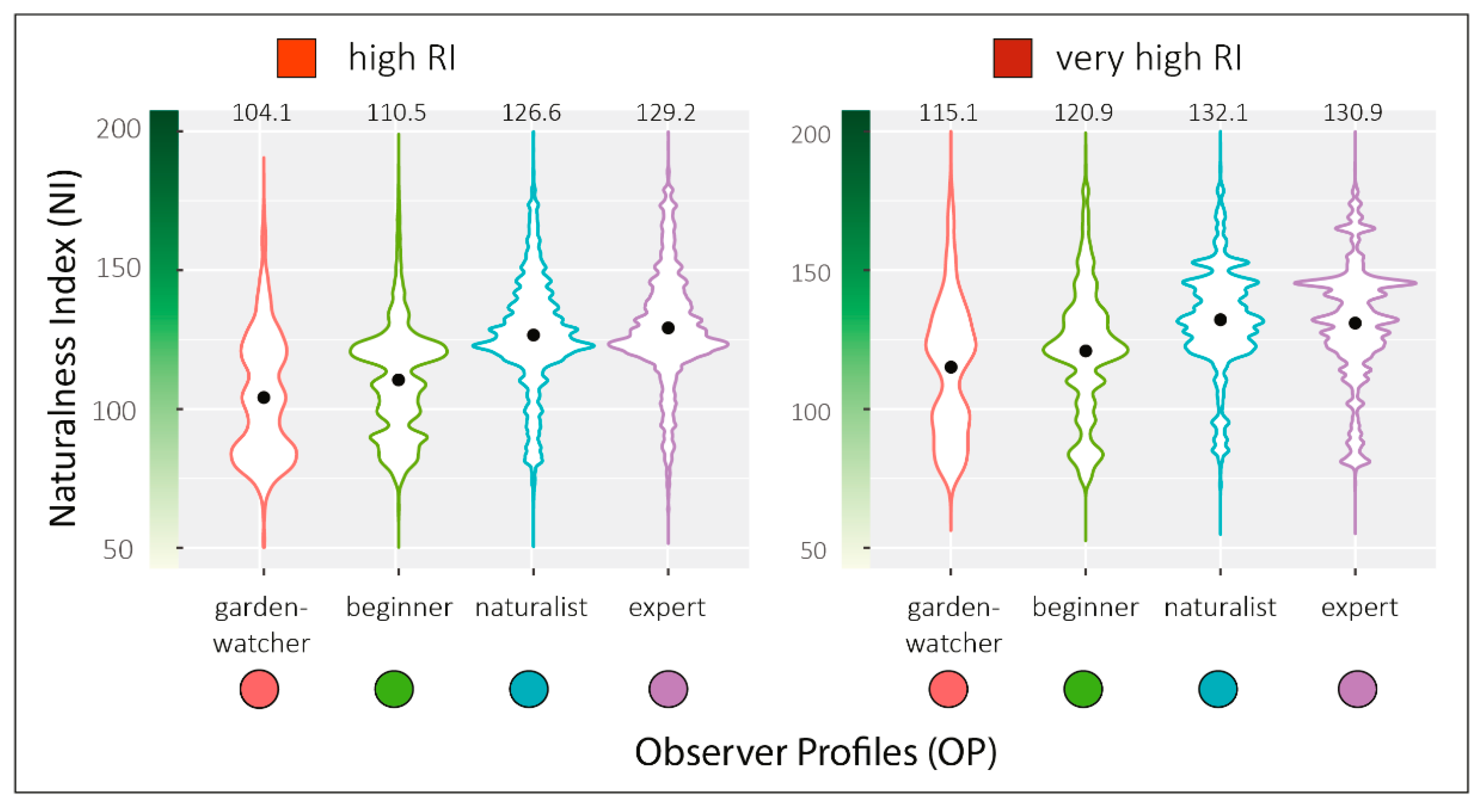
2.4.3. Testing the Effect of the Naturalness Index on the Recording Intensity of Observer Profiles at the 400 m2 Record Neighborhood Scale
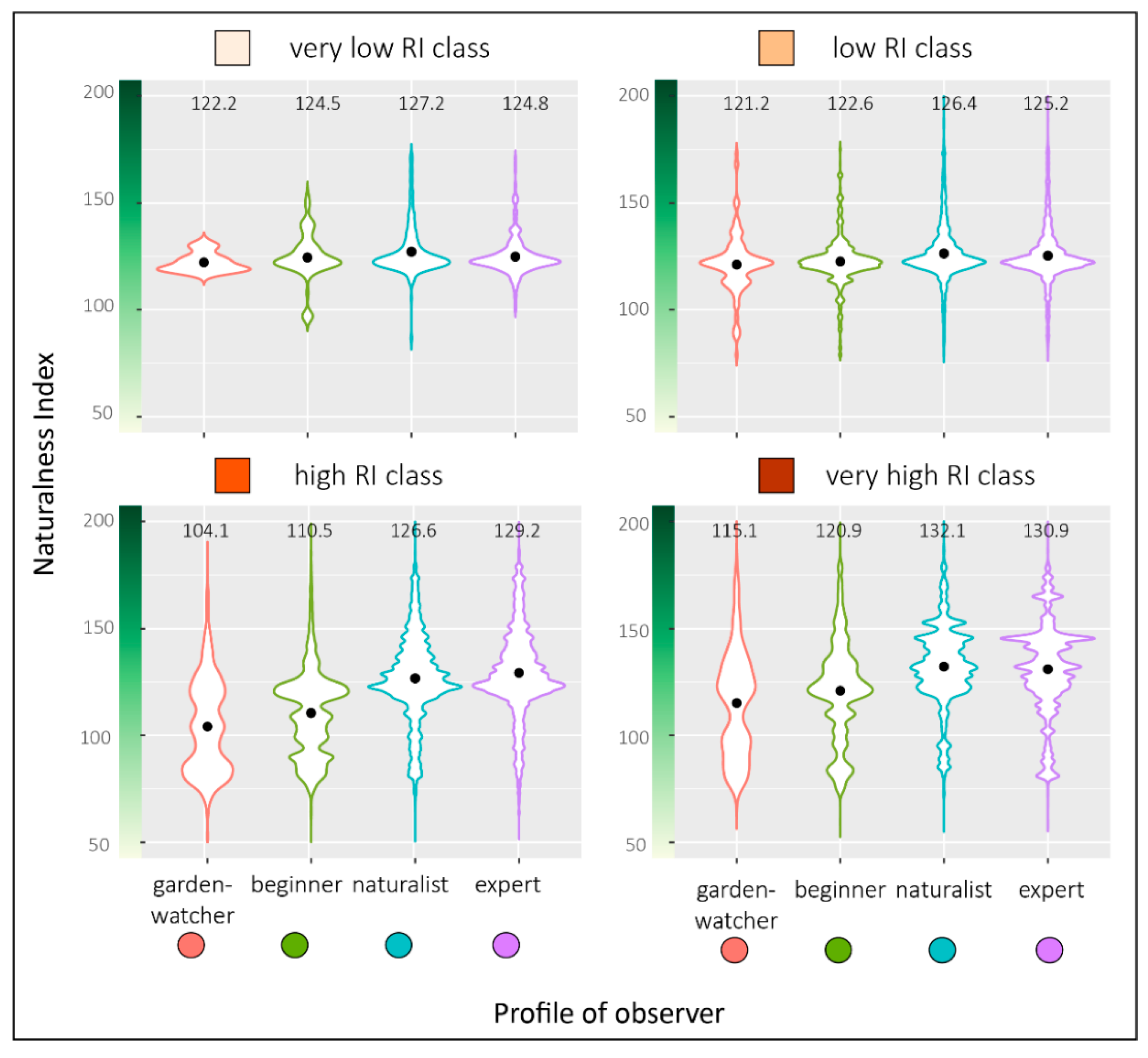
To test whether naturalness index (NI) in the neighborhood of bird records could explain recording intensity of the different observer profiles (OP), we calculated the mean NI of the total records for each OP. Contrary to
Section 2.4.1, NI was calculated at bird record scale in order to directly consider the neighborhood around each recording point (and not at the scale of the 4 km
2 grid). For this, we used the highest resolution of the NI map which is 20 m (i.e., 400 m
2). For each OP, mean NI of record neighborhoods were presented in violin plots to reflect the full distribution of the data, smoothed by a kernel density estimator.
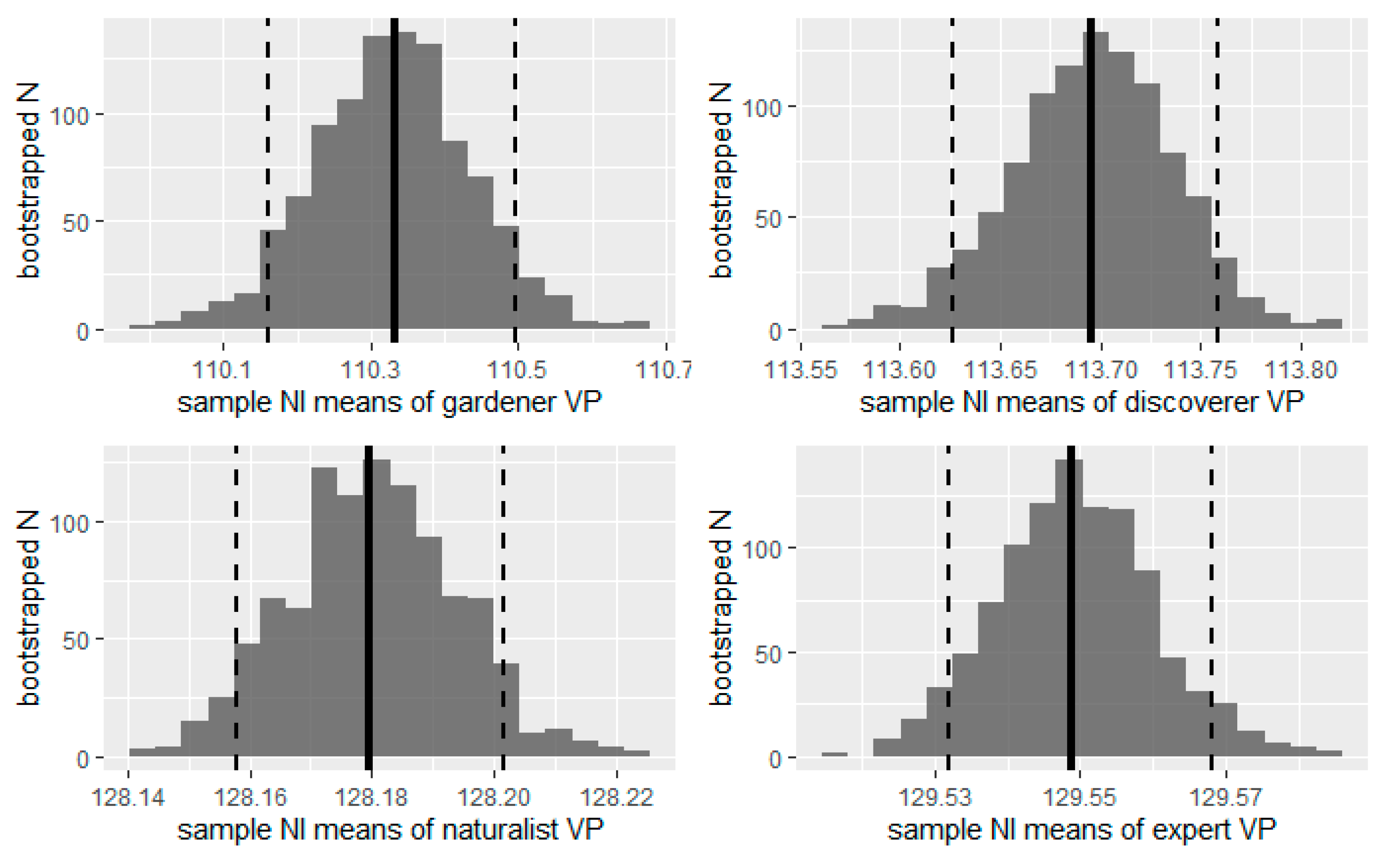
We then estimated a confidence interval (CI) of the NI means by bootstrapping method replication. For each OP, we resampled, replacing the original samples 999 times. We used the one.boot and perc function of the “simpleboot” R package for bootstrapping the mean statistic and extracting the CI at 95%. We then plotted the distribution of NI means as a histogram and added the initial sample NI mean and the CI boundaries (p = 0.05) for each of the four OP.
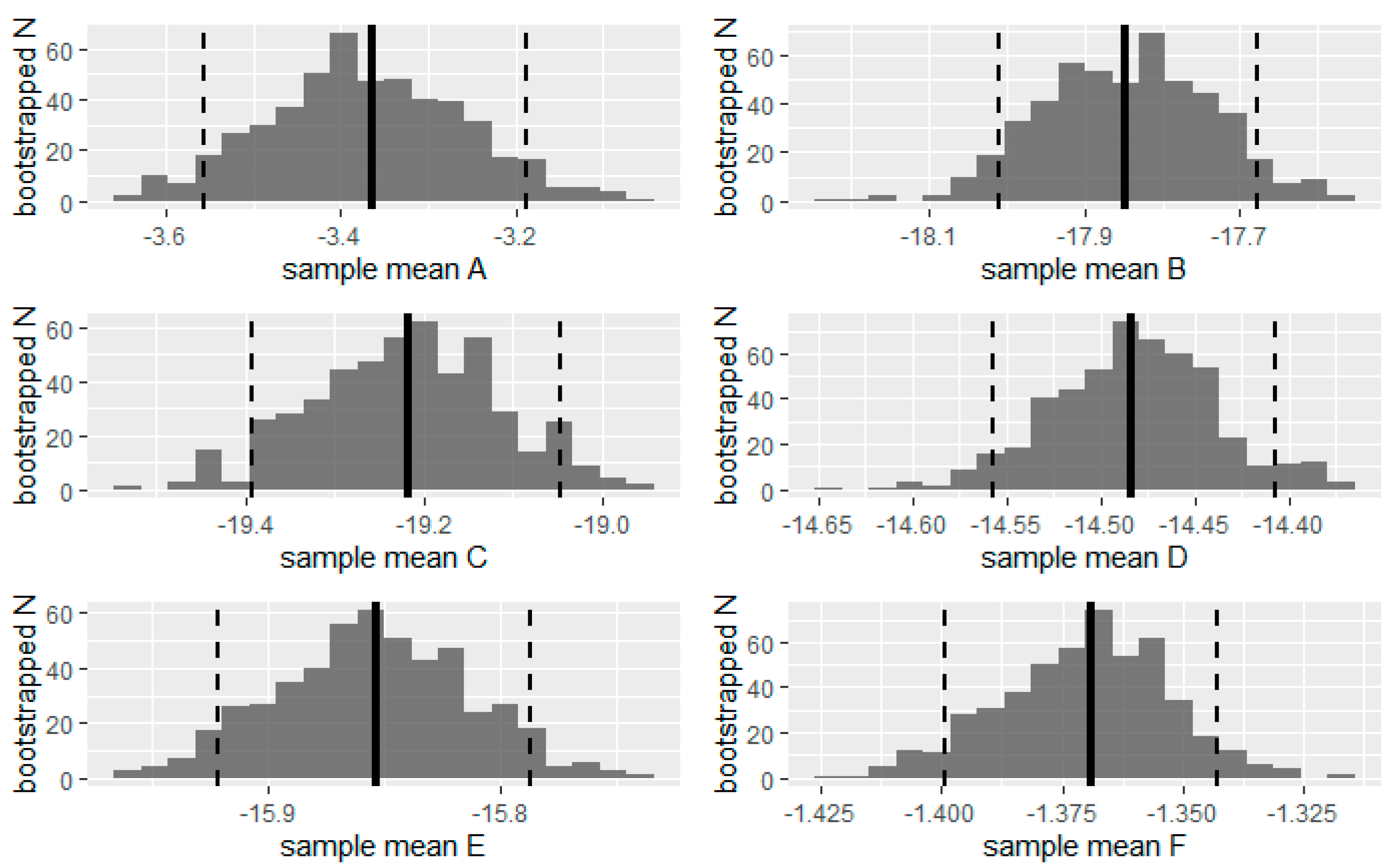
To test the differences in mean landscape NI between the OPs, we also calculated the CI for the pairwise comparisons. We used the two.boot function from the “simpleboot” package to bootstrap the difference between means of OP with 500 resamples and extract the CI at 95%. This number of bootstrapping was the maximum supported by the memory of our computer given the size of the original samples. We then plotted the distribution of differences as a histogram and added the initial sample mean and the confidence interval boundaries (p = 0.05) for each of the pairwise comparisons.
Finally, to ensure that the observed differences were not linked to the lack of data in some parts of the study area, this analysis concerned only the high and very high RI classes.
In addition to the R functions and packages already mentioned, we also used the following packages for our analyses and graphs: “ade4”, “corrplot”, “ggplot2”, “ggpubr”, “graphics”, “questionr”, “rstatix”, “vcd”.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











