
Deep Sequence Learning for Prediction of Daily NO2 Concentration in Coastal Cities of Northern China
 ,
,
Abstract
:1. Introduction
2. Study Area and Data
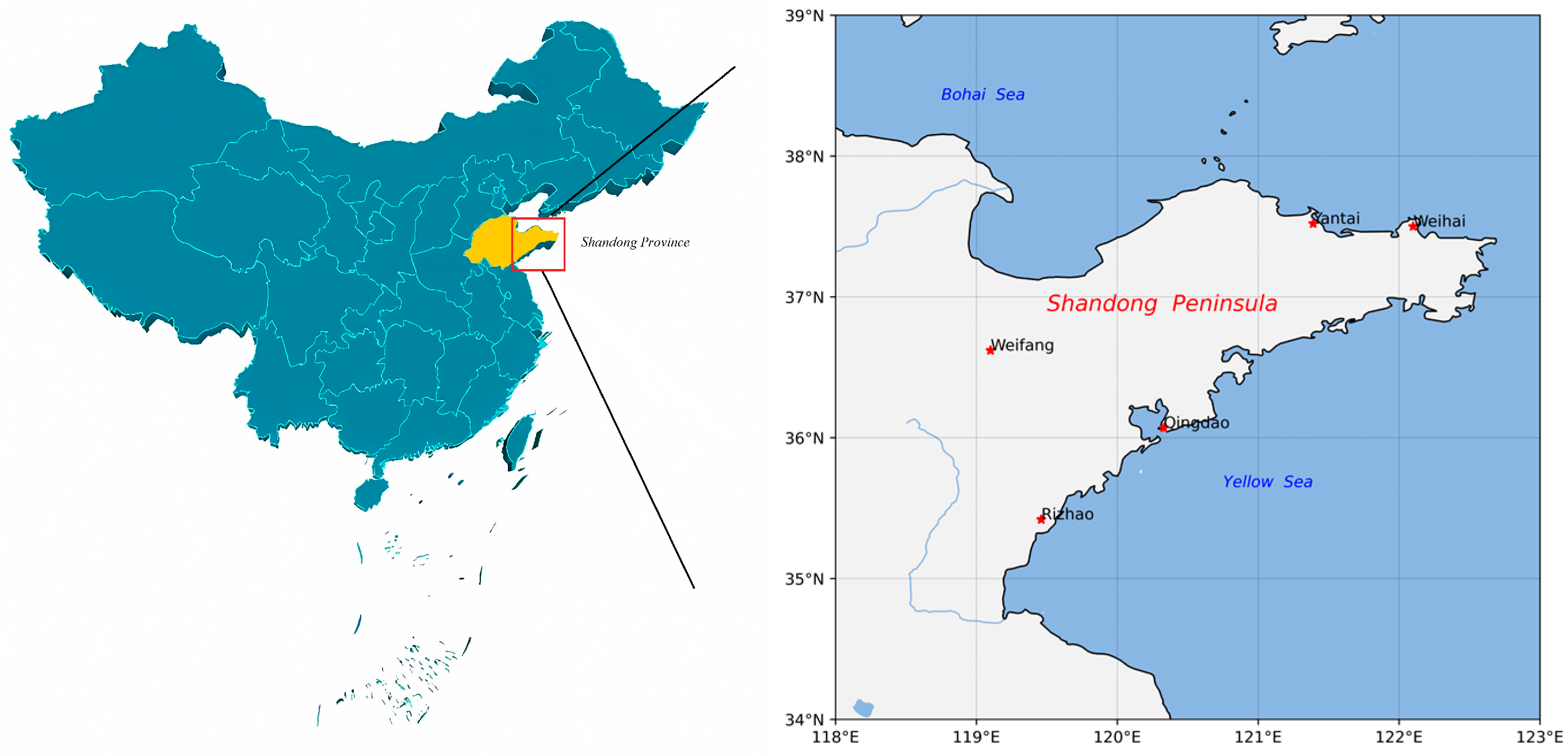
2.1. Study Area
2.2. Observation Data
3. Methodology
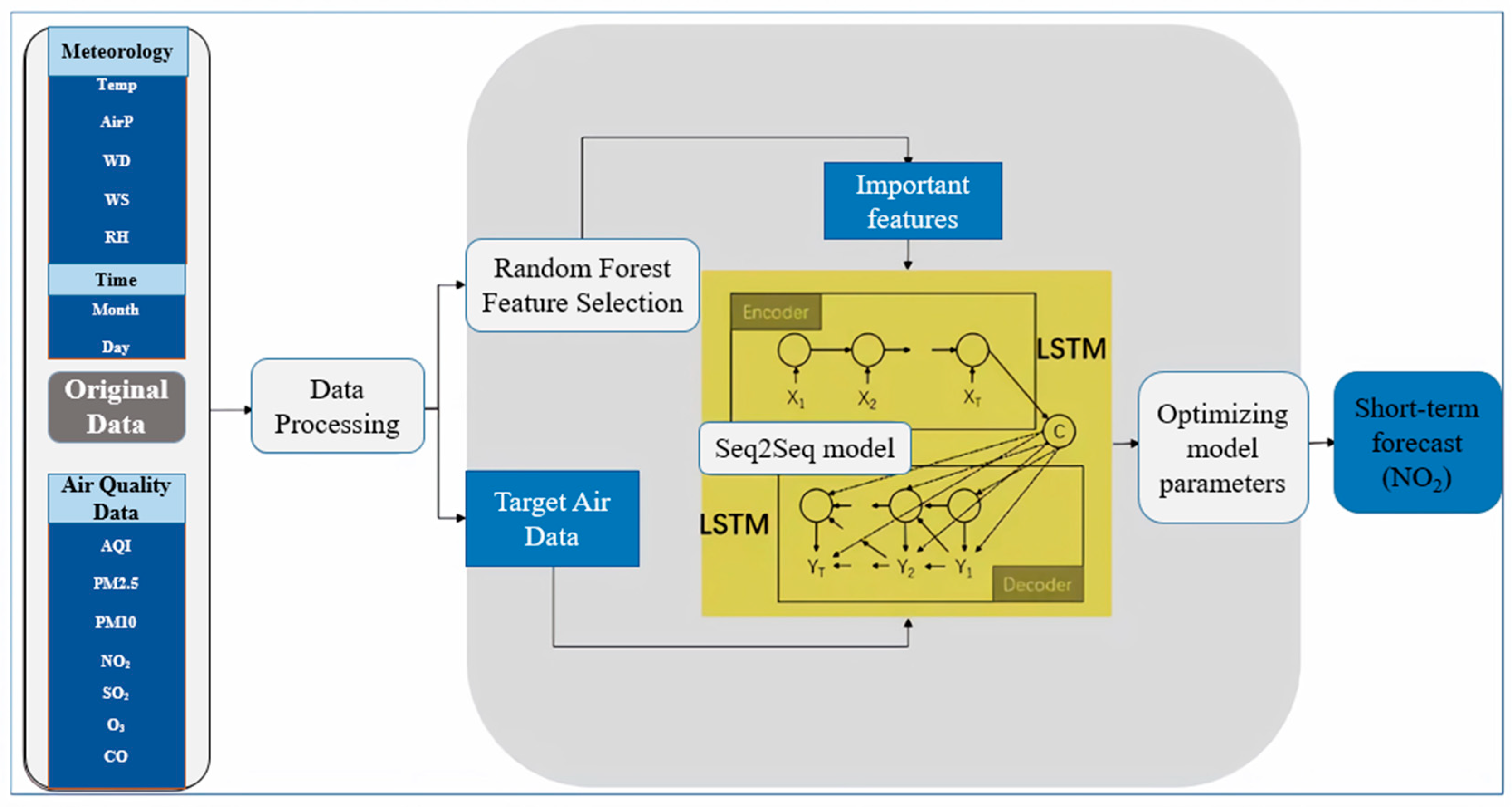
3.1. Hybrid Model Architecture
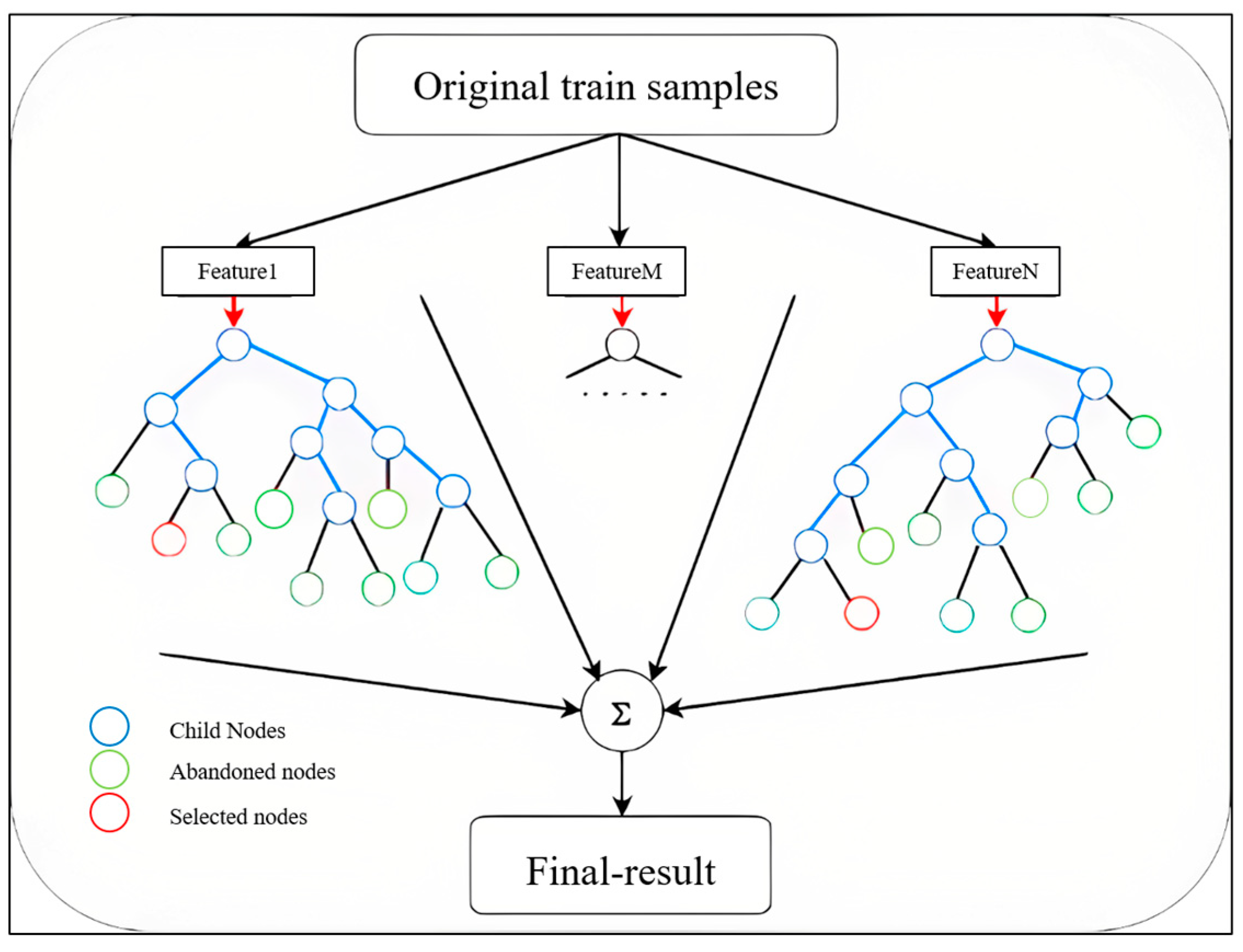
3.2. Feature Selection by Random Forest
3.3. Seq2Seq Prediction Model
3.4. Model Evaluation
4. Results and Discussion
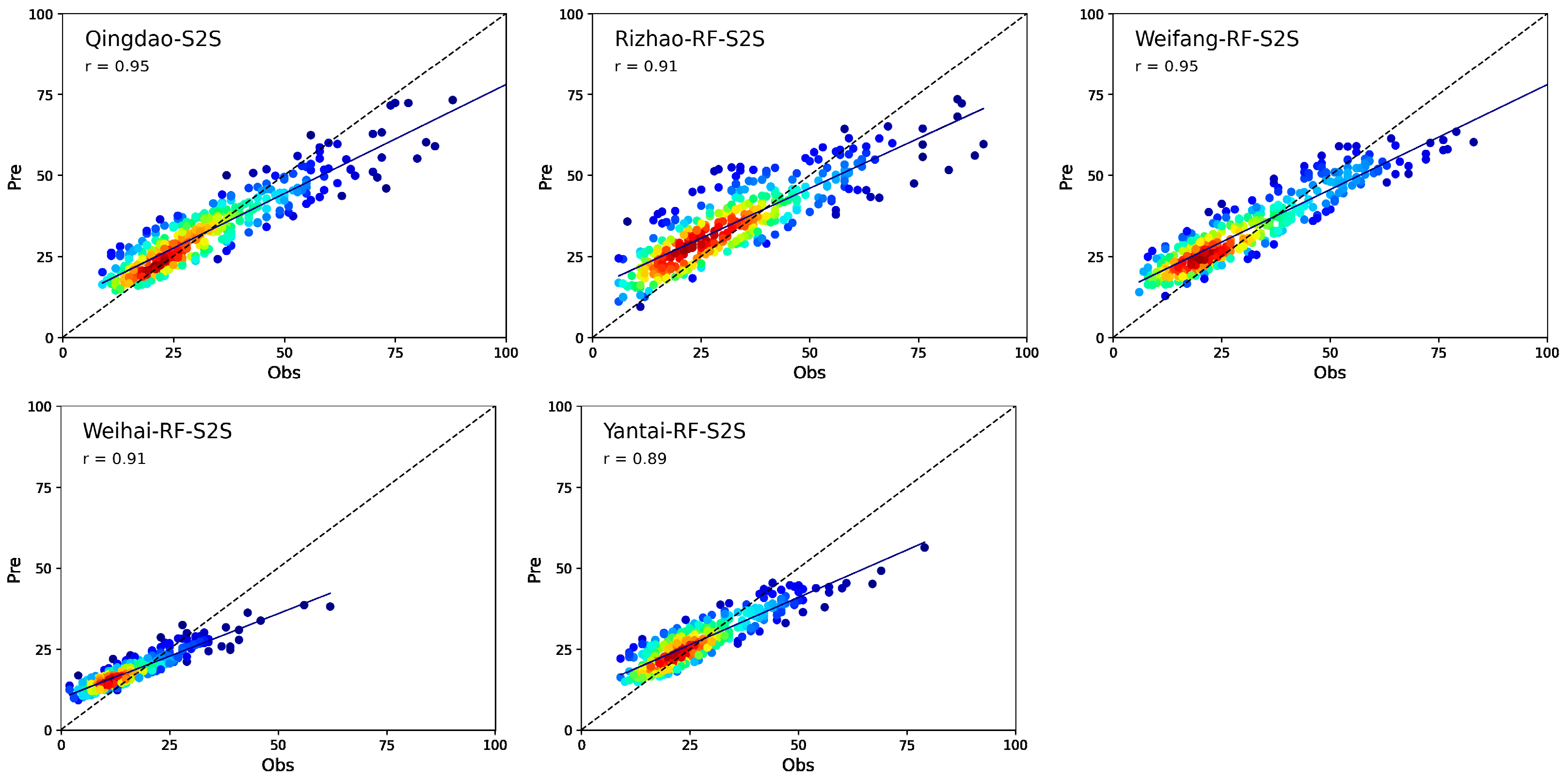
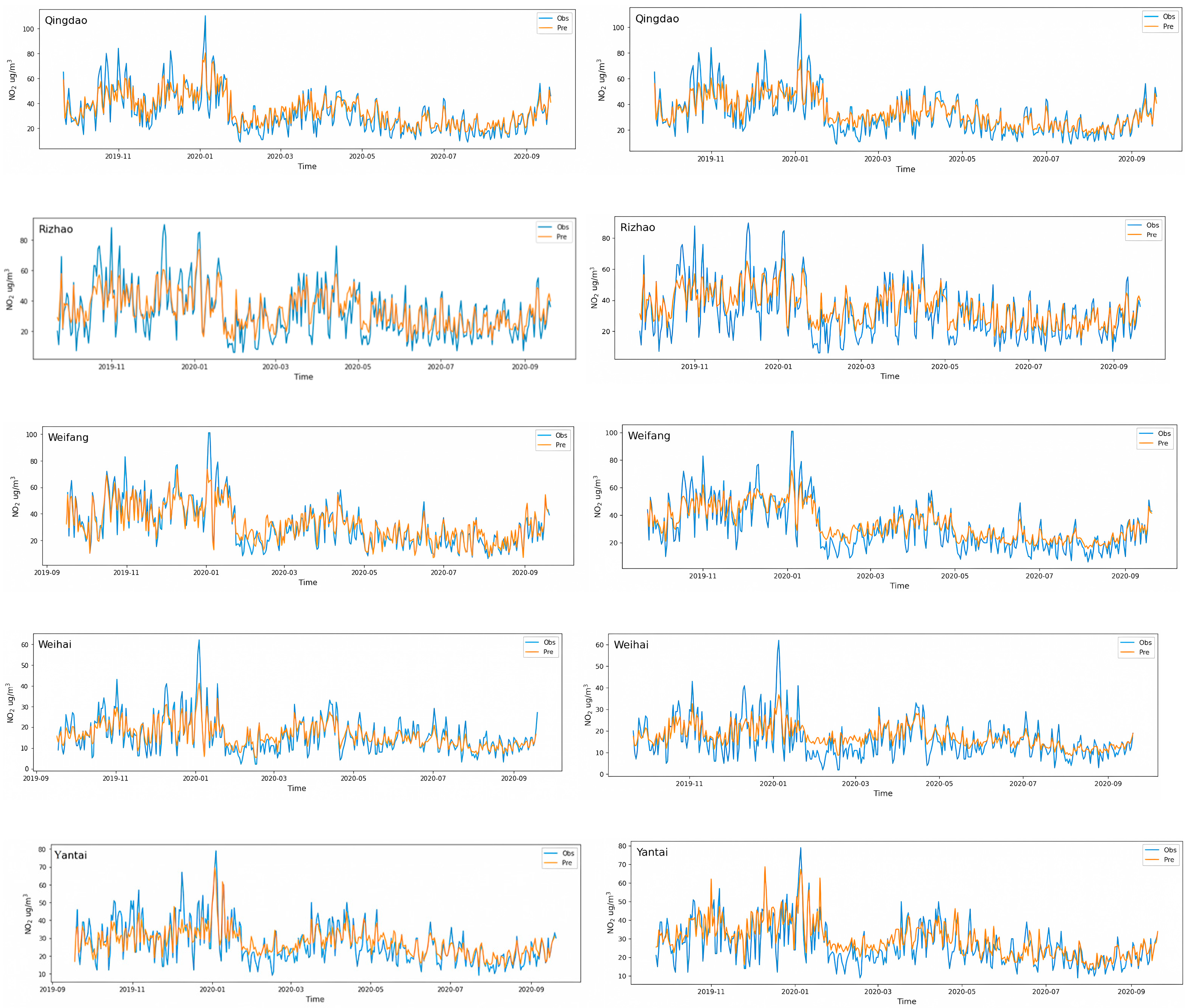
4.1. Evaluation of RF-S2S Model
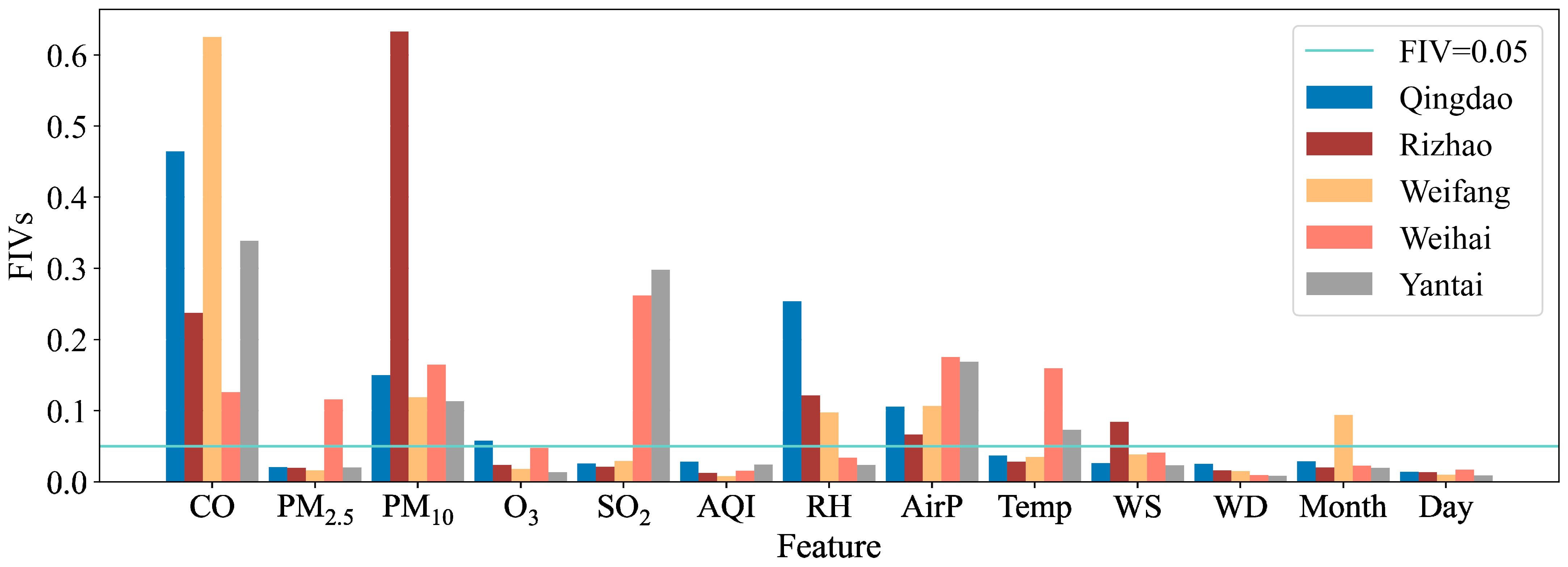
4.2. Important Features Influencing NO2 Prediction
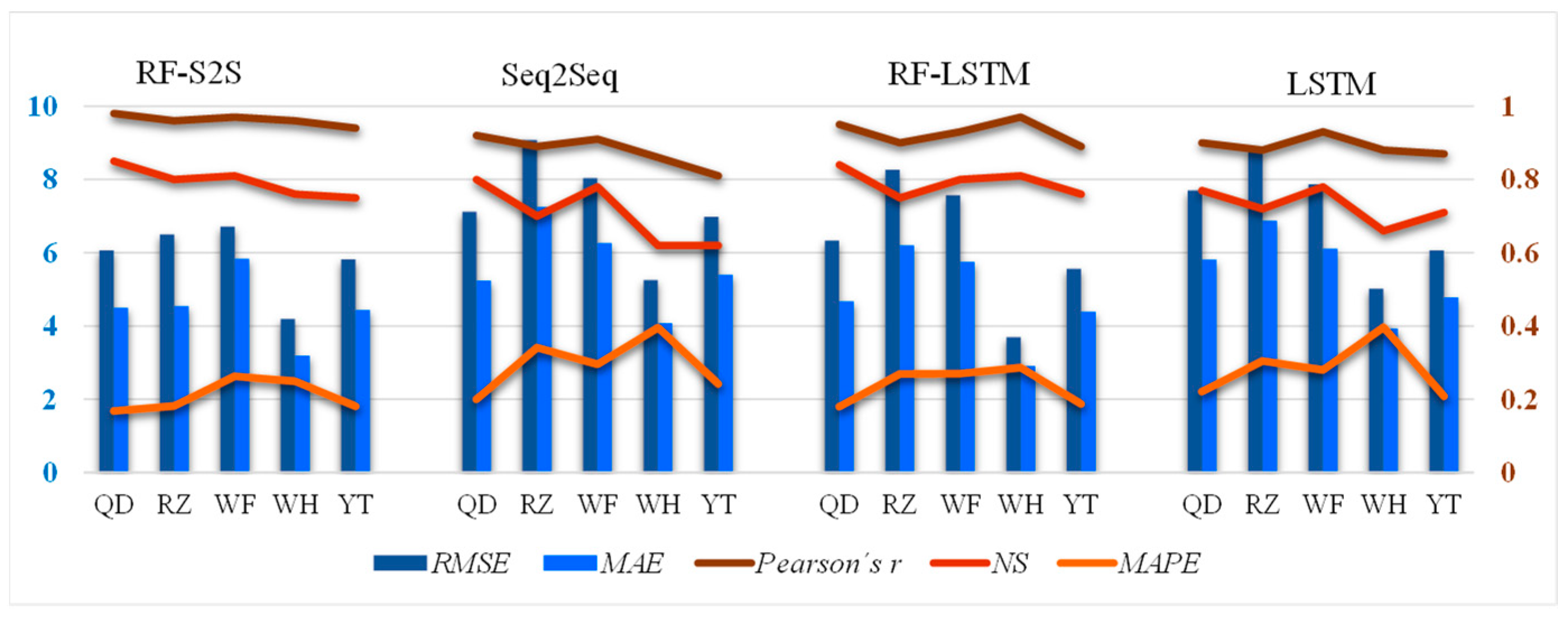
4.3. Comparison with Other Deep Sequence Learning Models without Feature Selection
4.4. Limitation and Improvement Project
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, F.; Ding, R.; Lei, R.; Cheng, H.; Liu, J.; Shen, C.; Cao, J. The short-term effects of air pollution on respiratory diseases and lung cancer mortality in Hefei: A time-series analysis. Respir. Med. 2019, 146, 57–65. [Google Scholar] [CrossRef]
- Zheng, J.; Jiang, P.; Qiao, W.; Zhu, Y.; Kennedy, E. Analysis of air pollution reduction and climate change mitigation in the industry sector of Yangtze River Delta in China. J. Clean. Prod. 2016, 114, 314–322. [Google Scholar] [CrossRef]
- Long, L.B.; She, Q.N.; Meng, Z.Q.; Liu, M.; Zhu, Y.; Yan, Y.Y. Characteristics and cluster analysis of air pollution in coastal areas of China. Res. Environ. Sci. 2018, 31, 2063–2072. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, F.; Hsieh, H.P. U-air: When urban air quality inference meets big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1436–1444. [Google Scholar] [CrossRef]
- Cao, Q.; Shen, L.; Chen, S.C.; Pui, D.Y.H. WRF modeling of PM2.5 remediation by SALSCS and its clean air flow over Beijing terrain. Sci. Total Environ. 2018, 626, 134–146. [Google Scholar] [CrossRef]
- Zhang, Q.; Xue, D.; Liu, X.H.; Gong, X.; Gao, H.W. Process analysis of PM2.5 pollution events in a coastal city of China using CMAQ. J. Environ. Sci. 2019, 79, 225–238. [Google Scholar] [CrossRef]
- Yu, S.; Zhang, Q.; Yan, R.; Wang, S.; Li, P.; Chen, B.; Liu, W.; Zhang, X. Origin of air pollution during a weekly heavy haze episode in Hangzhou, China. Environ. Chem. Lett. 2014, 12, 543–550. [Google Scholar] [CrossRef]
- Wang, D.; Jiang, B.; Li, F.; Lin, W. Investigation of the air pollution event in Beijing-Tianjin-Hebei region in December 2016 using WRF-chem. Adv. Meteorol. 2018, 2018, 1634578. [Google Scholar] [CrossRef]
- Rahimi, A. Short-term prediction of NO2 and NOx concentrations using multilayer perceptron neural network: A case study of Tabriz, Iran. Ecol. Process. 2017, 6, 4. [Google Scholar] [CrossRef] [Green Version]
- Navares, R.; Aznarte, J.L. Predicting air quality with deep learning LSTM: Towards comprehensive models. Ecol. Inform. 2020, 55, 101019. [Google Scholar] [CrossRef]
- Sayeed, A.; Choi, Y.; Eslami, E.; Lops, Y.; Roy, A.; Jung, J. Using a deep convolutional neural network to predict 2017 ozone concentrations, 24 hours in advance. Neural Netw. 2020, 121, 396–408. [Google Scholar] [CrossRef]
- Mehmood, K.; Bao, Y.; Cheng, W.; Khan, M.A.; Siddique, N.; Abrar, M.M.; Naidu, R. Predicting the quality of air with machine learning approaches: Current research priorities and future perspectives. J. Clean. Prod. 2022, 379, 134656. [Google Scholar] [CrossRef]
- Brunelli, U.; Piazza, V.; Pignato, L.; Sorbello, F.; Vitabile, S. Two-days ahead prediction of daily maximum concentrations of SO2, O3, PM10, NO2, CO in the urban area of Palermo, Italy. Atmos. Environ. 2007, 41, 2967–2995. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Reddy, V.; Yedavalli, P.; Mohanty, S.; Nakhat, U. Deep air: Forecasting air pollution in Beijing, China. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1–9. [Google Scholar]
- Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatiotemporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory. Sci. Total Environ. 2019, 664, 1–10. [Google Scholar] [CrossRef]
- Iskandaryan, D.; Ramos, F.; Trilles, S. Graph Neural Network for Air Quality Prediction: A Case Study in Madrid. IEEE Access 2023, 11, 2729–2742. [Google Scholar] [CrossRef]
- Yu, X.; Shi, S.; Xu, L. A spatial–temporal graph attention network approach for air temperature forecasting. Appl. Soft Comput. 2021, 113, 107888. [Google Scholar] [CrossRef]
- Jiang, W.; Luo, J. Graph neural network for traffic forecasting: A survey. Expert Syst. Appl. 2022, 207, 117921. [Google Scholar] [CrossRef]
- Bui, K.H.N.; Cho, J.; Yi, H. Spatial-temporal graph neural network for traffic forecasting: An overview and open research issues. Appl. Intell. 2022, 52, 2763–2774. [Google Scholar] [CrossRef]
- Ouyang, X.; Yang, Y.; Zhang, Y.; Zhou, W. Spatial-temporal dynamic graph convolution neural network for air quality prediction. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Ge, L.; Wu, K.; Zeng, Y.; Chang, F.; Wang, Y.; Li, S. Multi-scale spatiotemporal graph convolution network for air quality prediction. Appl. Intell. 2021, 51, 3491–3505. [Google Scholar] [CrossRef]
- Wang, C.; Zhu, Y.; Zang, T.; Liu, H.; Yu, J. Modeling inter-station relationships with attentive temporal graph convolutional network for air quality prediction. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8–12 March 2021; pp. 616–634. [Google Scholar] [CrossRef]
- Cabaneros, S.M.S.; Calautit, J.K.S.; Hughes, B.R. Hybrid artificial neural network models for effective prediction and mitigation of urban roadside NO2 pollution. Energy Procedia 2017, 142, 3524–3530. [Google Scholar] [CrossRef]
- Ma, J.; Ding, Y.; Cheng, J.C.; Jiang, F.; Wan, Z. A temporal-spatial interpolation and extrapolation method based on geographic Long Short-Term Memory neural network for PM2.5. J. Clean. Prod. 2019, 237, 117729. [Google Scholar] [CrossRef]
- Zhou, S.; Bethel, B.J.; Sun, W.; Zhao, Y.; Xie, W.; Dong, C. Improving Significant Wave Height Forecasts Using a Joint Empirical Mode Decomposition–Long Short-Term Memory Network. J. Mar. Sci. Eng. 2021, 9, 744. [Google Scholar] [CrossRef]
- Ashtab, M.; Ryoo, B.Y. Predicting Construction Workforce Demand Using a Combination of Feature Selection and Multivariate Deep-Learning Seq2seq Models. J. Constr. Eng. Manag. 2022, 148, 04022136. [Google Scholar] [CrossRef]
- Bai, Y.; Zeng, B.; Li, C.; Zhang, J. An ensemble long short-term memory neural network for hourly PM2.5 concentration forecasting. Chemosphere 2019, 222, 286–294. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.C.; Zhang, L.; Wang, Q.S.; Chen, J. A Novel Method for Regional NO2 Concentration Prediction Using Discrete Wavelet Transform and an LSTM Network. Comput. Intell. Neurosci. 2021, 2021, 6631614. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wu, L. On practical challenges of decomposition-based hybrid forecasting algorithms for wind speed and solar irradiation. Energy 2016, 112, 208–220. [Google Scholar] [CrossRef] [Green Version]
- Qian, Z.; Pei, Y.; Zareipour, H.; Chen, N. A review and discussion of decomposition-based hybrid models for wind energy forecasting applications. Appl. Energy 2019, 235, 939–953. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Chan, C.K.; Yao, X.H. Air pollution in mega cities in China. Atmos. Environ. 2008, 42, 1–42. [Google Scholar] [CrossRef]
- Liu, L.; Bei, N.; Hu, B.; Wu, J.R.; Liu, S.X.; Li, X.; Wang, R.N.; Liu, Z.R.; Shen, Z.X.; Li, G.H. Wintertime nitrate formation pathways in the north China plain: Importance of N2O5 heterogeneous hydrolysis. Environ. Pollut. 2020, 266, 115287. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, R.; Chen, J.; Rangel-Buitrago, N. The effectiveness of emission control policies in regulating air pollution over coastal ports of China: Spatiotemporal variations of NO2 and SO2. Ocean Coast. Manag. 2022, 219, 106064. [Google Scholar] [CrossRef]
- Carvalho, A.R.; Gama, C.; Monteiro, A. Investigating the contribution of sea salt to PM10 concentration values on the coast of Portugal. Air Qual. Atmos. Health 2021, 14, 1697–1708. [Google Scholar] [CrossRef]
- Bao, R.; Zhang, A. Does lockdown reduce air pollution? Evidence from 44 cities in northern China. Sci. Total Environ. 2020, 731, 139052. [Google Scholar] [CrossRef] [PubMed]
- Archer, K.J.; Kimes, R.V. Empirical characterization of random forest variable importance measures. Comput. Stat. Data Anal. 2008, 52, 2249–2260. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- García, M.V.; Aznarte, J.L. Shapley additive explanations for NO2 forecasting. Ecol. Inform. 2020, 56, 101039. [Google Scholar] [CrossRef]
- McCuen, R.H.; Knight, Z.; Cutter, A.G. Evaluation of the Nash-Sutcliffe efficiency index. J. Hydrol. Eng. 2006, 11, 597–602. [Google Scholar] [CrossRef]
- Xue, Y.; Peng, Z.; Liu, L. Analysis of distribution characteristics and influencing factors of air pollutants in typical coastal cities. Energy Environ. Prot. 2021, 35, 94–101. [Google Scholar]
- Li, M.; Li, S.; Li, D.Z.; Jiang, S.W.; Xu, S. Analysis and Prediction of Qingdao Atmospheric NO2 Concentration Factors. J. Environ. Sci. Manag. 2016, 41, 130–134. [Google Scholar]
- Xing, Z.W.; Wei, M.; Ning, W.T.; Zhang, M.G.; Li, K.; Jiang, W. Study on the cause of air pollution rebound in Weihai in early 2019 based on RAMS-CMAQ simulation. Acta Sci. Circumstantiae 2021, 41, 886–897. [Google Scholar] [CrossRef]
- Wang, Y.; Ying, Q.; Hu, J.; Zhang, H. Spatial and temporal variations of six criteria air pollutants in 31 provincial capital cities in China during 2013–2014. Environ. Int. 2014, 73, 413–422. [Google Scholar] [CrossRef] [PubMed]
- Zou, C.; Wu, L.; Li, X.Y.; Yuan, Y.; Jing, B.; Mao, H.J. Relationship between traffic flow and temporal and spatial variations of NO2 and CO in Nanjing. Acta Sci. Circumstantiae 2017, 37, 3894–3905. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Cornejo-Bueno, L.; Prieto, L.; Paredes, D.; García-Herrera, R. Feature selection in machine learning prediction systems for renewable energy applications. Renew. Sustain. Energy Rev. 2018, 90, 728–741. [Google Scholar] [CrossRef]
- Shamsoddini, A.; Aboodi, M.R.; Karami, J. Tehran air pollutants prediction based on random forest feature selection method. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 4. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Xu, J.; Matsumoto, K.; Ono, C. Sequence-to-Sequence Model with Attention for Time Series Classification. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 503–510. [Google Scholar] [CrossRef]
- Liu, B.; Wang, Y.; Meng, H.; Dai, Q.; Diao, L.; Wu, J.; Feng, Y. Dramatic changes in atmospheric pollution source contributions for a coastal megacity in northern China from 2011 to 2020. Atmos. Chem. Phys. 2022, 22, 8597–8615. [Google Scholar] [CrossRef]
- Meng, H.; Shen, Y.; Fang, Y.; Zhu, Y. Impact of the ‘Coal-to-Natural Gas’ Policy on Criteria Air Pollutants in Northern China. Atmosphere 2022, 13, 945. [Google Scholar] [CrossRef]
- Tan, W.; Liu, C.; Wang, S.S.; Xing, C.Z.; Su, W.J.; Zhang, C.X.; Xia, C.Z.; Liu, H.R.; Cai, Z.N.; Liu, J.G. Tropospheric NO2, SO2, and HCHO over the East China Sea, using ship-based MAX-DOAS observations and comparison with OMI and OMPS satellite data. Atmos. Chem. Phys. 2018, 18, 15387–15402. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Parameters | Value | ||
|---|---|---|---|
| Learning rate | 0.001 | ||
| Optimizer | Adam | ||
| Layers: 4 | Output Shape | Activation function | |
| Encoder Layer | LSTM | (Autoset, 13) | Tanh |
| Repeat vector | (Autoset, 3, 13) | - | |
| Decoder Layer | LSTM | (Autoset, 3, 64) | Tanh |
| Time distributed | (Autoset, 3, 1) | Sigmoid | |
| Cities | Selection Feature | Sum of Feature Importance Value |
|---|---|---|
| Qingdao | CO, RH, PM10, AirP, O3 | 0.82 |
| Rizhao | PM10, CO, RH | 0.81 |
| Weifang | CO, PM10, AirP, RH | 0.80 |
| Weihai | CO, SO2, PM2.5, PM10, AirP, Temp | 0.87 |
| Yantai | CO, SO2, PM10, AirP | 0.81 |
| Cities | NS | RMSE (µg/m3) | MAE (µg/m3) | MAPE (%) |
|---|---|---|---|---|
| Qingdao | 0.85 | 6.06 | 4.50 | 16.8 |
| Rizhao | 0.80 | 6.50 | 4.54 | 18.2 |
| Weifang | 0.81 | 6.71 | 5.84 | 26.3 |
| Weihai | 0.76 | 4.19 | 3.19 | 24.9 |
| Yantai | 0.75 | 5.82 | 4.43 | 18.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, X.; Gong, X.; Liu, X.; Zhao, X.; Meng, H.; Dong, Q.; Liu, G.; Gao, H. Deep Sequence Learning for Prediction of Daily NO2 Concentration in Coastal Cities of Northern China. Atmosphere 2023, 14, 467. https://doi.org/10.3390/atmos14030467
Jia X, Gong X, Liu X, Zhao X, Meng H, Dong Q, Liu G, Gao H. Deep Sequence Learning for Prediction of Daily NO2 Concentration in Coastal Cities of Northern China. Atmosphere. 2023; 14(3):467. https://doi.org/10.3390/atmos14030467
Chicago/Turabian StyleJia, Xingbin, Xiang Gong, Xiaohuan Liu, Xianzhi Zhao, He Meng, Quanyue Dong, Guangliang Liu, and Huiwang Gao. 2023. "Deep Sequence Learning for Prediction of Daily NO2 Concentration in Coastal Cities of Northern China" Atmosphere 14, no. 3: 467. https://doi.org/10.3390/atmos14030467