
Deep Learning-Based PM2.5 Long Time-Series Prediction by Fusing Multisource Data—A Case Study of Beijing
Abstract
:1. Introduction
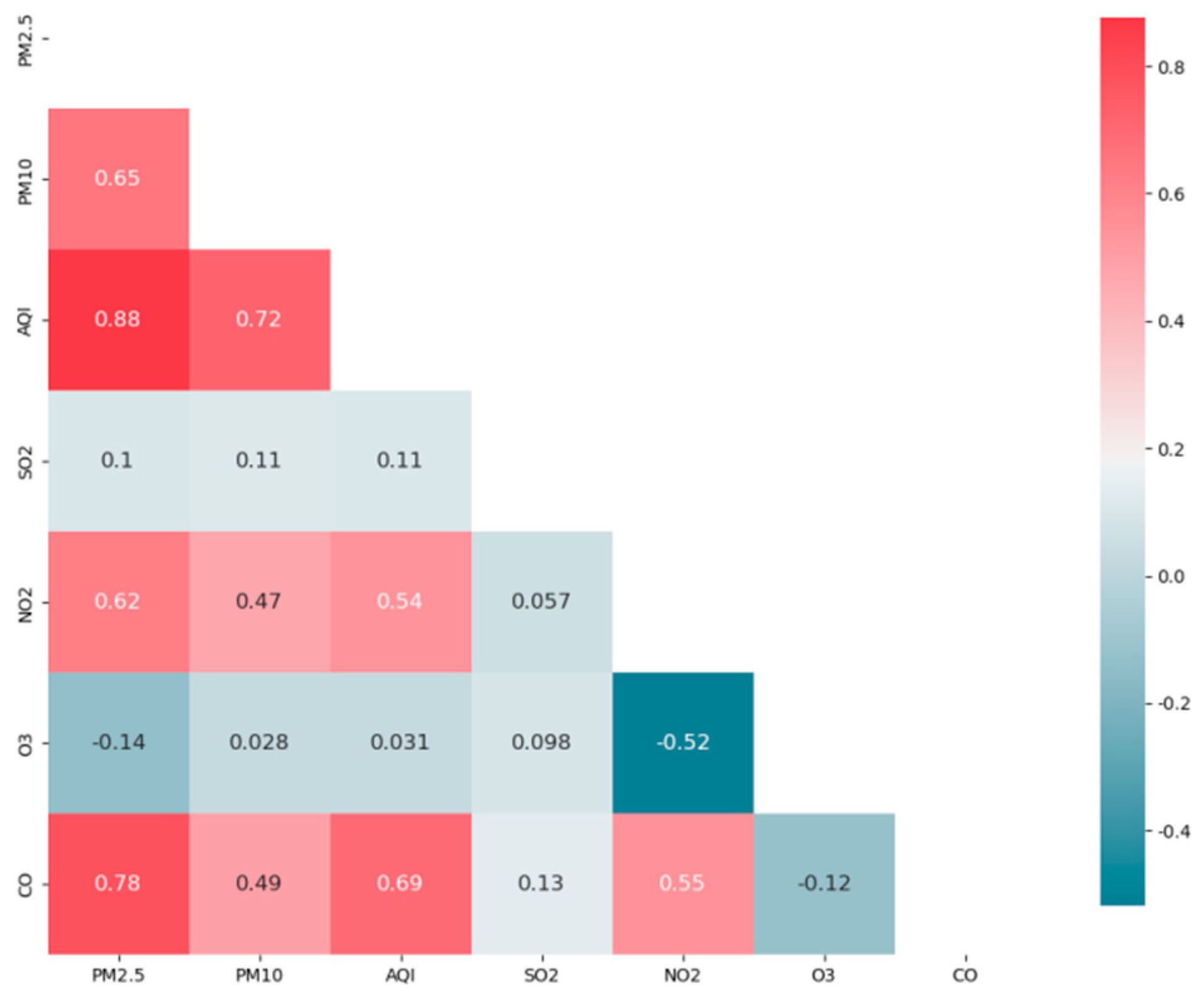
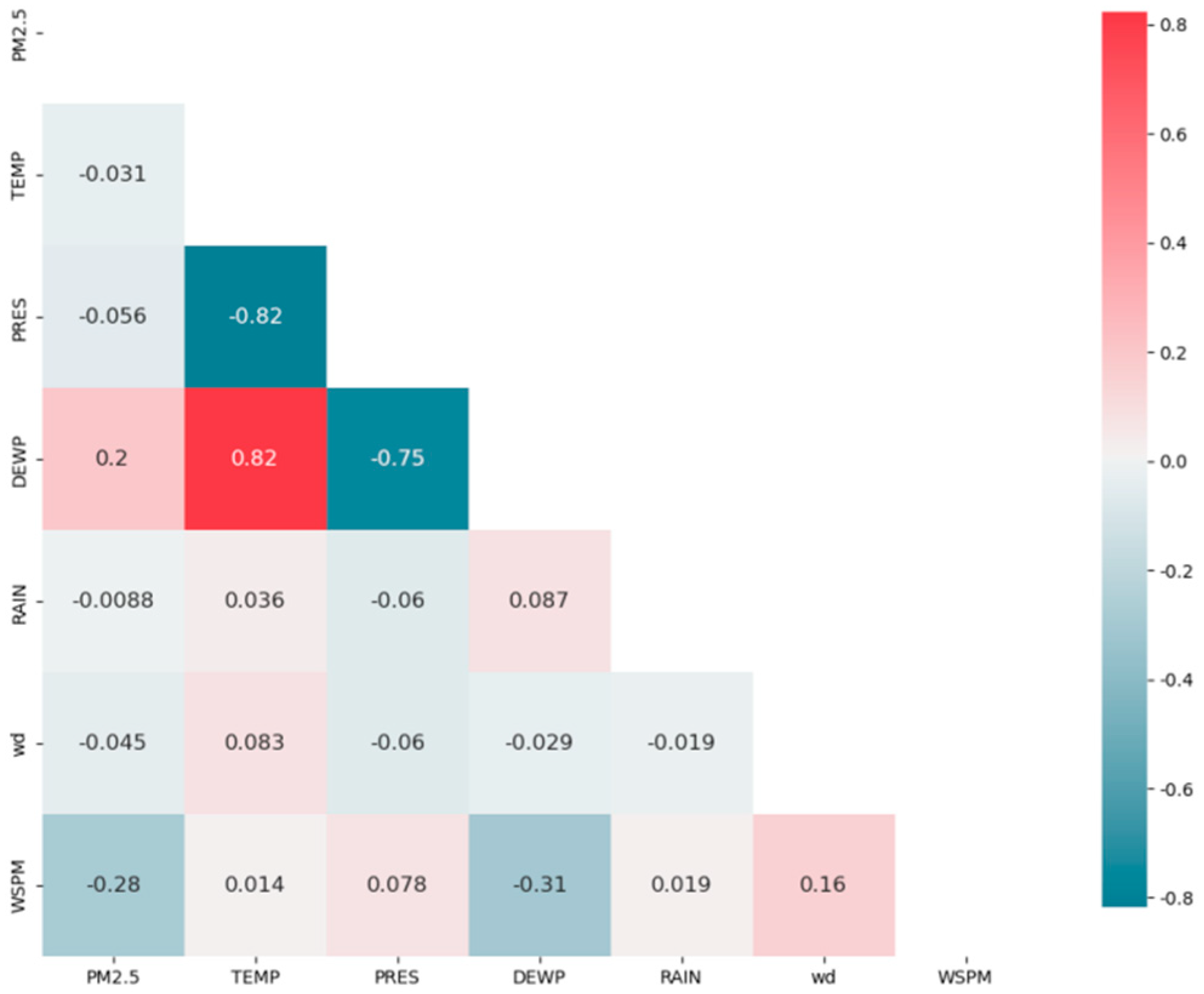
- The spatial and temporal correlation of historical air quality and meteorological data from 35 monitoring stations in Beijing is fully considered and effectively extracted. Through Spearman correlation analysis and access to atmospheric knowledge, AQI, CO, NO2, and PM10 concentrations from the air quality data and Dew Point Temperature (DEWP) and Wind Speed from the meteorological data are selected to better improve the prediction efficiency by almost 27%.
- The predictor including Spearman correlation analysis and Informer model are designed to predict the hourly PM2.5 concentration in Beijing. Informer receives the extra-long history input data and generates the predicted output directly in one step, avoiding accumulation of errors due to step-by-step prediction. The predictor effectively solves the problem of decreasing the accuracy of long time series in existing prediction methods.
- As a result of performance evaluation, the proposed model has a good performance in predicting the hourly PM2.5 concentration in future 7 days, 14 days, and one month. Compared with the existing methods, it has vastly improved at least 19–35%, and it has vital practical application significance for the government’s governance policies and people’s travel plans.
2. Materials and Methods
2.1. Data Collection
2.2. Data Description and Preprocessing
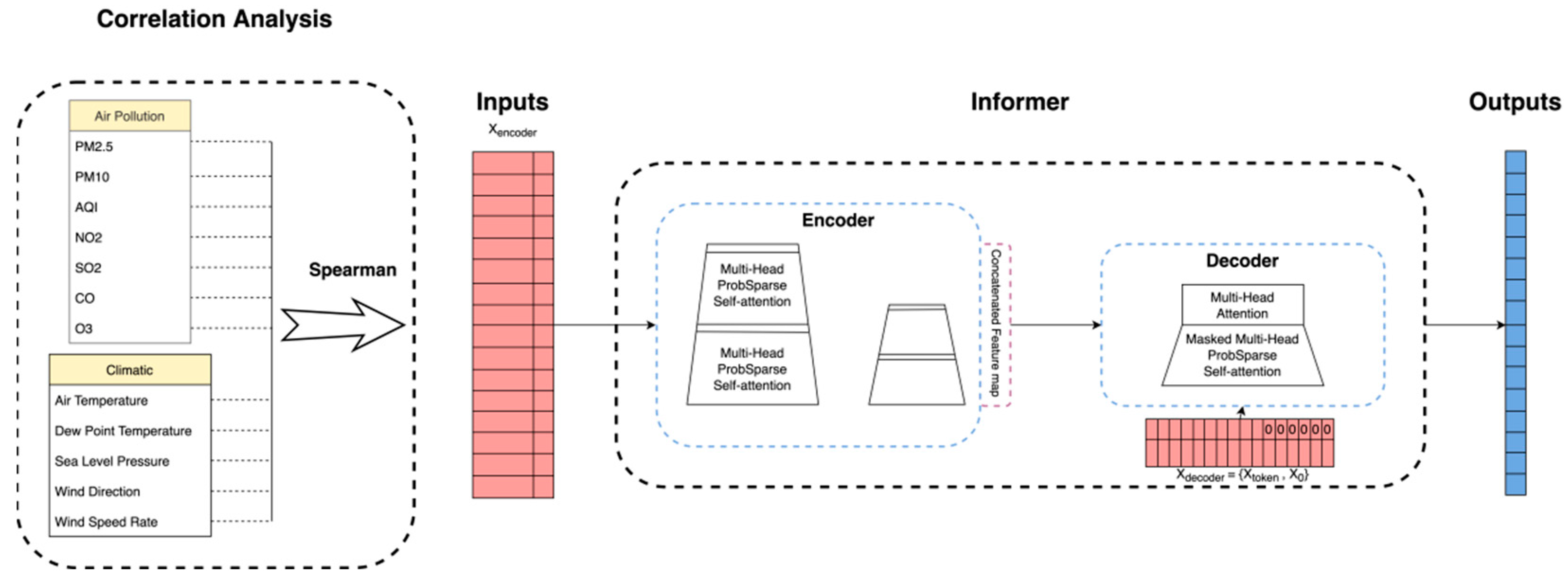
2.3. Correlation Analysis
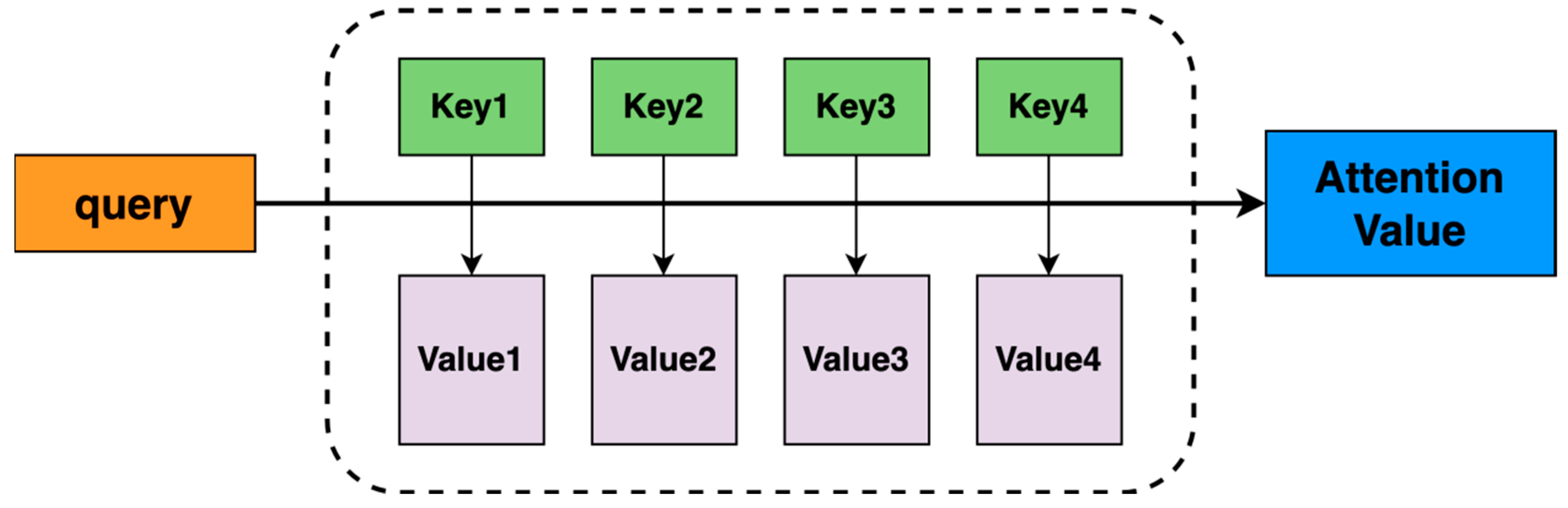
2.4. Attention Mechanism
2.5. Informer Model
2.6. Predictor Structure
2.7. Evaluation Indicators
3. Results
3.1. Correlation Analysis of Variables
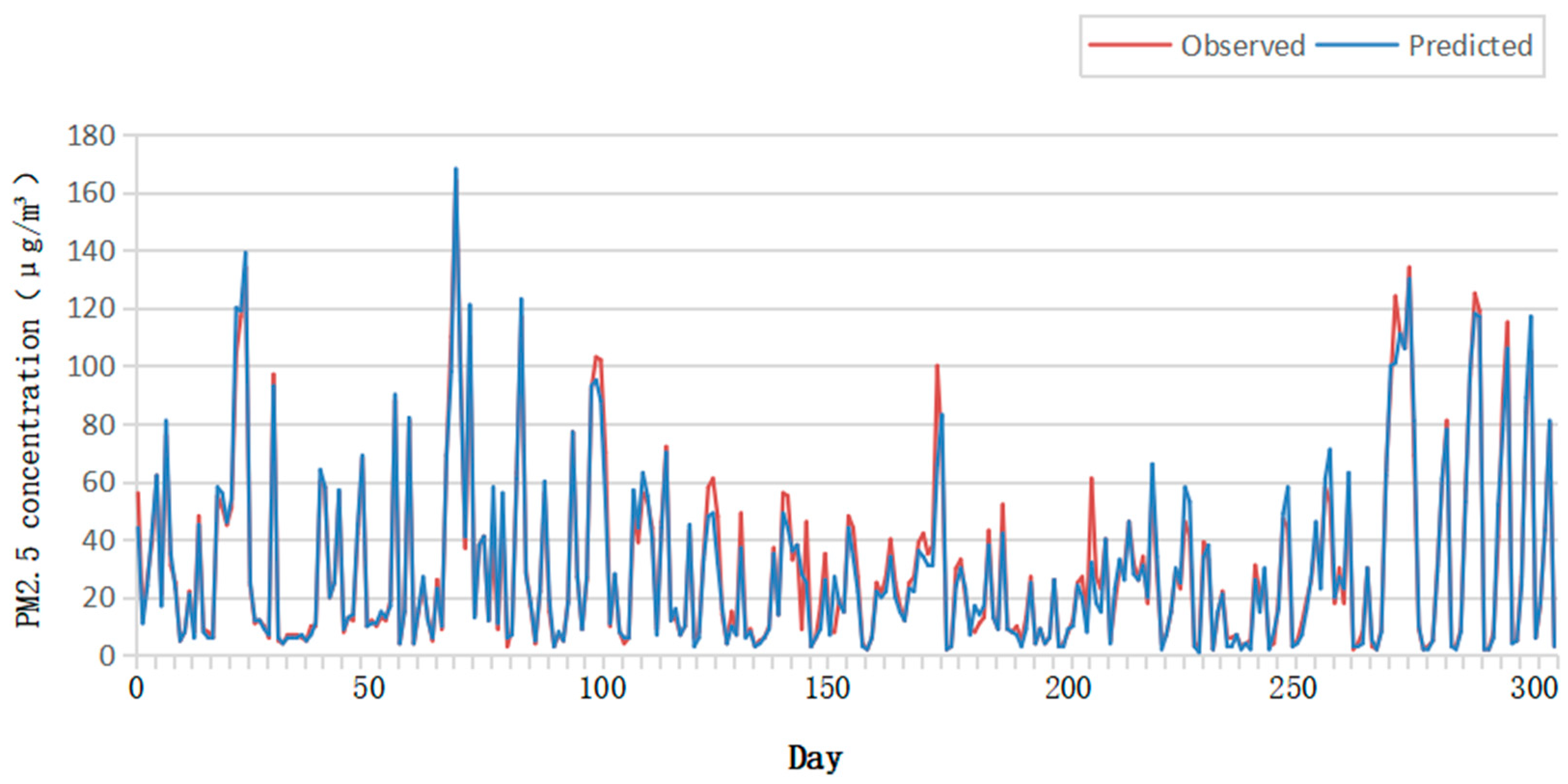
3.2. Prediction Performance Validation
3.3. Effects of Different Forecast Time on Model Performance
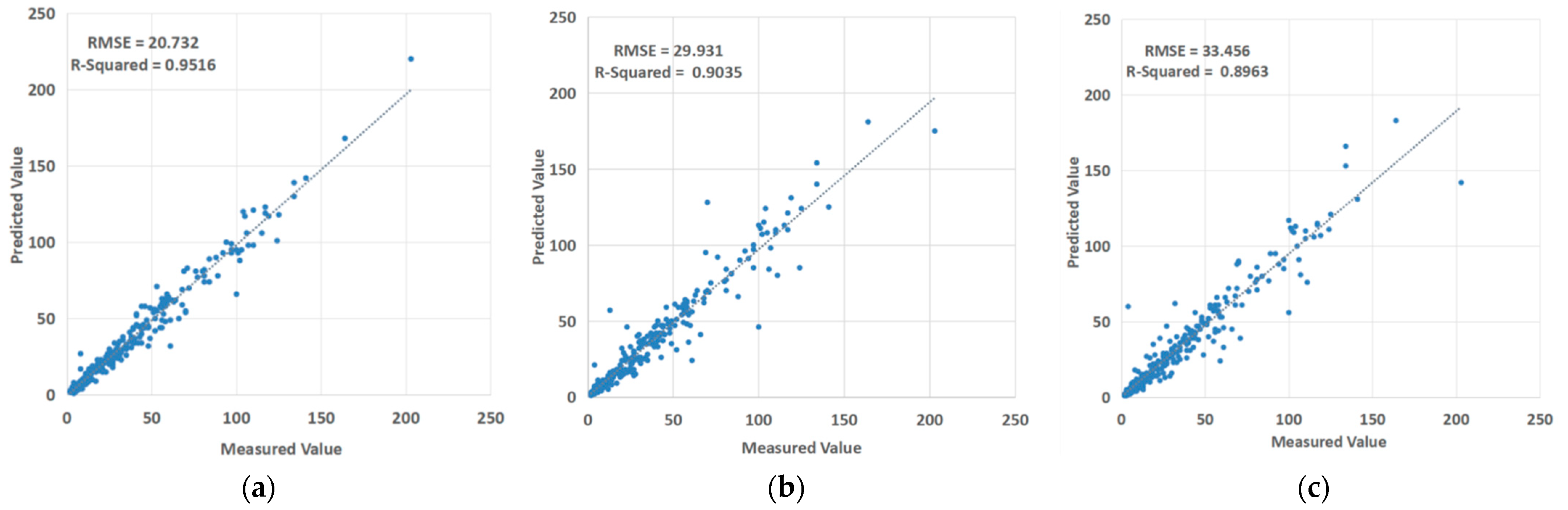
3.4. Comparison of Informer with Other Prediction Methods
- Through comparison, it can be found that more advanced models will obtain better PM2.5 prediction results with the same prediction time. For example, the introduction of the attention mechanism will reduce the error to a certain extent and optimize the performance of the LSTM, which shows that advanced models can effectively integrate the advantages of each algorithm component from multiple aspects and effectively improve the overall prediction accuracy of the prediction model. It fully demonstrates that the approach of feature extraction and integrated learning is important for optimizing the overall prediction performance of the model.
- The model proposed in this paper can achieve better prediction results than LSTM and attention-LSTM models for the tested prediction time series, which shows that the model proposed in this paper performs very well in the prediction of long time series and makes up for the shortcomings of the existing methods in the prediction of long time series. The proposed model has good practical application prospects in the PM2.5 concentration prediction problem. It proves the feasibility of using this method for PM2.5 concentration prediction, and it can also be implemented for the prediction of other air pollution indicators, such as AQI, CO, NO2, etc.
4. Discussion
4.1. Concentration Fluctuation Pattern of PM2.5
4.2. Model Selection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Riojas-Rodríguez, H.; Romieu, I.; Hernández-Ávila, M. Air pollution. In Occupational and Environmental Health; Oxford University Press: Oxford, UK, 2017; pp. 345–364. ISBN 9780190662677. [Google Scholar]
- WHO. Health Aspects of Air Pollution with Particulate Matter, Ozone and Nitrogen Dioxide. Tech. Rep. WHO 2003, 7–9. [Google Scholar]
- Xing, Y.F.; Xu, Y.H.; Shi, M.H.; Lian, Y.X. The impact of PM 2.5 on the human respiratory system. J. Thorac. 2016, 8, 69–74. [Google Scholar] [CrossRef]
- Kampa, M.; Castanas, E. Human health effects of air pollution. Environ. Pollut. 2008, 151, 362–367. [Google Scholar] [PubMed]
- WHO. Ambient air pollution: A global assessment of exposure and burden of disease. In WHO Library Cataloguing-in-Publication Data; WHO: Geneva, Switzerland, 2016. [Google Scholar]
- Tian, Y.; Jiang, Y.; Liu, Q.; Xu, D.; Zhao, S.; He, L.; Liu, H.; Xu, H. Temporal and spatial trends in air quality in Beijing. Landsc. Urban Plann. 2019, 185, 35–43. [Google Scholar] [CrossRef]
- Wang, G.; Xue, J.; Zhang, J.; Centre, N.M. Analysis of spatial-temporal distribution characteristics and main cause of air pollution in Beijing-Tianjin-Hebei region in 2014. Meteorol. Environ. 2016, 39, 34–42. [Google Scholar]
- Tang, H.; Chen, W.; Zhao, H. Diurnal, weekly and monthly spatial variations of air pollutants and air quality of Beijing. Atmos. Environ. 2015, 119, 21–34. [Google Scholar]
- Xu, W.; Tian, Y.; Xiao, Y.; Jiang, W.; Tian, L.; Liu, J. Study on the spatial distribution characteristics and the drivers of AQI in North China. Huanjing Kexue Xuebao/Acta Sci. Circumstantiae 2017, 37, 3085–3096. [Google Scholar]
- Baklanov, A.; Mestayer, P.G.; Clappier, A.; Zilitinkevich, S.; Joffre, S.; Mahura, A.; Nielsen, N.W. Towards improving the simulation of meteorological fields in urban areas through updated/advanced surface fluxes description. Atmos. Chem. Phys. 2008, 8, 523–543. [Google Scholar] [CrossRef]
- Kim, Y.; Fu, J.S.; Miller, T.L. Improving ozone modeling in complex terrain at afine grid resolution:part I-examinationof analysis nudging andall PBL schemes associated with LSMs in meteorological model. Atmos. Environ. 2010, 44, 523–532. [Google Scholar] [CrossRef]
- Woody, M.C.; Wong, H.W.; West, J.J.; Arunachalama, S. Multiscale predictions of aviation-attributable PM2.5 for U.S. airports modeled using CMAQ withplume-in-grid and an aircraft-specific 1-D emission model. Atmos. Environ. 2016, 147, 384–394. [Google Scholar] [CrossRef]
- Bray, C.D.; Battye, W.; Aneja, V.P.; Tong, D.; Lee, P.; Tang, Y.; Nowak, J.B. Evaluating ammonia (NH 3) predictions in the NOAA National Air Quality Forecast Capability (NAQFC) using in-situ aircraft and satellite measurements from the CalNex 2010 campaign. Atmos. Environ. 2017, 163, 65–76. [Google Scholar] [CrossRef]
- Zhou, G.; Xu, J.; Xie, Y.; Chang, L.; Gao, W.; Gu, Y.; Zhou, J. Numerical air quality forecasting over eastern China: An operational application of WRF-Chem. Atmos. Environ. 2017, 153, 94–108. [Google Scholar] [CrossRef]
- Carlo, P.D.; Pitari, G.; Mancini, E.; Gentile, S.; Pichelli, E.; Visconti, G. Evolution of surface ozone in central Italy based on observations and statistical model. J. Geophys. Res. 2007, 112. [Google Scholar] [CrossRef]
- Castellano, M.; Franco, A.; Cartelle, D.; Febrero, M.; Roca, E. Identification of NOx and ozone episodes and estimation of ozone by statistical analysis. Water Air Soil Pollut. 2009, 198, 95–110. [Google Scholar] [CrossRef]
- Gennaro, G.; Trizioa, L.; Gilioa, A.D.; Pey, J.; Pérez, N.; Cusack, M.; Alastuey, A.; Querol, X. Neural network model for the prediction of PM 10 daily concentrations in two sites in the Western Mediterranean. Sci. Total Environ. 2013, 463, 875–883. [Google Scholar] [CrossRef] [PubMed]
- Donnelly, A.; Misstear, B.; Broderick, B. Real time air quality forecasting using integrated parametric and non-parametric regression techniques. Atmos. Environ. 2015, 103, 53–65. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Lei, X.; Yuan, Y.; Muhammad Adnan, R. Monthly runoff forecasting based on LSTM–ALO model. Stoch. Environ. Res. Risk Assess. 2018, 32, 2199–2212. [Google Scholar] [CrossRef]
- Adnan, R.M.; Mostafa, R.R.; Elbeltagi, A.; Yaseen, Z.M.; Shahid, S.; Kisi, O. Development of new machine learning model for streamflow prediction: Case studies in Pakistan. Stoch. Environ. Res. Risk Assess. 2022, 36, 999–1033. [Google Scholar]
- Adnan, R.M.; Mostafa, R.R.; Islam, A.R.M.T.; Kisi, O.; Kuriqi, A.; Heddam, S. Estimating reference evapotranspiration using hybrid adaptive fuzzy inferencing coupled with heuristic algorithms. Comput. Electron. Agric. 2021, 191, 106541. [Google Scholar]
- Ikram, R.M.A.; Dai, H.-L.; Ewees, A.A.; Shiri, J.; Kisi, O.; Zounemat-Kermani, M. Application of improved version of multi verse optimizer algorithm for modeling solar radiation. Energy Rep. 2022, 8, 12063–12080. [Google Scholar] [CrossRef]
- Adnan, R.M.; Kisi, O.; Mostafa, R.R.; Ahmed, A.N.; El-Shafie, A. The potential of a novel support vector machine trained with modified mayfly optimization algorithm for streamflow prediction. Hydrol. Sci. J. 2022, 67, 161–174. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Ewees, A.A.; Parmar, K.S.; Yaseen, Z.M.; Shahid, S.; Kisi, O. The viability of extended marine predators algorithm-based artificial neural networks for streamflow prediction. Appl. Soft Comput. 2022, 131, 109739. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Dai, H.-L.; Chargari, M.M.; Al-Bahrani, M.; Mamlooki, M. Prediction of the FRP reinforced concrete beam shear capacity by using ELM-CRFOA. Measurement 2022, 205, 112230. [Google Scholar] [CrossRef]
- Pak, U.; Kim, C.; Ryu, U.; Sok, K.; Pak, S. A hybrid model based on convolutional neural networks and long short-term memory for ozone concentration prediction. Air Qual. Atmos. Health 2018, 11, 883–895. [Google Scholar] [CrossRef]
- Ong, B.T.; Sugiura, K.; Zettsu, K. Dynamic pre-training of deep recurrent neural networks for predicting environmental monitoring data. In Proceedings of the IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014; Volume 16, pp. 760–765. [Google Scholar] [CrossRef]
- Biancofiore, F.; Busilacchio, M.; Verdecchia, M.; Tomassetti, B.; Aruffo, E.; Bianco, S.; Di Tommaso, S.; Colangeli, C.; Rosatelli, G.; Di Carlo, P. Recursive neural network model for analysis and forecast of PM10 and PM2.5. Atmos. Pollut. 2017, 8, 652–659. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Soh, P.W.; Chang, J.W.; Huang, J.W. Adaptive deep learning-based air quality prediction model using the most relevant spatial-temporal relations. IEEE Access. 2018, 6, 38186–38199. [Google Scholar] [CrossRef]
- Liao, Q.; Zhu, M.; Wu, L.; Pan, X.; Tang, X.; Wang, Z. Deep learning for air quality forecasts: A review. Curr. Pollut. 2020, 6, 399–409. [Google Scholar] [CrossRef]
- Liu, H.; Yan, G.; Duan, Z.; Chen, C. Intelligent modeling strategies for forecasting air quality time series: A review. Appl. Soft Comput. 2021, 102, 106957. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2021; Volume 35, pp. 11106–11115. [Google Scholar] [CrossRef]
- Luo, Y.P.; Liu, M.J.; Gan, J.; Zhou, X.T.; Jiang, M.; Yang, R.B. Correlation study on PM2.5 and O3 mass concentrations in ambient air by taking urban cluster of Changsha, Zhuzhou and Xiangtan as an example. J. Saf. Environ. 2015, 15, 313–317. [Google Scholar]
- Zhang, Z.; Zhang, X.; Gong, D.; Quan, W.; Zhao, X.; Ma, Z.; Kim, S.J. Evolution of surface O3 and PM2.5 concentrations and their relationships with meteorological conditions over the last decade in Beijing. Atmos. Environ. 2015, 108, 67–75. [Google Scholar] [CrossRef]
- Cheng, Y.; Engling, G.; He, K.B.; Duan, F.K.; Ma, Y.L.; Du, Z.Y.; Liu, J.M.; Zheng, M.; Weber, R.J. Biomass burning contribution to Beijing aerosol. Atmos. Chem. Phys. 2013, 13, 7765–7781. [Google Scholar] [CrossRef]
- Cui, J.; Lang, J.; Chen, T.; Mao, S.; Cheng, S.; Wang, Z.; Cheng, N. A framework for investigating the air quality variation characteristics based on the monitoring data: Case study for Beijing during 2013–2016. J. Environ. 2019, 81, 225–237. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Q.; Sun, Y.L.; Wang, Z.; Yin, Y. Aerosol composition and sources during the Chinese Spring Festival: Fireworks, secondary aerosol, and holiday effects. Atmos. Chem. Phys. 2015, 15, 20617–20646. [Google Scholar]
- Zhang, Y.; Sun, Y.; Du, W.; Wang, Q.; Chen, C.; Han, T.; Lin, J.; Zhao, J.; Xu, W.; Gao, J.; et al. Response of aerosol composition to different emission scenarios in Beijing, China. Sci. Total Environ. 2016, 571, 902–908. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Variable | Range | Unit |
|---|---|---|---|
| Air Pollution | PM2.5 | [1, 427] | μg/m3 |
| PM10 | [0, 1016] | μg/m3 | |
| O3 | [1, 517] | μg/m3 | |
| CO | [0.1, 9] | μg/m3 | |
| NO2 | [1, 262] | μg/m3 | |
| SO2 | [1, 280] | μg/m3 | |
| AQI | [1, 500] | μg/m3 | |
| Meteorological | Air Temperature | [−19.4, 41.4] | °C |
| Dew Point Temperature | [−35.2, 31.2] | °C | |
| Sea Level Pressure | [982.6, 1042.1] | hPa | |
| Wind Direction | [0, 360] | ° | |
| Wind Speed Rate | [0.13, 2] | m/s |
| Input Variables | Output Variables | |||
|---|---|---|---|---|
| Air Pollution | Climatic | PM2.5(t + n) | ||
| AQI(t) 0.88 | CO(t) 0.78 | Air Temperature(t) −0.031 | Wind Direction(t) −0.045 | |
| PM10(t) 0.65 | NO2(t) 0.62 | Dew Point Temperature(t) 0.2 | Wind Speed(t) −0.28 | |
| O3(t) −0.14 | SO2(t) 0.1 | Sea Level Pressure(t) −0.056 | Rain(t) −0.0088 | |
| Network | 48 h | 7 Days | 14 Days | 30 Days | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| LSTM | 15.694 | 13.124 | 23.238 | 18.549 | 33.456 | 22.621 | 46.812 | 29.413 |
| Attention-LSTM | 14.283 | 12.437 | 21.419 | 15.205 | 29.931 | 20.468 | 44.093 | 25.123 |
| Our predictor | 11.276 | 9.213 | 17.498 | 13.503 | 20.732 | 14.693 | 24.211 | 18.867 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, M.; Zhang, Y.; Ren, Z. Deep Learning-Based PM2.5 Long Time-Series Prediction by Fusing Multisource Data—A Case Study of Beijing. Atmosphere 2023, 14, 340. https://doi.org/10.3390/atmos14020340
Niu M, Zhang Y, Ren Z. Deep Learning-Based PM2.5 Long Time-Series Prediction by Fusing Multisource Data—A Case Study of Beijing. Atmosphere. 2023; 14(2):340. https://doi.org/10.3390/atmos14020340
Chicago/Turabian StyleNiu, Meng, Yuqing Zhang, and Zihe Ren. 2023. "Deep Learning-Based PM2.5 Long Time-Series Prediction by Fusing Multisource Data—A Case Study of Beijing" Atmosphere 14, no. 2: 340. https://doi.org/10.3390/atmos14020340