
Development of Two-Dimensional Visibility Estimation Model Using Machine Learning: Preliminary Results for South Korea


Abstract
:1. Introduction
2. Materials and Methods
2.1. Overall Design of the Development of the 2D Visibility Estimation Model
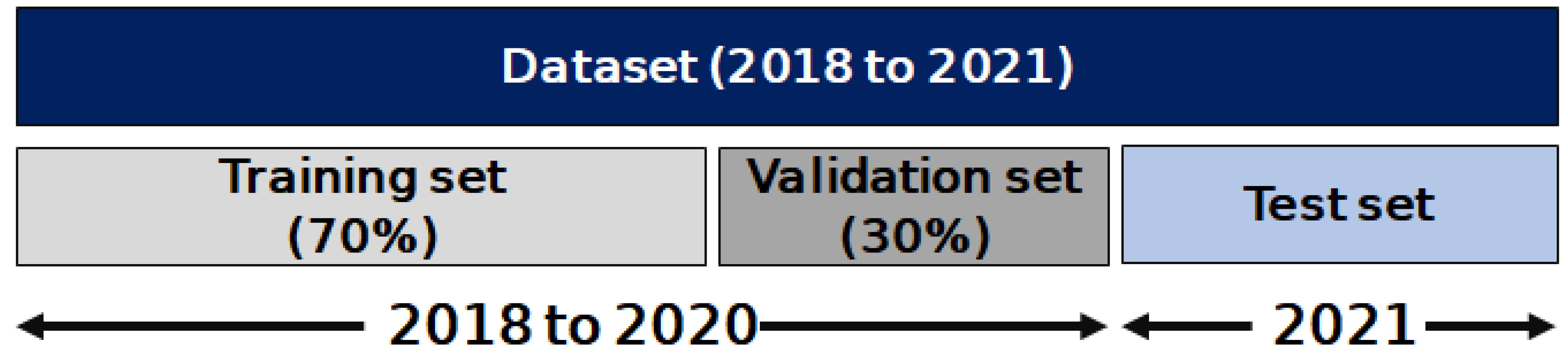
2.2. Data Collection
2.3. Spatial Interpolation Process Using IDW
2.4. Construction of 2D Visibility Estimation Model Using RF Method
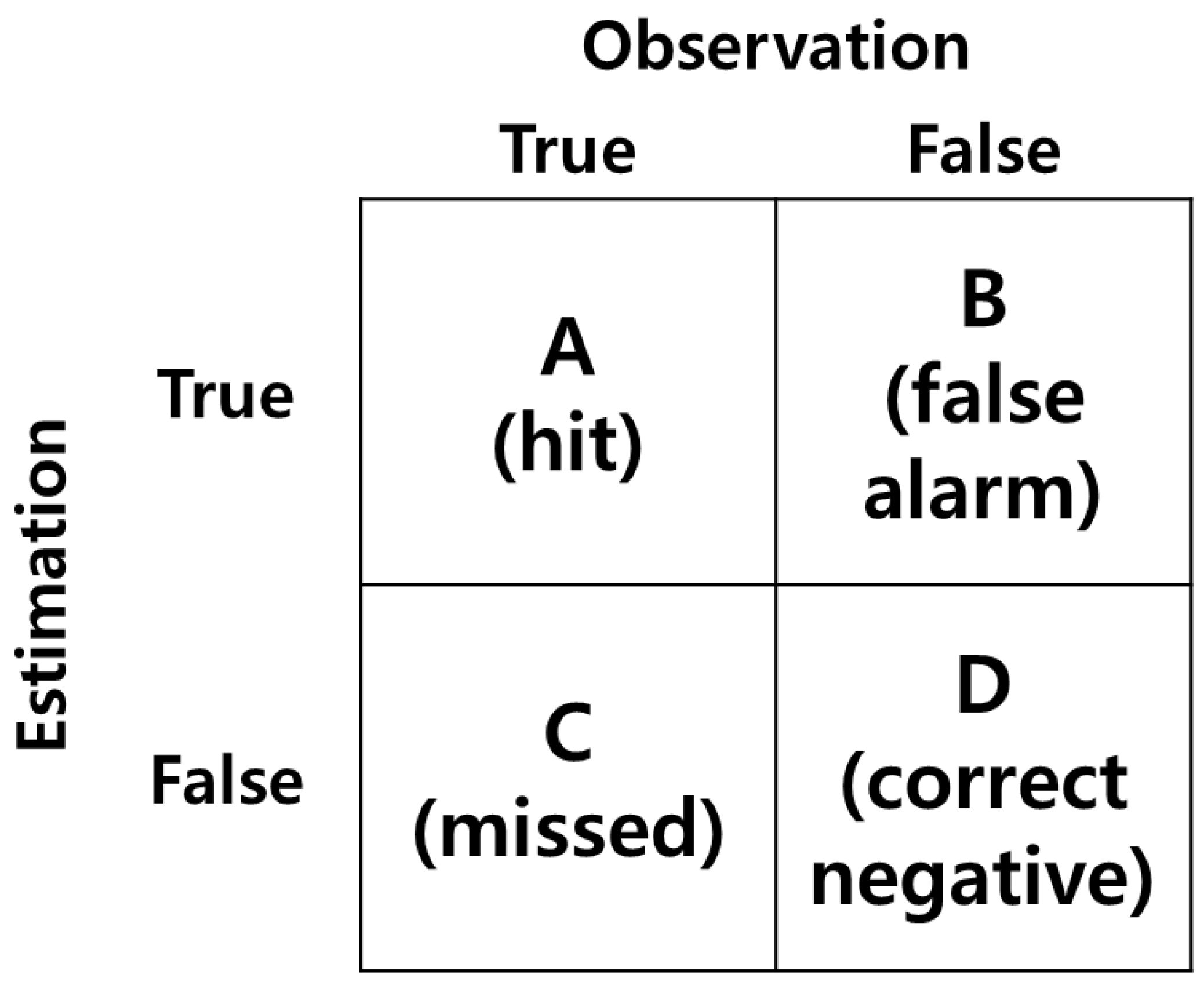
2.5. Assessment of Visibility Estimation Model
2.6. Effect of Geostatistical Interpolation on Visibility Estimation Model
3. Results and Discussion
3.1. Variable Importance
3.2. Visibility Estimation: Case Studies
3.3. Effect of Geostatistical Interpolation on Visibility Estimation Model
3.4. Assessment of Visibility Estimation Model
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fita, L.; Polcher, J.; Giannaros, T.M.; Lorenz, T.; Milovac, J.; Sofiadis, G.; Katragkou, E.; Bastin, S. CORDEX-WRF v1.3: Development of a module for the Weather Research and Forecasting (WRF) model to support the CORDEX community. Geosci. Model Dev. 2019, 12, 1029–1066. [Google Scholar] [CrossRef] [Green Version]
- Cornejo-Bueno, S.; Casillas-Pérez, D.; Cornejo-Bueno, L.; Chidean, M.I.; Caamaño, A.J.; Sanz-Justo, J.; Casanova-Mateo, C.; Salcedo-Sanz, S. Persistence analysis and prediction of low-visibility events at Valladolid airport, Spain. Symmetry 2020, 12, 1045. [Google Scholar] [CrossRef]
- Xiao, S.; Wang, Q.; Cao, J.; Huang, R.-J.; Chen, W.; Han, Y.; Xu, H.; Liu, S.; Zhou, Y.; Wang, P. Long-term trends in visibility and impacts of aerosol composition on visibility impairment in Baoji, China. Atmos. Res. 2014, 149, 88–95. [Google Scholar] [CrossRef]
- Babari, R.; Hautière, N.; Dumont, É.; Paparoditis, N.; Misener, J. Visibility monitoring using conventional roadside cameras–Emerging applications. Transp. Res. C Emerg. Technol. 2012, 22, 17–28. [Google Scholar] [CrossRef] [Green Version]
- Gultepe, I.; Sharman, R.; Williams, P.D.; Zhou, B.; Ellrod, G.; Minnis, P.; Trier, S.; Griffin, S.; Yum, S.; Gharabaghi, B. A review of high impact weather for aviation meteorology. Pure Appl. Geophys. 2019, 176, 1869–1921. [Google Scholar] [CrossRef]
- Shan, Y.; Zhang, R.; Gultepe, I.; Zhang, Y.; Li, M.; Wang, Y. Gridded visibility products over marine environments based on artificial neural network analysis. Appl. Sci. 2019, 9, 4487. [Google Scholar] [CrossRef] [Green Version]
- U.S. Department of Transportation Federal Highway Administration. Low Visibility. Available online: https://ops.fhwa.dot.gov/weather/weather_events/low_visibility.htm (accessed on 1 June 2022).
- Hyslop, N.P. Impaired visibility: The air pollution people see. Atmos. Environ. 2009, 43, 182–195. [Google Scholar] [CrossRef]
- Stocker, T. Climate Change 2013: The Physical Science Basis: Working Group I Contribution to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Singh, A.; George, J.P.; Iyengar, G.R. Prediction of fog/visibility over India using NWP Model. J. Earth Syst. Sci. 2018, 127, 26. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Zhang, G. Case Studies of Low-Visibility Forecasting in Falling Snow with WRF Model. J. Geophys. Res. Atmos. 2017, 122, 862–874. [Google Scholar] [CrossRef]
- Kim, M.; Lee, K.; Lee, Y.H. Visibility data assimilation and prediction using an observation network in South Korea. Pure Appl. Geophys. 2020, 177, 1125–1141. [Google Scholar] [CrossRef]
- Kim, B.-Y.; Cha, J.W.; Chang, K.-H.; Lee, C. Visibility Prediction over South Korea Based on Random Forest. Atmosphere 2021, 12, 552. [Google Scholar] [CrossRef]
- Ortega, L.C.; Otero, L.D.; Solomon, M.; Otero, C.E.; Fabregas, A. Deep learning models for visibility forecasting using climatological data. Int. J. Forecast. 2022, in press. [Google Scholar] [CrossRef]
- Chaabani, H.; Werghi, N.; Kamoun, F.; Taha, B.; Outay, F. Estimating meteorological visibility range under foggy weather conditions: A deep learning approach. Procedia Comput. Sci. 2018, 141, 478–483. [Google Scholar] [CrossRef]
- Palvanov, A.; Cho, Y.I. Visnet: Deep convolutional neural networks for forecasting atmospheric visibility. Sensors 2019, 19, 1343. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Fu, H.; Lo, W.-L. Meteorological visibility evaluation on webcam weather image using deep learning features. Int. J. Comput. Theory Eng. 2017, 9, 455–461. [Google Scholar] [CrossRef] [Green Version]
- You, Y.; Lu, C.; Wang, W.; Tang, C.-K. Relative CNN-RNN: Learning relative atmospheric visibility from images. IEEE Trans. Image Processing ITIP 2018, 28, 45–55. [Google Scholar] [CrossRef] [PubMed]
- Song, M.; Han, X.; Liu, X.F.; Li, Q. Visibility estimation via deep label distribution learning in cloud environment. J. Cloud Comput. 2021, 10, 46. [Google Scholar] [CrossRef]
- Lo, W.L.; Zhu, M.; Fu, H. Meteorology visibility estimation by using multi-support vector regression method. J. Adv. Inf. Technol. 2020, 11, 40–47. [Google Scholar] [CrossRef]
- Lo, W.L.; Chung, H.S.H.; Fu, H. Experimental evaluation of pso based transfer learning method for meteorological visibility estimation. Atmosphere 2021, 12, 828. [Google Scholar] [CrossRef]
- Li, J.; Lo, W.L.; Fu, H.; Chung, H.S.H. A transfer learning method for meteorological visibility estimation based on feature fusion method. Appl. Sci. 2021, 11, 997. [Google Scholar] [CrossRef]
- Kim, J.; Kim, S.H.; Seo, H.W.; Wang, Y.V.; Lee, Y.G. Meteorological characteristics of fog events in Korean smart cities and machine learning based visibility estimation. Atmos. Res. 2022, 275, 106239. [Google Scholar] [CrossRef]
- Bremnes, J.B.; Michaelides, S.C. Probabilistic visibility forecasting using neural networks. In Fog and Boundary Layer Clouds: Fog Visibility and Forecasting; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1365–1381. [Google Scholar]
- Marzban, C.; Leyton, S.; Colman, B. Ceiling and visibility forecasts via neural networks. Weather. Forecast. 2007, 22, 466–479. [Google Scholar] [CrossRef] [Green Version]
- Ortega, L.; Otero, L.D.; Otero, C. Application of machine learning algorithms for visibility classification. In Proceedings of the 2019 IEEE International Systems Conference (SysCon), Orlando, FL, USA, 8–11 April 2019; pp. 1–5. [Google Scholar]
- Bari, D.; Ouagabi, A. Machine-learning regression applied to diagnose horizontal visibility from mesoscale NWP model forecasts. SN Appl. Sci. 2020, 2, 556. [Google Scholar] [CrossRef] [Green Version]
- Chung, Y.; Kim, H.; Yoon, M. Observations of visibility and chemical compositions related to fog, mist and haze in South Korea. Water Air Soil Pollut. 1999, 111, 139–157. [Google Scholar] [CrossRef]
- Lee, S.H.; Kim, D.H.; Lee, H.W. Satellite-based assessment of the impact of sea-surface winds on regional atmospheric circulations over the Korean Peninsula. Int. J. Remote Sens. 2008, 29, 331–354. [Google Scholar] [CrossRef]
- Choi, S.W.; Kim, S.S. The past and current status of endangered butterflies in Korea. Entomol. Sci. 2012, 15, 1–12. [Google Scholar] [CrossRef]
- Jha, D.K.; Sabesan, M.; Das, A.; Vinithkumar, N.; Kirubagaran, R. Evaluation of Interpolation Technique for Air Quality Parameters in Port Blair, India. Univers. J. Environ. 2011, 1, 301–310. [Google Scholar]
- Gómez-Losada, Á.; Santos, F.M.; Gibert, K.; Pires, J.C. A data science approach for spatiotemporal modelling of low and resident air pollution in Madrid (Spain): Implications for epidemiological studies. Comput. Environ. Urban Syst. 2019, 75, 1–11. [Google Scholar] [CrossRef]
- Shukla, K.; Kumar, P.; Mann, G.S.; Khare, M. Mapping spatial distribution of particulate matter using Kriging and Inverse Distance Weighting at supersites of megacity Delhi. Sustain. Cities Soc. 2020, 54, 101997. [Google Scholar] [CrossRef]
- Tella, A.; Balogun, A.-L. Prediction of ambient PM10 concentration in Malaysian cities using geostatistical analyses. J. Geo Spat. Sci. Technol. 2021, 1, 115–127. [Google Scholar]
- Duynkerke, P.G. Radiation fog: A comparison of model simulation with detailed observations. Mon. Weather Rev. 1991, 119, 324–341. [Google Scholar] [CrossRef] [Green Version]
- Prusov, V.; Doroshenko, A. Computational Techniques for Modeling Atmospheric Processes; IGI Global: Hershey, PA, USA, 2017. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding variable importances in forests of randomized trees. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Van, R.G.; Drake, F. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Torre-Tojal, L.; Bastarrika, A.; Boyano, A.; Lopez-Guede, J.M.; Graña, M. Above-ground biomass estimation from LiDAR data using random forest algorithms. J. Comput. Sci. 2022, 58, 101517. [Google Scholar] [CrossRef]
- Mutanga, O.; Adam, E.; Cho, M.A. High density biomass estimation for wetland vegetation using WorldView-2 imagery and random forest regression algorithm. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 399–406. [Google Scholar] [CrossRef]
- Kuo, C.-Y.; Cheng, F.-C.; Chang, S.-Y.; Lin, C.-Y.; Chou, C.C.; Chou, C.-H.; Lin, Y.-R. Analysis of the major factors affecting the visibility degradation in two stations. J. Air Waste Manag. Assoc. 2013, 63, 433–441. [Google Scholar] [CrossRef] [Green Version]
- Elias, T.; Jolivet, D.; Mazoyer, M.; Dupont, J.-C. Favourable and Unfavourable Scenarii of Radiative Fog Formation Defined by Ground-Based and Satellite Observation Data. Aerosol Air Qual. Res. 2018, 18, 145–164. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Zhao, T.; Liu, D.; Gong, S.; Xu, J.; Ma, X. Quantifying the influences of PM2.5 and relative humidity on change of atmospheric visibility over recent winters in an urban area of East China. Atmosphere 2020, 11, 461. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Tiede, D.; Dabiri, Z.; Sudmanns, M.; Lang, S. Dwelling extraction in refugee camps using CNN-first experiences and lessons learnt. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 161–166. [Google Scholar] [CrossRef] [Green Version]
- Lathifah, S.N.; Nhita, F.; Aditsania, A.; Saepudin, D. Rainfall Forecasting using the Classification and Regression Tree (CART) Algorithm and Adaptive Synthetic Sampling (Study Case: Bandung Regency). In Proceedings of the 2019 7th International Conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–5. [Google Scholar]
- Krishna, P.R.; Ahammad, P.; Sethuraman, R. Hybrid Prediction Models for Rainfall Forecasting. Ann. Rom. Soc. Cell Biol. 2021, 25, 40–46. [Google Scholar]
- Manimannan, G.; Priya, R.L.; Reena, K.J.; Priya, S.K. Climate Changes of Tamilnadu Based on Rainfall Data Using Data Mining Model Evaluation and Cross Validation. IOSR J. Comput. Eng. 2018, 20, 32–38. [Google Scholar]
- New, M.; Hulme, M.; Jones, P. Representing twentieth-century space–time climate variability. Part II: Development of 1901–96 monthly grids of terrestrial surface climate. J. Clim. 2000, 13, 2217–2238. [Google Scholar] [CrossRef]
- Kirkwood, C.; Economou, T.; Pugeault, N.; Odbert, H. Bayesian deep learning for spatial interpolation in the presence of auxiliary information. Math. Geosci. 2022, 54, 507–531. [Google Scholar] [CrossRef]
- Gahrooei, M.R.; Yan, H.; Paynabar, K.; Shi, J. Multiple tensor-on-tensor regression: An approach for modeling processes with heterogeneous sources of data. Technometrics 2021, 63, 147–159. [Google Scholar] [CrossRef]
- Rajput, M.; Gahrooei, M.R.; Augenbroe, G. A statistical model of the spatial variability of weather for use in building simulation practice. Build. Environ. 2021, 206, 108331. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Site | Parameter (Abbreviation) | Unit | Temporal Resolution |
|---|---|---|---|---|
| Target variable | ASOS a (KMA b) | Visibility | km | Hourly |
| Meteorological input variables | AWS c (KMA) | Air temperature (T) | °C | |
| Pressure (P) | hPa | |||
| Wind speed (WS) | m/s | |||
| Humidity (Humid) | % | |||
| Precipitation (Precip) | mm | |||
| Delta temperature (ΔT) ΔT24, ΔT12, ΔT06 | °C | |||
| Air pollution input variables | AirKorea (KECO d) | O3 concentration (O3) | ppm | |
| CO concentration (CO) | ppm | |||
| SO2 concentration (SO2) | ppm | |||
| NO2 concentration (NO2) | ppm | |||
| PM10 concentration (PM10) | µg/cm3 | |||
| PM2.5 concentration (PM2.5) | µg/cm3 | |||
| Other input parameters | Solar zenith angle (SZA) | ° (degrees) | ||
| Number of ASOS Sites | Statistical Values | ||
|---|---|---|---|
| Total | 94 sites | Minimum | 0.05° |
| Distance ≤ 0.05° | 2 sites | Maximum | 1.8° |
| Distance ≤ 0.1° | 4 sites | Average | 0.28° |
| Distance ≤ 0.2° | 28 sites | Standard deviation | 0.23° |
| Distance ≤ 0.3° | 69 sites | ||
| Distance ≤ 0.4° | 87 sites | ||
| Visibility Range | Note | |
|---|---|---|
| A | 10 to 20 km | Good visibility (clear air) |
| B | 5 to 10 km | Moderate visibility |
| C | 0 to 5 km | Poor visibility |
| Station Name (Code) | Latitude | Longitude | Poor Visibility Cases | Notes |
|---|---|---|---|---|
| Daegwallyeong (100) | 37.6771° | 128.7183° | 10,981 | - Coastal area AirKorea sites are sparsely distributed |
| Incheon (112) | 37.4776° | 126.6244° | 12,242 | - Coastal areaAir Korea sites are sparsely distributed |
| Imsil (244) | 35.6120° | 127.2856° | 12,242 | - Inland area |
| Site Name | Distance between Site and Nearest Site | Absolute Mean Bias (Correlation Coefficient) | |
|---|---|---|---|
| Errororiginal | Erroradditional | ||
| Daegwallyeong | 0.19° | 1.56 km (0.83) | 1.74 km (0.81) |
| Incheon | 0.29° | 1.45 km (0.93) | 1.92 km (0.91) |
| Imsil | 0.22° | 1.81 km (0.79) | 1.75 km (0.78) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, W.; Park, J.; Kim, D.; Park, J.; Kim, S.; Lee, H. Development of Two-Dimensional Visibility Estimation Model Using Machine Learning: Preliminary Results for South Korea. Atmosphere 2022, 13, 1233. https://doi.org/10.3390/atmos13081233
Choi W, Park J, Kim D, Park J, Kim S, Lee H. Development of Two-Dimensional Visibility Estimation Model Using Machine Learning: Preliminary Results for South Korea. Atmosphere. 2022; 13(8):1233. https://doi.org/10.3390/atmos13081233
Chicago/Turabian StyleChoi, Wonei, Junsung Park, Daewon Kim, Jeonghyun Park, Serin Kim, and Hanlim Lee. 2022. "Development of Two-Dimensional Visibility Estimation Model Using Machine Learning: Preliminary Results for South Korea" Atmosphere 13, no. 8: 1233. https://doi.org/10.3390/atmos13081233