
Lightning Whistler Wave Speech Recognition Based on Grey Wolf Optimization Algorithm
 , ,
, ,
Abstract
:1. Introduction
2. Experimental
2.1. Data Source and Methodology
- Model hyperparameter optimization flow: on the validation set and train set, MFCC features of audio data are used as a basis to implement automatic hyperparameter searching for the LSTM neural network by the GWO algorithm. This is the core part of this article, so we will introduce it in detail step by step in Section 2.2, Section 2.3 and Section 2.4
- Model training flow: The LSTM neural network is set up using the optimal hyperparameters searched by GWO, and the recognition model is obtained by supervised learning on the train set, see the following paper for more details [12]
- Model application flow: The test set is fed into the recognition model to obtain results and evaluate the performance of the model. We analyzed the effect of the recognition model from different perspectives and compared our model with the recognition model obtained by Yuan et al. [12] to prove that our model performed better than the latter. Please see Section 3 for details.
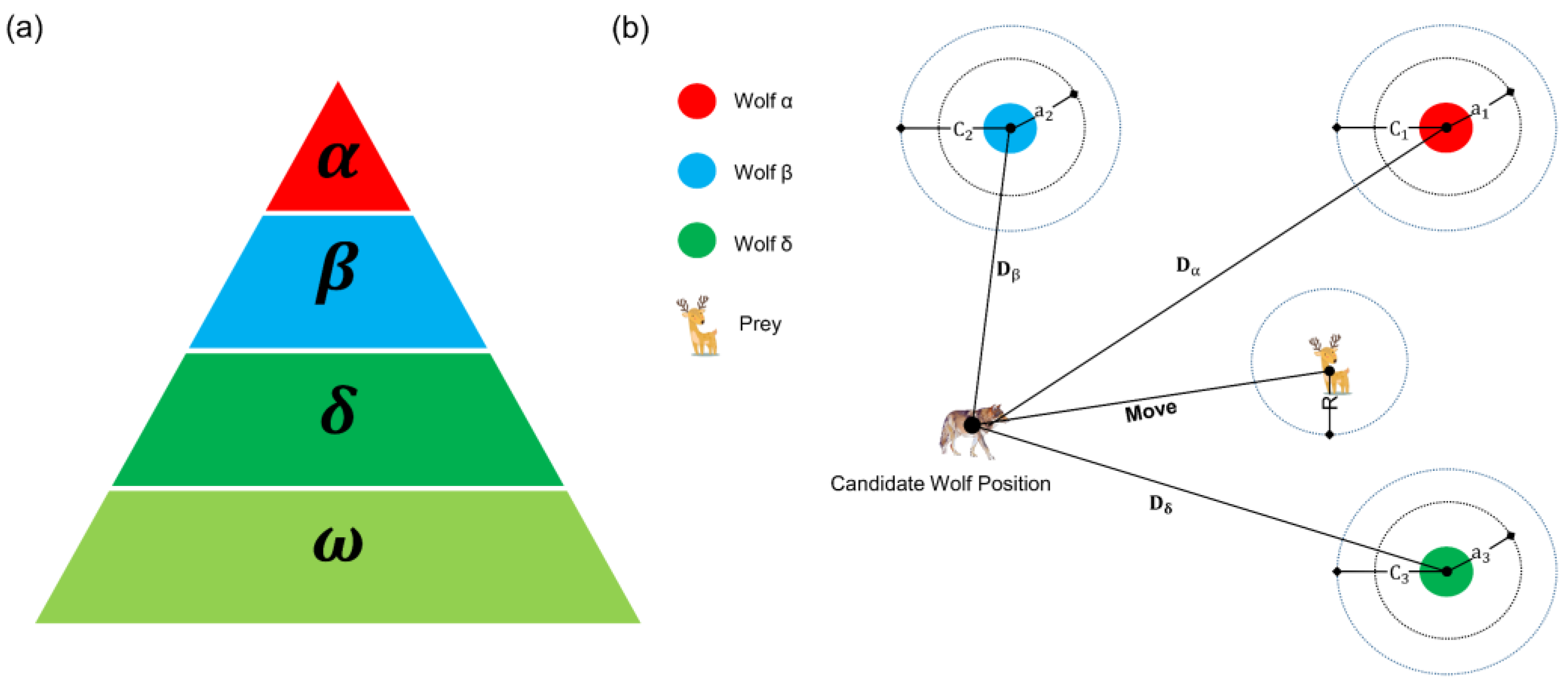
2.2. Grey Wolf Optimization
2.3. LSTM
2.4. GWO + LSTM Algorithm
- Initialize the GWO parameters (e.g., ,, ) and configure some parameters of the LSTM. For GWO, we set the grey wolf pack size to 5, the number of LSTM hyperparameters (hu and lr) to be optimized to 2, the upper and lower search (i.e., optimization) spaces to hu and lr, which are self-defined in Table 1 below. Initialize the spatial position of the wolf population, in this study this is a (5, 2) matrix, noting that the dimension of the spatial location is the number of hyperparameters to be optimized. Set the max iterations to 5, which is the termination condition of the algorithm. For the LSTM neural network, set the epoch to 5 and batch size to 16
- In each iteration, hyperparameters represented by every grey wolf position are substituted into the LSTM model for training and evaluation. In this step the train set is input into the LSTM model for training. Further, the trained model is utilized to evaluate the val data to obtain the accuracy metric. Next, according to Equation (6), we get the fitness of every wolf in this iteration. The smaller the fitness we get, the better the performance of the trained model we have. Finally, the three wolves with the smallest fitness in this iteration are selected or regarded as wolves , , and
- The top three wolves , , selected from step 2 lead the grey wolf pack to search for prey, and the position of each grey wolf is updated and changed according to Formulas (2)–(5)
- Repeat the above steps 2–3 until the termination condition (i.e., the max iterations) is met. The hyperparameter corresponding to the position of the final output wolf is the optimal hyperparameter of the LSTM model obtained by GWO searching. It is worth noting that for the process of GWO, it can be considered that the grey wolf position denotes the hyperparameter vector; after GWO completes all the iterations, wolf ’s position denotes both the prey position and the optimal hyperparameter vector.
3. Results
3.1. Comparison of Quantitative Results of Model Performance
3.2. Comparison of Visualization Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Helliwell, R. Whistlers and Related Ionospheric Phenomena; Courier Corporation: Chelmsford, MA, USA, 1965. [Google Scholar]
- Rycroft, M.J. Some Effects in the Middle Atmosphere Due to Lightning. J. Atmos. Terr. Phys. 1994, 56, 343–348. [Google Scholar] [CrossRef]
- Bayupati, I.P.A.; Kasahara, Y.; Goto, Y. Study of Dispersion of Lightning Whistlers Observed by Akebono Satellite in the Earth’s Plasmasphere. IEICE Trans. Commun. 2012, E95.B, 3472–3479. [Google Scholar] [CrossRef] [Green Version]
- Oike, Y.; Kasahara, Y.; Goto, Y. Spatial Distribution and Temporal Variations of Occurrence Frequency of Lightning Whistlers Observed by VLF/WBA Onboard Akebono. Radio Sci. 2014, 49, 753–764. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, Q.; Yang, D.; Liu, Q.; Zhima, Z.; Shen, X. Automatic recognition algorithm of lightning whistlers observed by the Search Coil Magnetometer onboard the Zhangheng-1 Satellite. Chin. J. Geophys. 2021, 64, 3905–3924. [Google Scholar]
- Shen, X.H.; Zhang, X.M.; Cui, J.; Zhou, X.; Jiang, W.L.; Gong, L.X.; Liu, Q.Q. Remote sensing application in earthquake science research and geophysical fields exploration satellite mission in China. J. Remote Sens. 2018, 22, 1–16. [Google Scholar]
- Zhang, X.M.; Qian, J.D.; Shen, X.H.; Liu, J.; Wang, Y.L.; Huang, J.P.; Zhao, S.F.; Ouyang, X.Y. The Seismic Application Progress in Electromagnetic Satellite and Future Devel-opment. Earthquake 2020, 40, 18–37. [Google Scholar]
- Luo, X.; Niu, S.; Zuo, Y.; Tao, Y. Simulation of high-energy electron diffusion in the inner radiation belt based on AKEBONO whistler wave parameters. Comput. Phys. 2017, 34, 335–343. [Google Scholar] [CrossRef]
- Horne, R.B.; Glauert, S.A.; Meredith, N.; Boscher, D.; Maget, V.; Heynderickx, D.; Pitchford, D. Space Weather Effects on Satellites and Forecasting the Earth’s Electron Radiation Belts with SPACECAST. Space Weather 2013, 11, 169–186. [Google Scholar] [CrossRef] [Green Version]
- Yuan, J.; Wang, Q.; Zhang, X.; Yang, D.; Wang, Z.; Zhang, L.; Shen, X.; Zeren, Z. Advances in the automatic detection algorithms for lightning whistlers recorded by electromagnetic satellite data. Chin. J. Geophys. 2021, 64, 1471–1495. [Google Scholar]
- Wang, Q.; Huang, J.; Zhang, X.; Shen, X.; Yuan, S.; Zeng, L.; Cao, J. China Seismo-Electromagnetic Satellite search coil magnetometer data and initial results. Earth Planet. Phys. 2018, 2, 462–468. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, Z.; Zeren, Z.; Wang, Z.; Feng, J.; Shen, X.; Wu, P.; Wang, Q.; Yang, D.; Wang, T.; et al. Automatic recognition algorithm of the lightning whistler waves by using speech processing technology. Chin. J. Geophys. 2022, 65, 882–897. [Google Scholar] [CrossRef]
- Begam, M. Voice Recognition Algorithms Using Mel Frequency Cepstral Coefficient (MFCC) and Dynamic Time Warping (DTW) Techniques. Comput. Res. Repos. 2010, 2, 138–143. [Google Scholar]
- Yang, F.; Wang, P.; Zhang, Y.; Zheng, L.; Lu, J. Survey of Swarm Intelligence Optimization Algorithms. In Proceedings of the 2017 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 27–29 October 2017; pp. 544–549. [Google Scholar]
- Kandasamy, P. Literature Review on Grey Wolf Optimization Techniques. Int. J. Sci. Res. (IJSR) 2020, 9, 1765–1769. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Karaboga, D.; Basturk, B. Artificial Bee Colony (ABC) Optimization Algorithm for Solving Constrained Optimization Problems. In Foundations of Fuzzy Logic and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2007; pp. 789–798. [Google Scholar]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant Colony Optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Eusuff, M.; Lansey, K.; Pasha, F. Shuffled Frog-Leaping Algorithm: A Memetic Meta-Heuristic for Discrete Optimization. Eng. Optim. 2006, 38, 129–154. [Google Scholar] [CrossRef]
- Yang, X.-S.; Deb, S. Cuckoo Search via Lévy Flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Wang, J.-S.; Li, S.-X. An Improved Grey Wolf Optimizer Based on Differential Evolution and Elimination Mechanism. Sci. Rep. 2019, 9, 7181. [Google Scholar] [CrossRef]
- Zhou, B.; Yang, Y.; Zhang, Y.; Gou, X.; Cheng, B.; Wang, J.; Li, L. Magnetic Field Data Processing Methods of the China Seismo-Electromagnetic Satellite. Earth Planet. Phys. 2018, 2, 455–461. [Google Scholar] [CrossRef]
- Molau, S.; Pitz, M.; Schluter, R.; Ney, H. Computing Mel-Frequency Cepstral Coefficients on the Power Spectrum. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Proceedings (Cat. No. 01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; Volume 1, pp. 73–76. [Google Scholar]
- Browne, M.W. Cross-Validation Methods. J. Math. Psychol. 2000, 44, 108–132. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Emary, E.; Zawbaa, H.M.; Grosan, C.; Hassenian, A.E. Feature Subset Selection Approach by Gray-Wolf Optimization. In Afro-European Conference for Industrial Advancement; Springer: Cham, Switzerland, 2015; pp. 1–13. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, Y.; Li, Z.; Pan, W. Grey Wolf Optimizer for Unmanned Combat Aerial Vehicle Path Planning. Adv. Eng. Softw. 2016, 99, 121–136. [Google Scholar] [CrossRef] [Green Version]
- Song, H.; Sulaiman, M.; Mohamed, M.R. An Application of Grey Wolf Optimizer for Solving Combined Economic Emission Dispatch Problems. Int. Rev. Model. Simulations (IREMOS) 2014, 7, 838. [Google Scholar] [CrossRef]
- Lu, C. Research on Multi-Objective Shop Scheduling Problem with Controllable Processing Time. Ph.D. Thesis, Huazhong University of Science and Technology, Wuhan, China, 2017. [Google Scholar]
- Sánchez, D.; Melin, P.; Castillo, O. A Grey Wolf Optimizer for Modular Granular Neural Networks for Human Recognition. Comput. Intell. Neurosci. 2017, 2017, e4180510. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Niu, P.; Niu, S.; Liu, N.; Chang, L. The Defect of the Grey Wolf Optimization Algorithm and Its Verification Method. Knowl.-Based Syst. 2019, 171, 37–43. [Google Scholar] [CrossRef]
- Zhang, X.F.; Wang, X.Y. Review of Gray Wolf Optimization Algorithm Research. Comput. Sci. 2019, 46, 30–38. [Google Scholar]
- Yang, B.; Zhang, X.; Yu, T.; Shu, H.; Fang, Z. Grouped Grey Wolf Optimizer for Maximum Power Point Tracking of Doubly-Fed Induction Generator Based Wind Turbine. Energy Convers. Manag. 2017, 133, 427–443. [Google Scholar] [CrossRef]
- Gao, Z.-M.; Zhao, J. An Improved Grey Wolf Optimization Algorithm with Variable Weights. Comput. Intell. Neurosci. 2019, 2019, e2981282. [Google Scholar] [CrossRef]
- Mehrotra, H.; Pal, S.K. Using Chaos in Grey Wolf Optimizer and Application to Prime Factorization. In Soft Computing for Problem Solving; Springer: Singapore, 2019; pp. 25–43. [Google Scholar] [CrossRef] [Green Version]
- Malik, M.R.S.; Mohideen, E.R.; Ali, L. Weighted Distance Grey Wolf Optimizer for Global Optimization Problems. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 10–12 December 2015; pp. 1–6. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A Novel Connectionist System for Unconstrained Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 855–868. [Google Scholar] [CrossRef] [Green Version]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Gers, F.A.; Eck, D.; Schmidhuber, J. Applying LSTM to Time Series Predictable Through Time-Window Approaches. In Neural Nets WIRN Vietri-01; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2002; pp. 193–200. [Google Scholar] [CrossRef]
- Pan, J.; Jing, B.; Jiao, X.; Wang, S. Analysis and Application of Grey Wolf Optimizer-Long Short-Term Memory. IEEE Access 2020, 8, 121460–121468. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Ruuska, S.; Hämäläinen, W.; Kajava, S.; Mughal, M.; Matilainen, P.; Mononen, J. Evaluation of the Confusion Matrix Method in the Validation of an Automated System for Measuring Feeding Behaviour of Cattle. Behav. Process. 2018, 148, 56–62. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters to Be Optimized | Searching Space |
|---|---|
| The number of hidden units (hu) | (64, 256) |
| learning rate (lr) | (0.01, 0.1) |
| Algorithm | hu | lr | Batch | Epoch | Optimizer | Loss Function | |
|---|---|---|---|---|---|---|---|
| Parameters | |||||||
| LSTM | 128 | 0.01 | 16 | 10 | Adagrad | binary_cross entropy | |
| GWO + LSTM | 185 | 0.1 | 16 | 10 | Adagrad | binary_cross entropy | |
| Data | Algorithm | (hu, lr) | Training Time (min) * | Evaluation Metrics | ||||
|---|---|---|---|---|---|---|---|---|
| AUC | Accuracy | F1 Score | Precision | Recall | ||||
| Train set | LSTM | (128, 0.01) | 0.27 | 0.9627 | 0.9637 | 0.9621 | 0.9465 | 0.9787 |
| GWO + LSTM | (185, 0.1) | 0.22 | 0.9771 | 0.9775 | 0.9767 | 0.9635 | 0.9904 | |
| Test set | LSTM | - | - | 0.9334 | 0.9354 | 0.9316 | 0.9078 | 0.9577 |
| GWO + LSTM | - | - | 0.954 | 0.9551 | 0.9529 | 0.9319 | 0.9752 | |
| Pack Size | Iterations | (hu, lr) | Searching Time (min) 1 | Training Time (min) 2 | Evaluation Metrics | ||||
|---|---|---|---|---|---|---|---|---|---|
| AUC | Accuracy | F1 Score | Precision | Recall | |||||
| 5 | 5 | (185, 0.1) | 2.88 | 0.22 | 0.954 | 0.9551 | 0.9529 | 0.9319 | 0.9752 |
| 6 | 5 | (197, 0.048) | 3.56 | 0.2 | 0.9532 | 0.9544 | 0.9522 | 0.9338 | 0.9721 |
| 7 | 5 | (182, 0.1) | 4.2 | 0.2 | 0.9543 | 0.9553 | 0.9534 | 0.9353 | 0.9726 |
| 8 | 5 | (177, 0.1) | 4.73 | 0.18 | 0.9547 | 0.9556 | 0.9537 | 0.9347 | 0.9738 |
| 9 | 5 | (181, 0.1) | 5.44 | 0.18 | 0.9545 | 0.9557 | 0.9535 | 0.9334 | 0.9749 |
| 10 | 5 | (146, 0.08) | 5.96 | 0.18 | 0.9537 | 0.9547 | 0.9528 | 0.9346 | 0.972 |
| 11 | 5 | (201, 0.098) | 6.56 | 0.19 | 0.954 | 0.9552 | 0.9531 | 0.9334 | 0.974 |
| 12 | 5 | (187, 0.098) | 7.15 | 0.19 | 0.9542 | 0.9554 | 0.9532 | 0.9334 | 0.9743 |
| Pack Size | Iterations | (hu, lr) | Searching Time (min) | Training Time (min) | Evaluation Metrics | ||||
|---|---|---|---|---|---|---|---|---|---|
| AUC | Accuracy | F1 Score | Precision | Recall | |||||
| 5 | 5 | (185, 0.1) | 2.88 | 0.22 | 0.954 | 0.9551 | 0.9529 | 0.9319 | 0.9752 |
| 5 | 6 | (191, 0.095) | 3.49 | 0.19 | 0.955 | 0.956 | 0.954 | 0.935 | 0.9741 |
| 5 | 7 | (87, 0.059) | 3.94 | 0.18 | 0.9527 | 0.9539 | 0.9517 | 0.9321 | 0.9725 |
| 5 | 8 | (131, 0.049) | 4.73 | 0.18 | 0.9504 | 0.9519 | 0.9493 | 0.9288 | 0.9714 |
| 5 | 9 | (167, 0.096) | 4.8 | 0.18 | 0.9542 | 0.9553 | 0.9532 | 0.9339 | 0.9738 |
| 5 | 10 | (117, 0.072 | 5.57 | 0.19 | 0.9535 | 0.9544 | 0.9527 | 0.9364 | 0.9699 |
| 5 | 11 | (146, 0.064) | 6.10 | 0.19 | 0.9525 | 0.9538 | 0.9514 | 0.9295 | 0.9747 |
| 5 | 12 | (145, 0.080) | 6.85 | 0.19 | 0.955 | 0.956 | 0.954 | 0.9348 | 0.9743 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, J.; Li, C.; Wang, Q.; Han, Y.; Wang, J.; Zeren, Z.; Huang, J.; Feng, J.; Shen, X.; Wang, Y. Lightning Whistler Wave Speech Recognition Based on Grey Wolf Optimization Algorithm. Atmosphere 2022, 13, 1828. https://doi.org/10.3390/atmos13111828
Yuan J, Li C, Wang Q, Han Y, Wang J, Zeren Z, Huang J, Feng J, Shen X, Wang Y. Lightning Whistler Wave Speech Recognition Based on Grey Wolf Optimization Algorithm. Atmosphere. 2022; 13(11):1828. https://doi.org/10.3390/atmos13111828
Chicago/Turabian StyleYuan, Jing, Chenxiao Li, Qiao Wang, Ying Han, Jialinqing Wang, Zhima Zeren, Jianping Huang, Jilin Feng, Xuhui Shen, and Yali Wang. 2022. "Lightning Whistler Wave Speech Recognition Based on Grey Wolf Optimization Algorithm" Atmosphere 13, no. 11: 1828. https://doi.org/10.3390/atmos13111828