
Development of Deep Learning Methodology for Maize Seed Variety Recognition Based on Improved Swin Transformer


Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Acquisition and Preprocessing
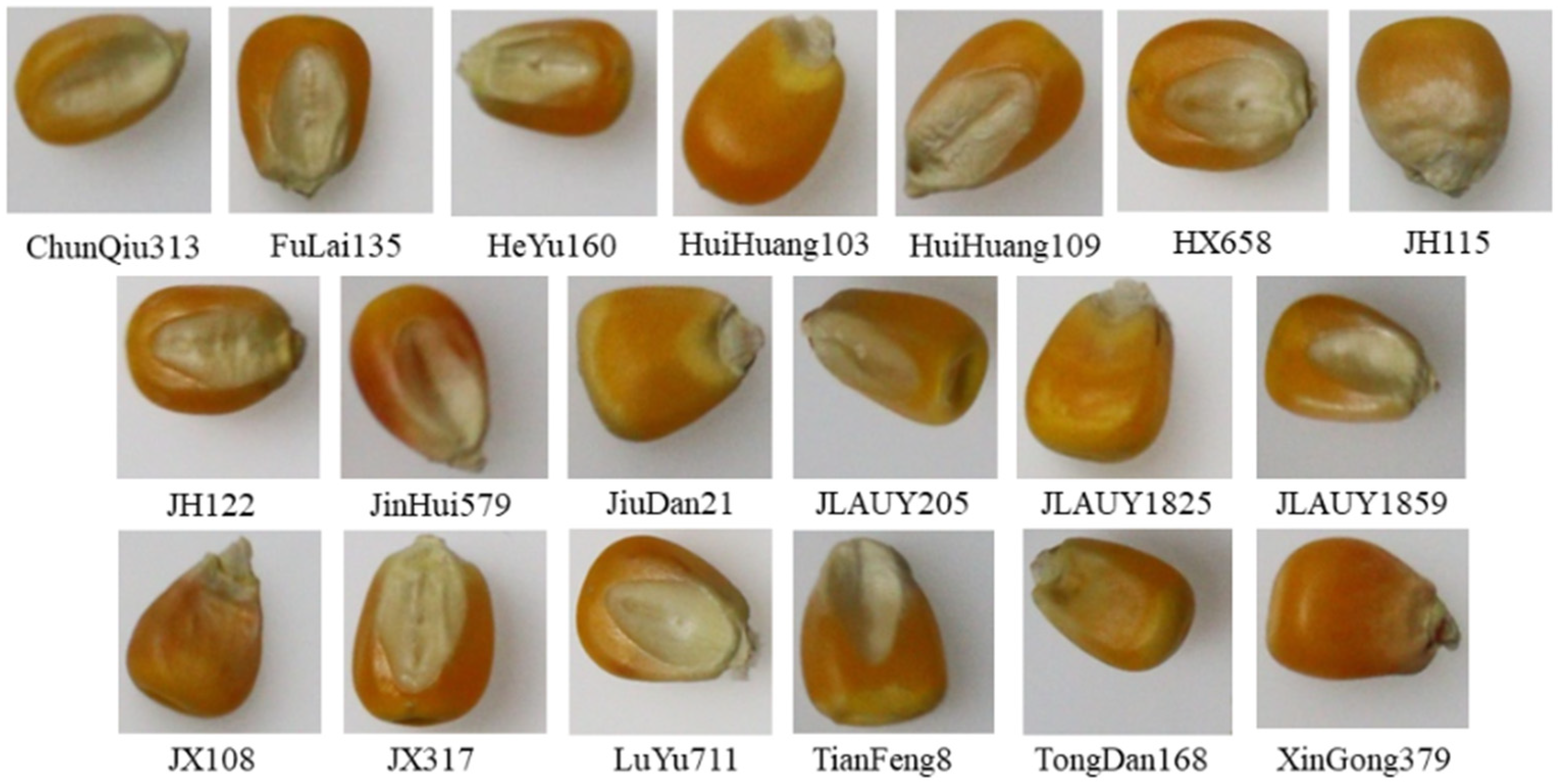
2.1.1. Data Source and Acquisition
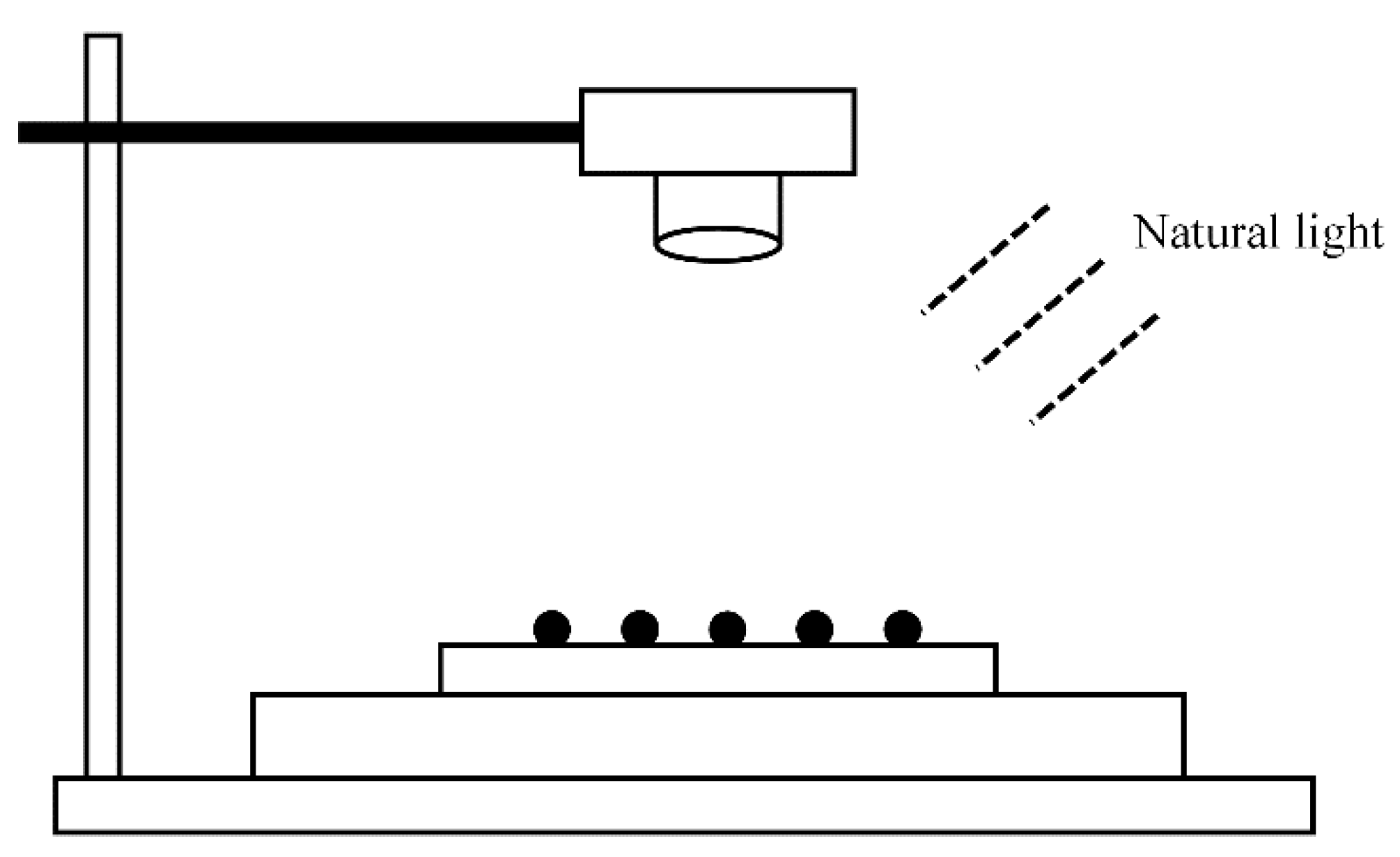
2.1.2. Image Preprocessing
2.2. Model Building
2.2.1. Transformer Model
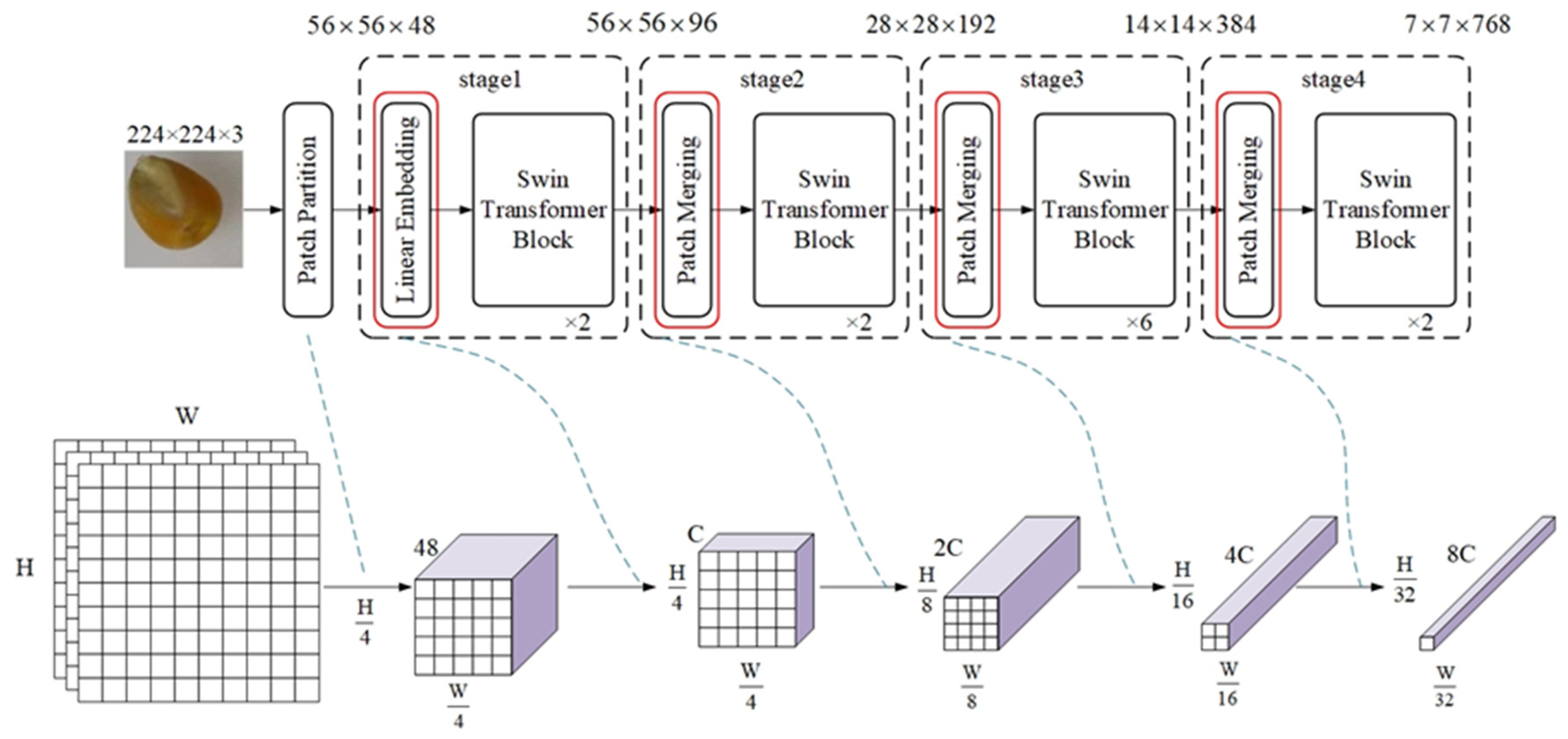
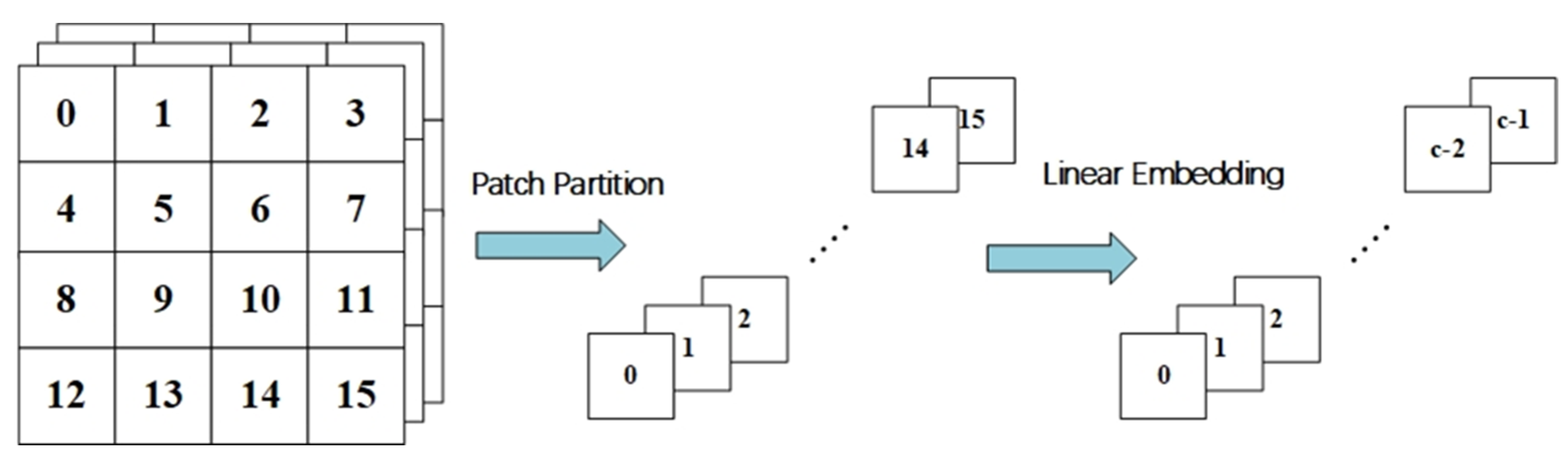
2.2.2. Swin Transformer Model
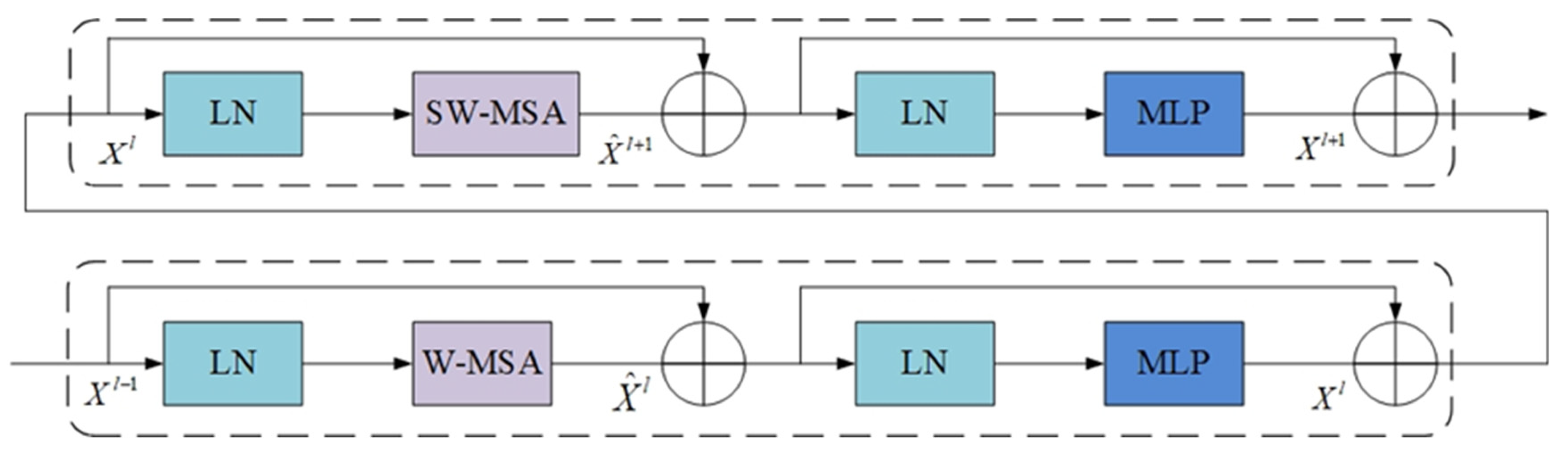
2.2.3. Swin Transformer Block
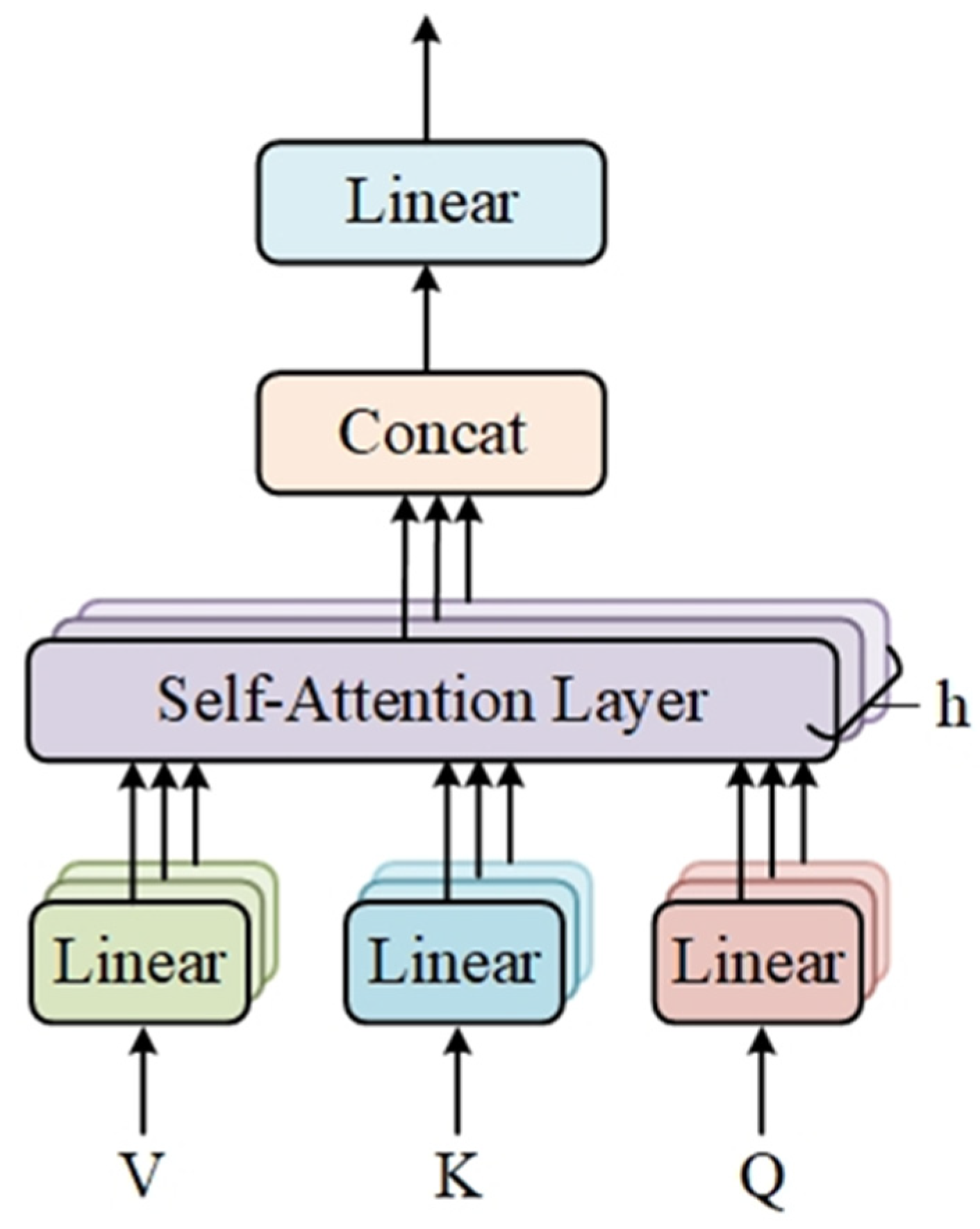
2.2.4. W-MSA Module and SW-MSA Module
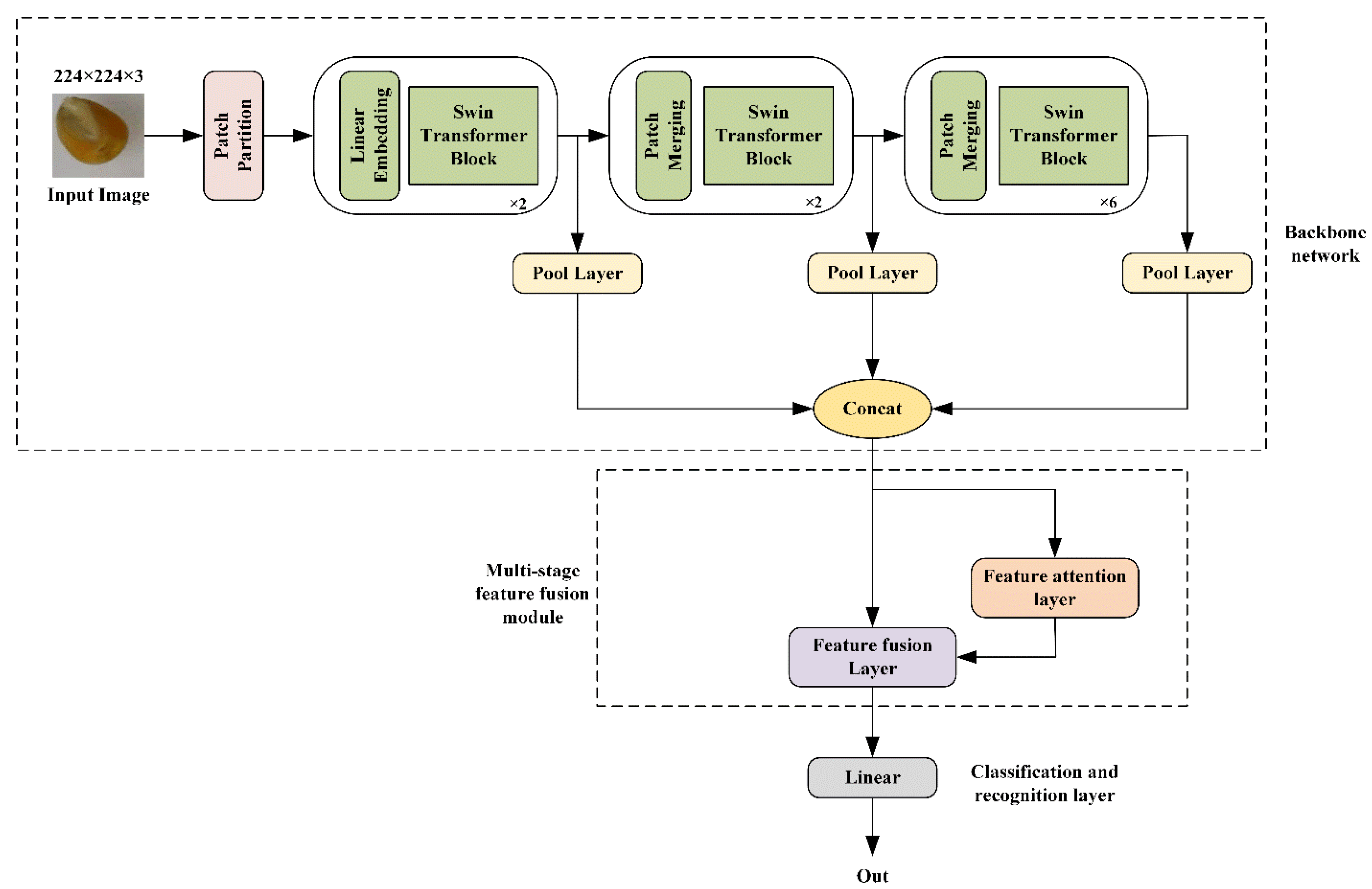
2.3. MFSwin-T Model Design
2.3.1. Backbone Network
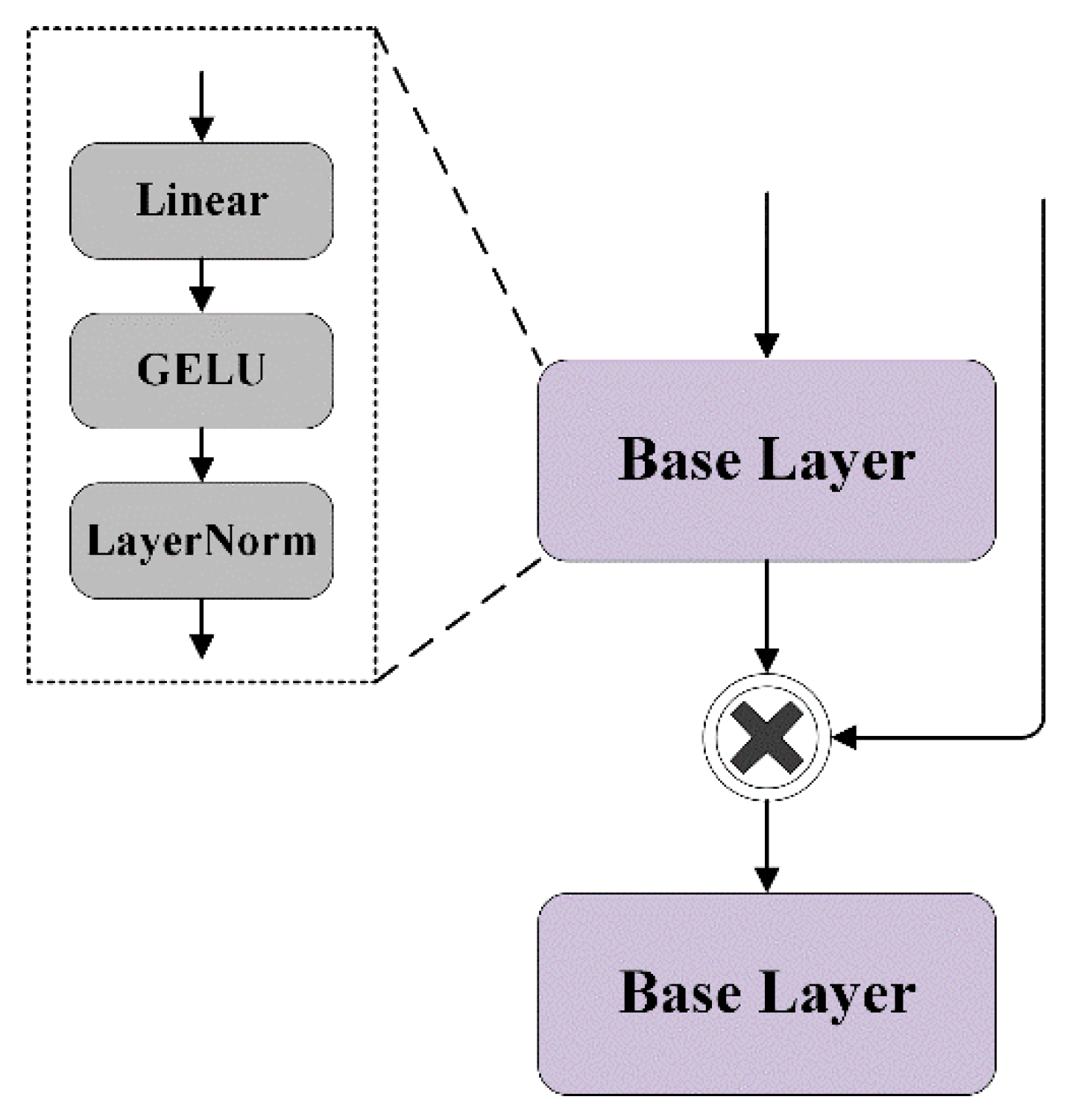
2.3.2. Multi-Stage Feature Fusion Module
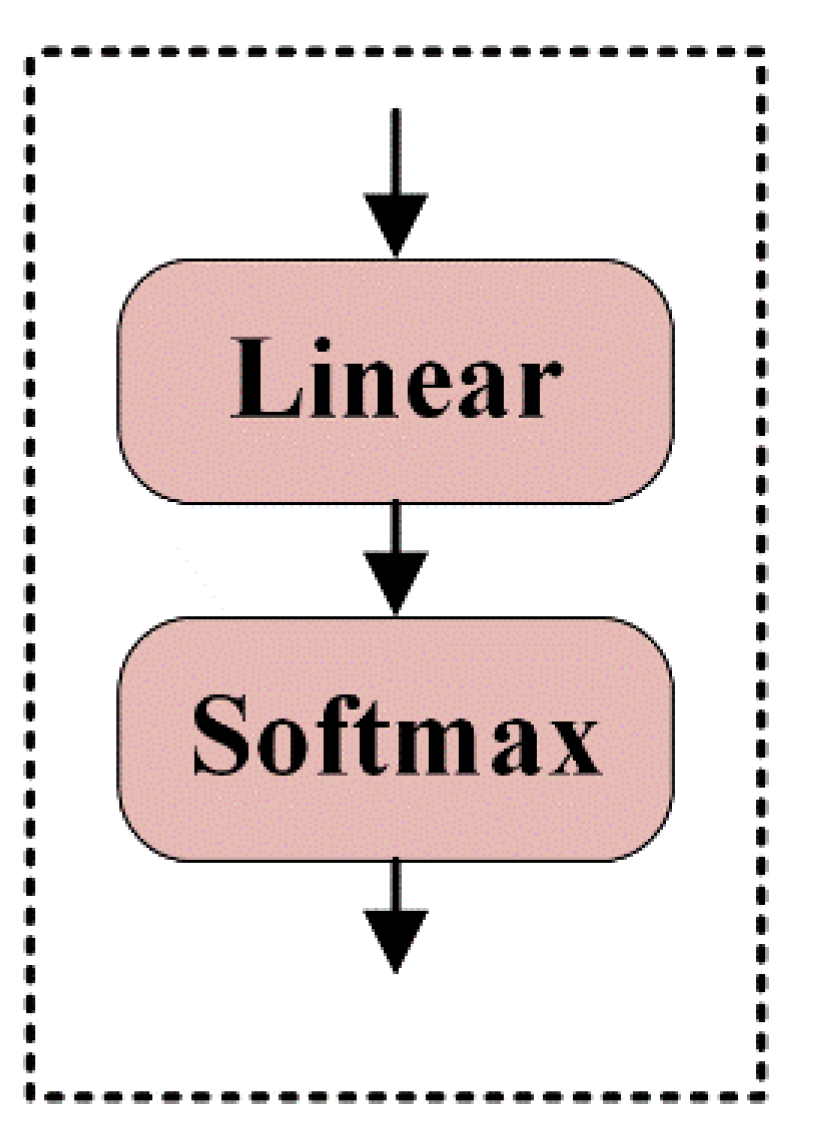
2.3.3. Classification and Recognition Layer
3. Results
3.1. Experimental Environment and Hyperparameters
3.2. Evaluation Indicators
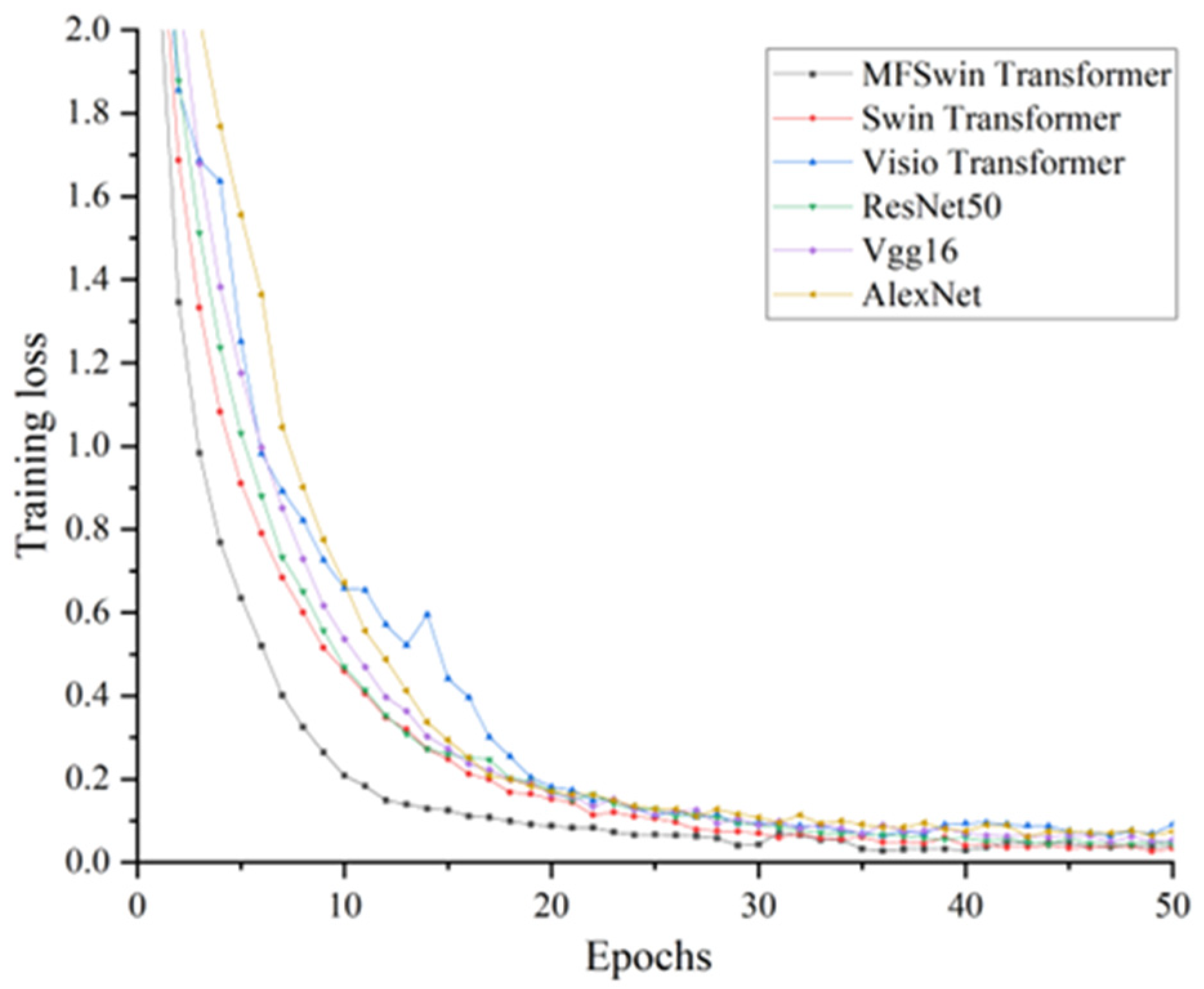
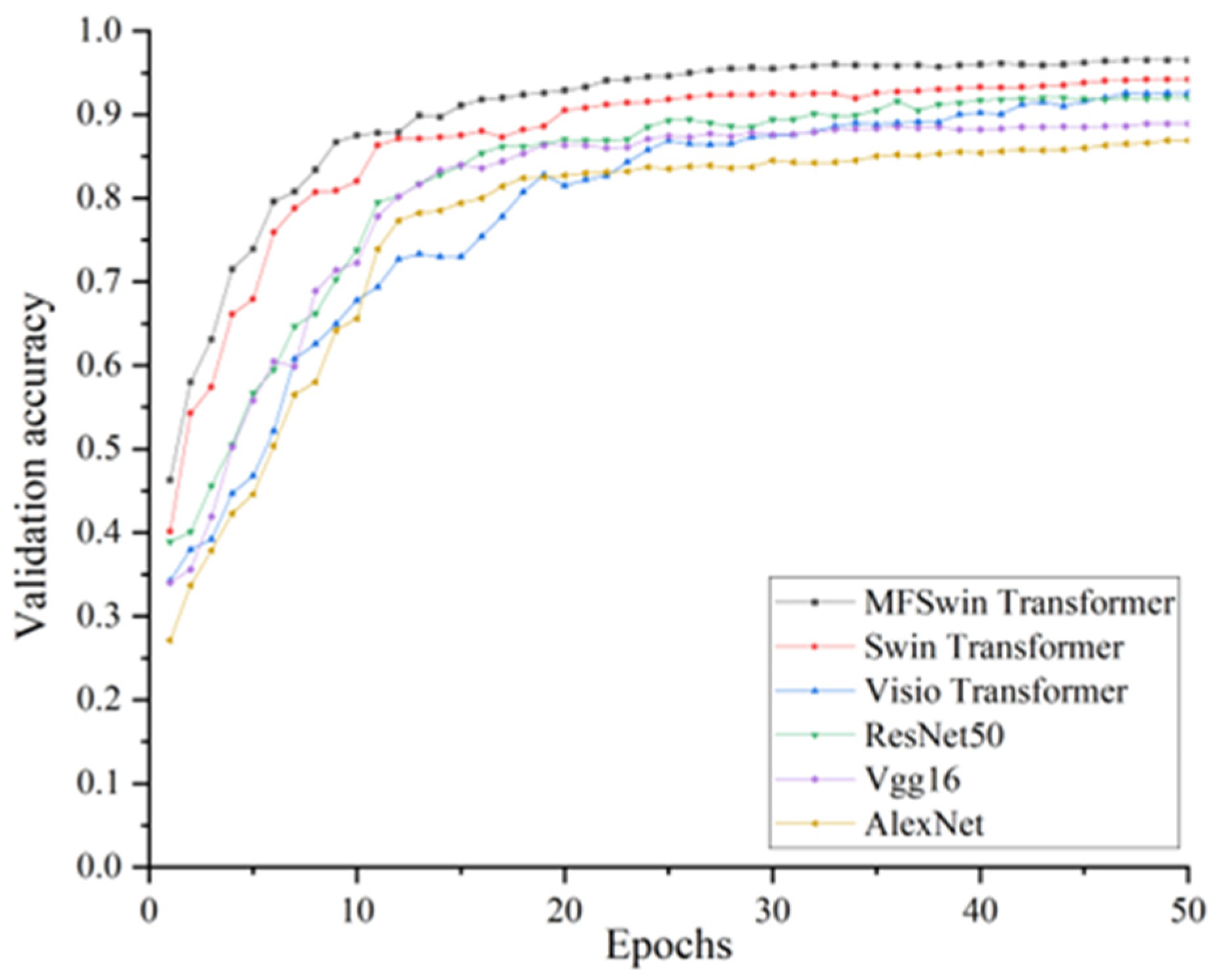
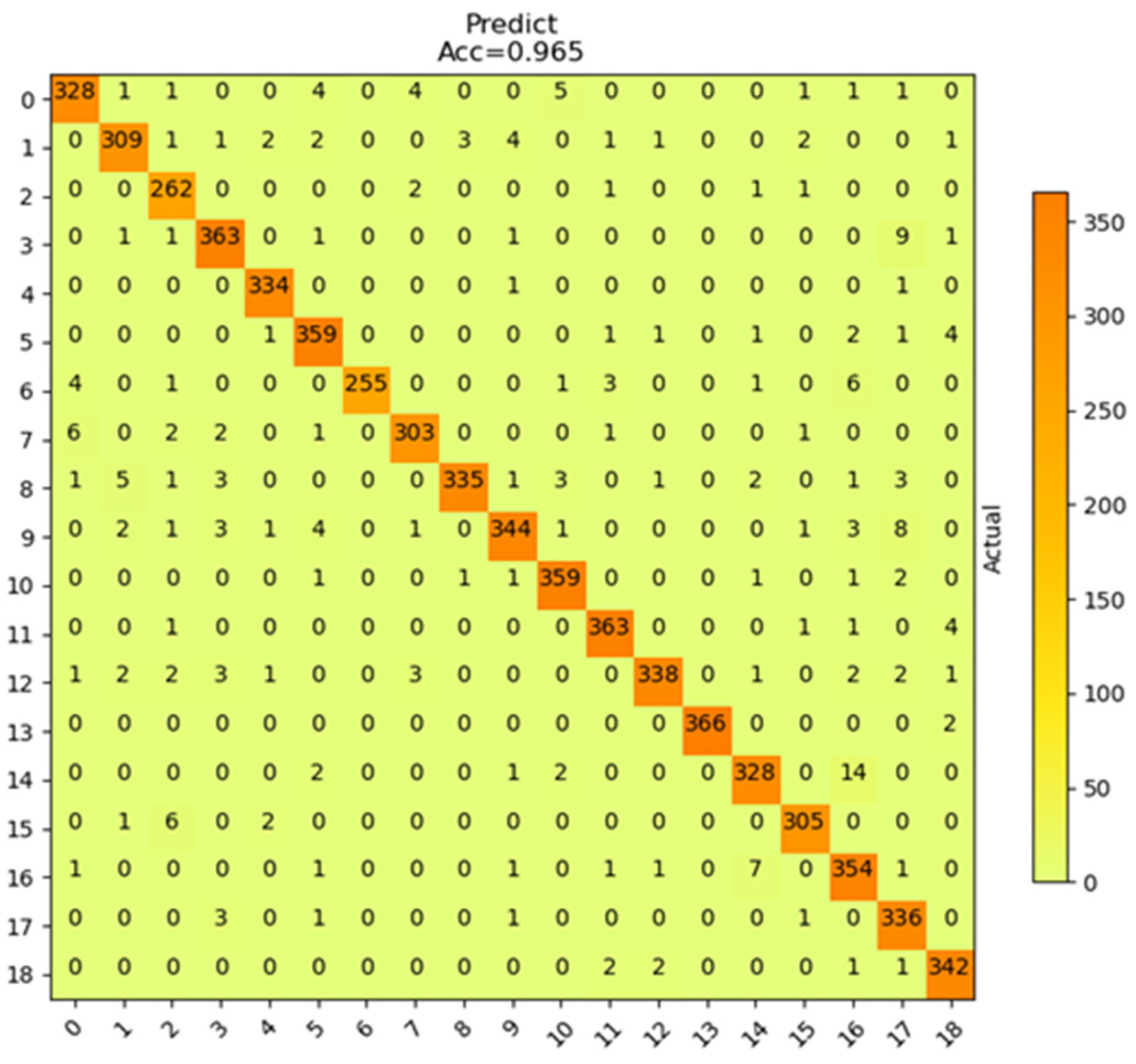
3.3. Analysis of Experimental Results and Evaluation of Network Performance
3.3.1. Deep Feature Extraction Experiment
3.3.2. Multi-Scale Feature Fusion Experiment
3.3.3. Multi-Scale Feature Fusion Experiment with Feature Attention Layer
3.4. Comparative Experiment and Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- García-Lara, S.; Serna-Saldivar, S.O.J.C. Corn History and Culture. Corn 2019, 1–18. [Google Scholar] [CrossRef]
- Aimin, C.; Jiugang, Z.; Hu, Z. Preliminary exploration on current situation and development of maize production in China. J. Agric. Sci. Technol. 2020, 22, 10. [Google Scholar]
- Costa, C.J.; Meneghello, G.E.; Jorge, M.H. The importance of physiological quality of seeds for agriculture. Colloquim Agrar. 2021, 17, 102–119. [Google Scholar] [CrossRef]
- Queiroz, T.; Valiguzski, A.; Braga, C. Evaluation of the physiological quality of seeds of traditional varieties of maize. Revista da Universidade Vale do Rio Verde 2019, 17, 20193215435. [Google Scholar]
- Sun, J.; Zou, Y. Analysis on the Method of Corn Seed Purity Identification. Hans J. Agric. Sci. 2020, 10, 292–298. [Google Scholar]
- TeKrony, D.M. Seeds: The delivery system for crop science. Crop Sci. 2006, 46, 2263–2269. [Google Scholar] [CrossRef]
- Sundaram, R.; Naveenkumar, B.; Biradar, S. Identification of informative SSR markers capable of distinguishing hybrid rice parental lines and their utilization in seed purity assessment. Euphytica 2008, 163, 215–224. [Google Scholar] [CrossRef]
- Ye-Yun, X.; Zhan, Z.; Yi-Ping, X. Identification and purity test of super hybrid rice with SSR molecular markers. Rice Sci. 2005, 12, 7. [Google Scholar]
- Satturu, V.; Rani, D.; Gattu, S. DNA fingerprinting for identification of rice varieties and seed genetic purity assessment. Agric. Res. 2018, 7, 379–390. [Google Scholar] [CrossRef]
- Pallavi, H.; Gowda, R.; Shadakshari, Y. Identification of SSR markers for hybridity and seed genetic purity testing in sunflower (Helianthus annuus L.). Helia 2011, 34, 59–66. [Google Scholar] [CrossRef] [Green Version]
- Lu, B.; Dao, P.D.; Liu, J. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Wang, C.; Liu, B.; Liu, L. A review of deep learning used in the hyperspectral image analysis for agriculture. Artif. Intell. Rev. 2021, 54, 5205–5253. [Google Scholar] [CrossRef]
- ElMasry, G.; Mandour, N.; Al-Rejaie, S. Recent applications of multispectral imaging in seed phenotyping and quality monitoring—An overview. Sensors 2019, 19, 1090. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hong, W.; Kun, W.; Jing-zhu, W. Progress in Research on Rapid and Non-Destructive Detection of Seed Quality Based on Spectroscopy and Imaging Technology. Spectrosc. Spectr. Anal. 2021, 41, 52–59. [Google Scholar]
- Wang, L.; Sun, D.; Pu, H. Application of Hyperspectral Imaging to Discriminate the Variety of Maize Seeds. Food Anal. Methods 2015, 9, 225–234. [Google Scholar] [CrossRef]
- Xia, C.; Yang, S.; Huang, M. Maize seed classification using hyperspectral image coupled with multi-linear discriminant analysis. Infrared Phys. Technol. 2019, 103, 103077. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, L. Corn seed variety classification based on hyperspectral reflectance imaging and deep convolutional neural network. Food Meas. Charact. 2020, 15, 484–494. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, X.; Su, Q. Maize seeds varieties identification based on multi-object feature extraction and optimized neural network. Trans. Chin. Soc. Agric. Eng. 2010, 26, 199–204. [Google Scholar]
- Kiratiratanapruk, K.; Sinthupinyo, W. Color and texture for corn seed classification by machine vision. In Proceedings of the 2011 International symposium on intelligent signal processing and communications systems (ISPACS), Chiang Mai, Thailand, 7–9 December 2011. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Stevens, E.; Antiga, L.; Viehmann, T. Deep Learning with PyTorch; Manning Publications: Greenwich, CT, USA, 2020. [Google Scholar]
- Wani, J.A.; Sharma, S.; Muzamil, M. Machine learning and deep learning based computational techniques in automatic agricultural diseases detection: Methodologies, applications, and challenges. Arch. Comput. Methods Eng. 2021, 29, 641–677. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Jena, B.; Saxena, S.; Nayak, G.k. Artificial intelligence-based hybrid deep learning models for image classification: The first narrative review. Comput. Biol. Med. 2021, 137, 104803. [Google Scholar] [CrossRef] [PubMed]
- Thenmozhi, K.; Reddy, U.S. Crop pest classification based on deep convolutional neural network and transfer learning. Comput. Electron. Agric. 2019, 164, 104906. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Wu, Z.; Zhao, B. Weed and corn seedling detection in field based on multi feature fusion and support vector machine. Sensors 2020, 21, 212. [Google Scholar] [CrossRef] [PubMed]
- Hu, D.; Ma, C.; Tian, Z. Rice Weed detection method on YOLOv4 convolutional neural network. In Proceedings of the 2021 International Conference on Artificial Intelligence, Big Data and Algorithms (CAIBDA), Xi’an, China, 28–30 May 2021. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Giménez-Gallego, J.; González-Teruel, J.; Jiménez-Buendía, M. Segmentation of multiple tree leaves pictures with natural backgrounds using deep learning for image-based agriculture applications. Appl. Sci. 2019, 10, 202. [Google Scholar] [CrossRef] [Green Version]
- Su, D.; Kong, H.; Qiao, Y. Data augmentation for deep learning based semantic segmentation and crop-weed classification in agricultural robotics. Comput. Electron. Agric. 2021, 190, 106418. [Google Scholar] [CrossRef]
- Gulzar, Y.; Hamid, Y.; Soomro, A.B. A Convolution Neural Network-Based Seed Classification System. Symmetry 2020, 12, 2018. [Google Scholar] [CrossRef]
- Sabanci, K.; Aslan, M.F.; Ropelewska, E. A convolutional neural network-based comparative study for pepper seed classification: Analysis of selected deep features with support vector machine. J. Food Process Eng. 2022, 45, e13955. [Google Scholar] [CrossRef]
- Hong, P.T.T.; Hai, T.T.T.; Hoang, V.T. Comparative study on vision based rice seed varieties identification. In Proceedings of the 2015 Seventh International Conference on Knowledge and Systems Engineering (KSE), Ho Chi Minh City, Vietnam, 8–10 October 2015. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.-M. A review of image denoising algorithms, with a new one. Multiscale Model. Simul. 2005, 4, 490–530. [Google Scholar] [CrossRef]
- Szostek, K.; Gronkowska-Serafin, J.; Piórkowski, A. Problems of corneal endothelial image binarization. Schedae Inform. 2011, 20, 211. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wan, X.; Zhang, X.; Liu, L. An Improved VGG19 Transfer Learning Strip Steel Surface Defect Recognition Deep Neural Network Based on Few Samples and Imbalanced Datasets. Appl. Sci. 2021, 11, 2606. [Google Scholar] [CrossRef]
- Lopez-del Rio, A.; Nonell-Canals, A.; Vidal, D. Evaluation of cross-validation strategies in sequence-based binding prediction using deep learning. J. Chem. Inf. Modeling 2019, 59, 1645–1657. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. Adv. Neural Inf. Processing Syst. 2017, 30, 1–11. [Google Scholar]
- Xi, C.; Lu, G.; Yan, J. Multimodal sentiment analysis based on multi-head attention mechanism. In Proceedings of the 4th International Conference on Machine Learning and Soft Computing, Haiphong City, Vietnam, 17–19 January 2020. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on visual transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M. Transformers in vision: A survey. ACM Comput. Surv. 2022. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Naseer, M.M.; Ranasinghe, K.; Khan, S.H. Intriguing properties of vision transformers. Adv. Neural Inf. Processing Syst. 2021, 34, 23296–23308. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2022. [Google Scholar]
- Zheng, H.; Wang, G.; Li, X. Swin-MLP: A strawberry appearance quality identification method by Swin Transformer and multi-layer perceptron. J. Food Meas. Charact. 2022, 1–12. [Google Scholar] [CrossRef]
- Xu, X.; Feng, Z.; Cao, C. An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- Jiang, W.; Meng, X.; Xi, J. Multilevel Attention and Multiscale Feature Fusion Network for Author Classification of Chinese Ink-Wash Paintings. Discret. Dyn. Nat. Soc. 2022, 2022, 1–10. [Google Scholar] [CrossRef]
- Qu, Z.; Cao, C.; Liu, L. A deeply supervised convolutional neural network for pavement crack detection with multiscale feature fusion. IEEE Trans. Neural Networks Learn. Syst. 2021, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Gu, J.; Wang, Z.; Kuen, J. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International conference on engineering and technology (ICET), Antalya, Turkey, 21–23 August 2017. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Li, Z.; Li, C. High performance vegetable classification from images based on alexnet deep learning model. J. Agric. Biol. Eng. 2018, 11, 217–223. [Google Scholar] [CrossRef]
- Wang, L.; Sun, J.; Wu, X. Identification of crop diseases using improved convolutional neural networks. IET Comput. Vis. 2020, 14, 538–545. [Google Scholar] [CrossRef]
- Lv, M.; Zhou, G.; He, M. Maize leaf disease identification based on feature enhancement and DMS-robust alexnet. EEE Access 2020, 8, 57952–57966. [Google Scholar] [CrossRef]
- Albashish, D.; Al-Sayyed, R.; Abdullah, A. Deep CNN model based on VGG16 for breast cancer classification. In Proceedings of the2021 International Conference on Information Technology (ICIT), Amman, Jordan, 14–15 July 2021. [Google Scholar]
- Zhu, H.; Yang, L.; Fei, J. Recognition of carrot appearance quality based on deep feature and support vector machine. Comput. Electron. Agric. 2021, 186, 106185. [Google Scholar] [CrossRef]
- Ishengoma, F.S.; Rai, I.A.; Said, R.N. Identification of maize leaves infected by fall armyworms using UAV-based imagery and convolutional neural networks. Comput. Electron. Agric. 2021, 184, 106124. [Google Scholar] [CrossRef]
- Mukti, I.Z.; Biswas, D. Transfer learning based plant diseases detection using ResNet50. In Proceedings of the 2019 4th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 20–22 December 2019. [Google Scholar]
- Gupta, K.; Rani, R.; Bahia, N.K. Plant-Seedling Classification Using Transfer Learning-Based Deep Convolutional Neural Networks. Int. J. Agric. Environ. Inf. Syst. 2020, 11, 25–40. [Google Scholar] [CrossRef]
- Sethy, P.K.; Barpanda, N.K.; Rath, A.K. Deep feature based rice leaf disease identification using support vector machine. Comput. Electron. Agric. 2020, 175, 105527. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
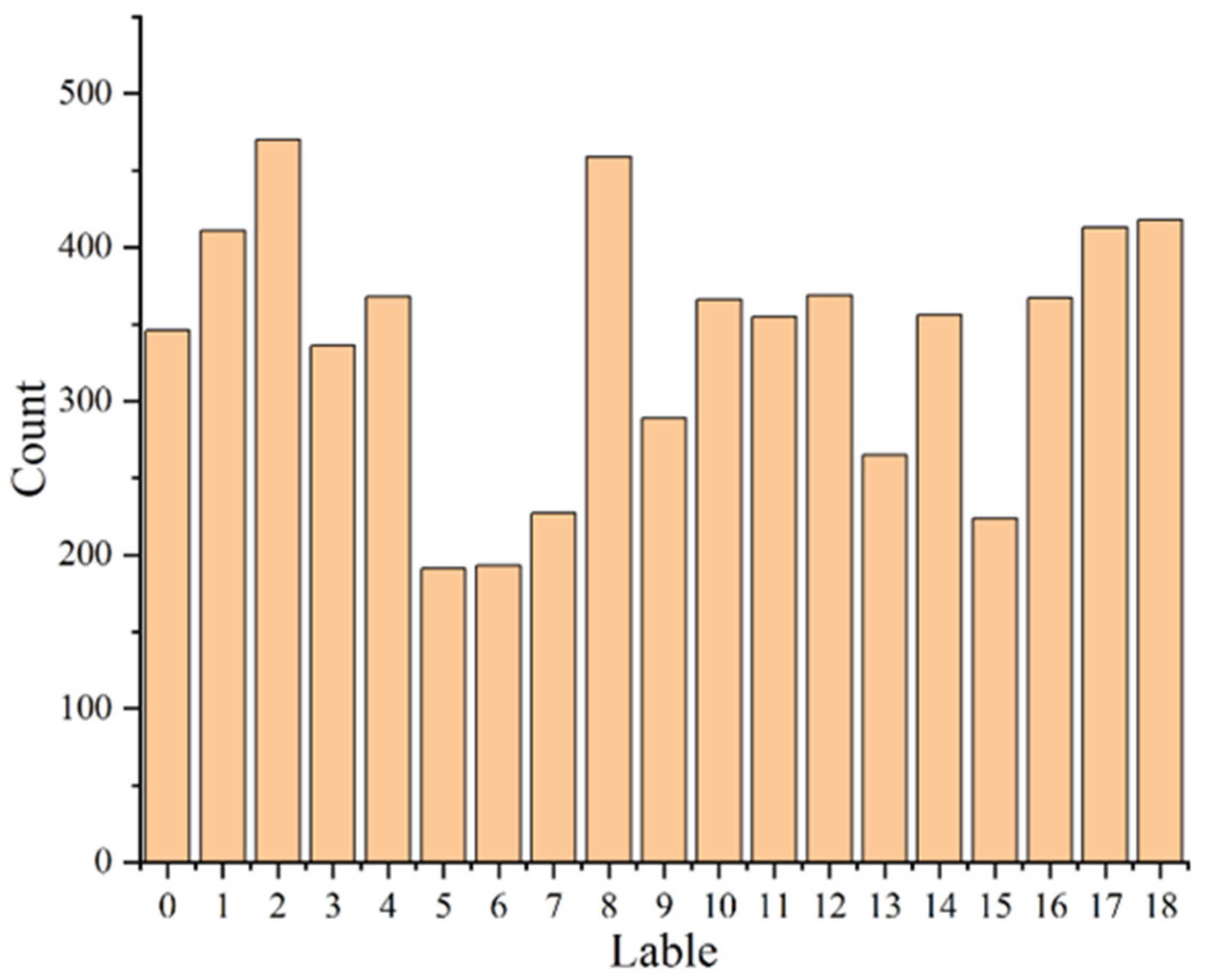
| Seed Category | Number of Original Samples | Number of Enhanced Samples | Label |
|---|---|---|---|
| ChunQiu313 | 346 | 1730 | 0 |
| FuLai135 | 411 | 1631 | 1 |
| HeYu160 | 470 | 1882 | 2 |
| HuiHuang103 | 336 | 1680 | 3 |
| HuiHuang109 | 368 | 1843 | 4 |
| HX658 | 191 | 1329 | 5 |
| JH115 | 193 | 1351 | 6 |
| JH122 | 227 | 1580 | 7 |
| JinHui579 | 459 | 1836 | 8 |
| JiuDan21 | 289 | 1728 | 9 |
| JLAUY205 | 366 | 1830 | 10 |
| JLAUY1825 | 355 | 1774 | 11 |
| JLAUY1859 | 369 | 1845 | 12 |
| JX108 | 265 | 1847 | 13 |
| JX317 | 356 | 1773 | 14 |
| LuYu711 | 224 | 1563 | 15 |
| TianFeng8 | 367 | 1835 | 16 |
| TongDan168 | 413 | 1703 | 17 |
| XinGong379 | 418 | 1740 | 18 |
| Total | 6423 | 32,500 | / |
| Accessories | Operating System | Development Framework | Development Language | CUDA | GPU | RAM |
|---|---|---|---|---|---|---|
| Parameter | Windows10 | Pytorch1.11.0 | Python3.8.3 | 11.4 | GeForce RTX 3080 | 32 G |
| Parameter. | Parameter Value |
|---|---|
| Epoch | 50 |
| Learning rate | 0.0001 |
| Batch-size | 32 |
| Optimizer | Adam |
| Confusion Matrix | Actual Results | ||
|---|---|---|---|
| Positive | Negative | ||
| Forecast Results | Positive | TP | FP |
| Negative | FN | TN | |
| Index | Formula | Significance |
|---|---|---|
| Accuracy | The number of correct predictions by the model, as a proportion of the total sample size | |
| m-Precision | Among the samples that the model predicts as positive, the model predicts the correct proportion of samples | |
| Precision | Average accuracy of 19 varieties | |
| m-Recall | In the samples whose true value is positive, the model predicts the correct proportion of samples | |
| Recall | Average recall rate of 19 varieties | |
| F1-Score | F1 score is the harmonic average of accuracy and recall |
| Evaluation Indicators | Method | ||
|---|---|---|---|
| Baseline | Multiscale Features | Multi-Scale Features + Feature Attention | |
| Average Accuracy (%) | 92.91 | 94.77 | 96.47 |
| Average Precision (%) | 93.36 | 94.26 | 96.53 |
| Average Recall (%) | 92.86 | 94.38 | 96.46 |
| Average F1-Score (%) | 93.00 | 94.27 | 96.47 |
| AlexNet | VGG16 | ResNet50 |
|---|---|---|
| Layer1: 11 × 11, 96; 3 × 3 Maxpool Layer2: 5 × 5, 256; 3 × 3 Maxpool Layer3: 3 × 3, 384 Layer4: 3 × 3, 384 Layer5: 3 × 3, 256; 3 × 3 Maxpool FC-1: 4096 FC-2: 4096 FC-3: 19 Classifier: Softmax | ; 2 × 2 Maxpool ; 2 × 2 Maxpool ; 2 × 2 Maxpool ; 2 × 2 Maxpool ; 2 × 2 Maxpool FC-1: 4096 FC-2: 4096 FC-3: 19 Classifier: Softmax | Layer1: 7 × 7, 64; 3 × 3 Maxpool FC-1: 19 Classifier: Softmax |
| Network | MFSwin-T | Swin-T | ViT | ResNet50 | AlexNet | Vgg16 |
|---|---|---|---|---|---|---|
| Average Accuracy (%) | 96.47 | 92.91 | 92.00 | 91.29 | 88.75 | 85.95 |
| Average Precision (%) | 96.53 | 93.36 | 92.23 | 91.58 | 88.87 | 86.06 |
| Average Recall (%) | 96.46 | 92.86 | 92.06 | 91.31 | 88.82 | 86.06 |
| Average F1-Score (%) | 96.47 | 93.00 | 92.06 | 91.35 | 88.76 | 85.97 |
| Network | FLOPs (G) | Params (M) | FPS |
|---|---|---|---|
| MFSwin-T | 3.783 | 12.83 | 341.18 |
| Swin-T | 4.351 | 27.49 | 306.62 |
| Vit | 16.848 | 86.21 | 240.09 |
| ResNet50 | 4.1095 | 23.55 | 304.65 |
| AlexNet | 0.711 | 57.08 | 365.76 |
| Vgg16 | 15.480 | 134.34 | 294.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bi, C.; Hu, N.; Zou, Y.; Zhang, S.; Xu, S.; Yu, H. Development of Deep Learning Methodology for Maize Seed Variety Recognition Based on Improved Swin Transformer. Agronomy 2022, 12, 1843. https://doi.org/10.3390/agronomy12081843
Bi C, Hu N, Zou Y, Zhang S, Xu S, Yu H. Development of Deep Learning Methodology for Maize Seed Variety Recognition Based on Improved Swin Transformer. Agronomy. 2022; 12(8):1843. https://doi.org/10.3390/agronomy12081843
Chicago/Turabian StyleBi, Chunguang, Nan Hu, Yiqiang Zou, Shuo Zhang, Suzhen Xu, and Helong Yu. 2022. "Development of Deep Learning Methodology for Maize Seed Variety Recognition Based on Improved Swin Transformer" Agronomy 12, no. 8: 1843. https://doi.org/10.3390/agronomy12081843