
A Dynamic Detection Method for Phenotyping Pods in a Soybean Population Based on an Improved YOLO-v5 Network
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Materials and Data Acquisition
2.1.1. Experimental Materials
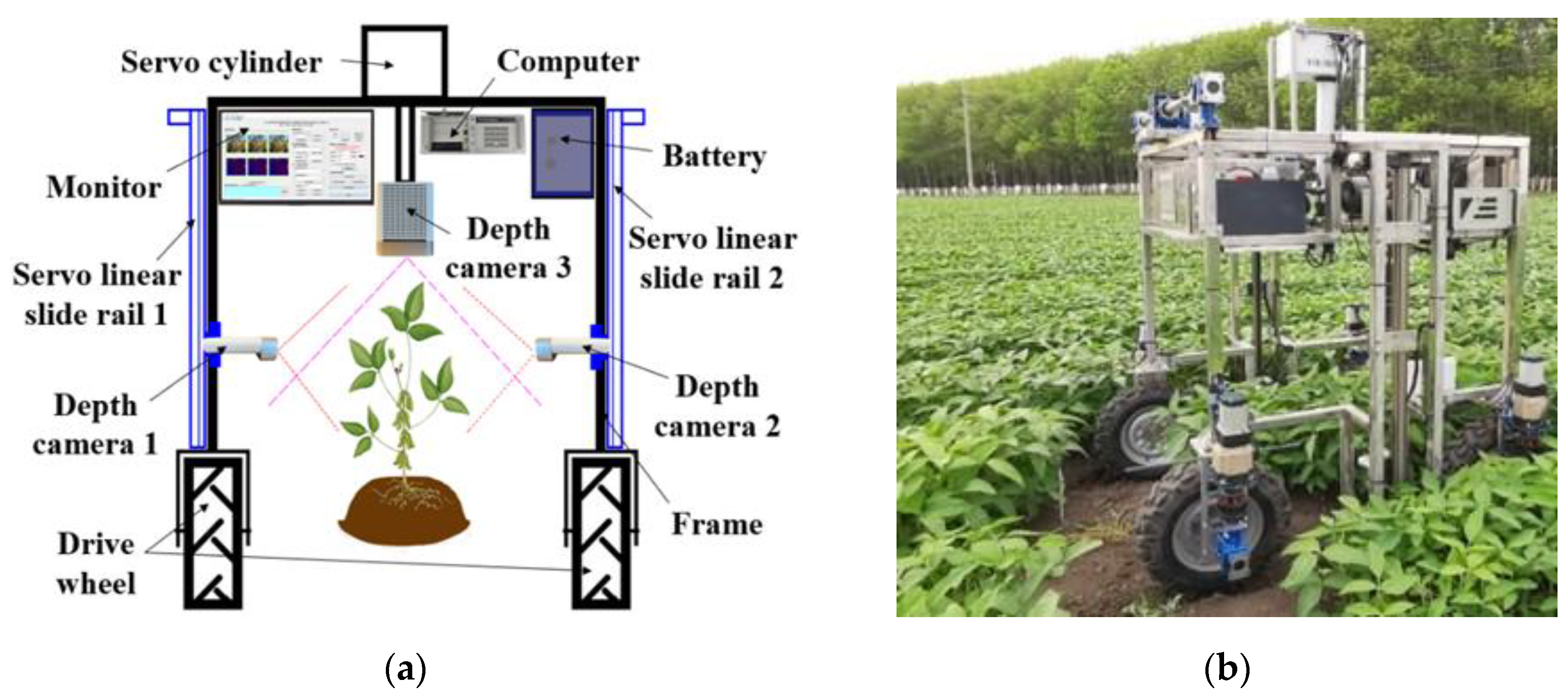
2.1.2. Construction of the Image Collection Platform
2.1.3. Data Acquisition
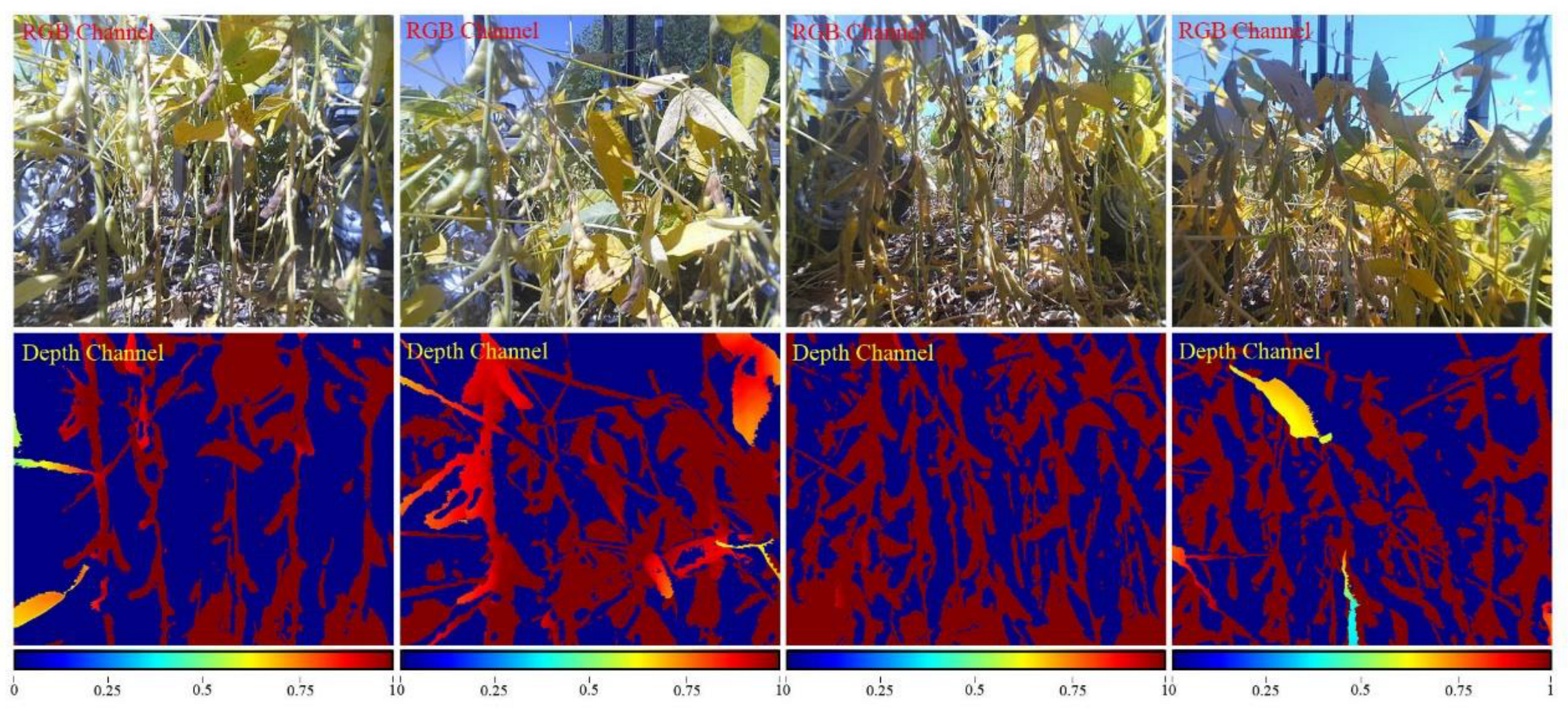
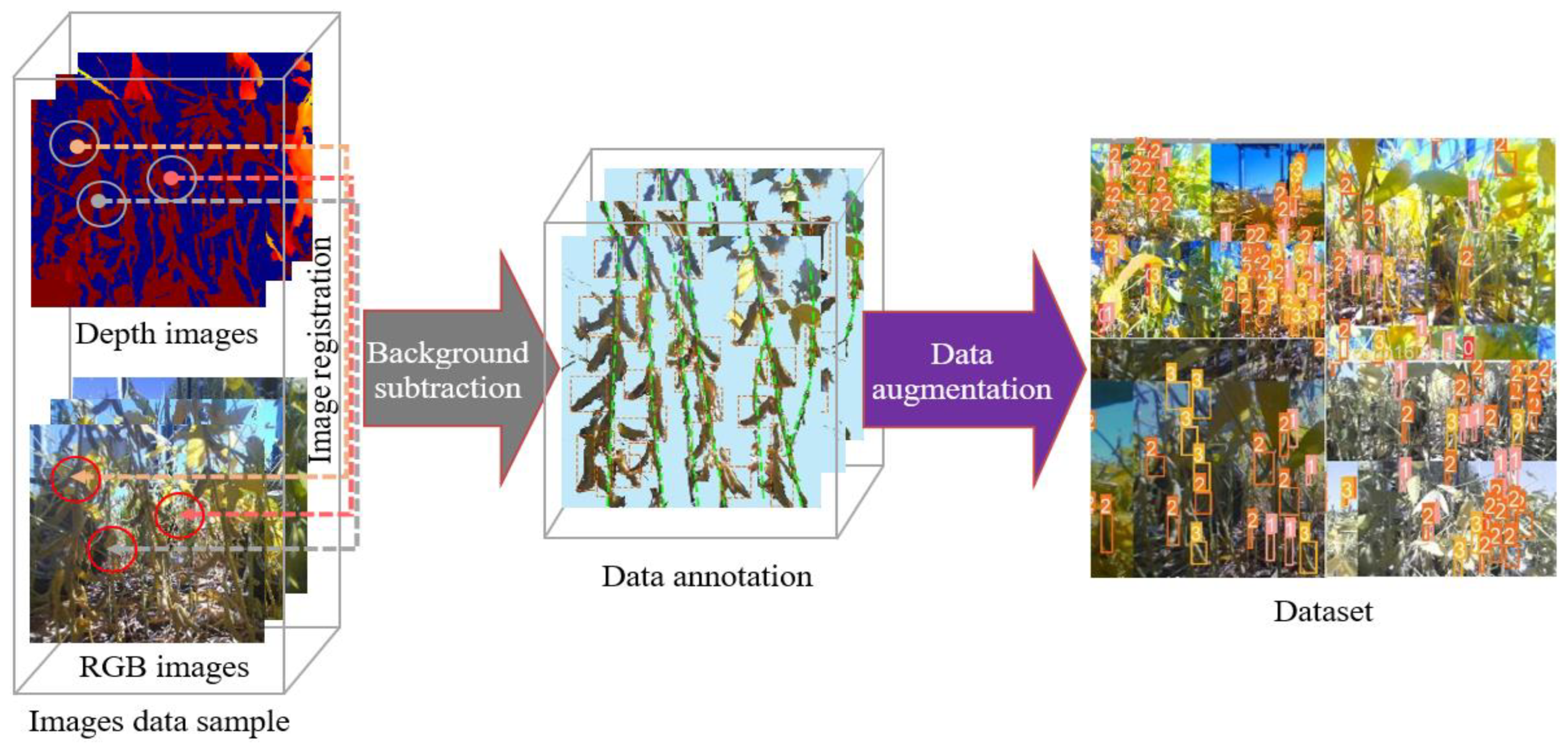
2.2. Data Preprocessing
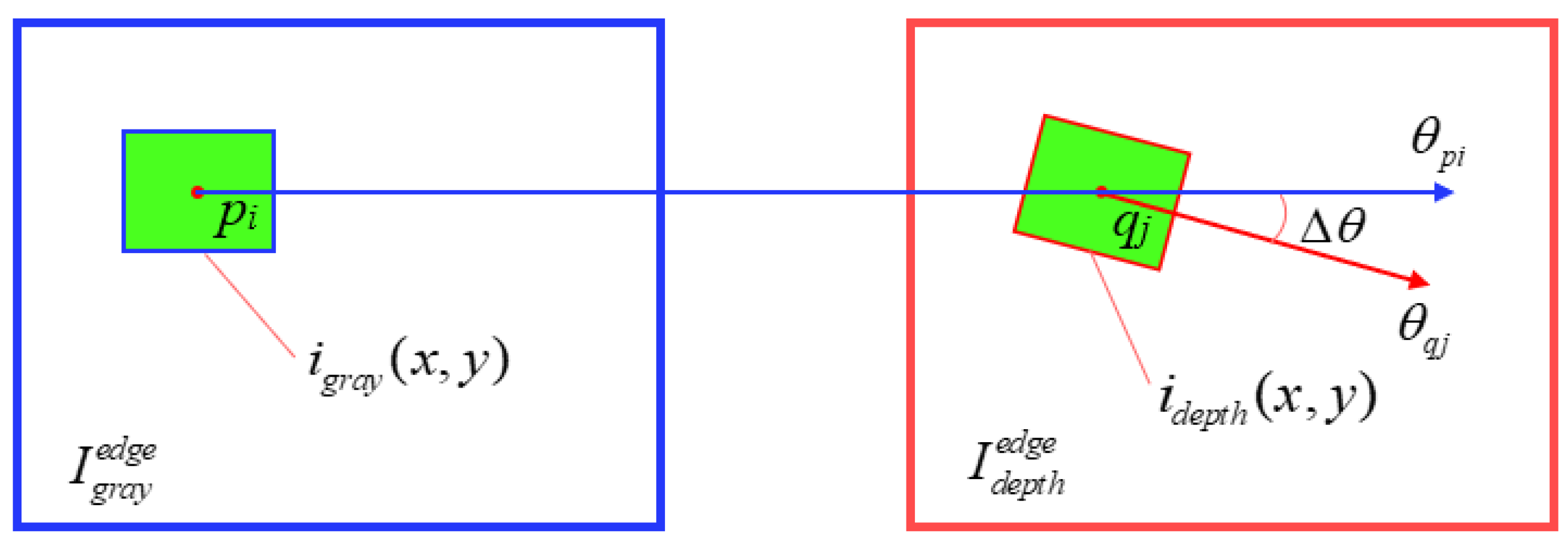
2.3. Detection Algorithm Principle
2.3.1. The YOLO-v5 Network Model
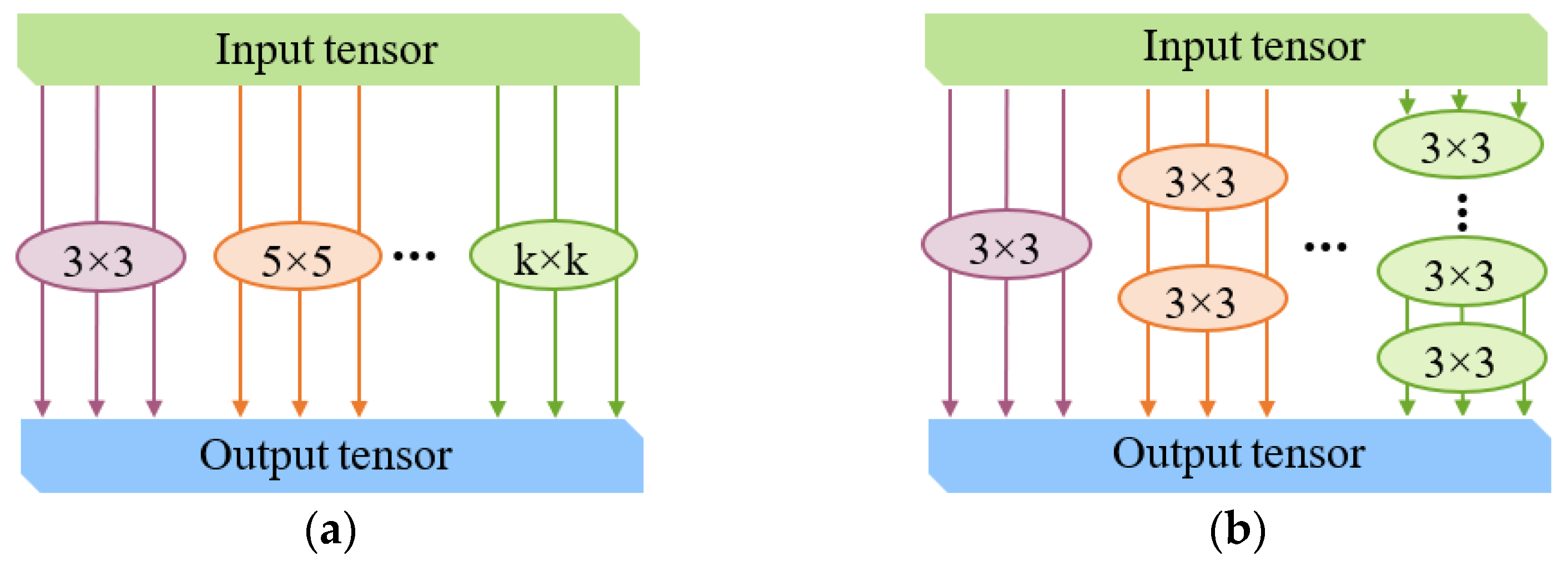
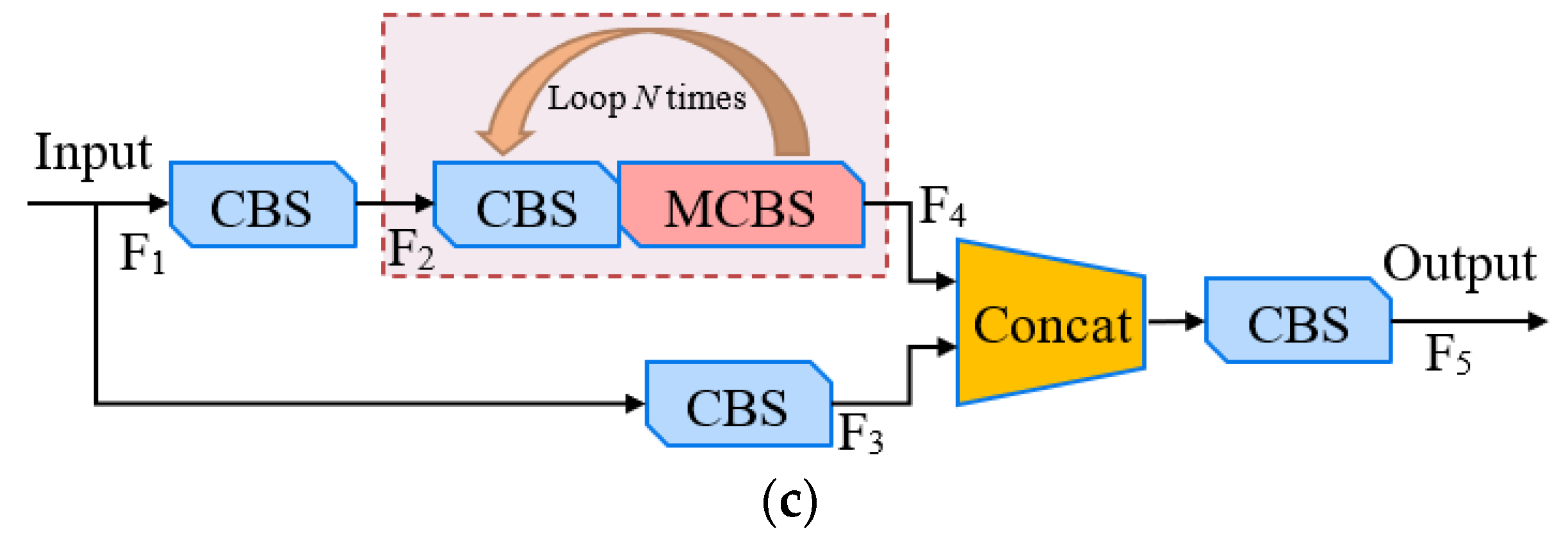
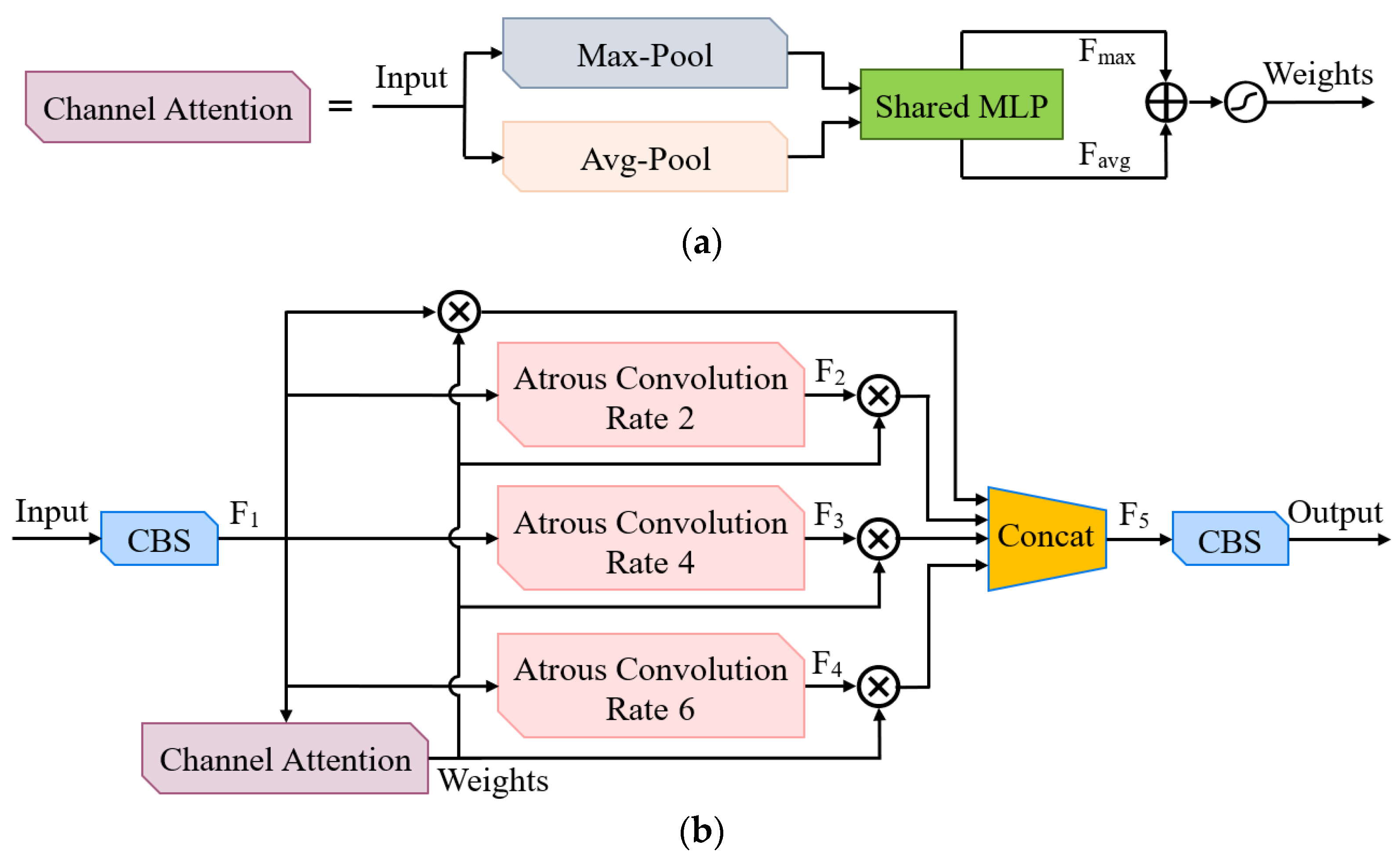
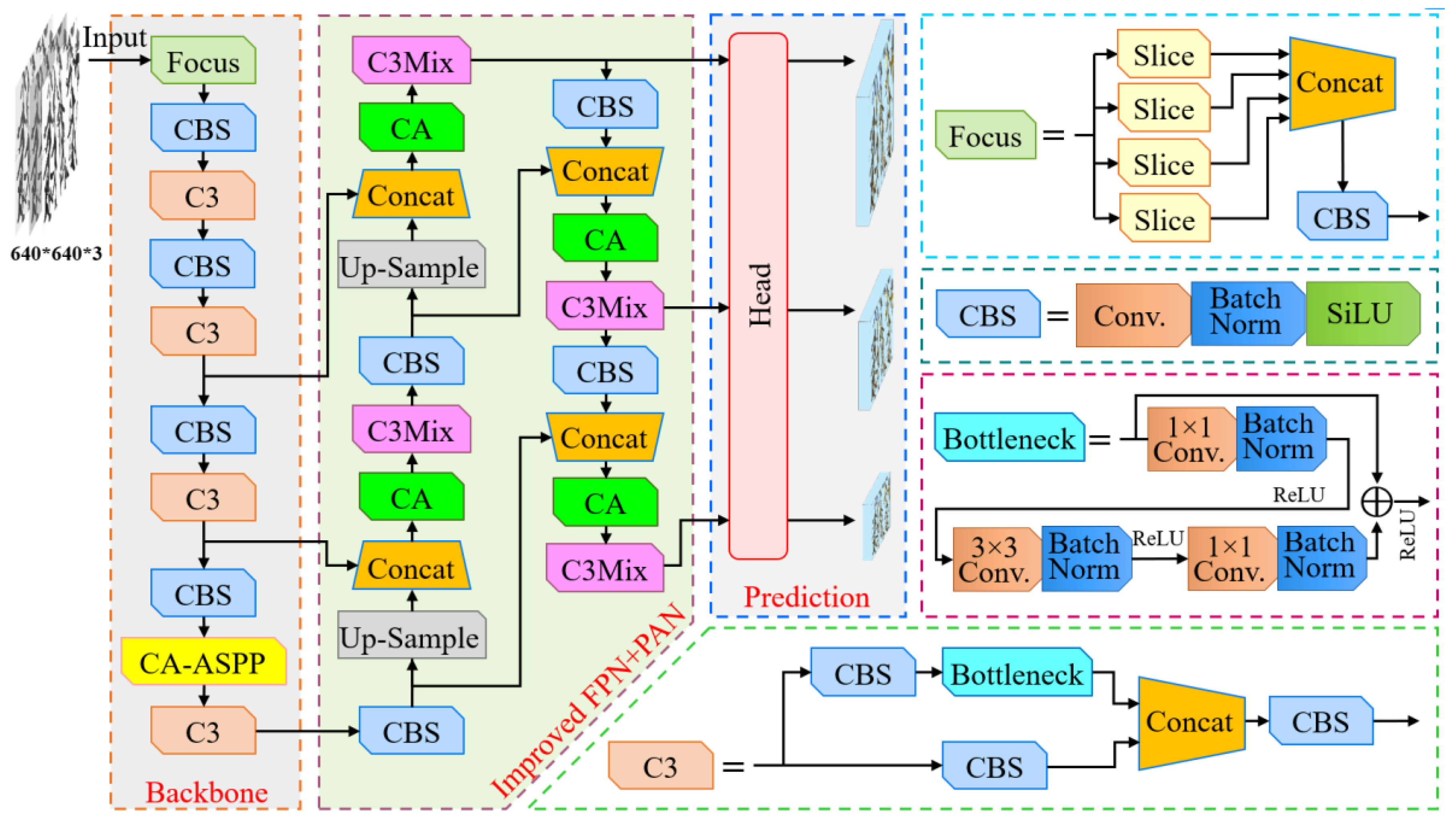
2.3.2. Improved YOLO-v5 Network Model
3. Results
3.1. Test Environment and Parameters
3.2. Evaluation of Model Performance
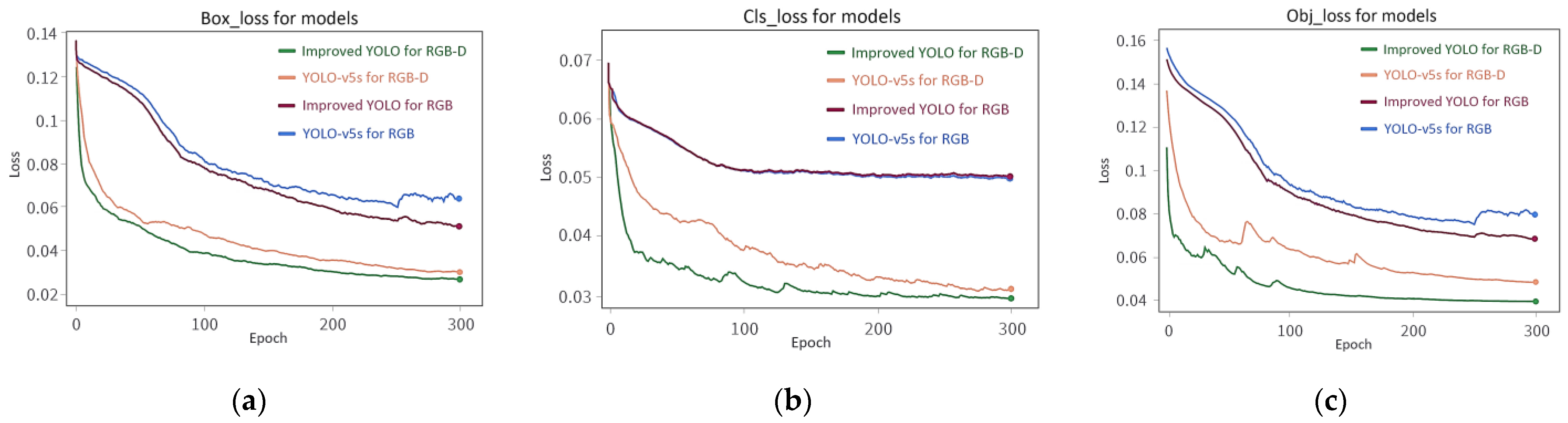
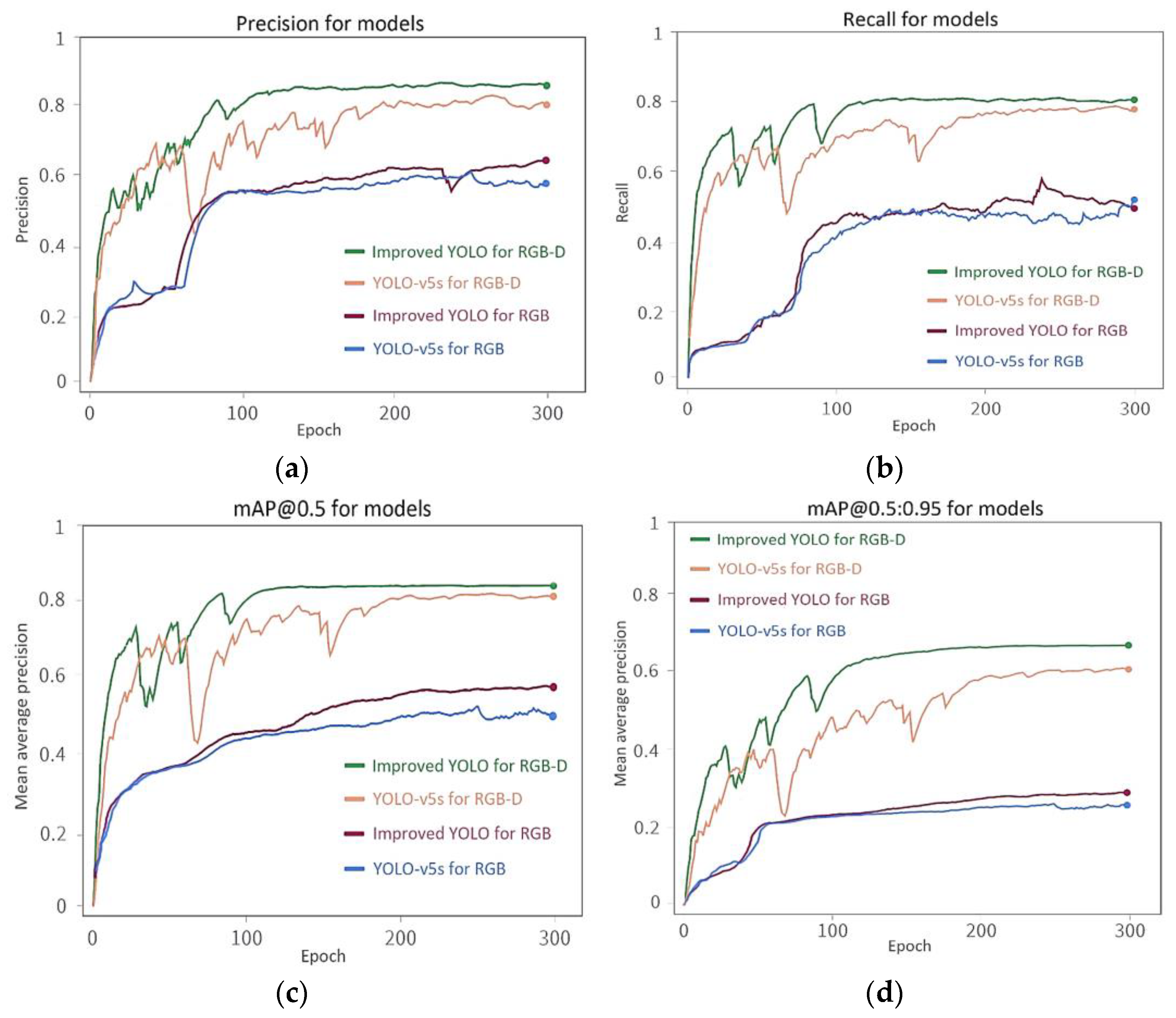
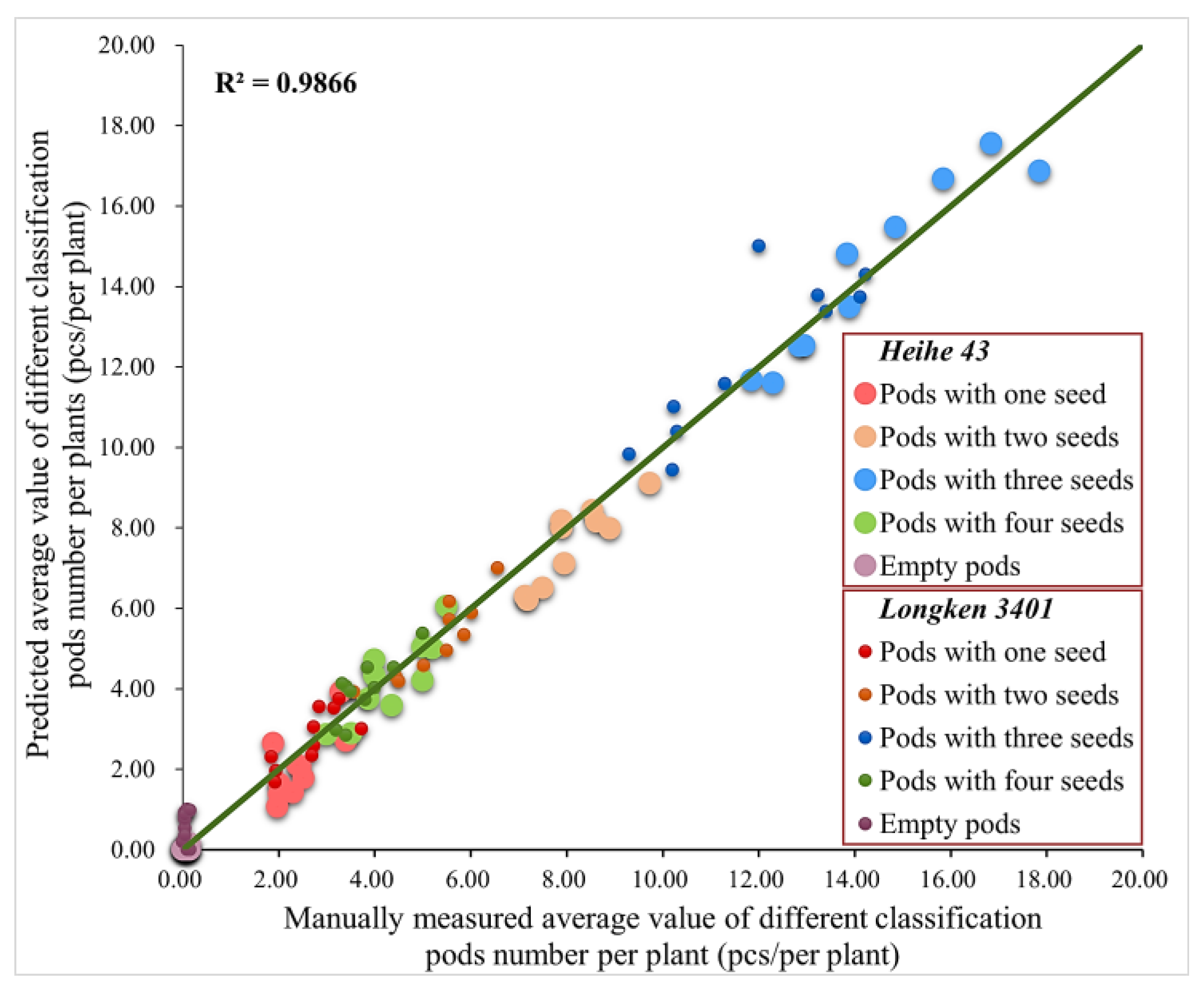
3.3. Analysis of Model Training for Different Datasets
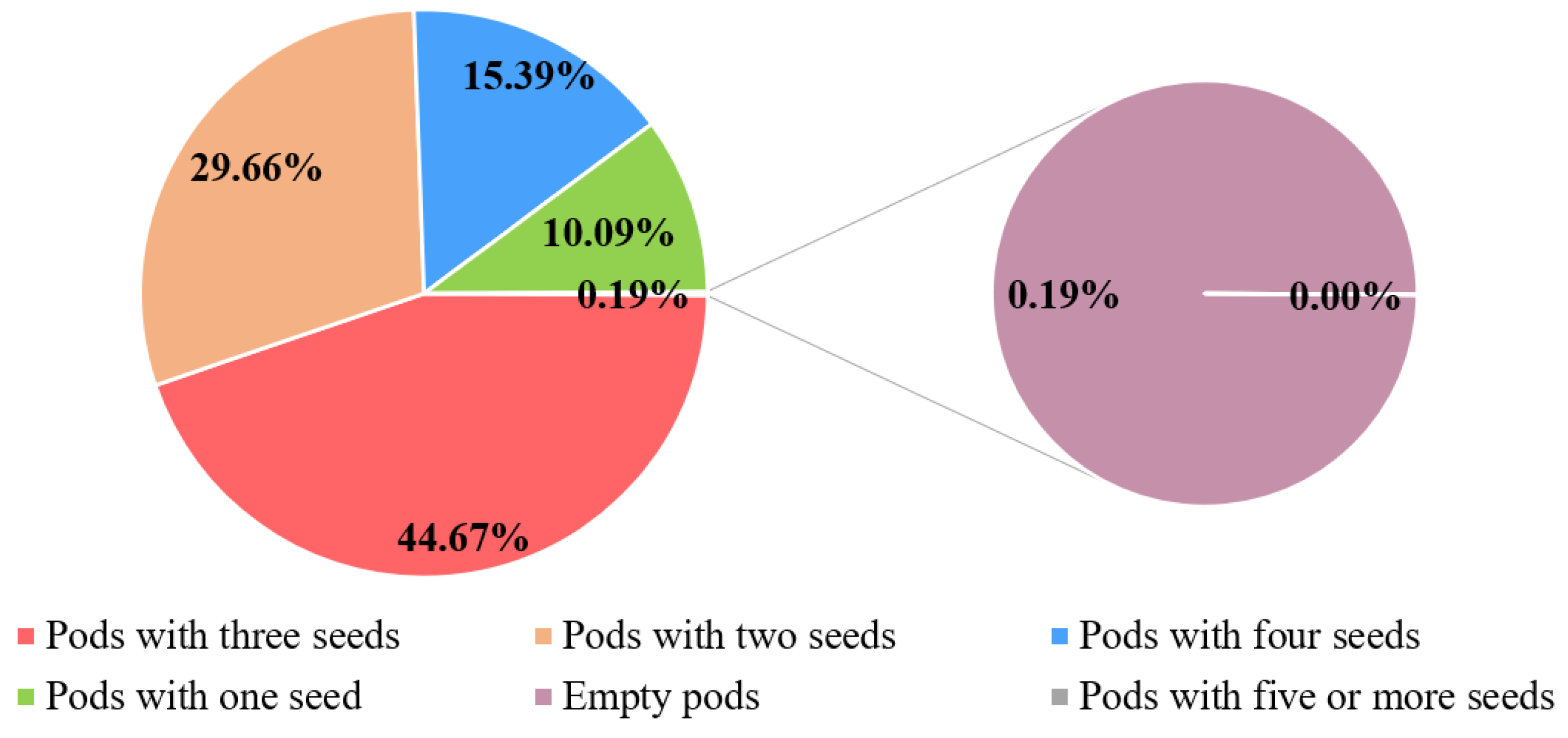
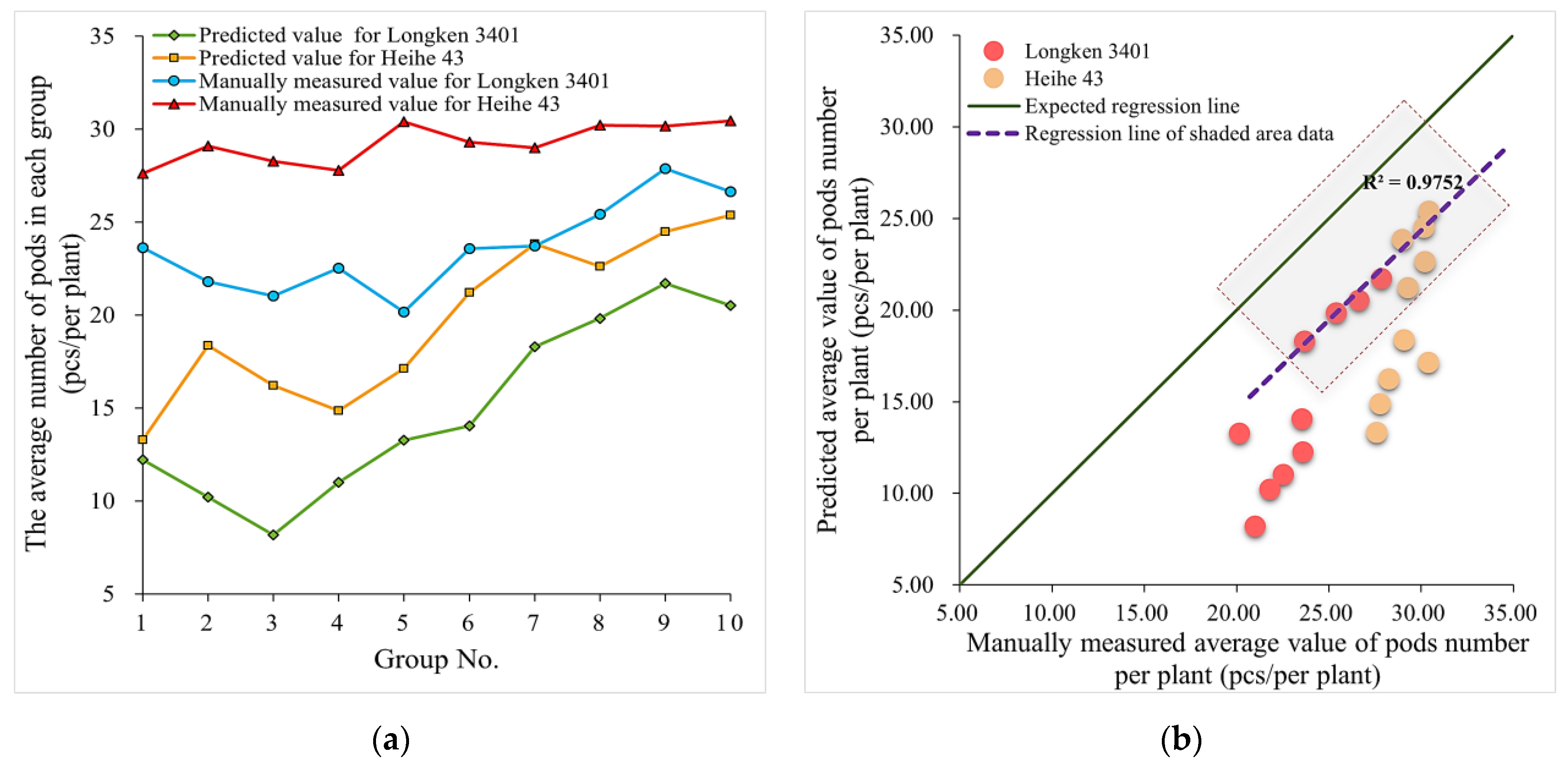
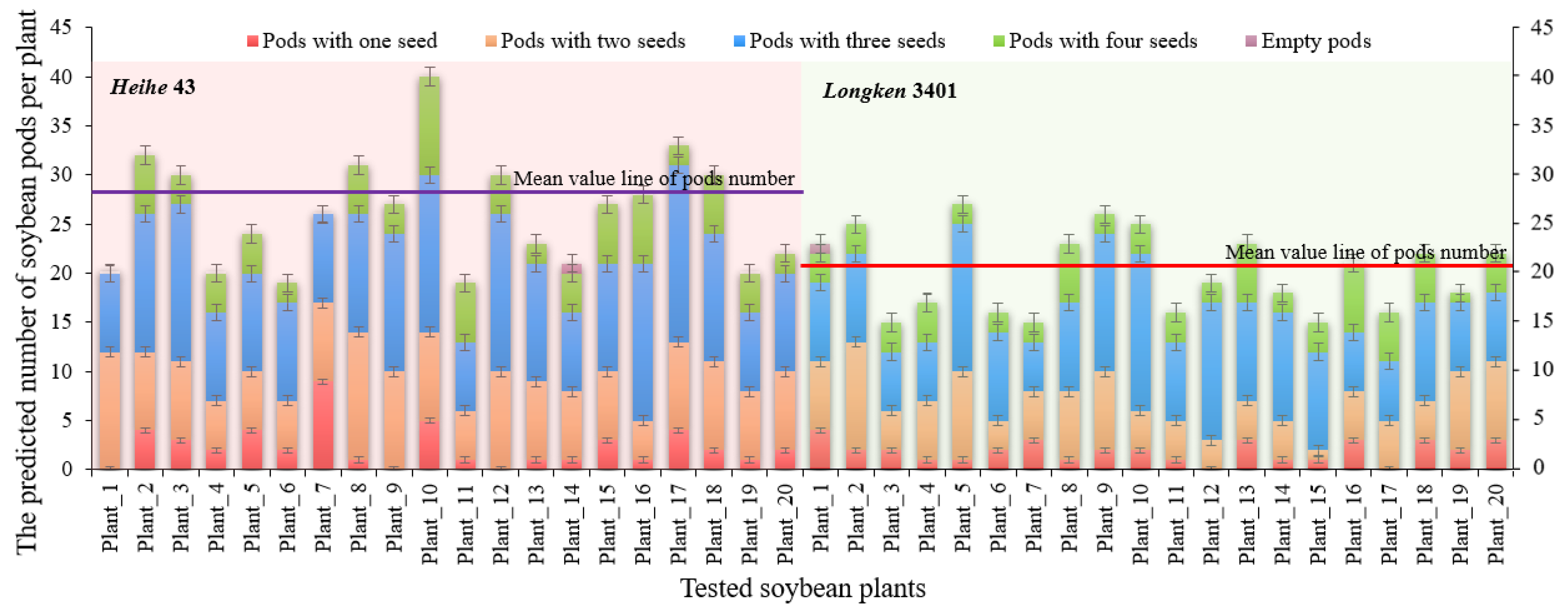
3.4. Analysis of Dynamic Detection Phenotyping of Pods in the Field
4. Discussion
5. Conclusions
- (1)
- The complex background of the natural environment greatly affected the detection of phenotypic traits of soybean pods. An RGB-depth fusion method to distinguish background could effectively improve the model performance for detecting soybean pods in complex field environments. Compared with network models trained on the RGB dataset, the recall and precision of models trained on the RGB-D dataset were increased by approximately 32% and 25%, respectively.
- (2)
- The improved YOLO-v5 network model established by introducing the improved FPN+PAN structure and CA-ASPP module had the further ability to detect small targets and distinguish between the background and foreground. Compared with YOLO-v5s, the precision of the improved YOLO-v5 increased by approximately 6%, reaching 88.14% precision for pod number detection for the 200 plants in the soybean population tested.
- (3)
- A soybean pod quantity compensation model was established by analyzing the influence of the number of individual plants in the soybean population on the detection precision of models to statistically correct various pod prediction quantities. The testing showed that after compensation calculation, the mean relative errors between the predicted and actual pod numbers were 2% to 3% for the two tested soybean varieties.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, S.; Zheng, L.; Yang, H.; Zhang, M.; Wu, T.; Sun, S.; Tomasetto, F.; Wang, M. A Synthetic Datasets Based Instance Segmentation Network for High-Throughput Soybean Pods Phenotype Investigation. Expert Syst. Appl. 2022, 192, 116403. [Google Scholar] [CrossRef]
- Lu, W.; Du, R.; Niu, P.; Xing, G.; Luo, H.; Deng, Y.; Shu, L. Soybean Yield Preharvest Prediction Based on Bean Pods and Leaves Image Recognition Using Deep Learning Neural Network Combined With GRNN. Front. Plant Sci. 2022, 12, 791256. [Google Scholar] [CrossRef] [PubMed]
- Momin, M.A.; Yamamoto, K.; Miyamoto, M.; Kondo, N.; Grift, T. Machine Vision Based Soybean Quality Evaluation. Comput. Electron. Agric. 2017, 140, 452–460. [Google Scholar] [CrossRef]
- Jiang, S.; An, H.; Luo, J.; Wang, X.; Shi, C.; Xu, F. Comparative Analysis of Transcriptomes to Identify Genes Associated with Fruit Size in the Early Stage of Fruit Development in Pyrus Pyrifolia. Int. J. Mol. Sci. 2018, 19, 2342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahman, S.U.; McCoy, E.; Raza, G.; Ali, Z.; Mansoor, S.; Amin, I. Improvement of Soybean; A Way Forward Transition from Genetic Engineering to New Plant Breeding Technologies. Mol. Biotechnol. 2022, 64, 1–19. [Google Scholar] [CrossRef]
- Wang, Y.-H.; Su, W.-H. Convolutional Neural Networks in Computer Vision for Grain Crop Phenotyping: A Review. Agronomy 2022, 12, 2659. [Google Scholar] [CrossRef]
- Zhou, S.; Mou, H.; Zhou, J.; Zhou, J.; Ye, H.; Nguyen, H.T. Development of an Automated Plant Phenotyping System for Evaluation of Salt Tolerance in Soybean. Comput. Electron. Agric. 2021, 182, 106001. [Google Scholar] [CrossRef]
- Yassue, R.M.; Galli, G.; Borsato, R., Jr.; Cheng, H.; Morota, G.; Fritsche-Neto, R. A Low-Cost Greenhouse-Based High-Throughput Phenotyping Platform for Genetic Studies: A Case Study in Maize under Inoculation with Plant Growth-Promoting Bacteria. Plant Phenome J. 2022, 5, e20043. [Google Scholar] [CrossRef]
- Warman, C.; Sullivan, C.M.; Preece, J.; Buchanan, M.E.; Vejlupkova, Z.; Jaiswal, P.; Fowler, J.E. A Cost-Effective Maize Ear Phenotyping Platform Enables Rapid Categorization and Quantification of Kernels. Plant J. 2021, 106, 566–579. [Google Scholar] [CrossRef]
- Ban, S.; Liu, W.; Tian, M.; Wang, Q.; Yuan, T.; Chang, Q.; Li, L. Rice Leaf Chlorophyll Content Estimation Using UAV-Based Spectral Images in Different Regions. Agronomy 2022, 12, 2832. [Google Scholar] [CrossRef]
- Deery, D.; Jimenez-Berni, J.; Jones, H.; Sirault, X.; Furbank, R. Proximal Remote Sensing Buggies and Potential Applications for Field-Based Phenotyping. Agronomy 2014, 4, 349–379. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Lin, C.; Peng, J.; Wang, J.; Zhai, R. Rapeseed Leaf Estimation Methods at Field Scale by Using Terrestrial LiDAR Point Cloud. Agronomy 2022, 12, 2409. [Google Scholar] [CrossRef]
- Thompson, A.L.; Thorp, K.R.; Conley, M.M.; Elshikha, D.M.; French, A.N.; Andrade-Sanchez, P.; Pauli, D. Comparing Nadir and Multi-Angle View Sensor Technologies for Measuring in-Field Plant Height of Upland Cotton. Remote Sens. 2019, 11, 700. [Google Scholar] [CrossRef] [Green Version]
- Shafiekhani, A.; Kadam, S.; Fritschi, F.B.; DeSouza, G.N. Vinobot and Vinoculer: Two Robotic Platforms for High-Throughput Field Phenotyping. Sensors 2017, 17, 214. [Google Scholar] [CrossRef] [PubMed]
- Herzig, P.; Borrmann, P.; Knauer, U.; Klück, H.-C.; Kilias, D.; Seiffert, U.; Pillen, K.; Maurer, A. Evaluation of RGB and Multispectral Unmanned Aerial Vehicle (UAV) Imagery for High-Throughput Phenotyping and Yield Prediction in Barley Breeding. Remote Sens. 2021, 13, 2670. [Google Scholar] [CrossRef]
- He, H.; Ma, X.; Guan, H. A Calculation Method of Phenotypic Traits of Soybean Pods Based on Image Processing Technology. Ecol. Inform. 2022, 69, 101676. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Z.; Wu, J.; Hu, Q.; Zhao, C.; Tan, C.; Teng, L.; Luo, T. An Improved Yolov3 Based on Dual Path Network for Cherry Tomatoes Detection. J. Food Process Eng. 2021, 44, e13803. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, J.; Chen, Y.; Yang, W.; Zhang, W.; He, Y. Real-Time Strawberry Detection Using Deep Neural Networks on Embedded System (Rtsd-Net): An Edge AI Application. Comput. Electron. Agric. 2022, 192, 106586. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Fu, X.; Meng, Z.; Wang, Z.; Yin, X.; Wang, C. Dynamic potato identification and cleaning method based on RGB-D. Eng. Agríc. 2022, 42, e20220010. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: Las Vegas, NV, USA, 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Guo, X.; Qiu, Y.; Nettleton, D.; Yeh, C.-T.; Zheng, Z.; Hey, S.; Schnable, P.S. KAT4IA: K-Means Assisted Training for Image Analysis of Field-Grown Plant Phenotypes. Plant Phenomics 2021, 2021, 9805489. [Google Scholar] [CrossRef] [PubMed]
- Guo, R.; Chongyu, Y.; Hong, H. Detection Method of Soybean Pod Number per Plant Using Improved YOLOv4 Algorithm. Trans. Chin. Soc. Agric. Eng. 2021, 37, 179–187. [Google Scholar]
- Li, R.; Wu, Y. Improved YOLO v5 Wheat Ear Detection Algorithm Based on Attention Mechanism. Electronics 2022, 11, 1673. [Google Scholar] [CrossRef]
- Ren, F.; Zhang, Y.; Liu, X.; Zhang, Y.; Liu, Y.; Zhang, F. Identification of Plant Stomata Based on YOLO v5 Deep Learning Model. In Proceedings of the 2021 5th International Conference on Computer Science and Artificial Intelligence, Beijing, China, 4–6 December 2021; pp. 78–83. [Google Scholar] [CrossRef]
- Pathoumthong, P.; Zhang, Z.; Roy, S.; El Habti, A. Rapid Non-Destructive Method to Phenotype Stomatal Traits. bioRxiv 2022. [Google Scholar] [CrossRef]
- Weerasekara, I.; Sinniah, U.R.; Namasivayam, P.; Nazli, M.H.; Abdurahman, S.A.; Ghazali, M.N. The Influence of Seed Production Environment on Seed Development and Quality of Soybean (Glycine max (L.) Merrill). Agronomy 2021, 11, 1430. [Google Scholar] [CrossRef]
- Xia, S.; Li, M. A Novel Image Edge Detection Algorithm Based on Multi-Scale Hybrid Wavelet Transform. In Proceedings of the International Conference on Neural Networks, Information, and Communication Engineering (NNICE), Qingdao, China, 25–27 March 2022; SPIE: Washington, DC, USA, 2022; Volume 12258, pp. 505–510. [Google Scholar] [CrossRef]
- Zhao, Y.; Shi, Y.; Wang, Z. The Improved YOLOV5 Algorithm and Its Application in Small Target Detection. In Proceedings of the Intelligent Robotics and Applications; Liu, H., Yin, Z., Liu, L., Jiang, L., Gu, G., Wu, X., Ren, W., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 679–688. [Google Scholar] [CrossRef]
- Zhang, C.; Ding, H.; Shi, Q.; Wang, Y. Grape Cluster Real-Time Detection in Complex Natural Scenes Based on YOLOv5s Deep Learning Network. Agriculture 2022, 12, 1242. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel Pruned YOLO V5s-Based Deep Learning Approach for Rapid and Accurate Apple Fruitlet Detection before Fruit Thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. Mixconv: Mixed Depthwise Convolutional Kernels. arXiv 2019, arXiv:1907.09595. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Leng, Z.; Tan, M.; Liu, C.; Cubuk, E.D.; Shi, X.; Cheng, S.; Anguelov, D. PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions. arXiv 2022, arXiv:2204.12511. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Parameter | Configuration |
|---|---|---|
| 1 | CPU | Intel Core i7 9700K |
| 2 | GPU | Nvidia GeForce RTX A3000, 6 GB VRAM |
| 3 | RAM | 16 GB DDR4 3200 MHz |
| 4 | GPU accelerated environment | CUDA 11.2 |
| 5 | Operating system | Ubuntu 18.04 LTE |
| 6 | IDE | Visual Studio Code 1.72.2 |
| 7 | Deep learning framework | PyTorch 1.8 |
| 8 | Benchmark model | YOLO-v5s |
| 9 | Computer vision library | OpenCV 4.5 |
| No. of Test Group | Total Number of Soybean Plants in Each Test Group | Average Number of Soybean Pods per Plant of Different Varieties | |||
|---|---|---|---|---|---|
| Longken 3401 | Heihe 43 | Longken 3401 | Heihe 43 | ||
| Identification Model Prediction Values (pcs/per Plant) | Manual Measurement Values (pcs/per Plant) | ||||
| 1 | 20 | 12.23 | 13.31 | 23.62 | 27.62 |
| 2 | 40 | 10.21 | 18.36 | 21.81 | 29.10 |
| 3 | 60 | 8.19 | 16.22 | 21.03 | 28.27 |
| 4 | 80 | 11.00 | 14.87 | 22.54 | 27.79 |
| 5 | 100 | 13.27 | 17.13 | 20.18 | 30.41 |
| 6 | 120 | 14.05 | 21.21 | 23.57 | 29.30 |
| 7 | 140 | 18.29 | 23.83 | 23.71 | 29.01 |
| 8 | 160 | 19.83 | 22.62 | 25.43 | 30.22 |
| 9 | 180 | 21.71 | 24.50 | 27.87 | 30.18 |
| 10 | 200 | 20.52 | 25.38 | 26.65 | 30.44 |
| Number of Plants in Soybean Population | Experimental Model | Evaluation Indicators (Unit: %) | |||
|---|---|---|---|---|---|
| Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | ||
| 20 | Improved YOLO-v5 | 82.72 | 74.54 | 81.26 | 52.43 |
| YOLO-v5s [35] | 77.13 | 73.92 | 76.47 | 50.17 | |
| Faster-RCNN [20] | 76.65 | 71.39 | 73.15 | 47.24 | |
| SSD [23] | 71.49 | 67.08 | 68.26 | 45.58 | |
| 80 | Improved YOLO-v5 | 83.50 | 74.63 | 80.95 | 51.75 |
| YOLO-V5s [35] | 81.14 | 71.57 | 77.02 | 47.32 | |
| Faster-RCNN [20] | 74.82 | 70.34 | 71.33 | 46.50 | |
| SSD [23] | 71.95 | 68.87 | 69.43 | 44.21 | |
| 140 | Improved YOLO-v5 | 86.26 | 77.66 | 85.31 | 53.20 |
| YOLO-V5s [35] | 81.91 | 74.33 | 81.12 | 51.19 | |
| Faster-RCNN [20] | 76.76 | 72.00 | 73.12 | 45.99 | |
| SSD [23] | 71.09 | 67.51 | 70.08 | 42.16 | |
| 200 | Improved YOLO-v5 | 88.14 | 78.35 | 87.87 | 58.53 |
| YOLO-V5s [35] | 82.10 | 74.97 | 82.90 | 54.67 | |
| Faster-RCNN [20] | 75.98 | 71.26 | 74.55 | 48.35 | |
| SSD [23] | 72.11 | 69.73 | 70.70 | 43.40 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, X.; Li, A.; Meng, Z.; Yin, X.; Zhang, C.; Zhang, W.; Qi, L. A Dynamic Detection Method for Phenotyping Pods in a Soybean Population Based on an Improved YOLO-v5 Network. Agronomy 2022, 12, 3209. https://doi.org/10.3390/agronomy12123209
Fu X, Li A, Meng Z, Yin X, Zhang C, Zhang W, Qi L. A Dynamic Detection Method for Phenotyping Pods in a Soybean Population Based on an Improved YOLO-v5 Network. Agronomy. 2022; 12(12):3209. https://doi.org/10.3390/agronomy12123209
Chicago/Turabian StyleFu, Xiaoming, Aokang Li, Zhijun Meng, Xiaohui Yin, Chi Zhang, Wei Zhang, and Liqiang Qi. 2022. "A Dynamic Detection Method for Phenotyping Pods in a Soybean Population Based on an Improved YOLO-v5 Network" Agronomy 12, no. 12: 3209. https://doi.org/10.3390/agronomy12123209