

A Stability Training Method of Legged Robots Based on Training Platforms and Reinforcement Learning with Its Simulation and Experiment

Abstract
:1. Introduction
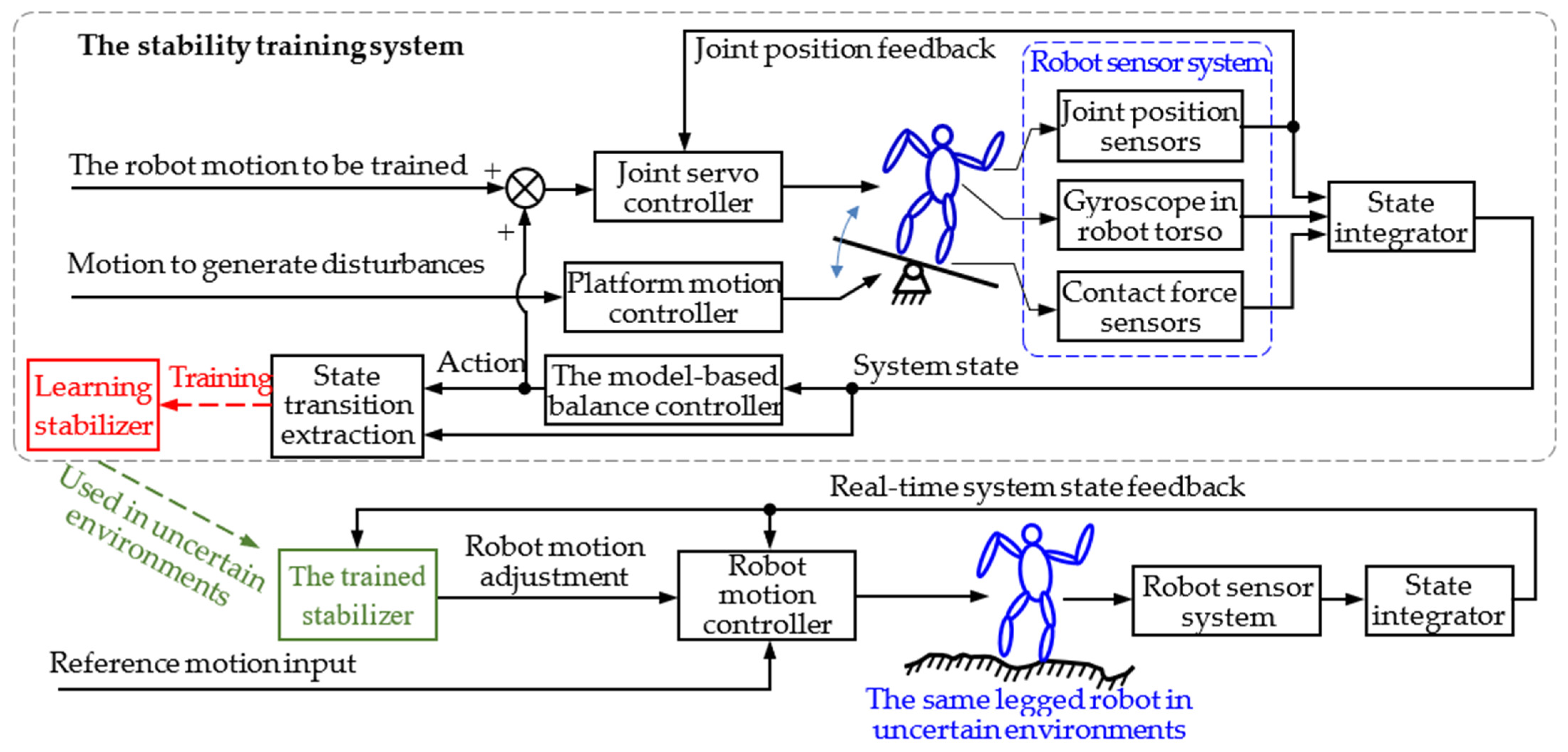
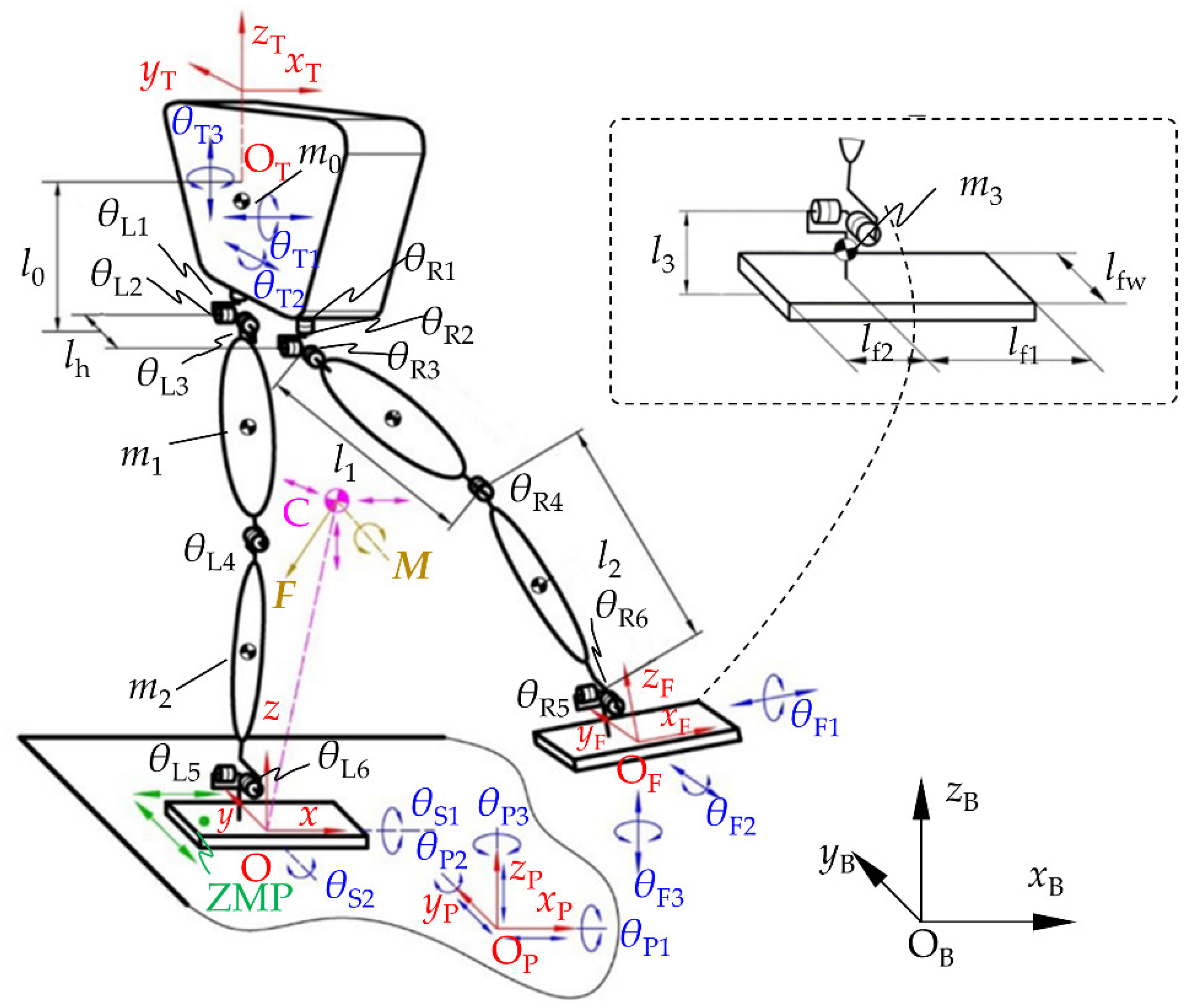
2. A General Model for Stability Training of Legged Robots
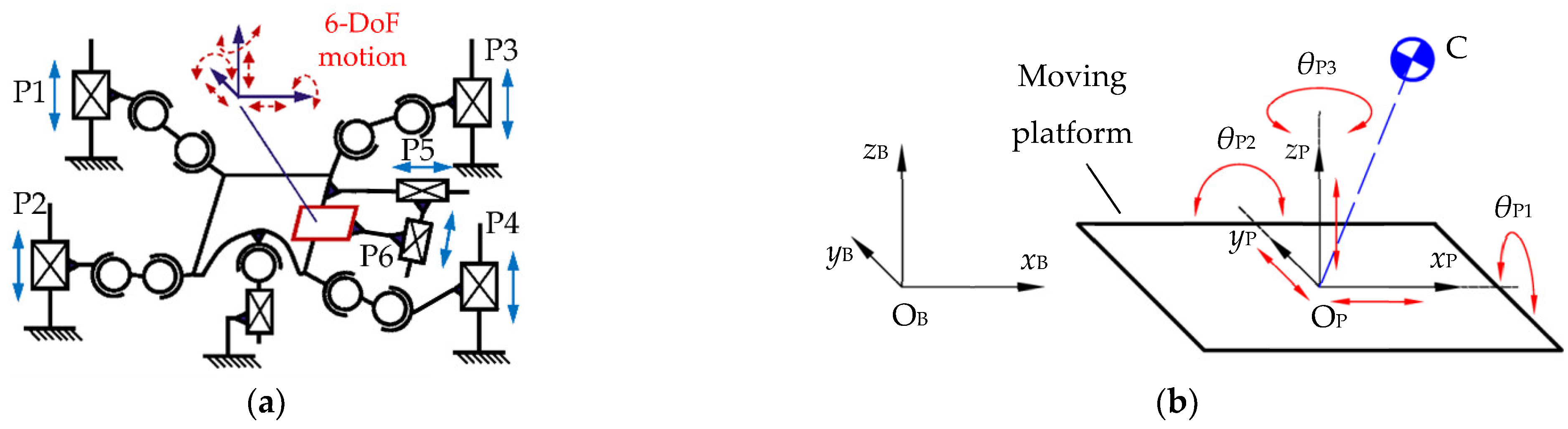
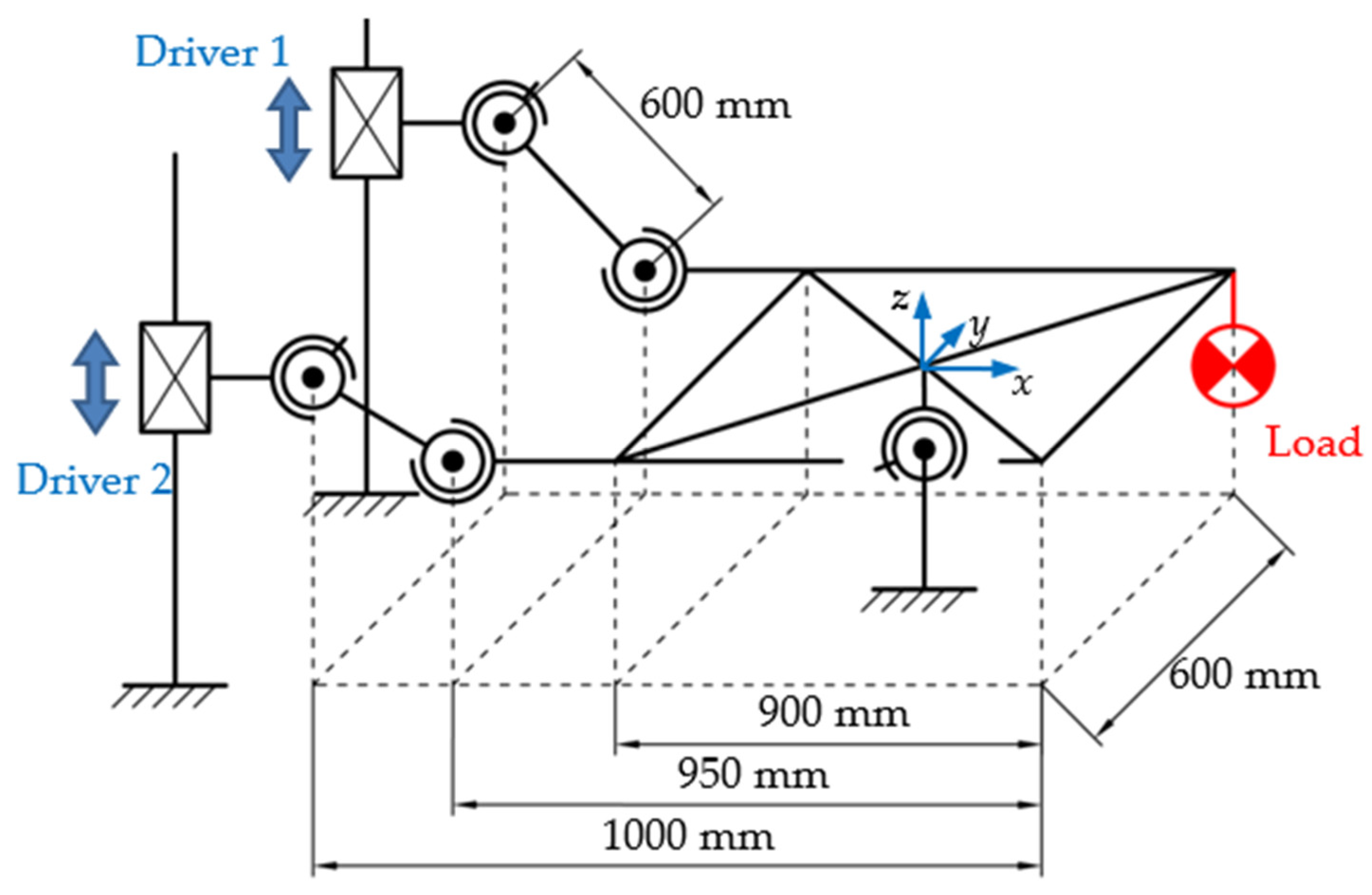
2.1. Environmental Disturbance Simulation Method based on Motion Platform
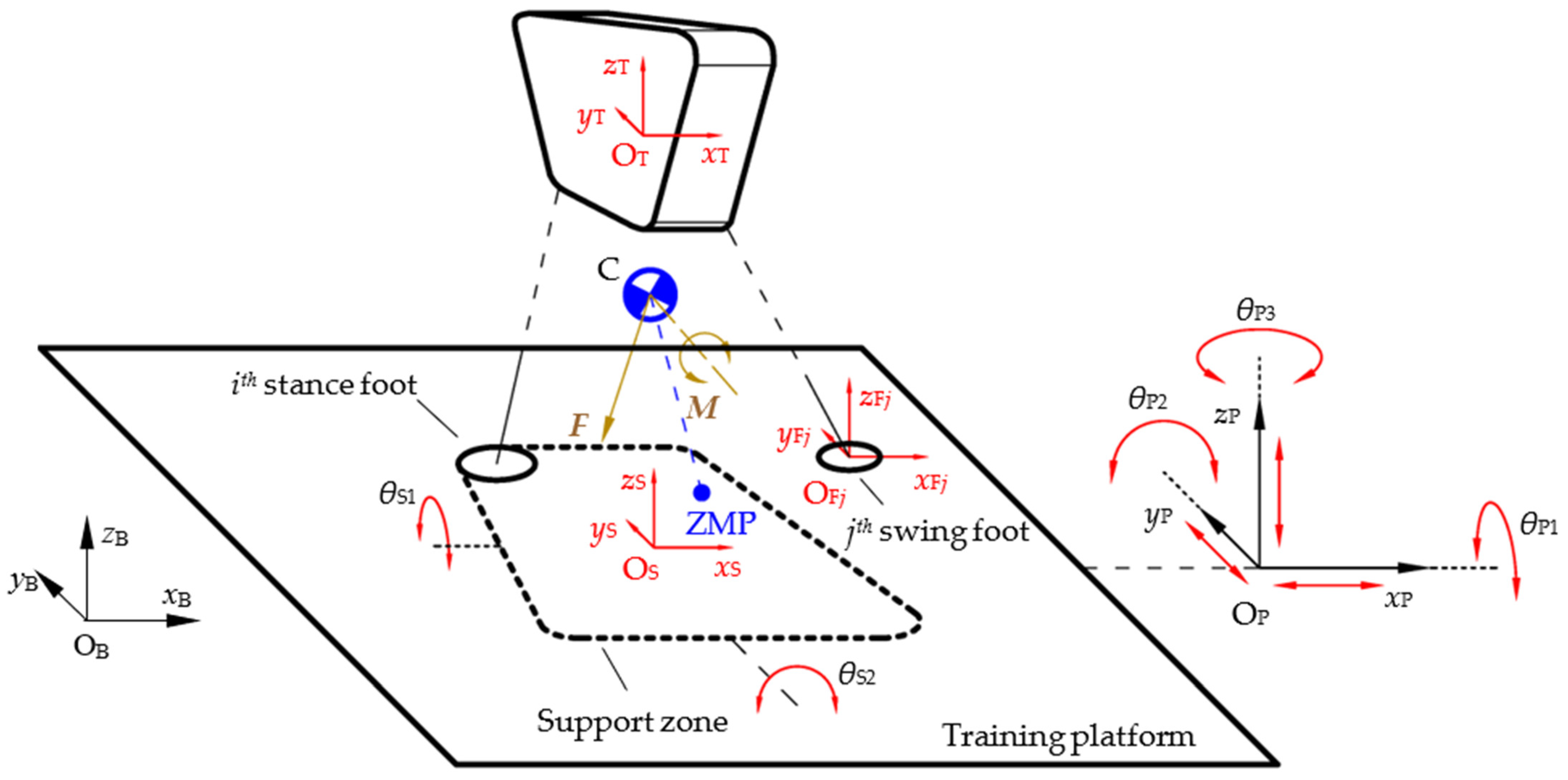
2.2. Model of the Training System
2.3. Action Set of Legged Robot
- (1)
- Single-joint action. When the robot’s joint reaches its position limit, velocity limit or acceleration limit, the motion of the robot will be affected, so joint limit avoidance is required.
- (2)
- Torso action. This kind of action is used to bring the robot stance leg back to the preset motion sample after other adjustments. The action variable is chosen as , and its adjustment is calculated using the PD control law shown in the following equation.
- (3)
- Swing foot action. Similar to the torso action, for the n2 swimming feet in the general model. The action variables are chosen as (j = 1, 2…n2) and the adjustment is calculated using the PD control law shown in the following equation.
- (4)
- CoM action. This type of action will directly adjust the robot CoM to keep balance on the moving platform. The action variable is chosen as the linear acceleration of the CoM. To keep the CoM above the stance legs, the adjustment is calculated according to the estimated position of the moving platform.
- (5)
- Inertial force/moment action. The inertial forces and moments influenced by the motion of the limbs are taken as a class of actions to cope with the perturbations. The action variables are chosen as the inertial force F and the inertial moment M at the CoM. The kinetic energy attenuation method proposed by the authors of [11] is used here to keep the robot balanced. The adjustment is calculated as follows:
- (6)
- ZMP action. As a common control strategy in robot balance control, changing the ZMP position within the support zone through limb motion can be used as a class of action in response to perturbations. Therefore, the action variables are chosen as xZMP and yZMP. Using the pose balance control method based on the CP point proposed by the authors of [8], the ZMP adjustment is calculated with the following equation:
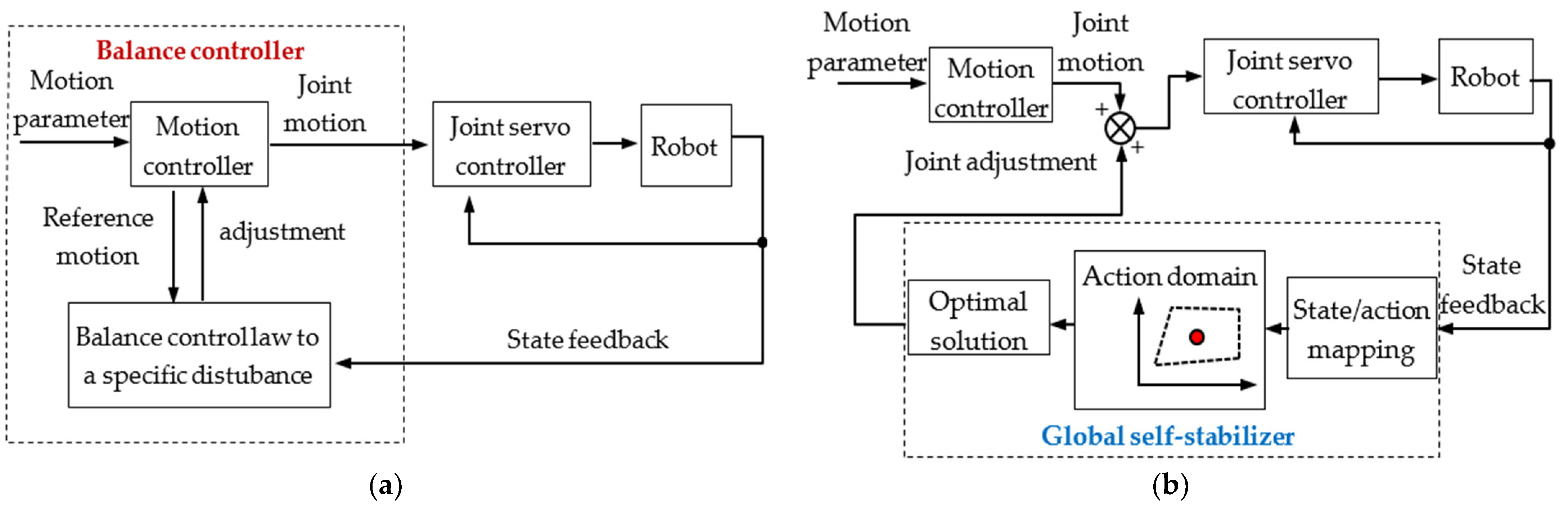
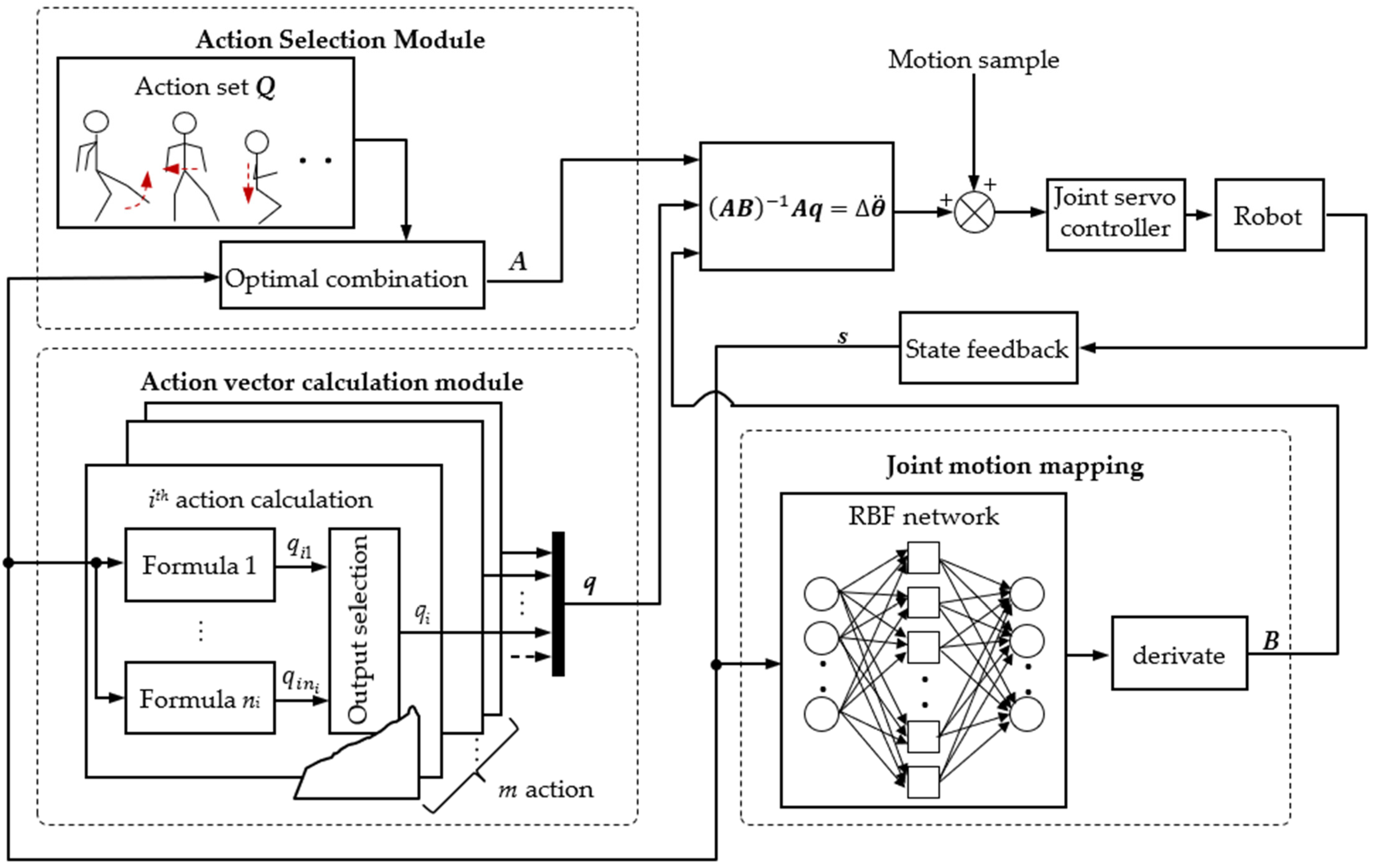
3. The Global Self-Stabilizer
3.1. Preprocessing and Structure of the Global Self-Stabilizer
3.2. Action Selection Module
3.3. Adjustment Calculation Module
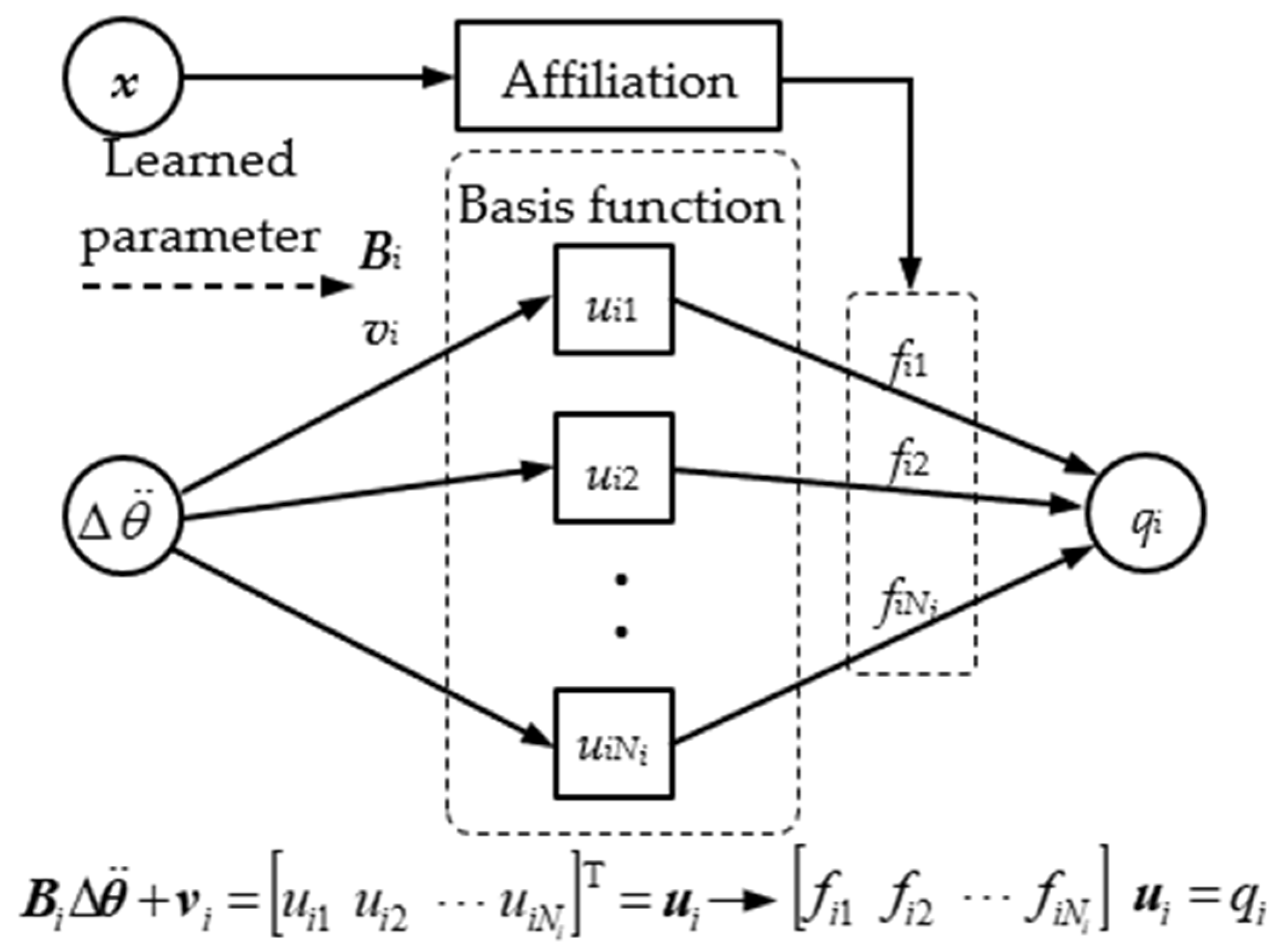
3.4. Joint Motion Mapping Module
4. Stability Training System of Biped Robots
4.1. Simulation Environment
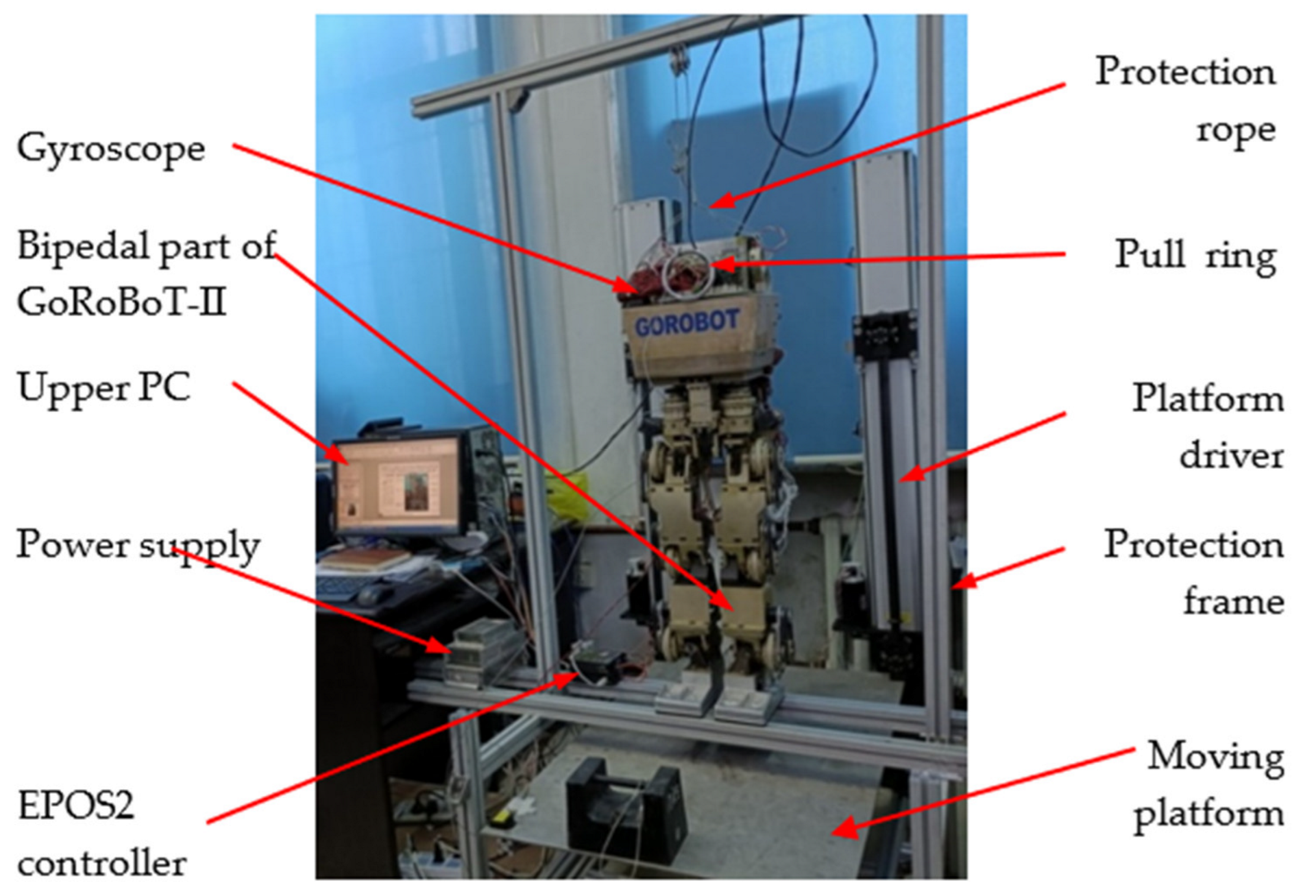
4.2. Experiment Environment
4.3. Balance Controllers for Stability Training Data Generation
- (1)
- CoM adjustment balance controller. This controller maintains the robot’s balance by keeping the robot’s CoM above its support zone. The action variable that must be selected is , and the action variable to be replaced can be , or in , and , or in . The former corresponds to adjusting the robot’s CoM by translational motion of the torso, and the latter by the swing foot.
- (2)
- Energy attenuation balance controller. This controller dissipates the system energy by making the inertial force and moment do negative work, thus achieving stabilization. The action variables to be selected are F and M. The action variables that can be removed are the torso acceleration or the swing leg acceleration , which correspond to the two ways of changing the inertial force and moment by the stance leg adjustment or the swing leg adjustment, respectively.
- (3)
- ZMP adjustment balance controller. This controller keeps the robot’s CP point in the center of the support zone by adjusting the ZMP. Therefore, the action variables that must be selected are xZMP and yZMP, and the substituted action variables can be or in , and or in , which is equivalent to the adjustment of the ZMP position by torso swing or swing leg kick.
5. Simulation Results
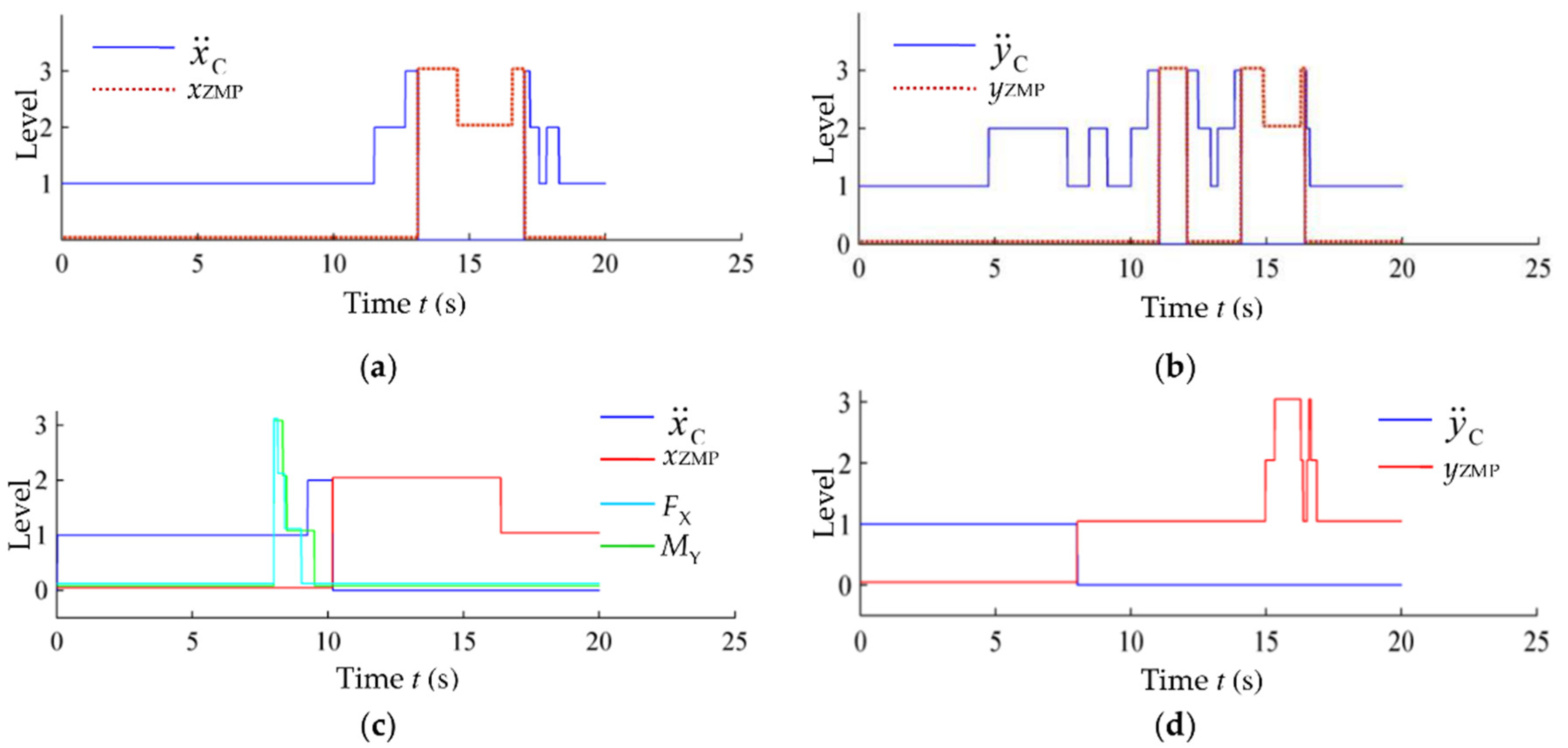
5.1. Stability Training in Simulation
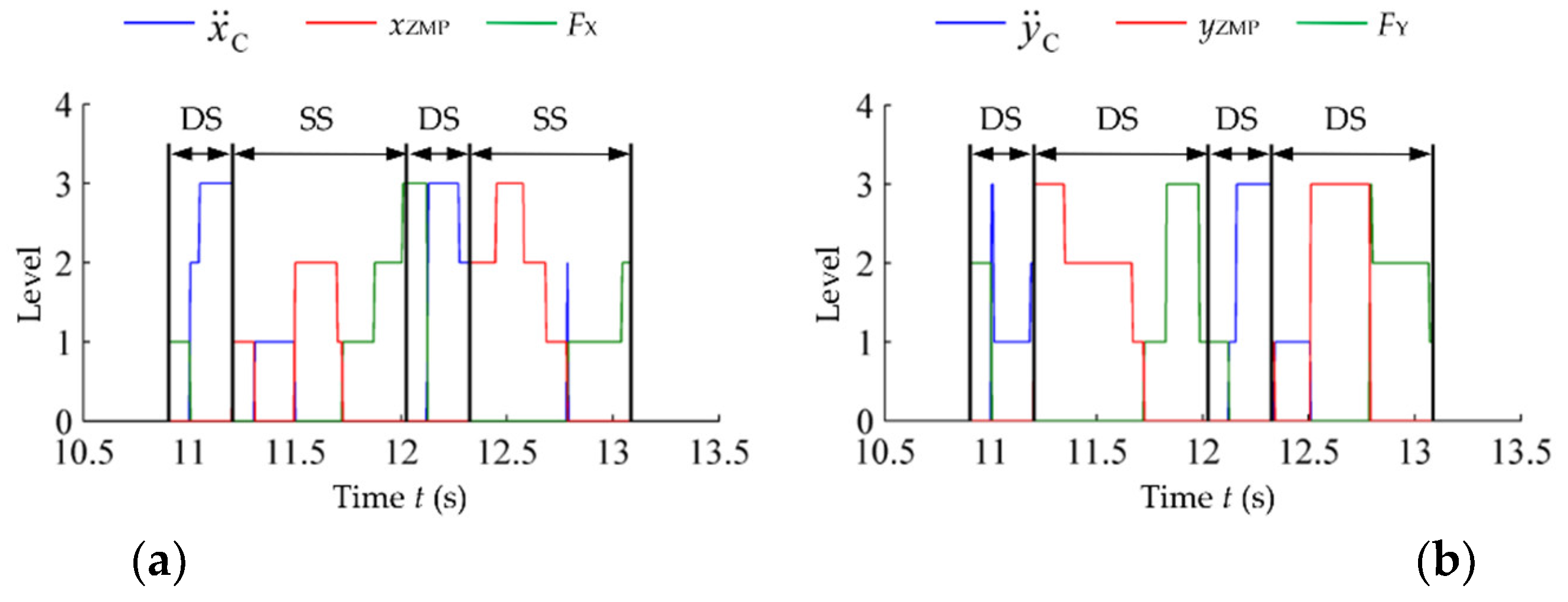
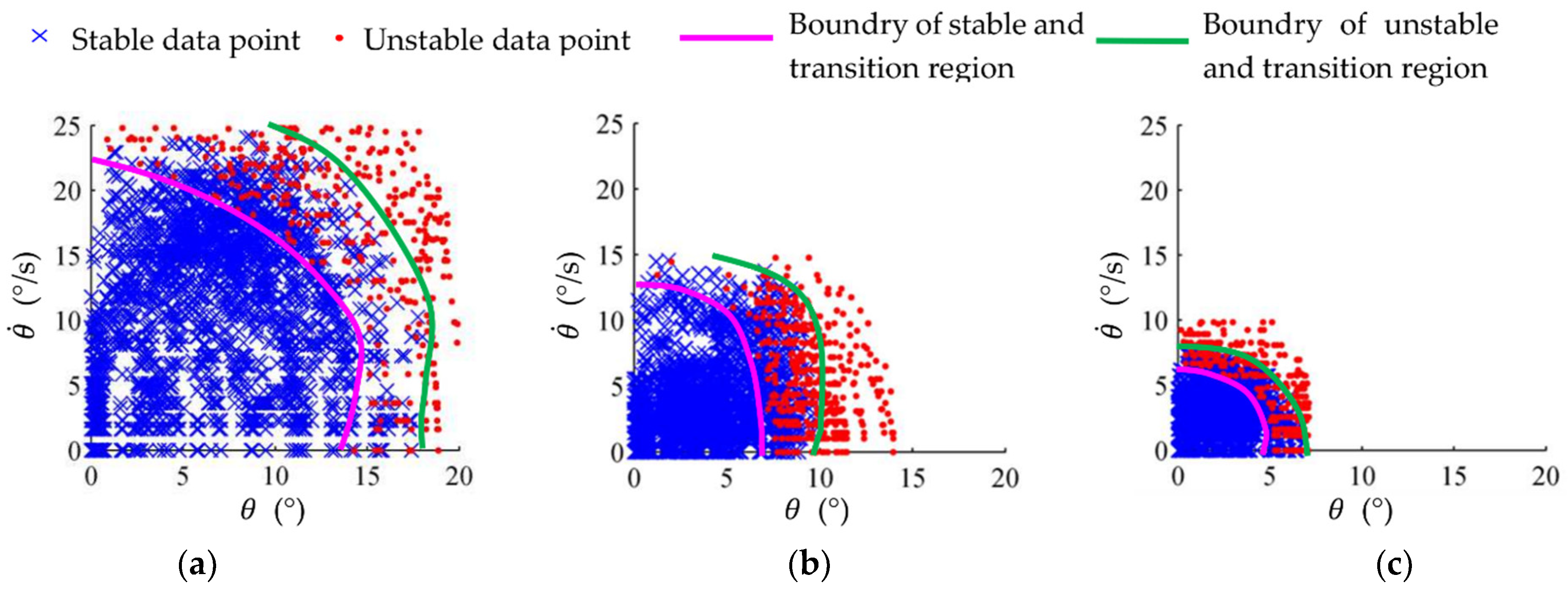
5.2. Stability Verification Simulation of the Trained Global Self-Stabilizer
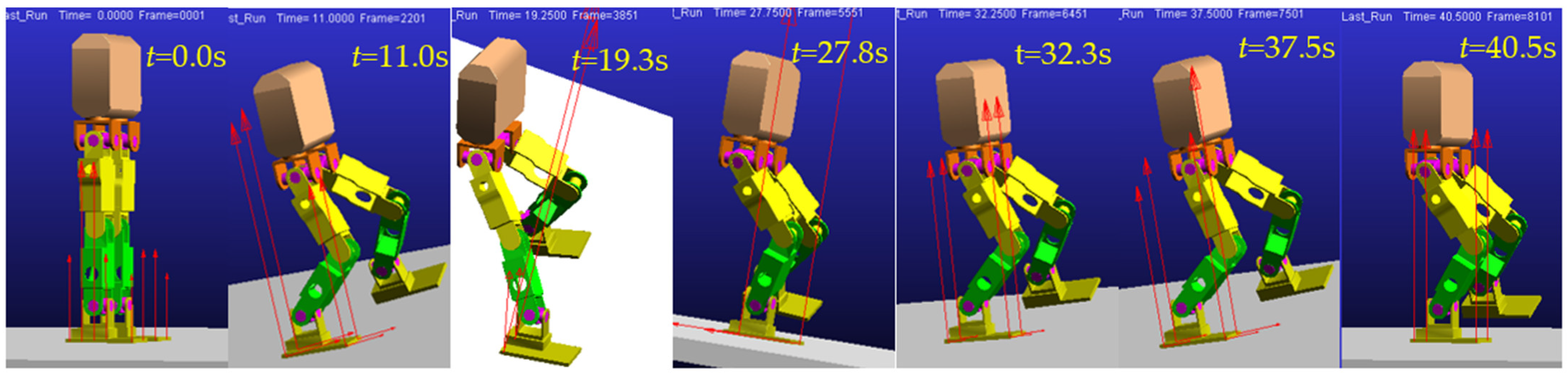
6. Experiment Results
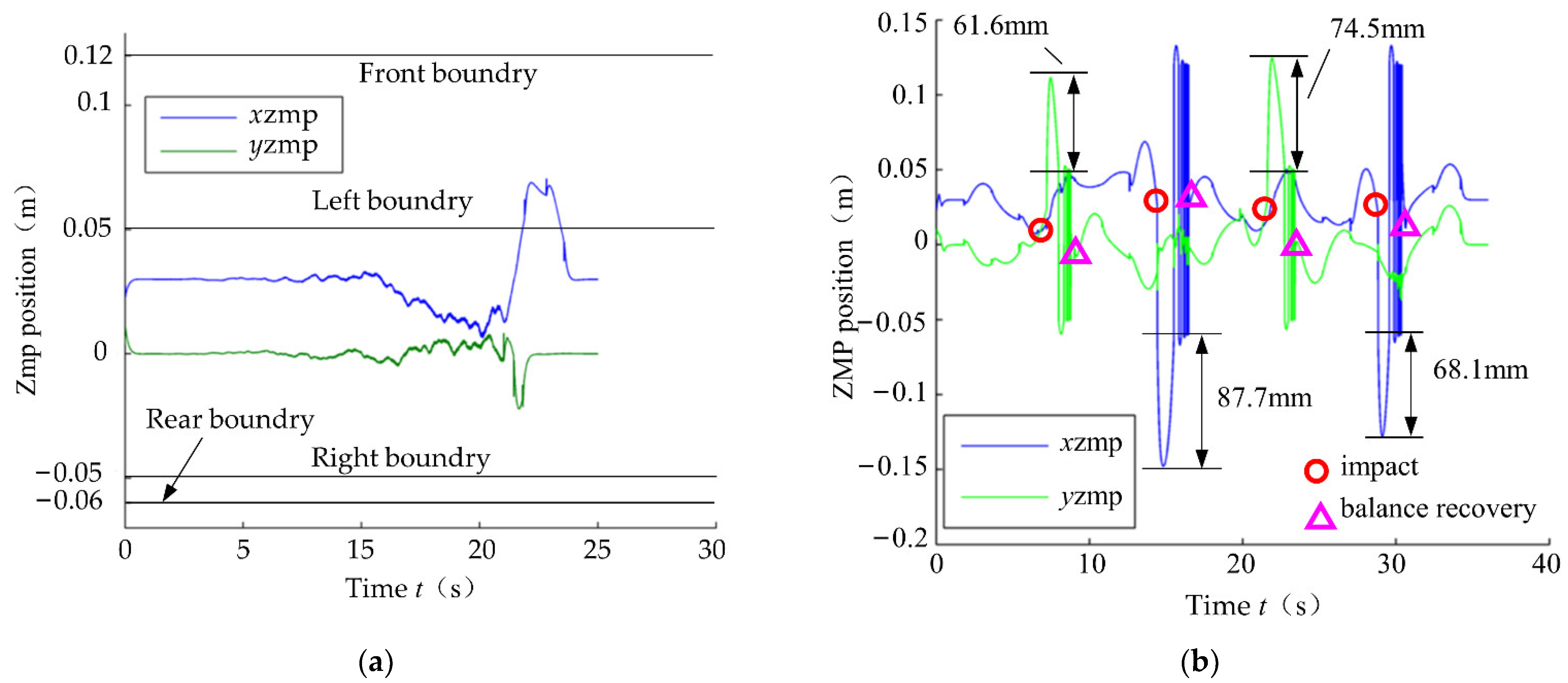
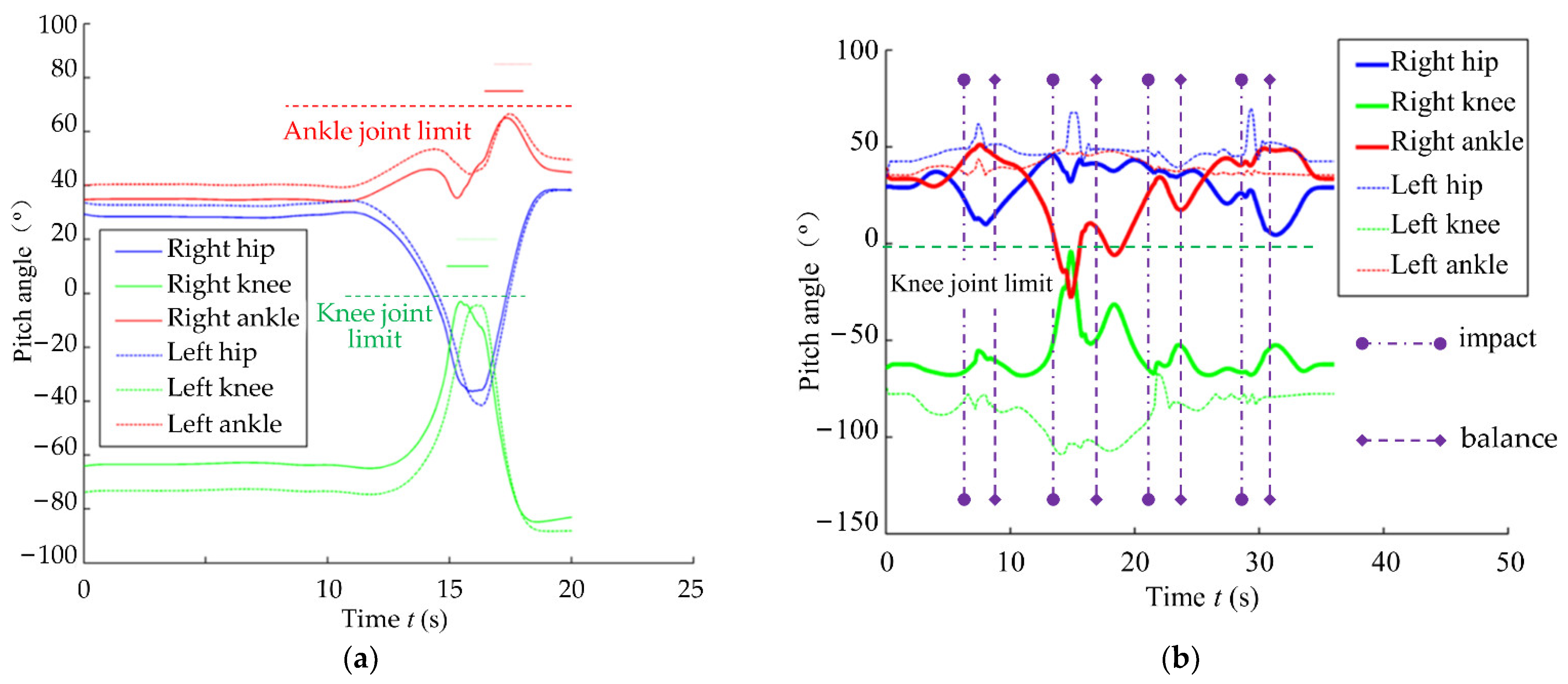
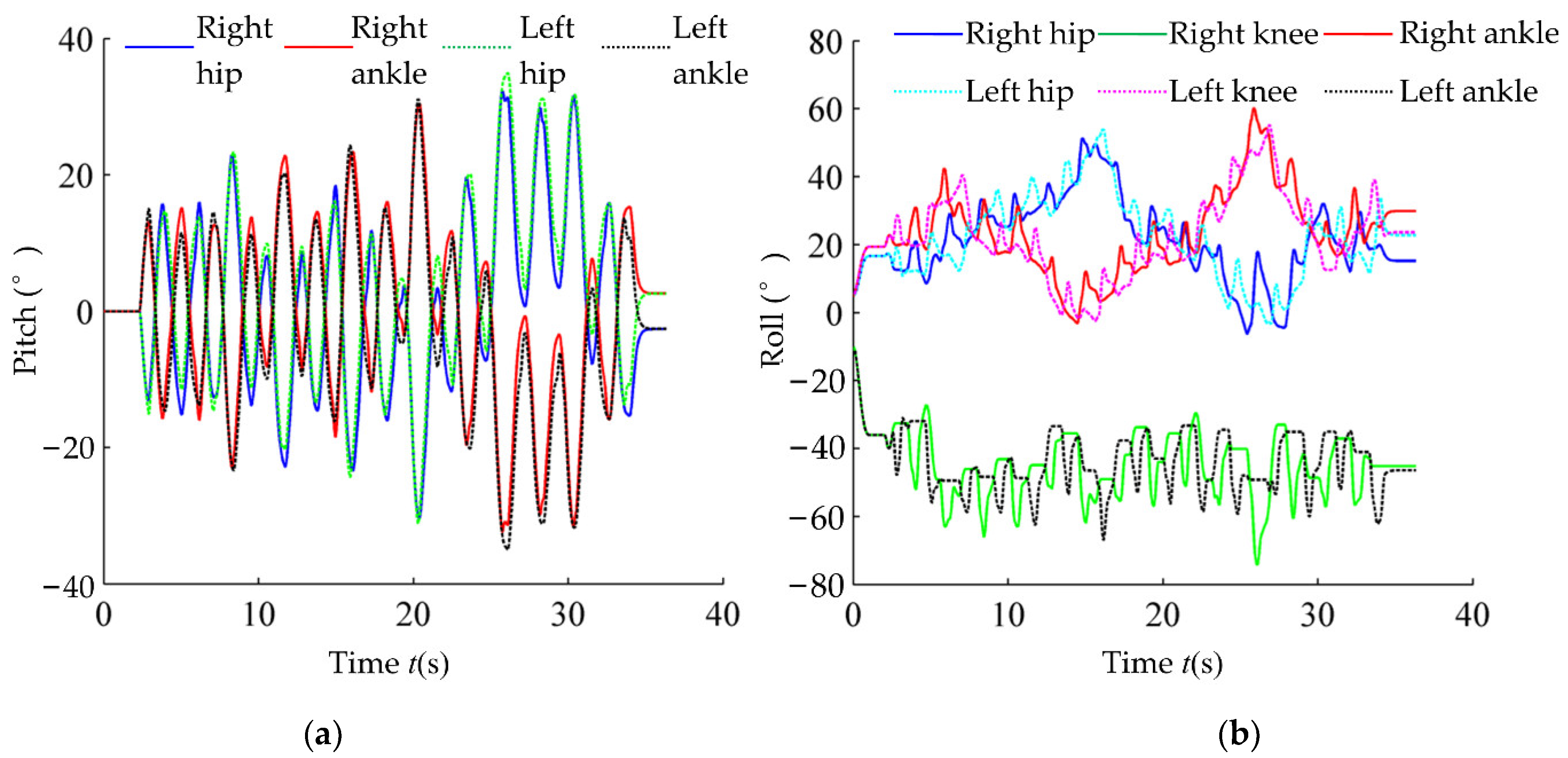
6.1. Stability Training Experiment
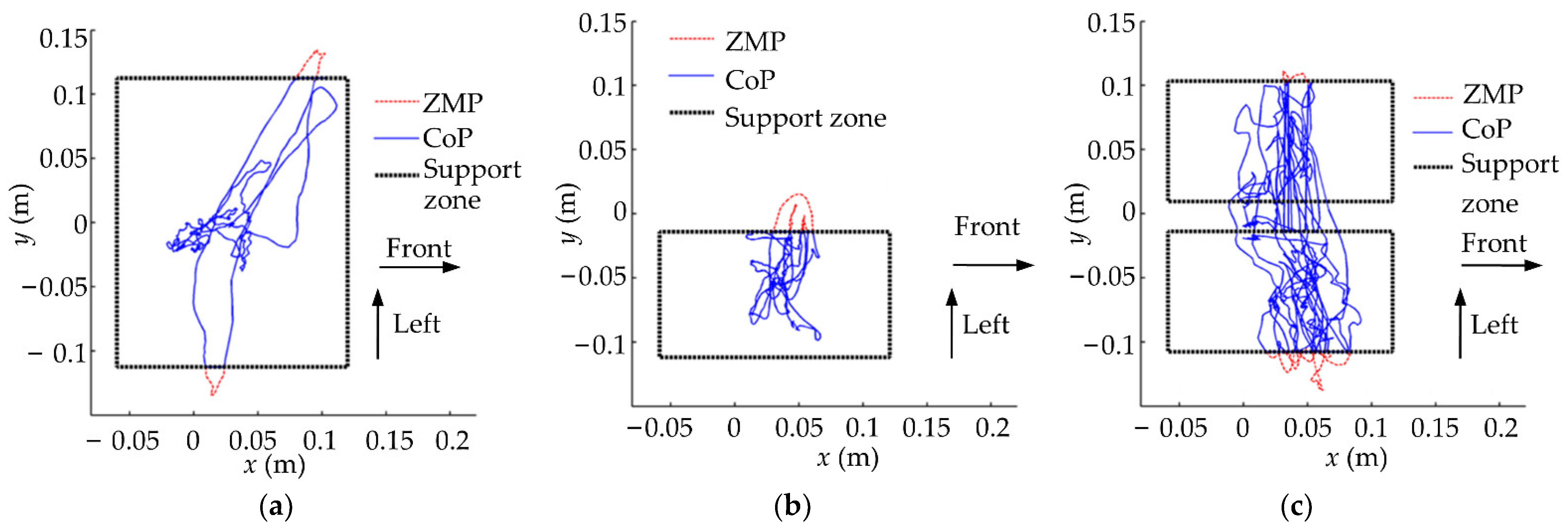
6.2. Stability Verification Experiment
7. Conclusions
- Simulation verification showed that the success rates of the trained global self-stabilizer, in three kinds of motion, under different disturbances, were higher than that of the model-based balance controller, with an improvement of at least 9.4%.
- Experiment verification showed that the trained global self-stabilizer could keep the robot balanced under the random amplitude-limited tilt perturbation. The success rates of the stability verification experiments could reach 75%, 60% and 55%, respectively, which were higher than the success rates obtained using the model-based balance controller during the training data generation (58.3%, 33.3% and 29.6%, respectively).
- The trained global self-stabilizer obtained different action combinations from the training data, and also continuously switched parameters according to the system state. This indicates that the designed global self-stabilizer was able to explore better state–action mapping from the training data and had the ability to learn and evolve continuously.
Author Contributions
Funding
Conflicts of Interest
References
- Borovac, B.; Vukobratovic, M.; Surla, D. An Approach to Biped Control Synthesis. Robotica 1989, 7, 231–241. [Google Scholar] [CrossRef]
- Yokoi, K.; Kanehiro, F.; Kaneko, K.; Kajita, S.; Fujiwara, K.; Hirukawa, H. Experimental study of humanoid robot HRP-1S. Int. J. Robot Res. 2004, 23, 351–362. [Google Scholar] [CrossRef]
- Hirukawa, H.; Kanehiro, F.; Kajita, S.; Fujiwara, K.; Yokoi, K.; Kaneko, K.; Harada, K. Experimental evaluation of the dynamic simulation of biped walking of humanoid robots. In Proceedings of the 20th IEEE International Conference on Robotics and Automation (ICRA), Taipei, Taiwan, 14–19 September 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 1640–1645. [Google Scholar]
- Okada, K.; Ogura, T.; Haneda, A.; Inaba, M. Autonomous 3D walking system for a humanoid robot based on visual step recognition and 3D foot step planner. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Barcelona, Spain, 18–22 April 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 623–628. [Google Scholar]
- Kim, J.W.; Tran, T.T.; Dang, C.V.; Kang, B. Motion and Walking Stabilization of Humanoids Using Sensory Reflex Control. Int. J. Adv. Robot Syst. 2016, 13, 77. [Google Scholar] [CrossRef]
- Kaewlek, N.; Maneewarn, T. Inclined Plane Walking Compensation for a Humanoid Robot. In Proceedings of the International Conference on Control, Automation and Systems (ICCAS 2010), Gyeonggi do, Korea, 27–30 October 2010; IEEE: Piscataway, NJ, USA, 2005; pp. 1403–1407. [Google Scholar]
- Yang, S.P.; Chen, H.; Fu, Z.; Zhang, W. Force-feedback based Whole-body Stabilizer for Position-Controlled Humanoid Robots. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Electr Network, Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7432–7439. [Google Scholar]
- Seo, K.; Kim, J.; Roh, K. Towards Natural Bipedal Walking: Virtual Gravity Compensation and Capture Point Control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 4019–4026. [Google Scholar]
- Elhasairi, A.; Pechev, A. Humanoid robot balance control using the spherical inverted pendulum mode. Front. Robot AI 2015, 2, 21. [Google Scholar] [CrossRef]
- Alcaraz-Jimenez, J.J.; Herrero-Perez, D.; Martinez-Barbera, H. Robust feedback control of ZMP-based gait for the humanoid robot Nao. Int. J. Robot Res. 2013, 32, 1074–1088. [Google Scholar] [CrossRef]
- Gao, L.Y.; Wu, W.G.; Ieee. Kinetic Energy Attenuation Method for Posture Balance Control of Humanoid Biped Robot under Impact Disturbance. In Proceedings of the 44th Annual Conference of the IEEE Industrial-Electronics-Society (IECON), Washington, DC, USA, 20–23 October 2018; pp. 2564–2569. [Google Scholar]
- Henaff, P.; Scesa, V.; Ben Ouezdou, F.; Bruneau, O. Real time implementation of CTRNN and BPTT algorithm to learn on-line biped robot balance: Experiments on the standing posture. Control Eng. Pract. 2011, 19, 89–99. [Google Scholar] [CrossRef]
- Shieh, M.Y.; Chang, K.H.; Chuang, C.Y.; Lia, Y.S.; Ieee. Development and implementation of an artificial neural network based controller for gait balance of a biped robot. In Proceedings of the 33rd Annual Conference of the IEEE-Industrial-Electronics-Society, Taipei, Taiwan, 5–8 November 2007; p. 2778. [Google Scholar]
- Zhou, C.J.; Meng, Q.C. Dynamic balance of a biped robot using fuzzy reinforcement learning agents. Fuzzy Sets Syst. 2003, 134, 169–187. [Google Scholar] [CrossRef]
- Ferreira, J.P.; Crisostomo, M.M.; Coimbra, A.P. SVR Versus Neural-Fuzzy Network Controllers for the Sagittal Balance of a Biped Robot. IEEE Trans. Neural Netw. 2009, 20, 1885–1897. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.J.; Ge, Q.B.; Ye, W.J.; Yuan, P.J. Dynamic Balance Optimization and Control of Quadruped Robot Systems With Flexible Joints. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 1338–1351. [Google Scholar] [CrossRef]
- Hwang, K.S.; Li, J.S.; Jiang, W.C.; Wang, W.H. Gait Balance of Biped Robot based on Reinforcement Learning. In Proceedings of the SICE Annual Conference, Nagoya University, Nagoya, Japan, 14–17 September 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 435–439. [Google Scholar]
- Hengst, B.; Lange, M.; White, B. Learning ankle-tilt and foot-placement control for flat-footed bipedal balancing and walking. In Proceedings of the 2011 11th IEEE-RAS International Conference on Humanoid Robots, Bled, Slovenia, 26–28 October 2011; pp. 288–293. [Google Scholar]
- Lin, J.L.; Hwang, K.S. Balancing and Reconstruction of Segmented Postures for Humanoid Robots in Imitation of Motion. IEEE Access 2017, 5, 17534–17542. [Google Scholar] [CrossRef]
- Hwang, K.S.; Jiang, W.C.; Chen, Y.J.; Shi, H.B. Motion Segmentation and Balancing for a Biped Robot’s Imitation Learning. IEEE Trans. Ind. Inform. 2017, 13, 1099–1108. [Google Scholar] [CrossRef]
- Liu, C.J.; Lonsberry, A.G.; Nandor, M.J.; Audu, M.L.; Lonsberry, A.J.; Quinn, R.D. Implementation of Deep Deterministic Policy Gradients for Controlling Dynamic Bipedal Walking. Biomimetics 2019, 4, 28. [Google Scholar] [CrossRef] [PubMed]
- Valle, C.M.C.O.; Tanscheit, R.; Mendoza, L.A.F. Computed-Torque Control of a Simulated Bipedal Robot with Locomotion by Reinforcement Learning. In Proceedings of the 2016 IEEE Latin American Conference on Computational Intelligence (La-Cci), Cartagena, Colombia, 2–4 November 2016. [Google Scholar]
- Li, Z.Y.; Cheng, X.X.; Peng, X.B.; Abbeel, P.; Levine, S.; Berseth, G.; Sreenath, K.; Ieee. Reinforcement Learning for Robust Parameterized Locomotion Control of Bipedal Robots. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May 30–5 June 2021; pp. 2811–2817. [Google Scholar]
- Wu, W.G.; Du, W.Q. Research of 6-DOF Serial-Parallel Mechanism Platform for Stability Training of Legged-Walking Robot. J. Harbin Inst. Technol. (New Ser.) 2014, 2, 75–82. [Google Scholar] [CrossRef]
- Wu, W.G.; Gao, L.Y. Posture self-stabilizer of a biped robot based on training platform and reinforcement learning. Robot Auton. Syst. 2017, 98, 42–55. [Google Scholar] [CrossRef]
- Jelsma, D.; Ferguson, G.D.; Smits-Engelsman, B.C.M.; Geuze, R.H. Short-term motor learning of dynamic balance control in children with probable Developmental Coordination Disorder. Res. Dev. Disabil. 2015, 38, 213–222. [Google Scholar] [CrossRef] [PubMed]
- Maciaszek, J.; Borawska, S.; Wojcikiewicz, J. Influence of Posturographic Platform Biofeedback Training on the Dynamic Balance of Adult Stroke Patients. J. Stroke Cerebrovasc. Dis. 2014, 23, 1269–1274. [Google Scholar] [CrossRef] [PubMed]
- DiFeo, G.; Curlik, D.M.; Shors, T.J. The motirod: A novel physical skill task that enhances motivation to learn and thereby increases neurogenesis especially in the female hippocampus. Brain Res. 2015, 1621, 187–196. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.G.; Gao, L.Y. Modular combined motion platform used for stability training and amplitude limiting random motion planning and control method. CN Patent CN110275551A, 7 December 2021. [Google Scholar]
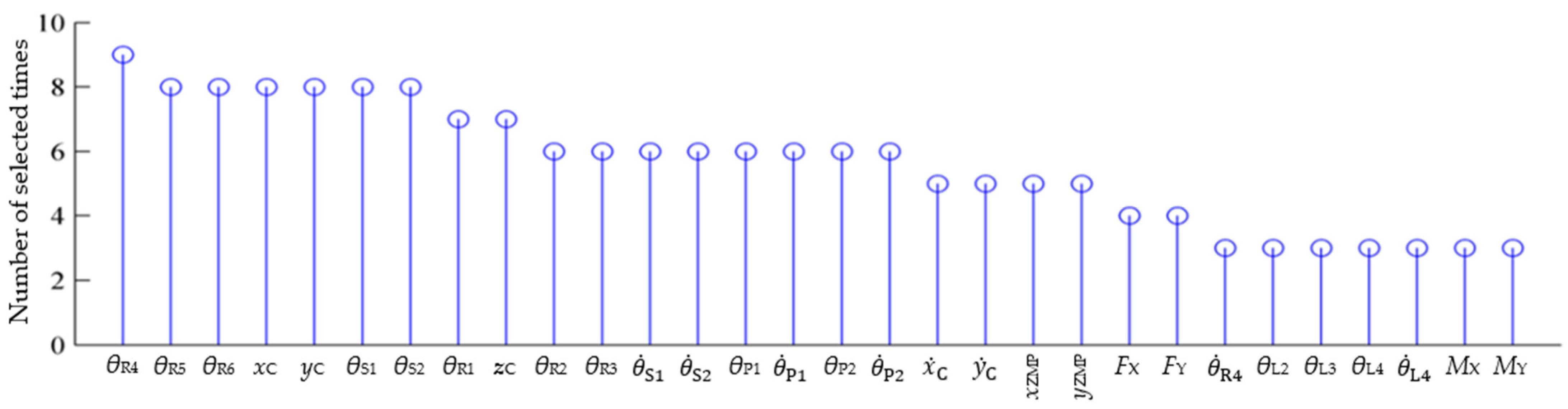
- Gao, L.Y.; Wu, W.G. Relevance assignation feature selection method based on mutual information for machine learning. Knowl.-Based Syst. 2020, 209, 106439. [Google Scholar] [CrossRef]
- Hou, Y.Y. Research on Flexible Drive Unit and Its Application in Humanoid Biped Robot. Ph.D. Dissertation, Harbin Institute of Technology, Harbin, China, 2014. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scholar | Algorithm | State Space | Action Space | Disturbance |
|---|---|---|---|---|
| Scesa et al. [12] | CTRNN | 6-d 1 continuous space | 3-d continuous space | Sagittal/lateral push |
| Shieh et al. [13] | FNN | 10-d continuous space | 1-d continuous space | Tilt/rugged ground |
| Zhou et al. [14] | Fuzzy reinforcement learning | Two 2-d continuous space | 1-d continuous space | None |
| Joao et al. [15] | SVM + FNN | 2-d continuous space | 1-d continuous space | None |
| Li et al. [16] | Fuzzy control + optimal control | Two 3-d continuous space | 3-d continuous space | None |
| Hwang et al. [17] | Q-learning | 82 discrete states | 24 discrete actions | Seesaw |
| Hengst et al. [18] | Q-learning | 4-d continuous space | 9 discrete actions | None |
| Hwang et al. [19,20] | Q-learning + Reconstruction of Segmented Postures | 8 discrete states | 25 discrete actions | None |
| Liu et al. [21] | DDPG | 4-d continuous space | 2-d continuous space | Sagittal impact |
| Valle et al. [22] | Approximate Q-learning | 66 discrete states | 8 discrete actions | None |
| Li et al. [23] | PPO | 20-d continuous space | 10-d continuous space | Load of 15% total mass |
| Category of System Variables | Definition of Variable | Symbolic Representation |
|---|---|---|
| Joint motion | Angle, angular velocity and acceleration of joints | , k = 1, 2, … NJ |
| Torso motion | Pose, velocity and acceleration of torso | |
| jth swing foot motion | Pose, velocity and acceleration of jth foot | |
| CoM motion | Pose, velocity and acceleration of CoM | |
| ZMP position | ZMP position in ΣOB | PZMP = [xZMP, yZMP, 0] T |
| Inertial force and moment | Resultant force and moment at CoM | F = [FX, FY, FZ] T M = [MX, MY, MZ] T |
| Support zone flip motion | flip angle, angular velocity and angular acceleration of ΣOS with respect to ΣOP | |
| Moving platform motion | Pose, velocity and acceleration of ΣOP |
| Action | Parameter | Meaning |
|---|---|---|
| Single-joint action | K11, K12, K13 | the compensation coefficients when the joint position, velocity and acceleration are close to the limit |
| ε11, ε12, ε13 | the width of the neighborhood where the joint position, velocity and acceleration start to avoid the limit | |
| L (·) | the compensation function for avoiding the joint limit | |
| Torso action | the torso target pose and velocity vector | |
| K21, K22 | the proportional and derivative coefficients for the torso adjustment | |
| Swing foot action | the swing foot target pose and velocity vector | |
| K31, K32 | the proportional and derivative coefficients for the swing foot adjustment | |
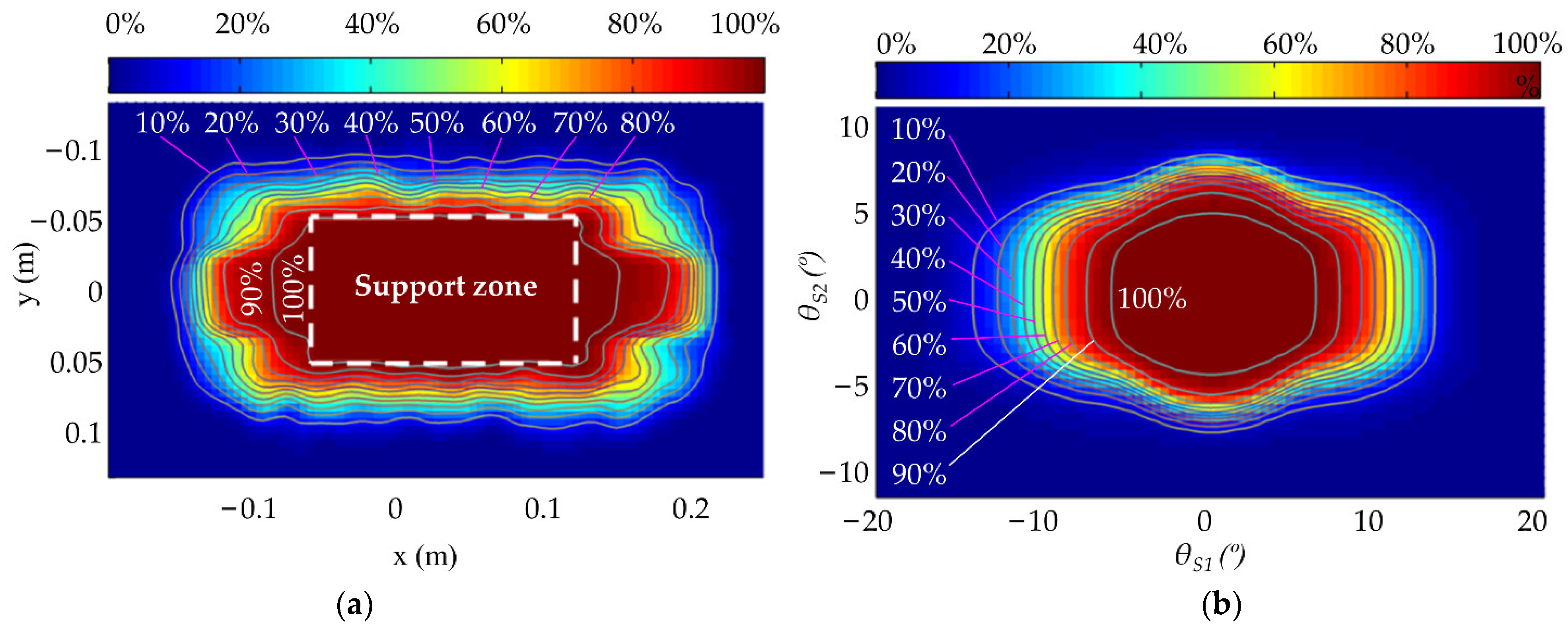
| CoM action | PS, PC | the position of the stance foot coordinate system origin OS and the robot CoM |
| lC | the distance from the robot CoM to the OS | |
| K41, K42 | the proportional and derivative coefficients of the CoM adjustment | |
| Inertial force/moment action | Flast, Mlast | the resultant inertial force and moment at the CoM in the last control cycle |
| mC | the total mass of the robot | |
| LC | the angular momentum about the CoM | |
| K51, K52 | the adjustment coefficients for the inertial force and moment | |
| ZMP action | xZMP, yZMP | position of the ZMP point along the x and y axes within ΣOS |
| PCP | the CP point position in the support zone | |
| P0 | the position of the center point of stance foot | |
| K6 | the coefficient for ZMP adjustment |
| Parameter | Length (mm) | Parameter | Length (mm) | Parameter | Mass (kg) |
|---|---|---|---|---|---|
| Torso length l0 | 300 | Hip width lh | 125 | Torso mass m0 | 12.5 |
| Thigh length l1 | 220 | Forefoot length lf1 | 120 | Thigh mass m1 | 6 |
| Calf length l2 | 189 | Hindfoot length lf2 | 60 | Calf mass m2 | 2.5 |
| Ankle height l3 | 104 | Foot width lfw | 90 | Foot mass m3 | 0.25 |
| Balance Controller | Behavior | Symbol | Activated Action Variables |
|---|---|---|---|
| CoM motion | Torso translation | TC | |
| jth swing foot kick | FC | ||
| Energy attenuation | Torso motion | TE | |
| jth swing foot motion | FE | ||
| CP balance control | Torso translation | TB | |
| jth swing foot kick | FB |
| Action | Parameter | Value | ||
|---|---|---|---|---|
| Level 1 | Level 2 | Level 3 | ||
| Single-joint action | (K11, K12, K13) | (5, 3, 1) | (4, 2, 1) | (3, 1, 1) |
| (ε1, ε2, ε3) | (4°, 6°/s, 12°/s2) | (7°, 10°/s, 20°/s2) | (10°, 15°/s, 30°/s2) | |
| Torso action | (K21, K22) | (14.1, 100) | (20, 100) | (28.2, 100) |
| Swing foot action | (K31, K32) | (14.1, 100) | (20, 100) | (28.2, 100) |
| CoM action | (K41, K42) | (14.1, 100) | (20, 100) | (28.2, 100) |
| Inertial force/moment action | (K51, K52) | (1, 0.5) | (1.5, 0.8) | (2, 1) |
| ZMP action | K6 | 0.8 | 1.2 | 1.6 |
| Variable | Selected State Variables | Number of Basis Function | |||
|---|---|---|---|---|---|
| Level 1 | Level 2 | Level 3 | |||
| Action variable | (i = 1, 2, …,6) | 52 * | 70 * | 64 * | |
| (i = 1, 2, …,6) | 55 * | 67 * | 59 * | ||
| xT, , xZMP, θR5, θR4 | 1872 | 1935 | 1763 | ||
| yT, , yZMP, θR6 | 1119 | 1328 | 1266 | ||
| zT, , θR4, | 1203 | 1298 | 1255 | ||
| θP1, , θT1, | 1353 | 1499 | 1296 | ||
| θP2, , θT2, | 1277 | 1394 | 1206 | ||
| θT3, , θR1 | 206 | 301 | 255 | ||
| xF, , MY, FX, θS2, | 2452 | 2571 | 2368 | ||
| yF, , MX, FY, θS1, | 2280 | 2246 | 2116 | ||
| zF, , θL4, | 1368 | 1420 | 1297 | ||
| θF1, , θL6, | 1385 | 1538 | 1226 | ||
| θF2, , θL5, | 1235 | 1496 | 1126 | ||
| θF3, , θL1 | 341 | 391 | 335 | ||
| xC, , xZMP, θS2, , θP2, , MY, FX, θR5, | 11,359 | 12,670 | 12,370 | ||
| yC, , yZMP, θS1, , θP1, , MX, FY, θR6, | 12,697 | 13,019 | 11,268 | ||
| zC, , θR4, , θL4, | 2332 | 2569 | 2571 | ||
| ΔFX | FX, xZMP, θS2, , θP2, , xC, | 5002 | 5233 | 5493 | |
| ΔFY | FY, yZMP, θS1, , θP1, , yC, | 5540 | 5981 | 6127 | |
| ΔFZ | θS2, , θS1, , zC, | 3627 | 3826 | 3695 | |
| ΔMX | yZMP, θS1, , θP1, , yC, | 3890 | 3452 | 3321 | |
| ΔMY | xZMP, θS2, , θP2, , xC, | 4023 | 3926 | 3751 | |
| ΔMZ | θS2, , θS1, | 1231 | 1396 | 1117 | |
| ΔxZMP | xZMP, θP1, , θP2, , θS1, θS2, xC, , yC, | 8695 | 9007 | 9861 | |
| ΔyZMP | yZMP, θP1, , θP2, , θS1, θS2, xC, , yC, | 8824 | 8937 | 9331 | |
| Joint mapping | ΔFX | xC, zC, θR1, θR2, θR3, θR4, θR5, θR6 | 6892 | ||
| ΔFY | yC, zC, θR1, θR2, θR3, θR4, θR5, θR6 | 7101 | |||
| ΔFZ | xC, yC, zC, θR1, θR2, θR3, θR4, θR5, θR6 | 7840 | |||
| ΔxZMP | xC, zC, θR1, θR2, θR3, θR4, θR5, θR6, θL2, θL3, FX, FZ, MY | 24,427 | |||
| ΔyZMP | yC, zC, θR1, θR2, θR3, θR4, θR5, θR6, θL2, θL3, FY, FZ, MX | 22,246 | |||
| Motion | Success Rate without Impact | Success Rate with Impact | ||
|---|---|---|---|---|
| Global Self-Stabilizer | Model-Based Controllers | Global Self-Stabilizer | Model-Based Controllers | |
| Double-leg stance | 97.4% | 88% (max) | 85.7% | 47% (max) |
| Single-leg stance | 94.2% | 75% (max) | 80.2% | 47% (max) |
| Stepping | 76.6% | 44% (max) | - | - |
| Platform Moving Parameter (Angle, Angular Velocity and Acceleration) | Success/Overall | ||
|---|---|---|---|
| Double-Leg Stance | Single-Leg Stance | Stepping | |
| ±7° ±10°/s, ±20°/s2 | 11/12 | 17/24 | 16/54 |
| ±14° ±15°/s, ±30°/s2 | 17/24 | 10/30 | - |
| ±20° ±20°/s, ±40°/s2 | 7/12 | - | - |
| ±20° ±25°/s, ±60°/s2 | 2/6 | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Gao, L.; Zhang, X. A Stability Training Method of Legged Robots Based on Training Platforms and Reinforcement Learning with Its Simulation and Experiment. Micromachines 2022, 13, 1436. https://doi.org/10.3390/mi13091436
Wu W, Gao L, Zhang X. A Stability Training Method of Legged Robots Based on Training Platforms and Reinforcement Learning with Its Simulation and Experiment. Micromachines. 2022; 13(9):1436. https://doi.org/10.3390/mi13091436
Chicago/Turabian StyleWu, Weiguo, Liyang Gao, and Xiao Zhang. 2022. "A Stability Training Method of Legged Robots Based on Training Platforms and Reinforcement Learning with Its Simulation and Experiment" Micromachines 13, no. 9: 1436. https://doi.org/10.3390/mi13091436