2.3. Datasets
As already shown in [
14], for the development of the deep-learning models implementing PMAs, the following data were used:
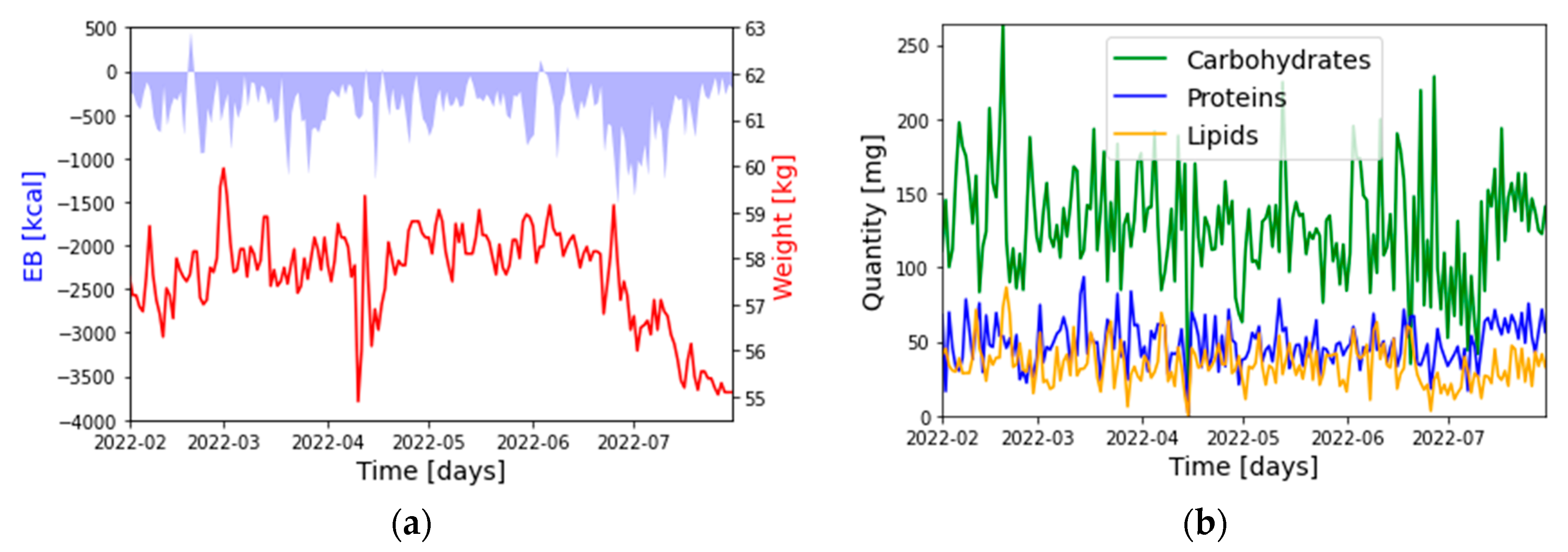
: Weight: [kg]
: Energy Balance (EB): [kcal]
: Carbohydrates: [g]
: Proteins: [g]
: Lipids: [g]
Where stands for variable j, with j = 1, …, 5.
In
Figure 1a,b, the representative time series of the five selected quantities are reported.
We reframed the time-series forecasting problem as a supervised learning problem, using lagged observations (including the seven days before the prediction, e.g.,
t − 1,
t − 2,
t − 7) as input variables to forecast the current time step (
t), as already explained in [
12]. The inputs of our model were
, with
i = 1, …, 7 indicating the lagged observation and
j = 1, …, 5 indicating the input variable. Therefore, the total number of inputs for the PMA was 7∙5 = 35. In this notation, the output of the PMA is
, i.e., the weight at time
t.
The dataset fed to the SARIMAX model is described in the next section.
2.4. Description of Models
As explained in the introduction, DDMs are divided into two types: statistical and deep-learning models. To select the best option for the development of the PMA, we chose to compare 4 different models:
SARIMAX:
The SARIMAX model (Seasonal Auto-Regressive Integrated Moving Average with eXogenous factors) is a linear regression model: an updated version of the ARIMA model. It is a seasonal equivalent model, like the SARIMA (Seasonal Auto-Regressive Integrated Moving Average) model, but it can also deal with exogenous factors, which are accounted for with an additional term, helping to reduce error values and improve overall model accuracy. This model is usually applied in time-series forecasting [
17].
The general form of a
SARIMA(
p,
d,
q)(
P,
D,
Q,
s) model is
where each term is defined as follows:
is the nonseasonal autoregressive lag polynomial;
is the seasonal autoregressive lag polynomial;
is the time series, differenced d times and seasonally differenced D times;
is the nonseasonal moving average lag polynomial;
is the seasonal moving average lag polynomial.
When dealing with n exogenous values, each defined at each time step,
t, denoted as
for
, the general form of the model becomes
where
is an additional parameter accounting for the relative weight of each exogenous variable.
For the SARIMAX model, , , and (i.e., EB and macronutrients) are considered as exogenous variables, with the weight as output. Considering our dataset structure, the exogenous variables at time t correspond to the inputs for the forecasting of the weight at time t + 1. However, in the SARIMAX equation, the exogenous term is considered at the same time, t, with respect to the output. To overcome this issue, we shifted the exogenous values of ΔT = 1 day with respect to weight. In this way, the exogenous term changed as follows: .
LSTM:
Long short-term memory (LSTM) networks [
18], a variant of the simplest recurrent neural networks (RNNs), can learn long-term dependencies and are the most widely used for working with sequential data such as time-series data [
19,
20,
21].
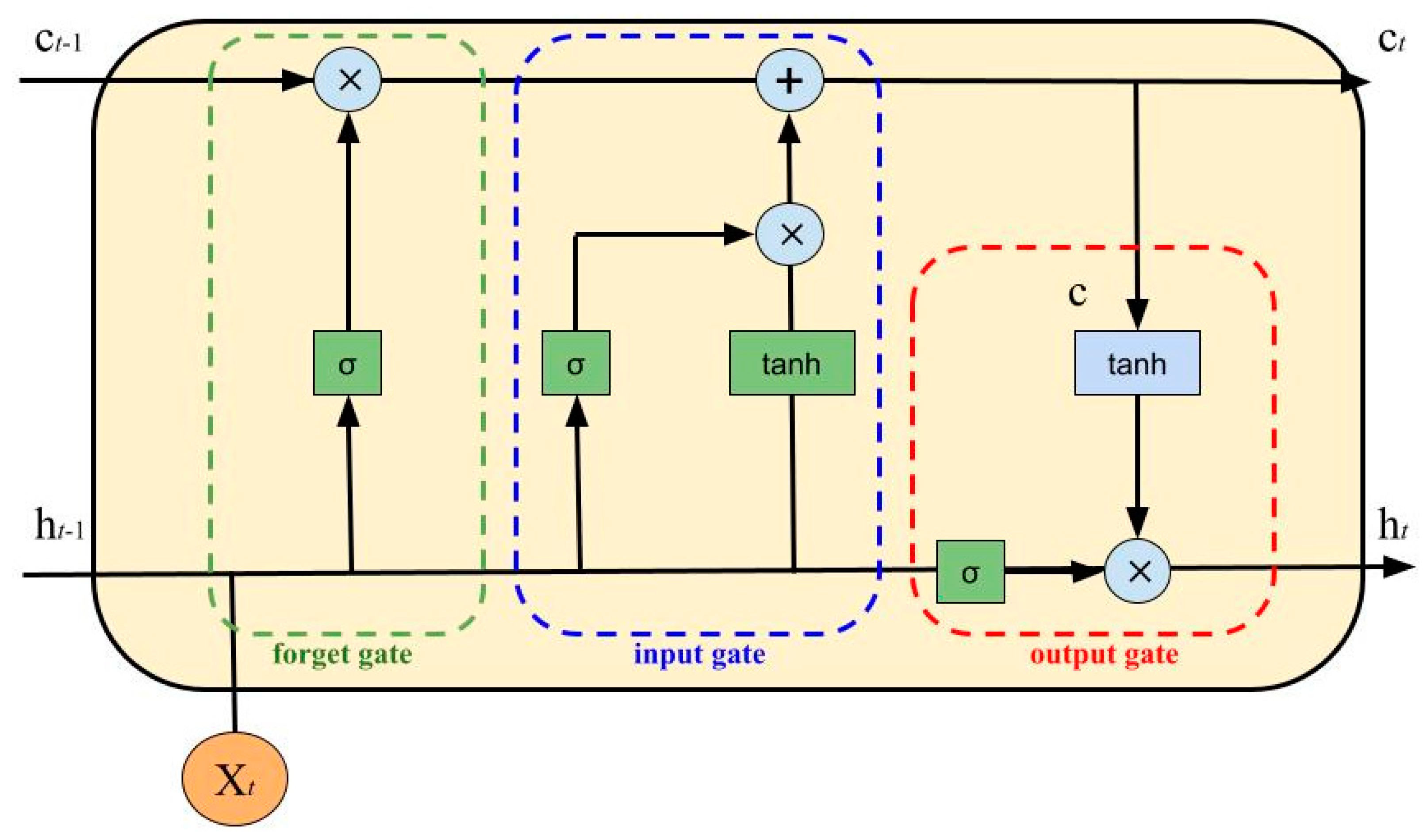
The LSTM cell (
Figure 2) uses an input gate, a forget gate and an output gate (a simple multilayer perceptron). Depending on data’s priority, these gates allow or deny data flow/passage. Moreover, they enhance the ability of the neural network to understand what needs to be saved, forgotten, remembered, paid attention to and output. The cell state and hidden state are used to gather data to be processed in the next state.
The gates have the following equations:
Cell State (Next Memory Input):
New State:
with
as the input vector,
as the output vector,
W and
U as parameter matrices and f as the parameter vector.
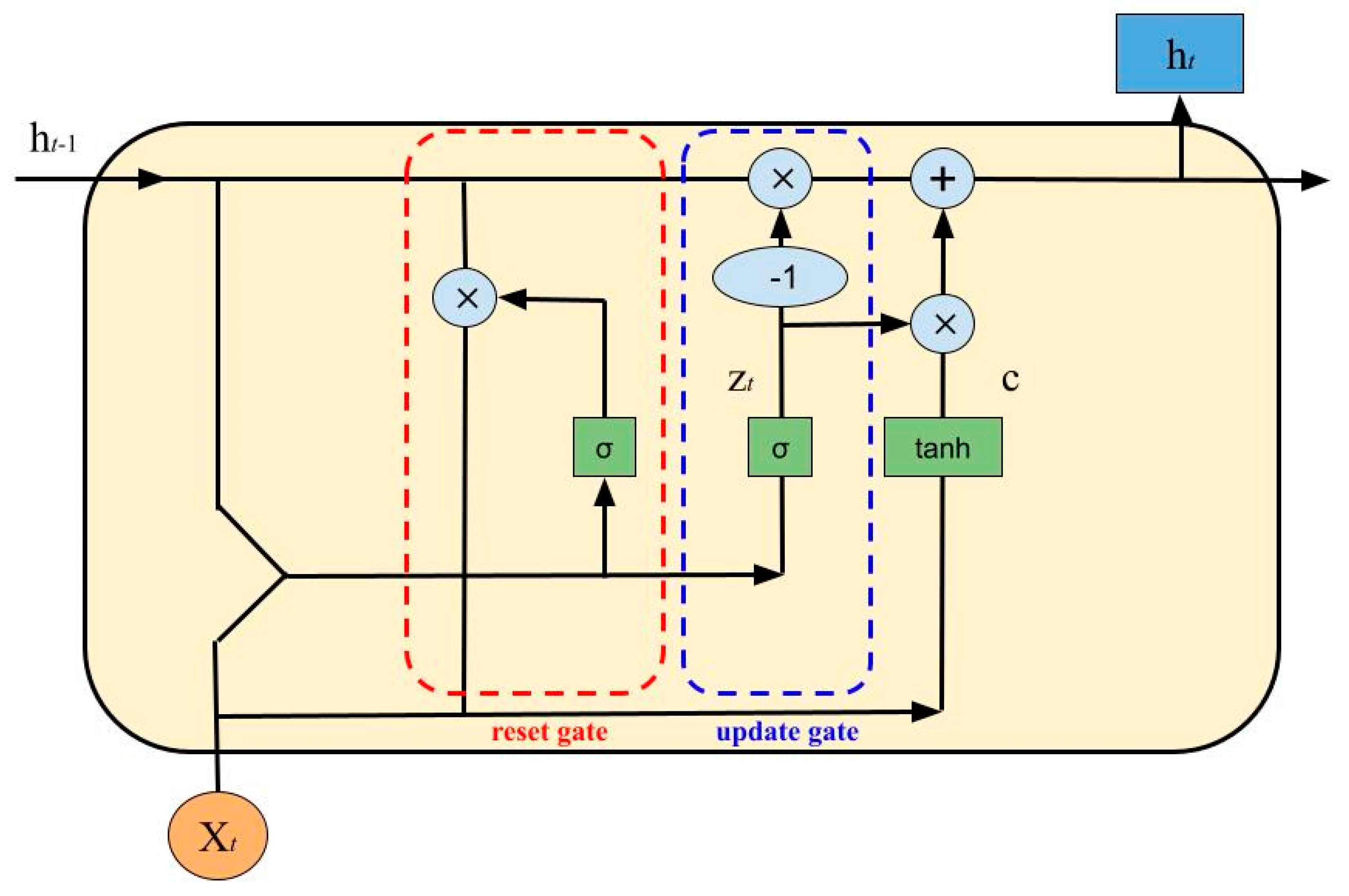
GRU:
The gated recurrent unit, just like the LSTM network, is a variant of the simplest RNN but with a less complicated structure. It has an update gate, z, and a reset gate, r. These two variables are vectors that determine what information passes or does not pass to output. With the reset gate, new input is combined with the previous memory while the update gate determines how much of the last memory to keep.
The GRU has the following equations:
Transformer:
LSTM and GRUs have been strongly established as state-of-the-art approaches in sequence modeling and transduction problems such as language modeling and machine translation [
22,
23,
24,
25,
26] because of their ability to memorize long-term dependency. Since they are inherently sequential, there is no parallelization within training examples, which makes batching across training examples more difficult as sequence lengths increase. Therefore, to allow modeling of dependencies for any distance in the input or output sequences, attention mechanisms have been integrated in compelling sequence modeling and transduction models in various tasks [
24,
27]. Commonly [
28], such attention mechanisms are used in conjunction with a recurrent network. In 2017, a team at Google Brain
® developed a new model [
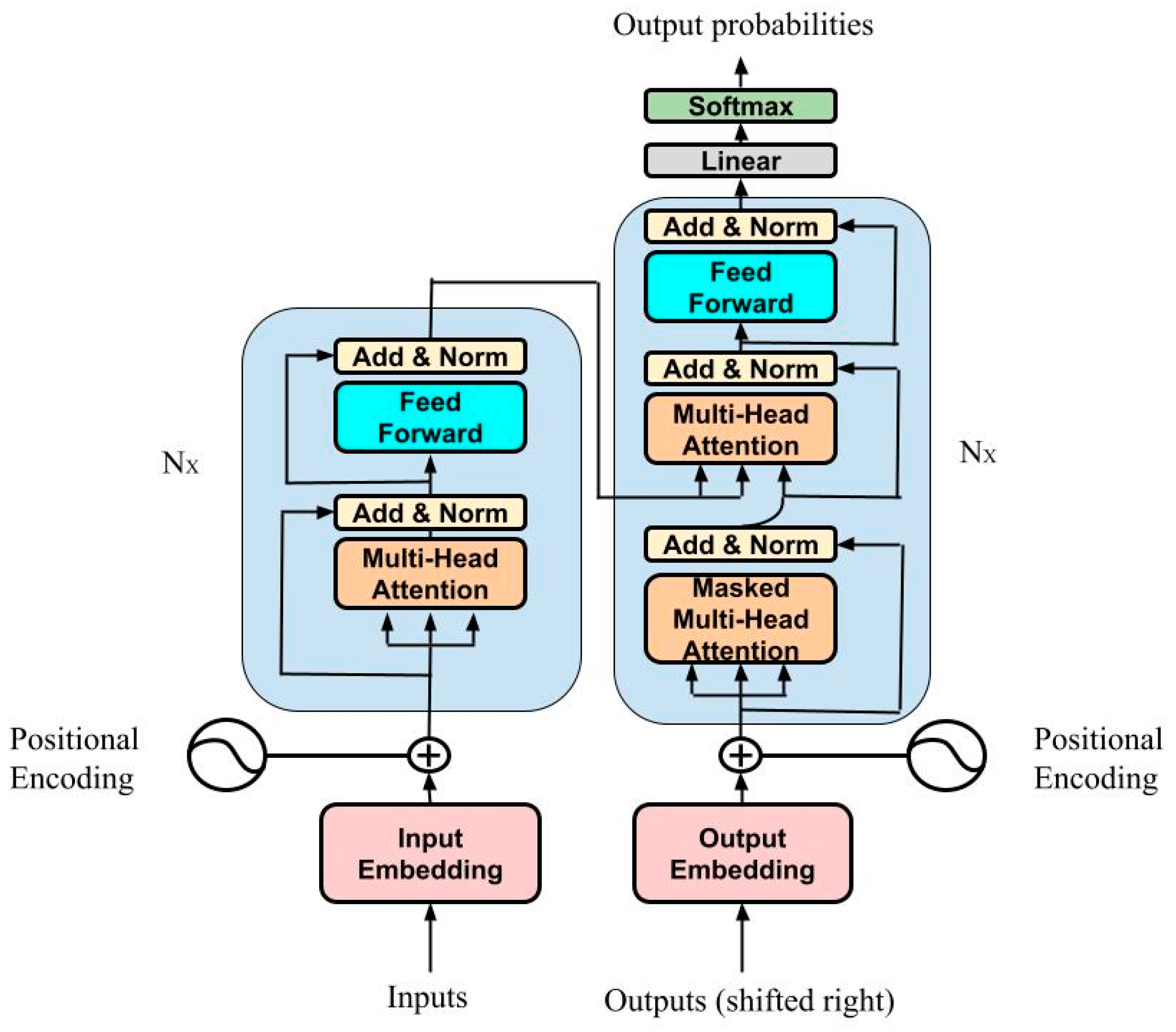
15], called “Transformer”, with an architecture that avoids recurrence and instead relies entirely on an attention mechanism to draw global dependencies between inputs and outputs. This architecture uses stacked self-attention and pointwise, fully connected layers for both the encoder and the decoder, shown in the left and right halves of
Figure 4, respectively. In
Supplementary Material (Section S2), a more accurate description of the model is reported.
2.5. Model Selection and Comparison
2.5.1. Implementation and Selection of Models
For each selected model, parameter scanning was performed, and the best model was selected. Below, procedures are indicated according to models.
SARIMAX:
Augmented Dickey–Fuller (ADF) tests, applied to a weight time series, yielded p-values larger than α = 0.05 for 90% of the overall participants. Therefore, we transformed the weight time series into a stationary one that performed first-order differentiation. The ADF test, repeated on preprocessed series, confirmed stationarities for all of the transformed time series. Following this adjustment, the terms d and D were each set to 1.
We started with fitting a SARIMAX model for all the datasets available, considering the ranges in
Table 1.
In the literature, the most common way to find the best parameters for SARIMAX models is based on a simple grid search following the Akaike information criterion (AIC) and the Bayesian information criterion (BIC), respectively. These criteria help to select the model that explains the greatest amount of variation using the fewest possible independent variables, using maximum likelihood estimation (MLE) [
29], and they both penalize a model for having increasing numbers of variables, to prevent overfitting.
Therefore, we ranked the models according to the lowest AIC values. The first 5 models were then trained on the datasets, and the root mean squared error (RMSE) scores were calculated. The model with the lowest RMSE was then selected.
The LSTM and GRU Models:
Hyperparameter tuning with the aim of minimizing loss function was carried out to select the best deep-learning model [
14]. Typically, in time-series forecasting, tuning is carried out to reduce the RMSE of test-training forecasting.
Considering that the LSTM and GRU models had the same configuration and the same hyperparameters, we proceeded with both to parameter scanning in the range shown in
Table 2.
We selected the best model via considering the lowest RMSE obtained from a prediction on the same training-test sets.
Transformer:
The implementation of this model into Keras was like that of the other two neural networks, with some exceptions for the hyperparameters. We considered a grid search that would take into account the range of the hyperparameters shown in
Table 3.
Differently from LSTM and GRU, there are two more parameters: head size, which is the dimensionality of the query, key and value tensors after the linear transformation, and num heads, which is the number of attention heads.
In this case, we also chose the best model via minimizing the RMSEs on the training-test sets.
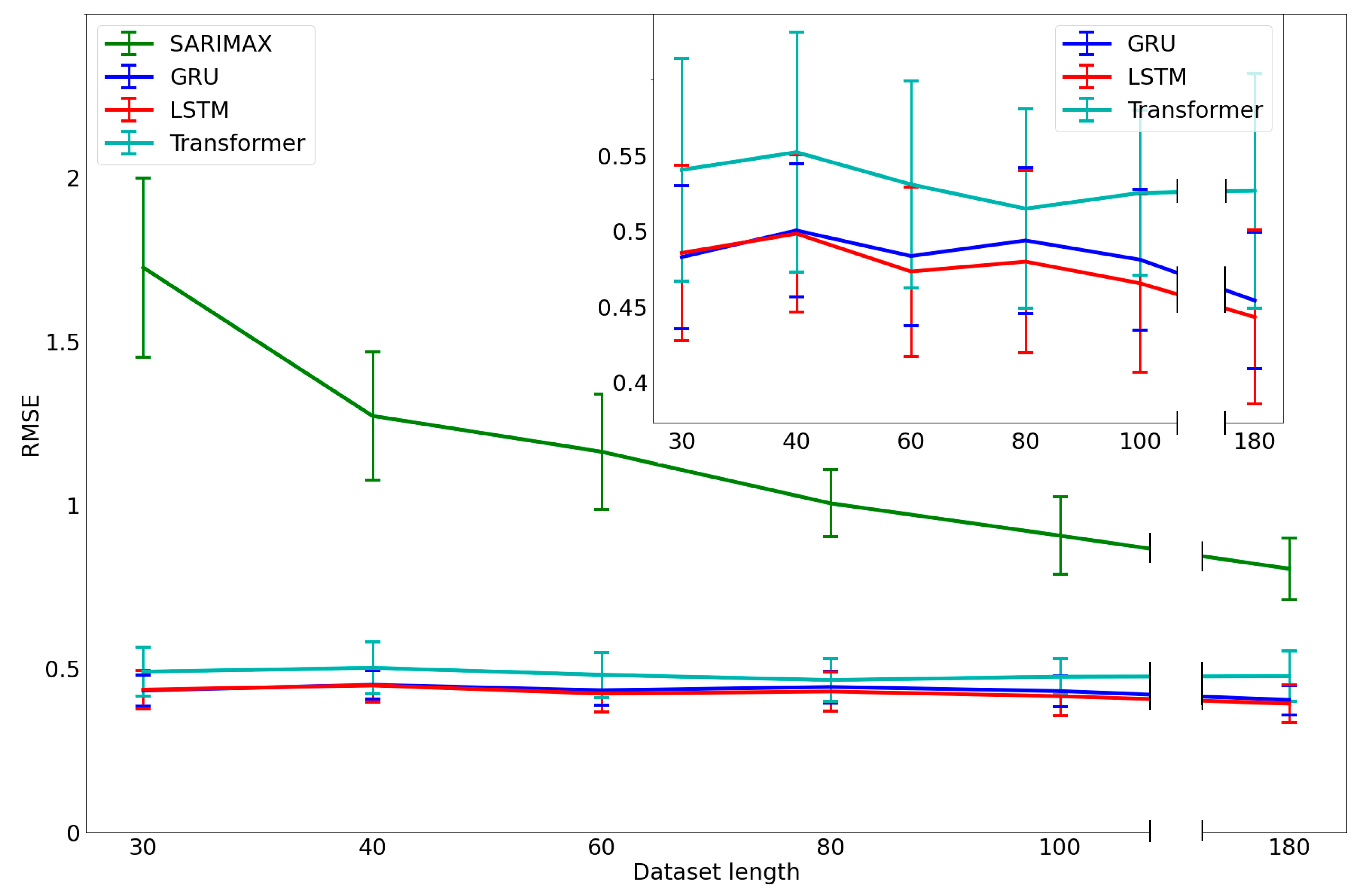
2.5.2. Performance of Models with Datasets of Varying Length
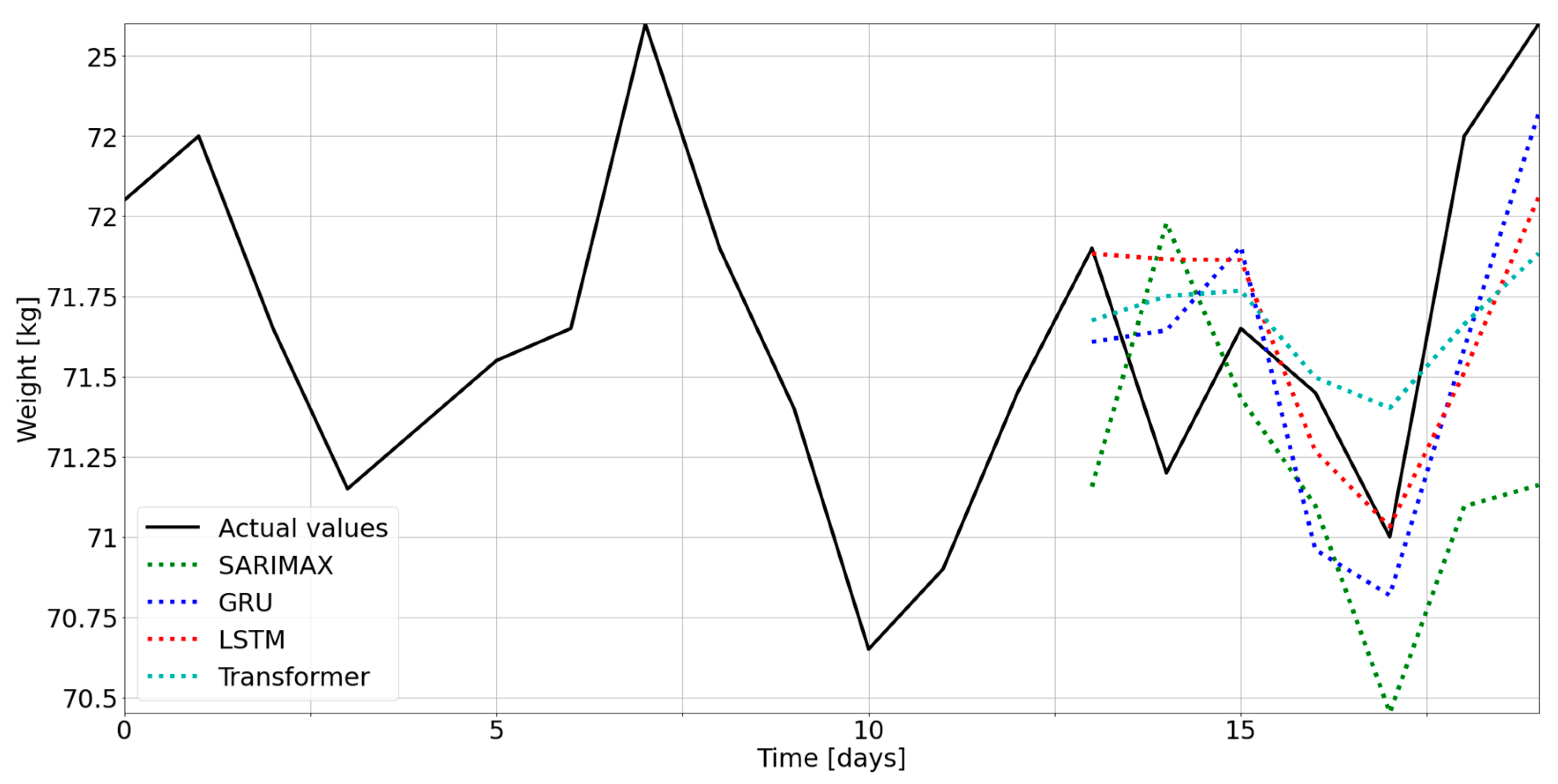
Following model selection and parameter optimization, we compared the models, considering, as a quality index, the RMSE, which indicates errors in weight prediction with a test-set length of 7 days, considering a training set of more than 100 days (mean ± SD = 161.3 ± 22.4) for each participant.
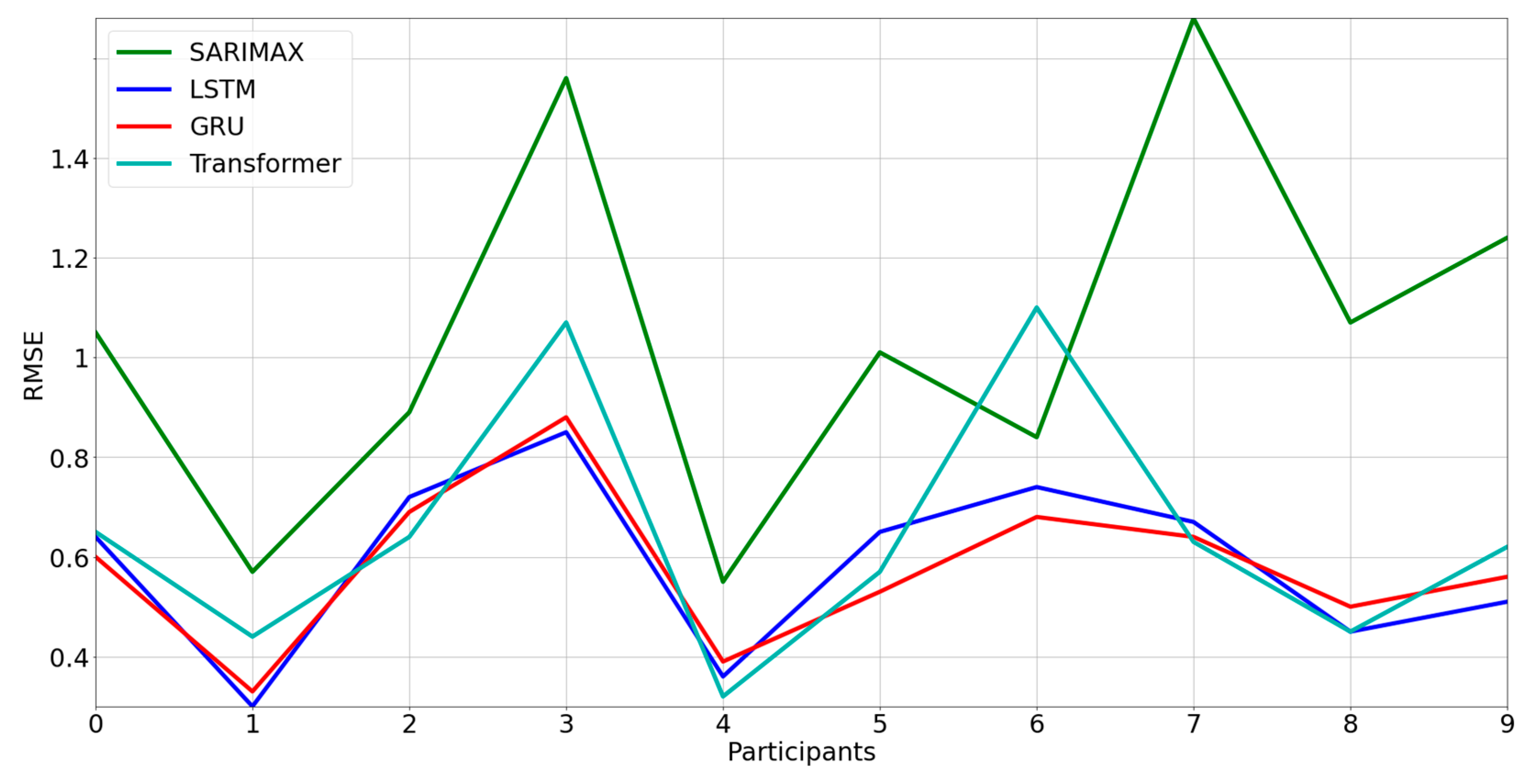
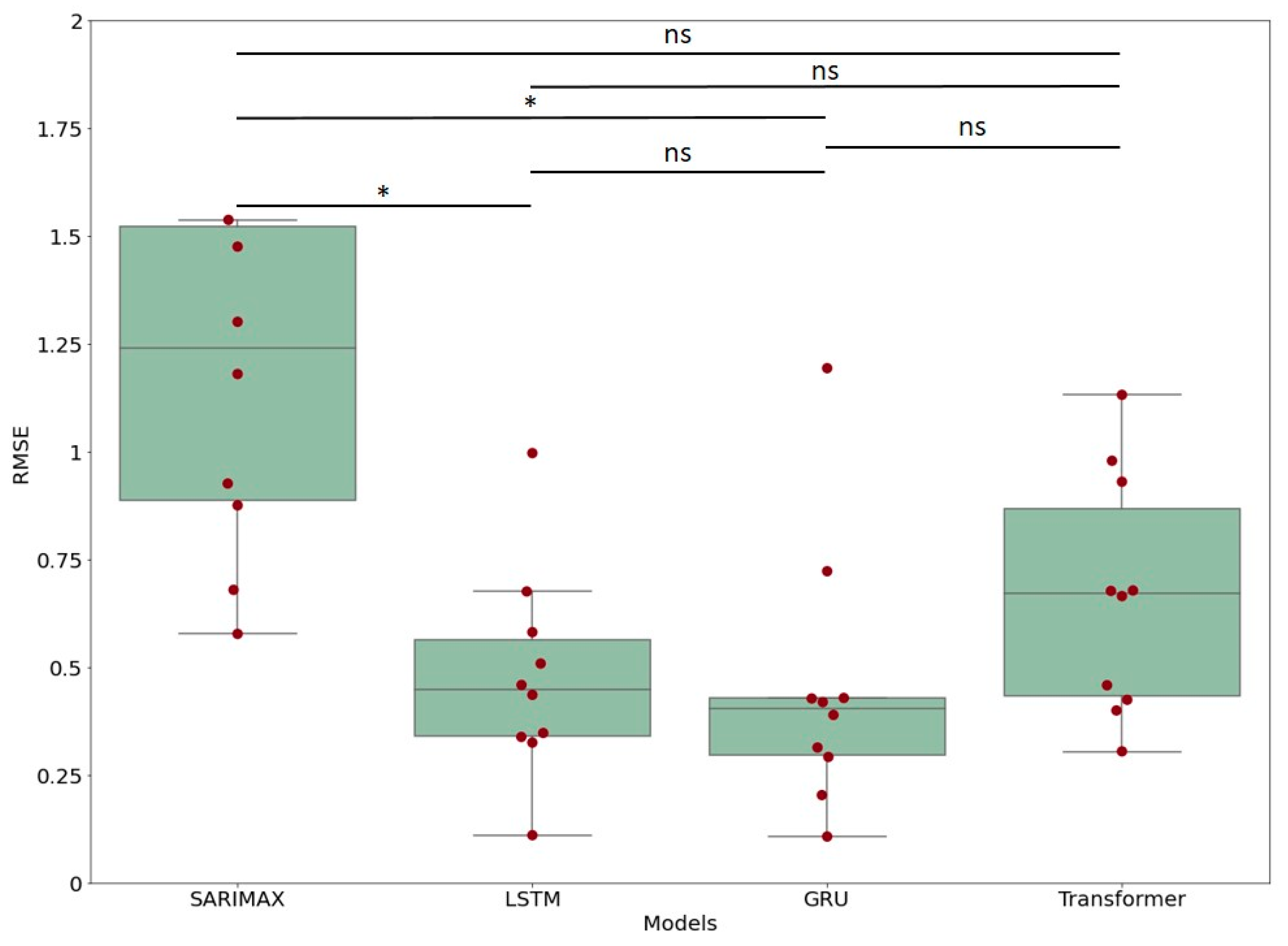
In addition, since scarcity of data is a common problem in deployment of PMAs in production, we tested the models in more realistic settings. We thus divided the dataset of each participant into 9 independent groups of 15 days. Then, we evaluated the RMSE on a test set with a length of 1 day for each group (with a training set of 14 elements). The final RMSE was the average of these 9 RMSEs. An ANOVA followed by a Tukey test was applied for pairwise comparison of RMSEs.
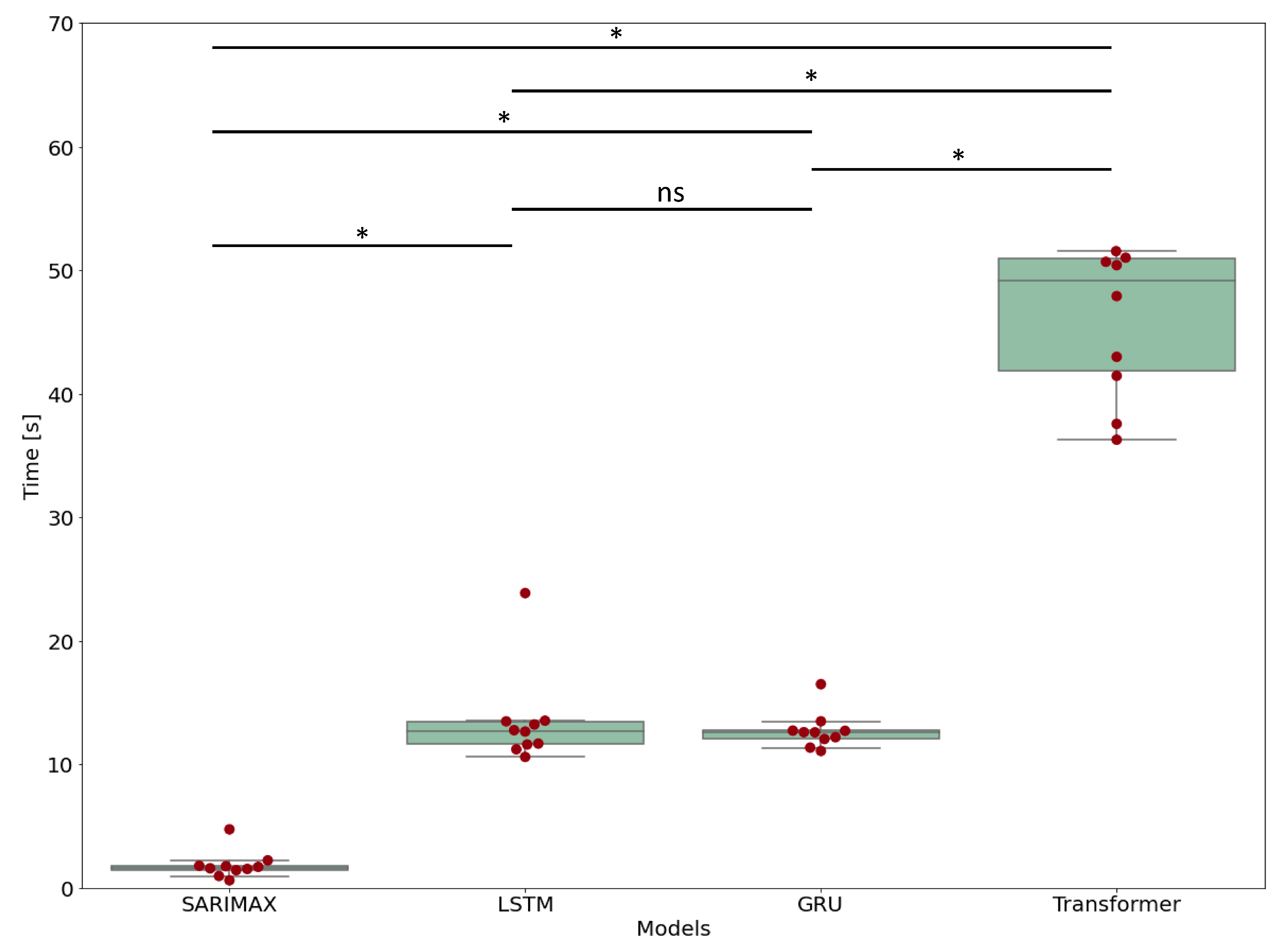
2.5.3. Computational Time
In addition to prediction performance, the computational times were calculated for the retraining and prediction phases for the four models.
A Kruskal–Wallis test followed by a Dunn test was applied for pairwise comparison of computational times.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}