
Infrared and Visible Image Fusion Method Based on a Principal Component Analysis Network and Image Pyramid

Abstract
:1. Introduction
- We propose a novel IR and visible image fusion method based on a PCANet and image pyramid, aiming to perform activity-level measurement and weight assignment through the lightweight deep learning model PCANet. The activity-level measurement obtained by the PCANet has a strong representation ability by focusing on IR target perception and visible-detail description.
- The effectiveness of the proposed algorithm was verified by 88 pairs of IR and visible images in total and 19 competitive methods, demonstrating that the proposed algorithm can achieve state-of-the-art performance in both visual quality and objective evaluation metrics.
2. Related Work
2.1. Principal Component Analysis Network (PCANet)
- In the training stage, the PCANet obtains the convolution kernel through PCA auto-encoding does not need to iterate calculations of the convolution kernel like other deep learning methods.
- As a lightweight network, PCANet has only a few hyperparameters to be trained.
2.2. Image Pyramids
2.3. Guided Filter
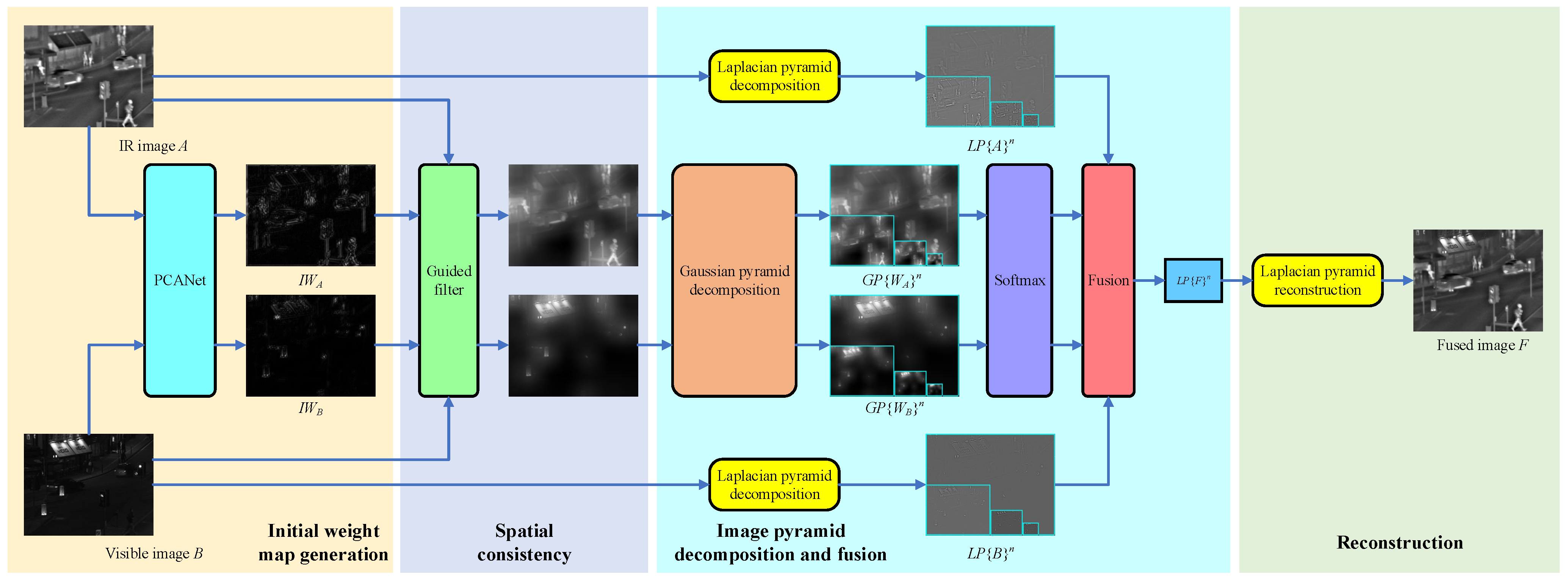
3. The Proposed Method
3.1. Overview
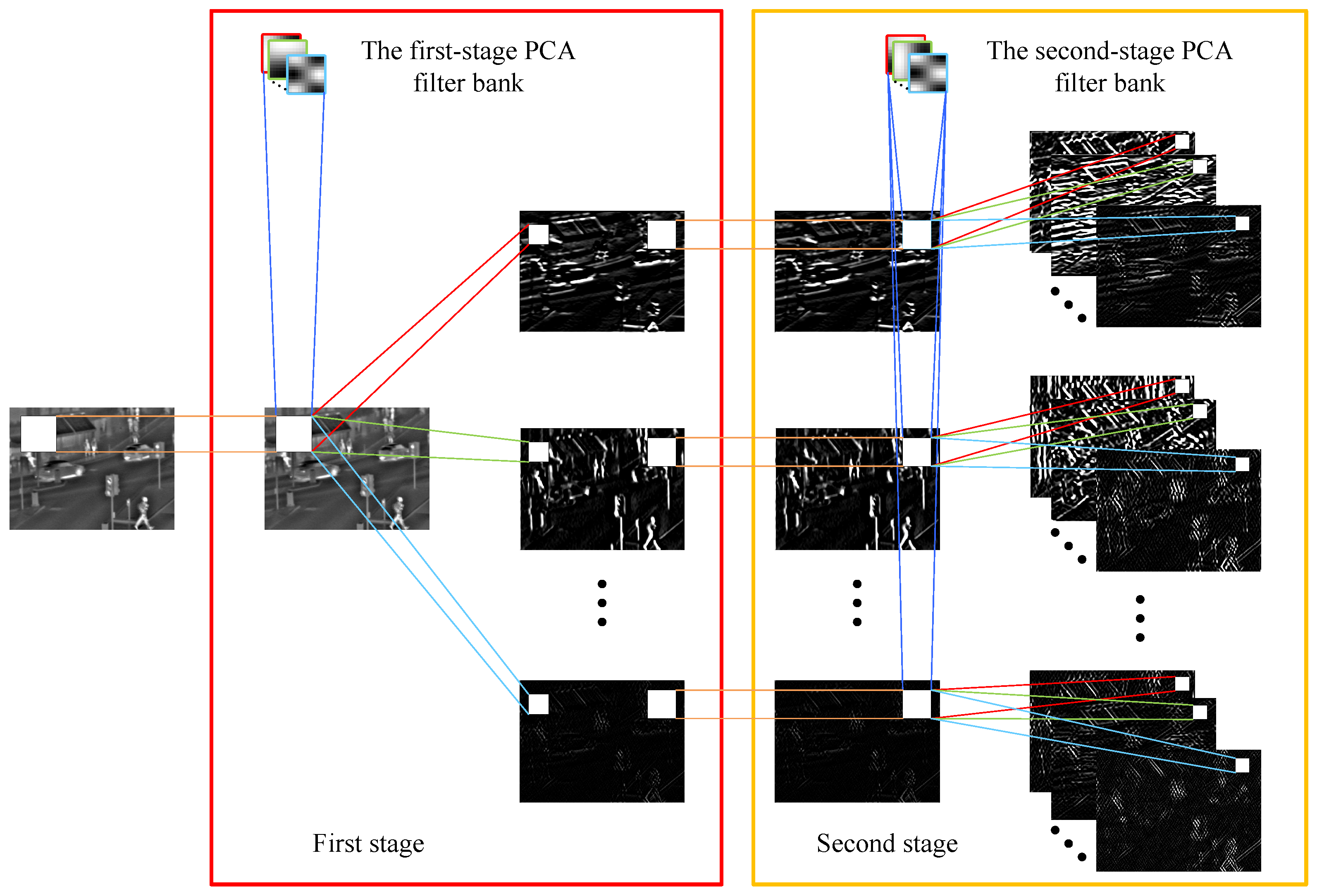
3.2. PCANet Design
3.3. Training
- The First Stage
- The Second Stage
3.4. Detailed Fusion Scheme
3.4.1. PCANet Initial Weight Map Generation
3.4.2. Spatial Consistency
3.4.3. Image-Pyramid Decomposition and Fusion
3.4.4. Reconstruction
| Algorithm 1 The proposed IR and visible image fusion algorithm. |
Training phase 1. Initialize PCANet; Testing (fusion) phase Part 1: PCANet initial weight map generation 1. Feed IR image A and visible image B into PCANet to obtain the initial weight maps according to Equations (26)–(29); Part 2: Spatial consistency 2. Perform guided filtering on the absolute values of and according to Equations (30) and (31); Part 3: image-pyramid decomposition and fusion 3. Perform n-layer Gaussian pyramid decomposition on and to generate the results and according to Equations (5) and (6); 4. Perform softmax operation at each layer to obtain and according to Equations (32) and (33); 5. Perform n-layer Laplacian pyramid decomposition on A and B to obtain and according to Equations (10) and (11); 6. Apply the weighted-average rule on each layer to generate the result according to Equation (34); Part 4: Reconstruction 7. Reconstruct the Laplacian pyramid to obtain the fused image F according to Equation (12). |
4. Experiments and Discussions
4.1. Datasets
4.2. Objective Image Fusion Quality Metrics
- Yang’s metric [35]: is a fusion metric based on structural information, which aims to calculate the degree to which structural information is transferred from the source images into the fused image;
- Gradient-based metric [36]: provides a fusion metric of image gradient, which reflects the degree of edge information of the source images preserved in the fusion image;
- Structural similarity index measure [37]: is a fusion index based on structural similarity, which mainly calculates the structural similarity between the fusion result and the source images;
- , and [38] calculate wavelet features, discrete cosine, and feature mutual information (FMI), respectively;
- Modified fusion artifacts measure [39]: provides a fusion index that introduces noise or artifacts in the fused image, reflecting the proportion of noise or artifacts generated in the fused image;
- Piella’s three metrics , , [40]: Piella’s three measures are on the basis of the structural similarity between source images and the fused image;
- Phase-congruency-based metric [41]: calculates the degree to which salient features in the source images are transferred to the fused image, and it is based on the absolute measure of image features;
- Chen–Varshney metric [42]: The metric is based on the human vision system and can fit the results of human visual inspection well;
- Chen–Blum metric [43]: is a fusion metric based on human visual perception quality.
4.3. Analysis of Free Parameters
4.3.1. The Effect of the Number of Filters
4.3.2. The Influence of Filter Size
4.4. Ablation Study
4.4.1. The Ablation Study of the Image Pyramid
4.4.2. The Ablation Study of the Guided Filter
4.5. Experimental Results and Discussion
4.5.1. Comparison with State-of-the-Art Competitive Algorithms on the TNO Dataset
4.5.2. Further Comparison on the RoadScene Dataset
4.6. Computational Efficiency
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qi, B.; Jin, L.; Li, G.; Zhang, Y.; Li, Q.; Bi, G.; Wang, W. Infrared and Visible Image Fusion Based on Co-Occurrence Analysis Shearlet Transform. Remote Sens. 2022, 14, 283. [Google Scholar] [CrossRef]
- Gao, X.; Shi, Y.; Zhu, Q.; Fu, Q.; Wu, Y. Infrared and Visible Image Fusion with Deep Neural Network in Enhanced Flight Vision System. Remote Sens. 2022, 14, 2789. [Google Scholar] [CrossRef]
- Burt, P.J.; Adelson, E.H. The Laplacian pyramid as a compact image code. In Readings in Computer Vision; Elsevier: Amsterdam, The Netherlands, 1987; pp. 671–679. [Google Scholar]
- Naidu, V. Image fusion technique using multi-resolution singular value decomposition. Defence Sci. J. 2011, 61, 479. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Manjunath, B.; Mitra, S.K. Multisensor image fusion using the wavelet transform. Gr. Models Image Process. 1995, 57, 235–245. [Google Scholar] [CrossRef]
- Lewis, J.J.; O’Callaghan, R.J.; Nikolov, S.G.; Bull, D.R.; Canagarajah, N. Pixel-and region-based image fusion with complex wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar] [CrossRef]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Gao, Z.; Zhang, C. Texture clear multi-modal image fusion with joint sparsity model. Optik 2017, 130, 255–265. [Google Scholar] [CrossRef]
- Zhang, Q.; Fu, Y.; Li, H.; Zou, J. Dictionary learning method for joint sparse representation-based image fusion. Opt. Eng. 2013, 52, 057006. [Google Scholar] [CrossRef]
- Liu, C.; Qi, Y.; Ding, W. Infrared and visible image fusion method based on saliency detection in sparse domain. Infrared Phys. Technol. 2017, 83, 94–102. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, H.; Ma, J. Classification saliency-based rule for visible and infrared image fusion. IEEE Trans. Comput. Imaging 2021, 7, 824–836. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. Int. J. Wavel. Multiresolut. Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H. A medical image fusion method based on convolutional neural networks. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–7. [Google Scholar]
- Li, H.; Wu, X.J.; Kittler, J. Infrared and visible image fusion using a deep learning framework. In Proceedings of the 2018 24th international conference on pattern recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Li, H.; Wu, X.J.; Durrani, T.S. Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Phys. Technol. 2019, 102, 103039. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2020, 70, 1–14. [Google Scholar] [CrossRef]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [Green Version]
- Mertens, T.; Kautz, J.; Van Reeth, F. Exposure fusion. In Proceedings of the 15th Pacific Conference on Computer Graphics and Applications (PG’07), Seoul, Republic of Korea, 29 October–2 November 2007; pp. 382–390. [Google Scholar]
- Piella, G. A general framework for multiresolution image fusion: From pixels to regions. Inf. Fusion 2003, 4, 259–280. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chen, L.; Zhou, Z.; Sun, X.; Dong, J. Human fall detection in surveillance video based on PCANet. Multimed. Tools Appl. 2016, 75, 11603–11613. [Google Scholar] [CrossRef]
- Gao, F.; Dong, J.; Li, B.; Xu, Q. Automatic change detection in synthetic aperture radar images based on PCANet. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1792–1796. [Google Scholar] [CrossRef]
- Song, X.; Wu, X.J. Multi-focus image fusion with PCA filters of PCANet. In Proceedings of the IAPR Workshop on Multimodal Pattern Recognition of Social Signals in Human–Computer Interaction, Beijing, China, 20 August 2018; pp. 1–17. [Google Scholar]
- Yang, W.; Si, Y.; Wang, D.; Guo, B. Automatic recognition of arrhythmia based on principal component analysis network and linear support vector machine. Comput. Biol. Med. 2018, 101, 22–32. [Google Scholar] [CrossRef]
- Zhang, G.; Si, Y.; Wang, D.; Yang, W.; Sun, Y. Automated detection of myocardial infarction using a gramian angular field and principal component analysis network. IEEE Access 2019, 7, 171570–171583. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar]
- Toet, A. TNO Image Fusion Dataset. 2014. Available online: https://figshare.com/articles/TN_Image_Fusion_Dataset/1008029 (accessed on 21 September 2022).
- Xu, H.; Ma, J.; Le, Z.; Jiang, J.; Guo, X. Fusiondn: A unified densely connected network for image fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12484–12491. [Google Scholar]
- Yang, C.; Zhang, J.Q.; Wang, X.R.; Liu, X. A novel similarity based quality metric for image fusion. Inf. Fusion 2008, 9, 156–160. [Google Scholar] [CrossRef]
- Xydeas, C.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Haghighat, M.; Razian, M.A. Fast-FMI: Non-reference image fusion metric. In Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT), Astana, Kazakhstan, 15–17 October 2014; pp. 1–3. [Google Scholar]
- Shreyamsha Kumar, B. Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform. Signal Image Video Process. 2013, 7, 1125–1143. [Google Scholar] [CrossRef]
- Piella, G.; Heijmans, H. A new quality metric for image fusion. In Proceedings of the 2003 International Conference on Image Processing (Cat. No. 03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 3, p. 173. [Google Scholar]
- Zhao, J.; Laganiere, R.; Liu, Z. Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement. Int. J. Innov. Comput. Inf. Control 2007, 3, 1433–1447. [Google Scholar]
- Chen, H.; Varshney, P.K. A human perception inspired quality metric for image fusion based on regional information. Inf. Fusion 2007, 8, 193–207. [Google Scholar] [CrossRef]
- Chen, Y.; Blum, R.S. A new automated quality assessment algorithm for image fusion. Image Vis. Comput. 2009, 27, 1421–1432. [Google Scholar] [CrossRef]
- Tan, W.; Zhou, H.; Song, J.; Li, H.; Yu, Y.; Du, J. Infrared and visible image perceptive fusion through multi-level Gaussian curvature filtering image decomposition. Appl. Opt. 2019, 58, 3064–3073. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12797–12804. [Google Scholar]
- Li, H.; Wu, X.J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Xu, H.; Wang, X.; Ma, J. DRF: Disentangled representation for visible and infrared image fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Du, Q.; Xu, H.; Ma, Y.; Huang, J.; Fan, F. Fusing infrared and visible images of different resolutions via total variation model. Sensors 2018, 18, 3827. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3 | 3 | 0.6868 | 0.3662 | 0.7495 | 0.4168 | 0.3991 | 0.9079 | 0.0000 | 0.8019 | 0.7429 | 0.3432 | 0.3211 | 500.3300 | 0.4732 |
| 3 | 4 | 0.6874 | 0.3669 | 0.7495 | 0.4168 | 0.3991 | 0.9079 | 0.0000 | 0.8021 | 0.7432 | 0.3439 | 0.3212 | 497.5229 | 0.4733 |
| 4 | 4 | 0.6878 | 0.3676 | 0.7494 | 0.4169 | 0.3991 | 0.9080 | 0.0000 | 0.8024 | 0.7435 | 0.3447 | 0.3216 | 500.7296 | 0.4730 |
| 4 | 5 | 0.6886 | 0.3685 | 0.7494 | 0.4169 | 0.3991 | 0.9080 | 0.0000 | 0.8026 | 0.7439 | 0.3456 | 0.3219 | 500.0824 | 0.4734 |
| 5 | 5 | 0.6883 | 0.3681 | 0.7494 | 0.4169 | 0.3991 | 0.9080 | 0.0000 | 0.8026 | 0.7438 | 0.3454 | 0.3216 | 500.4060 | 0.4729 |
| 5 | 6 | 0.6885 | 0.3683 | 0.7494 | 0.4170 | 0.3992 | 0.9080 | 0.0000 | 0.8026 | 0.7437 | 0.3454 | 0.3216 | 500.6746 | 0.4731 |
| 6 | 6 | 0.6887 | 0.3685 | 0.7494 | 0.4170 | 0.3992 | 0.9080 | 0.0000 | 0.8028 | 0.7439 | 0.3456 | 0.3217 | 500.3191 | 0.4732 |
| 6 | 7 | 0.6888 | 0.3687 | 0.7494 | 0.4171 | 0.3993 | 0.9080 | 0.0000 | 0.8028 | 0.7439 | 0.3455 | 0.3217 | 500.0603 | 0.4735 |
| 7 | 7 | 0.6894 | 0.3692 | 0.7494 | 0.4171 | 0.3994 | 0.9080 | 0.0000 | 0.8030 | 0.7441 | 0.3463 | 0.3219 | 499.6389 | 0.4735 |
| 7 | 8 | 0.6897 | 0.3696 | 0.7494 | 0.4172 | 0.3994 | 0.9081 | 0.0000 | 0.8031 | 0.7442 | 0.3465 | 0.3218 | 499.4519 | 0.4733 |
| 8 | 8 | 0.6920 | 0.3726 | 0.7493 | 0.4175 | 0.3996 | 0.9081 | 0.0000 | 0.8042 | 0.7455 | 0.3489 | 0.3228 | 499.3465 | 0.4750 |
| Size | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.6920 | 0.3726 | 0.7493 | 0.4175 | 0.3996 | 0.9081 | 0.0000 | 0.8042 | 0.7455 | 0.3489 | 0.3228 | 499.3465 | 0.4750 | |
| 0.7163 | 0.4020 | 0.7476 | 0.4195 | 0.3982 | 0.9108 | 0.0000 | 0.8131 | 0.7707 | 0.4152 | 0.3441 | 466.6789 | 0.4675 | |
| 0.7511 | 0.4434 | 0.7432 | 0.4244 | 0.3932 | 0.9133 | 0.0000 | 0.8216 | 0.8008 | 0.5020 | 0.3776 | 449.1673 | 0.4755 | |
| 0.7864 | 0.4786 | 0.7374 | 0.4306 | 0.3829 | 0.9150 | 0.0001 | 0.8251 | 0.8207 | 0.5659 | 0.4065 | 427.3843 | 0.4879 | |
| 0.8238 | 0.5097 | 0.7299 | 0.4406 | 0.3719 | 0.9162 | 0.0002 | 0.8240 | 0.8277 | 0.5998 | 0.4333 | 407.4069 | 0.4959 |
| Method | Time | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| With pyramid | 0.8238 | 0.5097 | 0.7299 | 0.4406 | 0.3719 | 0.9162 | 0.0002 | 0.8240 | 0.8277 | 0.5998 | 0.4333 | 407.4069 | 0.4959 | 257.6713 |
| Without pyramid | 0.8218 | 0.4936 | 0.7308 | 0.4366 | 0.3649 | 0.9162 | 0.0012 | 0.8269 | 0.8314 | 0.5937 | 0.4326 | 360.0513 | 0.5008 | 251.6412 |
| Type | Method | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MST | MSVD | 0.6297 | 0.3274 | 0.7220 | 0.2683 | 0.2382 | 0.8986 | 0.0022 | 0.7735 | 0.7091 | 0.3107 | 0.2456 | 549.9197 | 0.4428 |
| DWT | 0.7354 | 0.5042 | 0.6532 | 0.3678 | 0.2911 | 0.8970 | 0.0581 | 0.7632 | 0.7643 | 0.5499 | 0.2473 | 522.7137 | 0.4732 | |
| DTCWT | 0.7732 | 0.4847 | 0.6945 | 0.4127 | 0.3547 | 0.9122 | 0.0243 | 0.8019 | 0.8100 | 0.6361 | 0.3087 | 524.0247 | 0.4956 | |
| CVT | 0.7703 | 0.4644 | 0.6934 | 0.4226 | 0.4021 | 0.9095 | 0.0274 | 0.8017 | 0.8141 | 0.6365 | 0.2784 | 539.9093 | 0.4931 | |
| MLGCF | 0.7702 | 0.4863 | 0.7078 | 0.3717 | 0.3229 | 0.9009 | 0.0208 | 0.8063 | 0.8032 | 0.5694 | 0.2974 | 454.5477 | 0.4627 | |
| TE-MST | 0.7653 | 0.4503 | 0.7006 | 0.3749 | 0.3313 | 0.9075 | 0.0224 | 0.7775 | 0.7251 | 0.4518 | 0.2787 | 923.3319 | 0.4512 | |
| SR | JSM | 0.2233 | 0.0830 | 0.6385 | 0.1404 | 0.1061 | 0.8928 | 0.0048 | 0.6076 | 0.3961 | 0.0057 | 0.0604 | 676.3967 | 0.3086 |
| JSR | 0.6338 | 0.3392 | 0.6053 | 0.2208 | 0.1672 | 0.8839 | 0.0566 | 0.6858 | 0.7111 | 0.4051 | 0.2051 | 431.9517 | 0.4182 | |
| JSRSD | 0.5558 | 0.2981 | 0.5492 | 0.1981 | 0.1451 | 0.8632 | 0.1032 | 0.6322 | 0.6830 | 0.3389 | 0.1436 | 476.0037 | 0.4288 | |
| Other | GTF | 0.6639 | 0.3977 | 0.6706 | 0.4301 | 0.4059 | 0.9045 | 0.0103 | 0.7168 | 0.6571 | 0.3439 | 0.1991 | 1161.7491 | 0.3984 |
| methods | DRTV | 0.5906 | 0.3012 | 0.6622 | 0.4104 | 0.4198 | 0.8888 | 0.0214 | 0.7098 | 0.6502 | 0.2111 | 0.1016 | 1348.3111 | 0.4202 |
| Deep | FusionGAN | 0.5263 | 0.2446 | 0.6430 | 0.3754 | 0.3565 | 0.8889 | 0.0131 | 0.6626 | 0.5842 | 0.1370 | 0.1076 | 963.9209 | 0.4115 |
| learning | GANMcC | 0.5976 | 0.3056 | 0.6824 | 0.3820 | 0.3512 | 0.8980 | 0.0099 | 0.7197 | 0.6771 | 0.2768 | 0.2506 | 674.4502 | 0.4369 |
| PMGI | 0.7166 | 0.4040 | 0.6981 | 0.3948 | 0.3810 | 0.8996 | 0.0282 | 0.7771 | 0.7716 | 0.4566 | 0.2699 | 586.3804 | 0.4604 | |
| RFN-Nest | 0.6263 | 0.3453 | 0.6820 | 0.2976 | 0.2897 | 0.9032 | 0.0114 | 0.7345 | 0.7079 | 0.3010 | 0.2340 | 584.3049 | 0.4749 | |
| CSF | 0.6841 | 0.4136 | 0.6901 | 0.3007 | 0.2541 | 0.8826 | 0.0280 | 0.7578 | 0.7568 | 0.4753 | 0.2714 | 538.8530 | 0.4873 | |
| DRF | 0.4466 | 0.2024 | 0.6184 | 0.1694 | 0.1184 | 0.8866 | 0.0342 | 0.6400 | 0.5430 | 0.1025 | 0.0962 | 1004.4690 | 0.3941 | |
| FusionDN | 0.6856 | 0.3788 | 0.6230 | 0.3597 | 0.3097 | 0.8842 | 0.1356 | 0.7301 | 0.7467 | 0.4439 | 0.2678 | 633.9079 | 0.4935 | |
| DDcGAN | 0.6390 | 0.3364 | 0.5820 | 0.4114 | 0.3863 | 0.8760 | 0.1016 | 0.6530 | 0.5918 | 0.2060 | 0.1451 | 1017.1516 | 0.4360 | |
| Proposed | 0.8238 | 0.5097 | 0.7299 | 0.4406 | 0.3719 | 0.9162 | 0.0002 | 0.8240 | 0.8277 | 0.5998 | 0.4333 | 407.4069 | 0.4959 |
| Type | Method | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MST | MSVD | 0.6703 | 0.3694 | 0.7239 | 0.2724 | 0.2225 | 0.8571 | 0.0030 | 0.7723 | 0.6920 | 0.3006 | 0.3122 | 808.7879 | 0.4781 |
| DWT | 0.7732 | 0.5673 | 0.6455 | 0.4015 | 0.2677 | 0.8623 | 0.0496 | 0.7721 | 0.7757 | 0.5732 | 0.3266 | 769.0781 | 0.4922 | |
| DTCWT | 0.7517 | 0.4625 | 0.6645 | 0.3584 | 0.2415 | 0.8589 | 0.0386 | 0.7752 | 0.7610 | 0.4769 | 0.3255 | 800.1602 | 0.4976 | |
| CVT | 0.7990 | 0.4975 | 0.6785 | 0.4353 | 0.3738 | 0.8738 | 0.0277 | 0.8057 | 0.8068 | 0.6127 | 0.3523 | 982.3925 | 0.5075 | |
| MLGCF | 0.8136 | 0.5395 | 0.7064 | 0.3604 | 0.2783 | 0.8600 | 0.0174 | 0.8252 | 0.7899 | 0.5449 | 0.3732 | 795.6147 | 0.4647 | |
| TE-MST | 0.8534 | 0.5855 | 0.6983 | 0.4091 | 0.3093 | 0.8751 | 0.0199 | 0.8210 | 0.7799 | 0.5416 | 0.4262 | 981.4404 | 0.5305 | |
| SR | JSM | 0.2689 | 0.0983 | 0.6011 | 0.1538 | 0.1060 | 0.8426 | 0.0044 | 0.5105 | 0.2606 | 0.0008 | 0.0789 | 752.1129 | 0.2918 |
| JSR | 0.4876 | 0.2678 | 0.5774 | 0.1955 | 0.1601 | 0.8292 | 0.0389 | 0.6192 | 0.6128 | 0.2610 | 0.2039 | 591.9430 | 0.3618 | |
| JSRSD | 0.4595 | 0.2499 | 0.4937 | 0.1777 | 0.1437 | 0.8196 | 0.0859 | 0.5540 | 0.6420 | 0.2871 | 0.1442 | 509.1361 | 0.4136 | |
| Other | GTF | 0.6671 | 0.3007 | 0.6820 | 0.3755 | 0.3742 | 0.8721 | 0.0077 | 0.6782 | 0.5256 | 0.1842 | 0.2495 | 1595.9816 | 0.3950 |
| methods | DRTV | 0.5268 | 0.2310 | 0.6695 | 0.3379 | 0.3704 | 0.8478 | 0.0168 | 0.6883 | 0.5930 | 0.1187 | 0.1313 | 1672.9384 | 0.4308 |
| Deep | FusionGAN | 0.4997 | 0.2381 | 0.6025 | 0.3169 | 0.3312 | 0.8529 | 0.0151 | 0.6179 | 0.5254 | 0.1181 | 0.1387 | 1138.3050 | 0.4551 |
| learning | GANMcC | 0.6350 | 0.3511 | 0.6594 | 0.3693 | 0.3330 | 0.8561 | 0.0092 | 0.7094 | 0.6479 | 0.2718 | 0.3029 | 943.6773 | 0.4778 |
| PMGI | 0.7566 | 0.4718 | 0.6736 | 0.3875 | 0.3597 | 0.8597 | 0.0140 | 0.7819 | 0.7388 | 0.4448 | 0.3740 | 967.0633 | 0.5222 | |
| RFN-Nest | 0.5928 | 0.2906 | 0.6562 | 0.2723 | 0.2691 | 0.8627 | 0.0079 | 0.6831 | 0.6091 | 0.1779 | 0.2648 | 981.0049 | 0.4833 | |
| CSF | 0.7525 | 0.4916 | 0.6837 | 0.3258 | 0.2507 | 0.8536 | 0.0220 | 0.7793 | 0.7570 | 0.4763 | 0.3727 | 772.7454 | 0.5250 | |
| DRF | 0.4226 | 0.2078 | 0.5590 | 0.1858 | 0.1137 | 0.8402 | 0.0222 | 0.5808 | 0.4117 | 0.0459 | 0.1138 | 1668.1819 | 0.4167 | |
| FusionDN | 0.7681 | 0.4825 | 0.6478 | 0.3665 | 0.2943 | 0.8524 | 0.0686 | 0.7797 | 0.7616 | 0.4975 | 0.3522 | 1223.1102 | 0.5510 | |
| DDcGAN | 0.5267 | 0.2668 | 0.5491 | 0.3499 | 0.3451 | 0.8548 | 0.0587 | 0.5329 | 0.4443 | 0.1147 | 0.1723 | 1004.4252 | 0.4566 | |
| Proposed | 0.8720 | 0.5903 | 0.7252 | 0.4681 | 0.4065 | 0.8820 | 0.0001 | 0.8315 | 0.7959 | 0.5609 | 0.5286 | 683.7624 | 0.5357 |
| Method | FusionGAN | GANMcC | PMGI | RFN-Nest | CSF | DRF | FusionDN | DDcGAN | Proposed |
|---|---|---|---|---|---|---|---|---|---|
| Time | 170.4436 | 338.3344 | 36.9569 | 193.7670 | 899.4110 | 350.3019 | 330.3895 | 304.0095 | 255.6642 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Zou, Y.; Wang, G.; Lin, C. Infrared and Visible Image Fusion Method Based on a Principal Component Analysis Network and Image Pyramid. Remote Sens. 2023, 15, 685. https://doi.org/10.3390/rs15030685
Li S, Zou Y, Wang G, Lin C. Infrared and Visible Image Fusion Method Based on a Principal Component Analysis Network and Image Pyramid. Remote Sensing. 2023; 15(3):685. https://doi.org/10.3390/rs15030685
Chicago/Turabian StyleLi, Shengshi, Yonghua Zou, Guanjun Wang, and Cong Lin. 2023. "Infrared and Visible Image Fusion Method Based on a Principal Component Analysis Network and Image Pyramid" Remote Sensing 15, no. 3: 685. https://doi.org/10.3390/rs15030685