Figure 1.
Average number of LiDAR points and pseudo points of an object and the AP3D40 of the Voxel-RCNN and our DASANet at different distances.
Figure 1.
Average number of LiDAR points and pseudo points of an object and the AP3D40 of the Voxel-RCNN and our DASANet at different distances.
Figure 2.
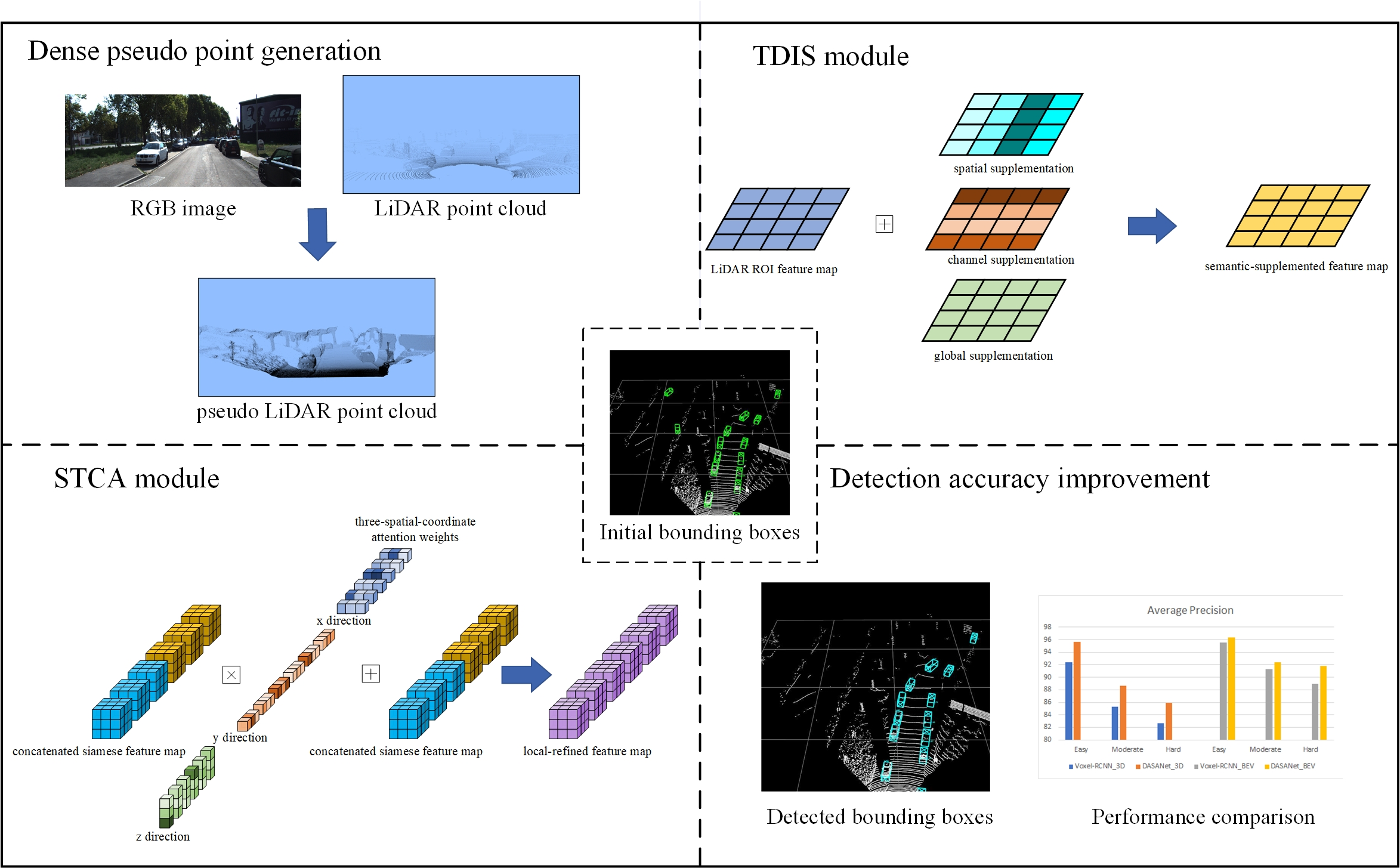
Overview of the proposed DASANet, which is a 3D object detector with two stages. In the first stage, given an RGB image, two groups of 3D feature maps are extracted from the corresponding LiDAR point cloud and the generated pseudo-LiDAR point cloud to obtain the initial proposals. In the second stage, the proposed TDIS module and the STCA module are used to obtain fused features with more abundant semantic representation and the detailed information for 3D object detection. The overall process of the DASANet is summarized in
Algorithm A1 in Appendix A.
Figure 2.
Overview of the proposed DASANet, which is a 3D object detector with two stages. In the first stage, given an RGB image, two groups of 3D feature maps are extracted from the corresponding LiDAR point cloud and the generated pseudo-LiDAR point cloud to obtain the initial proposals. In the second stage, the proposed TDIS module and the STCA module are used to obtain fused features with more abundant semantic representation and the detailed information for 3D object detection. The overall process of the DASANet is summarized in
Algorithm A1 in Appendix A.
Figure 3.
Overview of the TDIS module. First, the element subtraction of from , whose spatial direction is the spatial dimension flattening result of the 3D feature map along the channel dimension, is used to obtain differential feature map . Then, semantic feature maps , , and are computed using the feature enhancement operations with weights , , and . Finally, the feature supplementation operation is implemented using the spatial-dimension, channel-dimension, and all-element sum of and , , and to obtain the semantic-supplemented feature map .
Figure 3.
Overview of the TDIS module. First, the element subtraction of from , whose spatial direction is the spatial dimension flattening result of the 3D feature map along the channel dimension, is used to obtain differential feature map . Then, semantic feature maps , , and are computed using the feature enhancement operations with weights , , and . Finally, the feature supplementation operation is implemented using the spatial-dimension, channel-dimension, and all-element sum of and , , and to obtain the semantic-supplemented feature map .
Figure 4.
Overview of the STCA module, which consists of two parts (a Siamese sparse encoder and a three-dimension coordinate attention). With and as inputs, the Siamese sparse encoder outputs the feature maps and . Then, the concatenated feature map is input into the TCA to obtain the local-refined feature map .
Figure 4.
Overview of the STCA module, which consists of two parts (a Siamese sparse encoder and a three-dimension coordinate attention). With and as inputs, the Siamese sparse encoder outputs the feature maps and . Then, the concatenated feature map is input into the TCA to obtain the local-refined feature map .
Figure 5.
Pipeline of the TCA. In the squeeze step, , , and are output by the global average pooling along the x direction, y direction, and z direction, respectively, maintaining their channel dimensions. Then, two convolution operations are used to obtain the attention weights corresponding to three spatial coordinates, i.e., , , and . Finally, the feature of each spatial location is weighted along the channels to obtain the local-refined feature map .
Figure 5.
Pipeline of the TCA. In the squeeze step, , , and are output by the global average pooling along the x direction, y direction, and z direction, respectively, maintaining their channel dimensions. Then, two convolution operations are used to obtain the attention weights corresponding to three spatial coordinates, i.e., , , and . Finally, the feature of each spatial location is weighted along the channels to obtain the local-refined feature map .
Figure 6.
The structure of the auxiliary head. The auxiliary head consists of three two-layer MLPs. The one-dimension vectors flattened from and are input into the shared two-layer MLP whose output size is 256. The parallel two-layer MLPs are used to generate the class label and the regression parameters of the bounding boxes.
Figure 6.
The structure of the auxiliary head. The auxiliary head consists of three two-layer MLPs. The one-dimension vectors flattened from and are input into the shared two-layer MLP whose output size is 256. The parallel two-layer MLPs are used to generate the class label and the regression parameters of the bounding boxes.
Figure 7.
Visualization comparison of the proposed DASANet and the Voxel-RCNN in a complex-background situation.
Figure 7.
Visualization comparison of the proposed DASANet and the Voxel-RCNN in a complex-background situation.
Figure 8.
Visualization comparison of the proposed DASANet and the Voxel-RCNN in a long-distance situation.
Figure 8.
Visualization comparison of the proposed DASANet and the Voxel-RCNN in a long-distance situation.
Figure 9.
Visualization comparison of the proposed DASANet and the Voxel-RCNN in an occlusion situation.
Figure 9.
Visualization comparison of the proposed DASANet and the Voxel-RCNN in an occlusion situation.
Figure 10.
Visualization comparison of the proposed DASANet and the Voxel-RCNN in a large scene. Green boxes, blue boxes, and yellow boxes indicate the ground-truth, the DASANet prediction, and the Voxel-RCNN prediction, respectively.
Figure 10.
Visualization comparison of the proposed DASANet and the Voxel-RCNN in a large scene. Green boxes, blue boxes, and yellow boxes indicate the ground-truth, the DASANet prediction, and the Voxel-RCNN prediction, respectively.
Figure 11.
Visualization ablation comparison between the baseline, +TDIS, +STCA and +TDIS +STCA.
Figure 11.
Visualization ablation comparison between the baseline, +TDIS, +STCA and +TDIS +STCA.
Table 1.
Car 3D detection performance of different networks using the KITTI validation set. In modality, L denotes LiDAR, L + C denotes LiDAR and camera, and - denotes that the corresponding metric is not provided by the original paper.
Table 1.
Car 3D detection performance of different networks using the KITTI validation set. In modality, L denotes LiDAR, L + C denotes LiDAR and camera, and - denotes that the corresponding metric is not provided by the original paper.
| Networks | Modality | AP3D11 | AP3D40 |
|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard |
|---|
| SECOND | L | 88.61 | 78.62 | 77.22 | - | - | - |
| PointPillars | L | 86.62 | 76.06 | 68.91 | - | - | - |
| PointRCNN | L | 88.88 | 78.63 | 77.38 | - | - | - |
| SA-SSD | L | 90.15 | 79.91 | 78.78 | - | - | - |
| PV-RCNN | L | - | - | - | 92.57 | 84.83 | 82.69 |
| Voxel-RCNN | L | 89.41 | 84.52 | 78.93 | 92.38 | 85.29 | 82.26 |
| Pyramid-RCNN | L | 89.37 | 84.38 | 78.84 | - | - | - |
| MV3D | L + C | 86.55 | 78.10 | 76.67 | - | - | - |
| PointPainting | L + C | 88.38 | 77.74 | 76.76 | - | - | - |
| F-PointNet | L + C | 83.76 | 70.92 | 63.65 | - | - | - |
| Focals Conv | L + C | - | - | - | 92.26 | 85.32 | 82.95 |
| CLOCs | L + C | - | - | - | 92.78 | 85.94 | 83.25 |
| VFF | L + C | 89.51 | 84.76 | 79.21 | 92.47 | 85.65 | 83.38 |
| FusionRCNN | L + C | 89.90 | 86.45 | 79.32 | - | - | - |
| SFD | L + C | 89.74 | 87.12 | 85.20 | 95.47 | 88.56 | 85.74 |
| DASANet | L + C | 90.69 | 86.52 | 85.48 | 95.63 | 88.68 | 85.87 |
Table 2.
Car BEV detection performance of different networks using the KITTI validation set. In modality, L denotes LiDAR, L + C denotes LiDAR and camera, and - denotes that the corresponding metric is not provided by the original paper.
Table 2.
Car BEV detection performance of different networks using the KITTI validation set. In modality, L denotes LiDAR, L + C denotes LiDAR and camera, and - denotes that the corresponding metric is not provided by the original paper.
| Networks | Modality | APBEV11 | APBEV40 |
|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard |
|---|
| SECOND | L | 89.96 | 87.07 | 79.66 | - | - | - |
| PointPillars | L | 88.35 | 86.10 | 79.83 | - | - | - |
| PointRCNN | L | 89.78 | 86.19 | 85.02 | - | - | - |
| SA-SSD | L | - | - | - | 95.03 | 91.03 | 85.96 |
| PV-RCNN | L | - | - | - | 95.76 | 91.11 | 88.93 |
| Voxel-RCNN | L | - | - | - | 95.52 | 91.25 | 88.99 |
| MV3D | L + C | 86.55 | 78.10 | 76.67 | - | - | - |
| F-PointNet | L + C | 88.16 | 84.92 | 76.44 | 91.17 | 84.67 | 74.77 |
| Focals Conv | L + C | - | - | - | 94.45 | 91.51 | 91.21 |
| CLOCs | L + C | - | - | - | 93.05 | 89.80 | 86.57 |
| VFF | L + C | - | - | - | 95.65 | 91.75 | 91.39 |
| SFD | L + C | - | - | - | 96.24 | 92.09 | 91.32 |
| DASANet | L + C | 90.50 | 89.26 | 88.58 | 96.39 | 92.42 | 91.77 |
Table 3.
Car 3D and BEV detection performance of different networks using the KITTI test set. In modality, L denotes LiDAR, L + C denotes LiDAR and camera. The best results are bolded. - means that the data was not provided by the original paper.
Table 3.
Car 3D and BEV detection performance of different networks using the KITTI test set. In modality, L denotes LiDAR, L + C denotes LiDAR and camera. The best results are bolded. - means that the data was not provided by the original paper.
| Networks | Modality | AP3D40 | APBEV40 |
|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard |
|---|
| SECOND | L | 85.29 | 76.60 | 71.77 | 90.98 | 87.48 | 84.22 |
| PointPillars | L | 82.58 | 74.31 | 68.99 | 90.07 | 86.56 | 82.81 |
| PointRCNN | L | 86.96 | 75.64 | 70.70 | 92.13 | 87.39 | 82.72 |
| SA-SSD | L | 88.75 | 79.79 | 74.16 | 95.03 | 91.03 | 85.96 |
| PV-RCNN | L | 90.25 | 81.43 | 76.82 | 94.98 | 90.65 | 86.14 |
| Voxel-RCNN | L | 90.90 | 81.62 | 77.06 | 94.85 | 88.83 | 86.13 |
| Pyramid-RCNN | L | 88.39 | 82.08 | 77.49 | 92.19 | 88.84 | 86.21 |
| MV3D | L + C | 74.97 | 63.63 | 54.00 | 86.62 | 78.93 | 69.80 |
| PointPainting | L + C | 82.11 | 71.70 | 67.08 | 92.45 | 88.11 | 83.36 |
| F-PointNet | L + C | 82.19 | 69.79 | 60.59 | 91.17 | 84.67 | 74.77 |
| Focals Conv | L + C | 90.55 | 82.28 | 77.59 | 92.67 | 89.00 | 86.33 |
| CLOCs | L + C | 89.16 | 82.28 | 77.23 | 92.21 | 89.48 | 86.42 |
| VFF | L + C | 89.50 | 82.09 | 79.29 | - | - | - |
| FusionRCNN | L + C | 88.12 | 81.96 | 77.53 | - | - | - |
| SFD | L + C | 91.73 | 84.76 | 77.92 | 95.64 | 91.85 | 86.83 |
| DASANet | L + C | 91.77 | 84.98 | 80.21 | 95.50 | 91.69 | 88.89 |
Table 4.
Comparison of ablation performance using the KITTI validation set. The improvement denotes the difference from the baseline.
Table 4.
Comparison of ablation performance using the KITTI validation set. The improvement denotes the difference from the baseline.
| Networks | AP3D40 | APBEV40 |
|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard |
|---|
| Baseline | 92.38 | 85.29 | 82.66 | 95.52 | 91.25 | 88.99 |
| +TDIS | 93.31 | 86.15 | 83.60 | 96.48 | 91.93 | 89.51 |
| Improvement | +0.93 | +0.86 | +0.94 | +0.96 | +0.68 | +0.52 |
| +STCA | 93.58 | 86.16 | 85.06 | 96.57 | 91.81 | 91.24 |
| Improvement | +1.20 | +0.87 | +2.40 | +1.05 | +0.56 | +2.25 |
| +TDIS +STCA | 95.63 | 88.68 | 85.87 | 96.39 | 92.42 | 91.77 |
| Improvement | +3.25 | +3.39 | +3.21 | +0.87 | +1.17 | +2.78 |
Table 5.
Ablation comparisons of computational load and inference speed on the KITTI validation set.
Table 5.
Ablation comparisons of computational load and inference speed on the KITTI validation set.
| Networks | Params (M) | FLOPs (G) | FPS (Hz) |
|---|
| baseline | 6.9 | 22.7 | 25.2 |
| +TDIS | 26.2 | 28.0 | 14.5 |
| +STCA | 30.8 | 27.9 | 12.7 |
| +TDIS +STCA | 55.2 | 30.9 | 10.5 |
Table 6.
Comparisons using the KITTI validation set for different distances. The improvement denotes the difference from the baseline.
Table 6.
Comparisons using the KITTI validation set for different distances. The improvement denotes the difference from the baseline.
| Networks | AP3D40 | APBEV40 |
|---|
| 0 m–20 m | 20 m–40 m | 40 m-Inf | 0 m–20 m | 20 m–40 m | 40 m-Inf |
|---|
| Baseline | 92.11 | 74.99 | 13.85 | 95.49 | 86.50 | 25.64 |
| +TDIS +STCA | 95.01 | 78.91 | 22.27 | 98.05 | 88.05 | 35.14 |
| Improvement | +2.90 | +3.92 | +8.42 | +2.56 | +1.55 | +9.50 |
Table 7.
Comparisons using the KITTI validation set for different occlusion levels. Level 0, 1, and 2 denote that the object is fully visible, the object is partly occluded, and the object is difficult to see, respectively. The improvement denotes the difference from the baseline.
Table 7.
Comparisons using the KITTI validation set for different occlusion levels. Level 0, 1, and 2 denote that the object is fully visible, the object is partly occluded, and the object is difficult to see, respectively. The improvement denotes the difference from the baseline.
| Networks | AP3D40 | APBEV40 |
|---|
| Level 0 | Level 1 | Level 2 | Level 0 | Level 1 | Level 2 |
|---|
| Baseline | 54.70 | 67.40 | 51.59 | 57.66 | 74.68 | 64.97 |
| +TDIS +STCA | 55.29 | 69.66 | 56.29 | 58.10 | 77.68 | 68.20 |
| Improvement | +0.59 | +2.26 | +4.70 | +0.44 | +3.00 | +3.23 |
Table 8.
Comparisons using the KITTI validation set for different numbers of points in the GT bounding boxes. points. The improvement denotes the difference from the baseline.
Table 8.
Comparisons using the KITTI validation set for different numbers of points in the GT bounding boxes. points. The improvement denotes the difference from the baseline.
| Networks | AP3D40 | APBEV40 |
|---|
| <100p | 100 p–200 p | >200 p | <100 p | 100 p–200 p | >200 p |
|---|
| Baseline | 40.98 | 75.18 | 95.35 | 53.13 | 84.92 | 97.71 |
| +TDIS +STCA | 56.57 | 85.38 | 96.96 | 56.57 | 90.87 | 98.19 |
| Improvement | +15.59 | +10.20 | +1.61 | +3.44 | +5.95 | +0.48 |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}