1. Introduction
Recent years have seen an explosion in the use of unmanned aerial vehicles (UAVs) to a range of problems. However, many of these tasks require the system to operate in a variety of partially observable environments. The field of search and action tasks has an abundance of problems with this limitation, including but not limited to search and rescue [
1], environmental sampling and data collection [
2,
3,
4], the pursuit of targets in complex environments [
5,
6], and the underground mining and surveying of confined spaces [
7].
In addition to the difficulty of environmental uncertainty, these tasks are often also time-sensitive and benefit from the application of multi-agent solutions. However, the coordination of multiple agents over partially observable environments remains an area of exploration within the field of robotic planning and control.
In pursuit of enabling multiple agents to operate in partially observable environments, this paper proposes a modeling approach and planning and control software framework. The long term aim is the application of this framework to a number of remote sensing problem spaces, from searching for a variety of environments such as disaster zones, buildings, caves systems, and open or forested areas, to surveying potentially hazardous or difficult to reach points of interest.
The main contributions of this work are as follows:
Improvements to the existing NanoMap library [
8] to provide additional GPU-accelerated planning and control functionality
Extension of the NanoMap library to enable the efficient simulation of search and mapping problems for use with deep reinforcement learning algorithms.
A modeling approach and software framework for enabling multiple UAV agents to search and target-find in uncertain environments containing targets of uncertain location.
Validation of this multi-UAV framework in a simulated environment
The structure of this paper is as follows:
Section 2 outlines related works and the contribution of this work.
Section 3 defines the research problem and system requirements of the framework.
Section 4 defines the planning and control framework and introduces the major components.
Section 5 outlines how the NanoMap Library is extended to provide timely path finding solutions and the information required by the framework.
Section 6 outlines the global planner component and details how the multi-agent planning problem is formulated as a decentralized partially observable Markov decision process (DEC-POMDP).
Section 7 outlines the local controller component and details how the local control problem is formulated as two partially observable Markov decision processes (POMDPs). It also outlines how deep reinforcement learning (DRL) was applied to generate policies for these POMDPs.
Section 8 details the software architecture for the system.
Section 10 concludes, outlining the goals for future work.
2. Related Works
Remote sensing problems have a number of properties that can make them difficult for autonomous systems to solve. One major difficulty is that remote sensing problem environments often contain terrain that is too difficult for ground robots to efficiently traverse. As a result, UAVs have seen an increase in their application to these problems [
9], with the platform able to ignore many terrain-based difficulties. The application of multi-UAV systems to remote search and mapping tasks would prove particularly useful, enabling UAV-based systems to search or survey environments in minimal time.
Unfortunately, difficult terrain is not the only challenge these problems present. Uncertainty in the environment, uncertainty in the location of the objective or target, and uncertainty in localization all contribute heavily to the difficulty of remote search and mapping tasks.
Modeling uncertainty within robotics problems is often carried out by first defining the problem as a POMDP [
10] with solutions often provided using model-based algorithms and solvers [
11,
12,
13]. Model-based POMDP approaches have been used for UAV-based planning and control under uncertainty in the past. Vanegas and Gonzalez [
14] applied a model-based solver to target-find in the presence of sensor, localization, and target uncertainty, but operated within a limited and known environment. Zhu et al. [
15] propose a system for multi-UAV target finding under motion and observation uncertainty using a decentralized model-based POMDP approach. However, the complexity and size of the environments is limited, the obstacles are known prior to operation, and the rate of the motion planner is limited to 1Hz, limiting the suitability of the approach in the presence of dynamic hazards. Galvez-Serna et al. [
16] propose a model-based POMDP framework for planning autonomous UAV planetary exploration missions, validating the performance with simulated and real-world flight testing. Unfortunately, the hazards are known prior to operation and the environment complexity is low.
While model-based solvers show promise for UAV target-finding under uncertainty, producing near-optimal solutions if the problem is modeled appropriately, they have a number of limitations. These limitations include discrete action spaces [
11] or difficulty modeling continuous action spaces [
12], pauses in operation to calculate the next optimal trajectory [
11,
12], and long pre-planning times for each new environment. Another key difficulty is that model-based solvers often assume a static environment that is known prior to operation. This prior information is often baked into the model at run-time, and changes in the environment require the problem to be resolved when the environment differs from the prior knowledge [
11]. The difficulties and limitations of current model-based solvers for producing solutions to POMDPs with complex state and action spaces have limited their application.
An alternative approach to model-based solvers that has demonstrated exceptional performance when solving MDP and POMDP control tasks, from simulated robotic control tasks [
17,
18] to atari video games [
19], is deep reinforcement learning (DRL). Increases in the performance of DRL-based solutions have resulted in the application of the technology to a variety of robotic planning and control tasks. A deep Q-network approach has been applied to the exploration and navigation of outdoor environments [
20], and a multi-agent deep deterministic policy gradient method has been applied to multi-agent target assignment and path planning in the presence of threat areas [
21]. Xue and Gonsalves [
22] have applied DRL to vision-based UAVs for the purpose of avoiding obstacles. Both model-based and DRL-based POMDP solutions have been applied to single and multi-UAV problems containing a variety of uncertainties. However, the application of these solutions to the problem of multi-UAV search in uncertain environments with uncertain targets remains under-explored.
The application of DRL to search and mapping problems in uncertain environments also presents difficulties. While model-based solvers require a model of the problem during operation, DRL-based solvers require either training of the agent in the real-world or training on an adequate simulation of the problem. Unreal Engine has been used as a simulation environment for producing policies for UAV agents in the past [
22,
23], however a major drawback of Unreal Engine-based simulations for deep reinforcement learning is their computational cost and the difficulty of working with the game engine. Sapio et al. [
24] have proposed a development toolkit to lower the difficulty of working with Unreal Engine, but the performance of the engine is still a limitation. Oftentimes, DRL does not require a high-fidelity simulation to train an effective policy, and sacrificing fidelity for performance can improve the iteration time when training policies by orders of magnitude. An easy to use, high-performance simulation environment for training agents to search and map in unknown and uncertain environments is not readily available.
Another difficulty faced by UAV agents during flight is access to sufficient computational resources. Recognising the increasing availability of CUDA [
25] enabled single-board computers for remote sensing platforms, and prior work developed the GPU-accelerated probabilistic occupancy mapping library NanoMap [
8]. However, while sensor input processing has been accelerated with NanoMap, processing and solving three-dimensional (3D) occupancy grids for planning purposes is still computationally expensive for the CPU limited hardware commonly found on UAVs. GPU-accelerated path-solving and planning tools for occupancy grids would help to conserve the resources agents need for other tasks. While GPU-based all-pairs shortest path algorithms for graphs exist and are actively being improved [
26], such tools do not readily exist for use with NanoMap’s occupancy grids.
Localization is often a significant issue in robotics problems, and while POMDPs can be applied to the modeling of uncertainty in localization [
14] with a measure of success, the quality of localization solutions continues to improve. Single sensor solutions [
27], multi-sensor solutions [
28], and even distributed localization solutions [
29] are more capable than they have ever been. Even off-the-shelf visual inertial odometry solutions are quite capable, with Kim et al. [
30] demonstrating the exceptional accuracy of the Apple ARKit. With localization solutions continuing to show improvements in hardware and software, this work maintains a focus on planning and control for problems containing uncertainty in the target and uncertainty in the environment and assumes localization is provided by a third-party solution.
Table 1 outlines three research gaps identified within the literature and details the contributions of this work.
3. Research Problem and System Requirements
As discussed in
Section 2, the solution to multi-agent planning and control for UAV remote sensing must tackle a number of actively explored research problems. A complete framework would be capable of managing the following sources of uncertainty:
Uncertainty in the environment.
Uncertainty in target location(s).
Uncertain or limited communication between agents.
Uncertainty in localization.
Due to the complexity of the problem, it was decided that development would focus primarily on producing a framework for problems that contained:
Uncertainty in the environment.
Uncertainty in target location(s).
Limited communication between agents.
The largest assumption made for this iteration of the framework is that the agents have a method of global localization. The localization does not have to be perfect, but the framework assumes the agents have an accurate idea of their global position to enable cooperation between agents. Given the current state of localization technology as outlined in
Section 2, this is not an unreasonable assumption. However, future development aims to integrate the management of localization uncertainty in order to streamline the application of the framework to more problems.
Including this main assumption, the three primary assumptions made for development are as follows:
Communication between agents is reliable but limited.
Global localization for each agent is accurate.
Prior information of the environment is available, but may be incomplete.
The targeted problem uncertainties and desired performance can be mapped to the system requirements shown in
Table 2, with additional requirements added for practicality.
Requirement five was added because problems in large and complex environments benefit significantly from the application of multi-agent systems. Requirement six is a result of practical limitations related to testing. Access to three or more UAVs and a large environment in which to safely operate them was unavailable during this stage of development.
4. Framework Overview
The planning and control framework proposed in this work assumes the following multi-agent configuration.
Stated in
Section 3, managing uncertainty within localization is a target for future development. For this iteration of the work, it is assumed a third-party module is maintaining accurate global localization. As can be seen in
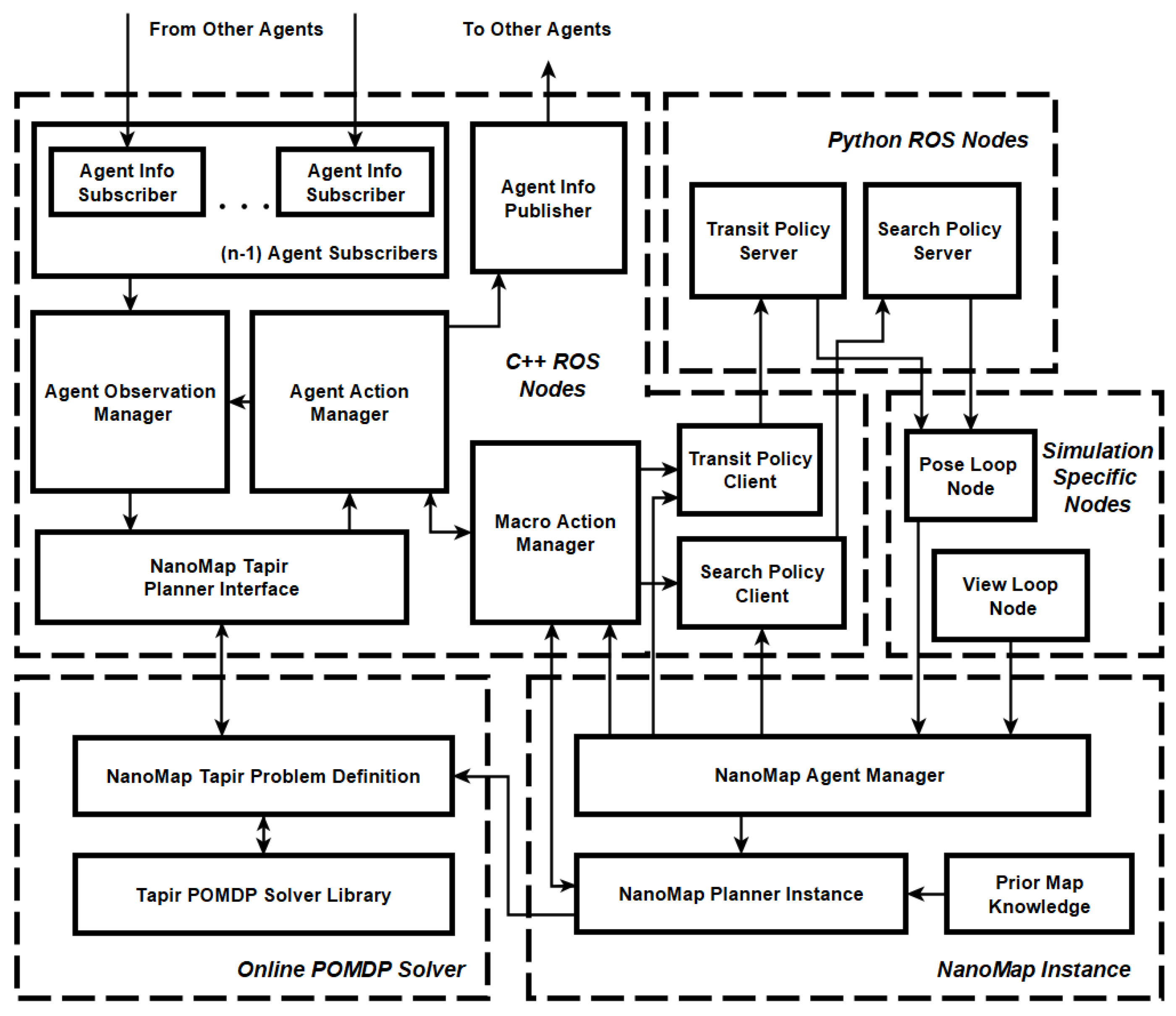
Figure 1, the planning and control framework receives localization and sensor data while transmitting information to and receiving information from the other agents. The framework uses the information available to produce velocity commands for an assumed hardware controller. The velocity commands generated by the framework control the agent such that it completes the desired tasks in cooperation with the other agents.
The planning and control framework can be broken down into three main components operating to produce the desired behavior, shown in
Figure 2.
As
Figure 2 illustrates, the sensor inputs and agent pose are processed into a NanoMap instance that manages information about the environment. This information is provided as required to the global planner and local controller. The global planner component is responsible for generating actions that direct the agent through the environment to complete the desired task in a cooperative fashion. Minimal information is shared between the global planners of each agent (only enough to satisfy the needs of the global planner model). Changing the DEC-POMDP model within the global planner component changes the high-level behavior of the agents.
The global planner component generates actions to be completed by the local controller. The local controller component is responsible for controlling the operation of the agent in potentially unknown and hazardous environments. Once the agent has completed the desired global action, the local controller reports the completion of the action to the global planner. In the case of the UAV search problem, the local controller contains two separate local control models, each producing different agent behavior. The modeling of the local control problem informs how an agent will interact with the environment and how an agent will behave in the presence of environmental uncertainty. A variety of robotic agents can be controlled granted the appropriate models are used within the local controller component.
The following
Section 5,
Section 6 and
Section 7 outline, in more detail, the NanoMap instance, the global planner, and the local controller.
6. Global Planner
While the calculated path-planning solutions are useful, without an appropriate mission planner to guide the interest of an agent, they are insufficient when the position of the target is unknown. This is the purpose of the global planner component of this work. Within the software framework proposed by this work, each agent has their own global planner that is responsible for generating macro-actions. These macro-actions direct the UAV to points of interest, with the goal finding a target or observing an area within the environment. Similar to prior works [
33], the global planner component utilizes the TAPIR solver library [
34] and the adaptive belief tree (ABT) [
11] algorithm to solve the proposed DEC-POMDP problem model and produce macro-actions for each agent.
Figure 11 outlines the main components of the global planner.
Global Planner DEC-POMDP Model
This subsection details the DEC-POMDP problem formulation used by the global planner.
Table 4 details the DEC-POMDP formulation.
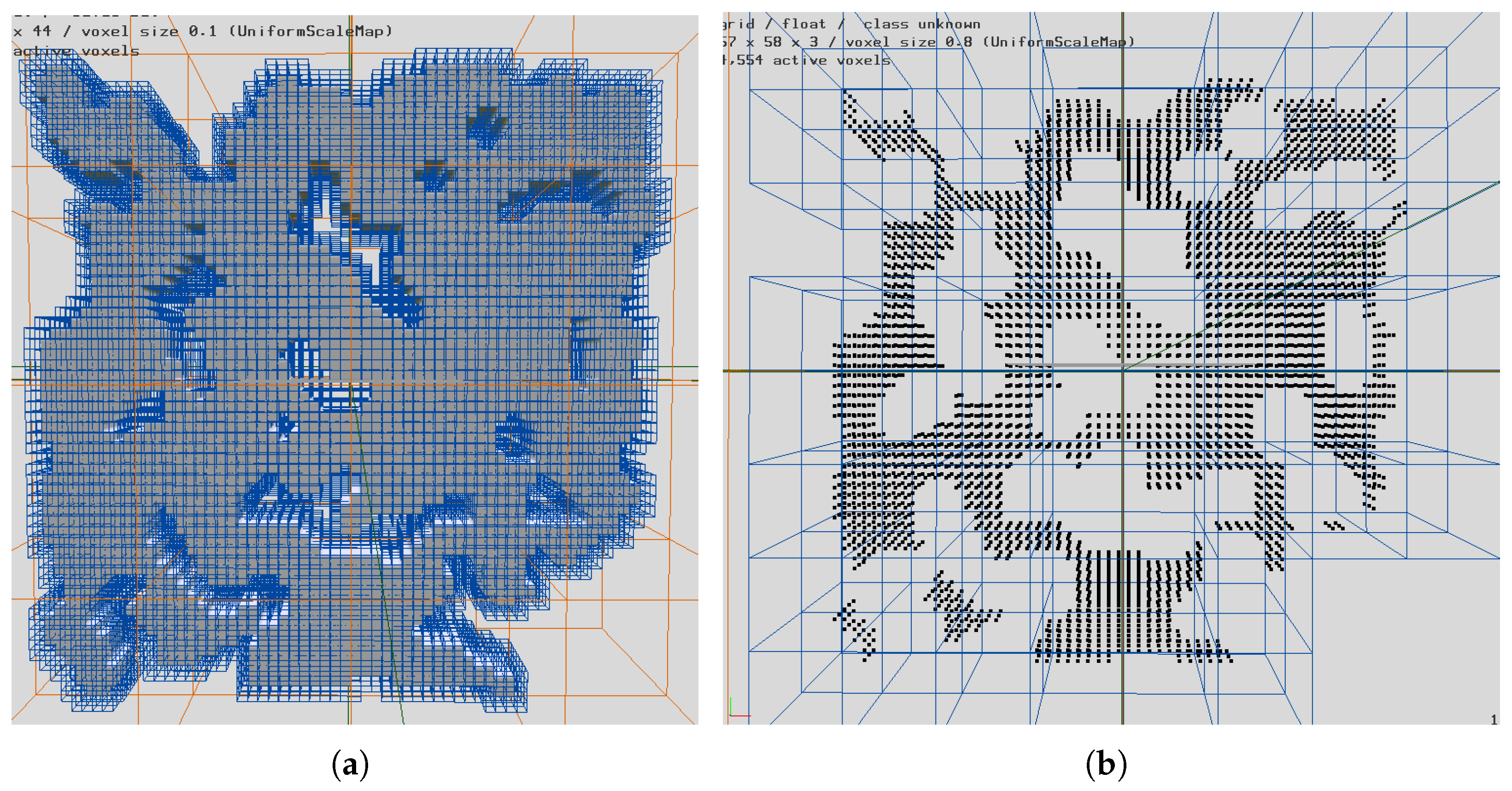
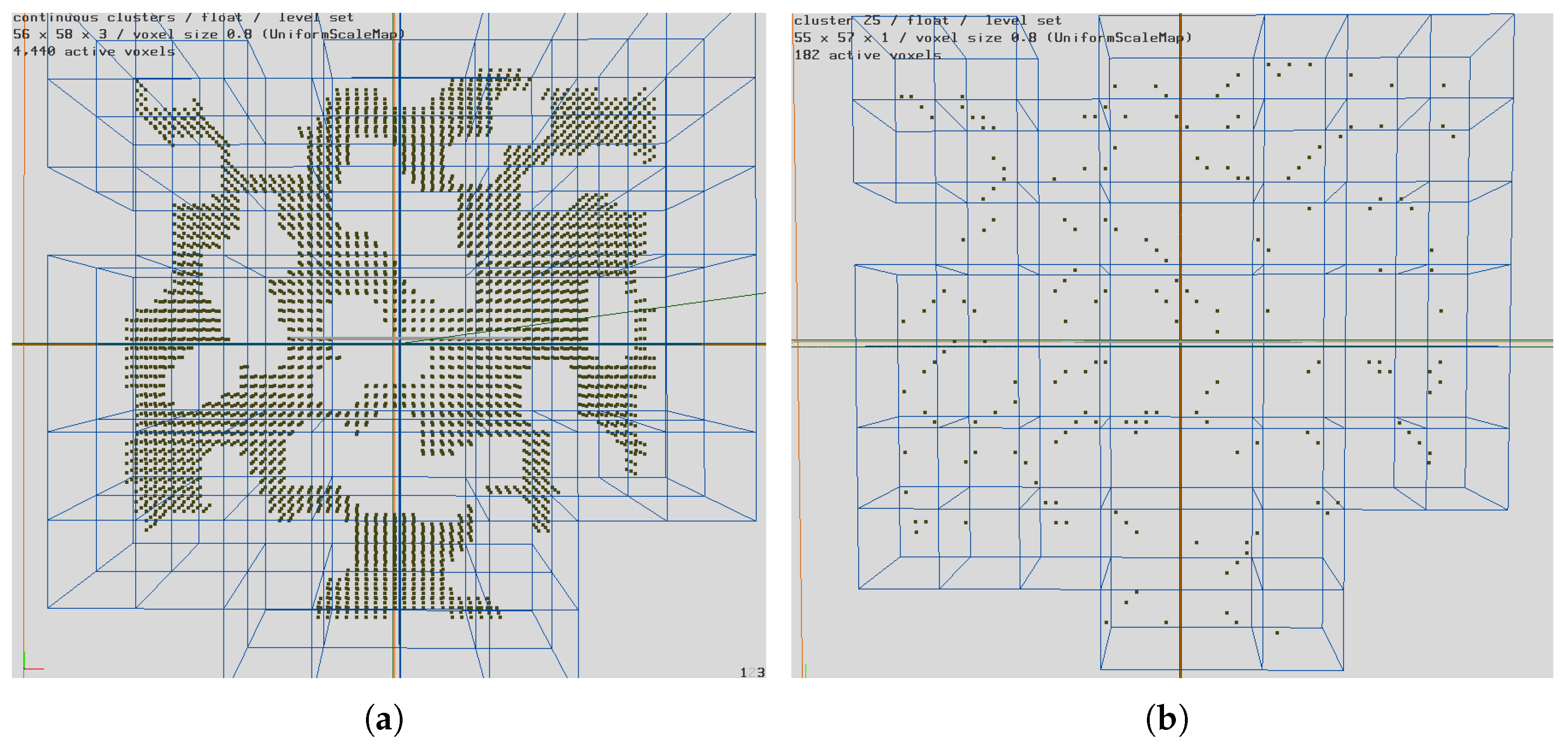
The state-space for the problem includes the graph of the global environment, the target location(s), the found status for each agent, the current agent locations, and the current search status for each agent. The environment representation is the graph created from the clusters of the global environment. Each cluster of the environment is a location to search or move to. This graph representation can be seen in
Figure 12.
The set of actions is variable between problems and is dependent on the current node of an agent within the environment graph and the number of connections the current node has within the graph.
The observation space contains the location for each agent and the search status for those agents. Each agent’s search status is a boolean array with a size one greater than the number of targets. The first entry in the array details whether an agent has completed a search within the cluster that it currently inhabits. The other entries in the array detail which targets were observed during that search.
Figure 13 shows the individual agent observation information for three separate agents in a graph environment and the combined observation used by each agent’s global planner.
Currently, communication is assumed to be minimal but reliable; however, a model that permits incomplete communication between agents could be used as a replacement or improvement to the current decentralized model.
The model is solved by each agent independently using the TAPIR POMDP solver library. For each agent, the corresponding solver only produces actions for the corresponding agent. Actions are randomly generated for the other agents during the tree roll-out of the planner. The solver then has the objective of producing a policy to complete the search of the environment while incurring the smallest cost possible given the assumed near-random nature of the other agents. Each observation of the location and search status of the other agents helps refine the belief of the planner, allowing an improved policy to be calculated during operation.
7. Local Controller
The local controller component for each agent is responsible for taking the action provided by the global planner and controlling the agent such that the action is completed. For the search and mapping problem, the proposed global planner only provides two types of actions: searching a cluster (search) or moving to a neighboring cluster (transit).
Figure 14 outlines the main components of the local controller.
Using the NanoMap instance, the necessary information is provided to the low level controller to complete the global planner macro-action. In the case of a transit action, the local controller uses information about the environment to control the agent to transit to the desired cluster while avoiding obstacles. This mode of operation is called “transit mode”. The agent is required to make the transit to the neighboring cluster and avoid hazards, but the agent is not pushed to explore the environment.
“Search mode” applies a policy that controls the agent to search a cluster, leveraging information extracted from the prior knowledge of the environment and the agent’s current knowledge of the environment to help in directing the search.
In both modes, motion control is handled by a policy trained using deep reinforcement learning.
7.1. The Local Controller Problem Models
The local controller models are defined as POMDPs. Both modes share similarities in their observations and states, with the main differences occurring in their reward structures.
Table 5 and
Table 6 outline the search and transit models.
The state-space for both problems contains the operating environment as defined by the map constructed by the agent, the position and orientation of the agent, and the velocity of the agent. Outside of the shared state information, each problem requires different goal information. The transit problem uses a single goal provided relative to the agent’s frame of reference that the agent must navigate toward. In the case of the search problem, the agent is provided with five nearby goals within the current cluster to observe. These goals update according to which areas have yet to be observed.
The actions set the desired x, y, z, and yaw velocities. The observations, rewards, and general operation of the models are described further below.
In the case of the transit problem, the agent is provided a goal it must reach, and reaching the goal provides the agent with a reward. During training, reaching a goal causes the generation of a new goal. The agent is also rewarded for each incremental move toward the transit goal.
In the case of the search problem, the agent is provided with five nearby points of interest to observe. Each time it observes a point of interest it is rewarded, and a new goal is generated from the remaining unobserved points of interest.
Both models share a collision cost and a continuity cost. The collision cost penalizes the agent for collisions, and the continuity cost rewards smooth and continuous actions, with the agent penalized for large changes in velocity between time steps.
The agent is provided with information about its surroundings via distance observations. These distance observations communicate the distance to unknown spaces and hazards according to the map constructed by the agent during operation. The observations map to a sphere projection to provide equal information coverage around the agent.
Figure 15 shows the visual representation of these observations. Unknown cells are treated as potentially hazardous cells when generating the observations to prevent the agent moving through unknown space without first observing it.
Additional observations are required to avoid violating the Markov assumption. First, a ‘steps until timeout’ observation is required because without it, a termination of a training episode via time-out is treated the same as a termination via collision. This creates difficulties when attempting to generate a valid solution and can completely ruin the quality of the solution. Additionally, both the actions (velocity commands) and the velocity observations for the prior step are provided as observations to implement the continuity cost without breaking the Markov assumption.
7.2. Training the Agent
The training of the two local controller policies was carried out using the Stable Baselines 3 (SB3) library [
35]. The Soft Actor Critic (SAC) algorithm [
36] implemented by SB3 was used for producing policies for both POMDPs.
Training the agent required generating random occupancy grid environments and randomized goals within those environments. The agent was randomly spawned into one of these generated environments in a safe location, and its operation was simulated. NanoMap was extended via a number of ‘gym’ variants of the base classes to enable the management and calculation of training-specific agent states and observations within an environment. A python wrapper for this code was then written to provide a python based OpenAI gym environment to SB3.
Figure 16 shows how NanoMap is utilized within an OpenAI gym style environment to provide access to C++ and GPU-accelerated operations when training an agent.
Once spawned into the random environment, the agent uses simulated sensing to construct an occupancy grid of the environment according to its observations. This occupancy grid is used to generate the environment-based hazard and unknown distance readings for the agent detailed in
Section 7.1 and shown in
Figure 15.
The use of NanoMap to simulate mapping and the generation of observations allows an agent to learn to navigate within the environment while considering the possibility that unknown obstacles may impede progress, and thus sensing these obstacles is critical to safe operation.
9. Evaluation
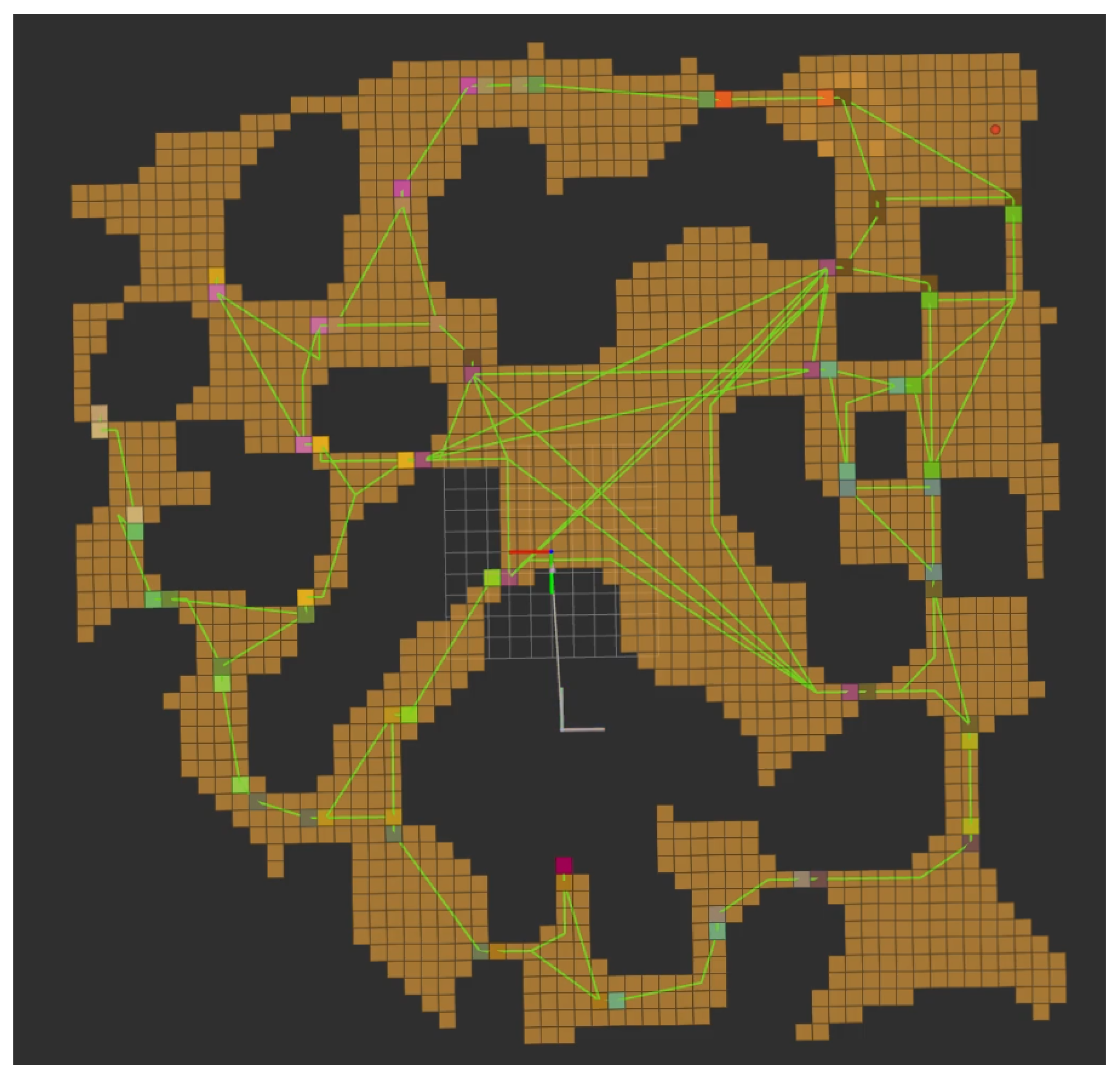
Evaluation of the framework was conducted with three sets of trials performed on the same randomly generated environment. The shape of the evaluation environment can be seen in
Figure 18. A video can be found on the NanoMap Youtube Channel (
https://youtu.be/FWLTIBuQVEw (accessed on 26 June 2023)) showing a selection of these trials. In the case of all trials, the time to complete a full search of the environment was recorded.
Table 7 details the results for all three trials, with
Figure 19,
Figure 20,
Figure 21 and
Figure 22 providing visualizations of the results of the trials.
The first trial was used to test the performance of the global planner. This global planner trial used a fixed action completion time to assess the impact of increasing the number of agents when using only the decentralized global planner. Five tests runs were conducted for each agent configuration, and the results were averaged. The completion time data for the global planner trials can be seen in
Table 5 and
Figure 19.
Additionally for this trial, the number of rooms searched by each agent was tracked. These values were organized from largest to smallest for each test and averaged to obtain an understanding of how increasing the number of agents for the test environment affects individual agent efficiency. These results can be seen in
Figure 20.
As can be seen from
Table 7 and
Figure 19, increasing the number of agents improves the time to complete a full search of the environment, demonstrating that even with minimal information sharing the agents are able to coordinate to improve target-finding performance. The improvement gained tapers off for the five agent trials, and this is a result reinforced by
Figure 20.
Figure 20 shows that for the test environment used in the trials, the use of three agents results in the number of searched rooms being well distributed across all agents.
Figure 20 shows that an additional fourth agent still contributes somewhat to the search but illustrates that a fifth agent contributes very little. This behavior can be considered a result of the size and shape of the environment. The global graph map of the environment is not large enough to meaningfully benefit from more than four agents, with only a small contribution provided by a fifth agent.
The second and third trials were conducted to test the performance of the full framework, combining the output of the local controller and global planner to complete a full search of the simulated environment with and without added obstacles. These trials were completed for one, two, and three agent configurations.
In both the second and third set of trials, four and five agent configurations were not tested as a result of a software limitation that could not be resolved in the time available. GPU-based Stable Baselines 3 inference of the transit and search models could only be performed for 3 agents on a single machine. Attempting to perform policy inference for four agents at a single time on a single machine resulted in instability that crashed the Python ROS nodes used to control the agents.
Figure 21 and
Figure 22 visualize the results of these trials, illustrating that increasing the number of agents translates to an improvement in the search time of the environment during the full operation of the framework. The second trial demonstrates how each instance of the framework can plan and control an agent to cooperatively search a large, partially observable, simulated environment. The third trial demonstrates that the framework is still capable of performing in an environment with increased uncertainty in the form of additional unknown obstacles. The average search times increased slightly as a consequence of these randomly introduced and unknown features. Improving the local controller model definitions and adding a more varied assortment of objects and obstacles to the training environment would further increase the performance of the control policies when operating in the presence of unknown obstacles.
10. Conclusions
This work extends the NanoMap library to provide GPU-accelerated planning and path-finding functionality for the occupancy grids produced by the library. Additional extensions were performed to enable the training of agents that require simulated sensing and mapping using Stable Baselines 3 and other approaches that use OpenAI gym style environments. Furthermore, a framework was developed that combines the NanoMap library, a DEC-POMDP model-based global planner, a deep reinforcement learning-based local controller, and ROS to enable multi-agent search and target finding for problems with target and environment uncertainty in large and complex environments. Simulated testing demonstrates the performance of the full framework for one, two, and three agent configurations and the performance of the global planner was validated for one, two, three, four, and five agent configurations.
Core aims for future work are as follows:
The development and integration of a method for managing localization uncertainty within NanoMap and the framework.
Streamlining the usability of the framework to provide researchers a flexible and high performance multi-agent planning and control framework for their own robotic solutions.
Validation of the framework with real-world testing.
Additional aims to improve the utility of the framework include:
Increasing the types of global planner and local controller models supported and available for use with the framework by default.
Adding support for dynamic environments and hazards to NanoMap.
Increasing the types of sensors and sensor data supported by NanoMap.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}