1. Introduction
In the rapidly changing modern society, phenomena such as soil erosion, geological disasters and deforestation occur from time to time [
1]. To build a modern smart city [
2,
3], it is necessary to monitor information about changes in the land [
4,
5]. Remote sensing change detection refers to the analysis and identification of changes between remote sensing images using statistics and mathematical models [
6]. We can obtain a large amount of ground surface details from very-high-resolution (VHR) remote sensing images, which can be used to compare geographic objects at different stages [
7]. Detecting detailed changes in geographic objects has important implications for map updating, urban planning, management and disaster management [
8,
9].
With the development of satellite technology, the resolution of remote sensing images also increases [
10,
11,
12]; the improvement in image resolution facilitates the acquisition of detailed information regarding ground objects, including their spatial, contrast and morphological relationships [
13,
14,
15]. It is important to exploit the correlation between these detailed features. It is easy to describe subject changes in both changing and invariant regions with a single change image, but it is difficult to reveal the details of VHR images. With the development of computer science, computer vision has been applied to many fields of remote sensing [
16]. It has become a hot point in remote sensing research of combination VHR image change detection and computer vision [
17], which aims to detect changes in multidirectional relationships between images using computer vision and change detection algorithms.
Remote sensing change detection involves primarily two methods: image direct comparison and post-classification comparison [
18]. The post-classification comparison method involves the classification of two images of different phases, followed by a comparison of the resulting ground feature types to obtain change detection results. However, this method only considers the current image, disregarding the interconnection between different time phase images, and it is difficult to label samples manually. Consequently, classification errors tend to accumulate and overlap between different objects, leading to inaccuracies during the detection process [
19]. In contrast, the direct comparison method is a widely used and straightforward approach for comparing two images [
20]. The quality of the direct comparison method relies on obtaining a difference image between images taken at two phases [
21,
22].
There are a variety of ways to produce difference images, such as the method of taking a logarithmic ratio of remote sensing images [
23]. Although the logarithmic method produces relatively good difference images for dual-temporal images, it has been observed that the resulting images lack adequate ground information. Therefore, some researchers have proposed an iterative robust graph-based method for change detection. This method uses the K-nearest neighbor and image cross-mapping techniques to obtain the forward and backward difference images [
24]; the Markov model is used to detect changes. Although the robustness is high, the iteration cycles of this method will affect the rate. For classical change detection methods, numerous scholars have conducted relevant research. Some researchers have proposed the use of spectral gradient difference (SGD) to describe the image difference [
25]. This method is capable of detecting more prominent feature types. However, it has a disadvantage in that it only considers the spectral characteristics between images and does not take other features into account. Some researchers have proposed an unsupervised change detection method based on the hybrid spectral difference (HSD), which combines the spectral value and spectral shape by fusing the difference images of spectral correlation mapper (SCM) and SGD to describe the change in spectral shape [
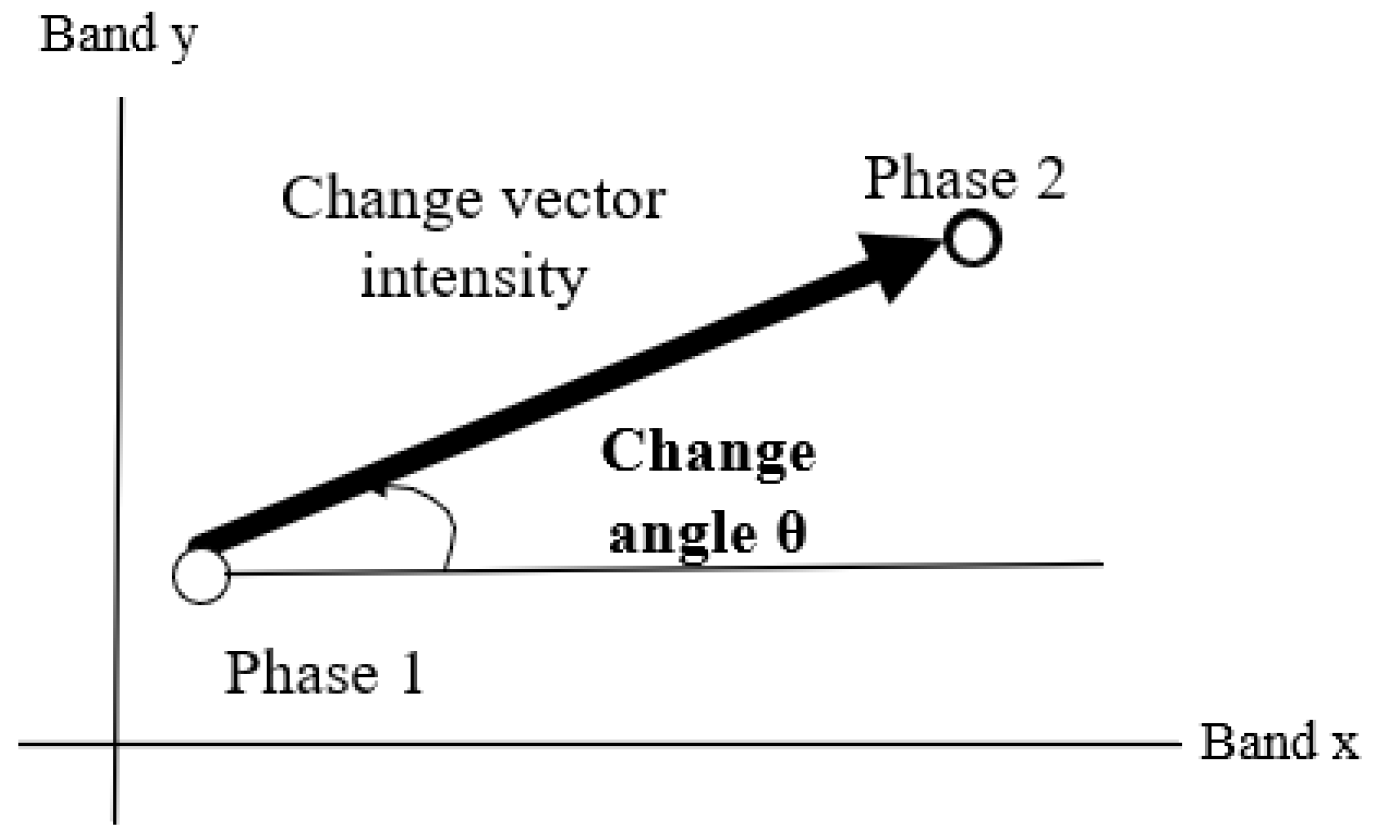
26]. One advantage of this method is that it can combine more change characteristics of the two images. One disadvantage is that many ground objects cannot be detected using a single pixel. Change vector analysis (CVA) was first used for change detection and applied to forest change [
27]. This paper introduces a digital method for change detection using multi-temporal Landsat data. The method calculates the spectral change vectors of two different dates. This method works well in low-resolution images, but its disadvantage is that it only considers a single feature. Since ground objects in VHR images are more complex, applying this method to VHR remote sensing images will result in a lot of noise. To address this limitation, some researchers have proposed a change detection method that combines multiple indexes and uses CVA and SGD to construct a change difference image [
28]. However, it has three disadvantages. First, although the two index algorithms are different, they both judge the changes based on image pixels. Second, although multiple index fusion can reduce part of salt and pepper noise, it still cannot use advanced features to express the whole VHR image. Third, multi-index fusion may lead to error superposition of change detection results.
In recent years, with the rapid development of various disciplines, various computer models have made outstanding progress in image processing, for example, machine learning models such as support vector machine (SVM) [
29], random forest (RF) [
30] and extreme learning machine (ELM) [
31]. Visual saliency detection technology has also advanced in leaps and bounds, such as a spectral residual approach (SRA) [
32], context-aware saliency detection (CASD) [
33] and the richer convolutional features method [
34]. Convolutional Neural Networks (CNN) for images have been developed in recent years, including U-Net [
35], GoogleNet [
36], ResNet [
37], etc. These networks show strong effects in various fields of remote sensing. VHR image change detection is roughly divided into three categories. The first category is to extract the image features first and then compare them to get the change detection results. For example, some researchers have used classification CNNs, which are the main method for learning deep features from VHR remote sensing images, to detect building changes from RGB aerial photographs [
38]. The second category is to use samples directly to train the change detection neural network model and then output the change image directly. For example, some researchers have used pre-trained image classification CNNs to extract change features [
39]. Some researchers have used improved attention mechanisms for training networks to extract change information [
40]. The third category uses some visual methods for unsupervised change detection based directly on images. For example, some researchers have proposed a base improved PCA-net model to implement VHR image change detection [
41]. It exhibits an excellent performance in the field of VHR change detection. As we all know, most VHR images mainly include four bands. For remote sensing change detection, simply using these visual models to input RGB band information may cause the loss of spectral bands, thus affecting the change detection results. Therefore, it is very important to construct the correlation between remote sensing change detection algorithms and visual models.
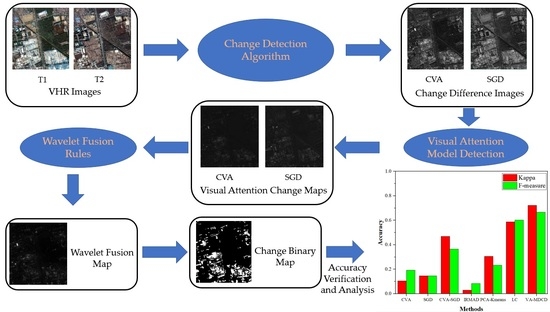
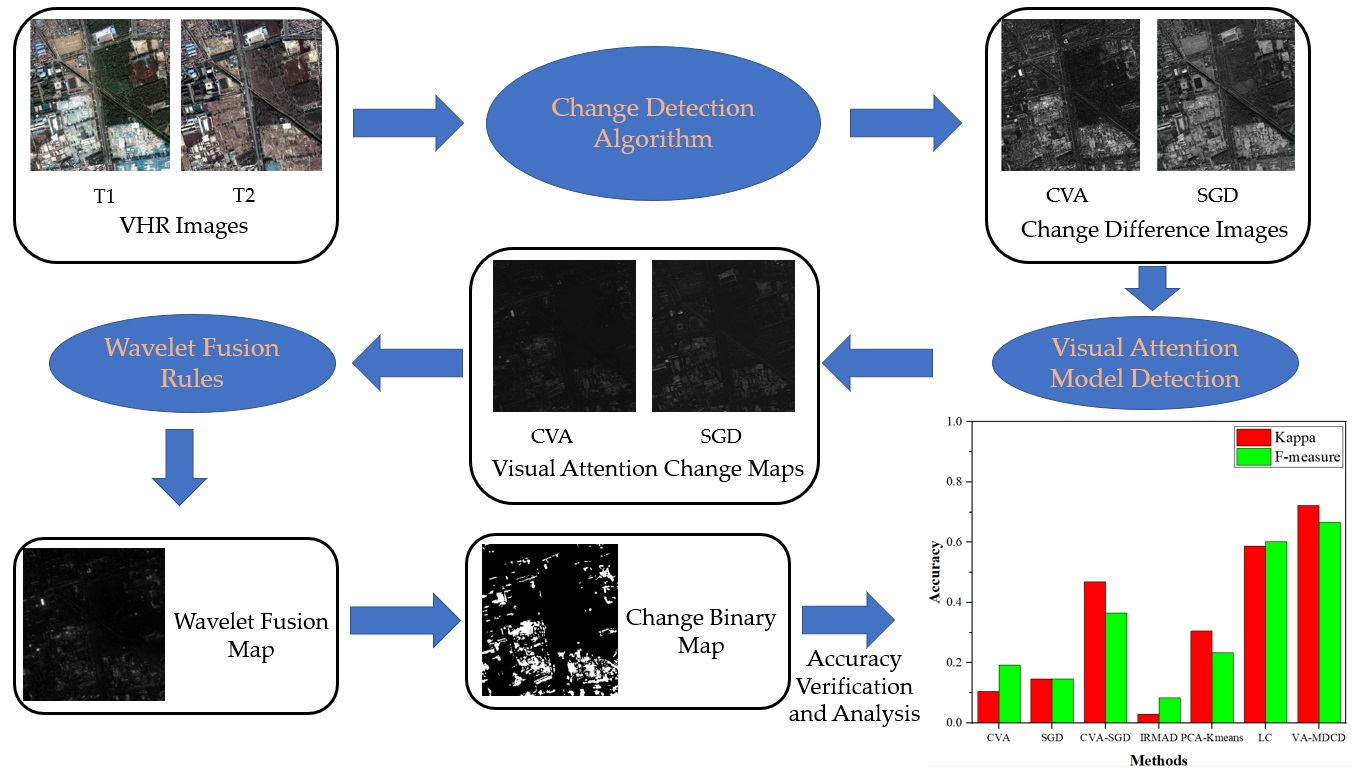
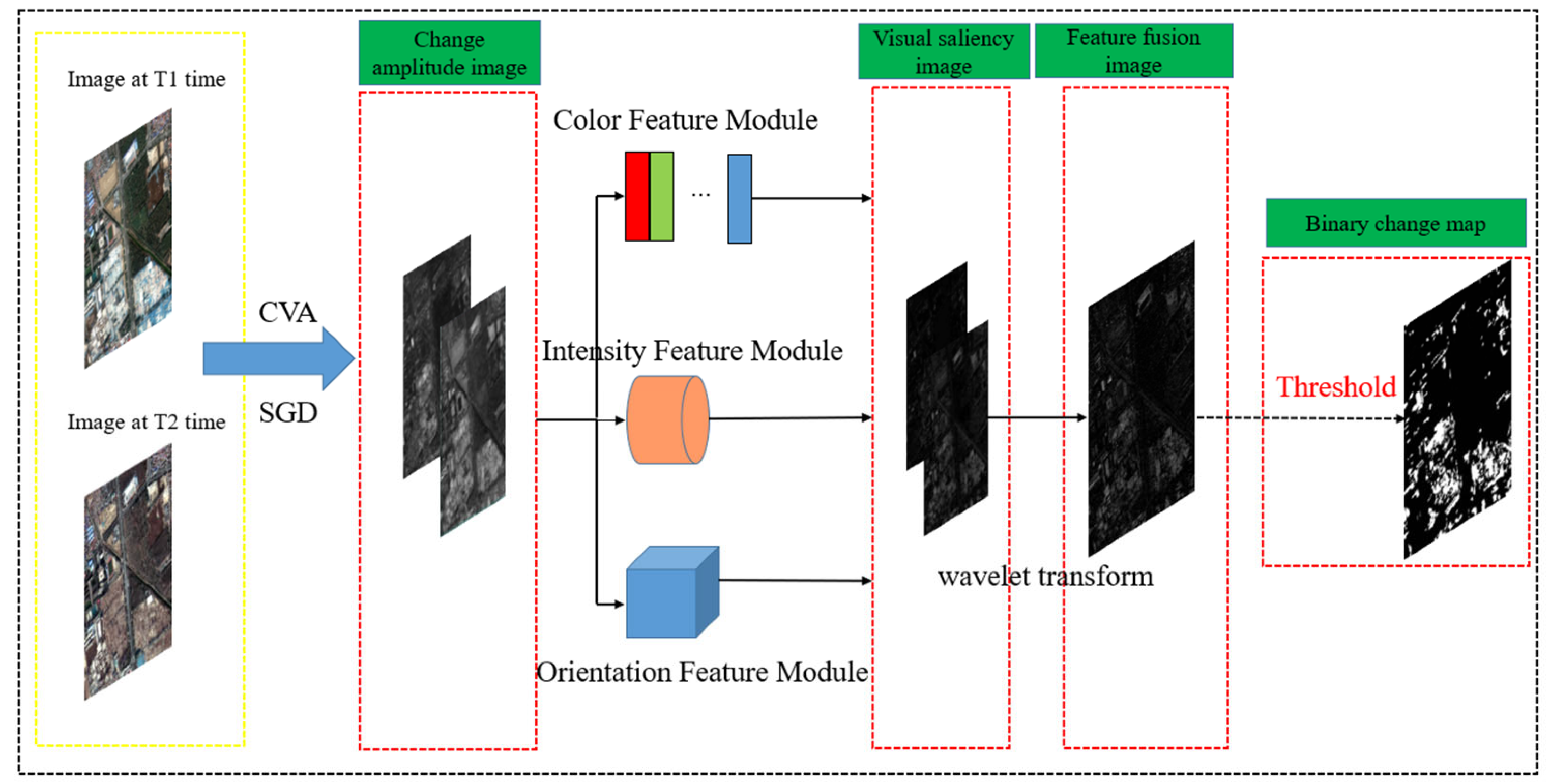
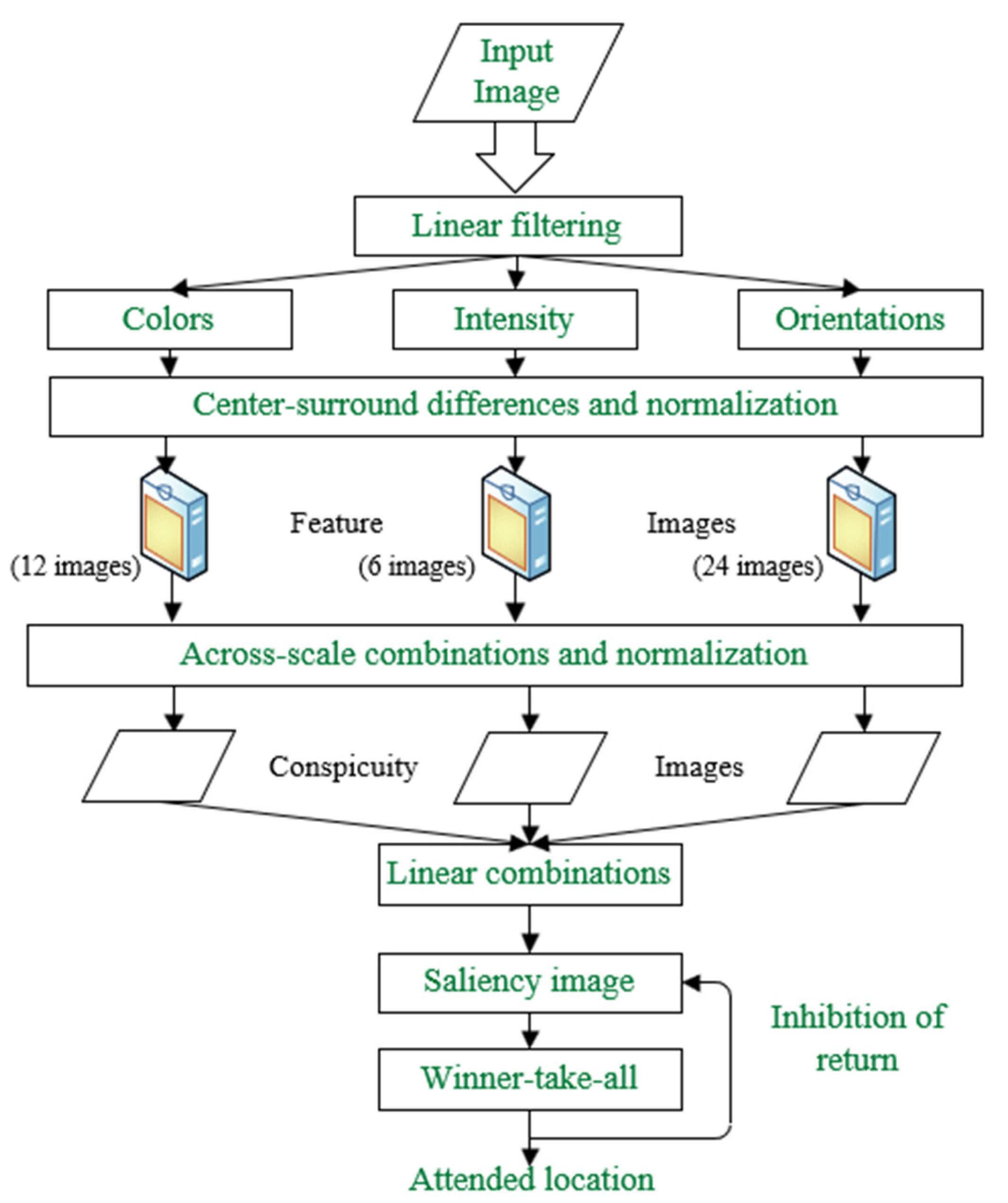
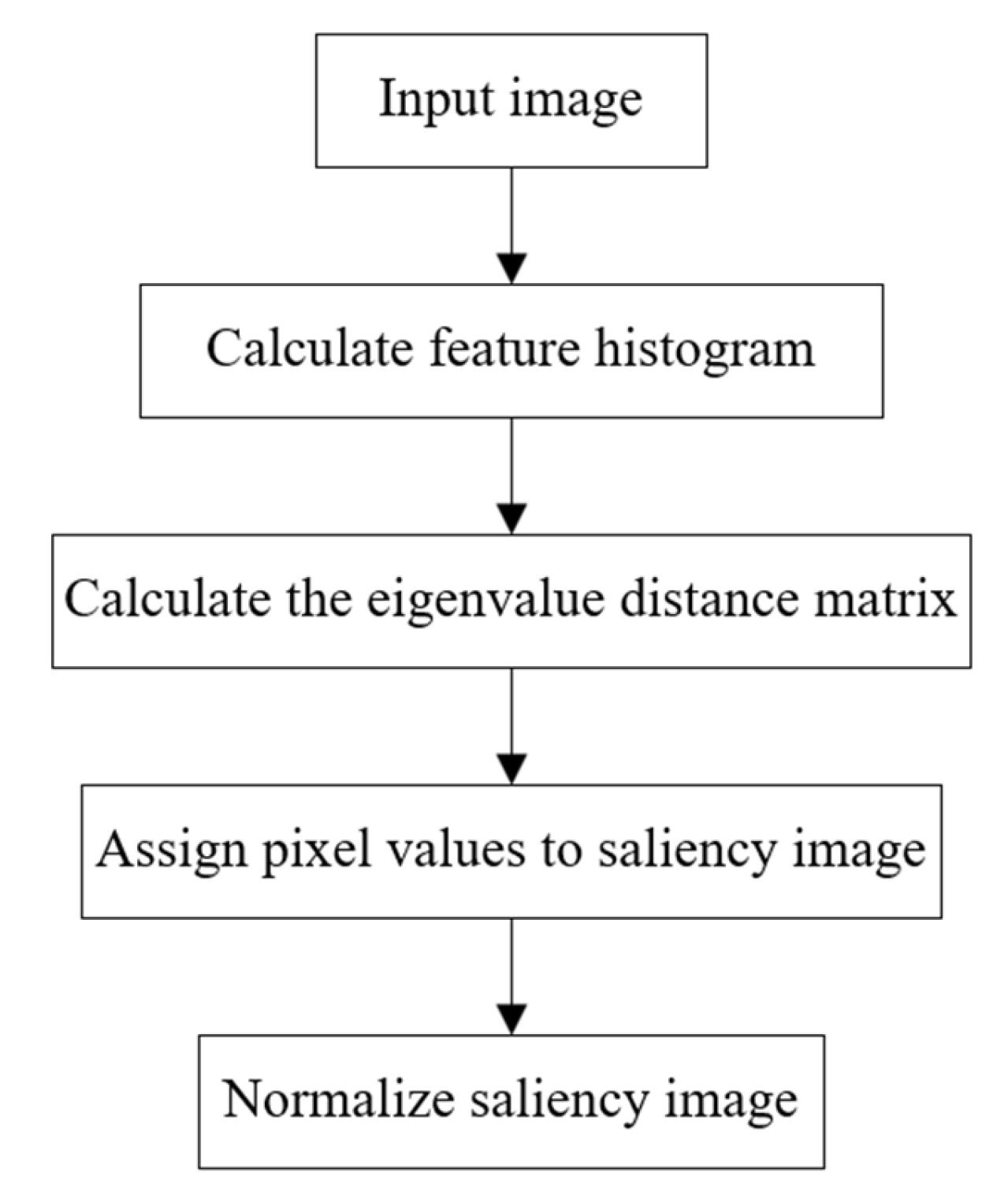
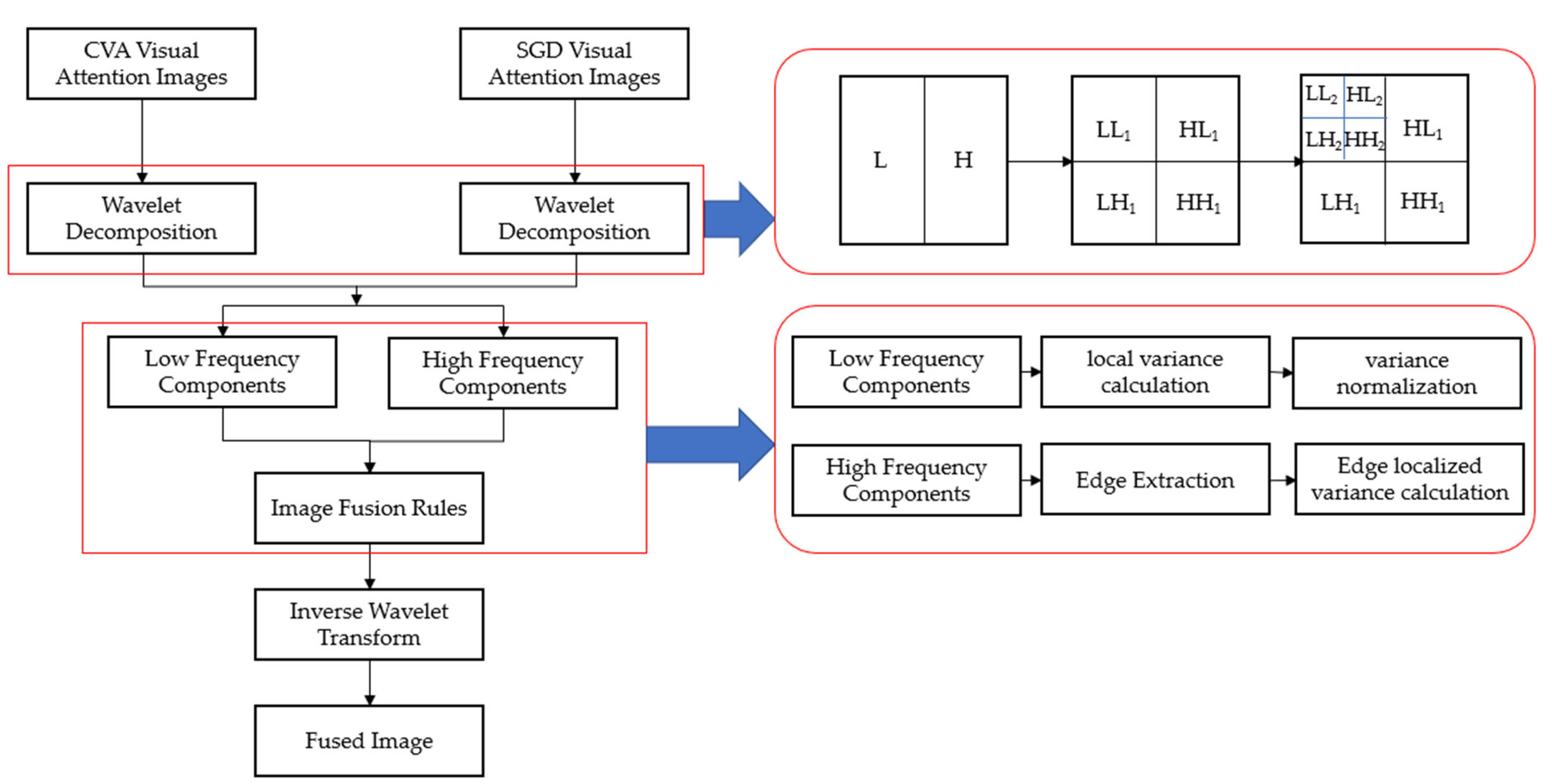
From the above analysis, it can be seen that some single feature indexes and their improved versions have different performance improvements in different aspects, but cannot express the global features of the image. The combined multi-index method does not perform well on highly complex VHR images. If a visual model is only used for VHR image change detection, the band information will be lost. Therefore, in order to overcome the problems mentioned above, we combine the visual attention model with difference image fusion and propose a multi-difference image fusion change detection algorithm based on visual attention (VA-MDCD). First, two difference images are calculated using CVA and SGD. Secondly, the two difference images are input into an Ltti visual model to calculate the color, intensity and orientation features of the images [
42,
43,
44]. These features are combined to produce two saliency feature maps. Thirdly, a fusion result is obtained by performing the wavelet fusion algorithm [
45] on two saliency feature images. Finally, the OTSU threshold segmentation algorithm (OTSU) [
46] is used to obtain the change detection result. Notably, the Ltti model utilizes visual attention to enhance the efficiency and accuracy of the fusion process, providing a more robust solution for image fusion [
42,
43,
44]. The VA-MDCD framework is designed to focus visual attention on areas of significant change. VA-MDCD can effectively combine image correlation to extract advanced features of images [
47,
48]. Before fusing the two indexes, VA-MDCD can significantly reduce the errors of the two indexes and focus on the real changes.
The highlights of this paper as follows: (1) a visual-attention-model-based change detection framework is proposed, which has a higher performance than the traditional multi-difference image fusion change detection method in VHR images with complex features; (2) the framework can detect changes in VHR images without the need for samples and can self-adapt to the extraction of change areas; (3) visual attention is added and a total of 42 change feature maps are computed to accurately capture changes. In total, the model has three change feature extraction modules, which compute 12 color feature maps, 6 intensity feature maps and 24 orientation feature maps (see
Section 2.2.2 for specific algorithms).
In the rest of this article,
Section 2 describes our proposed VA-MDCD approach and explains how to implement it.
Section 3 presents our analysis of the results obtained in the two experiments.
Section 4 details the design of ablation experiments to discuss the influence of different model structures on the proposed method, and
Section 5 summarizes our conclusions.
5. Conclusions
The introduction of this paper summarized the limitations of conventional techniques while suggesting new approaches to overcome these shortcomings. We proposed a novel approach to detect changes in remote sensing images using an attention model in computer vision, which has been called VA-MDCD.
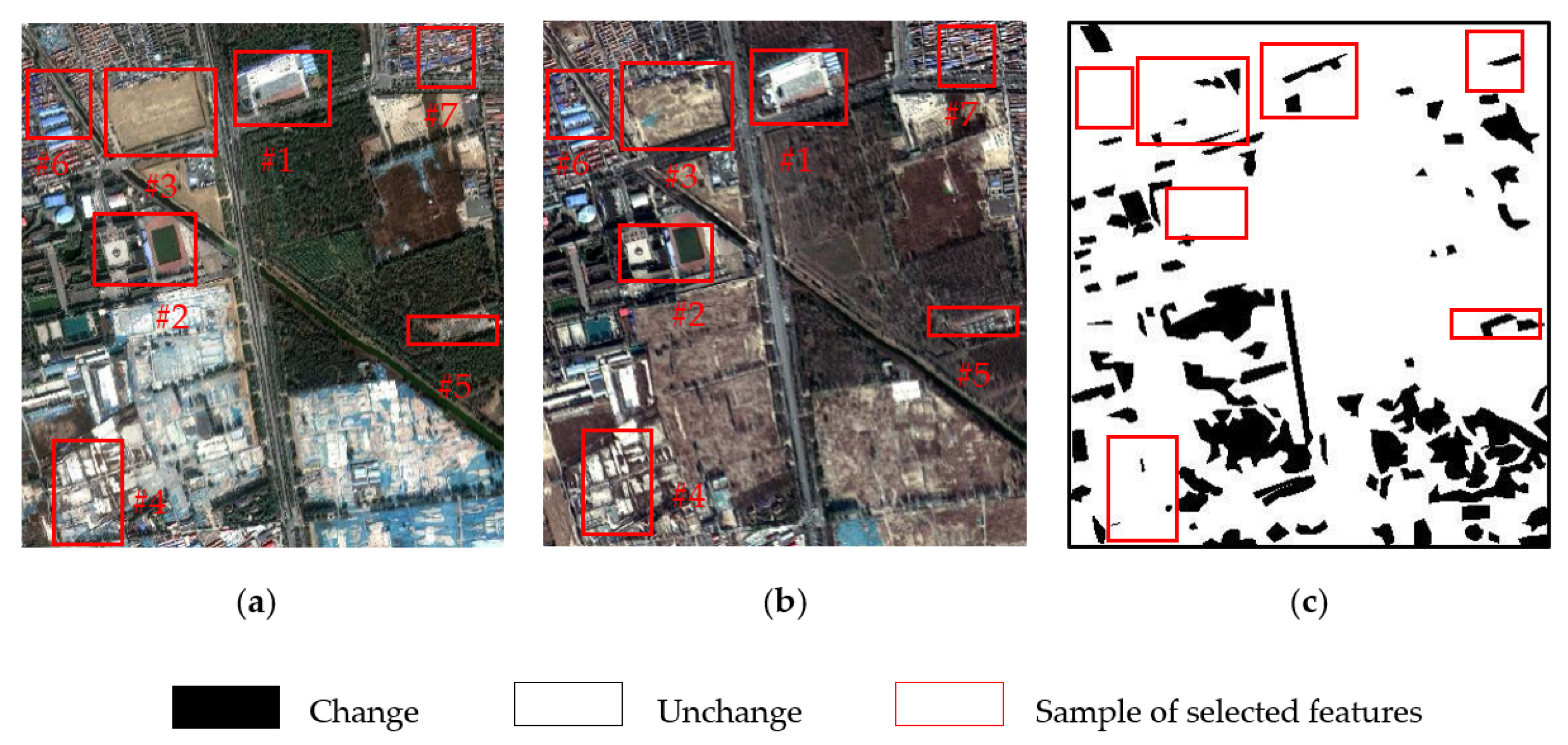
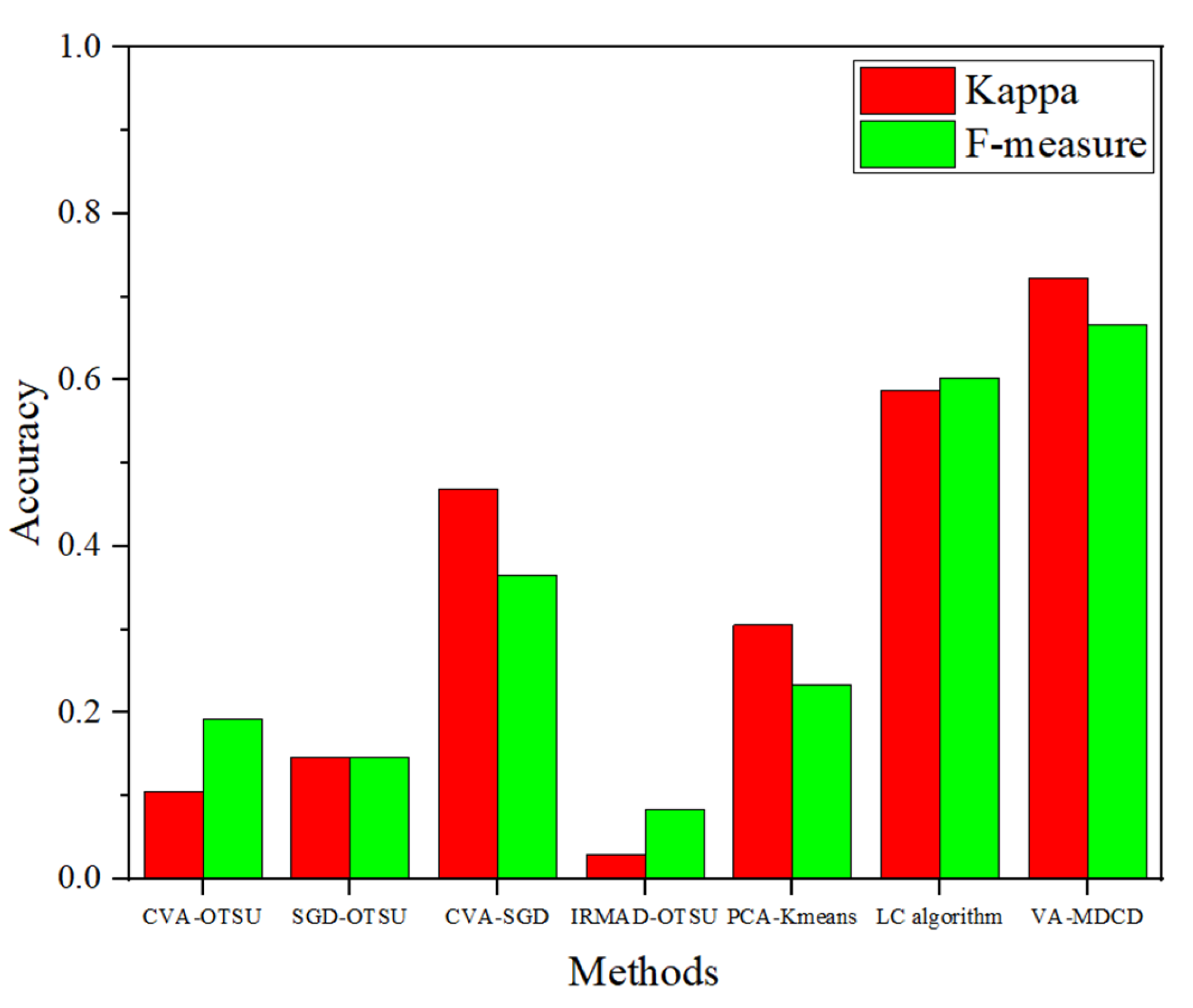
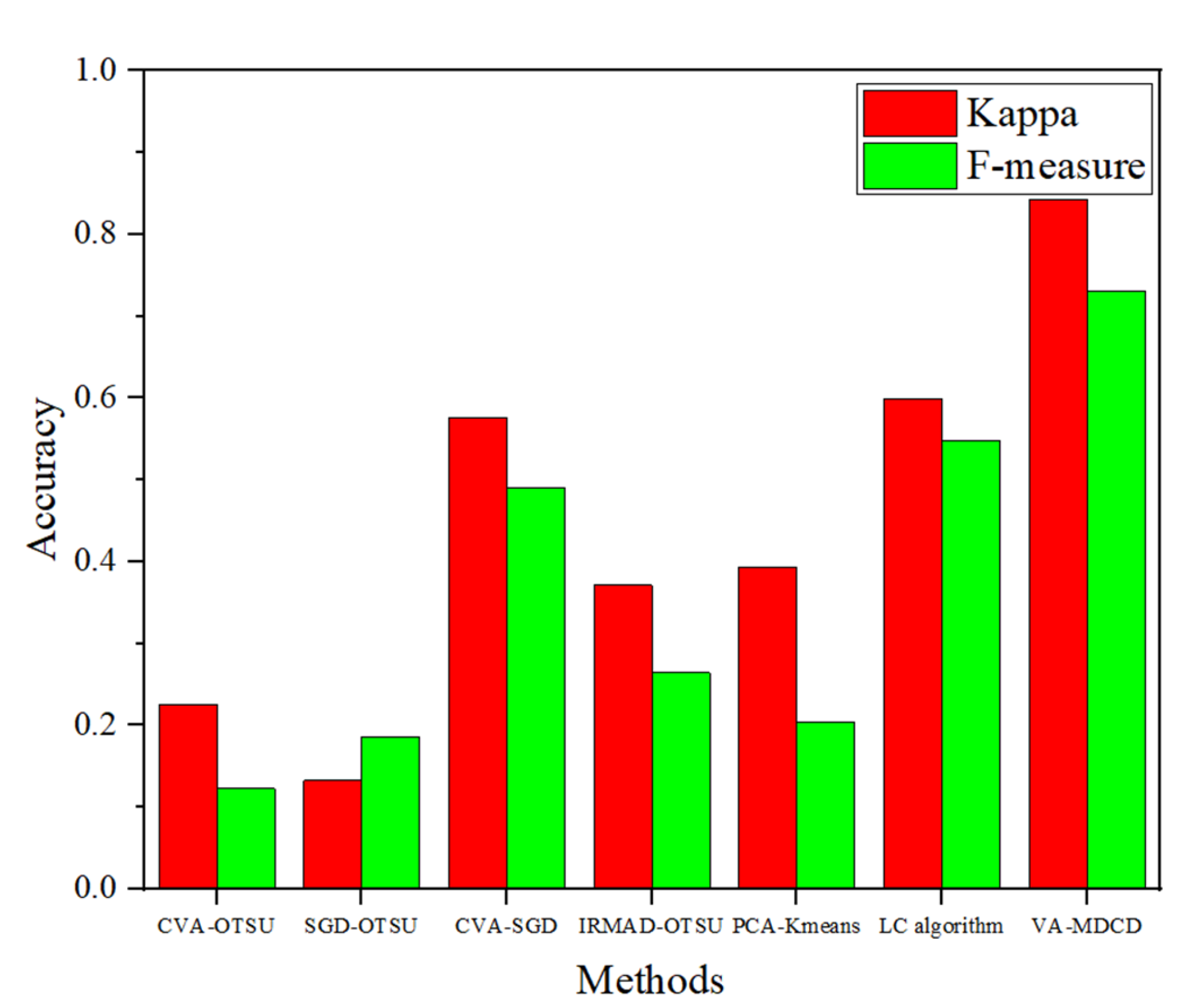
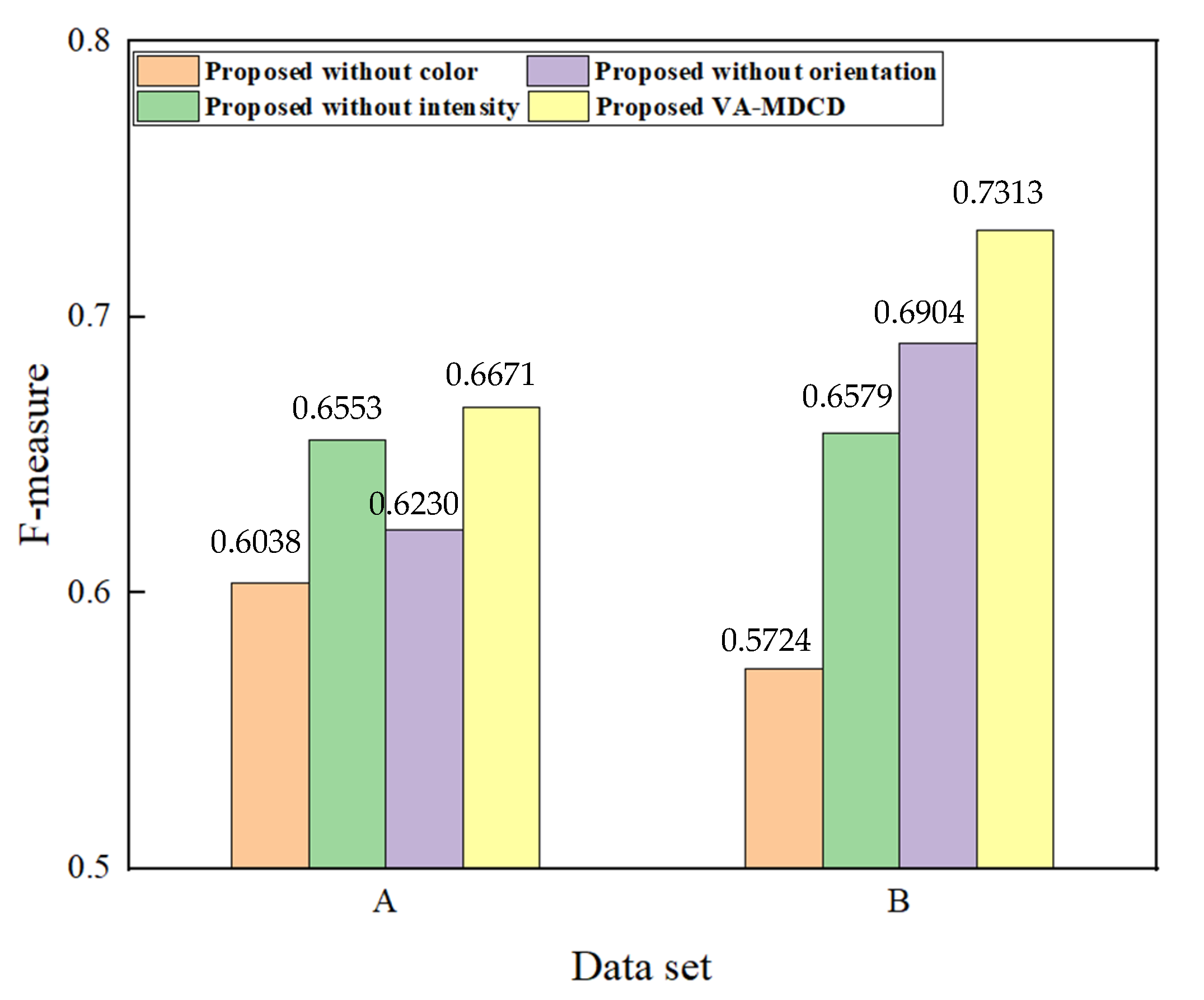
The experimental results obtained from two sets of VHR images validate the efficacy of the proposed VA-MDCD. First, our proposed VA-MDCD method can be used on VHR images and it can effectively identify the changes in VHR images. The experimental results show that this method not only has a higher F-measure and Kappa compared with other methods, but it can also reduce the FA of CVA-SGD. Second, the addition of a visual attention model helps to utilize the overall information of VHR images. Compared with the method using only spectral features, the proposed method can be applied to a wide range of VHR images. It not only contains the spectral information of the image, but also highlights the color, intensity and orientation information of the image. Third, after a statistical analysis of multiple pairs of samples that are easily affected by shooting angles, we conclude that the proposed VA-MDCD can reduce the error caused by the direct fusion of multiple difference images. In addition, we also designed an ablation experiment, and the model included four structures. Four groups of experiments were conducted on two datasets, respectively, and the F-measure value was calculated. The experimental results show that the proposed method has a higher F-measure, and the change detection effect of VA-MDCD proposed in this paper is better for both dataset compared to not using a color module, intensity module or orientation module.
The method in this paper is based on an improvement of unsupervised algorithms. Due to the lack of training samples, the method does not perform well when applied to extremely complex scenes. Therefore, in future studies, we will consider combining a visual attention model with deep learning and taking the visual attention model as the method of sample generation. This will not only reduce the complexity of manual sample labeling, but also generate reliable training samples.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}