

DSSFN: A Dual-Stream Self-Attention Fusion Network for Effective Hyperspectral Image Classification

Abstract
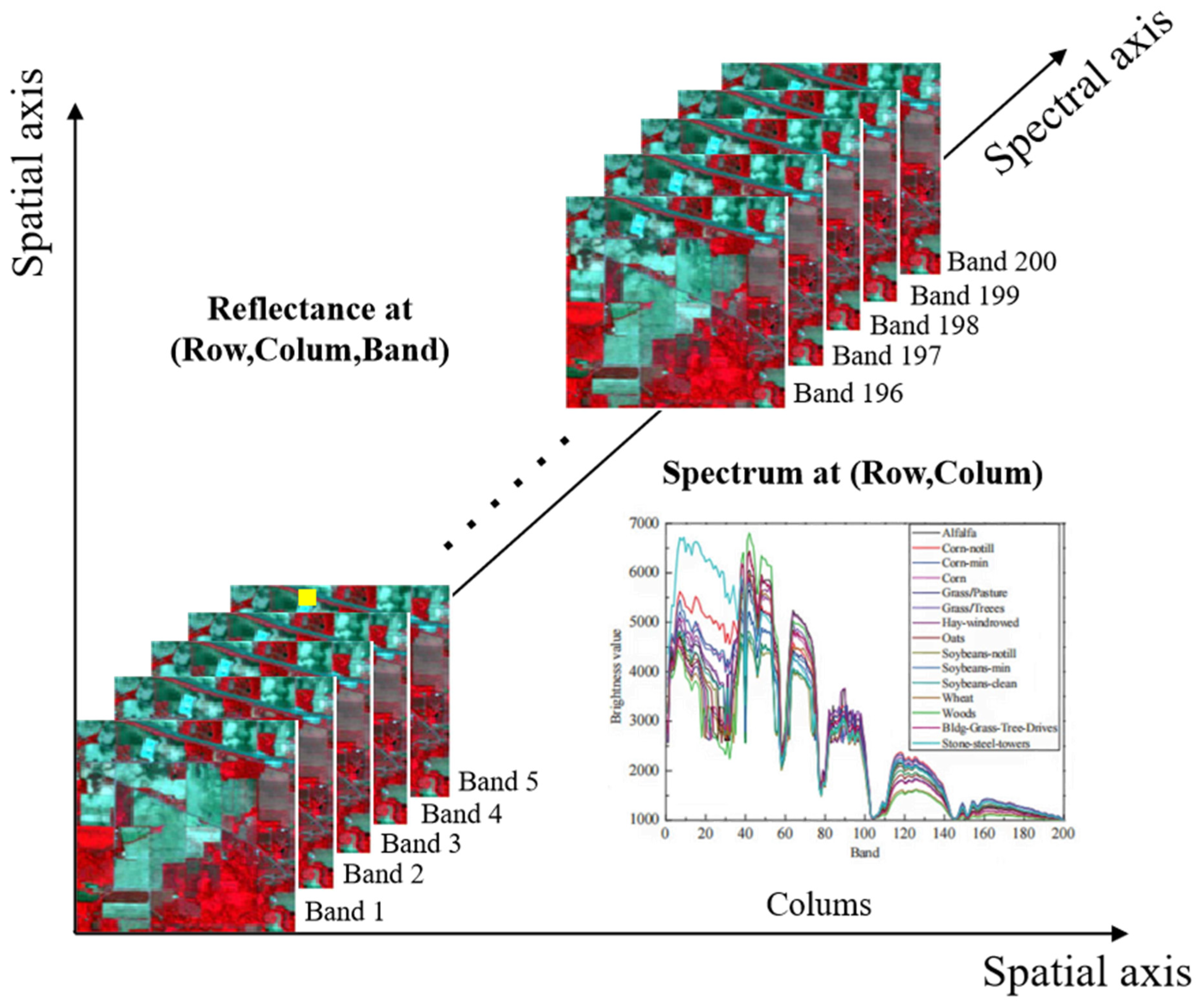
:1. Introduction
- A dual-stream hyperspectral classification network, DSSFN, is proposed. In comparison to the previous joint spectral-spatial network, not only does the self-attentive mechanism fully exploit the characteristics of hyperspectral data, but the pyramidal residual structure also achieves multi-scale feature extraction without deepening the network depth to generate high-quality feature discrimination results.
- To remove duplicate information in the original data, a novel sliding window-based band grouping method is adopted, and the matching filtering (MF)-based band sorting strategy is enhanced to further eliminate the influence of noisy bands and produce a more representative subset of bands.
2. The Basic Approach
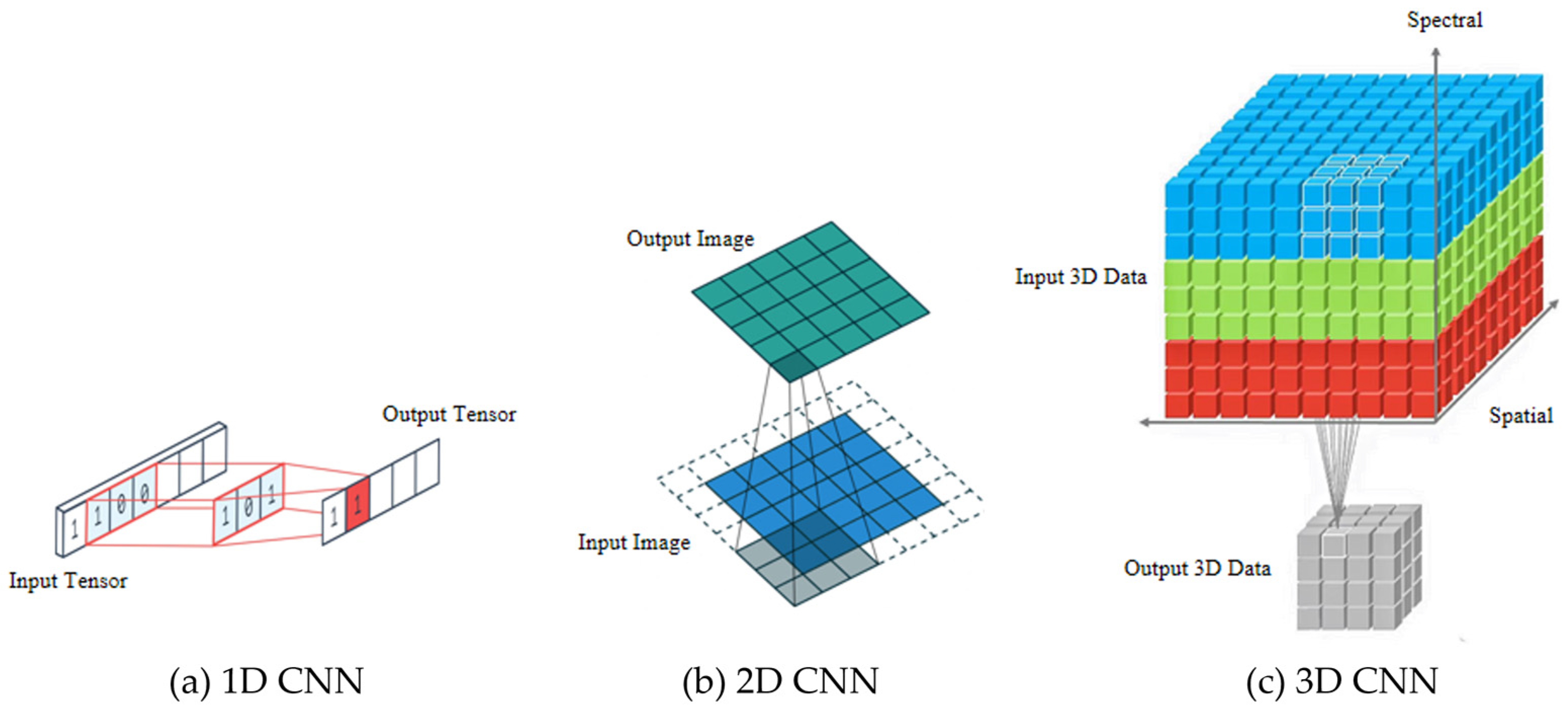
2.1. Hyperspectral Image Classification Based on CNNs
2.2. Band Selection Methods with Hyperspectral Images
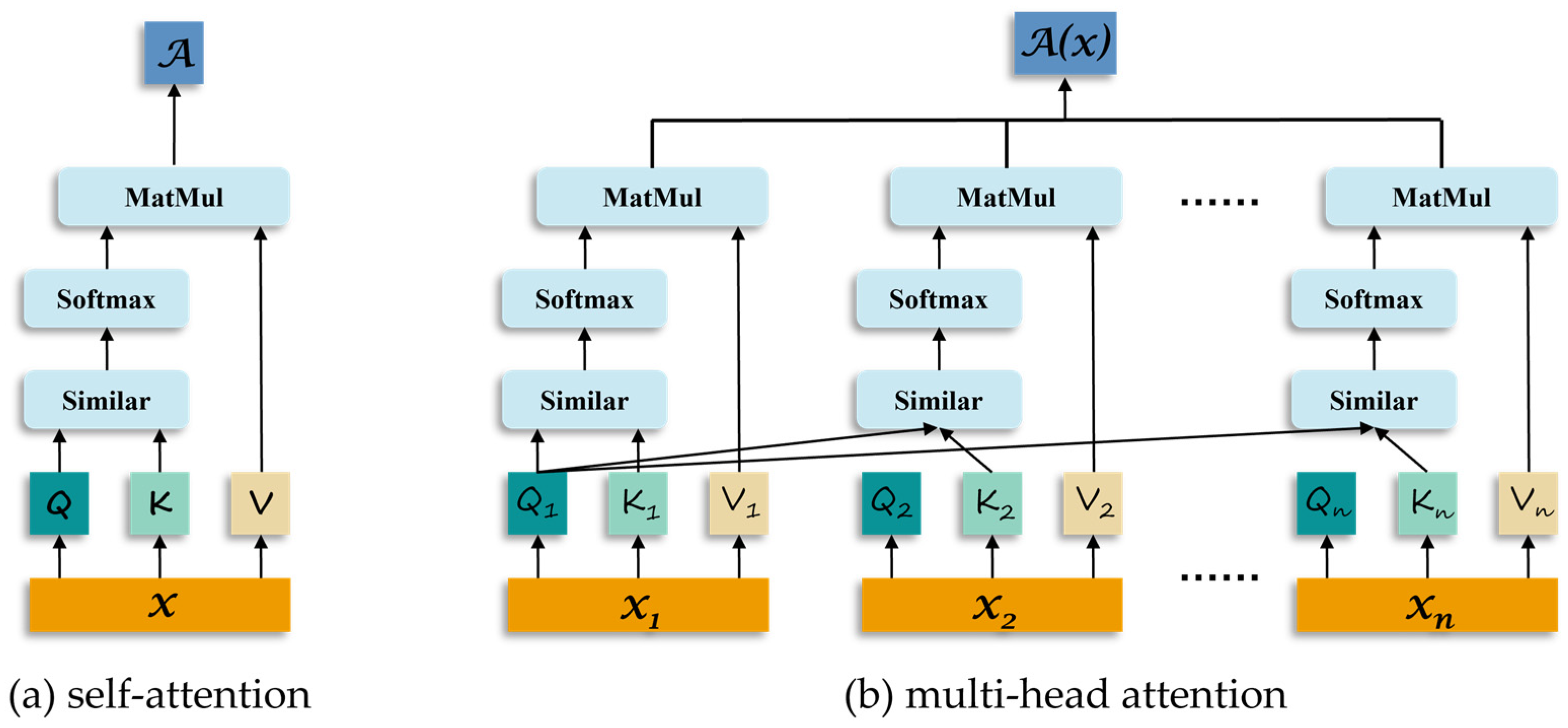
2.3. Self-Attention in the Transformer
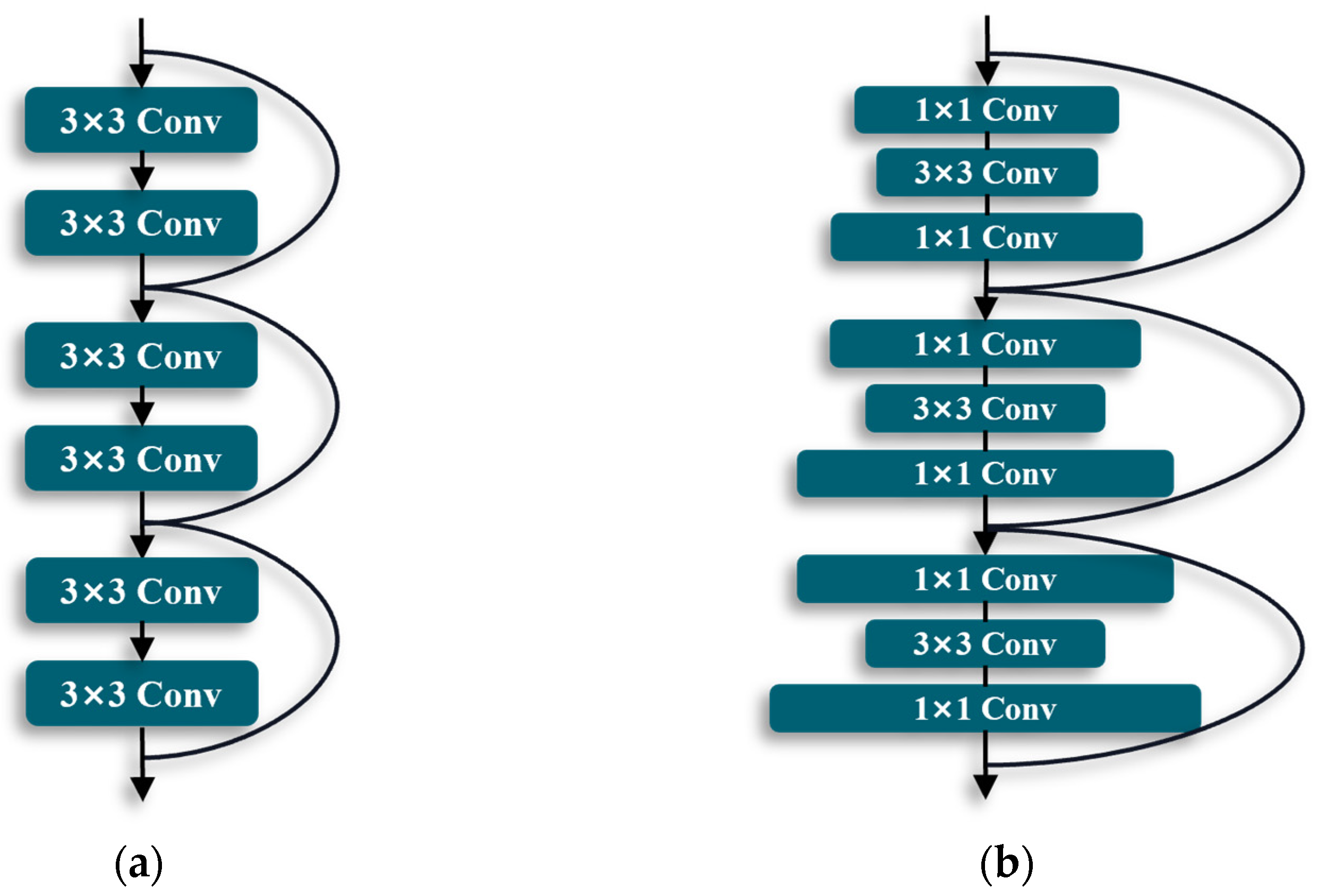
2.4. Pyramidal Residual Networks
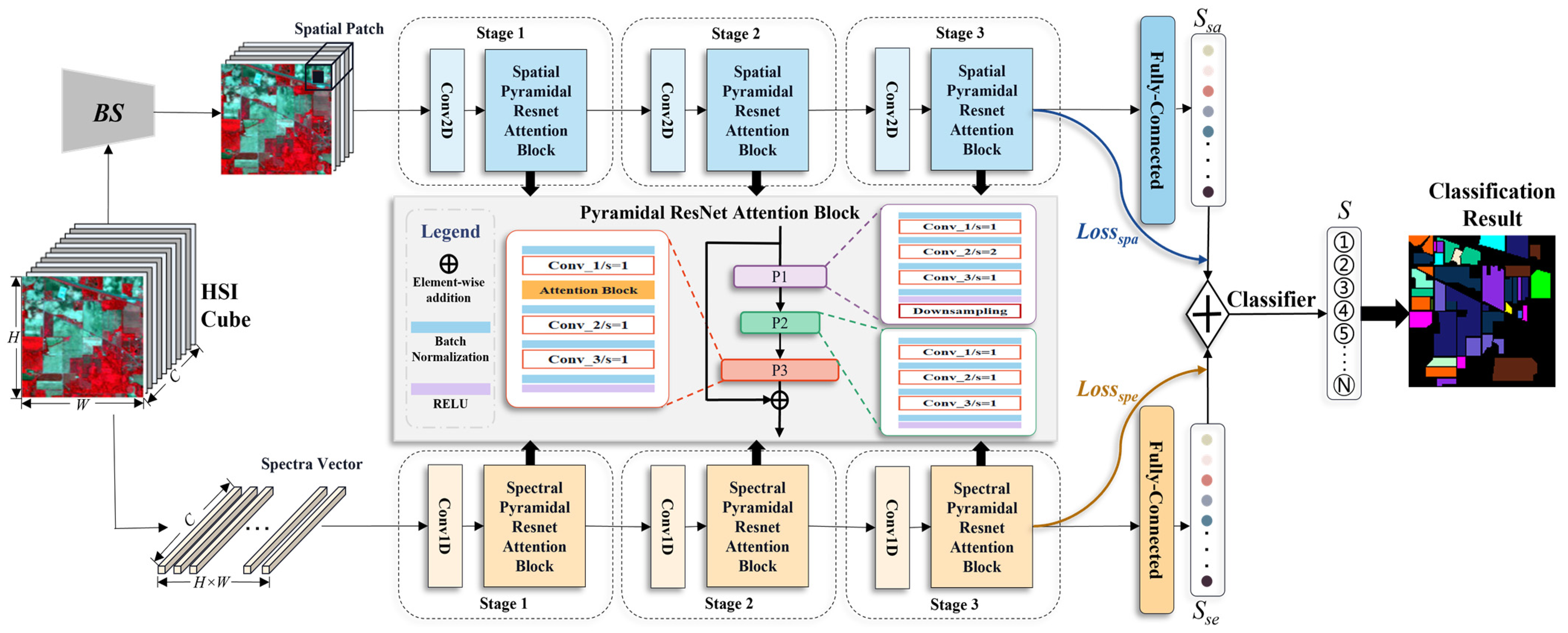
3. DSSFN: High-Performance Feature Extraction
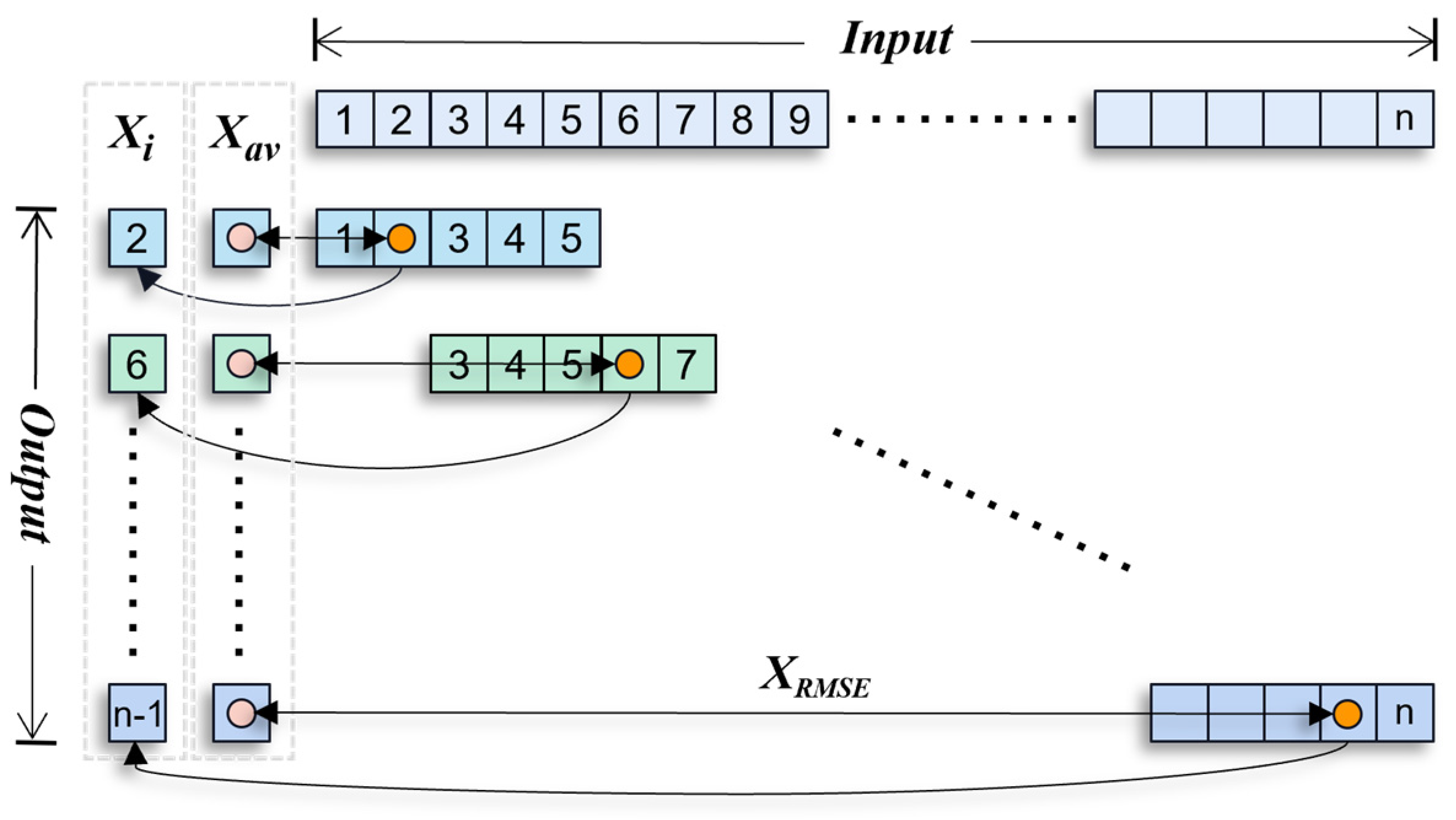
3.1. Sliding Window Grouped Normalized Matched Filter
3.2. Dual-Stream Convolutional Neural Network
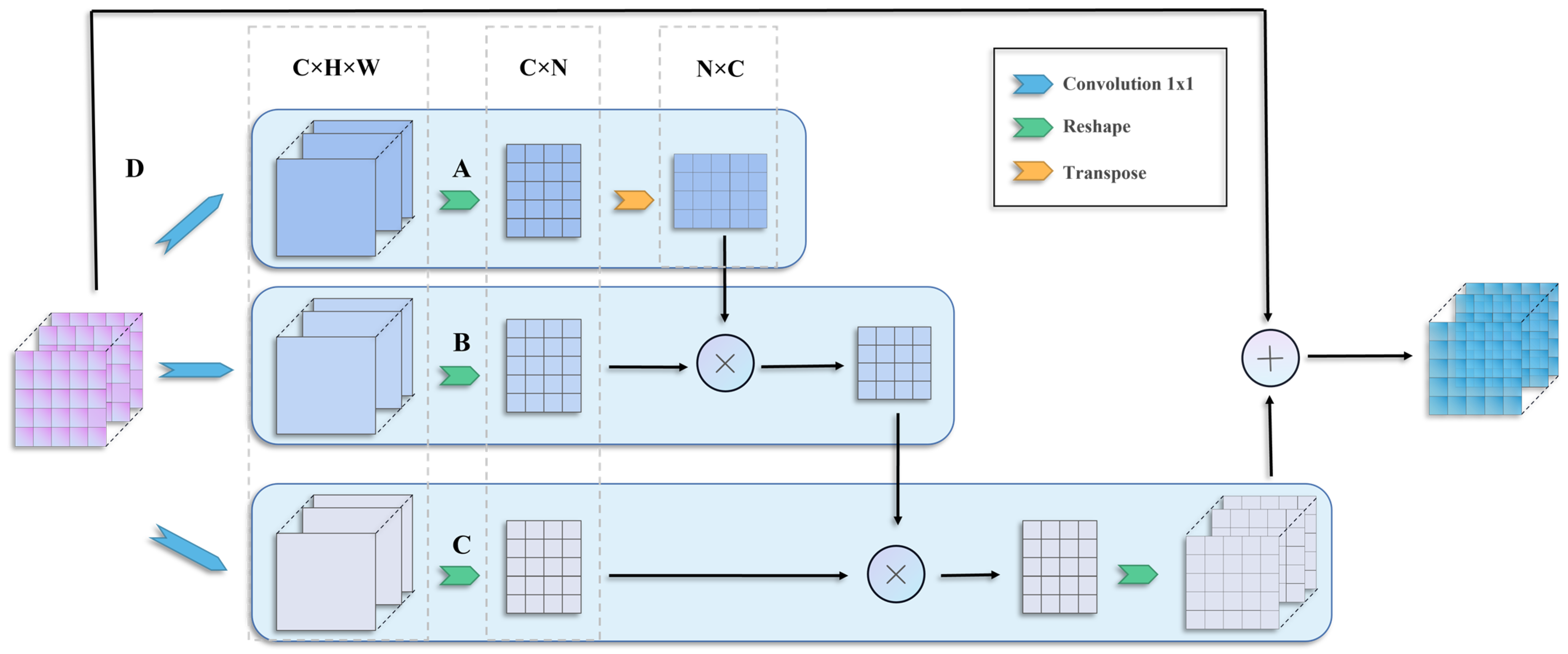
3.3. Self-Attention Mechanism
3.4. Fusion Weighted Mechanism
4. Experimental Results
4.1. Dataset Description
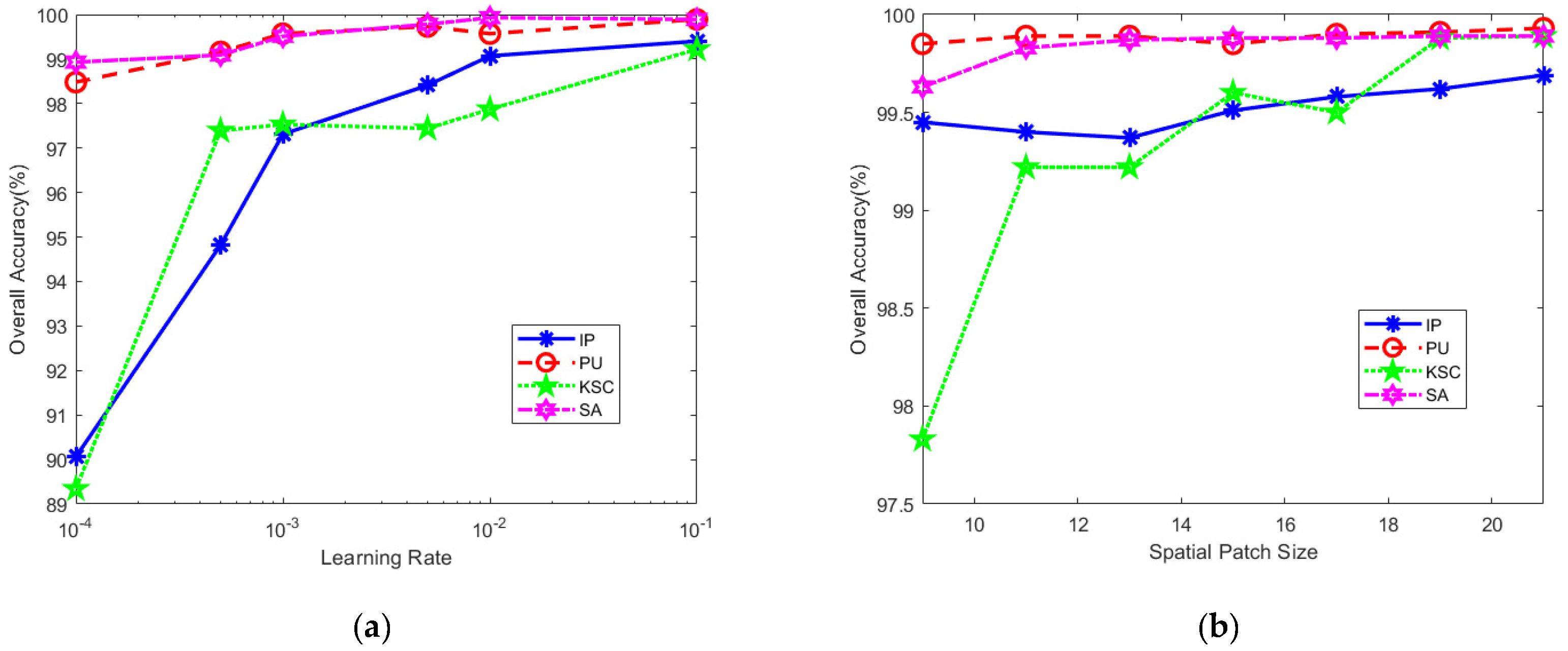
4.2. Parameter Settings
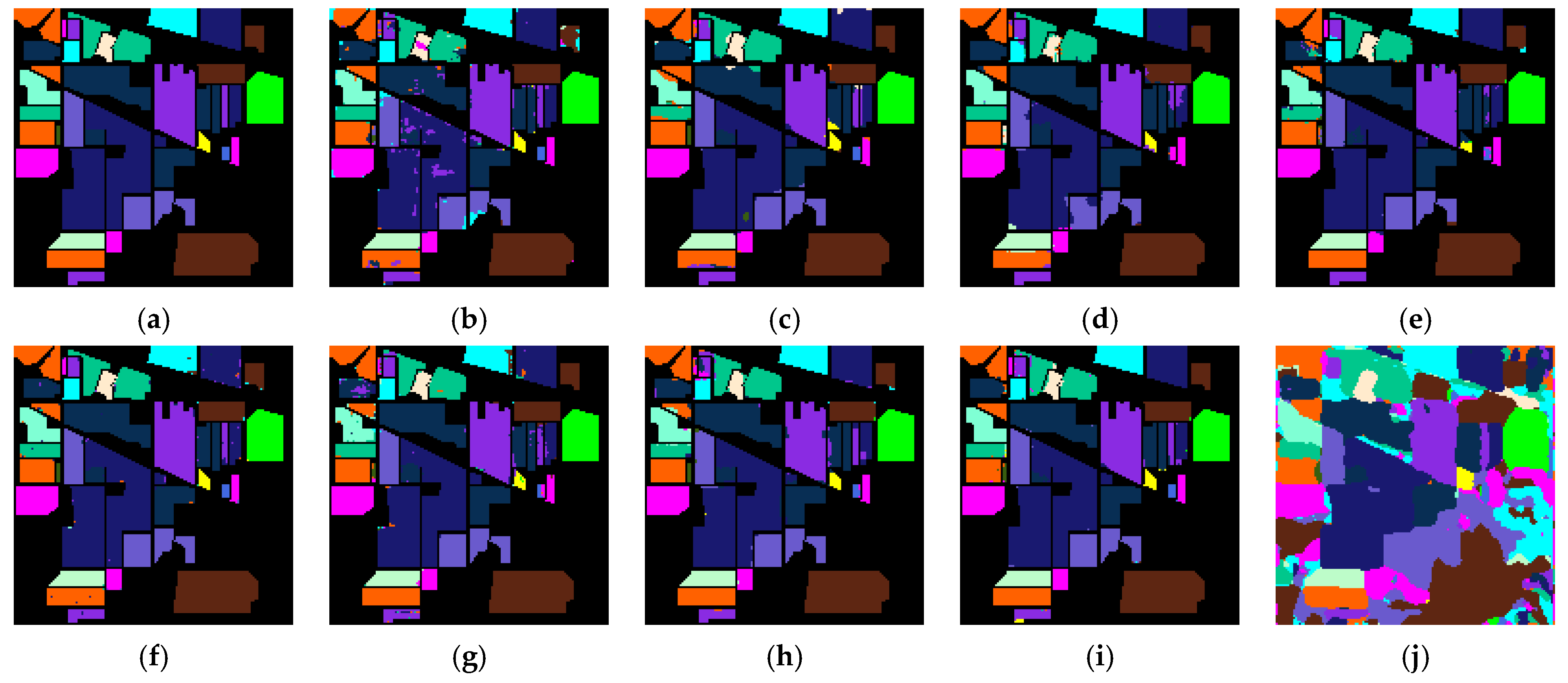
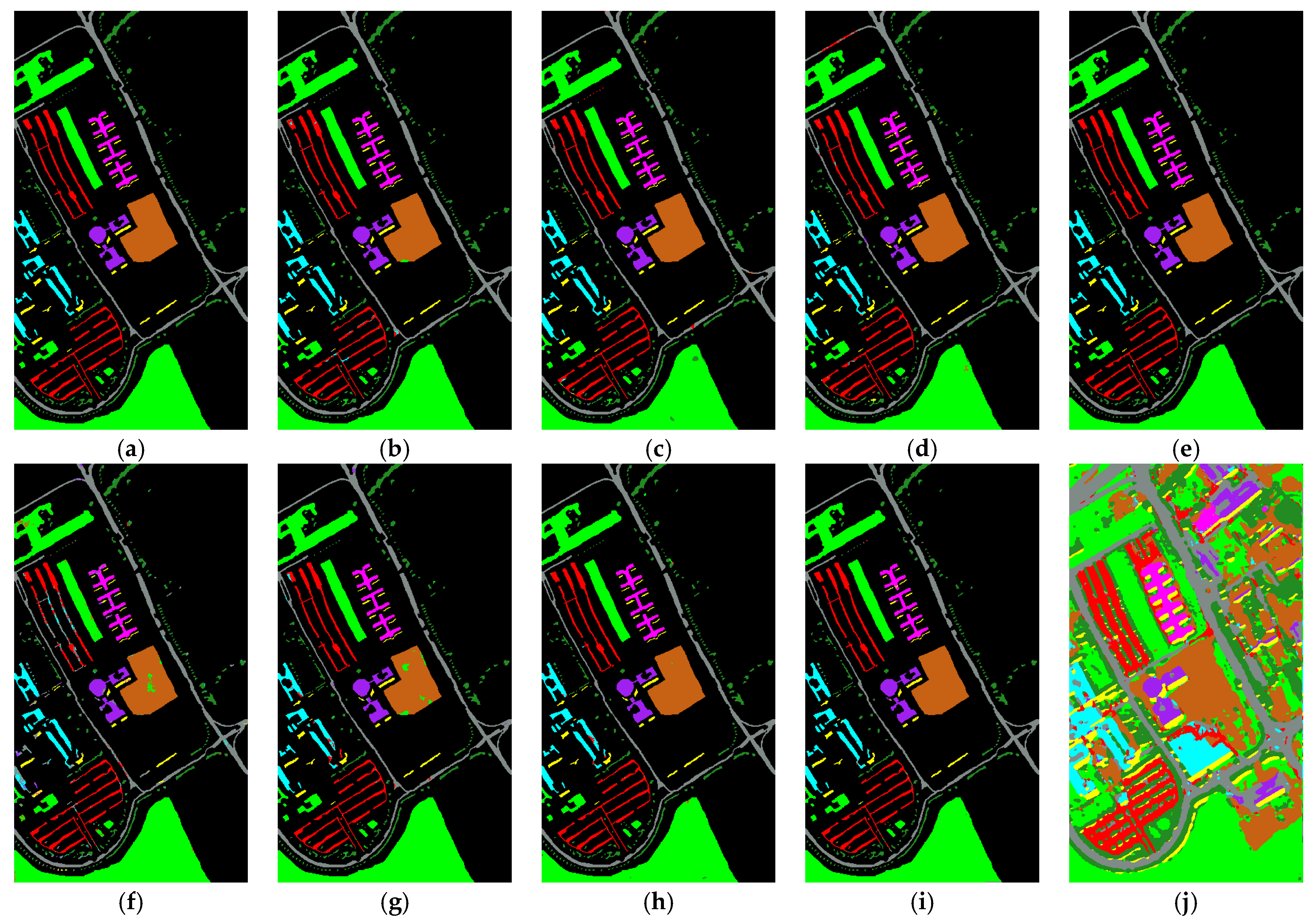
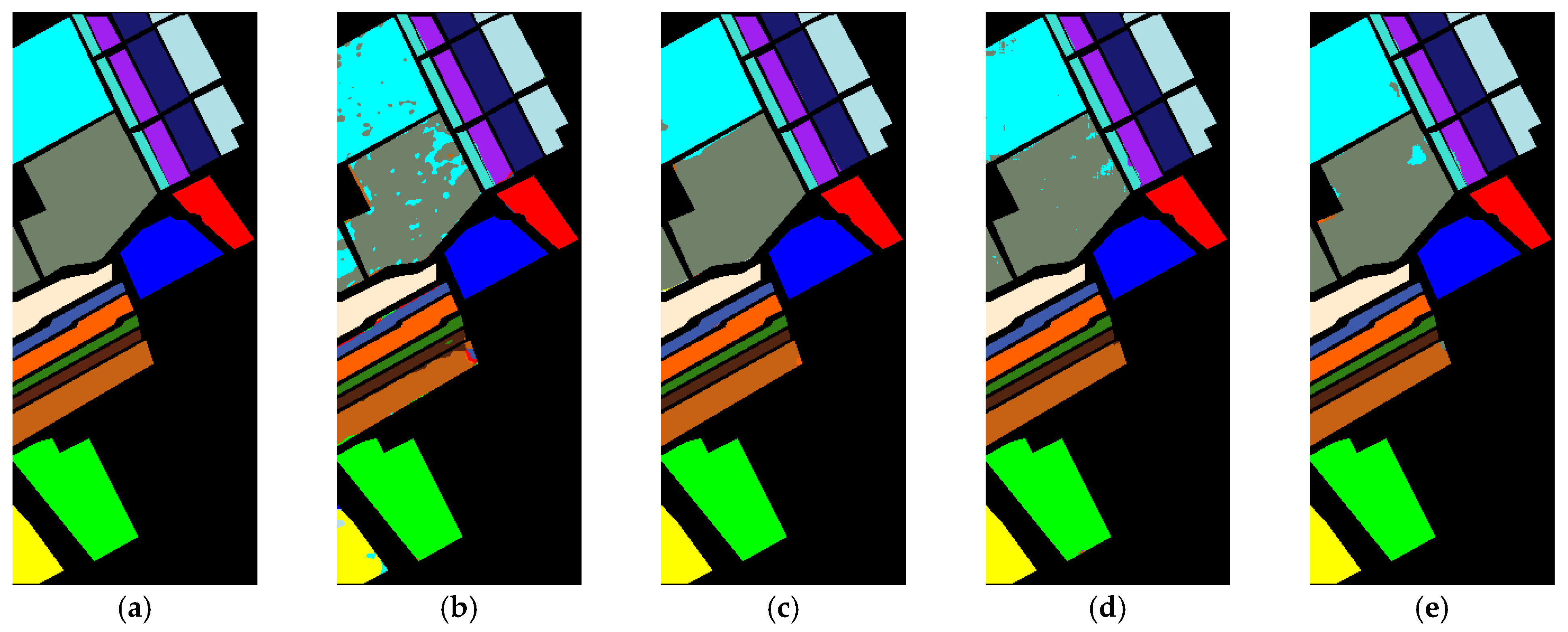
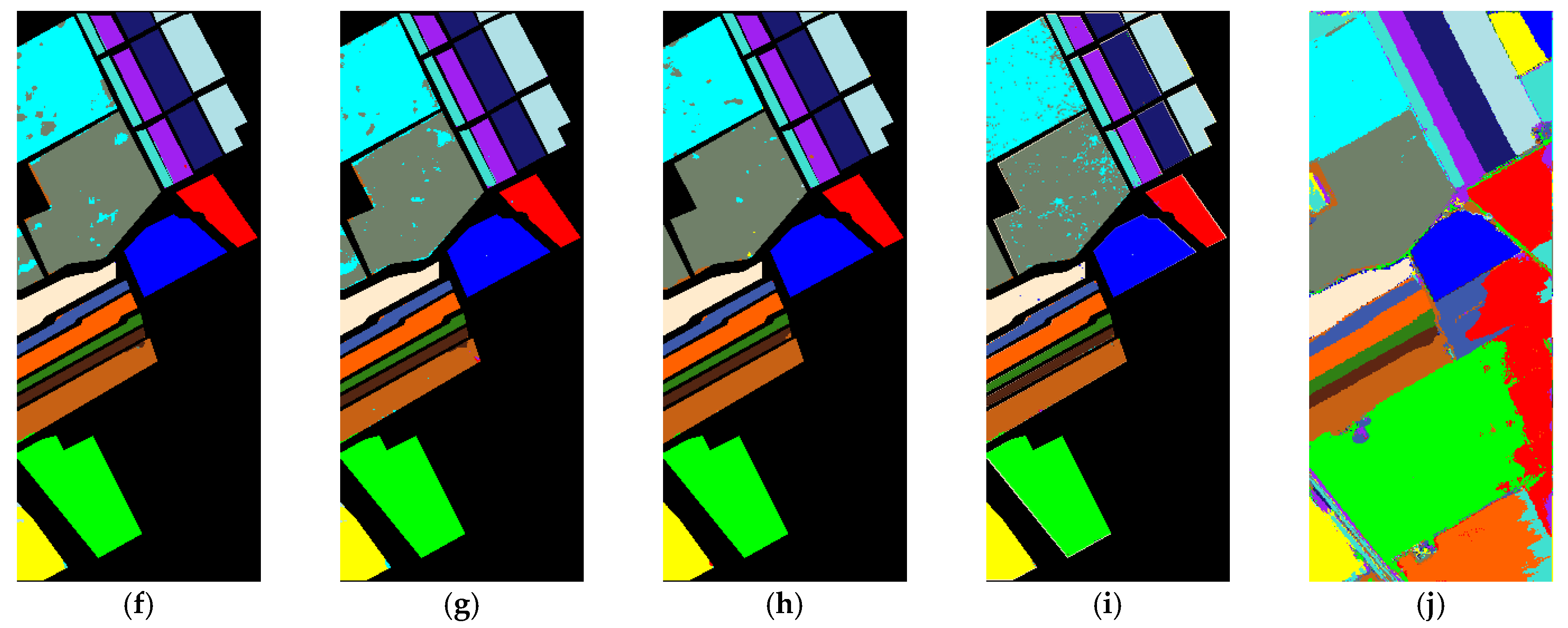
4.3. Experiment Results
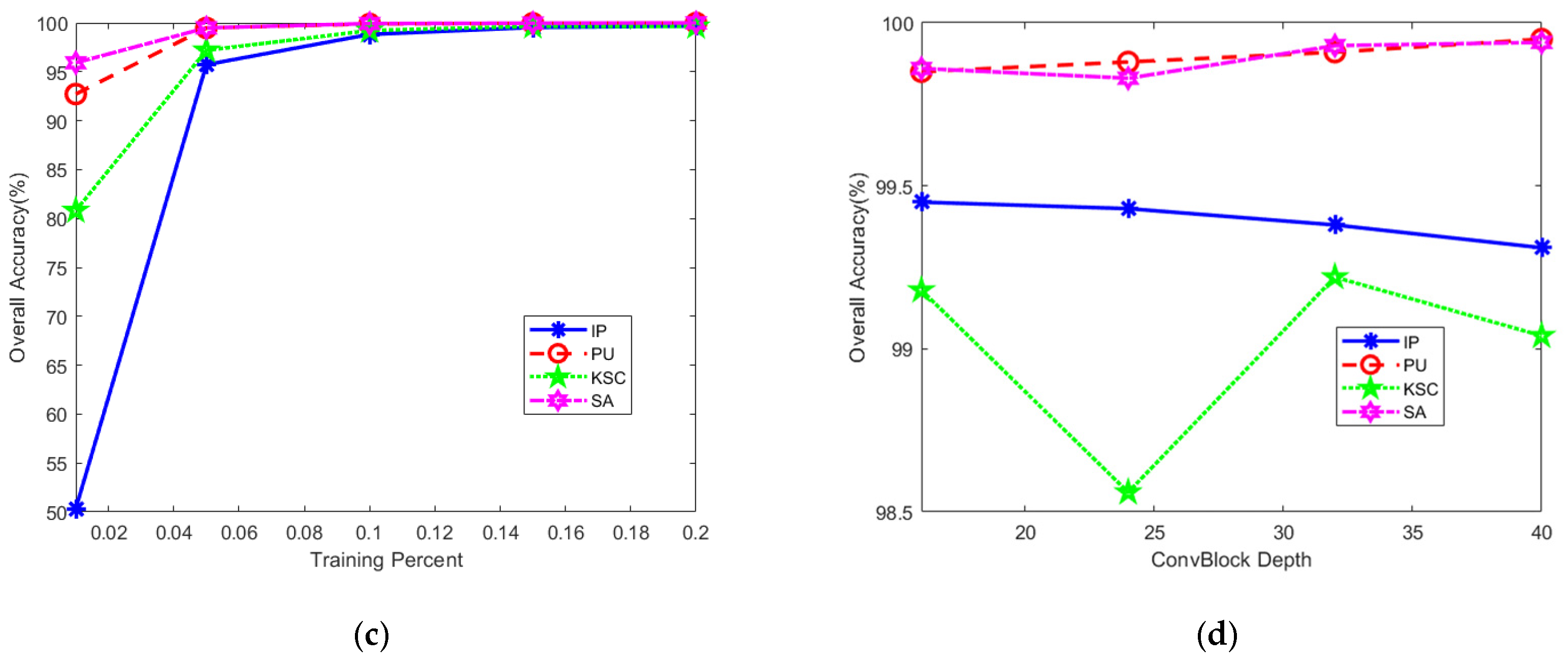
4.4. Discussion of Validity
4.4.1. Discussion of the Efficiency of the Self-Attention
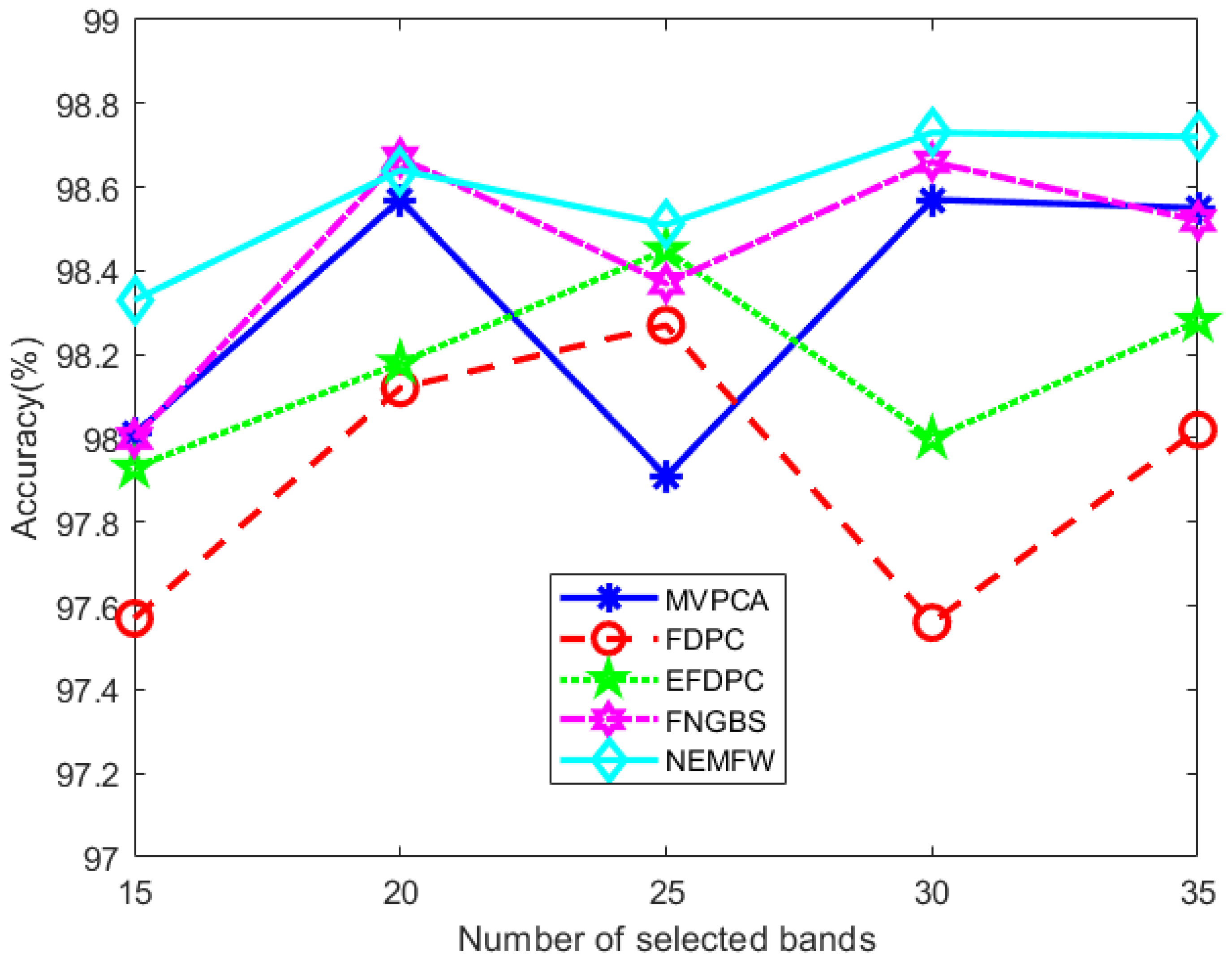
4.4.2. Discussion of the Validity of the Band Selection Method
4.4.3. Discussion of the Validity of Dual-Stream Networks
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Pearlman, J.S.; Barry, P.S.; Segal, C.C.; Shepanski, J.; Beiso, D.; Carman, S.L. Hyperion, a space-based imaging spectrometer. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1160–1173. [Google Scholar] [CrossRef]
- Jia, X.; Kuo, B.C.; Crawford, M.M. Feature Mining for Hyperspectral Image Classification. Proc. IEEE 2013, 101, 676–697. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Wan, Y.; Hu, X.; Zhong, Y.; Ma, A.; Wei, L.; Zhang, L. Tailings Reservoir Disaster and Environmental Monitoring Using the UAV-ground Hyperspectral Joint Observation and Processing: A Case of Study in Xinjiang, the Belt and Road. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 9713–9716. [Google Scholar]
- Gevaert, C.M.; Suomalainen, J.; Tang, J.; Kooistra, L. Generation of Spectral–Temporal Response Surfaces by Combining Multispectral Satellite and Hyperspectral UAV Imagery for Precision Agriculture Applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3140–3146. [Google Scholar] [CrossRef]
- Atkinson, J.T.; Ismail, R.; Robertson, M. Mapping Bugweed (Solanum mauritianum) Infestations in Pinus patula Plantations Using Hyperspectral Imagery and Support Vector Machines. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 17–28. [Google Scholar] [CrossRef] [Green Version]
- Grøtte, M.E.; Birkeland, R.; Honoré-Livermore, E.; Bakken, S.; Garrett, J.L.; Prentice, E.F.; Sigernes, F.; Orlandić, M.; Gravdahl, J.T.; Johansen, T.A. Ocean Color Hyperspectral Remote Sensing With High Resolution and Low Latency—The HYPSO-1 CubeSat Mission. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1000619. [Google Scholar] [CrossRef]
- Inoue, Y.; Dedieu, G.; Yoshida, N.; Saito, T.; Iwasaki, A.; Sakaiya, E. Assessing Crop Productivity in Decontaminated Farmland in Fukushima Using Micro-Satellite Venμs and Hyperspectral Sensing. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 5159–5162. [Google Scholar]
- Tan, K.; Wu, F.; Du, Q.; Du, P.; Chen, Y. A Parallel Gaussian–Bernoulli Restricted Boltzmann Machine for Mining Area Classification With Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 627–636. [Google Scholar] [CrossRef]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral Imaging for Military and Security Applications: Combining Myriad Processing and Sensing Techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Sun, W.; Yang, G.; Du, B.; Zhang, L.; Zhang, L. A Sparse and Low-Rank Near-Isometric Linear Embedding Method for Feature Extraction in Hyperspectral Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4032–4046. [Google Scholar] [CrossRef]
- Li, L.; Ge, H.; Gao, J.; Zhang, Y. Hyperspectral Image Feature Extraction Using Maclaurin Series Function Curve Fitting. Neural Process. Lett. 2019, 49, 357–374. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Chanussot, J.; Xu, J.; Zhu, X.X. Joint and Progressive Subspace Analysis (JPSA) With Spatial–Spectral Manifold Alignment for Semisupervised Hyperspectral Dimensionality Reduction. IEEE Trans. Cybern. 2021, 51, 3602–3615. [Google Scholar] [CrossRef] [PubMed]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef] [Green Version]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature Extraction for Hyperspectral Imagery: The Evolution From Shallow to Deep: Overview and Toolbox. IEEE Geosci. Remote Sens. Mag. 2020, 8, 60–88. [Google Scholar] [CrossRef]
- Sun, W.; Du, Q. Hyperspectral Band Selection: A Review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 118–139. [Google Scholar] [CrossRef]
- Sun, H.; Ren, J.; Zhao, H.; Sun, G.; Liao, W.; Fang, Z.; Zabalza, J. Adaptive Distance-Based Band Hierarchy (ADBH) for Effective Hyperspectral Band Selection. IEEE Trans. Cybern. 2022, 52, 215–227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Li, Q.; Li, X. A Fast Neighborhood Grouping Method for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5028–5039. [Google Scholar] [CrossRef]
- Sawant, S.S.; Manoharan, P.; Loganathan, A. Band selection strategies for hyperspectral image classification based on machine learning and artificial intelligent techniques –Survey. Arab. J. Geosci. 2021, 14, 646. [Google Scholar] [CrossRef]
- Zhang, R.; Ma, J. Feature selection for hyperspectral data based on recursive support vector machines. Int. J. Remote Sens. 2009, 30, 3669–3677. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, H.; Han, S.; Sun, Y.; Bai, Y. Spectral–Spatial HyperspectralImage Classification With K-Nearest Neighbor and Guided Filter. IEEE Access 2018, 6, 18582–18591. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef] [Green Version]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- He, L.; Li, J.; Liu, C.; Li, S. Recent Advances on Spectral–Spatial Hyperspectral Image Classification: An Overview and New Guidelines. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1579–1597. [Google Scholar] [CrossRef]
- Ahmad, M.; Shabbir, S.; Roy, S.K.; Hong, D.; Wu, X.; Yao, J.; Khan, A.M.; Mazzara, M.; Distefano, S.; Chanussot, J. Hyperspectral Image Classification—Traditional to Deep Models: A Survey for Future Prospects. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 968–999. [Google Scholar] [CrossRef]
- Zisserman, K.S.A. Two stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing System; MIT Press: Cambridge, MA, USA, 2014; pp. 568–576. [Google Scholar]
- Xue, Z.; Qian, S. Two-Stream Translating LSTM Network for Mangroves Mapping Using Sentinel-2 Multivariate Time Series. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4401416. [Google Scholar] [CrossRef]
- Wan, B.; Jiang, W.; Fang, Y.; Wen, W.; Liu, H. Dual-stream Self-attention Network for Image Captioning. In Proceedings of the 2022 IEEE International Conference on Visual Communications and Image Processing (VCIP), Suzhou, China, 13–16 December 2022; pp. 1–5. [Google Scholar]
- Zhang, Y.; Huynh, C.P.; Ngan, K.N. Feature Fusion With Predictive Weighting for Spectral Image Classification and Segmentation. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6792–6807. [Google Scholar] [CrossRef]
- Hao, S.; Wang, W.; Ye, Y.; Nie, T.; Bruzzone, L. Two-Stream Deep Architecture for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2349–2361. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification With Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Cui, Y.; Li, W.; Chen, L.; Gao, S.; Wang, L. Double-Branch Local Context Feature Extraction Network for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6011005. [Google Scholar] [CrossRef]
- Roy, S.K.; Manna, S.; Song, T.; Bruzzone, L. Attention-Based Adaptive Spectral–Spatial Kernel ResNet for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7831–7843. [Google Scholar] [CrossRef]
- Li, N.; Wang, Z. Spectral-Spatial Fused Attention Network for Hyperspectral Image Classification. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3832–3836. [Google Scholar]
- Zhong, Z.; Li, Y.; Ma, L.; Li, J.; Zheng, W.-S. Spectral–Spatial Transformer Network for Hyperspectral Image Classification: A Factorized Architecture Search Framework. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5514715. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Self-Attention Context Network: Addressing the Threat of Adversarial Attacks for Hyperspectral Image Classification. IEEE Trans. Image Process. 2021, 30, 8671–8685. [Google Scholar] [CrossRef]
- Qing, Y.; Huang, Q.; Feng, L.; Qi, Y.; Liu, W. Multiscale Feature Fusion Network Incorporating 3D Self-Attention for Hyperspectral Image Classification. Remote Sensing 2022, 14, 742. [Google Scholar] [CrossRef]
- Xia, J.; Cui, Y.; Li, W.; Wang, L.; Wang, C. Lightweight Self-Attention Residual Network for Hyperspectral Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6009305. [Google Scholar] [CrossRef]
- Ghamisi, P.; Yokoya, N.; Li, J.; Liao, W.; Liu, S.; Plaza, J.; Rasti, B.; Plaza, A. Advances in Hyperspectral Image and Signal Processing: A Comprehensive Overview of the State of the Art. IEEE Geosci. Remote Sens. Mag. 2017, 5, 37–78. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Yu, X.; Zhang, P.; Yu, A.; Fu, Q.; Wei, X. Supervised deep feature extraction for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1909–1921. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef] [Green Version]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Amar, C.B. 3-D Deep Learning Approach for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Conese, C.; Maselli, F.J.I.J.o.P.; Sensing, R. Selection of optimum bands from TM scenes through mutual information analysis. ISPRS J. Photogramm. Remote Sens. 1993, 48, 2–11. [Google Scholar] [CrossRef]
- Stearns, S.; Wilson, B.; Peterson, J. Dimensionality Reduction by Optimal Band Selection for Pixel Classification of Hyperspectral Imagery; SPIE: Bellingham, WA, USA, 1993; Volume 2028. [Google Scholar]
- Te-Ming, T.; Chin-Hsing, C.; Jiunn-Lin, W.; Chein, I.C. A fast two-stage classification method for high-dimensional remote sensing data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 182–191. [Google Scholar] [CrossRef] [Green Version]
- Yanfeng, G.; Ye, Z. Unsupervised subspace linear spectral mixture analysis for hyperspectral images. In Proceedings of the Proceedings 2003 International Conference on Image Processing (Cat. No.03CH37429), Barcelona, Spain, 14–17 September 2003; pp. 1–801. [Google Scholar]
- Wang, Q.; Zhang, F.; Li, X. Optimal Clustering Framework for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5910–5922. [Google Scholar] [CrossRef] [Green Version]
- Shahwani, H.; Bui, T.D.; Jeong, J.P.; Shin, J. A stable clustering algorithm based on affinity propagation for VANETs. In Proceedings of the 2017 19th International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Republic of Korea, 19–22 February 2017; pp. 501–504. [Google Scholar]
- Zeng, M.; Cai, Y.; Cai, Z.; Liu, X.; Hu, P.; Ku, J. Unsupervised Hyperspectral Image Band Selection Based on Deep Subspace Clustering. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1889–1893. [Google Scholar] [CrossRef]
- Jia, S.; Tang, G.; Zhu, J.; Li, Q. A Novel Ranking-Based Clustering Approach for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 88–102. [Google Scholar] [CrossRef]
- Xu, B.; Li, X.; Hou, W.; Wang, Y.; Wei, Y. A Similarity-Based Ranking Method for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9585–9599. [Google Scholar] [CrossRef]
- Datta, A.; Ghosh, S.; Ghosh, A. Combination of Clustering and Ranking Techniques for Unsupervised Band Selection of Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2814–2823. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification With Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5518615. [Google Scholar] [CrossRef]
- Roy, S.K.; Deria, A.; Shah, C.; Haut, J.M.; Du, Q.; Plaza, A. Spectral–Spatial Morphological Attention Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5503615. [Google Scholar] [CrossRef]
- Huang, L.; Chen, Y.; He, X. Spectral–Spatial Masked Transformer With Supervised and Contrastive Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5508718. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, X.; Chen, Y.; Lin, Z. Spatial-Spectral Transformer for Hyperspectral Image Classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Qing, Y.; Liu, W.; Feng, L.; Gao, W. Improved Transformer Net for Hyperspectral Image Classification. Remote Sens. 2021, 13, 2216. [Google Scholar] [CrossRef]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the Integration of Self-Attention and Convolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 805–815. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part IV 14. pp. 630–645. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Han, D.; Kim, J.; Kim, J. Deep pyramidal residual networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5927–5935. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.J.; Pla, F. Deep Pyramidal Residual Networks for Spectral–Spatial Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 740–754. [Google Scholar] [CrossRef]
- Sergey, I.; Christian, S. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Xu, Y.; Du, B.; Zhang, L. Beyond the Patchwise Classification: Spectral-Spatial Fully Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Big Data 2020, 6, 492–506. [Google Scholar] [CrossRef]
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M. Imaging spectroscopy and the airborne visible/infrared imaging spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- Kunkel, B.; Blechinger, F.; Lutz, R.; Doerffer, R.; Van der Piepen, H.; Schroder, M. ROSIS (Reflective Optics System Imaging Spectrometer)-A candidate instrument for polar platform missions. In Optoelectronic Technologies for Remote Sensing from Space; SPIE: Bellingham, WA, USA, 1988; pp. 134–141. [Google Scholar]
- Cao, X.; Liu, Z.; Li, X.; Xiao, Q.; Feng, J.; Jiao, L. Nonoverlapped Sampling for Hyperspectral Imagery: Performance Evaluation and a Cotraining-Based Classification Strategy. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5506314. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.K.; Chatterjee, S.; Bhattacharyya, S.; Chaudhuri, B.B.; Platoš, J. Lightweight Spectral–Spatial Squeeze-and- Excitation Residual Bag-of-Features Learning for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5277–5290. [Google Scholar] [CrossRef]
- He, J.; Zhao, L.; Yang, H.; Zhang, M.; Li, W. HSI-BERT: Hyperspectral Image Classification Using the Bidirectional Encoder Representation From Transformers. IEEE Trans. Geosci. Remote Sens. 2020, 58, 165–178. [Google Scholar] [CrossRef]
- Wang, D.; Du, B.; Zhang, L.; Xu, Y. Adaptive Spectral–Spatial Multiscale Contextual Feature Extraction for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2461–2477. [Google Scholar] [CrossRef]
- Zhu, M.; Jiao, L.; Liu, F.; Yang, S.; Wang, J. Residual Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 449–462. [Google Scholar] [CrossRef]
- Bai, J.; Ding, B.; Xiao, Z.; Jiao, L.; Chen, H.; Regan, A.C. Hyperspectral Image Classification Based on Deep Attention Graph Convolutional Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5504316. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–Spatial Feature Tokenization Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Chein, I.C.; Qian, D.; Tzu-Lung, S.; Althouse, M.L.G. A joint band prioritization and band-decorrelation approach to band selection for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2631–2641. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSRN | HSN | S3EResBOF | HSI-BERT | ASSMN | RSSAN | DAGAN | SSFTT | DSSFN | |
|---|---|---|---|---|---|---|---|---|---|
| OA | 94.16 ± 0.01 | 95.75 ± 2.87 | 97.02 ± 0.79 | 97.75 ± 0.00 | 98.30 ± 0.51 | 95.17 ± 0.76 | 96.86 ± 0.36 | 97.47 | 98.77 ± 0.26 |
| AA | 92.67 ± 0.01 | 92.56 ± 4.91 | 95.08 ± 2.59 | 90.13 ± 0.02 | 99.09 ± 0.36 | 92.54 ± 1.87 | 95.80 ± 0.87 | 96.57 | 97.76 ± 0.54 |
| KAPPA | 93.37 ± 0.06 | 95.17 ± 3.24 | 96.61 ± 0.91 | 97.43 ± 0.01 | 97.03 ± 0.59 | 94.49 ± 1.99 | 96.42 ± 0.41 | 97.11 | 98.81 ± 0.11 |
| 1 | 100 | 87.91 | 94.79 | 72.68 | 99.23 | 87.10 | 92.78 | 95.12 | 100 |
| 2 | 98.12 | 93.64 | 96.41 | 96.06 | 96.48 | 90.89 | 94.34 | 97.67 | 95.59 |
| 3 | 98.46 | 94.97 | 96.52 | 97.62 | 98.68 | 90.88 | 96.68 | 98.87 | 97.61 |
| 4 | 97.04 | 89.64 | 95.88 | 97.28 | 99.71 | 81.82 | 97.56 | 91.55 | 95.1 |
| 5 | 97.16 | 95.12 | 95.18 | 97.51 | 98.88 | 98.81 | 95.95 | 96.32 | 98.63 |
| 6 | 98.88 | 96.97 | 98.77 | 81.37 | 99.97 | 98.43 | 98.42 | 99.54 | 97.69 |
| 7 | 41.94 | 87.62 | 76.98 | 62.40 | 98.75 | 94.74 | 90.00 | 100 | 100 |
| 8 | 99.89 | 99.13 | 99.82 | 100 | 100 | 98.50 | 99.81 | 100 | 100 |
| 9 | 33.33 | 71.81 | 98.41 | 38.89 | 100 | 71.43 | 94.00 | 88.89 | 97 |
| 10 | 99.16 | 95.26 | 96.37 | 97.21 | 98.2 | 94.40 | 92.59 | 97.71 | 93.62 |
| 11 | 86.37 | 97.30 | 97.54 | 99.35 | 97.29 | 97.73 | 98.21 | 98.69 | 98 |
| 12 | 79.73 | 93.51 | 95.99 | 95.08 | 99.23 | 93.72 | 96.36 | 98.13 | 95.88 |
| 13 | 98.53 | 96.70 | 96.80 | 98.80 | 99.52 | 100 | 99.46 | 97.28 | 96.1 |
| 14 | 99.74 | 98.31 | 98.44 | 99.51 | 99.45 | 99.21 | 99.12 | 99.91 | 98.9 |
| 15 | 89.55 | 94.76 | 98.55 | 99.14 | 100 | 87.73 | 97.41 | 98.84 | 97.02 |
| 16 | 86.24 | 88.30 | 84.87 | 91.81 | 100 | 95.31 | 90.12 | 95.54 | 95.35 |
| SSRN | HSN | S3EResBOF | HSI-BERT | ASSMN | RSSAN | DAGAN | SSFTT | DSSFN | |
|---|---|---|---|---|---|---|---|---|---|
| OA | 98.41 ± 0.02 | 96.52 ± 0.83 | 92.91 ± 5.12 | 97.69 ± 0.00 | 98.44 ± 0.45 | 93.04 ± 0.51 | 97.20 ± 0.57 | 93.82 ± 4.76 | 98.9 ± 0.23 |
| AA | 97.15 ± 0.02 | 94.40 ± 1.32 | 92.25 ± 4.05 | 95.89 ± 0.04 | 98 ± 0.36 | 90.33 ± 0.62 | 95.40 ± 0.17 | 89.60 ± 8.46 | 97.93 ± 1.01 |
| KAPPA | 98.23 ± 0.02 | 96.12 ± 0.93 | 92.11 ± 5.70 | 97.42 ± 0.01 | 98.27 ± 1.44 | 93.30 ± 1.71 | 96.89 ± 0.64 | 93.10 ± 5.38 | 98.7 ± 0.29 |
| 1 | 100 | 96.68 | 94.94 | 99.94 | 97.09 | 98.61 | 97.04 | 99.50 | 99.08 |
| 2 | 94.00 | 93.89 | 88.71 | 99.63 | 96.91 | 88.05 | 92.81 | 88.51 | 94.02 |
| 3 | 90.99 | 90.21 | 80.73 | 89.48 | 93.88 | 90.07 | 97.64 | 62.00 | 98.04 |
| 4 | 95.26 | 79.39 | 76.42 | 76.99 | 93.25 | 91.23 | 93.96 | 68.81 | 88.47 |
| 5 | 97.66 | 85.06 | 84.61 | 83.19 | 98.15 | 89.79 | 82.52 | 85.12 | 80 |
| 6 | 98.84 | 92.61 | 94.69 | 98.06 | 97.73 | 85,75 | 90.05 | 71.37 | 100 |
| 7 | 89.86 | 93.76 | 98.27 | 100 | 98.85 | 93.57 | 91.61 | 65.00 | 92.38 |
| 8 | 100 | 98.38 | 87.17 | 99.33 | 98.98 | 93.03 | 97.77 | 93.62 | 100 |
| 9 | 100 | 99.73 | 99.49 | 100 | 99.72 | 98.35 | 99.32 | 84.27 | 98.85 |
| 10 | 100 | 99.73 | 95.50 | 100 | 99.97 | 87.20 | 99.67 | 94.95 | 98.51 |
| 11 | 96.32 | 99.94 | 99.95 | 100 | 100 | 98.23 | 99.73 | 98.99 | 100 |
| 12 | 100 | 97.91 | 98.78 | 99.96 | 99.47 | 96.74 | 98.14 | 93.30 | 100 |
| 13 | 100 | 99.86 | 100 | 100 | 100 | 97.69 | 99.98 | 99.99 | 100 |
| SSRN | HSN | S3EResBOF | HSI-BERT | ASSMN | RSSAN | DAGAN | SSFTT | DSSFN | |
|---|---|---|---|---|---|---|---|---|---|
| OA | 99.52 ± 0.01 | 98.69 ± 1.40 | 97.68 ± 1.43 | 99.17 ± 0.00 | 96.26 ± 1.08 | 98.65 ± 0.31 | 99.44 ± 0.02 | 99.21 | 99.83 ± 0.02 |
| AA | 99.13 ± 0.01 | 98.36 ± 1.70 | 96.63 ± 1.80 | 99.79 ± 0.00 | 98.12 ± 0.32 | 97.93 ± 0.56 | 99.28 ± 0.02 | 98.69 | 99.26 ± 0.15 |
| KAPPA | 99.36 ± 0.02 | 98.24 ± 1.89 | 96.92 ± 1.88 | 99.05 ± 0.00 | 95.06 ± 1.4 | 98.22 ± 0.45 | 99.26 ± 0.02 | 99.15 | 99.78 ± 0.06 |
| 1 | 99.85 | 99.17 | 98.71 | 99.90 | 96.8 | 99.16 | 99.70 | 99.33 | 99.19 |
| 2 | 99.97 | 99.31 | 99.86 | 100 | 94.06 | 99.36 | 99.74 | 99.92 | 99.96 |
| 3 | 97.26 | 97.22 | 92.03 | 99.63 | 97.95 | 95.17 | 98.34 | 98.29 | 98.21 |
| 4 | 97.19 | 96.66 | 89.14 | 99.08 | 99.21 | 98.09 | 99.09 | 98.49 | 99.83 |
| 5 | 99.53 | 99.78 | 99.10 | 100 | 100 | 99.36 | 100 | 99.53 | 100 |
| 6 | 100 | 98.69 | 98.73 | 99.99 | 97.92 | 99.43 | 99.60 | 100 | 99.88 |
| 7 | 99.71 | 99.25 | 99.25 | 99.98 | 99.54 | 94.95 | 99.13 | 99.13 | 98.66 |
| 8 | 99.19 | 96.09 | 96.35 | 99.76 | 97.68 | 96.55 | 97.91 | 98.05 | 99.76 |
| 9 | 99.46 | 99.11 | 96.47 | 99.81 | 99.94 | 99.40 | 100 | 95.44 | 99.79 |
| SSRN | HSN | S3EResBOF | HSI-BERT | ASSMN | RSSAN | DAGAN | SSFTT | DSSFN | |
|---|---|---|---|---|---|---|---|---|---|
| OA | 96.62 ± 0.98 | 98.90 ± 1.60 | 98.37 ± 0.30 | 99.56 ± 0.089 | 98.44 ± 0.36 | 97.28 ± 2.42 | 99.04 ± 0.02 | 96.47 ± 0.56 | 99.67 ± 0.34 |
| AA | 98.49 ± 0.38 | 99.29 ± 1.04 | 99.16 ± 0.31 | 99.84 ± 0.022 | 99.36 ± 0.05 | 98.42 ± 1.11 | 99.39 ± 0.01 | 97.57 ± 0.35 | 99.36 ± 0.75 |
| KAPPA | 96.23 ± 1.08 | 98.77 ± 1.78 | 98.18 ± 0.70 | 99.42 ± 0.13 | 98.26 ± 0.26 | 96.97 ± 2.73 | 98.93 ± 0.02 | 96.07 ± 0.62 | 99.64 ± 0.28 |
| 1 | 100 | 99.99 | 99.93 | 100 | 100 | 99.98 | 100 | 99.92 | 99.95 |
| 2 | 99.98 | 99.93 | 100 | 100 | 100 | 99.69 | 100 | 99.99 | 99.97 |
| 3 | 100 | 99.95 | 99.97 | 100 | 99.89 | 99.72 | 100 ± 0.00 | 99.99 | 100 |
| 4 | 99.52 | 98.82 | 97.75 | 100 | 100 | 98.34 | 99.87 | 96.45 | 96.2 |
| 5 | 99.63 | 99.73 | 99.75 | 99.92 | 99.3 | 98.58 | 99.57 | 98.86 | 97.18 |
| 6 | 100 | 99.85 | 99.96 | 100 | 100 | 99.76 | 100 | 99.86 | 99.14 |
| 7 | 100 | 99.85 | 99.99 | 99.96 | 100 | 99.63 | 99.89 | 98.94 | 99.49 |
| 8 | 95.57 | 97.44 | 98.09 | 98.48 | 95.51 | 95.26 | 98.34 | 92.64 | 99.68 |
| 9 | 100 | 99.97 | 100 | 100 | 100 | 99.72 | 100 | 99.98 | 99.58 |
| 10 | 97.45 | 98.50 | 99.57 | 99.93 | 99.62 | 97.68 | 99.63 | 97.99 | 98.63 |
| 11 | 98.24 | 97.93 | 99.80 | 100 | 100 | 100.00 | 98.97 | 99.98 | 98.79 |
| 12 | 99.87 | 99.62 | 99.92 | 100 | 100 | 99.96 | 100 | 97.61 | 100 |
| 13 | 99.75 | 99.95 | 99.62 | 100 | 100 | 99.24 | 99.66 | 94.4 | 99.78 |
| 14 | 99.93 | 99.70 | 99.67 | 100 | 100 | 96.35 | 98.54 | 95.17 | 99.43 |
| 15 | 85.83 | 97.48 | 92.63 | 99.26 | 96.21 | 90.76 | 96.33 | 89.92 | 99.5 |
| 16 | 100 | 99.94 | 99.97 | 99.97 | 99.3 | 100.00 | 99.39 | 99.48 | 100 |
| IP | PU | SA | KSC | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OA | AA | KAPPA | OA | AA | KAPPA | OA | AA | KAPPA | OA | AA | KAPPA | |
| M-att | 99.4 | 99.19 | 99.31 | 97.95 | 97.31 | 97.28 | 99.51 | 99.55 | 99.49 | 99.21 | 98.44 | 99.12 |
| M-o | 98.35 | 97.19 | 98.12 | 97.55 | 96.65 | 96.75 | 98.63 | 99.12 | 98.47 | 98.78 | 98.17 | 98.65 |
| IP | PU | SA | KSC | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SPE | SPA | Fusion | SPE | SPA | Fusion | SPE | SPA | Fusion | SPE | SPA | Fusion | |
| OA | 82.63 | 97.56 | 98.77 | 95.33 | 99.82 | 99.83 | 92.87 | 99.8 | 99.82 | 83.86 | 98.73 | 98.9 |
| MIOU | 63.59 | 89.55 | 92.79 | 89.43 | 99.44 | 99.47 | 92.49 | 99.33 | 99.38 | 61.66 | 95.94 | 96.11 |
| FWIOU | 71.02 | 95.29 | 97.76 | 91.31 | 99.65 | 99.67 | 87.6 | 99.61 | 99.64 | 75.24 | 97.59 | 97.93 |
| KAPPA | 80.18 | 97.22 | 98.81 | 93.83 | 99.76 | 99.78 | 92.05 | 99.78 | 99.8 | 82.01 | 98.59 | 98.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Zheng, N.; Wang, F. DSSFN: A Dual-Stream Self-Attention Fusion Network for Effective Hyperspectral Image Classification. Remote Sens. 2023, 15, 3701. https://doi.org/10.3390/rs15153701
Yang Z, Zheng N, Wang F. DSSFN: A Dual-Stream Self-Attention Fusion Network for Effective Hyperspectral Image Classification. Remote Sensing. 2023; 15(15):3701. https://doi.org/10.3390/rs15153701
Chicago/Turabian StyleYang, Zian, Nairong Zheng, and Feng Wang. 2023. "DSSFN: A Dual-Stream Self-Attention Fusion Network for Effective Hyperspectral Image Classification" Remote Sensing 15, no. 15: 3701. https://doi.org/10.3390/rs15153701