1. Introduction
There has been a growing interest in distinguishing disparate land-cover objects with available hyperspectral images (HSIs) recorded by special satellites [
1,
2,
3]. Unlike traditional remote sensing imagery, HSI generally holds tens of thousands of sophisticated areal observations with hundreds of consecutive-wavelength spectral variables. It has been proven that abundant spectra and intensive scene pixels are beneficial to recognize different unmarked surfaces [
4,
5]. Despite the potential mentioned above, the attributes also have inevitably brought some obstacles to classifying HSIs, which include, but are not limited to the following: (1) the increments of band number and pixel size remarkably increase the time and cost of data processing and storage, and (2) the irreparable lacking of class labels and the huge spectral dimension quickly bring Hughes phenomenon, which significantly decreases the performance of classification or detection techniques [
6,
7].
It is known that reducing the number of recorded spectra is an effective solution to these issues [
8,
9]. In reality, since there exist amounts of redundancy, many highly correlative adjacent spectral variables may negatively influence the usefulness of global information [
10]. Therefore, feature selection, i.e., band selection, is a helpful way to solve the mentioned problems by finding a band subset of meaningful details and low similarity to improve the analysis efficiency. Moreover, the band selection protects the input HSI’s original spatial information. It is conducive to further investigation, precisely the main reason that makes band selection outshine other dimension reduction methods [
11,
12].
Recently, many valid spectral band selection models have been presented, which can be seen as homogeneous [
13,
14,
15] and global in manner [
16,
17,
18,
19,
20,
21], according to whether HSI is divided into disparate hybrid homogeneous groups. Among the global ways, several spectral bands are straightly acquired from the global information with specific metrics or strategies. However, since different homogeneous regions correspond to objects with distinct characteristics, globally measuring the informative scores of any bands is inappropriate [
22,
23]. Unfortunately, it may even be prevented from working when performing on vast HSI under limited facility conditions. According to the similarity among bands or pixels, homogeneous manners typically divide the whole spectral or spatial pixel set into different homogeneous groups, performing specific metrics or strategies within each group to acquire the final integrated band subset. The retained features are more irrelevant and less redundant, and the burden of data analysis is significantly reduced.
Generally speaking, homogeneous methodologies can be divided into nonadjacent [
13,
14,
15] and adjacent manners [
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34]. The former tends to formulate band clusters with quantified similarities among any two variables, ignoring contextual information because of unordered assumptions [
24]. Fortunately, the latter utilizes context to segment the entire HSI into connected homogeneous groups [
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34]. Recently, several novel adjacent manners have been presented and proven effective. Among these techniques, researchers usually establish a graph with a projection of spectral bands with a 2-D spatial structure to segment the pixel set into diverse homogeneous regions [
28,
29,
30,
31,
32,
33,
34] or employ algebraic algorithms to divide the spectral set into neighboring groups [
24,
25,
26,
27]. For instance, to extract the contextual information of spectral bands, Wang et al. [
24] developed a neighborhood band grouping mechanism to shrink the correlation evaluation to connected bands, which is conducive to protecting the main structure of highly related spectral variables. Identically, Zhang et al. [
33,
34] utilized graph representation to display spatial and spectral structural information, where nonadjacent bands are also considered irrelevant. Although these methods can group adjacent variables, they must be revised. Firstly, it should be noted that neither the 1-D algebraic algorithm nor the 2-D similarity graph of one dimension considers the structural information of the other dimension. Specifically, most similarity indexes, such as Euclidean distance [
24], entropy [
26,
27,
35], and
l2,1-norm [
33,
34], regard that the bands or pixels (the other dimension) are equally essential by assuming that the bands are independent or stretching the 2-D pixel matrix into a 1-D vector. Even the graph-based superpixel segmentation [
31,
32,
33,
34] is employed on a 2-D pixel matrix with a spectral transformation. The vectorial shift or unordered assumption leaves the central but implicit information out of consideration, including textual and geometric information conducive to classification.
After dividing, the adjacent manners usually adopt specific metrics to acquire the top influential bands within each group and then integrate them [
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34]. However, the weighting indexes have some issues. The metrics include two categories: individual metrics [
36,
37] and mutual metrics [
38,
39,
40]. The former only considers each spectrum’s information, whereas the latter focuses on the relationship with other similar bands. These indexes either focus on the most quantified informative band of partial pixels or the most relevant band of each group, making it impossible to acquire representative and informative information simultaneously. Some models employed a combination of information and correlation qualifications to solve this problem [
24,
38]. Unfortunately, this type of algorithm may integrate conflicting indicators of disparate purposes, ignoring precise quantification of the significance of each component to the aggregative indexes. Furthermore, several adjacent band grouping models adopted a voting strategy [
32] or iterative learning [
33,
34] within each group to search for proper subsets, which may bring more burdens of data processing.
Recently, due to the excellent generalization capability of distinguishing distinct spatial and spectral information in an underlying nonlinear structure, deep learning-based techniques have been increasingly applied in the classification of remote sensing images [
41,
42,
43,
44,
45,
46]. However, similar to existing nondeep learning models, most existing deep learning models rarely simultaneously exploit homogeneous spatial and spectral information, ignoring exploring the redundancy between the bands and the pixels simultaneously. Furthermore, these deep learning techniques overrely on the amounts of training samples and ask for sufficient internal storage, precisely opposite to our objectives of utilizing a small pixel patch to conduct band selection efficiently.
Above all, there are several open questions when it comes to the adjacent band- or pixel-based local feature selection:
The data processing requires careful consideration and efficient utilization of original structural, morphological, or supplementary information. Specifically, when dealing with either pixels or bands, the other is usually turned into tractable vectors or mutually independent vertexes. As a result, the central but implicit features may be abandoned, bringing distorted estimation to some extent.
For the score evaluation of each spectral band, the metrics need to consider the otherness of heterogeneous regions. Furthermore, the components of existing hybrid indexes may conflict when setting up particular metrics to obtain a subset.
To address the issues mentioned above, a novel feature selection methodology of dual homogeneous patches-based hybrid superpixelwise adjacent band grouping and informative mutuality ranking is created for hyperspectral classification, referred to as PHSIMR. The dominating contributions of the proposed framework are highlighted as follows.
We design a hybrid superpixelwise adjacent band grouping on a homogeneous pixel patch to acquire similar and adjacent band groups, combing a finely designed algorithm to smooth boundary curves automatically. Instead of finding one component of hundreds of spectral features as the graph’s vertexes, our method retains complete and ordered contextual and morphological spectral and spatial information within the homogeneous spatial region. Moreover, the adopted pixel patch only contains several homolabeled adjacent spatial points so that the processing is efficient.
The article also created a metric for band selection termed simplified informative mutuality, which can naturally measure each band’s influential score in the correlation degree with other homogeneous bands. Analogously, the proposed regional informative mutuality ranking algorithm is employed on homogeneous band groups and a pixel patch containing more homolabeled samples than the former utilized.
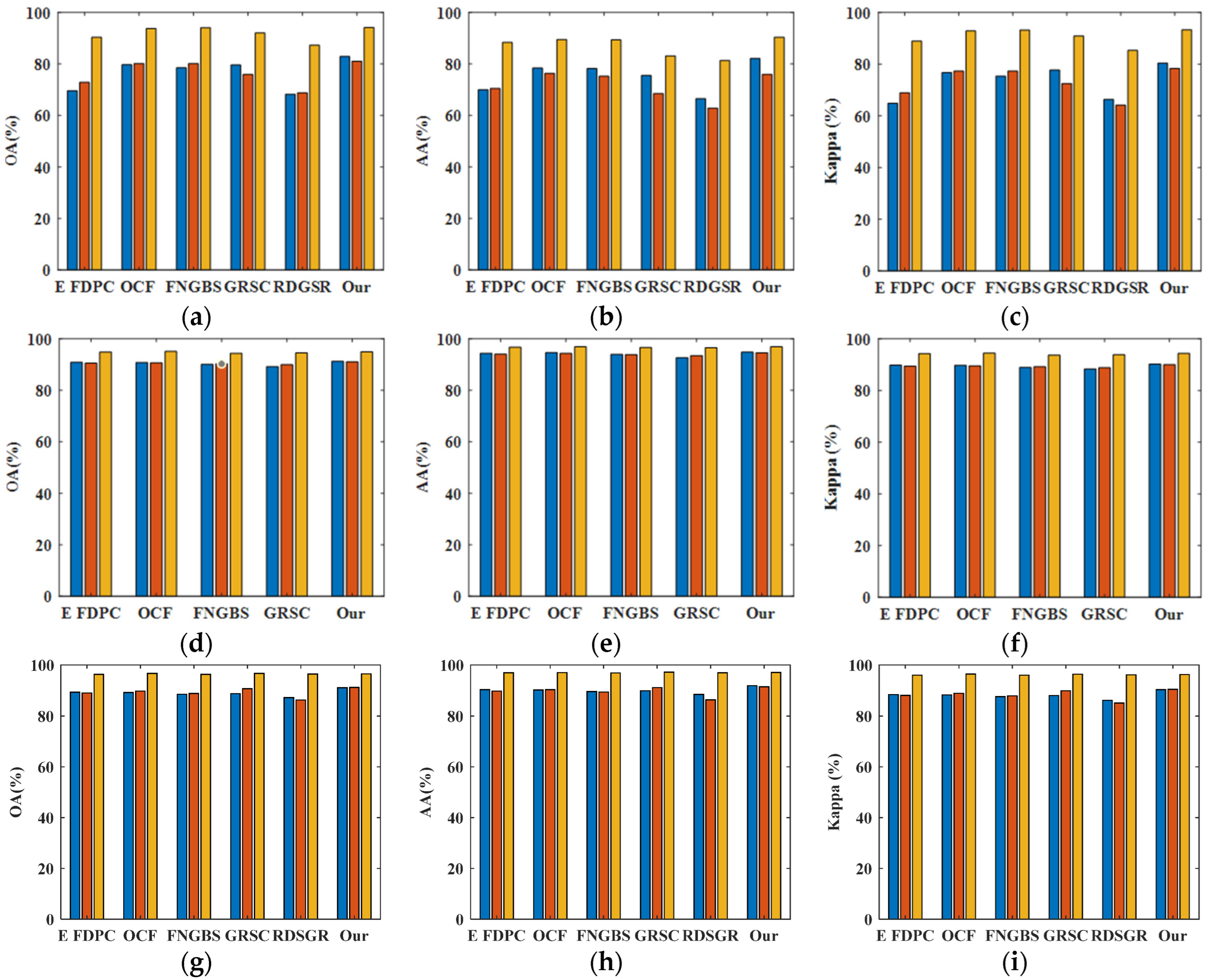
Based on the employed homogeneous pixels and bands, the designed model is efficient, considers spatial and spectral contextual information, and can formulate representative, low-redundant, and informative band subsets. A series of comparative experiments on three benchmark HSIs demonstrates the efficiency and effectiveness of the proposed PHSIMR.
The remainder of this paper is organized as follows.
Section 2 introduces the detailed descriptions of our band selection model, including homogeneous patch-based hybrid superpixelwise adjacent band grouping-based and homogeneous–multivariate patch-based informative mutuality. After that, a series of comparative experiments in
Section 3 is conducted on three publicly available hyperspectral data sets. The discussion is given in
Section 4. Finally,
Section 5 presents the conclusion.
2. Proposed Methodology
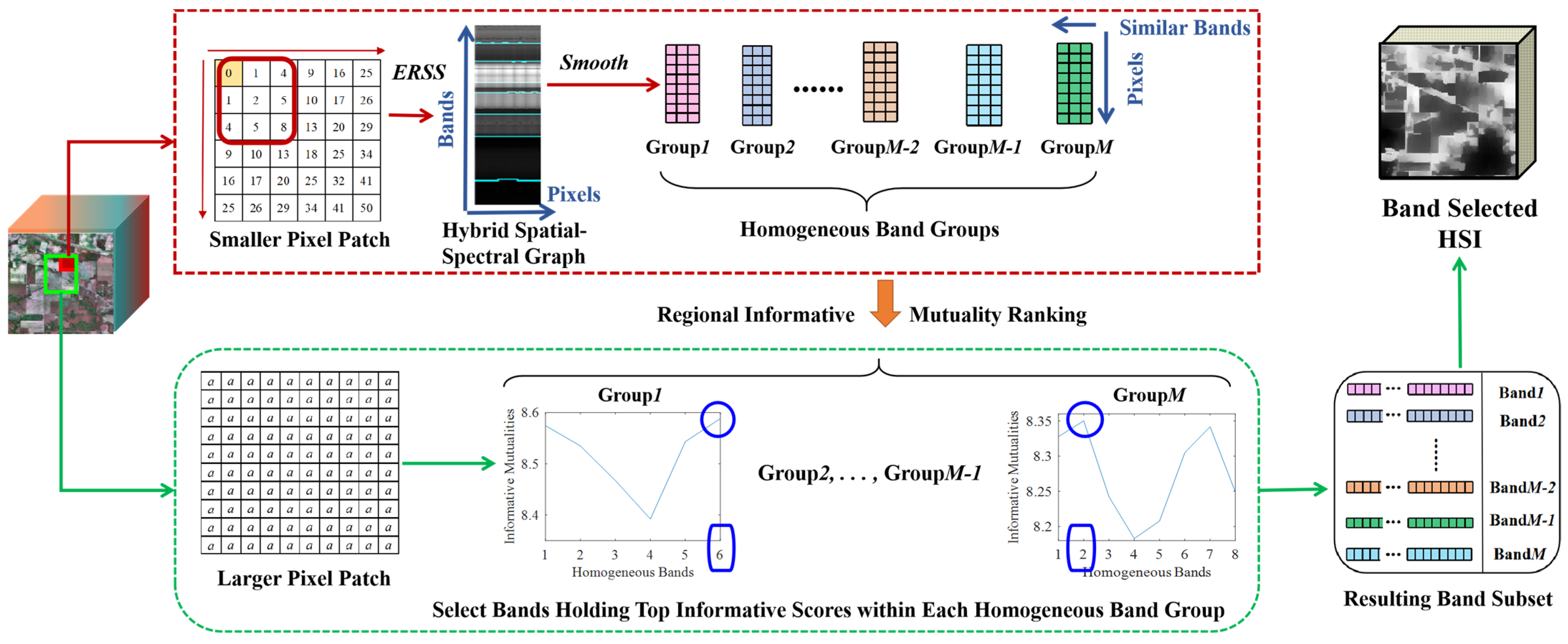
In this section, we expound on the proposed band selection module, whose flowchart is demonstrated in
Figure 1.
First of all, the hybrid superpixelwise adjacent band grouping algorithm is conducted on a small homogeneous pixel patch. Specifically, we employed a small homogeneous pixel patch containing several neighboring homolabeled spatial pixels to construct a hybrid spatial–spectral graph, a 2-D grayscale image with all bands in rows and selected pixels in columns. Subsequently, the entropy rate superpixel segmentation (ERSS) [
23] is performed on the 2-D grayscale image to acquire adjacent homogeneous band groups, combing with a finely designed algorithm to smooth boundary details automatically. Then, the developed regional informative mutuality ranking algorithm is exploited on a larger pixel patch to select the most representative, low-redundant, and informative bands holding top informative scores within each homogeneous band group. The second homogeneous pixel patch is more extensive than the former, and the dual homogeneous spatial patches are homolabeled.
2.1. Hybrid Superpixelwise Adjacent Band Grouping
For HSIs, it is known that adjacent homolabeled objects usually show similar spectral distributions among various bands. The particular affinity between geographic region and object category makes it possible to analyze HSI from a regional point of view [
22]. Meanwhile, remarkable similarity exists among adjacent homogeneous spectral bands [
24]. It is worth noting that the interference of noises is much smaller than the difference between heterogeneous features. Above all, since local adjacent pixels marked with the same class label are highly homogeneous, exploiting spectral contextual information from a homogeneous patch is feasible.
2.1.1. Construction of Hybrid Spatial–Spectral Graph
The input original HSI data cube can be represented as a three-order data cube
, in which
W,
C, and
B represent the numbers of rows, columns, and bands of the original HSI, respectively. Before band grouping, we employ a local pixel patch containing homolabeled adjacent pixels to explore spectral bands’ geographic correlation. It is known that the distance of pixels in HSI represents the distance of the geographical locations in the actual scene [
1]. Therefore, the closer the land-surface objects are, the more likely they are to exhibit similar properties. Inspired by this, a hybrid spatial–spectral band graph,
, is constructed, where each row represents one band vector within the spatial area of
adjacent uniform pixels as:
where
is the
jth observation of the
ith spectrum vector, and
K is the pixel length of the hybrid remodeling graph. Since the spectral dimension is fixed in rows, the hybrid spatial–spectral band graph
mainly depends on the choice of
K homogeneous pixels.
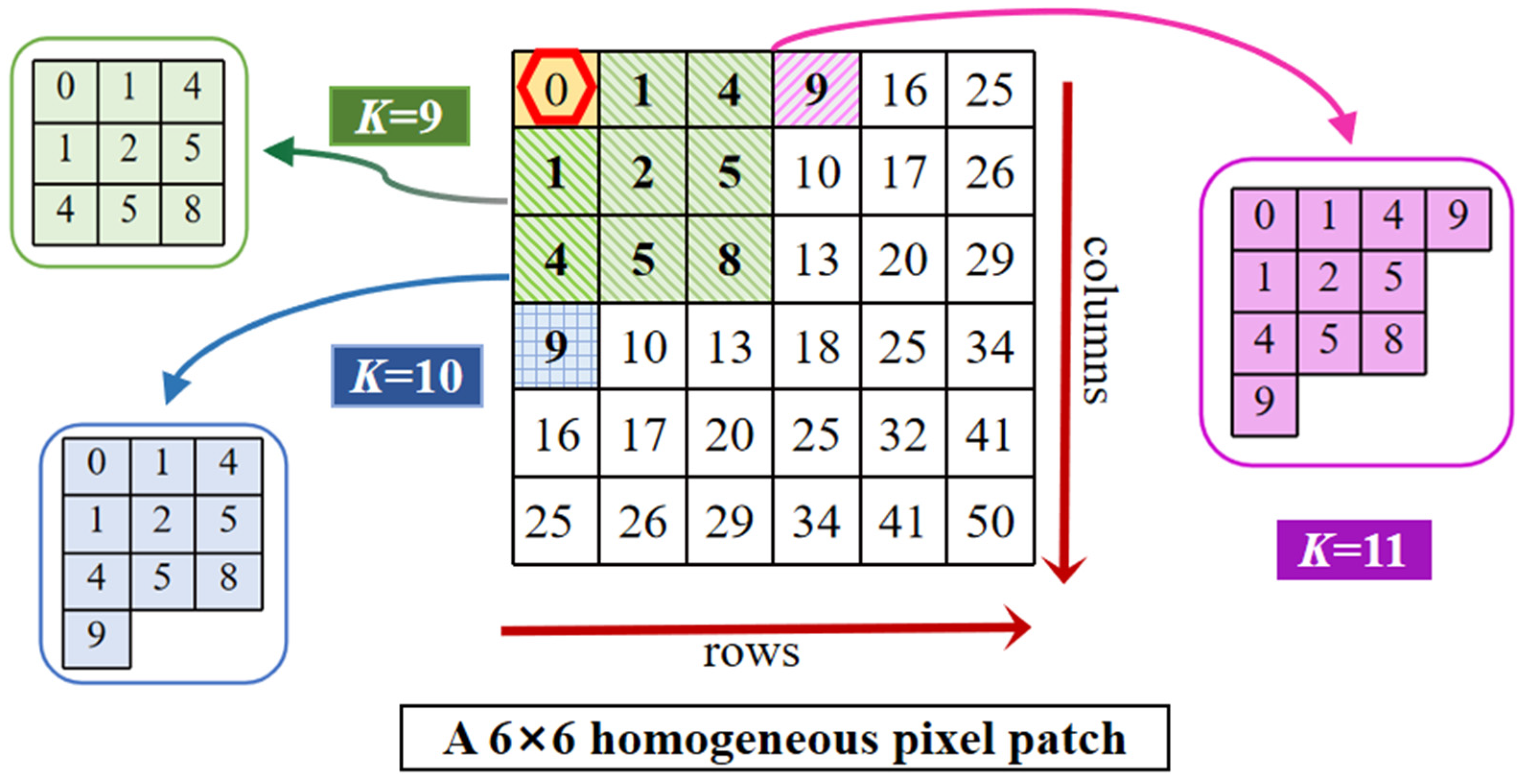
An ingenious strategy is designed to form actionable local pixel regions to obtain an optimal result, considering the consistency of pixel structure with natural structure. More precisely, we determine a local homogeneous pixel patch within a specific homolabeled area and experiment on the pixel patch according to the Euclidean square distance. After immobilizing a reference pixel, the Euclidean square distance is calculated to measure the distance from a geographically adjacent pixel to the fixed reference pixel. The distance map of 6 × 6 local pixels is shown in
Figure 2, where each cell stands for one pixel, and the corresponding value is the distance to the initial spatial point located in the upper left corner of a testing patch, shown by the red regular hexagon.
As the sample region’s size rises, adding other samples to the pixel patch no longer decreases the overall distances to the reference sample. Hence, the selection strategy will help us find the optimal experimental patch as small as possible while validating the effectiveness of spatial homogeneity (found in the following subsection). In addition, local patch processing can significantly reduce the computational cost and exploit contextual characteristics to increase the performance of the band group.
2.1.2. Superpixelwise Adjacent Band Grouping
After hybrid graph construction,
M connected homogeneous band regions can be generated by conducting ERSS [
23] on
as follows:
Here,
represents the results by dividing the whole
B bands into
M connected clusters. The ERSS is steered on the spatial–spectral graph for generating level and smooth boundaries among heterogeneous bands. Instead of creating only one component by projecting spatial vectors or spectral variables [
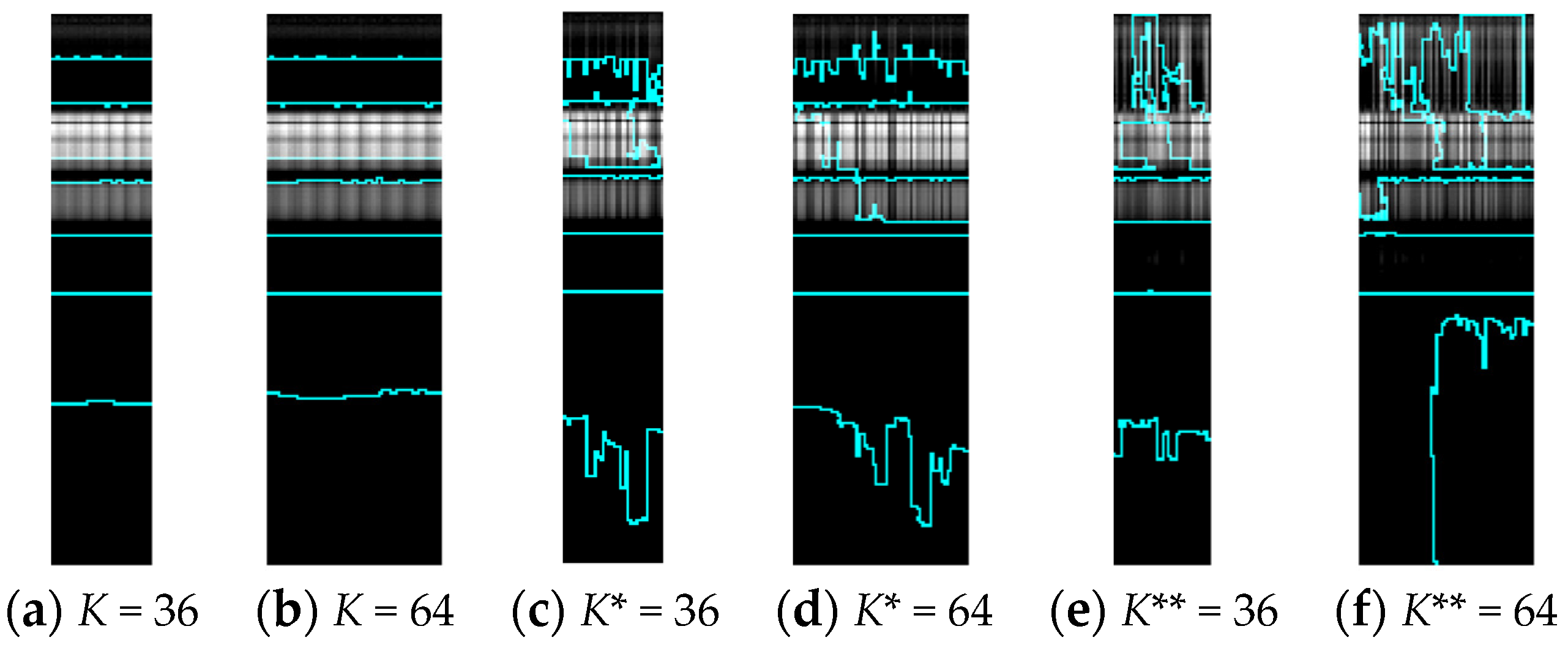
22], the proposed model retains the original spectral contextual features and primary texture information. Adjacent band grouping maps on the different experimental pixel regions in Indian Pines are demonstrated in
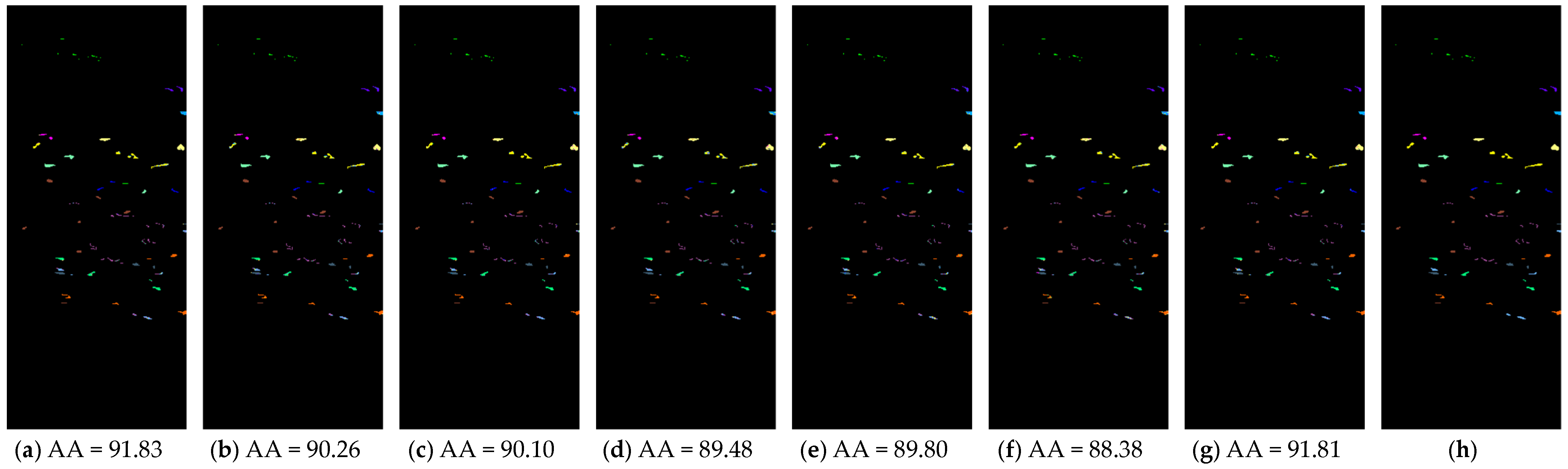
Figure 3.
In
Figure 3,
K represents the number of pixels of the remodeling homogeneous hybrid graph,
K* stands for the pixel size of the chart that holds randomly selected homolabeled pixels, and
K** denotes the size of random pixels sampling from the global spatial set. The number of resulting band clusters
W is fixed at 8, with boundary curves in green.
According to
Figure 3, the performance of the proposed neighboring and local regional approach is superior to other sampling groups. Compared to (c)–(f), the borders of (a) and (b) are closer to the proposal we want to achieve, i.e., smooth and horizontal truncation to distinguish disparate spectral channels. The homogeneous pixel-patch methodology’s necessity, feasibility, and serviceability have been proven.
This strategy increases the averaging distance of selected pixels as the number of selected adjacent pixels rises. It is known that the spread of pixels in HSI represents the distance of the geographical locations in the actual scene. Therefore, the closer the land-surface objects are, the more likely they are to exhibit similar properties. Concretely, the overall similarity among the selected pixels increases as the testing region expands. Thus, we can easily find the minimum number of adjacent pixels to construct the 2-D grayscale image, obtaining more smooth heterogeneous band boundaries and reducing operating costs significantly. The superpixel-based band grouping method can not only regard the bands and pixels as variables and protect the original pixelwise value, but also set the stage for visualized neighboring band grouping with a 2-D variable graph rather than 1-D parallel spectral variables. Therefore, the complete and ordered contextual and morphological spectral and spatial information within the homogeneous spatial region are retained, significantly improving the effectiveness and efficiency of the proposed model by conducting a regional informative band selection on dual homogeneous pixel patches within each homogeneous band group.
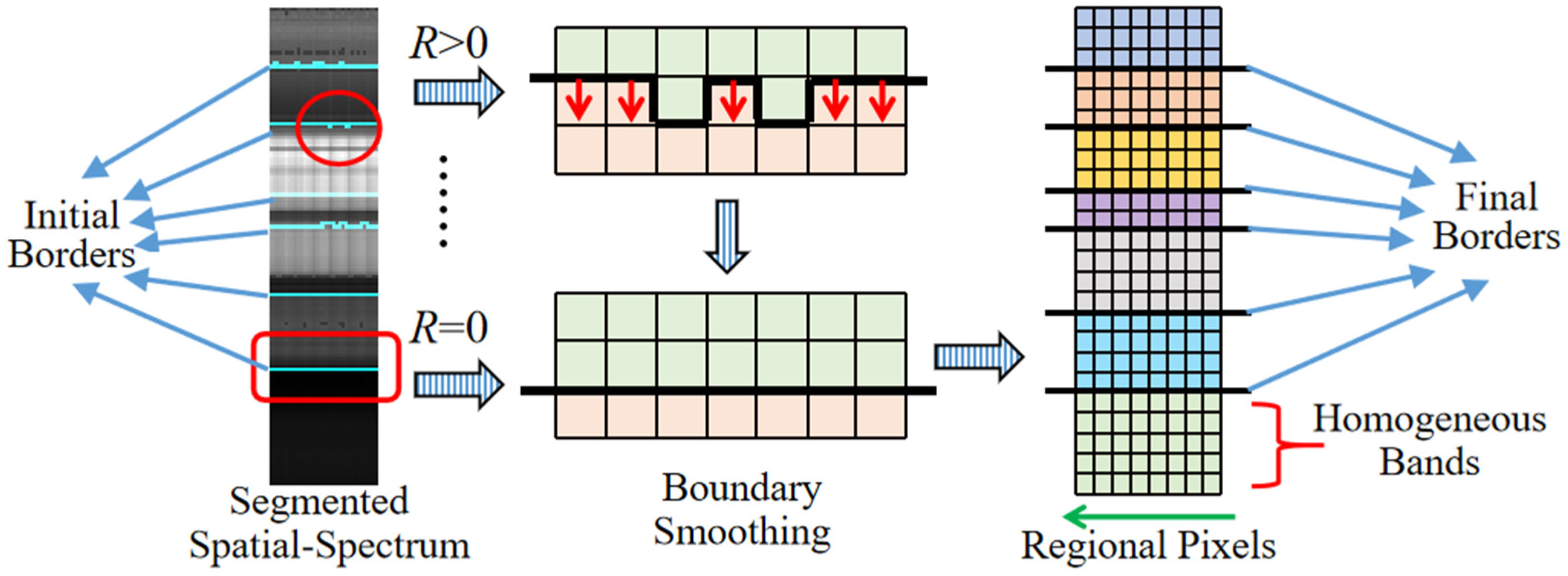
Although our approach is excellent, it is difficult to achieve faultless performance for the noticeable humps among the heterogeneous bands. There are two treated solutions to this issue: one is reducing the samples as much as possible; the other is manipulating a simple parallel shifting scheme. The latter can be achieved as follows. Assuming that one boundary is located in the
nth band, the marker value
v of the
ith pixel
below the ultimate curve must meet the requirement of
R = 0, where
R is given by:
where the mod is adapted to return the residue
R when the former number of the mod is divided by
K. Since the parameter tuning region contains 6 × 6 pixels, the upper limit of
K is fixed at 36. The bands are entirely separated by manually moving the nonhorizontal boundaries into a straight line along the band direction. In reality, the optimum size of the experimental region is almost always at most 16 invariably. The parallel shifting scheme is figuratively illustrated in
Figure 4.
2.1.3. Model Optimization
The solution to the problem of how to acquire the optimal patch size is displayed in this part. To weigh the performance, a measure of confusion
of the
nth band of
is adopted as follows:
where
l is the number of indexes acquired by the ERSS on the
nth row of
, and
denotes the length of index
t developed by the ERSS. Perfect always results in the same index for each spectral row. Otherwise,
l will surpass 1, so the confusion value is over 0. The confusion measure is also termed information entropy, which can reflect the confusion degrees of data distribution. Considering all rows of spectral bands, the global perplexity index is given by
The index
can explicitly measure the mass of the result on
with
K pixels. It is known that the less experimental confusion, the better the acquiring performance. Therefore, the treated way of obtaining the illustration is
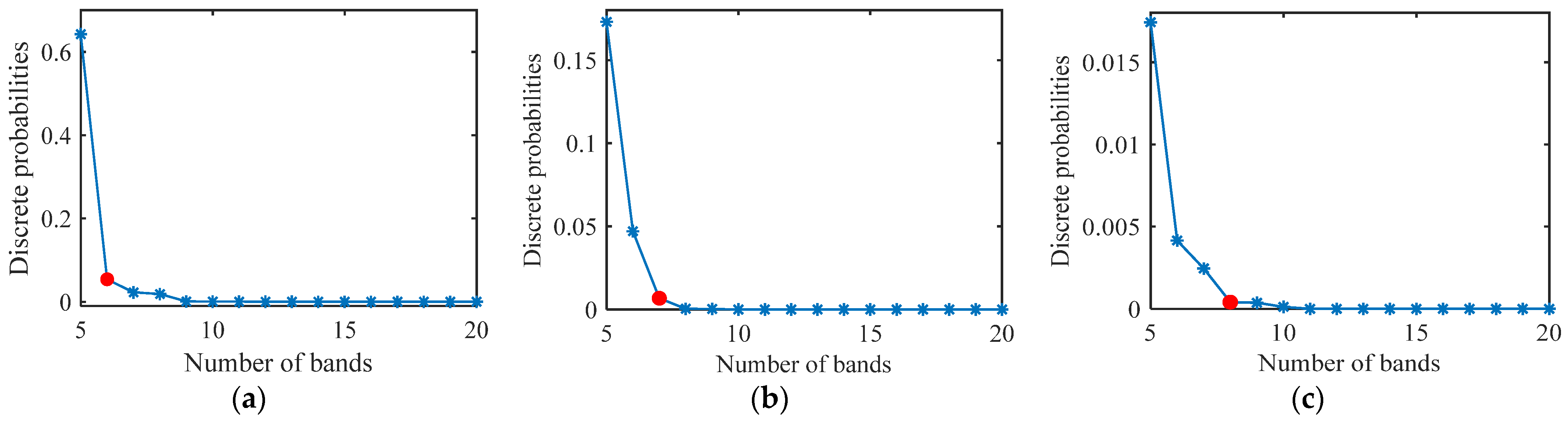
Here, since the parameter tuning is on the local pixel region of 6 × 6, the upper limit of K is fixed at 36. On the strength that the satisfactory will appear simultaneously with the same M and different K, S is set as the initial setup of the minimal patch size of K, significantly affecting the outcomes. In practice, different values of K result in various maps. Consequently, a threshold needs to be set for the parameter S. The specific setting of S is illustrated in the experiment section. Above all, the minimum column length that corresponded to the minimized is size of the final optimal experimental patch.
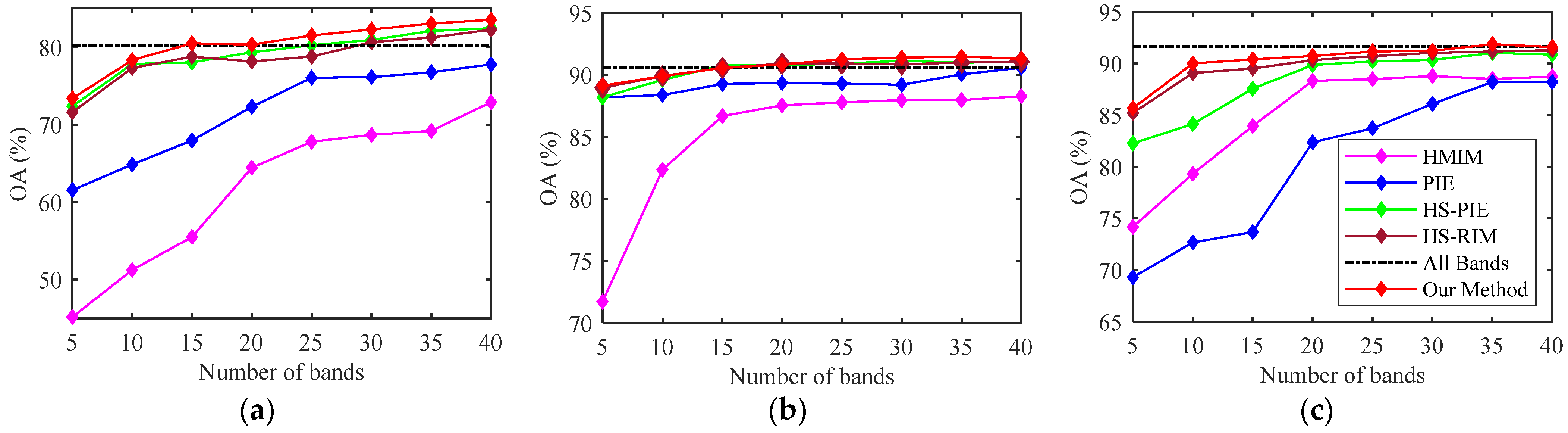
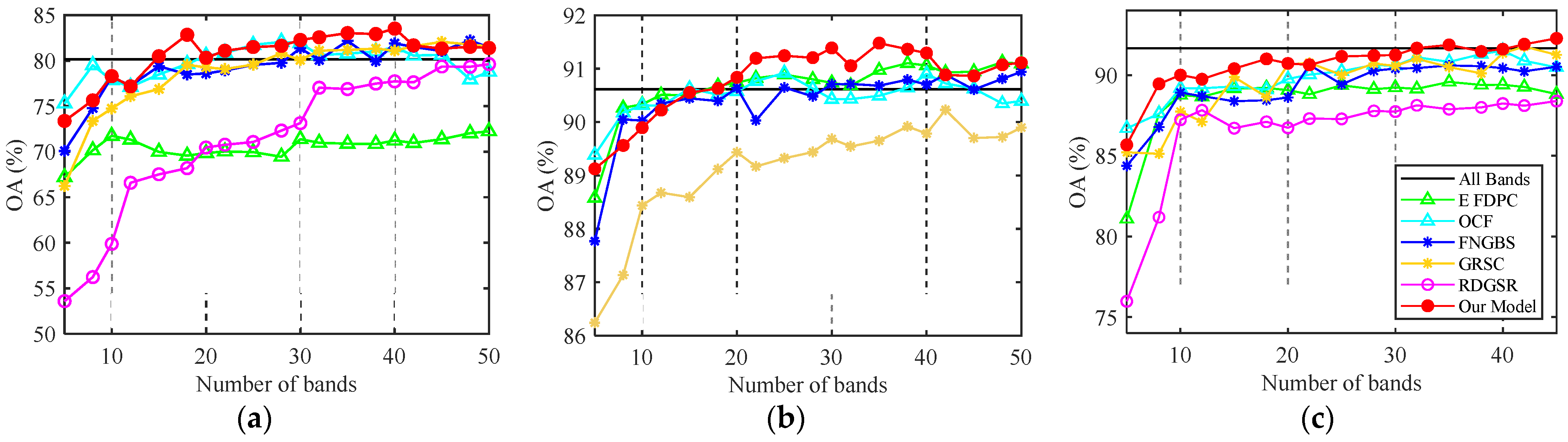
2.2. Informative Mutuality Ranking
After band grouping, we acquire M homogeneous connected band clusters, where adjacent spectral features have high intergroup variability and high intragroup correlation. A representative and low-redundant band subset can be set up by picking the most informative element within each group. A homogeneous pixel patch is adopted, similar to the aforementioned pixel patch for adjacent band grouping. The utilized patch is larger than the former one (i.e., ), but they both belong to a homolabeled region. Such operation reduces the running cost of band selection while avoiding the sampling uncertainty and unknown influence of other heterogeneous samples, which is proven effective via the experiment results.
Motivated by matrix-based Rényi’s α-order multivariate entropy function [
47], we integrate the information weighting index into the above hybrid graph-based adjoining band grouping. Meanwhile, the measurement of informative importance on each intragroup spectral feature is also predigested because of its inherent nature. Specifically, a region that contains
H adjacent homolabeled pixels can be reformulated as
. Supposing that all bands have been partitioned into
M homogeneous and balanced groups, the corresponding band subset
of the
kth group is formulated by
where
is the length of the
kth homogeneous group, and
(
= 1, 2, …,
) stands for the
kth band vector of the set
. Actually, most of the set
holds the same index
k by the ERSS via Equation (2). Within any homogeneous band subset
(
k = 1, 2, …,
M), the locally informative mutuality
of the band
with other homoregional spectral bands
can be generated by
where
is the matrix-based Rényi’s α-order entropy function on
, which is a natural extension and generalization of the widely used Shannon’s entropy. The matrix-based Rényi’s α-order entropy can not only evaluate the entropy of the single variable (i.e.,
) or the multivariate joint entropy among multiple variables (i.e.,
), which can be formulated without probability density estimation as
Here,
tr denotes the trace function of the input square matrix,
, and
represents the normalized Gram matrices evaluated over the band
. By exploring the normalized positive definite square matrix over multiple spectral bands, the entropy can be directly calculated from the hyperspectral data without inaccurate probability density estimation over the high-dimensional data cube. Denoting
C ◦ D the Hadamard product between the matrices
C and
D holding multiple spectral variables, the matrix-based multivariate joint Rényi’s α-order entropy of
can be rewritten as:
where
,
, …, and
are the normalized Gram matrices estimated over spectral bands
,
, …, and
, respectively. The utilization of the Gram matrices
,
, …, and
simplifies the calculation of the joint distribution to paired-element multiplication. Furthermore, based on the commutativity of the Hadamard product, the simplified multivariate patch-based informative mutuality
of
can be defined as
It is worth noting that Equation (11) stands for the quantized informative score of the band , and denotes the quantized informative score of the rest. Since the total information is fixed, more significant remaining informative quantization will lead to larger informative mutuality. Moreover, more enormous rest information means a higher correlation of with other homogeneous bands. From this point, Equation (11) reflects the quantized information of each band’s influential score, i.e., the correlation degrees with other homogeneous bands. In other words, more considerable means a higher correlation with other homogeneous bands.
Based on the homogeneity of each band group, the selected band has the highest correlation with other intragroup bands and low relation with other intergroup bands. Thus, the obtained band subset of representative, low-redundant, and informative is finally formulated as follows:
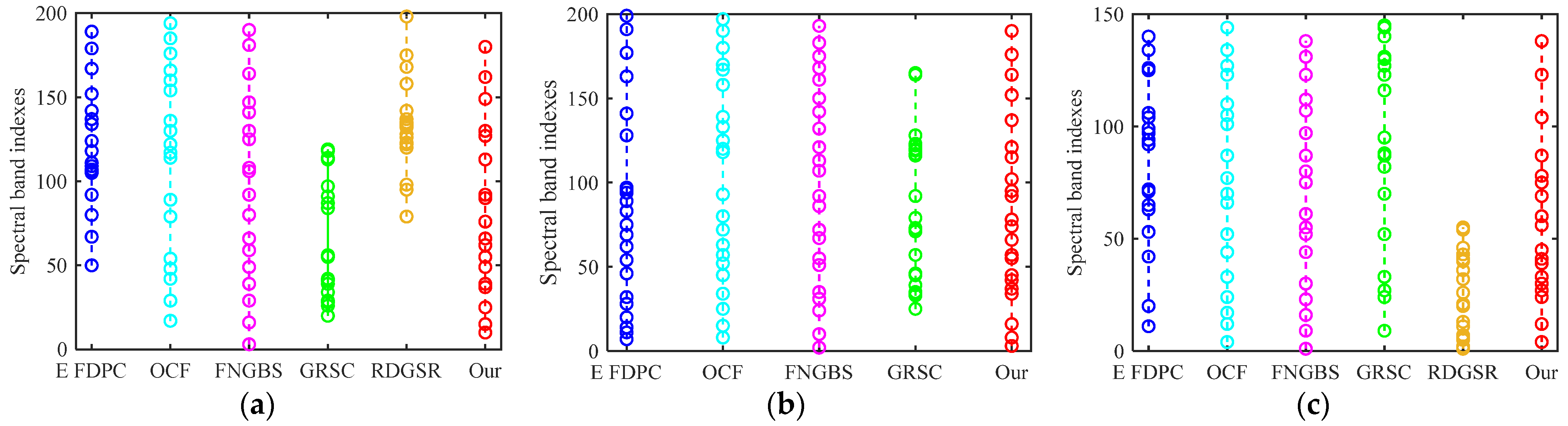
Unlike some typical band selection methods that evaluate the correlation between spectral variables and category labels, the band selection strategy in our article is narrowed into partial domains. Thus, the computing burdens and costs tomes can be remarkably reduced. With the local homogeneous spatial and spectral patches, we rank the evaluations of simplified informative mutuality according to the descending order and then find the top values within each spectral group.
2.3. Time Complexity Analysis
The computational complexity of the proposed PHSIMR in Algorithm 1 will be discussed as follows.
P denotes the number of all spatial pixels, i.e.,
P =
W ×
C. The main contribution to the complexity of the hybrid superpixelwise adjacent band grouping is the acquisition of
, requiring the complexity of
(
BK × log(
BK)). To calculate
K, the time cost is
(
P). Besides, heterogeneous boundary smoothing is obtained by Equation (3), which takes
(
BK) to achieve Equation (7). The main contribution of the complexity of the homogeneous and multivariate patch-based informative mutuality is to rank the mutuality values within each band group via Equations (11) and (12). They take
for the informative calculation within the
kth homogeneous band group and
(
) for ranking. Above all, the overall time complexity of MGSR is
(
BK × log(
BK) +
P +
.
| Algorithm 1 PHSIMR |
- Input:
Hyperspectral data set , the number of selected bands M, the initial setup of homogeneous patch size for S, the patch size for information ranking H. - Output:
The final spectral band subset. - 1:
Search for the optimal homogeneous patch size for K with S via Equation (6). - 2:
Establish a homogeneous hybrid spectral–spatial graph . - 3:
Segment into via Equation (2). - 4:
Smooth heterogeneous boundary to obtain homogeneous band groups via Equation (3). - 5:
Construct another homogeneous patch . - 6:
Calculate simplified informative mutuality within each band group via Equation (11). - 7:
Rank the mutuality values within to find the top band via Equation (12). - 8:
Integrate all top bands into the final band subset.
|
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}