1. Introduction
Hyperspectral imaging allows the acquisition of multivariate images containing information in hundreds of narrow and contiguous spectral bands [
1], where each image pixel is a full-spectrum measurement of an area of the surface. Since many surface materials have unique spectral features, the technique can detect and identify surface materials via a comparison of a spectrum sample with diagnostic spectra obtained from known materials. Hyperspectral imaging has been widely used in various fields, such as geological mapping, plant cover and soil studies, atmospheric research, environmental monitoring, and so on. However, due to the limitation of the spatial resolution of remote sensing devices and the complexity and diversity of surface objects, the spectrum of pixels, i.e., the data from imaging a portion of the surface under study will often contain spectral contributions from more than a single material. Such mixed pixels commonly exist in remote sensing images and significantly degrade the classification accuracy of hyperspectral images and the detection of specific target materials [
2]. In order to improve the accuracy of remote sensing applications, spectral unmixing (SU) is necessary; the spectrum of a mixed pixel must be decomposed and represented as a mix of spectra, called endmembers, generated by component materials, and the respective proportions, called abundances, of their contributions to the spectrum of the mixed pixel.
Any SU technique depends on understanding (or assuming) the mechanism of spectral mixing. There are two common types of spectral mixing models: linear mixing models and nonlinear mixing models. Because of the simple principle and clear physical meaning of the linear spectral mixing model, most of the early spectral unmixing methods were proposed based on the linear mixing model. Spectral unmixing using linear mixing models is accomplished in two steps. The first step is to extract endmembers; typical endmember-extraction methods include the N-FINDR algorithm [
3], the simplex growing algorithm (SGA) [
4], and vertex component analysis (VCA) [
5]. The second step is to perform abundance inversion based on endmember and spectral data, and the common method is the fully constrained least squares method (FCLS) [
6]. The linear mixing model is suitable for ground objects that are essentially linear mixtures and ground objects that can be considered linear mixtures on a large scale.
For the fine spectral analysis of some micro-scale ground objects or the identification of some low-probability targets, a nonlinear mixing model is required. Several typical nonlinear mixing models have been proposed, for example, the Fan model [
7], the Nascimento model [
8], the Hapke model [
9], the generalized bilinear model (GBM) [
10], and the post-nonlinear mixed model [
11]. These better explain the multiple scattering and mixing of photons from ground objects in complex scenes.
The endmember is susceptible to variation due to the influence of atmosphere, illumination, terrain, and the intrinsic variability in the endmember [
12]. The variations affect the accuracy of unmixing and the robustness of unmixing algorithms. Therefore, large efforts have recently been dedicated to mitigating the effects of spectral variability in SU.
Spectral unmixing methods based on the nonlinear mixing model perform well for some scenes because the nonlinear mixing model can explain non-negligible spectral variabilities. However for various reasons, unmixing methods based on nonlinear models are not favored; such models have a large capacity that can lead to overfitting and poor controllability [
13], and deep learning-based methods that account for endmember variability using nonlinear mixing models often lack interpretability, so the estimation of endmembers present at different locations in the scene is difficult [
14]. Spectral variable unmixing studies typically use analysis methods that are based on linear mixing models. Studies have included the extended linear mixing model (ELMM) [
15], the generalized linear mixing model (GLMM) [
16], the perturbed linear mixing model (PLMM) [
17], and the augmented linear mixing model (ALMM) [
18]. The ELMM is provably obtainable from the Hapke model by continually simplifying physical assumptions [
19]. By only taking scaling factors into account, the ELMM is incomplete because certain consequential spectral variabilities are not representable using only scaling factors. The ELMM can be extended for the GLMM by defining three-dimensional tensors. The GLMM allows for the consideration of band-dependent scaling factors for the endmember signatures and can represent a larger variety of realistic spectral variations of the endmembers [
16]. The PLMM considers that, in the absence of any prior knowledge about variability [
20], the variability is modeled using an additive perturbation term for each endmember [
21]. The PLMM lacks a physical meaning because the spectral variability cannot be adequately represented by only an additional term. The ALMM addresses the limitations of the ELMM and PLMM models by considering the scaling factors and other spectral variability simultaneously, according to their distinctive properties; the alternating direction method of the multiplier is used to solve the mixing model.
Besides the spectral mixing model, the algorithm used to solve the model is also important. Compared with the traditional convex optimization algorithm, the method based on neural networks is more convenient and efficient to implement, and its convergence is also better. The autoencoder (AE) is a typical unsupervised deep learning network, which generally consists of an encoder and a decoder. The encoder can map the input into a hidden layer containing low-dimensional embedding (i.e., abundances), and the decoder can reconstruct the original input from low-dimensional embedding [
22]. The AE method has the advantages of good convergence and easy solutions and is suitable for resolving the issues listed above. In recent years, the extensive in-depth study of AEs and their application has led to the proposal of a series of spectral unmixing algorithms based on AEs, such as non-negative sparse autoencoders (NNSAEs) [
23], stacked non-negative sparse autoencoders (SNSAs) [
24], deep learning autoencoder unmixing (DAEU) [
25], and convolutional neural network autoencoder unmixing (CNNAEU) [
26]. The output of the encoder of an ordinary AE is only a value that represents the attributes of the latent variable; the research on applications in hyperspectral unmixing has developed the variational autoencoder (VAE) [
27], whose encoder outputs the probability distribution of each latent variable to make its results more representative.
1.1. Motivation
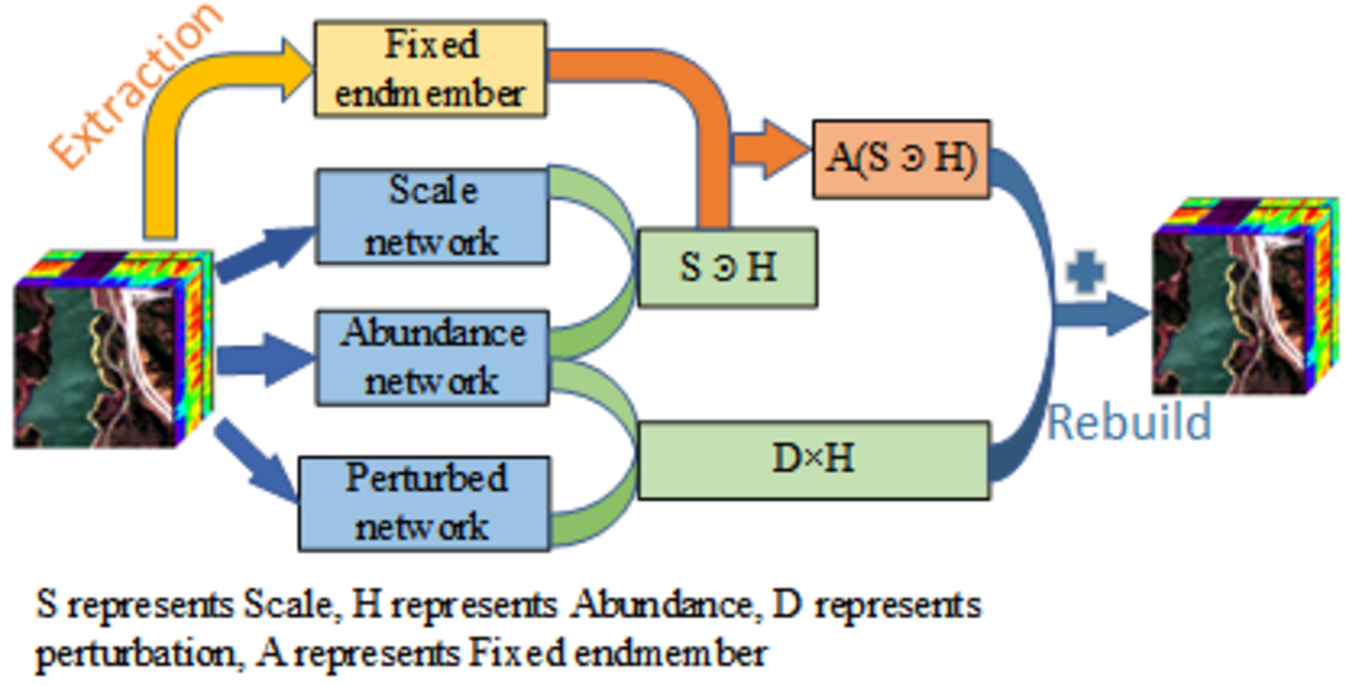
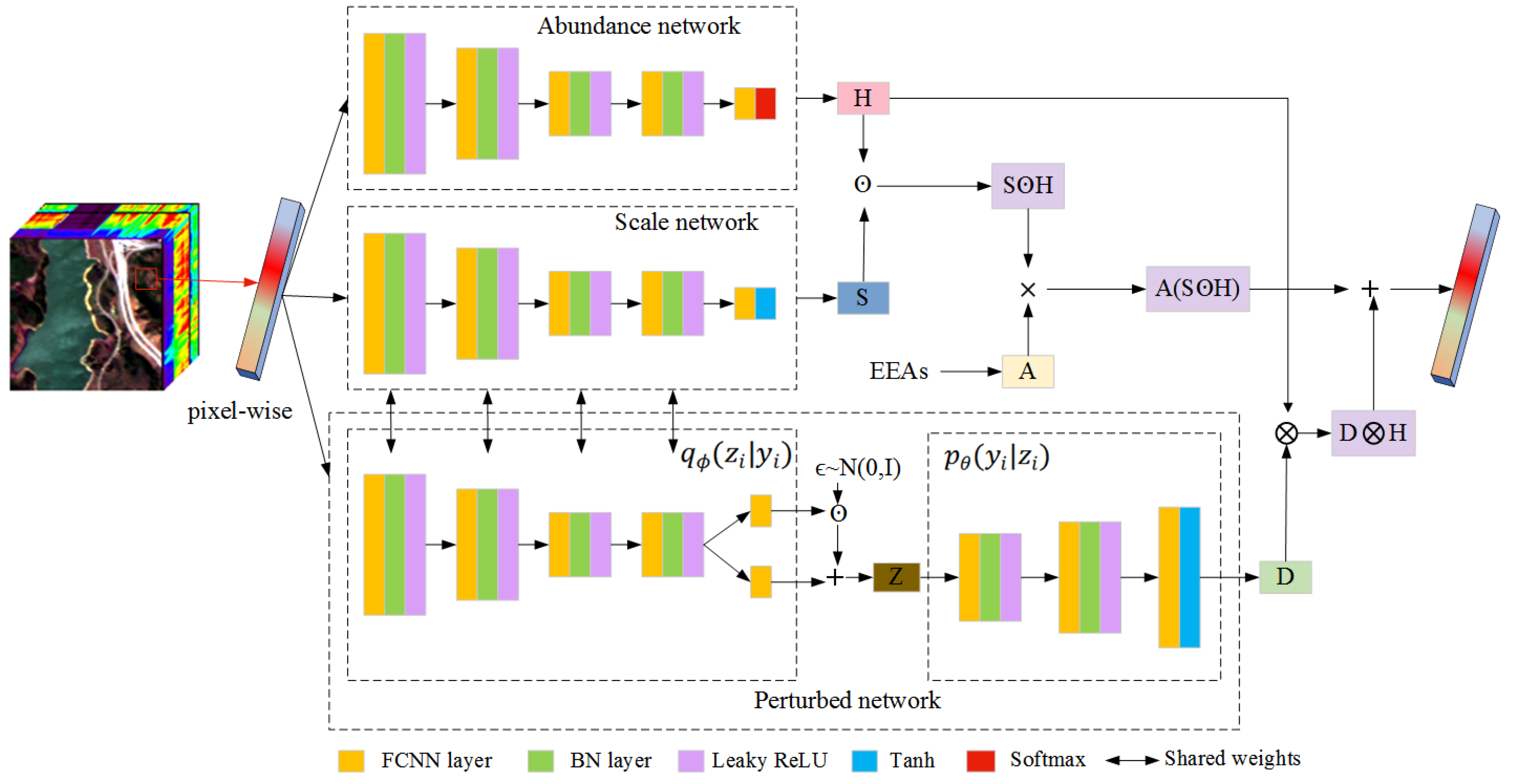
Although the ALMM effectively overcomes the deficiencies, the model is difficult to implement with deep learning networks because there are more unknown terms to be solved than with other models. The scale factor and additive perturbation complement each other to better fit the target spectrum [
28]. This paper comprehensively considers the factors of spectral variability and combines the common ELMM and PLMM into a new scaled and perturbed linear mixing model (SPLMM), which, unlike the ALMM, can be efficiently solved using end-to-end neural networks.
PLMM assumes that spectral variability follows a Gaussian distribution [
18], which is not strictly true in real scenarios. The Probabilistic Generative Model for Hyperspectral Unmixing (PGMSU) [
14] can approximate arbitrary endmember distributions and so address endmember variability, allowing the fitting of arbitrary endmember distributions through the nonlinear modeling capability of VAEs [
29]. Drawing on the ideas behind the PGMSU, a network for the proposed SPLMM is constructed, which simultaneously solves the abundances, scales, and approximate arbitrary perturbation distributions. Suitable constraints on scale and perturbations are added to enhance the robustness of the model, and the sparse constraint of abundance is added to prevent overfitting.
1.2. Contributions
The specific contributions of this paper are summarized as follows:
We propose a new spectral mixing model, SPLMM, and a corresponding solving network. SPLMM comprehensively considers the influence of scale and perturbation factors and better explains the variability of endmembers. Using the neural network to solve the model not only reduces the use of parameters but also makes the model more convenient and efficient to implement, and the convergence to the solution is improved.
We propose a new network modeling method to enhance the estimation of endmembers. Determining the initial fixed endmembers by extracting endmembers, using the fully connected neural network to construct the scale, and using the nonlinear modeling ability of the VAE to fit any perturbation distribution, which not only limits the range of endmembers but also better fits various situations of variable endmembers.
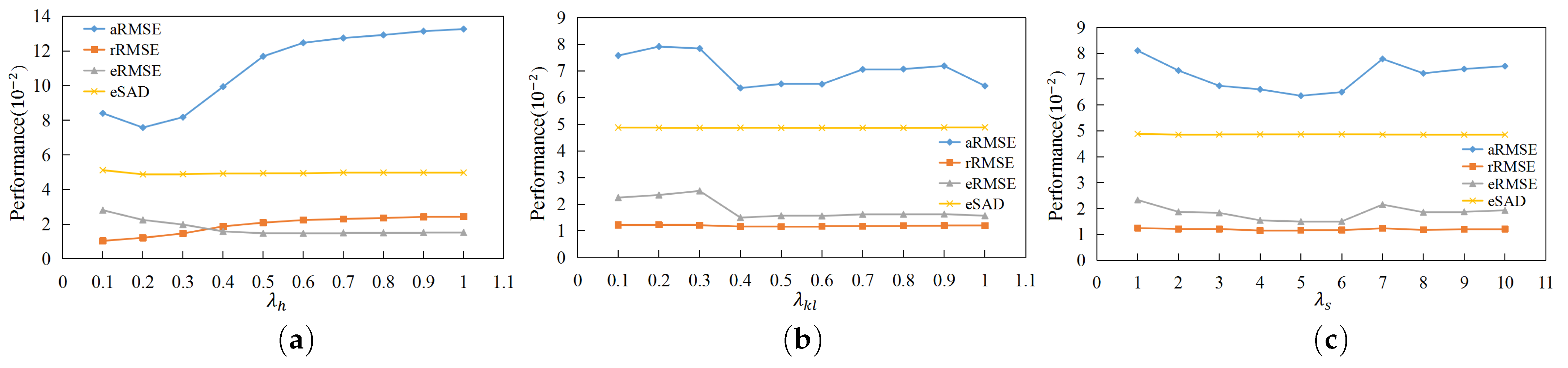
We propose adding various regularization constraints. The spatial smoothness constraint is added to the scale, and the regularization constraint is added to the perturbation, which improves the robustness of the model. For abundance, adding sparse constraints helps prevent overfitting.
The organization of this article is as follows.
Section 2 describes works related to the theoretical analysis of the proposed SPLMM.
Section 3 presents the proposed model and its implementation details.
Section 4 introduces experimental results and comparisons. Finally,
Section 5 presents conclusions.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}