1. Introduction
Recently, hyperspectral images (HSIs) have received remarkable interest as a result of their numerous continuous spectral bands, large spectral range, and high spectral resolution. This prominent spectral resolution enables more precise observations of land cover, making HSIs invaluable resources for remote sensing change detection (CD). CD is the process used to identify and analyze differences between images of the same area taken at different times. This can be used for agricultural monitoring [
1], resource exploration, land-change monitoring, potential anomaly identification [
2,
3,
4], and various other applications. With the help of rich spectral information, HSI CD has the potential to identify finer changes.
Traditional CD methods for HSIs can be classified into three categories: (i) image algebra-based methods; (ii) image transformation; and (iii) classification-based methods. They obtain the similarities among HSI pixels by applying hand-crafted feature extraction techniques. Specifically, image algebra-based methods employ algebraic techniques, such as image difference [
5] and image log ratio [
6], to measure the difference in images and further generate a change detection map. Change Vector Analysis (CVA) [
7] is a classical image algebra method that calculates the magnitude and direction between two pixels of bi-temporal images. Later, many variants of the CVA method were developed, such as Deep CVA (DCVA) [
8] and Robust CVA (RCVA) [
9], to improve detection performance. DCVA employs a pretrained Convolutional Neural Network (CNN) to extract deep features. To reduce spurious changes, RCVA accounts for pixel neighborhood effects. Image algebra methods are fast and easy to implement because they directly perform mathematical operations on the corresponding bands. Meanwhile, the simple operation makes them susceptible to imaging conditions and noise. Image-transformation-based methods transfer temporal variants into a specific feature space to identify the changes. Principal Component Analysis (PCA) [
10] is utilized to reduce redundancy and noise within data while simultaneously extracting essential information and characteristics from HSIs. Multivariate Alteration Detection (MAD) utilizes canonical correlation analysis to transform the hyperspectral data into a new coordinate system to statistically detect changes [
11]. Iterative Reweighted MAD (IR-MAD) [
12] incorporates weights for each pixel based on the chi-squared distribution at every iteration to enhance change detection performance. By assigning appropriate weights, IR-MAD can effectively mitigate the influence of noisy or outlier pixels. Hou et al. [
13] proposed a tensor-based framework, Tensor Decomposition and Reconstruction Detector (TDRD), which uses tensor representation and Tucker decomposition to extract high-level semantic information and remove the effects of irrelevant changes to improve accuracy. These image transformation methods are capable of enhancing the discrimination between changed and unchanged features by reducing dimension and noise. However, it is time-consuming to transform complicated images. Classification-based methods [
14,
15] compare the classification results of bi-temporal images to generate “from-to” change detection results. Therefore, the detection results are heavily dependent on the classification accuracy. In summary, these traditional methods exploit shallow features to generate change maps, resulting in a lack of robustness across different or complex scenes, and they do not easily select appropriate thresholds. In addition, these approaches do not consider the intrinsic connection between HSI bands and ignore the physical meaning of continuous spectral signatures.
To overcome the constraints of traditional methods, recent research has focused on integrating Deep Learning (DL) techniques with a particular emphasis on CNNs as powerful tools for HSI CD. Due to their ability to capture spatial semantic information effectively, CNNs have made remarkable progress in the domains of computer vision (CV) [
16,
17,
18] and remote sensing [
19,
20,
21]. Wang et al. [
22] presented a two-dimensional (2D) CNN to integrate local information and learn meaningful features from a subpixel-represented, mixed-affinity matrix. With the help of CNN’s own structure, Saha et al. [
23] extracted low-level semantic features from bi-temporal images without any training. In [
24,
25], both a one-dimensional (1D) CNN and a 2D CNN were used to explore spectral and spatial information, respectively. Zhan et al. [
26] employed a three-dimensional (3D) CNN to extract tensor features and generate a change map with the similarity measurement of tensor pairs. Ou et al. [
27] proposed a band selection strategy to alleviate band redundancy before feeding the difference image into a CNN-based framework. Wang et al. [
28] designed self-calibrated convolution to make full use of inter-spatial and inter-spectral dependencies by heterogeneously exploiting convolutional filters. In [
29], Zhao et al. extracted spatial–spectral features using a simplified autoencoder without requiring prior information. Seydi et al. [
30] employed multi-dimensional convolution and depth-wise dilated convolution to extract different features. The above algorithms improved the accuracy of change detection by designing different network structures to effectively leverage spatial information. However, they compare the characteristics of bi-temporal images using difference [
23,
24,
27] or concatenation [
22,
25,
28,
29,
30] and are unable to learn temporal change information well. This becomes a key factor restricting further improvements in change detection accuracy.
Therefore, several researchers [
31,
32,
33] introduced Recurrent Neural Networks (RNNs) to extract change information, and Long Short-Term Memory (LSTM) is most often used to overcome the problem of gradient vanishing. Lyu et al. [
31] introduced RNNs to change detection to learn a change rule with good transferability for the first time. In [
32], convolutional LSTM was employed to model temporal change information while maintaining the spatial structure. Recurrent CNN (ReCNN) [
34] also employs LSTM to capture the temporal change information of change after exacting spatial features using a 2D CNN. Shi et al. [
33] used multipath convolutional LSTM to extract temporal–spatial–spectral features, and the various hidden states of LSTM were combined to exploit multiscale features. Although the introduction of RNNs improves the utilization of time information, these methods still extract the time dependency after extracting the features of bitemporal images. Moreover, they lack consideration of the importance of different types of information.
Attention mechanisms can help deep learning models selectively focus on relevant input features and suppress irrelevant ones, improving their ability to represent and process complex input data. This can lead to improvements in various AI tasks such as natural language processing (NLP) [
35,
36,
37], and CV [
38,
39,
40,
41]. In HSI CD, attention mechanisms have been incorporated into different methods and shown considerable potential to boost CD performance. Gong et al. [
42] incorporated spectral and spatial attention mechanisms to selectively weight the various bands and regions in the input images for CD. Wang et al. [
43] introduced a simple attention mechanism to measure the weights of different features before concatenating them. Huang et al. [
44] integrated parallel spatial and spectral attention to adaptively enhance the relevant global dependencies. Qu et al. [
45] designed an attention module to better capture the contextual relationships between different regions and spectral bands, yielding more effective information transfer between different levels of feature maps. Wang et al. [
46] proposed a Siamese-based network that incorporated a Convolutional Block Attention Module (CBAM) to adaptively reform the semantic features. In [
47], an improved CBAM module was used to emphasize meaningful information and suppress irrelevant information during feature transformation. Qu et al. [
48] introduced the graph attention network to HSI CD for the first time, which leveraged the spatial–temporal joint correlations to explore multiple features. In [
49], cross-temporal attention was designed to explore the temporal change information between bi-temporal features. Ou et al. [
50] performed attention operations on image patches of different scales at the same time so that the central pixel to be detected in the fused feature map has a higher weight. The Transformer [
37] is a network built on the multi-head self-attention (MHSA) mechanism to selectively attend to relevant information and disregard irrelevant input, allowing for it to model long-range dependencies without considering the actual distance. Transformer models have shown considerable potential for sequential data analysis. They have also been successfully applied in the HSI CD task [
51,
52]. Ding et al. [
51] employed the Transformer encoders to capture spatial–temporal change information from the concatenated pixel sequences. Wang et al. [
52] used a temporal transformer to capture change information from the spatial–spectral features extracted using the transformer-based Siamese network. Although they achieved a good performance, [
51] neglects the exploitation of spectral information, and the network structure of [
52] is still based on the Siamese network. It should be noted that the method proposed in this paper has a different perspective from the Transformer used in [
52]. We constructed a single-branch network to extract spectral and temporal information simultaneously. Although the aforementioned DL-based algorithms have demonstrated favorable change detection outcomes, they still have the following limitations:
- (1)
HSIs consist of a number of spectral bands that afford detailed spectral information. CNNs are vector-based methods that process input data as collections of pixel vectors. Consequently, due to this narrow perception, CNNs are deemed unsuitable for effectively processing the rich spectral information in HSIs.
- (2)
CNN-based methods are designed to extract features from local regions of an image and typically perform poorly when capturing long-distance sequential dependencies. This is because CNNs lack the ability to model nonlinear relationships between distant inputs and require larger receptive fields to capture such relationships.
- (3)
The identification of subtle changes in HSIs is heavily reliant on the temporal dependency between bi-temporal features. The above methods, which employ Siamese-based networks to extract bi-temporal image features independently, are insufficient when addressing the regions of change and exploiting the temporal dependency of HSIs.
Hyperspectral data can be viewed as a collection of spectral sequences in spectral space [
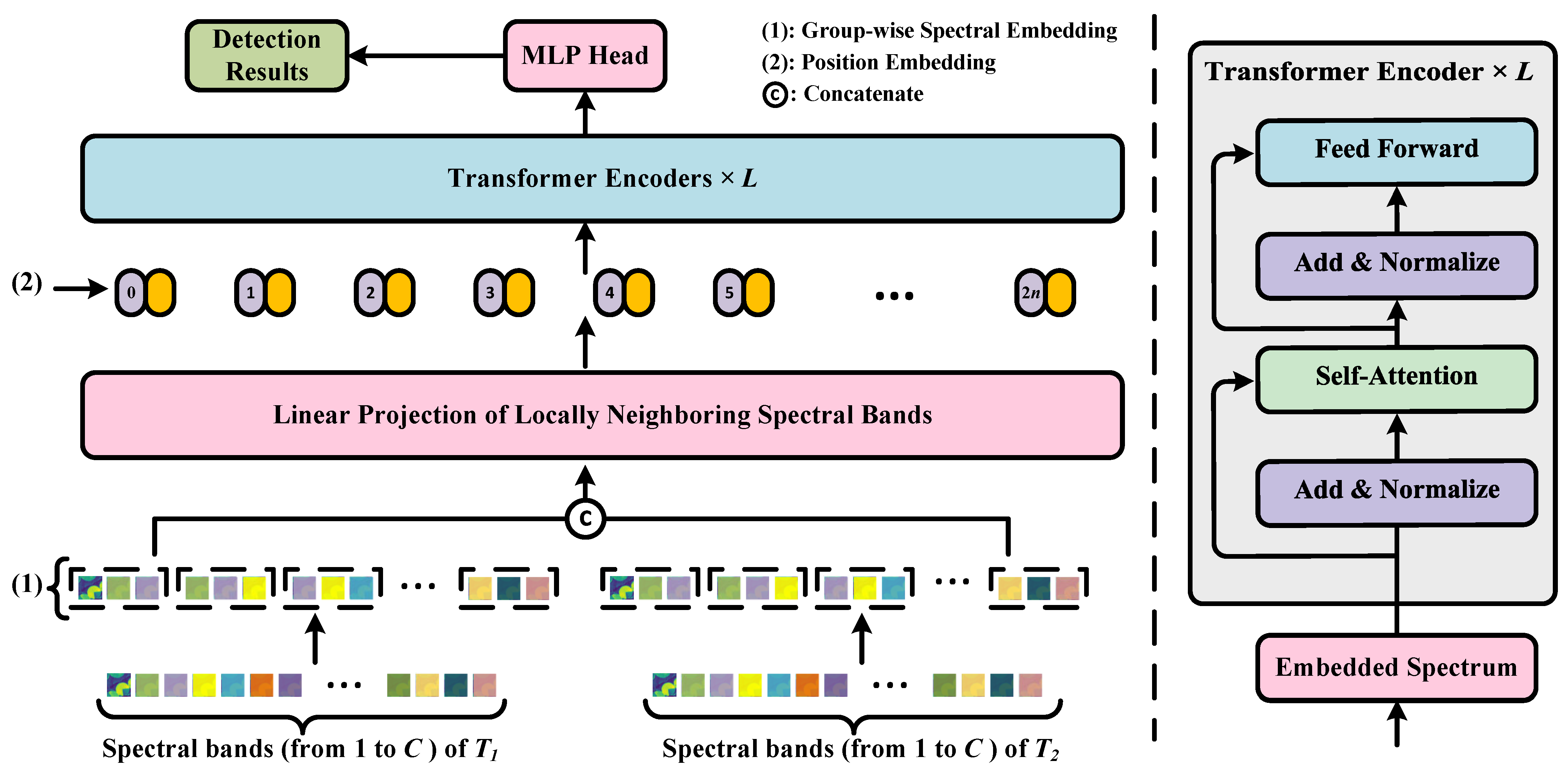
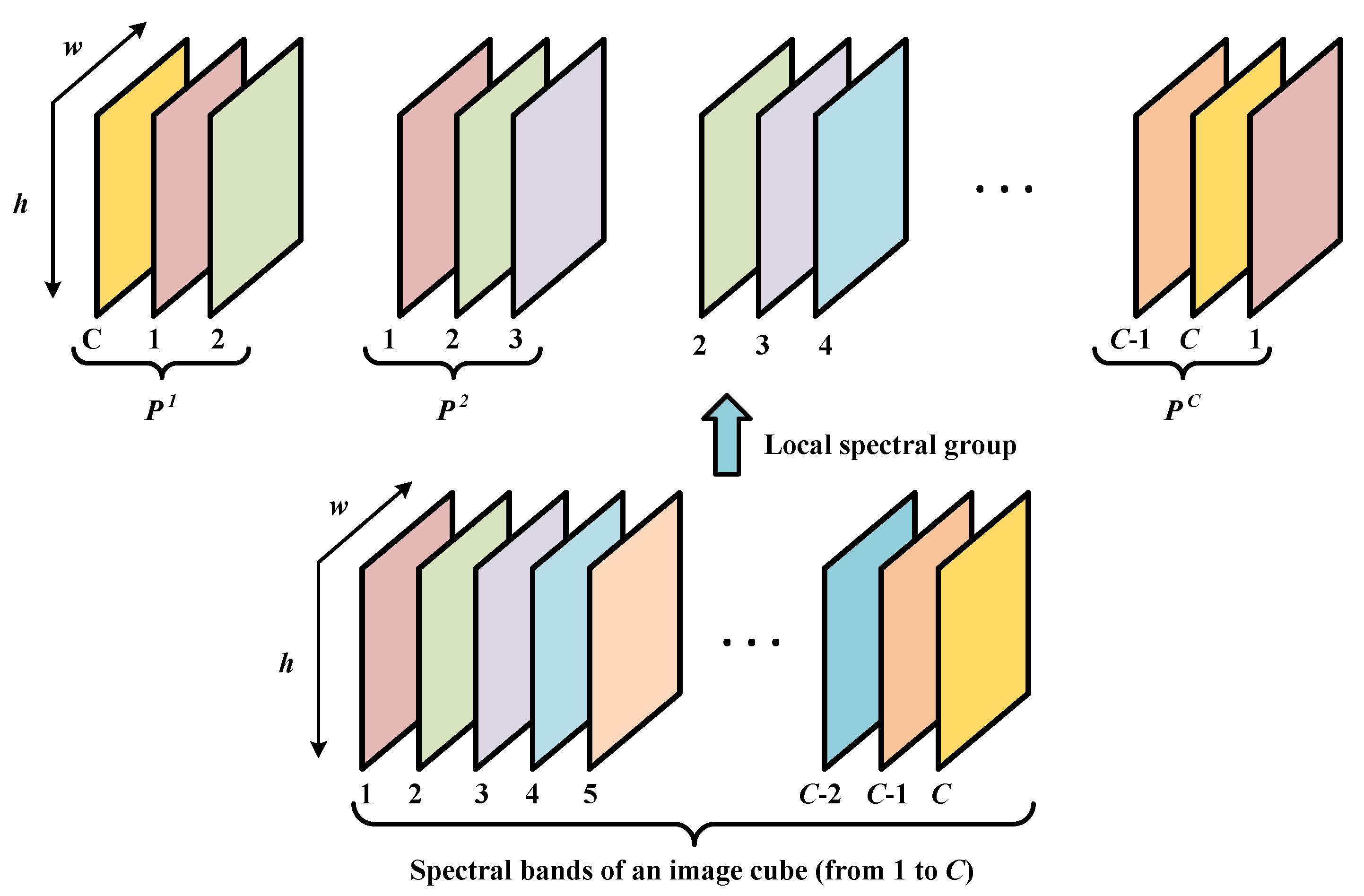
53], and each position on the image corresponds to a temporal variation. This motivates us to explore the representation of hyperspectral pixels and their temporal correlation from a sequential perspective. The Transformer can be adapted to address HSI CD problems by utilizing its long-range modeling ability to characterize the correlation and variability between different spectral bands, as well as the temporal dependency. In this context, we proposed a novel Spectral–Temporal Transformer (STT) for HSI CD. By concatenating the feature embeddings of each image in spectral order, the STT effectively extracts and integrates rich sequence information of the spectrum and time space. With the help of the MHSA mechanism, spectral and temporal information is refined to obtain fused weighted features, which enhances the utilization of temporal information and makes the change features more discriminative.
The main contributions of this paper are summarized as follows:
- (1)
The STT is designed with a global spectrum–time-receptive field, enabling the joint capture of spectral information and temporal dependency. By concatenating the feature embeddings in spectral order, the STT learns different representative features between two bands, regardless of spectral or temporal distance, strengthening the utilization of temporal change information.
- (2)
We propose a Spectral–Temporal Transformer (STT) for HSI CD, which is the first time the HSI CD task is processed from a completely sequence-based perspective. This enables us to adaptively capture the discriminative sequential properties, e.g., the correlation and variability between different spectral bands and temporal dependency.
The remainder of this paper is organized as follows:
Section 2 elaborates on the proposed Spectral–Temporal Transformer (STT) method.
Section 3 presents the comparative outcomes of various algorithms on three HSI CD datasets. In
Section 4, there is a discussion of the entire paper. Finally,
Section 5 provides conclusive remarks.
4. Discussion
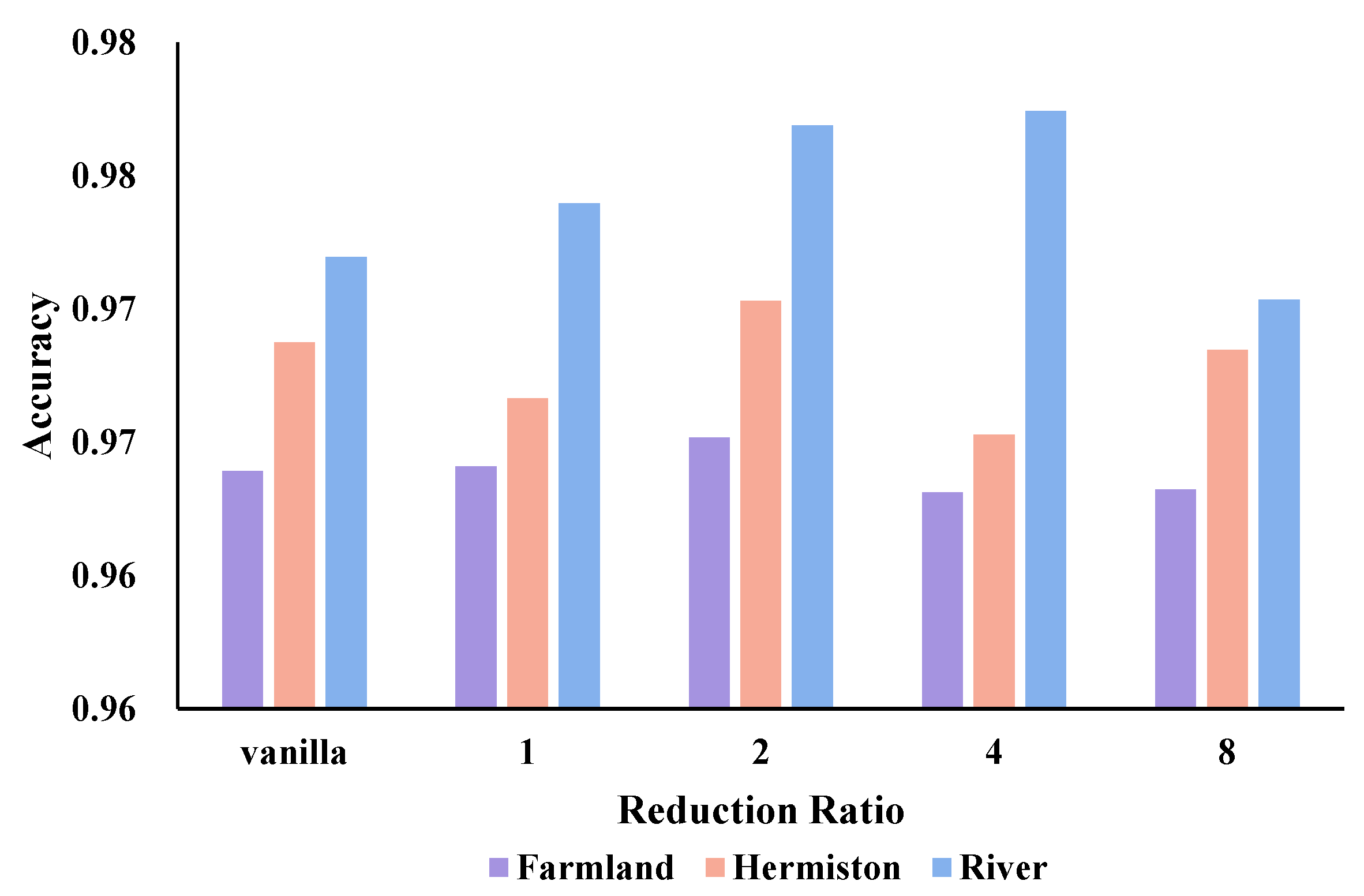
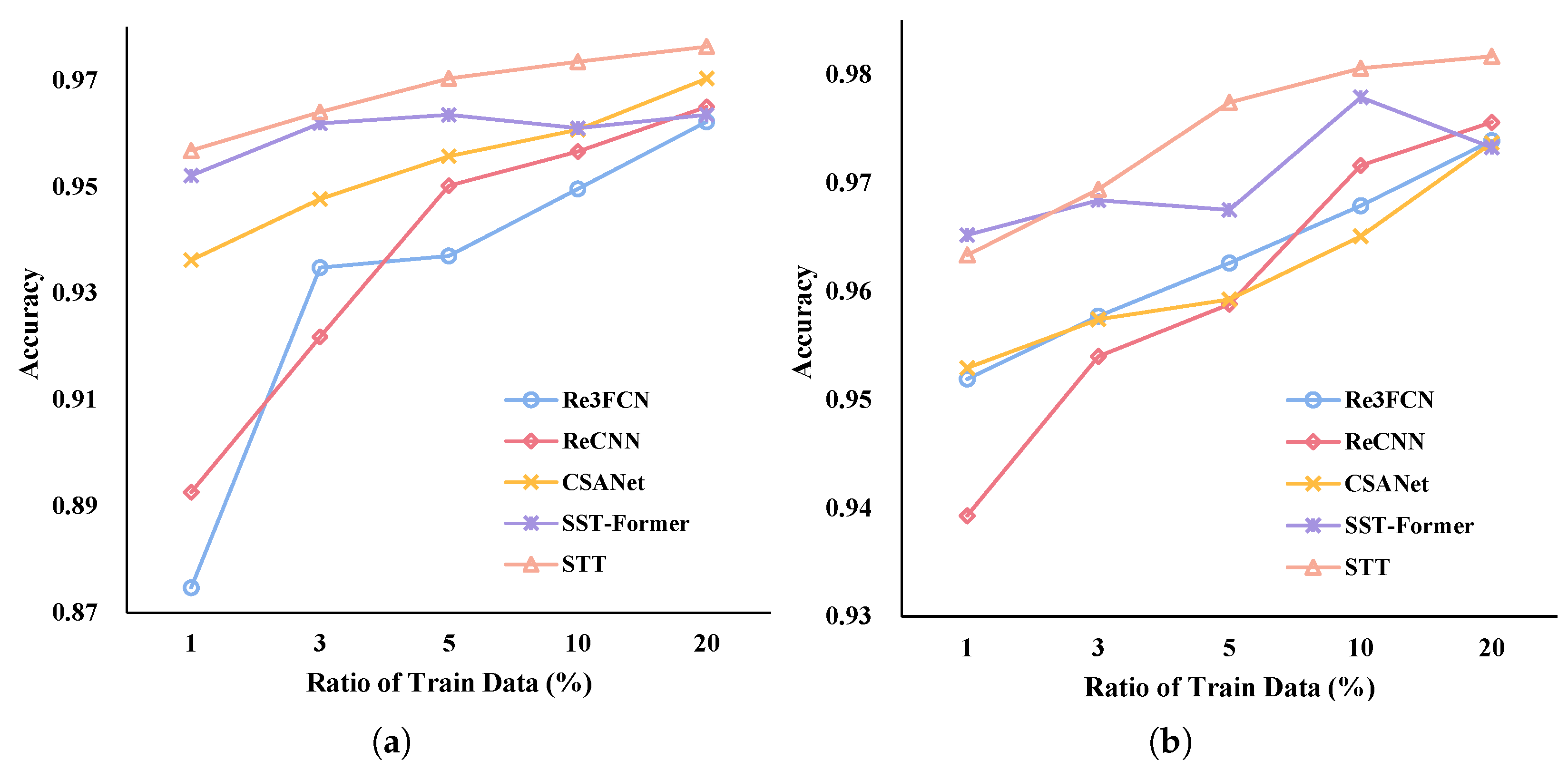
To verify the effectiveness of the proposed Spectral–Temporal Transformer, we perform a series of experiments with varying parameters on three widely used hyperspectral image change detection datasets and compare the results with those obtained from eight other methods: CVA, PCA–CVA, TDRD, UTCNN, Re3FCN, ReCNN, CSANet, and SST–Former.
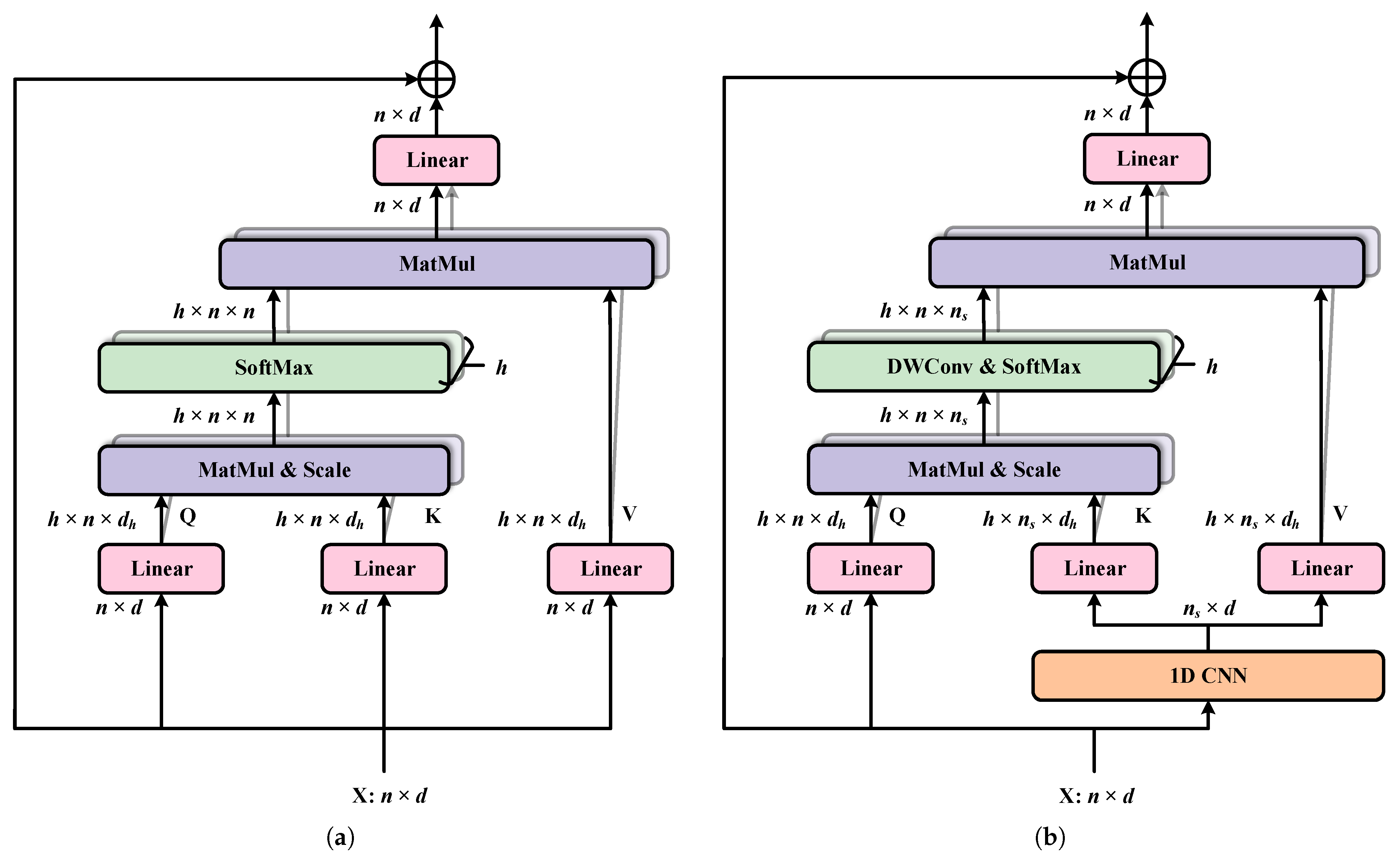
Aiming to fully explore the discriminative sequential properties of bi-temporal HSIs, e.g., the correlation and variability between different spectral bands, and temporal dependency, we construct a global spectrum–time-receptive field based on Transformer in the proposed STT method. Group-wise band embedding and efficient multi-head self-attention are employed to strengthen the use of local band information and improve computation efficiency, respectively.
We utilize OA and Kappa scores as objective evaluation measures to comprehensively assess the performance of the proposed methods in HSI CD, enabling a rigorous comparison of different approaches. As presented in
Figure 7,
Figure 8 and
Figure 9, our proposed method exhibits the best visual performance. As presented in
Table 4,
Table 5 and
Table 6, the proposed method offers superior detection abilities compared to other algorithms. In particular, on the River dataset with more bands, our proposed method has a significant lead thanks to the full exploitation of the sequence properties of HSIs. Based on the analysis of the detection results, we can conclude that the STT has an excellent detection performance compared to the above methods. These results highlight the effectiveness and potential of STT in addressing the HSI CD task, providing valuable insights into the performance of different methods.
While our algorithm demonstrates a superior detection performance, it is important to note that several limitations still exist, which must be addressed in future research. The incorporation of spatial information is essential in remote sensing image processing. Although we can obtain spatial information from image patches, the spatial structure is lost in the subsequent feature-extraction process. This highlights the need for further research to address the challenge of preserving spatial information.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}