
A Detection Method for Collapsed Buildings Combining Post-Earthquake High-Resolution Optical and Synthetic Aperture Radar Images


Abstract
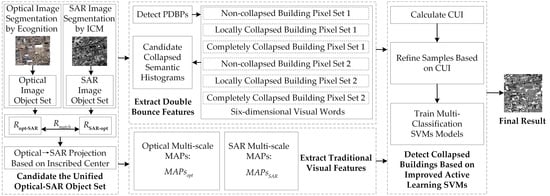
:
1. Introduction
- (1)
- Methods based on pre-earthquake and post-earthquake images: Such methods can be used to evaluate the damage degree of buildings by extracting changes of typical features from pre-earthquake/post-earthquake images [9]. Due to the introduction of pre-earthquake data for reference, other ground objects with features similar to collapsed buildings that have existed before earthquakes generally can be effectively eliminated from detection results by using such methods. In spite of this, normal urban evolution may also produce abundant changes in addition to earthquake impact. Furthermore, the lack of pre-earthquake data after earthquakes is often the bottleneck that restricts the popularization and application of such methods [10,11,12].
- (2)
- Methods based on post-earthquake images: Such methods eliminate the dependence on pre-earthquake data and have stronger universality compared with methods based on pre-earthquake and post-earthquake images [13]. Collapsed buildings are depicted by extracting manually defined or automatically extracted features such as spectra, texture and space and thus an appropriate classifier is selected for prediction [14]. Even so, the diversity of collapsed buildings and complexity of post-earthquake scenarios lead to more prominent problems of different objects with the same spectra and same object with different spectra, which requires establishing more discriminative classification models. Furthermore, the lack of elevation information, as the direct evidence to determine whether buildings collapse or not, is still the main challenge in practical application of such methods [15].
- (3)
- Methods combining elevation data: Based on remote sensing images, elevation information provided by elevation data, such as LiDAR and digital elevation model (DEM), is used in such methods as a strong basis for determining whether buildings collapse or not [16,17,18]. Although remote sensing images are strongly complementary with elevation data, it is not a common practice to specially collect and produce elevation data only for the detection of collapsed buildings in practical application. In addition, there is no reliable method for scanning and measuring collapsed buildings at present.
2. Methodology
2.1. Construction of the Unified Optical-SAR Object Set Based on OpticalandSAR-ObjectsExtraction
2.1.1. Image Segmentation
2.1.2. Establishment of the Coarse Registration-Based Affine Transformation Equation
2.1.3. Projection of Inscribed Centers of Objects and Region Growing
2.2. Extraction of Double Bounce Features Based on Double Bounce Collapse Semantic
2.2.1. Detection of PDBPs
2.2.2. Construction of the Collapse Semantic Histogram
- Pixel set 1 of non-collapsed buildings. Double bounce of non-collapsed buildings usually appears as a highlighted line at the corner of a building. Therefore, line segments of double bounce with features of non-collapsed buildings overlap or are adjacent to profiles of the objects, showing a similar curvature and direction and a certain length. The specific search and discrimination steps are shown as follows:
- Pixel set 1 of locally collapsed buildings. In , blurred line segments with the length smaller than or equal to are retained, namely the constructed visual word.
- Pixel set 1 of completely collapsed buildings. Except for PDBPs which have been defined as visual words, the other PDBPs located on the profile or within one pixel outside the profile are the constructed visual word.
- Pixel set 2 of non-collapsed buildings. Within pixels in profile, a candidate blurred line-segment set meeting conditions is searched from any one pixel . Except for different starting points and scopes of search, other steps are exactly the same as above. Because the blurred line segments in are located inside , the is directly regarded as the constructed visual word.
- Pixel set 2 of locally collapsed buildings. In , PDBPs without being defined as visual words are defined as and the ratio of the number of to the total number of pixels is . Furthermore, the ratio of the total number of PDBPs in the SAR image to the total number of pixels is defined as . If , is the constructed visual word.
- Pixel set 2 of completely collapsed buildings. In , PDBPs without being defined as visual words are the constructed visual word.
2.3. Extraction of Traditional Visual Features Based on MAPs
2.4. Detection of Collapsed Buildings Based on Improved Active Learning SVMs
3. Experiments and Evaluation
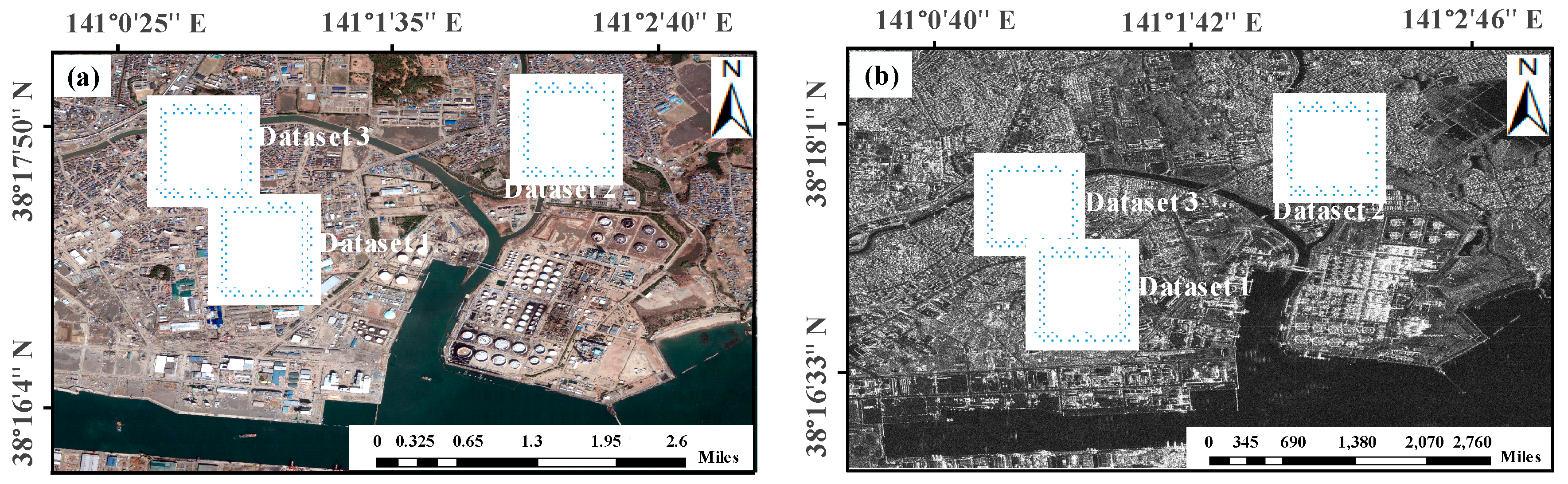
3.1. Study Area and Dataset Description
3.2. Experimental Settings and Methods for Comparison
3.3. General Results and Analysis
3.4. Visual Comparison of Representative Patches
4. Discussion
4.1. Validity Analysis of Combined Optical and SAR Images
4.2. Validity Analysis of DoubleBounceCollapseSemantic
4.3. Validity Analysis of CUI
4.4. Analysis of Effects of the Number of Initial Training Samples
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moya, L.; Geiß, C.; Hashimoto, M.; Mas, E. Disaster Intensity-Based Selection of Training Samples for Remote Sensing Building Damage Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8288–8304. [Google Scholar] [CrossRef]
- Cotrufo, S.; Sandu, C.; Tonolo, F.G.; Boccardo, P. Building damage assessment scale tailored to remote sensing vertical imagery. Eur. J. Remote Sens. 2018, 51, 991–1005. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhao, S.; Jin, H.; Li, Y.; Guo, Y. A method of combined texture features and morphology for building seismic damage information extraction based on GF remote sensing images. Acta Seismol. 2019, 5, 658–670. [Google Scholar]
- Rui, Z.; Yi, Z.; Shi, W. Construction and Application of a Post-Quake House Damage Model Based on Multiscale Self-Adaptive Fusion of Spectral Textures Images. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 6631–6634. [Google Scholar]
- Rui, X.; Cao, Y.; Yuan, X.; Kang, Y.; Song, W. DisasterGAN: Generative Adversarial Networks for Remote Sensing Disaster Image Generation. Remote Sens. 2021, 13, 4284. [Google Scholar] [CrossRef]
- Wen, Q.; Jiang, K.; Wang, W.; Liu, Q.; Guo, Q.; Li, L.; Wang, P. Automatic Building Extraction from Google Earth Images under Complex Backgrounds Based on Deep Instance Segmentation Network. Sensors 2019, 19, 333. [Google Scholar] [CrossRef] [Green Version]
- Janalipour, M.; Mohammadzadeh, A. A novel and automatic framework for producing building damage map using post-event LiDAR data. Int. J. Disaster Risk Reduct. 2019, 39, 101238. [Google Scholar] [CrossRef]
- Kaoshan, D.; Ang, L.; Hexiao, Z. Surface damage quantification of post-earthquake building based on terrestrial laser scan data. Struct. Control. Health Monit. 2018, 25, e2210. [Google Scholar]
- Jihui, T.; Deren, L.; Wenqing, F. Detecting Damaged Building Regions Based on Semantic Scene Change from Multi-Temporal High-Resolution Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2017, 6, 131. [Google Scholar]
- Jun, L.; Pei, L. Extraction of Earthquake-Induced Collapsed Buildings from Bi-Temporal VHR Images Using Object-Level Homogeneity Index and Histogram. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2755–2770. [Google Scholar]
- Akhmadiya, A.; Nabiyev, N.; Moldamurat, K. Use of Sentinel-1 Dual Polarization Multi-Temporal Data with Gray Level Co-Occurrence Matrix Textural Parameters for Building Damage Assessment. Pattern Recognit. Image Anal. 2021, 31, 240–250. [Google Scholar] [CrossRef]
- Zhou, Z.; Gong, J.; Hu, X. Community-scale multi-level post-hurricane damage assessment of residential buildings using multi-temporal airborne LiDAR data. Autom. Constr. 2019, 98, 30–45. [Google Scholar] [CrossRef]
- Jiang, X.; He, Y.; Li, G.; Liu, Y. Building Damage Detection via Superpixel-Based Belief Fusion of Space-Borne SAR and Optical Images. IEEE Sens. J. 2019, 20, 2008–2022. [Google Scholar] [CrossRef]
- Xin, Y.; Ming, L.; Jun, W. Building-Based Damage Detection from Postquake Image Using Multiple-Feature Analysis. IEEE Geosci. Remote Sens. Lett. 2017, 14, 499–503. [Google Scholar]
- Chen, Q.; Yang, H.; Li, L.; Liu, X. A Novel Statistical Texture Feature for SAR Building Damage Assessment in Different Polarization Modes. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 154–165. [Google Scholar] [CrossRef]
- Wang, X.; Li, P. Extraction of urban building damage using spectral, height and corner information from VHR satellite images and airborne LiDAR data. ISPRS J. Photogramm. Remote Sens. 2020, 159, 322–336. [Google Scholar] [CrossRef]
- Adriano, B.; Xia, J.; Baier, G.; Yokoya, N.; Koshimura, S. Multi-Source Data Fusion Based on Ensemble Learning for Rapid Building Damage Mapping during the 2018 Sulawesi Earthquake and Tsunami in Palu, Indonesia. Remote Sens. 2019, 11, 886. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Luan, Y.; Li, Z.; Liu, X.; Li, C.; Chang, X. Mozambique Flood (2019) Caused by Tropical Cyclone Idai Monitored from Sentinel-1 and Sentinel-2 Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8761–8772. [Google Scholar] [CrossRef]
- Zheng, W.; Hu, D.; Wang, J. Fault Localization Analysis Based on Deep Neural Network. Math. Probl. Eng. 2016, 4, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Xu, W.; Chen, H.; Jiang, J.; Li, X. A Novel Framework Based on Mask R-CNN and Histogram Thresholding for Scalable Segmentation of New and Old Rural Buildings. Remote Sens. 2021, 13, 1070. [Google Scholar] [CrossRef]
- Mahmoud, A.; Mohamed, S.; El-Khoribi, R.; Abdelsalam, H. Object Detection Using Adaptive Mask RCNN in Optical Remote Sensing Images. Int. Intell. Eng. Syst. 2020, 13, 65–76. [Google Scholar] [CrossRef]
- Zhao, K.; Kang, J.; Jung, J.; Sohn, G. Building Extraction from Satellite Images Using Mask R-CNN With Building Boundary Regularization. In CVPR Workshops; IEEE: New York, NY, USA, 2018; pp. 247–251. [Google Scholar]
- Bhuiyan, M.A.E.; Witharana, C.; Liljedahl, A.K. Use of Very High Spatial Resolution Commercial Satellite Imagery and Deep Learning to Automatically Map Ice-Wedge Polygons across Tundra Vegetation Types. J. Imaging 2020, 6, 137. [Google Scholar] [CrossRef] [PubMed]
- Witharana, C.; Bhuiyan, A.E.; Liljedahl, A.K.; Kanevskiy, M.; Epstein, H.E.; Jones, B.M.; Daanen, R.; Griffin, C.G.; Kent, K.; Jones, M.K.W. Understanding the synergies of deep learning and data fusion of multispectral and panchromatic high resolution commercial satellite imagery for automated ice-wedge polygon detection. ISPRS J. Photogramm. Remote Sens. 2020, 170, 174–191. [Google Scholar] [CrossRef]
- Ferro, A.; Brunner, D.; Bruzzone, L.; Lemoine, G. On the Relationship Between Double Bounce and the Orientation of Buildings in VHR SAR Images. IEEE Geosci. Remote Sens. Lett. 2011, 8, 612–616. [Google Scholar] [CrossRef]
- Cho, K.; Park, S.; Cho, J.; Moon, H.; Han, S. Automatic Urban Area Extraction from SAR Image Based on Morphological Operator. IEEE Geosci. Remote Sens. Lett. 2021, 18, 831–835. [Google Scholar] [CrossRef]
- Zhang, A.; Sun, G.; Liu, S. Multi-scale segmentation of very high-resolution remote sensing image based on gravitational field and optimized region merging. Multimed. Tools Appl. 2017, 76, 15105–15122. [Google Scholar] [CrossRef]
- Nazarinezhad, J.; Dehghani, M. A contextual-based segmentation of compact PolSAR images using Markov Random Field (MRF) model. Int. J. Remote Sens. 2018, 40, 985–1010. [Google Scholar] [CrossRef]
- Li, Q.; Yin, K.; Yuan, G. ROI Extraction of Village Targets and Heterogeneous Image Registration. Modern Radar. 2019, 41, 31–36. [Google Scholar]
- Huang, H.; Li, X.; Chen, C. Individual Tree Crown Detection and Delineation from Very-High-Resolution UAV Images Based on Bias Field and Marker-Controlled Watershed Segmentation Algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2253–2262. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, Z.; Chen, X.; Li, S.; Zhou, Y. Dictionary Learning-Based Hough Transform for Road Detection in Multispectral Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2330–2334. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, Y.; Chen, X.; Jiang, H.; Mukherjee, M.; Wang, S. Automatic Building Detection from High-Resolution Remote Sensing Images Based on Joint Optimization and Decision Fusion of Morphological Attribute Profiles. Remote Sens. 2021, 13, 357. [Google Scholar] [CrossRef]
- Shi, F.; Wang, C.; Shen, Y.; Zhang, Y.; Qui, X. High-resolution Remote Sensing Image Post-earthquake Building Detection Based on Sparse Dictionary. Chin. J. Sci. Instrum. 2020, 41, 205–213. [Google Scholar]
- Du, Y.; Gong, L.; Li, Q. Earthquake-Induced Building Damage Assessment on SAR Multi-Texture Feature Fusion. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 6608–6610. [Google Scholar]
- Wang, C.; Qiu, X.; Huan, H.; Wang, S.; Zhang, Y.; Chen, X.; He, W. Earthquake-Damaged Buildings Detection in Very High-Resolution Remote Sensing Images Based on Object Context and Boundary Enhanced Loss. Remote Sens. 2021, 13, 3119. [Google Scholar] [CrossRef]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. arXiv 2020, arXiv:2004.08790. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method/ Indicator | OA (%) | FP (%) | FN (%) | Pnb (%) | Pcb (%) | Po (%) |
|---|---|---|---|---|---|---|
| Evaluation Criteria | The Higher the Better | The Lower the Better | The Lower the Better | The Higher the Better | The Higher the Better | The Higher the Better |
| Proposed method | 82.39 | 9.65 | 17.61 | 52.92 | 74.57 | 88.55 |
| SD-OPT | 75.85 | 14.59 | 25.15 | 41.35 | 46.82 | 92.62 |
| RF-SAR | 63.99 | 21.96 | 36.01 | 25.29 | 44.51 | 73.17 |
| OCR-BE | 78.46 | 13.31 | 15.35 | 78.94 | 29.48 | 90.10 |
| UNet 3+ | 77.28 | 15.80 | 19.96 | 80.21 | 14.45 | 92.52 |
| Method/ Indicator | OA (%) | FP (%) | FN (%) | Pnb (%) | Pcb (%) | Po (%) |
|---|---|---|---|---|---|---|
| Evaluation Criteria | The Higher the Better | The Lower the Better | The Lower the Better | The Higher the Better | The Higher the Better | The Higher the Better |
| Proposed method | 80.60 | 10.74 | 19.40 | 50.22 | 73.94 | 85.68 |
| SD-OPT | 74.66 | 14.51 | 26.34 | 17.77 | 47.22 | 87.14 |
| RF-SAR | 63.41 | 22.39 | 36.59 | 24.38 | 29.63 | 74.02 |
| OCR-BE | 77.14 | 12.49 | 22.20 | 76.03 | 22.30 | 87.26 |
| UNet 3+ | 76.80 | 11.87 | 24.59 | 50.00 | 21.76 | 89.73 |
| Method/ Indicator | OA (%) | FP (%) | FN (%) | Pnb (%) | Pcb (%) | Po (%) |
|---|---|---|---|---|---|---|
| Evaluation Criteria | The Higher the Better | The Lower the Better | The Lower the Better | The Higher the Better | The Higher the Better | The Higher the Better |
| Proposed method | 78.61 | 12.80 | 22.69 | 55.08 | 75.47 | 83.51 |
| SD-OPT | 66.81 | 19.90 | 33.19 | 45.72 | 41.13 | 77.17 |
| RF-SAR | 59.23 | 25.60 | 40.77 | 22.73 | 27.55 | 74.77 |
| OCR-BE | 76.39 | 13.92 | 22.89 | 63.98 | 33.32 | 85.04 |
| UNet 3+ | 75.11 | 14.43 | 25.55 | 65.24 | 9.43 | 92.88 |
| Datasets | Method/Indicator | OA (%) | FP (%) | FN (%) | Pnb (%) | Pcb (%) | Po (%) |
|---|---|---|---|---|---|---|---|
| Evaluation Criteria | The Higher the Better | The Lower the Better | The Lower the Better | The Lower the Better | The Higher the Better | The Higher the Better | |
| Dataset 1 | Optical and SAR | 82.39 | 9.65 | 17.61 | 52.92 | 74.57 | 88.55 |
| Optical | 66.49 | 30.56 | 27.12 | 40.86 | 46.59 | 75.79 | |
| SAR | 74.68 | 14.49 | 23.32 | 50.19 | 57.23 | 81.10 | |
| Dataset 2 | Optical and SAR | 80.60 | 10.74 | 19.40 | 50.22 | 73.94 | 85.68 |
| Optical | 64.62 | 20.76 | 30.38 | 38.43 | 47.66 | 72.24 | |
| SAR | 74.71 | 14.48 | 25.29 | 45.04 | 54.91 | 83.33 | |
| Dataset 3 | Optical and SAR | 78.61 | 12.80 | 22.69 | 55.08 | 75.47 | 83.51 |
| Optical | 65.40 | 19.95 | 31.65 | 69.79 | 50.57 | 67.02 | |
| SAR | 72.30 | 16.07 | 25.70 | 45.45 | 62.91 | 79.76 |
| Datasets | Method/Indicator | OA (%) | FP (%) | FN (%) | Pnb (%) | Pcb (%) | Po (%) |
|---|---|---|---|---|---|---|---|
| Evaluation Criteria | The Higher the Better | The Lower the Better | The Lower the Better | The Higher the Better | The Higher the Better | The Higher the Better | |
| Dataset 1 | √ DoubleBounceCollapseSemantic | 82.39 | 9.65 | 17.61 | 52.92 | 74.57 | 88.55 |
| – DoubleBounceCollapseSemantic | 78.83 | 11.86 | 20.81 | 48.64 | 67.63 | 85.52 | |
| Dataset 2 | √ DoubleBounceCollapseSemantic | 80.60 | 10.74 | 19.40 | 50.22 | 73.94 | 85.68 |
| – DoubleBounceCollapseSemantic | 77.26 | 12.44 | 23.01 | 46.28 | 64.46 | 84.48 | |
| Dataset 3 | √ DoubleBounceCollapseSemantic | 78.61 | 12.80 | 22.69 | 55.08 | 75.47 | 83.51 |
| – DoubleBounceCollapseSemantic | 74.69 | 15.29 | 25.40 | 42.25 | 68.68 | 81.47 |
| Datasets | Method/Indicator | OA (%) | FP (%) | FN (%) |
|---|---|---|---|---|
| Evaluation Criteria | The Higher the Better | The Lower the Better | The Lower the Better | |
| Dataset 1 | √ CUI | 82.39 | 9.65 | 17.61 |
| – CUI | 81.58 | 9.81 | 18.33 | |
| Dataset 2 | √ CUI | 80.60 | 10.74 | 19.40 |
| – CUI | 79.07 | 12.45 | 20.01 | |
| Dataset 3 | √ CUI | 78.61 | 12.80 | 22.69 |
| – CUI | 76.90 | 13.27 | 23.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Zhang, Y.; Xie, T.; Guo, L.; Chen, S.; Li, J.; Shi, F. A Detection Method for Collapsed Buildings Combining Post-Earthquake High-Resolution Optical and Synthetic Aperture Radar Images. Remote Sens. 2022, 14, 1100. https://doi.org/10.3390/rs14051100
Wang C, Zhang Y, Xie T, Guo L, Chen S, Li J, Shi F. A Detection Method for Collapsed Buildings Combining Post-Earthquake High-Resolution Optical and Synthetic Aperture Radar Images. Remote Sensing. 2022; 14(5):1100. https://doi.org/10.3390/rs14051100
Chicago/Turabian StyleWang, Chao, Yan Zhang, Tao Xie, Lin Guo, Shishi Chen, Junyong Li, and Fan Shi. 2022. "A Detection Method for Collapsed Buildings Combining Post-Earthquake High-Resolution Optical and Synthetic Aperture Radar Images" Remote Sensing 14, no. 5: 1100. https://doi.org/10.3390/rs14051100