
Spatial Analysis of Flood Hazard Zoning Map Using Novel Hybrid Machine Learning Technique in Assam, India
 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
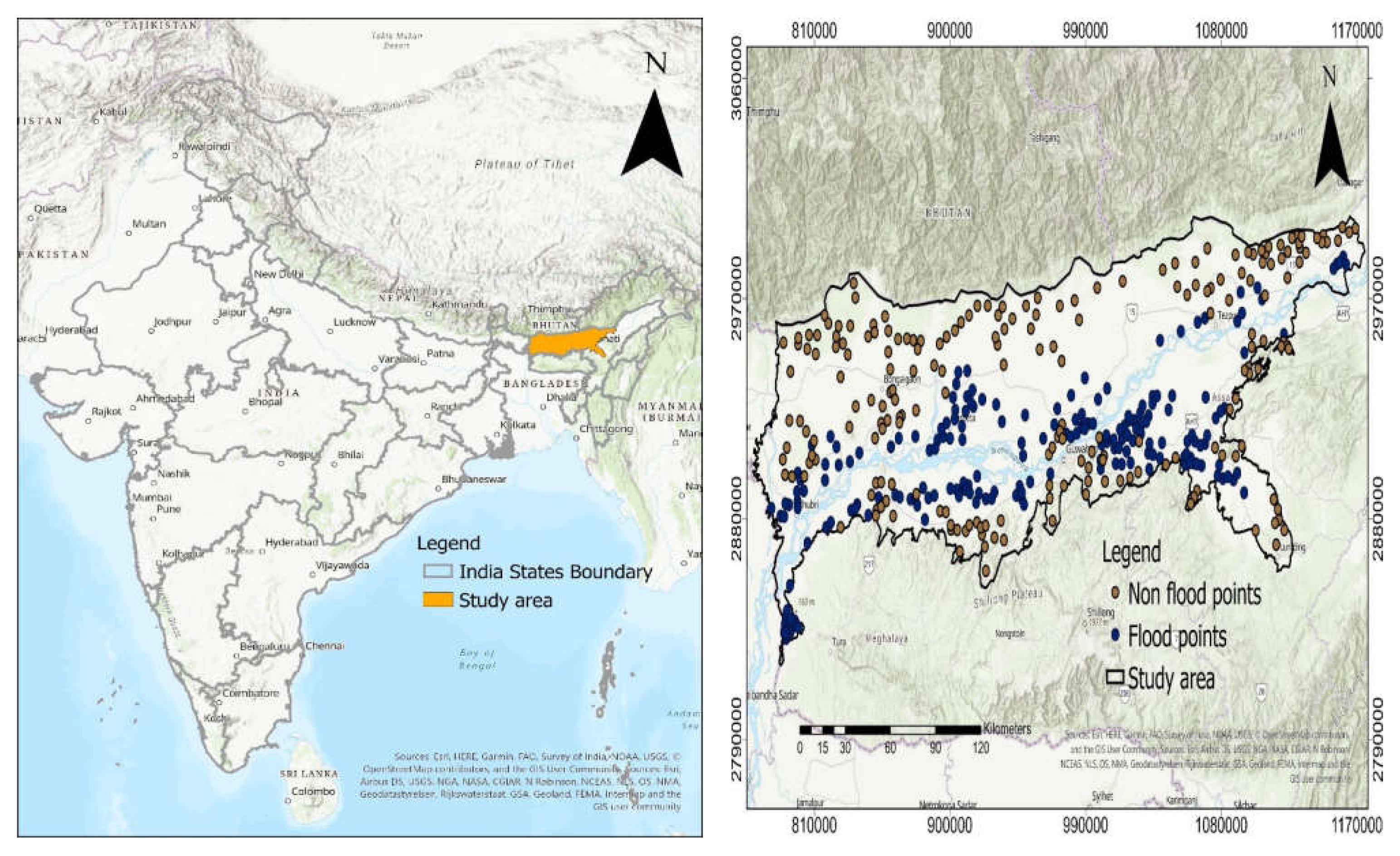
2.1. Study Area
2.2. Historical Flood Inventory Mapping
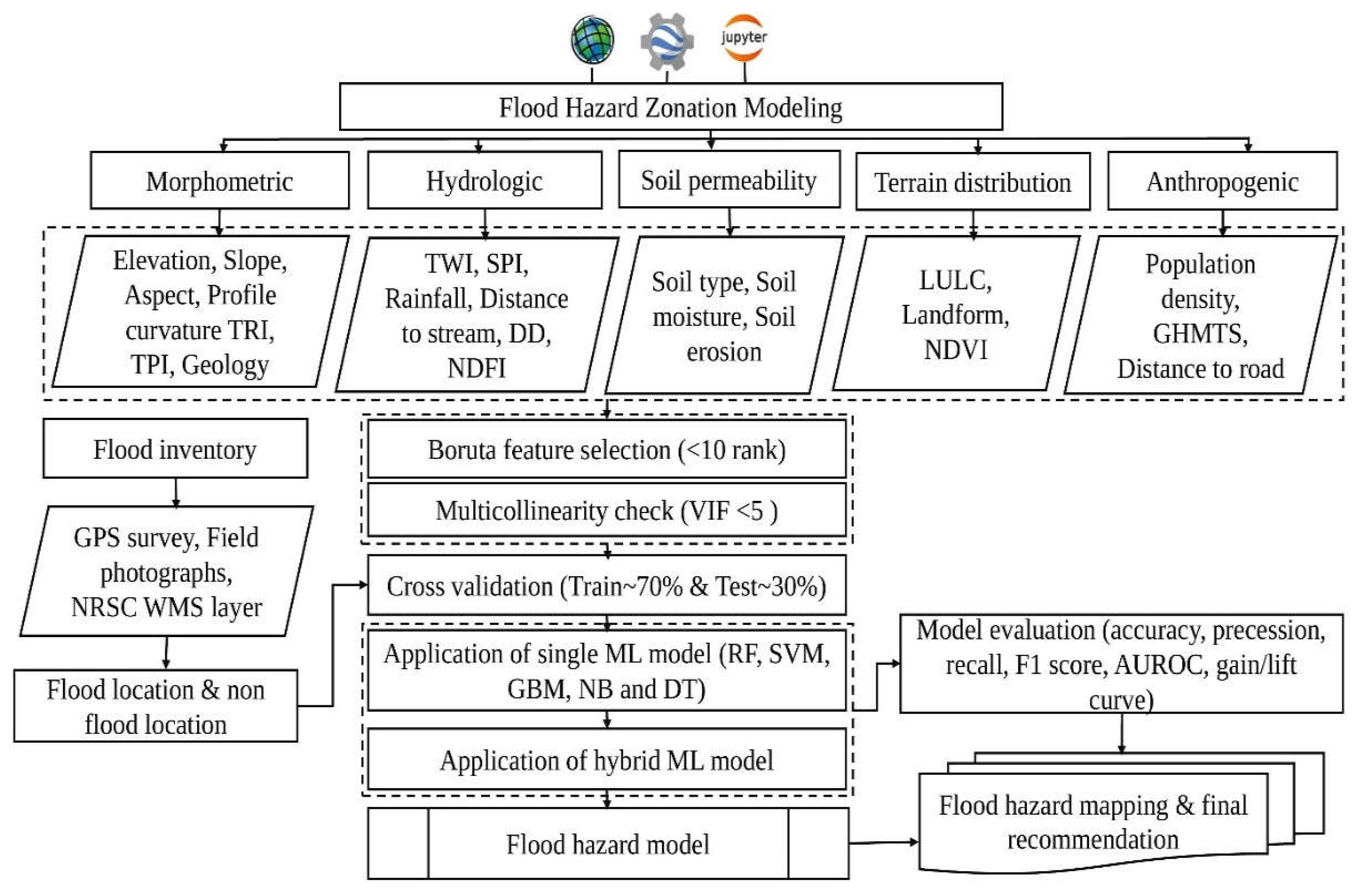
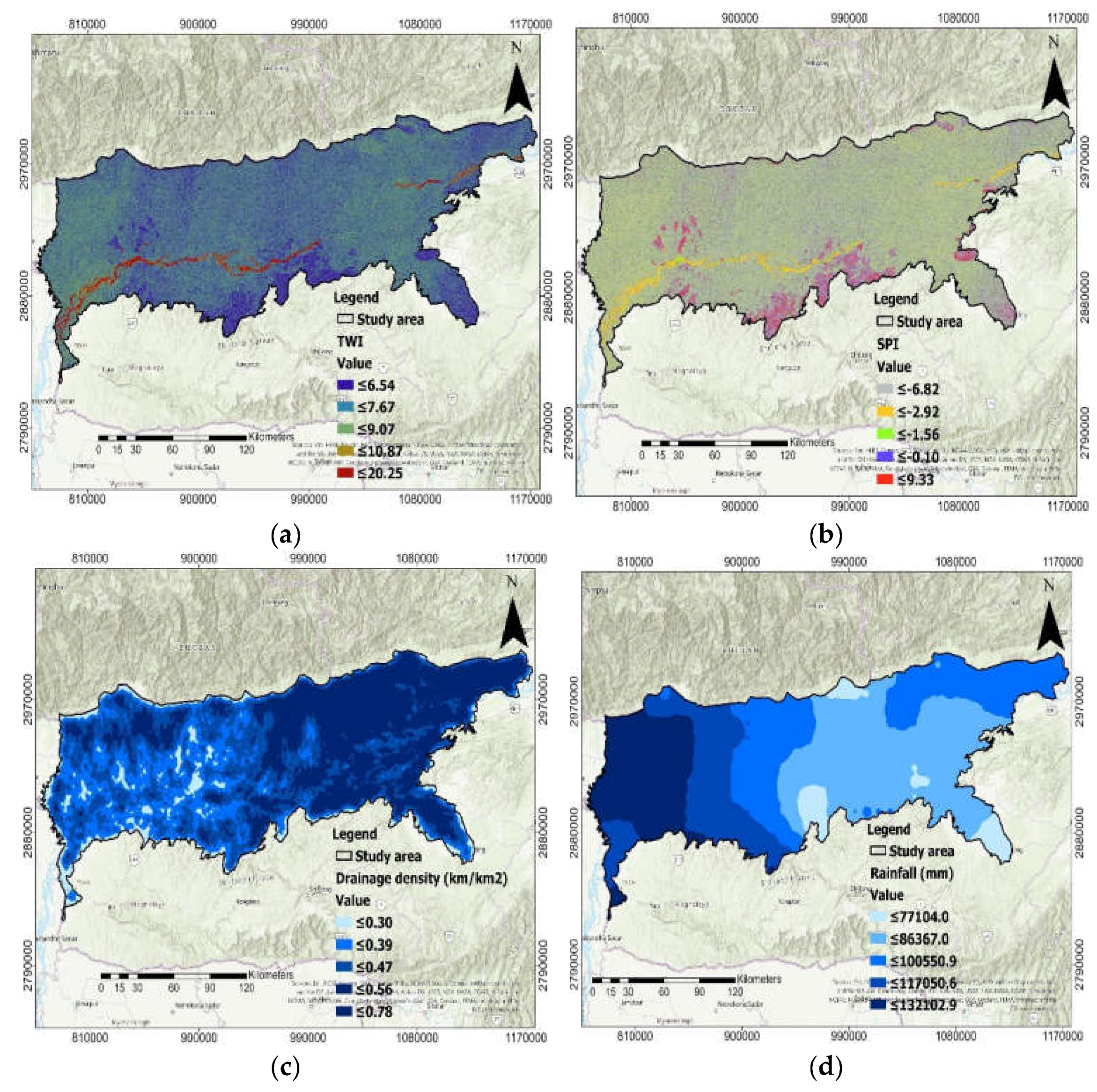
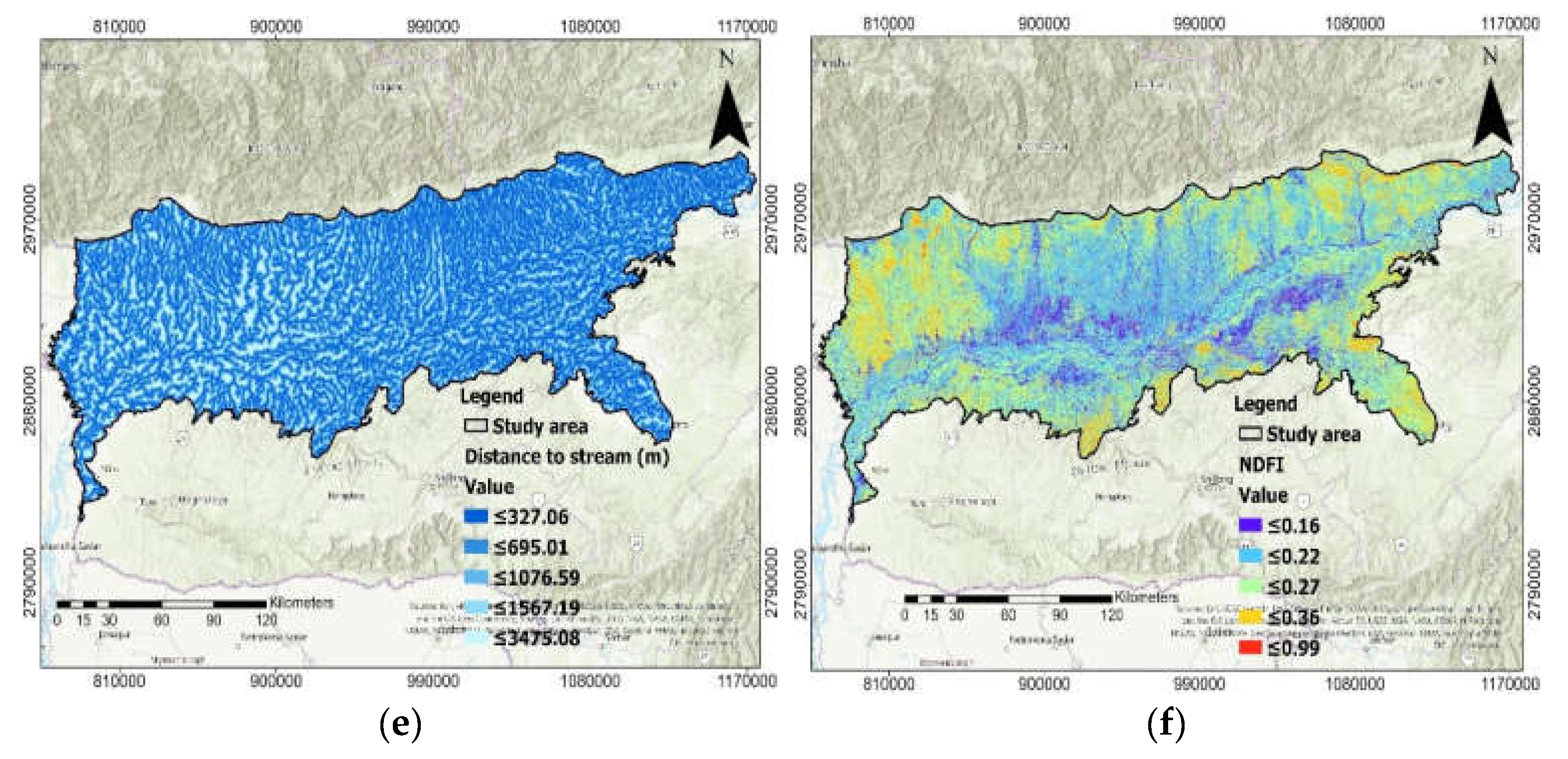
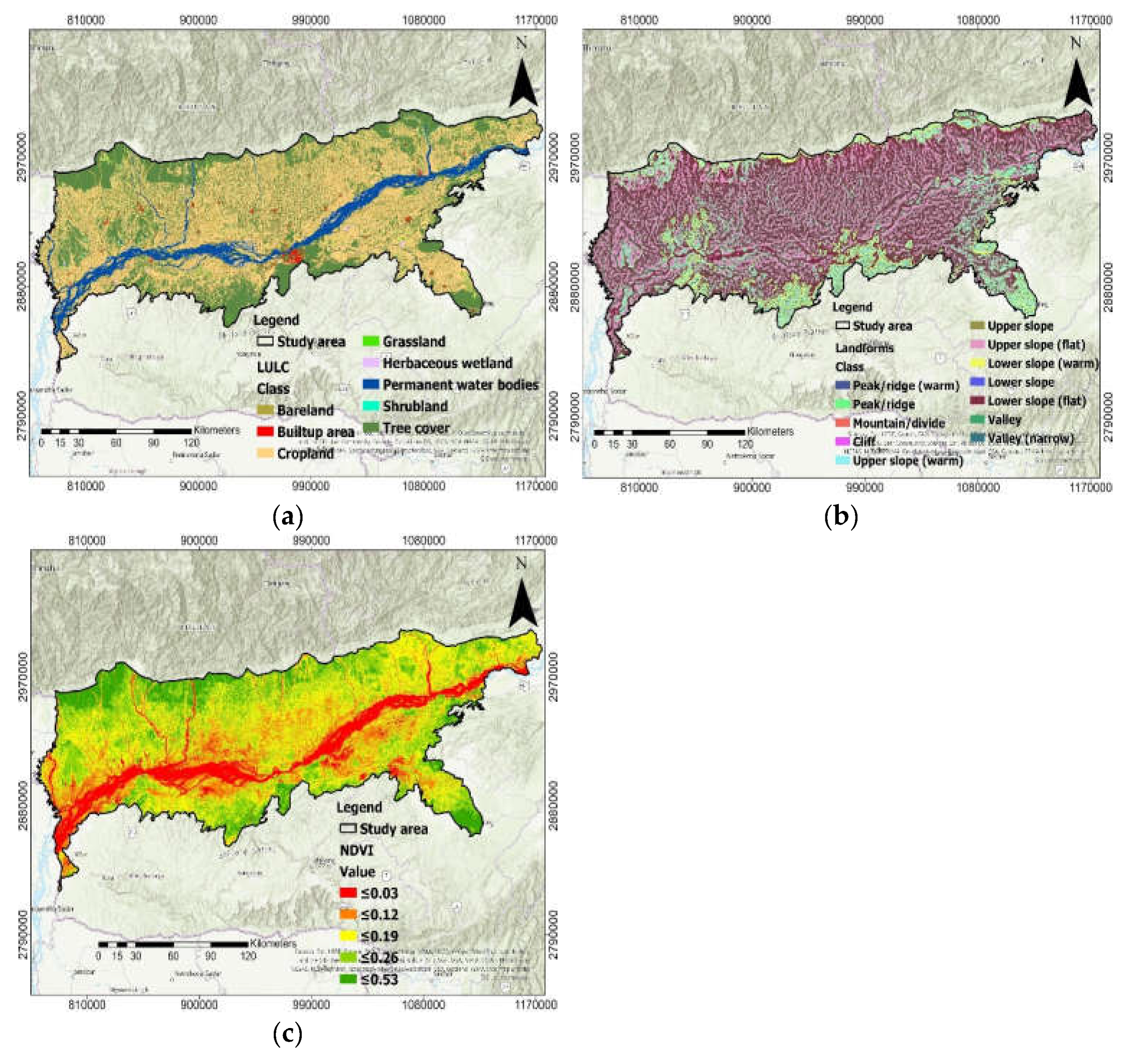
2.3. Flood-Causative Factors
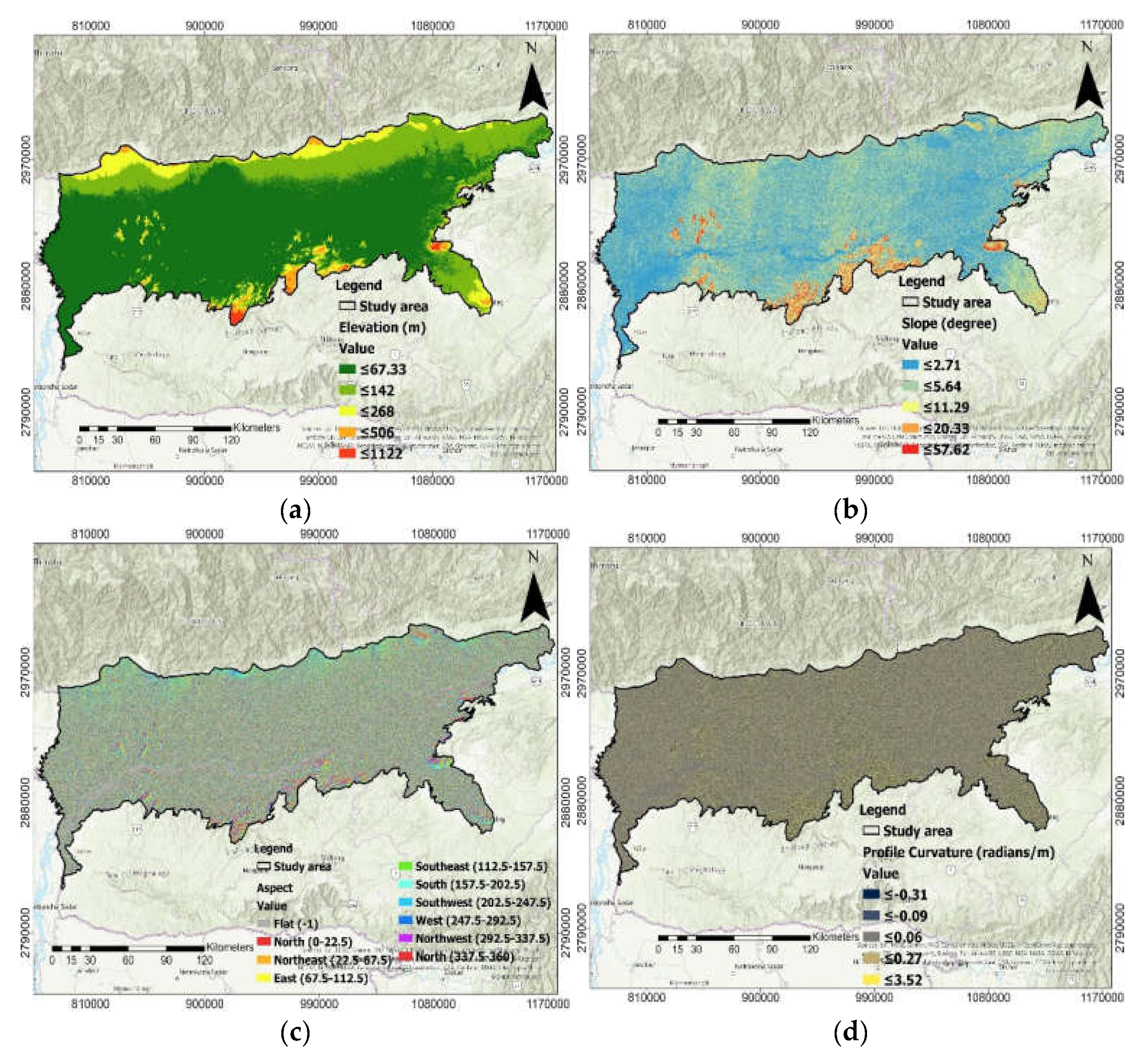
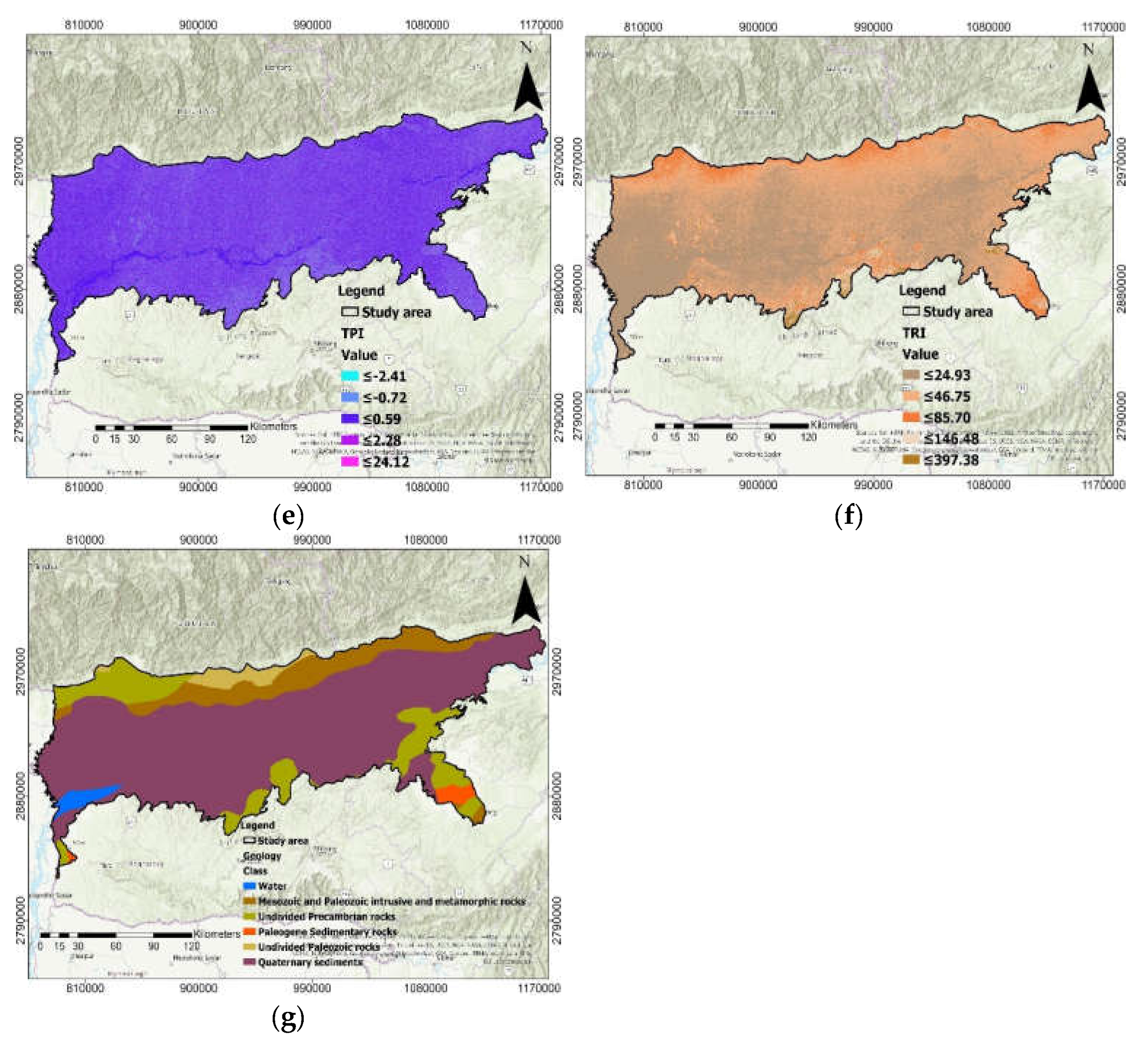
2.4. Morphometric Factors
2.5. Hydrologic Factors
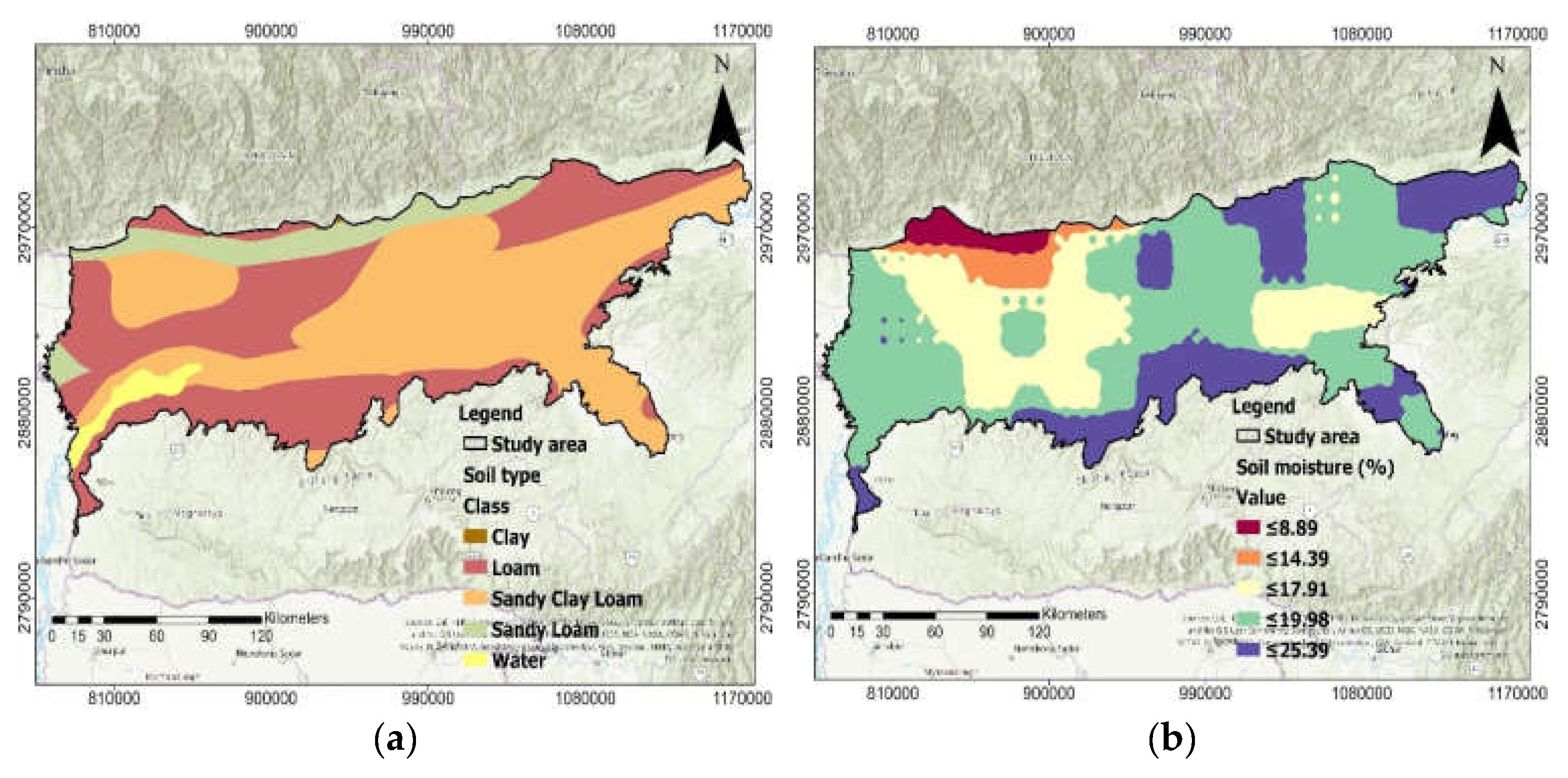
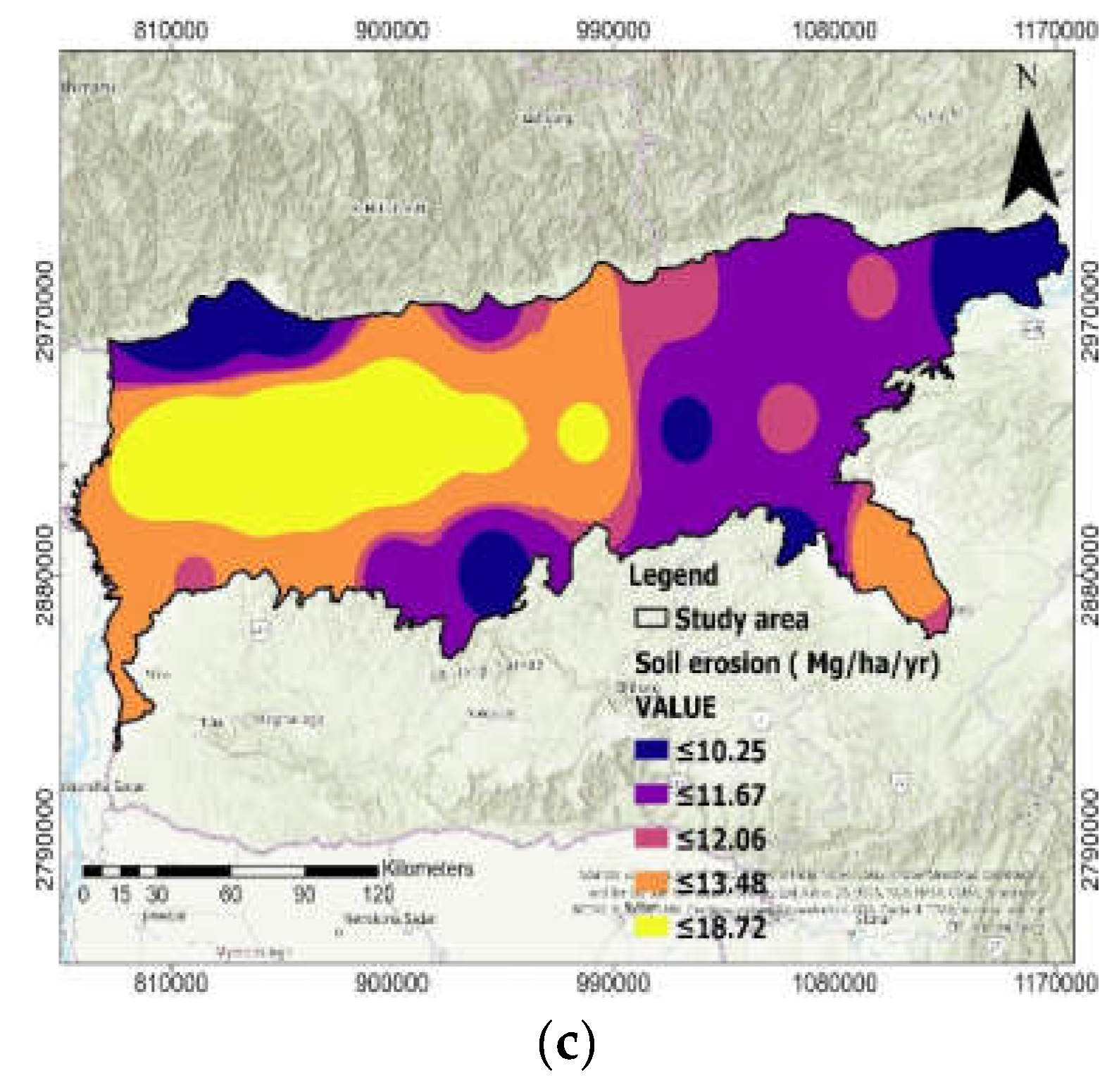
2.6. Soil Permeability Factors
2.7. Terrain Distribution Factors
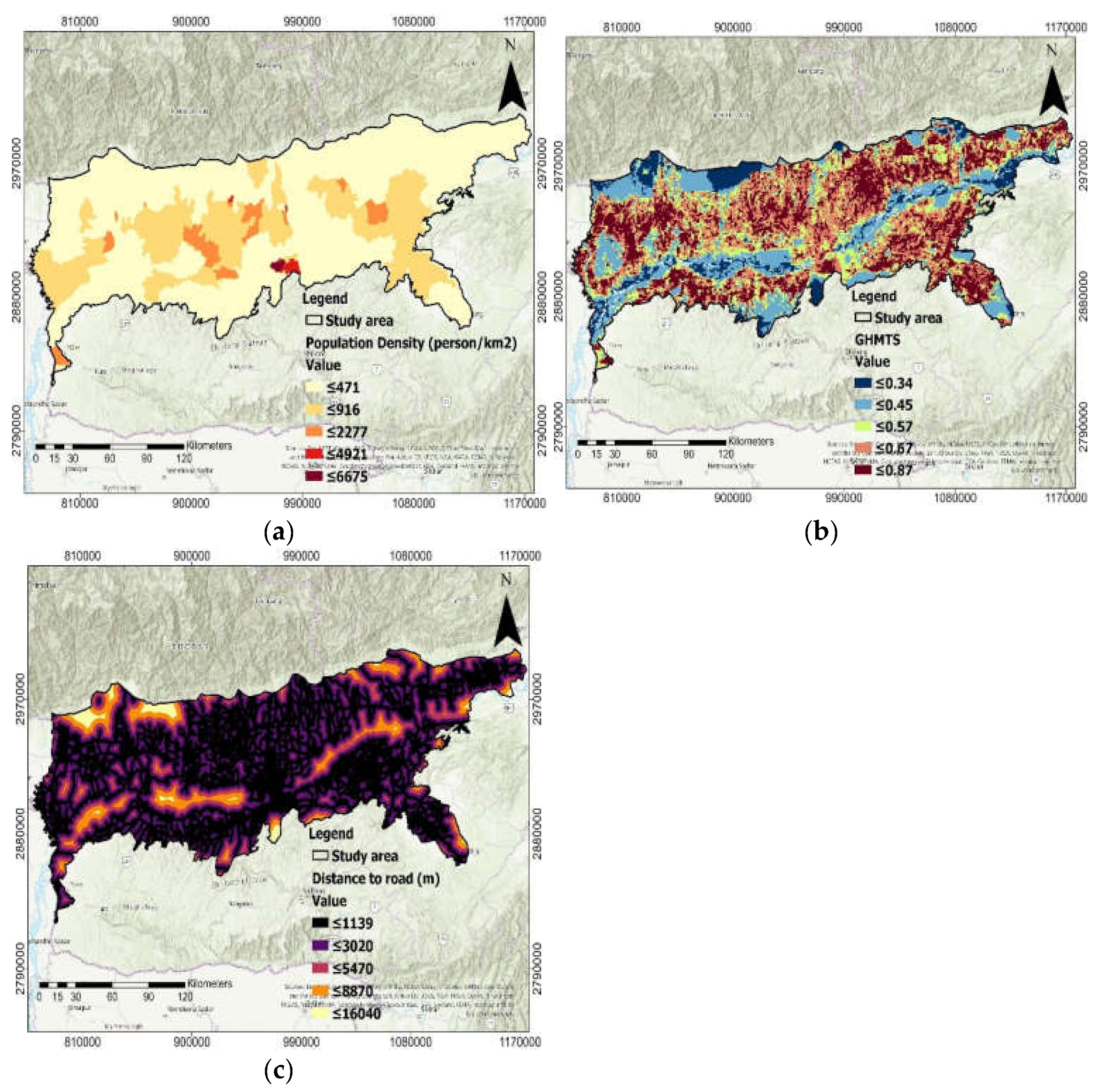
2.8. Anthropogenic Inferences Factors
2.9. Boruta Feature Ranking and Multicollinearity Check
2.10. Machine Learning Model
2.10.1. Random Forest
2.10.2. Support Vector Machine
2.10.3. Gradient Boosting Model
2.10.4. Naïve Bayes
2.10.5. Decision Tree
2.10.6. Hybrid Modeling
2.11. Model Validation and Performance Evaluation
3. Results
3.1. Multicollinearity Test and Boruta Feature Ranking
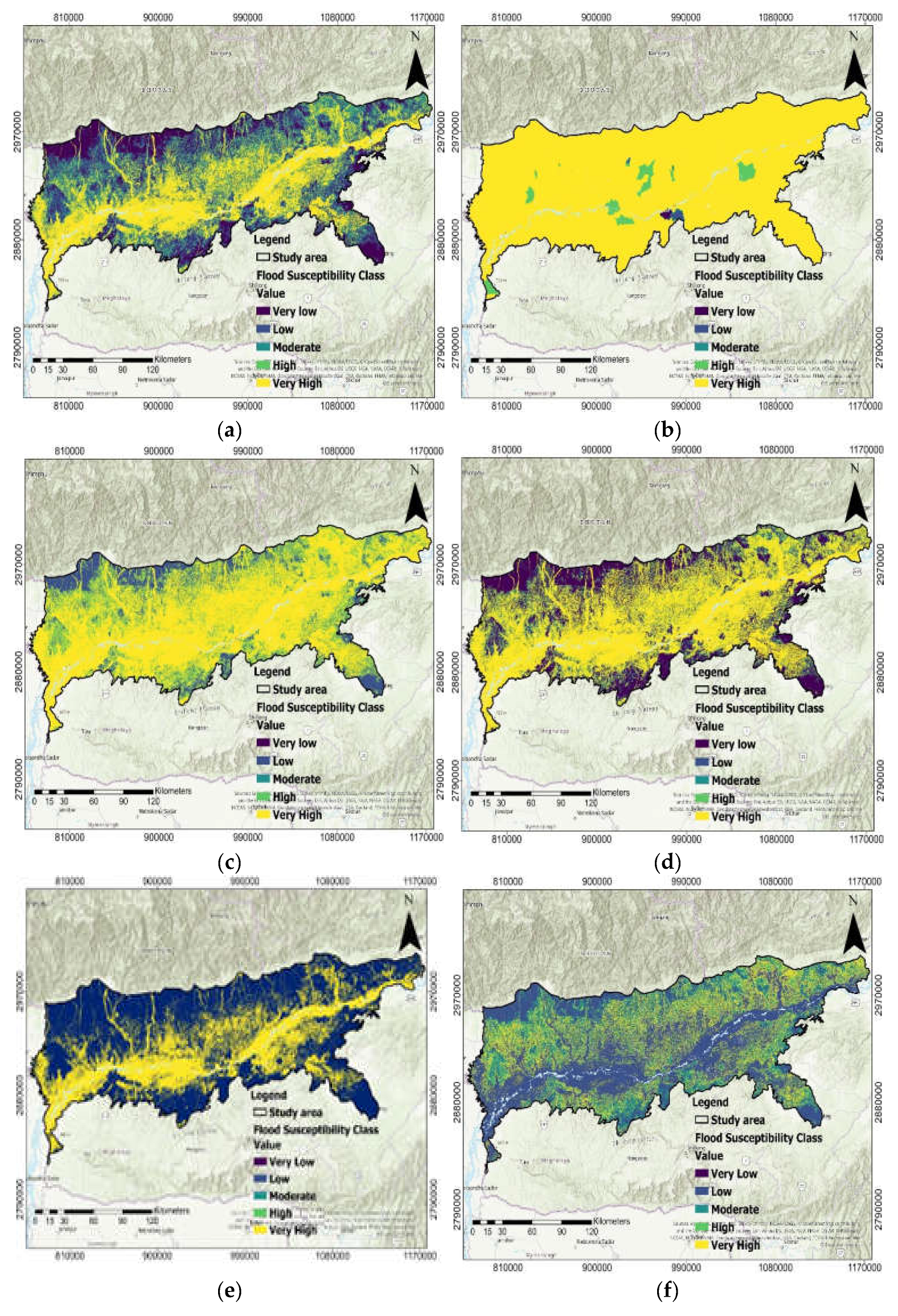
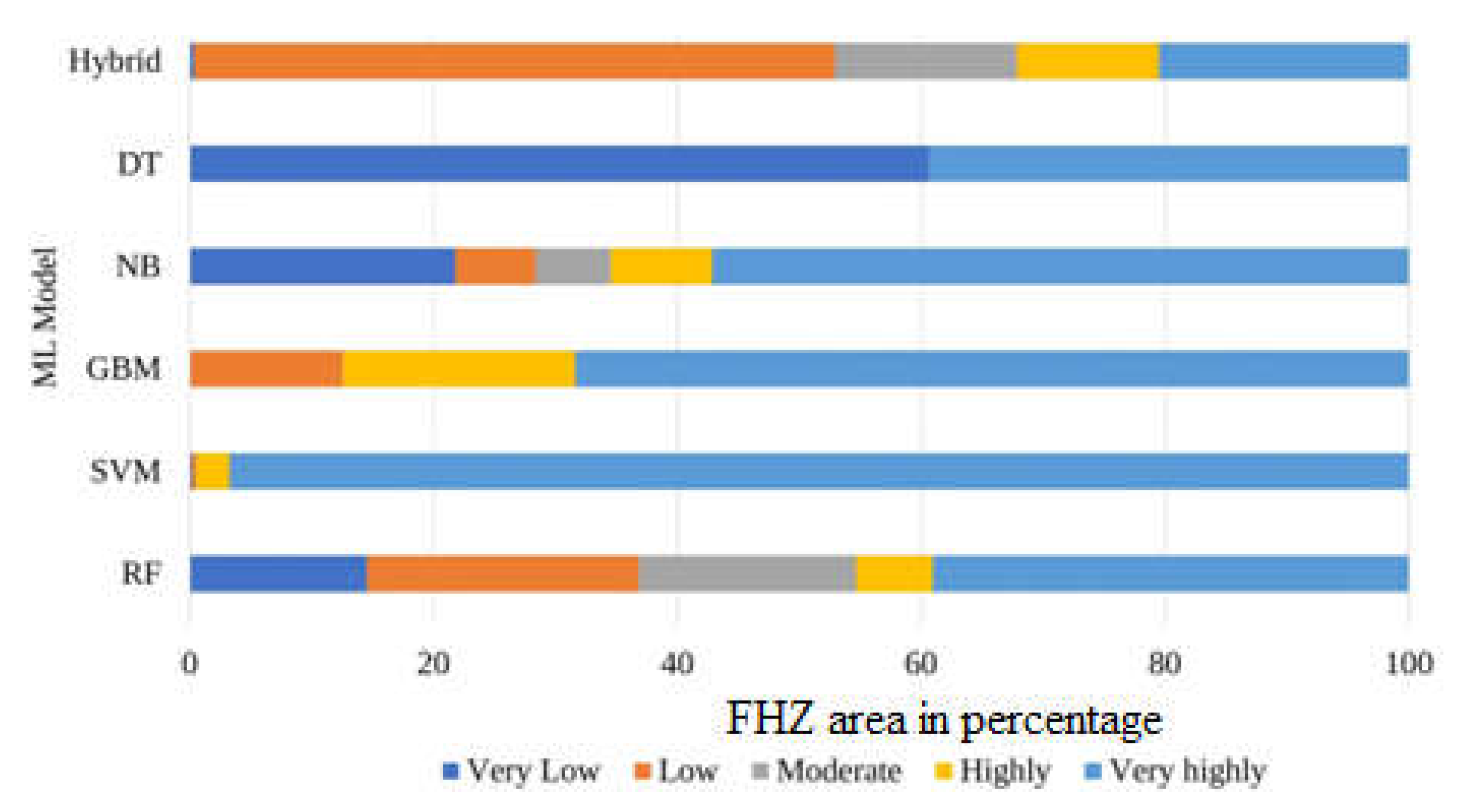
3.2. Flood Hazard Zoning
3.3. Validation of ML Models
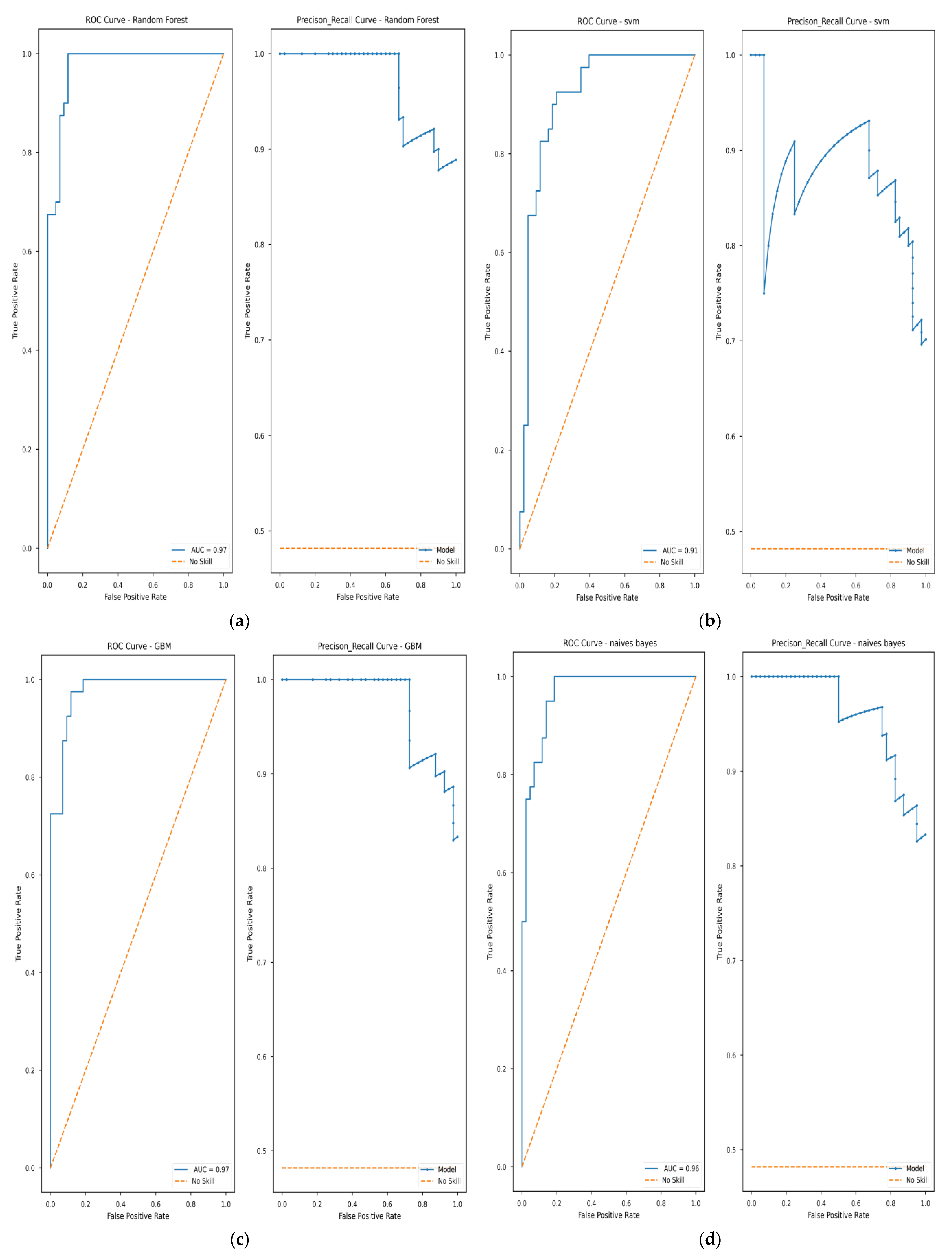
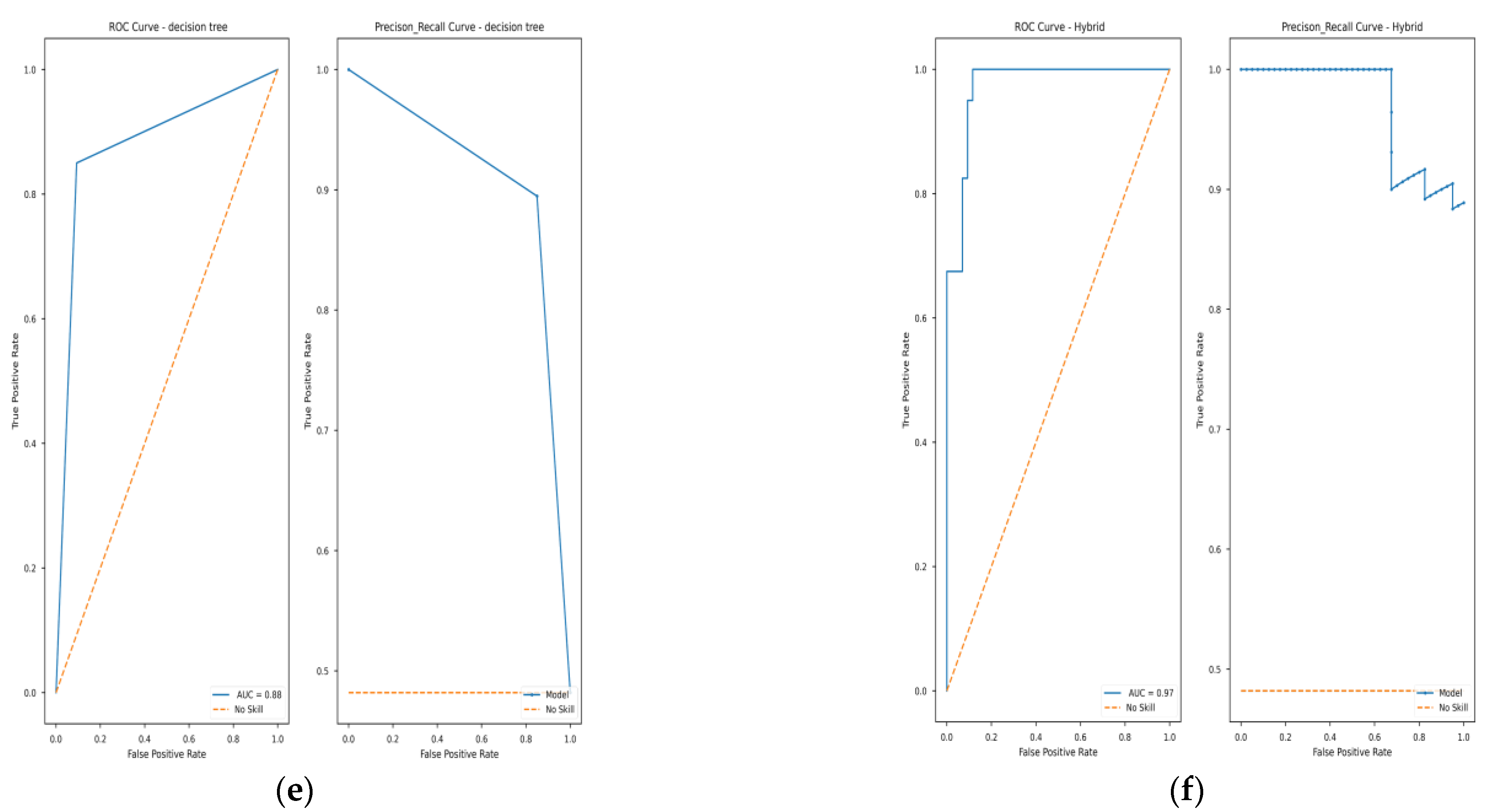
3.3.1. AUROC Evaluation
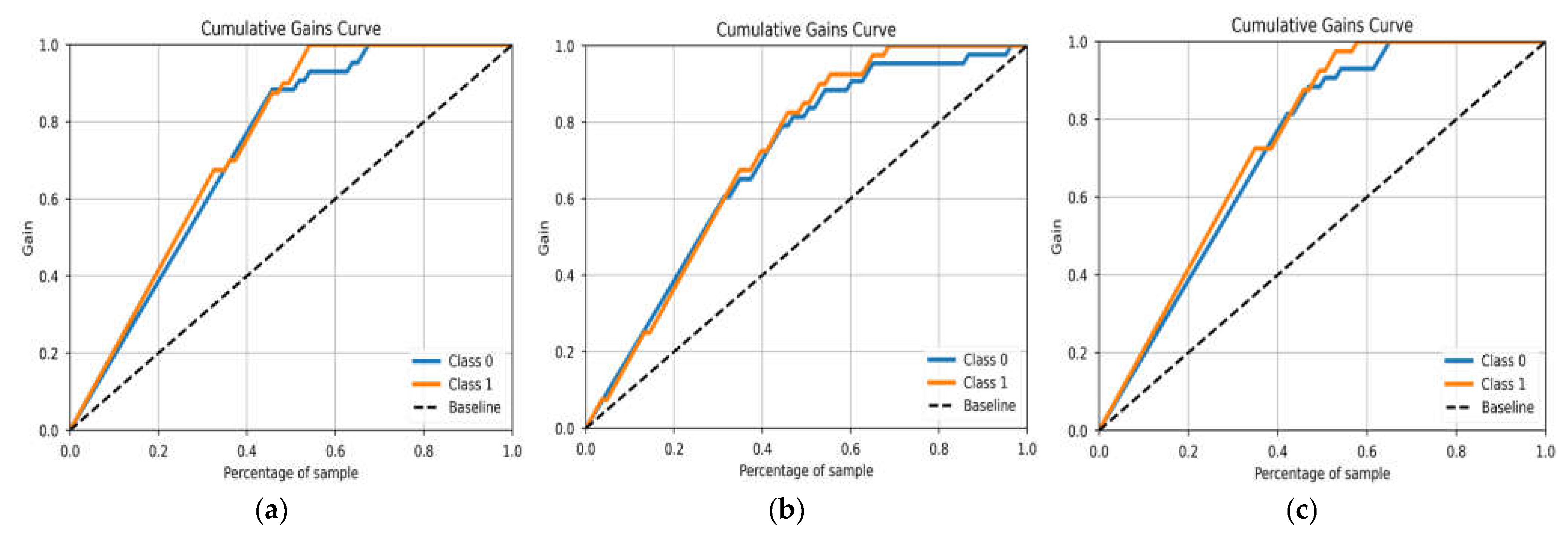
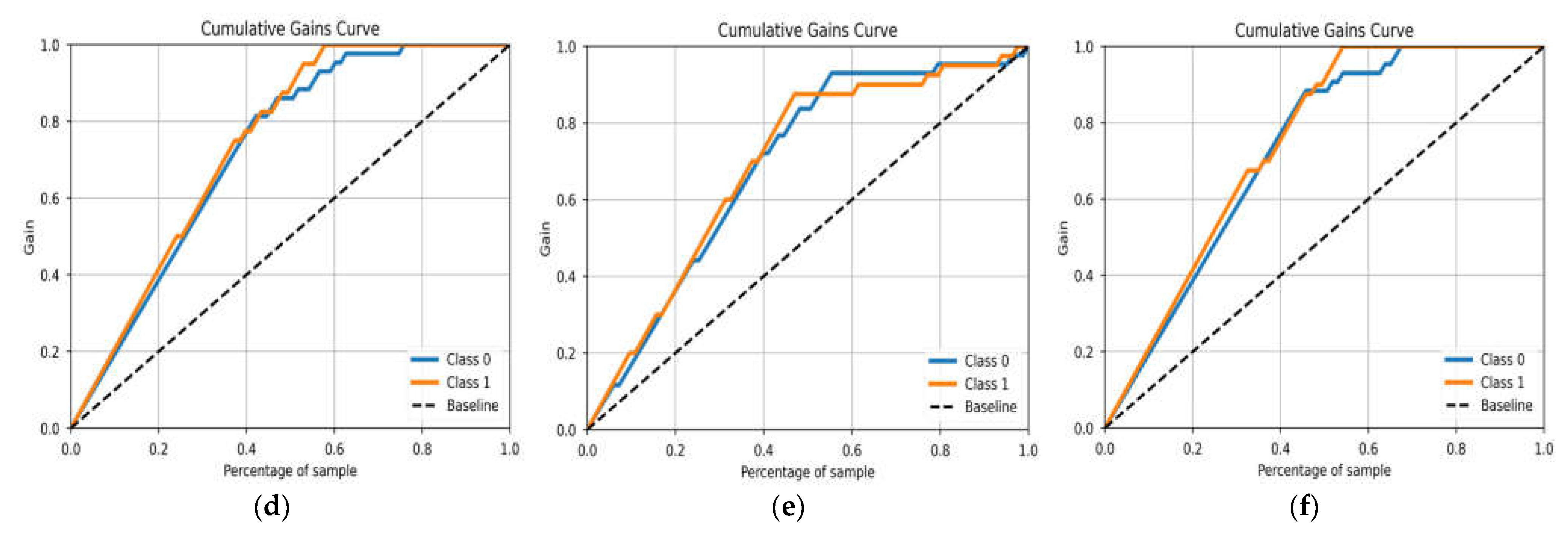
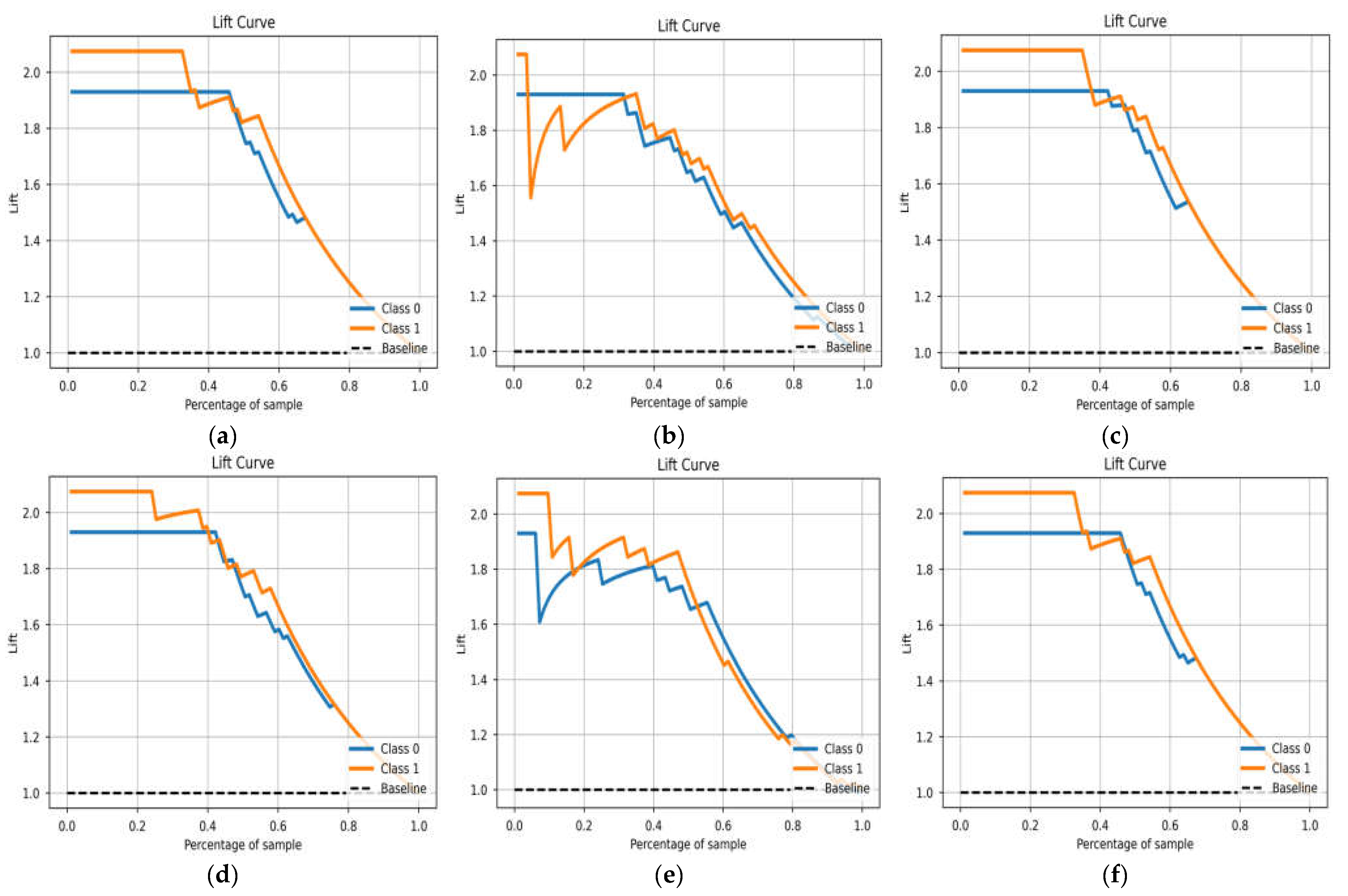
3.3.2. Cumulative Gain and Lift Curve Evaluation
4. Discussion
4.1. Flood Hazard Zoning Criteria Selection
4.2. Multicollinearity Test and Boruta Feature Rank
4.3. Flood Hazard Zoning
4.4. ML Model Validation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arora, A.; Arabameri, A.; Pandey, M.; Siddiqui, M.A.; Shukla, U.K.; Bui, D.T.; Mishra, V.N.; Bhardwaj, A. Optimization of State-of-the-Art Fuzzy-Metaheuristic Anfis-Based Machine Learning Models for Flood Susceptibility Prediction Mapping in the Middle Ganga Plain, India. Sci. Total. Environ. 2020, 750, 141565. [Google Scholar] [CrossRef] [PubMed]
- WHO (World Health Organization). Floods. 2017. Available online: https://www.who.int/health-topics/floods (accessed on 13 January 2022).
- UNISDR (United Nations Office for Disaster Risk Reduction). Economic 1998-2017 Losses, Poverty & DISASTERS, 2017.1-30. Available online: www.unisdr.org (accessed on 21 January 2022).
- NDMA. (National Disaster Management Authority), Government of India, Floods. 2018. Available online: https://ndma.gov.in/Natural-Hazards/Floods (accessed on 21 January 2022).
- López, P.L.; Sultana, T.; Kafi, M.A.H.; Hossain, M.S.; Khan, A.S.; Masud, M.S. Evaluation of Global Water Resources Reanalysis Data for Estimating Flood Events in the Brahmaputra River Basin. Water Resour. Manag. 2020, 34, 2201–2220. [Google Scholar] [CrossRef]
- NRSC (National Remote Sensing Centre). India, Flood Inundation Maps -2022. 2016. Available online: https://www.nrsc.gov.in/Floods_Inundation_2022?language_content_entity=en (accessed on 10 January 2022).
- RBA. (Rashtriya Barh Ayog). Flood and Erosion Problem. 2009. Available online: https://waterresources.assam.gov.in/portlets/flood-erosion-problems (accessed on 14 March 2021).
- UNISDR. (United Nations Office for Disaster Risk Reduction). Sendai Framework for Disaster Risk Reduction 2015—2030, 2015,1-35, UNISDR/GE/2015—ICLUX EN5000 1st edition. Available online: https://www.unisdr.org (accessed on 13 April 2022).
- El-Haddad, B.A.; Youssef, A.M.; Pourghasemi, H.R.; Pradhan, B.; El-Shater, A.-H.; El-Khashab, M.H. Flood susceptibility prediction using four machine learning techniques and comparison of their performance at Wadi Qena Basin, Egypt. Nat. Hazards 2021, 105, 83–114. [Google Scholar] [CrossRef]
- Vilasan, R.T.; Kapse, V.S. Evaluation of the prediction capability of AHP and F-AHP methods in flood susceptibility mapping of Ernakulam district (India). Nat. Hazards 2022, 112, 1767–1793. [Google Scholar] [CrossRef]
- Gupta, L.; Dixit, J. A GIS-based flood risk mapping of Assam, India, using the MCDA-AHP approach at the regional and administrative level. Geocarto Int. 2022. [Google Scholar] [CrossRef]
- Swain, K.C.; Singha, C.; Nayak, L. Flood Susceptibility Mapping through the GIS-AHP Technique Using the Cloud. ISPRS Int. J. Geo-Inf. 2020, 9, 720. [Google Scholar] [CrossRef]
- Parsian, S.; Amani, M.; Moghimi, A.; Ghorbanian, A.; Mahdavi, S. Flood Hazard Mapping Using Fuzzy Logic, Analytical Hierarchy Process, and Multi-Source Geospatial Datasets. Remote Sens. 2021, 13, 4761. [Google Scholar] [CrossRef]
- Szul, T.; Tabor, S.; Pancerz, K. Application of the BORUTA Algorithm to Input Data Selection for a Model Based on Rough Set Theory (RST) to Prediction Energy Consumption for Building Heating. Energies 2021, 14, 2779. [Google Scholar] [CrossRef]
- Hen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B.; et al. Modeling flood susceptibility using data-driven approaches of naïve Bayes tree, alternating decision tree, and random forest methods. Sci. Total. Environ. 2019, 701, 134979. [Google Scholar] [CrossRef]
- Islam, A.R.M.T.; Talukdar, S.; Mahato, S.; Kundu, S.; Eibek, K.U.; Pham, Q.B.; Kuriqi, A.; Linh, N.T.T. Flood susceptibility modelling using advanced ensemble machine learning models. Geosci. Front. 2020, 12, 101075. [Google Scholar] [CrossRef]
- Madhuri, R.; Sistla, S.; Raju, K.S. Application of machine learning algorithms for flood susceptibility assessment and risk management. J. Water Clim. Chang. 2021, 12, 2608–2623. [Google Scholar] [CrossRef]
- Pandey, M.; Arora, A.; Arabameri, A.; Costache, R.; Kumar, N.; Mishra, V.N.; Nguyen, H.; Mishra, J.; Siddiqui, M.A.; Ray, Y.; et al. Flood Susceptibility Modeling in a Subtropical Humid Low-Relief Alluvial Plain Environment: Application of Novel Ensemble Machine Learning Approach. Front. Earth Sci. 2021, 9, 659296. [Google Scholar] [CrossRef]
- Costache, R.; Arabameri, A.; Elkhrachy, I.; Ghorbanzadeh, O.; Pham, Q.B. Detection of areas prone to flood risk using state-of-the-art machine learning models. Geomat. Nat. Hazards Risk 2021, 12, 1488–1507. [Google Scholar] [CrossRef]
- Eslaminezhad, S.A.; Eftekhari, M.; Azma, A.; Kiyanfar, R.; Akbari, M. Assessment of flood susceptibility prediction based on optimized tree-based machine learning models. J. Water Clim. Chang. 2022, 13, 2353–2385. [Google Scholar] [CrossRef]
- Costache, R.; Pham, Q.B.; Avand, M.; Linh, N.T.T.; Vojtek, M.; Vojteková, J.; Lee, S.; Khoi, D.N.; Nhi, P.T.T.; Dung, T.D. Novel hybrid models between bivariate statistics, artificial neural networks and boosting algorithms for flood susceptibility assessment. J. Environ. Manag. 2020, 265, 110485. [Google Scholar] [CrossRef]
- Sankaranarayanan, S.; Prabhakar, M.; Satish, S.; Jain, P.; Ramprasad, A.; Krishnan, A. Flood prediction based on weather parameters using deep learning. J. Water Clim. Chang. 2020, 11, 1766–1783. [Google Scholar] [CrossRef]
- Eini, M.; Kaboli, H.S.; Rashidian, M.; Hedayat, H. Hazard and vulnerability in urban flood risk mapping: Machine learning techniques and considering the role of urban districts. Int. J. Disaster Risk Reduct. 2020, 50, 101687. [Google Scholar] [CrossRef]
- Janizadeh, S.; Vafakhah, M.; Kapelan, Z.; Dinan, N.M. Novel Bayesian Additive Regression Tree Methodology for Flood Susceptibility Modeling. Water Resour. Manag. 2021, 35, 4621–4646. [Google Scholar] [CrossRef]
- Ahmadlou, M.; Ghajari, Y.E.; Karimi, M. Enhanced Classification and Regression Tree (Cart) by Genetic Algorithm (Ga) and Grid Search (Gs) for Flood Susceptibility Mapping and Assessment. Geocarto Int. 2022. [Google Scholar] [CrossRef]
- Janizadeh, S.; Avand, M.; Jaafari, A.; Van Phong, T.; Bayat, M.; Ahmadisharaf, E.; Prakash, I.; Pham, B.T.; Lee, S. Prediction Success of Machine Learning Methods for Flash Flood Susceptibility Mapping in the Tafresh Watershed, Iran. Sustainability 2019, 11, 5426. [Google Scholar] [CrossRef]
- Sachdeva, S.; Kumar, B. Flood susceptibility mapping using extremely randomized trees for Assam 2020 floods. Ecol. Inform. 2022, 67, 101498. [Google Scholar] [CrossRef]
- Prasad, P.; Loveson, V.J.; Das, B.; Kotha, M. Novel ensemble machine learning models in flood susceptibility mapping. Geocarto Int. 2021, 37, 4571–4593. [Google Scholar] [CrossRef]
- Dodangeh, E.; Choubin, B.; Eigdir, A.N.; Nabipour, N.; Panahi, M.; Shamshirband, S.; Mosavi, A. Integrated machine learning methods with resampling algorithms for flood susceptibility prediction. Sci. Total Environ. 2020, 705, 135983. [Google Scholar] [CrossRef] [PubMed]
- Ahmadlou, M.; Al-Fugara, A.; Al-Shabeeb, A.R.; Arora, A.; Al-Adamat, R.; Pham, Q.B.; Al-Ansari, N.; Linh, N.T.T.; Sajedi, H. Flood susceptibility mapping and assessment using a novel deep learning model combining multilayer perceptron and autoencoder neural networks. J. Flood Risk Manag. 2020, 14, e12683. [Google Scholar] [CrossRef]
- Ha, H.; Luu, C.; Bui, Q.D.; Pham, D.-H.; Hoang, T.; Nguyen, V.-P.; Vu, M.T.; Pham, B.T. Flash flood susceptibility prediction mapping for a road network using hybrid machine learning models. Nat. Hazards 2021, 109, 1247–1270. [Google Scholar] [CrossRef]
- Hosseini, F.S.; Choubin, B.; Mosavi, A.; Nabipour, N.; Shamshirband, S.; Darabi, H.; Haghighi, A.T. Flash-flood hazard assessment using ensembles and Bayesian-based machine learning models: Application of the simulated annealing feature selection method. Sci. Total Environ. 2020, 711, 135161. [Google Scholar] [CrossRef]
- Xi, W.; Li, G.; Moayedi, H.; Nguyen, H. A particle-based optimization of artificial neural network for earthquake-induced landslide assessment in Ludian county, China. Geomat. Nat. Hazards Risk 2019, 10, 1750–1771. [Google Scholar] [CrossRef] [Green Version]
- Al-Abadi, A.M.; Al-Najar, N.A. Comparative assessment of bivariate, multivariate and machine learning models for mapping flood proneness. Nat. Hazar. 2020, 100, 461–491. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Kumar, L.; Jebur, M.N.; Shabani, F. Evaluating the application of the statistical index method in flood susceptibility mapping and its comparison with frequency ratio and logistic regression methods. Geomat. Nat. Hazards Risk 2018, 10, 79–101. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Li, J.; Liu, M.; Liu, W.; Hong, H. Flood susceptibility assessment based on a novel random Naïve Bayes method: A comparison between different factor discretization methods. Catena 2020, 190, 104536. [Google Scholar] [CrossRef]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An Ensemble Prediction of Flood Susceptibility Using Multivariate Discriminant Analysis, Classification and Regression Trees, and Support Vector Machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef]
- Goffi, A.; Stroppiana, D.; Brivio, P.A.; Bordogna, G.; Boschetti, M. Towards an automated approach to map flooded areas from Sentinel-2 MSI data and soft integration of water spectral features. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101951. [Google Scholar] [CrossRef]
- Rawat, A.; Bisht, M.P.S.; Sundriyal, Y.P.; Banerjee, S.; Singh, V. Assessment of soil erosion, flood risk and groundwater potential of Dhanari watershed using remote sensing and geographic information system, district Uttarkashi, Uttarakhand, India. Appl. Water Sci. 2021, 11, 119. [Google Scholar] [CrossRef]
- Mind’je, R.; Li, L.; Amanambu, A.C.; Nahayo, L.; Nsengiyumva, J.B.; Gasirabo, A.; Mindje, M. Flood susceptibility modeling and hazard perception in Rwanda. Int. J. Disas Risk Reduc. 2019, 38, 101211. [Google Scholar] [CrossRef]
- Theobald, D.M.; Harrison-Atlas, D.; Monahan, W.B.; Albano, C.M. Ecologically-Relevant Maps of Landforms and Physiographic Diversity for Climate Adaptation Planning. PLoS ONE 2015, 10, e0143619. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, C.M.; Oakleaf, J.R.; Theobald, D.M.; Baruch-Mordo, S.; Kiesecker, J. Global Human Modification of Terrestrial Systems. 2020, Palisades, NY: NASA Socioeconomic Data and Applications Center (SEDAC). Available online: https://sedac.ciesin.columbia.edu/data/set/lulc-human-modification-terrestrial-systems (accessed on 13 January 2021).
- Saha, S.; Roy, J.; Arabameri, A.; Blaschke, T.; Tien Bui, D. Machine Learning-Based Gully Erosion Susceptibility Mapping: A Case Study of Eastern India. Sensors 2020, 20, 1313. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Li, Q.; Wang, H.; Deng, M. A machine learning ensemble approach based on random forest and radial basis function neural network for risk evaluation of regional flood disaster: A case study of the yangtze river delta, China. Int. J. Environ. Res. Public Health 2020, 17, 49. [Google Scholar] [CrossRef] [Green Version]
- Mirzaei, S.; Vafakhah, M.; Pradhan, B.; Alavi, S.J. Flood susceptibility assessment using extreme gradient boosting (EGB). Iran. Earth Sci. Inform. 2020, 14, 51–67. [Google Scholar] [CrossRef]
- Abu El-Magd, S.A. Random forest and naïve Bayes approaches as tools for flash flood hazard susceptibility prediction, South Ras El-Zait, Gulf of Suez Coast, Egypt. Arab. J. Geosci. 2022, 15, 217. [Google Scholar] [CrossRef]
- Luu, C.; Nguyen, D.D.; Van Phong, T.; Prakash, I.; Pham, B.T. Using Decision Tree J48 Based Machine Learning Algorithm for Flood Susceptibility Mapping: A Case Study in Quang Binh Province, Vietnam. In CIGOS 2021, Emerging Technologies and Applications for Green Infrastructure. Lecture Notes in Civil Engineering; Ha-Minh, C., Tang, A.M., Bui, T.Q., Vu, X.H., Huynh, D.V.K., Eds.; Springer: Singapore, 2022; Volume 203. [Google Scholar] [CrossRef]
- Liu, J.; Wang, J.; Xiong, J.; Cheng, W.; Sun, H.; Yong, Z.; Wang, N. Hybrid Models Incorporating Bivariate Statistics and Machine Learning Methods for Flash Flood Susceptibility Assessment Based on Remote Sensing Datasets. Remote Sens. 2021, 13, 4945. [Google Scholar] [CrossRef]
- Lombana, L.; Martínez-Graña, A. A Flood Mapping Method for Land Use Management in Small-Size Water Bodies: Validation of Spectral Indexes and a Machine Learning Technique. Agronomy 2022, 12, 1280. [Google Scholar] [CrossRef]
- Song, D.; Zhang, Q.; Wang, B.; Yin, C.; Xia, J. A Novel Dual Branch Neural Network Model for Flood Monitoring in South Asia Based on CYGNSS Data. Remote Sens. 2022, 14, 5129. [Google Scholar] [CrossRef]
- Askar, S.; Zeraat Peyma, S.; Yousef, M.M.; Prodanova, N.A.; Muda, I.; Elsahabi, M.; Hatamiafkoueieh, J. Flood Susceptibility Mapping Using Remote Sensing and Integration of Decision Table Classifier and Metaheuristic Algorithms. Water 2022, 14, 3062. [Google Scholar] [CrossRef]
- Panahi, M.; Dodangeh, E.; Rezaie, F.; Khosravi, K.; Van Le, H.; Lee, M.J.; Lee, S.; Pham, T.B. Flood spatial prediction modeling using a hybrid of meta optimization and support vector regression modeling. Catena 2021, 199, 105114. [Google Scholar] [CrossRef]
- Shahabi, H.; Shirzadi, A.; Ghaderi, K.; Omidvar, E.; Al-Ansari, N.; Clague, J.J.; Geertsema, M.; Khosravi, K.; Amini, A.; Bahrami, S.; et al. Flood Detection and Susceptibility Mapping Using Sentinel-1 Remote Sensing Data and a Machine Learning Approach: Hybrid Intelligence of Bagging Ensemble Based on K-Nearest Neighbor Classifier. Remote Sens. 2020, 12, 266. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.J.; Lin, H.-J.; Liou, J.-J.; Cheng, C.-T.; Chen, Y.-M. Assessment of Flood Risk Map under Climate Change RCP8.5 Scenarios in Taiwan. Water 2022, 14, 207. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SL No. | Data Type | Sources | Description | Spatial Map |
|---|---|---|---|---|
| 1. | Digital elevation model (DEM) | https://earthexplorer.usgs.gov * | ASTER DEM (30 m) | Elevation, Aspect, Slope, Profile curvature TWI, TRI, TPI, and SPI, |
| 2. | European Union/ESA/Copernicus | Google Earth Engine | Sentinel-2B MSI (10 m) | NDVI, NDFI |
| 3. | ESA/World Cover | Google Earth Engine | ESA/WorldCover/v100, (10 m) | LULC |
| 4. | Global ALOS Landforms | Google Earth Engine | CSP/ERGo/1_0/Global/ALOS_landforms (90 m) | Landform |
| 5. | Soil data | https://www.fao.org/soils-portal/soil-survey/soil-maps-and-databases/harmonized-world-soil-database-v12/en/ * | Harmonized World Soil Database v1.2 (30 arc-second raster) | Soil type |
| 6. | NASA-USDA Enhanced SMAP Global Soil Moisture | NASA GSFC/Google Earth Engine | NASA_USDA/HSL/SMAP10KM_soil_moisture (10 km) | Soil moisture |
| 7. | Rainfall (mm/day) | UCSB/CHG/Google Earth Engine | UCSB-CHG/CHIRPS/DAILY (0.05°) | Rainfall |
| 8. | Soil erosion (Mg/ha/y) | European Soil Data Centre (ESDAC) | Global Land Degradation as Debts. (0.4 degrees) | Soil erosion |
| 9. | Geologic | USGS | U.S. Geological Survey World Energy Project,2000, Version 2.0, vector layer | Geology |
| 10. | Stream network | https://www.hydrosheds.org/ ** | WWF/HydroSHEDS/v1/FreeFlowingRivers, vector layer | Drainage density, distance to stream |
| 11. | Road network | https://www.openstreetmap.org/export#map=7/26.069/92.855 ** | Road network in Assam region, vector layer | distance to stream |
| 12. | NASA Socioeconomic Data and Applications Center | Google Earth Engine | CIESIN/GPWv4.11/GPW_Population_Density (927.67 m) | Population Density |
| 13. | The Global Human Modification of Terrestrial Systems | NASA Socioeconomic Data and Applications Center | The Global Human Modification of Terrestrial Systems v1 (2016), 1 km | GHMTS |
| Model Name | Best Tuning Parameters |
|---|---|
| Random forest | ‘estimator__criterion’: ‘gini’; ‘estimator__max_depth’: 5, ‘estimator__min_samples_split’: 2, ‘estimator__n_estimators’: 100, ‘estimator__bootstrap’: True, |
| Support vector machine | ‘estimator__C’: 1.0, ‘estimator__kernel’: ‘rbf’, ‘estimator__tol’: 0.001, ‘n_features_to_select’: 5, ‘estimator__cache_size’: 200, ‘estimator__probability’: True |
| Gradient boosting | ‘estimator__learning_rate’: 0.05, n_estimators = 15, ‘estimator__criterion’: ‘friedman_mse’, ‘estimator__max_depth’: 3, ‘estimator__tol’: 0.0001, max_features = ‘log2′ ‘estimator__min_samples_split’: 2 |
| Naïve Bayes | ‘verbose’: False, ‘kbest’: SelectKBest (k = 6), ‘model’: GaussianNB (), ‘kbest__k’: 6, ‘model__var_smoothing’: 1 × 10−9 |
| Decision tree | ‘estimator__criterion’: ‘gini’, ‘estimator__max_depth’: 4, ‘estimator__min_samples_leaf’: 1, ‘estimator__min_samples_split’: 2, ‘n_features_to_select’: 5, ‘estimator__splitter’: ‘best’, |
| Factors | VIF | Boruta Rank |
|---|---|---|
| Elevation | 2.10 | 1 |
| Landform | 1.99 | 1 |
| Soil moisture | 1.28 | 1 |
| Slope | 1.57 | 1 |
| TRI | 2.01 | 1 |
| LULC | 2.33 | 1 |
| NDVI | 2.45 | 1 |
| NDFI | 1.07 | 1 |
| Distance to stream | 1.43 | 1 |
| Rainfall | 1.67 | 1 |
| Population density | 1.40 | 1 |
| GHMTS | 1.46 | 1 |
| Distance to road | 1.54 | 1 |
| Geology | 1.39 | 1 |
| SPI | 2.72 | 2 |
| TWI | 3.28 | 2 |
| Soil erosion | 1.68 | 2 |
| Drain density | 1.57 | 3 |
| Profile curvature | 2.33 | 4 |
| TPI | 2.67 | 5 |
| Soil type | 1.33 | 6 |
| Aspect | 1.07 | 7 |
| Classifiers | Test accuracy | Precision | Recall | F1 Score | AUROC |
|---|---|---|---|---|---|
| RF | 0.90 | 0.94 | 0.89 | 0.91 | 0.97 |
| SVM | 0.86 | 0.78 | 0.97 | 0.87 | 0.91 |
| GBM | 0.90 | 0.95 | 0.87 | 0.91 | 0.97 |
| NB | 0.95 | 0.85 | 0.95 | 0.89 | 0.96 |
| DT | 0.93 | 0.92 | 0.92 | 0.93 | 0.88 |
| Hybrid | 0.94 | 0.95 | 0.94 | 0.94 | 0.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singha, C.; Swain, K.C.; Meliho, M.; Abdo, H.G.; Almohamad, H.; Al-Mutiry, M. Spatial Analysis of Flood Hazard Zoning Map Using Novel Hybrid Machine Learning Technique in Assam, India. Remote Sens. 2022, 14, 6229. https://doi.org/10.3390/rs14246229
Singha C, Swain KC, Meliho M, Abdo HG, Almohamad H, Al-Mutiry M. Spatial Analysis of Flood Hazard Zoning Map Using Novel Hybrid Machine Learning Technique in Assam, India. Remote Sensing. 2022; 14(24):6229. https://doi.org/10.3390/rs14246229
Chicago/Turabian StyleSingha, Chiranjit, Kishore Chandra Swain, Modeste Meliho, Hazem Ghassan Abdo, Hussein Almohamad, and Motirh Al-Mutiry. 2022. "Spatial Analysis of Flood Hazard Zoning Map Using Novel Hybrid Machine Learning Technique in Assam, India" Remote Sensing 14, no. 24: 6229. https://doi.org/10.3390/rs14246229