
Terrain-Net: A Highly-Efficient, Parameter-Free, and Easy-to-Use Deep Neural Network for Ground Filtering of UAV LiDAR Data in Forested Environments
 , , , ,
, , , ,
Abstract
:1. Introduction
- Currently, there are very few filtering algorithms that use point convolution on point cloud. We investigated the performance of KPConv operator directly in ground filtering and found that such general purposed point operator performed excellently.
- To our best knowledge, the self-attention technique is still not fully investigated for point cloud processing, especially the combination of self-attention and point convolution. We studied the impact of their combination on ground filtering and proposed a delicate network that can extract both local and global features.
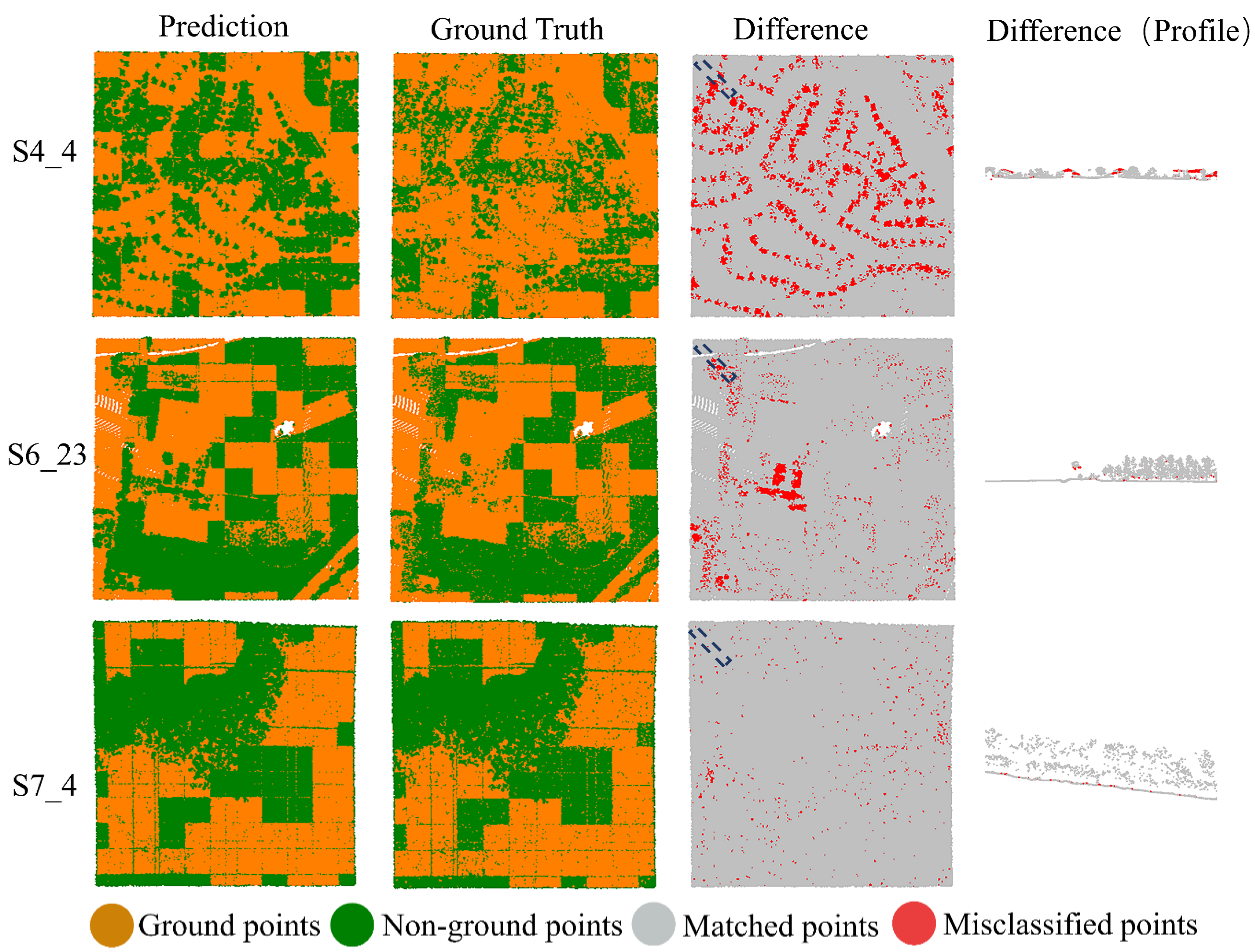
- Terrain-net performs well in complex forested environments, and we verified that it has generalization ability to large scenes and other environments. This is a positive sign that point cloud deep learning approaches are hopefully able to extend their usage for a wider range of cross-disciplines such as vegetation or ecosystem investigations.
2. Materials and Methods
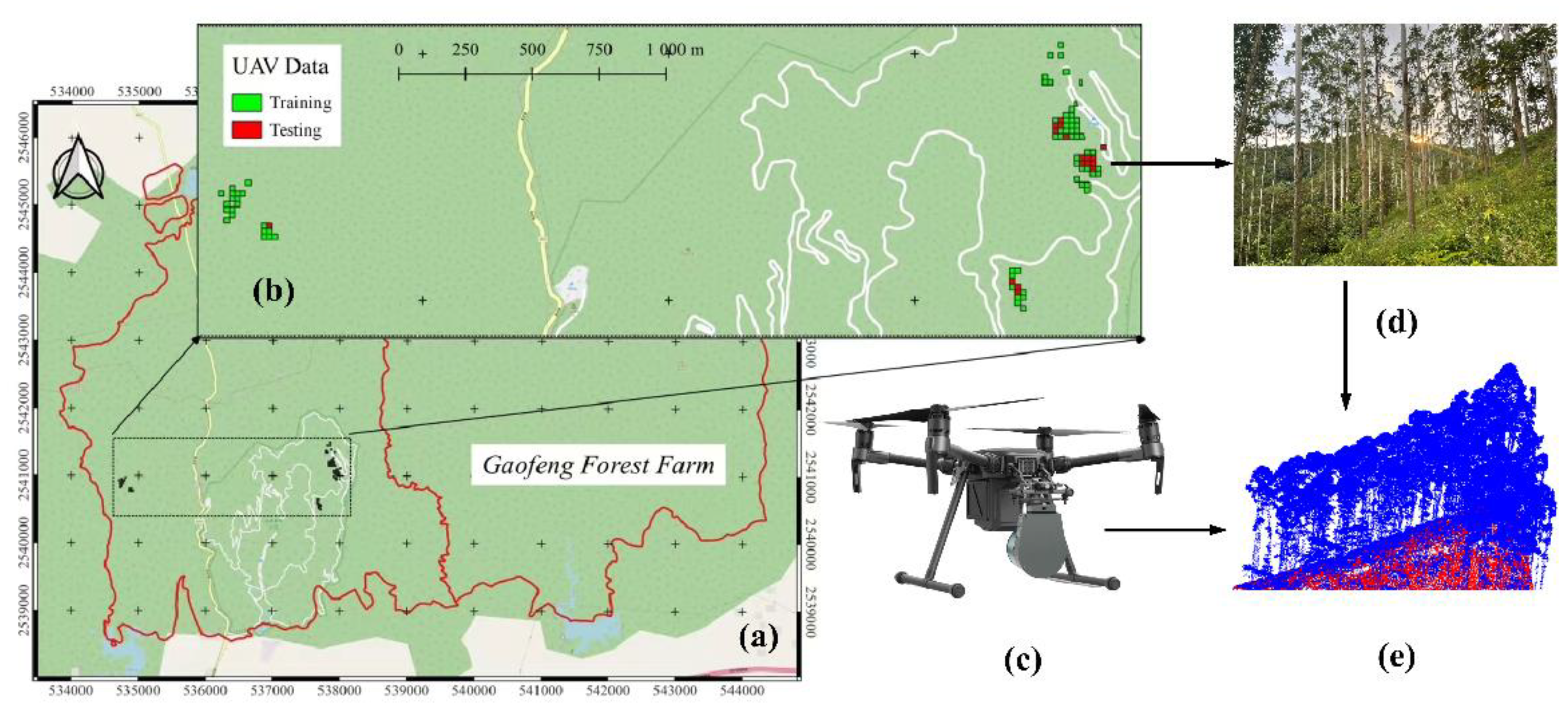
2.1. Study Area and UAV Data Collection
2.2. Dataset Preparation
2.3. Additional Third-Party Dataset
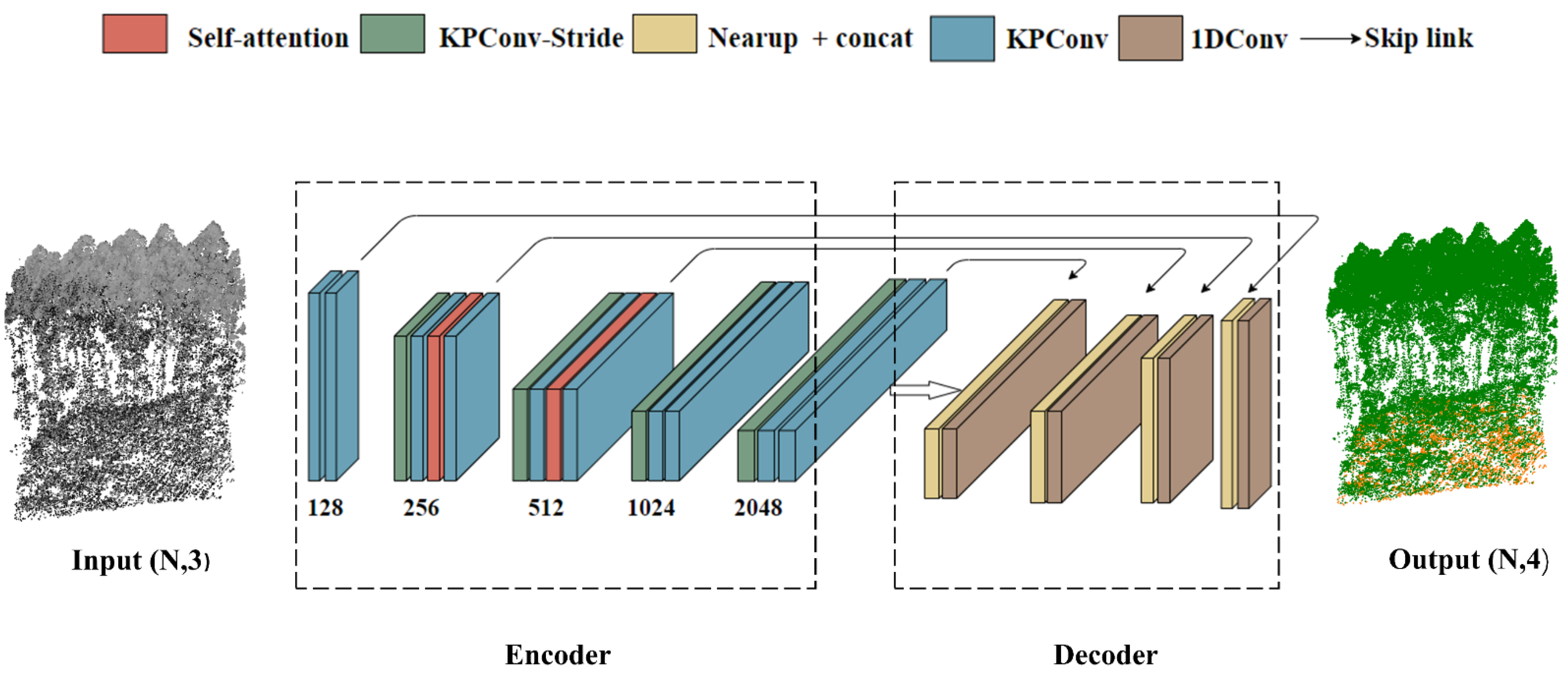
2.4. Terrain-Net Network Establishment
2.4.1. Terrain-Net Architecture
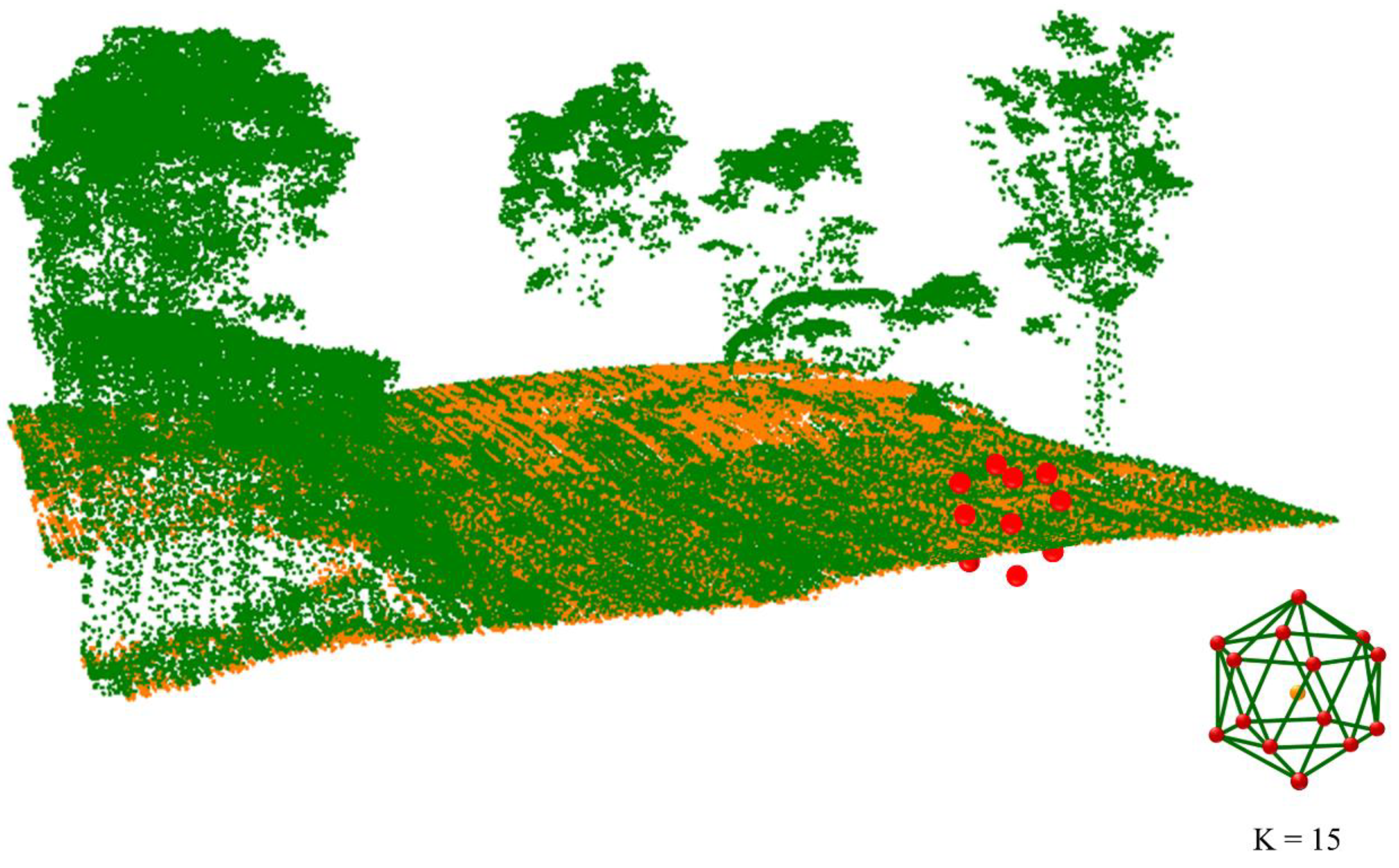
2.4.2. KPConv Point Convolution Operator
2.4.3. Self-Attention Operator
2.5. Model Training
3. Results
3.1. Performance Metrics
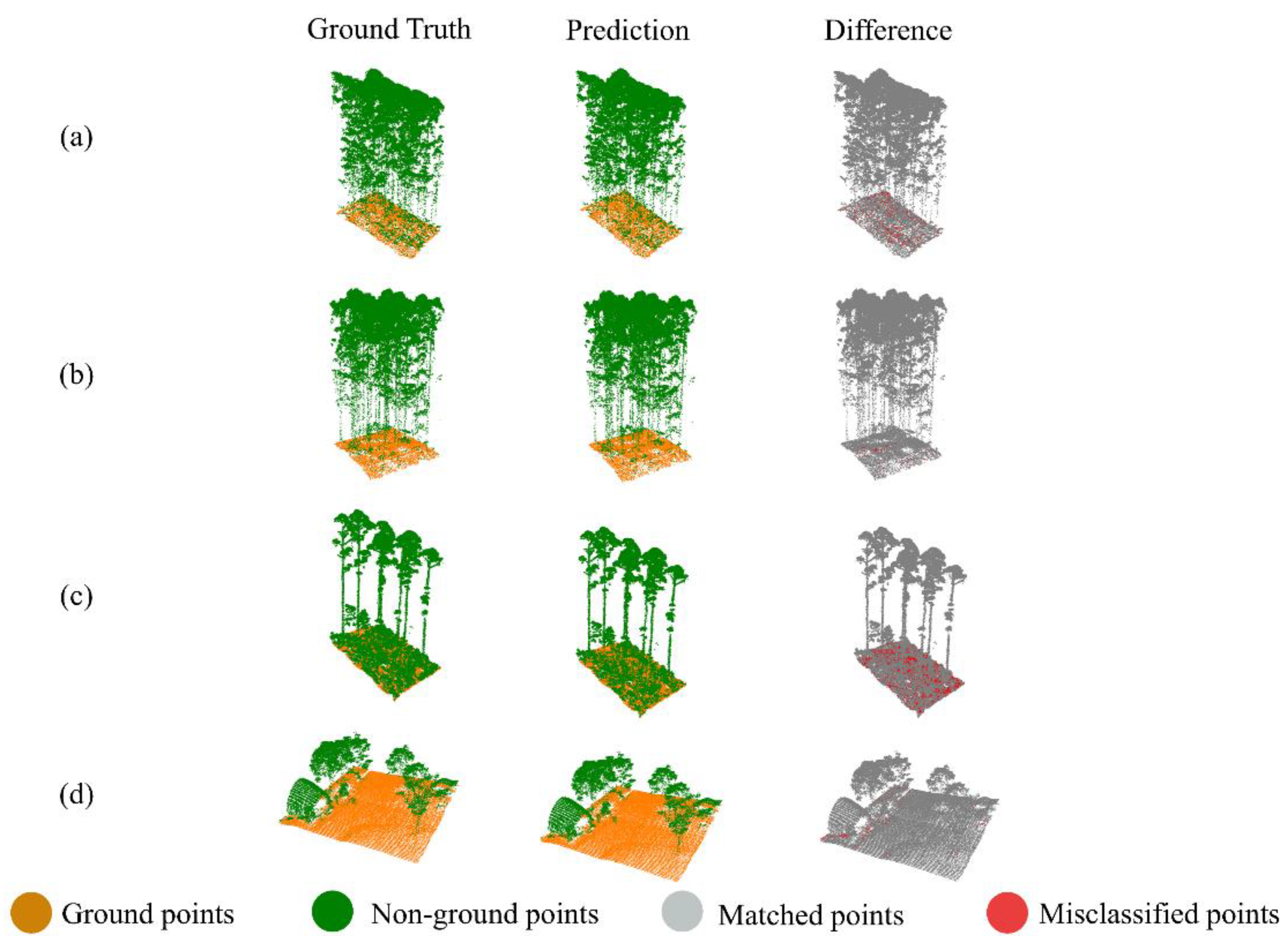
3.2. Evaluation Results of UAV Point Cloud
3.3. Evaluation Results of Additional Third-Party Dataset
4. Discussion
4.1. Comparative Analyses with Traditional Methods and Models
4.2. Effectiveness Verification of Self-Attention
4.3. Selection of the Self-Attention Type and Variants
4.4. Model Transferring Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forest Environment | Train Dataset | Test Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Mean Point Density (m−2) | Number of Tiles | Tree Species | Slope Range (°) | Mean Point Density (m−2) | Number of Tiles | Tree Species | Slope Range/(°) | |
| Dense vegetation with flat terrain | 793.22 | 9 | Eucalyptus, Castanopsis | [0, 6.5] | 955.74 | 3 | Eucalyptus Magnolia | [0,5] |
| Dense vegetation with slope | 684.48 | 35 | Eucalyptus, Magnolia, Michelia | [10.5, 38] | 610.38 | 8 | Eucalyptus Castanopsis | [12.5, 33] |
| Sparse vegetation with flat terrain | 201.01 | 8 | Eucalyptus, bamboo | [0,7] | 282.39 | 1 | Eucalyptus | [0,0] |
| Sparse vegetation with slope | 290.72 | 18 | Eucalyptus, Chinese fir | [10,36] | 370.17 | 5 | Eucalyptus Michelia | [18,32] |
| Reference | |||
|---|---|---|---|
| Non-ground (0) | Ground (1) | ||
| Prediction | Non-ground (0) | TN (True negative) | FN (False negative) |
| Ground (1) | FP (False positive) | TP (True positive) | |
| Abbreviation | Meaning | Formula |
|---|---|---|
| OA | overall accuracy | |
| RG | Recall of ground points | |
| RNG | Recall of non-ground points | |
| PG | Precision of ground points | |
| PNG | Precision of non-ground points | |
| IoUG | IoU of ground points | |
| IoUNG | IoU of non-ground points | |
| FG | F1-score of ground points | |
| FNG | F1-score of non-ground points | |
| MIoU | Mean value of IoUG and IoUNG | |
| Kp | Kappa coefficient |
References
- Pearce, D.W. The Economic Value of Forest Ecosystems. Ecosyst. Health 2001, 7, 284–296. [Google Scholar] [CrossRef] [Green Version]
- Zimble, D.A.; Evans, D.L.; Carlson, G.C.; Parker, R.C.; Grado, S.C.; Gerard, P.D. Characterizing Vertical Forest Structure Using Small-Footprint Airborne LiDAR. Remote Sens. Environ. 2003, 87, 171–182. [Google Scholar] [CrossRef] [Green Version]
- Krisanski, S.; Taskhiri, M.S.; Turner, P. Enhancing Methods for Under-Canopy Unmanned Aircraft System Based Photogrammetry in Complex Forests for Tree Diameter Measurement. Remote Sens. 2020, 12, 1652. [Google Scholar] [CrossRef]
- Guo, Q.; Su, Y.; Hu, T.; Guan, H.; Jin, S.; Zhang, J.; Zhao, X.; Xu, K.; Wei, D.; Kelly, M.; et al. Lidar Boosts 3D Ecological Observations and Modelings: A Review and Perspective. IEEE Geosci. Remote Sens. Mag. 2021, 9, 232–257. [Google Scholar] [CrossRef]
- Hu, X.; Yuan, Y.; Shan, J.; Hyyppä, J.; Waser, L.T.; Li, X.; Thenkabail, P.S. Deep-Learning-Based Classification for DTM Extraction from ALS Point Cloud. Remote Sens. 2016, 8, 730. [Google Scholar] [CrossRef] [Green Version]
- Vosselman, G. Slope Based Filtering of Laser Altimetry Data. Int. Arch. Photogramm. Remote Sens. 2000, 33, 935–942. [Google Scholar]
- Meng, X.; Wang, L.; Silván-Cárdenas, J.L.; Currit, N. A Multi-Directional Ground Filtering Algorithm for Airborne LIDAR. ISPRS J. Photogramm. Remote Sens. 2009, 64, 117–124. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.K.; Tseng, Y.H. Dem Generation from Airborne Lidar Data by an Adaptive Dual-Directional Slope Filter. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, 38, 628–632. [Google Scholar]
- Sithole, G.; Vosselman, G. Filtering of Airborne Laser Scanner Data Based on Segmented Point Clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2005, 36, W19. [Google Scholar]
- Zhang, K.; Chen, S.C.; Whitman, D.; Shyu, M.L.; Yan, J.; Zhang, C. A Progressive Morphological Filter for Removing Nonground Measurements from Airborne LIDAR Data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 872–882. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Gong, P.; Baldocchi, D.; Xie, G. Filtering Airborne Laser Scanning Data with Morphological Methods. Photogramm. Eng. Remote Sens. 2007, 73, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Axelsson, P. DEM Generation from Laser Scanner Data Using Adaptive TIN Models. Int. Arch. Photogramm. Remote Sens. 2000, 23, 110–117. [Google Scholar]
- Kraus, K.; Pfeifer, N. Determination of Terrain Models in Wooded Areas with Airborne Laser Scanner Data. ISPRS J. Photogramm. Remote Sens. 1998, 53, 193–203. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; Volume 1. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Yi, L.; Su, H.; Guo, X.; Guibas, L. SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2016; Volume 2017, pp. 2282–2290. [Google Scholar]
- Xu, Y.; Fan, T.; Xu, M.; Zeng, L.; Qiao, Y. SpiderCNN: Deep Learning on Point Sets with Parameterized Convolutional Filters. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2018; Volume 11212 LNCS, pp. 87–102. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. Pointweb: Enhancing Local Neighborhood Features for Point Cloud Processing. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 5565–5573. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–3 October 2015; Volume 2015, pp. 922–928. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Simonovsky, M.; Komodakis, N. Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3693–3702. [Google Scholar]
- Qi, Y.; Dong, X.H.; Chen, P.; Lee, K.H.; Lan, Y.; Lu, X.; Jia, R.; Deng, J.; Zhang, Y. Canopy Volume Extraction of Citrus Reticulate Blanco Cv. Shatangju Trees Using UAV Image-Based Point Cloud Deep Learning. Remote Sens. 2021, 13, 3437. [Google Scholar] [CrossRef]
- Chen, J.; Chen, Y.; Liu, Z. Classification of Typical Tree Species in Laser Point Cloud Based on Deep Learning. Remote Sens. 2021, 13, 4750. [Google Scholar] [CrossRef]
- Xu, L.; Zheng, S.; Na, J.; Yang, Y.; Mu, C.; Shi, D. A Vehicle-Borne Mobile Mapping System Based Framework for Semantic Segmentation and Modeling on Overhead Catenary System Using Deep Learning. Remote Sens. 2021, 13, 4939. [Google Scholar] [CrossRef]
- Widyaningrum, E.; Bai, Q.; Fajari, M.K.; Lindenbergh, R.C. Airborne Laser Scanning Point Cloud Classification Using the Dgcnn Deep Learning Method. Remote Sens. 2021, 13, 859. [Google Scholar] [CrossRef]
- Sun, C.; Zhang, F.; Zhao, P.; Zhao, X.; Huang, Y.; Lu, X. Automated Simulation Framework for Urban Wind Environments Based on Aerial Point Clouds and Deep Learning. Remote Sens. 2021, 13, 2383. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, X.; Xiao, Y.; Zhao, Q.; Wan, S. Three-Dimensional Urban Land Cover Classification by Prior-Level Fusion of Lidar Point Cloud and Optical Imagery. Remote Sens. 2021, 13, 4928. [Google Scholar] [CrossRef]
- Rizaldy, A.; Persello, C.; Gevaert, C.M.; Oude Elberink, S.J. Fully Convolutional Networks for Ground Classification from Lidar Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 8. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Tan, B.; Pei, H.; Jiang, W. Segmentation and Multi-Scale Convolutional Neural Network-Based Classification of Airborne Laser Scanner Data. Sensors 2018, 18, 3347. [Google Scholar] [CrossRef] [Green Version]
- Schmohl, S.; Sörgel, U. Submanifold Sparse Convolutional Networks for Semantic Segmentation of Large-Scale ALS Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, IV-2/W5, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Yotsumata, T.; Sakamoto, M.; Satoh, T. Quality Improvement for Airborne Lidar Data Filtering Based on Deep Learning Method. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 355–360. [Google Scholar] [CrossRef]
- Nurunnabi, A.; Teferle, F.N.; Li, J.; Lindenbergh, R.C.; Hunegnaw, A. An Efficient Deep Learning Approach for Ground Point Filtering in Aerial Laser Scanning Point Clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, 43, 1–8. [Google Scholar] [CrossRef]
- Janssens-Coron, E.; Guilbert, E. Ground Point Filtering from Airborne Lidar Point Clouds Using Deep Learning: A Preliminary Study. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 1559–1565. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2016; Volume 2017, pp. 652–660. [Google Scholar]
- Jin, S.; Su, Y.; Zhao, X.; Hu, T.; Guo, Q. A Point-Based Fully Convolutional Neural Network for Airborne LiDAR Ground Point Filtering in Forested Environments. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3958–3974. [Google Scholar] [CrossRef]
- Krisanski, S.; Taskhiri, M.S.; Aracil, S.G.; Herries, D.; Turner, P. Sensor Agnostic Semantic Segmentation of Structurally Diverse and Complex Forest Point Clouds Using Deep Learning. Remote Sens. 2021, 13, 1413. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 2017. [Google Scholar]
- Huang, S.; Liu, L.; Dong, J.; Fu, X.; Huang, F. SPGCN: Ground Filtering Method Based on Superpoint Graph Convolution Neural Network for Vehicle LiDAR. J. Appl. Remote Sens. 2022, 16. [Google Scholar] [CrossRef]
- Chen, L.; Chen, W.; Xu, Z.; Huang, H.; Wang, S.; Zhu, Q.; Li, H. DAPnet: A Double Self-Attention Convolutional Network for Point Cloud Semantic Labeling. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3958–3974. [Google Scholar] [CrossRef]
- Soilán, M.; Nóvoa, A.; Sánchez-Rodríguez, A.; Riveiro, B.; Arias, P. Semantic Segmentation of Point Clouds with Pointnet and Kpconv Architectures Applied to Railway Tunnels. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 5, 281–288. [Google Scholar] [CrossRef]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Kada, M.; Kuramin, D. ALS Point Cloud Classification Using Pointnet++ and KPCONV with Prior Knowledge. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, 46, 91–96. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-Cross Attention for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018. [Google Scholar]
- Qin, N.; Tan, W.; Ma, L.; Zhang, D.; Li, J. OpenGF: An Ultra-Large-Scale Ground Filtering Dataset Built upon Open ALS Point Clouds around the World. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. PCT: Point Cloud Transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Meng, X.; Currit, N.; Zhao, K. Ground Filtering Algorithms for Airborne LiDAR Data: A Review of Critical Issues. Remote Sens. 2010, 2, 833–860. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.S.; Koltun, V. Point Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16259–16268. [Google Scholar]






| Name | Land Type | Size/(m2) | Terrain Features and Tree Distribution |
|---|---|---|---|
| S4_4 | Small City | 500 × 500 | Local undulating ground with many middle-size buildings and sparse tree distribution. |
| S6_23 | Village | 500 × 500 | Natural ground with a few scattered buildings and large area of tree distribution. |
| S7_4 | Mountain | 500 × 500 | Slope ground with dense vegetation |
| Method | Ground | Non-Ground | Kp (%) | MIoU (%) | OA (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | ||||
| Slope-based | 75.2 | 98.5 | 84.8 | 74.5 | 99.4 | 88.5 | 93.2 | 88.1 | 78.6 | 81.3 | 91.5 |
| Morphology-based | 80.0 | 95.8 | 86.8 | 77.4 | 98.6 | 91.5 | 94.7 | 94.7 | 81.8 | 83.9 | 93.0 |
| Surface-based | 69.2 | 97.7 | 80.4 | 68.2 | 98.8 | 83.8 | 90.0 | 83.2 | 71.5 | 75.7 | 88.3 |
| CSF | 99.7 | 73.6 | 84.0 | 73.5 | 86.8 | 99.8 | 92.2 | 86.8 | 77.1 | 80.2 | 90.5 |
| KP-FCNN | 96.0 | 85.9 | 90.7 | 83.6 | 96.9 | 99.2 | 98.0 | 96.1 | 88.7 | 89.6 | 96.7 |
| Terrain-net | 95.5 | 92.9 | 94.2 | 89.0 | 98.6 | 99.1 | 98.8 | 97.7 | 93.0 | 93.3 | 98.0 |
| Name | Ground | Non-Ground | OA (%) | Kp (%) | ||
|---|---|---|---|---|---|---|
| IoU (%) | F1-Score (%) | IoU (%) | F1-Score (%) | |||
| S4_4 | 86.0 | 92.4 | 82.3 | 90.3 | 91.5 | 82.9 |
| S6_23 | 92.8 | 96.3 | 94.6 | 97.2 | 96.6 | 93.5 |
| S7_4 | 92.8 | 96.3 | 96.4 | 98.0 | 97.6 | 94.4 |
| Model | Ground | Non-Ground | Kp (%) | MIoU (%) | OA (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | ||||
| KP-FCNN (original) | 96.0 | 85.9 | 90.7 | 83.6 | 96.9 | 99.2 | 98.0 | 96.1 | 88.7 | 89.6 | 96.7 |
| KP-FCNN (more blocks) | 99.1 | 83.6 | 90.7 | 83.0 | 96.1 | 99.8 | 97.9 | 96.0 | 88.7 | 89.5 | 96.6 |
| Terrain-net | 95.5 | 92.9 | 94.2 | 89.0 | 98.6 | 99.1 | 98.8 | 97.7 | 93.0 | 93.3 | 98.0 |
| Model | Ground | Non-Ground | Kp (%) | MIoU (%) | OA (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | ||||
| Scalar attention (Equation (3)) | 96.7 | 91.2 | 93.9 | 88.5 | 98.1 | 99.3 | 98.7 | 97.5 | 92.6 | 93.0 | 96.7 |
| Scalar attention (Equation (4)) | 95.5 | 92.9 | 94.2 | 89.0 | 98.6 | 99.1 | 98.8 | 97.7 | 93.0 | 93.3 | 98.0 |
| Scalar attention (Equation (5)) | 95.5 | 92.4 | 94.0 | 88.6 | 98.4 | 99.1 | 98.7 | 97.6 | 92.7 | 93.1 | 97.8 |
| Vector attention (Equation (6)) | 96.7 | 91.2 | 93.9 | 88.5 | 98.2 | 99.3 | 98.7 | 97.5 | 92.6 | 93.0 | 97.9 |
| Vector attention (Equation (7)) | 91.7 | 95.5 | 93.5 | 87.8 | 99.1 | 98.3 | 98.7 | 97.5 | 92.2 | 92.6 | 97.9 |
| Model | Ground | Non-Ground | Kp (%) | MIoU (%) | OA (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | ||||
| 1 self-attention block | 85.2 | 92.7 | 93.9 | 88.6 | 98.5 | 99.0 | 98.7 | 97.6 | 92.7 | 93.1 | 97.8 |
| 2 self-attention blocks | 95.5 | 92.9 | 94.2 | 89.0 | 98.6 | 99.1 | 98.8 | 97.7 | 93.0 | 93.3 | 98.0 |
| 3 self-attention blocks | 93.3 | 94.5 | 93.9 | 88.5 | 98.9 | 98.6 | 98.8 | 97.6 | 92.7 | 93.1 | 98.0 |
| 4 self-attention blocks | 94.9 | 93.1 | 94.0 | 88.7 | 98.6 | 98.9 | 98.8 | 97.6 | 92.8 | 93.2 | 98.0 |
| 8 self-attention blocks | 93.3 | 94.5 | 93.9 | 88.5 | 98.9 | 98.6 | 98.8 | 97.6 | 92.7 | 93.1 | 98.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Lu, H.; Wang, H.; Qi, J.; Yang, G.; Pang, Y.; Dong, H.; Lian, Y. Terrain-Net: A Highly-Efficient, Parameter-Free, and Easy-to-Use Deep Neural Network for Ground Filtering of UAV LiDAR Data in Forested Environments. Remote Sens. 2022, 14, 5798. https://doi.org/10.3390/rs14225798
Li B, Lu H, Wang H, Qi J, Yang G, Pang Y, Dong H, Lian Y. Terrain-Net: A Highly-Efficient, Parameter-Free, and Easy-to-Use Deep Neural Network for Ground Filtering of UAV LiDAR Data in Forested Environments. Remote Sensing. 2022; 14(22):5798. https://doi.org/10.3390/rs14225798
Chicago/Turabian StyleLi, Bowen, Hao Lu, Han Wang, Jianbo Qi, Gang Yang, Yong Pang, Haolin Dong, and Yining Lian. 2022. "Terrain-Net: A Highly-Efficient, Parameter-Free, and Easy-to-Use Deep Neural Network for Ground Filtering of UAV LiDAR Data in Forested Environments" Remote Sensing 14, no. 22: 5798. https://doi.org/10.3390/rs14225798