1. Introduction
With the development of satellite, aviation, and unmanned aerial vehicle (UAV) technology, huge amounts of high-resolution (HR) remote sensing images have been captured in a constant stream [
1,
2,
3]. These HR remote sensing images have been applied to land cover classification [
4,
5,
6], change detection [
7,
8,
9], target recognition [
10,
11], and image restoration and registration [
12,
13], for example. This brings opportunities for us to observe fine objects such as buildings, roads, vehicles, etc. Among them, buildings are one of the most important targets in the surface coverage of remote sensing images. Therefore, building detection or extraction has become a hot topic of study, as it plays a crucial role in digital city construction and management [
11,
14,
15] and sustainable urban development [
16,
17], among other applications.
Although building detection has made some progress in recent years, the widespread use of HR remote sensing images from different sensors has brought new challenges to this task [
18,
19]. These challenges include mainly the following:
- (a)
A large number of fine ground targets can be depicted by very-high-resolution aerial imagery, e.g., trees, roads, vehicles, and swimming pools, etc. However, these targets often easily interfere with the identification of buildings due to their similar features (e.g., spectrum, shape, size, structure, etc.).
- (b)
In urban areas, tall buildings often have severe geometric distortions caused by fixed sensor imaging angles. This may lead to accurate building detection becoming challenging.
- (c)
With the rapid development of urbanization, many cities and rural areas are interspersed with tall buildings and short buildings. Tall buildings often exhibit large shadows when imaged by the sun. This phenomenon may not only make it difficult to accurately detect tall buildings themselves, but may also obscure other features (especially short buildings), thus limiting the effective detection of buildings.
Recently, deep-learning-based building detection techniques have been introduced to alleviate these challenges to some extent [
20]. State-of-the-art (SOTA) methods are able to improve the performance of building detection through a variety of techniques, including the introduction of multi-scale modules [
21,
22], edge information [
23,
24], and attention mechanisms [
25,
26]. For instance, Ji et al. proposed a Siamese U-Net (SiU-Net) for building extraction, which can enhance multi-scale feature extraction by adding a branch with a small resolution downsampled input image [
19]. In [
27], a named Building Residual Refine Network (BRRNet) was designed to achieve accurate and complete building extraction. This network is composed of a prediction module and a residual refinement module. In the prediction module, an atrous convolution is employed to capture multi-scale global features. The residual refinement module can refine the initial result of the prediction module, thereby obtaining a more accurate and complete building detection. Yang et al. promoted an edge-aware network, which consists of image segmentation networks and edge perception networks [
28]. The network combines the network with edge-aware loss to achieve better performance.
These previous networks have achieved good detection results. Some methods effectively enhance the feature characterization ability of the network by some attention or multi-scale operations, thus improving the detection effect. Some recent approaches propose the introduction of edge information (edge module or edge loss supervision) to help building recognition. However, there are still some limitations to overcome. First, supervised learning strategies by introducing edge loss directly outside the network structure can lead to difficult convergence and less stable results. Second, the combination of roughly applied edge information and convolutional networks is both difficult to be well embedded in the neural network and prone to introduce some interference information from other ground target edges. Finally, edge information tends to represent only high-frequency information of buildings, whereas low-frequency information is equally important in pixel-level prediction tasks. Therefore, enhancing both high-frequency and low-frequency information can further improve the building feature characterization ability.
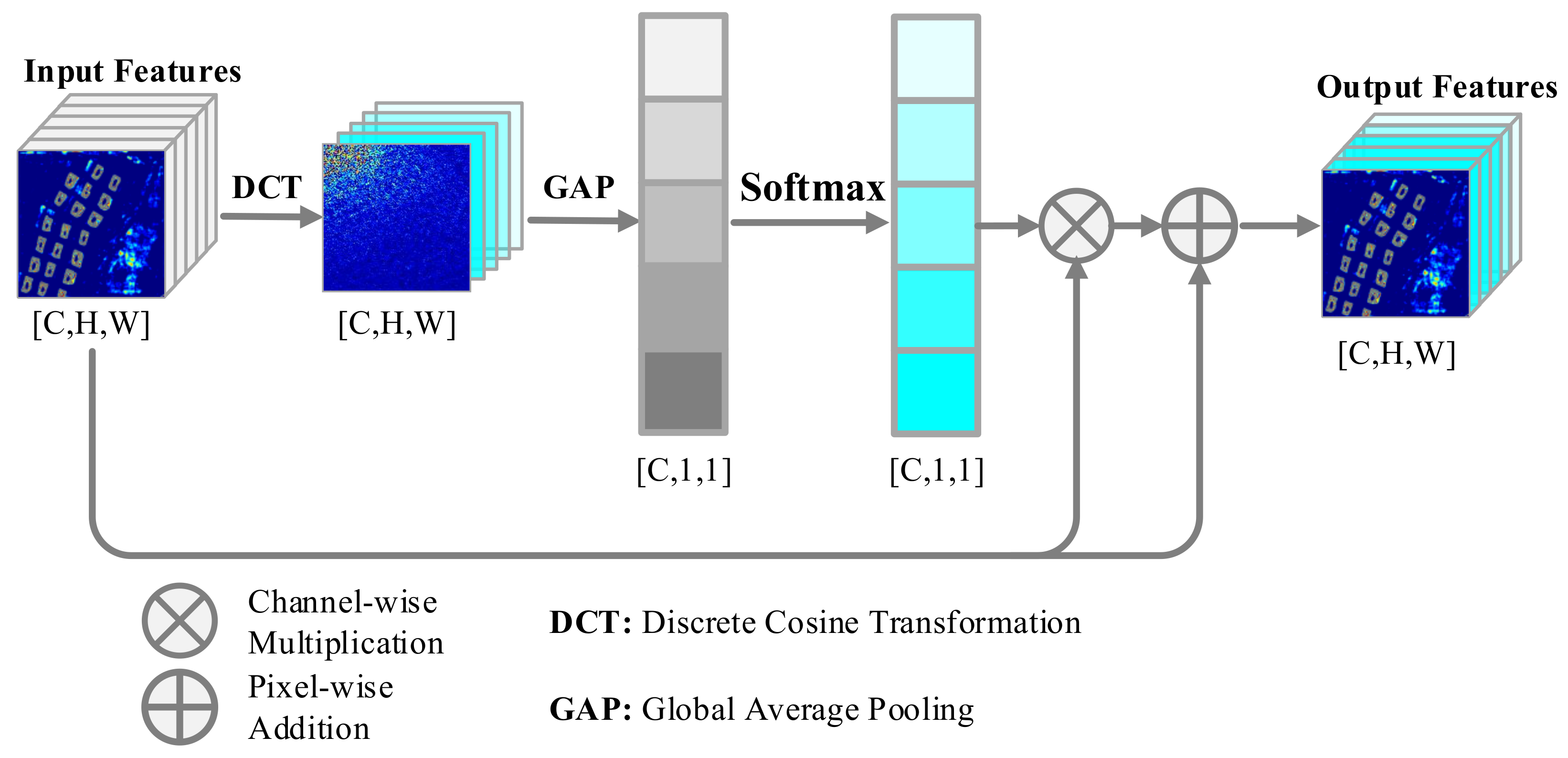
To address the aforementioned issues, our solutions are motivated by the following two aspects. On the one hand, Zheng et al. proposed a high frequency attention Siamese network for building change detection [
29]. The study has verified that the introduction of high frequency information can enhance the network’s ability to sense buildings. However, introducing frequency domain information directly in the building detection task can easily introduce interference information from other features, thus limiting the building feature extraction. For this reason, inspired by this approach, we perform feature enhancement by introducing the attention module of the global feature map with frequency domain information. In particular, the average frequency spectral intensity of an image can express the amount of high frequency information contained in the image as a whole. This can effectively evaluate the features that are more conducive to building extraction. Therefore, the introduction of average frequency spectral intensity will be beneficial to building detection tasks. In this case, building detection performance may be further improved when both high-frequency and low-frequency information are considered in the network. On the other hand, atrous spatial pyramid pooling (ASPP) is often used to capture multi-scale features in remote sensing image understanding [
30,
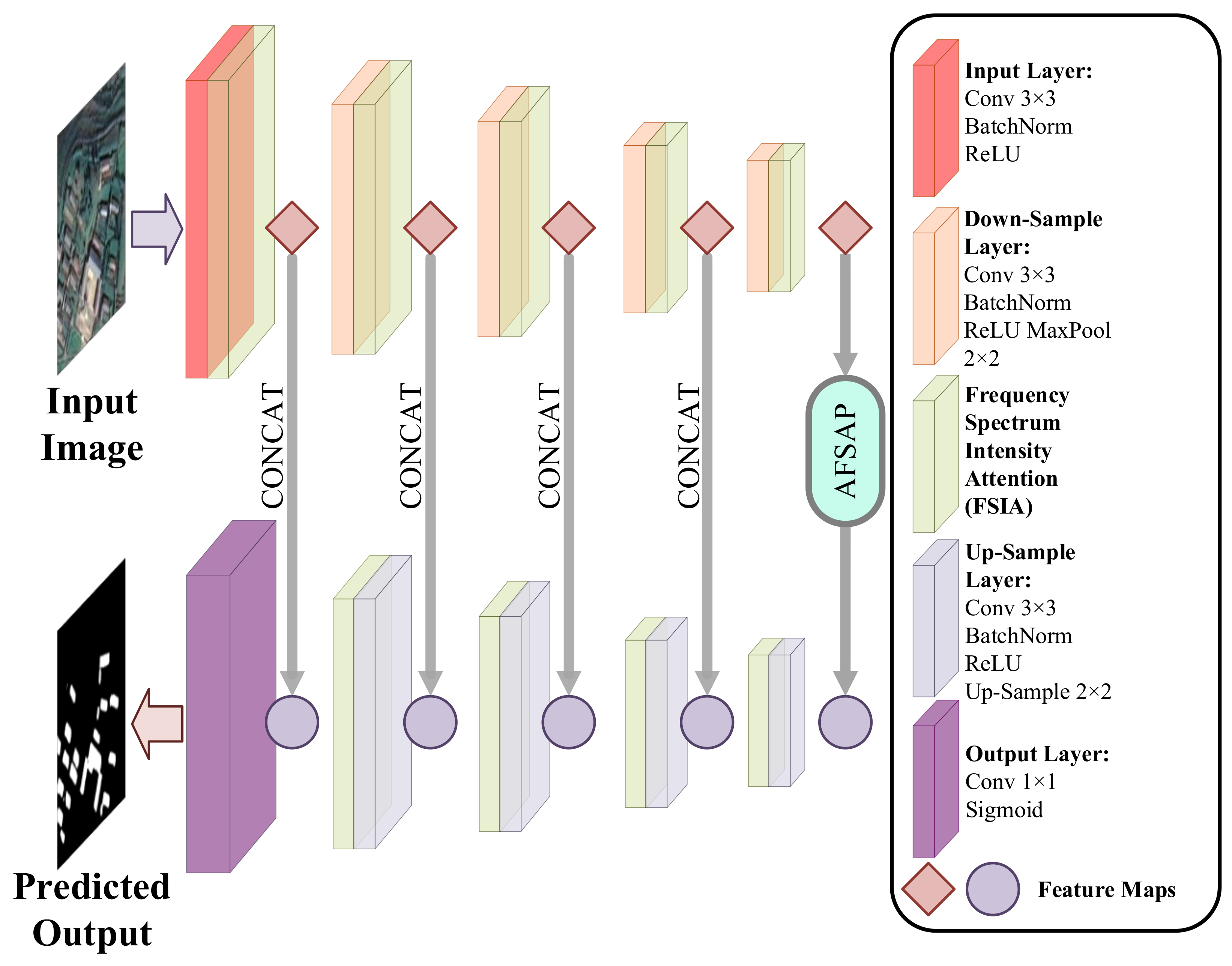
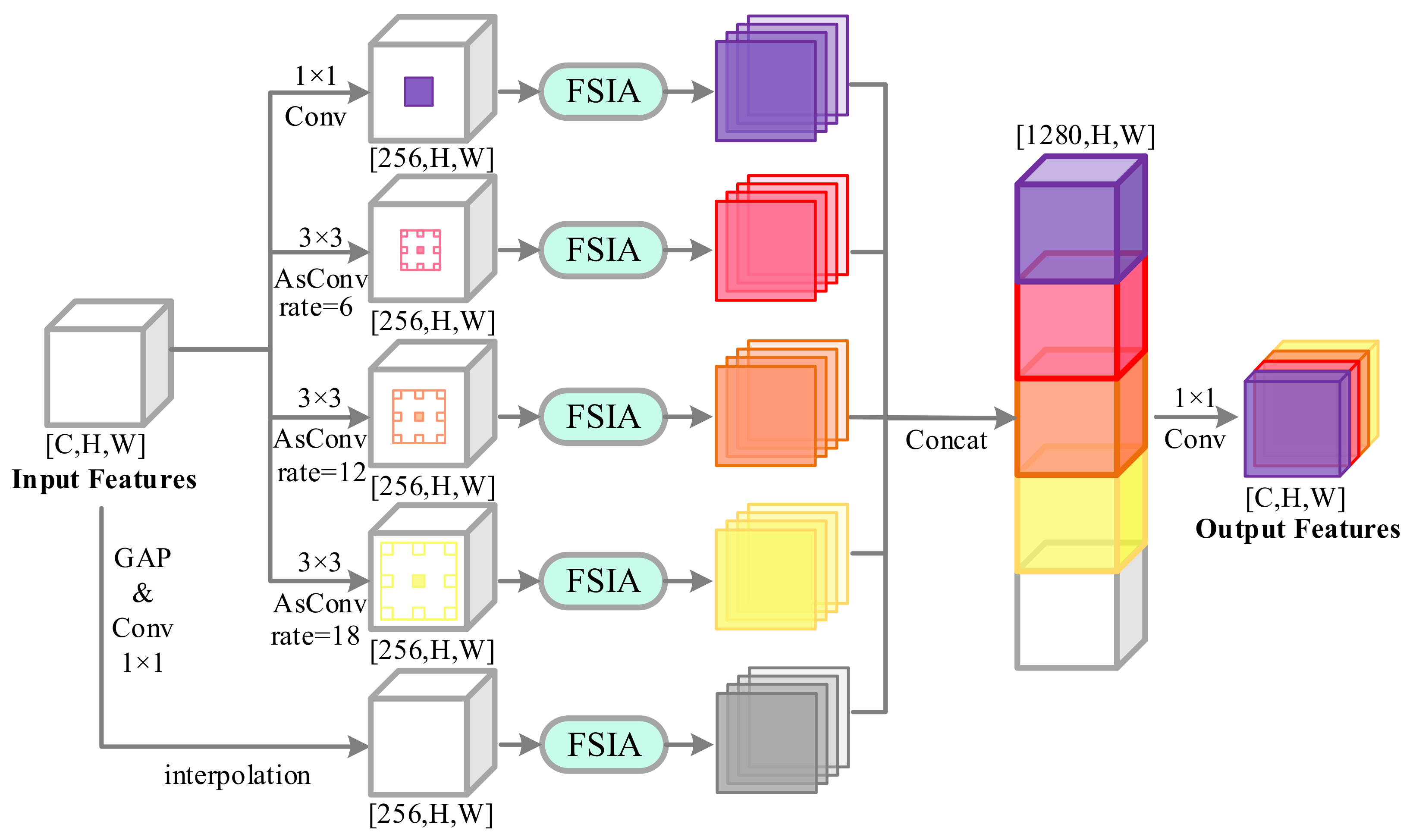
31]. However, different building features can be obtained by using atrous convolution with different atrous rates. In this context, it would enhance the building feature representation if the features with high response to the building semantic features at each scale are emphasized while the features with low response are weakened. According to these motivations, we propose a frequency spectrum intensity attention network (FSIANet) for building detection. The major contributions of this paper include the following three aspects:
- (1)
This paper proposes a novel computational intelligence approach for automatic building detection, named FSIANet. In the proposed FSIANet, we devised a plug-and-play FSIA without the requirement of learnable parameters. The FSIA mechanism based on frequency–domain information can effectively evaluate the informative abundance of the feature maps and enhance feature representation by emphasizing more informative feature maps. To this end, The FSIANet can significantly improve the building detection performance.
- (2)
An atrous frequency spectrum attention pyramid (AFSAP) is devised in the proposed FSIANet. It is able to mine multi-scale features. At the same time, by introducing FSIA in ASPP, it can emphasize the features with high response to building semantic features at each scale and weaken the features with low response, which will enhance the building feature representation.
- (3)
The experimental results on two large public datasets (Inria [
18] and East Asia [
19]) have demonstrated that the proposed FSIANet can achieve a more effective building detection compared to other classical and SOTA approaches.
The remainder of this article is arranged as follows.
Section 2 reviews the relevant literature. Methodology and experiments are presented in
Section 3 and
Section 4. Finally,
Section 6 concludes this article.
2. Related Work
In the past decade, building detection and roof extraction has been a hot research topic in the field of remote sensing. In the early stage, some handcrafted building features are used to implement building detection and extraction, such as pixel shape index [
32], morphological profiles [
33], etc. For example, Huang et al. combined the information of the morphological building index and the morphological shadow index for building extraction. Other morphological building index-based methods are available in [
34,
35,
36]; Bi et al. proposed a multi-scale filtering building index to reduce the noise of building map in [
21]. Although relying on these early hand-made building features can extract buildings from HR impacts, these methods are still poor in terms of accuracy and completeness of building detection and extraction.
With the rapid development of deep learning technology, deep learning has been extensively extended to the field of remote sensing. So far, deep-learning-based building detection approaches have become the most advanced technology. In the early stage, researchers treated the building detection task as an image segmentation task. Therefore, semantic segmentation networks widely used in computer vision can be directly applied to achieve building detection tasks, such as fully convolutional network (FCN) [
37], U-Net [
38], SegNet [
39], etc. The introduction of these deep-learning-based methods leads to a significant improvement in the performance of building detection and extraction compared to hand-crafted feature methods. Nonetheless, with the unprecedented increase in the spatial resolution of images, researchers still found some new challenges, that is, buildings with large or small scales are difficult to accurately identify due to the local receptive fields of convolutional neural networks (CNN).
To overcome the above limitation, many multi-scale CNN have further promoted computer vision [
40]. For instance, Zhao et al. designed a pyramid scene parsing network (PSPNet) for semantic segmentation [
41]. In the PSPNet [
41], a pyramid pooling module is used to capture global features, thereby improving the multi-scale feature extraction capability of the network. In [
42], an atrous spatial pyramid pooling (ASPP) is devised to effectively enlarge the receptive field of the network, thereby improving the multi-scale feature representation ability of the network. These multi-scale CNN in computer vision have also been developed in the field of remote sensing [
43,
44]. Wang et al. promoted a novel FCN for dense semantic labeling [
45]. This network can effectively mine multi-scale features by combining the advantages of both encoder-decoder and ASPP. Yu et al. applied an end-to-end segmentation network for pixel-level building detection, which combines the ASPP and skip connections generative adversarial segmentation network to aggregate multi-scale contextual information [
31]. Similar research also includes [
46,
47,
48].
In recent years, attention mechanisms have been widely used in deep learning [
9,
49,
50,
51], especially computer vision. Attention mechanisms commonly used in computer vision and remote sensing image processing can be divided into two major categories according to the function of the attention mechanism [
52,
53]: channel attention and spatial attention. Channel attention aims to enhance the feature representation ability of the network by selecting important feature channels [
54,
55,
56]. Spatial attention is able to generate an attention mask in the spatial domain and employ it to emphasize the most task-relevant spatial regions [
57,
58]. In addition to multi-scale CNN, driven by the attention mechanism, it is another effective technique to improve the performance of building detection. For instance, spatial and channel attention mechanisms are simultaneously used to emphasize spatial regions and feature channels with high semantic responses to buildings, thereby improving the capability of the building feature extraction [
59]. In [
60], a pyramid attention network (PANet) is promoted to achieve pixel-level semantic segmentation; an encoder-decoder network based on attention-gate and ASPP (AGPNet) is proposed for building detection from UAV images [
25]; Guo et al. [
61] devised a scene-driven multitask parallel attention network to overcome the large intraclass variance of buildings in different scenes; other attention-based methods are available in [
62,
63]. Recently, many experts have designed some novel networks dedicated to automatic building detection and extraction. Transformer-based methods are the latest and most compelling new network structures. Wang et al. promoted a vision transformer network for building extraction [
44]. A transformer-based multi-scale feature learning network was proposed in [
64]. In addition, a new deep architecture, named Res2-Unet, was proposed for building detection [
65]. This architecture is an end-to-end structure, which can exploit multi-scale learning at a granular level to extend the receptive field. These methods further advance the development of building detection.
In summary, although some progress has been made in previous work, there are still certain limitations that need to be further addressed. In particular, there is a lack of research on the role of frequency–domain information in building detection tasks. For one thing, the combination of roughly applied edge information and convolutional networks is both difficult to be well embedded in the neural network and prone to introduce some interference information from other ground target edges. For another thing, edge information tends to represent only high-frequency information of buildings, whereas low-frequency information is equally important in pixel-level prediction tasks.
5. Discussion
From the extensive experiments conducted above, it can be concluded that the proposed FSIA mechanism and AFSAP module can efficiently improve the performance of building extraction. In this section, these contributions are further discussed.
In FSIA, we utilize DCT to evaluate how informative a feature is, and reweight the features accordingly. Since its benefit has been confirmed in building extraction, it may potentially improve the performance of CNN-based methods over similar tasks such as change detection and road extraction, even more computer vision tasks. Considering that FSIA has no supervised parameters, it can be used in any CNN-based method without training. However, there are still several disadvantages to this distinctive attention mechanism. The most notable of them is that DCT can be time-consuming when processing feature maps with large spatial sizes. This problem can be further overcome in future work with a lightweight transformation.
6. Conclusions
In this work, efforts have been made to better tackle automatic building detection tasks in HR remote sensing data by proposing some computational-intelligence-based techniques. Namely, a classic encoder-decoder-like end-to-end deep convolutional neural network, FSIANet, with two newly proposed modules, FSIA and AFSAP, is exploited. The FSIA is able to mine useful information from the frequency spectrum of extracted features, thus improving the global feature representation of FSIANet. Notably, it does not need to be trained to acquire reliable ability, which is different from most of the other attention mechanisms. In addition, the ASPP-inspired feature pyramid, AFSAP, is utilized to promote the detection of building-like objects. Compared to ASPP, the AFSAP can achieve more pronounced performance improvement with the help of FSIA. As a result, the proposed FSIANet has successfully outperformed several newly proposed cutting-edge deep-learning-based methods in two widely used large-scale HR remote sensing building detection datasets. For future work, more efforts can be made to expand the usage of frequency–domain-based analysis in the deep-learning-based methods, which have the potential to facilitate finer annotation of buildings in complicated scenes.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}