
Power Line Extraction Framework Based on Edge Structure and Scene Constraints
Abstract
:1. Introduction
2. Related Works
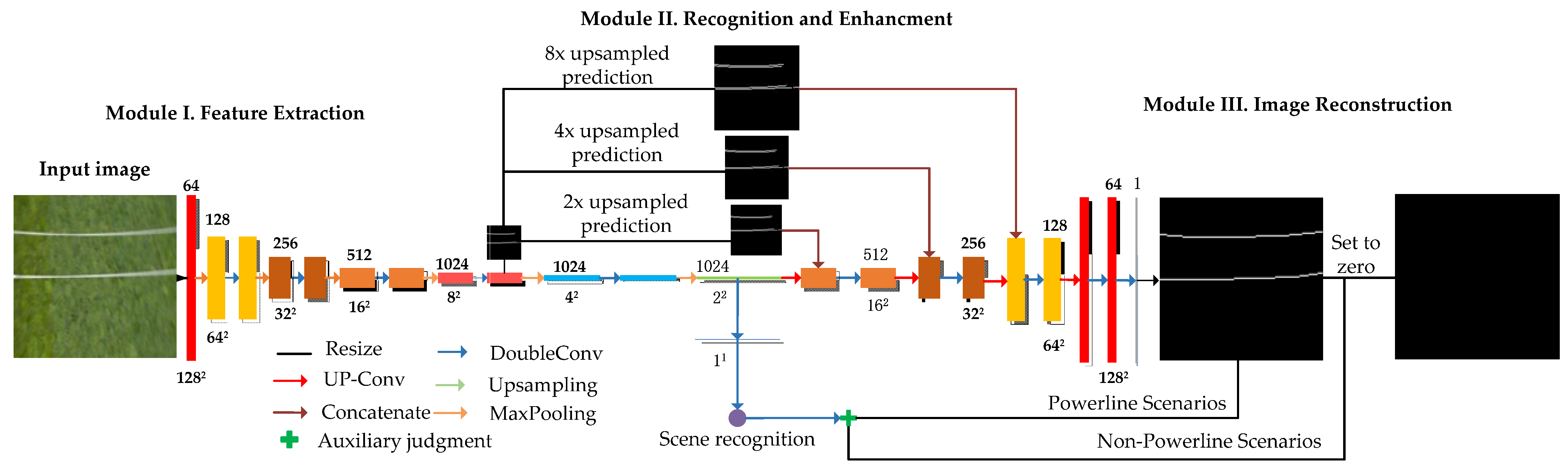
3. The Proposed PLE Framework
3.1. Scene Rule Constraints
3.2. Network Model Design
3.3. Self-Learning Multi-Loss Smoothing Technique
3.3.1. Label Smoothing
3.3.2. Self-Learning Smoothing Loss
4. Experimental Results and Analysis
4.1. Power Line Dataset and Experimental Configuration
4.2. Performance Evaluation Metrics
4.2.1. MIoU [44]
4.2.2. PA [44]
4.2.3. FWIoU [44]
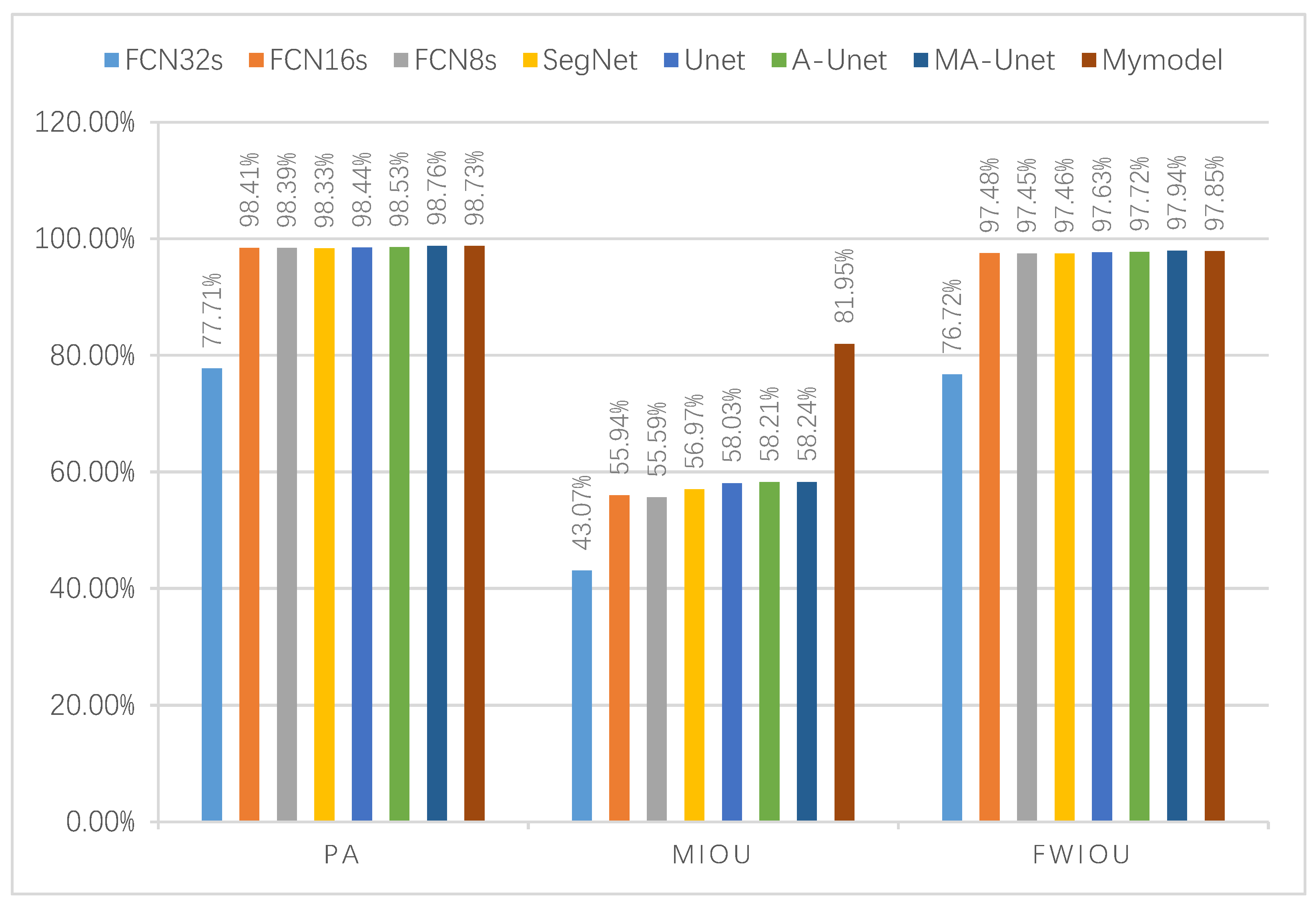
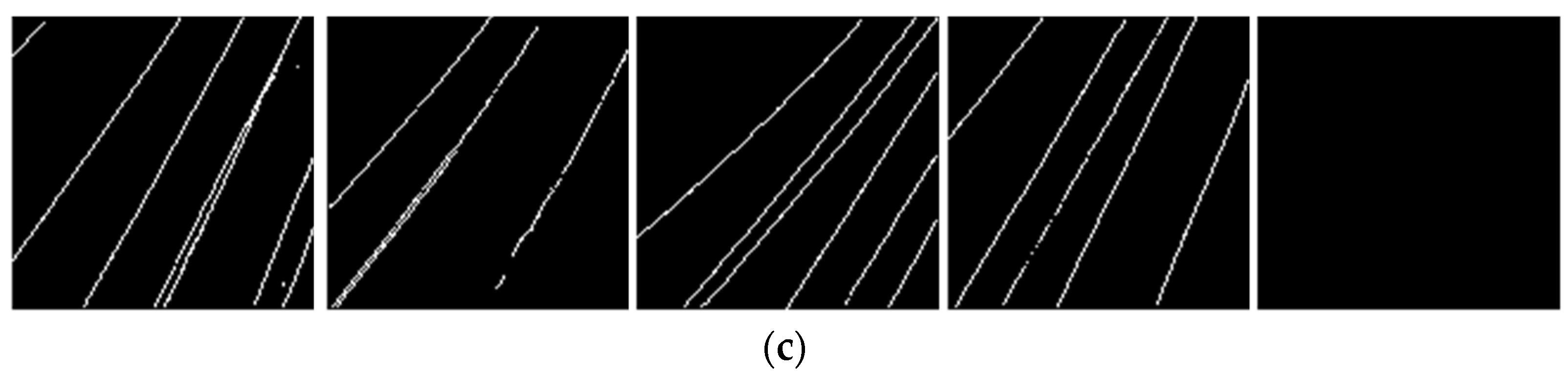
4.3. Comparison Results
5. Robustness and Generalization Test
5.1. Performance Robustness Test
5.1.1. Fog Test
5.1.2. Strong Light Test
5.1.3. Snow Fall Test
5.1.4. Motion Blur Test
5.2. Generalization Test
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar]
- Liu, M.; Li, Z.; Li, Y.; Liu, Y. A fast and accurate method of power line intelligent inspection based on edge computing. IEEE Trans. Instrum. Meas. 2022, 71, 3506512. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Liu, Y.; Li, E.; Peng, J.; Liang, Z. A review on state-of-the-art power line inspection techniques. IEEE Trans. Instrum. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, C.; Xu, C.; Xiong, F.; Zhang, Y.; Umer, T. Energy-effificient industrial internet of UAVs for power line inspection in smart grid. IEEE Trans. Ind. Inform. 2018, 14, 2705–2714. [Google Scholar] [CrossRef]
- Silano, G.; Baca, T.; Penicka, R.; Liuzza, D.; Saska, M. Power line inspection tasks with multi-aerial power line inspection tasks with multi-aerial logic specifications. IEEE Robot. Autom. Lett. 2021, 6, 4169–4176. [Google Scholar] [CrossRef]
- Sumagayan, M.; Premachandra, C.; Mangorsi, R.; Salaan, C.; Premachandra, H.; Kawanaka, H. Detecting power lines using point instance network for distribution line inspection. IEEE Access 2021, 9, 107998–108008. [Google Scholar] [CrossRef]
- Shuang, F.; Chen, X.; Li, Y.; Wang, Y.; Miao, N.; Zhou, Z. PLE: Power Line Extraction Algorithm for UAV-Based Power Inspection; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Xu, C.; Li, Q.; Zhou, Q.; Zhang, S.; Yu, D.; Ma, Y. Power line-guided automatic electric transmission line inspection system. IEEE Trans. Instrum. Meas. 2022, 71, 3512118. [Google Scholar] [CrossRef]
- Zhang, X.; Xiao, G.; Gong, K.; Ye, P. Power line detection for aircraft safety based on image processing techniques: Advances and recommendations. IEEE Aerosp. Electron. Syst. Mag. 2019, 34, 54–62. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, X.; Yao, H.; Tian, M. Survey of power line extraction methods based on visible light aerial image. Power Syst. Technol. 2021, 45, 1536–1546. [Google Scholar]
- Zou, K.; Jiang, Z.; Zhang, Q. Research progresses and trends of power line extraction based on machine learning. In Proceedings of the 2nd International Symposium on Computer Engineering and Intelligent Communications (ISCEIC), Nanjing, China, 6–8 August 2021; pp. 211–215.
- Tong, W.; Li, B.; Yuan, J.; Zhao, S. Transmission line extraction and recognition from natural complex background. In Proceedings of the 2009 International Conference on Machine Learning and Cybernetics (ICMLC), Baoding, China, 12–15 July 2009; pp. 2473–2477. [Google Scholar]
- Cao, W.; Yang, X.; Zhu, L.; Han, J.; Wang, T. Power line detection based on symmetric partial derivative distribution prior. In Proceedings of the 2013 IEEE International Conference on Information and Automation (ICIA), Yinchuan, China, 26–28 August 2013; pp. 767–772. [Google Scholar]
- Gerke, M.; Seibold, P. Visual inspection of power lines by UAS. In Proceedings of the 2014 International Conference and Exposition on Electrical and Power Engineering (EPE), Iasi, Romania, 16–18 October 2014; pp. 1077–1082. [Google Scholar]
- Tian, F.; Wang, Y.; Zhu, L. Power line recognition and tracking method for UAVs inspection. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 2136–2141. [Google Scholar]
- Alpatov, B.; Babayan, P.; Shubin, N. Robust line detection using Weighted Radon Transform. In Proceedings of the 2014 3rd Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 15–19 June 2014; pp. 148–151. [Google Scholar]
- Zhu, L.Y.; Cao, Y.; Han, J.; Du, Y. A double-side filter based power line recognition method for UAV vision system. In Proceedings of the 2013 IEEE International Conference on Robotics and Biometric (ROBIO), Shenzhen, China, 12–14 December 2013; pp. 2655–2660. [Google Scholar]
- Chen, Y.; Li, Y.; Zhang, H.; Tong, L.; Cao, Y.; Xue, Z. Automatic power line extraction from high resolution remote sensing imagery based on an improved radon transform. Pattern Recognit. 2016, 49, 174–186. [Google Scholar] [CrossRef]
- Zhao, H.; Lei, J.; Wang, X.; Zhao, L.; Tian, M.; Cao, W.; Yao, H.; Cai, B. Power line identification algorithm for aerial image in complex background. Bull. Surv. Mapp. 2019, 0, 28–32. [Google Scholar]
- Zhao, L.; Wang, X.; Yao, H.; Tian, M.; Gong, L. Power line extraction algorithm based on local context information. High Volt. Eng. 2021, 47, 2553–2563. [Google Scholar]
- Shan, H.; Zhang, J.; Cao, X.; Li, X.; Wu, D. Multiple auxiliaries assisted airborne power line detection. IEEE Trans. Ind. Electron. 2017, 64, 4810–4819. [Google Scholar] [CrossRef]
- Pan, C.; Shan, H.; Cao, X.; Li, X.; Wu, D. Leveraging spatial context disparity for power line detection. Cognit. Comput. 2017, 9, 766–779. [Google Scholar] [CrossRef]
- Zhang, J.; Shan, H.; Cao, X.; Yan, P.; Li, X. Pylon line spatial correlation assisted transmission line detection. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 2890–2905. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, J.; Cao, X.; Yan, P.; Li, X. Object-aware power line detection using color and near-infrared images. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 1374–1389. [Google Scholar] [CrossRef]
- Zhao, W.; Dong, Q.; Zuo, Z. A method combining line detection and semantic segmentation for power line extraction from unmanned aerial vehicle images. Remote Sens. 2022, 14, 1367. [Google Scholar] [CrossRef]
- Gerek, Ö.; Benligiray, B. Visualization of power lines recognized in aerial images using deep learning. In Proceedings of the 26th IEEE Signal Processing and Communications Applications Conference, Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar]
- Gubbi, J.; Varghese, A.; Balamuralidhar, P. A new deep learning architecture for detection of long linear infrastructure. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications, Nagoya, Japan, 8–12 May 2017; pp. 207–210. [Google Scholar]
- Pan, C.X.; Cao, X.; Wu, D. Power line detection via background noise removal. In Proceedings of the 2016 IEEE Global Conference on Signal and Information Processing, Washington, DC, USA, 7–9 December 2016; pp. 871–875. [Google Scholar]
- Zhu, K.; Xu, C.; Cai, G.; Wei, Y. Fast-PLDN: Fast power line detection network. J. Real-Time Image Process. 2022, 19, 3–13. [Google Scholar] [CrossRef]
- Choi, H.; Koo, G.; Kim, B.; Kim, S. Weakly supervised power line detection algorithm using a recursive noisy label update with refined broken line segments. Expert Syst. Appl. 2021, 165, 113895.1–113895.9. [Google Scholar] [CrossRef]
- Li, Y.; Pan, C.; Cao, X.; Wu, D. Power line detection by pyramidal patch classification. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 3, 416–426. [Google Scholar] [CrossRef]
- Xu, G.; Li, G. Research on lightweight neural network of aerial power line image segmentation. J. Image Gr. 2021, 26, 2605–2618. [Google Scholar]
- Nguyen, V.; Jenssen, R.; Roverso, D. LS-Net: Fast single-shot line-segment detector. Mach. Vis. Appl. 2021, 32, 12. [Google Scholar] [CrossRef]
- Gao, Z.; Yang, G.; Li, E.; Liang, Z.; Guo, R. Efficient parallel branch network with multi-scale feature fusion for real-time overhead power line segmentation. IEEE Sens. J. 2021, 21, 12220–12227. [Google Scholar] [CrossRef]
- Liu, J.; Li, Y.; Gong, Z.; Liu, X.; Zhou, Y. Power line recognition method via fully convolutional network. J. Image Gr. 2020, 25, 956–966. [Google Scholar]
- Yetgin, Ö.; Benligiray, B.; Gerek, Ö. Power line recognition from aerial images with deep learning. IEEE Trans. Aerosp. Electron. Syst 2019, 55, 2241–2252. [Google Scholar] [CrossRef]
- Li, Y.; Xiao, Z.; Zhen, X.; Cao, X. Attentional information fusion networks for cross-scene power line detection. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1635–1639. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, W.; Yu, H.; Zhang, H.; Xia, G. Detecting power lines in UAV images with convolutional features and structured constraints. Remote Sens. 2019, 11, 1342. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sanderson, E.; Matuszewski, B.J. FCN-transformer feature fusion for polyp segmentation. Lect. Notes Comput. Sci. 2022, 13413, 892–907. [Google Scholar] [CrossRef]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision transformer adapter for dense predictions. arXiv 2022, arXiv:2205.08534v2. [Google Scholar]
- Shi, W.; Xu, J. SSformer: A lightweight transformer for semantic segmentation. arXiv 2022, arXiv:2208.02034v1. [Google Scholar]
- Yetgin, Ö.; Gerek, Ö. Ground Truth of Powerline Dataset (Infrared-IR and Visible Light-VL), Mendeley Data, V9. Available online: https://data.mendeley.com/datasets/twxp8xccsw/9 (accessed on 26 June 2019). [CrossRef]
- Garcia, A.; Escolano, S.; Oprea, S.; Martinez, V.; Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. Lect. Notes Comput. Sci. 2015, 9351, 234–241. [Google Scholar]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Wang, Y. MA-Unet: An improved version of Unet based on multi-scale and attention mechanism for medical image segmentation, In Proceedings of the 3rd International conference on Electronics and Communication Network and Computer Technology (ECNCT), Harbin, China, 7 March 2022; Volume 12167. [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | Configuration |
|---|---|
| Operating system | 64 bit version of Windows 10 |
| Central Processing Unit (CPU) Graphic Processing Unit (GPU) | Intel(R) Core(TM) i9-10900k CPU @ 3.70 GHz NVIDIA GeForce RTX 2070 8G |
| Deep learning framework | PyTorch1.7 |
| Compilers | PyCharm |
| Scripting language | Python 3.7 |
| Solid State Disk (SSD) | 500 GB |
| Parameters | Configuration |
|---|---|
| Input Size | 128 × 128 × 3 |
| Batch size | 10 |
| Optimizer | Adam |
| Learning rate | 0.001 |
| Training epochs | 50 |
| PLE Methods | Average Inference Time (ms) |
|---|---|
| FCN32s | 167.78 |
| FCN16s | 163.65 |
| FCN8s | 174.83 |
| SegNet | 225.68 |
| Unet | 214.27 |
| Attention-Unet | 227.69 |
| MA-Unet | 388.05 |
| The proposed | 383.35 |
| Scenes | PA | MIOU | FWIOU |
|---|---|---|---|
| Foggy | 97.75% | 80.90% | 96.86% |
| Strong light | 97.73% | 80.20% | 96.85% |
| Snow fall | 97.35% | 53.85% | 96.33% |
| motion blur | 97.71% | 77.89% | 96.63% |
| Method | PA | MIOU | FWIOU |
|---|---|---|---|
| The proposed model | 98.06% | 70.07% | 96.26% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, K.; Jiang, Z. Power Line Extraction Framework Based on Edge Structure and Scene Constraints. Remote Sens. 2022, 14, 4575. https://doi.org/10.3390/rs14184575
Zou K, Jiang Z. Power Line Extraction Framework Based on Edge Structure and Scene Constraints. Remote Sensing. 2022; 14(18):4575. https://doi.org/10.3390/rs14184575
Chicago/Turabian StyleZou, Kuansheng, and Zhenbang Jiang. 2022. "Power Line Extraction Framework Based on Edge Structure and Scene Constraints" Remote Sensing 14, no. 18: 4575. https://doi.org/10.3390/rs14184575