
MID: A Novel Mountainous Remote Sensing Imagery Registration Dataset Assessed by a Coarse-to-Fine Unsupervised Cascading Network



Abstract
:
1. Introduction
- (1)
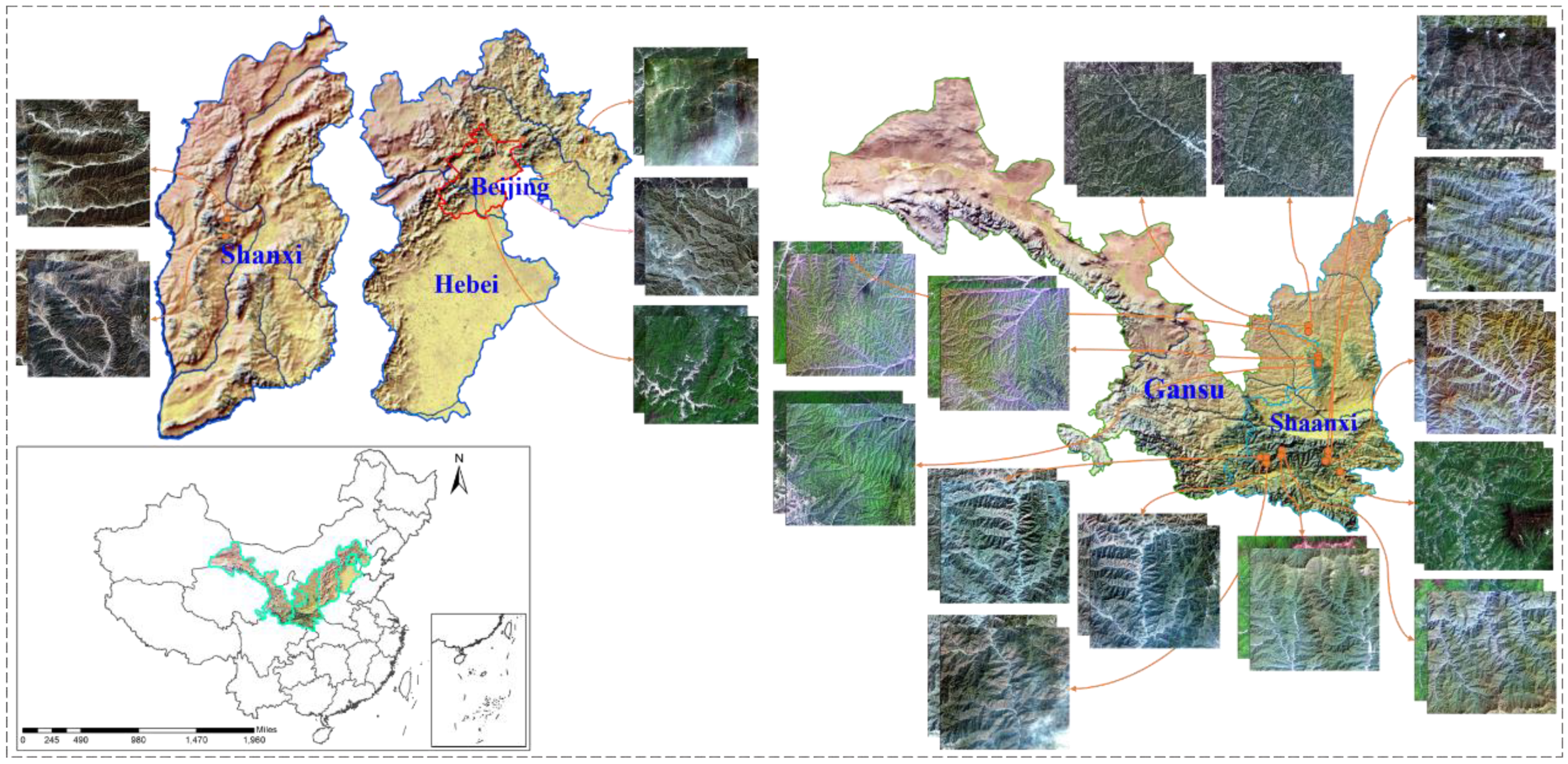
- First, for the first time, a mountainous remote sensing imagery dataset (MID) for geometric registration is constructed. The dataset consists of 4093 pairs of image patches located in some specified mountains in China;
- (2)
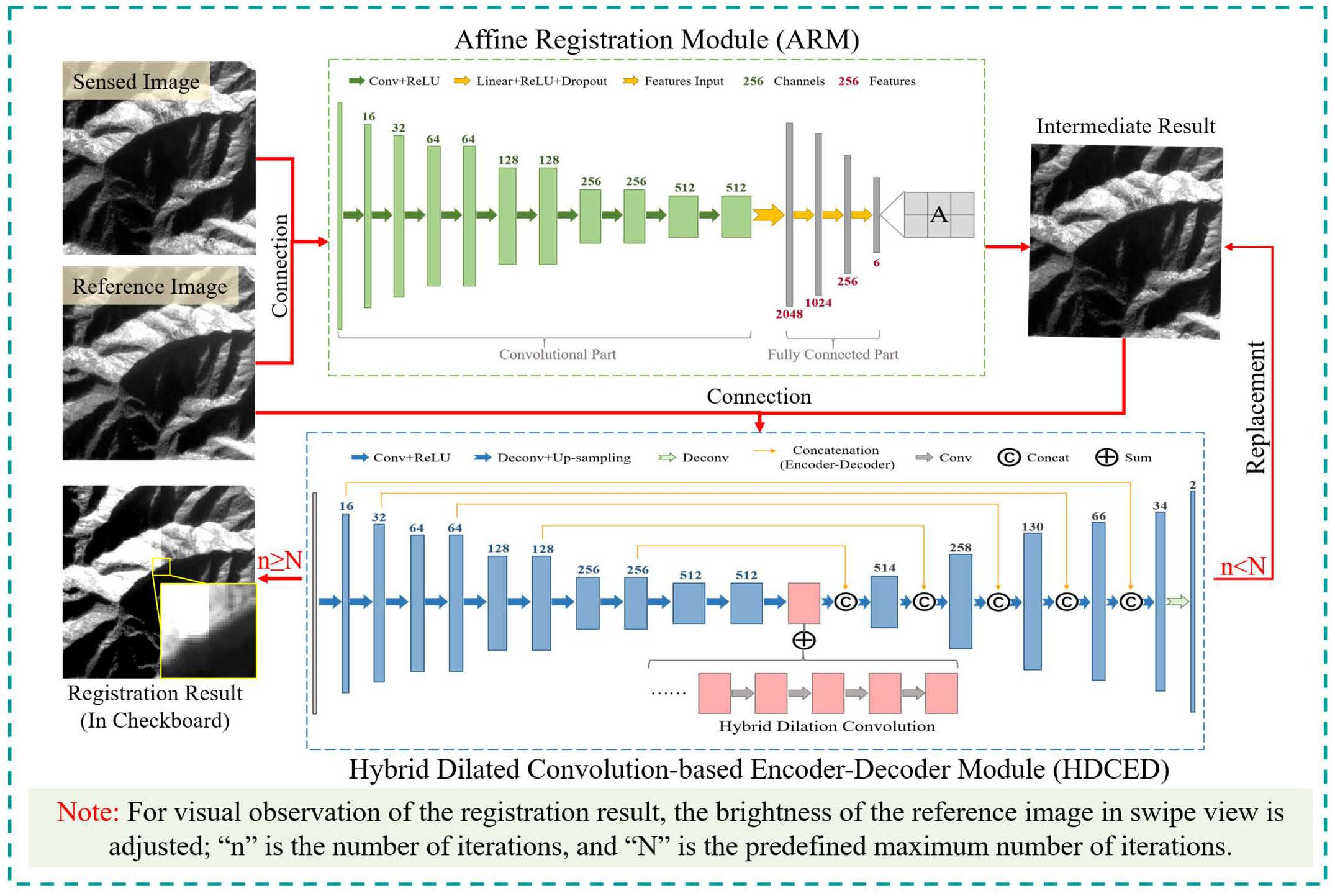
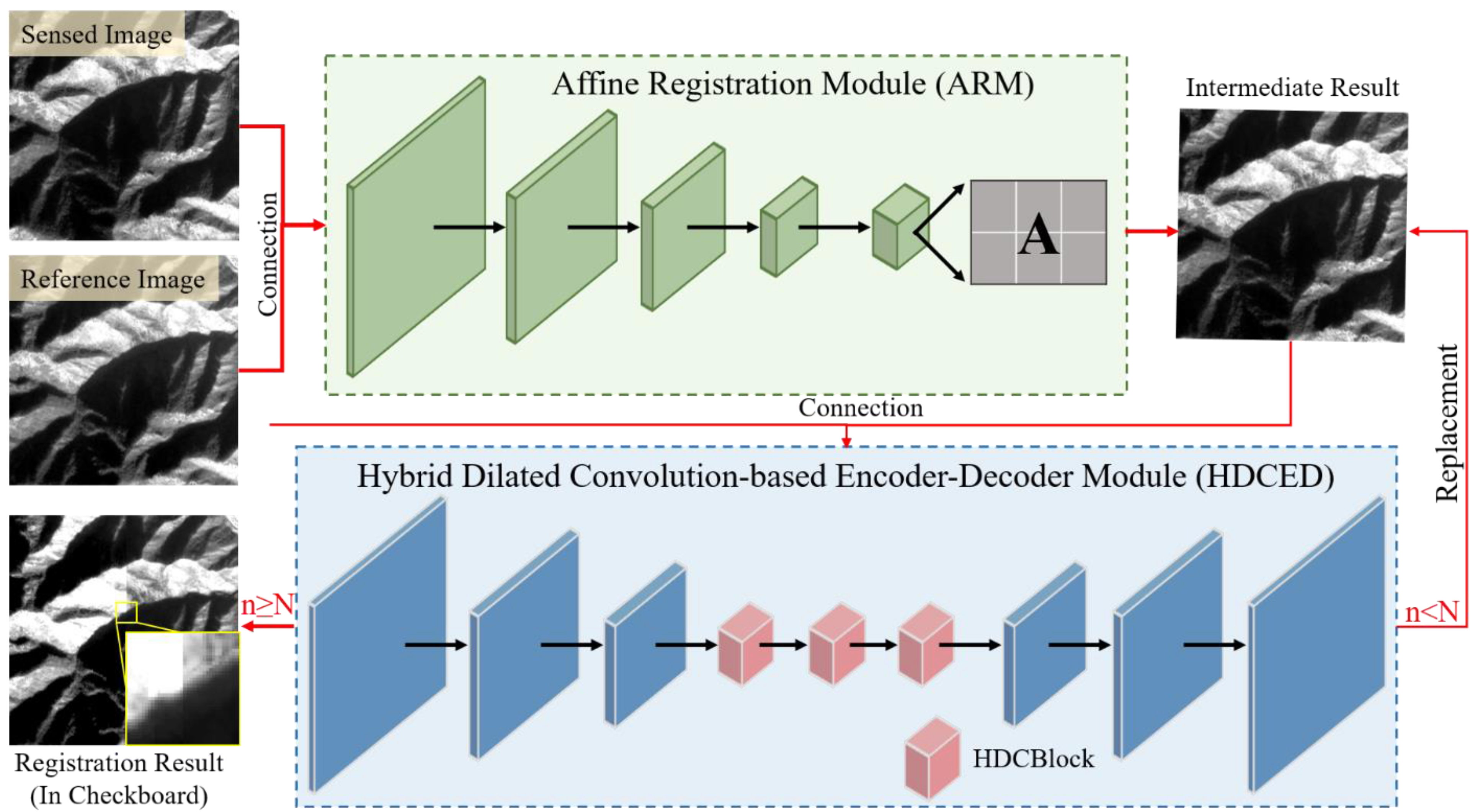
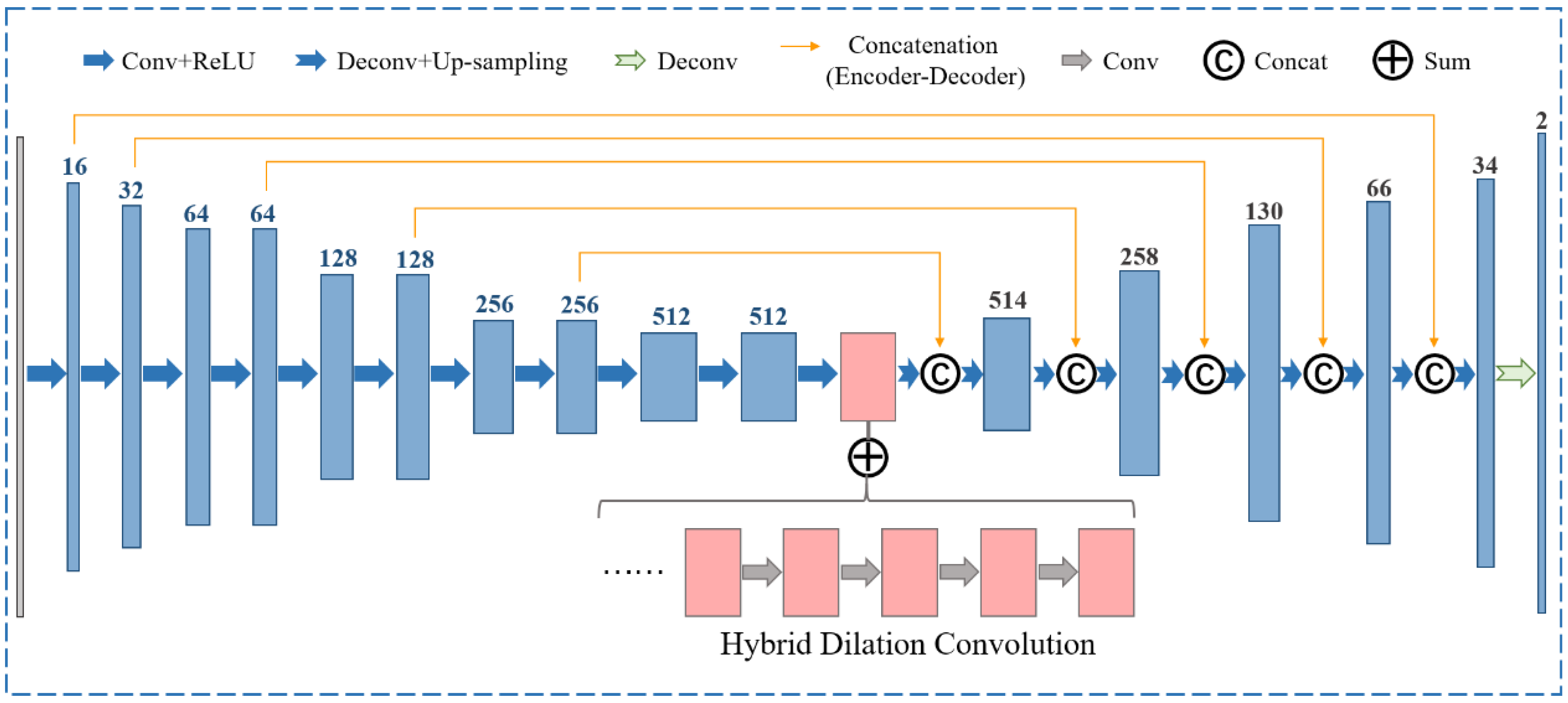
- Then, a coarse-to-fine unsupervised cascading convolutional network is developed, consisting of an affine registration module (ARM) and an iterative hybrid dilation convolution-based encoder–decoder (HDCED) module. The entire network is trained in an end-to-end manner, and the previous result is always connected to the reference image as the input of the subsequent process.
2. The Mountainous Remote Sensing Imagery Dataset (MID)
2.1. Construction of the MID
2.2. Splits of the Dataset
3. Coarse-to-Fine Unsupervised Cascading Networks for Geometric Registration
3.1. Network Architecture
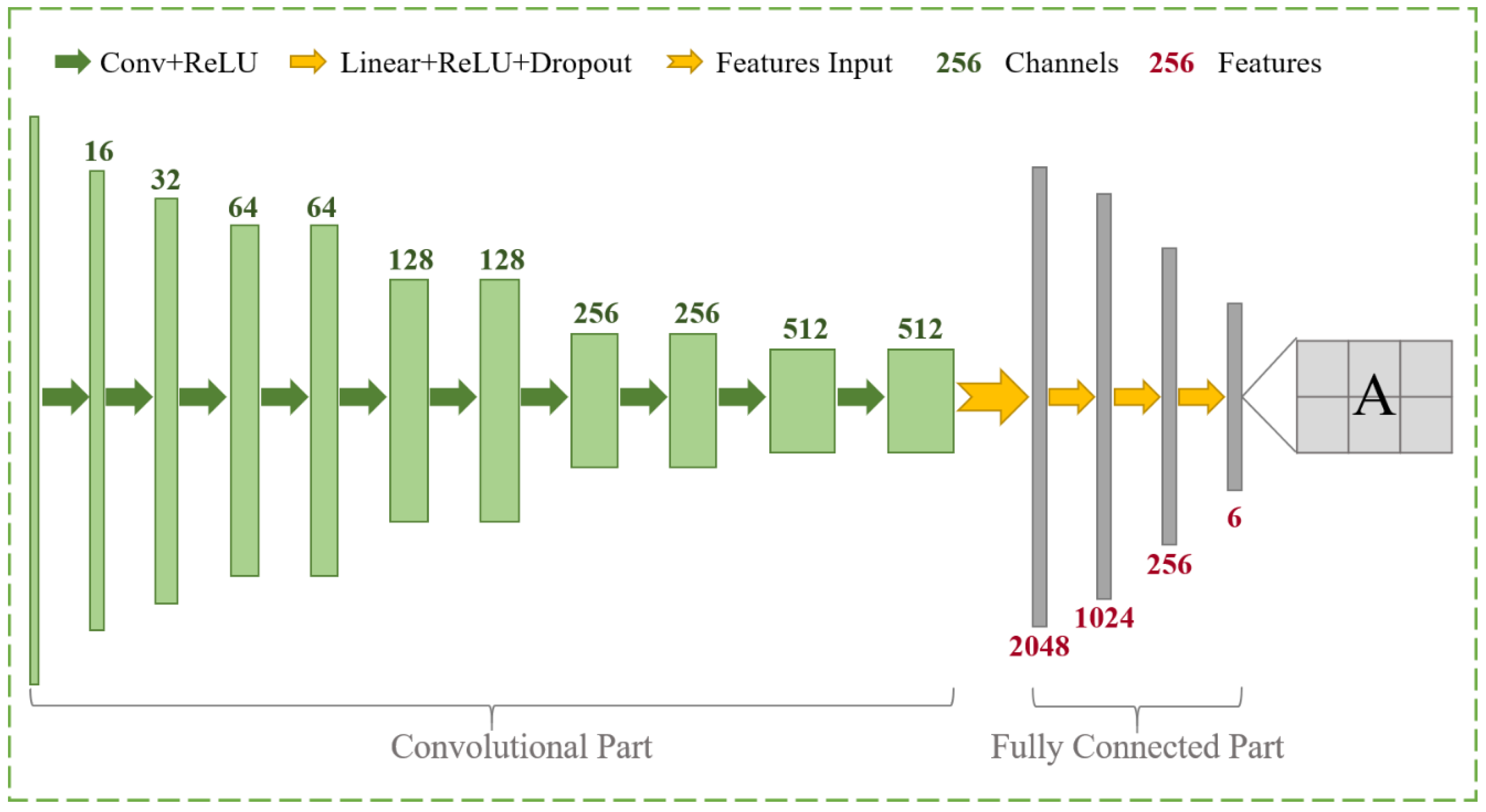
3.1.1. The Coarse Alignment Using the ARM
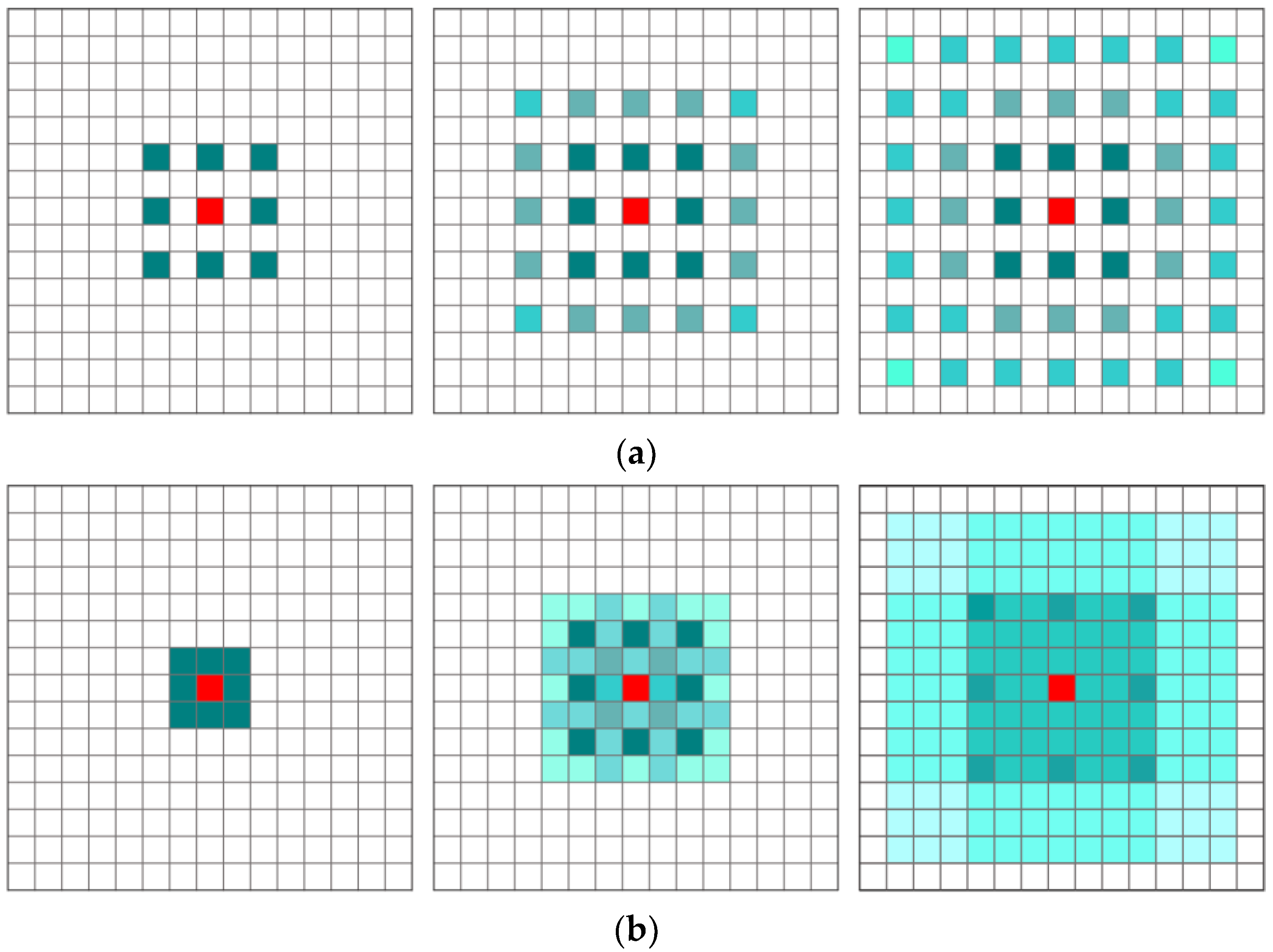
3.1.2. The Refinement Registration Network with the HDCED
3.2. Implementation Details of the Proposed Framework
4. Experiments
4.1. Evaluation Metrics and Experimental Scheme
4.2. Ablation Experiment for the Proposed Algorithm
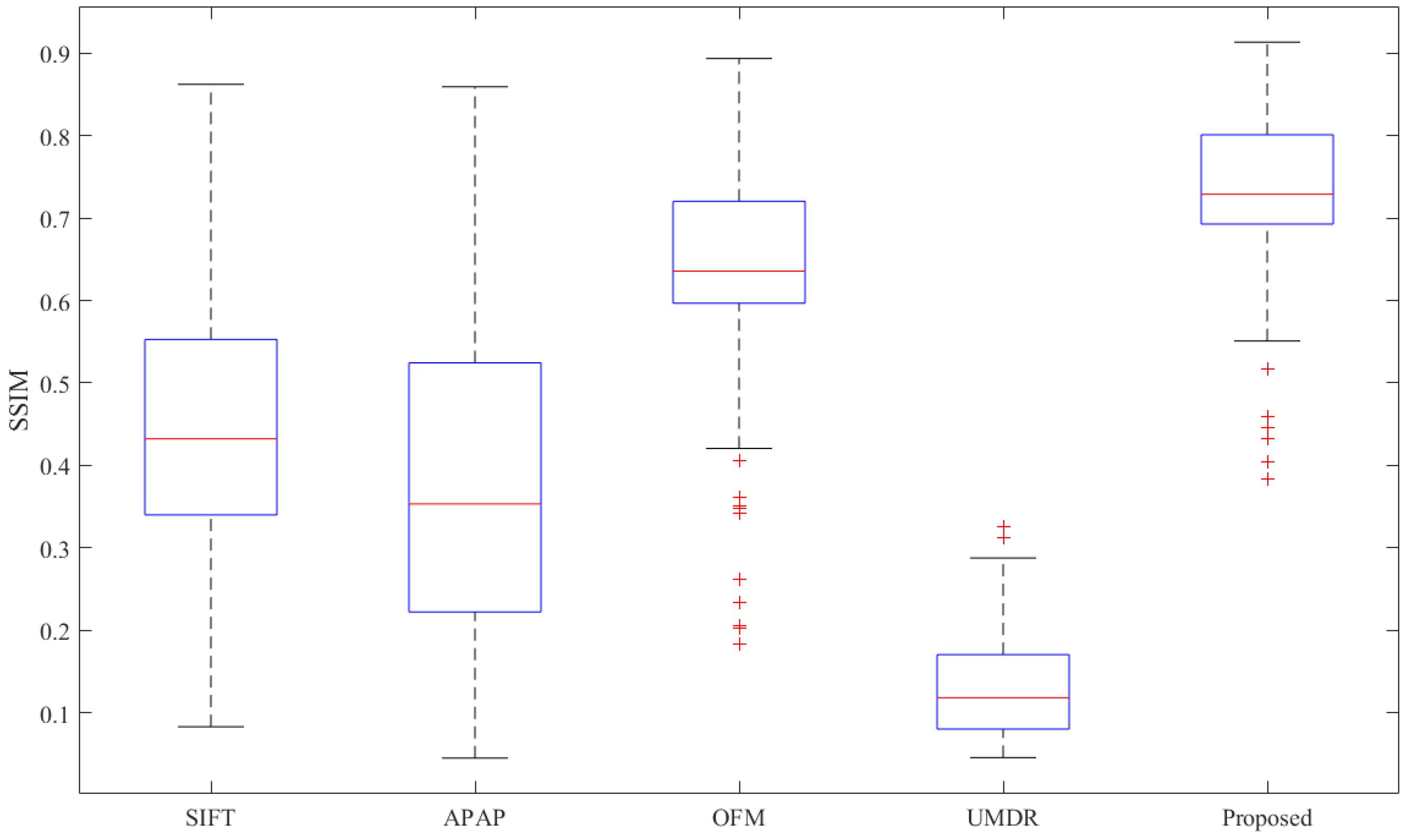
4.3. Comparison between the Proposed and Other Algorithms
5. Discussion
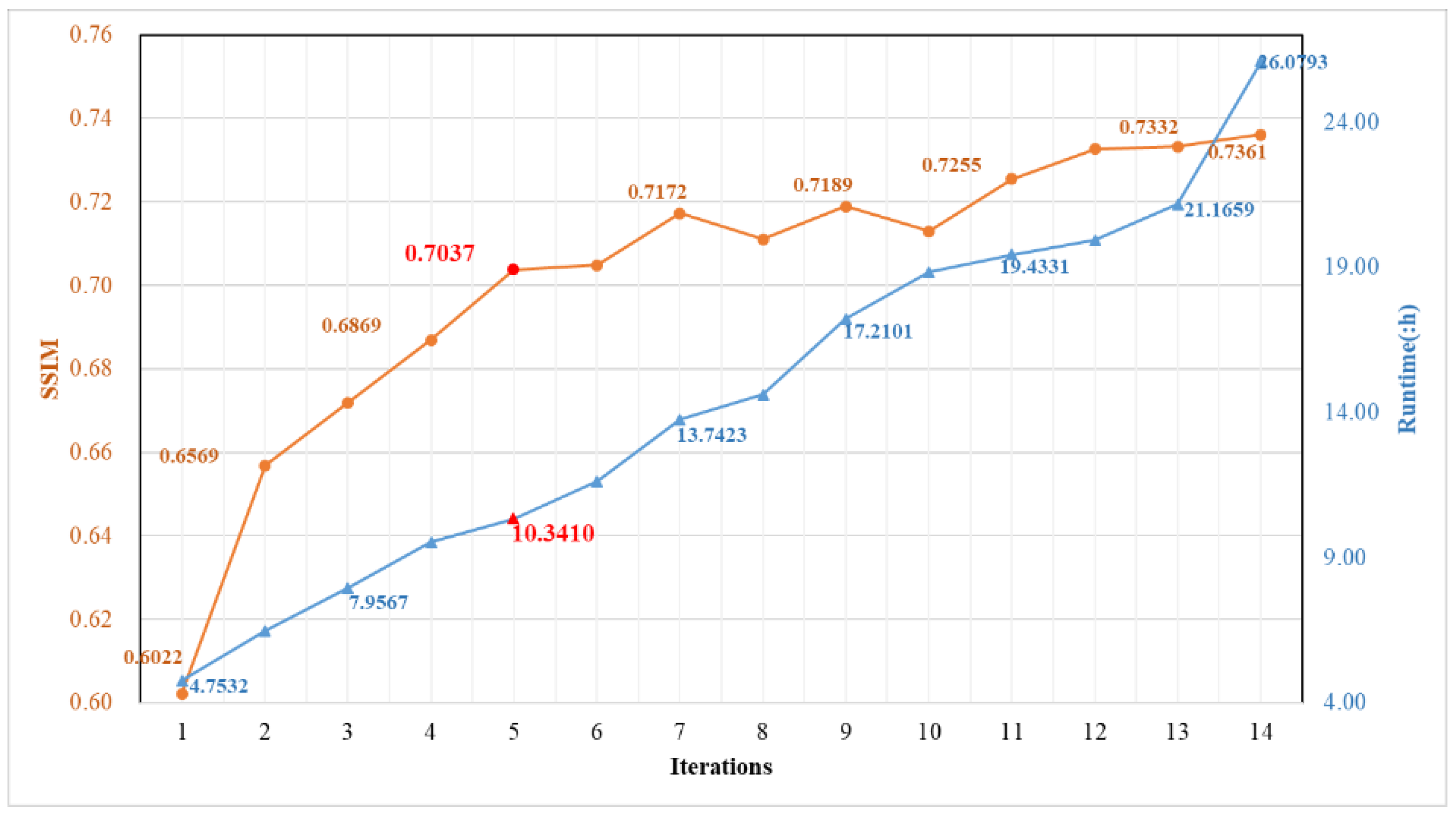
5.1. Definition of the Number of Iterations for Refinement Registration Using the HDCED
5.2. Limitation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jiang, X.; Ma, J.; Fan, A.; Xu, H.; Lin, G.; Lu, T.; Tian, X. Robust Feature Matching for Remote Sensing Image Registration via Linear Adaptive Filtering. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1577–1591. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, J.-W.; Zhu, C.-Z.; Bai, Z.-F.; Miao, Q.-G.; Ma, W.-P.; Gong, M.-G. Computational Intelligence in Remote Sensing Image Registration: A survey. Int. J. Autom. Comput. 2020, 18, 1–17. [Google Scholar] [CrossRef]
- Zitová, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef]
- Feng, R.; Shen, H.; Bai, J.; Li, X. Advances and Opportunities in Remote Sensing Image Geometric Registration: A systematic review of state-of-the-art approaches and future research directions. IEEE Geosci. Remote Sens. Mag. 2021, 9, 120–142. [Google Scholar] [CrossRef]
- Ye, Y.; Bruzzone, L.; Shan, J.; Bovolo, F.; Zhu, Q. Fast and Robust Matching for Multimodal Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9059–9070. [Google Scholar] [CrossRef]
- Ye, Y.; Shan, J.; Bruzzone, L.; Shen, L. Robust Registration of Multimodal Remote Sensing Images Based on Structural Similarity. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2941–2958. [Google Scholar] [CrossRef]
- Gong, M.; Zhao, S.; Jiao, L.; Tian, D.; Wang, S. A Novel Coarse-to-Fine Scheme for Automatic Image Registration Based on SIFT and Mutual Information. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4328–4338. [Google Scholar] [CrossRef]
- Yan, H.; Yang, S.; Xue, Q.; Zhang, N. HR optical and SAR image registration using uniform optimized feature and extend phase congruency. Int. J. Remote Sens. 2021, 43, 52–74. [Google Scholar] [CrossRef]
- Brigot, G.; Colin-Koeniguer, E.; Plyer, A.; Janez, F. Adaptation and Evaluation of an Optical Flow Method Applied to Coregistration of Forest Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2923–2939. [Google Scholar] [CrossRef]
- Xiang, Y.; Wang, F.; Wan, L.; Jiao, N.; You, H. OS-Flow: A Robust Algorithm for Dense Optical and SAR Image Registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6335–6354. [Google Scholar] [CrossRef]
- Feng, R.; Du, Q.; Shen, H.; Li, X. Region-by-Region Registration Combining Feature-Based and Optical Flow Methods for Remote Sensing Images. Remote Sens. 2021, 13, 1475. [Google Scholar] [CrossRef]
- Feng, R.; Du, Q.; Luo, H.; Shen, H.; Li, X.; Liu, B. A registration algorithm based on optical flow modification for multi-temporal remote sensing images covering the complex-terrain region. Natl. Remote Sens. Bull. 2021, 25, 630–640. [Google Scholar]
- Plyer, A.; Colin-Koeniguer, E.; Weissgerber, F. A New Coregistration Algorithm for Recent Applications on Urban SAR Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2198–2202. [Google Scholar] [CrossRef]
- Paul, S.; Pati, U.C. A comprehensive review on remote sensing image registration. Int. J. Remote Sens. 2021, 42, 5396–5432. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Liu, H. Robust Optical and SAR Image Registration Based on OS-SIFT and Cascaded Sample Consensus. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Yang, W.; Wang, X.; Moran, B.; Wheaton, A.; Cooley, N. Efficient registration of optical and infrared images via modified Sobel edging for plant canopy temperature estimation. Comput. Electr. Eng. 2012, 38, 1213–1221. [Google Scholar] [CrossRef]
- Palenichka, R.M.; Zaremba, M.B. Automatic Extraction of Control Points for the Registration of Optical Satellite and LiDAR Images. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2864–2879. [Google Scholar] [CrossRef]
- Kuppala, K.; Banda, S.; Barige, T.R. An overview of deep learning methods for image registration with focus on feature-based approaches. Int. J. Image Data Fusion 2020, 11, 113–135. [Google Scholar] [CrossRef]
- Gang, H.; Yun, Z. Combination of feature-based and area-based image registration technique for high resolution remote sensing image. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Barcelona, Spain, 23–28 July 2007; pp. 377–380. [Google Scholar]
- Zhang, P.; Luo, X.; Ma, Y.; Wang, C.; Wang, W.; Qian, X. Coarse-to-Fine Image Registration for Multi-Temporal High Resolution Remote Sensing Based on a Low-Rank Constraint. Remote Sens. 2022, 14, 573. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Pallotta, L.; Giunta, G.; Clemente, C. Subpixel SAR Image Registration Through Parabolic Interpolation of the 2-D Cross Correlation. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4132–4144. [Google Scholar] [CrossRef]
- Feng, R.; Du, Q.; Li, X.; Shen, H. Robust registration for remote sensing images by combining and localizing feature- and area-based methods. ISPRS J. Photogramm. Remote Sens. 2019, 151, 15–26. [Google Scholar] [CrossRef]
- Ye, Y.; Shan, J. A local descriptor based registration method for multispectral remote sensing images with non-linear intensity differences. ISPRS J. Photogramm. Remote Sens. 2014, 90, 83–95. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Merkle, N.; Auer, S.; Muller, R.; Reinartz, P. Exploring the Potential of Conditional Adversarial Networks for Optical and SAR Image Matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1811–1820. [Google Scholar] [CrossRef]
- Hughes, L.H.; Schmitt, M.; Mou, L.; Wang, Y.; Zhu, X.X. Identifying Corresponding Patches in SAR and Optical Images With a Pseudo-Siamese CNN. IEEE Geosci. Remote Sens. Lett. 2018, 15, 784–788. [Google Scholar] [CrossRef]
- Hoffmann, S.; Brust, C.-A.; Shadaydeh, M.; Denzler, J. Registration of High Resolution Sar and Optical Satellite Imagery Using Fully Convolutional Networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 5152–5155. [Google Scholar] [CrossRef]
- Quan, D.; Wang, S.; Ning, M.; Xiong, T.; Jiao, L. Using deep neural networks for synthetic aperture radar image registration. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2799–2802. [Google Scholar] [CrossRef]
- Ye, F.; Su, Y.; Xiao, H.; Zhao, X.; Min, W. Remote Sensing Image Registration Using Convolutional Neural Network Features. IEEE Geosci. Remote Sens. Lett. 2018, 15, 232–236. [Google Scholar] [CrossRef]
- Ma, W.; Zhang, J.; Wu, Y.; Jiao, L.; Zhu, H.; Zhao, W. A Novel Two-Step Registration Method for Remote Sensing Images Based on Deep and Local Features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4834–4843. [Google Scholar] [CrossRef]
- Zhang, H.; Ni, W.; Yan, W.; Xiang, D.; Wu, J.; Yang, X.; Bian, H. Registration of Multimodal Remote Sensing Image Based on Deep Fully Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3028–3042. [Google Scholar] [CrossRef]
- Quan, D.; Wang, S.; Gu, Y.; Lei, R.; Yang, B.; Wei, S.; Hou, B.; Jiao, L. Deep Feature Correlation Learning for Multi-Modal Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchnet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- Quan, D.; Liang, X.; Wang, S.; Wei, S.; Li, Y.; Huyan, N.; Jiao, L. AFD-Net: Aggregated Feature Difference Learning for Cross-Spectral Image Patch Matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Wang, S.; Quan, D.; Liang, X.; Ning, M.; Guo, Y.; Jiao, L. A deep learning framework for remote sensing image registration. ISPRS J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Li, L.; Han, L.; Ding, M.; Liu, Z.; Cao, H. Remote Sensing Image Registration Based on Deep Learning Regression Model. IEEE Geosci. Remote Sens. Lett. 2020, 19, 8002905. [Google Scholar] [CrossRef]
- Li, L.; Han, L.; Ding, M.; Cao, H.; Hu, H. A deep learning semantic template matching framework for remote sensing image registration. ISPRS J. Photogramm. Remote Sens. 2021, 181, 205–217. [Google Scholar] [CrossRef]
- Haskins, G.; Kruger, U.; Yan, P. Deep learning in medical image registration: A survey. Mach. Vis. Appl. 2020, 31, 8. [Google Scholar] [CrossRef]
- Zampieri, A.; Charpiat, G.; Girard, N.; Tarabalka, Y. Multimodal Image Alignment Through a Multiscale Chain of Neural Networks with Application to Remote Sensing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 679–696. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Deep image homography estimation. arXiv 2016, arXiv:1606.03798. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Papadomanolaki, M.; Christodoulidis, S.; Karantzalos, K.; Vakalopoulou, M. Unsupervised Multistep Deformable Registration of Remote Sensing Imagery Based on Deep Learning. Remote Sens. 2021, 13, 1294. [Google Scholar] [CrossRef]
- Balakrishnan, G.; Zhao, A.; Sabuncu, M.R.; Guttag, J.; Dalca, A.V. VoxelMorph: A Learning Framework for Deformable Medical Image Registration. IEEE Trans. Med. Imaging 2019, 38, 1788–1800. [Google Scholar] [CrossRef] [Green Version]
- Stergios, C.; Mihir, S.; Maria, V.; Guillaume, C.; Marie-Pierre, R.; Stavroula, M.; Nikos, P. Linear and Deformable Image Registration with 3D Convolutional Neural Networks. In Image Analysis for Moving Organ, Breast, and Thoracic Images; Springer: Cham, Switzerland, 2018; pp. 13–22. [Google Scholar] [CrossRef]
- Vakalopoulou, M.; Christodoulidis, S.; Sahasrabudhe, M.; Mougiakakou, S.; Paragios, N. Image Registration of Satellite Imagery with Deep Convolutional Neural Networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 4939–4942. [Google Scholar] [CrossRef]
- Zhao, S.; Dong, Y.; Chang, E.I.; Xu, Y. Recursive cascaded networks for unsupervised medical image registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 10600–10610. [Google Scholar]
- Zhao, S.; Lau, T.; Luo, J.; Chang, E.I.-C.; Xu, Y. Unsupervised 3D End-to-End Medical Image Registration With Volume Tweening Network. IEEE J. Biomed. Health Inform. 2019, 24, 1394–1404. [Google Scholar] [CrossRef]
- Tian, B.; Li, Z.; Zhang, M.; Huang, L.; Qiu, Y.; Li, Z.; Tang, P. Mapping Thermokarst Lakes on the Qinghai–Tibet Plateau Using Nonlocal Active Contours in Chinese GaoFen-2 Multispectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1–14. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Li, X.; Chen, S.; Hu, X.; Yang, J. Understanding the Disharmony Between Dropout and Batch Normalization by Variance Shift. In Proceedings of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2677–2685. [Google Scholar] [CrossRef]
- Fang, Y.; Li, Y.; Tu, X.; Tan, T.; Wang, X. Face completion with Hybrid Dilated Convolution. Signal Process. Image Commun. 2019, 80, 115664. [Google Scholar] [CrossRef]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 107. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zaragoza, J.; Chin, T.J.; Tran, Q.H.; Suter, D. As-Projective-As-Possible Image Stitching with Moving DLT. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1285–1298. [Google Scholar]
- Han, Y.; Bovolo, F.; Bruzzone, L. An Approach to Fine Coregistration Between Very High Resolution Multispectral Images Based on Registration Noise Distribution. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6650–6662. [Google Scholar] [CrossRef]
- Wong, A.; Clausi, D.A. ARRSI: Automatic Registration of Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1483–1493. [Google Scholar] [CrossRef]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for neural networks for image processing. arXiv 2015, arXiv:1511.08861. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Luo, S.; Li, H.; Shen, H. Deeply supervised convolutional neural network for shadow detection based on a novel aerial shadow imagery dataset. ISPRS J. Photogramm. Remote Sens. 2020, 167, 443–457. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| 11-11-2021 | 28-05-2020 | 09-06-2017 | 22-11-2021 | 13-01-2017 | 25-04-2020 | 19-10-2020 | 02-04-2016 | 29-09-2021 | 29-09-2021 |
| 27-10-2021 | 08-05-2021 | 01-07-2021 | 13-01-2017 | 22-11-2021 | 25-04-2020 | 02-04-2016 | 19-10-2020 | 09-05-2021 | 09-05-2021 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | |
| 29-09-2021 | 29-09-2021 | 29-09-2021 | 09-05-2021 | 29-09-2021 | 26-01-2021 | 11-01-2021 | 04-12-2019 | 05-12-2016 | |
| 09-05-2021 | 09-05-2021 | 09-05-2021 | 29-09-2021 | 09-05-2021 | 11-01-2021 | 26-01-2021 | 16-02-2020 | 26-10-2018 |
| Experiment | Indicators | Original | ARM | Proposed |
|---|---|---|---|---|
| Test-1 | MI (↑) | 0.2650 | 1.0730 | 1.2459 |
| SSIM (↑) | 0.1735 | 0.1880 | 0.9115 | |
| Test-2 | MI (↑) | 0.2428 | 0.9370 | 1.0843 |
| SSIM (↑) | 0.1175 | 0.2273 | 0.8592 | |
| Test-3 | MI (↑) | 0.1712 | 0.6416 | 0.7277 |
| SSIM (↑) | 0.1676 | 0.6846 | 0.8490 | |
| Test-4 | MI (↑) | 0.0779 | 0.4422 | 0.5515 |
| SSIM (↑) | 0.1591 | 0.2914 | 0.7690 |
| Original | SIFT | APAP | OFM | UMDR | Proposed | |
|---|---|---|---|---|---|---|
| test 1 | 39.8819 | 2.8262 | 2.5981 | 3.5969 | 39.436 | 0.4099 |
| test 2 | 39.0149 | 3.7366 | 2.0555 | 3.5231 | 32.5883 | 0.6124 |
| test 3 | 20.9156 | 1.6163 | 1.5411 | 0.4330 | 19.4459 | 0.3708 |
| test 4 | 26.0337 | 0.5000 | 1.9333 | 0.4743 | 25.5903 | 0.2739 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, R.; Li, X.; Bai, J.; Ye, Y. MID: A Novel Mountainous Remote Sensing Imagery Registration Dataset Assessed by a Coarse-to-Fine Unsupervised Cascading Network. Remote Sens. 2022, 14, 4178. https://doi.org/10.3390/rs14174178
Feng R, Li X, Bai J, Ye Y. MID: A Novel Mountainous Remote Sensing Imagery Registration Dataset Assessed by a Coarse-to-Fine Unsupervised Cascading Network. Remote Sensing. 2022; 14(17):4178. https://doi.org/10.3390/rs14174178
Chicago/Turabian StyleFeng, Ruitao, Xinghua Li, Jianjun Bai, and Yuanxin Ye. 2022. "MID: A Novel Mountainous Remote Sensing Imagery Registration Dataset Assessed by a Coarse-to-Fine Unsupervised Cascading Network" Remote Sensing 14, no. 17: 4178. https://doi.org/10.3390/rs14174178