
An Adaptive Capsule Network for Hyperspectral Remote Sensing Classification



Abstract
:
1. Introduction
2. Materials and Methods
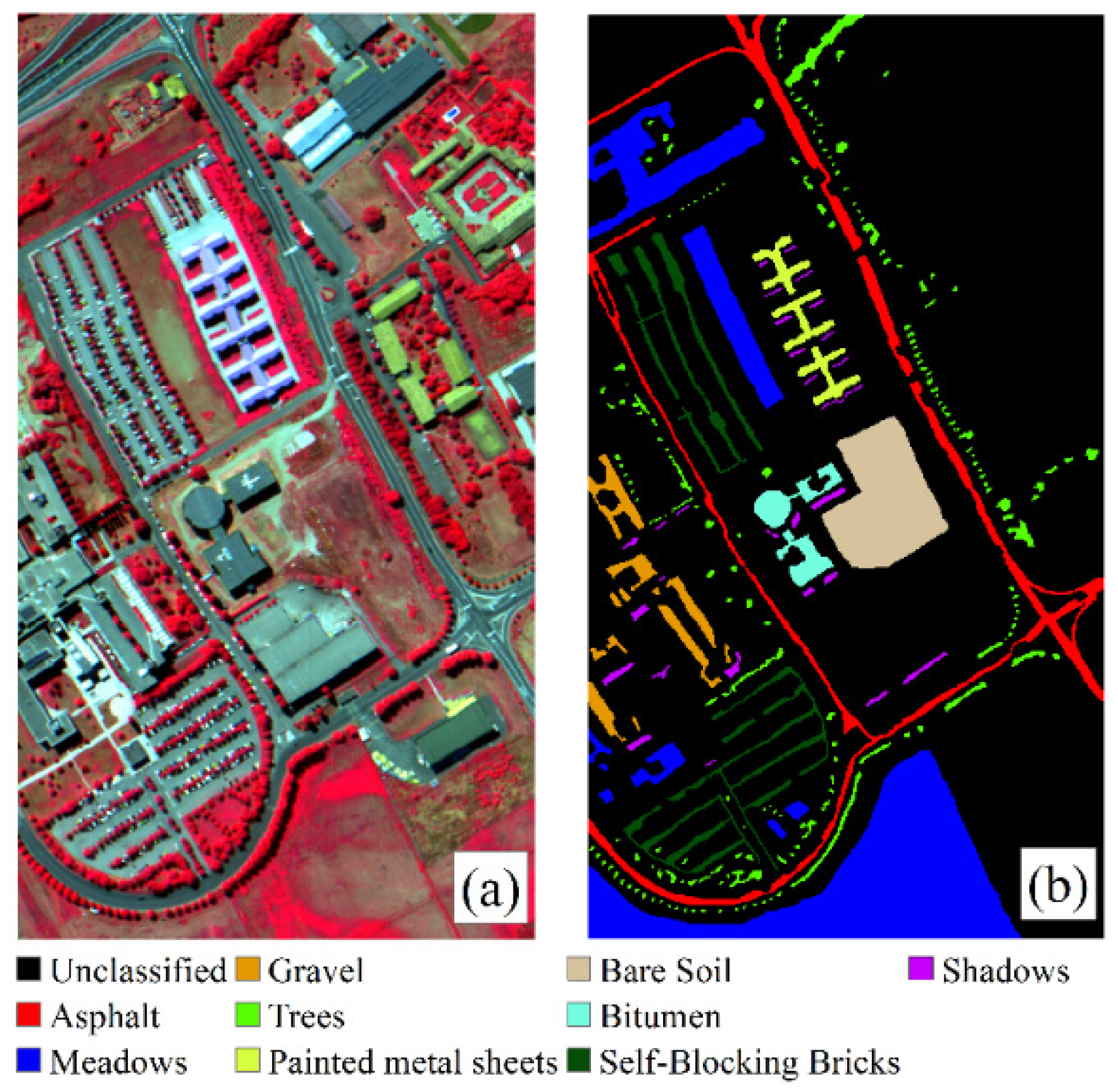
2.1. Data Source
2.2. Method
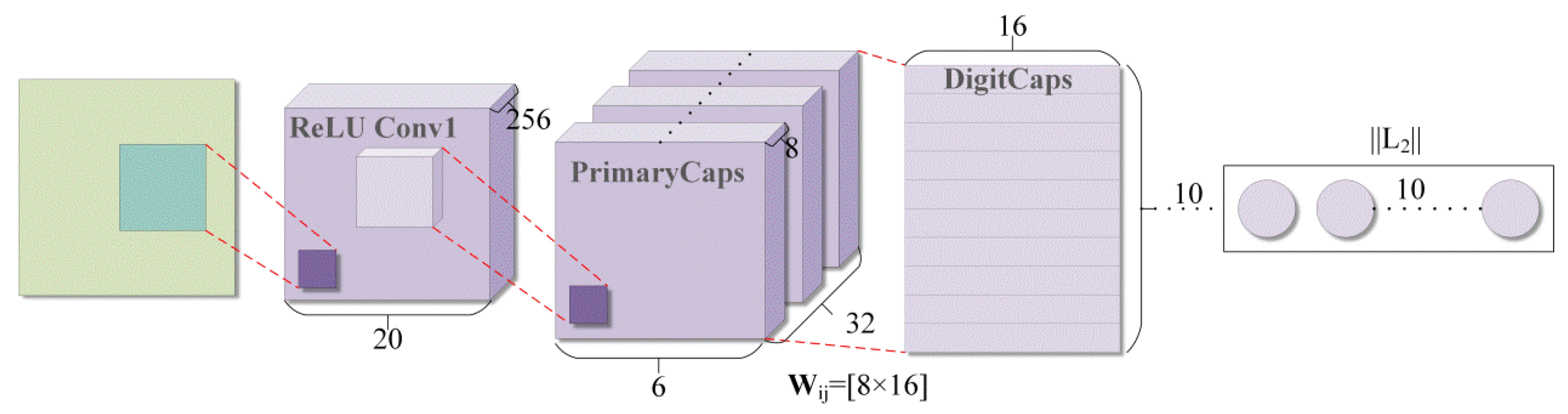
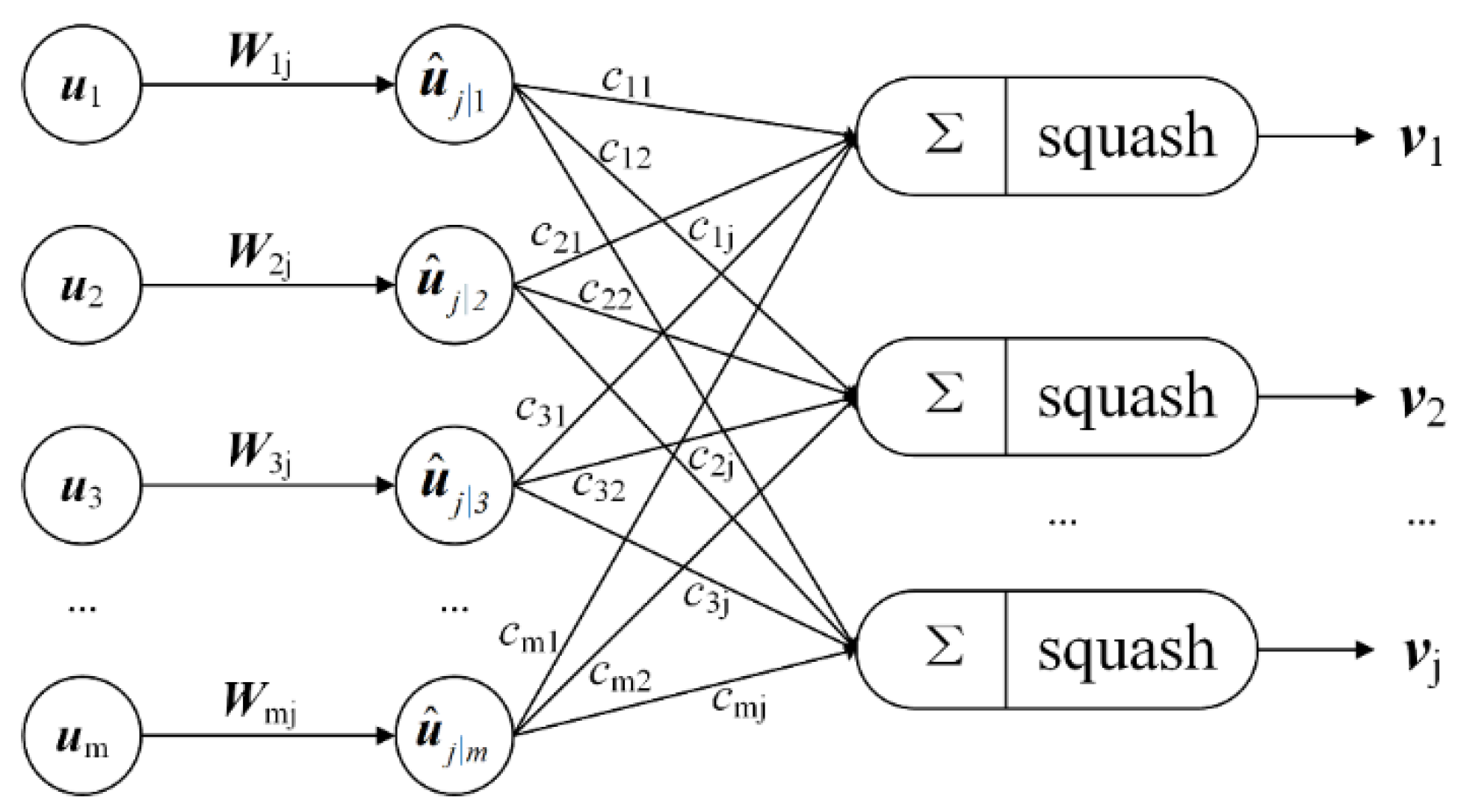
2.2.1. Overview of Capsule Network
| Algorithm 1: Dynamic routing algorithm. |
| 1: procedure Routing (, r, l) 2: for every capsule i in layer l and capsule j in layer (l+1): . 3: for r iterations do 4: for every capsule i in layer l: 5: for every capsule j in layer (l+1): 6: for every capsule j in layer (l+1): 7: for every capsule i in layer l and capsule j in layer (l+1): 8: return |
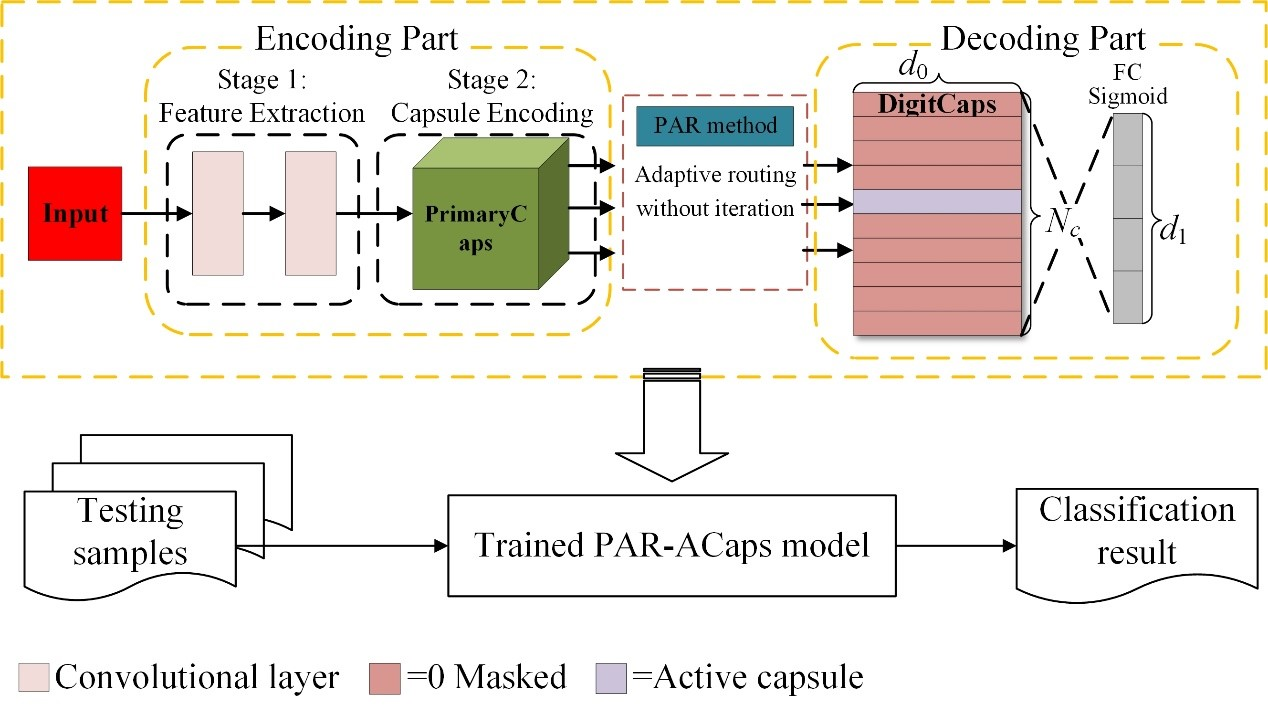
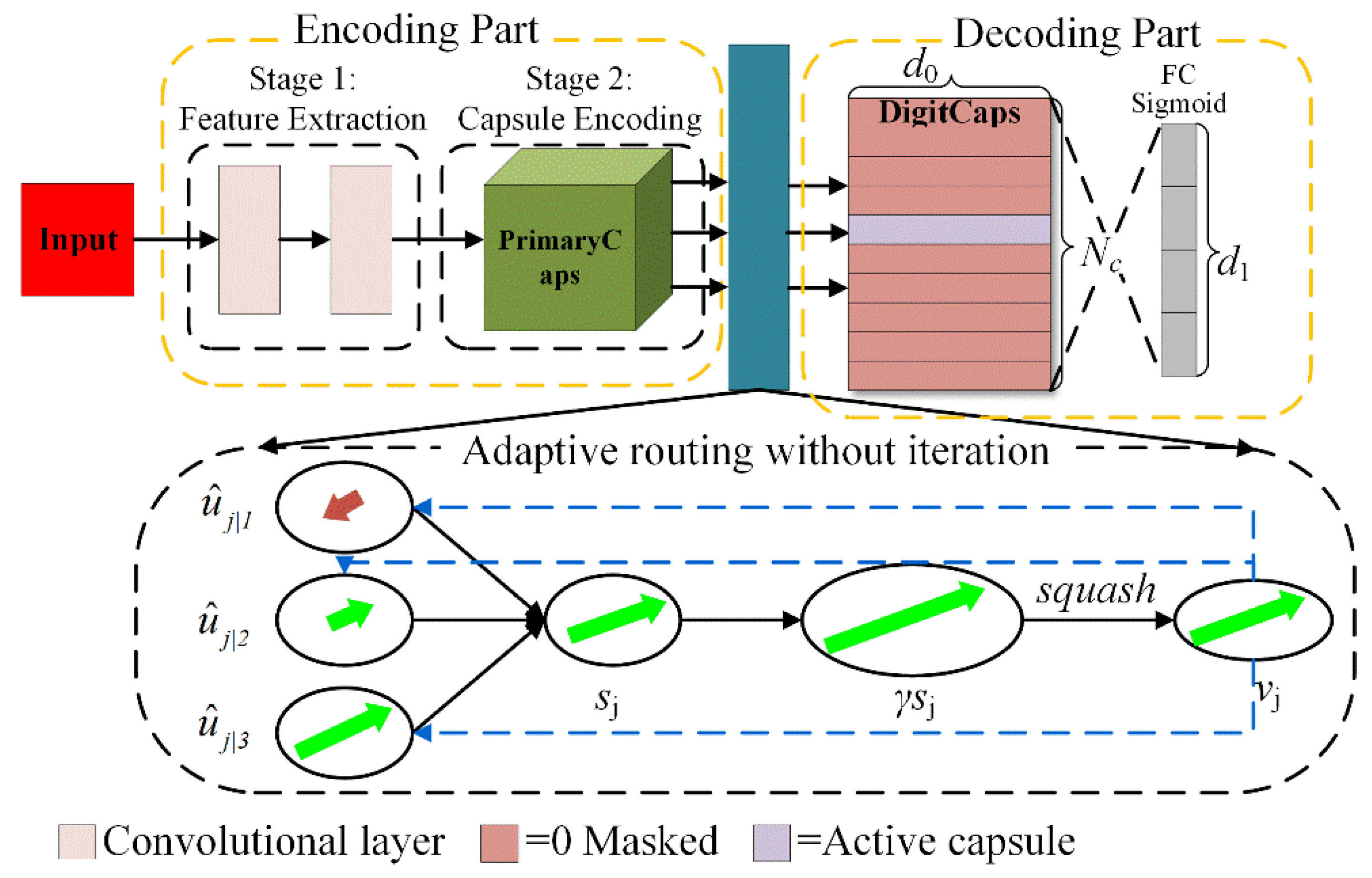
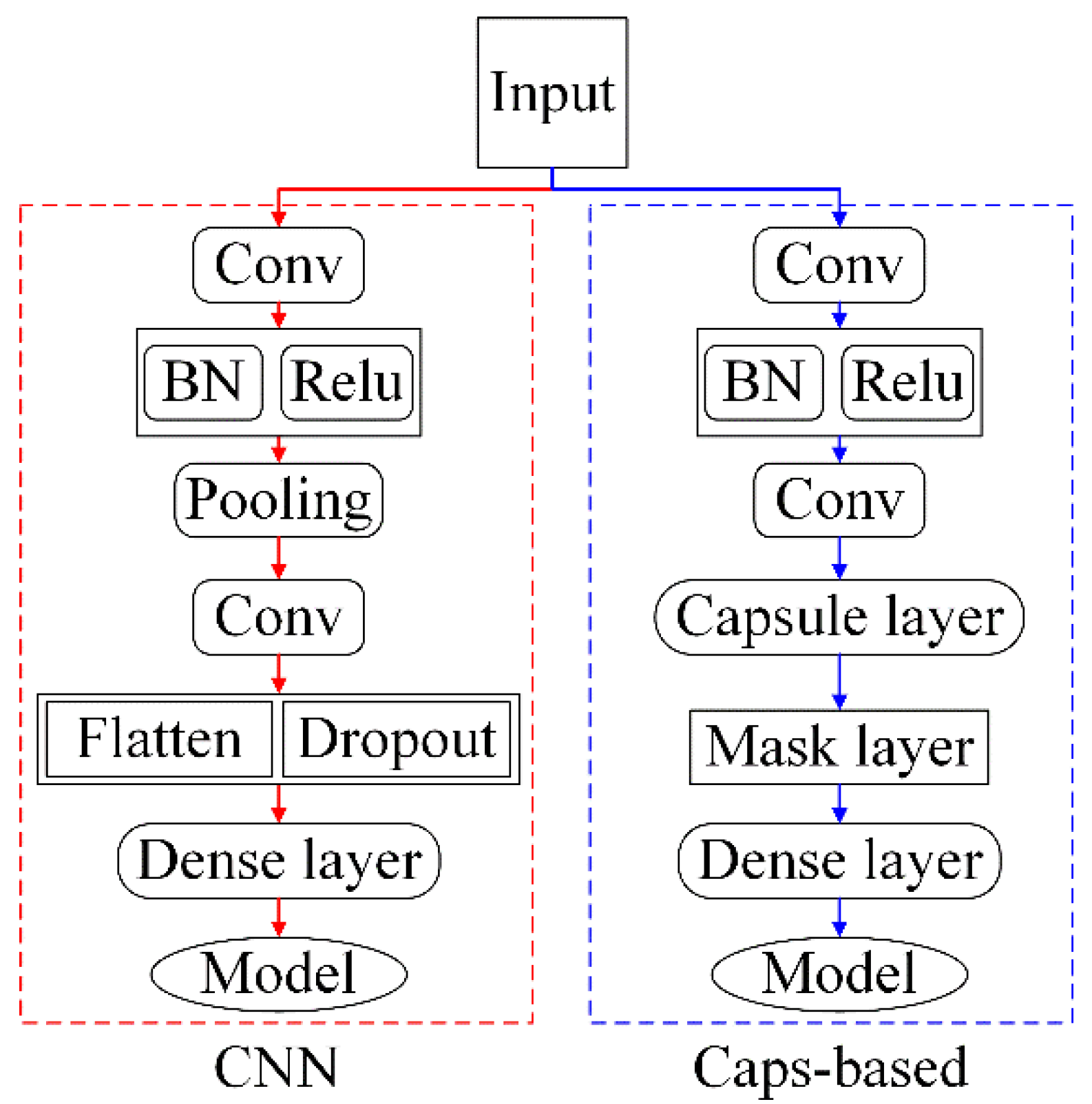
2.2.2. PAR-Based Adaptive Capsule Network
- The architecture of ACaps
- Adaptive routing algorithm without iteration
- PAR method
| Algorithm 2: Adaptive routing without iteration. |
| 1: procedure Routing (, r, l) 2: capsule i in layer l and capsule j in layer (l+1) 3: 4: 5: 6: return 7: end procedure |
3. Results
3.1. Experimental Settings
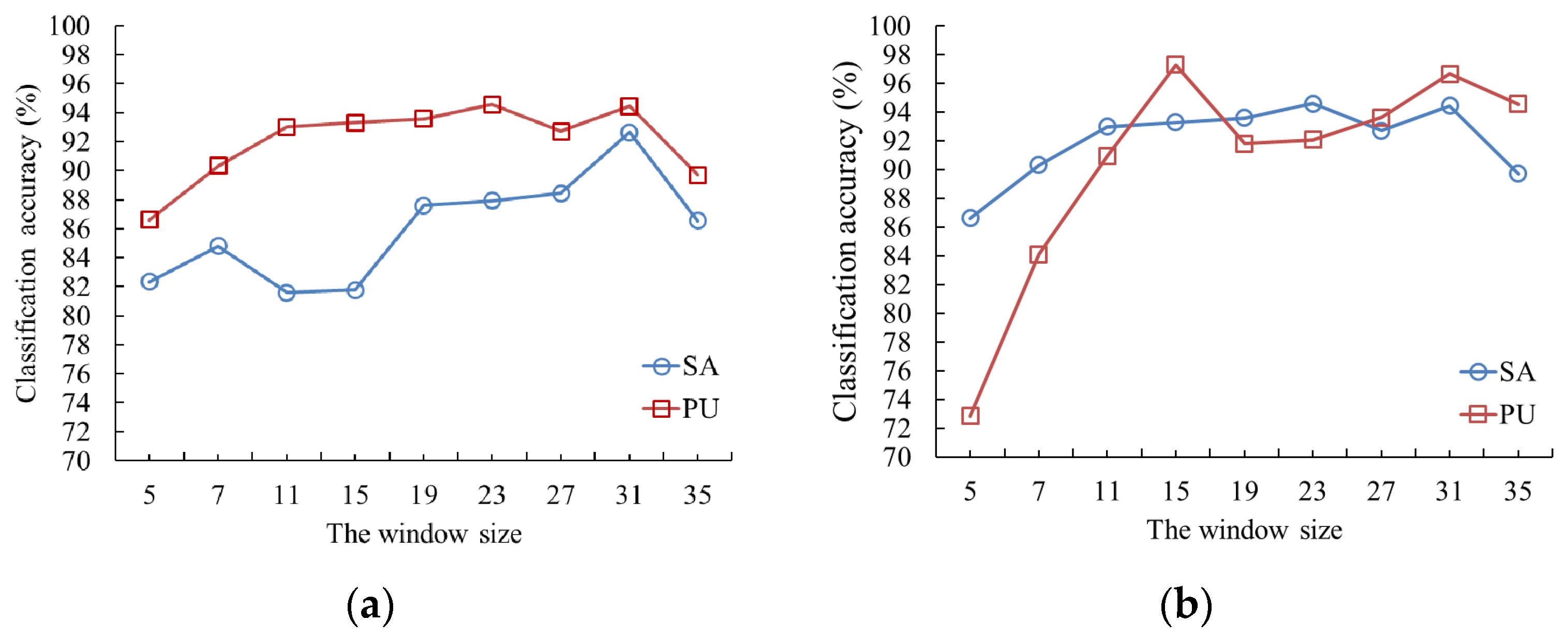
3.1.1. The Effect of the Window Size
3.1.2. The Effect of Gradient Coefficient
3.2. Classification Result
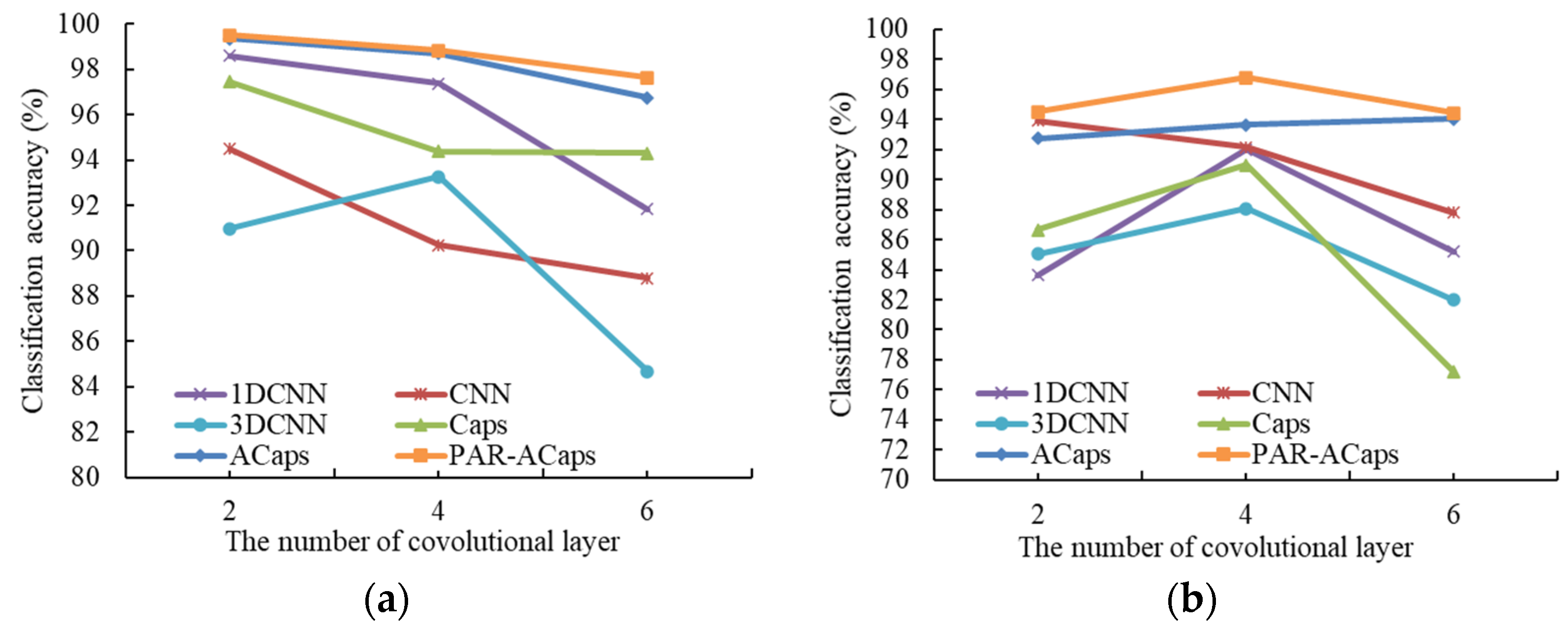
3.2.1. The Classification Performance of ACaps with Shallow Architecture
3.2.2. The Classification Performance of PAR-ACaps with Deeper Architecture
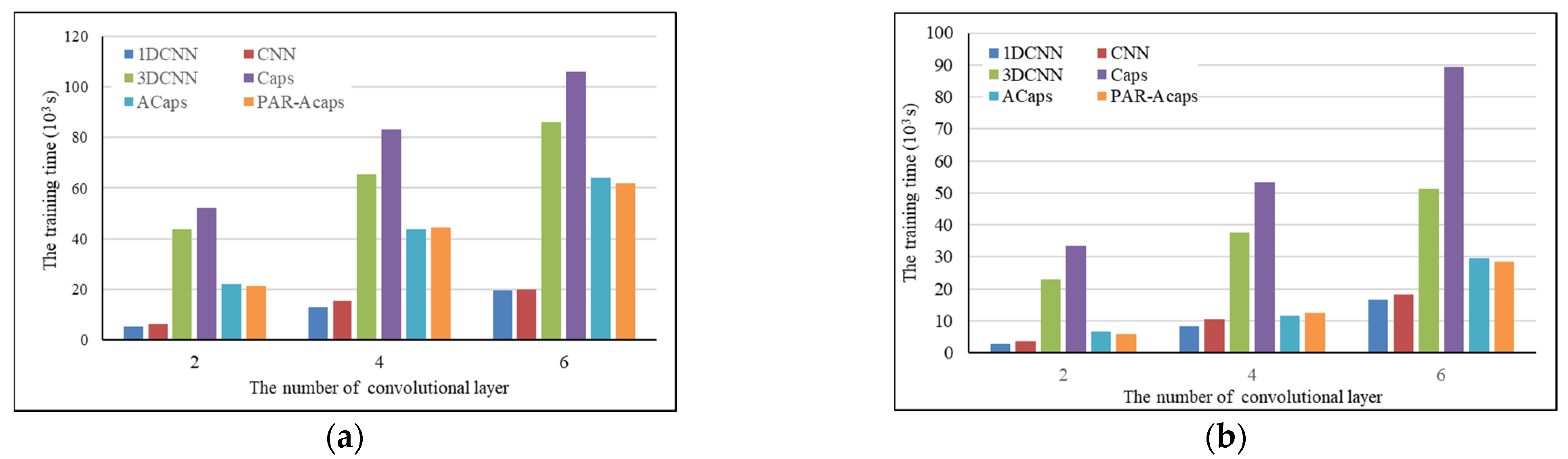
3.3. Computational Efficiency
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Feddema, J.J.; Oleson, K.W.; Bonan, G.B.; Mearns, L.O.; Buja, L.E.; Meehl, G.A.; Washington, W.M. The importance of land-cover change in simulating future climates. Science 2005, 310, 1674–1678. [Google Scholar] [CrossRef] [Green Version]
- Ding, X.; Zhang, S.; Li, H.; Wu, P.; Dale, P.; Liu, L.; Cheng, S. A restrictive polymorphic ant colony algorithm for the optimal band selection of hyperspectral remote sensing images. Int. J. Remote Sens. 2020, 41, 1093–1117. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, J.; Ma, Y.; An, J.; Ren, G.; Li, X. Hyperspectral coastal wetland classification based on a multiobject convolutional neural network model and decision fusion. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1110–1114. [Google Scholar] [CrossRef]
- Ding, X.; Li, H.; Yang, J.; Dale, P.; Chen, X.; Jiang, C.; Zhang, S. An improved ant colony algorithm for optimized band selection of hyperspectral remotely sensed imagery. IEEE Access 2020, 8, 25789–25799. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bera, S.; Shrivastava, V.K. Analysis of various optimizers on deep convolutional neural network model in the application of hyperspectral remote sensing image classification. Int. J. Remote Sens. 2020, 41, 2664–2683. [Google Scholar] [CrossRef]
- Liang, M.; Hu, X. Recurrent convolutional neural network for object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3367–3375. [Google Scholar]
- Li, H.; Zhang, C.; Zhang, S.; Atkinson, P.M. A hybrid OSVM-OCNN method for crop classification from fine spatial resolution remotely sensed imagery. Remote Sens. 2019, 11, 2370. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Pan, X.; Li, H.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J. Photogramm. Remote Sens. 2018, 140, 133–144. [Google Scholar] [CrossRef] [Green Version]
- Othman, E.; Bazi, Y.; Alajlan, N.; Alhichri, H.; Melgani, F. Using convolutional features and a sparse autoencoder for land-use scene classification. Int. J. Remote Sens. 2016, 37, 2149–2167. [Google Scholar] [CrossRef]
- Sharma, A.; Liu, X.; Yang, X.; Shi, D. A patch-based convolutional neural network for remote sensing image classification. Neural Netw. 2017, 95, 19–28. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote. Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Alam, F.I.; Zhou, J.; Liew, A.W.C.; Jia, X. CRF learning with CNN features for hyperspectral image segmentation. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; IEEE: New York, NY, USA, 2016; pp. 6890–6893. [Google Scholar]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W.; Li, S. A CNN with multiscale convolution and diversified metric for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3599–3618. [Google Scholar] [CrossRef]
- Khotimah, W.N.; Bennamoun, M.; Boussaid, F.; Sohel, F.; Edwards, D. A High-Performance Spectral-Spatial Residual Network for Hyperspectral Image Classification with Small Training Data. Remote Sens. 2020, 12, 3137. [Google Scholar] [CrossRef]
- Xiang, C.; Zhang, L.; Tang, Y.; Zou, W.; Xu, C. ACaps: A novel multi-scale capsule network. IEEE Signal Process. Lett. 2018, 25, 1850–1854. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 3856–3866. [Google Scholar]
- Ren, Q.; Shang, S.; He, L. 2019 Adaptive Routing Between Capsules. arXiv 2019, arXiv:1911.08119. [Google Scholar]
- Nguyen, C.D.T.; Dao, H.H.; Huynh, M.T.; Phu Ward, T. ResCap: Residual Capsules Network for Medical Image Segmentation. In Proceedings of the 2019 Kidney Tumor Segmentation Challenge: KiTS19, Shenzhen, China, 13 October 2019. [Google Scholar]
- Chen, R.; Jalal, M.A.; Mihaylova, L. Learning capsules for vehicle logo recognition. In Proceedings of the 2018 21st International Conference on Information Fusion, Cambridge, UK, 10–13 July 2018; pp. 565–572. [Google Scholar]
- Duarte, K.; Rawat, Y.; Shah, M. Videocapsulenet: A simplified network for action detection. In Advances in Neural Information Processing Systems; 2018; pp. 7610–7619. Available online: https://dl.acm.org/doi/10.5555/3327757.3327860 (accessed on 18 May 2021).
- Beşer, F.; Kizrak, M.A.; Bolat, B.; Yildirim, T. Recognition of sign language using capsule networks. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.; Li, J.; Pla, F. Capsule networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2145–2160. [Google Scholar] [CrossRef]
- Wang, W.Y.; Li, H.C.; Pan, L.; Yang, G.; Du, Q. Hyperspectral Image Classification Based on Capsule Network. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 3571–3574. [Google Scholar]
- Deng, F.; Pu, S.; Chen, X.; Shi, Y.; Yuan, T.; Pu, S. Hyperspectral image classification with capsule network using limited training samples. Sensors 2018, 18, 3153. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Z.; Kleinhans, A.; Sandhu, G.; Patel, I.; Unnikrishnan, K.P. Capsule networks with max-min normalization. arXiv 2019, arXiv:1903.09662. [Google Scholar]
- Jia, B.; Huang, Q. DE-CapsNet: A diverse enhanced capsule network with disperse dynamic routing. Appl. Sci. 2020, 10, 884. [Google Scholar] [CrossRef] [Green Version]
- Kwabena, P.M.; Weyori, B.A.; Mighty, A.A. Exploring the performance of LBP-capsule networks with K-Means routing on complex images. J. King Saud Univ. Comput. Inf. Sci. 2020. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, X. Reducing the dilution: An analysis of the information sensitiveness of capsule network with a practical solution. arXiv 2019, arXiv:1903.10588. [Google Scholar]
- Hinton, G.E.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- De Leeuw, J.; Jia, H.; Yang, L.; Liu, X.; Schmidt, K.; Skidmore, A.K. Comparing accuracy assessments to infer superiority of image classification methods. Int. J. Remote Sens. 2006, 27, 223–232. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class No. | Land Cover/Use Type | Number of Samples | |||
|---|---|---|---|---|---|---|
| Training | Validation | Test | Total | |||
| SA | 1 | Brocoli_green_weeds_1 | 100 | 100 | 191 | 391 |
| 2 | Corn_senesced_green_weeds | 390 | 390 | 563 | 1343 | |
| 3 | Lettuce_romaine_4wk | 150 | 150 | 316 | 616 | |
| 4 | Lettuce_romaine_5wk | 470 | 470 | 585 | 1525 | |
| 5 | Lettuce_romaine_6wk | 210 | 210 | 254 | 674 | |
| 6 | Lettuce_romaine_7wk | 250 | 250 | 299 | 799 | |
| PU | 1 | Asphalt | 1000 | 1000 | 4631 | 6631 |
| 2 | Meadows | 1000 | 1001 | 16,650 | 18,651 | |
| 3 | Gravel | 460 | 461 | 1180 | 2101 | |
| 4 | Trees | 890 | 891 | 1285 | 3066 | |
| 5 | Painted metal sheets | 400 | 401 | 546 | 1347 | |
| 6 | Bare Soil | 1000 | 1001 | 3030 | 5031 | |
| 7 | Bitumen | 400 | 401 | 531 | 1332 | |
| 8 | Self-Blocking Bricks | 1000 | 1001 | 1683 | 3684 | |
| 9 | Shadows | 260 | 261 | 428 | 949 | |
| PU | 98.50 | 99.06 | 99.16 | 98.70 |
| SA | 88.22 | 88.81 | 95.41 | 80.25 |
| Class No. | RF | SVM | 1DCNN | CNN | 3DCNN | Caps | ACaps | PAR-ACaps |
|---|---|---|---|---|---|---|---|---|
| 1 | 88.41 | 92.67 | 99.69 | 98.18 | 97.60 | 94.66 | 100 | 100 |
| 2 | 88.23 | 94.19 | 98.62 | 96.38 | 88.42 | 90.56 | 99.79 | 99.82 |
| 3 | 73.29 | 84.66 | 99.79 | 98.05 | 91.41 | 68.39 | 99.79 | 99.79 |
| 4 | 96.85 | 98.66 | 96.45 | 98.03 | 98.55 | 97.04 | 97.33 | 97.45 |
| 5 | 99.29 | 99.76 | 99.52 | 44.70 | 0.00 | 100 | 100 | 100 |
| 6 | 90.36 | 93.60 | 99.17 | 89.96 | 98.21 | 100 | 100 | 99.98 |
| 7 | 88.34 | 92.19 | 100 | 99.02 | 98.29 | 98.10 | 100 | 100 |
| 8 | 69.31 | 60.37 | 94.71 | 94.39 | 97.74 | 98.45 | 94.32 | 96.39 |
| 9 | 100 | 100 | 99.64 | 96.42 | 99.64 | 95.71 | 98.57 | 98.03 |
| OA | 87.56 | 91.59 | 98.59 | 94.49 | 90.97 | 97.46 | 99.36 | 99.51 |
| K | 0.82 | 0.87 | 0.97 | 0.91 | 0.87 | 0.96 | 0.98 | 0.99 |
| Class No. | RF | SVM | 1DCNN | CNN | 3DCNN | Caps | ACaps | PAR-ACaps |
|---|---|---|---|---|---|---|---|---|
| 1 | 99.47 | 99.47 | 51.15 | 100 | 100 | 100 | 100 | 99.86 |
| 2 | 2.93 | 29.66 | 87.78 | 92.06 | 45.64 | 69.99 | 72.29 | 82.46 |
| 3 | 87.97 | 96.83 | 99.18 | 96.30 | 93.35 | 79.90 | 99.36 | 98.18 |
| 4 | 100 | 100 | 99.93 | 99.71 | 100 | 93.93 | 100 | 98.41 |
| 5 | 100 | 100 | 100 | 99.47 | 100 | 97.24 | 100 | 99.70 |
| 6 | 99.66 | 100 | 100 | 100 | 98.99 | 93.47 | 99.33 | 97.99 |
| OA | 73.43 | 81.56 | 83.65 | 93.92 | 85.05 | 86.66 | 92.75 | 94.52 |
| K | 0.68 | 0.77 | 0.69 | 0.89 | 0.81 | 0.83 | 0.91 | 0.93 |
| Dataset | RF | SVM | 1DCNN | CNN | 3DCNN | Caps | ACaps | |
|---|---|---|---|---|---|---|---|---|
| p-value | PU | 0.0 | 0.0 | 2.674 × 10−12 | 3.458 × 10−15 | 4.327 × 10−19 | 1.806 × 10−16 | 1.046 × 10−9 |
| SA | 3.863 × 10−134 | 7.238 × 10−64 | 9.652 × 10−32 | 8.773 × 10−43 | 6.984 × 10−33 | 6.698 × 10−38 | 3.675 × 10−12 |
| 4 convolutional layers | ||||||
| Class no. | 1DCNN | CNN | 3DCNN | Caps | ACaps | PAR-ACaps |
| 1 | 98.55 | 94.83 | 94.70 | 88.68 | 99.27 | 99.20 |
| 2 | 97.06 | 87.82 | 99.05 | 95.74 | 98.70 | 98.75 |
| 3 | 98.15 | 96.06 | 98.77 | 96.72 | 99.79 | 99.69 |
| 4 | 97.67 | 91.71 | 97.56 | 91.05 | 96.89 | 97.11 |
| 5 | 100 | 97.94 | 0.00 | 99.05 | 100 | 100 |
| 6 | 99.65 | 91.31 | 93.81 | 99.58 | 99.93 | 99.94 |
| 7 | 100 | 96.09 | 88.04 | 98.45 | 98.78 | 99.26 |
| 8 | 90.91 | 88.25 | 67.84 | 87.95 | 96.13 | 97.29 |
| 9 | 97.50 | 95.80 | 100 | 87.61 | 95.00 | 96.07 |
| OA | 97.38 | 90.25 | 93.27 | 94.38 | 98.70 | 98.83 |
| K | 0.96 | 0.86 | 0.90 | 0.91 | 0.98 | 0.98 |
| 6 convolutional layers | ||||||
| 1 | 97.99 | 98.91 | 81.42 | 93.09 | 95.65 | 97.32 |
| 2 | 90.38 | 85.99 | 81.32 | 93.71 | 98.01 | 98.34 |
| 3 | 97.54 | 98.97 | 91.20 | 97.34 | 97.34 | 97.95 |
| 4 | 97.11 | 96.89 | 98.11 | 90.63 | 94.12 | 95.28 |
| 5 | 98.82 | 96.75 | 0.00 | 98.47 | 98.35 | 98.47 |
| 6 | 87.52 | 99.73 | 99.86 | 97.90 | 99.96 | 99.82 |
| 7 | 98.78 | 98.82 | 99.02 | 99.02 | 99.26 | 99.63 |
| 8 | 87.43 | 77.19 | 95.29 | 94.90 | 85.37 | 90.07 |
| 9 | 94.64 | 96.35 | 99.64 | 87.67 | 90.71 | 93.92 |
| OA | 91.84 | 88.79 | 84.67 | 94.31 | 96.76 | 97.63 |
| K | 0.88 | 0.84 | 0.78 | 0.91 | 0.95 | 0.96 |
| 4 convolutional layers | ||||||
| Class No. | 1DCNN | CNN | 3DCNN | Caps | Acaps | PAR-ACaps |
| 1 | 100 | 100 | 100 | 100 | 100 | 100 |
| 2 | 71.40 | 68.24 | 58.61 | 68.56 | 75.84 | 89.43 |
| 3 | 95.56 | 97.40 | 90.50 | 96.04 | 98.73 | 98.10 |
| 4 | 100 | 98.94 | 100 | 99.91 | 100 | 99.82 |
| 5 | 100 | 99.84 | 100 | 100 | 100 | 100 |
| 6 | 99.33 | 98.32 | 100 | 96.99 | 100 | 98.66 |
| OA | 91.98 | 92.15 | 88.08 | 90.98 | 93.65 | 96.80 |
| K | 0.90 | 0.90 | 0.85 | 0.88 | 0.92 | 0.96 |
| 6 convolutional layers | ||||||
| 1 | 100 | 99.47 | 100 | 97.73 | 100 | 100 |
| 2 | 47.42 | 57.66 | 39.07 | 44.87 | 77.50 | 79.18 |
| 3 | 91.13 | 92.19 | 84.17 | 65.50 | 98.52 | 98.10 |
| 4 | 100 | 99.43 | 100 | 97.72 | 99.94 | 100 |
| 5 | 100 | 99.86 | 100 | 85.43 | 100 | 100 |
| 6 | 98.99 | 99.44 | 98.32 | 90.07 | 100 | 100 |
| OA | 85.19 | 87.79 | 81.97 | 77.18 | 94.03 | 94.42 |
| K | 0.81 | 0.85 | 0.78 | 0.72 | 0.92 | 0.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, X.; Li, Y.; Yang, J.; Li, H.; Liu, L.; Liu, Y.; Zhang, C. An Adaptive Capsule Network for Hyperspectral Remote Sensing Classification. Remote Sens. 2021, 13, 2445. https://doi.org/10.3390/rs13132445
Ding X, Li Y, Yang J, Li H, Liu L, Liu Y, Zhang C. An Adaptive Capsule Network for Hyperspectral Remote Sensing Classification. Remote Sensing. 2021; 13(13):2445. https://doi.org/10.3390/rs13132445
Chicago/Turabian StyleDing, Xiaohui, Yong Li, Ji Yang, Huapeng Li, Lingjia Liu, Yangxiaoyue Liu, and Ce Zhang. 2021. "An Adaptive Capsule Network for Hyperspectral Remote Sensing Classification" Remote Sensing 13, no. 13: 2445. https://doi.org/10.3390/rs13132445