1. Introduction
When planning most projects pertinent to geotechnical issues and rock engineering, it is of high importance to properly analyze how the intact rock behaves and carefully estimate its associated mechanical properties. The intact rock elastic modulus (E) has substantial effects on both the initial and final steps of designing geoscience-related projects, which include planning tunnels; designing blasting operations in rock materials; analyzing the constancy of rock slopes; and designing rock pillars, roads, dams, bridges, etc. Moreover, E is the most significant parameter applied to analyzing the stress-strain chart of rock specimens in a laboratory. E also plays an important role in analyzing the deformations and breakage of rocks surrounding underground excavation projects. As a result, inaccurate predictions of E can result in serious damages, leading to economic issues and severe safety problems due to the breakage probability during construction processes [
1,
2]. Thus, it is necessary to determine the E value quickly and accurately in order to correctly plan geo-engineering structures, accurately design mining- and civil engineering-related projects, and enhance the general safety level and effectiveness of operations at hand.
In general, the E value can be obtained using direct or indirect methods. The former are typically carried out within rock mechanics laboratories, where rock core specimens are subjected to experiments in a variety of conditions [
1,
2,
3]. In contrast, indirect methods make use of predictive equations or models to estimate E. The direct methods have accuracy, but at the same time, they suffer from some drawbacks. First, it is not easy to provide the required specimens during the coring process with a high level of accuracy, especially in jointed, layered, and weakened rock structures. Second, it is both difficult and time consuming to prepare the core specimens with the appropriate geometry for the purpose of carrying out laboratory E tests. Such issues hinder the use of direct methods unless there is a high necessity [
3,
4,
5].
Due to the above-mentioned challenges, various indirect methods have been introduced in the literature on the basis of predictive models/algorithms and equations to determine the E value of intact rocks. These methods have been normally configured based on arithmetical and smart intelligent models. Statistical models generally make use of simple or multiple regression models aiming to develop a number of empirical equations between the E value and effective mechanical and physical rock properties. The literature consists of numerous empirical equations formed based on analyzing petrology and mineralogy in addition to values estimated using the rock physical and mechanical properties, such as Schmidt hammer numbers [
6], porosity of rock [
7], slake durability of rock [
8], and compressional/primary wave velocity [
9].
In recent years, scholars have made several efforts to develop artificial intelligence (AI) models applicable to mining and rock engineering problems. Such efforts have resulted in a number of novel models proposed to estimate E and some other rock mechanical properties. These are mostly based on probable and intelligent methods, such as particle swarm optimization (PSO), fuzzy inference systems (FISs), genetic algorithms (GAs), Bayesian methods, adaptive neuro-fuzzy inference systems (ANFIS), tree models, extreme gradient-boosting (XGB), and artificial neural networks (ANNs), as well as their hybridized forms [
10,
11,
12,
13,
14,
15,
16]. Sarkhani Benemaran et al. [
17] employed an XGB model in combination with several optimization algorithms to predict the resilient modulus of flexible pavement foundations. They concluded the effectiveness of PSO-XGB models in this field. In another study, conducted by Shahani et al. [
18], different AI models such as XGB, gradient-boosted tree regressors (GBTRs), Catboost, and light gradient-boosting machines were used to predict E. According to their results, the performance of GBTR was better than that of the other developed models. Recently, Tsang et al. [
19] predicted the E values through some other models, i.e., extreme gradient-boosting trees, ANNs, random forests, and classification and regression trees. The results showed that the extreme gradient-boosting trees predicted the E value with the highest accuracy.
Such applications show that intelligent algorithms typically outperform the traditionally used statistical methods regarding E value prediction.
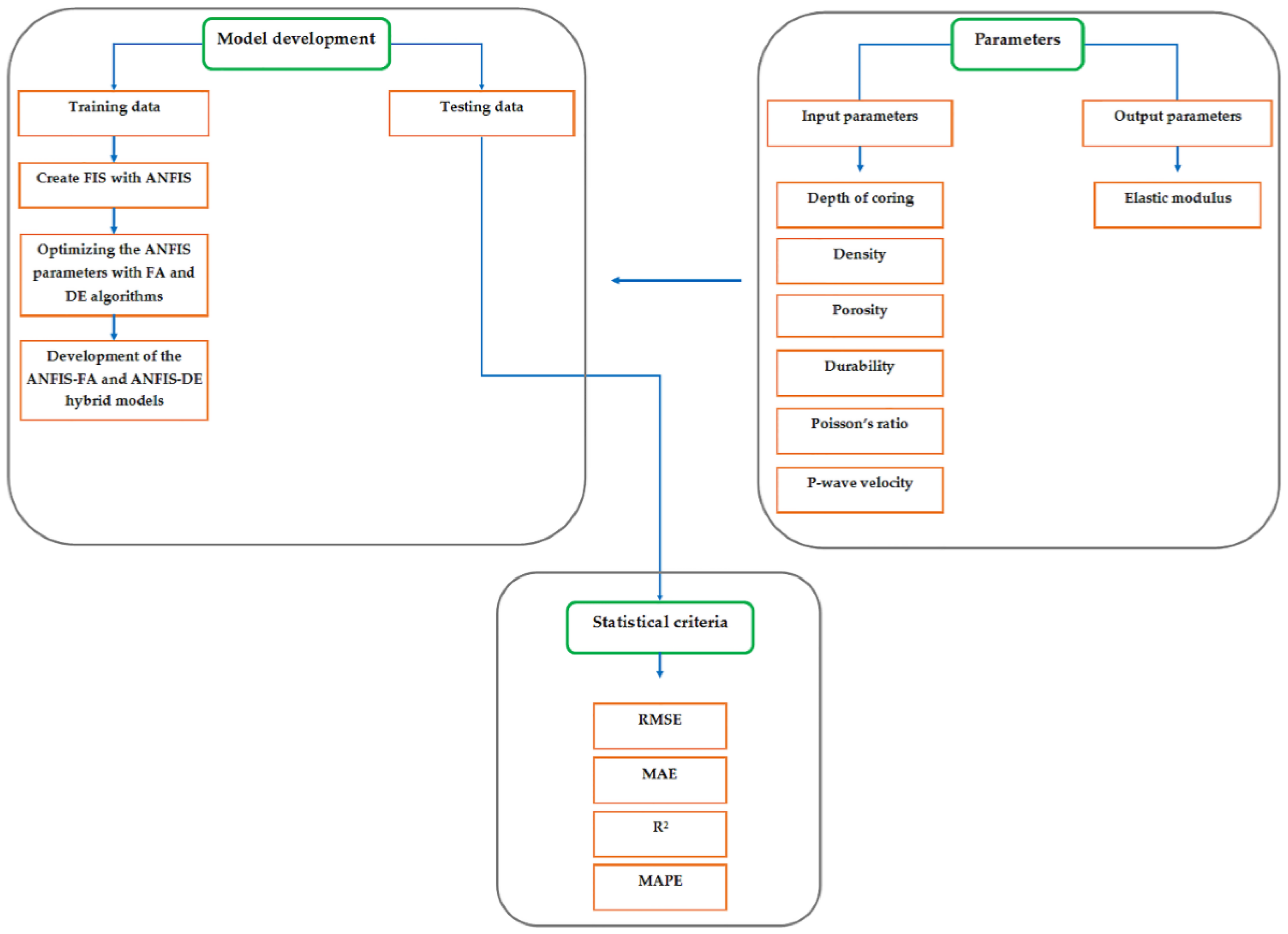
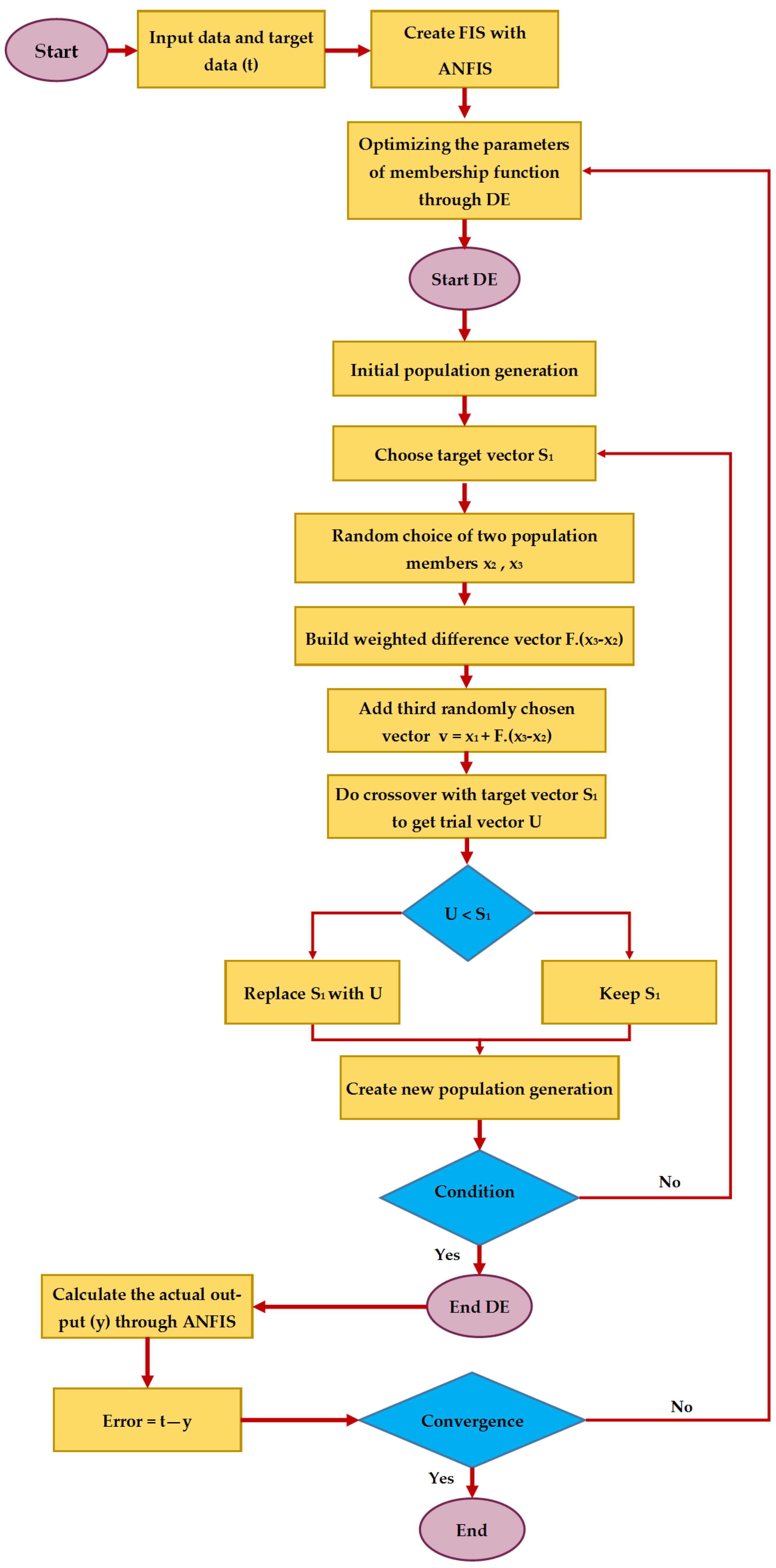
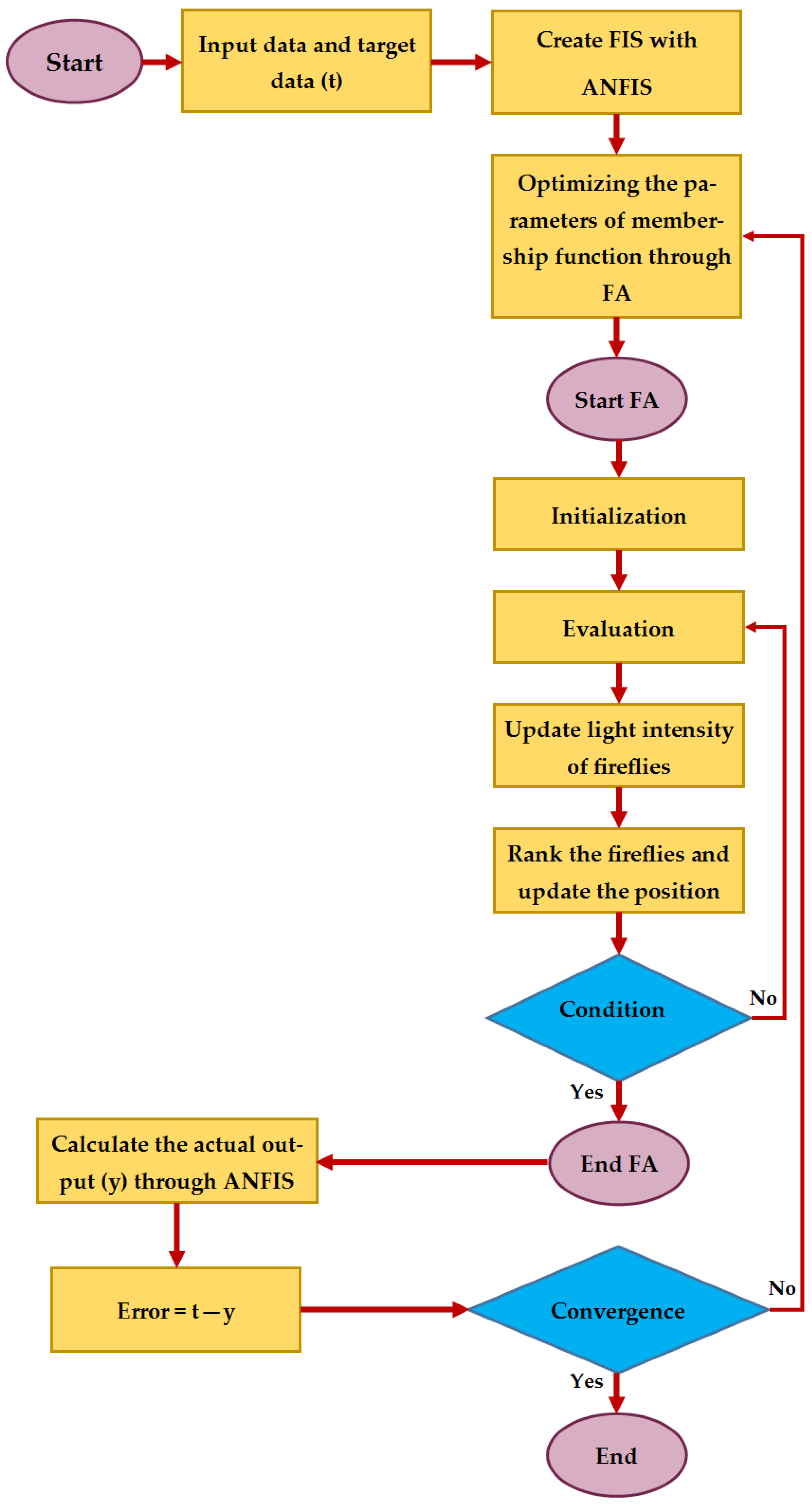
The present study is carried out to assess the potential of applying two hybrid evolutionary models to predict E. The proposed models are based on the integrated expert systems comprising ANFIS with two optimization algorithms, i.e., the firefly algorithm (FA) and differential evolution (DE). To check the effectiveness of FA and DE, the results of ANFIS-FA and ANFIS-DE are then compared with the ANFIS and NN results. The rest of this study is organized as follows. In
Section 2, the source of the database is described. Then, the methodologies used in this paper and their implementations are explained in detail in
Section 3. Finally,
Section 4 and
Section 5 present the results/discussions and conclusions of this study, respectively.
2. Source of Database
An inclusive database is needed to be formed for E modeling by means of indirect intelligent methods. Such data were obtained through performing laboratory experiments on the core specimens provided from the excavation drilling processes carried out in two under-construction dam sites, namely the Bakhtiari and Azad dams located in Iran. The precise location of the Azad dam site is in the west of Iran, 40 km away from the western city of Sanandaj in the Kurdistan state. It is situated on the Sanandaj–Marivan cities road inside Kurdistan, with the 46°32′57″ to 35°19′59″ geographical coordinates of eastern and northern latitudes, respectively. The construction of this dam is currently in progress. It is mainly aimed at supplying electrical energy and producing power plant storage. The dimensions (length, height, and width) and water storage capacity of this dam are 595 m, 115 m, 11 m, and 260,000,000 m3, respectively.
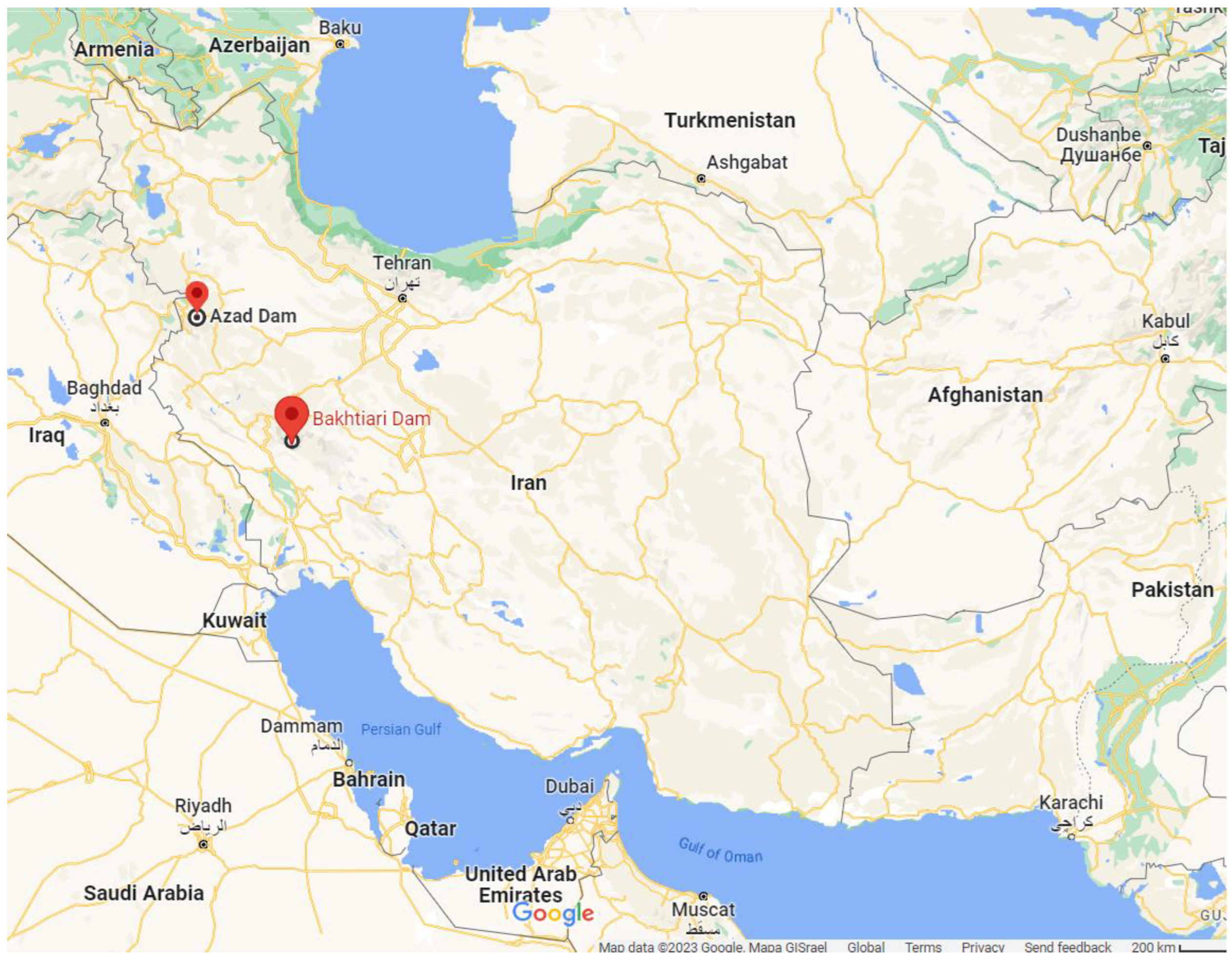
The Bakhtiari dam is located in the Zagros Highlands, 65 km southwest of the town of Dorud in the Lorestan state, and 70 km northeast of the town of Andimeshk in Khuzestan, Iran. The position of the dam site is at the 48°45′34.87″ to 32°57′23.58″ geographical coordinates of eastern and northern latitudes, respectively (
Figure 1). The dam was built upon the Bakhtiari River, aiming to provide adequate water for many purposes, such as drinking, electrical power generation, flood control, and agricultural activities. The dam’s body is at an elevation of 840 m. In addition, in the case of this dam, the peak elevation, crown width, crown length, and foundation width are 325 m, 10 m, 434 m, and 30 m, respectively [
20]. The situations of both case studies (the Azad and Bakhtiari dams) on the Iran map are illustrated in
Figure 1.
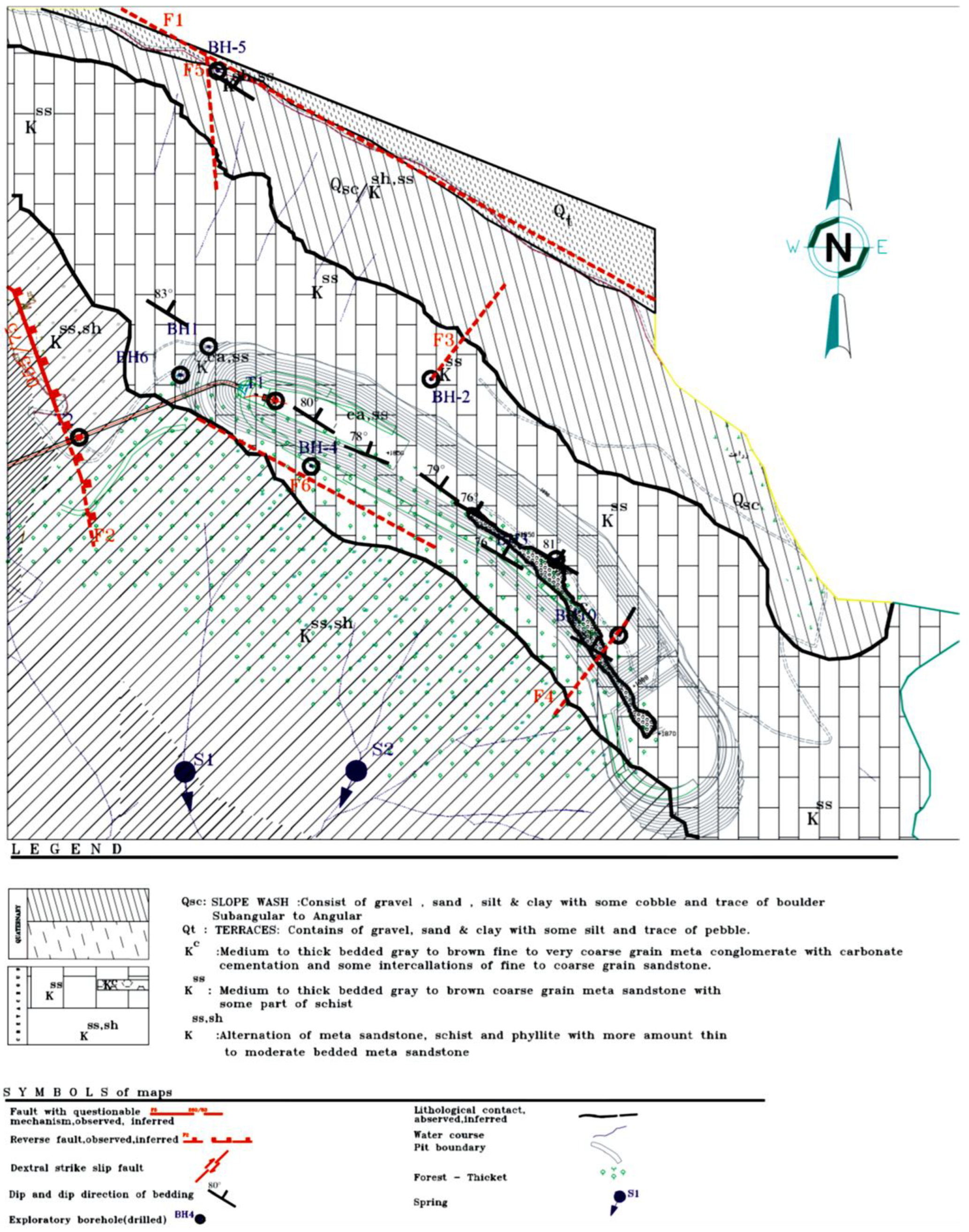
The Azad dam comprises a series of common structures, such as tailraces, higher deposits, different caverns, gurgitation storages, and access tunnels. Geologically, this dam is situated in Iran’s famous formation, Sanandaj–Sirjan, with an alternation of schist, sandstone, limestone, and phylite rocks. The bedrock of the dam mainly comprises sandstone with a low degree of metamorphic, phyllite, and schist. Additionally, within the highland areas, lenses of limestone are also observable. From the stratigraphy point of view, rock outliers from the higher Cretaceous period to the present can be observed within the investigated region. Such rocks consist of four types from the past to the current session: (1) metamorphic rock related to the Cretaceous period that includes a combination of clay and shale; (2) phyllite formation rocks related to the participation of the Cretaceous Paleocene periods, containing limestone and shale with sand; (3) rocks related to the participation of the Paleocene and Eocene periods, comprising sandstone, shale, limestone lenses, and volcanic rocks; and (4) formations related to the Quaternary period, consisting of shallow terraces and debris. From a tectonic viewpoint, the Sarvabad, Kargineh, and Satileh faults are situated 23, 4.5, and 32 km to the south, east, and northeast of the Azad dam, respectively [
21]. The geological conditions and faults of the Azad dam site are shown in
Figure 2.
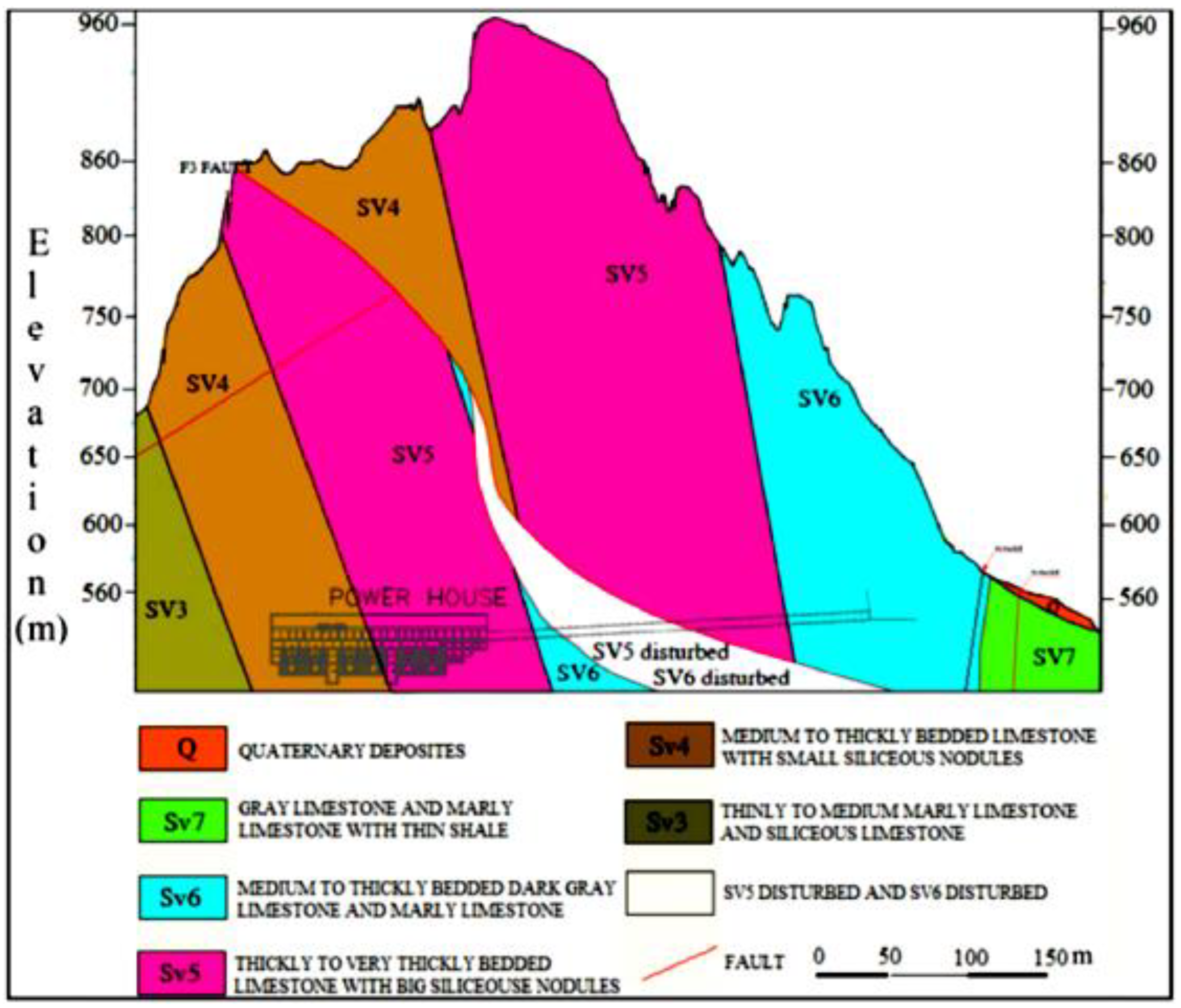
The Bakhtiari dam’s bedrock is made of separate limestone and limestone combined with marl, which incorporates chert nodes. The limestone sections might be synthesized by a combined dolomite substance. From the perspective of geological structure, the dam area is positioned within the pleated Zagros, a portion of the tectono-sediment region of the Zagros. In the lowest northern portion, the area is restricted by pushed Zagros, while in the southwest, it is confined by the Khuzestan plain. With regard to the age of the compressed reservoirs of the area, they date back to between the Triassic and Pliocene eras, and then would have been wrinkled from the Plio-Pleistocene via the latest Alpine organic phase. A number of syncline and anticline sets have been created through such tectonism procedures. Primarily, the above arrangements have been identified by perpendicular axial levels related to the lots of pushed faults in the Zagros area. Additionally, key bed-rocks of the investigated area are made of limestone siliceous related to the current famous formation, Sarvak. This formation (Sarvak) belongs to the Bangestan collection of the middle period of the Cretaceous [
20]. For a better review, the geological cross-section of the Bakhtiary dam and plant site is shown in
Figure 3.
Database Description
To create inclusive datasets, adequate core samples with NX sizes, i.e., 54 mm in diameter, perpendicular cylindrical shapes, and ratios of height to diameter in the middle of 2:1 to 2.5:1 were used based on the process recommended by the ISRM [
22,
23]. The samples were arranged from the two dam sites introduced before. When the core specimens were prepared, their various characteristics, such as E value, porosity, density, and durability index, were measured in a laboratory. Furthermore, in the course of the coring operation, each sample’s coring depth was recorded for the purpose of evaluating its impact on the rocks’ geomechanical properties. The laboratory experiments in this study were carried out totally based on the ISRM and ASTM standard methods [
22,
23]. In this regard, a total of 50 test series were done successfully, and the outputs were documented in the cases of all variables noted above. As a result, 50 datasets were provided, aiming to construct the ANFIS-FA, ANFIS-DE, ANFIS, and NN models. Then, a sorting approach was adopted to divide the available database into training (constructing) and testing datasets. Roughly 20% of the database was determined as the testing dataset in order to be used later in the process of evaluating the models built in this paper.
Note that the ratio of 80 to 20 for training and testing groups has been widely suggested by many scholars, such as Ye et al. [
24], Fang et al. [
25], Nguyen et al. [
26], and Zhou et al. [
27]. Aside from that, we also tested the ratio of 70:30. Nevertheless, the 80:20 ratio had better performance; thus, this ratio was used in this study.
The statistical characteristics of all variables used in this study are shown in
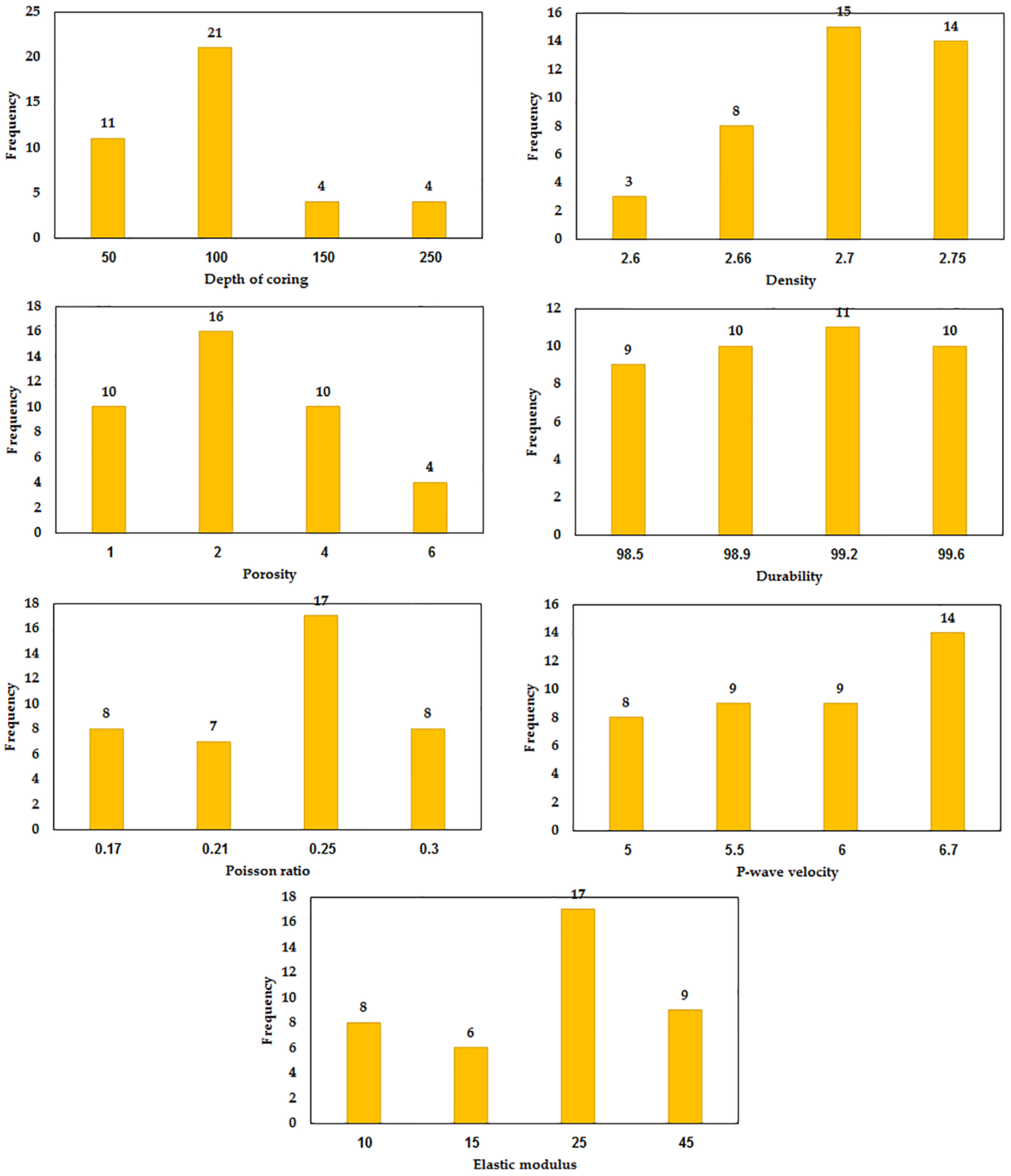
Table 1. For a better view, the frequency histogram of all input and output variables are depicted in
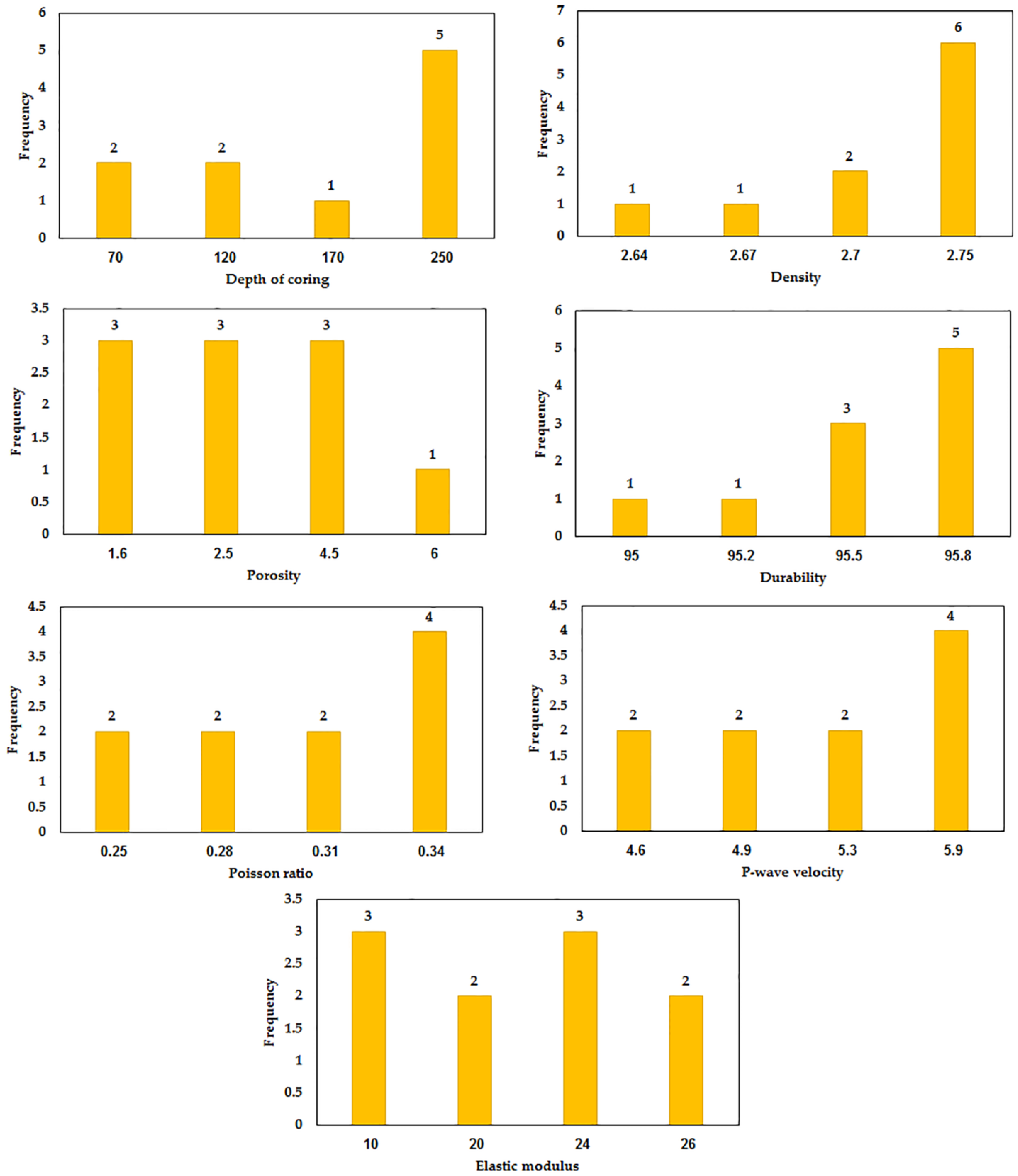
Figure 4 and
Figure 5. For example, in
Figure 4, regarding the depth of coring variables, 11, 21, 4, and 4 data were varied in the range of 0–50 m, 50–100 m, 100–150 m, and 150–250 m, respectively. In addition,
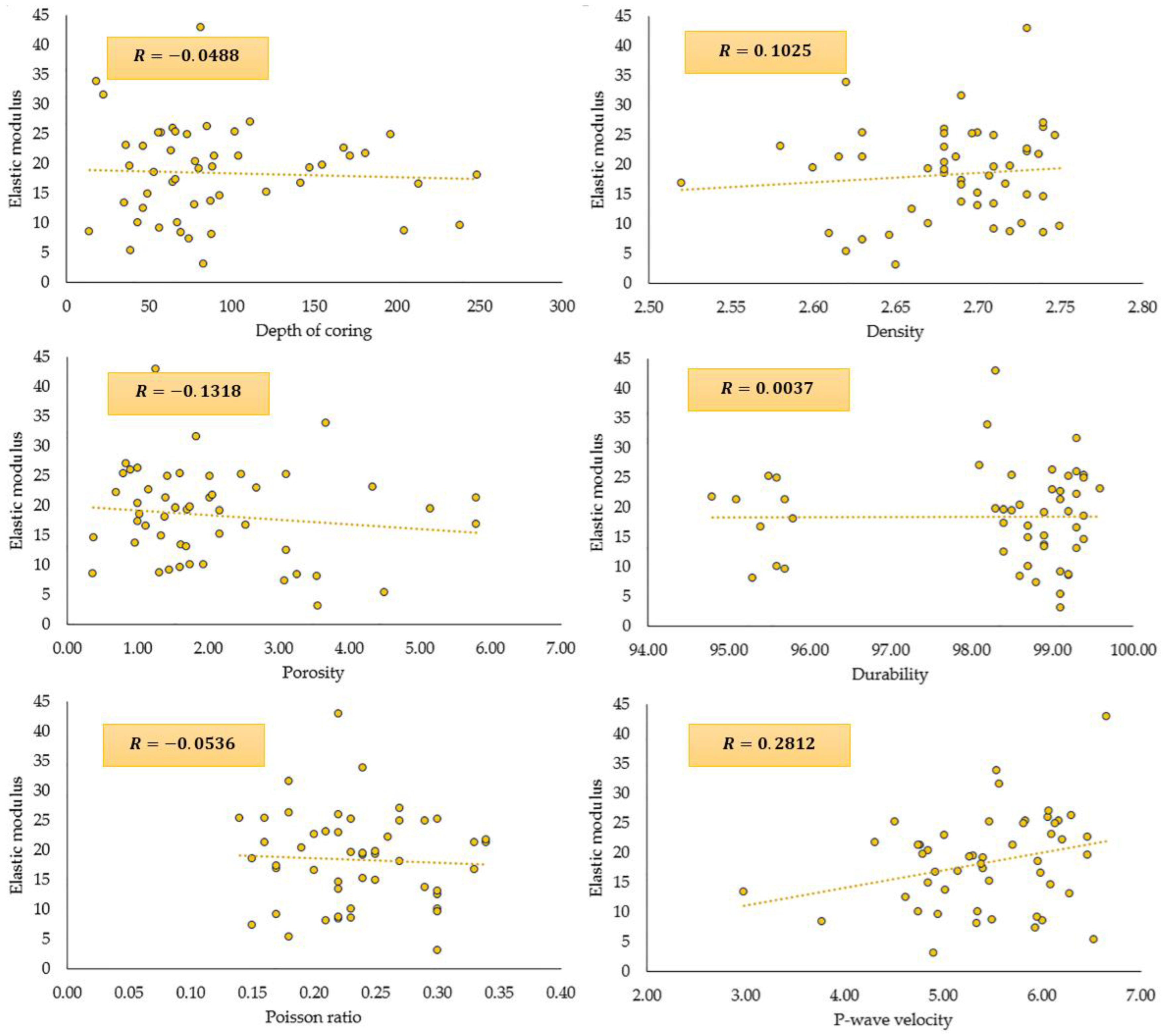
Figure 6 illustrates the Pearson correlation plots for all variables.
4. Results and Discussion
The present study was aimed at examining the effectiveness of the FA and DE algorithms in optimizing ANFIS for the prediction of E. The results obtained from the proposed ANFIS-FA and ANFIS-DE models were compared to those of ANFIS and NN models. Here, the models’ prediction capabilities were assessed regarding RMSE, mean of average percentage error (MAPE), mean of absolute error (MAE), variance account for (VAF),
A10-index, and performance index (PI) [
33,
34,
35,
36,
37], as presented in the following equations:
where
n stands for the number of data (
n = 50), and
,
, and
signify the actual, estimated, and average of actual E values, respectively. Additionally, m10 is the number of data with values of rate actual/predicted values (ranging from 0.9 to 1.1), and R in Equation (6) is the correlation coefficient.
Table 8 presents the MAPE (%), MAE, RMSE, VAF(%), and
A10-Index values attained by the developed models.
As can be observed in
Table 8, the lowest MAPE (%), MAE, RMSE, and PI values were determined for the ANFIS-FA model as 6.254%, 1.1, 1.152, and 0.031, respectively. In addition, the highest VAF (%) and
A10-index values were determined for the ANFIS-FA model as 98.778% and 0.9, respectively. These values were calculated for the ANFIS-DE model as 1.827, 1.662, 9.452%, 0.049, 96.957%, and 0.6, respectively; for the ANFIS model as 2.557, 2.456, 13.965%, 0.070, 92.514%, and 0.4, respectively; and for the NN model as 2.781, 2.639, 15.006%, 0.076, 90.985%, and 0.4, respectively. According to
Table 8, the highest total rank values for both the training and testing groups were obtained by the ANFIS-FA model. It is worth mentioning that the bolded amounts in
Table 8 are related to the best results (highest rank) obtained from the ANFIS-FA model. For a better overview, the predicted E values provided by all models in the testing phase are depicted in
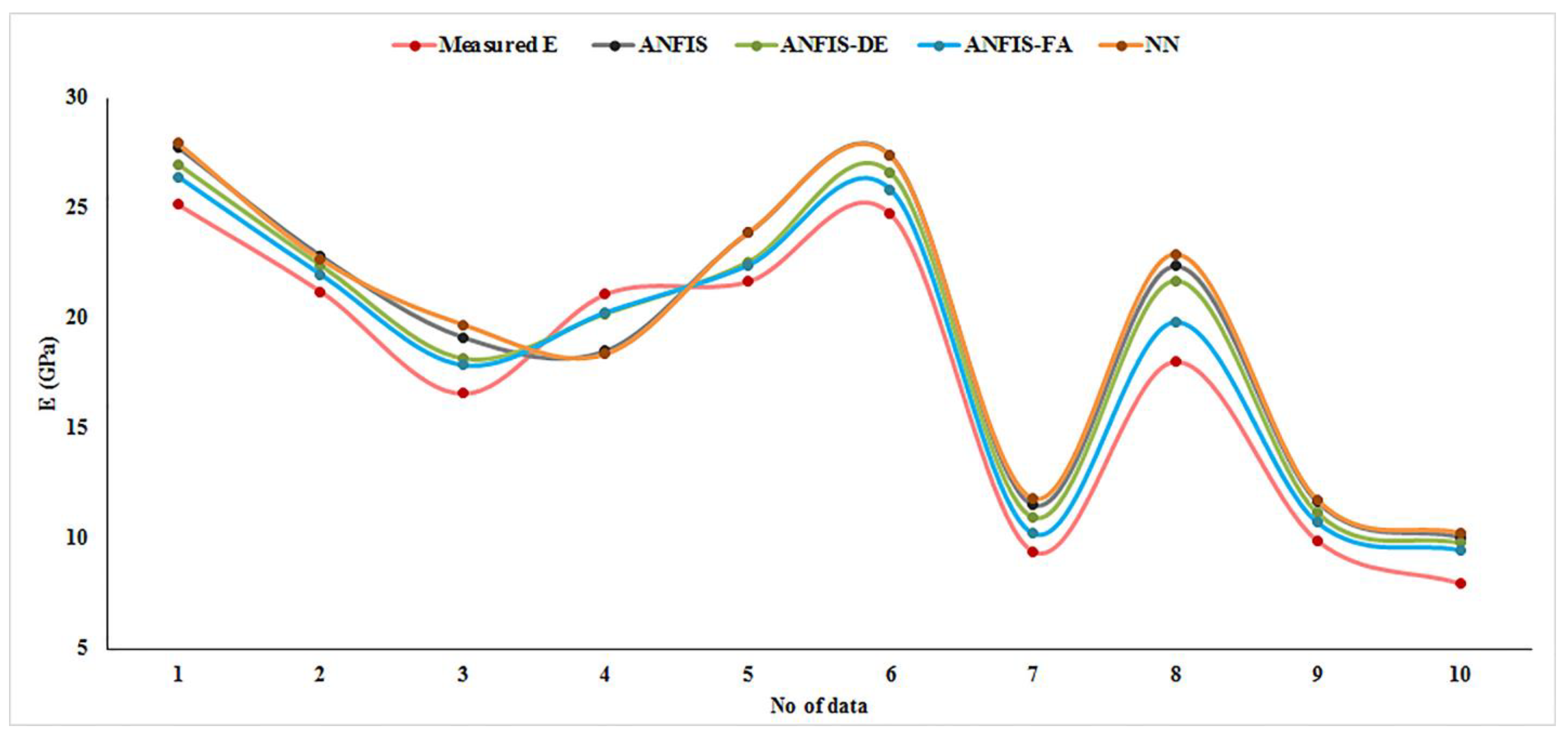
Figure 11. Additionally,
Figure 12 shows the amount of error for each model related to the testing phase. According to these two figures, the prediction of E by the ANFIS-FA model is very accurate and closer to measured E values. In addition,
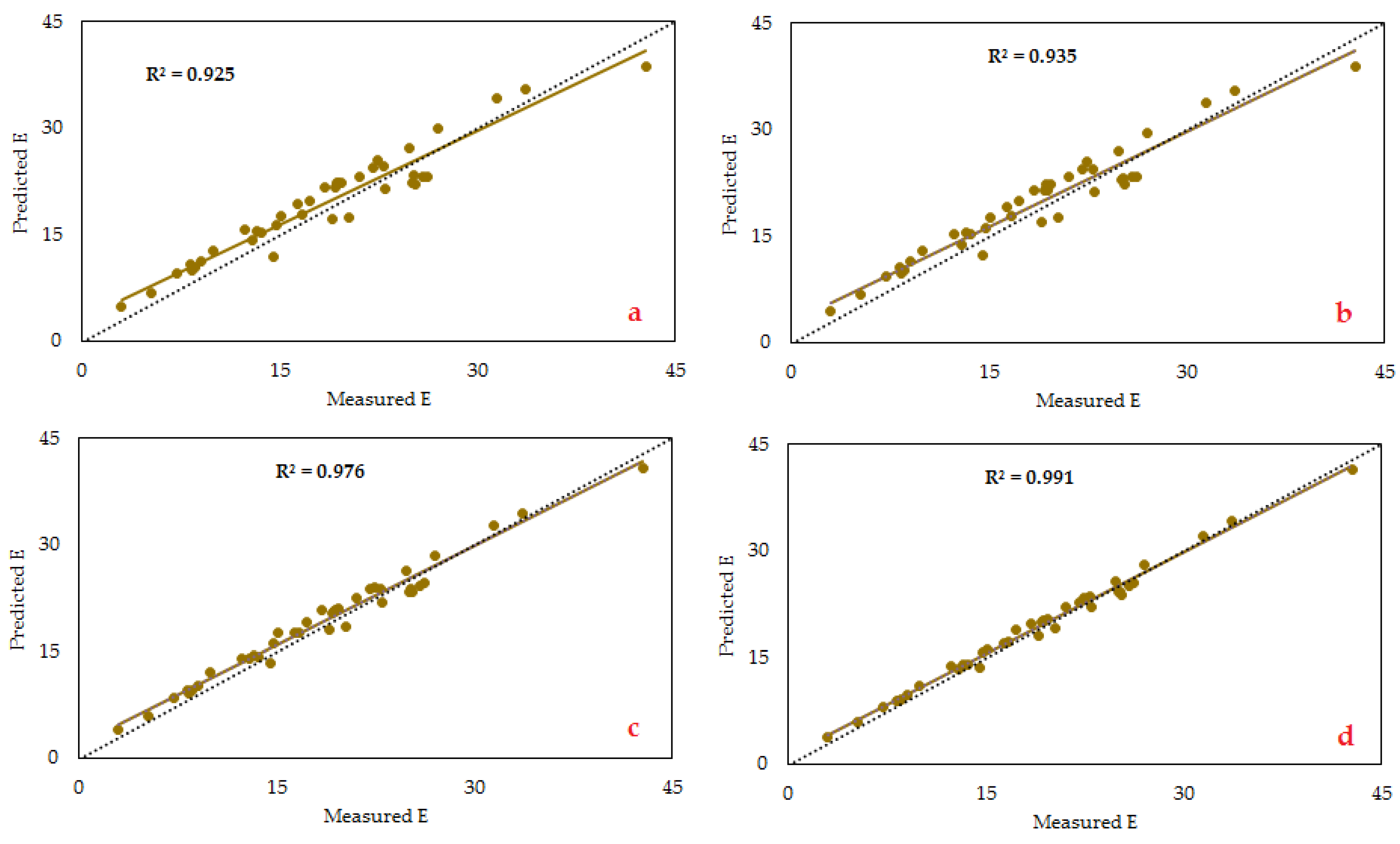
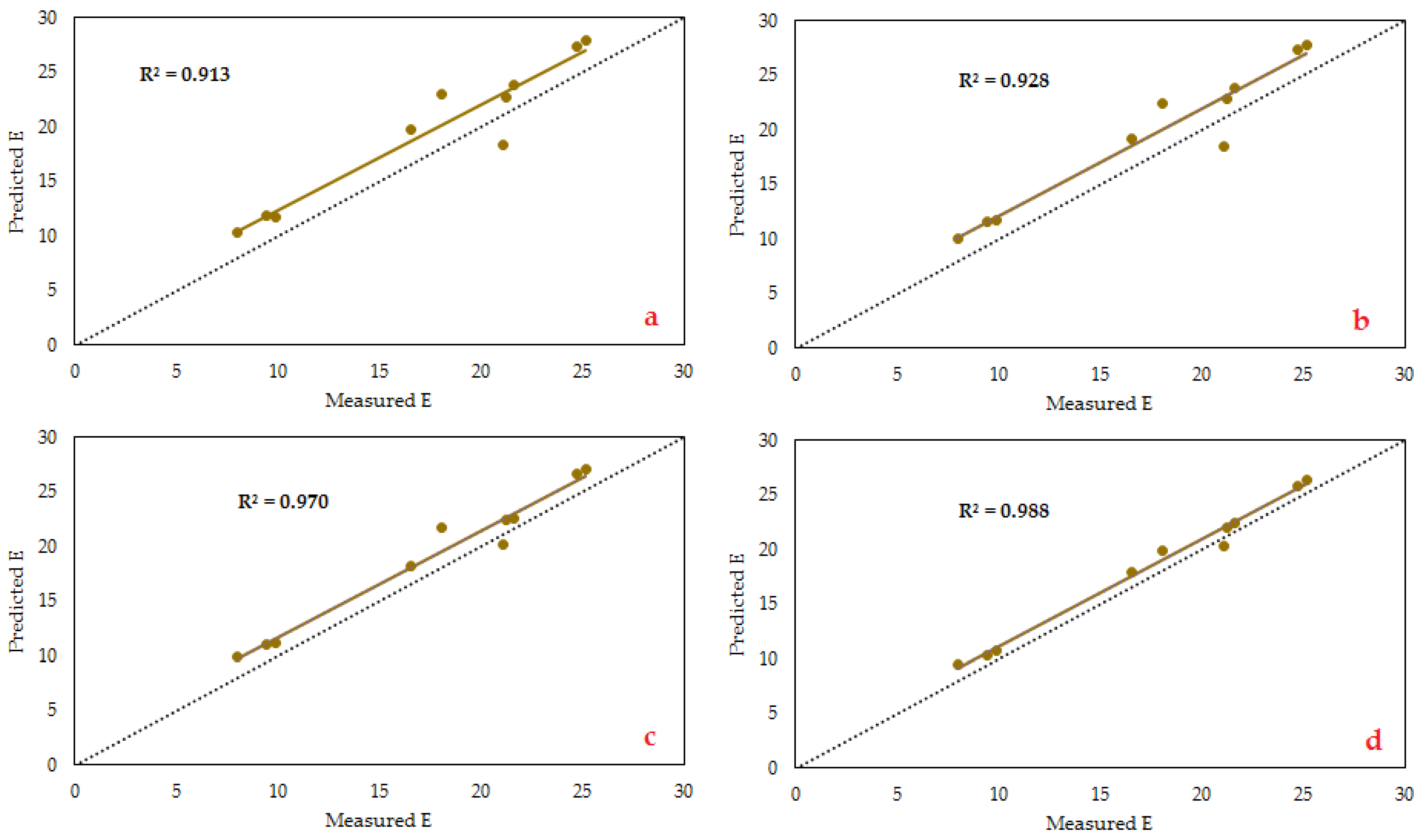
Figure 13 and
Figure 14 demonstrate the scatter plots of actual versus estimated E values with the use of all predictive models. The figures show that the ANFIS-FA model obtained a greater value for the coefficients of determination (
R2). The
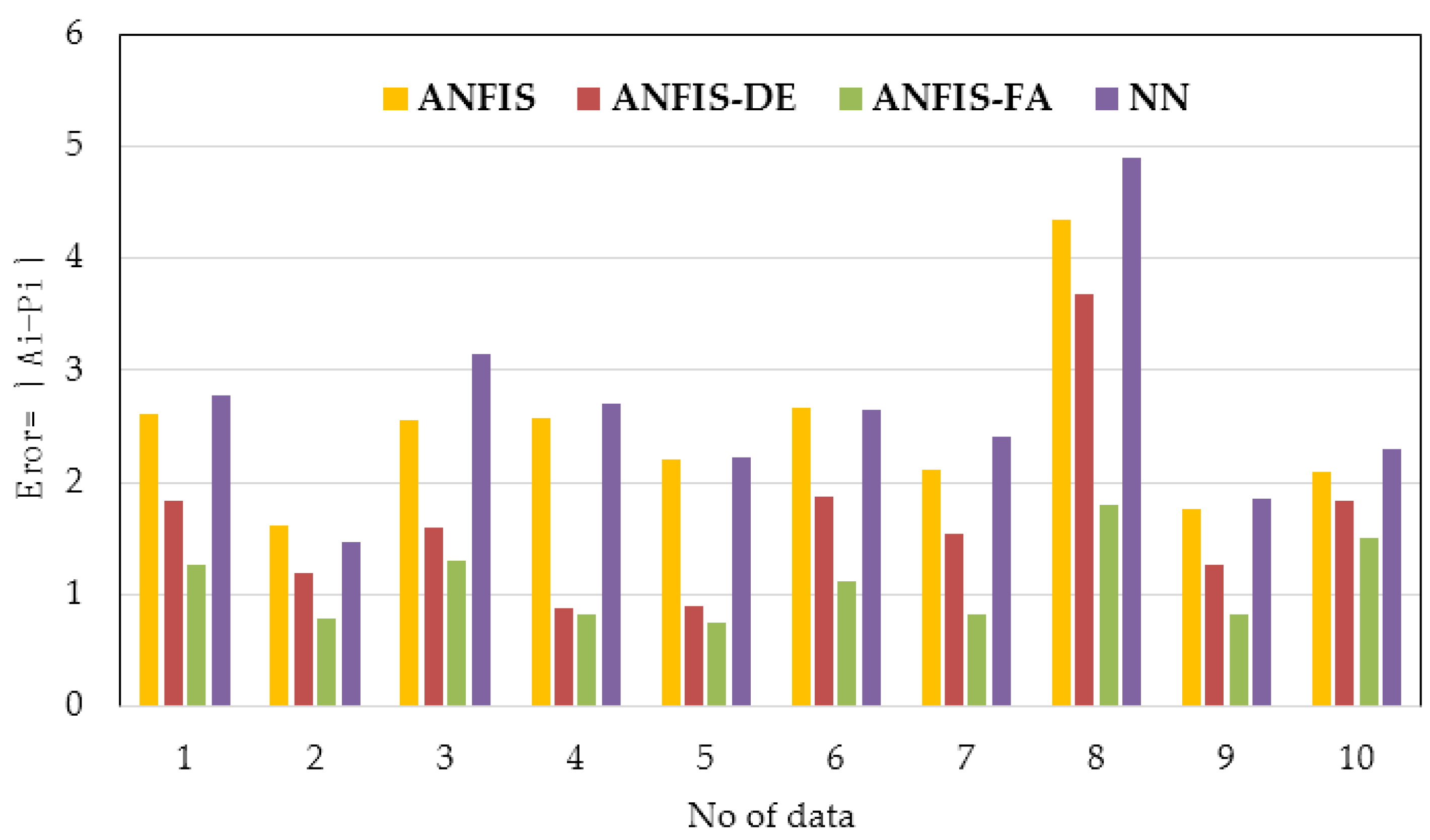
R2 values of 0.988, 0.970, 0.928, and 0.913 were obtained by the ANFIS-FA, ANFIS-DE, ANFIS, and NN models, respectively. Accordingly, FA was more effective in comparison with DE in regard to the ANFIS improvement. Furthermore, the absolute error of ANFIS-FA, ANFIS-DE, ANFIS, and NN models in predicting E for testing datasets (ten datasets) is depicted in
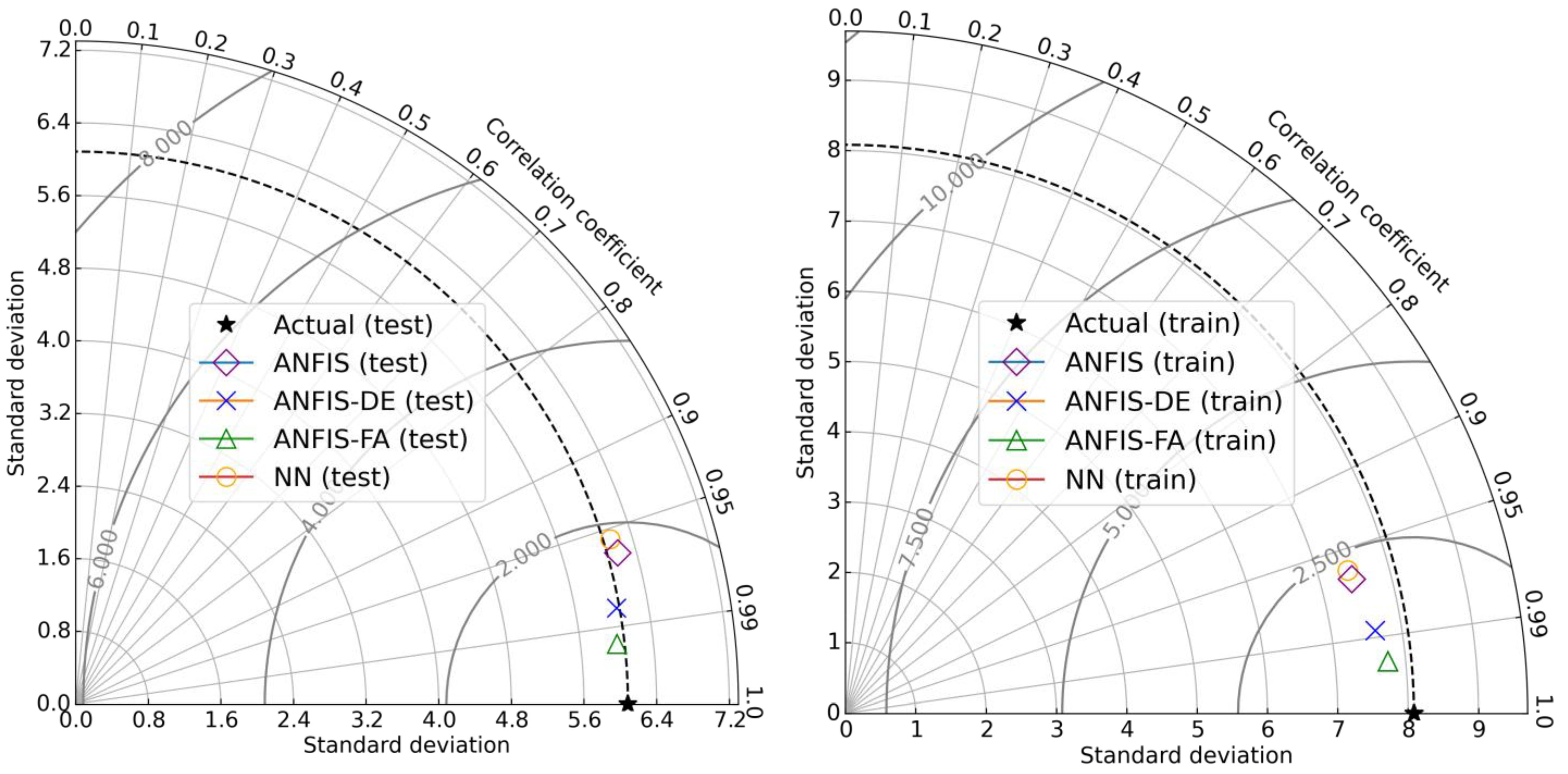
Figure 15. According to this Figure, the orange-coloured line, which was obtained by the ANFIS-FA model, yields the lowest absolute error for all ten datasets. Moreover, the Taylor diagrams for both training and testing groups are shown in
Figure 16. The results show that the ANFIS-FA has a stronger potential to predict E than the others. In this study, a sensitivity analysis was also performed. For this work, the effect of removing each input variable on E for the ANFIS-FA was calculated. In this regard, six new models based on the combination of input variables were constructed, as follows:
Model 1: inputs: all variables given in
Table 1.
Model 2: inputs: all variables given in
Table 1 except the depth of coring.
Model 3: inputs: all variables given in
Table 1 except density.
Model 4: inputs: all variables given in
Table 1 except porosity.
Model 5: inputs: all variables given in
Table 1 except durability.
Model 6: inputs: all variables given in
Table 1 except Poisson ratio.
Model 7: inputs: all variables given in
Table 1 except P-wave velocity.
Figure 11.
Comparing the values of E predicted by the four models.
Figure 11.
Comparing the values of E predicted by the four models.
Figure 12.
Amount of error for each model, as related to the testing phase.
Figure 12.
Amount of error for each model, as related to the testing phase.
Figure 13.
Comparison of the actual E value with those predicted, obtained by (a) NN, (b) ANFIS, (c) ANFIS-DE, and (d) ANFIS-FA for the training group.
Figure 13.
Comparison of the actual E value with those predicted, obtained by (a) NN, (b) ANFIS, (c) ANFIS-DE, and (d) ANFIS-FA for the training group.
Figure 14.
Comparison of the actual E value with those predicted, obtained by (a) NN, (b) ANFIS, (c) ANFIS-DE, and (d) ANFIS-FA for the testing group.
Figure 14.
Comparison of the actual E value with those predicted, obtained by (a) NN, (b) ANFIS, (c) ANFIS-DE, and (d) ANFIS-FA for the testing group.
Figure 15.
Absolute error values obtained by the models using the testing phase.
Figure 15.
Absolute error values obtained by the models using the testing phase.
Figure 16.
Taylor diagrams obtained by the predictive models.
Figure 16.
Taylor diagrams obtained by the predictive models.
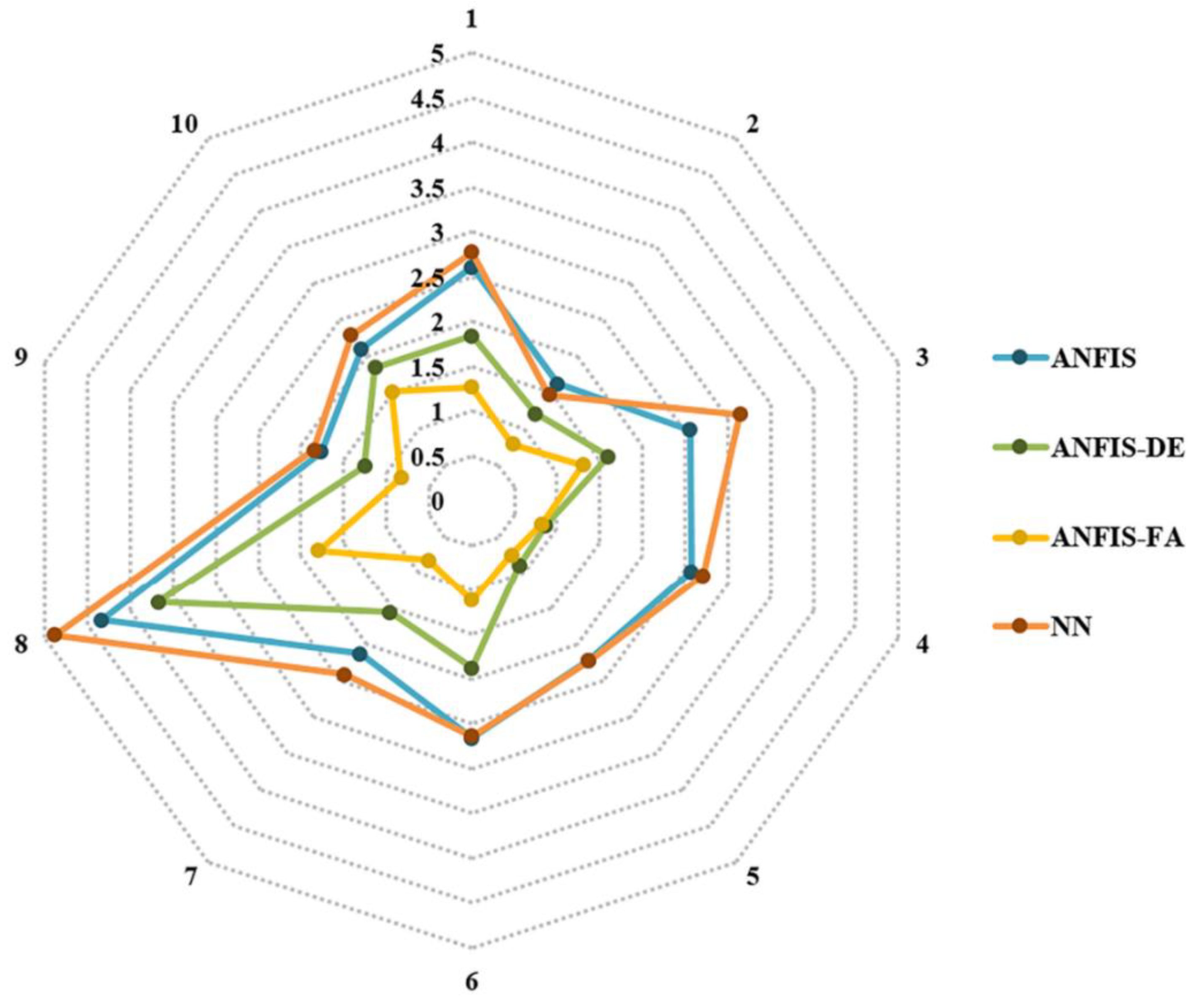
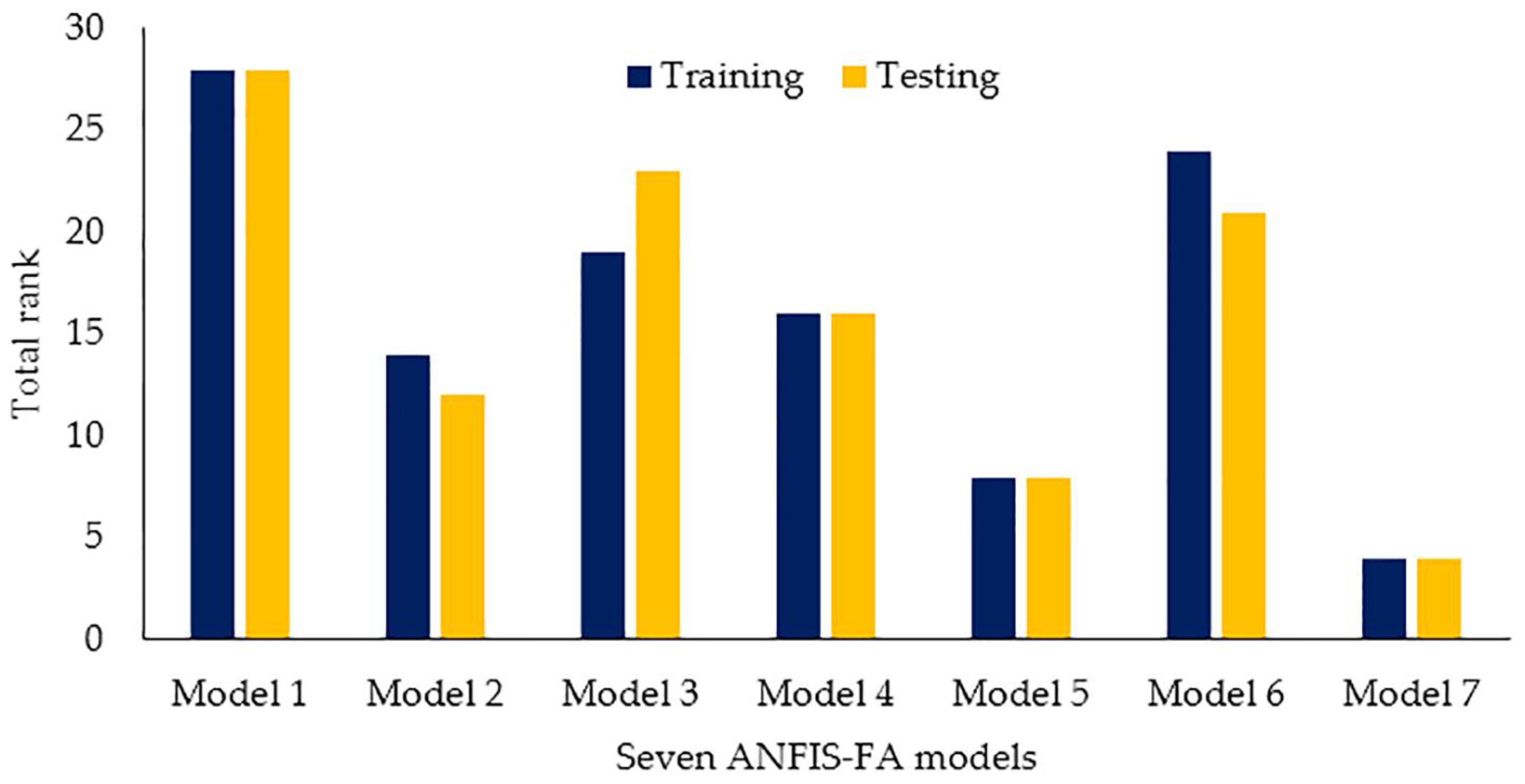
The results of the above models are presented in
Table 9, which shows that models 1 and 7 had the highest total rank (i.e., the best performance) and lowest total rank (i.e., the worst performance), respectively (
Figure 17). Note that, the results of model 1 is bolded in
Table 9. The results of presented in
Table 9 indicated that once the P-wave velocity was removed from the modeling, the worst performance was obtained; thus, P-wave velocity can be determined as the most effective variable in the modeling.
5. Conclusions
The elastic modulus (E) is considered one of the most significant factors in the primary and ultimate plans of projects related to the geo-engineering field. As a result, it is highly necessary to predict E with a high accuracy level. This paper examined the use of two hybrid evolutionary models, namely ANFIS-FA and ANFIS-DE, to predict E. Additionally, the traditional ANFIS and NN models were developed for comparison aims. In total, 50 datasets were collected during the drilling process in the Azad and Bakhtiari under-construction dams in Iran. Out of the 50 datasets, 40 were used to construct the models, and the remaining datasets were used to test them. The input parameters considered in the construction of the models were porosity, density, depth of coring, Poisson’s ratio, compressional/primary wave velocity, and durability, which were assigned as the input variables, whereas E was the output/target variable. Finally, some statistical indices were designed in order to demonstrate the capacity of the models in the prediction of E. According to the findings, the following results and remarks can be briefly listed:
The results demonstrated that ANFIS-FA was the most suitable model for the prediction of E in the cases studied. The ANFIS-DE, ANFIS, and NN models were identified as the next cases in this rank.
The FA and DE algorithms strongly improved the ANFIS performance in terms of predicting the E value. This confirms the effectiveness of FA and DE; accordingly, these two algorithms can be effectively used to address other predicting problems in rock engineering fields.
The results of sensitivity analysis showed that the P-wave velocity was the most effective parameter on the intensity of E.
For future studies in this field, other evolutionary algorithms, e.g., the central force optimization, chicken swarm optimization, elephant search algorithm, and flower pollination algorithm, could be implemented to enhance the ANFIS performance.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}