
Vendor-Agnostic Reconfiguration of Kubernetes Clusters in Cloud Federations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Cloud bursting facilitates an application scenario where a portion of workloads is dynamically migrated from an on-premise private cloud to public cloud platforms to cope with peaks and spikes in workload while reducing capital expenditures;
- High availability and geodistribution requires replicating an application across different availability zones and different regions, respectively. The latter is necessary to offer a the same quality of service level to end-users across the world;
- Security policy and regulation compliance requires that sensitive workloads and data are deployed on-premise, whereas insensitive traffic and workloads can be handled by elastic public clouds.
- We propose a feature-oriented approach where K8s clusters can be reconfigured by means of declarative configuration of desired optional features. An optional feature corresponds here to a specific functionality of Kubernetes that is not enabled by default, yet it is clearly described in the open-source documentation of Kubernetes with precise instructions how to enable it. Based on a previous case study of feature incompatibilities between three leading K8s vendors—Azure Kubernetes Service (AKS), Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE)—we have identified more than 30 optional features that were stable or highly demanded but that were locked by at least two vendors in different enabled or disabled states, leading to feature incompatibilities that violate at least one of the aforementioned consistency requirements;
- We account all feature incompatibilities to three configuration manifests of the open-source K8s distribution that are partially or completely hidden by proprietary customization interfaces of the three vendors;
- We describe in detail what are the most prevailing vendor-agnostic reconfiguration tactics in industry for changing a broad set of configuration settings. We point out that these tactics are all based on imperative configuration management that suggests one-off installation without further monitoring. This is not in line with the Kubernetes philosophy of declarative configuration management where a separate control loop continuously monitors for differences between desired and actual system configuration states;
- We extend KubeFed, a popular tool for federation of K8s clusters, with an API and autonomic controller for declarative feature compatibility management. As such, cluster administrators and application managers can submit feature configuration manifests to this API to specify what desired features all member clusters in a federation should have. The controller detects missing features in the member clusters. If a cluster does not support one or more desired features, the controller will apply the aforementioned imperative reconfigurations tactics to install them. It will further monitor the member cluster and generate events to report successful or pending installation of the desired features;
- We make an empirical evaluation of the controller and the three vendor-agnostic reconfiguration tactics with respect to (i) the impact of the reconfigured K8s features on the performance of applications, (ii) the disruption of running applications during the reconfiguration process and (iii) the total reconfiguration time.
2. Background
2.1. Basics of Kubernetes
2.1.1. Container
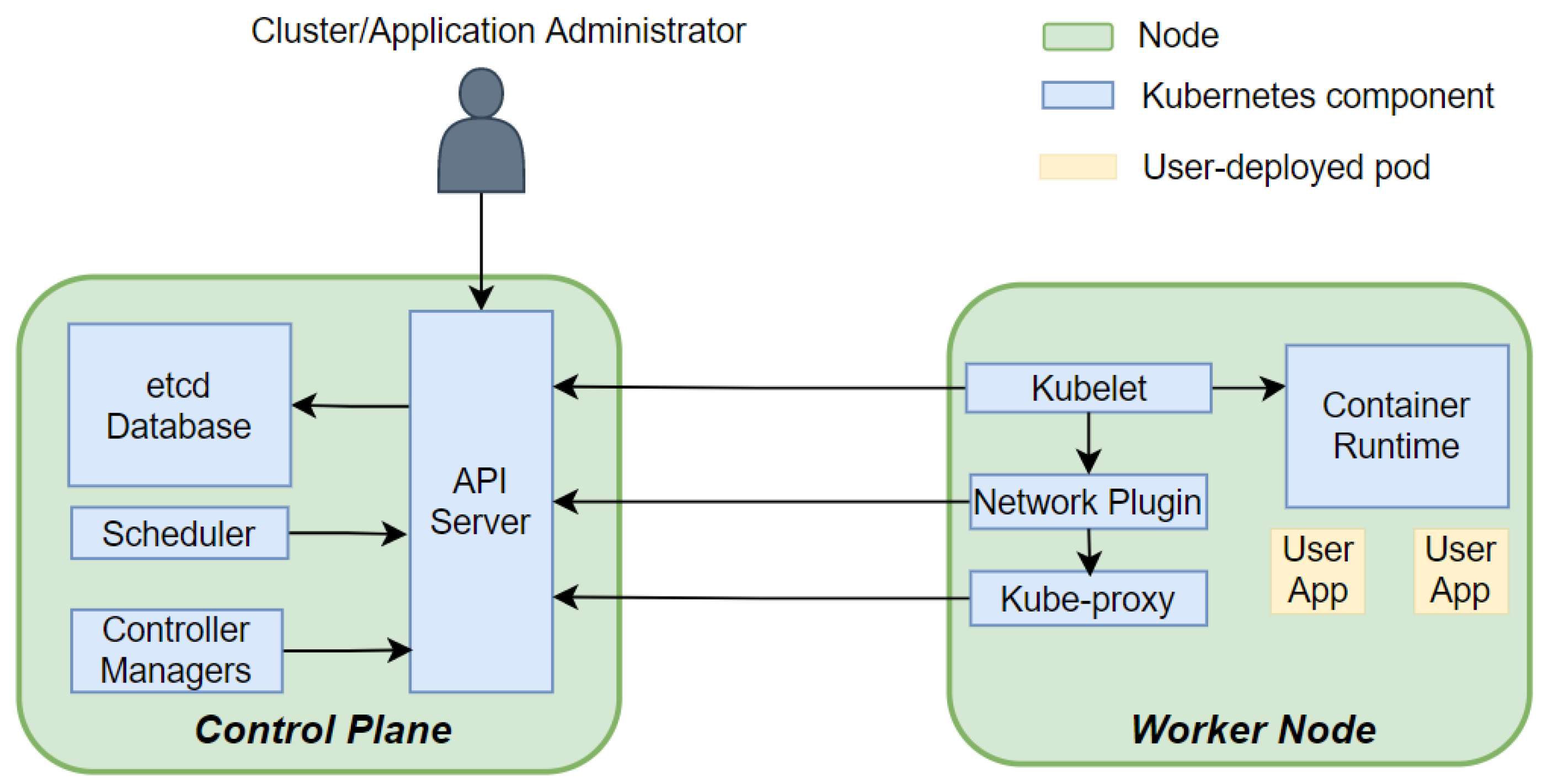
2.1.2. Kubernetes Architecture
- API server is the central point of communication among the components of the cluster. It exposes various RESTful APIs, through which worker node agents, controllers, users and applications can create, query or update cluster and application resources. These APIs are an abstraction of the actual resources deployed. Here, we introduce the APIs resources that are used in this paper:
- –
- Pod is the atomic unit of deployment in Kubernetes, consisting of one or more tightly coupled containers. A pod can be thought of as a virtual host for containers, and all containers in it share the same Linux network namespace and cgroup parent;
- –
- Deployment represents a set of pod replicas managed by the Deployment controller. We can specify the desired number of replicas and the updating strategy in the Deployment API. The Deployment controller will enforce our specification;
- –
- Daemonset represents a pod that should be deployed on every node of the cluster, and every node should only have one copy of the pod;
- –
- Service is an API resource that specifies a stable network access point behind a set of volatile pods;
- –
- Custom Resource Definition (CRD), customresource represents extended API resources in the API server. We can use this API to introduce new custom APIs;
- etcd Database is a key-value database that stores the desired and actual states of all API resource objects. After the API server receives the client’s request, it will query or update the corresponding resource states in the etcd database [18];
- Controller Manager, controller contains many built-in controllers that implement control loops to manage resources of various built-in API types like Deployments and Services. For example, the Deployment Controller monitors the actual number of replicas of pods in a Deployment and performs actions to make it match the desired number as described by users;
- Scheduler is responsible for placing pods on the appropriate worker nodes based on the node states and the requirements of the pods.
- Container Runtime is responsible for container image pulling/pushing to and from a central container registry as well as the creation, execution and resource monitoring of containers;
- Network Plugin is responsible for creating a virtual network bridge on each node of the cluster and configuring routing rules on each node to manage the connectivity between containers;
- Kube-Proxy is a clusterwide load balancer that exposes a pool of pods to external clients via a stable Service IP, which is created via a Service API object. It watches the Services and associate Endpoint resource objects on the API server and maintains network and routing rules on the nodes to implement customizable (e.g., using session affinity) round-robin load balancing. The Kube-Proxy runs as a pod in worker nodes;
- Kubelet is the essential component on the worker node. It watches the pod resource objects on the API server to detect changes about Pods on its node. It interacts with the container runtime, the network plugin and other add-ons to ensure that the container running state is consistent with the specification of the pod manifest. For example, if the Kubelet sees that the pods to be created have specific resource limits, it will first interact with the container runtime to create a pod-level network namespace with a particular cgroup parent setting.
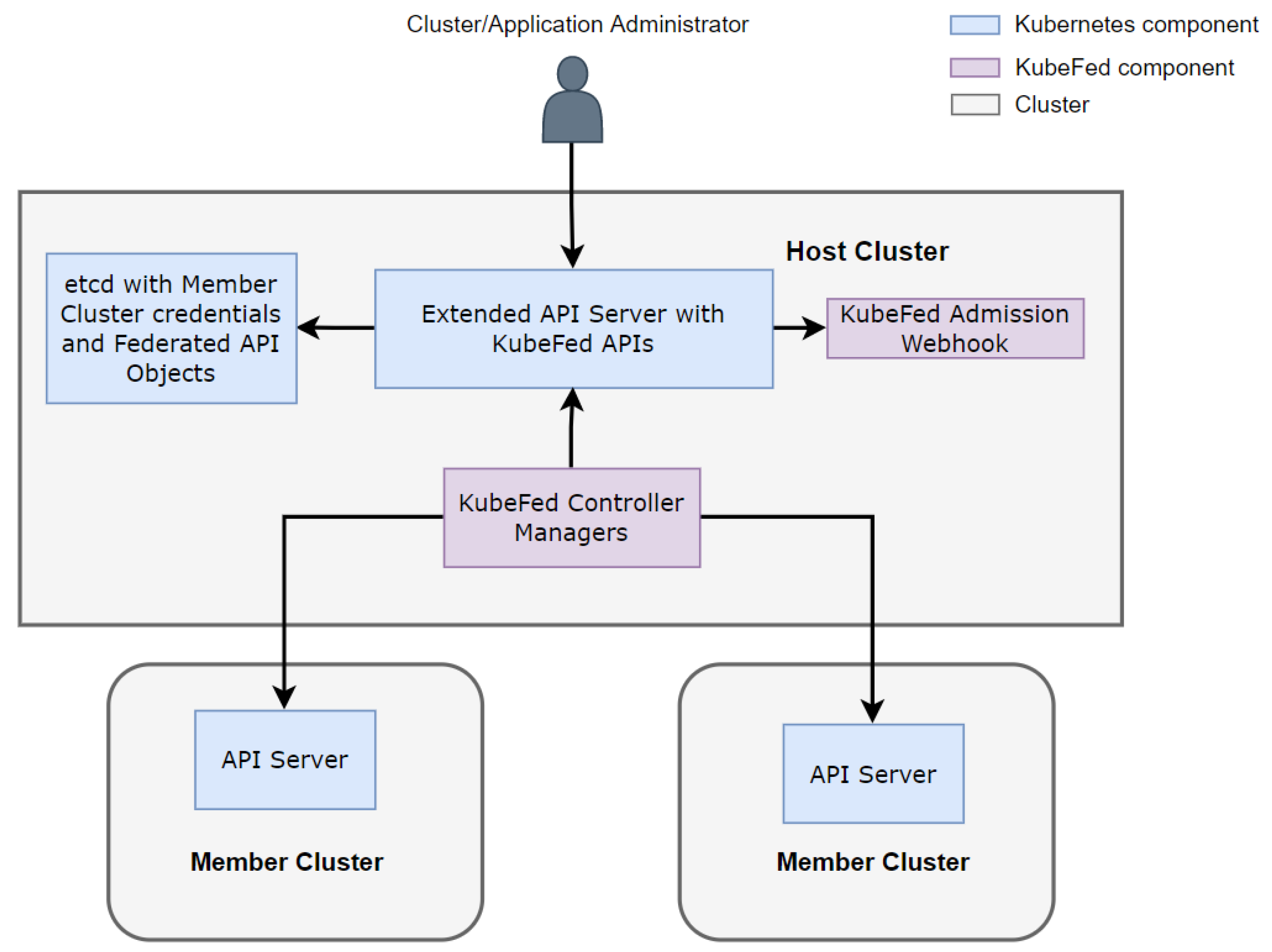
2.2. Kubernetes Cluster Federation
- Host Cluster is a Kubernetes cluster where the KubeFed Control Plane resides. It extends the API server with KubeFed APIs and deploys KubeFed controller managers. KubeFed controllers can access the credentials of managed member clusters and communicate with their API servers. Users create and manage federated resources through the KubeFed API, and KubeFed controllers propagate the changes of federated resources to the corresponding member clusters according to the specification provided by the user. The KubeFed admission webhook is responsible for validating the federated resources, such as when we want to create a federated custom resource object; the webhook will only allow it if all member cluster support this custom resource. In addition, a host cluster can also become a member cluster at the same time;
- Member Clusters are the place where workloads and resources are actually deployed in the cluster federation. It is no different from normal clusters. It does not know anything about the other member clusters and the presence of the host cluster. Kubefed Controllers in the host cluster are like any other ordinary clients of the member cluster’s API server;
3. Related Work
3.1. Transferability of Cloud-Native Applications in Cloud Federations
3.2. Current Feature Reconfiguration Approaches for K8s in Industry
4. Analysis of the Feature Compatibility Problem
4.1. API Server Configuration
- Admission controllers. These are modular interceptors that wrap the API server. Although these interceptors are defined as part of the open-source distribution of K8s, we have found in our previous work’ [35] that 7 out of 28 admission controllers were not consistently set across the studied vendors for K8s version v1.13;
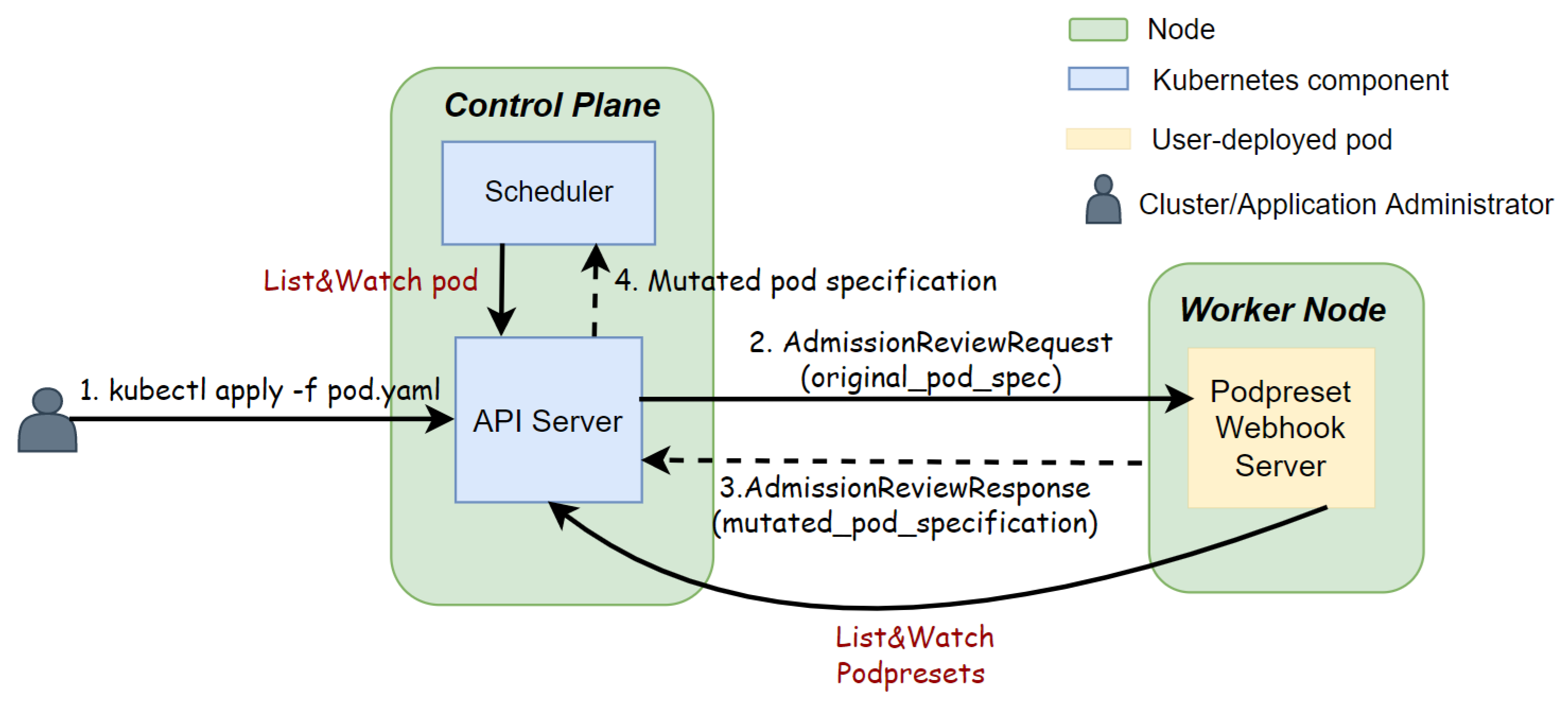
- The RESTful APIs. The RESTful APIs of the API server are organized into different API groups that can be enabled or disabled. For example, for K8s v1.13, we found that EKS does not support the k8s.metrics.io API group that is needed for auto-scaling of containers. Another problem are the deprecated APIs that are still highly demanded. For example, the PodPreset API has been removed after K8s version v1.19. Hosted K8s products only offer the latest versions; therefore, the PodPreset API is not available anymore, yet there is still a high demand for this feature in the OpenShift community [9];
- Feature gates for beta features. Each K8s version introduces new alpha features that can and should be disabled via feature gates when running clusters in production environments. These alpha features may disappear or be promoted to the stable stage in a successive K8s version, after which the feature gate is removed. However, between the alpha and stable stage, there is the beta stage and beta features are enabled by default in the open-source distribution. However, they can be disabled by K8s vendors. In the latest version of K8s, there are more than 40 beta features. In our previous work [35], we found differences between the three K8s vendors with respect to 2 beta feature gates. Unfortunately, also different alpha features were enabled;
- Encryption of secrets stored in etcd is a feature to prevent attackers to read secrets from the etcd database in the clear.
4.2. KubeletConfiguration Manifest
- Supported container runtimes. The main container runtimes are containerd and cri-o (docker has been deprecated). Various libraries and settings must be installed on the worker nodes themselves in order to make the selected container runtime work;
- Supported authentication and authorization schemes of the Kubelet with respect to securing the Kubelet API and authenticating the Kubelet to the API server;
- Various logging features such as container log rotation;
- Container image garbage collection;
- CPU management policies for reserving CPUs to specific Pods.
4.3. Configuration of Network Plugins
- External Source Network Address Translation (sNAT) for Pod IPs. IP addresses of Pods cannot be routed to from outside of the cluster. With sNAT enabled, it becomes possible to connect to Pods from outside the cluster via stable external IP addresses;
- Network policies. The K8s networking model requires that every worker node and pod must be able to connect to any other Pod IP address. Network policies allows expressing distributed firewall rules across the cluster to properly segment different applications from each other. This feature is only supported by some CNI plugins and there exists various implementations that differ in performance overhead and types of network policies;
- Multiple network interfaces per Pod. This is only supported by the Multus CNI plugin;
- Reimplementation of the kube-proxy with more efficient load balancing at the level of the Linux kernel and reduction of the number of hops across nodes when forwarding requests to and returning responses from pods;
- Encryption of control plane and data plane messages.
5. Reconfiguration Tactics
5.1. API Server Configuration
5.2. KubeletConfiguration Manifest
5.3. CNI Network Plugin
6. Design and Implementation of the Autonomic Feature Management Controller
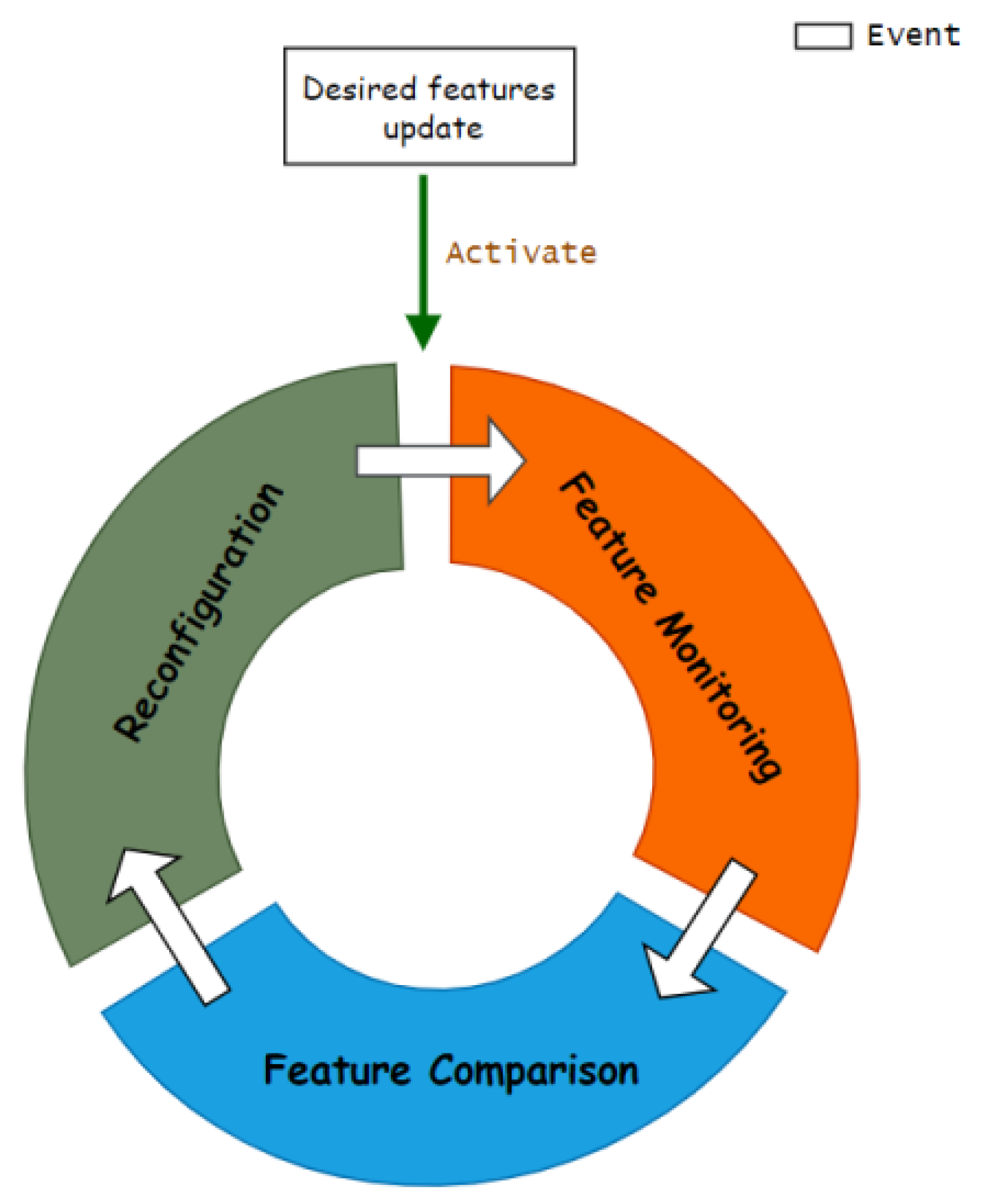
6.1. Design of the Control Loop
- The user specifies the desired features that each member cluster should support through a declarative API;
- The controller monitors actual supported features and compares them with the desired features for each member cluster;
- If a desired feature is not supported in the cluster, the controller performs the vendor-agnostic feature reconfiguration tactics to activate the missing feature.
6.2. Controller Implementation
6.2.1. Custom Resource: Featureconfig
| Listing 1 Example YAML file for Featureconfig API. |
|
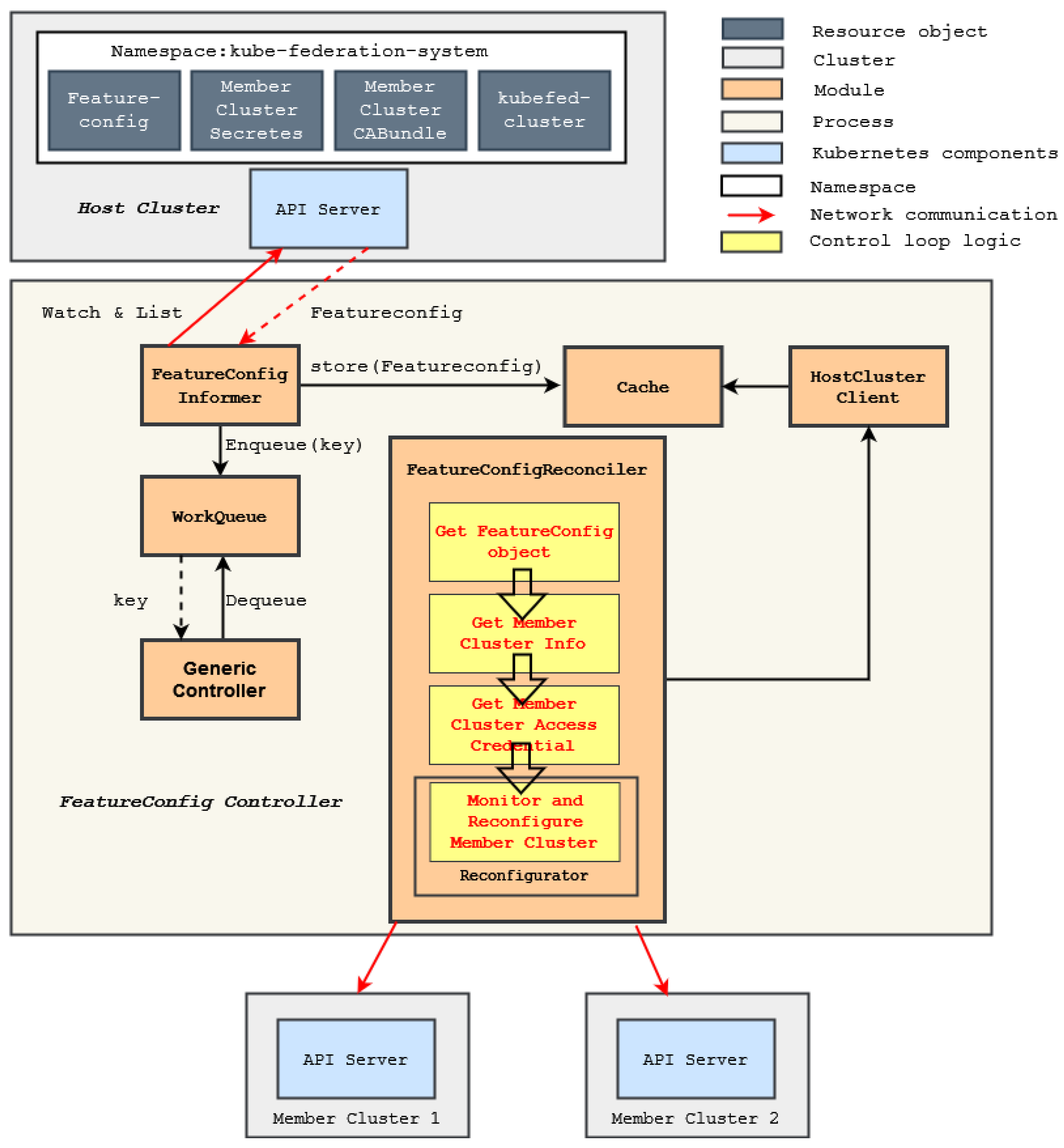
6.2.2. Controller Architecture
- Informer is responsible for watching our custom API resource Featureconfig in the host cluster. If a Featureconfig object changes, the informer updates the corresponding object in the Cache and enqueues the object’s key (name and namespace) as an event into the WorkQueue;
- Cache is a local store that caches resource objects managed by the controller to reduce the load of the host cluster’s API server;
- WorkQueue stores events that need to be processed, which are the key (name and namespace) of changed Featureconfig objects;
- Generic Controller is responsible for dequeuing an event from the WorkQueue and calling the Reconcile method in the FeatureconfigReconciler with this event;
- Client can be used by our reconciler to communicate with the API server of the host cluster. If the object of the reconciler wants to fetch is already in the Cache, the Client will fetch the object from the Cache directly instead of sending a request to the API server.
| Algorithm 1: Reconcile method in FeatureconfigReconiler. |
Data: The key of a Featureconfig object Result: All member clusters support features specified in the Featureconfig object Desired_ f eatures := Client.GetFeatureCon f ig(key); Member_clusters := Client.GetMemberClusters(KubeFedCluster);  |
| Listing 2 Reconfigurator Interface. |
|
- Reconfigure is the method where we monitor and apply vendor-agnostic reconfiguration tactics for one or more desired features. It takes the desired features and credentials to communicate with a member cluster. For all desired features that the reconfigurator is able to configure, the reconfigurator will check if any of the desired features are not yet enabled in the cluster. If so, it will apply one of the vendor-agnostic tactic for these missing features, and it returns true. If the member cluster supports all desired features, it will apply nothing and therefore return false;
- Wait_for_up is the method that waits until the features of the reconfigurator’s interest are all successfully activated. This is because the tactics take some time to execute, mostly because of the stages of creating a Daemonset and pulling container images for these Daemonset pods on all worker nodes.
6.2.3. Feature Monitoring
- API server: The API server has an endpoint /apis to list all installed API resources. The controller interacts with this endpoint and see if the desired API resource is supported;
- Kubelet: The Kubelet of a worker node exposes the endpoint /configz to get its configurations. However, the credential to access Kubelet endpoints is only available in the API server, which is managed by vendors for a cluster of a hosted product type. Therefore, we should use the API server’s endpoint /proxy to redirect our requests to Kubelet. The Kubelet returns its settings in JSON format, and then the controller can inspect the current CPU manager policy;
- Network plugin: We found that although the network plugin mode is one of the Kubelet configurations, it is not returned when we call the Kubelet configz endpoints. Therefore, the controller inspects the network plugin mode by directly observing the name of the Daemonset that is installed by the CNI plugin.
7. Evaluation
7.1. Research Questions
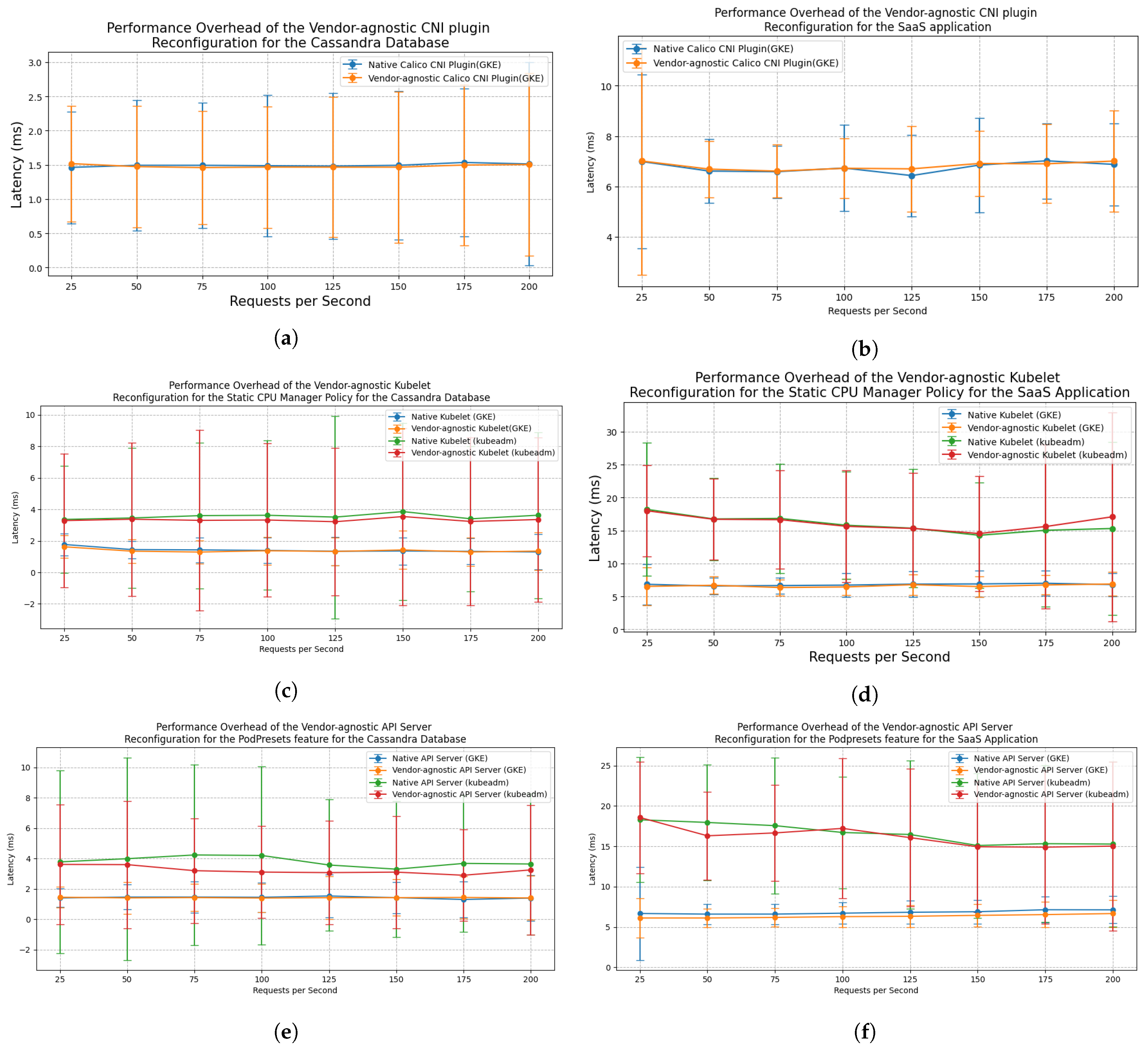
- Question 1: What is the performance overhead of reconfigured features during normal operation of cloud-native applications compared to native features supported by Kubernetes?One of the goals of our vendor-agnostic reconfiguration tactics and controller is to reduce the operational cost of multicluster management. However, if the reconfigured feature has a significant performance overhead on the normal operation of the cluster or application, this would outweigh the benefits of vendor-agnostic reconfiguration. So, we need reconfigured features to have as little impact on performance as possible in comparison to a Kubernetes cluster where the features are configured as instructed in the official K8s documentation [5].
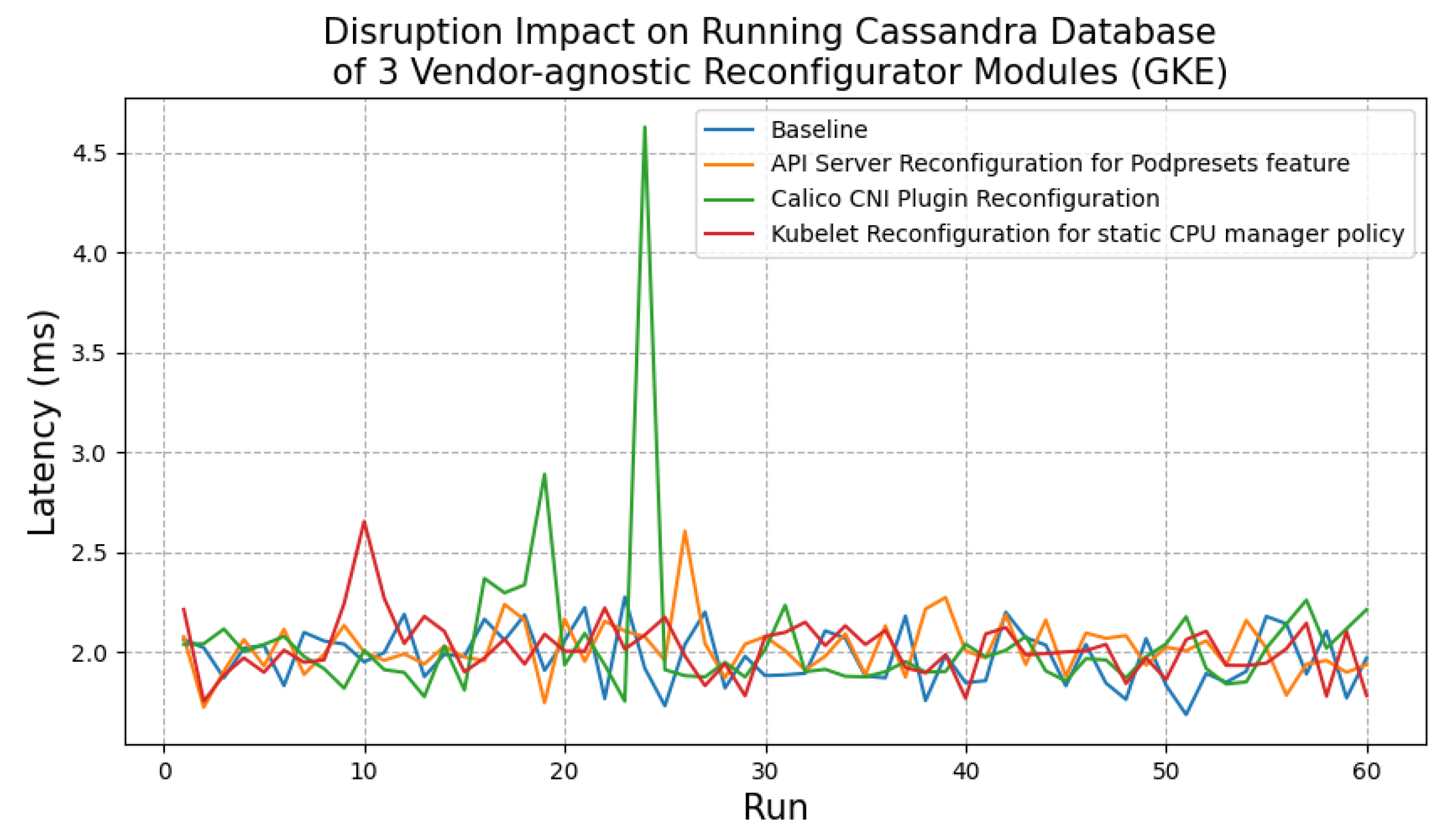
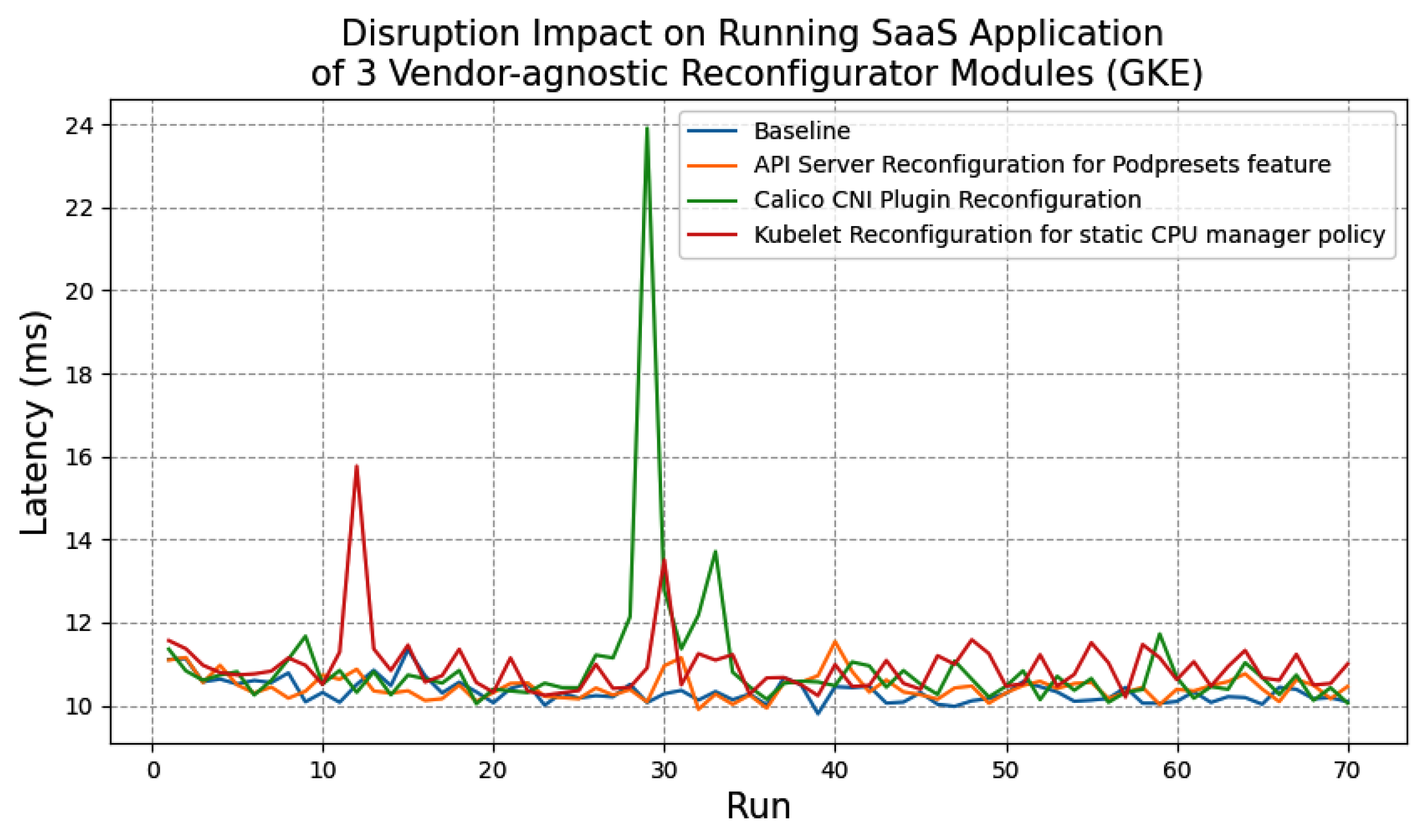
- Question 2: What is the disruption impact on running applications when reconfiguring?For Kubernetes production clusters, we want the controllers to have less impact on running applications or services when executing reconfiguration tactics to ensure the normal operation of the business.
- Question 3: What is the time to reconfigure features in a newly created cluster without any application running?In the context of cloud bursting, K8s clusters must be set up only when there is an imminent workload peak. As such, clusters must be launched and configured as quickly as possible.
7.2. Evaluation Environment
7.2.1. Test Applications
- Cassandra Database: The Cassandra database is a distributed, high-performance and highly available NoSQL database widely used in the industry [52]. We evaluate our research questions by measuring the latency of CPU-intensive write operations at various workload levels (i.e., number of writes/sec);
- Configurable SaaS Application: This SaaS application can be configured to perform a combination of CPU-, disk- or memory-intensive operations [53]. Again, here, we measure the latency of CPU-intensive operations.
7.2.2. Kubernetes Clusters
- On-premise clusters on Openstack: The testbed for on-premise clusters is an isolated part of a private OpenStack cloud, version 21.2.4. The OpenStack cloud consists of a master–worker architecture with two controller machines and droplets on which virtual machines can be scheduled. The droplets have 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz; i.e., 2 x (14 cores, 28 threads), and 256 GB RAM. Each droplet has two 10Gbit network interfaces. The K8s cluster used in the evaluation was deployed using Kubeadm [55]. Kubeadm is an installer product that offers a rich yet proprietary customization interface [55]. Additionally, we use Terraform scripts to automate the testbed creation process. Our on-premise clusters have a control plane node of resource size c4m4 (4 cores and 4 GB memory) and worker nodes of size c4m4;
- GKE cluster: We use GKE [34] as our base line to compare the impact of our vendor-agnostic reconfiguration tactics and controller on Kubernetes of a hosted product type. GKE’s default cluster uses Kubenet, so all experiments related to switching the Network Plugin are only carried out on GKE. Moreover, like on-premise clusters, GKE can support creating clusters with our selected features through its proprietary interfaces. For example, we can use NodeConfig file to partially modify the KubeletConfiguration manifest [38], create older clusters to support deprecated APIs and enable network policy to use the CNI network plugin [56]. Our GKE clusters have a hardware setup with a vendor-managed control plane and two e2-highcpu-4 (4 cores and 4 GB memory) instances as worker nodes.
7.3. Experimental Results and Findings
7.3.1. Experiment 1: Performance Overhead of Reconfigured Features
Experimental Setup
Experimental Results and Findings
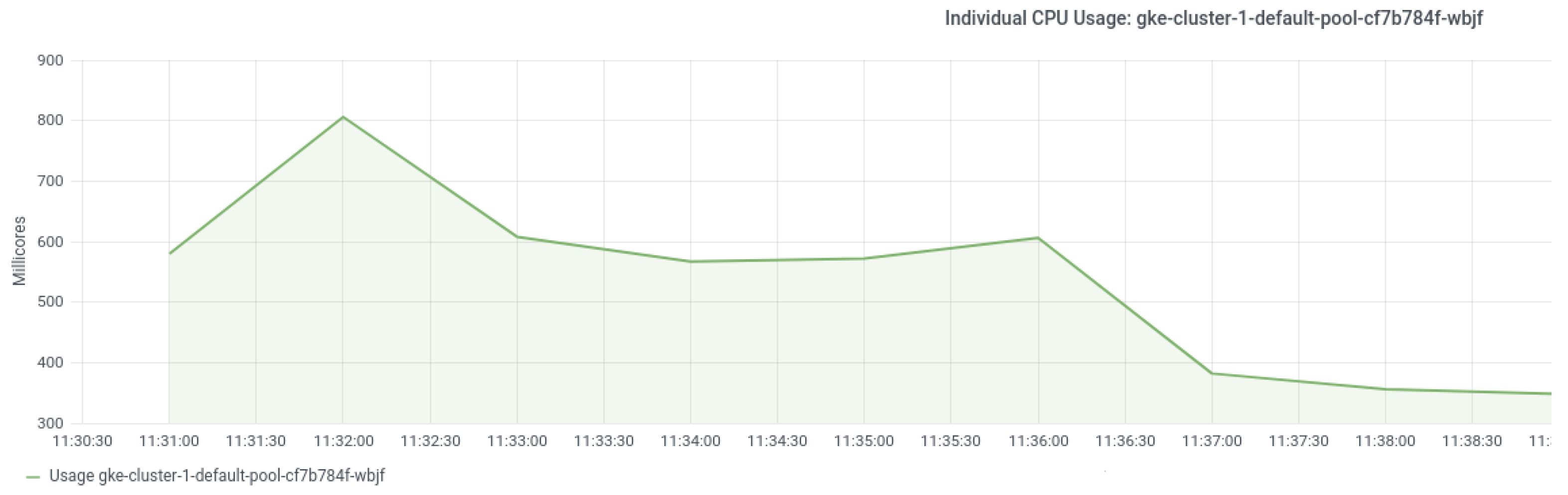
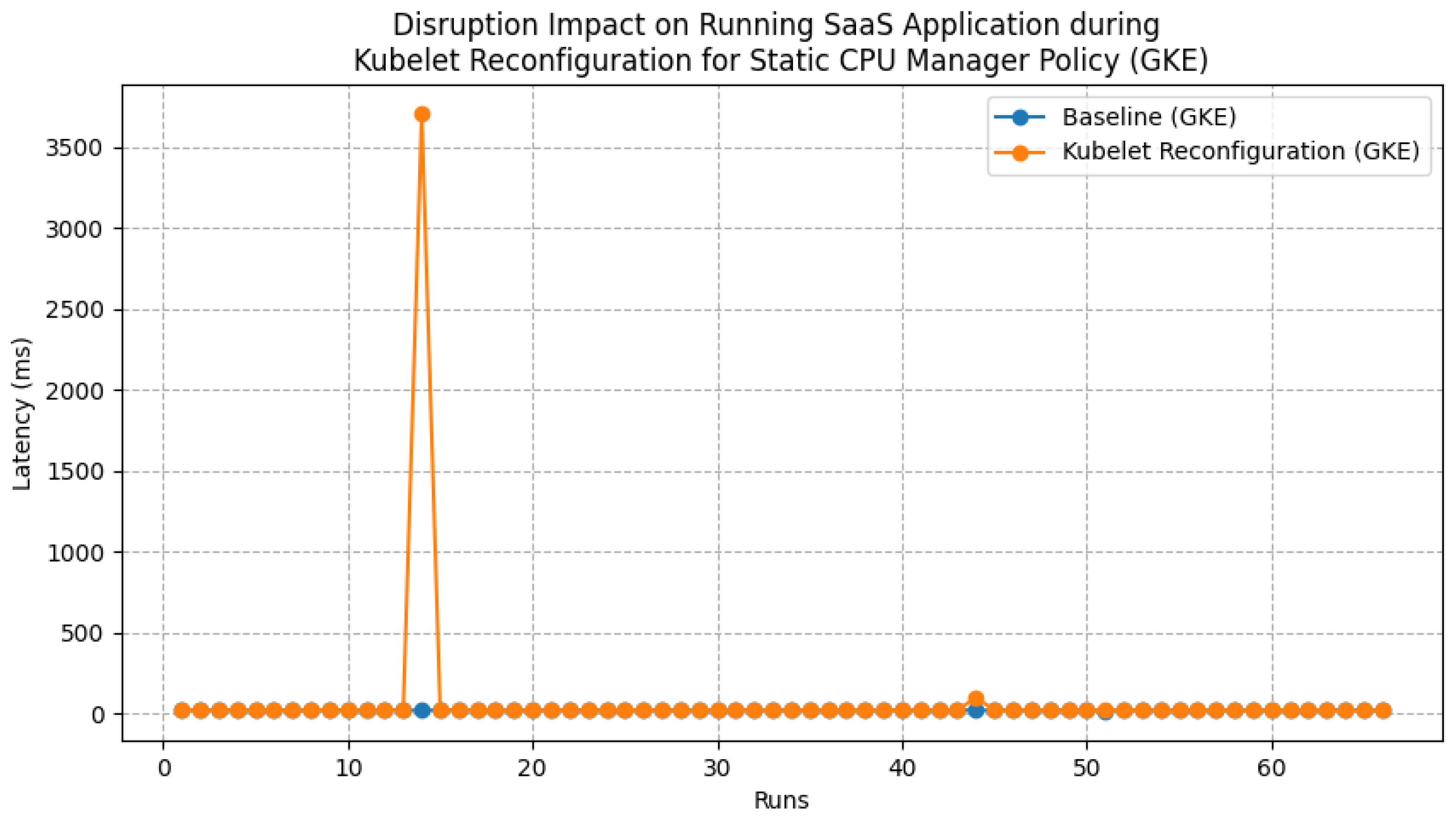
7.3.2. Experiment 2: Disruption Impact on Running Applications When Reconfiguring
Experimental Setup
Experimental Results and Findings
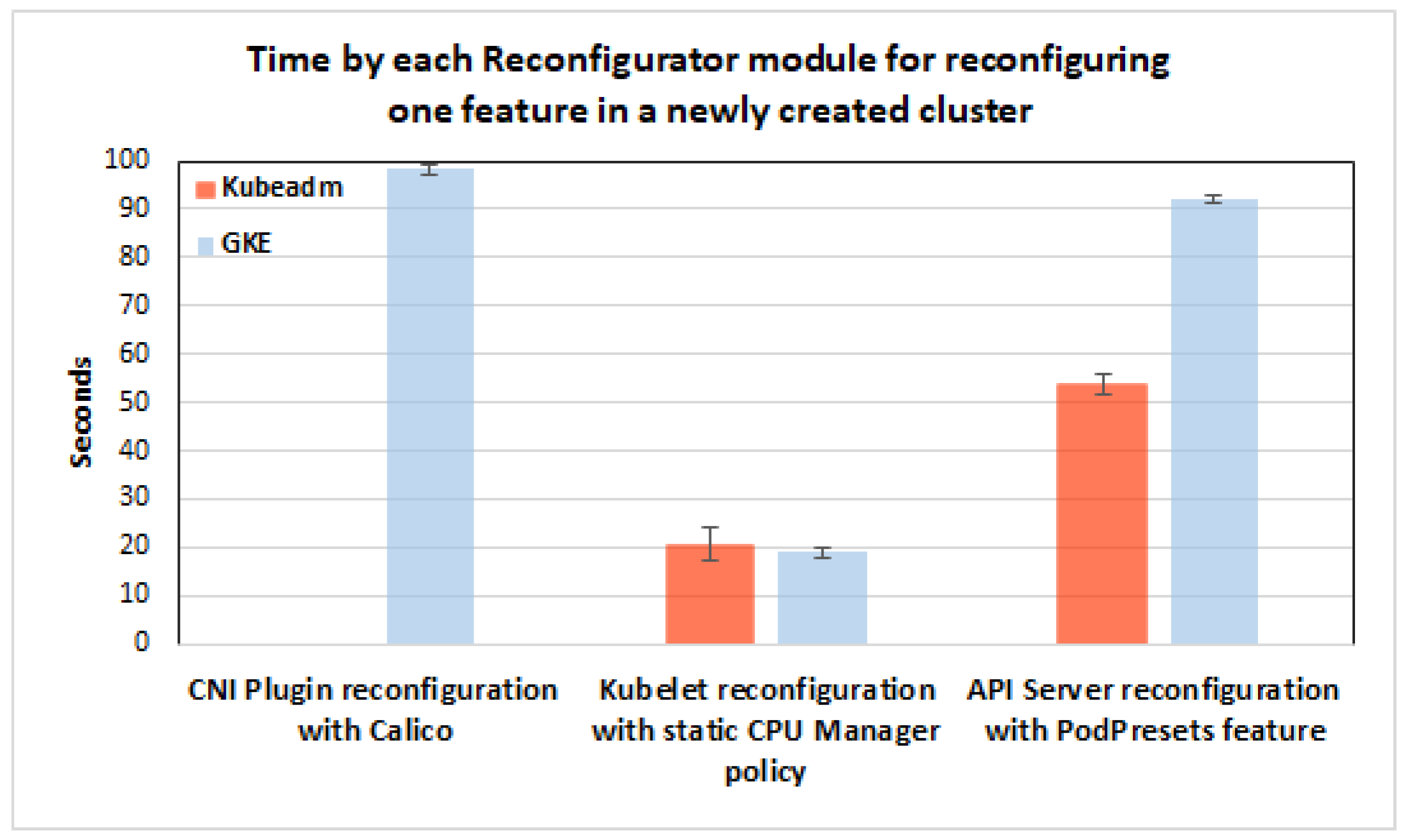
7.3.3. Experiment 3: Time to Reconfigure Features in a Newly Created Cluster without any Application Running
Experimental Setup
Experimental Results and Findings
8. Discussion of Limitations
8.1. Reliability Barriers
8.2. Security Barriers
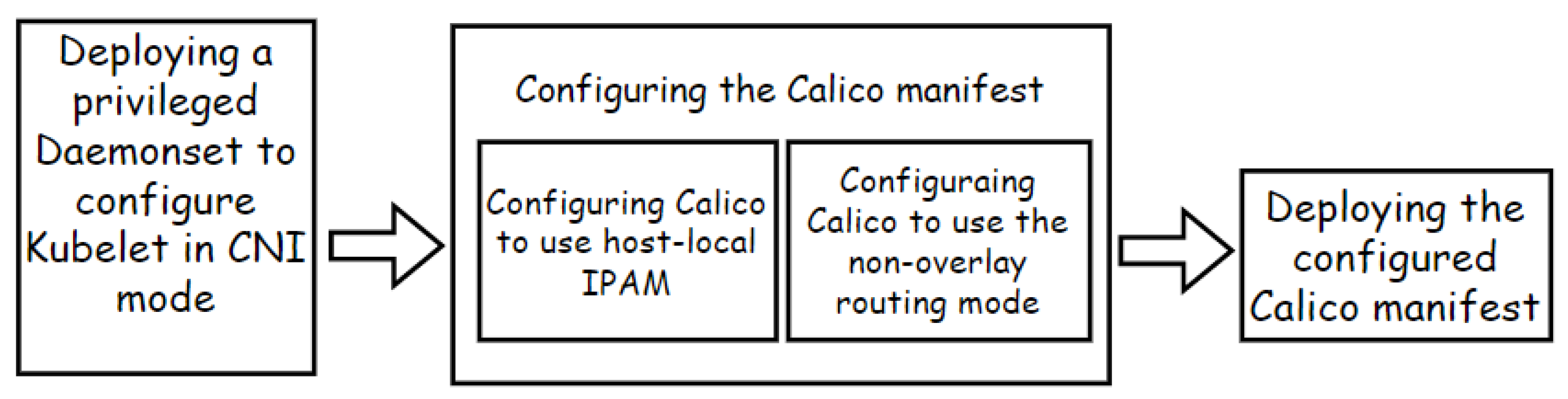
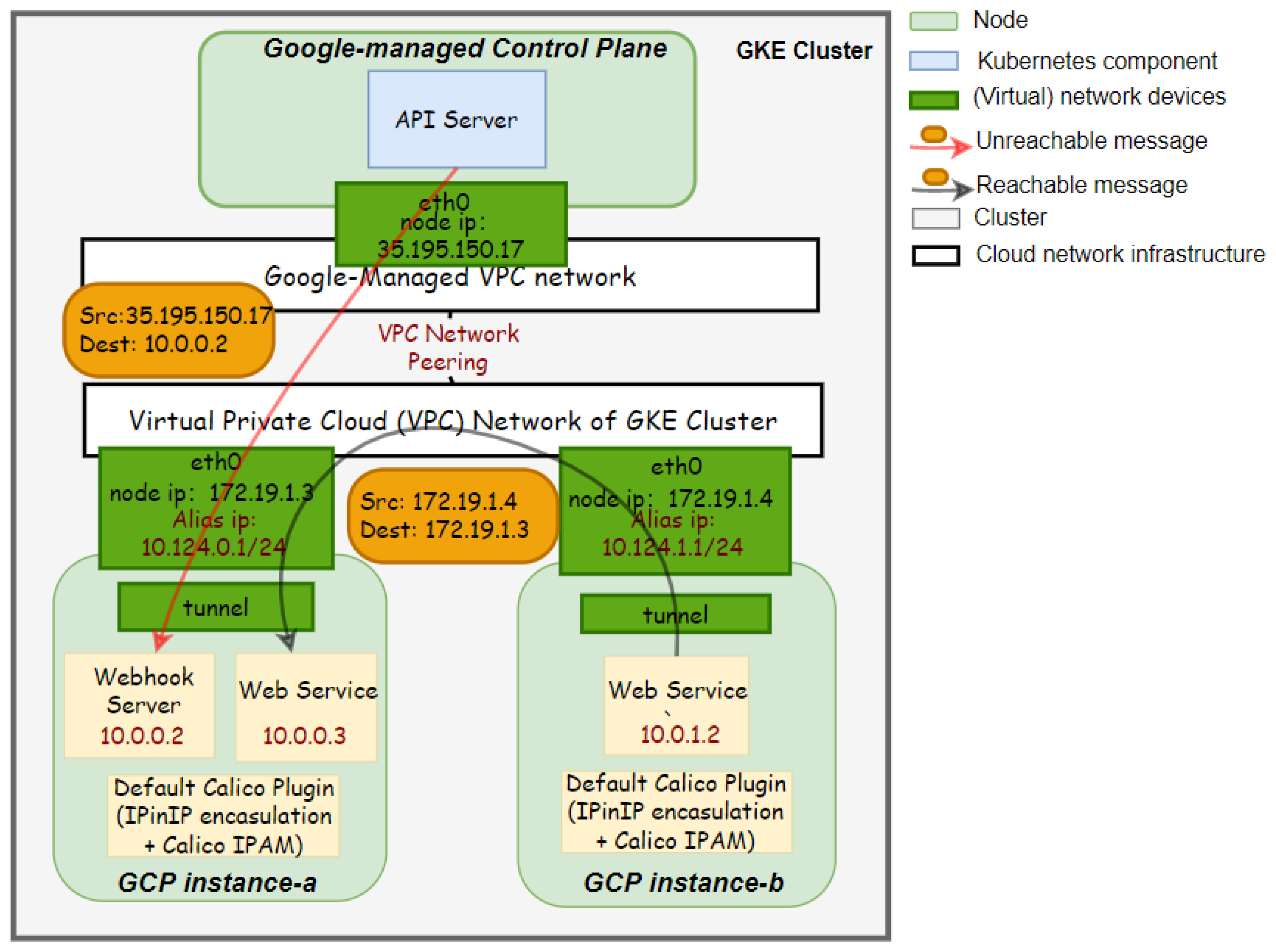
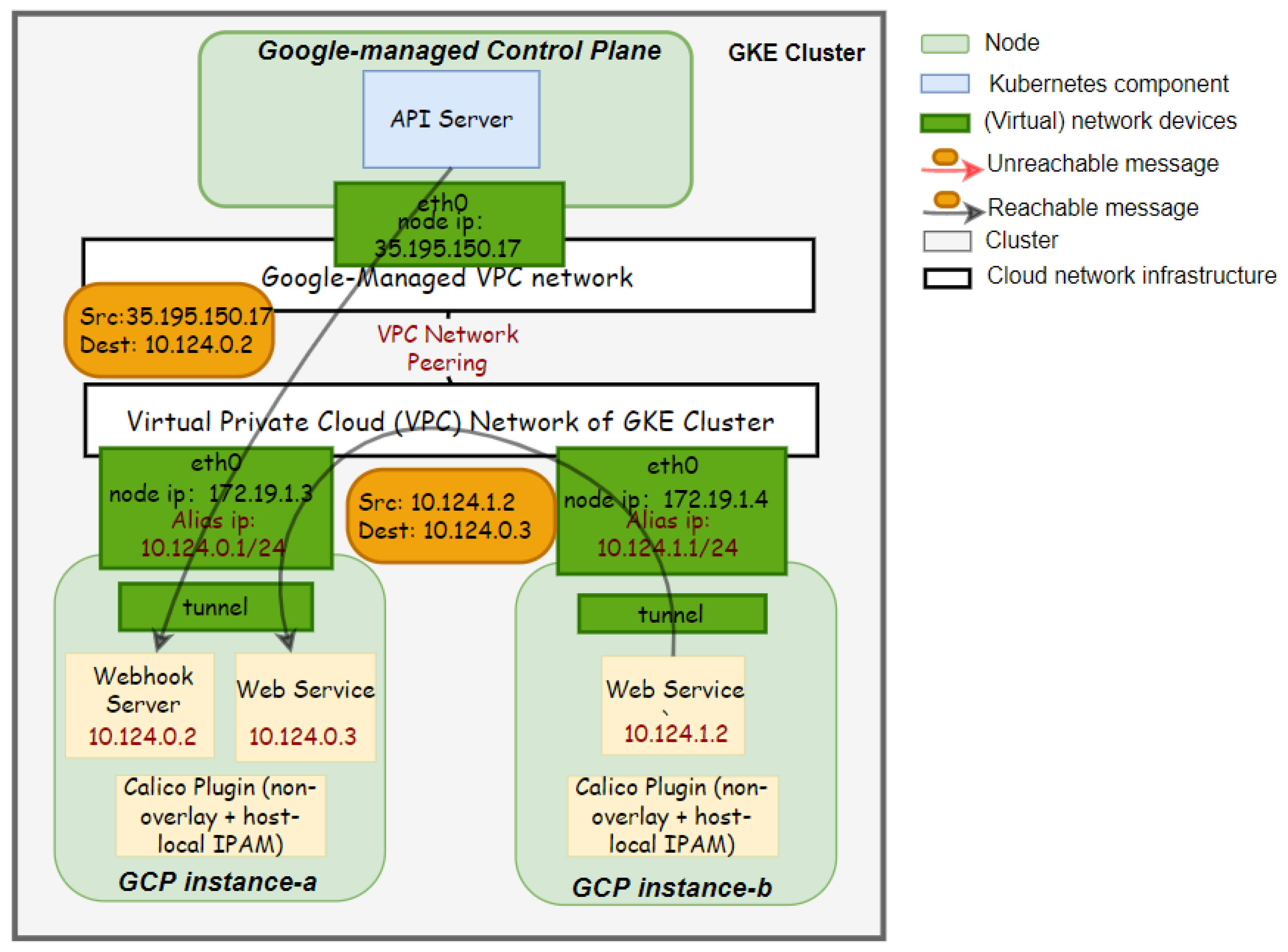
8.3. CNI Plugin Reconfiguration in Hosted K8s Products
8.4. Barriers in Edge and Fog Computing Solutions
8.5. Limitations of the Study
9. Conclusions
9.1. Summary of our Feature Compatibility Management Approach
- Question 1: What is the performance overhead of reconfigured features during normal operation of cloud-native applications compared to native features supported by Kubernetes?We have found that the performance overhead of applications that run on a cluster with our reconfigured features is close to a cluster that is configured using the official documentation.
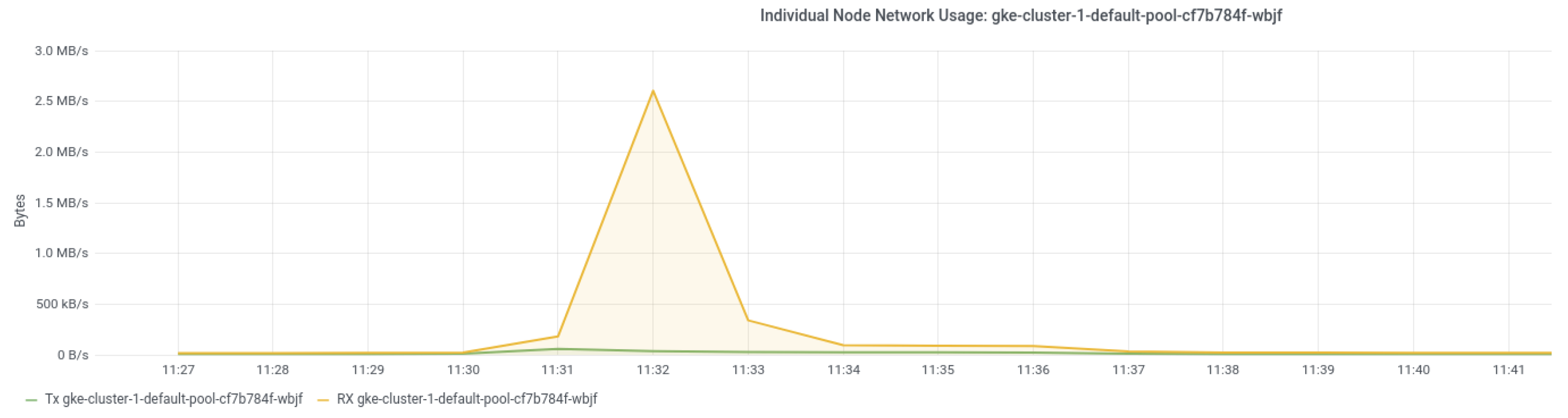
- Question 2: What is the disruption impact on running applications when reconfiguring?When reconfiguring incompatible features, our approach brings a disruption impact on running applications, especially when reconfiguring CNI network plugins. By analyzing the resource usage of nodes, we hypothesize the reason for this could be that the image pulling and container creation process occupy a significant amount of network and computing resources on host machines. Additionally, while reconfiguring the Calico CNI plugin and KubeletConfiguration, the procedure of restarting the Kubelet may cause pods with readiness or liveness probes to become inaccessible through their exposed services for a while.
- Question 3: What is the time to reconfigure features in a newly created cluster without any application running?We have evaluated the reconfiguration time for three relevant features and found that all features could be reconfigured within 100 seconds. It is worth noting that the controller takes significantly less time to reconfigure the CNI network plugin than GKE’s proprietary interface that restarts all worker nodes and gradually migrates Pods by restarting them on the new nodes.
9.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moreno-Vozmediano, R.; Montero, R.S.; Llorente, I.M. IaaS cloud architecture: From virtualized datacenters to federated cloud infrastructures. Computer 2012, 45, 65–72. [Google Scholar] [CrossRef]
- Buyya, R.; Ranjan, R.; Calheiros, R.N. Intercloud: Utility-oriented federation of cloud computing environments for scaling of application services. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, Busan, Korea, 21–23 May 2010; pp. 13–31. [Google Scholar]
- Grozev, N.; Buyya, R. Inter-cloud architectures and application brokering: Taxonomy and survey. Softw. Pract. Exp. 2014, 44, 369–390. [Google Scholar] [CrossRef]
- Kratzke, N. About the complexity to transfer cloud applications at runtime and how container platforms can contribute? In Proceedings of the International Conference on Cloud Computing and Services Science, Porto, Portugal, 24–26 April 2017; pp. 19–45. [Google Scholar]
- Kubernetes. Available online: https://kubernetes.io/ (accessed on 19 December 2022).
- Considerations for Large Clusters. Available online: https://kubernetes.io/docs/setup/best-practices/cluster-large/ (accessed on 28 November 2022).
- Jeffery, A.; Howard, H.; Mortier, R. Rearchitecting Kubernetes for the edge. In Proceedings of the 4th International Workshop on Edge Systems, Analytics and Networking (EdgeSys ’21), Online, UK, 26 April 2021; pp. 7–12. [Google Scholar]
- Budigiri, G.; Baumann, C.; Mühlberg, J.T.; Truyen, E.; Joosen, W. Network Policies in Kubernetes: Performance evaluation and security analysis. In Proceedings of the 2021 Joint European Conference on Networks and Communications & 6G Summit (EuCNC/6G Summit), Porto, Portugal, 8–11 June 2021; pp. 407–412. [Google Scholar]
- A PodPreset Based Webhook Admission Controller. Available online: https://cloud.redhat.com/blog/a-podpreset-based-webhook-admission-controller (accessed on 28 November 2022).
- Apache Mesos. Available online: https://mesos.apache.org/ (accessed on 19 December 2022).
- Truyen, E.; Van Landuyt, D.; Preuveneers, D.; Lagaisse, B.; Joosen, W. A comprehensive feature comparison study of open-source container orchestration frameworks. Appl. Sci. 2019, 9, 931. [Google Scholar] [CrossRef]
- Linux Programmer’s Manual—Namespaces. Available online: http://man7.org/linux/man-pages/man7/namespaces.7.html (accessed on 19 December 2022).
- Linux Programmer’s Manual—Cgroups. Available online: https://man7.org/linux/man-pages/man7/cgroups.7.html (accessed on 19 December 2022).
- Bernstein, D. Containers and cloud: From lxc to docker to kubernetes. IEEE Cloud Comput. 2014, 1, 81–84. [Google Scholar] [CrossRef]
- Verma, A.; Pedrosa, L.; Korupolu, M.; Oppenheimer, D.; Tune, E.; Wilkes, J. Large-scale cluster management at google with borg. In Proceedings of the Tenth European Conference on Computer Systems, Bordeaux, France, 21–24 April 2015; pp. 1–17. [Google Scholar]
- Declarative Management of Kubernetes Objects Using Configuration Files. Available online: https://kubernetes.io/docs/tasks/manage-kubernetes-objects/declarative-config/ (accessed on 19 December 2022).
- Kubernetes Components. Available online: https://kubernetes.io/docs/concepts/overview/components/ (accessed on 19 December 2022).
- etcd: A Distributed, Reliable Key-Value Store for the Most Critical Data of a Distributed System. Available online: https://etcd.io/ (accessed on 19 December 2022).
- Kubernetes Federation Evolution. Available online: https://kubernetes.io/blog/2018/12/12/kubernetes-federation-evolution/ (accessed on 19 December 2022).
- Open Cluster Management. Available online: https://open-cluster-management.io/ (accessed on 19 December 2022).
- Open Cluster Management: Architecture. Available online: https://open-cluster-management.io/concepts/architecture/ (accessed on 19 December 2022).
- Kubernetes Cluster Federation. Available online: https://github.com/kubernetes-sigs/kubefed (accessed on 19 December 2022).
- Kubefed: User Guide. Available online: https://github.com/kubernetes-sigs/kubefed/blob/master/docs/userguide.md (accessed on 19 December 2022).
- Larsson, L.; Gustafsson, H.; Klein, C.; Elmroth, E. Decentralized kubernetes federation control plane. In Proceedings of the IEEE/ACM 13th International Conference on Utility and Cloud Computing (UCC 2020), Leicester, UK, 7–10 December 2020; pp. 354–359. [Google Scholar]
- Kratzke, N.; Peinl, R. Clouns—A cloud-native application reference model for enterprise architects. In Proceedings of the IEEE 20th International Enterprise Distributed Object Computing Workshop (EDOCW), Vienna, Austria, 5–9 September 2016; pp. 1–10. [Google Scholar]
- Herbst, N.R.; Kounev, S.; Reussner, R. Elasticity in cloud computing: What it is, and what it is not. In Proceedings of the 10th International Conference on Autonomic Computing (ICAC 13), San Jose, CA, USA, 26–28 June 2013; pp. 23–27. [Google Scholar]
- Abdo, J.B.; Demerjian, J.; Chaouchi, H.; Barbar, K.; Pujolle, G. Broker-based cross-cloud federation manager. In Proceedings of the 8th International Conference for Internet Technology and Secured Transactions (ICITST-2013), London, UK, 9–12 December 2013; pp. 244–251. [Google Scholar]
- Kratzke, N. Smuggling multi-cloud support into cloud-native applications using elastic container platforms. In Proceedings of the 7th International Conference on Cloud Computing and Services Science (CLOSER 2017), Porto, Portugal, 24–26 April 2017; pp. 57–70. [Google Scholar]
- Cilium: Quick Installation. Available online: https://docs.cilium.io/en/stable/gettingstarted/k8s-install-default/ (accessed on 9 December 2022).
- Operator Pattern. Available online: https://kubernetes.io/docs/concepts/extend-kubernetes/operator/ (accessed on 19 December 2022).
- Policy Collection. Available online: https://github.com/stolostron/policy-collection/blob/main/stable/ (accessed on 28 November 2022).
- Amazon Elastic Kubernetes Service. Available online: https://aws.amazon.com/eks/ (accessed on 1 December 2022).
- Azure Kubernetes Service. Available online: https://azure.microsoft.com/en-us/services/kubernetes-service/ (accessed on 1 December 2022).
- Google Kubernetes Engine. Available online: https://cloud.google.com/kubernetes-engine (accessed on 1 December 2022).
- Truyen, E.; Kratzke, N.; Van Landuyt, D.; Lagaisse, B.; Joosen, W. Managing feature compatibility in Kubernetes: Vendor comparison and analysis. IEEE Access 2020, 8, 228420–228439. [Google Scholar] [CrossRef]
- Kube-Apiserver. Available online: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/ (accessed on 1 December 2022).
- Customize Node Configuration for Azure Kubernetes Service (AKS) Node Pools. Available online: https://docs.microsoft.com/en-us/azure/aks/custom-node-configuration/ (accessed on 19 December 2022).
- Customizing Node System Configuration. Available online: https://cloud.google.com/kubernetes-engine/docs/how-to/node-system-config (accessed on 19 December 2022).
- Customizing Kubelet Configuration. Available online: https://eksctl.io/usage/customizing-the-kubelet/ (accessed on 9 December 2022).
- cloud-init Documentation. Available online: https://cloudinit.readthedocs.io/en/latest/ (accessed on 19 December 2022).
- Creating and Configuring Instances: Configuring an Instance. Available online: https://cloud.google.com/container-optimized-os/docs/how-to/create-configure-instance#configuring_an_instance/ (accessed on 19 December 2022).
- Amazon, Launch Template Support: Amazon EC2 User Data. Available online: https://docs.aws.amazon.com/eks/latest/userguide/launch-templates#amazon_ec2_user_data (accessed on 19 December 2022).
- cloud-init Support for Virtual Machines in Azure. Available online: https://docs.microsoft.com/en-us/azure/virtual-machines/linux/using-cloud-init/ (accessed on 19 December 2022).
- Dynamic Admission Control. Available online: https://kubernetes.io/docs/reference/access-authn-authz/extensible-admission-controllers/ (accessed on 19 December 2022).
- Automatically Bootstrapping GKE Nodes with Daemonsets. Available online: https://cloud.google.com/solutions/automatically-bootstrapping-gke-nodes-with-daemonsets (accessed on 19 December 2022).
- Initialize Your AKS Nodes with Daemonsets. Available online: https://medium.com/@patnaikshekhar/initialize-your-aks-nodes-with-daemonsets-679fa81fd20e (accessed on 19 December 2022).
- Configure Liveness, Readiness and Startup Probes. Available online: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/ (accessed on 19 December 2022).
- VPC-Native Clusters. Available online: https://cloud.google.com/kubernetes-engine/docs/concepts/alias-ips (accessed on 19 December 2022).
- Use Kubenet Networking with Your Own IP Address Ranges in Azure Kubernetes Service (AKS). Available online: https://docs.microsoft.com/en-us/azure/aks/configure-kubenet/ (accessed on 19 December 2022).
- Amazon EKS Networking. Available online: https://docs.aws.amazon.com/eks/latest/userguide/eks-networking.html (accessed on 19 December 2022).
- The Kubebuilder Book. Available online: https://book.kubebuilder.io/ (accessed on 19 December 2022).
- Apache Cassandra. Available online: https://cassandra.apache.org/_/index.html (accessed on 19 December 2022).
- Truyen, E.; Jacobs, A.; Verreydt, S.; Beni, E.H.; Lagaisse, B.; Joosen, W. Feasibility of container orchestration for adaptive performance isolation in multi-tenant SaaS applications. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 162–169. [Google Scholar]
- Delnat, W.; Truyen, E.; Rafique, A.; Van Landuyt, D.; Joosen, W. K8-scalar: A workbench to compare autoscalers for container-orchestrated database clusters. In Proceedings of the 13th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Gothenburg, Sweden, 28–29 May 2018; pp. 33–39. [Google Scholar]
- Kubeadm. Available online: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/ (accessed on 19 December 2022).
- GKE: Creating a Network Policy. Available online: https://cloud.google.com/kubernetes-engine/docs/how-to/network-policy (accessed on 19 December 2022).
- Secure Traffic between Pods Using Network Policies in Azure Kubernetes Service (AKS). Available online: https://docs.microsoft.com/en-us/azure/aks/use-network-policies (accessed on 19 December 2022).
- Walraven, S.; Van Landuyt, D.; Truyen, E.; Handekyn, K.; Joosen, W. Efficient customization of multi-tenant Software-as-a-Service applications with service lines. J. Syst. Softw. 2014, 91, 48–62. [Google Scholar] [CrossRef]















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Truyen, E.; Xie, H.; Joosen, W. Vendor-Agnostic Reconfiguration of Kubernetes Clusters in Cloud Federations. Future Internet 2023, 15, 63. https://doi.org/10.3390/fi15020063
Truyen E, Xie H, Joosen W. Vendor-Agnostic Reconfiguration of Kubernetes Clusters in Cloud Federations. Future Internet. 2023; 15(2):63. https://doi.org/10.3390/fi15020063
Chicago/Turabian StyleTruyen, Eddy, Hongjie Xie, and Wouter Joosen. 2023. "Vendor-Agnostic Reconfiguration of Kubernetes Clusters in Cloud Federations" Future Internet 15, no. 2: 63. https://doi.org/10.3390/fi15020063