
Adversarial Machine Learning Attacks against Intrusion Detection Systems: A Survey on Strategies and Defense

Abstract
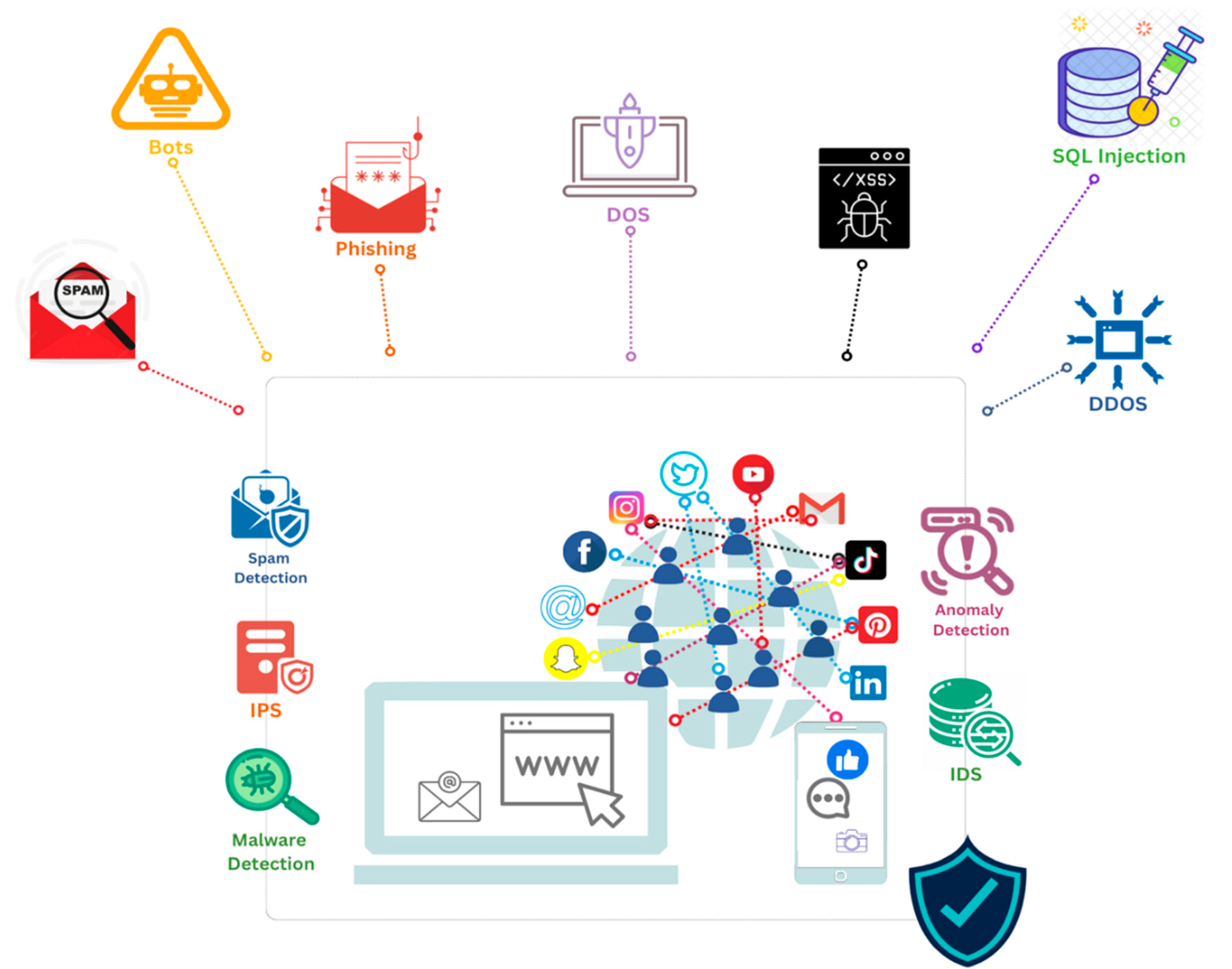
:1. Introduction
- We analyze related surveys in the field of AML.
- We present a general overview of the use of ML on an IDS in order to enhance its performance.
- We clarify all types of adversarial attacks against ML and DL models and the differences between them, in addition to the challenges that face the launch of adversarial attacks.
- We display the adversarial attacks launched against ML/DL-based IDS models in particular.
- We present the different types of defense strategies to address adversarial attacks.
- We investigate the gaps in the related literature and suggest some future research directions.
2. Related Surveys
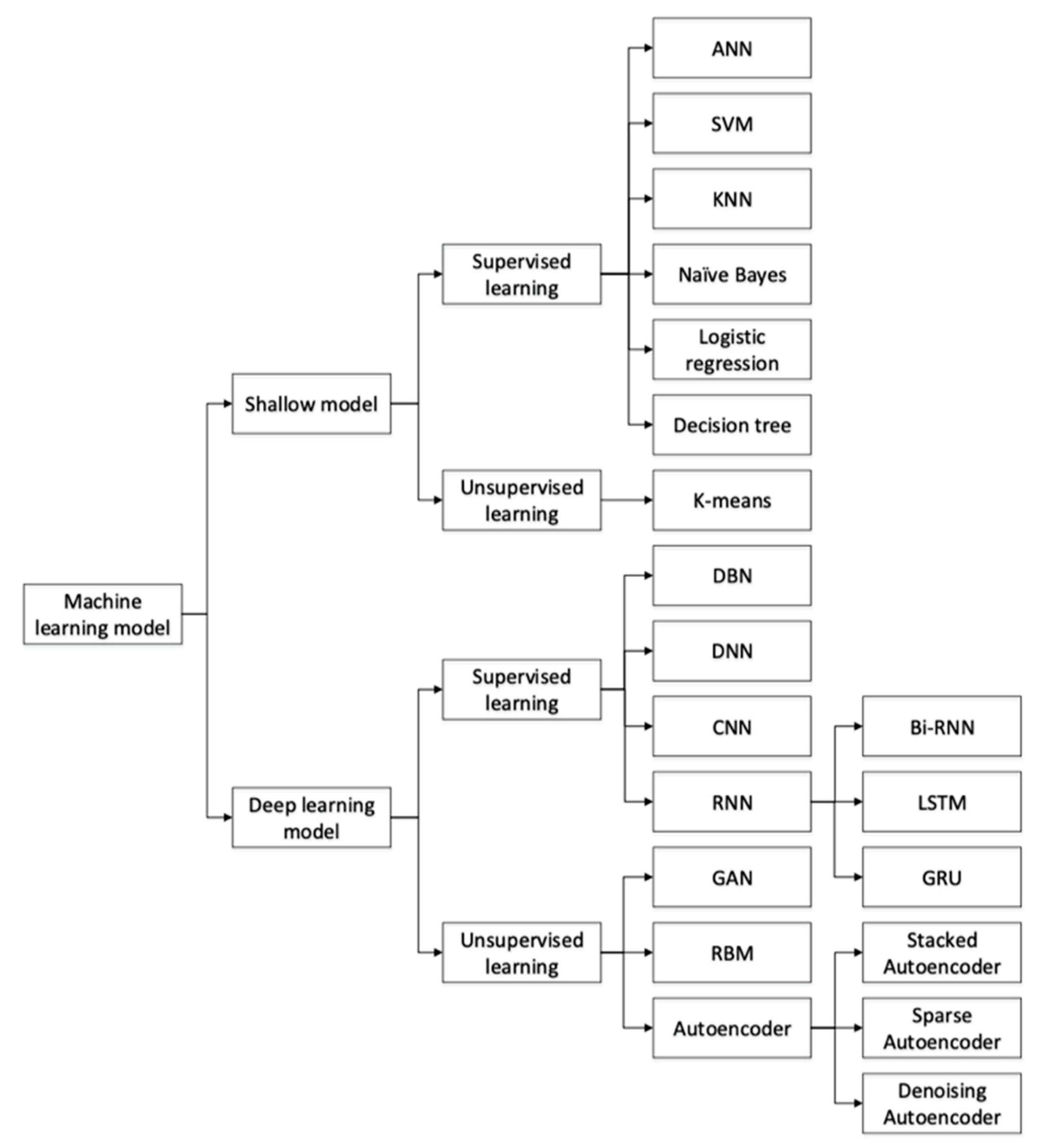
3. Intrusion Detection System Based on ML
3.1. Supervised Machine Learning
3.2. Unsupervised Learning
3.3. Artificial Neural Network (ANN)
3.4. Deep Neural Network (DNN)
3.5. Support Vector Machine (SVM)
3.6. Generative Adversarial Network (GAN)
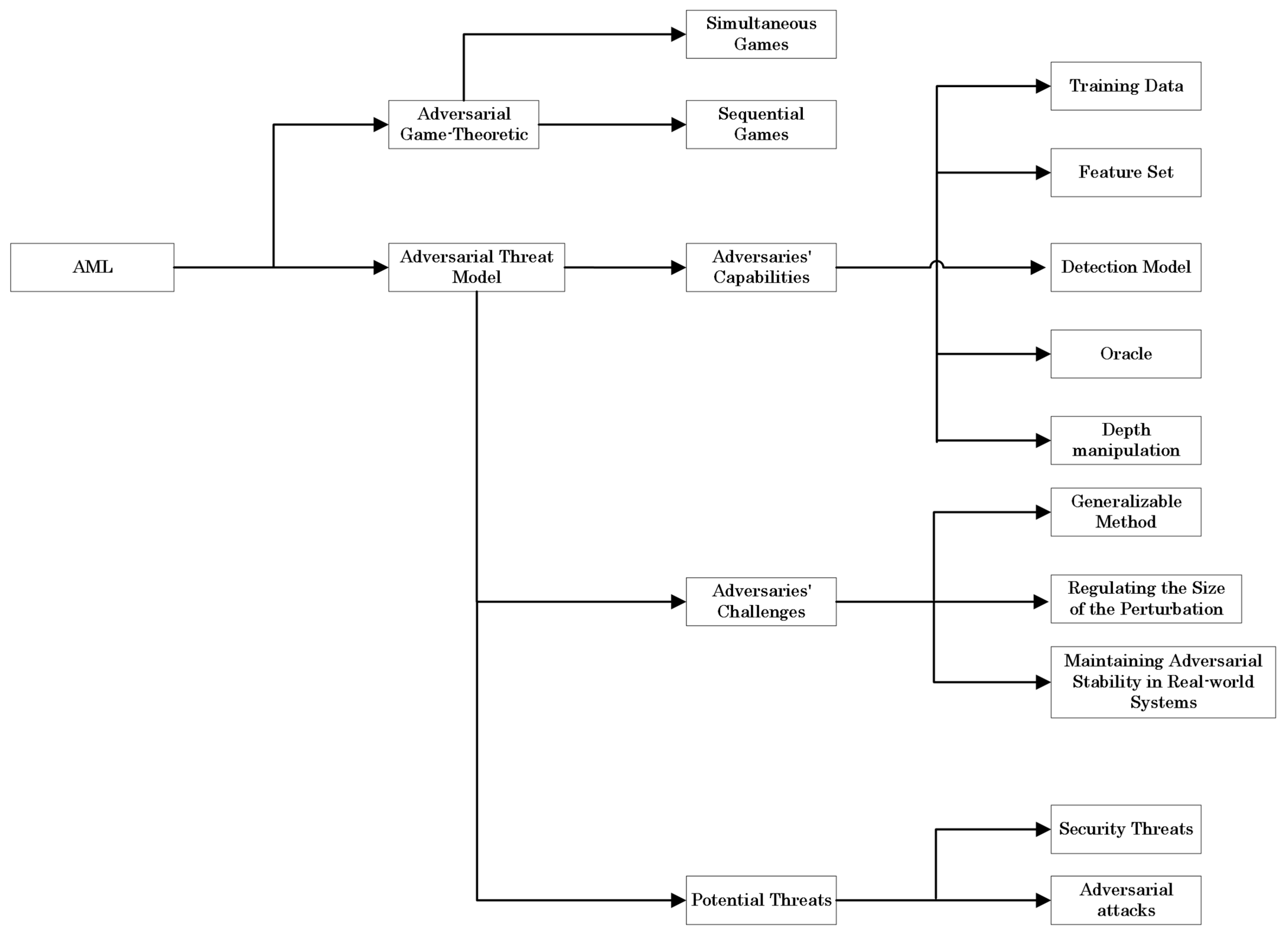
4. Adversarial Machine Learning
4.1. Adversarial Game-Theoretic
4.2. Adversarial Threat Model
4.2.1. Adversary Capabilities
4.2.2. Adversaries Challenges
- a.
- Generalizable Method
- b.
- Regulating the Size of the Perturbation
- c.
- Maintaining Adversarial Stability in Real-World Systems
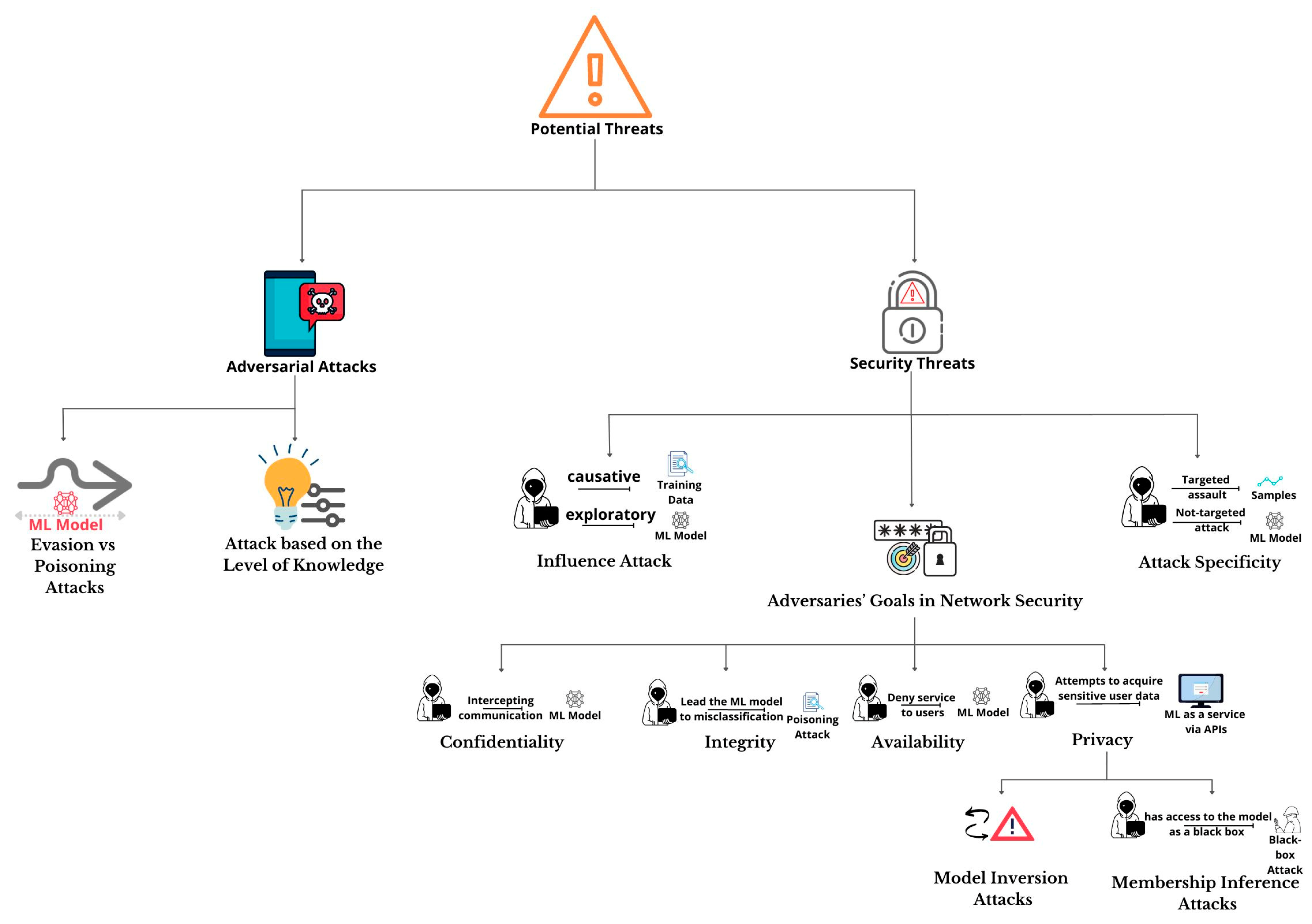
4.2.3. Potential Threats
- a.
- Security Threats
- b.
- Influence Attack
- c.
- Adversaries’ Goals in Network Security
- i.
- Confidentiality
- ii.
- Integrity
- iii.
- Availability
- iv.
- Privacy
- d.
- Attack Specificity
- e.
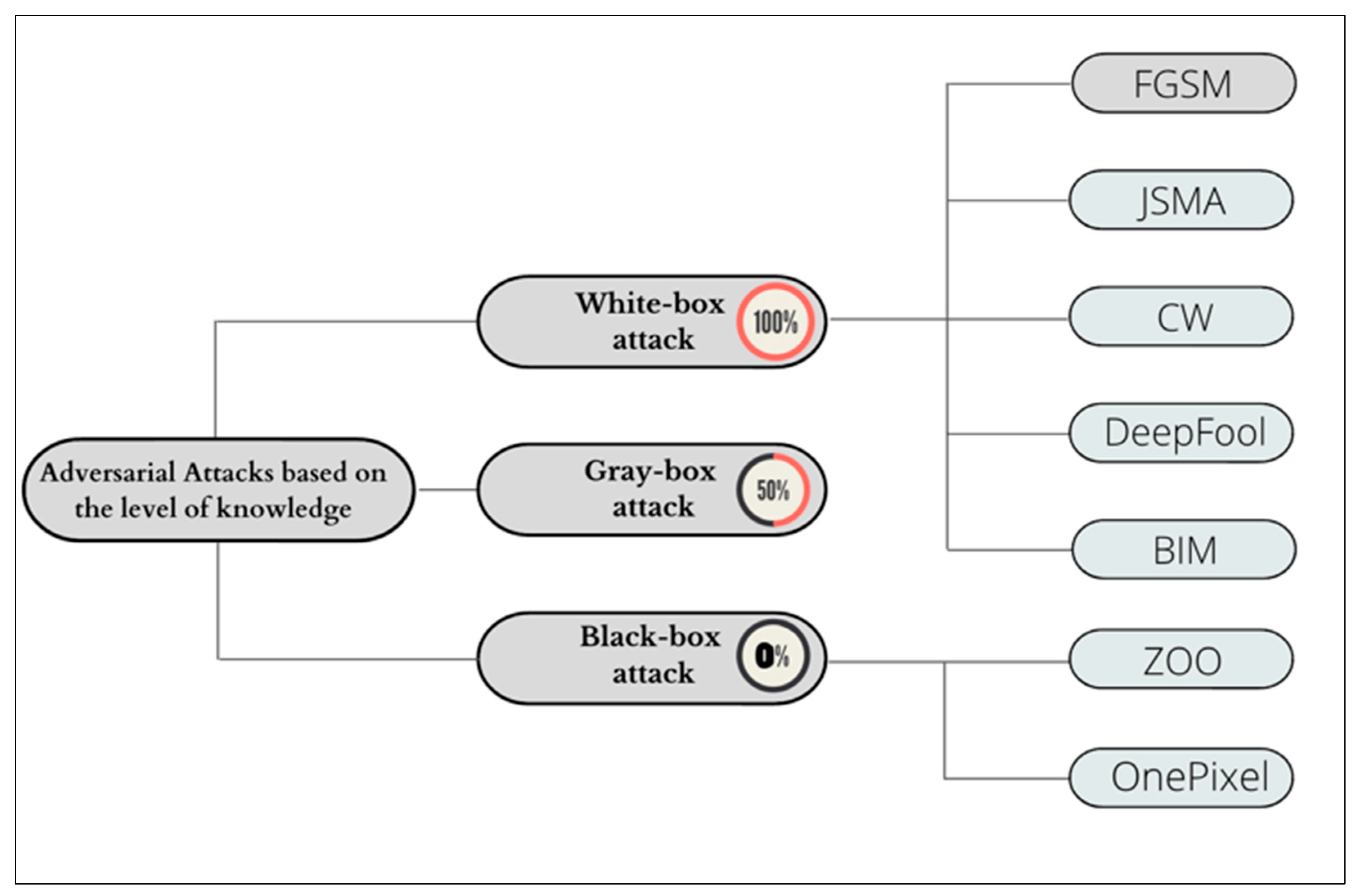
- Adversarial Attacks
- i.
- White-Box Attack
- Fast Gradient Sign Method (FGSM)
- Jacobian-Based Saliency Map Attack (JSMA)
- CW Attack
- DeepFool
- Basic Iterative Method (BIM)
- ii.
- Black-Box Attack
- Zeroth-Order Optimization (ZOO)
- OnePixel
- iii.
- Gray-Box Attack
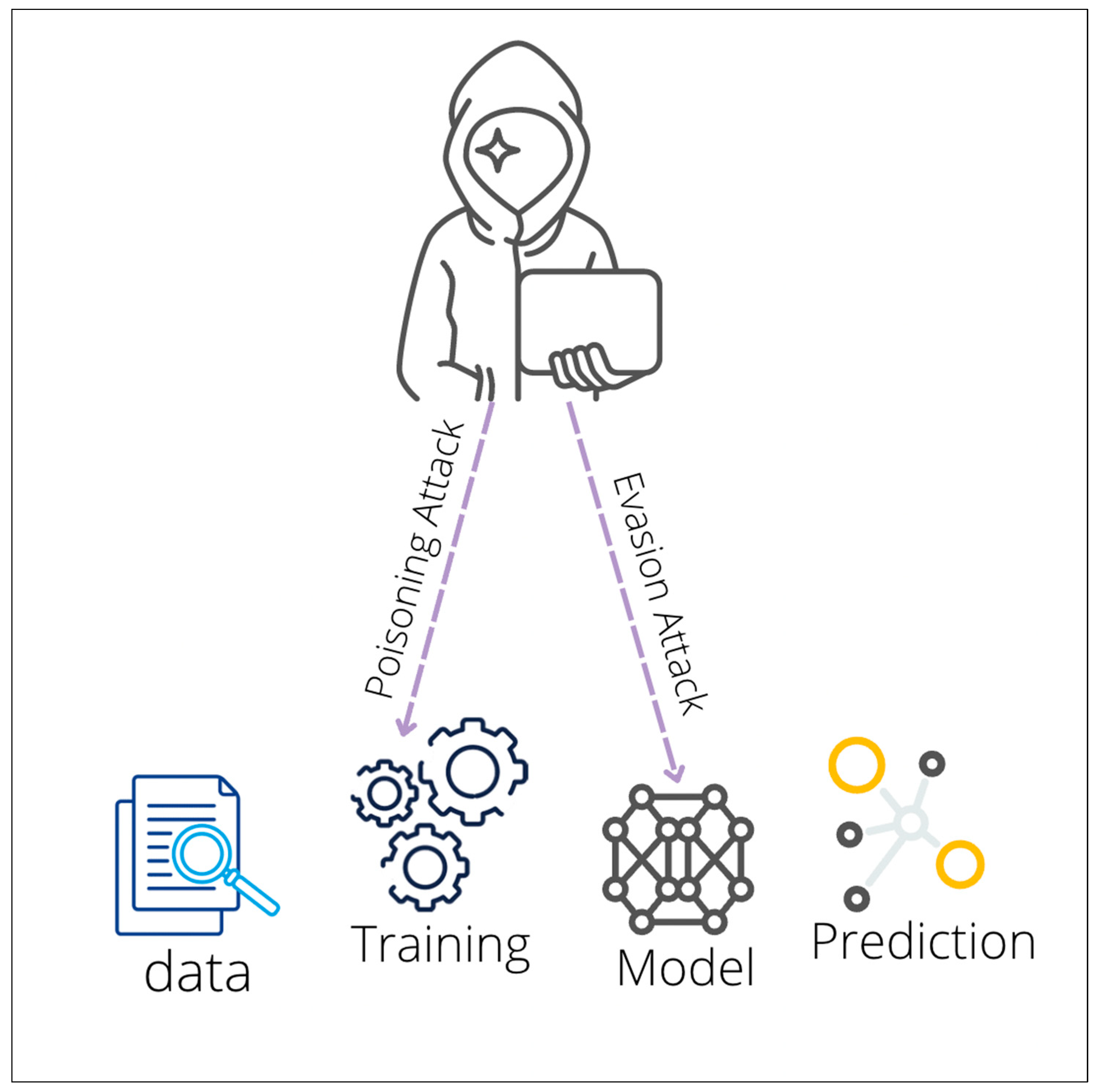
- f.
- Evasion vs. Poisoning Attacks
- Evasion Attack
- Poisoning Attack
5. Machine Learning Adversaries against IDS
5.1. White-Box Attacks against IDS
5.1.1. A White-Box Attack against MLP
5.1.2. A White-Box Attack against DNN
5.1.3. A White-Box Attack against IDS in Industrial Controlling Systems (ICS)
5.1.4. Monte Carlo (MC)
5.2. Black-Box Attacks against IDS
5.2.1. FGSM, PGD, and CW Attacks against GAN
5.2.2. Deceiving GAN by Using FSGM
5.2.3. A Black-Box Attack Using GAN
5.2.4. IDSGAN
5.2.5. DIGFuPAS
5.2.6. Anti-Intrusion Detection AutoEncoder (AIDAE)
5.2.7. DDoS Attack by Using GAN
6. Benchmark Datasets
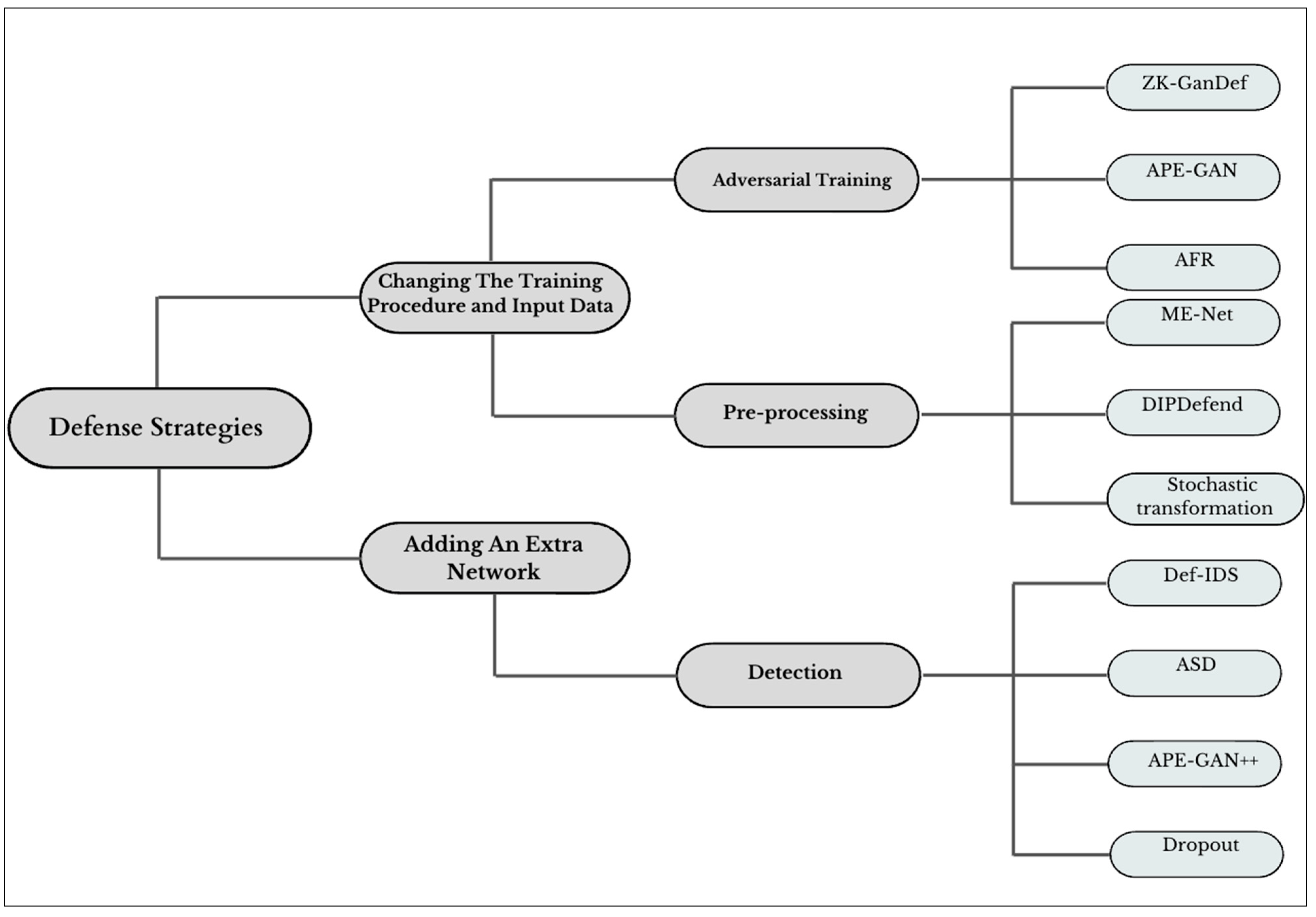
7. Defense Strategies
7.1. Changing the Training Procedure and Input Data
7.1.1. Adversarial Training
- 1.
- ZK-GanDef
- 2.
- AFR
- 3.
- APE-GAN
7.1.2. Preprocessing
- 4.
- ME-Net
- 5.
- DIPDefend
- 6.
- Stochastic Transformation-based Defenses
7.2. Adding an Extra Network
Detection
- 7.
- Def-IDS
- 8.
- ASD
- 9.
- APE-GAN++
- 10.
- Dropout
- 11.
- Adversary Detection Network
- 12.
- GAN-Based Defense
8. Challenges and Future Directions
8.1. Key Research Challenges and Gaps
- The adversarial examples have transferability properties, indicating that adversarial examples created for one model will most likely work for other models [102,103]. This can be utilized as the basis for various black-box attacks in which a substitute model generates adversarial instances that are then presented to the target model [9].
- Defenses are sometimes tailored to a specific assault strategy and are less suitable as a generic defense [34]. For example, the authors in [79] suggested a method to detect adversarial attacks even though it is not compared to other techniques. Because it is considered a relatively new topic, it is not easy to evaluate this research. However, in our opinion, it is considered helpful research since it covers a new topic with solutions based on experiments and presents the results.
- Each domain has unique features; therefore, it is more challenging to spot disturbances when modifications are performed on the network traffic data [30].
- A critical component of defensive tactics is their ability to withstand all attacks. Nevertheless, most defense techniques are ineffective against black-box attacks [95] or need more experimentation, as in [44]. In addition, some of the strategies are ineffective, such as adversarial training, which has flaws and may be evaded [77].
- The AML term is widespread in image classification, but it is relatively new and shallow in the cybersecurity area, especially in IDSs. Thus, some defense methods ensured their effectiveness in protecting IDS specifically. On the other hand, the rest had successfully applied defense strategies in the computer vision field, such as APE-GAN++.
- In detection strategies, in the worst situation, it is possible to attack the detector that the ML and DL models employ to identify their adversaries [49].
- Some of the defense ideas are repeated, such as using GAN in various research forms, demonstrating its efficacy to the reader. Unfortunately, using GAN is not always the best choice; for example, in [48], the authors mentioned that it might lead the model to misclassification.
- To address white-box attacks, the defender can impede the transferability of adversarial examples. However, a comprehensive defense method could not be used for all ML/DL applications [35].
- Most studies demonstrated how to improve a model’s accuracy rather than its resilience and robustness [44].
- The datasets must reflect current traits because network traffic behavior patterns change over time. Unfortunately, the majority of publicly accessible IDS datasets lack modern traffic characteristics. According to the authors in [44], there is a shortcoming in the IDS’s datasets; thus, the IDS lacks a dataset that can include all types of network attacks. However, using the GAN-IDS will offer a high volume of attacks in training since it can generate more attack types. Then, we can use the discriminators to distinguish new attacks [27]. Furthermore, in [106], the authors also presented research on handling this shortage.
8.2. Future Directions
- There is no way to evaluate something without experimentation, but we may draw some conclusions from the experiment’s owners. These defense strategies, for example, had been used against white-box attacks, but what about black-box attacks? Thus, there is a need for techniques to counter the black-box attack in the future. In contrast, in [103], the authors presented an approach to address transferable adversarial attacks. We believe it to be a promising defense approach with excellent efficiency against black-box attacks, although it has been examined using a white-box attack.
- In the future, there will be a demand for a solution that handles all types of adversaries that affect the robustness of an IDS.
- Various models may necessitate several defenses [9]. Thus, they need to measure their effectiveness in protecting ML and DL based on IDS.
- Some researchers have stated that their technique may be used in other ML/DL models or is available online for experimentation. Therefore, we suggest increasing the effectiveness of the dropout strategy to make it more reliable and suitable for additional domains such as IDS.
- In this paper, we focus on IDSs; generally, we think that protecting ML/DL-based IDSs is easier to preserve since it is difficult to deceive IDSs because the features contain discrete and non-continuous values [107]. Therefore, we believe that enhancing the GAN defense strategies such as APE-GAN++ will make them more reliable for IDSs, which will be a valuable technique for handling adversaries in the future. Moreover, Table 5 demonstrates a comparison between these strategies.
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ford, V.; Siraj, A. Applications of machine learning in cyber security. In Proceedings of the 27th International Conference on Computer Applications in Industry and Engineering, New Orleans, LA, USA, 13–15 October 2014; Volume 118. [Google Scholar]
- Denning, D.E. An intrusion-detection model. IEEE Trans. Softw. Eng. 1987, 2, 222–232. [Google Scholar] [CrossRef]
- Liao, H.-J.; Lin, C.-H.R.; Lin, Y.-C.; Tung, K.-Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Aldweesh, A.; Derhab, A.; Emam, A.Z. Deep learning approaches for anomaly-based intrusion detection systems: A survey, taxonomy, and open issues. Knowledge-Based Syst. 2020, 189, 105124. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef] [Green Version]
- Pervez, M.S.; Farid, D.M. Feature selection and intrusion classification in NSL-KDD cup 99 dataset employing SVMs. In Proceedings of the the 8th International Conference on Software, Knowledge, Information Management and Applications (SKIMA 2014), Dhaka, Bangladesh, 18–20 December 2014; pp. 1–6. [Google Scholar]
- Gu, X.; Easwaran, A. Towards safe machine learning for cps: Infer uncertainty from training data. In Proceedings of the Proceedings of the 10th ACM/IEEE International Conference on Cyber-Physical Systems, Montreal, QC, Canada, 16–18 April 2019; pp. 249–258.
- Ghafouri, A.; Vorobeychik, Y.; Koutsoukos, X. Adversarial regression for detecting attacks in cyber-physical systems. arXiv 2018, arXiv:1804.11022. [Google Scholar]
- McCarthy, A.; Ghadafi, E.; Andriotis, P.; Legg, P. Functionality-Preserving Adversarial Machine Learning for Robust Classification in Cybersecurity and Intrusion Detection Domains: A Survey. J. Cybersecurity Priv. 2022, 2, 154–190. [Google Scholar] [CrossRef]
- Yang, K.; Liu, J.; Zhang, C.; Fang, Y. Adversarial examples against the deep learning based network intrusion detection systems. In Proceedings of the MILCOM 2018–2018 IEEE Military Communications Conference (MILCOM), Los Angeles, CA, USA, 29–31 October 2018; pp. 559–564. [Google Scholar]
- Alhajjar, E.; Maxwell, P.; Bastian, N. Adversarial machine learning in Network Intrusion Detection Systems. Expert Syst. Appl. 2021, 186, 115782. [Google Scholar] [CrossRef]
- Dalvi, N.; Domingos, P.; Mausam; Sanghai, S.; Verma, D. Adversarial classification. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Miningk, New York, NY, USA, 22 August 2004; pp. 99–108. [Google Scholar] [CrossRef] [Green Version]
- Matsumoto, T.; Matsumoto, H.; Yamada, K.; Hoshino, S. Impact of artificial” gummy” fingers on fingerprint systems. In Optical Security and Counterfeit Deterrence Techniques IV; International Society for Optics and Photonics: San Jose, CA, USA, 2002; Volume 4677, pp. 275–289. [Google Scholar]
- Ayub, M.A.; Johnson, W.A.; Talbert, D.A.; Siraj, A. Model Evasion Attack on Intrusion Detection Systems using Adversarial Machine Learning. In Proceedings of the 2020 54th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 18–20 March 2020. [Google Scholar] [CrossRef]
- Suo, H.; Wan, J.; Zou, C.; Liu, J. Security in the internet of things: A review. In Proceedings of the 2012 International Conference on Computer Science and Electronics Engineering, Hangzhou, China, 23–25 March 2012; Volume 3, pp. 648–651. [Google Scholar]
- Wang, X.; Li, J.; Kuang, X.; Tan, Y.; Li, J. The security of machine learning in an adversarial setting: A survey. J. Parallel Distrib. Comput. 2019, 130, 12–23. [Google Scholar] [CrossRef]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. Adversarial Attacks and Defences: A Survey. arXiv 2018, arXiv:1810.00069. Available online: http://arxiv.org/abs/1810.00069 (accessed on 18 October 2022). [CrossRef]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Zhou, Y.; Kantarcioglu, M.; Xi, B. A survey of game theoretic approach for adversarial machine learning. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1259. [Google Scholar] [CrossRef]
- Dasgupta, B.; Collins, J. A survey of game theory methods for adversarial machine learning in cybersecurity tasks. Amnesty Int. J. 2019, 40, 31–43. [Google Scholar] [CrossRef] [Green Version]
- Duddu, V. A survey of adversarial machine learning in cyber warfare. Def. Sci. J. 2018, 68, 356. [Google Scholar] [CrossRef] [Green Version]
- Ibitoye, O.; Abou-Khamis, R.; Matrawy, A.; Shafiq, M.O. The Threat of Adversarial Attacks on Machine Learning in Network Security—A Survey. arXiv 2019, arXiv:1911.02621. Available online: http://arxiv.org/abs/1911.02621 (accessed on 22 December 2022).
- Qayyum, A.; Qadir, J.; Bilal, M.; Al-Fuqaha, A. Secure and Robust Machine Learning for Healthcare: A Survey. IEEE Rev. Biomed. Eng. 2021, 14, 156–180. [Google Scholar] [CrossRef]
- Homoliak, I.; Teknos, M.; Ochoa, M.; Breitenbacher, D.; Hosseini, S.; Hanacek, P. Improving network intrusion detection classifiers by non-payload-based exploit-independent obfuscations: An adversarial approach. arXiv 2018, arXiv:1805.02684. [Google Scholar] [CrossRef]
- Khamis, R.A.; Shafiq, M.O.; Matrawy, A. Investigating Resistance of Deep Learning-based IDS against Adversaries using min-max Optimization. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020. [Google Scholar] [CrossRef]
- Yuan, X. Phd forum: Deep learning-based real-time malware detection with multi-stage analysis. In Proceedings of the 2017 IEEE International Conference on Smart Computing (SMARTCOMP), Hong Kong, China, 29–31 May 2017; pp. 1–2. [Google Scholar]
- Shahriar, M.H.; Haque, N.I.; Rahman, M.A.; Alonso, M. G-IDS: Generative Adversarial Networks Assisted Intrusion Detection System. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 376–385. [Google Scholar] [CrossRef]
- Huang, L.; Joseph, A.D.; Nelson, B.; Rubinstein, B.I.P.; Tygar, J.D. Adversarial machine learning. In Proceedings of the 4th ACM Workshop on SECURITY and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; pp. 43–58. [Google Scholar]
- Shetty, S.; Ray, I.; Ceilk, N.; Mesham, M.; Bastian, N.; Zhu, Q. Simulation for Cyber Risk Management–Where are we, and Where do we Want to Go? In Proceedings of the 2019 Winter Simulation Conference (WSC), National Harbor, MD, USA, 8–11 December 2019; pp. 726–737. [Google Scholar]
- Apruzzese, G.; Andreolini, M.; Ferretti, L.; Marchetti, M.; Colajanni, M. Modeling Realistic Adversarial Attacks against Network Intrusion Detection Systems. Digit. Threat. Res. Pract. 2021, 3, 1–19. [Google Scholar] [CrossRef]
- Sarker, I.H.; Abushark, Y.B.; Alsolami, F.; Khan, A.I. Intrudtree: A machine learning based cyber security intrusion detection model. Symmetry 2020, 12, 754. [Google Scholar] [CrossRef]
- Khalil, K.; Qian, Z.; Yu, P.; Krishnamurthy, S.; Swami, A. Optimal monitor placement for detection of persistent threats. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washinton, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Liu, G.; Khalil, I.; Khreishah, A. ZK-GanDef: A GAN Based Zero Knowledge Adversarial Training Defense for Neural Networks. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019; pp. 64–75. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Li, C. Adversarial examples: Opportunities and challenges. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2578–2593. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial Examples: Attacks and Defenses for Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing machine learning models via prediction apis. In Proceedings of the 25th {USENIX} Security Symposium ({USENIX} Security 16), Berkeley, CA, USA, 10–12 August 2016; pp. 601–618. [Google Scholar]
- Xi, B. Adversarial machine learning for cybersecurity and computer vision: Current developments and challenges. Wiley Interdiscip. Rev. Comput. Stat. 2020, 12. [Google Scholar] [CrossRef]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 12–18 October 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 Acm Sigsac Conference on Computer and Communications Security, New York, NY, USA, 24–28 October 2016; pp. 1528–1540. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Zizzo, G.; Hankin, C.; Maffeis, S.; Jones, K. INVITED: Adversarial machine learning beyond the image domain. In Proceedings of the 56th Annual Design Automation Conference 2019, New York, NY, USA, 2 June 2019. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Pujari, M.; Cherukuri, B.P.; Javaid, A.Y.; Sun, W. An Approach to Improve the Robustness of Machine Learning based Intrusion Detection System Models Against the Carlini-Wagner Attack. In Proceedings of the 2022 IEEE International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 27–29 July 2022; pp. 62–67. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: London, UK, 2018; pp. 99–112. ISBN 1351251384. [Google Scholar]
- Wang, Z. Deep Learning-Based Intrusion Detection with Adversaries. IEEE Access 2018, 6, 38367–38384. [Google Scholar] [CrossRef]
- Martins, N.; Cruz, J.M.; Cruz, T.; Henriques Abreu, P. Adversarial Machine Learning Applied to Intrusion and Malware Scenarios: A Systematic Review. IEEE Access 2020, 8, 35403–35419. [Google Scholar] [CrossRef]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On detecting adversarial perturbations. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017; pp. 1–12. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, New York, NY, USA, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Guo, S.; Zhao, J.; Li, X.; Duan, J.; Mu, D.; Jing, X. A Black-Box Attack Method against Machine-Learning-Based Anomaly Network Flow Detection Models. Secur. Commun. Netw. 2021, 2021, 5578335. [Google Scholar] [CrossRef]
- Chen, P.-Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.-J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, New York, NY, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef] [Green Version]
- Laskov, P. Practical evasion of a learning-based classifier: A case study. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; pp. 197–211. [Google Scholar]
- Corona, I.; Giacinto, G.; Roli, F. Adversarial attacks against intrusion detection systems: Taxonomy, solutions and open issues. Inf. Sci. 2013, 239, 201–225. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy—ICISSP, Madeira, Portugal, 22–24 January 2018; pp. 108–116. [Google Scholar] [CrossRef]
- Viegas, E.K.; Santin, A.O.; Oliveira, L.S. Toward a reliable anomaly-based intrusion detection in real-world environments. Comput. Netw. 2017, 127, 200–216. [Google Scholar] [CrossRef]
- Zhang, X.; Zheng, X.; Wu, D.D. Attacking Attacking DNN-based DNN-based Intrusion Intrusion Detection Detection Models Models Attacking Intrusion Detection Models Models Attacking Intrusion Detection Attacking DNN-based Intrusion Detection Models. IFAC Pap. 2020, 53, 415–419. [Google Scholar] [CrossRef]
- Anthi, E.; Williams, L.; Rhode, M.; Burnap, P.; Wedgbury, A. Adversarial attacks on machine learning cybersecurity defences in Industrial Control Systems. J. Inf. Secur. Appl. 2021, 58, 102717. [Google Scholar] [CrossRef]
- Zhao, S.; Li, J.; Wang, J.; Zhang, Z.; Zhu, L.; Zhang, Y. AttackGAN: Adversarial Attack against Black-box IDS using Generative Adversarial Networks. Procedia Comput. Sci. 2021, 187, 128–133. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009, Ottawa, ON, Canada, 8–10 July 2009. [Google Scholar] [CrossRef] [Green Version]
- Piplai, A.; Sree, S.; Chukkapalli, L.; Joshi, A. NAttack ! Adversarial Attacks to Bypass a GAN Based Classifier Trained to Detect Network Intrusion. Available online: https://ieeexplore.ieee.org/abstract/document/9123023 (accessed on 21 December 2022).
- Usama, M.; Asim, M.; Latif, S.; Qadir, J. Ala-Al-Fuqaha Generative adversarial networks for launching and thwarting adversarial attacks on network intrusion detection systems. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 78–83. [Google Scholar] [CrossRef]
- Lin, Z.; Shi, Y.; Xue, Z. IDSGAN: Generative Adversarial Networks for Attack Generation Against Intrusion Detection. In Lecture Notes in Computer Science. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics); Springer: Cham, Germany, 2022; 13282 LNAI; pp. 79–91. [Google Scholar] [CrossRef]
- Duy, P.T.; Tien, L.K.; Khoa, N.H.; Hien, D.T.T.; Nguyen, A.G.T.; Pham, V.H. DIGFuPAS: Deceive IDS with GAN and function-preserving on adversarial samples in SDN-enabled networks. Comput. Secur. 2021, 109, 102367. [Google Scholar] [CrossRef]
- Chen, J.; Wu, D.; Zhao, Y.; Sharma, N.; Blumenstein, M.; Yu, S. Fooling intrusion detection systems using adversarially autoencoder. Digit. Commun. Netw. 2021, 7, 453–460. [Google Scholar] [CrossRef]
- Chauhan, R.; Shah Heydari, S. Polymorphic Adversarial DDoS attack on IDS using GAN. In Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC), Montreal, QC, Canada, 20–22 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Janusz, A.; Kałuza, D.; Chądzyńska-Krasowska, A.; Konarski, B.; Holland, J.; Ślęzak, D. IEEE BigData 2019 cup: Suspicious network event recognition. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5881–5887. [Google Scholar]
- Gonzalez-Cuautle, D.; Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, L.K.; Portillo-Portillo, J.; Olivares-Mercado, J.; Perez-Meana, H.M.; Sandoval-Orozco, A.L. Synthetic minority oversampling technique for optimizing classification tasks in botnet and intrusion-detection-system datasets. Appl. Sci. 2020, 10, 794. [Google Scholar] [CrossRef] [Green Version]
- Jatti, S.A.V.; Kishor Sontif, V.J.K. Intrusion detection systems. Int. J. Recent Technol. Eng. 2019, 8, 3976–3983. [Google Scholar] [CrossRef]
- Yilmaz, I.; Masum, R.; Siraj, A. Addressing Imbalanced Data Problem with Generative Adversarial Network for Intrusion Detection. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020; pp. 25–30. [Google Scholar] [CrossRef]
- Huang, S.; Lei, K. IGAN-IDS: An imbalanced generative adversarial network towards intrusion detection system in ad-hoc networks. Ad Hoc Netw. 2020, 105, 102177. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015. [Google Scholar] [CrossRef]
- Panigrahi, R.; Borah, S. A detailed analysis of CICIDS2017 dataset for designing Intrusion Detection Systems. Int. J. Eng. Technol. 2018, 7, 479–482. [Google Scholar]
- Li, J. hua Cyber security meets artificial intelligence: A survey. Front. Inf. Technol. Electron. Eng. 2018, 19, 1462–1474. [Google Scholar] [CrossRef]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Song, D.; Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Tramer, F.; Prakash, A.; Kohno, T. Physical adversarial examples for object detectors. In Proceedings of the 12th USENIX Workshop on Offensive Technologies (WOOT 18), Baltimore, MD, USA, 13–14 August 2018. [Google Scholar]
- Pawlicki, M.; Choraś, M.; Kozik, R. Defending network intrusion detection systems against adversarial evasion attacks. Futur. Gener. Comput. Syst. 2020, 110, 148–154. [Google Scholar] [CrossRef]
- Han, D.; Wang, Z.; Zhong, Y.; Chen, W.; Yang, J.; Lu, S.; Shi, X.; Yin, X. Evaluating and Improving Adversarial Robustness of Machine Learning-Based Network Intrusion Detectors. IEEE J. Sel. Areas Commun. 2021, 39, 2632–2647. [Google Scholar] [CrossRef]
- Jin, G.; Shen, S.; Zhang, D.; Dai, F.; Zhang, Y. APE-GAN: Adversarial Perturbation Elimination with GAN. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3842–3846. [Google Scholar] [CrossRef] [Green Version]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial examples for semantic segmentation and object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–19 October 2017; pp. 1369–1378. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Guo, C.; Rana, M.; Cisse, M.; Van Der Maaten, L. Countering adversarial images using input transformations (2018). arXiv 2018, arXiv:1711.00117. [Google Scholar]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-gan: Protecting classifiers against adversarial attacks using generative models. arXiv 2018, arXiv:1805.06605. [Google Scholar]
- Yang, Y.; Zhang, G.; Katabi, D.; Xu, Z. ME-Net: Towards effective adversarial robustness with matrix estimation. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 12152–12173. [Google Scholar]
- Dai, T.; Feng, Y.; Chen, B.; Lu, J.; Xia, S.T. Deep image prior based defense against adversarial examples. Pattern Recognit. 2022, 122, 108249. [Google Scholar] [CrossRef]
- Enhancing Transfomation Based Defenses against Adversarial Attacks With A Distribution Classifier. Available online: https://openreview.net/pdf?id=BkgWahEFvr (accessed on 21 December 2022).
- Prakash, A.; Moran, N.; Garber, S.; DiLillo, A.; Storer, J. Deflecting adversarial attacks with pixel deflection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8571–8580. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating adversarial effects through randomization. arXiv 2017, arXiv:1711.01991. [Google Scholar]
- Akhtar, N.; Liu, J.; Mian, A. Defense against universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3389–3398. [Google Scholar]
- Lee, K.; Lee, K.; Lee, H.; Shin, J. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. Pixeldefend: Leveraging generative models to understand and defend against adversarial examples. arXiv 2018, arXiv:1710.10766. [Google Scholar]
- Wang, J.; Pan, J.; Alqerm, I.; Liu, Y. Def-IDS: An Ensemble Defense Mechanism against Adversarial Attacks for Deep Learning-based Network Intrusion Detection. In Proceedings of the 2021 International Conference on Computer Communications and Networks (ICCCN), Athens, Greece, 19–22 July 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Peng, Y.; Fu, G.; Luo, Y.; Hu, J.; Li, B.; Yan, Q. Detecting Adversarial Examples for Network Intrusion Detection System with GAN. In Proceedings of the 2020 IEEE 11th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 16–18 October 2020; pp. 6–10. [Google Scholar]
- Yang, R.; Chen, X.Q.; Cao, T.J. APE-GAN++: An Improved APE-GAN to Eliminate Adversarial Perturbations. IAENG Int. J. Comput. Sci. 2021, 48, 1–18. [Google Scholar]
- Jayashankar, T.; Le Roux, J.; Moulin, P. Detecting audio attacks on ASR systems with dropout uncertainty. In Proceedings of the 21st Annual Conference of the International Speech Communication Association, Shanghai, China, 25–29 October 2020; pp. 4671–4675. [Google Scholar] [CrossRef]
- Feinman, R.; Curtin, R.R.; Shintre, S.; Gardner, A.B. Detecting adversarial samples from artifacts. arXiv 2017, arXiv:1703.00410. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Grosse, K.; Manoharan, P.; Papernot, N.; Backes, M.; McDaniel, P. On the (statistical) detection of adversarial examples. arXiv 2017, arXiv:1702.06280. [Google Scholar]
- Carlini, N.; Katz, G.; Barrett, C.; Dill, D.L. Provably minimally-distorted adversarial examples. arXiv 2017, arXiv:1709.10207. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Chhabra, A.; Mohapatra, P. Moving Target Defense against Adversarial Machine Learning. In Proceedings of the MTD 2021—Proceedings of the 8th ACM Workshop on Moving Target Defense, co-located with CCS 2021, New York, NY, USA, 15 November 2021; pp. 29–30. [Google Scholar] [CrossRef]
- Hashemi, M.J.; Cusack, G.; Keller, E. Towards evaluation of nidss in adversarial setting. In Proceedings of the 3rd ACM CoNEXT Workshop on Big DAta, Machine Learning and Artificial Intelligence for Data Communication Networks, New York, NY, USA, 9 December 2019; pp. 14–21. [Google Scholar]
- Bhagoji, A.N.; Cullina, D.; Sitawarin, C.; Mittal, P. Enhancing robustness of machine learning systems via data transformations. In Proceedings of the 2018 52nd Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 21–23 March 2018; pp. 1–5. [Google Scholar]
- Thakkar, A.; Lohiya, R. A review of the advancement in intrusion detection datasets. Procedia Comput. Sci. 2020, 167, 636–645. [Google Scholar] [CrossRef]
- Labaca-Castro, R.; Biggio, B.; Dreo Rodosek, G. Poster: Attacking malware classifiers by crafting gradient-attacks that preserve functionality. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 11–15 November 2019; pp. 2565–2567. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Highlights | Domain | General Contribution | Applications of ML in Network Security | Adversarial Attack’s Methods | Solutions For Adversarial Attacks | Open Research Issues |
|---|---|---|---|---|---|---|---|---|
| [21] | 2018 | It examined ML system threat models and outlined alternative attack and defense strategies. | ML/DL methods in various domains. |
| ✖ | ✓ | ✓ | ✖ |
| [18] | 2018 | It thoroughly overviewed adversarial assaults on deep learning in computer vision. | ML/DL methods in computer vision. |
| ✖ | ✓ | ✓ | ✓ |
| [17] | 2018 | It explored some of the state-of-the-art adversarial attacks and suggested countermeasures. | ML/DL methods in various domains. |
| ✖ | ✓ | ✓ | ✓ |
| [23] | 2018 | It provided a thorough introduction to various topics related to adversarial deep learning. | ML/DL methods in various domains. |
| ✖ | ✓ | ✓ | ✓ |
| [16] | 2019 | It gave a thorough summary of the research on the security characteristics of ML algorithms in hostile environments. | ML/DL methods in various domains. |
| ✖ | ✓ | ✓ | ✓ |
| [19] | 2019 | It provided a thorough overview of all game theory in AML. | Adversarial game-theoretic model in various domains. |
| ✖ | ✓ | ✖ | ✓ |
| [20] | 2019 | It presented the current and recent methods used to strengthen an ML system against adversarial attacks utilizing the computational framework of game theory. | ML/DL methods in cybersecurity tasks. |
| ✖ | ✓ | ✖ | ✓ |
| [22] | 2019 | It introduced the taxonomy of ML in network security applications. In addition, it presented several adversarial attacks on ML in network security and provided two categorization algorithms for these assaults. | ML/DL methods in network security applications. |
| ✓ | ✓ | ✓ | ✓ |
| [5] | 2019 | It discussed building IDS with the ML and DL models, potentially improving IDS performance. | ML/DL methods in IDS. |
| ✓ | ✖ | ✖ | ✓ |
| [23] | 2021 | It briefly outlined the obstacles involved in using ML/DL approaches in various healthcare application domains from a security and privacy perspective. | ML/DL methods in healthcare. |
| ✖ | ✓ | ✓ | ✓ |
| [9] | 2022 | It presented the AML with an adversary’s perspective in the cybersecurity domain and NIDS. | ML/DL methods in cybersecurity tasks. |
| ✓ | ✓ | ✓ | ✓ |
| Ref. | year | Adversarial Generating Method | Objectives | (ML/DL) Technique | Dataset | Evaluation Metrics | Limitations | Results |
|---|---|---|---|---|---|---|---|---|
| [67] | 2019 | AIDAE | It evaluated the performance of the IDS facing adversarial attacks and enhanced its robustness. |
|
|
| The authors did not mention a defense method against this attack. | The AIDAE model crafted adversarial attacks that evade IDSs. |
| [64] | 2019 | GAN | It made the performance of the IDS more robust in detecting adversarial attacks. |
|
|
| This GAN training worked only for IDSs and did not evolve for other networks. | The GAN training increased the performance of IDSs. |
| [63] | 2020 | FSGM | Training the GAN classifier and making it robust against adversarial attacks. |
|
|
| The authors did not mention how to address and defend against these attacks. | The GAN classifier had been deceived by adversarial attacks and misclassified the “attack” samples as “non-attack.” |
| [14] | 2020 | Jacobian-based saliency map attack (JSMA). | It proved that the attackers could exploit the vulnerabilities to escape from intrusion detection systems. |
|
| There were no experiments on defense methods implemented by the researchers. | The accuracy of the IDS classifier dropped to 22.52% and 29.87% for CICIDS [57] and TRAbID [58] datasets. | |
| [68] | 2020 | GAN | To highlight the IDS vulnerabilities. |
|
|
| It is required to be used in a variety of attacks in order to fool any IDS. | Transmitting attack data without being detected by the IDS was quite successful. |
| [59] | 2020 |
| Evaluating the robustness of DNN against adversarial attacks. |
|
|
| It lacked extract comprehensive information. | The attacks could notably affect the DNN model. |
| [11] | 2021 |
| Detecting the vulnerability in NIDS which assists organizations in protecting their networks. |
|
|
| In the NIDS scenarios, it was unclear why some were more resilient than others. | The MLP model had the best accuracy under adversarial attacks with an 83.27% classification rate. |
| [61] | 2021 | -GAN. | Proving that using GAN to attack IDS can achieve a higher rate of compromission and misclassification. |
|
|
| It lacked defense mechanisms. | The experiments resulted in a higher rate of GAN attacks: about 87.18%. |
| [66] | 2021 | -DIGFuPAS | Evaluating the resilience of the IDS against altered attack types. |
|
|
| The IDS robustness issues were not addressed. | DIGFuPAS might easily fool the IDS without revealing the classification models’ information, according to this experimental research. |
| [60] | 2021 | (JSMA) | Presenting the practical module of adversarial attacks against IDS methods. |
|
|
| The authors applied these adversarial attacks on two IDSs, but it might not affect other ML. | The random forest and J48 performance decreased. |
| [65] | 2022 | GAN | Providing malicious feature records of the attack traffic that can trick and evade defensive system detection. |
|
|
| _ | The assessment of IDSGAN demonstrated its efficiency in producing adversarial harmful traffic records of various assaults, bringing down the detection rates of various IDS models to almost 0%. |
| Dataset | Features | Classes | Number of Records |
|---|---|---|---|
| NSL-KDD [62] |
|
|
|
| UNSW-NB15 [71] |
|
|
|
| CICIDS2017 [57] |
|
|
|
| Year | Method | Description | Result | |
|---|---|---|---|---|
| [49] | 2017 | Adversary Detection Network | The authors suggested training a binary detector network to distinguish between samples from the original dataset and adversarial instances. | DeepFool adversary-specific detectors performed admirably compared to all other adversarial attacks. |
| [81] | 2017 | APE-GAN | This method was based on training the model to remove the adversarial perturbation before feeding the processed sample to classification networks. Then, they generated adversarial samples and used the discriminator to discriminate those samples. | The researchers might infer that the APE-GAN has a wide range of applications because it works despite no understanding of the model on which it is based. |
| [98] | 2017 | Dropout | Dropout is a random process that perturbs the model’s architecture [98]. Furthermore, this study focused on the ability to apply CW attacks in this field as well as the ability to detect them. | This defense detected adversarial examples effectively [97]. |
| [86] | 2019 | ME-Net | This method takes incomplete or damaged images and eliminates noise from these images. Furthermore, there are two stages for the image before being processed; first, arbitrary pixels are discarded from the picture, and then the picture is rebuilt using ME. | The ME-Net made deep neural networks more robust against adversarial attacks than other methods. |
| [87] | 2020 | Stochastic transformation-based defenses | In the first place, the researchers investigated the impact of random image alterations on clean pictures to understand better how accuracy deteriorates. They trained a unique classifier to identify distinguishing characteristics in the distributions of softmax outputs of converted clean pictures and predict the class label. | Untargeted assaults on CNN have been studied, and it would be interesting to compare their distribution classifier approach with targeted attacks. |
| [80] | 2021 | AFR | This method implemented an attack on NIDS and then suggested adversarial feature reduction (AFR), which decreased the attack’s efficacy by reducing adversarial feature development. | The implemented attack achieved more than a 97% rate in half cases, and the proposed defense technique (AFR) successfully minimized such attacks. |
| [87] | 2021 | DIPDefend | This method examined the internal prior of the image and then divided them into two steps: robust feature learning and non-robust feature learning. It reconstructed the image by beginning with a robust feature and then a non-robust feature to make them stronger against adversarial attacks. | It can be applied without pretraining, making it useful in various situations. |
| Ref. | Year | Defense Approach | Attack Type | Dataset | ML/DL Model | Can Address New Types of Attacks? | Defense Category | Result |
|---|---|---|---|---|---|---|---|---|
| [32] | 2019 | ZK-GanDef | White-box |
| NN | Yes | Changing the training procedure and input data | ZK-GanDef enhanced the accuracy by 49.17% against adversarial attacks compared to other attacks. |
| [95] | 2020 | ASD | White-box |
| DNN | Not apparent | Adding an extra network | ASD improved the accuracy by 26.46% in the PGD adversarial environment and 11.85% in the FGSM adversarial environment, but the influence of ASD on some attacks was not apparent. |
| [94] | 2021 | Def-IDS | White-box |
| DNN | Yes | Adding an extra network | The experiments showed that the Def-IDS could increase the robustness of NIDS by enhancing the accuracy of detecting adversarial attacks. |
| [96] | 2021 | APE-GAN++ | White-box |
| CNN | Yes | Adding an extra network | APE-GAN++ achieved an outstanding performance than other defenses, including the APE-GAN. |
| [44] | 2022 | GAN-based defense | White-box |
|
| Not apparent | Adding an extra network | The IDS performance improved, and its accuracy increased. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, A.; Rassam, M.A. Adversarial Machine Learning Attacks against Intrusion Detection Systems: A Survey on Strategies and Defense. Future Internet 2023, 15, 62. https://doi.org/10.3390/fi15020062
Alotaibi A, Rassam MA. Adversarial Machine Learning Attacks against Intrusion Detection Systems: A Survey on Strategies and Defense. Future Internet. 2023; 15(2):62. https://doi.org/10.3390/fi15020062
Chicago/Turabian StyleAlotaibi, Afnan, and Murad A. Rassam. 2023. "Adversarial Machine Learning Attacks against Intrusion Detection Systems: A Survey on Strategies and Defense" Future Internet 15, no. 2: 62. https://doi.org/10.3390/fi15020062