
Tree Species Classification Based on PointNet++ and Airborne Laser Survey Point Cloud Data Enhancement
Abstract
:1. Introduction
2. Overview of Study Area and Data Prediction Processing
2.1. Study Area and Experimental Instruments
2.2. Data Preprocessing
2.2.1. Noise Removal
2.2.2. Ground Point Classification
2.2.3. Single-Tree Segmentation
2.2.4. Field Investigation and Manual Adjustment
2.3. Down-Sampling of Point Clouds
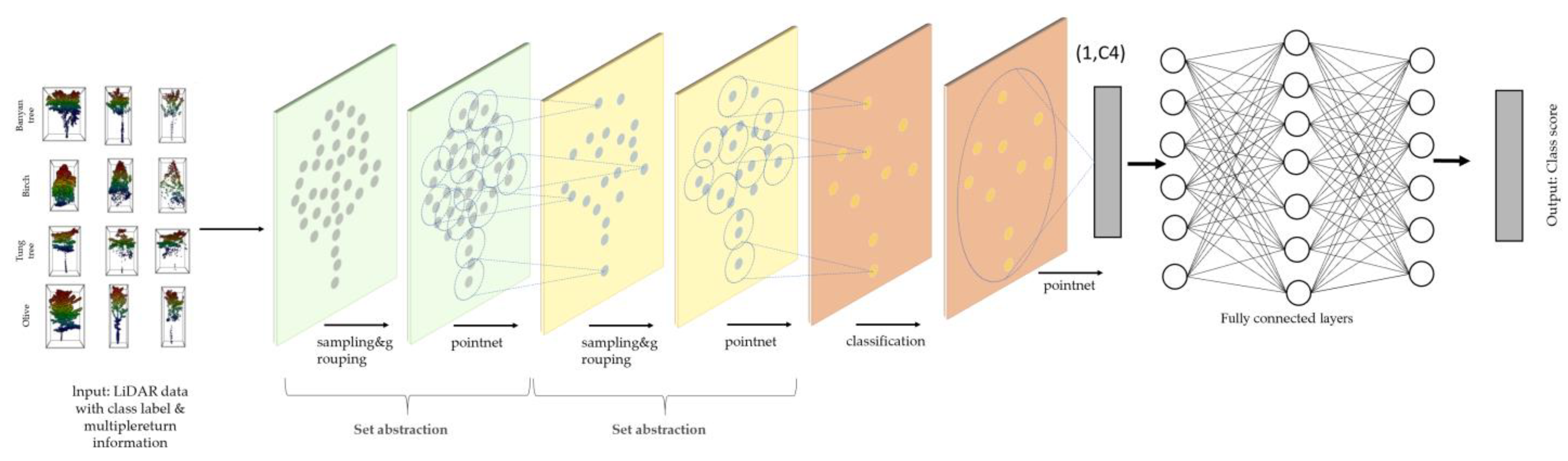
3. Model Training
4. Results
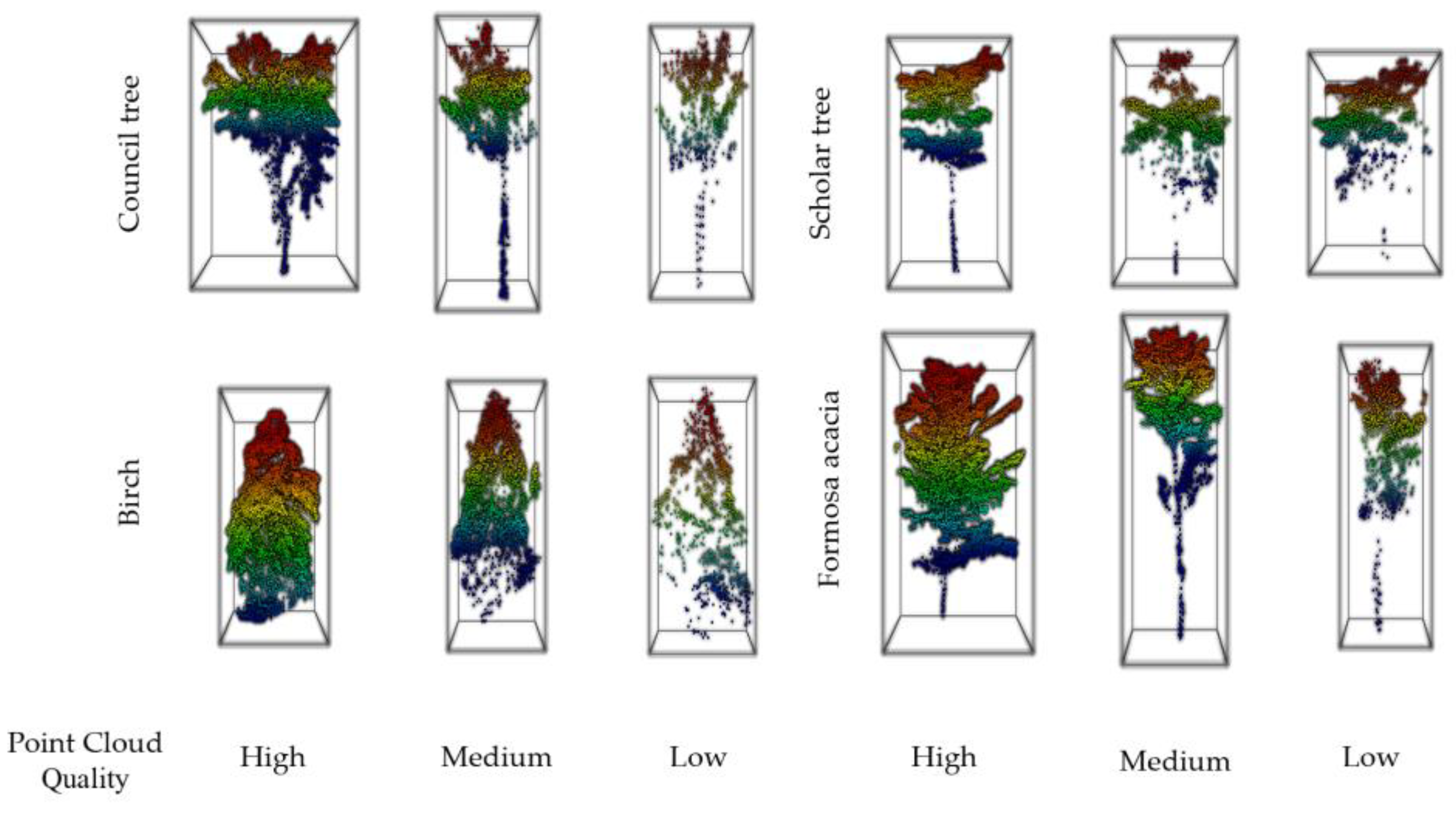
4.1. Results Acquired after Down-Sampling
4.2. Down-Sampling Results of Point Clouds after Enhancement
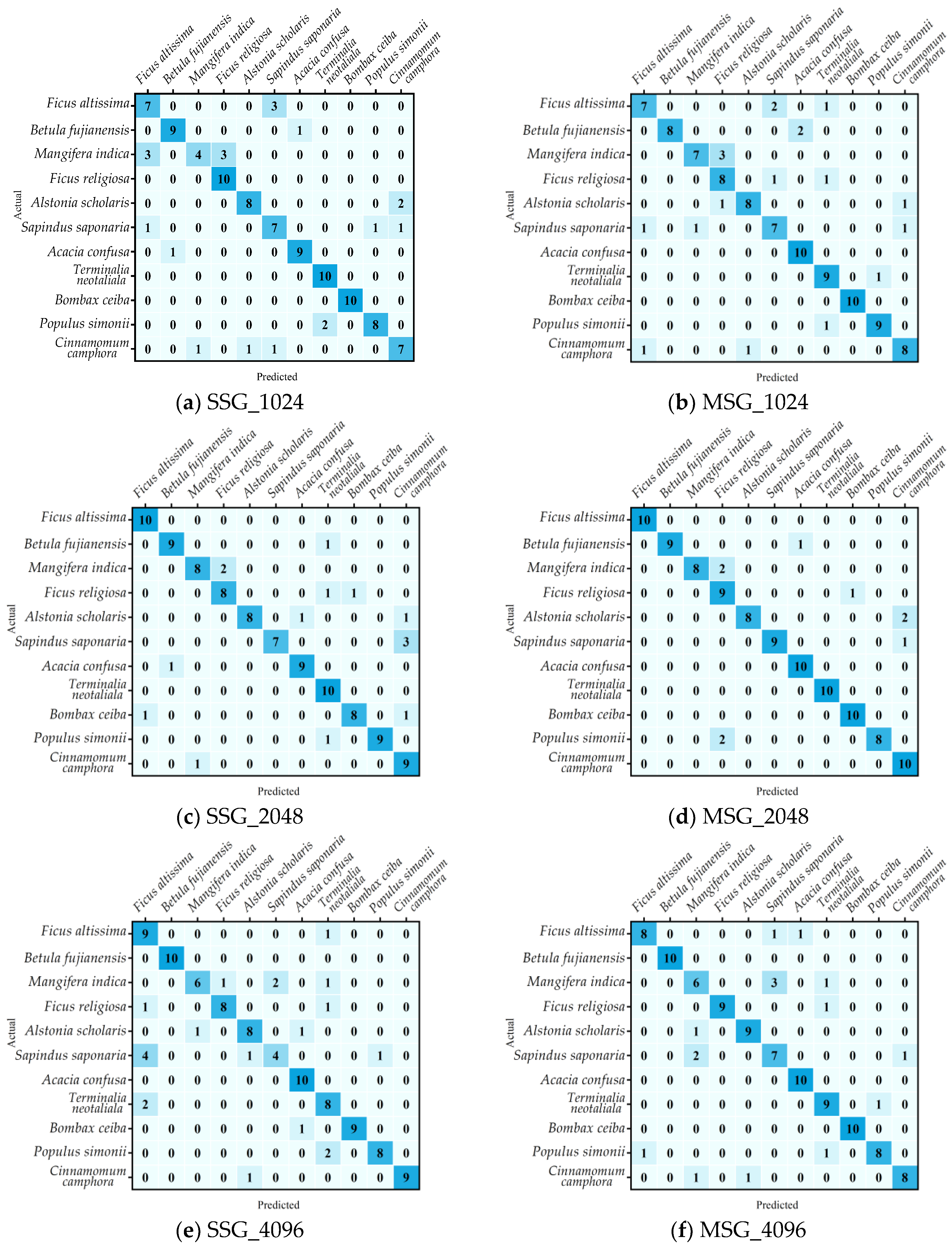
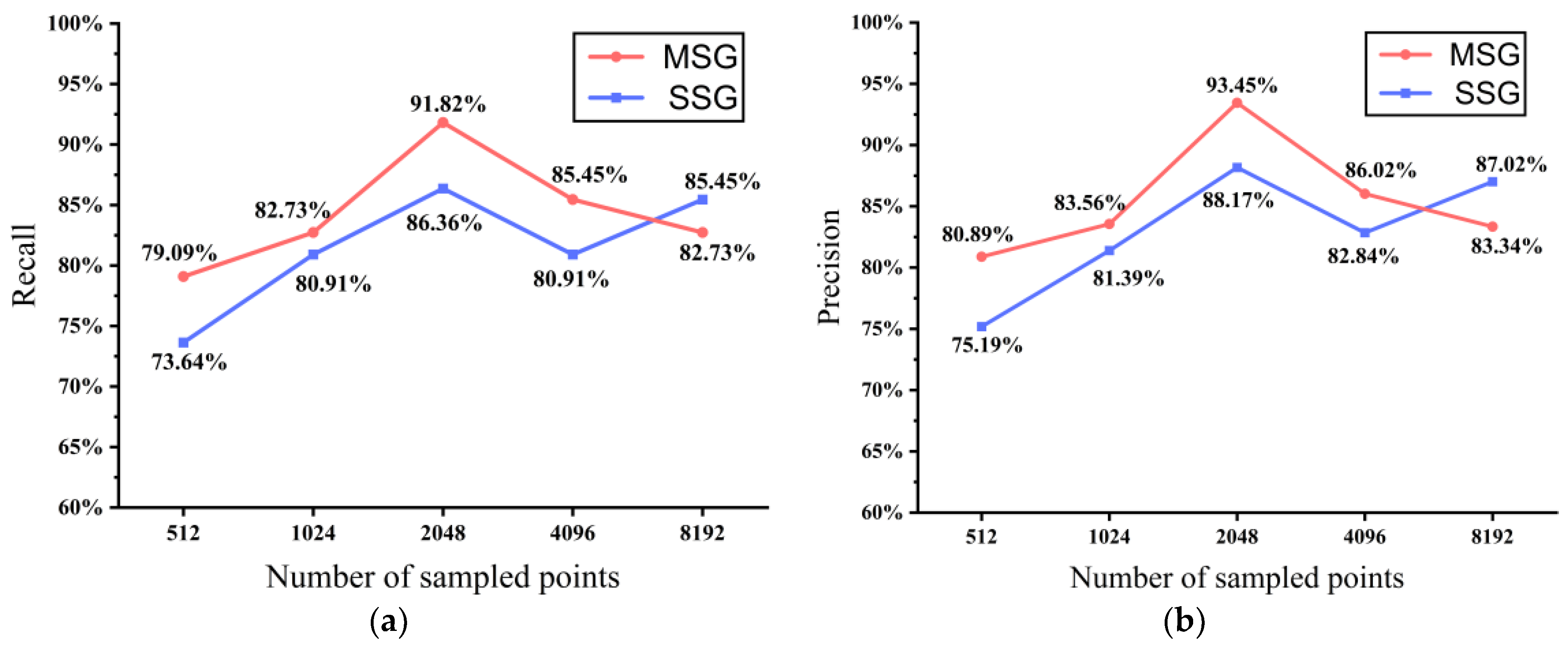
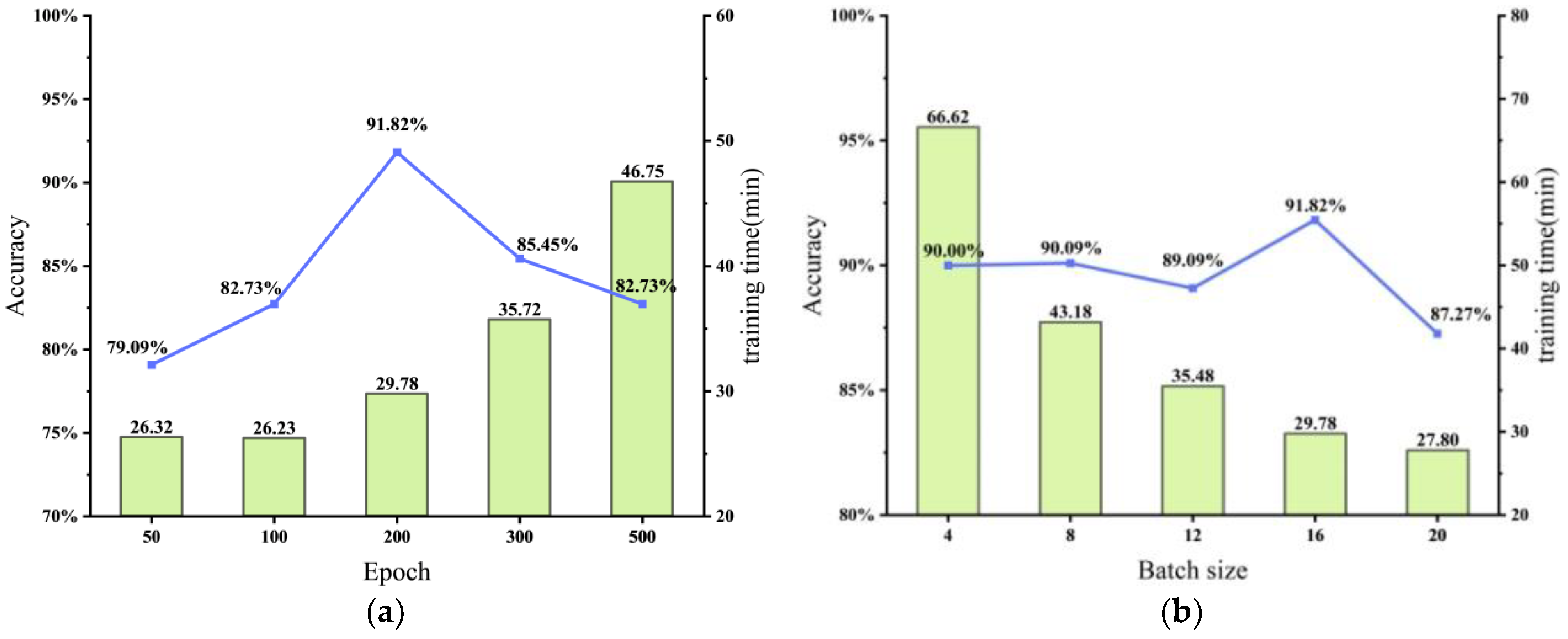
4.3. Comparison of the Results with Other Hyperparameters
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Y.; Pan, C.-L.; Liao, H.-T. Carbon neutrality policies and technologies: A scientometric analysis of social science disciplines. Front. Environ. Sci. 2021, 9, 1736. [Google Scholar] [CrossRef]
- Wu, W.; Zhu, Y.; Wang, Y. Spatio-temporal pattern, evolution and influencing factors of forest carbon sinks in Zhejiang Province, China. Forests 2023, 14, 445. [Google Scholar] [CrossRef]
- Roberge, C. Inventory Strategies for Monitoring and Evaluation of Forest Damage. Ph.D. Thesis, Swedish University of Agricultural Sciences, Uppsala, Sweden, 2017. [Google Scholar]
- Shi, Y.; Wang, S.; Zhou, S.; Kamruzzaman, M.M. Study on modeling method of forest tree image recognition based on CCD and theodolite. IEEE Access 2020, 8, 159067–159076. [Google Scholar] [CrossRef]
- Xu, H.; Qiang, S.; Han, Z.; Guo, J.; Huang, Z.; Sun, H.; He, S.; Ding, H.; Wu, H.; Wan, F.J.B. The status and causes of alien species invasion in China. Biodivers. Conserv. 2006, 15, 2893–2904. [Google Scholar] [CrossRef]
- Libby, R.; Sato, A.Y.; Alapai, L.; Brawner, W.P.; Carter, Y.Y.; Carter, K.A.; Tomich, K.; Ticktin, T. A Hawaiian tropical dry forest regenerates: Natural regeneration of endangered species under biocultural restoration. Sustainability 2022, 14, 1159. [Google Scholar] [CrossRef]
- Tewari, V.P. Forest inventory, assessment, and monitoring, and long-term forest observational studies, with special reference to India. For. Sci. Technol. 2016, 12, 24–32. [Google Scholar] [CrossRef]
- Gao, D.; Sun, Q.; Hu, B.; Zhang, S. A framework for agricultural pest and disease monitoring based on Internet-of-things and unmanned aerial vehicles. Sensors 2020, 20, 1487. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, K.; Zhang, X. An improved res-UNet model for tree species classification using airborne high-resolution images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gong, W.; Hu, X.; Gong, J. Forest type identification with random forest using Sentinel-1A, Sentinel-2A, multi-temporal Landsat-8 and DEM data. Remote Sens. 2018, 10, 946. [Google Scholar] [CrossRef] [Green Version]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First experience with Sentinel-2 data for crop and tree species classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Bolyn, C.; Michez, A.; Gaucher, P.; Lejeune, P.; Bonnet, S. Forest mapping and species composition using supervised per pixel classification of Sentinel-2 imagery. BASE 2018, 22, 172–187. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree species classification with random forest using very high spatial resolution 8-band WorldView-2 satellite data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef] [Green Version]
- Ballanti, L.; Blesius, L.; Hines, E.; Kruse, B. Tree species classification using hyperspectral imagery: A comparison of two classifiers. Remote Sens. 2016, 8, 445. [Google Scholar] [CrossRef] [Green Version]
- Krahwinkler, P.; Rossmann, J. Tree Species Classification and Input Data Evaluation. Eur. J. Remote Sens. 2013, 46, 535–549. [Google Scholar] [CrossRef] [Green Version]
- Tuominen, S.; Näsi, R.; Honkavaara, E.; Balazs, A.; Hakala, T.; Viljanen, N.; Pölönen, I.; Saari, H.; Ojanen, H. Assessment of classifiers and remote sensing features of hyperspectral imagery and stereo-photogrammetric point clouds for recognition of tree species in a forest area of high species diversity. Remote Sens. 2018, 10, 714. [Google Scholar] [CrossRef] [Green Version]
- Pellikka, P.; King, D.J.; Leblanc, S.G. Quantification and reduction of bidirectional effects in aerial cir imagery of deciduous forest using two reference land surface types. Remote Sens. Rev. 2000, 19, 259–291. [Google Scholar] [CrossRef]
- Wehr, A.; Lohr, U. Airborne laser scanning—An introduction and overview. ISPRS J. Photogramm. 1999, 54, 68–82. [Google Scholar] [CrossRef]
- Korpela, I.; Ørka, H.O.; Maltamo, M.; Tokola, T.; Hyyppä, J. Tree species classification using airborne LiDAR–effects of stand and tree parameters, downsizing of training set, intensity normalization, and sensor type. Silva Fenn. 2010, 44, 319–339. [Google Scholar] [CrossRef] [Green Version]
- Budei, B.C.; St-Onge, B.; Hopkinson, C.; Audet, F.-A. Identifying the genus or species of individual trees using a three-wavelength airborne lidar system. Remote Sens. Environ. 2018, 204, 632–647. [Google Scholar] [CrossRef]
- Hovi, A.; Korhonen, L.; Vauhkonen, J.; Korpela, I. LiDAR waveform features for tree species classification and their sensitivity to tree- and acquisition related parameters. Remote Sens. Environ. 2016, 173, 224–237. [Google Scholar] [CrossRef]
- Blomley, R.; Hovi, A.; Weinmann, M.; Hinz, S.; Korpela, I.; Jutzi, B. Tree species classification using within crown localization of waveform LiDAR attributes. ISPRS J. Photogramm. 2017, 133, 142–156. [Google Scholar] [CrossRef]
- Kukkonen, M.; Maltamo, M.; Korhonen, L.; Packalen, P. Multispectral airborne LiDAR data in the prediction of boreal tree species composition. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3462–3471. [Google Scholar] [CrossRef]
- Michałowska, M.; Rapiński, J. A review of tree species classification based on airborne LiDAR data and applied classifiers. Remote Sens. 2021, 13, 353. [Google Scholar] [CrossRef]
- Sanaa, F.; Imane, S.; Mohamed, B.; Kenza, A.E.K.; Souhail, K.; Lfalah, H.; Khadija, M. Biomass and carbon stock quantification in cork Oak Forest of Maamora using a new approach based on the combination of aerial laser scanning carried by unmanned aerial vehicle and terrestrial laser scanning data. Forests 2022, 13, 1211. [Google Scholar] [CrossRef]
- Kuma, P.; McDonald, A.J.; Morgenstern, O.; Querel, R.; Silber, I.; Flynn, C.J. Ground-based lidar processing and simulator framework for comparing models and observations (ALCF 1.0). Geosci. Model Dev. 2021, 14, 43–72. [Google Scholar] [CrossRef]
- Ruhan, A.; Du, W.; Ying, H.; Wei, B.; Shan, Y.; Dai, H. Estimation of aboveground biomass of individual trees by backpack LiDAR based on parameter-optimized quantitative structural models (AdQSM). Forests 2023, 14, 475. [Google Scholar] [CrossRef]
- Su, Y.; Guo, Q.; Jin, S.; Guan, H.; Sun, X.; Ma, Q.; Hu, T.; Wang, R.; Li, Y. The development and evaluation of a backpack LiDAR system for accurate and efficient forest inventory. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1660–1664. [Google Scholar] [CrossRef]
- Okyay, U.; Telling, J.; Glennie, C.L.; Dietrich, W.E. Airborne lidar change detection: An overview of earth sciences applications. Earth Sci. Rev. 2019, 198, 102929. [Google Scholar] [CrossRef]
- Wu, H.; Yang, H.; Huang, S.; Zeng, D.; Liu, C.; Zhang, H.; Guo, C.; Chen, L. Classification of point clouds for indoor components using few labeled samples. Remote Sens. 2020, 12, 2181. [Google Scholar] [CrossRef]
- Seidel, D.; Annighöfer, P.; Thielman, A.; Seifert, Q.E.; Thauer, J.H.; Glatthorn, J.; Ehbrecht, M.; Kneib, T.; Ammer, C. Predicting tree species from 3D laser scanning point clouds using deep learning. Front. Plant Sci. 2021, 12, 635440. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3-d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Zhou, X.; Dai, N.; Cheng, X.; Thompson, A.; Leach, R. Intelligent classification for three-dimensional metal powder particles. Powder Technol. 2022, 397, 117018. [Google Scholar] [CrossRef]
- Yang, J.; Li, Z.; Zhan, P.; Li, X.; Wang, K.; Han, J.; Yang, P. Proximal femur parameter measurement via improved PointNet++. Int. J. Med. Robot. Comput. Assist. Surg. 2022, 19, e2494. [Google Scholar] [CrossRef] [PubMed]
- Jing, Z.; Guan, H.; Zhao, P.; Li, D.; Yu, Y.; Zang, Y.; Wang, H.; Li, J. Multispectral LiDAR point cloud classification using SE-PointNet++. Remote Sens. 2021, 13, 2516. [Google Scholar] [CrossRef]
- Liu, B.; Chen, S.; Huang, H.; Tian, X. Tree species classification of backpack laser scanning data using the PointNet++ point cloud deep learning method. Remote Sens. 2022, 14, 3809. [Google Scholar] [CrossRef]
- LiDAR360—Point Cloud Processing Software. Available online: https://greenvalleyintl.com/LiDAR360/ (accessed on 5 February 2023).
- Chen, C.; Guo, J.; Wu, H.; Li, Y.; Shi, B. Performance comparison of filtering algorithms for high-density airborne LiDAR point clouds over complex LandScapes. Remote Sens. 2021, 13, 2663. [Google Scholar] [CrossRef]
- Nie, S.; Wang, C.; Dong, P.; Xi, X.; Luo, S.; Qin, H. A revised progressive TIN densification for filtering airborne LiDAR data. Measurement 2017, 104, 70–77. [Google Scholar] [CrossRef]
- Persson, A.; Holmgren, J.; Soderman, U. Detecting and measuring individual trees using an airborne laser scanner. Photogramm. Eng. Remote Sens. 2002, 68, 925–932. [Google Scholar]
- Zhao, Y.; Chen, H.; Zeng, L.; Li, Z.; Chen, G.; Chen, H.; Li, Z. Improved Pointnet++ algorithm based on density related-farthest point sampling. SSRN Electron. J. 2023. preprint. [Google Scholar] [CrossRef]
- Dovrat, O.; Lang, I.; Avidan, S. Learning to sample. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 2755–2764. [Google Scholar] [CrossRef]
- Sarode, V.; Li, X.; Goforth, H.; Aoki, Y.; Srivatsan, R.A.; Lucey, S.; Choset, H. Pcrnet: Point Cloud Registration Network Using Pointnet Encoding. arXiv 2019, arXiv:1908.07906. [Google Scholar]
- Zhang, Y.; Liang, G.; Salem, T.; Jacobs, N. Defense-pointnet: Protecting pointnet against adversarial attacks. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5654–5660. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Li, W.; Liu, H.; Wang, Y.; Gui, G. Optimized PointNet for 3D Object Classification; Springer: Cham, Switzerland, 2019; pp. 271–278. [Google Scholar]
- Cao, X.; Wang, W.; Nagao, K.; Nakamura, R. Psnet: A style transfer network for point cloud stylization on geometry and color. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 3326–3334. [Google Scholar] [CrossRef]
- Qian, G.; Li, Y.; Peng, H.; Mai, J.; Hammoud, H.; Elhoseiny, M.; Ghanem, B. Pointnext: Revisiting Pointnet++ with improved training and scaling strategies. Adv. Neural Inf. Process. Syst. 2022, 35, 23192–23204. [Google Scholar]
- Sakharova, E.K.; Nurlyeva, D.D.; Fedorova, A.A.; Yakubov, A.R.; Kanev, A.I. Issues of Tree Species Classification from LiDAR Data Using Deep Learning Model; Springer: Cham, Switzerland, 2022; pp. 319–324. [Google Scholar]
- Zhan, D.; Liang, D.; Jin, H.; Wu, X.; Mbbos, G.C.N. MBBOS-GCN: Minimum bounding box over-segmentation—Graph convolution 3D point cloud deep learning model. J. Appl. Remote Sens. 2022, 16, 016502. [Google Scholar] [CrossRef]
- Yao, W.; Krzystek, P.; Heurich, M. Tree species classification and estimation of stem volume and DBH based on single tree extraction by exploiting airborne full-waveform LiDAR data. Remote Sens. Environ. 2012, 123, 368–380. [Google Scholar] [CrossRef]
- Terryn, L.; Calders, K.; Disney, M.; Origo, N.; Malhi, Y.; Newnham, G.; Raumonen, P.; Kerblom, M.Å.; Verbeeck, H. Tree species classification using structural features derived from terrestrial laser scanning. ISPRS J. Photogramm. 2020, 168, 170–181. [Google Scholar] [CrossRef]
- Zou, X.; Cheng, M.; Wang, C.; Xia, Y.; Li, J. Tree classification in complex forest point clouds based on deep learning. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2360–2364. [Google Scholar] [CrossRef]
- Mizoguchi, T.; Ishii, A.; Nakamura, H.; Inoue, T.; Takamatsu, H. Lidar-based individual tree species classification using convolutional neural network. In Proceedings of the Videometrics, Range Imaging, and Applications XIV, Munich, Germany, 26–27 June 2017; pp. 193–199. [Google Scholar]
- Diab, A.; Kashef, R.; Shaker, A. Deep Learning for LiDAR Point Cloud Classification in Remote Sensing. Sensors 2022, 22, 7868. [Google Scholar] [CrossRef]
- Chen, J.; Chen, Y.; Liu, Z. Classification of typical tree species in laser point cloud based on deep learning. Remote Sens. 2021, 13, 4750. [Google Scholar] [CrossRef]
- Liu, M.; Han, Z.; Chen, Y.; Liu, Z.; Han, Y. Tree species classification of LiDAR data based on 3D deep learning. Measurement 2021, 177, 109301. [Google Scholar] [CrossRef]
- Xi, Z.; Hopkinson, C.; Rood, S.B.; Peddle, D.R. See the forest and the trees: Effective machine and deep learning algorithms for wood filtering and tree species classification from terrestrial laser scanning. ISPRS J. Photogramm. 2020, 168, 1–16. [Google Scholar] [CrossRef]
- Chen, Y.; Hu, V.T.; Gavves, E.; Mensink, T.; Mettes, P.; Yang, P.; Snoek, C.G.M. PointMixup: Augmentation for Point Clouds; Springer: Cham, Switzerland, 2020; pp. 330–345. [Google Scholar]
- Li, R.; Li, X.; Heng, P.-A.; Fu, C.-W. Pointaugment: An auto-augmentation framework for point cloud classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6377–6386. [Google Scholar] [CrossRef]
- Xiao, A.; Huang, J.; Guan, D.; Cui, K.; Lu, S.; Shao, L. PolarMix: A General Data Augmentation Technique for LiDAR Point Clouds. arXiv 2022, arXiv:2208.00223. [Google Scholar]
- Arief, H.A.A.; Indahl, U.G.; Strand, G.-H.; Tveite, H. Addressing overfitting on point cloud classification using Atrous XCRF. ISPRS J. Photogramm. 2019, 155, 90–101. [Google Scholar] [CrossRef] [Green Version]
- Guan, H.; Yu, Y.; Ji, Z.; Li, J.; Zhang, Q. Deep learning-based tree classification using mobile LiDAR data. Remote Sens. Lett. 2015, 6, 864–873. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | SAL-1500 |
|---|---|
| Measurement Rate | 2,000,000 points/s |
| Scanning Speed | 400 lines/s |
| Flight Altitude | 200 m |
| System Relative Accuracy | 20 mm |
| Field of View | 360° |
| Tree Species | Scientific Names | Number of Points | ||
|---|---|---|---|---|
| Average | Maximum | Minimum | ||
| Birch | Betula fujianensis | 4232 | 13,642 | 933 |
| Bodhi tree | Ficus religiosa | 4838 | 11,345 | 1539 |
| Scholar tree | Alstonia scholaris | 1687 | 5278 | 398 |
| Formosa acacia | Acacia confusa | 3763 | 8975 | 1113 |
| Terminalia neotaliala | Terminalia neotaliala | 6017 | 15,509 | 1350 |
| Simon poplar | Populus simonii | 4534 | 10,499 | 664 |
| Camphor tree | Cinnamomum camphora | 1965 | 5426 | 607 |
| Council tree | Ficus altissima | 2253 | 6558 | 701 |
| Mango tree | Mangifera indica | 4079 | 10,020 | 1509 |
| Wingleaf soapberry | Sapindus saponaria | 3367 | 8030 | 1120 |
| Cotton tree | Bombax ceiba | 511 | 1454 | 134 |
| Others | 5951 | 38,124 | 152 | |
| Tree Species | Scientific Names | Number of Samples | Average Number of Points | ||
|---|---|---|---|---|---|
| Train | Test | Train | Test | ||
| Birch | Betula fujianensis | 40 | 10 | 4453 | 2947 |
| Bodhi tree | Ficus religiosa | 40 | 10 | 4573 | 5602 |
| Scholar tree | Alstonia scholaris | 40 | 10 | 1731 | 1232 |
| Formosa acacia | Acacia confusa | 40 | 10 | 3451 | 5012 |
| Terminalia neotaliala | Terminalia neotaliala | 40 | 10 | 5982 | 6159 |
| Simon poplar | Populus simonii | 38 | 10 | 4399 | 5048 |
| Camphor tree | Cinnamomum camphora | 40 | 10 | 1496 | 1858 |
| Council tree | Ficus altissima | 40 | 10 | 2236 | 1924 |
| Mango tree | Mangifera indica | 40 | 10 | 4335 | 4063 |
| Wingleaf soapberry | Sapindus saponaria | 38 | 10 | 3633 | 2356 |
| Cotton tree | Bombax ceiba | 40 | 10 | 525 | 391 |
| Total | 438 | 110 | / | / | |
| Hyperparameter | Value | Declaration |
|---|---|---|
| Training Model | SSG/MSG | Simplified sampling and grouping Multi-scale sampling and grouping |
| Batch size | 4\8\12\16\20 | Number of batches in each epoch |
| Number of points | 512\1024\2048\4096\8192 | Number of points per individual tree sample |
| Epoch | 50\100\200\300\500 | Number of times to traverse the entire training dataset during training |
| Optimizer | Adam | An algorithm to update and calculate the internal parameters of the model to reduce the training error |
| Learning rate | 0.001 | The step size to update in each iteration |
| Decay rate | 0.0001 | Used to reduce the learning rate to help the model converge better |
| Recall | Precision | Accuracy | |
|---|---|---|---|
| SSG_512 | 73.64 | 73.64 | 75.19 |
| MSG_512 | 79.09 | 79.09 | 80.89 |
| Recall | Precision | Accuracy | |
|---|---|---|---|
| SSG_1024 | 80.91 | 80.91 | 81.39 |
| MSG_1024 | 82.73 | 82.73 | 83.56 |
| SSG_2048 | 86.36 | 88.17 | 88.17 |
| MSG_2048 | 91.82 | 93.45 | 93.45 |
| SSG_4096 | 81.82 | 81.82 | 85.48 |
| MSG_4096 | 87.27 | 87.27 | 90.99 |
| SSG_8192 | 80.91 | 80.91 | 82.84 |
| MSG_8192 | 85.45 | 85.45 | 86.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Z.; Wei, J.; Zhang, R.; Zhang, W. Tree Species Classification Based on PointNet++ and Airborne Laser Survey Point Cloud Data Enhancement. Forests 2023, 14, 1246. https://doi.org/10.3390/f14061246
Fan Z, Wei J, Zhang R, Zhang W. Tree Species Classification Based on PointNet++ and Airborne Laser Survey Point Cloud Data Enhancement. Forests. 2023; 14(6):1246. https://doi.org/10.3390/f14061246
Chicago/Turabian StyleFan, Zhongmou, Jinhuang Wei, Ruiyang Zhang, and Wenxuan Zhang. 2023. "Tree Species Classification Based on PointNet++ and Airborne Laser Survey Point Cloud Data Enhancement" Forests 14, no. 6: 1246. https://doi.org/10.3390/f14061246