
Quantitative Analysis of Forest Water COD Value Based on UV–vis and FLU Spectral Information Fusion

Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
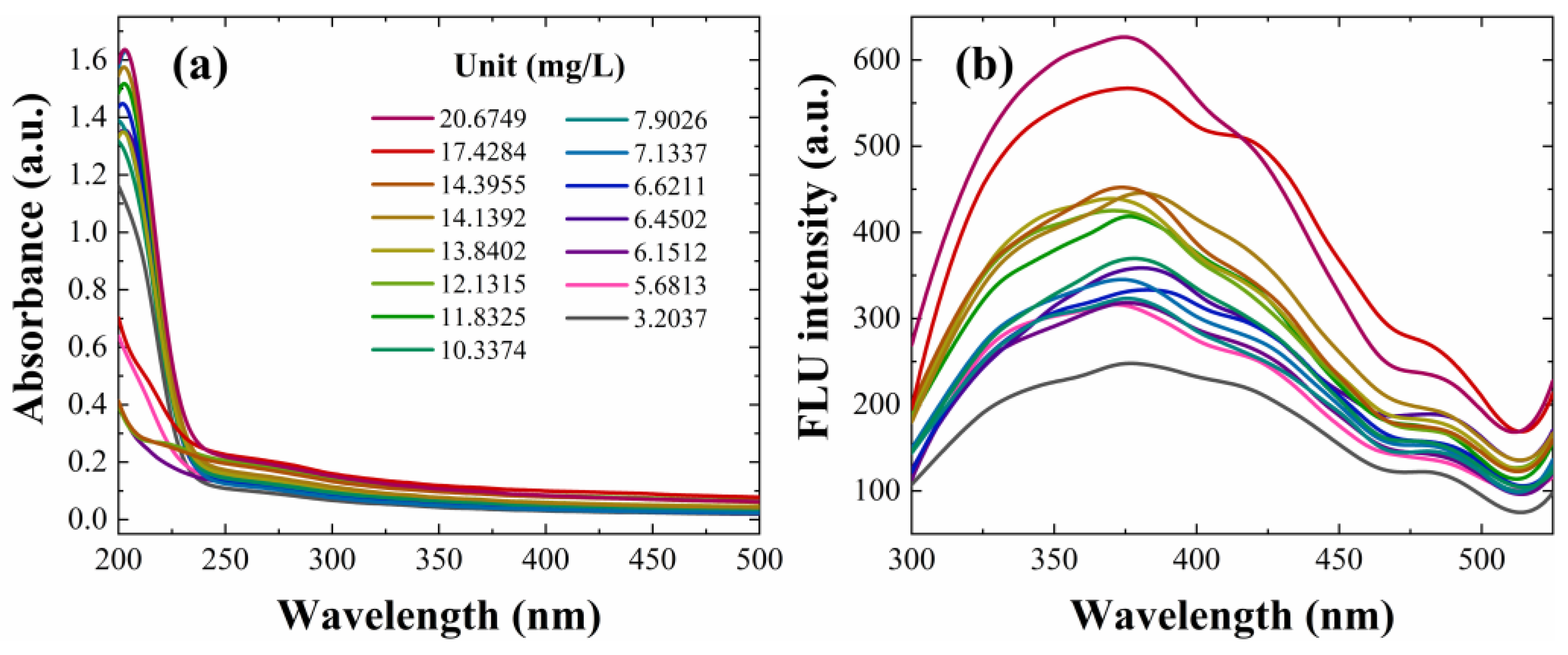
2.2. Spectra Acquisition
3. Model Algorithm
4. Results and Analysis
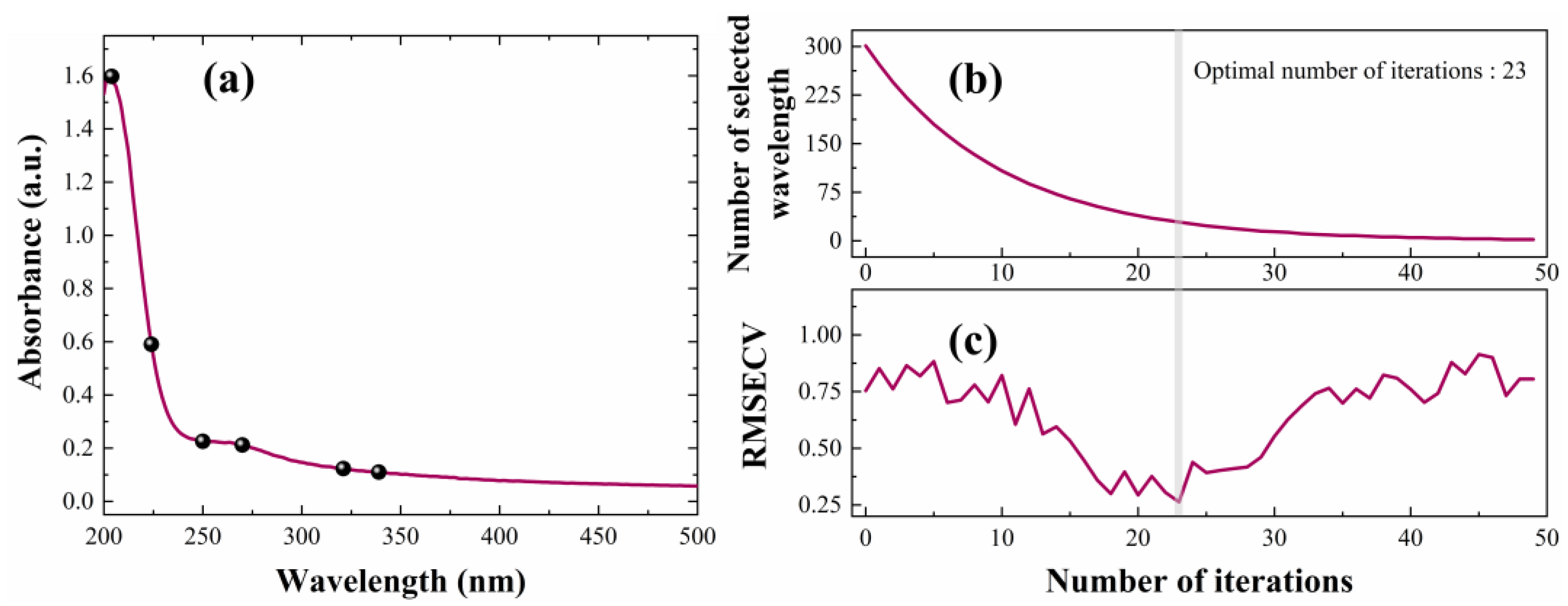
4.1. Spectral Feature Selection
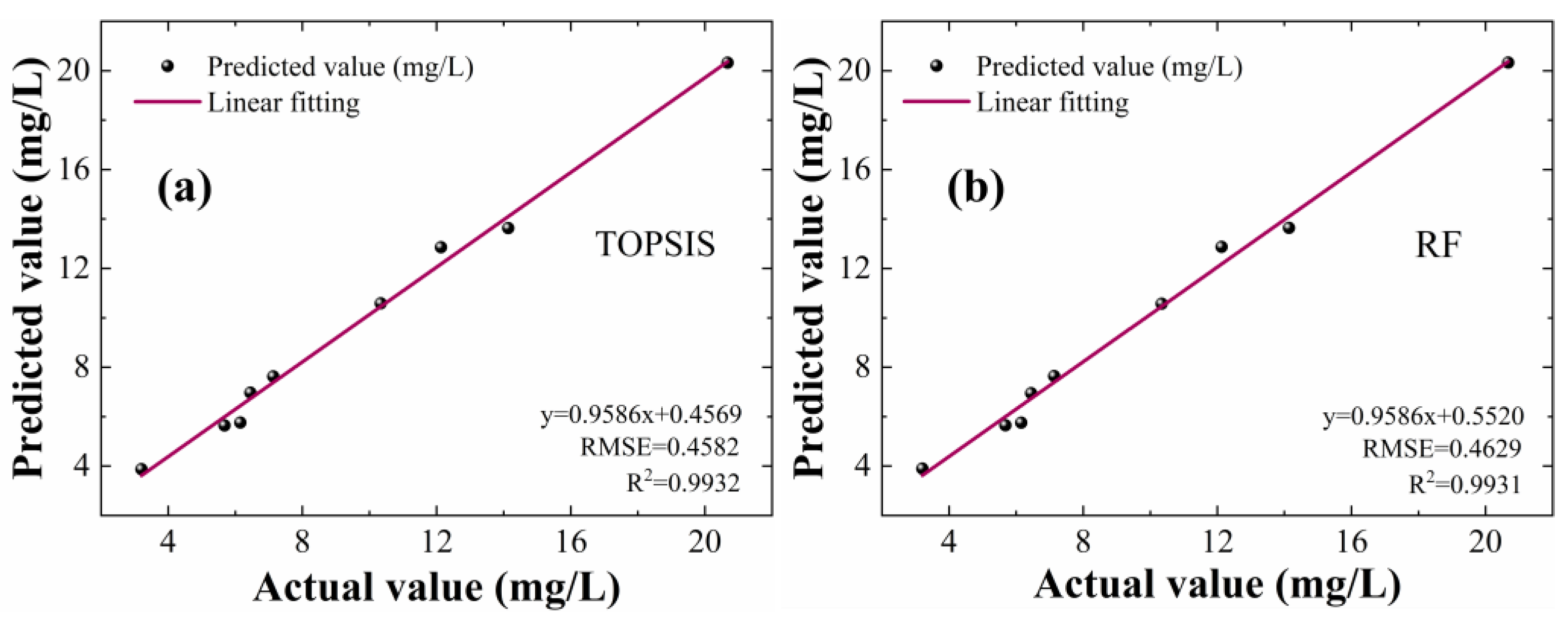
4.2. Analysis and Comparison of Modeling Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Geerdink, R.B.; Sebastiaan van den Hurk, R.; Epema, O.J. Chemical Oxygen Demand: Historical Perspectives and Future Challenges. Anal. Chim. Acta 2017, 961, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Ma, J. Determination of Chemical Oxygen Demand in Aqueous Samples with Non-Electrochemical Methods. Trends Environ. Anal. Chem. 2017, 14, 37–43. [Google Scholar] [CrossRef]
- Gandaseca, S.; Rosli, N.; Ngayop, J.; Arianto, C.I. Status of Water Quality Based on the Physico-Chemical Assessment on River Water at Wildlife Sanctuary Sibuti Mangrove Forest, Miri Sarawak. Am. J. Environ. Sci. 2011, 7, 269–275. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Luo, G.; He, L.J.; Xu, J.; Lyu, J. Analytical Approaches for Determining Chemical Oxygen Demand in Water Bodies: A Review. Crit. Rev. Anal. Chem. 2018, 48, 47–65. [Google Scholar] [CrossRef] [PubMed]
- Sagan, V.; Peterson, K.T.; Maimaitijiang, M.; Sidike, P.; Sloan, J.; Greeling, B.A.; Maalouf, S.; Adams, C. Monitoring Inland Water Quality Using Remote Sensing: Potential and Limitations of Spectral Indices, Bio-Optical Simulations, Machine Learning, and Cloud Computing. Earth-Sci. Rev. 2020, 205, 103187. [Google Scholar] [CrossRef]
- Chen, J.; Liu, S.; Qi, X.; Yan, S.; Guo, Q. Study and Design on Chemical Oxygen Demand Measurement Based on Ultraviolet Absorption. Sens. Actuators B Chem. 2018, 254, 778–784. [Google Scholar] [CrossRef]
- Jia, W.; Zhang, H.; Ma, J.; Liang, G.; Wang, J.; Liu, X. Study on the Predication Modeling of COD for Water Based on UV-VIS Spectroscopy and CNN Algorithm of Deep Learning. Spectrosc. Spectr. Anal. 2020, 40, 2981. [Google Scholar]
- Kunpeng, Z.; Xufang, B.; Weihong, B. Detection of Chemical Oxygen Demand (COD) of Water Quality Based on Fluorescence Multi-Spectral Fusion. Spectrosc. Spectr. Anal. 2019, 39, 813–817. [Google Scholar]
- Bengraïne, K.; Marhaba, T.F. Predicting Organic Loading in Natural Water Using Spectral Fluorescent Signatures. J. Hazard. Mater. 2004, 108, 207–211. [Google Scholar] [CrossRef]
- An, H.; Zhai, C.; Zhang, F.; Ma, Q.; Sun, J.; Tang, Y.; Wang, W. Quantitative Analysis of Chinese Steamed Bread Staling Using NIR, MIR, and Raman Spectral Data Fusion. Food Chem. 2023, 405, 134821. [Google Scholar] [CrossRef]
- Lin, H.; Lin, J.; Wang, F. An Innovative Machine Learning Model for Supply Chain Management. J. Innov. Knowl. 2022, 7, 100276. [Google Scholar] [CrossRef]
- Jing, Z.L.; Pan, H.; Qin, Y.Y. Current Progress of Information Fusion in China. Chin. Sci. Bull. 2013, 58, 4533–4540. [Google Scholar] [CrossRef]
- Ruser, H.; Leon, F.P. Informationsfusion—Eine Übersicht. Tech. Mess. 2007, 74, 93–102. [Google Scholar] [CrossRef]
- Lin, J.; Bai, D.; Xu, R.; Lin, H. TSBA-YOLO: An Improved Tea Diseases Detection Model Based on Attention Mechanisms and Feature Fusion. Forests 2023, 14, 619. [Google Scholar] [CrossRef]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor Data Fusion: A Review of the State-of-the-Art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Xiao, F. Multi-Sensor Data Fusion Based on the Belief Divergence Measure of Evidences and the Belief Entropy. Inf. Fusion 2019, 46, 23–32. [Google Scholar] [CrossRef]
- Diez-Olivan, A.; Del Ser, J.; Galar, D.; Sierra, B. Data Fusion and Machine Learning for Industrial Prognosis: Trends and Perspectives towards Industry 4.0. Inf. Fusion 2019, 50, 92–111. [Google Scholar] [CrossRef]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean Yield Prediction from UAV Using Multimodal Data Fusion and Deep Learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
- Hua, M.; Xu, Z. Physical Random Access Signal Design for 5G Mobile Satellite Communication Systems. Phys. Commun. 2022, 55, 101908. [Google Scholar] [CrossRef]
- Hua, M.; Zhang, T. Random Access Sequence Set Design in Wireless Cellular Communication Networks. Phys. Commun. 2023, 56, 101953. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Wang, L.; Li, L.; Guo, L.; Yang, M.; Huang, F.; Zhao, H. Determination of 10-HDA in Royal Jelly by ATR-FTMIR and NIR Spectral Combining with Data Fusion Strategy. Optik 2020, 203, 164052. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Y.; Xia, J.; Xiong, Y.; Min, S. Quantitative Analysis of Honey Adulteration by Spectrum Analysis Combined with Several High-Level Data Fusion Strategies. Vib. Spectrosc. 2020, 108, 103060. [Google Scholar] [CrossRef]
- Wang, L.; Meng, J.; Huang, R.; Zhu, H.; Peng, K. Incremental Feature Weighting for Fuzzy Feature Selection. Fuzzy Sets Syst. 2019, 368, 1–19. [Google Scholar] [CrossRef]
- Hu, X.; Zhou, P.; Li, P.; Wang, J.; Wu, X. A Survey on Online Feature Selection with Streaming Features. Front. Comput. Sci. 2018, 12, 479–493. [Google Scholar] [CrossRef]
- Lin, H.; Tang, C. Analysis and Optimization of Urban Public Transport Lines Based on Multiobjective Adaptive Particle Swarm Optimization. IEEE Trans. Intell. Transp. Syst. 2021, 23, 16786–16798. [Google Scholar] [CrossRef]
- Lin, H.; Tang, C. Intelligent Bus Operation Optimization by Integrating Cases and Data Driven Based on Business Chain and Enhanced Quantum Genetic Algorithm. IEEE Trans. Intell. Transp. Syst. 2022, 23, 9869–9882. [Google Scholar] [CrossRef]
- Lin, H.; Han, Y.; Cai, W.; Jin, B. Traffic Signal Optimization Based on Fuzzy Control and Differential Evolution Algorithm. IEEE Trans. Intell. Transp. Syst. 2022, 1–12. [Google Scholar] [CrossRef]
- Wu, D.; Nie, P.; He, Y.; Wang, Z.; Wu, H. Spectral Multivariable Selection and Calibration in Visible-Shortwave near-Infrared Spectroscopy for Non-Destructive Protein Assessment of Spirulina Microalga Powder. Int. J. Food Prop. 2013, 16, 1002–1015. [Google Scholar] [CrossRef]
- Tang, R.; Chen, X.; Li, C. Detection of Nitrogen Content in Rubber Leaves Using Near-Infrared (NIR) Spectroscopy with Correlation-Based Successive Projections Algorithm (SPA). Appl. Spectrosc. 2018, 72, 740–749. [Google Scholar] [CrossRef]
- Wang, Z.; Niu, Y. Regional Electricity Consumption Based on Least Squares Support Vector Machine. In Proceedings of the Fifth International Conference on Machine Vision (ICMV 2012): Algorithms, Pattern Recognition, and Basic Technologies, Wuhan, China, 20–21 April 2012; Volume 8784, p. 87840C. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, S.; Liu, W.; Yang, X.; Luo, J. Least-Squares Support Vector Machine and Successive Projection Algorithm for Quantitative Analysis of Cotton-Polyester Textile by near Infrared Spectroscopy. J. Near Infrared Spectrosc. 2018, 26, 34–43. [Google Scholar] [CrossRef] [Green Version]
- Bleiholder, J.; Naumann, F. Data Fusion. ACM Comput. Surv. 2009, 41, 1–41. [Google Scholar] [CrossRef]
- Meng, Q.; Zhang, C.; Song, T.; Li, N. The Application of the Improved TOPSIS Method in Bid Evaluation of Highway Construction. Appl. Mech. Mater. 2012, 178–181, 1365–1368. [Google Scholar]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A Comparison of Random Forest Variable Selection Methods for Classification Prediction Modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Ishwaran, H. Random Forests for Genomic Data Analysis. Genomics 2012, 99, 323–329. [Google Scholar] [CrossRef] [Green Version]
- Charef, A.; Ghauch, A.; Baussand, P.; Martin-Bouyer, M. Water Quality Monitoring Using a Smart Sensing System. Meas. J. Int. Meas. Confed. 2000, 28, 219–224. [Google Scholar] [CrossRef]
- Huang, P.; Li, Y.; Yu, Q.; Wang, K.; Yin, H.; Hou, D.; Zhang, G. Classification of Organic Contaminants in Water Distribution Systems Developed by SPA and Multi-Classification SVM Using UV-Vis Spectroscopy. Spectrosc. Spectr. Anal. 2020, 40, 2267–2272. [Google Scholar]
- Biancolillo, A.; Bucci, R.; Magrì, A.L.; Magrì, A.D.; Marini, F. Data-Fusion for Multiplatform Characterization of an Italian Craft Beer Aimed at Its Authentication. Anal. Chim. Acta 2014, 820, 23–31. [Google Scholar] [CrossRef]
- Song, X.; Du, G.; Li, Q.; Tang, G.; Huang, Y. Rapid Spectral Analysis of Agro-Products Using an Optimal Strategy: Dynamic Backward Interval PLS–Competitive Adaptive Reweighted Sampling. Anal. Bioanal. Chem. 2020, 412, 2795–2804. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, J.Y.; Wang, Y.Z. FT-MIR and NIR Spectral Data Fusion: A Synergetic Strategy for the Geographical Traceability of Panax Notoginseng. Anal. Bioanal. Chem. 2018, 410, 91–103. [Google Scholar] [CrossRef]
- Dhanalakshmi, C.S.; Madhu, P.; Karthick, A.; Mathew, M.; Vignesh Kumar, R. A Comprehensive MCDM-Based Approach Using TOPSIS and EDAS as an Auxiliary Tool for Pyrolysis Material Selection and Its Application. Biomass Convers. Biorefin. 2022, 12, 5845–5860. [Google Scholar] [CrossRef]
- Menze, B.H.; Kelm, B.M.; Masuch, R.; Himmelreich, U.; Bachert, P.; Petrich, W.; Hamprecht, F.A. A Comparison of Random Forest and Its Gini Importance with Standard Chemometric Methods for the Feature Selection and Classification of Spectral Data. BMC Bioinform. 2009, 10, 213. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sampling Area | Number of Samples | Actual COD Value (mg/L) |
|---|---|---|
| Dongshuiguan | 3 | 20.6749 |
| Bonsai Garden | 3 | 17.4284 |
| Tsui Chau | 3 | 14.3955 |
| Pingjiang Bridge | 3 | 14.1392 |
| Diaoyutai | 3 | 13.8402 |
| Baima Lake | 3 | 12.1315 |
| Hanzhongmen | 3 | 11.8325 |
| Xianhe Bridge | 3 | 10.3374 |
| Shuiximen | 3 | 7.9026 |
| Caochang Gate | 3 | 7.1337 |
| Laiyan Bridge | 3 | 6.6211 |
| Zhonghua Gate | 3 | 6.4502 |
| Xuanwu Gate | 3 | 6.1512 |
| Xi’an Gate | 3 | 5.6813 |
| Front Lake | 3 | 3.2037 |
| Model | UV–vis | FLU | Feature-Level Fusion | Decision-Level Fusion | ||||
|---|---|---|---|---|---|---|---|---|
| CARS | SPA | CARS | SPA | CARS | SPA | ENTROPY TOPSIS | RF | |
| RMSE (mg/L) | 1.3698 | 2.2109 | 1.2909 | 2.3423 | 0.7886 | 0.9079 | 0.4582 | 0.4629 |
| R2 | 0.9466 | 0.9318 | 0.9680 | 0.9068 | 0.9830 | 0.9754 | 0.9932 | 0.9931 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Ma, X.; Teng, Y.; Li, S.; Jin, Y.; Du, J.; Jiang, L. Quantitative Analysis of Forest Water COD Value Based on UV–vis and FLU Spectral Information Fusion. Forests 2023, 14, 1361. https://doi.org/10.3390/f14071361
Li C, Ma X, Teng Y, Li S, Jin Y, Du J, Jiang L. Quantitative Analysis of Forest Water COD Value Based on UV–vis and FLU Spectral Information Fusion. Forests. 2023; 14(7):1361. https://doi.org/10.3390/f14071361
Chicago/Turabian StyleLi, Chun, Xin Ma, Yan Teng, Shaochen Li, Yuanyin Jin, Jie Du, and Ling Jiang. 2023. "Quantitative Analysis of Forest Water COD Value Based on UV–vis and FLU Spectral Information Fusion" Forests 14, no. 7: 1361. https://doi.org/10.3390/f14071361