1. Introduction
Forest harvesting is a critical operation within the forestry industry’s production cycle that has garnered significant attention. The choice of the harvesting method depends primarily on factors such as the forest type, species, desired products, and terrain conditions, with the slope of the land being the most crucial variable in determining the machinery employed. In areas with slopes exceeding 60%, forestry harvesting strategies are mainly limited to logging towers or equipment secured with cable supports. Concerns arise regarding internal extraction processes on properties and transportation for raw material processing. Various research approaches address timber extraction on properties, ranging from manual collection processes to sophisticated planning techniques [
1]. Trees can be extracted using land-based or aerial methods [
2].
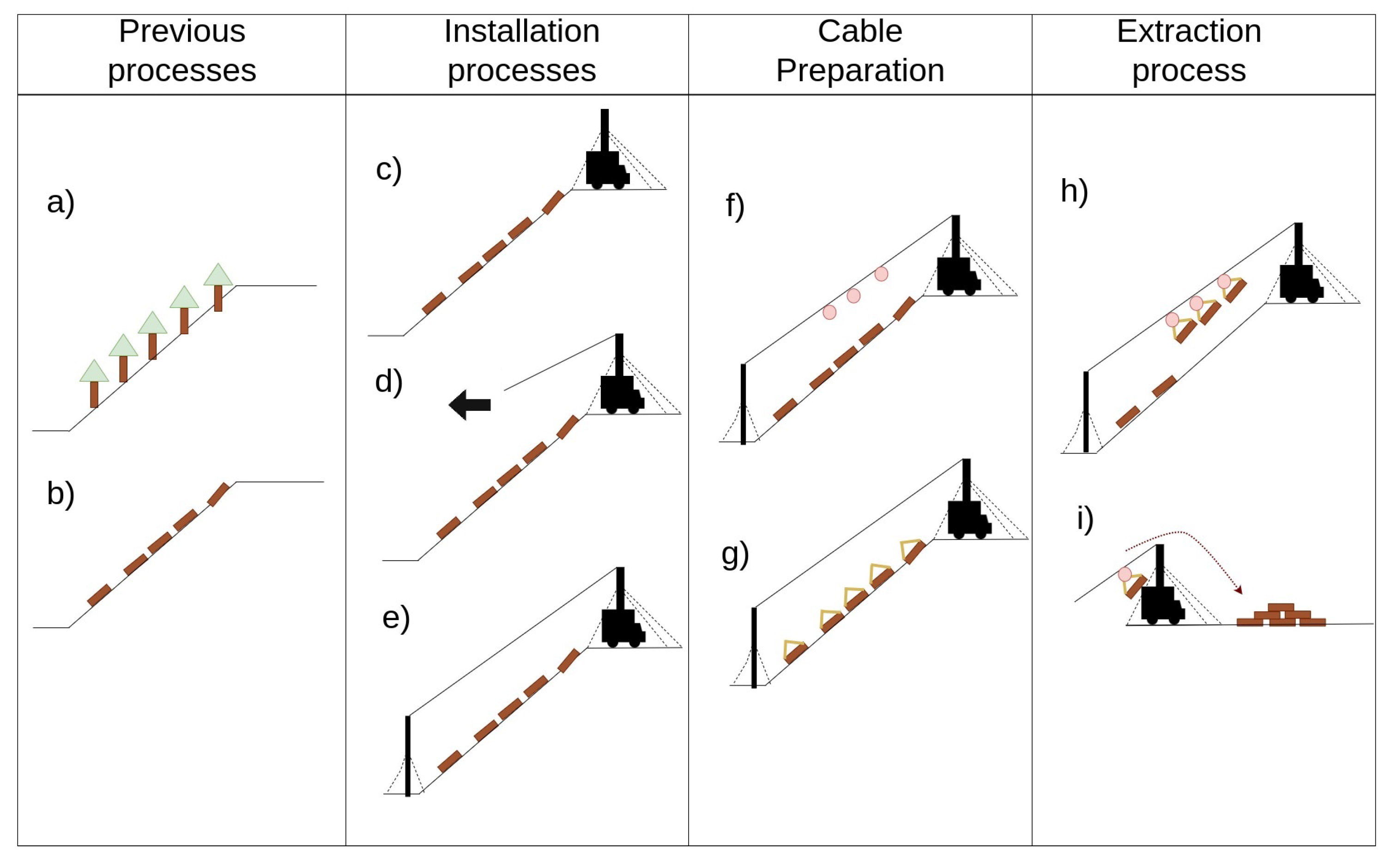
Skyline tower harvesting is a logging method that employs mechanized towers to access trees on steep or challenging terrain. Utilizing extraction cables attached to each tree, this technique is typically employed in areas with high slopes where traditional access to timber is not feasible. Equipped with a lifting platform and cable system, these towers enable operators to safely cut trees from above, resulting in a more efficient and less environmentally damaging approach than conventional logging methods. However, this method also presents drawbacks, such as the high cost of machinery, specialized training requirements, and increased workplace accident risks. Trees must be felled, prepared for extraction using specialized slope techniques, and arranged for rapid removal (see
Figure 1a,b). The cables are installed via a tower or logging cable that necessitates intermediate and final supports to ensure its stability, load support, and process continuity as the load is raised to the unloading area at the top of the slope (see
Figure 1c). Installation of the extraction cable should be conducted from the yarder tower to the anchor point, typically by specialized technicians (see
Figure 1d,e).
Upon completing the cable installation, the extraction process, known as “Full Tree,” begins. A carriage is installed on the skyline (see
Figure 1f), and trees are secured to the cable in a process called bracing, which attaches them to the cart running along the logging cable (see
Figure 1g). The cart is then retracted, and trees are dragged over the slope to the landing site or logging yard. At this location, trees are unloaded, cut, sorted, and transported to industrial facilities (see
Figure 1h,i). Notably, a single cable can extract multiple trees per cycle, often between two and eight trees, depending on factors such as the machinery power and resistance, slope, cable tension, tree size, and other terrain aspects. A tree recovery round is referred to as a logging cycle, and minimizing the number of cycles is essential for reducing labor costs.
The environmental impact of aerial timber extraction is significantly lower than that of land-based methods. Ground-based extraction often leads to soil erosion as timber is moved down slopes, negatively affecting the soil quality. Consequently, the employment of aerial extraction methods with reduced operating times is crucial for mitigating the environmental challenges of this type of harvest.
The economic dimension of the extraction process warrants a mention. Specifically, the cost associated with setting up skylines plays a pivotal role in the planning phase, as it directly impacts the process’ economic feasibility. Should the installation expenses surpass the returns from the harvest, cable extraction will become nonviable.
A crucial aspect of the timber extraction process is the installation and removal times for the entire operation. As mentioned earlier, using a skyline system for “clean” extraction requires the installation of one or more towers on a given property. The position of the tower’s “foothold” must also be strategically determined to maximize tree extraction. Additionally, each cable has a specific timber capacity per logging cycle, resulting in combinatorial challenges that are often intractable [
3]. Consequently, an optimization problem must be defined to minimize installation times for the cable extraction problem, considering both geometric and capacity constraints.
Numerous studies have addressed cable tree extraction and optimization. In [
3], the facility location theory is employed to assign lines to different properties. In [
4], the extraction costs of timbers are minimized using Geographic Information Systems (GIS) data and a heuristic that minimizes harvest costs is introduced. The work described in [
5] proposes a tabu search that tackles two forest harvesting problems: machinery location selection and access network design for extraction. The authors compare their approach with a mixed programming mathematical model using CPLEX, demonstrating that the tabu search achieves better results with less computational time. In [
6], various mathematical models based on [
3] are presented for steep terrain with different cable lengths, demonstrating their applicability in 18 plans. A metaheuristic for the European Cableway Location Problem is introduced in [
7], where a heuristic and a greedy metaheuristic are tested with test instances and a real case. The authors argue that both approaches are equally effective and could potentially minimize costs in the planning process. In [
2], a mixed-integer linear programming approach is presented to minimize road design costs for vehicles and cable design. The results are compared to [
1], with computation times ranging between 4 min and 8 h. In [
8], two new formulations for the cable tree removal problem are introduced based on a model presented in [
6]. The approaches yield favorable results depending on the specific parameters used for the problem.
Several scientific studies focused on the monitoring of extraction cables have been published recently. A notable one is the article from [
9], which details a monitoring system that uses the Geographical Navigation Satellite System (GNSS). With this system, the authors manage to identify 98% of the measured cycles, providing valuable data for the analysis of cables and their operations. In a different approach, the study presented in [
10] concentrates on the physical state of the cables, comparing tensile forces to static calculations. To address the inherent limitation of static data, a simulation based on finite elements (FEN) was employed. The researchers suggest that the FEN simulation is useful for analyzing the tensile forces of the horizon. Going a step further in complexity, the article presented in [
11] examines the forces affecting the extraction cables by adopting a nonlinear approach. This method provides a comprehensive solution, allowing adaptations based on specific configurations by adding equations to the existing system. Lastly, the article [
12] proposes a predictive method for the cable trajectory using software called Seilaplan, which is specifically designed for cable extraction technologies in Central Europe. The accuracy of the predictions is based on the Zweifel approach and was validated with real data, demonstrating reliable results, as measured by RMSE values. In this way, the importance of the study of extraction cables for forestry harvesting is evident, and the study is very important for different aspects of the forestry field.
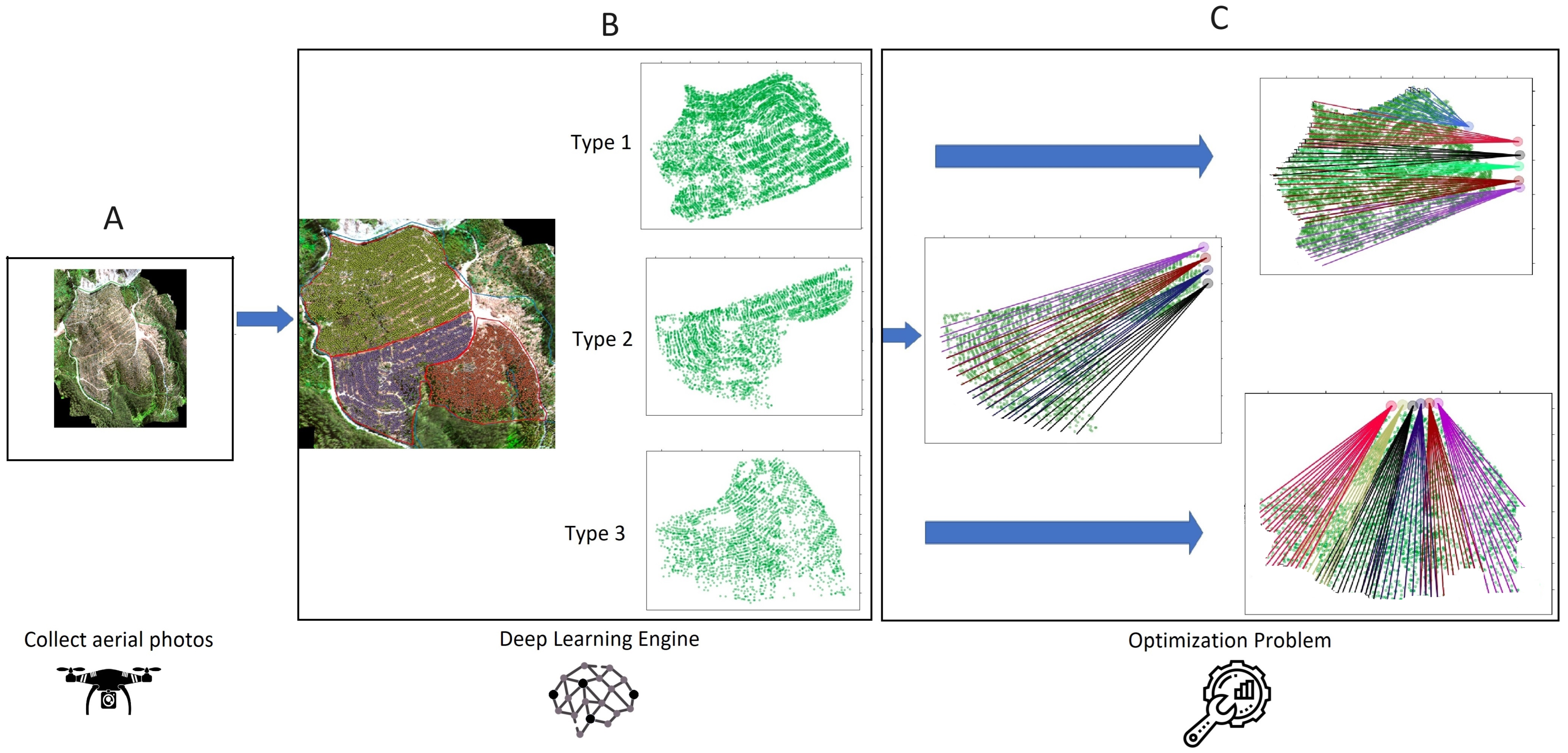
One of the primary factors that determines the efficiency and yield of forest harvesting with Skyline Towers is the placement of logging lines, which depends heavily on the forest conditions and tree positions on the slope. Accurate information about tree locations and sizes is crucial during the harvest planning phase. Typically, highly experienced operators make decisions based on their expertise, as this information is not readily available before a harvesting operation. Having precise tree locations would facilitate the definition of logging cable directions, the determination of intermediate and final support trees, the estimation of the number of logging cycles for each line, and the calculation of harvest yields, times, and costs more accurately. Moreover, it would help to minimize environmental costs by reducing soil compaction caused by logging lines. Improved harvest planning can be achieved with high-quality cartography and aerial images, which most harvesting companies possess. However, this requires a pre-processing phase for information. Deep Learning, a branch of Artificial Intelligence, can identify and segment objects within an image, making it possible to locate individual trees in a forest. The authors of this research are developing a Deep-Learning-based platform to identify and locate trees in Skyline Tower harvest sectors, which can then serve as the input for mathematical optimization processes to solve the problem of optimal logging cable allocation. This approach enhances the precision and efficiency of forest harvesting operations while minimizing environmental impacts.
Although the presented results are competitive, it is essential to introduce metaheuristics that minimize installation and operation times for large-scale planning with manageable durations. This article defines a binary mathematical programming model to optimize the installation and removal of timbers in cable logging operations. The model considers the tree allocation to cables, optimal cable selection based on the tower and stringer, cable intersections, and the extraction cable capacity. Furthermore, a hybrid approach is introduced to address the problem: a genetic algorithm assigns trees to lines and minimizes their number, followed by a mathematical model that utilizes the best individual to solve the logging cycle problem concerning the cable capacity. Lastly, comprehensive computational results are showcased, in which the manual planning approach (MPA) is compared with those generated using mathematical models. Additionally, a comparison is drawn with our two-phase algorithm. All discussed approaches are tested under real-world scenarios.
The rest of this article is organized as follows: in
Section 2, we present the problem modeling related to the issue at hand.
Section 3 introduces the integer mathematical programming formulation for the problem.
Section 4 describes the two-phase approach, which employs a genetic algorithm and a mathematical model based on
Section 3 to generate logging cycles.
Section 5 provides details of the computational experiments, while
Section 6 concludes our article with a summary of the findings.
2. Related Work—Modeling of the Cable Extraction Problem
The tree extraction process begins in a predetermined sector where each tree’s location, weight, and extraction time—the duration it takes to move the tree from the ground to a cable—have been meticulously cataloged. These trees are then transported to a specific area for stacking in anticipation of their subsequent removal by trucks. The primary aim of this model is to streamline the sequence of tree extraction from the ground to the landing area while optimizing the selection of extraction cables. This strategy is designed to decrease the overall operational times, including those required for installing a tower, setting up cables, tree extraction, and the complete logging cycle.
2.1. Yarder Installation Time
The installation time for a yarder varies based on its location and the specific model of the tower being used. We maintain the installation time in the tower model for our model, allowing only the installation site to vary. This site is typically located within the landing area, where the trees are gathered for stacking. The extraction operation’s specific location fundamentally determines the tower’s quantity and positioning.
2.2. Cable Installation Time and Tree Removal
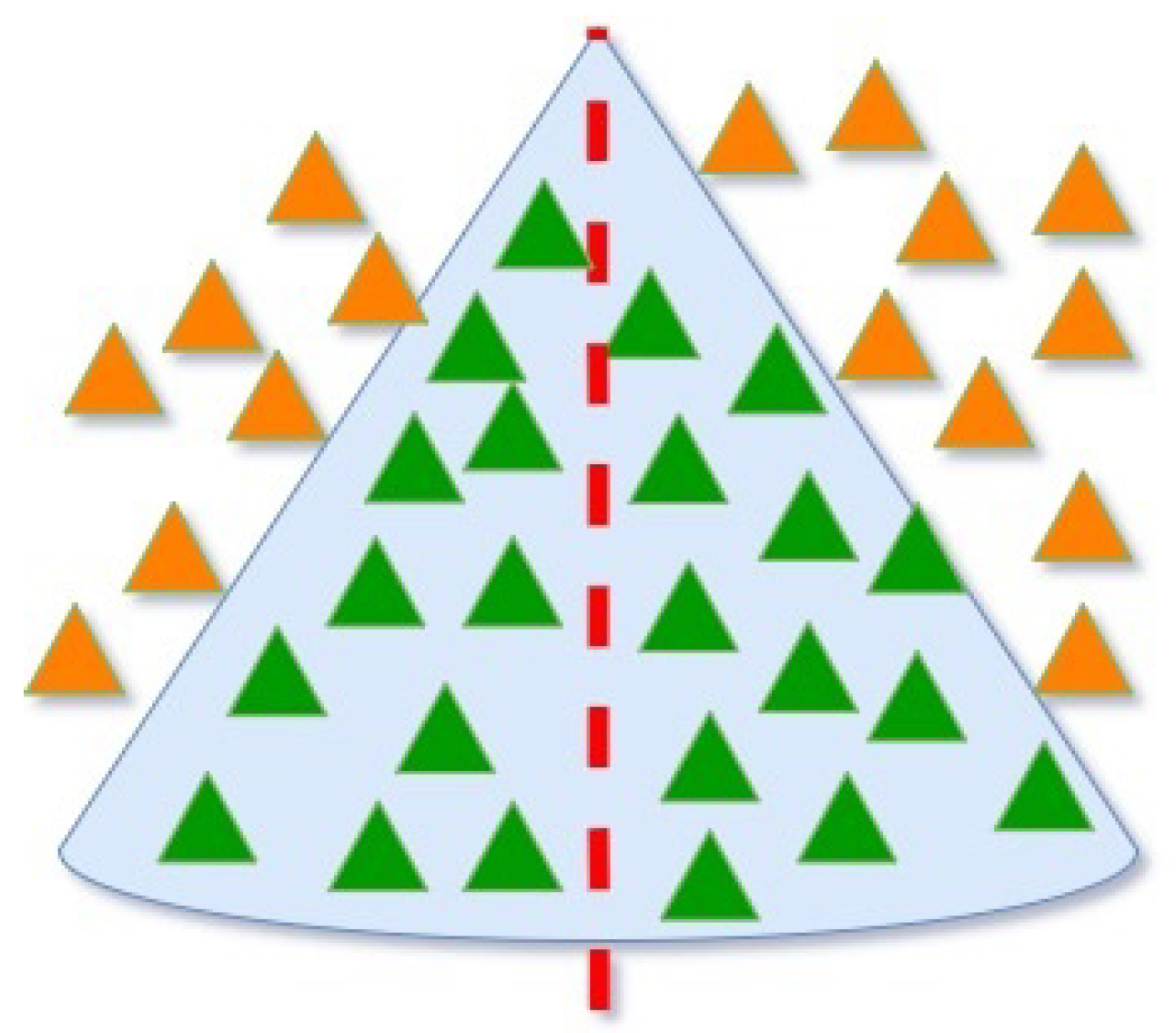
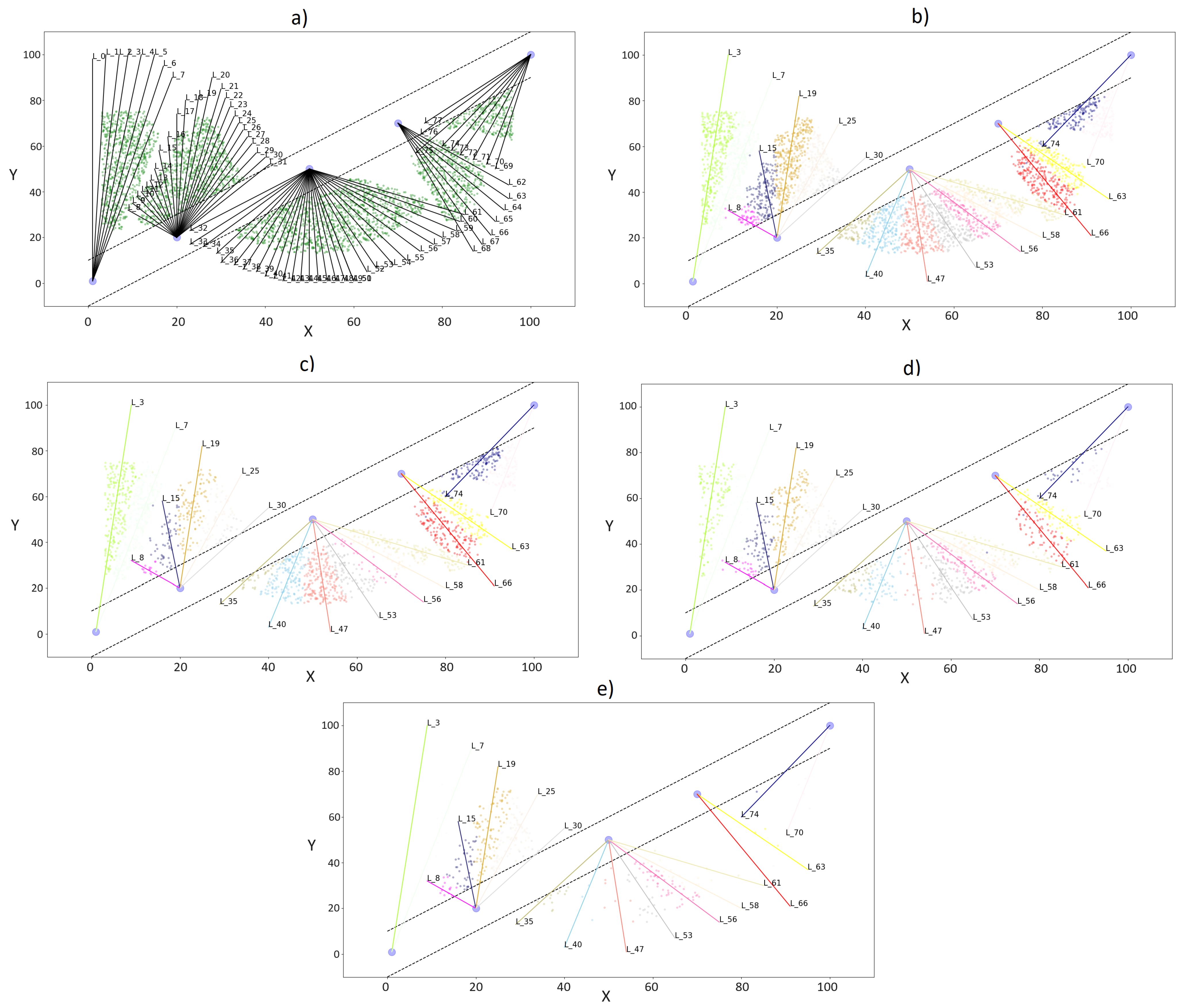
An array of cables stemming from various yarders is crucial for tree extraction. It is essential to judiciously select the appropriate cables to ensure an efficient extraction process. Every cable corresponds to a potential extraction area that takes the shape of a cone, as illustrated in
Figure 2. This cone-shaped area signifies the space within which the cable can operate effectively, thereby delineating its range of extraction. The design of this cone is crucial, as it governs the cable’s extraction capacity and operational efficiency.
Given the unique extraction area associated with each cable, every tree within the property under study must be extracted using a single cable. As such, each tree must be systematically aligned with a specific extraction cable dictated by the spatial limitations of the defined cone-shaped logging. This constraint mandates a strategic mapping of trees to cables, ensuring that each tree falls within the operational boundaries of its assigned cable. This careful coordination maximizes the extraction efficiency and minimizes the potential damage to the surrounding forested area during the extraction process.
2.3. Logging Cycles
Every extraction line in a logging operation features an unique characteristic called logging cycles. These cycles are quantitatively defined by the number of trees a single cable can haul during a single procedure or turn. The cable’s reach and strength, the size of the trees, and the terrain all factor into this calculation, which is pivotal for efficiency and productivity. Each logging cycle is further associated with a set of variables that require careful optimization. Firstly, there is the cycle time—the duration it takes to complete one extraction cycle. The aim is to minimize this time without compromising safety or efficacy, as it directly impacts the overall productivity of the logging operation. Faster cycle times mean that more trees can be extracted per unit of time, thereby enhancing the throughput and efficiency of the logging process. Secondly, there is the concept of cycle capacity. This term relates to the maximum effort or forces that the extraction line can exert in a single cycle, which in turn depend on the weight of the tree to be extracted and the distance between the tree and the logging line. This capacity must be sufficient to haul the tree from its original position to the extraction point. Factors such as the size and weight of the tree, the cable type and condition, the land gradient, and the distance to be covered all play roles in determining the cycle capacity.
In essence, these two parameters—cycle time and cycle capacity—are critical for logging operations. They must be carefully balanced and optimized, as they directly influence the extraction process’ efficiency, safety, and productivity. By understanding and improving these aspects, logging operations can significantly increase their performance and sustainability.
The capacity of a logging cycle is a critical threshold that an extraction line must respect.
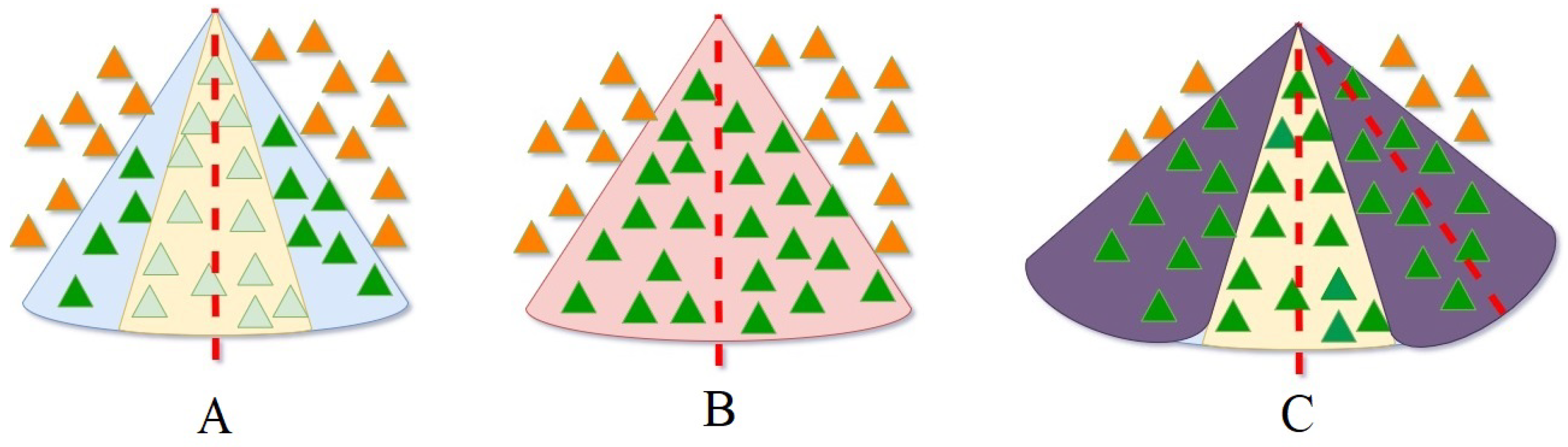
Figure 3 illustrates the various states of an extraction line. In
Figure 3A, the blue area represents potential extraction, but the line capacity restricts extraction to trees within the yellow cone.
Figure 3B depicts a saturated line with a red cone, where assigning all trees from the potential area is impossible.
Figure 3C presents a scenario with three extraction cables; the central wire is unsaturated due to the allocation of trees to the surrounding cables.
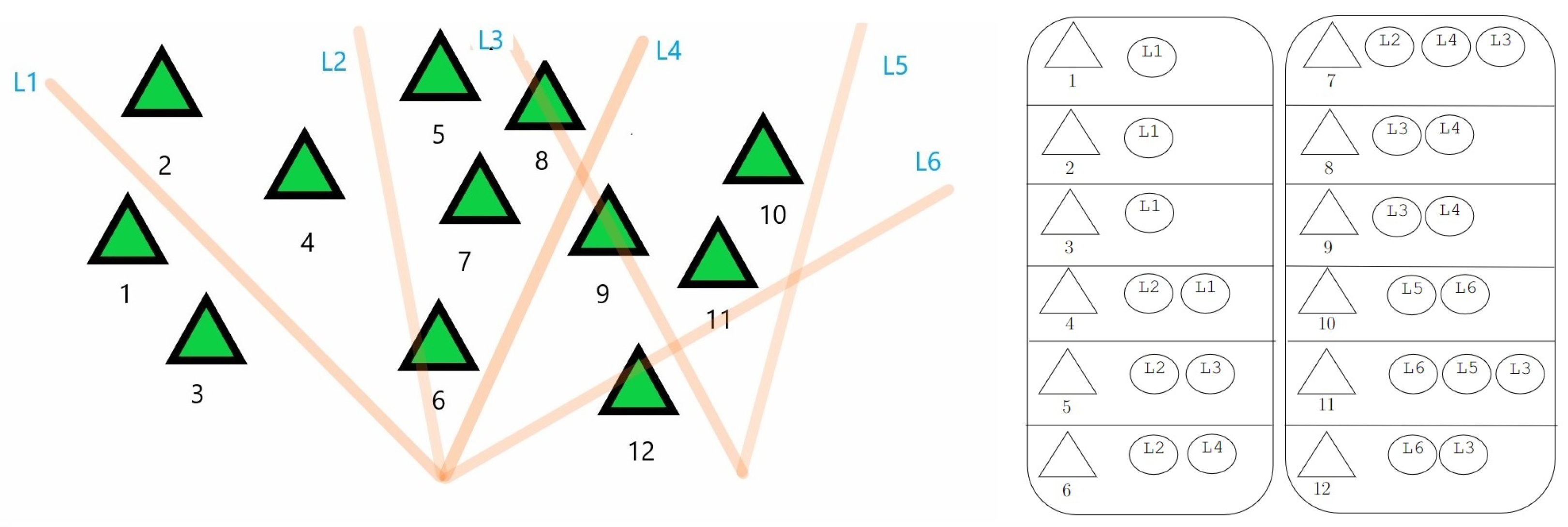
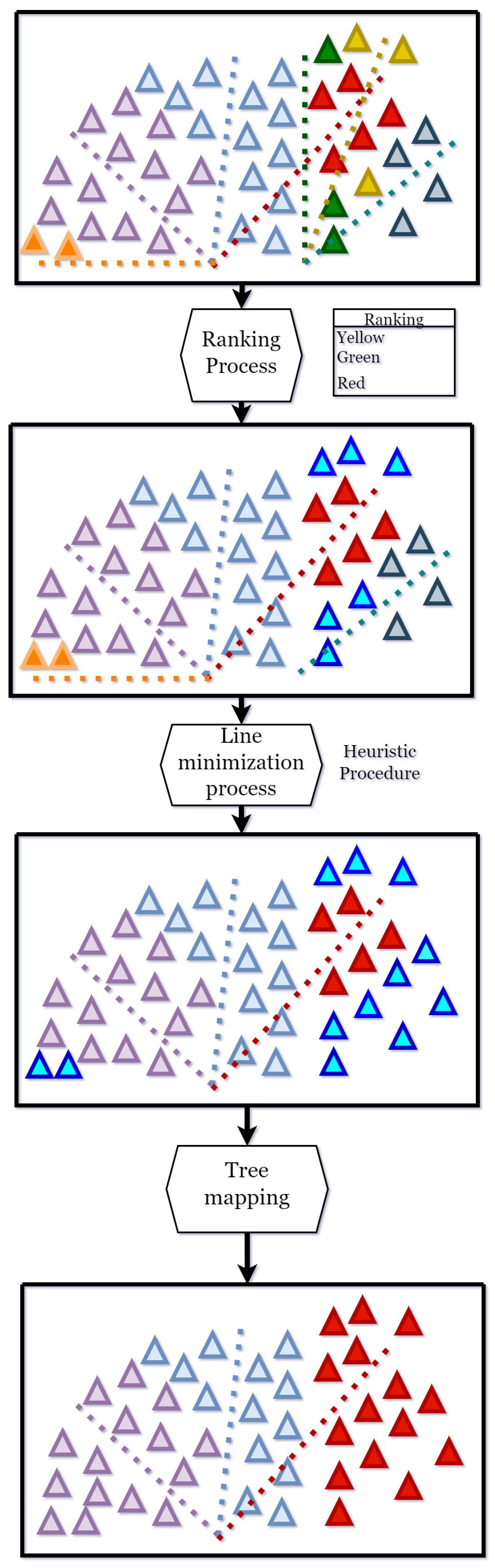
Each extraction cable possesses a capacity specific to its respective logging cycle.
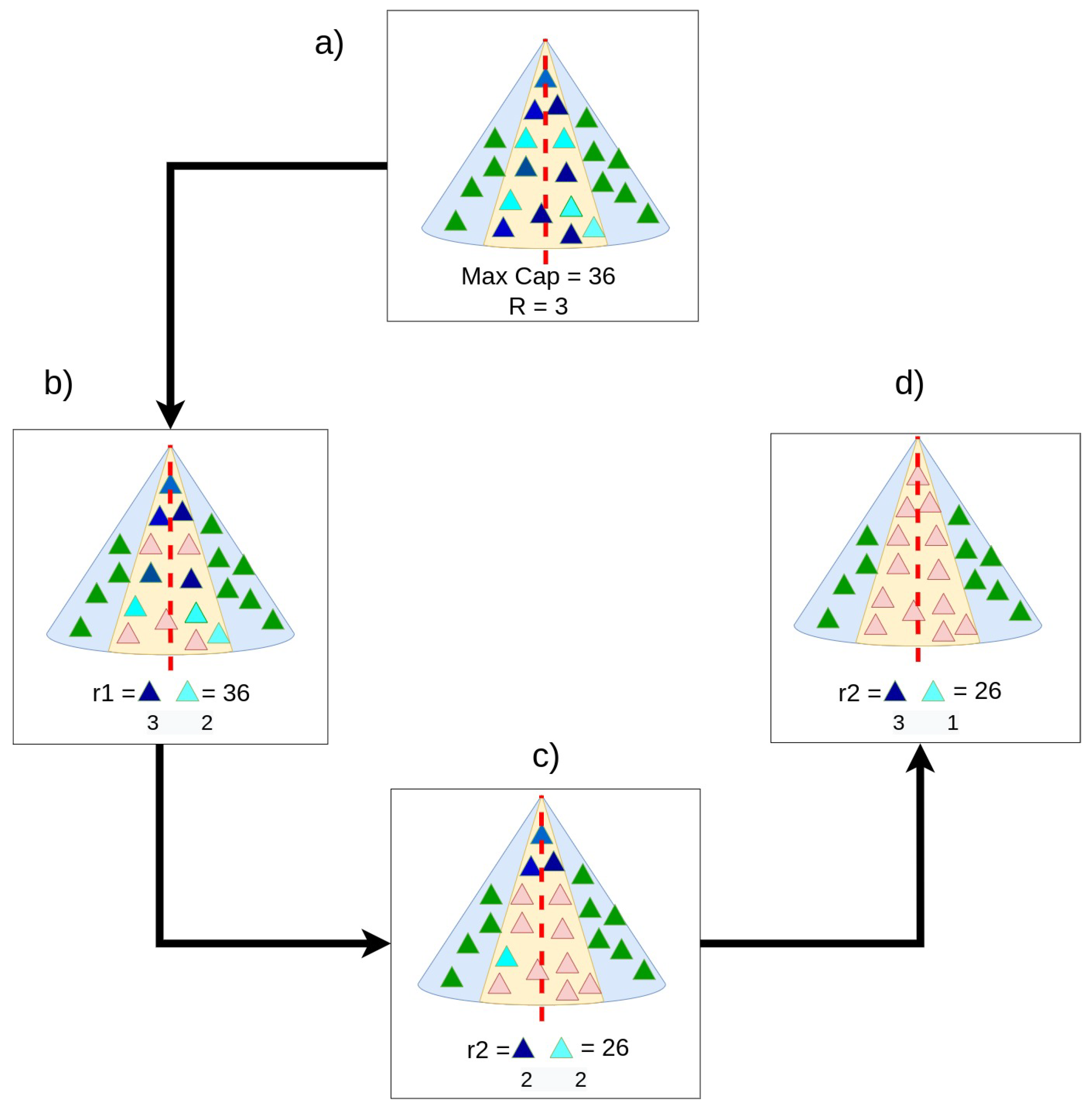
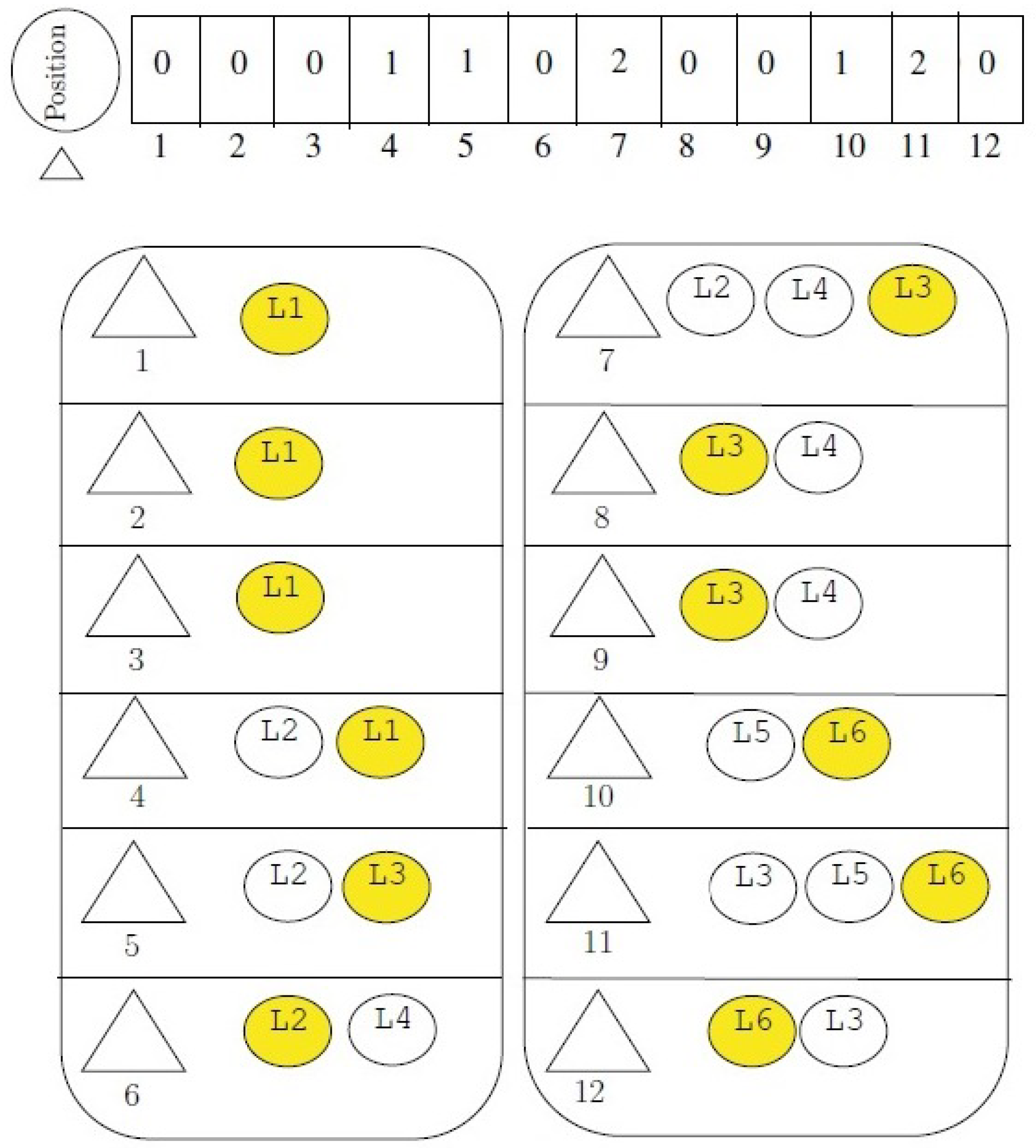
Figure 4a shows the timber cycle concept by defining a simple area notation: green triangles represent trees that are accessible to the cable but not assigned to it. In contrast, light blue triangles signify trees that are assigned to the cable and hence to a logging cycle. The extraction cable can execute three logging cycles (
) with a maximum capacity of 36 units per cycle. Trees depicted as light blue triangles consume three units of cable capacity, while the blue triangles utilize ten units. In the first logging cycle,
, shown in
Figure 4b, three blue triangles (3 × 10 = 30 capacity units) and two light blue triangles (2 × 3 = 6 capacity units) are extracted. This results in the feasible cycle capacity of 36 units being fully utilized. The extracted triangles are marked in red. The second logging cycle,
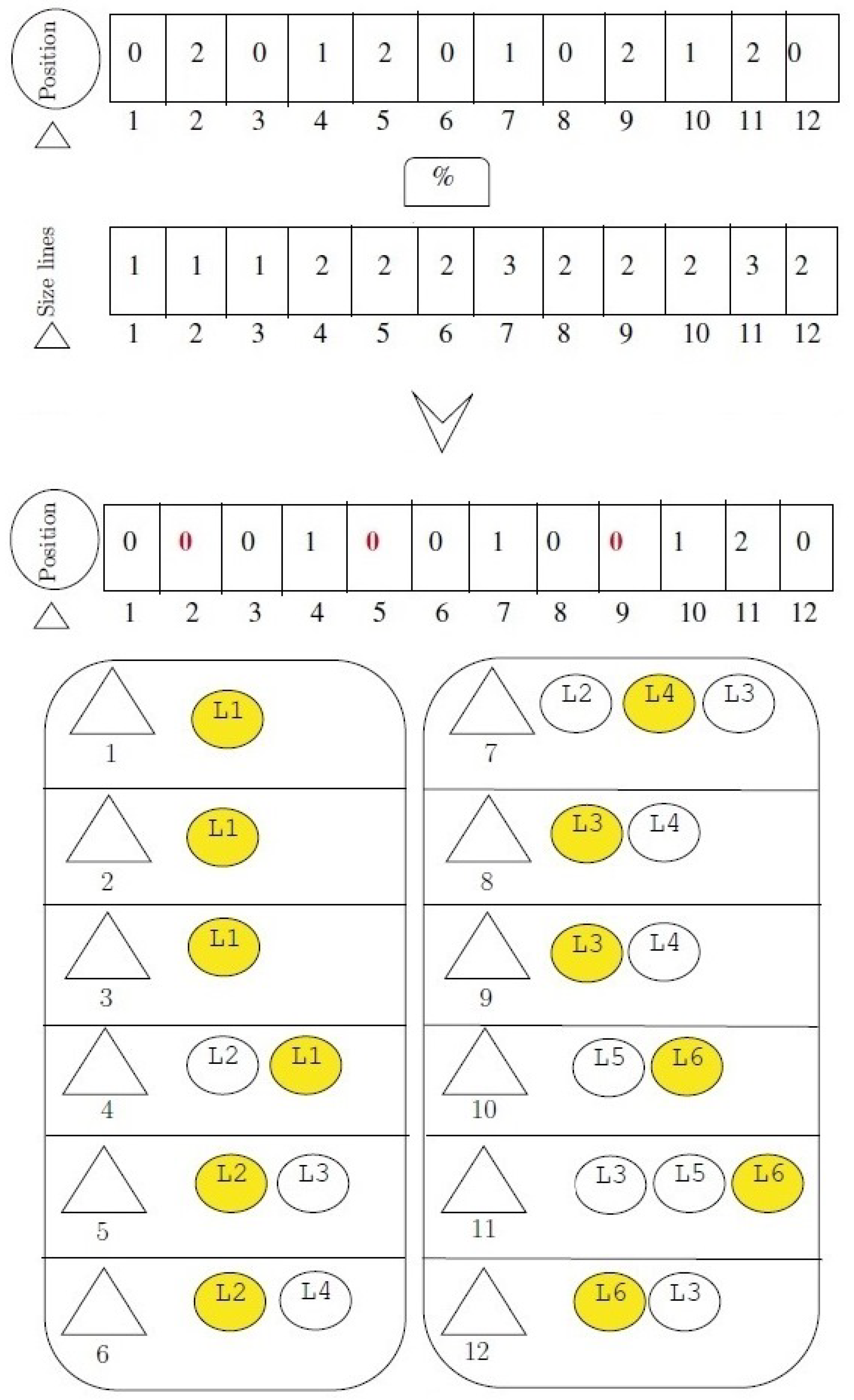
, represented in
Figure 4c, extracts two blue triangles (2 × 10 = 20 capacity units) and two light blue triangles (2 × 3 = 6 capacity units), yielding a feasible capacity utilization of 26 units. Finally, the third and last logging cycle,
, shown in
Figure 4d, extracts three blue triangles (3 × 10 = 30 capacity units) and one light blue triangle (1 × 3 = 3 capacity units), thereby utilizing a feasible capacity of 33 units.
2.4. Description of the Problem
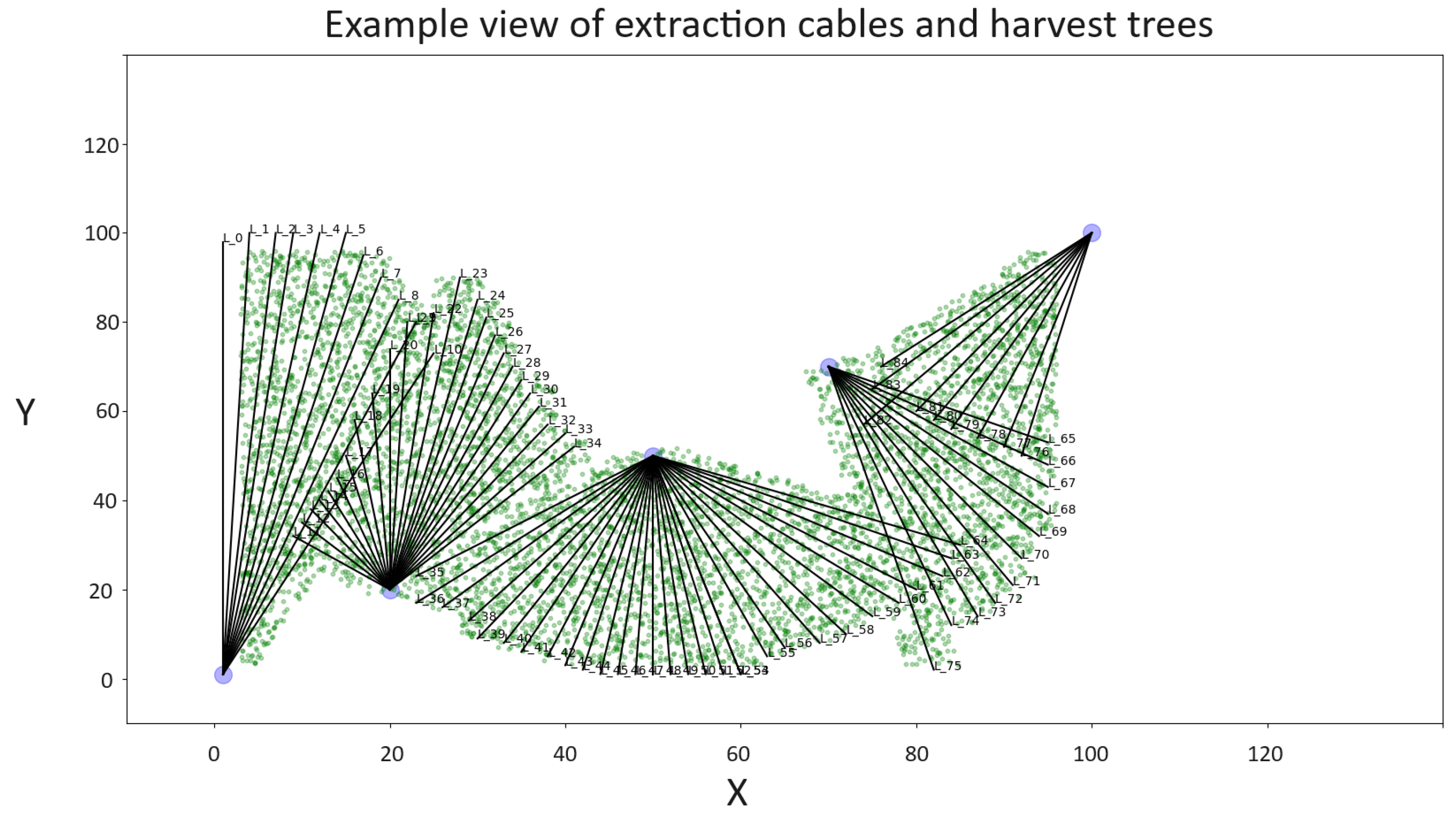
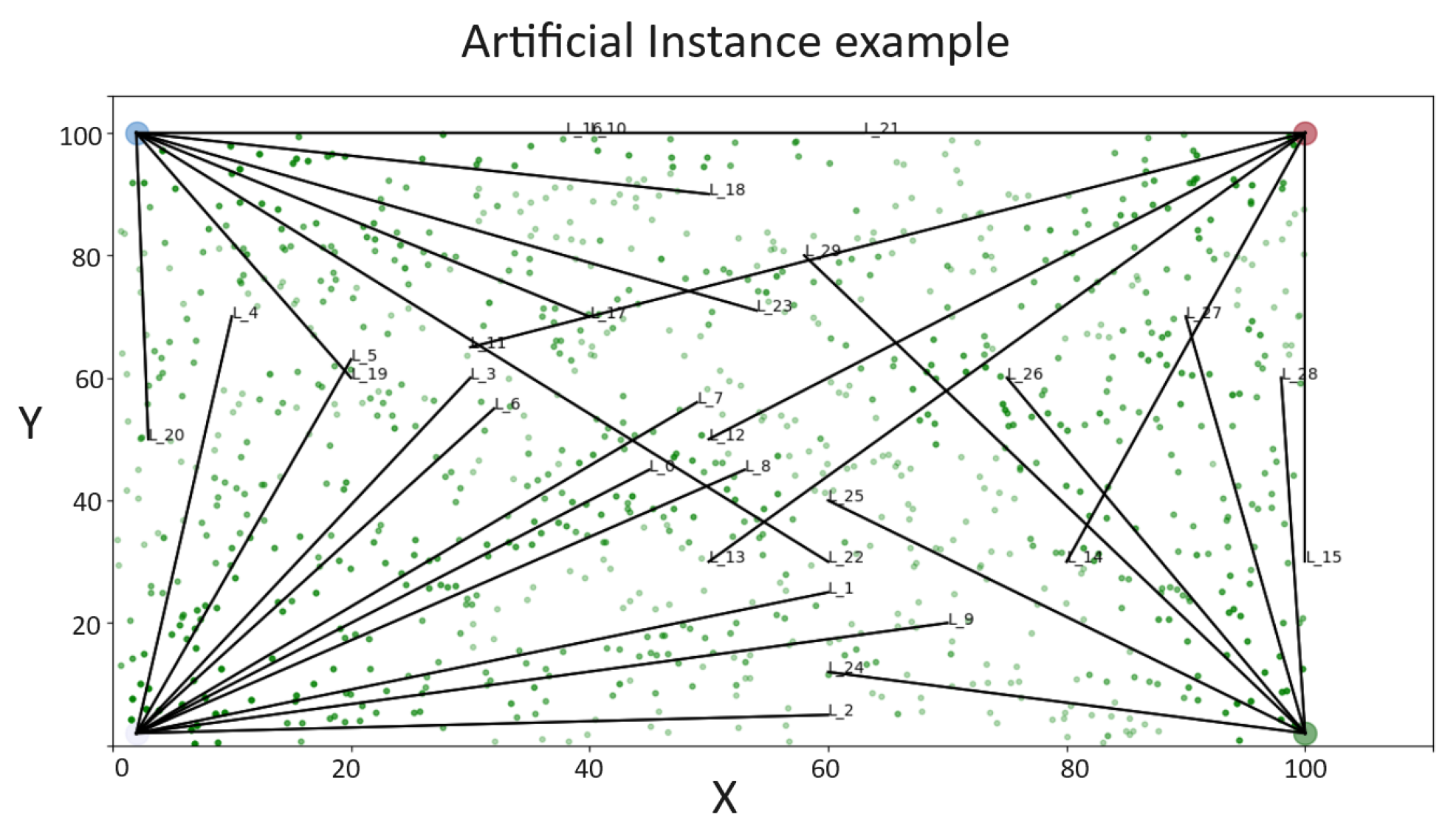
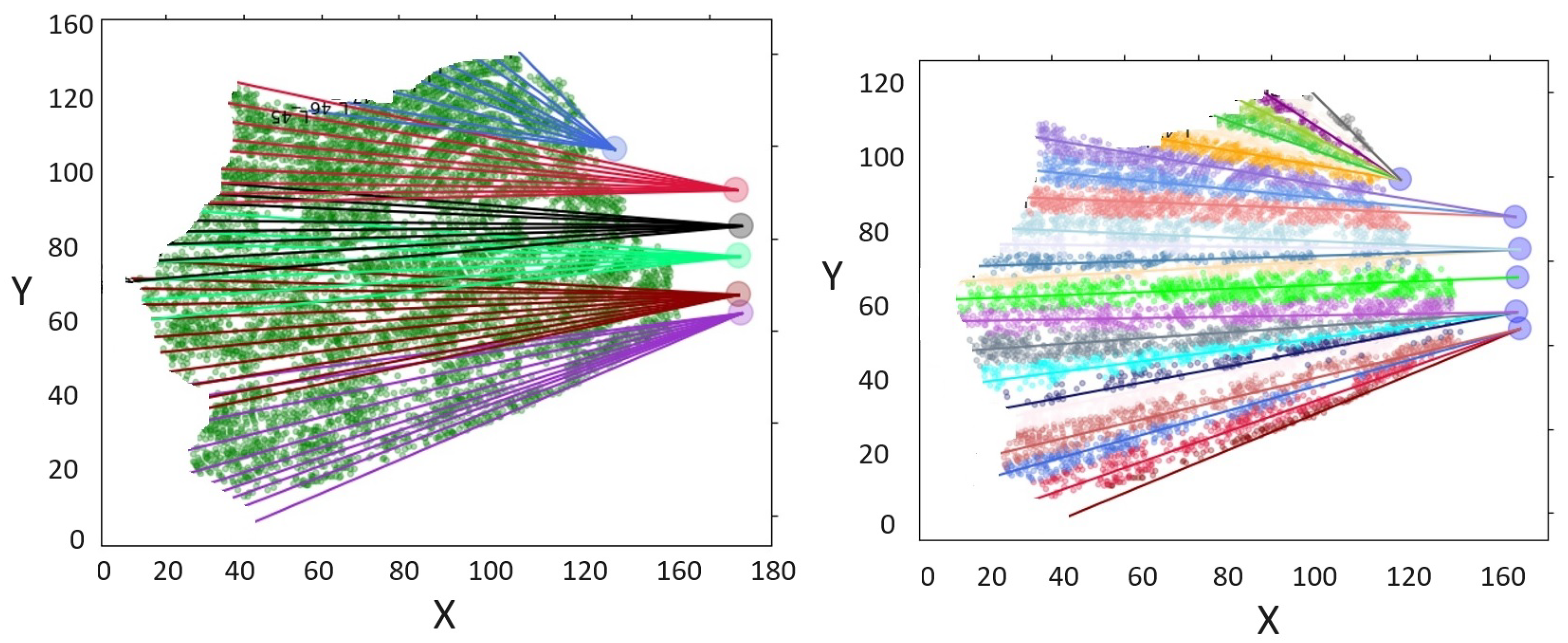
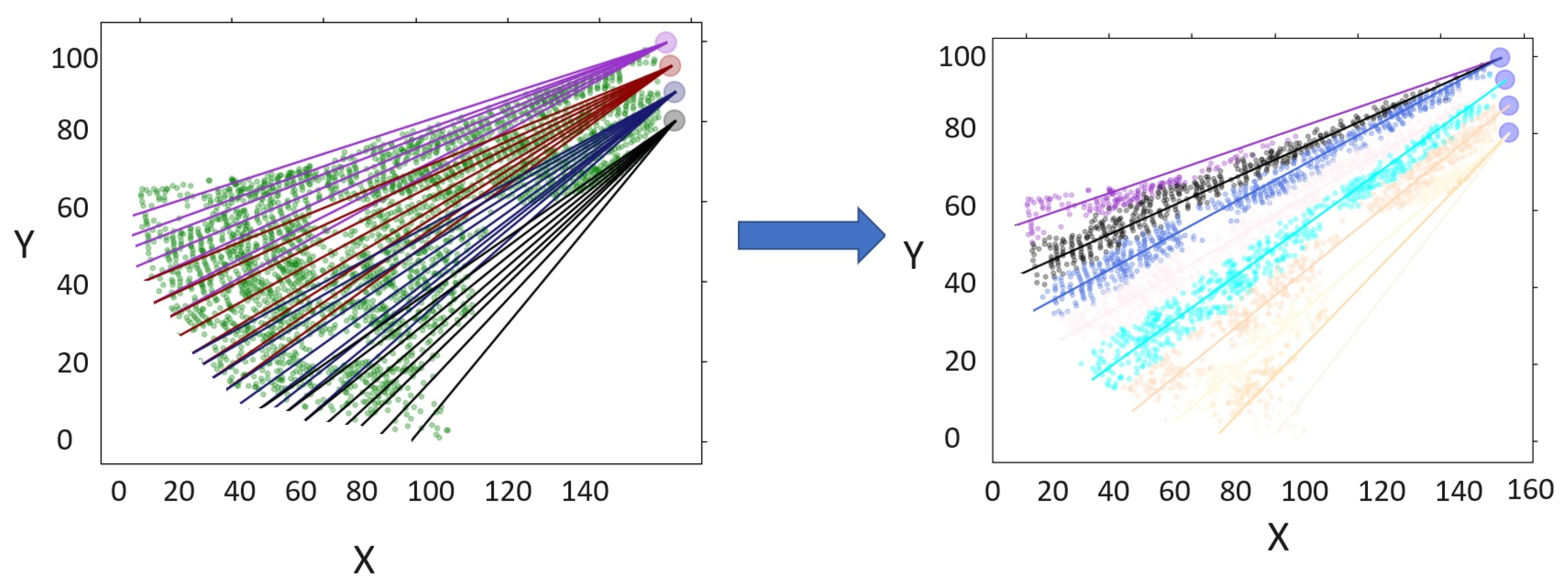
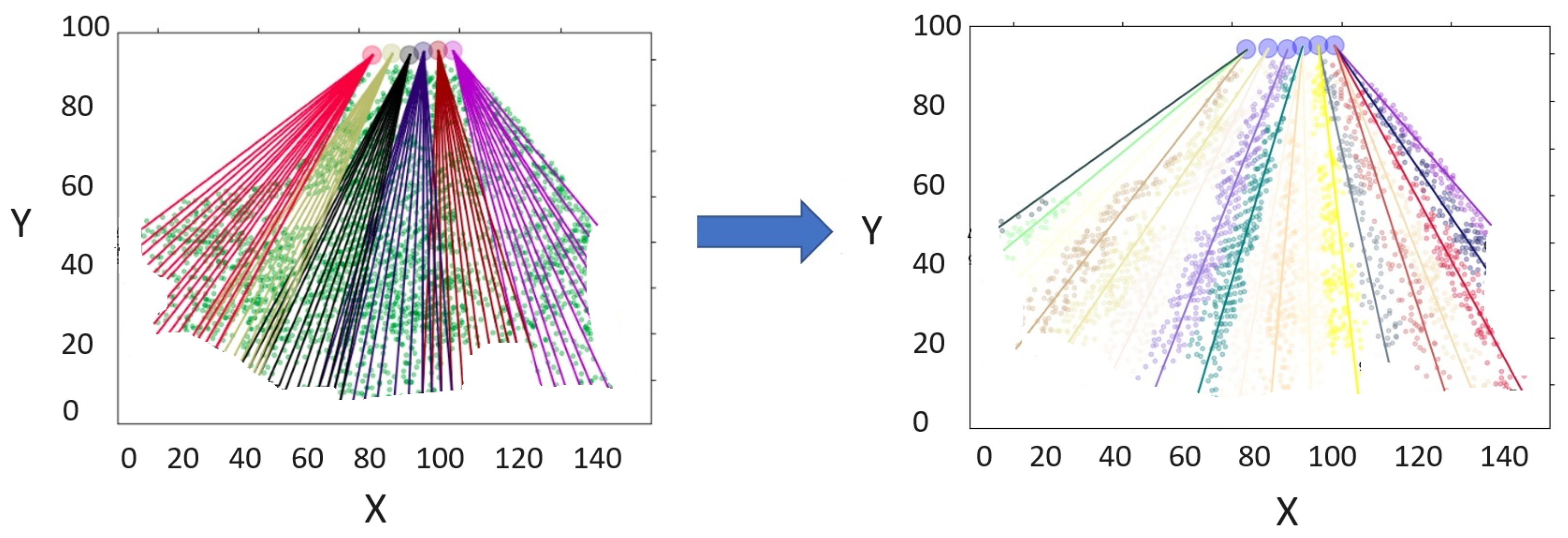
Every tree in a designated sector must be fully extracted, as illustrated by
Figure 5, which presents a typical example for this process. The example scenario presented was artificially generated to better explain the completeness of the problem. The depicted stage features five towers, each equipped with an extraction cable. As
Figure 2 demonstrates, every cable possesses a corresponding extraction logging cone. These cones can overlap with adjacent logging cones, creating areas of intersection. However, a tree falling within this intersection must be exclusively associated with a single line to avoid conflicts and ensure efficient extraction. The example also reveals intersections between different cables, a situation that should be avoided when selecting cables for this task. Overlapping lines could lead to confusion in the assignment of trees and reduce the overall efficiency of the logging process.
In the following section, a mathematical model is introduced. This model effectively addresses the challenge of assigning trees to individual lines and selecting the optimal lines to ensure the most efficient extraction process is produced.
3. Problem Description and Mathematical Formulation
A mathematical model can be defined to solve the tree assignment problem. For this reason, the indices, sets, variables, and parameters are defined. First, the indices are determined: for the tree selection
, for the yarder selection
, for the extraction cable selection
, and indices for a single revolution of a single cable
. Second, previously defined sets of cables are determined depending on the geometry:
corresponding to a set of cables that intersects cable
l and
corresponding to a set of cables that starts from the yarder
Y. The parameters are shown in
Table 1. In this way, the cables allow all of the trees of the problem with the following decision variables to be extracted:
The mathematical model minimizes the extraction and installation time of the problem subject to different constraints. The objective function in Equation (
1) has four main components: minimizing the installation time of the selected yarder
y, minimizing the installation time of the cable
l that starts from the yarder
y, minimizing the extraction of each tree
t by cable
l in revolution
r, and minimizing the time that the logging cycle
r belongs to the cable
l. Constraint (
2) ensures that every tree is associated with a single cable during a single revolution. Constraint (
3) ensures that there is no infeasible selection of extraction cables for the problem considering intersections. To achieve this, it is essential to ensure that each cable
does not intersect with the cable
. Constraint (
4) makes sure that the yarder
y is selected if a cable
is also selected. Constraint (
5) makes sure that the cable
l is selected if a tree
t associated with the variable
is selected. Finally, the model variables are defined in the Constraint (
7).
s.t
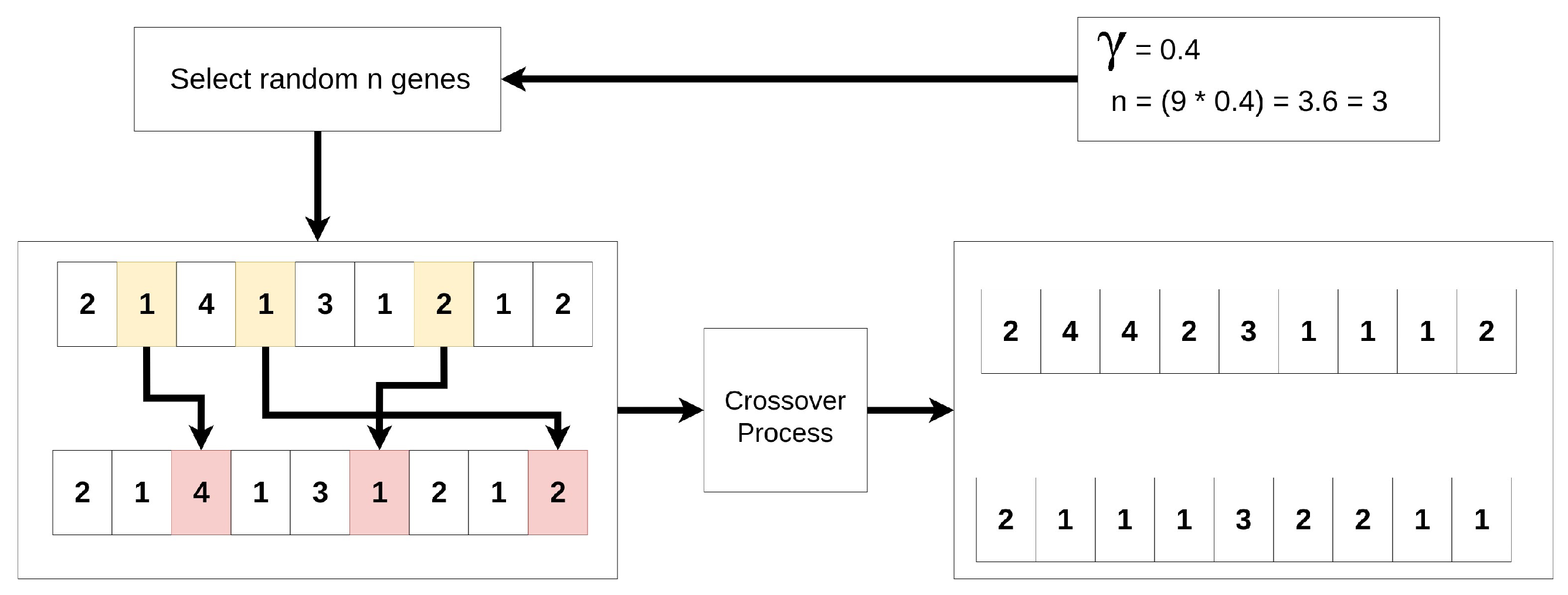
The following section defines a two-phase algorithm to solve the proposed problem: a genetic algorithm that solves the allocation of the trees for a single line and a mathematical model that performs the logging cycles for the best solution from the genetic algorithm.
6. Conclusions
In this paper, we developed a model for an optimization problem associated with forest harvesting. The model addresses three crucial aspects: the implementation time of extraction cables and corresponding yarders, the time required to extract timber based on its distance from the line, and the generation of logging cones. We provided a binary integer linear model and a two-phase approach employing a genetic algorithm. Finally, we compared our different approaches with a manual planning approach (MPA).
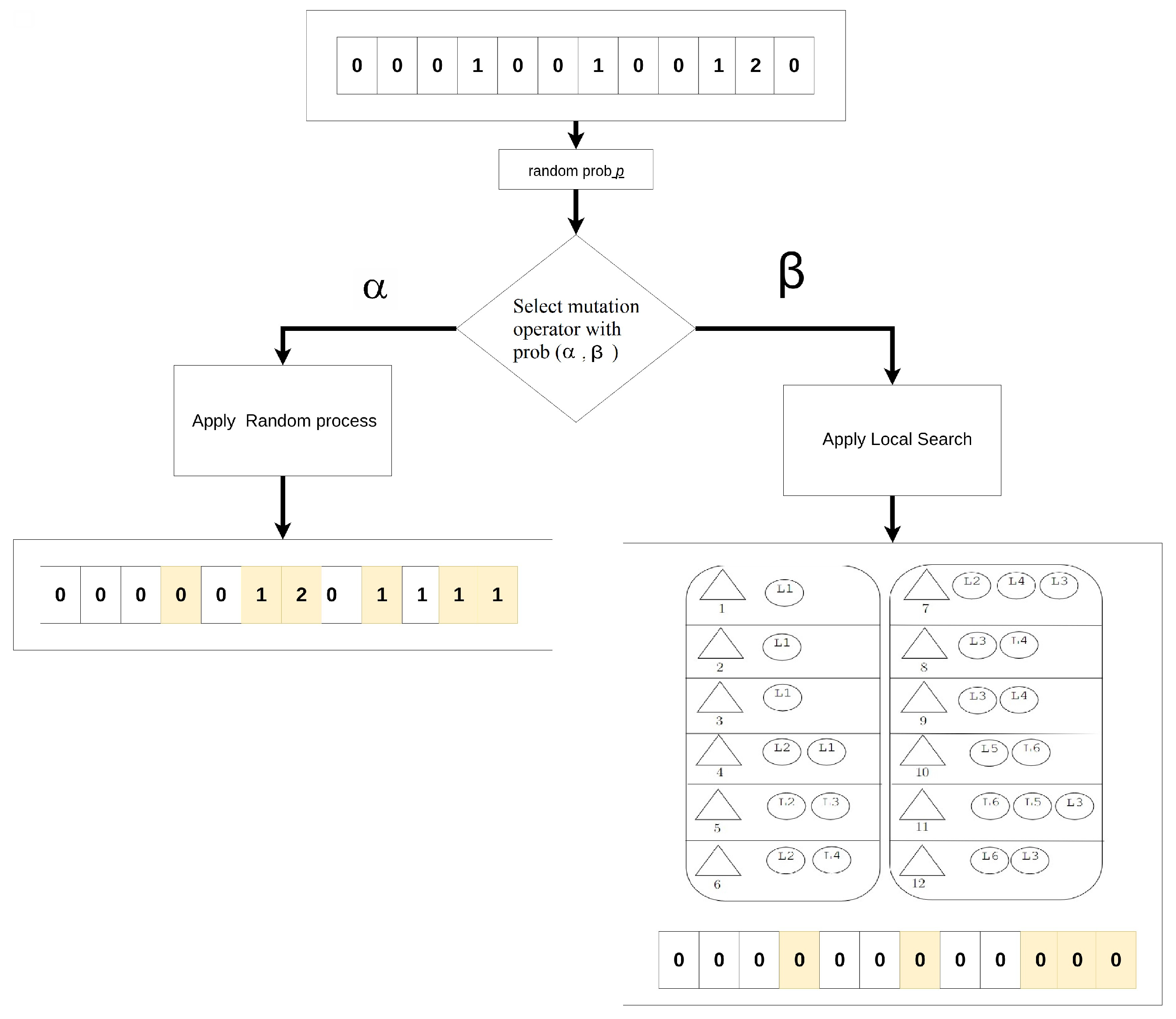
The genetic algorithm is implemented through a two-phase procedure. In the first phase, the evolutionary process identifies candidate lines for extraction, and the fitness function leads to a repair process for the chromosomes of the population. In the second phase, a mathematical model generates the logging cones for each line associated with the best individual selected by the metaheuristic.
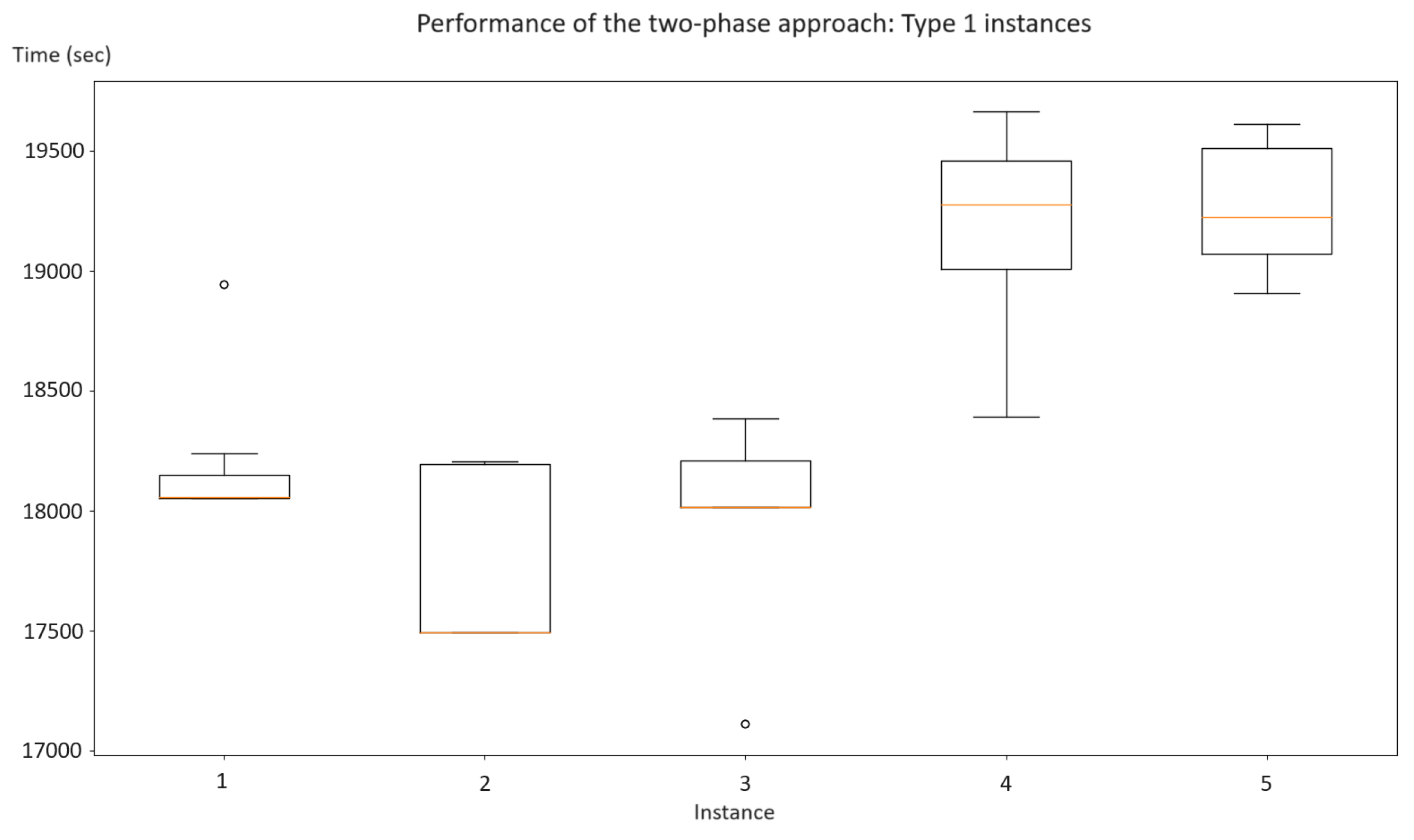
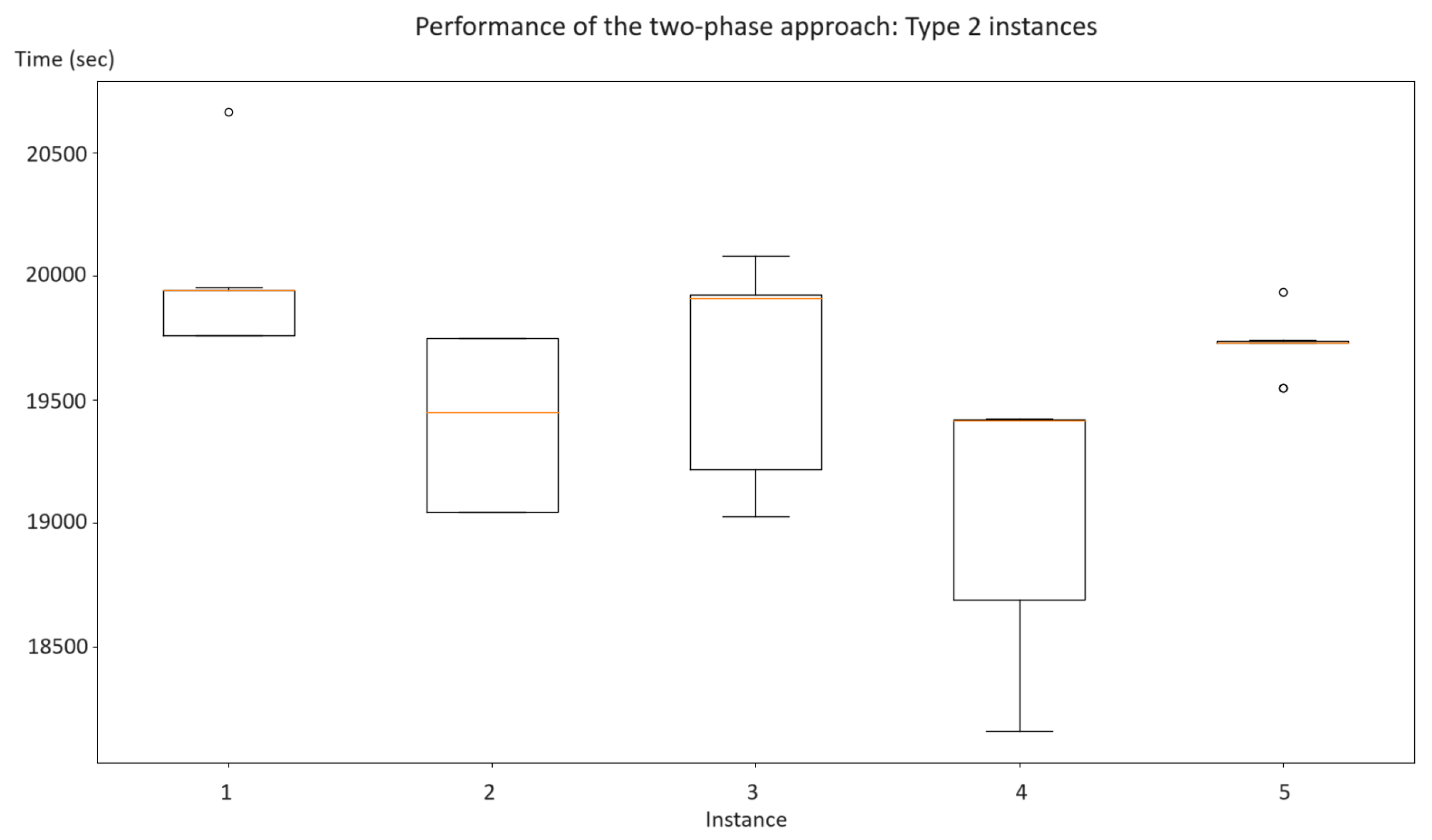
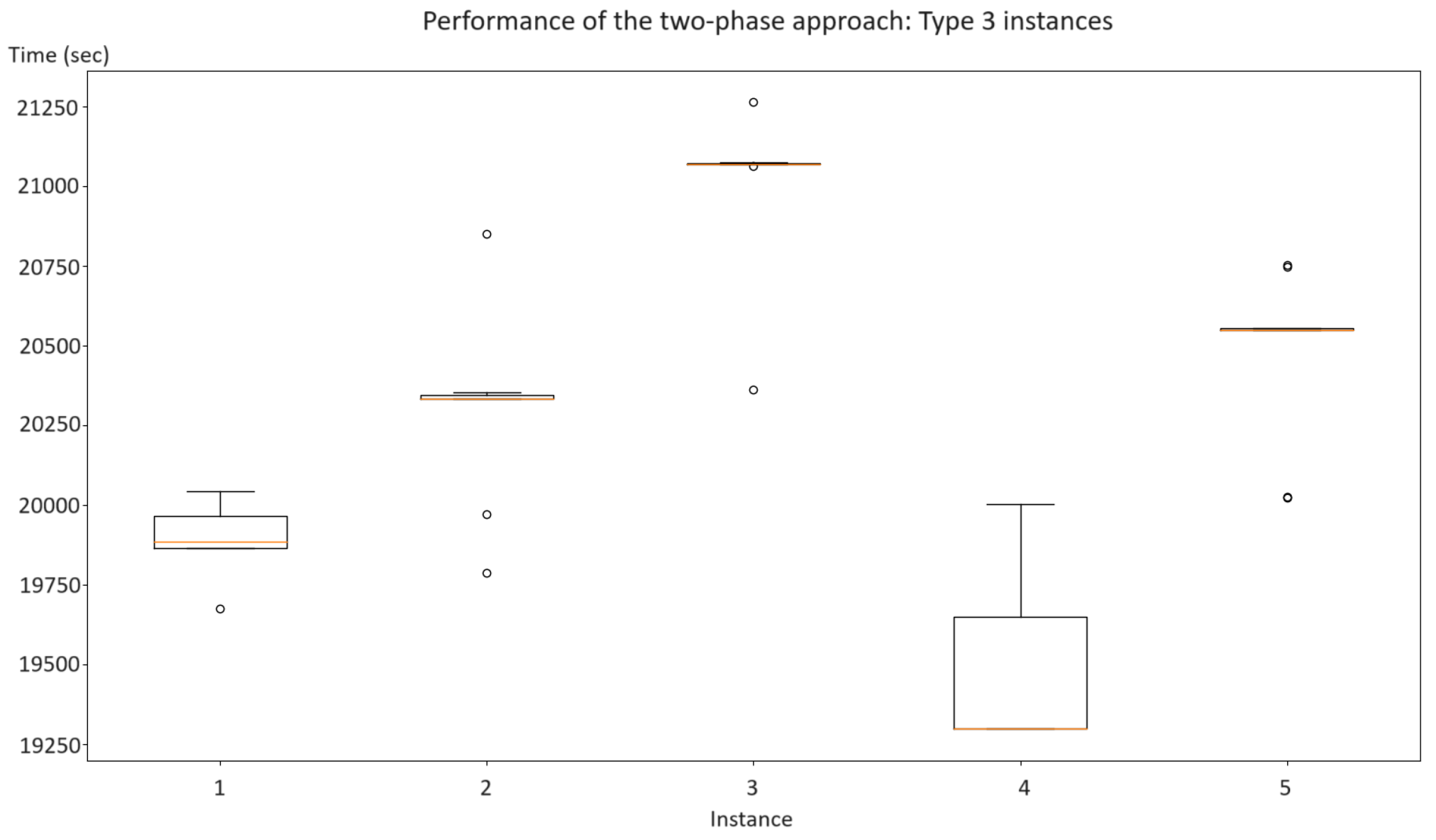
Our findings suggest that the two-phase algorithm offers promising results with a shorter computational time than those provided by a traditional mathematical model. In the cases examined (both randomly generated for this study and real cases from the forestry industry), optimal results were not achieved within an established threshold of 500 s using Gurobi 9.5 and CPLEX 20.0. However, our two-phase approach managed to optimize feasible solutions.
Concerning the topologies addressed in the article, we wish to emphasize that our proposed methodologies are versatile enough to adapt to any given configuration. When observed geometrically, there is a distinct difference between artificial topologies and those derived from real scenarios using drones and Deep Learning. In both situations, our strategies (model and heuristic) have consistently yielded efficient planning times. For future endeavors, we are open to exploring different topological variations and incorporating additional influential factors.
Implementing this approach within companies is entirely feasible. If the focus is on considering extraction and installation times, both the mathematical model and the genetic algorithm approach can be tailored to suit any topology. However, when integrating factors such as fixed expenses, variable expenses, or other input data, the core problem evolves. This necessitates the formulation of new strategies, which could be explored in future research, incorporating insights from existing publications on the topic.
There are several possibilities for future research based on this study. For instance, reducing the problem’s solution space may facilitate obtaining solutions more efficiently. First, a heuristic approach based on Machine Learning could be employed to predict potential lines for harvesting, using various images for training. A second approach is to enhance the proposed genetic algorithm, including a local search after mutation. This process could intensify the chromosomes and allow for better line selection, avoiding local optima. Lastly, it is feasible to consider the application of Lagrangian relaxations to the mathematical model, which could improve bounds during the search process within solvers.
The results of this research are experimental, but they provide a first approach to the integration between Deep Learning and optimization algorithms for the positioning of logging lines. In a first instance, this research addressed the problem in two dimensions, but further experiments should incorporate the topography of the terrain, dasometric variables of the forest, and the operational constraints that this produces in harvesting operations with logging towers.

 ,
, 




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}