

Inverse Reinforcement Learning as the Algorithmic Basis for Theory of Mind: Current Methods and Open Problems

{kind=link}
Abstract
:1. Introduction
2. Background
Given(1) measurements of an agent’s behaviour over time, in a variety of circumstances, (2) if needed, measurements of the sensory inputs to that agent, (3) if available, a model of the environment.Determinethe reward function being optimised.
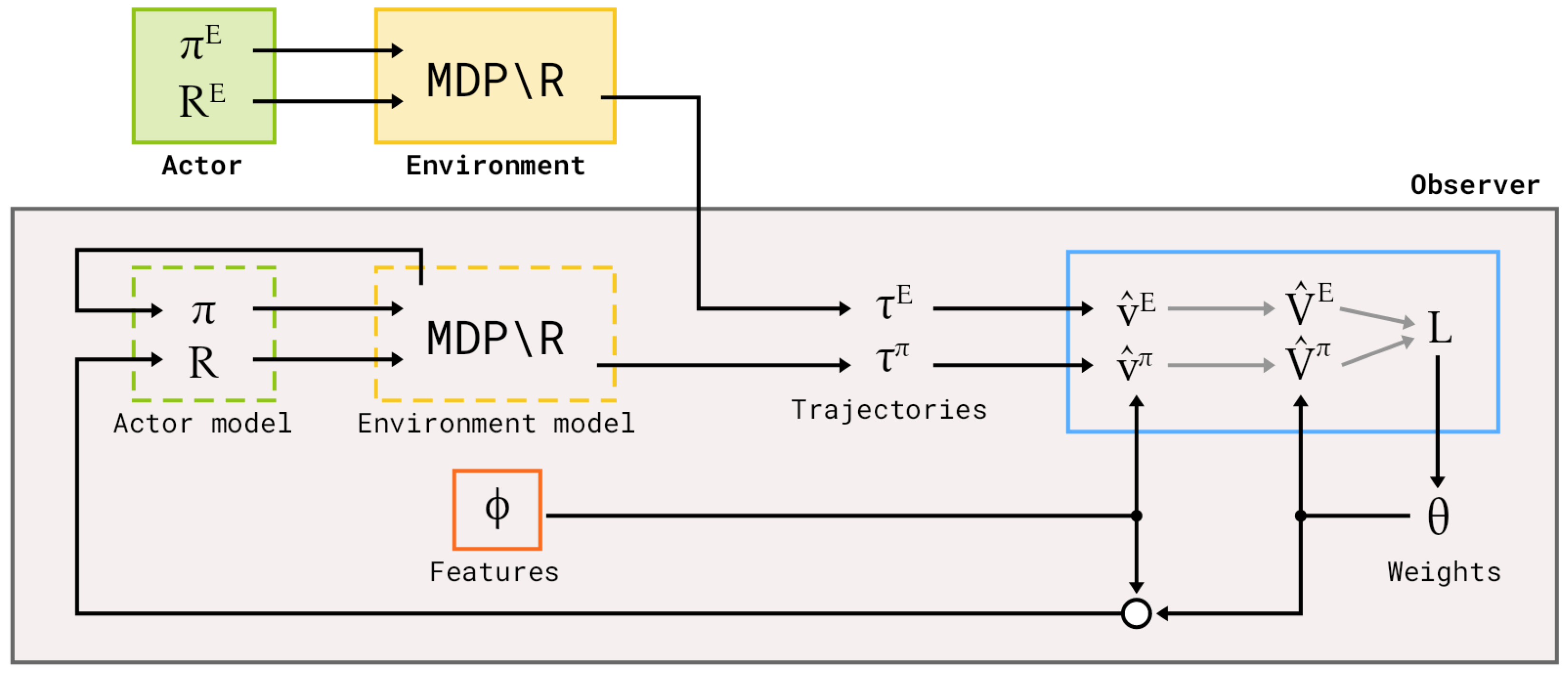
2.1. Problem Formulation and Notation
- —a (finite) set of states
- —a finite set of k actions
- —the state transition probabilitieswhen performing a in s
- —a probability distribution over S fromwhich the initial state is drawn (∼D)
- —a time discount factor
- —a reward function whose absolute valueis bounded by .
2.2. IRL Concepts
2.3. Boltzmann Policies
3. Inferring an Agent’s Desires
3.1. Reward Function Discrimination
3.1.1. Maximum Margin Methods
3.1.1.1. Foundational Work
| Algorithm 1: Algorithm from [40] |
 |
3.1.1.2. Feature Expectation Matching
| Algorithm 2: Excerpt from the algorithm in [42], with adapted notation. |
 |
3.1.1.3. Multiplicative Weights Apprenticeship Learning
3.1.1.4. Linear Programming Apprenticeship Learning
| Algorithm 3: Multiplicative Weights Apprenticeship Learning (MWAL) Algorithm [43] |
 |
3.1.1.5. Maximum Margin Planning
3.1.1.6. Policy Matching
3.1.2. Probabilistic Methods
3.1.2.1. Tree Traversal
| Algorithm 4: Metropolis–Hastings-based approach to approximate from [46] |
 |
3.1.2.2. Policy Walk
| Algorithm 5: Policy Walk Algorithm [59] |
 |
- for prior-agnostic context, a uniform distribution over or an improper prior over ;
- for real-world MDP with parsimonious reward structures, a Gaussian or Laplacian prior (over ); and
- for planning-type problems, where most states can be expected to have low or negative rewards, with some having high rewards, a Beta distribution (over ).
3.1.2.3. Structured Generalisation
3.1.3. Maximum Entropy Methods
3.1.3.1. Maximum Entropy IRL
| Algorithm 6: Maximum Entropy IRL Algorithm [52] |
 |
3.1.3.2. Maximum Causal Entropy IRL
| Algorithm 7: Maximum causal entropy algorithm [63,67] |
 |
3.1.3.3. Extensions
3.1.4. MAP Inference Generalisation
3.1.5. Linearly-Solvable MDPs
3.1.6. Direct Methods
3.1.6.1. Structured Classification-Based IRL
3.1.6.2. Cascaded Supervised IRL
3.1.6.3. Empirical Q-Space Estimation
3.1.6.4. Direct Loss Minimisation
3.1.6.5. Policy Gradient Minimisation
3.1.7. Adversarial Methods
3.2. Reward Function Characterisation
- From current features , optimise (Equations (22) and (23)) and compute the loss-augmented reward function .
- Train under current and obtain the best loss-augmented . Early on in the process, this may differ greatly from the given , as the features are not yet expressive enough.
- Gather a training dataset of features for the classifier, comprising:
- (a)
- , positive examples from ,
- (b)
- , negative examples from .
- Train a classifier on this data to generalise to other .
- Update the feature matrix (expanding in d) by classifying every with the classifier.
4. Inferring an Agent’s Beliefs
4.1. Transition Dynamics
4.2. State Observability
5. Agent’s Intentions
5.1. Suboptimal Demonstrations
5.2. Multiple Intentions
6. Further Considerations
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Frith, C.; Frith, U. Theory of Mind. Curr. Biol. 2005, 15, R644–R645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dennett, D.C. Précis of The Intentional Stance. Behav. Brain Sci. 1988, 11, 495–505. [Google Scholar] [CrossRef]
- Shevlin, H.; Halina, M. Apply Rich Psychological Terms in AI with Care. Nat. Mach. Intell. 2019, 1, 165–167. [Google Scholar] [CrossRef]
- Mitchell, J.P. Mentalizing and Marr: An Information Processing Approach to the Study of Social Cognition. Brain Res. 2006, 1079, 66–75. [Google Scholar] [CrossRef]
- Lockwood, P.L.; Apps, M.A.J.; Chang, S.W.C. Is There a ‘Social’ Brain? Implementations and Algorithms. Trends Cogn. Sci. 2020, 24, 802–813. [Google Scholar] [CrossRef]
- Rusch, T.; Steixner-Kumar, S.; Doshi, P.; Spezio, M.; Gläscher, J. Theory of Mind and Decision Science: Towards a Typology of Tasks and Computational Models. Neuropsychologia 2020, 146, 107488. [Google Scholar] [CrossRef]
- Bakhtin, A.; Brown, N.; Dinan, E.; Farina, G.; Flaherty, C.; Fried, D.; Goff, A.; Gray, J.; Hu, H.; Jacob, A.P.; et al. Human-Level Play in the Game of Diplomacy by Combining Language Models with Strategic Reasoning. Science 2022, 378, 1067–1074. [Google Scholar] [CrossRef]
- Perez-Osorio, J.; Wykowska, A. Adopting the Intentional Stance toward Natural and Artificial Agents. Philos. Psychol. 2020, 33, 369–395. [Google Scholar] [CrossRef] [Green Version]
- Harré, M.S. Information Theory for Agents in Artificial Intelligence, Psychology, and Economics. Entropy 2021, 23, 310. [Google Scholar] [CrossRef]
- Williams, J.; Fiore, S.M.; Jentsch, F. Supporting Artificial Social Intelligence With Theory of Mind. Front. Artif. Intell. 2022, 5, 750763. [Google Scholar] [CrossRef]
- Ho, M.K.; Saxe, R.; Cushman, F. Planning with Theory of Mind. Trends Cogn. Sci. 2022, 26, 959–971. [Google Scholar] [CrossRef]
- Cohen, P.R.; Levesque, H.J. Intention Is Choice with Commitment. Artif. Intell. 1990, 42, 213–261. [Google Scholar] [CrossRef]
- Premack, D.; Woodruff, G. Does the Chimpanzee Have a Theory of Mind? Behav. Brain Sci. 1978, 1, 515–526. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, C.F.; Sridharan, N.S.; Goodson, J.L. The Plan Recognition Problem: An Intersection of Psychology and Artificial Intelligence. Artif. Intell. 1978, 11, 45–83. [Google Scholar] [CrossRef]
- Pollack, M.E. A Model of Plan Inference That Distinguishes between the Beliefs of Actors and Observers. In Proceedings of the 24th Annual Meeting on Association for Computational Linguistics (ACL ’86), New York, NY, USA, 24–27 June 1986; pp. 207–214. [Google Scholar] [CrossRef] [Green Version]
- Konolige, K.; Pollack, M.E. A Representationalist Theory of Intention. In Proceedings of the 13th International Joint Conference on Artifical Intelligence (IJCAI ’93), Chambery, France, 28 August–3 September 1993; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993; Volume 1, pp. 390–395. [Google Scholar]
- Yoshida, W.; Dolan, R.J.; Friston, K.J. Game Theory of Mind. PLoS Comput. Biol. 2008, 4, e1000254. [Google Scholar] [CrossRef]
- Baker, C.; Saxe, R.; Tenenbaum, J. Bayesian Theory of Mind: Modeling Joint Belief-Desire Attribution. In Proceedings of the Annual Meeting of the Cognitive Science Society, Boston, MA, USA, 20–23 July 2011; pp. 2469–2474. [Google Scholar]
- Baker, C.L.; Jara-Ettinger, J.; Saxe, R.; Tenenbaum, J. Rational Quantitative Attribution of Beliefs, Desires and Percepts in Human Mentalizing. Nat. Hum. Behav. 2017, 1, 64. [Google Scholar] [CrossRef]
- Rabinowitz, N.; Perbet, F.; Song, F.; Zhang, C.; Eslami, S.M.A.; Botvinick, M. Machine Theory of Mind. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4218–4227. [Google Scholar]
- Langley, C.; Cirstea, B.I.; Cuzzolin, F.; Sahakian, B.J. Theory of Mind and Preference Learning at the Interface of Cognitive Science, Neuroscience, and AI: A Review. Front. Artif. Intell. 2022, 5, 62. [Google Scholar] [CrossRef]
- Jara-Ettinger, J. Theory of Mind as Inverse Reinforcement Learning. Curr. Opin. Behav. Sci. 2019, 29, 105–110. [Google Scholar] [CrossRef]
- Osa, T.; Pajarinen, J.; Neumann, G.; Bagnell, J.A.; Abbeel, P.; Peters, J. An Algorithmic Perspective on Imitation Learning. ROB 2018, 7, 1–179. [Google Scholar] [CrossRef]
- Ab Azar, N.; Shahmansoorian, A.; Davoudi, M. From Inverse Optimal Control to Inverse Reinforcement Learning: A Historical Review. Annu. Rev. Control 2020, 50, 119–138. [Google Scholar] [CrossRef]
- Arora, S.; Doshi, P. A Survey of Inverse Reinforcement Learning: Challenges, Methods and Progress. Artif. Intell. 2021, 297, 103500. [Google Scholar] [CrossRef]
- Shah, S.I.H.; De Pietro, G. An Overview of Inverse Reinforcement Learning Techniques. Intell. Environ. 2021, 29, 202–212. [Google Scholar] [CrossRef]
- Adams, S.; Cody, T.; Beling, P.A. A Survey of Inverse Reinforcement Learning. Artif. Intell. Rev. 2022, 55, 4307–4346. [Google Scholar] [CrossRef]
- Albrecht, S.V.; Stone, P. Autonomous Agents Modelling Other Agents: A Comprehensive Survey and Open Problems. Artif. Intell. 2018, 258, 66–95. [Google Scholar] [CrossRef] [Green Version]
- González, B.; Chang, L.J. Computational Models of Mentalizing. In The Neural Basis of Mentalizing; Gilead, M., Ochsner, K.N., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 299–315. [Google Scholar] [CrossRef]
- Kennington, C. Understanding Intention for Machine Theory of Mind: A Position Paper. In Proceedings of the 31st IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 29 August–2 September 2022; pp. 450–453. [Google Scholar] [CrossRef]
- Keeney, R.L. Multiattribute Utility Analysis—A Brief Survey. In Systems Theory in the Social Sciences: Stochastic and Control Systems Pattern Recognition Fuzzy Analysis Simulation Behavioral Models; Bossel, H., Klaczko, S., Müller, N., Eds.; Interdisciplinary Systems Research/Interdisziplinäre Systemforschung, Birkhäuser: Basel, Switzerland, 1976; pp. 534–550. [Google Scholar] [CrossRef] [Green Version]
- Russell, S. Learning Agents for Uncertain Environments (Extended Abstract). In Proceedings of the Eleventh Annual Conference on Computational Learning Theory (COLT ’98), Madison, WI, USA, 24–26 July 1998; Association for Computing Machinery: New York, NY, USA, 1998; pp. 101–103. [Google Scholar] [CrossRef] [Green Version]
- Baker, C.L.; Tenenbaum, J.B.; Saxe, R.R. Bayesian Models of Human Action Understanding. In Proceedings of the 18th International Conference on Neural Information Processing Systems (NIPS ’05), Vancouver, BC, Canada, 5–8 December 2005; MIT Press: Cambridge, MA, USA, 2005; pp. 99–106. [Google Scholar]
- Syed, U.; Bowling, M.; Schapire, R.E. Apprenticeship Learning Using Linear Programming. In Proceedings of the 25th International Conference on Machine Learning (ICML ’08), Helsinki, Finland, 5–9 July 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 1032–1039. [Google Scholar] [CrossRef]
- Boularias, A.; Chaib-draa, B. Apprenticeship Learning with Few Examples. Neurocomputing 2013, 104, 83–96. [Google Scholar] [CrossRef]
- Carmel, D.; Markovitch, S. Learning Models of the Opponent’s Strategy in Game Playing. In Proceedings of the AAAI Fall Symposium on Games: Planing and Learning, Raleigh, NC, USA, 22–24 October 1993; pp. 140–147. [Google Scholar]
- Samuelson, P.A. A Note on the Pure Theory of Consumer’s Behaviour. Economica 1938, 5, 61–71. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Ziebart, B.D.; Bagnell, J.A.; Dey, A.K. Modeling Interaction via the Principle of Maximum Causal Entropy. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML ’10), Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 1255–1262. [Google Scholar]
- Ng, A.Y.; Russell, S.J. Algorithms for Inverse Reinforcement Learning. In Proceedings of the Seventeenth International Conference on Machine Learning (ICML ’00), Stanford, CA, USA, 29 June–2 July 2000; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2000; pp. 663–670. [Google Scholar]
- Chajewska, U.; Koller, D. Utilities as Random Variables: Density Estimation and Structure Discovery. In Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence (UAI ’00), Stanford, CA, USA, 30 June–3 July 2000. [Google Scholar] [CrossRef]
- Abbeel, P.; Ng, A.Y. Apprenticeship Learning via Inverse Reinforcement Learning. In Proceedings of the Twenty-First International Conference on Machine Learning (ICML ’04), Banff, AB, Canada, 4–8 July 2004; Association for Computing Machinery: New York, NY, USA, 2004. [Google Scholar] [CrossRef]
- Syed, U.; Schapire, R.E. A Game-Theoretic Approach to Apprenticeship Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; Platt, J., Koller, D., Singer, Y., Roweis, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2007; Volume 20. [Google Scholar]
- Von Neumann, J. On the Theory of Parlor Games. Math. Ann. 1928, 100, 295–320. [Google Scholar]
- Freund, Y.; Schapire, R.E. Adaptive Game Playing Using Multiplicative Weights. Games Econ. Behav. 1999, 29, 79–103. [Google Scholar] [CrossRef] [Green Version]
- Chajewska, U.; Koller, D.; Ormoneit, D. Learning an Agent’s Utility Function by Observing Behavior. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML ’01), Williamstown, MA, USA, 28 June–1 July 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 35–42. [Google Scholar]
- Gallese, V.; Goldman, A. Mirror Neurons and the Simulation Theory of Mind-Reading. Trends Cogn. Sci. 1998, 2, 493–501. [Google Scholar] [CrossRef]
- Shanton, K.; Goldman, A. Simulation Theory. WIREs Cogn. Sci. 2010, 1, 527–538. [Google Scholar] [CrossRef]
- Ratliff, N.D.; Bagnell, J.A.; Zinkevich, M.A. Maximum Margin Planning. In Proceedings of the 23rd International Conference on Machine Learning (ICML ’06), Pittsburgh, PA, USA, 25–29 June 2006; ACM Press: Pittsburgh, PA, USA, 2006; pp. 729–736. [Google Scholar] [CrossRef] [Green Version]
- Reddy, S.; Dragan, A.; Levine, S.; Legg, S.; Leike, J. Learning Human Objectives by Evaluating Hypothetical Behavior. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 8020–8029. [Google Scholar]
- Neu, G.; Szepesvári, C. Training Parsers by Inverse Reinforcement Learning. Mach. Learn. 2009, 77, 303. [Google Scholar] [CrossRef]
- Ziebart, B.D.; Maas, A.; Bagnell, J.A.; Dey, A.K. Maximum Entropy Inverse Reinforcement Learning. In Proceedings of the 23rd National Conference on Artificial Intelligence-Volume 3 (AAAI ’08), Chicago, IL, USA, 13–17 July 2008; AAAI Press: Chicago, OL, USA, 2008; pp. 1433–1438. [Google Scholar]
- Neu, G.; Szepesvári, C. Apprenticeship Learning Using Inverse Reinforcement Learning and Gradient Methods. In Proceedings of the Twenty-Third Conference on Uncertainty in Artificial Intelligence (UAI ’07), Vancouver, BC, Canada, 19–22 July 2007; AUAI Press: Arlington, VA, USA, 2007; pp. 295–302. [Google Scholar]
- Ni, T.; Sikchi, H.; Wang, Y.; Gupta, T.; Lee, L.; Eysenbach, B. F-IRL: Inverse Reinforcement Learning via State Marginal Matching. In Proceedings of the 2020 Conference on Robot Learning, Virtual Event, 16–18 November 2020; pp. 529–551. [Google Scholar]
- Lopes, M.; Melo, F.; Montesano, L. Active Learning for Reward Estimation in Inverse Reinforcement Learning. In Proceedings of the 2009 European Conference on Machine Learning and Knowledge Discovery in Databases-Volume Part II (ECMLPKDD ’09), Bled, Slovenia, 7–11 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 31–46. [Google Scholar]
- Jin, M.; Damianou, A.; Abbeel, P.; Spanos, C. Inverse Reinforcement Learning via Deep Gaussian Process. In Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI), Sydney, Australia, 11–15 August 2017; p. 10. [Google Scholar]
- Roa-Vicens, J.; Chtourou, C.; Filos, A.; Rullan, F.; Gal, Y.; Silva, R. Towards Inverse Reinforcement Learning for Limit Order Book Dynamics. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar] [CrossRef]
- Chan, A.J.; Schaar, M. Scalable Bayesian Inverse Reinforcement Learning. In Proceedings of the 2021 International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Ramachandran, D.; Amir, E. Bayesian Inverse Reinforcement Learning. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI ’07), Hyderabad, India, 6–12 January 2007; pp. 2586–2591. [Google Scholar]
- Choi, J.; Kim, K.e. MAP Inference for Bayesian Inverse Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; Curran Associates, Inc.: Red Hook, NY, USA, 2011. [Google Scholar]
- Melo, F.S.; Lopes, M.; Ferreira, R. Analysis of Inverse Reinforcement Learning with Perturbed Demonstrations. In Proceedings of the 19th European Conference on Artificial Intelligence, Lisbon, Portugal, 16–20 August 2010; pp. 349–354. [Google Scholar]
- Rothkopf, C.A.; Dimitrakakis, C. Preference Elicitation and Inverse Reinforcement Learning. In Proceedings of the Machine Learning and Knowledge Discovery in Databases (ECMLPKDD ’11), Athens, Greece, 5–9 September 2011; Gunopulos, D., Hofmann, T., Malerba, D., Vazirgiannis, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 34–48. [Google Scholar] [CrossRef] [Green Version]
- Ziebart, B.D.; Bagnell, J.A.; Dey, A.K. The Principle of Maximum Causal Entropy for Estimating Interacting Processes. IEEE Trans. Inf. Theory 2013, 59, 1966–1980. [Google Scholar] [CrossRef] [Green Version]
- Kramer, G. Directed Information for Channels with Feedback. Ph.D. Thesis, Hartung-Gorre Germany, Swiss Federal Institute of Technology, Zurich, Switzerland, 1998. [Google Scholar]
- Bloem, M.; Bambos, N. Infinite Time Horizon Maximum Causal Entropy Inverse Reinforcement Learning. In Proceedings of the 53rd IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014; pp. 4911–4916. [Google Scholar] [CrossRef]
- Zhou, Z.; Bloem, M.; Bambos, N. Infinite Time Horizon Maximum Causal Entropy Inverse Reinforcement Learning. IEEE Trans. Autom. Control 2018, 63, 2787–2802. [Google Scholar] [CrossRef]
- Ziebart, B.D. Modeling Purposeful Adaptive Behavior with the Principle of Maximum Causal Entropy. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 2010. [Google Scholar]
- Boularias, A.; Kober, J.; Peters, J. Relative Entropy Inverse Reinforcement Learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 182–189. [Google Scholar]
- Snoswell, A.J.; Singh, S.P.N.; Ye, N. Revisiting Maximum Entropy Inverse Reinforcement Learning: New Perspectives and Algorithms. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI ’20), Canberra, ACT, Australia, 1–4 December 2020; pp. 241–249. [Google Scholar] [CrossRef]
- Aghasadeghi, N.; Bretl, T. Maximum Entropy Inverse Reinforcement Learning in Continuous State Spaces with Path Integrals. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 1561–1566. [Google Scholar] [CrossRef] [Green Version]
- Audiffren, J.; Valko, M.; Lazaric, A.; Ghavamzadeh, M. Maximum Entropy Semi-Supervised Inverse Reinforcement Learning. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3315–3321. [Google Scholar]
- Finn, C.; Christiano, P.; Abbeel, P.; Levine, S. A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models. arXiv 2016, arXiv:1611.03852. [Google Scholar] [CrossRef]
- Shiarlis, K.; Messias, J.; Whiteson, S. Inverse Reinforcement Learning from Failure. In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems (AAMAS ’16), Singapore, 9–13 May 2016; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2016; pp. 1060–1068. [Google Scholar]
- Viano, L.; Huang, Y.T.; Kamalaruban, P.; Weller, A.; Cevher, V. Robust Inverse Reinforcement Learning under Transition Dynamics Mismatch. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–14 December 2021; Curran Associates, Inc.: Red Hook, NY, USA, 2021; 34, pp. 25917–25931. [Google Scholar]
- Sanghvi, N.; Usami, S.; Sharma, M.; Groeger, J.; Kitani, K. Inverse Reinforcement Learning with Explicit Policy Estimates. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; pp. 9472–9480. [Google Scholar] [CrossRef]
- Dvijotham, K.; Todorov, E. Inverse Optimal Control with Linearly-Solvable MDPs. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML ’10), Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 335–342. [Google Scholar]
- Todorov, E. Linearly-Solvable Markov Decision Problems. In Advances in Neural Information Processing Systems 19, Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; Schölkopf, B., Platt, J.C., Hofmann, T., Eds.; MIT Press: Cambridge, MA, USA, 2006; pp. 1369–1376. [Google Scholar]
- Klein, E.; Geist, M.; Piot, B.; Pietquin, O. Inverse Reinforcement Learning through Structured Classification. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS ’12), Lake Tahoe, NV, USA, 3–8 December 2012; Curran Associates, Inc.: Red Hook, NY, USA, 2012; 25. [Google Scholar]
- Klein, E.; Piot, B.; Geist, M.; Pietquin, O. A Cascaded Supervised Learning Approach to Inverse Reinforcement Learning. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 23–27 September 2013; Lecture Notes in Computer Science; Blockeel, H., Kersting, K., Nijssen, S., Železný, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–16. [Google Scholar] [CrossRef]
- Doerr, A.; Ratliff, N.; Bohg, J.; Toussaint, M.; Schaal, S. Direct Loss Minimization Inverse Optimal Control. In Proceedings of the Robotics: Science and Systems Conference, Rome, Italy, 13–17 July 2015. [Google Scholar]
- Pirotta, M.; Restelli, M. Inverse Reinforcement Learning through Policy Gradient Minimization. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Metelli, A.M.; Pirotta, M.; Restelli, M. Compatible Reward Inverse Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Ho, J.; Ermon, S. Generative Adversarial Imitation Learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Yu, L.; Yu, T.; Finn, C.; Ermon, S. Meta-Inverse Reinforcement Learning with Probabilistic Context Variables. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Fu, J.; Luo, K.; Levine, S. Learning Robust Rewards with Adverserial Inverse Reinforcement Learning. In Proceedings of the 6th International Conference on Learning Representations (ICLR ’18), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, P.; Li, H.; Chan, C.Y. Meta-Adversarial Inverse Reinforcement Learning for Decision-making Tasks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 12632–12638. [Google Scholar] [CrossRef]
- Peng, X.B.; Kanazawa, A.; Toyer, S.; Abbeel, P.; Levine, S. Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, P.; Wang, P.; Liu, D.; Chen, J.; Li, H.; Chan, C.Y.; Chan, C.Y. Decision Making for Autonomous Driving via Augmented Adversarial Inverse Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar] [CrossRef]
- Sun, J.; Yu, L.; Dong, P.; Lu, B.; Zhou, B. Adversarial Inverse Reinforcement Learning With Self-Attention Dynamics Model. IEEE Robot. Autom. Lett. 2021, 6, 1880–1886. [Google Scholar] [CrossRef]
- Zhou, L.; Small, K. Inverse Reinforcement Learning with Natural Language Goals. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar] [CrossRef]
- Ratliff, N.; Bradley, D.; Bagnell, J.; Chestnutt, J. Boosting Structured Prediction for Imitation Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–9 December 2006; MIT Press: Cambridge, MA, USA, 2006; Volume 19. [Google Scholar]
- Ratliff, N.D.; Silver, D.; Bagnell, J.A. Learning to Search: Functional Gradient Techniques for Imitation Learning. Auton. Robot 2009, 27, 25–53. [Google Scholar] [CrossRef]
- Levine, S.; Popovic, Z.; Koltun, V. Feature Construction for Inverse Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS ’10), Vancouver, BC, Canada, 6–11 December 2010; Curran Associates, Inc.: Red Hook, NY, USA, 2010; Volume 23. [Google Scholar]
- Jin, Z.J.; Qian, H.; Zhu, M.L. Gaussian Processes in Inverse Reinforcement Learning. In Proceedings of the 2010 International Conference on Machine Learning and Cybernetics (ICMLC ’10), Qingdao, China, 11–14 July 2010; Volume 1, pp. 225–230. [Google Scholar] [CrossRef]
- Levine, S.; Popovic, Z.; Koltun, V. Nonlinear Inverse Reinforcement Learning with Gaussian Processes. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–17 December 2011; Curran Associates, Inc.: Red Hook, NY, USA, 2011; Volume 24. [Google Scholar]
- Wulfmeier, M.; Ondruska, P.; Posner, I. Maximum Entropy Deep Inverse Reinforcement Learning. arXiv 2015, arXiv:1507.04888. [Google Scholar] [CrossRef]
- Levine, S.; Koltun, V. Continuous Inverse Optimal Control with Locally Optimal Examples. In Proceedings of the 29th International Conference on Machine Learning (ICML ’12), Edinburgh, Scotland, 26 June–1 July2012; Omnipress: Madison, WI, USA, 2012; pp. 475–482. [Google Scholar]
- Kim, K.E.; Park, H.S. Imitation Learning via Kernel Mean Embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Choi, J.; Kim, K.E. Bayesian Nonparametric Feature Construction for Inverse Reinforcement Learning. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence (IJCAI ’13), Beijing, China, 3–9 August 2013; p. 7. [Google Scholar]
- Michini, B.; How, J.P. Bayesian Nonparametric Inverse Reinforcement Learning. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Bristol, UK, 24–28 September 2012; Lecture Notes in Computer Science; Flach, P.A., De Bie, T., Cristianini, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 148–163. [Google Scholar] [CrossRef] [Green Version]
- Wulfmeier, M.; Wang, D.Z.; Posner, I. Watch This: Scalable Cost-Function Learning for Path Planning in Urban Environments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 2089–2095. [Google Scholar] [CrossRef]
- Bogdanovic, M.; Markovikj, D.; Denil, M.; de Freitas, N. Deep Apprenticeship Learning for Playing Video Games. In Papers from the 2015 AAAI Workshop; AAAI Technical Report WS-15-10; The AAAI Press: Palo Alto, CA, USA, 2015. [Google Scholar]
- Markovikj, D. Deep Apprenticeship Learning for Playing Games. Master’s Thesis, University of Oxford, Oxford, UK, 2014. [Google Scholar]
- Xia, C.; El Kamel, A. Neural Inverse Reinforcement Learning in Autonomous Navigation. Robot. Auton. Syst. 2016, 84, 1–14. [Google Scholar] [CrossRef]
- Uchibe, E. Model-Free Deep Inverse Reinforcement Learning by Logistic Regression. Neural. Process Lett. 2018, 47, 891–905. [Google Scholar] [CrossRef] [Green Version]
- Finn, C.; Levine, S.; Abbeel, P. Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization. In Proceedings of the 33rd International Conference on International Conference on Machine Learning (ICML ’16), New York, NY, USA, 19–24 June 2016; Volume 48, pp. 49–58. [Google Scholar]
- Achim, A.M.; Guitton, M.; Jackson, P.L.; Boutin, A.; Monetta, L. On What Ground Do We Mentalize? Characteristics of Current Tasks and Sources of Information That Contribute to Mentalizing Judgments. Psychol. Assess. 2013, 25, 117–126. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.; Garg, S.; Shiragur, K.; Ermon, S. Reward Identification in Inverse Reinforcement Learning. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 5496–5505. [Google Scholar]
- Cao, H.; Cohen, S.; Szpruch, L. Identifiability in Inverse Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–14 December 2021; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 12362–12373. [Google Scholar]
- Tauber, S.; Steyvers, M. Using Inverse Planning and Theory of Mind for Social Goal Inference. In Proceedings of the 33rd Annual Meeting of the Cognitive Science Society, Boston, MA, USA, 20–23 July 2011; Volume 1, pp. 2480–2485. [Google Scholar]
- Rust, J. Structural Estimation of Markov Decision Processes. In Handbook of Econometrics; Elsevier: Amsterdam, The Netherlands, 1994; Volume 4, pp. 3081–3143. [Google Scholar] [CrossRef]
- Damiani, A.; Manganini, G.; Metelli, A.M.; Restelli, M. Balancing Sample Efficiency and Suboptimality in Inverse Reinforcement Learning. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 4618–4629. [Google Scholar]
- Jarboui, F.; Perchet, V. A Generalised Inverse Reinforcement Learning Framework. arXiv 2021, arXiv:2105.11812. [Google Scholar] [CrossRef]
- Bogert, K.; Doshi, P. Toward Estimating Others’ Transition Models under Occlusion for Multi-Robot IRL. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Ramponi, G.; Likmeta, A.; Metelli, A.M.; Tirinzoni, A.; Restelli, M. Truly Batch Model-Free Inverse Reinforcement Learning about Multiple Intentions. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, Virtual Event, 26–28 August 2020; pp. 2359–2369. [Google Scholar]
- Xue, W.; Lian, B.; Fan, J.; Kolaric, P.; Chai, T.; Lewis, F.L. Inverse Reinforcement Q-Learning Through Expert Imitation for Discrete-Time Systems. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Donge, V.S.; Lian, B.; Lewis, F.L.; Davoudi, A. Multi-Agent Graphical Games with Inverse Reinforcement Learning. IEEE Trans. Control. Netw. Syst. 2022. [Google Scholar] [CrossRef]
- Herman, M.; Gindele, T.; Wagner, J.; Schmitt, F.; Burgard, W. Inverse Reinforcement Learning with Simultaneous Estimation of Rewards and Dynamics. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 102–110. [Google Scholar]
- Reddy, S.; Dragan, A.; Levine, S. Where Do You Think You’ Re Going? Inferring Beliefs about Dynamics from Behavior. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Gong, Z.; Zhang, Y. What Is It You Really Want of Me? Generalized Reward Learning with Biased Beliefs about Domain Dynamics. Proc. AAAI Conf. Artif. Intell. 2020, 34, 2485–2492. [Google Scholar] [CrossRef]
- Munzer, T.; Piot, B.; Geist, M.; Pietquin, O.; Lopes, M. Inverse Reinforcement Learning in Relational Domains. In Proceedings of the 24th International Conference on Artificial Intelligence (IJCAI ’15), Buenos Aires, Argentina, 25–31 July 2015; AAAI Press: Palo Alto, CA, USA, 2015; pp. 3735–3741. [Google Scholar]
- Chae, J.; Han, S.; Jung, W.; Cho, M.; Choi, S.; Sung, Y. Robust Imitation Learning against Variations in Environment Dynamics. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 2828–2852. [Google Scholar]
- Golub, M.; Chase, S.; Yu, B. Learning an Internal Dynamics Model from Control Demonstration. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 606–614. [Google Scholar]
- Rafferty, A.N.; LaMar, M.M.; Griffiths, T.L. Inferring Learners’ Knowledge From Their Actions. Cogn. Sci. 2015, 39, 584–618. [Google Scholar] [CrossRef]
- Rafferty, A.N.; Jansen, R.A.; Griffiths, T.L. Using Inverse Planning for Personalized Feedback. In Proceedings of the 9th International Conference on Educational Data Mining, Raleigh, NC, USA, 29 June–2 July 2016; p. 6. [Google Scholar]
- Choi, J.; Kim, K.E. Inverse Reinforcement Learning in Partially Observable Environments. J. Mach. Learn. Res. 2011, 12, 691–730. [Google Scholar]
- Baker, C.L.; Saxe, R.; Tenenbaum, J.B. Action Understanding as Inverse Planning. Cognition 2009, 113, 329–349. [Google Scholar] [CrossRef]
- Nielsen, T.D.; Jensen, F.V. Learning a Decision Maker’s Utility Function from (Possibly) Inconsistent Behavior. Artif. Intell. 2004, 160, 53–78. [Google Scholar] [CrossRef] [Green Version]
- Zheng, J.; Liu, S.; Ni, L.M. Robust Bayesian Inverse Reinforcement Learning with Sparse Behavior Noise. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence (AAAI ’14), Québec City, QC, Canada 27–31 July 2014; AAAI Press: Palo Alto, CA, USA, 2014; pp. 2198–2205. [Google Scholar]
- Lian, B.; Xue, W.; Lewis, F.L.; Chai, T. Inverse Reinforcement Learning for Adversarial Apprentice Games. IEEE Trans. Neural Netw. 2021. [Google Scholar] [CrossRef]
- Noothigattu, R.; Yan, T.; Procaccia, A.D. Inverse Reinforcement Learning From Like-Minded Teachers. Proc. AAAI Conf. Artif. Intell. 2021, 35, 9197–9204. [Google Scholar] [CrossRef]
- Brown, D.; Goo, W.; Nagarajan, P.; Niekum, S. Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 783–792. [Google Scholar]
- Armstrong, S.; Mindermann, S. Occam’ s Razor Is Insufficient to Infer the Preferences of Irrational Agents. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Ranchod, P.; Rosman, B.; Konidaris, G. Nonparametric Bayesian Reward Segmentation for Skill Discovery Using Inverse Reinforcement Learning. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October October 2015; pp. 471–477. [Google Scholar] [CrossRef]
- Henderson, P.; Chang, W.D.; Bacon, P.L.; Meger, D.; Pineau, J.; Precup, D. OptionGAN: Learning Joint Reward-Policy Options Using Generative Adversarial Inverse Reinforcement Learning. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar] [CrossRef]
- Babeş-Vroman, M.; Marivate, V.; Subramanian, K.; Littman, M. Apprenticeship Learning about Multiple Intentions. In Proceedings of the 28th International Conference on International Conference on Machine Learning (ICML ’11), Bellevue, WA, USA, 28 June–2 July 2011; Omnipress: Madison, WI, USA, 2011; pp. 897–904. [Google Scholar]
- Likmeta, A.; Metelli, A.M.; Ramponi, G.; Tirinzoni, A.; Giuliani, M.; Restelli, M. Dealing with Multiple Experts and Non-Stationarity in Inverse Reinforcement Learning: An Application to Real-Life Problems. Mach. Learn. 2021, 110, 2541–2576. [Google Scholar] [CrossRef]
- Gleave, A.; Habryka, O. Multi-Task Maximum Entropy Inverse Reinforcement Learning. arXiv 2018, arXiv:1805.08882. [Google Scholar] [CrossRef]
- Dimitrakakis, C.; Rothkopf, C.A. Bayesian Multitask Inverse Reinforcement Learning. In Proceedings of the Recent Advances in Reinforcement Learning—9th European Workshop (EWRL), Athens, Greece, 9–11 September 2011; Lecture Notes in Computer Science; Sanner, S., Hutter, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 273–284. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.; Kim, K.e. Nonparametric Bayesian Inverse Reinforcement Learning for Multiple Reward Functions. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS ’12), Lake Tahoe, NV, USA, 3–8 December 2012; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Arora, S.; Doshi, P.; Banerjee, B. Min-Max Entropy Inverse RL of Multiple Tasks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June; pp. 12639–12645. [CrossRef]
- Bighashdel, A.; Meletis, P.; Jancura, P.; Jancura, P.; Dubbelman, G. Deep Adaptive Multi-Intention Inverse Reinforcement Learning. ECML/PKDD 2021, 2021, 206–221. [Google Scholar] [CrossRef]
- Almingol, J.; Montesano, L. Learning Multiple Behaviours Using Hierarchical Clustering of Rewards. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 4608–4613. [Google Scholar] [CrossRef]
- Belogolovsky, S.; Korsunsky, P.; Mannor, S.; Tessler, C.; Zahavy, T. Inverse Reinforcement Learning in Contextual MDPs. Mach. Learn. 2021, 110, 2295–2334. [Google Scholar] [CrossRef]
- Sharifzadeh, S.; Chiotellis, I.; Triebel, R.; Cremers, D. Learning to Drive Using Inverse Reinforcement Learning and Deep Q-Networks. In Proceedings of the NIPS Workshop on Deep Learning for Action and Interaction. arXiv 2017, arXiv:1612.03653. [Google Scholar] [CrossRef]
- Brown, D.; Coleman, R.; Srinivasan, R.; Niekum, S. Safe Imitation Learning via Fast Bayesian Reward Inference from Preferences. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 12–18 July 2020; pp. 1165–1177. [Google Scholar]
- Imani, M.; Ghoreishi, S.F. Scalable Inverse Reinforcement Learning Through Multifidelity Bayesian Optimization. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4125–4132. [Google Scholar] [CrossRef]
- Garg, D.; Chakraborty, S.; Cundy, C.; Song, J.; Ermon, S. IQ-Learn: Inverse Soft-Q Learning for Imitation. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–14 December 2021; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 4028–4039. [Google Scholar]
- Liu, S.; Jiang, H.; Chen, S.; Ye, J.; He, R.; Sun, Z. Integrating Dijkstra’s Algorithm into Deep Inverse Reinforcement Learning for Food Delivery Route Planning. Transp. Res. Part E Logist. Transp. Rev. 2020, 142, 102070. [Google Scholar] [CrossRef]
- Xu, K.; Ratner, E.; Dragan, A.; Levine, S.; Finn, C. Learning a Prior over Intent via Meta-Inverse Reinforcement Learning. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6952–6962. [Google Scholar]
- Seyed Ghasemipour, S.K.; Gu, S.S.; Zemel, R. SMILe: Scalable Meta Inverse Reinforcement Learning through Context-Conditional Policies. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Boularias, A.; Krömer, O.; Peters, J. Structured Apprenticeship Learning. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Bristol, UK, 24–28 September 2012; Lecture Notes in Computer Science; Flach, P.A., De Bie, T., Cristianini, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 227–242. [Google Scholar] [CrossRef] [Green Version]
- Bogert, K.; Doshi, P. Multi-Robot Inverse Reinforcement Learning under Occlusion with Estimation of State Transitions. Artif. Intell. 2018, 263, 46–73. [Google Scholar] [CrossRef]
- Jin, W.; Kulić, D.; Mou, S.; Hirche, S. Inverse Optimal Control from Incomplete Trajectory Observations. Int. J. Robot. Res. 2021, 40, 848–865. [Google Scholar] [CrossRef]
- Suresh, P.S.; Doshi, P. Marginal MAP Estimation for Inverse RL under Occlusion with Observer Noise. In Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence, Eindhoven, The Netherlands, 1–5 August 2022; pp. 1907–1916. [Google Scholar]
- Torabi, F.; Warnell, G.; Stone, P. Recent Advances in Imitation Learning from Observation. In Proceedings of the Electronic Proceedings of IJCAI (IJCAI ’19), Macao, China, 10–16 August 2019; pp. 6325–6331. [Google Scholar]
- Das, N.; Bechtle, S.; Davchev, T.; Jayaraman, D.; Rai, A.; Meier, F. Model-Based Inverse Reinforcement Learning from Visual Demonstrations. In Proceedings of the 2020 Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 1930–1942. [Google Scholar]
- Zakka, K.; Zeng, A.; Florence, P.; Tompson, J.; Bohg, J.; Dwibedi, D. XIRL: Cross-embodiment Inverse Reinforcement Learning. In Proceedings of the 5th Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 537–546. [Google Scholar]
- Liu, Y.; Gupta, A.; Abbeel, P.; Levine, S. Imitation from Observation: Learning to Imitate Behaviors from Raw Video via Context Translation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1118–1125. [Google Scholar] [CrossRef] [Green Version]
- Hadfield-Menell, D.; Russell, S.J.; Abbeel, P.; Dragan, A. Cooperative Inverse Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Amin, K.; Jiang, N.; Singh, S. Repeated Inverse Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep Reinforcement Learning from Human Preferences. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Bobu, A.; Wiggert, M.; Tomlin, C.; Dragan, A.D. Inducing Structure in Reward Learning by Learning Features. Int. J. Robot. Res. 2022, 41, 497–518. [Google Scholar] [CrossRef]
- Chang, L.J.; Smith, A. Social Emotions and Psychological Games. Curr. Opin. Behav. Sci. 2015, 5, 133–140. [Google Scholar] [CrossRef]
- Rabin, M. Incorporating Fairness into Game Theory and Economics. Am. Econ. Rev. 1993, 83, 1281–1302. [Google Scholar]
- Falk, A.; Fehr, E.; Fischbacher, U. On the Nature of Fair Behavior. Econ. Inq. 2003, 41, 20–26. [Google Scholar] [CrossRef]
- Preckel, K.; Kanske, P.; Singer, T. On the Interaction of Social Affect and Cognition: Empathy, Compassion and Theory of Mind. Curr. Opin. Behav. Sci. 2018, 19, 1–6. [Google Scholar] [CrossRef]
- Ong, D.C.; Zaki, J.; Goodman, N.D. Computational Models of Emotion Inference in Theory of Mind: A Review and Roadmap. Top. Cogn. Sci. 2019, 11, 338–357. [Google Scholar] [CrossRef]
- Lise, W. Estimating a Game Theoretic Model. Comput. Econ. 2001, 18, 141–157. [Google Scholar] [CrossRef]
- Bajari, P.; Hong, H.; Ryan, S.P. Identification and Estimation of a Discrete Game of Complete Information. Econometrica 2010, 78, 1529–1568. [Google Scholar] [CrossRef]
- Waugh, K.; Ziebart, B.D.; Bagnell, J.A. Computational Rationalization: The Inverse Equilibrium Problem. In Proceedings of the 28th International Conference on International Conference on Machine Learning (ICML ’11), Bellevue, WA, USA, 28 June–2 July 2011; Omnipress: Madison, WI, USA, 2011; pp. 1169–1176. [Google Scholar]
- Kuleshov, V.; Schrijvers, O. Inverse Game Theory: Learning Utilities in Succinct Games. In Proceedings of the Web and Internet Economics, Amsterdam, The Netherlands, 9–12 December 2015; Lecture Notes in Computer Science; Markakis, E., Schäfer, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 413–427. [Google Scholar] [CrossRef]
- Cao, K.; Xie, L. Game-Theoretic Inverse Reinforcement Learning: A Differential Pontryagin’s Maximum Principle Approach. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Natarajan, S.; Kunapuli, G.; Judah, K.; Tadepalli, P.; Kersting, K.; Shavlik, J. Multi-Agent Inverse Reinforcement Learning. In Proceedings of the 2010 Ninth International Conference on Machine Learning and Applications (ICMLA ’10), Washington, DC, USA, 12–14 December 2010; pp. 395–400. [Google Scholar] [CrossRef] [Green Version]
- Reddy, T.S.; Gopikrishna, V.; Zaruba, G.; Huber, M. Inverse Reinforcement Learning for Decentralized Non-Cooperative Multiagent Systems. In Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC) (IEEE SMC ’12), Seoul, Republic of Korea, 14–17 October 2012; pp. 1930–1935. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, L.; Liu, J.; Hu, S. Individual-Level Inverse Reinforcement Learning for Mean Field Games. arXiv 2022, arXiv:2202.06401. [Google Scholar] [CrossRef]
- Harré, M.S. What Can Game Theory Tell Us about an AI ‘Theory of Mind’? Games 2022, 13, 46. [Google Scholar] [CrossRef]
- Wellman, H.M.; Miller, J.G. Including Deontic Reasoning as Fundamental to Theory of Mind. HDE 2008, 51, 105–135. [Google Scholar] [CrossRef]
- Sanfey, A.G. Social Decision-Making: Insights from Game Theory and Neuroscience. Science 2007, 318, 598–602. [Google Scholar] [CrossRef] [Green Version]
- Adolphs, R. The Social Brain: Neural Basis of Social Knowledge. Annu. Rev. Psychol. 2009, 60, 693–716. [Google Scholar] [CrossRef] [Green Version]
- Peterson, J.C.; Bourgin, D.D.; Agrawal, M.; Reichman, D.; Griffiths, T.L. Using Large-Scale Experiments and Machine Learning to Discover Theories of Human Decision-Making. Science 2021, 372, 1209–1214. [Google Scholar] [CrossRef]
- Gershman, S.J.; Gerstenberg, T.; Baker, C.L.; Cushman, F.A. Plans, Habits, and Theory of Mind. PLoS ONE 2016, 11, e0162246. [Google Scholar] [CrossRef] [Green Version]
- Harsanyi, J.C. Games with Incomplete Information Played by “Bayesian” Players, I–III. Part III. The Basic Probability Distribution of the Game. Manag. Sci. 1968, 14, 486–502. [Google Scholar] [CrossRef]
- Conway, J.R.; Catmur, C.; Bird, G. Understanding Individual Differences in Theory of Mind via Representation of Minds, Not Mental States. Psychon. Bull. Rev. 2019, 26, 798. [Google Scholar] [CrossRef] [Green Version]
- Velez-Ginorio, J.; Siegel, M.H.; Tenenbaum, J.; Jara-Ettinger, J. Interpreting Actions by Attributing Compositional Desires. In Proceedings of the 39th Annual Meeting of the Cognitive Science Society, London, UK, 16–29 July 2017. [Google Scholar]
- Sun, L.; Zhan, W.; Tomizuka, M. Probabilistic Prediction of Interactive Driving Behavior via Hierarchical Inverse Reinforcement Learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2111–2117. [Google Scholar] [CrossRef]
- Kolter, J.; Abbeel, P.; Ng, A. Hierarchical Apprenticeship Learning with Application to Quadruped Locomotion. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; Curran Associates, Inc.: Red Hook, NY, USA, 2007; Volume 20. [Google Scholar]
- Natarajan, S.; Joshi, S.; Tadepalli, P.; Kersting, K.; Shavlik, J. Imitation Learning in Relational Domains: A Functional-Gradient Boosting Approach. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Okal, B.; Gilbert, H.; Arras, K.O. Efficient Inverse Reinforcement Learning Using Adaptive State-Graphs. In Proceedings of the Robotics: Science and Systems XI Conference (RSS ’15), Rome, Italy, 13–17 July 2015; p. 2. [Google Scholar]
- Gao, X.; Gong, R.; Zhao, Y.; Wang, S.; Shu, T.; Zhu, S.C. Joint Mind Modeling for Explanation Generation in Complex Human-Robot Collaborative Tasks. In Proceedings of the 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020; pp. 1119–1126. [Google Scholar] [CrossRef]
- Bard, N.; Foerster, J.N.; Chandar, S.; Burch, N.; Lanctot, M.; Song, H.F.; Parisotto, E.; Dumoulin, V.; Moitra, S.; Hughes, E.; et al. The Hanabi Challenge: A New Frontier for AI Research. Artif. Intell. 2020, 280, 103216. [Google Scholar] [CrossRef]
- Heidecke, J. Evaluating the Robustness of GAN-Based Inverse Reinforcement Learning Algorithms. Master’s Thesis, Universitat Politècnica de Catalunya, Barcelona, Spain, 2019. [Google Scholar]
- Snoswell, A.J.; Singh, S.P.N.; Ye, N. LiMIIRL: Lightweight Multiple-Intent Inverse Reinforcement Learning. arXiv 2021, arXiv:2106.01777. [Google Scholar] [CrossRef]
- Toyer, S.; Shah, R.; Critch, A.; Russell, S. The MAGICAL Benchmark for Robust Imitation. arXiv 2020, arXiv:2011.00401. [Google Scholar] [CrossRef]
- Waade, P.T.; Enevoldsen, K.C.; Vermillet, A.Q.; Simonsen, A.; Fusaroli, R. Introducing Tomsup: Theory of Mind Simulations Using Python. Behav. Res. Methods 2022. [Google Scholar] [CrossRef] [PubMed]
- Conway, J.R.; Bird, G. Conceptualizing Degrees of Theory of Mind. Proc. Natl. Acad. Sci. USA 2018, 115, 1408–1410. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruiz-Serra, J.; Harré, M.S. Inverse Reinforcement Learning as the Algorithmic Basis for Theory of Mind: Current Methods and Open Problems. Algorithms 2023, 16, 68. https://doi.org/10.3390/a16020068
Ruiz-Serra J, Harré MS. Inverse Reinforcement Learning as the Algorithmic Basis for Theory of Mind: Current Methods and Open Problems. Algorithms. 2023; 16(2):68. https://doi.org/10.3390/a16020068
Chicago/Turabian StyleRuiz-Serra, Jaime, and Michael S. Harré. 2023. "Inverse Reinforcement Learning as the Algorithmic Basis for Theory of Mind: Current Methods and Open Problems" Algorithms 16, no. 2: 68. https://doi.org/10.3390/a16020068