
Feature Selection and Model Evaluation for Threat Detection in Smart Grids



Abstract
:1. Introduction
- We reviewed papers related to machine learning-based threat detection in smart grids;
- We conducted a thorough review of the datasets pertaining to machine learning-based threat detection;
- We identified the most frequently used algorithms for threat, anomaly, or incident detection in smart grids;
- We compared the effectiveness of the filter, wrapper, and embedded methods for feature selection, as well as accuracy, F1-score, Cohen’s kappa, and ROC AUC metrics;
- We proposed the optimal method for feature selection;
- We proposed new feature sets for training machine learning algorithms on the CSE CIC IDS2018 dataset;
- We found the most suitable method to compare results between different studies in the context of imbalance datasets and threat detection in smart grids;
- We identified the most common errors and shortcomings in adopting best practices in data analysis;
- We suggested several solutions that should be taken into account while conducting further studies related to the analysis of threats in smart grids.
- We confirmed that Cohen’s kappa and F1-score are more suitable for comparison with imbalanced datasets;
- We strongly suggested the use of a baseline model that should serve as a reference point throughout the research;
- We recommended the use of feature selection methods based on random forest, ANOVA F-value, or logistic regression with L1 regularisation for processing large datasets;
- We identified that the use of more than one metric should not be neglected in academic studies, especially in the case of experiments with imbalanced datasets;
- We stated that it is fundamental to have a clear and thorough description of the entire process of model creation, starting from data preparation through to model setup, testing methodology, and result visualisation.
2. State of the Art
3. Threats and Threat Detection Solutions
3.1. Intrusion Detection and Prevention Systems
3.2. Security Information and Event Management Tools
3.3. Firewalls
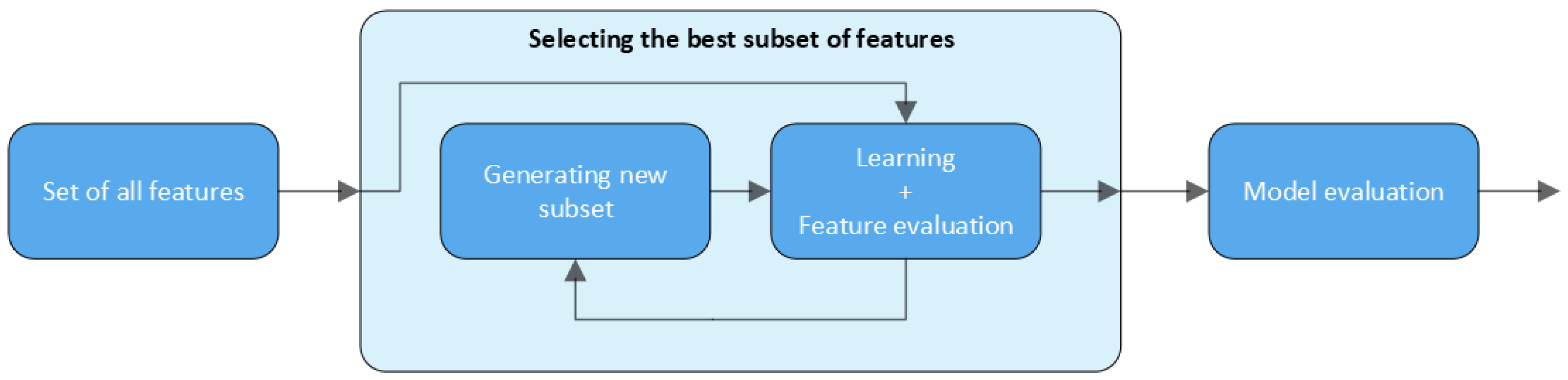
4. Feature Selection
- Embedded (intrinsic or implicit) methods;
- Filter methods;
- Wrapper methods.
4.1. Filter Methods
4.1.1. Chi Square
4.1.2. ANOVA F-Test
4.2. Wrapper Methods
Recursive Feature Elimination
4.3. Embedded Methods
5. Data Preparation and Overview
- Removal of the old samples (before year 2000): four entries from Thursday 01-03-2018 and eight entries from Friday 02-03-2018.
- Removal of void features (zeroed columns): Bwd PSH Flags, Bwd URG Flags, Fwd Byts/b Avg, Fwd Pkts/b Avg, Fwd Blk Rate Avg, Bwd Byts/b Avg, Bwd Pkts/b Avg, and Bwd Blk Rate Avg.
- Removal of 22,954 samples with NaN values and replacement of infinity values for 120,000,000 value, as the observed maximum of other features.
- Removal of void features (zeroed columns): Bwd PSH Flags, Fwd URG Flags, Bwd URG Flags, CWE Flag Count, Fwd Byts/b Avg, Fwd Pkts/b Avg, Fwd Blk Rate Avg, Bwd Byts/b Avg, Bwd Pkts/b Avg, and Bwd Blk Rate Avg.
- Remove of non-relevant feature: Flow Id.
- Removal of 36,767 samples with NaN values and replacement of infinity values for 120,000,000 value, as observed maximum of other features.
6. Methodology
6.1. Feature Selection
6.2. Models and Training
7. Results
8. Conclusions
- Feature selection methods based on random forest, ANOVA F-value and logistic regression with L1 regularisation have proven their robustness and are recommended for processing large datasets.
- The baseline model serves superbly as a reference point throughout the research. The same holds true for the basic solution for feature selection, which relied on randomly selected features. This aspect should not be ignored in scientific research, as it appears to be the case in most publications.
- Compared to the widely used accuracy metric, Cohen’s kappa and F1-score metrics are more suitable for comparison with imbalanced datasets. Once again, the use of more than one metric should not be neglected in academic studies, especially in the case of experiments on imbalanced datasets where appropriate metrics need to be used.
- Finally, it is fundamental to have a clear and thorough description of the entire process of model creation, starting from data preparation, through model setup, testing methodology, and result visualisation. The absence of such information undermines the credibility of a study and makes it impossible to make meaningful comparisons with future research.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Data Type | Description |
|---|---|---|
| ACK Flag Cnt | int64 | Number of packets with ACK flag |
| Active Max | float64 | Maximum time a flow was active before becoming idle |
| Active Mean | float64 | Mean time a flow was active before becoming idle |
| Active Min | float64 | Minimum time a flow was active before becoming idle |
| Active Std | float64 | Standard deviation time a flow was active before becoming idle |
| Bwd Blk Rate Avg | int64 | Average number of bulk rate in the backward direction |
| Bwd Byts/b Avg | int64 | Average number of bytes bulk rate in the backward direction |
| Bwd Header Len | int64 | Total bytes used for headers in the backward direction |
| Bwd IAT Max | float64 | Maximum time between two packets sent in the backward direction |
| Bwd IAT Mean | float64 | Mean time between two packets sent in the backward direction |
| Bwd IAT Min | float64 | Minimum time between two packets sent in the backward direction |
| Bwd IAT Std | float64 | Standard deviation time between two packets sent in the backward direction |
| Bwd IAT Tot | float64 | Total time between two packets sent in the backward direction |
| Bwd PSH Flags | int64 | Number of times the PSH flag was set in packets travelling in the backward direction (0 for UDP) |
| Bwd Pkt Len Max | float64 | Maximum size of packet in backward direction |
| Bwd Pkt Len Mean | float64 | Mean size of packet in backward direction |
| Bwd Pkt Len Min | float64 | Minimum size of packet in backward direction |
| Bwd Pkt Len Std | float64 | Standard deviation size of packet in backward direction |
| Bwd Pkts/b Avg | int64 | Average number of packets bulk rate in the backward direction |
| Bwd Pkts/s | float64 | Number of backward packets per second |
| Bwd Seg Size Avg | float64 | Average size observed in the backward direction |
| Bwd URG Flags | int64 | Number of times the URG flag was set in packets travelling in the backward direction (0 for UDP) |
| CWE Flag Count | int64 | Number of packets with CWE flag |
| Down/Up Ratio | float64 | Download and upload ratio |
| Dst IP | object | Destination IP address |
| Dst Port | int64 | Destination port |
| ECE Flag Cnt | int64 | Number of packets with ECE flag |
| FIN Flag Cnt | int64 | Number of packets with FIN flag |
| Flow Byts/s | float64 | Flow byte rate that is number of packets transferred per second |
| Flow Duration | int64 | Flow duration |
| Flow IAT Max | float64 | Maximum time between two flows |
| Flow IAT Mean | float64 | Average time between two flows |
| Flow IAT Min | float64 | Minimum time between two flows |
| Flow IAT Std | float64 | Standard deviation time two flows |
| Flow ID | object | Flow ID |
| Flow Pkts/s | float64 | Flow packets rate that is number of packets transferred per second |
| Fwd Act Data Pkts | int64 | Number of packets with at least 1 byte of TCP data payload in the forward direction |
| Fwd Blk Rate Avg | int64 | Average number of bulk rate in the forward direction |
| Fwd Byts/b Avg | int64 | Average number of bytes bulk rate in the forward direction |
| Fwd Header Len | int64 | Total bytes used for headers in the forward direction |
| Fwd IAT Max | float64 | Maximum time between two packets sent in the forward direction |
| Fwd IAT Mean | float64 | Mean time between two packets sent in the forward direction |
| Fwd IAT Min | float64 | Minimum time between two packets sent in the forward direction |
| Fwd IAT Std | float64 | Standard deviation time between two packets sent in the forward direction |
| Fwd IAT Tot | float64 | Total time between two packets sent in the forward direction |
| Fwd PSH Flags | int64 | Number of times the PSH flag was set in packets travelling in the forward direction (0 for UDP) |
| Fwd Pkt Len Max | float64 | Maximum size of packet in forward direction |
| Fwd Pkt Len Mean | float64 | Average size of packet in forward direction |
| Fwd Pkt Len Min | float64 | Minimum size of packet in forward direction |
| Fwd Pkt Len Std | float64 | Standard deviation size of packet in forward direction |
| Fwd Pkts/b Avg | int64 | Average number of packets bulk rate in the forward direction |
| Fwd Pkts/s | float64 | Number of forward packets per second |
| Fwd Seg Size Avg | float64 | Average size observed in the forward direction |
| Fwd Seg Size Min | int64 | Minimum segment size observed in the forward direction |
| Fwd URG Flags | int64 | Number of times the URG flag was set in packets travelling in the forward direction (0 for UDP) |
| Idle Max | float64 | Maximum time a flow was idle before becoming active |
| Idle Mean | float64 | Mean time a flow was idle before becoming active |
| Idle Min | float64 | Minimum time a flow was idle before becoming active |
| Idle Std | float64 | Standard deviation time a flow was idle before becoming active |
| Init Bwd Win Byts | int64 | Number of bytes sent in initial window in the backward direction |
| Init Fwd Win Byts | int64 | Number of bytes sent in initial window in the forward direction |
| Label | object | Label |
| PSH Flag Cnt | int64 | Number of packets with PUSH flag |
| Pkt Len Max | float64 | Maximum length of a flow |
| Pkt Len Mean | float64 | Mean length of a flow |
| Pkt Len Min | float64 | Minimum length of a flow |
| Pkt Len Std | float64 | Standard deviation length of a flow |
| Pkt Len Var | float64 | Minimum inter-arrival time of packet |
| Pkt Size Avg | float64 | Average size of packet |
| Protocol | int64 | Protocol |
| RST Flag Cnt | int64 | Number of packets with RST flag |
| SYN Flag Cnt | int64 | Number of packets with SYN flag |
| Src IP | object | Source IP address |
| Src Port | int64 | Source port |
| Subflow Bwd Byts | int64 | The average number of bytes in a sub flow in the backward direction |
| Subflow Bwd Pkts | int64 | The average number of packets in a sub flow in the backward direction |
| Subflow Fwd Byts | int64 | The average number of bytes in a sub flow in the forward direction |
| Subflow Fwd Pkts | int64 | The average number of packets in a sub flow in the forward direction |
| Timestamp | datetime64 [ns] | Timestamp |
| Tot Bwd Pkts | int64 | Total packets in the backward direction |
| Tot Fwd Pkts | int64 | Total packets in the forward direction |
| TotLen Bwd Pkts | float64 | Total size of packet in backward direction |
| TotLen Fwd Pkts | float64 | Total size of packet in forward direction |
| URG Flag Cnt | int64 | Number of packets with URG flag |
References
- Ding, J.; Qammar, A.; Zhang, Z.; Karim, A.; Ning, H. Cyber Threats to Smart Grids: Review, Taxonomy, Potential Solutions, and Future Directions. Energies 2022, 15, 6799. [Google Scholar] [CrossRef]
- Communications Security Establishment and The Canadian Institute for Cybersecurity—A Realistic Cyber Defense Dataset (CSE-CIC-IDS2018). 2018. Available online: https://registry.opendata.aws/cse-cic-ids2018 (accessed on 6 October 2022).
- Rapacz, S.; Chołda, P.; Natkaniec, M. A Method for Fast Selection of Machine-Learning Classifiers for Spam Filtering. Electronics 2021, 10, 2083. [Google Scholar] [CrossRef]
- McQuin, C.; Goodman, A.; Chernyshev, V.; Kamentsky, L.; Cimini, B.A.; Karhohs, K.W.; Doan, M.; Ding, L.; Rafelski, S.M.; Thirstrup, D.; et al. CellProfiler 3.0: Next-generation image processing for biology. PLoS Biol. 2018, 16, e2005970. [Google Scholar] [CrossRef] [Green Version]
- Weiss, J.; Raghu, V.K.; Bontempi, D.; Christiani, D.C.; Mak, R.H.; Lu, M.T.; Aerts, H.J. Deep learning to estimate lung disease mortality from chest radiographs. Nat. Commun. 2023, 14, 2797. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Hong, L.; Wang, L.; Zhang, R.; Pijush, S.; Zhang, W. Prediction of wall deflection induced by braced excavation in spatially variable soils via convolutional neural network. Gondwana Res. 2022. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, C.; Tang, L.; Gu, X.; Wang, L. Efficient time-variant reliability analysis of Bazimen landslide in the Three Gorges Reservoir Area using XGBoost and LightGBM algorithms. Gondwana Res. 2022. [Google Scholar] [CrossRef]
- Baryannis, G.; Dani, S.; Antoniou, G. Predicting supply chain risks using machine learning: The trade-off between performance and interpretability. Future Gener. Comput. Syst. 2019, 101, 993–1004. [Google Scholar] [CrossRef]
- Ni, D.; Xiao, Z.; Lim, M.K. A systematic review of the research trends of machine learning in supply chain management. Int. J. Mach. Learn. Cybern. 2019, 11, 1463–1482. [Google Scholar] [CrossRef]
- Mololoth, V.K.; Saguna, S.; Åhlund, C. Blockchain and Machine Learning for Future Smart Grids: A Review. Energies 2023, 16, 528. [Google Scholar] [CrossRef]
- Tufail, S.; Parvez, I.; Batool, S.; Sarwat, A. A Survey on Cybersecurity Challenges, Detection, and Mitigation Techniques for the Smart Grid. Energies 2021, 14, 5894. [Google Scholar] [CrossRef]
- Kanimozhi, V.; Jacob, T.P. Artificial Intelligence based Network Intrusion Detection with Hyper-Parameter Optimization Tuning on the Realistic Cyber Dataset CSE-CIC-IDS2018 using Cloud Computing. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 4–6 April 2019; pp. 33–36. [Google Scholar] [CrossRef]
- Gardner, M.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Chastikova, V.A.; Sotnikov, V.V. Method of analyzing computer traffic based on recurrent neural networks. J. Phys. Conf. Ser. 2019, 1353, 012133. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Gu, Q.; Zhu, L.; Cai, Z. Evaluation Measures of the Classification Performance of Imbalanced Data Sets. In Proceedings of the Computational Intelligence and Intelligent Systems; Cai, Z., Li, Z., Kang, Z., Liu, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 461–471. [Google Scholar]
- Fatourechi, M.; Ward, R.K.; Mason, S.G.; Huggins, J.; Schlögl, A.; Birch, G.E. Comparison of Evaluation Metrics in Classification Applications with Imbalanced Datasets. In Proceedings of the 2008 Seventh International Conference on Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008; pp. 777–782. [Google Scholar] [CrossRef]
- Chadza, T.; Kyriakopoulos, K.G.; Lambotharan, S. Contemporary Sequential Network Attacks Prediction using Hidden Markov Model. In Proceedings of the 2019 17th International Conference on Privacy, Security and Trust (PST), Fredericton, NB, Canada, 26–28 August 2019; pp. 1–3. [Google Scholar] [CrossRef] [Green Version]
- Weng, C.G.; Poon, J. A New Evaluation Measure for Imbalanced Datasets. In Proceedings of the 7th Australasian Data Mining Conference, Glenelg/Adelaide, SA, Australia, 27–28 November 2008; Volume 87, pp. 27–32. [Google Scholar]
- Bekkar, M.; Djema, H.; Alitouche, T. Evaluation measures for models assessment over imbalanced data sets. J. Inf. Eng. Appl. 2013, 3, 27–38. [Google Scholar]
- Filho, F.; Silveira, F.; Junior, A.; vargas solar, G.; Silveira, L. Smart Detection: An Online Approach for DoS/DDoS Attack Detection Using Machine Learning. Secur. Commun. Netw. 2019, 2019, 749. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Safavian, S.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Dreiseitl, S.; Ohno-Machado, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef] [Green Version]
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In Proceedings of the COMPSTAT’2010; Lechevallier, Y., Saporta, G., Eds.; Springer: Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Hu, W.; Hu, W.; Maybank, S. AdaBoost-Based Algorithm for Network Intrusion Detection. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2008, 38, 577–583. [Google Scholar] [CrossRef] [PubMed]
- Raeder, T.; Forman, G.; Chawla, N.V. Learning from Imbalanced Data: Evaluation Matters. In Data Mining: Foundations and Intelligent Paradigms: Volume 1: Clustering, Association and Classification; Holmes, D.E., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 315–331. [Google Scholar] [CrossRef]
- Basnet, R.B.; Shash, R.; Johnson, C.; Walgren, L.; Doleck, T. Towards Detecting and Classifying Network Intrusion Traffic Using Deep Learning Frameworks. J. Internet Serv. Inf. Secur. 2019, 9, 1–17. [Google Scholar]
- Ferrag, M.A.; Maglaras, L.; Moschoyiannis, S.; Janicke, H. Deep learning for cyber security intrusion detection: Approaches, datasets, and comparative study. J. Inf. Secur. Appl. 2020, 50, 102419. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Soman, K.; Poornachandran, P. Evaluation of Recurrent Neural Network and Its Variants for Intrusion Detection System IDS. Int. J. Inf. Syst. Model. Des. 2017, 8, 43–63. [Google Scholar] [CrossRef]
- Al-Mhiqani, M.; Ahmad, R.; Zainal Abidin, Z. An Integrated Imbalanced Learning and Deep Neural Network Model for Insider Threat Detection. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 2021. [Google Scholar] [CrossRef]
- Chen, H.; Murray, A. Continuous restricted Boltzmann machine with an implementable training algorithm. Vision Image Signal Process. IEE Proc. 2003, 150, 153–158. [Google Scholar] [CrossRef] [Green Version]
- Gao, N.; Gao, L.; Gao, Q.; Wang, H. An Intrusion Detection Model Based on Deep Belief Networks. In Proceedings of the 2014 Second International Conference on Advanced Cloud and Big Data, Huangshan, China, 20–22 November 2014; pp. 247–252. [Google Scholar] [CrossRef]
- Alom, M.Z.; Bontupalli, V.; Taha, T.M. Intrusion detection using deep belief networks. In Proceedings of the 2015 National Aerospace and Electronics Conference (NAECON), Dayton, OI, USA, 15–19 June 2015; pp. 339–344. [Google Scholar] [CrossRef]
- Li, Y. Research on Application of Convolutional Neural Network in Intrusion Detection. In Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 25–27 September 2020; pp. 720–723. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Hinton, G. Deep Boltzmann Machines. In Proceedings of the Twelth International Conference on Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; van Dyk, D., Welling, M., Eds.; Hilton Clearwater Beach Resort: Clearwater Beach, FL, USA, 2009; Volume 5, pp. 448–455. [Google Scholar]
- Seo, S.; Park, S.; Kim, J. Improvement of Network Intrusion Detection Accuracy by Using Restricted Boltzmann Machine. In Proceedings of the 2016 8th International Conference on Computational Intelligence and Communication Networks (CICN), Dehradun, India, 23–25 December 2016; pp. 413–417. [Google Scholar] [CrossRef]
- Chuang, P.J.; Wu, D.Y. Applying Deep Learning to Balancing Network Intrusion Detection Datasets. In Proceedings of the 2019 IEEE 11th International Conference on Advanced Infocomm Technology (ICAIT), Jinan, China, 18–20 October 2019; pp. 213–217. [Google Scholar] [CrossRef]
- Xu, C.; Shen, J.; Du, X.; Zhang, F. An Intrusion Detection System Using a Deep Neural Network With Gated Recurrent Units. IEEE Access 2018, 6, 48697–48707. [Google Scholar] [CrossRef]
- Atefinia, R.; Ahmadi, M. Network Intrusion Detection using Multi-Architectural Modular Deep Neural Network. J. Supercomput. 2021, 77, 3571–3593. [Google Scholar] [CrossRef]
- Karatas, G.; Demir, O.; Sahingoz, O.K. Increasing the Performance of Machine Learning-Based IDSs on an Imbalanced and Up-to-Date Dataset. IEEE Access 2020, 8, 32150–32162. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Int. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Sawadogo, L.M.; Bassolé, D.; Koala, G.; Sié, O. Intrusions Detection and Classification Using Deep Learning Approach. In Proceedings of the Research in Computer Science and Its Applications, Virtual, 17–19 June 2021; Faye, Y., Gueye, A., Gueye, B., Diongue, D., Nguer, E.H.M., Ba, M., Eds.; Springer: Cham, Switzerland, 2021; pp. 40–51. [Google Scholar]
- Stryczek, S.; Natkaniec, M. Internet Threat Detection in Smart Grids Based on Network Traffic Analysis Using LSTM, IF, and SVM. Energies 2023, 16, 329. [Google Scholar] [CrossRef]
- Peng, C.; Sun, H.; Yang, M.; Wang, Y.L. A Survey on Security Communication and Control for Smart Grids Under Malicious Cyber Attacks. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1554–1569. [Google Scholar] [CrossRef]
- Gunduz, M.Z.; Das, R. Cyber-security on smart grid: Threats and potential solutions. Comput. Netw. 2020, 169, 107094. [Google Scholar] [CrossRef]
- Sakhnini, J.; Karimipour, H.; Dehghantanha, A.; Parizi, R.M.; Srivastava, G. Security aspects of Internet of Things aided smart grids: A bibliometric survey. Internet Things 2021, 14, 100111. [Google Scholar] [CrossRef]
- Caprolu, M.; Raponi, S.; Di Pietro, R.; Antonopoulos, A. FORTRESS: An Efficient and Distributed Firewall for Stateful Data Plane SDN. Sec. Commun. Netw. 2019, 2019, 6874592. [Google Scholar] [CrossRef] [Green Version]
- Weber, R.; Schek, H.J.; Blott, S. A Quantitative Analysis and Performance Study for Similarity-Search Methods in High-Dimensional Spaces. In Proceedings of the 24rd International Conference on Very Large Data Bases, San Francisco, CA, USA, 26–29 August 1998; VLDB ’98. pp. 194–205. [Google Scholar]
- Butcher, B.; Smith, B.J. Feature Engineering and Selection: A Practical Approach for Predictive Models. Am. Stat. 2020, 74, 308–309. [Google Scholar] [CrossRef]
- Borisov, V.; Haug, J.; Kasneci, G. CancelOut: A Layer for Feature Selection in Deep Neural Networks. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2019: Deep Learning, Munich, Germany, 17–19 September 2019; Tetko, I.V., Kůrková, V., Karpov, P., Theis, F., Eds.; Springer: Cham, Switzerland, 2019; pp. 72–83. [Google Scholar]
- Gidey, H.T.; Guo, X.; Li, L.; Zhang, Y. Heterogeneous Transfer Learning for Wi-Fi Indoor Positioning Based Hybrid Feature Selection. Sensors 2022, 22, 5840. [Google Scholar] [CrossRef] [PubMed]
- Attallah, O. Tomato Leaf Disease Classification via Compact Convolutional Neural Networks with Transfer Learning and Feature Selection. Horticulturae 2023, 9, 149. [Google Scholar] [CrossRef]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 1999. [Google Scholar]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. A review of feature selection methods on synthetic data. Knowl. Inf. Syst. 2013, 34, 483–519. [Google Scholar] [CrossRef]
- Granitto, P.M.; Furlanello, C.; Biasioli, F.; Gasperi, F. Recursive feature elimination with random forest for PTR-MS analysis of agroindustrial products. Chemom. Intell. Lab. Syst. 2006, 83, 83–90. [Google Scholar] [CrossRef]
- Zimmermann, J.; Clark, A.; Mohay, G.; Pouget, F.; Dacier, M. The use of packet inter-arrival times for investigating unsolicited Internet traffic. In Proceedings of the First International Workshop on Systematic Approaches to Digital Forensic Engineering (SADFE’05), Taiwan, China, 7–9 November 2005; pp. 89–104. [Google Scholar] [CrossRef] [Green Version]
- Sharafaldin, I.; Habibi Lashkari, A.; Ghorbani, A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Madeira, Portugal, 22–24 January 2018; pp. 108–116. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]














| Method | Advantages | Disadvantages | Examples |
|---|---|---|---|
| Filter | Independence of the classifier Lower computational cost (compare to wrappers) Relatively fast Good generalisation ability | Ignores interaction with the classifier Ignores feature dependencies | Chi square Euclidean distance Information gain Correlation-based feature selection |
| Wrapper | Interaction with the classifier Accounts for feature dependencies | Depends on classifier selection Overfitting risk Computationally expensive | Sequential forward selection Recursive feature elimination Genetic algorithms |
| Embedded | Interaction with the classifier Lower computational cost (compare to wrappers) Accounts for feature dependencies | Depends on classifier selection | Decision trees Multivariate adaptive regression spline models Least absolute shrinkage and selection operator |
| Label | Count | As a Percentage |
|---|---|---|
| Benign | 6,112,137 | 73.7808% |
| DDOS attack-HOIC | 686,012 | 8.2810% |
| DoS attacks-Hulk | 461,912 | 5.5758% |
| Bot | 286,191 | 3.4547% |
| FTP-BruteForce | 193,360 | 2.3341% |
| SSH-Bruteforce | 187,589 | 2.2644% |
| Infilteration | 161,934 | 1.9547% |
| DoS attacks-SlowHTTPTest | 139,890 | 1.6886% |
| DoS attacks-GoldenEye | 41,508 | 0.5011% |
| DoS attacks-Slowloris | 10,990 | 0.1327% |
| DDOS attack-LOIC-UDP | 1730 | 0.0209% |
| Brute Force-Web | 611 | 0.0074% |
| Brute Force-XSS | 230 | 0.0028% |
| SQL Injection | 87 | 0.0011% |
| Label | Count | As a Percentage |
|---|---|---|
| Benign | 7,372,557 | 92.75% |
| DDoS attacks-LOIC-HTTP | 576,191 | 7.25% |
| Feature Selection Method | Parameters |
|---|---|
| Random selection | None |
| Recursive feature elimination with random forest (RFE RF) | Number of trees: 50 |
| Chi2 | None |
| ANOVA F-value | None |
| Random forest (RF) | Number of trees: 100 |
| Logistic regression with L1 regularisation (LR L1) | Penalty: L1 Solver: saga Dual formulation: false C: 0.1 Class weight: balanced Max number of iterations: 100 |
| Linear support vector classification (LSVC) | Penalty: L1 Dual formulation: false C: 0.01 Class weight: balanced |
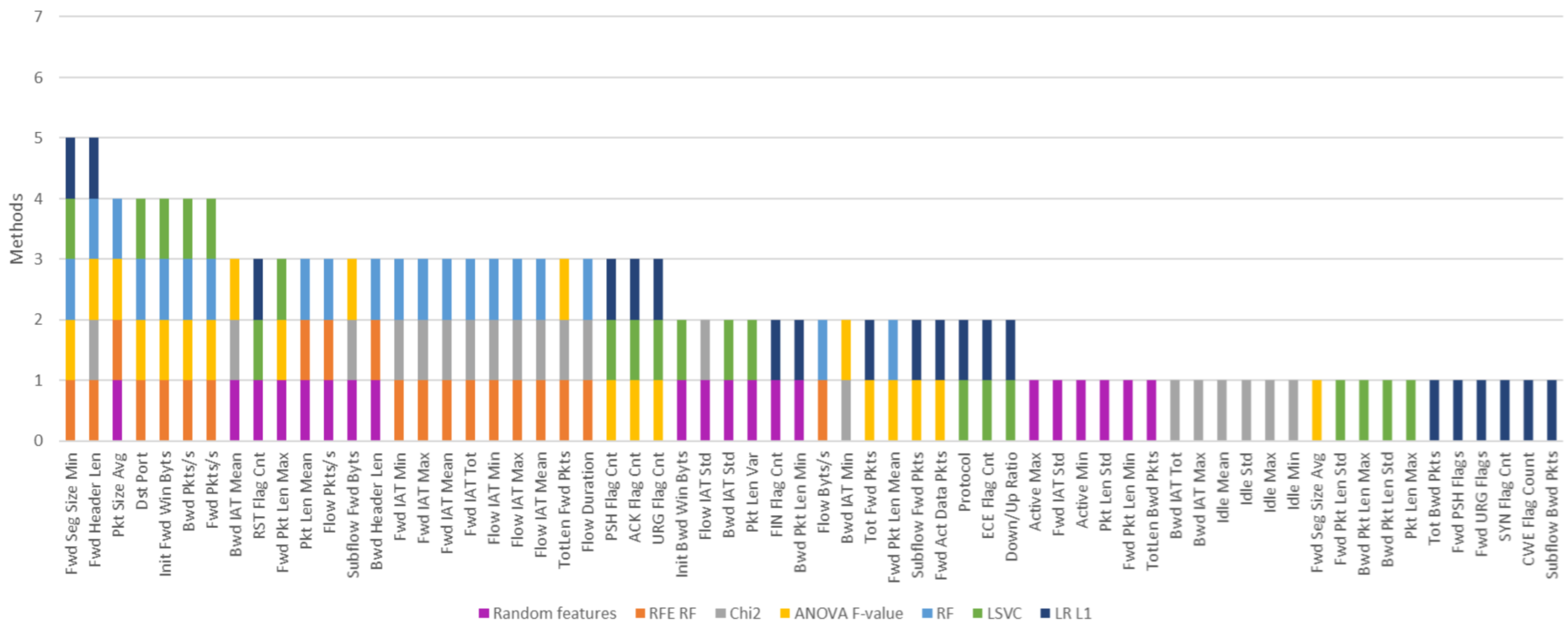
| Feature | Rank | Feature | Rank | Feature | Rank |
|---|---|---|---|---|---|
| Dst Port | 1 | Tot Bwd Pkts | 6 | ECE Flag Cnt | 30 |
| Fwd Seg Size Min | 1 | Pkt Len Max | 7 | Bwd IAT Tot | 31 |
| Init Fwd Win Byts | 1 | Subflow Bwd Byts | 8 | Bwd IAT Max | 32 |
| Pkt Size Avg | 1 | Bwd Pkt Len Std | 9 | Idle Min | 33 |
| Pkt Len Mean | 1 | TotLen Bwd Pkts | 10 | Bwd IAT Std | 34 |
| Bwd Pkts/s | 1 | Tot Fwd Pkts | 11 | Idle Mean | 35 |
| Fwd Pkts/s | 1 | Pkt Len Std | 12 | Idle Max | 36 |
| Fwd Header Len | 1 | Fwd Seg Size Avg | 13 | Down/Up Ratio | 37 |
| Fwd IAT Min | 1 | Bwd Pkt Len Mean | 14 | Active Mean | 38 |
| Fwd IAT Max | 1 | ACK Flag Cnt | 15 | Idle Std | 39 |
| Fwd IAT Mean | 1 | Flow IAT Std | 16 | Fwd Pkt Len Min | 40 |
| Fwd IAT Tot | 1 | Subflow Fwd Pkts | 17 | Active Min | 41 |
| Flow IAT Min | 1 | Bwd Seg Size Avg | 18 | Active Max | 42 |
| Flow IAT Max | 1 | PSH Flag Cnt | 19 | Bwd Pkt Len Min | 43 |
| Flow IAT Mean | 1 | Bwd Pkt Len Max | 20 | Active Std | 44 |
| Flow Pkts/s | 1 | Subflow Fwd Byts | 21 | Pkt Len Min | 45 |
| Bwd Header Len | 1 | URG Flag Cnt | 22 | FIN Flag Cnt | 46 |
| Flow Byts/s | 1 | RST Flag Cnt | 23 | Protocol | 47 |
| TotLen Fwd Pkts | 1 | Fwd Act Data Pkts | 24 | Fwd PSH Flags | 48 |
| Flow Duration | 1 | Fwd IAT Std | 25 | SYN Flag Cnt | 49 |
| Fwd Pkt Len Max | 2 | Bwd IAT Min | 26 | Fwd URG Flags | 50 |
| Init Bwd Win Byts | 3 | Pkt Len Var | 27 | CWE Flag Count | 51 |
| Fwd Pkt Len Mean | 4 | Bwd IAT Mean | 28 | ||
| Subflow Bwd Pkts | 5 | Fwd Pkt Len Std | 29 |
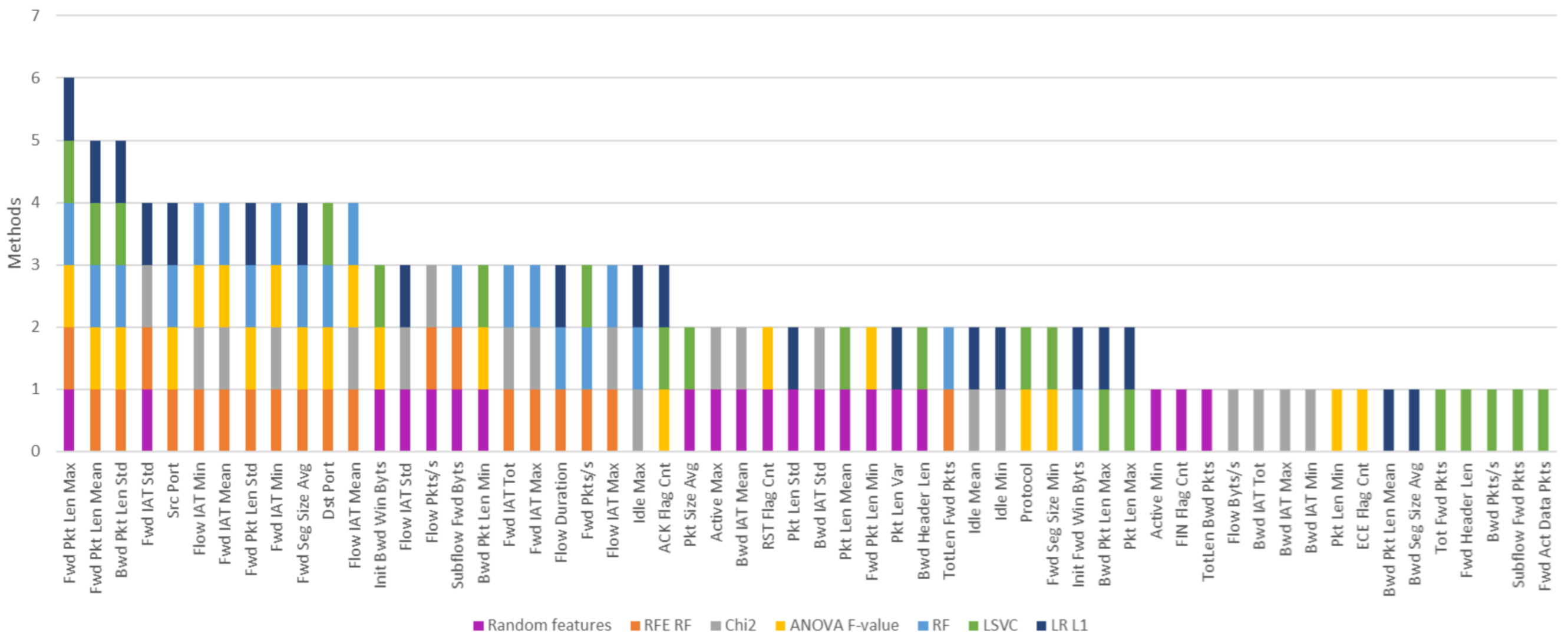
| Feature | Rank | Feature | Rank Feature | Rank | |
|---|---|---|---|---|---|
| Src Port | 1 | Subflow Fwd Pkts | 7 | Fwd Act Data Pkts | 30 |
| Flow IAT Min | 1 | ACK Flag Cnt | 8 | Bwd Pkts/s | 31 |
| Subflow Fwd Byts | 1 | Fwd Seg Size Min | 9 | TotLen Bwd Pkts | 32 |
| Fwd IAT Tot | 1 | Pkt Len Var | 10 | Protocol | 33 |
| Fwd IAT Mean | 1 | Idle Mean | 11 | Bwd IAT Tot | 34 |
| Fwd Pkt Len Std | 1 | Tot Fwd Pkts | 12 | URG Flag Cnt | 35 |
| Fwd Pkt Len Mean | 1 | Fwd Header Len | 13 | Bwd IAT Mean | 36 |
| Fwd IAT Std | 1 | Bwd Pkt Len Max | 14 | Bwd Seg Size Avg | 37 |
| Fwd Pkt Len Max | 1 | Idle Max | 15 | PSH Flag Cnt | 38 |
| Fwd IAT Max | 1 | Subflow Bwd Pkts | 16 | Pkt Len Min | 39 |
| TotLen Fwd Pkts | 1 | Pkt Len Max | 17 | Active Max | 40 |
| Fwd IAT Min | 1 | Tot Bwd Pkts | 18 | Bwd IAT Min | 41 |
| Fwd Seg Size Avg | 1 | Bwd Header Len | 19 | RST Flag Cnt | 42 |
| Flow Duration | 1 | Idle Min | 20 | Idle Std | 43 |
| Fwd Pkts/s | 1 | Active Min | 21 | Bwd IAT Max | 44 |
| Dst Port | 1 | Pkt Size Avg | 22 | Fwd Pkt Len Min | 45 |
| Flow IAT Max | 1 | Bwd IAT Std | 23 | ECE Flag Cnt | 46 |
| Flow IAT Mean | 1 | Active Mean | 24 | Down/Up Ratio | 47 |
| Flow Pkts/s | 2 | Pkt Len Mean | 25 | SYN Flag Cnt | 48 |
| Bwd Pkt Len Std | 3 | Subflow Bwd Byts | 26 | Fwd PSH Flags | 49 |
| Pkt Len Std | 4 | Bwd Pkt Len Mean | 27 | FIN Flag Cnt | 50 |
| Flow IAT Std | 5 | Flow Byts/s | 28 | Bwd Pkt Len Min | 51 |
| Init Fwd Win Byts | 6 | Init Bwd Win Byts | 29 | Active Std | 52 |
| Method | Random | RFE RF | Chi2 | ANOVA F-Value | RF | LR l1 | LSVC |
|---|---|---|---|---|---|---|---|
| Random | 100.00% | 11.11% | 8.11% | 11.11% | 11.11% | 14.29% | 8.11% |
| RFE RF | 11.11% | 100.00% | 33.33% | 25.00% | 90.48% | 14.29% | 5.26% |
| Chi2 | 8.11% | 33.33% | 100.00% | 14.29% | 29.03% | 0.00% | 2.56% |
| ANOVA F-value | 11.11% | 25.00% | 14.29% | 100.00% | 25.00% | 29.03% | 25.00% |
| RF | 11.11% | 90.48% | 29.03% | 25.00% | 100.00% | 14.29% | 5.26% |
| LR L1 | 14.29% | 14.29% | 0.00% | 29.03% | 14.29% | 100.00% | 25.00% |
| LSVC | 8.11% | 5.26% | 2.56% | 25.00% | 5.26% | 25.00% | 100.00% |
| Method | Random | RFE RF | Chi2 | ANOVA F-Value | RF | LR l1 | LSVC |
|---|---|---|---|---|---|---|---|
| Random | 100.00% | 11.11% | 17.65% | 14.29% | 5.26% | 14.29% | 17.65% |
| RFE RF | 11.11% | 100.00% | 29.03% | 37.93% | 81.82% | 25.00% | 14.29% |
| Chi2 | 17.65% | 29.03% | 100.00% | 11.11% | 25.00% | 14.29% | 0.00% |
| ANOVA F-value | 14.29% | 37.93% | 11.11% | 100.00% | 37.93% | 21.21% | 29.03% |
| RF | 5.26% | 81.82% | 25.00% | 37.93% | 100.00% | 29.03% | 14.29% |
| LR L1 | 14.29% | 25.00% | 14.29% | 21.21% | 29.03% | 100.00% | 17.65% |
| LSVC | 17.65% | 14.29% | 0.00% | 29.03% | 14.29% | 17.65% | 100.00% |
| Method | Random | A RFE RF | A Chi2 | A ANOVA F-Value | A RF | A LR l1 | A LSVC |
|---|---|---|---|---|---|---|---|
| Random | 100.00% | 11.11% | 8.11% | 11.11% | 11.11% | 14.29% | 8.11% |
| B RFE RF | 11.11% | 42.86% | 33.33% | 21.21% | 42.86% | 14.29% | 0.00% |
| B Chi2 | 17.65% | 29.03% | 60.00% | 5.26% | 29.03% | 2.56% | 0.00% |
| B ANOVA F-value | 14.29% | 17.65% | 11.11% | 17.65% | 21.21% | 33.33% | 17.65% |
| B RF | 5.26% | 42.86% | 37.93% | 25.00% | 42.86% | 17.65% | 0.00% |
| B LR L1 | 14.29% | 5.26% | 14.29% | 14.29% | 8.11% | 25.00% | 2.56% |
| B LSVC | 17.65% | 25.00% | 2.56% | 42.86% | 29.03% | 37.93% | 25.00% |
| Model | Configuration |
|---|---|
| Dummy classifier | Strategy = ‘most_frequent’ |
| Random forest classifier (RF) from sklearn.ensemble package | n_estimators = 12 criterion = ‘gini’ max_depth = 22 min_samples_split = 10 class_weight = ‘balanced’ |
| Multi-layer perceptron classifier (MLP) from sklearn.neural_network package | hidden_layer_sizes = (15) activation = ‘relu’ solver = ‘adam’ batch_size = ‘auto’ alpha = 0.001 learning_rate_init = 0.001 max_iter = 20 |
| Model | Configuration |
|---|---|
| Dummy classifier | strategy = ‘most_frequent’ |
| Random forest classifier (RF) from sklearn.ensemble package | n_estimators = 12 criterion = ‘gini’ max_depth = 22 min_samples_split = 10 random_state = 2021 class_weight = ‘balanced’ |
| Multi-layer perceptron classifier (MLP) from sklearn.neural_network package | hidden_layer_sizes = (15) activation = ‘relu’ solver = ‘adam’ batch_size = ‘auto’ alpha = 0.001 learning_rate_init = 0.001 max_iter = 20 |
| Linear support vector classifier (LSVC) from sklearn.svm package | penalty = ‘l2’ loss = ‘squared_hinge’ dual = False C = 1.0 class_weight = ‘balanced’ max_iter = 50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gwiazdowicz, M.; Natkaniec, M. Feature Selection and Model Evaluation for Threat Detection in Smart Grids. Energies 2023, 16, 4632. https://doi.org/10.3390/en16124632
Gwiazdowicz M, Natkaniec M. Feature Selection and Model Evaluation for Threat Detection in Smart Grids. Energies. 2023; 16(12):4632. https://doi.org/10.3390/en16124632
Chicago/Turabian StyleGwiazdowicz, Mikołaj, and Marek Natkaniec. 2023. "Feature Selection and Model Evaluation for Threat Detection in Smart Grids" Energies 16, no. 12: 4632. https://doi.org/10.3390/en16124632