1. Introduction
Wind energy is a highly efficient and renewable energy. Its development and utilization have been widely recognized [
1]. The intermittent and randomness of wind speed bring stern challenges for the stable operation of power systems [
2,
3]. Accurate prediction of wind speed will benefit the exploitation of wind energy. Wind speed prediction is a hot research topic, and a number of prediction methods have been proposed over the past decades which can be classified into physical models, statistical models, machine learning models, and combination models [
4].
As wind is a multi-scale physical phenomenon, numerical weather predictions (NWP) provide straightforwad wind speed predictions with physical advantages [
5]. The physical model based on NWP applies historical meteorological factors such as temperature and barometric pressure to predict the wind speed over a long period [
6]. Additionally, wind speed prediction is applied using physical approximation and spatial correlation fluid dynamics models [
7,
8]. However, the physical model is complex in modeling, poor in prediction accuracy, and its scope of application is limited. It is not suitable for short-term wind speed prediction. Recently, a data-driven method based on stacked bidirectional long short-term memory (BiLSTM) for wind turbine wake prediction was proposed by Geibel and Bangga [
9], and satisfactory prediction accuracy was achieved, indicating that a data-driven approach can offer an alternative to conventional prediction methods.
Statistical models use the linear mapping relationship between historical weather conditions and wind speed and utilize series data to predict the future wind speed series through this relationship [
10]. Traditional statistical modes such as auto-regression (AR) [
11], auto-regressive moving average (ARMA) [
12], auto-regressive integrated moving average (ARIMA), and auto-regressive conditional heteroskedasticity (ARCH) are widely used in the field of time series prediction [
13]. For instance, the ARCH model was used to predict the revenues of the financial stock market [
14]. Radziukynas adopted a classical ARIMA model to predict short-term wind speed series [
15]. Tian and Wang et al. proposed a prediction method based on ARMA and echo state network (ESN) compensation to deal with the statistical characteristics of wind speed series, which can obtain accurate prediction results [
16]. As mentioned above, the statistical models often uses the historical wind speed data to establish linear wind speed prediction models, but due to the strong nonlinearity of data, the model parameters are difficult to determine, and the prediction accuracy is not satisfied.
To improve the accuracy of the wind speed prediction, statistical models based on artificial intelligence were proposed. Compared with statistical models, artificial intelligence prediction models have outstanding capabilities in processing nonlinear wind speed time series. With the rapid development of artificial intelligence, great effort has been made to improve the accuracy and universality of wind speed prediction. Nair and Jisma presented ANN and ARIMA to predict the wind speed at three different locations in India in different time periods, which reduces the nonlinear characteristics of the wind speed series [
17]. In another work, Shukur and Lee proposed the Kalman filter (KF) and an ANN hybrid model based on ARIMA to deal with the nonlinearity and uncertainty of wind speed [
18]. Machine learning models based on neural network have became popular in short-term wind speed prediction [
19]. For example, the prediction models based on back-propagation neural networks (BPNN) [
20], least square support vector machines (LSSVM) [
21], support vector regressions (SVR) [
22], extreme learning machines (ELM) [
23], Elman neural networks (ENN) [
24], adaptive wavelet neural networks (AWNN) [
25], and recurrent neural networks (RNN) [
26] perform well when dealing with time series with nonlinear characteristics. However, these techniques are all built with single neural network models, which may result in local optimization or over-fitting problems in short-term wind speed prediction.
To improve the prediction performance, researchers introduced combination models to integrate the advantages of every single model. The combination prediction model combines data preprocessing, an optimization algorithm, a and predictor, which shows outstanding performance in wind speed prediction. The data preprocessing strategy composed of outlier detection and data decomposition can greatly ameliorate the prediction performance of the whole model [
27]. The missing original data and outlier problems caused by human, weather, and other factors are the primary problems to be addressed in the field of wind speed prediction. After outlier processing, taking into account the nonlinearity and noise characteristics of wind speed [
28], the data decomposition method can drop the instability of wind speed correlation series and abandon redundant information and combine with a machine learning model to enhance the predictability of wind speed [
29]. For instance, Mi and Zhao [
30] applied the singular spectrum analysis (SSA) model to denoise the original wind speed data to capture the complex dynamic characteristics of wind speed, which combines the adaptive structure learning of neural networks with long- and short-term memory networks (LSTM) to predict wind speed in three wind farms in Xinjiang, China. The proposed model has good prediction performance. A hybrid method of empirical mode decomposition (EMD) and ARIMA-ANN is proposed to improve the prediction accuracy of time series [
31]. Zhan and Tian et al. [
32,
33] studied the two-stage decomposition model of the complementary ensemble empirical mode decomposition (CEEMD) and local mean decomposition (LMD) to achieve intrinsic mode functions (IMFs) of different regularity degrees, which was applied to (support vector machine) SVM and T-S fuzzy neural network (FNN) prediction. Duan et al. [
34] proposed variational mode decomposition (VMD) to extract the local characteristics of the original wind speed series and constructed an integrated prediction model using deep belief network (DBN) optimized by particle swarm optimization (PSO), which overcomes the shortcomings of linear weighted combination, and the performance of the prediction model is better than many traditional models. Meanwhile, the wavelet transform (WT) [
35] method shows advantages in extracting and studying the characteristics of wind speed in the time domain and frequency domains and solves the randomness and complexity of wind speed signals. Liu et al. [
36] designed a hybrid model combining wavelet decomposition (WD) and LSTM to predict China’s wind power generation in the next two years. The experiment showed that this model effectively improves the accuracy of the prediction.
In addition to the above models, the decomposition-based method may contribute to large differences in prediction performance. For the decomposed models, in terms of generalization performance, sometimes they cannot capture the characteristics of wind speed. As such, the prediction accuracy and training speed of the model are affected because the advantage of parameter optimization is not considered. To avoid these problems, an adaptive short-term wind speed predictor is formed based on the model of optimization algorithm [
37], which reduces the prediction error and achieves good prediction results. As an example, Bai et al. [
38] proposed a dynamic integrated wind speed prediction model, a hybrid model composed of VMD and a genetic algorithm (GA)-optimized double-layer staged training echo state network (DESN), which used the DESN to process nonlinear series and capture time information of different time scales, and the model has better time-varying and robustness through nonlinear weighted combination mechanism. Wu and Wang et al. [
39], considering the accuracy and stability of the model, applied multi-objective grey wolf optimization (MOGWO) to optimize ELM to form a new integrated global wind speed prediction method. Neshat [
40] combined effective hierarchical decomposition technology and deep learning optimization methods to develop a combined model with deep feature selection and optimal intrinsic mode functions to predict the forward time step of wind speed data from Baltic offshore wind farms. Tian et al. [
41] utilized EMD to decompose the original wind speed data into IMFs with different frequencies, and then embedded multiple IMFs into the enhanced network of improved sparrow search algorithm (ISSA) optimized LSTM for prediction, which solved the problem of slow convergence speed of previous models and being easy to fall into local optimum. The results indicate that the model of EMD and ISSA optimization LSTM has good predictive ability. The literature review shows that using the diversity of optimization algorithms to predict the wind speed prediction model with the best parameters, which can improve the prediction accuracy and stability of the model to a certain extent.
Short-term prediction is to predict wind speed from 10 min to 30 min in advance. It is conducive to the timely and reasonable dispatching of the power grid, maintenance of power quality, and the stable operation of the power system. Because of the uncertainty of wind speed, short-term wind speed prediction has great practical significance and application value. In the field of short-term wind speed prediction, wind speed is an important indicator that affects wind power generation. However, due to many uncertain factors, the integrity of the original wind speed data has been destroyed. The rapid change in wind speed leads to the nonlinear and nonstationary characteristics of wind speed series. EMD is an adaptive data decomposition method [
42] suitable for processing nonlinear and unstable time series, but its decomposition has the problem of model-mixing and the uncertainty of the maximum number of iterations in the sifting process, which affects the performance of the wind speed data decomposition method. Hence, VMD has a better decomposition effect and is more robust when dealing with complex wind speed time series [
43]. What is undesirable is that VMD requires artificial parameters and lacks rigor. Therefore, in consideration of the completeness and predictability of wind speed data, data preprocessing strategy plays an important role in the study of short-term wind speed prediction.
Reviewing the above-mentioned methods, the combined method based on the decomposition denoising method and the optimization parameter method are discussed, and the research contributions of these methods and their shortcomings are summarized. To this end, this study considers the generalization ability and stability of the prediction model and develops a short-term multi-step wind speed prediction method with adaptive robust decomposition characteristics that combines a data-processing strategy, a cascade optimization strategy, and a prediction strategy [
44]. The method includes a data preprocessing strategy based on wavelet soft threshold denoising (WSTD), robust empirical mode decomposition (REMD) and variational mode decomposition (VMD), cascade optimization based on the hybrid grey wolf optimization algorithm (HGWO) strategy, and a prediction strategy based on deep gated recurrent unit (DGRU), which is achieved satisfactory results in the field of short-term wind speed prediction. The primary innovations and contributions of this research are as follows:
- (1)
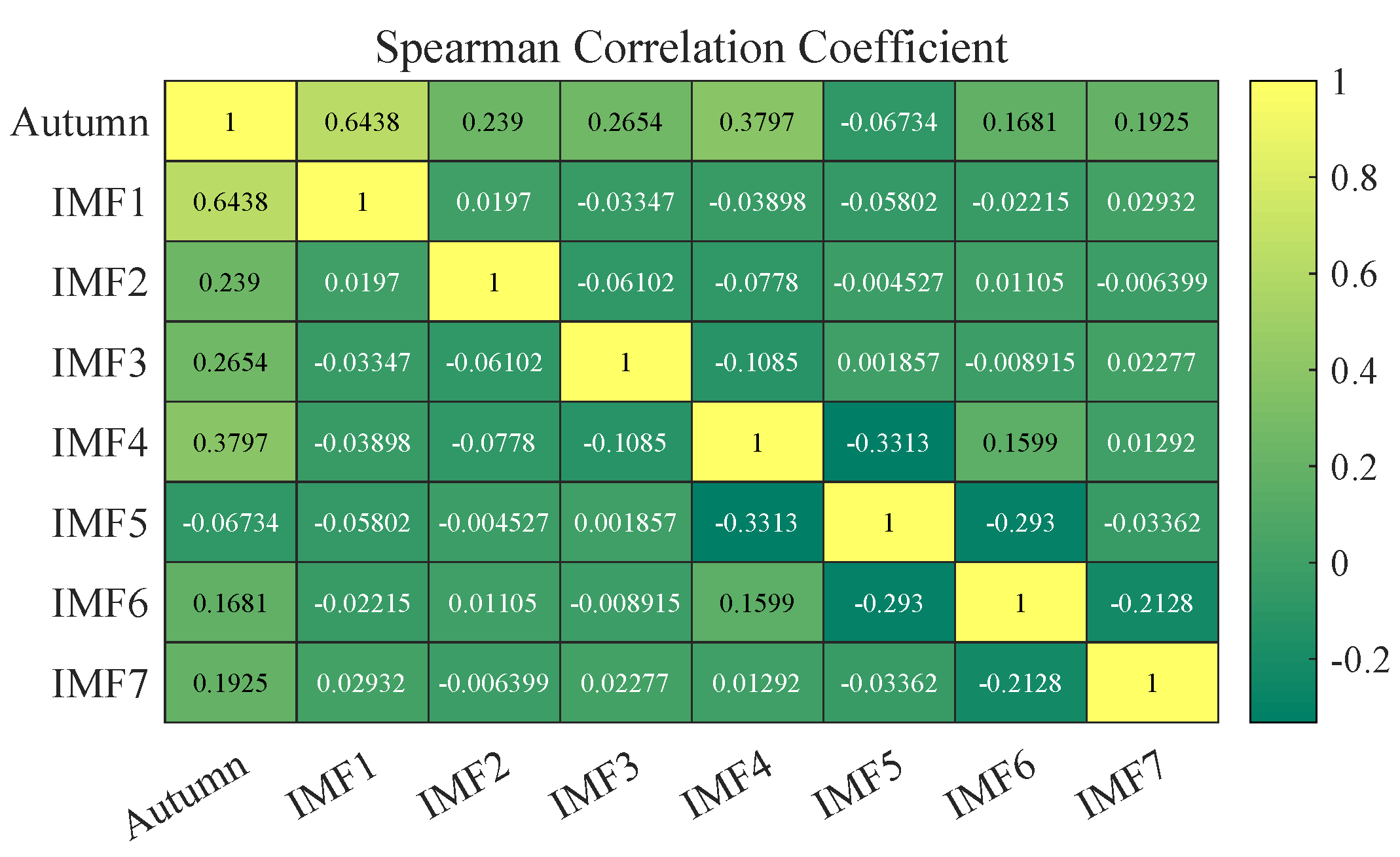
Data preprocessing strategy: A novel and efficient two-stage data preprocessing technology is proposed. WSTD filters out the redundant noise of the original wind speed series. One-stage REMD decomposes to obtain a series of IMFs to eliminate random fluctuations. To reduce the error, Spearman correlation analysis is used to analyze the correlation between each IMF and the original wind speed time series, group reconstruction, reduce the accumulation of errors, and prepare high-quality data for prediction purposes.
- (2)
Cascade optimization strategy: The cascading optimization strategy based on HGWO, which is used for the first time, and the optimized VMD is used to decompose the IMFs with strong correlation in the wind speed correlation series in the second stage to further explore the potential characteristic information of the wind speed. On this basis, it is more robust to deal with time series of complex characteristics.
- (3)
Prediction strategy: The strategy of cascading optimization is adopted to dynamically analyze the optimal input parameters and optimal network structure of the GRU deep learning model, and the reorganized wind speed correlation sub-series are predicted and superimposed in the future time step to complete deeper wind speed characteristic extraction and learning, which greatly enhance the stability and generalization of the model.
- (4)
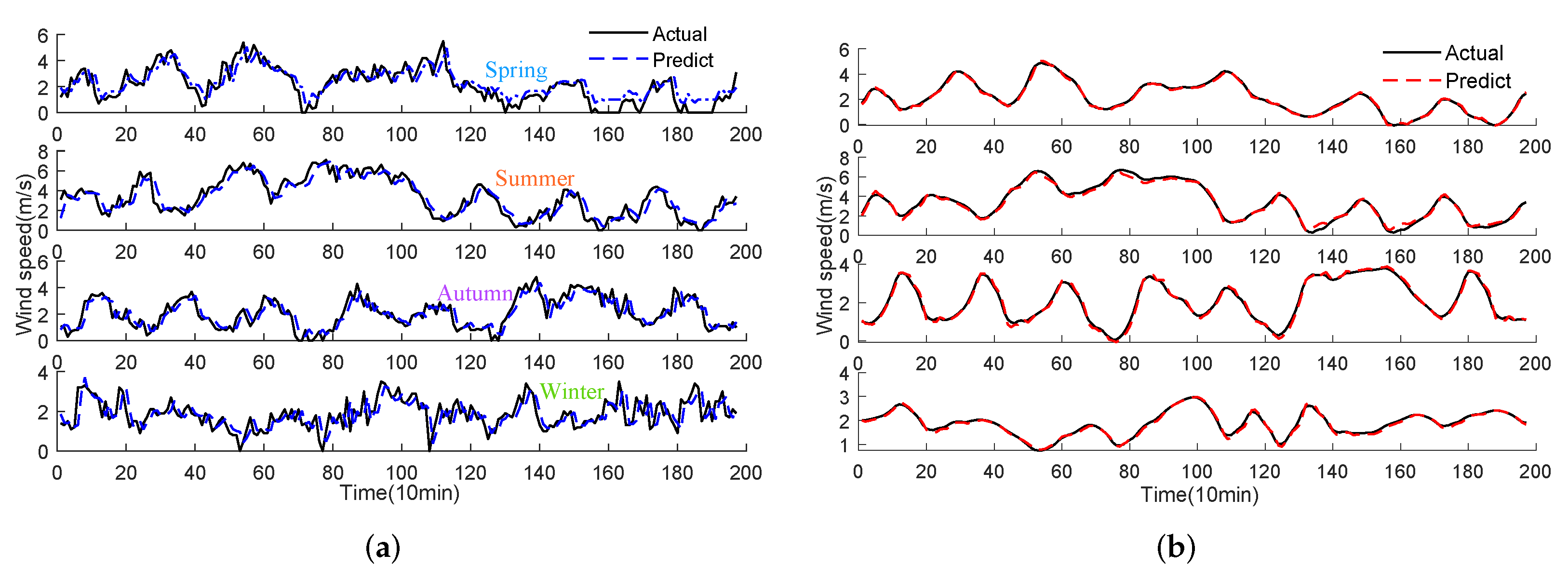
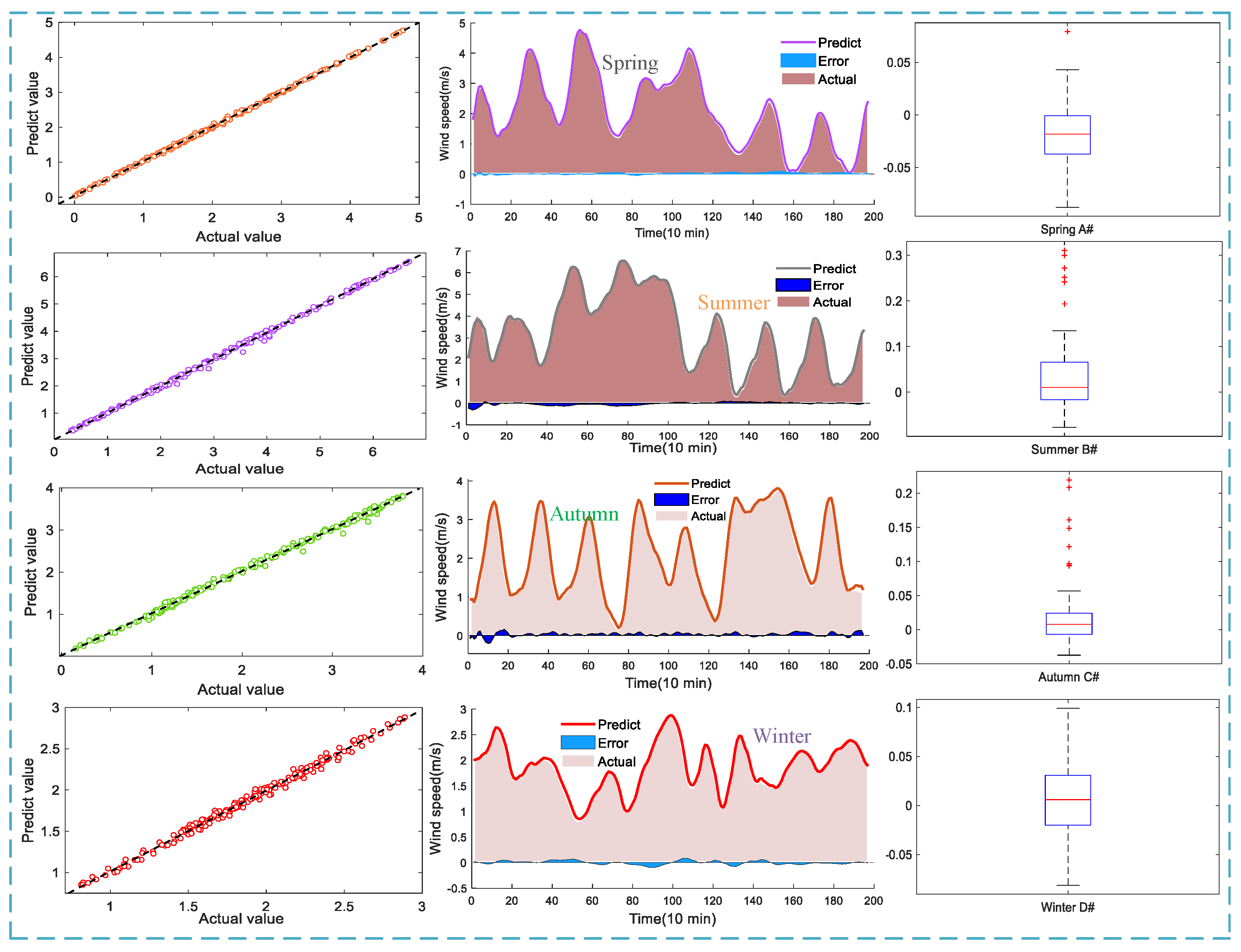
The combined multi-step wind speed prediction method of WSTD, REMD, and HGWO-VMD-GRU is proposed, which integrates the advantages of each single model. The wind speed datasets of different seasons in the Shanghai Bay area are selected to verify the validity of the model, and the final conclusion is reached by testing and analyzing three different benchmark models with the classic single models, the decomposition optimization models, and other combined models.
The paper is organized as follows. In
Section 2, we introduce the basic theory of the relevant methods and the framework of the proposed prediction system.
Section 3 gives a comprehensive discussion on the experimental results from various prediction models. In
Section 4, we draw the conclusion.
4. Conclusions
Accurate wind speed prediction can effectively improve wind energy utilization. This study proposes an adaptive two-stage decomposition integrated system for short-term wind speed prediction. The system is based on a data preprocessing strategy, a cascade optimization strategy, and a deep learning prediction strategy.
First, the wind speed is decomposed using WSTD and REMD into a series of components that change smoothly and have obvious changing regularity, thus greatly reducing the interference and coupling between different features and improving the quality of subsequent data. The VMD is employed for the secondary decomposition, and it is integrated with the Spearman criterion to revise the accumulation of errors of the model during the first decomposition, reduce the model complexity, and obtain the long-term, fluctuating, trends of the wind power signal. The potential characteristics of wind speed series are acquired, and their dynamic characteristics are captured by in-depth analysis.
Then, HGWO is adopted to optimize VMD and GRU, which effectively avoids the limitation of empirically set parameters, and make up for the defect that the parameters fall into the local optimum. Using the most advanced deep learning model, an adaptive parameter selection process is advanced.
Finally, the improved GRU method strengthens the characteristic information and inline relationships of wind speed data and can comprehensively mine the characteristics of wind power, perform feature mining, and ensure the prediction accuracy and stability of the model. Four datasets in different seasons are selected for multi-step ahead prediction of the wind speed. The results show that the proposed WSTD-REMD-AVMD-DGRU model developed in this study has robust and accurate prediction performance, which can provide the best forecast results for wind series.
The present model realizes a whole adaptive process of wind speed prediction and overcomes the problems of experience adjustment, incomplete wind speed information mining, and inaccurate single-model prediction that inhibited traditional models. Moreover, the present model is robust and generalizable, which can be easily extended to time series prediction in meteorology, mechanical engineering, finance, biology, etc.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}