
A Flexible Top-Down Data-Driven Stochastic Model for Synthetic Load Profiles Generation


Abstract
:1. Introduction
- It requires just one input data record of suitable length for model parameters estimation. As a consequence, the model can be used in quite heterogeneous scenarios. Furthermore, the generated SLPs can have arbitrary length and time resolution.
- SLP generation relies on data clustering techniques, time-inhomogeneous Markov chains and Gaussian Mixture Models (GMM) fitting.
- Unlike other similar works, in order to ensure a good consistency between the original LPs and the SLPs, multiple features are evaluated and kept under control both in the time and power domain.
2. Related Work on Top-Down SLPs Modeling
2.1. Data Preprocessing
2.2. Stochastic Model Structure
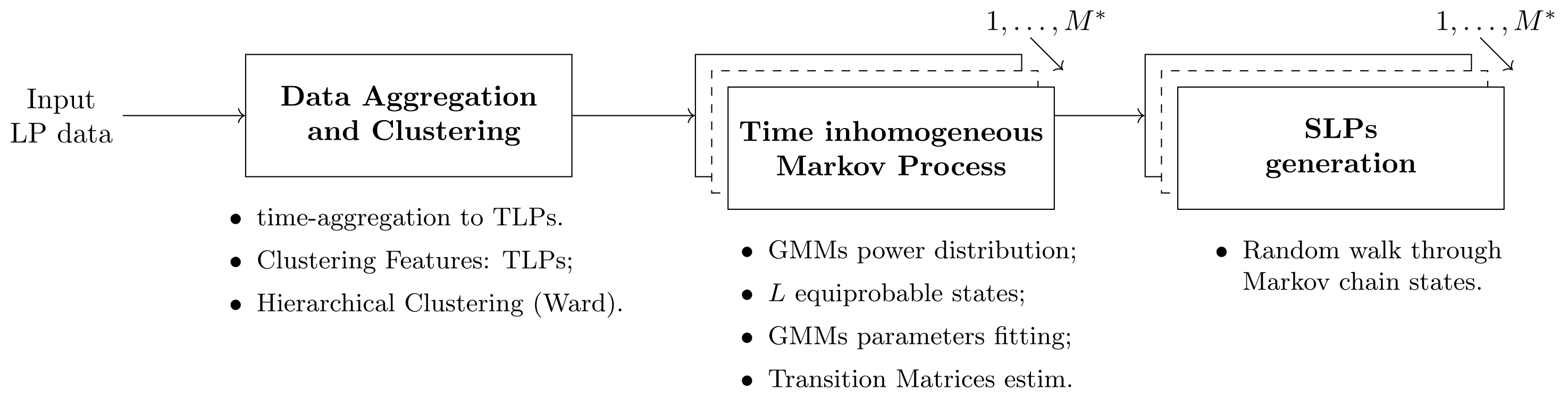
3. Model Description
- data aggregation and clustering,
- Markov chain model definition and
- SLP generation.
3.1. Data Aggregation and Clustering
- Initially, the elements of (i.e., at level 0 for a sequence number ) are exactly N clusters consisting of 1 TDLP each. As a consequence, the initial NOC value M is and the dissimilarity matrix is computed as follows:where is the distance between each pair of clusters r and k. If the Ward’s method is used, initially coincides with the squared Euclidean distance between TDLPs and , i.e., .
- Starting from the current matrix , the clusters with the least dissimilarity, i.e., those with indexesare merged into a new cluster and the sequence number j is incremented by 1. Furthermore, matrix is updated by deleting the rows and columns associated with clusters and , and by adding a new row and column including the distances between the newly formed cluster (labeled as p) and all the others. In particular, if the Ward’s linkage method is used, the value of is updated recursively using the Lance–Williams expression reported in [48,49]. Observe that both the number of clusters M and the size of matrix are decreased by 1.
- If a new clustering attempt is performed restarting from step 2; otherwise the algorithm ends.
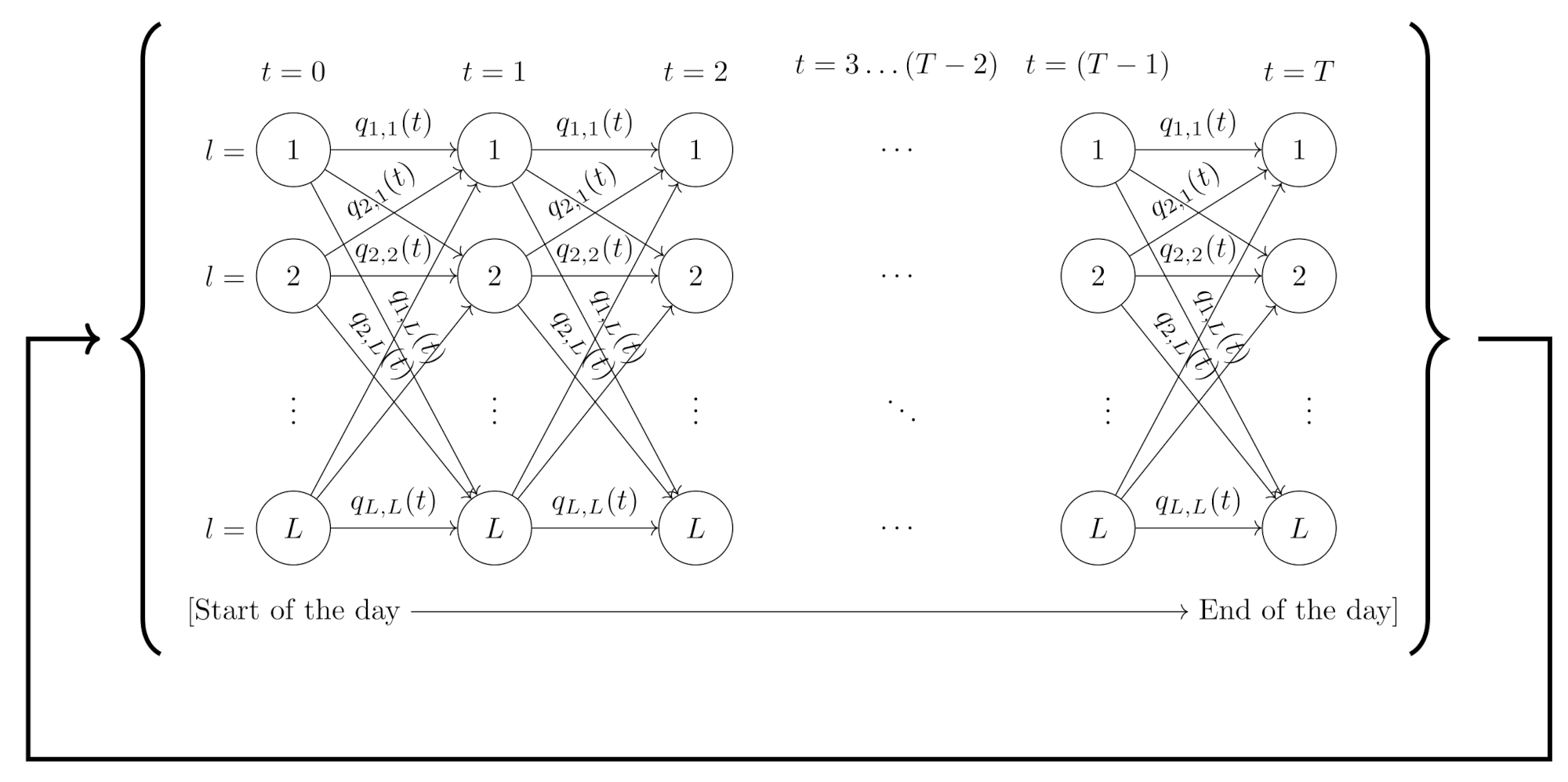
3.2. Markov Chain Model Definition
- it is irreducible and aperiodic;
- it certainly admits an invariant measure for with , as the probability of visiting every state of the model is constant over time. In particular, it results by construction that .
- it is time-inhomogeneous since the elements of transition matrix(with being the probability of moving from state i to state j) change as a function of time. Therefore, a sequence of T transition matrices must be estimated to implement the model.
3.3. SLPs Generation
- is the number of Gaussian components for the -th cluster at time t;
- coefficients (for with ) are the mixing probabilities;
- , for , are the mean values of the Gaussian components; and, finally, , for , are the respective variances.
4. Results and Discussion
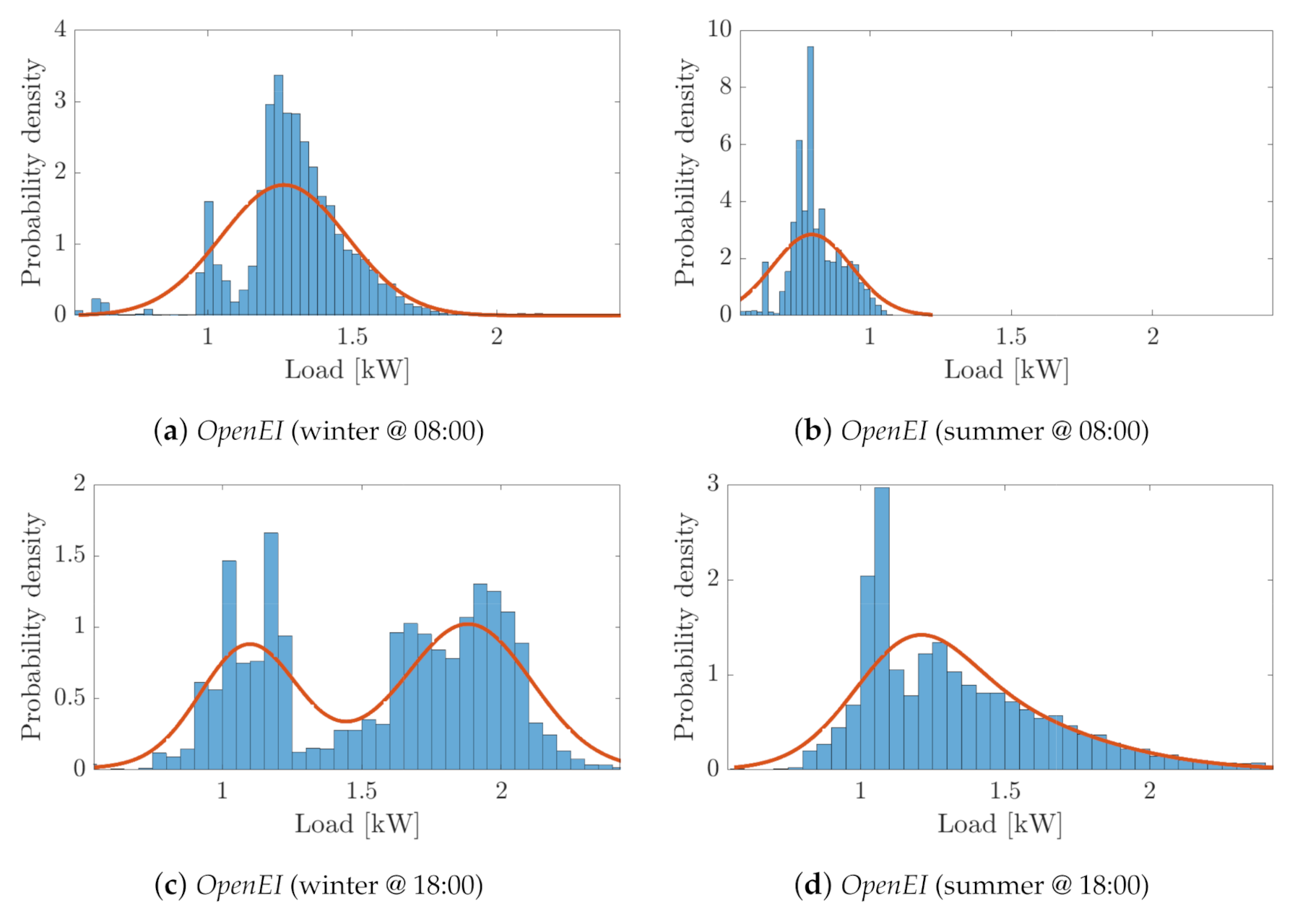
- The first data set, briefly referred to as OpenEI database (OEI – Commercial and Residential Hourly Load Profiles for all TMY3 Locations in the United States, Open Energy Data Initiative, https://data.openei.org/submissions/153 ) includes almost 3000 commercial and residential yearly load profiles reconstructed with hourly resolution on the basis of the weather and location data of the “typical meteorological year 3” (TMY3).
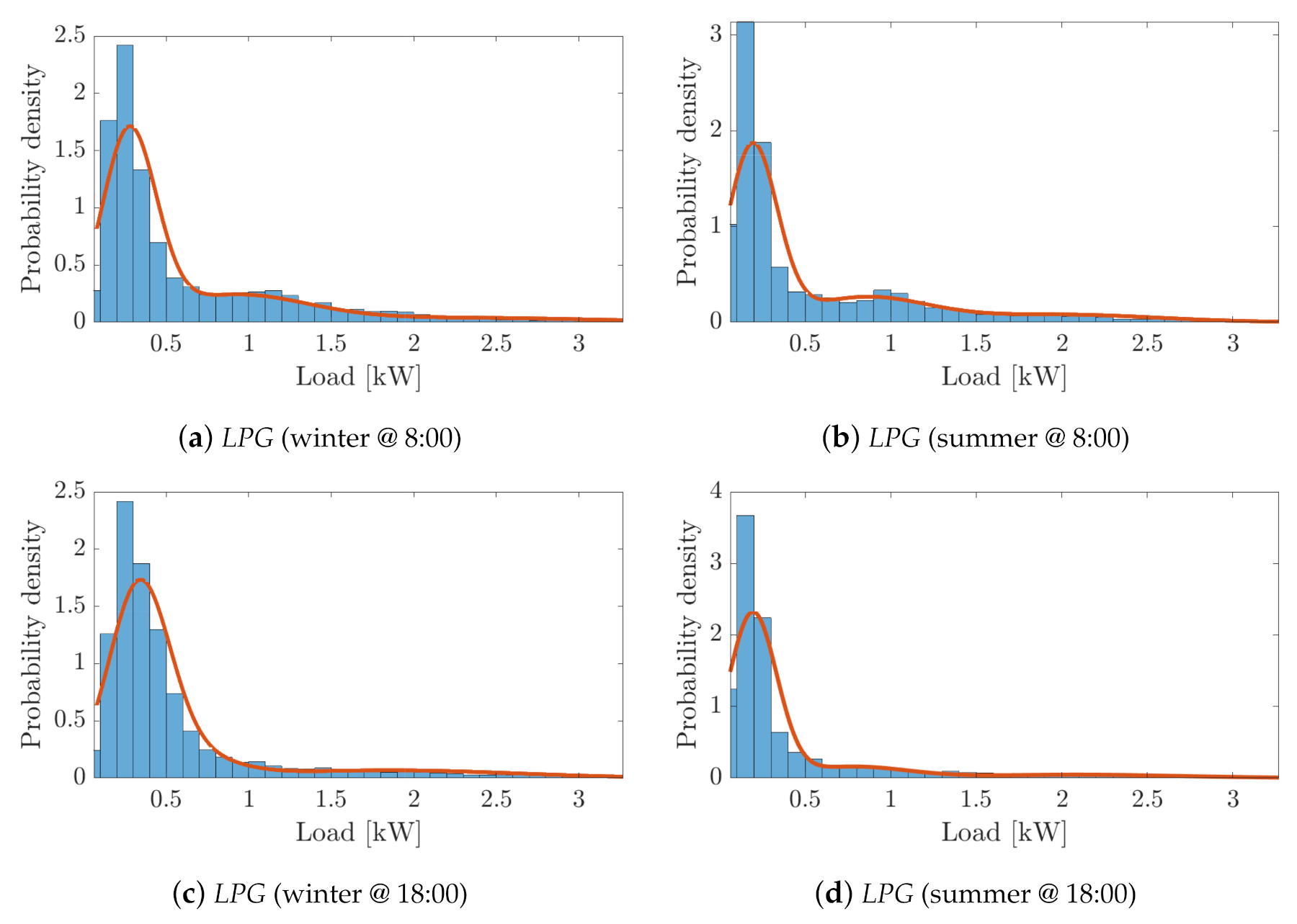
- The second data set, referred to as Load Profile Generator (LPG – A Bottom-Up Customizable Load Generator, Noah Pflugradt, https://www.loadprofilegenerator.de) features around 300 load consumption profiles of typical German households with a 15-minute time step.
- Finally, the third data set, labeled as CER residential (CER Smart Metering Project—Electricity Customer Behaviour Trial, 2009—2010, accessed via the Irish Social Science Data Archive—www.ucd.ie/issda) consists of real anonymized measurement data collected every 30 min from over 5000 Irish households that joined the project.
4.1. Clustering Results
4.2. Markov Chains Settings
- this value is small enough (but not too small) to have a reasonably low estimation uncertainty of the elements of transition matrices even with clusters with a low numerosity;
- this number of states is in line with those reported in other works on the same topic, e.g., in [30];
- finally, processing burden and computational times are reasonable, as it will be shown in Section 4.4.
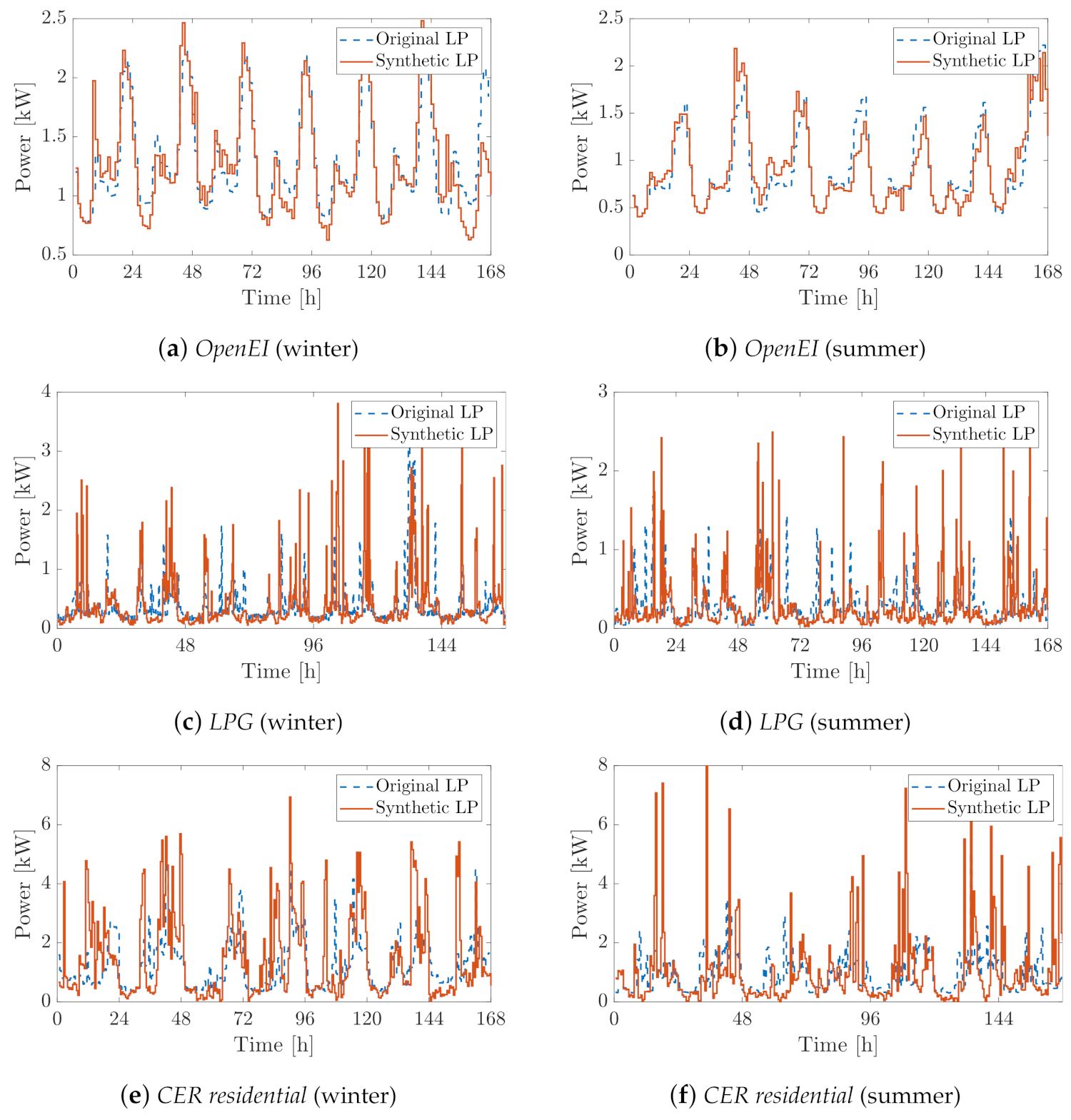
4.3. Performance Evaluation
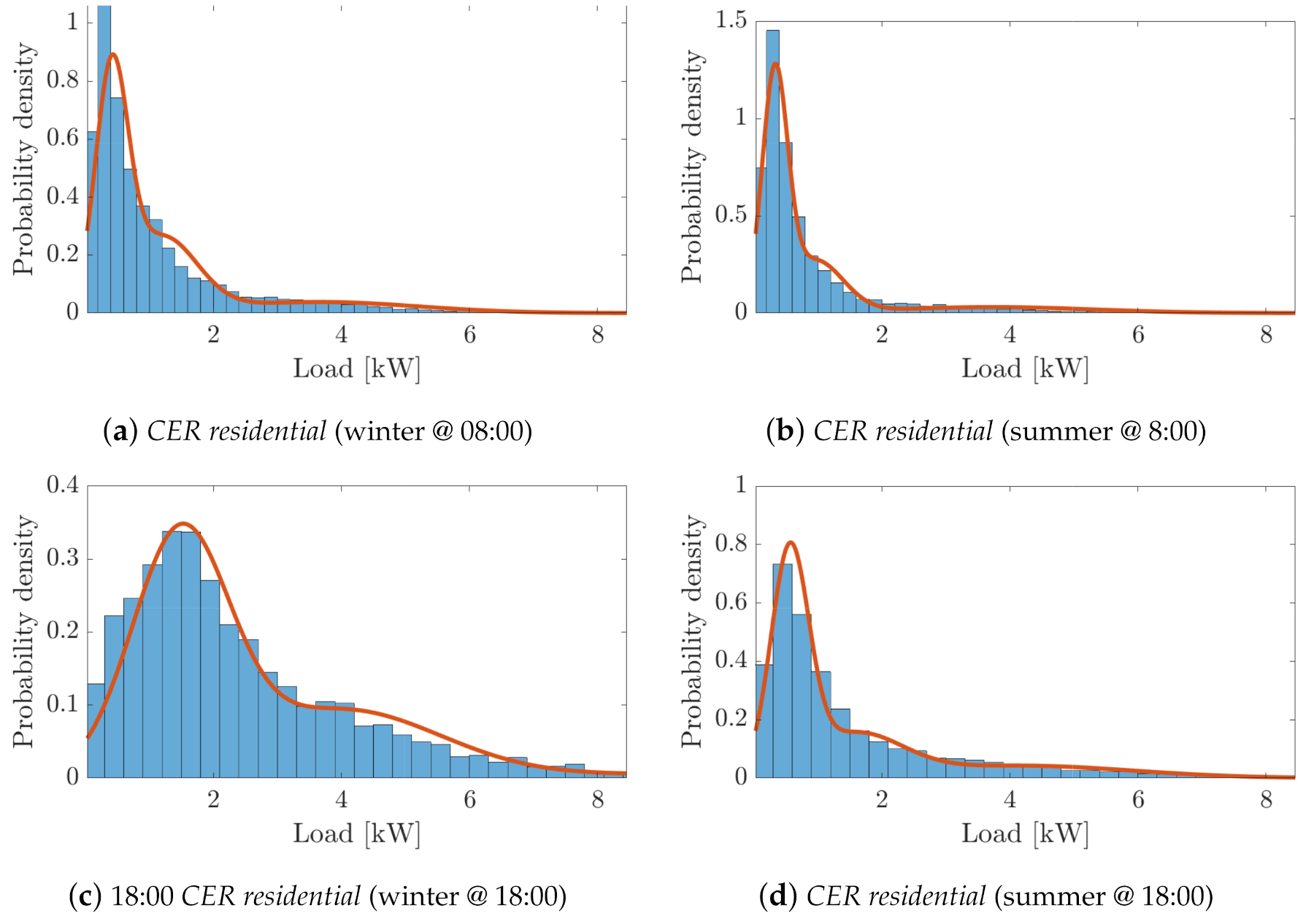
- First, the PDFs of the SLPs are qualitatively compared with the histograms of the original LPs at different times of the day.
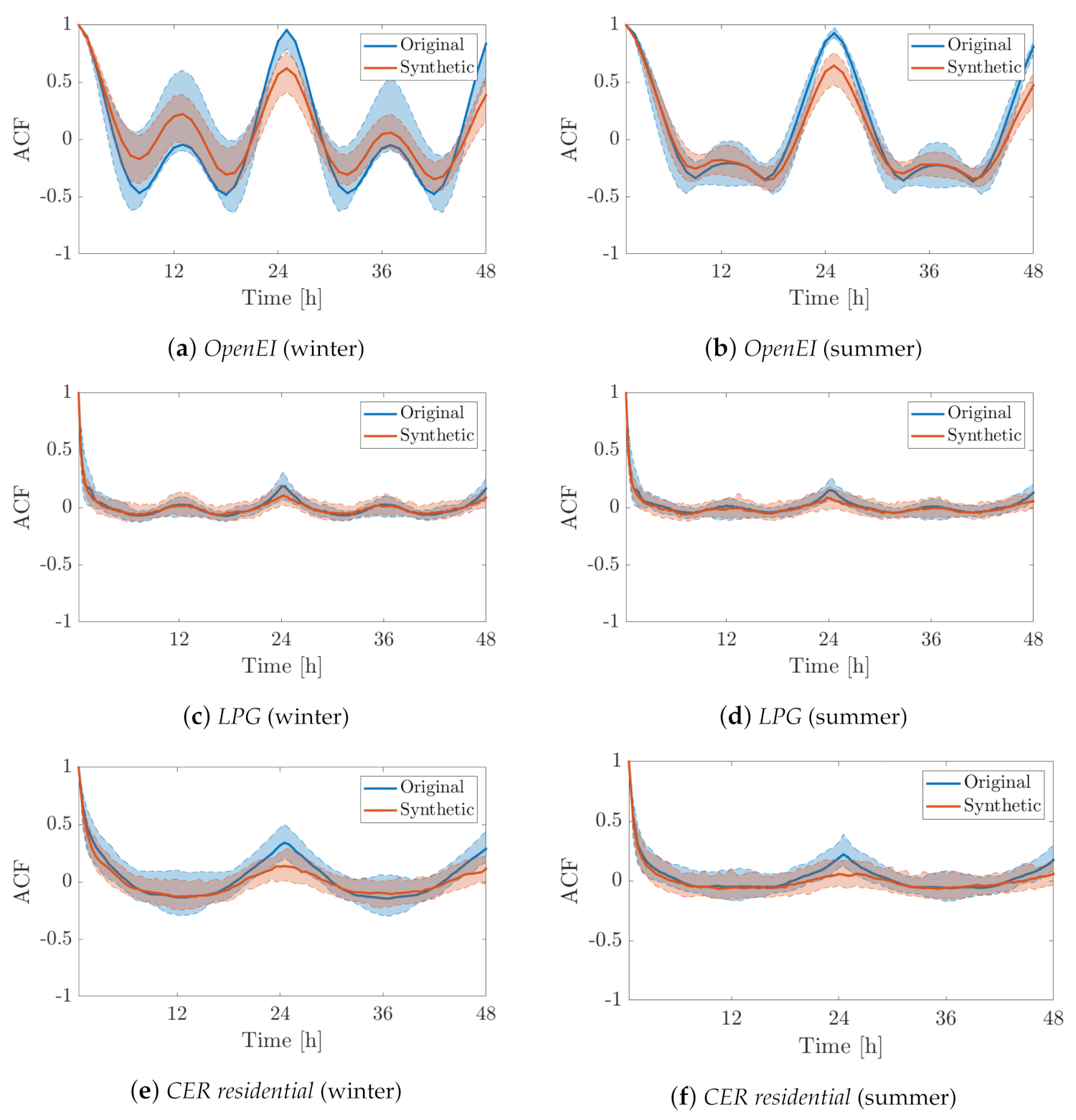
- Then, the capability of the proposed model to describe the intra-day behavior of the original LPs is evaluated by comparing their autocorrelation functions (ACFs).
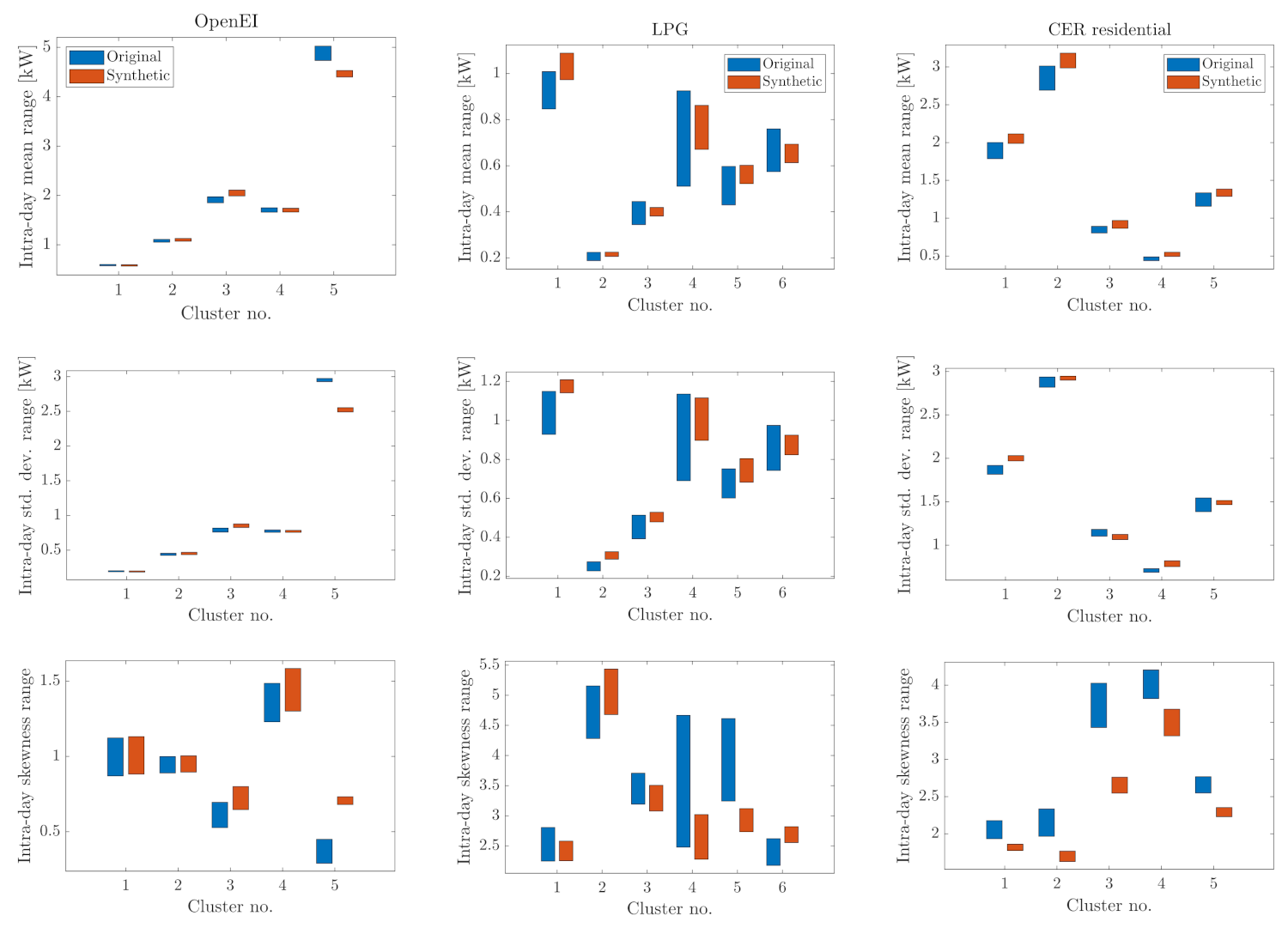
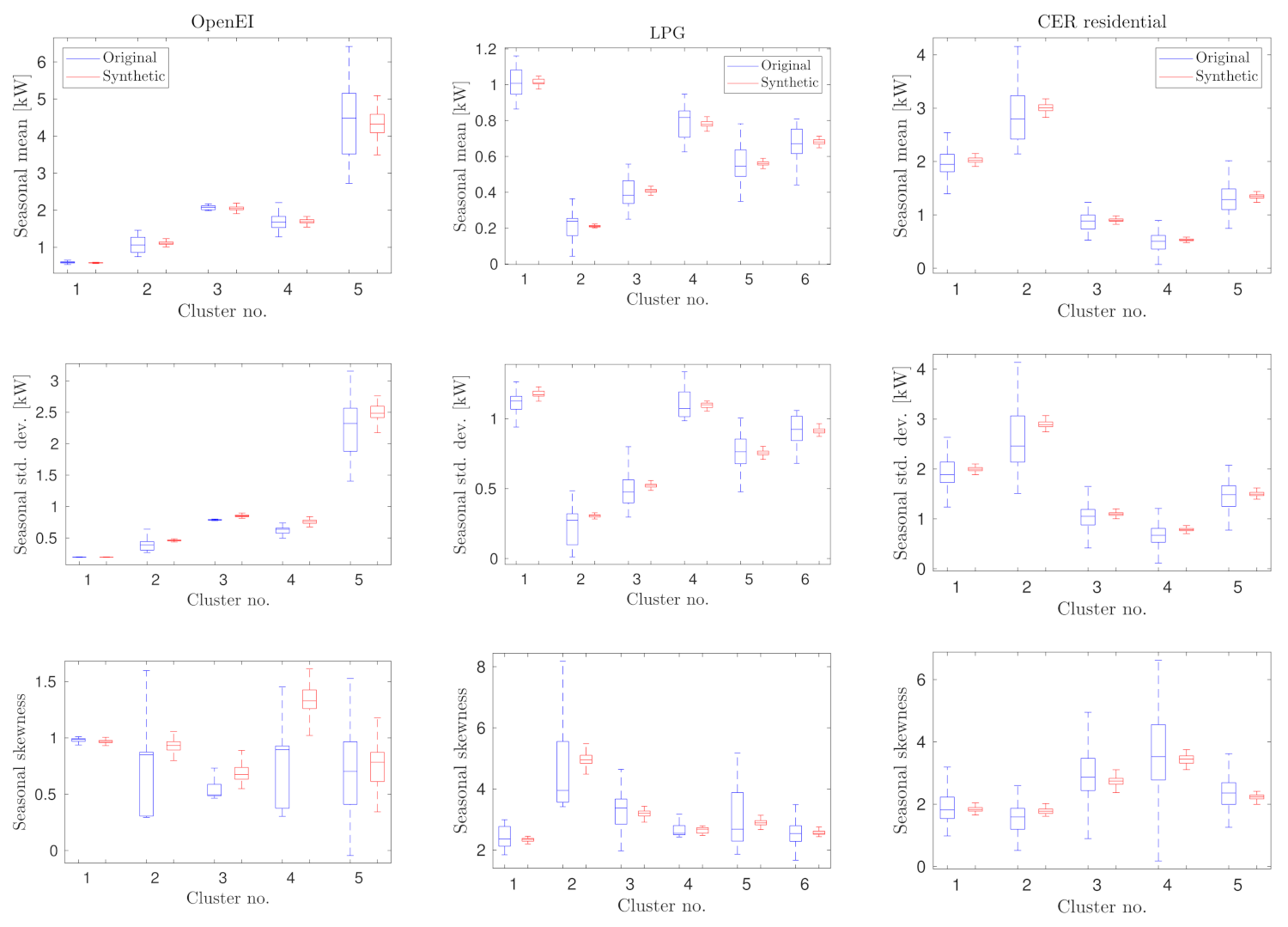
- Finally, a deeper quantitative comparison of the main stochastic features of the load profile distributions is performed. This analysis is carried out for each cluster by comparing the mean, standard deviation and skewness values of the PDFs of both the SLPs and the original LPs, both within a typical day of each season and within the cluster population over the whole season.
4.4. Discussion
5. Conclusions
- Load flow analyses in time-varying operating conditions, especially when the grid under study consists of many buses and the original LP data are scarce.
- Correct sizing of grid components and devices (e.g., transformers, shunt capacitors and power converters) to improve, at a design level, grid robustness under stressed, non-ideal conditions.
- Definition of possible baseline scenarios to evaluate the impact of different centralized or distributed optimal control strategies for load peak shaving, users’ costs minimization or system resilience improvement.
- Benchmarking of power systems and distribution systems state estimation algorithms.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ajadi, T.; Cuming, V.; Boyle, R.; Strahan, D.; Kimmel, M.; Michael, L. Global Trends in Renewable Energy Investment 2020. 2020. Available online: https://www.fs-unep-centre.org/wp-content/uploads/2020/06/GTR_2020.pdf (accessed on 3 November 2021).
- Dharmakeerthi, C.H.; Mithulananthan, N.; Saha, T.K. Overview of the impacts of plug-in electric vehicles on the power grid. In Proceedings of the 2011 IEEE PES Innovative Smart Grid Technologies, Anaheim, CA, USA, 17–19 January 2011; pp. 1–8. [Google Scholar] [CrossRef]
- Thormann, B.; Kienberger, T. Evaluation of Grid Capacities for Integrating Future E-Mobility and Heat Pumps into Low-Voltage Grids. Energies 2020, 13, 5083. [Google Scholar] [CrossRef]
- Karimi, M.; Mokhlis, H.; Naidu, K.; Uddin, S.; Bakar, A.H.A. Photovoltaic penetration issues and impacts in distribution network—A review. Renew. Sust. Energy Rev. 2016, 53, 594–605. [Google Scholar] [CrossRef]
- Pieltain Fernández, L.; Gómez San Román, T.; Cossent, R.; Mateo Domingo, C.; Frías, P. Assessment of the impact of plug-in electric vehicles on distribution networks. IEEE Trans. Power Syst. 2011, 26, 206–213. [Google Scholar] [CrossRef]
- Macii, D.; Fontanelli, D.; Barchi, G. A Distribution System State Estimator Based on an Extended Kalman Filter Enhanced with a Prior Evaluation of Power Injections at Unmonitored Buses. Energies 2020, 13, 6054. [Google Scholar] [CrossRef]
- Barchi, G.; Macii, D. A photovoltaics-aided interlaced extended Kalman filter for distribution systems state estimation. Sustain. Energy Grids Netw. 2021, 26, 100438. [Google Scholar] [CrossRef]
- Wieland, T.; Reiter, M.; Schmautzer, E.; Fickert, L. Modern Grid Planing—A Probabilistic Approach for Low Voltage Networks facing New Challenges. In Proceedings of the 23rd International Conference on Electricity Distribution (CIRED 2015), Lyon, France, 15–18 June 2015; pp. 1–5. [Google Scholar]
- Ismael, S.M.; Abdel Aleem, S.H.E.; Abdelaziz, A.Y.; Zobaa, A.F. State-of-the-art of hosting capacity in modern power systems with distributed generation. Renew. Energy 2019, 130, 1002–1020. [Google Scholar] [CrossRef]
- Fatima, S.; Püvi, V.; Arshad, A.; Pourakbari-Kasmaei, M.; Lehtonen, M. Comparison of Economical and Technical Photovoltaic Hosting Capacity Limits in Distribution Networks. Energies 2021, 14, 2405. [Google Scholar] [CrossRef]
- Alaton, C.; Tounquet, F. Benchmarking Smart Metering Deployment in the EU-28. 2020. Available online: https://op.europa.eu/s/omSNhttps://op.europa.eu/s/omSN (accessed on 3 November 2021).
- Jardini, J.A.; Tahan, C.M.V.; Gouvea, M.R.; Ahn, S.U.; Figueiredo, F.M. Daily load profiles for residential, commercial and industrial low voltage consumers. IEEE Trans. Power Deliv. 2000, 15, 375–380. [Google Scholar] [CrossRef] [Green Version]
- Sharma, V.; Haque, M.H.; Aziz, S.M. PV generation and load profile data of net zero energy homes in South Australia. Data Brief 2019, 25, 104235. [Google Scholar] [CrossRef]
- Machado, J.A.C.; Carvalho, P.M.S.; Ferreira, L.A.F.M. Building Stochastic Non-Stationary Daily Load/Generation Profiles for Distribution Planning Studies. IEEE Trans. Power Syst. 2018, 33, 911–920. [Google Scholar] [CrossRef]
- Brodén, D.A.; Paridari, K.; Nordström, L. Matlab applications to generate synthetic electricity load profiles of office buildings and detached houses. In Proceedings of the IEEE Innovative Smart Grid Technologies—Asia (ISGT-Asia), Auckland, New Zealand, 4–7 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Bouderraoui, H.; Chami, M. SGSim: Load Profile Generator for Smart Grid Applications. In Proceedings of the 2018 Renewable Energies, Power Systems Green Inclusive Economy (REPS-GIE), Casablanca, Morocco, 23–24 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Uimonen, S.; Lehtonen, M. Simulation of Electric Vehicle Charging Stations Load Profiles in Office Buildings Based on Occupancy Data. Energies 2020, 13, 5700. [Google Scholar] [CrossRef]
- Corrà, M.; Fusari, E.; Ferrari, A.; MacIi, D. A System Based on IoT Platforms and Occupancy Monitoring for Energy-Efficient HVAC Management. In Proceedings of the 2019 IEEE 5th International forum on Research and Technology for Society and Industry (RTSI), Florence, Italy, 9–12 September 2019; pp. 347–352. [Google Scholar] [CrossRef]
- Grandjean, A.; Adnot, J.; Binet, G. A review and an analysis of the residential electric load curve models. Renew. Sustain. Energy Rev. 2012, 16, 6539–6565. [Google Scholar] [CrossRef]
- Richardson, I.; Thomson, M.; Infield, D.; Clifford, C. Domestic electricity use: A high-resolution energy demand model. Energy Build. 2010, 42, 1878–1887. [Google Scholar] [CrossRef] [Green Version]
- Sandels, C.; Widén, J.; Nordström, L. Forecasting household consumer electricity load profiles with a combined physical and behavioral approach. Appl. Energy 2014, 131, 267–278. [Google Scholar] [CrossRef]
- Armstrong, M.M.; Swinton, M.C.M.C.; Ribberink, H.; Beausoleil-Morrison, I.; Millette, J. Synthetically derived profiles for representing occupant-driven electric loads in Canadian Housing. J. Build. Perform. Simul. 2009, 2, 15–30. [Google Scholar] [CrossRef] [Green Version]
- Widén, J.; Wäckelgård, E. A high-resolution stochastic model of domestic activity patterns and electricity demand. Appl. Energy 2010, 87, 1880–1892. [Google Scholar] [CrossRef]
- Nijhuis, M.; Gibescu, M.; Cobben, J.F.G. Bottom-up Markov Chain Monte Carlo approach for scenario based residential load modelling with publicly available data. Energy Build. 2016, 112, 121–129. [Google Scholar] [CrossRef] [Green Version]
- Paatero, J.V.; Lund, P.D. A model for generating household electricity load profiles. Int. J. Energy Res. 2006, 30, 273–290. [Google Scholar] [CrossRef] [Green Version]
- Bottaccioli, L.; Di Cataldo, S.; Acquaviva, A.; Patti, E. Realistic Multi-Scale Modeling of Household Electricity Behaviors. IEEE Access 2019, 7, 2467–2489. [Google Scholar] [CrossRef]
- Yao, R.; Steemers, K. A method of formulating energy load profile for domestic buildings in the UK. Energy Build. 2005, 37, 663–671. [Google Scholar] [CrossRef]
- Sandels, C.; Brodén, D.; Widén, J.; Nordström, L.; Andersson, E. Modeling office building consumer load with a combined physical and behavioral approach: Simulation and validation. Appl. Energy 2016, 162, 472–485. [Google Scholar] [CrossRef]
- Chicco, G.; Napoli, R.; Piglione, F. Comparisons among clustering techniques for electricity customer classification. IEEE Trans. Power Syst. 2006, 21, 933–940. [Google Scholar] [CrossRef]
- Labeeuw, W.; Deconinck, G. Residential Electrical Load Model Based on Mixture Model Clustering and Markov Models. IEEE Trans. Ind. Inform. 2013, 9, 1561–1569. [Google Scholar] [CrossRef]
- Singh, R.; Pal, B.C.; Jabr, R.A. Statistical Representation of Distribution System Loads Using Gaussian Mixture Model. IEEE Trans. Power Syst. 2010, 25, 29–37. [Google Scholar] [CrossRef] [Green Version]
- Räsänen, T.; Voukantsis, D.; Niska, H.; Karatzas, K.; Kolehmainen, M. Data-based method for creating electricity use load profiles using large amount of customer-specific hourly measured electricity use data. Appl. Energy 2010, 87, 3538–3545. [Google Scholar] [CrossRef]
- Natale, N.; Pilo, F.; Pisano, G.; Troncia, M.; Bignucolo, F.; Coppo, M.; Pesavento, N.; Turri, R. Assessment of typical residential customers load profiles by using clustering techniques. In Proceedings of the 2017 AEIT International Annual Conference, Cagliari, Italy, 20–22 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Tsekouras, G.J.; Hatziargyriou, N.D.; Dialynas, E.N. Two-Stage Pattern Recognition of Load Curves for Classification of Electricity Customers. IEEE Trans. Power Syst. 2007, 22, 1120–1128. [Google Scholar] [CrossRef]
- Zoltán, K. EU Energy Consumer Classification. Technical Report. Natconsumers Consortium. 2016. Available online: https://ec.europa.eu/research/participants/documents/downloadPublic?documentIds=080166e5aba985df&appId=PPGMS (accessed on 1 November 2021).
- Benítez, I.; Quijano, A.; Díez, J.L.; Delgado, I. Dynamic clustering segmentation applied to load profiles of energy consumption from Spanish customers. Int. J. Electr. Power Energy Syst. 2014, 55, 437–448. [Google Scholar] [CrossRef]
- Gerbec, D.; Gasperic, S.; Smon, I.; Gubina, F. Allocation of the load profiles to consumers using probabilistic neural networks. IEEE Trans. Power Syst. 2005, 20, 548–555. [Google Scholar] [CrossRef]
- Granell, R.; Axon, C.J.; Wallom, D.C.H. Impacts of Raw Data Temporal Resolution Using Selected Clustering Methods on Residential Electricity Load Profiles. IEEE Trans. Power Syst. 2015, 30, 3217–3224. [Google Scholar] [CrossRef] [Green Version]
- Munkhammar, J.; Rydén, J.; Widén, J. Characterizing probability density distributions for household electricity load profiles from high-resolution electricity use data. Appl. Energy 2014, 135, 382–390. [Google Scholar] [CrossRef]
- Herman, R.; Kritzinger, J.J. The statistical description of grouped domestic electrical load currents. Electr. Power Syst. Res. 1993, 27, 43–48. [Google Scholar] [CrossRef]
- Huang, Y.; Zhan, J.; Luo, C.; Wang, L.; Wang, N.; Zheng, D.; Fan, F.; Ren, R. An electricity consumption model for synthesizing scalable electricity load curves. Energy 2019, 169, 674–683. [Google Scholar] [CrossRef]
- Gros, D.; Wiest, P.; Rudion, K.; Groß, D.; Wiest, P.; Rudion, K. Comparison of stochastic load profile modeling approaches for low voltage residential consumers. In Proceedings of the 2017 IEEE Manchester PowerTech, Manchester, UK, 18–22 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Zufferey, T.; Toffanin, D.; Toprak, D.; Ulbig, A.; Hug, G. Generating Stochastic Residential Load Profiles from Smart Meter Data for an Optimal Power Matching at an Aggregate Level. In Proceedings of the 2018 Power Systems Computation Conference (PSCC), Dublin, Ireland, 11–15 June 2018; pp. 1–7. [Google Scholar] [CrossRef]
- McLoughlin, F.; Duffy, A.; Conlon, M.; McLoughlin, F.; Conlon, M. The Generation of Domestic Electricity Load Profiles through Markov Chain Modelling. Euro-Asian J. Sustain. Energy Dev. Policy 2010, 3, 12. [Google Scholar]
- Groß, D.; Wiest, P.; Rudion, K.; Probst, A. Parametrization of stochastic load profile modeling approaches for smart grid simulations. In Proceedings of the 2017 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT-Europe), Torino, Italy, 26–29 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Papaefthymiou, G.G.; Klöckl, B.; Klockl, B. MCMC for wind power simulation. IEEE Trans. Energy Convers. 2008, 23, 234–240. [Google Scholar] [CrossRef] [Green Version]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. WIREs Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Lance, G.N.; Williams, W.T. A General Theory of Classificatory Sorting Strategies: 1. Hierarchical Systems. Comput. J. 1967, 9, 373–380. [Google Scholar] [CrossRef] [Green Version]
- Wishart, D. 256. Note: An Algorithm for Hierarchical Classifications. Biometrics 1969, 25, 165–170. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, G.; Lu, J.; Feng, X.; Yang, W. A New Index and Classification Approach for Load Pattern Analysis of Large Electricity Customers. IEEE Trans. Power Syst. 2012, 27, 153–160. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Saloff-Coste, L.; Zúñiga, J. Convergence of some time inhomogeneous Markov chains via spectral techniques. Stoch. Process. Their Appl. 2007, 117, 961–979. [Google Scholar] [CrossRef] [Green Version]
- McLachlan, G.; Peel, D. Finite Mixture Models; Wiley Series in Probability and Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2000. [Google Scholar] [CrossRef]
- Salvador, S.; Chan, P. Determining the number of clusters/segments in hierarchical clustering/segmentation algorithms. In Proceedings of the 16th IEEE International Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 15–17 November 2004; pp. 576–584. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database Name | Population Size N | NOC M | DBI Values | Rejected Clusters | % of Users within Valid Clusters |
|---|---|---|---|---|---|
| OpenEI | 2789 | 5 | 0.61 | 0 | 21, 33, 9, 33, 4 |
| LPG | 325 | 7 | 1.18 | 1 | 6, 10, 41, 4, 27, 10 |
| CER residential | 3790 | 5 | 1.90 | 0 | 12, 3, 20, 25, 40 |
| Database Name | Time Resolution | Data Clustering | Model Parameters Estimation | SLPs Generation |
|---|---|---|---|---|
| OpenEI | 1 h | 2 min | 6 min | 3 min |
| LPG | 15 min | 52 s | 5 min | 5 min |
| CER residential | 30 min | 15 min | 18 min | 7 min |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dalla Maria, E.; Secchi, M.; Macii, D. A Flexible Top-Down Data-Driven Stochastic Model for Synthetic Load Profiles Generation. Energies 2022, 15, 269. https://doi.org/10.3390/en15010269
Dalla Maria E, Secchi M, Macii D. A Flexible Top-Down Data-Driven Stochastic Model for Synthetic Load Profiles Generation. Energies. 2022; 15(1):269. https://doi.org/10.3390/en15010269
Chicago/Turabian StyleDalla Maria, Enrico, Mattia Secchi, and David Macii. 2022. "A Flexible Top-Down Data-Driven Stochastic Model for Synthetic Load Profiles Generation" Energies 15, no. 1: 269. https://doi.org/10.3390/en15010269