Artificial Learning Dispatch Planning for Flexible Renewable-Energy Systems


Abstract
:1. Introduction
1.1. Energy Market Participation
1.2. Existing Dispatch Strategies
1.3. Machine Learning in Energy Applications
1.4. Objectives of the Current Work
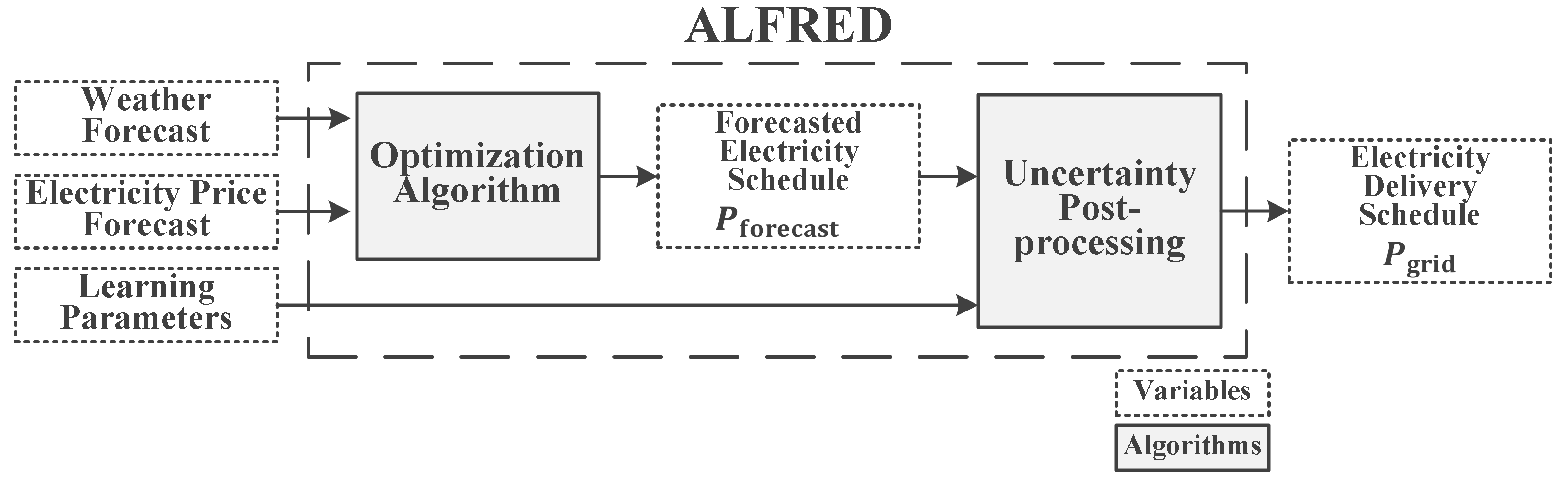
2. Materials and Methods
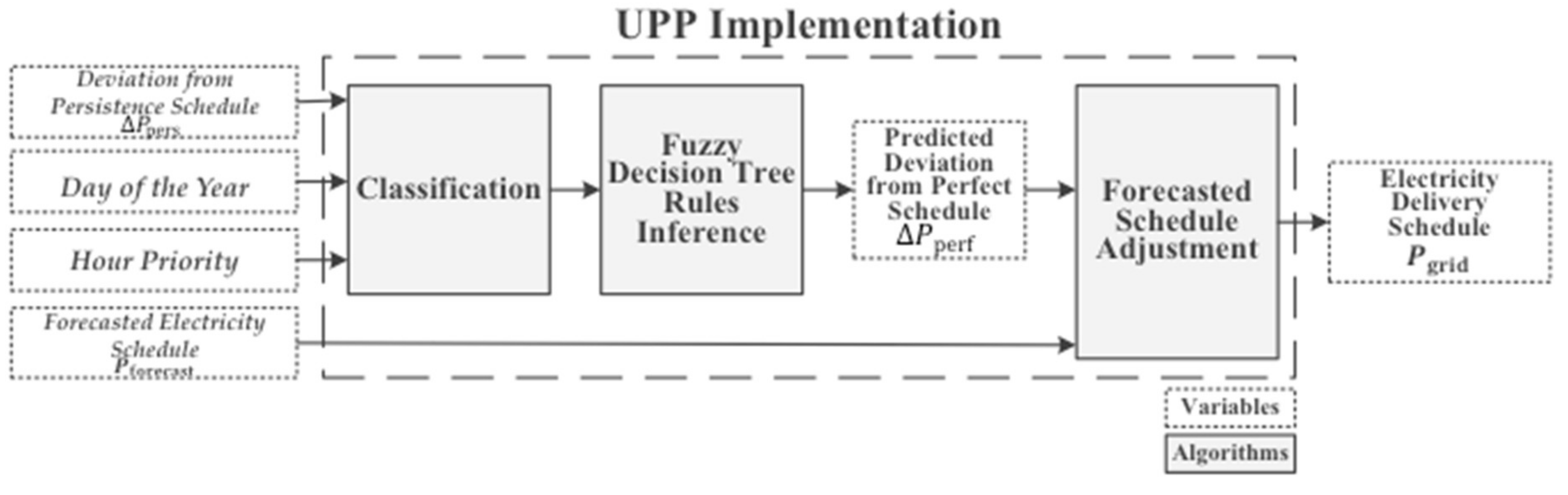
2.1. Uncertainty Post-Processing: A Machine-Learning Approach
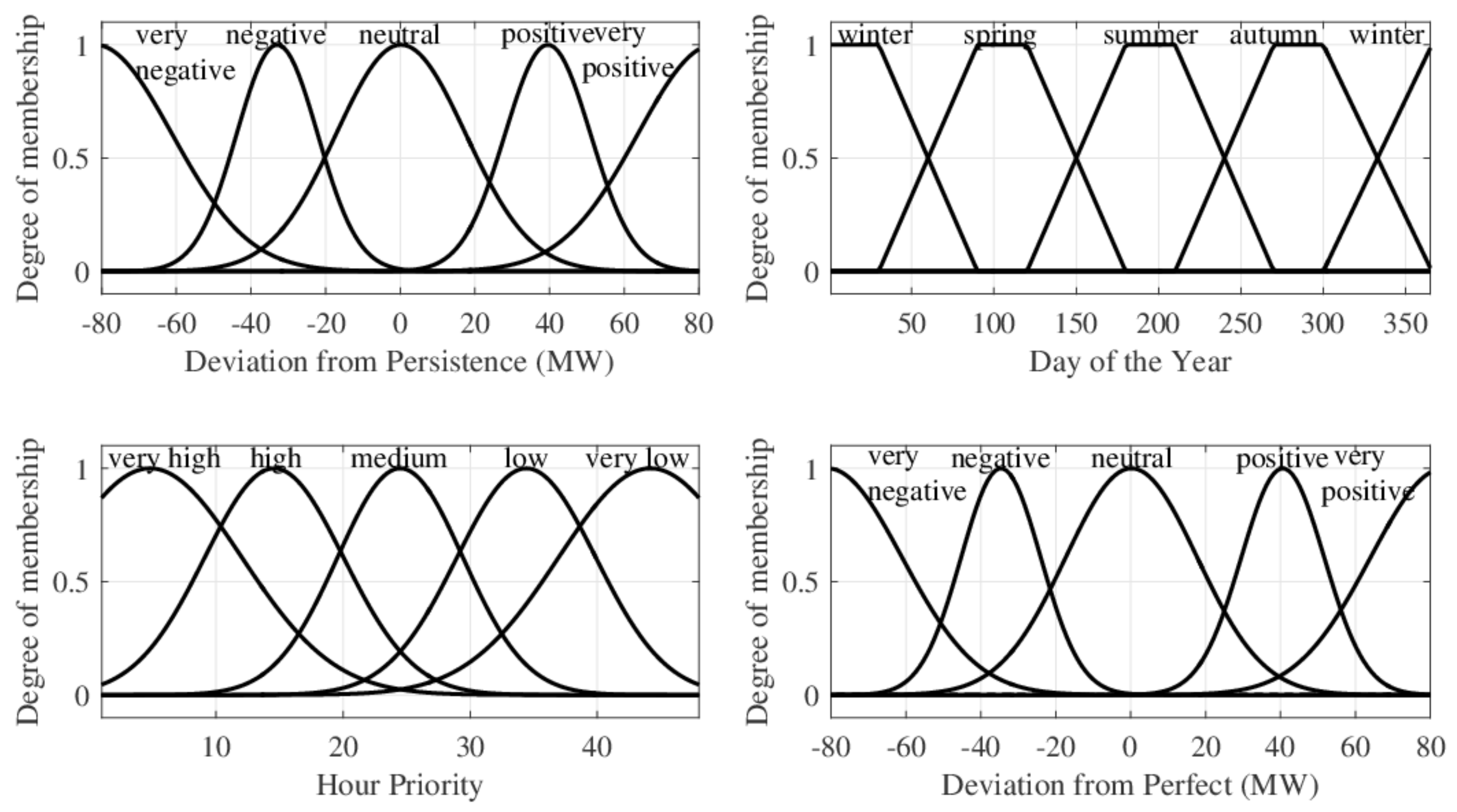
- Deviation of forecasted electricity schedule from schedule obtained with persistence forecast. Persistence forecast is the benchmark in forecasting, used when no forecast product is available. This forecast considers the observation of the previous day as the following day’s prediction. Its performance is frequently acceptable, being considered as a challenging model to overcome. Therefore, the difference between the forecasted power schedule, obtained by the optimization algorithm, and the schedule developed based on a persistence forecast can support the decision for the following day’s scheduling, calculated as:
- Day of the year. This parameter reflects seasonal influences on the dispatch planning, related to resource availability and price variations;
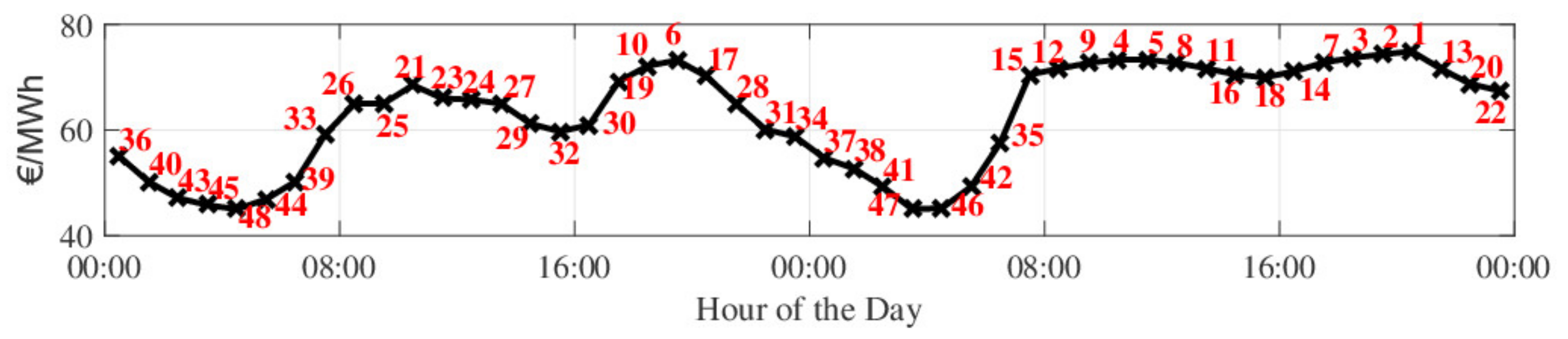
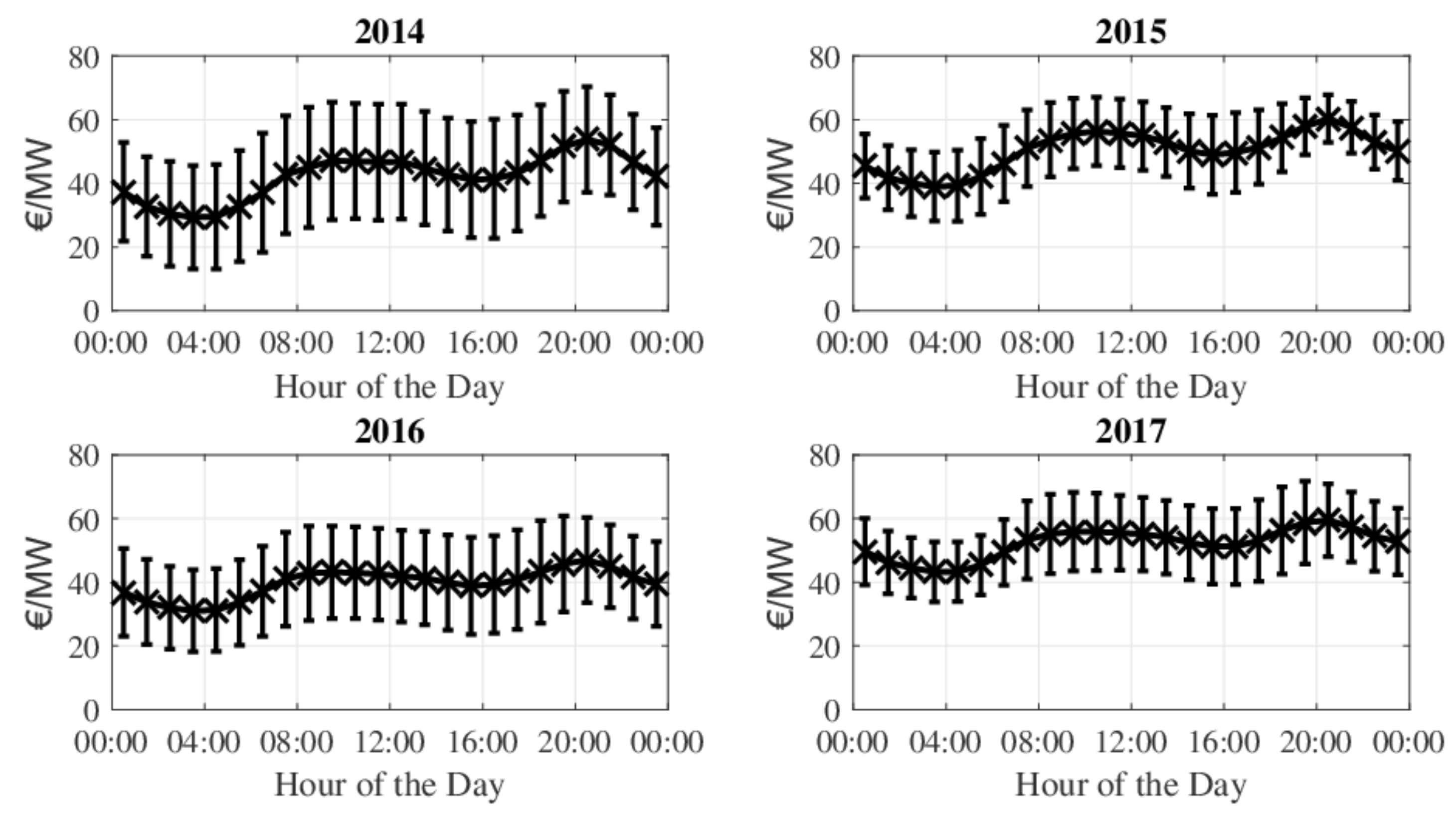
- Scheduling hour priority according to market price. Time instants are categorized according to their price, reflecting the priority of when production is desired (Figure 2). Higher price hours have higher priority, in a decreasing order until the lowest price. For hours with same price, higher priority is given to the earlier one, as energy losses are expected to be avoided, if production occurs earlier, and the meteorological forecast is usually more accurate for prior time instants;
- Deviation of forecasted electricity schedule from schedule obtained with perfect forecast. A perfect forecast considers the real weather observations as the prediction. A schedule based on this forecast is considered as the real optimum, with no uncertainties. Therefore, the perfect forecast delivery schedule is the objective to be reached. The difference between the forecasted power schedule, obtained by the optimization algorithm, and the schedule developed based on a perfect forecast reflects the deviation in relation to a schedule that would follow perfect weather and market predictions, calculated as:
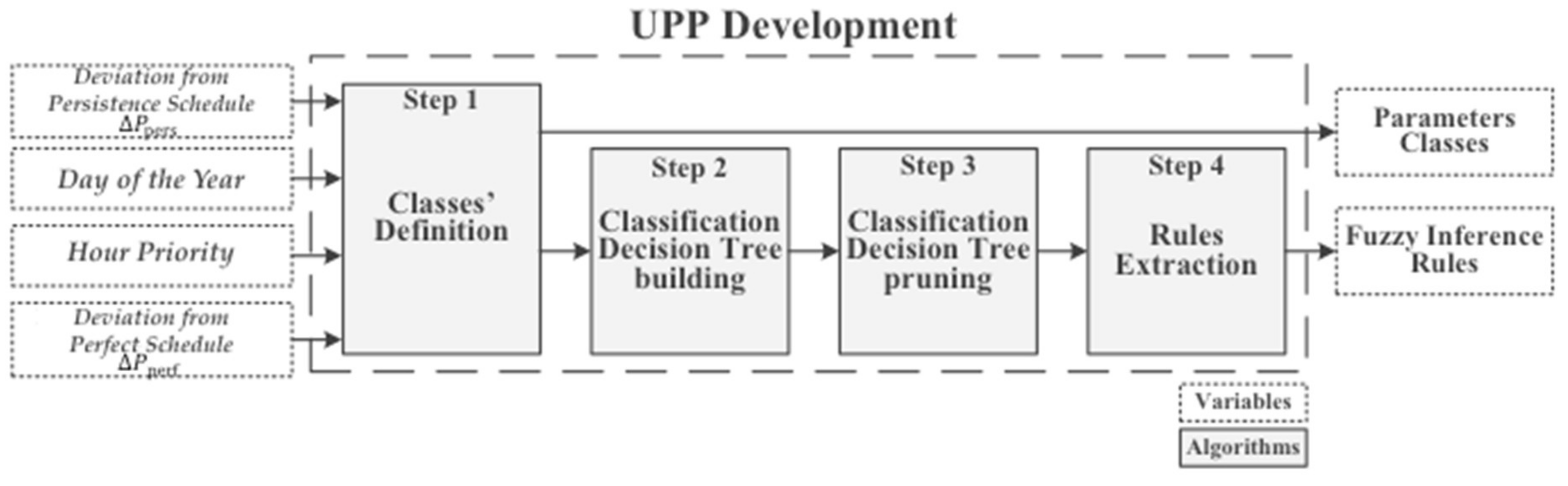
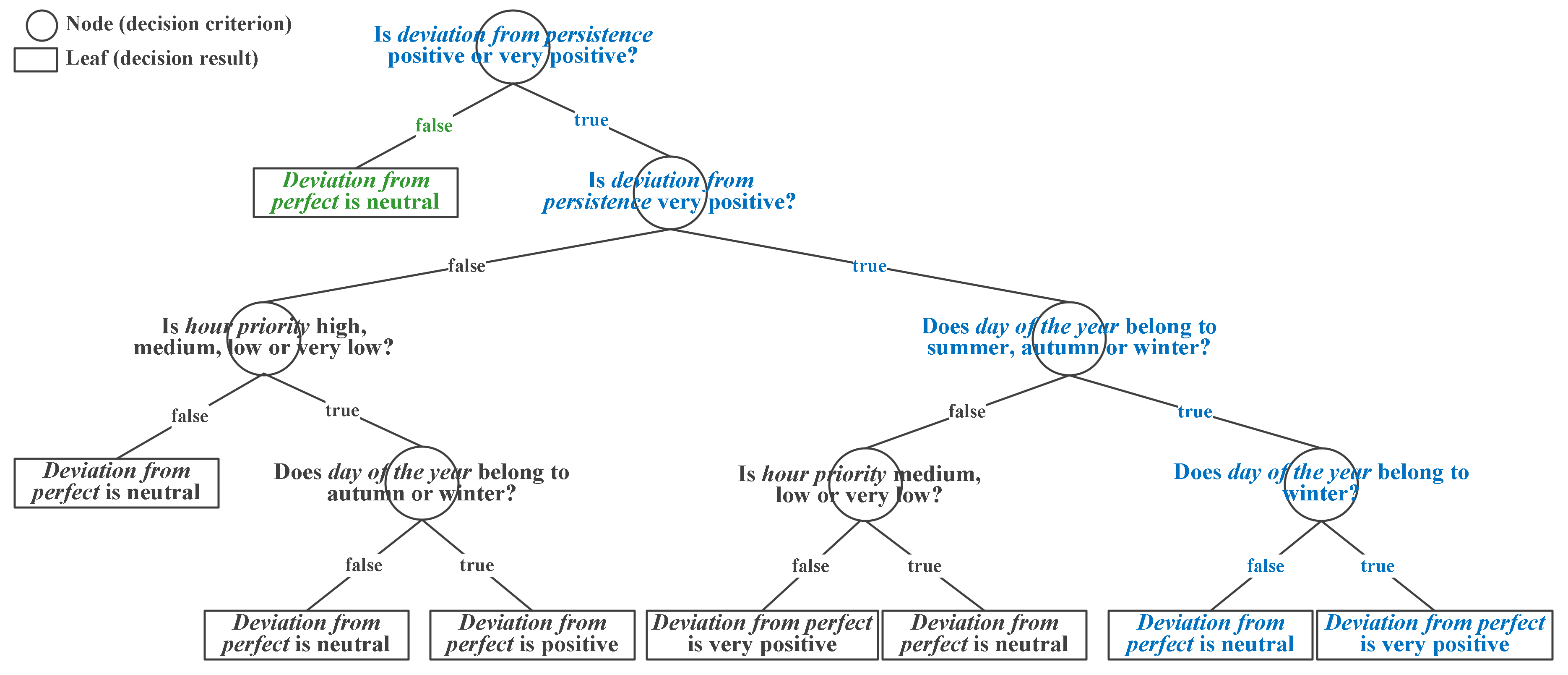
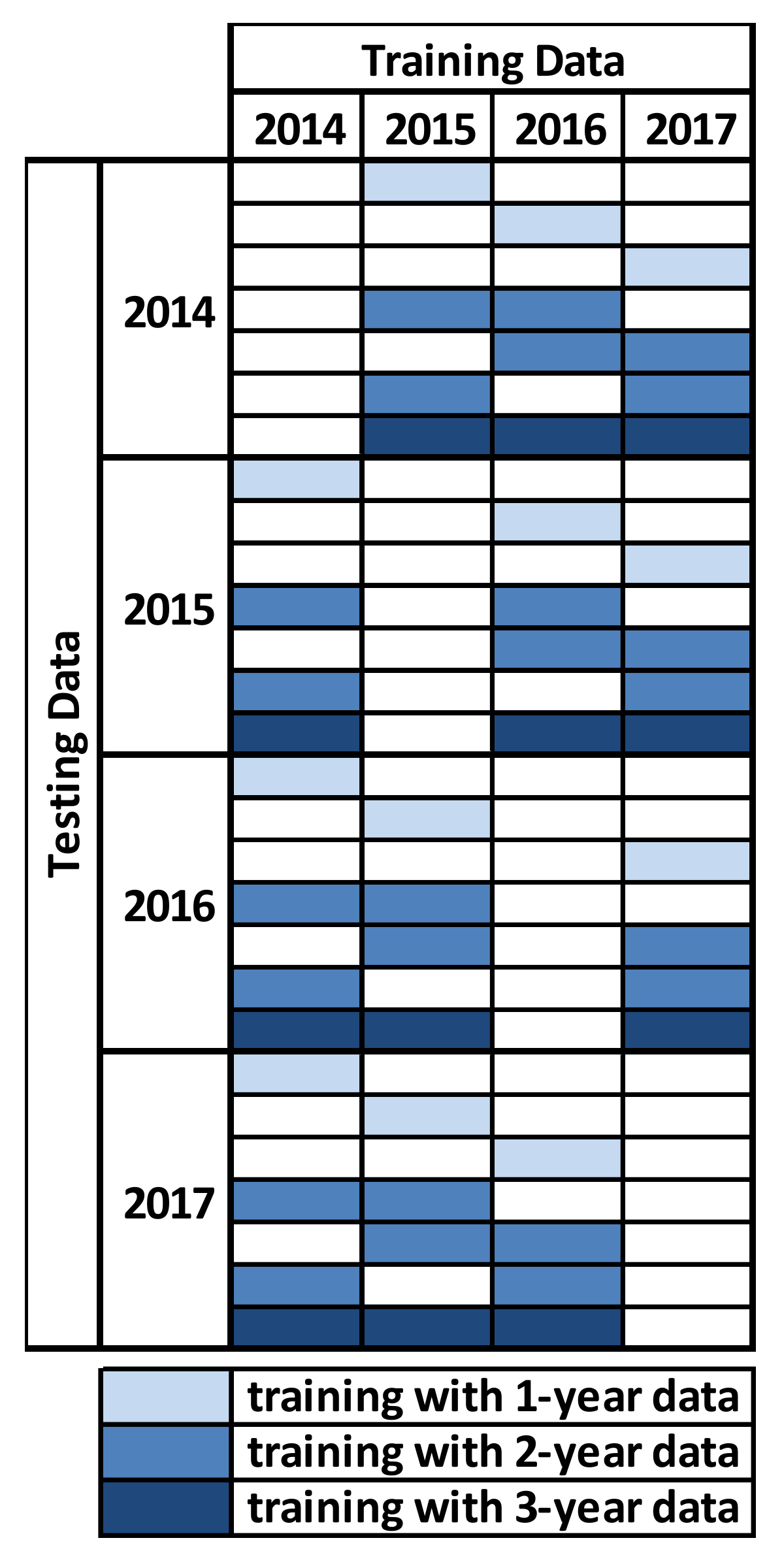
2.2. Uncertainty Post-Processing (UPP) Development: The Training Phase
- Rule 1:
- If deviation from persistence is very positive AND day of the year belongs to winter, THEN deviation from perfect is very positive.
- Rule 2:
- If deviation from persistence is very positive AND day of the year belongs to autumn or summer, THEN deviation from perfect is neutral.
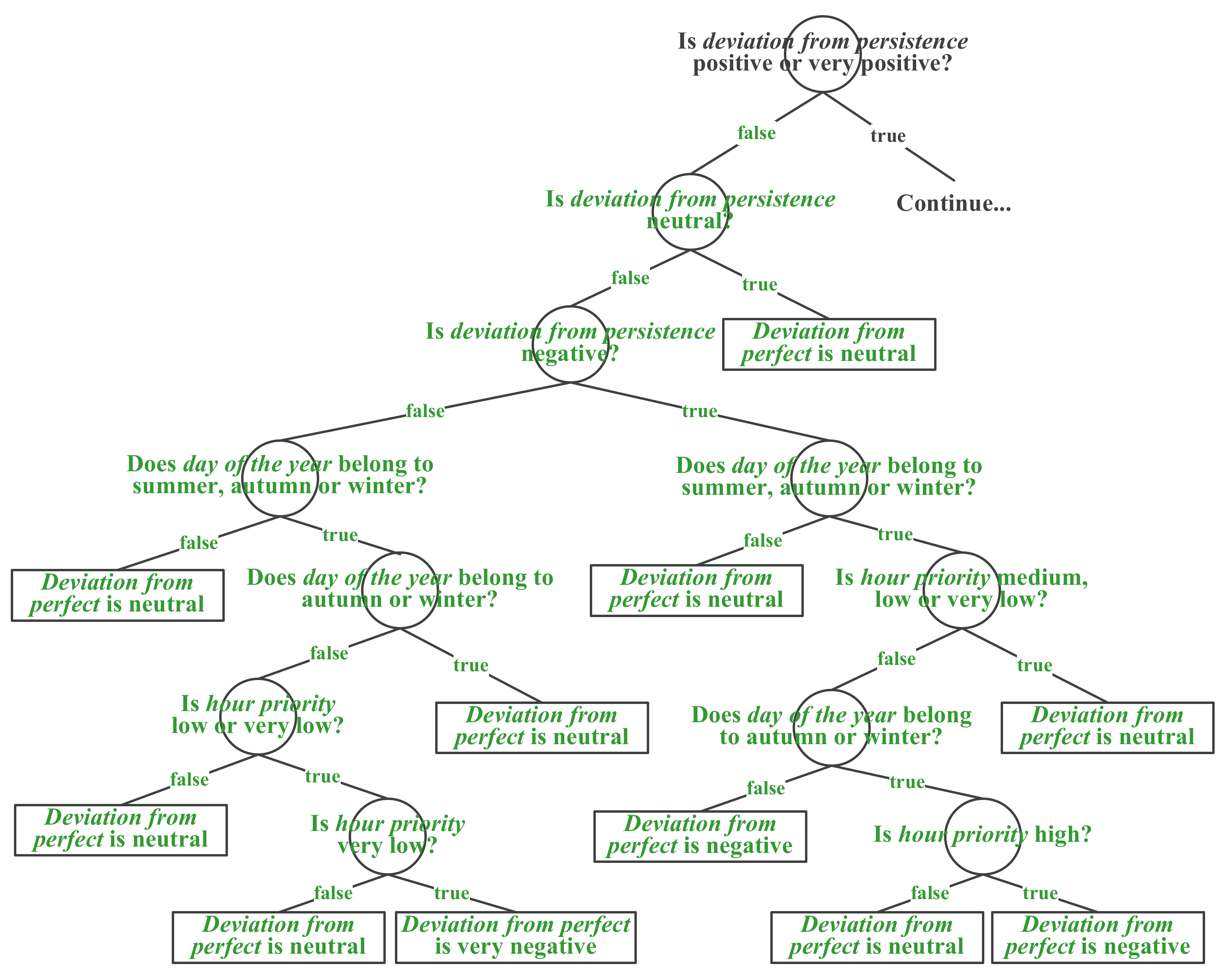
2.3. UPP Implementation: The Testing Phase
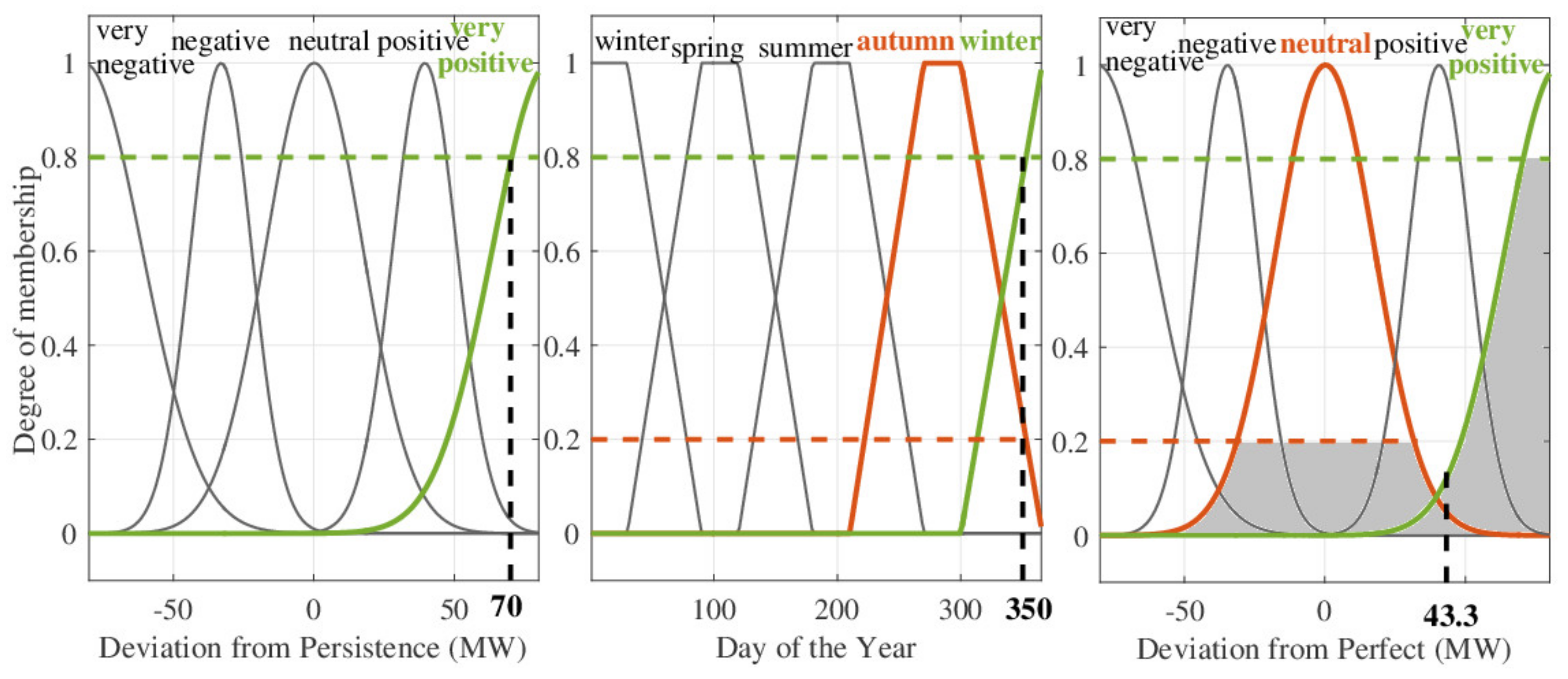
- Rule 1:
- If deviation from persistence is 80% very positive AND day of the year belongs 80% to winter, THEN deviation from perfect is 80% very positive.
- Rule 2:
- If deviation from persistence is 80% very positive AND day of the year belongs to 20% autumn, THEN deviation from perfect is 20% neutral.
3. Results
3.1. Simulations’ Data and Conditions
- Persistence schedule: based on the optimization performed with the persistence weather forecast, used as benchmark for comparison;
- Perfect schedule: based on the optimization performed with the perfect weather forecast, aiming to analyze the maximum possible benefit, when uncertainties do not play a role;
- Forecast product schedule without uncertainty post processing (UPP) application: based only on the optimization algorithm applied with the deterministic ECMWF weather forecast, aiming to analyze an optimal schedule based on a weather forecast product, without considering the uncertainty processing;
- Forecast product schedule with UPP application: based on the complete ALFRED strategy, aiming to evaluate the effectiveness of the proposed artificial learner in combination with an optimization algorithm. This last scheduling setup was adopted several times for each simulated year, considering the different training data setups combination.
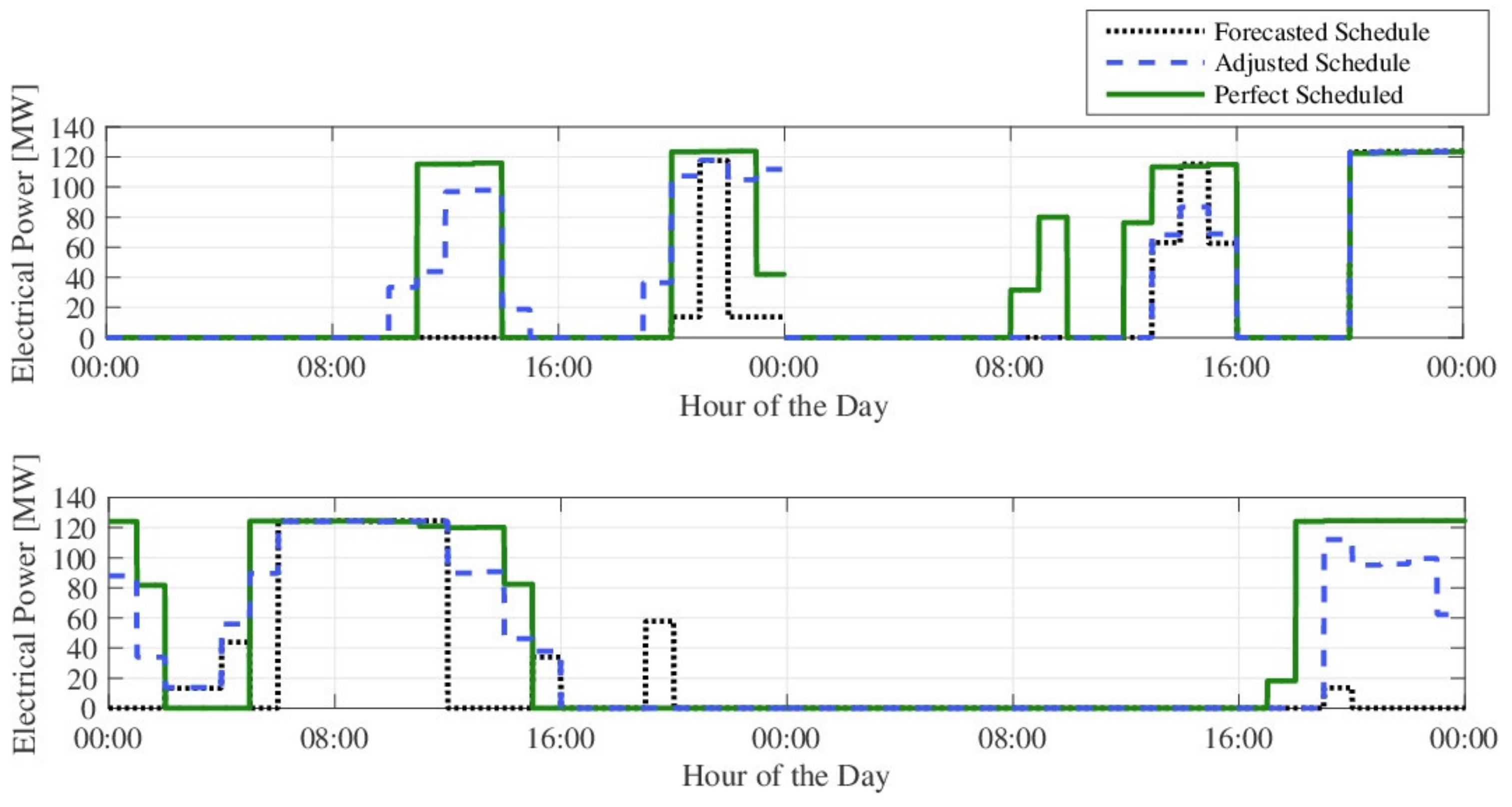
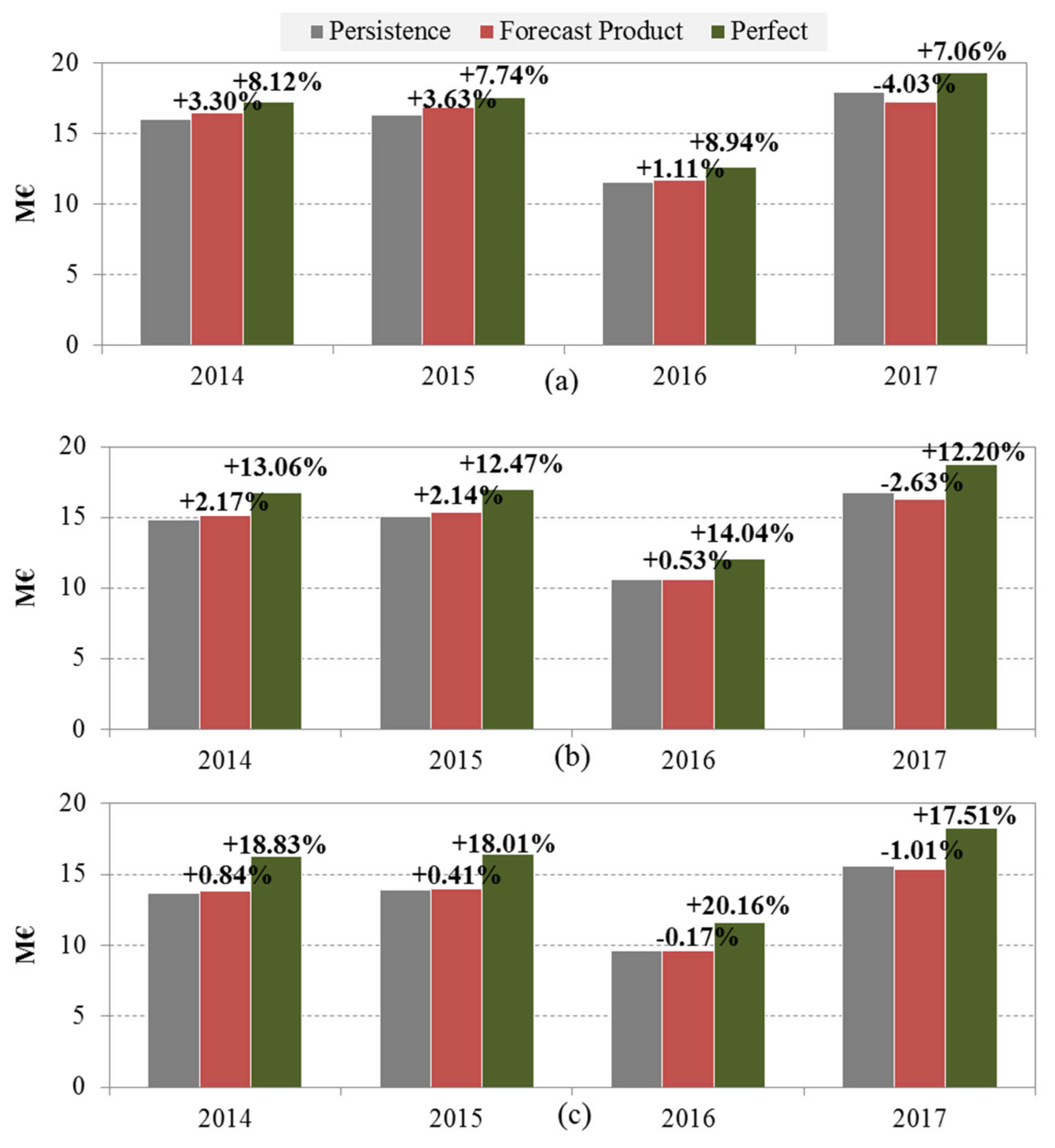
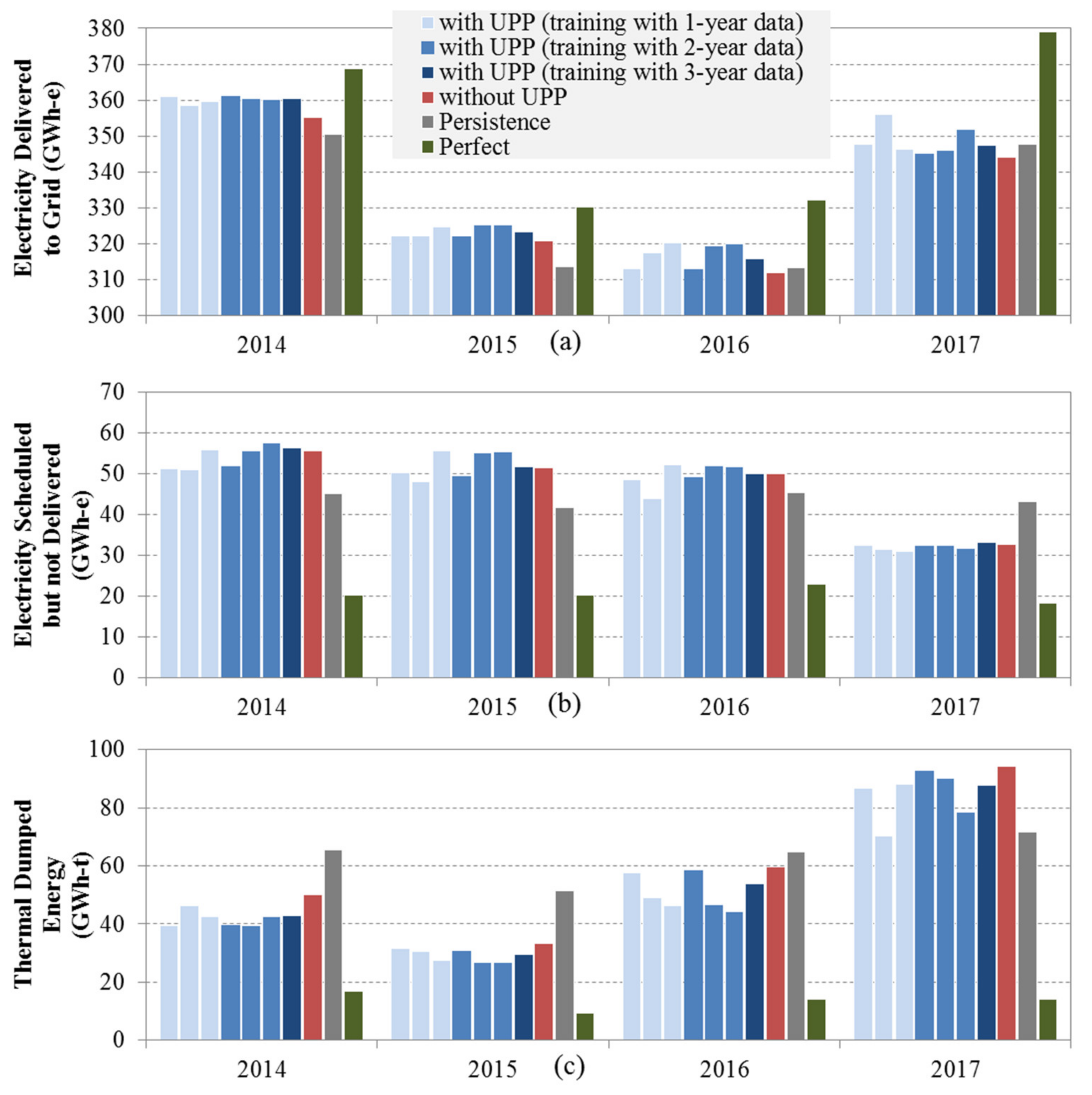
3.2. Optimization Results without UPP Learning Application
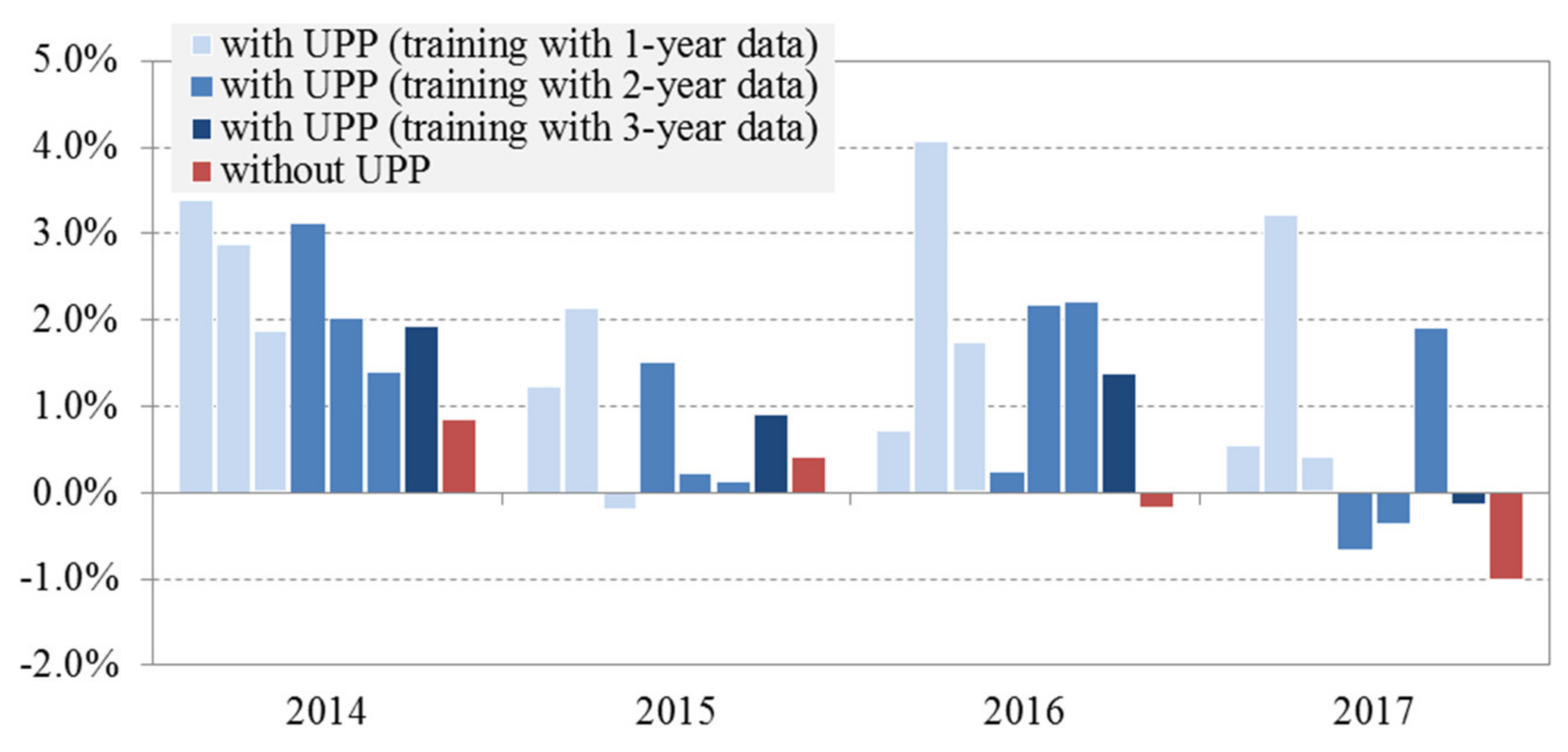
3.3. Optimization Results with UPP Learning Application
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| Forecasted electrical power schedule based on optimization algorithm | |
| Final scheduled electrical power to be delivered to grid | |
| Scheduled electrical power based on perfect forecast | |
| Scheduled electrical power based on persistence forecast | |
| Deviation from forecasted schedule to perfect schedule | |
| Deviation from forecasted schedule to perfect schedule |
References
- IRENA. Adapting Market Design to High Shares of Variable Renewable Energy; International Renewable Energy Agency: Abu Dhabi, United Arab Emirates, 2017. [Google Scholar]
- Castillo, A.; Gayme, D.F. Grid-scale energy storage applications in renewable energy integration: A survey. Energy Convers. Manag. 2014, 87, 885–894. [Google Scholar] [CrossRef]
- Hoff, T.E.; Perez, R.; Margolis, R.M. Maximizing the value of customer-sited PV systems using storage and controls. Sol. Energy 2007, 81, 940–945. [Google Scholar] [CrossRef]
- Nottrott, A.; Kleissl, J.; Washom, B. Storage dispatch optimization for grid-connected combined photovoltaic-battery storage systems. IEEE Power Energy Soc. Gen. Meet. 2012, 1–7. [Google Scholar]
- Hanna, R.; Kleissl, J.; Nottrott, A.; Ferry, M. Energy dispatch schedule optimization for demand charge reduction using a photovoltaic-battery storage system with solar forecasting. Sol. Energy 2014, 103, 269–287. [Google Scholar] [CrossRef]
- Vasallo, M.J.; Bravo, J.M. A novel two-model based approach for optimal scheduling in CSP plants. Sol. Energy 2016, 126, 73–92. [Google Scholar] [CrossRef]
- Pousinho, H.M.I.; Contreras, J.; Pinson, P.; Mendes, V. Robust optimisation for self-scheduling and bidding strategies of hybrid CSP–fossil power plants. Int. J. Electr. Power Energy Syst. 2015, 67, 639–650. [Google Scholar] [CrossRef]
- Dominguez, R.; Baringo, L.; Conejo, A.J. Optimal offering strategy for a concentrating solar power plant. Appl. Energy 2012, 98, 316–325. [Google Scholar] [CrossRef]
- He, G.; Chen, Q.; Kang, C.; Xia, Q. Optimal Offering Strategy for Concentrating Solar Power Plants in Joint Energy, Reserve and Regulation Markets. IEEE Trans. Sustain. Energy 2016, 7, 1245–1254. [Google Scholar] [CrossRef]
- Wagner, M.J.; Newman, A.; Hamilton, W.T.; Braun, R. Optimized dispatch in a first-principles concentrating solar power production model. Appl. Energy 2017, 203, 959–971. [Google Scholar] [CrossRef]
- Wittmann, M.; Eck, M.; Pitz-Paal, R.; Muller-Steinhagen, H. Methodology for optimized operation strategies of solar thermal power plants with integrated heat storage. Sol. Energy 2011, 85, 653–659. [Google Scholar] [CrossRef]
- Burghi, A.C.D.A.; Hirsch, T.; Pitz-Paal, R. FRED: The Flexible Renewable Energy System Dispatch Optimizer. J. Sol. Energy Eng. 2019, 141, 051009. [Google Scholar] [CrossRef]
- Maringer, D.G. Heuristic Optimization. In Portfolio Management with Heuristic Optimization; Springer Science and Business Media LLC: New York, NY, USA, 2006; Volume 8, pp. 38–76. [Google Scholar]
- Wehenkel, L. Machine learning approaches to power-system security assessment. IEEE Expert 1997, 12, 60–72. [Google Scholar] [CrossRef] [Green Version]
- Boyen, X.P.; Wehenkel, L. Fuzzy Decision Tree Induction for Power System Security Assessment; Elsevier BV: Amsterdam, The Netherlands, 1995; Volume 28, pp. 299–304. [Google Scholar]
- Rudin, C.; Waltz, D.; Anderson, R.N.; Boulanger, A.; Salleb-Aouissi, A.; Chow, M.; Dutta, H.; Gross, P.N.; Huang, B.; Ierome, S.; et al. Machine Learning for the New York City Power Grid. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 328–345. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Negnevitsky, M.; Mandal, P.; Srivastava, A.K. Machine Learning Applications for Load, Price and Wind Power Prediction in Power Systems. In Proceedings of the 2009 15th International Conference on Intelligent System Applications to Power Systems; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2009; pp. 1–6. [Google Scholar]
- Wan, C.; Xu, Z.; Pinson, P.; Dong, Z.Y.; Wong, K.P. Probabilistic Forecasting of Wind Power Generation Using Extreme Learning Machine. IEEE Trans. Power Syst. 2013, 29, 1033–1044. [Google Scholar] [CrossRef] [Green Version]
- Sharma, N.; Sharma, P.; Irwin, D.; Shenoy, P. Predicting solar generation from weather forecasts using machine learning. In Proceedings of the 2011 IEEE International Conference on Smart Grid Communications (SmartGridComm); Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2011; pp. 528–533. [Google Scholar]
- Daud, M.Z.; Mohamed, A.; Hannan, M. An improved control method of battery energy storage system for hourly dispatch of photovoltaic power sources. Energy Convers. Manag. 2013, 73, 256–270. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5 Programs for Machine Learning; Morgan Kaufmann Publisher, Inc.: San Mateo, CA, USA, 1993. [Google Scholar]
- Zhang, J.J.; Wang, F.-Y.; Wang, Q.; Hao, D.; Yang, X.; Gao, W.; Zhao, X.; Zhang, Y. Parallel dispatch: A new paradigm of electrical power system dispatch. IEEE/CAA J. Autom. Sin. 2017, 5, 311–319. [Google Scholar] [CrossRef]
- Janikow, C. Fuzzy decision trees: Issues and methods. IEEE Trans. Syst. Man Cybern. Part B 1998, 28, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Ahmadi, E.; Javadi, H.; Khansefid, A.; Asadi, A.; Ebadzadeh, M.M.; Timmerman, D. Fuzzy decision tree learning for preoperative classification of adnexal masses. In Proceedings of the International Conference on Health Informatics, Rome, Italy, 26–29 January 2011; pp. 364–375. [Google Scholar]
- Wehenkel, L.A. Automatic Learning Techniques in Power Systems; Springer Science and Business Media LLC: New York, NY, USA, 1998; pp. 140–144. [Google Scholar]
- Olaru, C.; Wehenkel, L. A complete fuzzy decision tree technique. Fuzzy Sets Syst. 2003, 138, 221–254. [Google Scholar] [CrossRef] [Green Version]
- Lo, K.; Abidin, H.I.H.Z. The fuzzy decision tree application to a power system problem. COMPEL Int. J. Comput. Math. Electr. Electron. Eng. 2004, 23, 436–451. [Google Scholar] [CrossRef]
- Adamo, J. Fuzzy decision trees. Fuzzy Sets Syst. 1980, 4, 207–219. [Google Scholar] [CrossRef]
- Du, E.; Du, E.; Hodge, B.-M.; Kang, C.; Kroposki, B.; Xia, Q. Economic justification of concentrating solar power in high renewable energy penetrated power systems. Appl. Energy 2018, 222, 649–661. [Google Scholar] [CrossRef]
- Gordon, A.D.; Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Taylor & Francis: Thames, Oxfordshire, UK, 1984. [Google Scholar]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- OMIE. Resultados del Mercado. 2018. Available online: http://www.omie.es/ (accessed on 1 April 2018).
- Schroedter-Homscheidt, M.; Benedetti, A.; Killius, N. Verification of ECMWF and ECMWF/MACC’s global and direct irradiance forecasts with respect to solar electricity production forecasts. Meteorol. Z. 2016, 26, 1–19. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Parameter | Value | Classification |
|---|---|---|
| Deviation from persistence | 70 MW | 0.8 very positive |
| Day of the year | 350 | 0.8 winter 0.2 autumn |
| Hour priority | 10 | 0.7 very high 0.7 high |
| Simulated Year | DNI | Persistence Forecast | Forecast Product | Perfect Forecast |
|---|---|---|---|---|
| 2014 | Yearly Sum (kWh/m2) RMSE | 2397.04 296.11 | 2244.52 215.84 | 2399.49 0 |
| 2015 | Yearly Sum (kWh/m2) RMSE | 2220.50 296.57 | 2123.09 219.10 | 2218.04 0 |
| 2016 | Yearly Sum (kWh/m2) RMSE | 2220.50 289.28 | 2026.67 207.48 | 2223.38 0 |
| 2017 | Yearly Sum (kWh/m2) RMSE | 2391.92 356.84 | 2095.52 269.26 | 2387.87 0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
do Amaral Burghi, A.C.; Hirsch, T.; Pitz-Paal, R. Artificial Learning Dispatch Planning for Flexible Renewable-Energy Systems. Energies 2020, 13, 1517. https://doi.org/10.3390/en13061517
do Amaral Burghi AC, Hirsch T, Pitz-Paal R. Artificial Learning Dispatch Planning for Flexible Renewable-Energy Systems. Energies. 2020; 13(6):1517. https://doi.org/10.3390/en13061517
Chicago/Turabian Styledo Amaral Burghi, Ana Carolina, Tobias Hirsch, and Robert Pitz-Paal. 2020. "Artificial Learning Dispatch Planning for Flexible Renewable-Energy Systems" Energies 13, no. 6: 1517. https://doi.org/10.3390/en13061517