
Artificial Intelligence Implementation in Healthcare: A Theory-Based Scoping Review of Barriers and Facilitators
 , ,
, ,  ,
,  , and
, and
Abstract
:1. Introduction
1.1. Artificial Intelligence
1.2. Implementation Science
1.3. Pilot Study vs. Implementation Trial
1.4. Objectives
2. Methodology
2.1. Protocol
2.2. Eligibility Criteria
2.3. Information Sources and Selecting Sources of Evidence
2.4. Search Query and Two-Phase Search
(«machine learning»[Title/Abstract] OR machine learning[mesh] OR «artificial intelligence»[Title/Abstract] OR artificial intelligence[mesh] OR «deep learning»[Title/Abstract] OR deep learning[mesh] OR «neural network»[Title/Abstract] OR «image analysis»[Title/Abstract] OR «deep neural networks»[Title/Abstract] OR «supervised learning»[Title/Abstract] OR «unsupervised learning»[Title/Abstract] OR «reinforcement learning»[Title/Abstract] OR «automated algorithms»[Title/Abstract] OR «adaptive algorithms» [Title/Abstract]) AND (implement* [Title] OR practice [Title] OR approved [Title]) AND (y_10[Filter]))
2.5. Data Extraction and Items
2.6. Critical Appraisal of Individual Sources of Evidence
2.7. Synthesis of Results
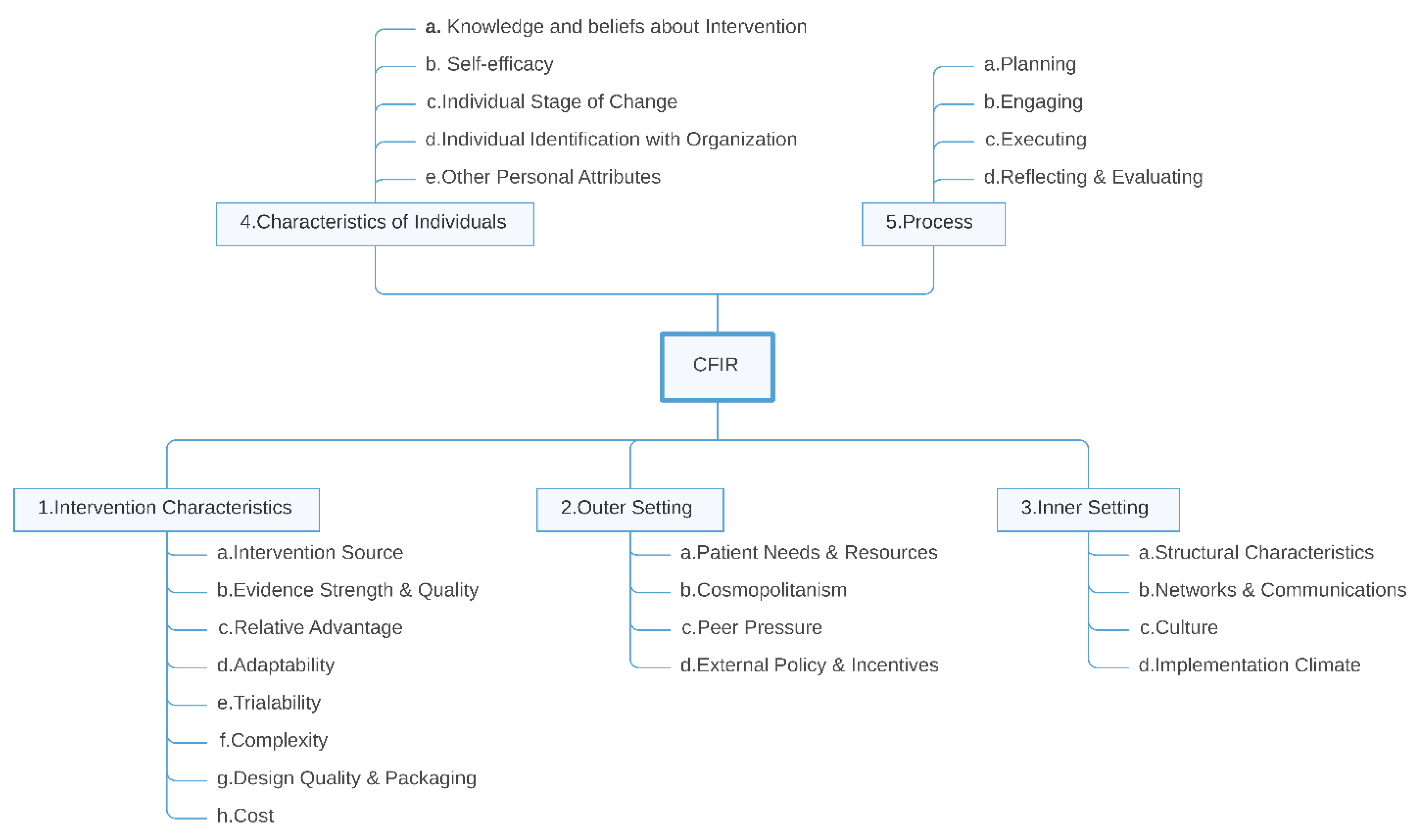
2.8. Open Inductive Coding and Mapping onto the CFIR Framework
3. Results
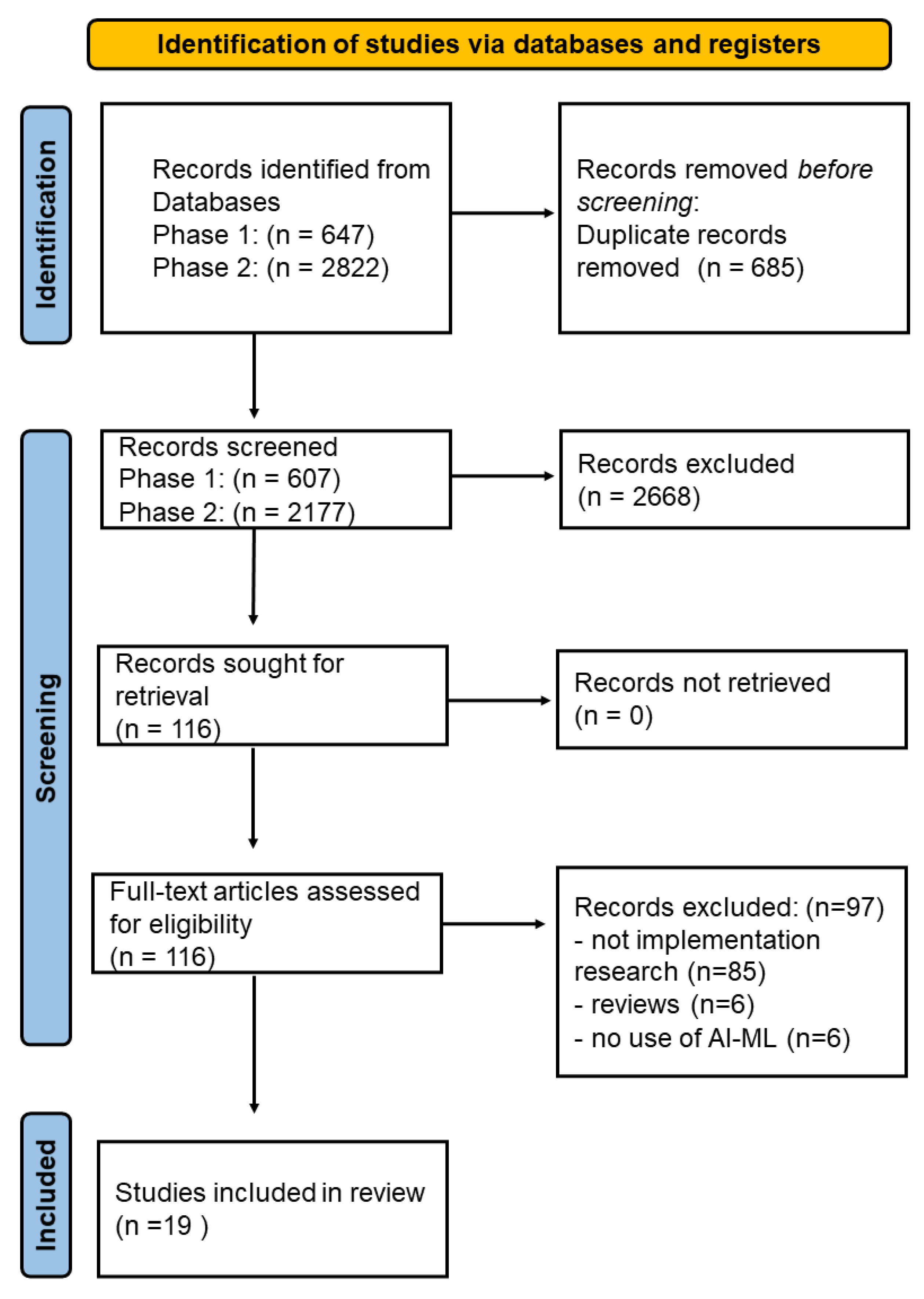
3.1. Selection of Sources of Evidence
3.2. Results of Individual Sources of Evidence
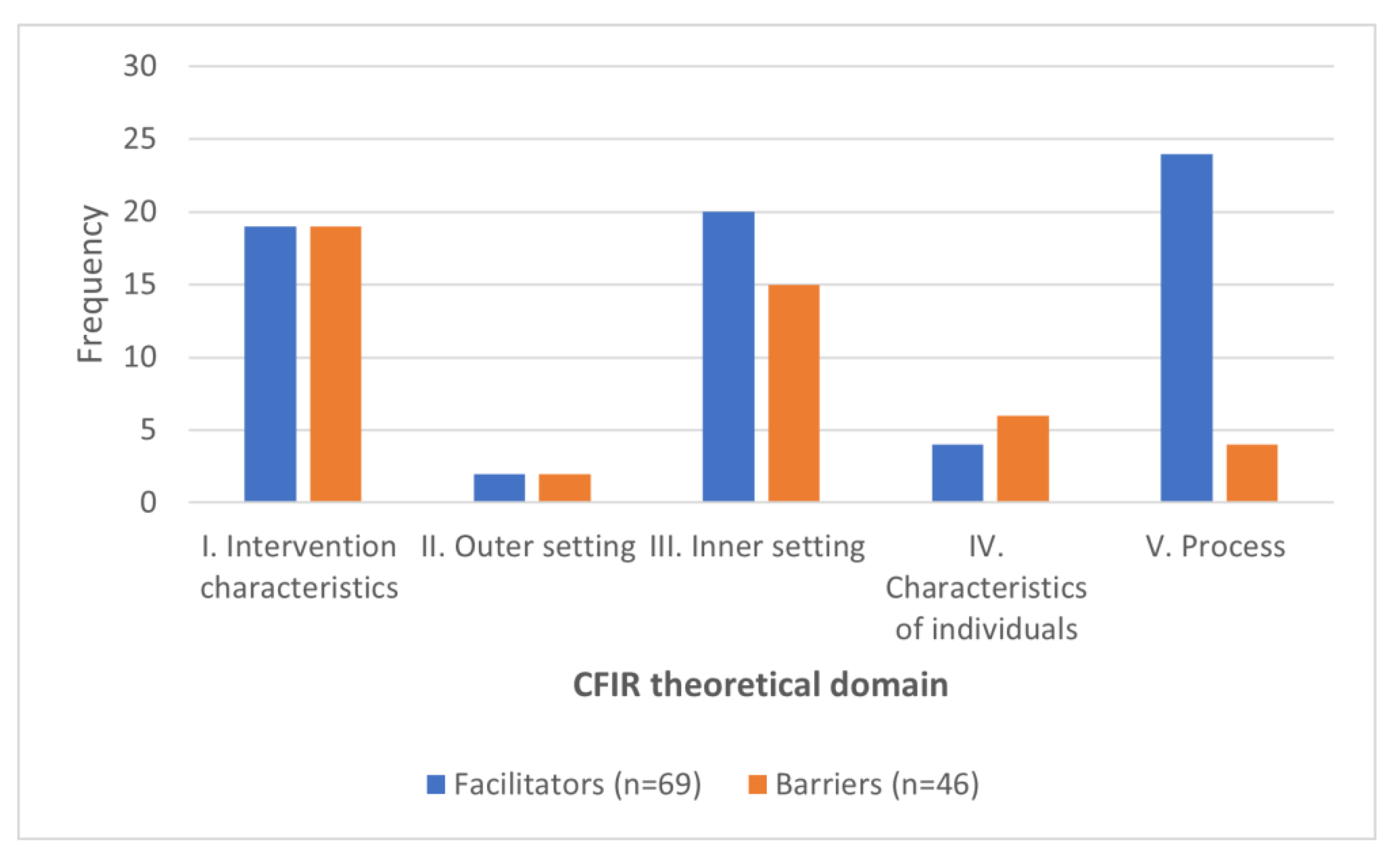
3.3. Mapping Extracted Concepts to CFIR
4. Discussion
4.1. Intervention Characteristics
4.1.1. Evidence Strength and Quality
4.1.2. Design Quality and Complexity
4.1.3. Interoperability, Adaptability and Generalizability
4.1.4. Integration with Clinical Workflow
“Models that require additional work, even if it is as little as looking at another screen and clicking a few more times, are much less likely to be implemented or sustained”[44].
4.2. Outer Setting
External Policies and Incentives
4.3. Inner Setting
Resource Availability
“…key data that reliably predict the outcome of interest may not be readily available as structured, discrete data inputs from the EHR…”[43]
4.4. Characteristics of Individuals
Knowledge, Beliefs and Other Personal Attributes
“Clinical leaders prioritized positive predictive value as a performance measure and were willing to trade-off model interpretability for performance gains”.
4.5. Process
Champions and Key Stakeholders
4.6. Implication of the Results and Recommendations for the Future
4.7. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Ismail, L.; Materwala, H.; Karduck, A.P.; Adem, A. Requirements of Health Data Management Systems for Biomedical Care and Research: Scoping Review. J. Med. Internet Res. 2020, 22, e17508. [Google Scholar] [CrossRef] [PubMed]
- Ismail, L.; Materwala, H.; Tayefi, M.; Ngo, P.; Karduck, A.P. Type 2 Diabetes with Artificial Intelligence Machine Learning: Methods and Evaluation. Arch. Comput. Methods Eng. 2022, 29, 313–333. [Google Scholar] [CrossRef]
- Victor Mugabe, K. Barriers and facilitators to the adoption of artificial intelligence in radiation oncology: A New Zealand study. Tech. Innov. Patient Support Radiat. Oncol. 2021, 18, 16–21. [Google Scholar] [CrossRef] [PubMed]
- Strohm, L.; Hehakaya, C.; Ranschaert, E.R.; Boon, W.P.C.; Moors, E.H.M. Implementation of artificial intelligence (AI) applications in radiology: Hindering and facilitating factors. Eur Radiol. 2020, 30, 5525–5532. [Google Scholar] [CrossRef] [PubMed]
- Morrison, K. Artificial intelligence and the NHS: A qualitative exploration of the factors influencing adoption. Future Healthc. J. 2021, 8, e648–e654. [Google Scholar] [CrossRef] [PubMed]
- Warsavage, T., Jr.; Xing, F.; Barón, A.E.; Feser, W.J.; Hirsch, E.; Miller, Y.E. Quantifying the incremental value of deep learning: Application to lung nodule detection. PLoS ONE 2020, 15, e0231468. [Google Scholar] [CrossRef]
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 2019, 6, 94–98. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Capobianco, E. High-dimensional role of AI and machine learning in cancer research. Br. J. Cancer 2022, 126, 523–532. [Google Scholar] [CrossRef] [PubMed]
- Mazaheri, S.; Loya, M.F.; Newsome, J.; Lungren, M.; Gichoya, J.W. Challenges of Implementing Artificial Intelligence in Interventional Radiology. Semin. Intervent. Radiol. 2021, 38, 554–559. [Google Scholar] [CrossRef]
- Fischer, U.M.; Shireman, P.K.; Lin, J.C. Current applications of artificial intelligence in vascular surgery. Semin. Vasc. Surg. 2021, 34, 268–271. [Google Scholar] [CrossRef] [PubMed]
- Ben Ali, W.; Pesaranghader, A.; Avram, R.; Overtchouk, P.; Perrin, N.; Laffite, S. Implementing Machine Learning in Interventional Cardiology: The Benefits Are Worth the Trouble. Front Cardiovasc. Med. 2021, 8, 711401. [Google Scholar] [CrossRef] [PubMed]
- Nilsen, P. Making sense of implementation theories, models and frameworks. Implement. Sci. 2015, 10, 53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eccles, M.P.; Mittman, B.S. Welcome to Implementation Science. Implement. Sci. 2006, 1, 1. [Google Scholar] [CrossRef] [Green Version]
- Van de Velde, S.; Heselmans, A.; Delvaux, N.; Brandt, L.; Marco-Ruiz, L.; Spitaels, D.; Cloetens, H.; Kortteisto, T.; Roshanov, P.; Kunnamo, I. A systematic review of trials evaluating success factors of interventions with computerised clinical decision support. Implement. Sci. 2018, 13, 114. [Google Scholar] [CrossRef] [PubMed]
- Gaudet-Blavignac, C.; Foufi, V.; Bjelogrlic, M.; Lovis, C. Use of the Systematized Nomenclature of Medicine Clinical Terms (SNOMED CT) for Processing Free Text in Health Care: Systematic Scoping Review. J. Med. Internet Res. 2021, 23, e24594. [Google Scholar] [CrossRef]
- Soares, A.; Jenders, R.A.; Harrison, R.; Schilling, L.M. A Comparison of Arden Syntax and Clinical Quality Language as Knowledge Representation Formalisms for Clinical Decision Support. Appl. Clin. Inform. 2021, 12, 495–506. [Google Scholar] [CrossRef]
- Ismail, L.; Materwala, H.; Znati, T.; Turaev, S.; Khan, M.A. Tailoring time series models for forecasting coronavirus spread: Case studies of 187 countries. Comput. Struct. Biotechnol. J. 2020, 18, 2972–3206. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Curran, G.M.; Bauer, M.; Mittman, B.; Pyne, J.M.; Stetler, C. Effectiveness-implementation hybrid designs: Combining elements of clinical effectiveness and implementation research to enhance public health impact. Med. Care 2012, 50, 217–226. [Google Scholar] [CrossRef] [Green Version]
- Pearson, N.; Naylor, P.-J.; Ashe, M.C.; Fernandez, M.; Yoong, S.L.; Wolfenden, L. Guidance for conducting feasibility and pilot studies for implementation trials. Pilot Feasibility Stud. 2020, 6, 167. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.; Horsley, T.; Weeks, L.; et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): Checklist and Explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef]
- Arksey, H.; O’Malley, L. Scoping studies: Towards a methodological framework. Int. J. Soc. Res. Methodol. 2005, 8, 19–32. [Google Scholar] [CrossRef] [Green Version]
- Benjamens, S.; Dhunnoo, P.; Meskó, B. The state of artificial intelligence-based FDA-approved medical devices and algorithms: An online database. NPJ Digit. Med. 2020, 3, 118. [Google Scholar] [CrossRef]
- Levac, D.; Colquhoun, H.; O’Brien, K.K. Scoping studies: Advancing the methodology. Implement. Sci. 2010, 5, 69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—A web and mobile app for systematic reviews. Syst. Rev. 2016, 5, 210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hong, Q.N.; Gonzalez-Reyes, A.; Pluye, P. Improving the usefulness of a tool for appraising the quality of qualitative, quantitative and mixed methods studies, the Mixed Methods Appraisal Tool (MMAT). J. Eval. Clin. Pract. 2018, 24, 459–467. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Damschroder, L.J.; Aron, D.C.; Keith, R.E.; Kirsh, S.R.; Alexander, J.A.; Lowery, J.C. Fostering implementation of health services research findings into practice: A consolidated framework for advancing implementation science. Implement. Sci. 2009, 4, 50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van de Velde, S.; Kunnamo, I.; Roshanov, P.; Kortteisto, T.; Aertgeerts, B.; Vandvik, P.O.; Flottorp, S. The GUIDES checklist: Development of a tool to improve the successful use of guideline-based computerised clinical decision support. Implement. Sci. 2018, 13, 86. [Google Scholar] [CrossRef]
- Kuckartz, U.; Rädiker, S. Analyzing Qualitative Data with MAXQDA; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Lee, E.K.; Atallah, H.Y.; Wright, M.D.; Post, E.T.; Thomas, C., IV; Wu, D.T.; Haley, L.L., Jr. Transforming hospital emergency department workflow and patient care. Interfaces 2015, 45, 58–82. [Google Scholar] [CrossRef]
- McCoy, A.; Das, R. Reducing patient mortality, length of stay and readmissions through machine learning-based sepsis prediction in the emergency department, intensive care unit and hospital floor units. BMJ Open Quality 2017, 6, e000158. [Google Scholar] [CrossRef]
- Moon, K.J.; Jin, Y.; Jin, T.; Lee, S.M. Development and validation of an automated delirium risk assessment system (Auto-DelRAS) implemented in the electronic health record system. Int. J. Nurs Stud. 2018, 77, 46–53. [Google Scholar] [CrossRef] [PubMed]
- Van der Heijden, A.A.; Abramoff, M.D.; Verbraak, F.; van Hecke, M.V.; Liem, A.; Nijpels, G. Validation of automated screening for referable diabetic retinopathy with the IDx-DR device in the Hoorn Diabetes Care System. Acta Ophthalmol. 2018, 96, 63–68. [Google Scholar] [CrossRef] [PubMed]
- Schuh, C.; de Bruin, J.S.; Seeling, W. Clinical decision support systems at the Vienna General Hospital using Arden Syntax: Design, implementation, and integration. Artif. Intell. Med. 2018, 92, 24–33. [Google Scholar] [CrossRef] [PubMed]
- Guo, P.; Deng, W. (Eds.) Design and Implementation of Intelligent Medical Customer Service Robot Based on Deep Learning. In Proceedings of the 2019 16th International Computer Conference on Wavelet Active Media Technology and Information Processing, Chengdu, China, 13–15 December 2019. [Google Scholar]
- Cruz, N.P.; Canales, L.; Muñoz, J.G.; Pérez, B.; Arnott, I. Improving Adherence to Clinical Pathways through Natural Language Processing on Electronic Medical Records. In MEDINFO 2019: Health and Wellbeing e-Networks for All; IOS Press: Amsterdam, The Netherlands, 2019; pp. 561–565. [Google Scholar]
- Joerin, A.; Rauws, M.; Ackerman, M.L. Psychological artificial intelligence service, Tess: Delivering on-demand support to patients and their caregivers: Technical report. Cureus 2019, 11, e3972. [Google Scholar] [CrossRef] [Green Version]
- Gonçalves, L.S.; Amaro, M.L.M.; Romero, A.L.M.; Schamne, F.K.; Fressatto, J.L.; Bezerra, C.W. Implementation of an Artificial Intelligence Algorithm for sepsis detection. Rev. Bras Enferm. 2020, 73, e20180421. [Google Scholar] [CrossRef]
- Sendak, M.P.; Ratliff, W.; Sarro, D.; Alderton, E.; Futoma, J.; Gao, M. Real-world integration of a sepsis deep learning technology into routine clinical care: Implementation study. JMIR Med. Inform. 2020, 8, e15182. [Google Scholar] [CrossRef]
- Gonzalez-Briceno, G.; Sanchez, A.; Ortega-Cisneros, S.; Contreras, M.S.G.; Diaz, G.A.P.; Moya-Sanchez, E.U. Artificial intelligence-based referral system for patients with diabetic retinopathy. Computer 2020, 53, 77–87. [Google Scholar] [CrossRef]
- Xu, H.; Li, P.; Yang, Z.; Liu, X.; Wang, Z.; Yan, W.; He, M.; Chu, W.; She, Y.; Li, Y.; et al. Construction and application of a medical-grade wireless monitoring system for physiological signals at general wards. J. Med. Syst. 2020, 44, 1–15. [Google Scholar] [CrossRef]
- Romero-Brufau, S.; Wyatt, K.D.; Boyum, P.; Mickelson, M.; Moore, M.; Cognetta-Rieke, C. Implementation of artificial intelligence-based clinical decision support to reduce hospital readmissions at a regional hospital. Appl. Clin. Inform. 2020, 11, 570–577. [Google Scholar] [CrossRef]
- Scheinker, D.; Brandeau, M.L. Implementing analytics projects in a hospital: Successes, failures, and opportunities. INFORMS J. Appl. Anal. 2020, 50, 176–189. [Google Scholar] [CrossRef]
- Davis, M.A.; Rao, B.; Cedeno, P.; Saha, A.; Zohrabian, V.M. Machine Learning and Improved Quality Metrics in Acute Intracranial Hemorrhage by Non-Contrast Computed Tomography. Curr. Probl. Diagn. Radiol. 2020, 51, 556–561. [Google Scholar] [CrossRef] [PubMed]
- Petitgand, C.; Motulsky, A.; Denis, J.-L.; Régis, C. Investigating the Barriers to Physician Adoption of an Artificial Intelligence-Based Decision Support System in Emergency Care: An Interpretative Qualitative Study. In Digital Personalized Health and Medicine; IOS Press: Amsterdam, The Netherlands, 2020; pp. 1001–1005. [Google Scholar]
- Betriana, F.; Tanioka, T.; Osaka, K.; Kawai, C.; Yasuhara, Y.; Locsin, R.C. Interactions between healthcare robots and older people in Japan: A qualitative descriptive analysis study. Jpn. J. Nurs. Sci. 2021, 18, e12409. [Google Scholar] [CrossRef] [PubMed]
- Betriana, F.; Tanioka, T.; Osaka, K.; Kawai, C.; Yasuhara, Y.; Locsin, R.C. Improving the delivery of palliative care through predictive modeling and healthcare informatics. J. Am. Med. Inform. Assoc. 2021, 28, 1065–1073. [Google Scholar]
- Cho, K.J.; Kwon, O.; Kwon, J.M.; Lee, Y.; Park, H.; Jeon, K.H.; Kim, K.H.; Park, J.; Oh, B.H. Detecting patient deterioration using artificial intelligence in a rapid response system. Crit. Care Med. 2020, 48, e285–e289. [Google Scholar] [CrossRef]
- Dovigi, E.; Kwok, E.Y.L.; English, J.C., 3rd. A Framework-Driven Systematic Review of the Barriers and Facilitators to Teledermatology Implementation. Curr. Dermatol. Rep. 2020, 9, 353–361. [Google Scholar] [CrossRef]
- Servaty, R.; Kersten, A.; Brukamp, K.; Möhler, R.; Mueller, M. Implementation of robotic devices in nursing care. Barriers and facilitators: An integrative review. BMJ Open 2020, 10, e038650. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Cortez, P.; Embrechts, M.J. Using sensitivity analysis and visualization techniques to open black box data mining models. Inf. Sci. 2013, 225, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Strumbelj, E.; Kononenko, I. An efficient explanation of individual classifications using game theory. J. Mach. Learn. Res. 2010, 11, 18. [Google Scholar]
- Henelius, A.; Puolamäki, K.; Boström, H.; Asker, L.; Papapetrou, P. A peek into the black box: Exploring classifiers by randomization. Data Min. Knowl. Discov. 2014, 28, 1503–1529. [Google Scholar] [CrossRef]
- Wang, D.; Ogihara, M.; Gallo, C.; Villamar, J.A.; Smith, J.D.; Vermeer, W.; Cruden, G.; Benbow, N.; Brown, C.H. Automaticlassification of communication logs into implementation stages via text analysis. Implement. Sci. 2016, 11, 119. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Inclusion | Exclusion | |
|---|---|---|
| Population |
|
|
| Intervention |
|
|
| Comparator |
|
|
| Outcomes |
|
|
| Study type |
|
|
| Data Type | Examples |
|---|---|
| Study | authors, year, title, journal |
| Description | country of implementation, product name, company/research group, timeline for implementation, implementation phase |
| Role of AI | patient group, primary users, training required, medical specialty, medical task |
| Technology | AI methods, algorithms, hardware, transparency, interpretability, explainability |
| Data | type of input, sample size for training |
| Ethics | security and privacy, bias, other ethics issues |
| Clinical Validation | type, sample size |
| Legal | process for approval, approval status, other legal issues/processes |
| Barriers Facilitators | qualitative methods used to extract the barriers and facilitators |
| Study (Year) | Country | Medical Field | Medical Tasks (Problem) | Primary Users | AI Techniques |
|---|---|---|---|---|---|
| Lee [31] (2015) | USA | Emergency Dept. patients | Screening | Clinicians, nurses, planners | Machine learning |
| McCoy [32] (2017) | USA | Sepsis | Screening | Clinicians and nurses | Machine learning |
| Moon [33] (2018) | Korea | Delirium | Screening | Clinicians | Logistic regression |
| van der Heijden [34] (2018) | Netherlands | Diabetes/retinopathy | Screening | Clinicians | Deep Learning |
| Schuh [35] (2018) | Austria | All patients | Screening | Clinicians | Deep learning, fuzzy logic, decision tree |
| Guo [36] (2019) | China | All patients | Screening | Patients | Deep learning |
| Cruz [37] (2019) | Spain | Cardiology, Gastrointerology, Psychiatry | Quality improvement | Clinicians (GPs, Pediatricians) | Deep learning |
| Joerin [38] (2019) | USA/Canada | Psychology | Treatment | Staff, patients and family caregivers | Natural language processing |
| Gonçalves [39] (2020) | Brazil | Sepsis | Screening | Nurses | Deep learning |
| Sendak [40] (2020) | USA | Sepsis | Screening | Clinicians | Deep Learning |
| Gonzalez-Briceno [41](2020) | Mexico | Diabetes/retinophathy | Screening | Clinicians | Deep Learning |
| Xu [42] (2020) | China | All patients | Screening | Nurses and clinicians | Deep learning |
| Cho2020 [20] | Korea | Cardiology | Screening | Nurses and clinicians | Deep learning |
| Romero-Brufau [43] (2020) | USA | All patients | Screening, prognosis, treatment | Clinicians, outpatient care coordinators | Decision tree |
| Scheinker [44] (2020) | USA | Chronic kidney disease, diabetes | Screening, prognosis, treatment | Clinicians | Deep learning |
| Davis [45] (2020) | USA | Radiology | Screening | Clinicians | Deep learning |
| Petitgand [46] (2020) | Canada | Emergency Dept. | Diagnose | Clinicians | Deep learning |
| Betriana [47] (2021) | Japan | Mental health | Treatment | Patients (receiver) nurse (controller) | Not specified |
| Murphree [48] (2021) | USA | Palliative care | Screening | Palliative care team (clinicians) | Gradient Boosting Machine (GBM) |
| Theme | Facilitators | Barriers | Concept |
|---|---|---|---|
| Evaluation and testing | 8 | 3 | - |
| Background | 5 | 2 | Experiences and prior knowledge, Prior evidence, Healthcare demand |
| Management and engagement | 27 | - | External collaboration, Planning, Feedback incorporation, Communication, Involvement, Motivation, Leadership, Education of workforce, Patient needs, Champions |
| Data quality and management | 1 | 6 | Data availability, Data quality |
| Trust and transparency | 1 | 5 | Interpretability, Trust |
| Clinical workflow | 4 | 4 | Integration, Disruptiveness (alert fatigue) |
| Interoperability | 2 | 7 | Model Interoperability, Data interoperability, Generalizability |
| Finance and resources | 1 | 3 | Available Resources, Cost |
| Technical design | 7 | 4 | Usability, Documentation and presentation of results, Adaptability, Innovation, Complexity, Trialability |
| AI policy and regulation | 1 | 2 | Organizational policy and culture, Regulation and law |
| Totals | 57 | 36 |
| Study | Facilitators | Barriers |
|---|---|---|
| Lee [31] | Healthcare demand, Evaluation and testing, Generalizability, Data availability, Available Resources, Trialability, Motivation | Regulation and law |
| Betriana [47] | Healthcare demand, Planning, Education of workforce, Involvement, Evaluation and testing | -- |
| Cho [49] | Generalizability, Evaluation and testing | Evaluation and testing, Interpretability, Model interoperability |
| Cruz [37] | Evaluation and testing, Integration, Leadership, Usability | Data availability |
| Davis [45] | Integration, Usability | Evaluation and testing, Trust |
| Gonçalves [39] | Motivation, Experiences and prior knowledge | -- |
| Joerin [38] | Involvement, Evaluation and testing, Patient needs, Adaptability | -- |
| McCoy [32] | Healthcare demand, Communication, Feedback incorporation, Education of workforce | Disruptiveness (alert fatigue) |
| Moon [33] | -- | Model Interoperability, Data quality |
| Murphree [48] | Involvement, Communication | Generalizability |
| Petitgand [46] | Involvement, Organizational policy and culture | Data interoperability, Usability, Documentation and presentation of results, Trust |
| Romero-Brufau [43] | Planning, Involvement, Education of workforce, Adaptability | Usability, Data quality, Data availability, Generalizability, Evaluation and testing |
| Scheinker [44] | Prior evidence, Involvement, Planning, Evaluation and testing | Trust, Complexity, Disruptiveness |
| Schuh [35] | -- | Data quality, Experiences and prior knowledge, Cost, Regulation and law, Data interoperability |
| Sendak [40] | Involvement, Planning, External collaboration, Leadership, Integration, Interpretability, Evaluation and testing, Champions, Education of workforce | Cost, Trust, Available Resources, Generalizability, Prior evidence, Integration |
| Xu [42] | Education of workforce, Evaluation and testing, Innovation, Usability, Integration | Data availability, Integration |
| Gonzalez-Briceno [41] | -- | -- |
| Guo [36] | -- | -- |
| van der Heijden [34] | -- | -- |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chomutare, T.; Tejedor, M.; Svenning, T.O.; Marco-Ruiz, L.; Tayefi, M.; Lind, K.; Godtliebsen, F.; Moen, A.; Ismail, L.; Makhlysheva, A.; et al. Artificial Intelligence Implementation in Healthcare: A Theory-Based Scoping Review of Barriers and Facilitators. Int. J. Environ. Res. Public Health 2022, 19, 16359. https://doi.org/10.3390/ijerph192316359
Chomutare T, Tejedor M, Svenning TO, Marco-Ruiz L, Tayefi M, Lind K, Godtliebsen F, Moen A, Ismail L, Makhlysheva A, et al. Artificial Intelligence Implementation in Healthcare: A Theory-Based Scoping Review of Barriers and Facilitators. International Journal of Environmental Research and Public Health. 2022; 19(23):16359. https://doi.org/10.3390/ijerph192316359
Chicago/Turabian StyleChomutare, Taridzo, Miguel Tejedor, Therese Olsen Svenning, Luis Marco-Ruiz, Maryam Tayefi, Karianne Lind, Fred Godtliebsen, Anne Moen, Leila Ismail, Alexandra Makhlysheva, and et al. 2022. "Artificial Intelligence Implementation in Healthcare: A Theory-Based Scoping Review of Barriers and Facilitators" International Journal of Environmental Research and Public Health 19, no. 23: 16359. https://doi.org/10.3390/ijerph192316359