
Image Quality Assessment for Realistic Zoom Photos

(This article belongs to the Section Intelligent Sensors)
Abstract
:1. Introduction
1.1. Difference between Zoom Photos and Gaussian Blur Images
1.2. Laboratory Measurements of Targets vs. Perceptual Metrics on Natural Photos
1.3. Limitations of Sharpness, Super-Resolution, and General-Purpose Metrics
1.4. The Contribution of This Article
- First, we construct a realistic zoom database by collecting 20 phone cameras and shooting them in 45 texture-complex scenes. Mean expert opinion scores and several analyses are also provided. Compared to existing gaussian blur databases, our database contains the most authentically distorted photos and scenes. The image resolution is also the highest.
- We are the first to derive the whole formulation of the free-energy under the sparse representation model, according to which a new sharpness index is proposed.
- A novel zoom quality metric is proposed which incorporates image sharpness and naturalness. Natural scene statistics are included as a mechanism to prevent over-sharpening and penalize unnatural appearances.
- The zoom quality metric is tested in both unsharp masking simulations and the zoom photo database, which outperforms existing sharpness and general-purpose QA models.
2. Realistic Zoom Photo Database
2.1. The Construction Process and Comparison with Other Databases
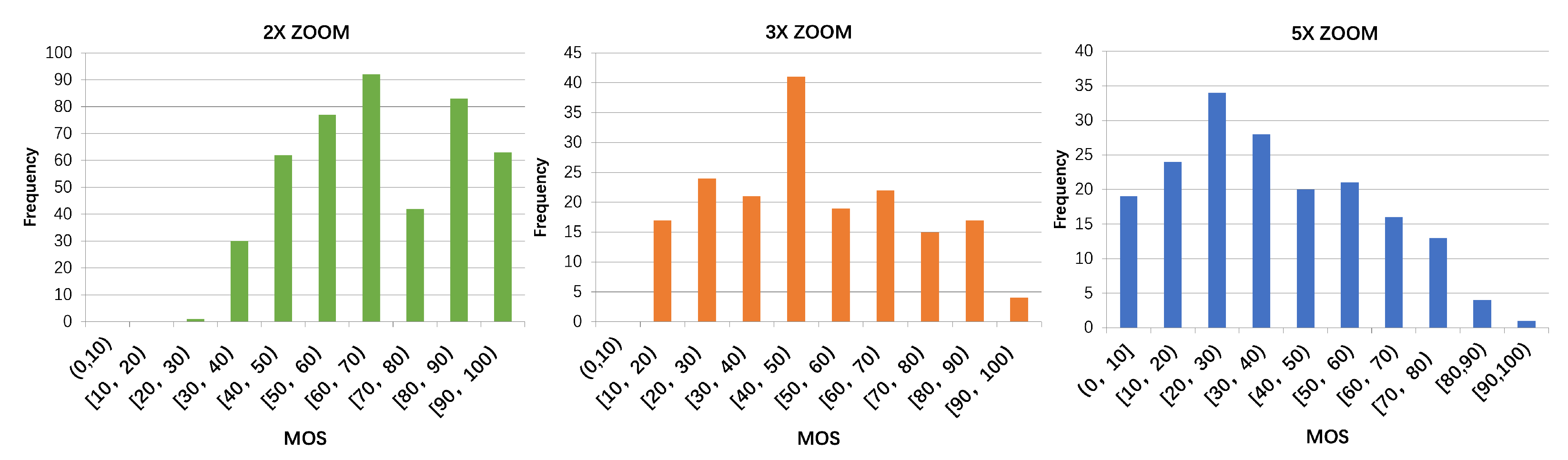
2.2. Subjective Quality-Evaluation Study and Analysis
3. Methodology
3.1. The Image Sharpness Measurement
3.1.1. Formulation of Free-Energy Principle
3.1.2. Approximation of the Brain Generative Model
3.1.3. The Sharpness Index
3.2. The Image Naturalness Measurement
3.3. The Final Zoom Quality Metric
4. Experiments
4.1. Implementation Details
| Algorithm 1: Pseudo-code of the proposed zoom quality metric | ||
Input: Zoom photo I, over-completer DCT dictionary D, mean and variances of pristine MVG parameters , , weighting parameters , w and l. | ||
| 1 | Initialization: | |
| 2 | Compute the photo gradient using Sobel operator; | |
| 3 | Partition the photo I into non-overlapping 96 x 96 patches | |
| 4 | The measurement of sharpness: | |
| 5 | foreach do | |
| 6 | Solve the sparse coding coefficients using the OMP algorithm [73]; | |
| 7 | Calculate the patch variance ; | |
| 8 | Sort and select the top patches according to the variance ; | |
| 9 | end | |
| 10 | Compute mean KL-divergence or energy: | |
| 11 | Compute the residual gradient image: | |
| 12 | Compute entropy of the residual:
| |
| 13 | The sharpness index:
| |
| 14 | The measurement of naturalness: | |
| 15 | foreach do | |
| 16 | Compute the MSCN map of I using (20) | |
| 17 | ||
| 18 | end | |
| 19 | Estimate the and through (25) | |
| 20 | The naturalness index: Output: Zoom quality metric | |
4.2. Illustrative Results
- 1
- In its top row, the quality of A1 > A2 > A3. Specifically, A1 is a 5× zoom photo taken with an optical camera, while A2 comes from a smaller sensor and looks more grainy. A3 is interpolated from a 3× zoom camera, which suffers from zoom blur. From Figure 9, we can observe that the sharpness score (i.e., ) wrongly judges A2 > A1 > A3, and the naturalness score (i.e., ) mistakes A1 > A3 > A2. This fact reveals drawbacks of the and : over-estimates the sharpening effect (A2 > A1), while over-emphasizes the image naturalness or smoothness (A3 > A2). In contrast, our zoom quality metric, indicated by the level sets of straight lines in Figure 9, successfully gives the order of A1 > A2 > A3;
- 2
- Similarly, in the second row of Figure 8, all B1, B2 and B3 are 5× zoom photos interpolated from three 2× optical lenses but with different ISPs and post-processing algorithms. The quality order is B1 > B2 > B3. However, the of B2 is larger than B1 because of annoying artifacts. Although the predicts the quality of B1 > B2 without error, it over-estimates the zoom blur (softness) present in B3, thus wrongly judging B3 > B2. By combining the with , the correct order of B1 > B2 > B3 can be achieved with our metric Q;
- 3
- In the bottom row, C1 is the original “hestain” image, and C2 and C3 are created using the Matlab imsharpen function with different amounts of unmask sharpening. The quality order is C2 > C1 > C3, as it is well-known that moderate amounts of sharpening can improve an image’s perceptual quality, while excessive sharpening would lead to a more unnatural appearance, thereby degrading the naturalness. However, from Figure 9, we can see the scores increase monotonically with the sharpening amounts, that is, C3 > C2 > C1, while the penalizes the C2 too much, leading to C1 > C2 > C3. In contrast, our metric Q can evaluate them more appropriately (C2 > C1 > C3). This fact implies our zoom quality metric can be used to control the parameter of sharpening algorithms.
4.3. Performance Comparison
4.4. The Discussion of w: The Tradeoff between Sharpness and Naturalness
4.5. Limitations of the Current Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CMOS | Complementary Metal Oxide Semiconductor |
| DSLR | Digital Single-Lens Reflex |
| ISP | Image Signal Processor |
| IQA | Image Quality Assessment |
| PDAF | Phase-Detection Auto Focus |
| MOS | Mean Opinion Score |
| RR-IQA | Reduced-Reference Image Quality Assessment |
| NR-IQA | No-Reference Image Quality Assessment |
| HDR | High Dynamic Range |
| SROCC | Spearman Rank Order Correlation Coefficient |
| KROCC | Kendall Rank Order Correlation Coefficient |
| PLCC | Pearson Linear Correlation Coefficient |
| VQEG | Video Quality Experts Group |
References
- Nakazawa, K.; Yamamoto, J.; Mori, S.; Okamoto, S.; Shimizu, A.; Baba, K.; Fujii, N.; Uehara, M.; Hiramatsu, K.; Kumano, H.; et al. 3D Sequential Process Integration for CMOS Image Sensor. In Proceedings of the 2021 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 11–16 December 2021; pp. 30.4.1– 30.4.4. [Google Scholar]
- Zaitsu, K.; Matsumoto, A.; Nishida, M.; Tanaka, Y.; Yamashita, H.; Satake, Y.; Watanabe, T.; Araki, K.; Nei, N.; Nakazawa, K.; et al. A 2-Layer Transistor Pixel Stacked CMOS Image Sensor with Oxide-Based Full Trench Isolation for Large Full Well Capacity and High Quantum Efficiency. In Proceedings of the 2022 VLSI Technology and Circuits, Honolulu, HI, USA, 12–17 June 2022; pp. 286–287. [Google Scholar]
- Venezia, V.C.; Hsiung, A.C.W.; Yang, W.Z.; Zhang, Y.; Zhao, C.; Lin, Z.; Grant, L.A. Second Generation Small Pixel Technology Using Hybrid Bond Stacking. Sensors 2018, 18, 667. [Google Scholar] [CrossRef] [PubMed]
- Yun, J.; Lee, S.; Cha, S.; Kim, J.; Lee, J.; Kim, H.; Lee, E.; Kim, S.; Hong, S.; Kim, H.; et al. A 0.6 μm Small Pixel for High Resolution CMOS Image Sensor with Full Well Capacity of 10,000e- by Dual Vertical Transfer Gate Technology. In Proceedings of the 2022 VLSI Technology and Circuits, Honolulu, HI, USA, 12–17 June 2022; pp. 351–352. [Google Scholar]
- Lee, W.; Ko, S.; Kim, J.H.; Kim, Y.S.; Kwon, U.; Kim, H.; Kim, D.S. Simulation-based study on characteristics of dual vertical transfer gates in sub-micron pixels for CMOS image sensors. Solid State Electron. 2022, 198, 108472. [Google Scholar] [CrossRef]
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Audio. Speech Lang. Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, Q.; Ng, R.; Koltun, V. Zoom to learn, learn to zoom. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3762–3770. [Google Scholar]
- Wronski, B.; Garcia-Dorado, I.; Ernst, M.; Kelly, D.; Krainin, M.; Liang, C.K.; Levoy, M.; Milanfar, P. Handheld multi-frame super-resolution. ACM Trans. Graph. 2019, 38, 1–18. [Google Scholar] [CrossRef]
- Cao, F.; Guichard, F.; Hornung, H. Measuring texture sharpness of a digital camera. In Digital Photography V; SPIE: Bellingham, WA, USA, 2009; Volume 7250, pp. 146–153. [Google Scholar]
- Artmann U., W.D. Interaction of image noise, spatial resolution, and low contrast fine detail preservation in digital image processing. In Digital Photography V; SPIE: Bellingham, WA, USA, 2009; Volume 7250, pp. 154–162. [Google Scholar]
- Phillips, J.; Coppola, S.M.; Jin, E.W.; Chen, Y.; Clark, J.H.; Mauer, T.A. Correlating objective and subjective evaluation of texture appearance with applications to camera phone imaging. In Digital Photography V; SPIE: Bellingham, WA, USA, 2009; Volume 7242, pp. 67–77. [Google Scholar]
- Marziliano, P.; Dufaux, F.; Winkler, S.; Ebrahimi, T. Perceptual blur and ringing metrics: Application to JPEG2000. Signal Process. Image Commun. 2004, 19, 163–172. [Google Scholar] [CrossRef]
- Ferzli, R.; Karam, L.J. A no-reference objective image sharpness metric based on the notion of just noticeable blur (JNB). IEEE Trans. Image Process. 2009, 18, 717–728. [Google Scholar] [CrossRef] [PubMed]
- Sadaka, N.G.; Karam, L.J.; Ferzli, R.; Abousleman, G.P. A no-reference perceptual image sharpness metric based on saliency-weighted foveal pooling. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 369–372. [Google Scholar]
- Narvekar, N.D.; Karam, L.J. A no-reference perceptual image sharpness metric based on a cumulative probability of blur detection. In Proceedings of the 2009 International Workshop on Quality of Multimedia Experience, San Diego, CA, USA, 29–31 July 2009; pp. 87–91. [Google Scholar]
- Yan, Q.; Xu, Y.; Yang, X. No-reference image blur assessment based on gradient profile sharpness. In Proceedings of the 2013 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), London, UK, 5–7 June 2013; pp. 1–4. [Google Scholar]
- Vu, C.T.; Phan, T.D.; Chandler, D.M. S3: A spectral and spatial measure of local perceived sharpness in natural images. IEEE Trans. Image Process. 2012, 21, 934–945. [Google Scholar] [CrossRef] [PubMed]
- Vu, P.V.; Chandler, D.M. A fast wavelet-based algorithm for global and local image sharpness estimation. IEEE Signal Process. Lett. 2012, 19, 423–426. [Google Scholar] [CrossRef]
- Hassen, R.; Wang, Z.; Salama, M.M. Image sharpness assessment based on local phase coherence. IEEE Trans. Image Process. 2013, 22, 2798–2810. [Google Scholar] [CrossRef]
- Li, C.; Yuan, W.; Bovik, A.; Wu, X. No-reference blur index using blur comparisons. Electron. Lett. 2011, 47, 962–963. [Google Scholar] [CrossRef]
- Li, L.; Lin, W.; Wang, X.; Yang, G.; Bahrami, K.; Kot, A.C. No-reference image blur assessment based on discrete orthogonal moments. IEEE Trans. Cybernet. 2015, 46, 39–50. [Google Scholar] [CrossRef] [PubMed]
- Gu, K.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. No-Reference Image Sharpness Assessment in Autoregressive Parameter Space. IEEE Trans. Image Process. 2015, 24, 3218–3231. [Google Scholar] [PubMed]
- Li, L.; Wu, D.; Wu, J.; Li, H.; Lin, W.; Kot, A.C. Image sharpness assessment by sparse representation. IEEE Trans. Multimedia 2016, 18, 1085–1097. [Google Scholar] [CrossRef]
- Han, Z.; Zhai, G.; Liu, Y.; Gu, K.; Zhang, X. A reduced-reference quality assessment scheme for blurred images. In Proceedings of the 2016 Visual Communications and Image Processing (VCIP), Chengdu, China, 27–30 November 2016; pp. 1–4. [Google Scholar]
- Liu, Y.; Gu, K.; Zhai, G.; Liu, X.; Zhao, D.; Gao, W. Quality assessment for real out-of-focus blurred images. J. Vis. Commun. Image Represent. 2017, 46, 70–80. [Google Scholar] [CrossRef]
- Saad, M.A.; Le Callet, P.; Corriveau, P. Blind image quality assessment: Unanswered questions and future directions in the light of consumers needs. VQEG eLetter 2014, 1, 62–66. [Google Scholar]
- Krasula, L.; Le Callet, P.; Fliegel, K.; Kilma, M. Quality Assessment of Sharpened Images: Challenges, Methodology, and Objective Metrics. IEEE Trans. Image Process. 2017, 26, 1496–1508. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Wang, Z.; Chen, Z. Image Super-Resolution Quality Assessment: Structural Fidelity Versus Statistical Naturalness. In Proceedings of the 13th International Conference on Quality of Multimedia Experience (QoMEX), Online, 14–17 June 2021; pp. 61–64. [Google Scholar]
- Zhou, W.; Wang, Z. Quality Assessment of Image Super-Resolution: Balancing Deterministic and Statistical Fidelity. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 934–942. [Google Scholar]
- Jiang, Q.; Liu, Z.; Gu, K.; Shao, F.; Zhang, X.; Liu, H.; Lin, W. Single Image Super-Resolution Quality Assessment: A Real-World Dataset, Subjective Studies, and an Objective Metric. IEEE Trans. Image Process. 2022, 31, 2279–2294. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 26, 1496–1508. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a completely blind image quality analyzer. IEEE Signal Process Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Liu, Y.; Gu, K.; Zhang, Y.; Li, X.; Zhai, G.; Zhao, D.; Gao, W. Unsupervised Blind Image Quality Evaluation via Statistical Measurements of Structure, Naturalness, and Perception. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 929–943. [Google Scholar] [CrossRef]
- Min, X.; Zhai, G.; Gu, K.; Liu, Y.; Yang, X. Blind Image Quality Estimation via Distortion Aggravation. IEEE Trans. Broadcast. 2018, 64, 508–517. [Google Scholar] [CrossRef]
- Min, X.; Gu, K.; Zhai, G.; Liu, J.; Yang, X.; Chen, C.W. Blind Quality Assessment Based on Pseudo-Reference Image. IEEE Trans. Multimedia 2018, 20, 2049–2062. [Google Scholar] [CrossRef]
- Zhai, G.; Wu, X.; Yang, X.; Lin, W.; Zhang, W. A psychovisual quality metric in free-energy principle. newblock IEEE Trans. Image Process. 2012, 21, 41–52. [Google Scholar] [CrossRef] [PubMed]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Sheikh, H.R.; Wang, Z.; Cormack, L.; Bovik, C. LIVE Image Quality Assessment Database Release 2. 2006. Available online: http://live.ece.utexas.edu/research/quality (accessed on 20 March 2023).
- Ponomarenko, N.; Lukin, V.; Zelensky, A.; Egiazarian, K.; Carli, M.; Battisti, F. TID2008-a database for evaluation of full-reference visual quality assessment metrics. Adv. Mod. Radioelectron. 2009, 10, 30–45. [Google Scholar]
- Ponomarenko, N.; Jin, L.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Image database TID2013: Peculiarities, results and perspectives. Signal Process. Image Commun. 2015, 30, 57–77. [Google Scholar] [CrossRef]
- Jayaraman, D.; Mittal, A.; Moorthy, A.K.; Bovik, A.C. Objective quality assessment of multiply distorted images. In Proceedings of the 2012 Conference Record of the Forty Sixth Asilomar Conference on Dignals, Dystems and Computers (ASILOMAR), Pacific Grove, CA, USA, 4–7 November 2012; pp. 1693–1697. [Google Scholar]
- Ciancio, A.; da Costa, A.L.N.T.; da Silva, E.A.; Said, A.; Samadani, R.; Obrador, P. No-reference blur assessment of digital pictures based on multifeature classifiers. IEEE Trans. Image Process. 2011, 20, 64–75. [Google Scholar] [CrossRef]
- Li, Y.F.; Yang, C.K.; Chang, Y.Z. Photo composition with real-time rating. Sensors 2020, 20, 582. [Google Scholar] [CrossRef]
- Nikkanen, J.; Gerasimow, T.; Lingjia, K. Subjective effects of white-balancing errors in digital photography. Opt. Eng. 2008, 47, 113201. [Google Scholar]
- Recommendation ITU-R BT. Methodology for the Subjective Assessment of the Quality of Television Pictures; International Telecommunication Union: Geneva, Switzerland, 2002. [Google Scholar]
- Gu, K.; Liu, M.; Zhai, G.; Yang, X.; Zhang, W. Quality assessment considering viewing distance and image resolution. IEEE Trans. Broadcast. 2015, 61, 520–531. [Google Scholar] [CrossRef]
- Han, Z.; Liu, Y.; Xie, R. A large-scale image database for benchmarking mobile camera quality and NR-IQA algorithms. Displays 2023, 76, 102366. [Google Scholar] [CrossRef]
- Gliem, J.A.; Gliem, R.R. Calculating, Interpreting, and Reporting Cronbach’s Alpha Reliability Coefficient for Likert-Type Dcales; Midwest Research-to-Practice Conference in Adult, Continuing, and Community: Bloomington, IN, USA, 2003. [Google Scholar]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision, Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar]
- Xu, L.; Lu, C.; Xu, Y.; Jia, J. Image smoothing via L-0 gradient minimization. In Proceedings of the 2011 SIGGRAPH Asia Conference, Hong Kong, China, 12–15 December 2011; pp. 1–12. [Google Scholar]
- Larson, E.C.; Chandler, D. Categorical Image Quality (CSIQ) Database. 2010. Available online: http://vision.okstate.edu/csiq (accessed on 20 March 2023).
- Friston, K. The free-energy principle: A unified brain theory? Nature Pev. Neurosci. 2010, 11, 127–138. [Google Scholar] [CrossRef] [PubMed]
- MacKay, D.J. Ensemble learning and evidence maximization. Proc. Nips. Citeseer 1995, 10, 4083. [Google Scholar]
- Feynman, R.P. Statistical Mechanics: A Set of Lectures; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Liu, Y.; Zhai, G.; Liu, X.; Zhao, D. Perceptual image quality assessment combining free-energy principle and sparse representation. In Proceedings of the 2016 IEEE International Symposium on Circuits and Systems (ISCAS), Montreal, QC, Canada, 22–25 May 2016; pp. 1586–1589. [Google Scholar]
- Blumensath, T.; Davies, M.E. Iterative thresholding for sparse approximations. J. Fourier Anal. Appl. 2008, 14, 629–654. [Google Scholar] [CrossRef]
- Peleg, T.; Eldar, Y.C.; Elad, M. Exploiting statistical dependencies in sparse representations for signal recovery. IEEE Trans. Signal Process. 2012, 60, 2286–2303. [Google Scholar] [CrossRef]
- Duarte, M.F.; Eldar, Y.C. Structured compressed sensing: From theory to applications. IEEE Trans. Signal Process. 2011, 59, 4053–4085. [Google Scholar] [CrossRef]
- Wu, J.; Lin, W.; Shi, G.; Liu, A. Perceptual quality metric with internal generative mechanism. IEEE Trans. Image Process. 2012, 22, 43–54. [Google Scholar]
- Liu, Y.; Zhai, G.; Gu, K.; Liu, X.; Zhao, D.; Gao, W. Reduced-Reference Image Quality Assessment in Free-Energy Principle and Sparse Representation. IEEE Trans. Multimedia 2018, 20, 379–391. [Google Scholar] [CrossRef]
- Zoran, D.; Weiss, Y. Scale invariance and noise in natural images. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2209–2216. [Google Scholar]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, L.; Bovik, A.C. A feature-enriched completely blind image quality evaluator. IEEE Trans. Image Process. 2015, 24, 2579–2591. [Google Scholar] [CrossRef] [PubMed]
- Ruderman, D.L. The statistics of natural images. Netw. Comput. Neural Syst. 1994, 5, 517. [Google Scholar] [CrossRef]
- Sharifi, K.; Leon-Garcia, A. Estimation of shape parameter for generalized Gaussian distributions in subband decompositions of video. IEEE Trans. Circuits Syst. Video Technol. 1995, 5, 52–56. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. A DCT Statistics-Based Blind Image Quality Index. IEEE Signal Process. Lett. 2010, 17, 583–586. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.; Bovik, A. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Zhai, G.; Zhang, W.; Yang, X.; Xu, Y. Image quality assessment metrics based on multi-scale edge presentation. In Proceedings of the IEEE Workshop on Signal Processing Systems Design and Implementation, Athens, Greece, 2–4 November 2005; pp. 331–336. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. IEEE Int. Conf. Comput. Vision 2001, 2, 416–423. [Google Scholar]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Liu, Y.; Gu, K.; Li, X.; Zhang, Y. Blind image quality assessment by natural scene statistics and perceptual characteristics. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–91. [Google Scholar] [CrossRef]
- Wu, Q.; Wang, Z.; Li, H. A highly efficient method for blind image quality assessment. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 339–343. [Google Scholar]
- Xue, W.; Zhang, L.; Mou, X. Learning without human scores for blind image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 995–1002. [Google Scholar]
- Moorthy, A.K.; Bovik, A.C. A two-step framework for constructing blind image quality indices. IEEE Signal Process. Lett. 2010, 17, 513–516. [Google Scholar] [CrossRef]
- Xue, W.; Mou, X.; Zhang, L.; Bovik, A.C.; Feng, X. Blind image quality assessment using joint statistics of gradient magnitude and Laplacian features. IEEE Trans. Image Process. 2014, 23, 4850–4862. [Google Scholar] [CrossRef] [PubMed]
- Rohaly, A.M.; Libert, J.; Corriveau, P.; Webster, A.; Baroncini, V.; Beerends, J.; Blin, J.L.; Contin, L.; Hamada, T.; Harrison, D.; et al. Final report from the video quality experts group on the validation of objective models of video quality assessment. ITU-T Stand. Contrib. COM 2000, 1, 9–80. [Google Scholar]
- Zhang, Z.; Sun, W.; Min, X.; Zhu, W.; Wang, T.; Lu, W.; Zhai, G. A No-Reference Deep Learning Quality Assessment Method for Super-Resolution Images Based on Frequency Maps. In Proceedings of the ISCAS, New York, NY, USA, 18–22 June 2022; pp. 3170–3174. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Values |
|---|---|
| Evaluation method | single-stimulus within a scene |
| Evaluation scales | continuous quality scales from 0 to 100 |
| Evaluation standard | image clarity instead of color or overall quality |
| Image number | 20 mobile cameras × 45 scenes |
| Image encoder | JPEG and HEIF |
| Image resolution | mostly 4000 × 3000 |
| Subjects | ten experienced experts |
| Viewing angle | can be adjusted by the subject |
| Room illuminance | low |
| Databases | No. of Ref. Scenes | No. of Dist. Images | No. of Dist. Types | No. of Blurred Levels/Images | Creation Process | Resolution | Subjects No. |
|---|---|---|---|---|---|---|---|
| LIVE [38] | 29 | 779 | 5 | 4/174 | Gaussian blur | 568 × 712 | 20–29 |
| TID2018 [39] | 25 | 1700 | 17 | 4/100 | Gaussian blur | 512 × 384 | 838 |
| TID2013 [40] | 25 | 3000 | 24 | 5/125 | Gaussian blur | 512 × 384 | 971 |
| CSIQ [51] | 30 | 866 | 6 | 5/150 | Gaussian blur | 512 × 512 | 25 |
| LIVE MD [41] | 15 | 450 | 2 | 15/225 | Gaussian blur+wn | 1280 × 720 | 18 |
| BID [42] | N.A. | 585 | 5 | N.A./585 | shot by the author | 1280 × 960 | 180 in total |
| Out-of-focus [25] | 30 | 150 | 1 | 5/150 | shot by the author | 720 × 480 | 26 |
| Our ZPHD | 45 | 900 | 20 | N.A./900 | shot by the author | 4000 × 3000 | 10 experts |
| Methods | SROCC | KROCC | PLCC |
|---|---|---|---|
| NIQE [32] | 0.8493 | 0.6863 | 0.8490 |
| SNP-NIQE [33] | 0.7216 | 0.3754 | 0.6932 |
| IL-NIQE [65] | 0.5022 | 0.3034 | 0.5257 |
| NPQI [74] | 0.7247 | 0.5506 | 0.7106 |
| LPSI [75] | 0.7538 | 0.6620 | 0.7435 |
| QAC [76] | 0.6892 | 0.5831 | 0.6431 |
| BIQI [77] | 0.7576 | 0.5419 | 0.7344 |
| BRISQUE [31] | 0.6385 | 0.4530 | 0.6700 |
| BLIINDS-II [64] | 0.5265 | 0.3031 | 0.5134 |
| M3 [78] | 0.4078 | 0.2263 | 0.4530 |
| JNB [13] | 0.7580 | 0.6678 | 0.7699 |
| CPBD [18] | 0.8305 | 0.6713 | 0.8017 |
| FISH [15] | 0.7662 | 0.6076 | 0.7423 |
| LPC [19] | 0.8567 | 0.7046 | 0.8436 |
| SPARISH [23] | 0.8456 | 0.6871 | 0.8328 |
| S3 [17] | 0.7962 | 0.6153 | 0.7829 |
| S3-III [27] | 0.8114 | 0.6347 | 0.8163 |
| The proposed metric | 0.9216 | 0.7908 | 0.9129 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Z.; Liu, Y.; Xie, R.; Zhai, G. Image Quality Assessment for Realistic Zoom Photos. Sensors 2023, 23, 4724. https://doi.org/10.3390/s23104724
Han Z, Liu Y, Xie R, Zhai G. Image Quality Assessment for Realistic Zoom Photos. Sensors. 2023; 23(10):4724. https://doi.org/10.3390/s23104724
Chicago/Turabian StyleHan, Zongxi, Yutao Liu, Rong Xie, and Guangtao Zhai. 2023. "Image Quality Assessment for Realistic Zoom Photos" Sensors 23, no. 10: 4724. https://doi.org/10.3390/s23104724