In this section, we describe the selected datasets and the baseline methods, and perform a series of experiments to validate the proposed method. Firstly, the proposed method is compared with the state-of-the-art methods and validated by statistical hypothesis testing. Then, the robustness of the method is verified on data with different contamination ratios. Furthermore, the effectiveness of each module of the method is verified by ablation experiments. Finally, sensitivity analyses are also implemented to explore the response of the model to different hyperparameters. The code is available at
https://github.com/guoguohang/CLPNM_AD, (accessed on 15 March 2023).
5.5. Effectiveness Evaluation
On four datasets, we examine the effectiveness of CLPNM-AD compared with that of six baseline methods. We use bold font to indicate the best score and underlined font to indicate the second-best score.
Table 3 shows the average
scores and standard deviations of CLPNM-AD as well as the baseline methods. The
score of CLPNM-AD surpasses all baseline methods on all datasets. Specifically, CLPNM-AD performs significantly better than the baseline methods on Thyroid and Micius, which achieves 11.5% and 11.0% improvement compared to the sub-optimal approaches DAGMM and LOF. For Satellite and Satimage datasets, CLPNM-AD still surpasses the next best method DAGMM and GOAD by 3.5% and 0.8%, respectively.
OC-SVM maps samples to one side of the hyperplane using a kernel function and does not take into account the semantic information shared by different samples. Simply mapping these samples to one side of the hyperplane tends to result in the overlapping of samples and thus makes it difficult to distinguish between normal and abnormal samples. Therefore, the results in
Table 3 show that OC-SVM performs poorly among all methods.
LOF uses the distance between a sample and its surrounding points for anomaly detection, which takes into account the local similarity of the samples and to some extent the semantic similarity information of the samples. As a result, LOF outperforms OC-SVM, particularly on the Micius dataset, where OC-SVM performs suboptimally. However, because LOF is based on the original samples and lacks feature extraction capability, it cannot effectively model the data’s characteristics.
DAGMM uses the reconstruction error and intermediate layer vectors as feature vectors, followed by a Gaussian mixture model for anomaly detection, achieving good performance on most datasets because the mixture component of the Gaussian mixture model models the semantic category information of the samples. However, DAGMM performs poorly on the Micius dataset because the distinction between normal and abnormal samples was not very clear, and it cannot map different semantic category samples apart, resulting in poor performance.
DSVDD achieves anomaly detection by mapping samples into a hypersphere, but it lacks the ability to capture the semantic information of the samples and maps all samples into the same hypersphere, which results in samples with different semantic information overlapping in the feature space and does not facilitate the distinguishing of normal and abnormal samples. As can be seen from
Table 3, DSVDD achieves poor performance on the Micius dataset, as does DAGMM.
GOAD augments the samples with a random affine transformation and then maps the augmented samples to the feature space for anomaly detection by predicting the transform used. The affine transform is used as the semantic class in this approach, and the augmented samples obtained using the same affine transform are clustered into one class in the feature space. Such an approach lacks sample semantic information modeling and achieves good results when the anomalous samples are of a single semantic category and the anomaly rate is low, e.g., as shown in
Table 3, the model performs well on the Satimage dataset but performs poorly on the Satellite dataset where the anomalous samples contain more semantic categories and the anomaly rate is high.
In comparison to GOAD, NeuTraL AD employs a trainable multilayer neural network as the data augmentation function and a loss function similar to contrast loss to separate samples with different transformations for anomaly detection. The method suffers from the same limitation of a lack of sample semantic information modeling, and thus its performance is inadequate, as shown in
Table 3.
Overall, CLPNM-AD outperforms all baselines on four datasets. The one-dimensional convolutional network in CLPNM-AD helps to capture the features of the samples, which can be adapted to anomaly detection tasks on different datasets. In addition, the consistency loss in CLPNM-AD helps the network to capture the semantic information of the samples, while the hard negative mixing strategy provides stronger guidance to help the contrast loss to separate and disperse the semantically different samples onto the hypersphere as much as possible, which allows the model to accurately profile the normal samples and thus make the normal and abnormal samples more distinguishable.
To quantitatively assess the effectiveness of CLPNM-AD, we statistically evaluate the results of 20 runs of CLPNM-AD with six baseline methods on four datasets using the Wilcoxon rank sum test. We test which of the null hypothesis H0 or the alternative hypothesis H1 holds for each pair of methods: H0: A ≈ B, H1: A > B, where A represents the score of CLPNM-AD on a specific dataset and B represents the score of the baseline method on the same dataset, A ≈ B means that the results of the two methods compared are not significantly different and A > B means that the results of A are better than those of B. For each test, we compute the p-value, and the hypothesis is tested at a significance level of .
As shown in
Table 4, except for GOAD on Satimage, all Wilcoxon test results meet
, allowing us to reject the null hypothesis H0 and accept the alternative hypothesis H1. This means that CLPNM-AD outperforms the baseline methods in all cases except for the Satimage dataset, where CLPNM-AD has nearly the same excellent results as GOAD.
In general, on all datasets, the CLPNM-AD method outperforms all baseline methods, and the advantage is statistically significant.
5.6. Robustness Evaluation
In satellite telemetry anomaly detection applications, the training data are frequently mixed with noisy data, or the anomalous samples are incorrectly labeled as normal during the training dataset construction, so we need to investigate the model’s sensitivity to contamination. In this experiment, we investigate how CLPNM-AD and all baselines respond to contaminated training data. We adopt the experiment setup in the literature [
11] according to which, in each run, all of the anomaly data are combined with 50% of the randomly selected normal data to form the test set, and the remaining 50% of the normal data are mixed with
of the anomaly data for model training. We examine the model’s average
value when the contamination ratio is
.
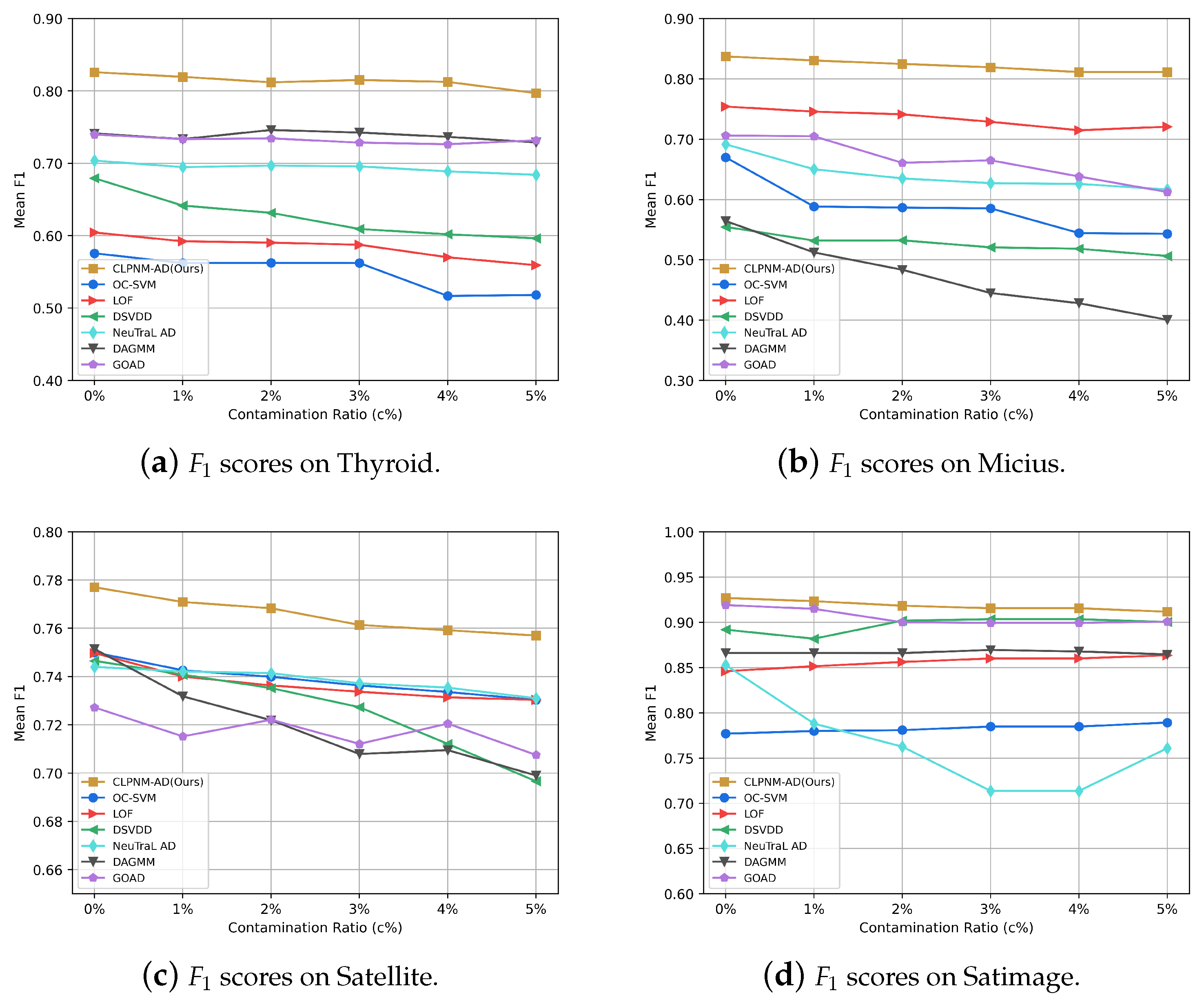
Figure 4 illustrates the
score of CLPNM-AD and all baselines after 20 runs. As expected, contaminated training data have a detrimental impact on detection accuracy in the majority of the situations. The mean
score of CLPNM-AD declines somewhat across all datasets when the contamination ratio
grows from
to
. When the contamination ratio is increased from 0 to 5%, the performance of CLPNM-AD decreased by 3.51%, 3.08%, 2.57% and 1.64% on the Thyroid, Micius, Satellite and Satimage datasets, respectively. Such a performance decline is somewhat tolerable. We also note that CLPNM-AD outperforms the baseline methods at different contamination ratios on all datasets.
CLPNM-AD has a certain tolerance for contaminated data, which may be because the consistency loss allocates the samples in a batch equally into each semantic category, preventing contaminated samples from being assigned to the same cluster. As a result, the contaminated samples have less impact on the probability distribution calculation of each semantic category, making the model somewhat robust to the anomalous samples mixed in the training set.
In general, CLPNM-AD is robust against contaminated data, maintaining good performance as the contamination ratio increases from 1% to 5% and always outperforming the performance of all baselines. In addition, to concentrate the model on the anomaly detection task and obtain greater anomaly detection accuracy, the model must be trained with a high-quality dataset, i.e., a clean dataset or a dataset with a low contamination ratio.
5.7. Ablation Experiment
In this experiment, we investigate the impact of various modules in the model. We repeat our experiment with/without a specific key module. These key modules are primarily vanilla InfoNCE loss , clustering consistency objective loss and the negative samples mixing strategy, where and negative samples mixing strategy form .
As shown in
Table 5, our full model achieves the best performance on all datasets. When only
is used, the method performs poorly because it makes no sense to emphasize consistency without the similarity information between samples as a semantic category guide. When only
is used, the method performs better than when only
is used because
can explore the consistency of positive samples in the feature space while also pushing negative samples away, resulting in a more conducive semantic structure to detect anomalies. Combining
and
for model training outperforms
and
alone on most datasets. This is probably because
can further exploit the semantic similarity information extracted by
to make the clusters more separable and thus facilitate anomaly detection. Our full model achieves the best performance due to the ability of hard negative samples to contribute a larger magnitude gradient to update the network parameters, while also weakening the contribution of false negative samples to the gradient, preventing semantic similarity from being broken and thus facilitating the separation of normal and abnormal samples. In conclusion, these ablation experiments validate that each module in our model is useful and necessary.
5.8. Sensitivity Studies
In this section, we discuss the effect of the number of prototypes K and batch size N on the performance of CLPNM-AD on the Thyroid, Micius, Satellite and Satimage datasets.
Figure 5 depicts the performance of CLPNM-AD with varying numbers of prototypes
. It can be observed that CLPNM-AD is resistant to prototype numbers on Micius, Satellite and Satimage. In the case of Thyroid, the number of prototypes has an evident effect on CLPNM-AD, with
decreasing as
K increases from 4 to 24. We conjecture that the model degeneration on Thyroid is due to the fact that the dataset itself has specific semantic clusters, the number of which is close to four, and increasing the number of prototypes too much will break this semantic structure.
Figure 6 illustrates the detection performance of CLPNM-AD with batch size
. On Micius, Satellite and Satimage, we can see that CLPNM-AD is not sensitive to batch size, and the performance does not vary significantly when the batch size
N is varied. On Thyroid, however, CLPNM-AD was more clearly affected by the batch size, with the method achieving the best performance at batch size
. This may be because too small batches contain too few samples and lack negative samples to guide network learning, while too large batches cause the network to converge more slowly and fail to fully converge for a given epoch number.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}