
Keypoint-Based Robotic Grasp Detection Scheme in Multi-Object Scenes


Abstract
:1. Introduction
- A new scheme of robot grasping detection based on keypoint, which is different from the anchor-based scheme in the previous work, is proposed.
- A new network is proposed that detects objects and grasp at the same time and matches the affiliation between them in multi-object scenes.
- A matching strategy of objects and grasps is proposed, which makes the result more accurate.
2. Related Works
3. The Proposed Method
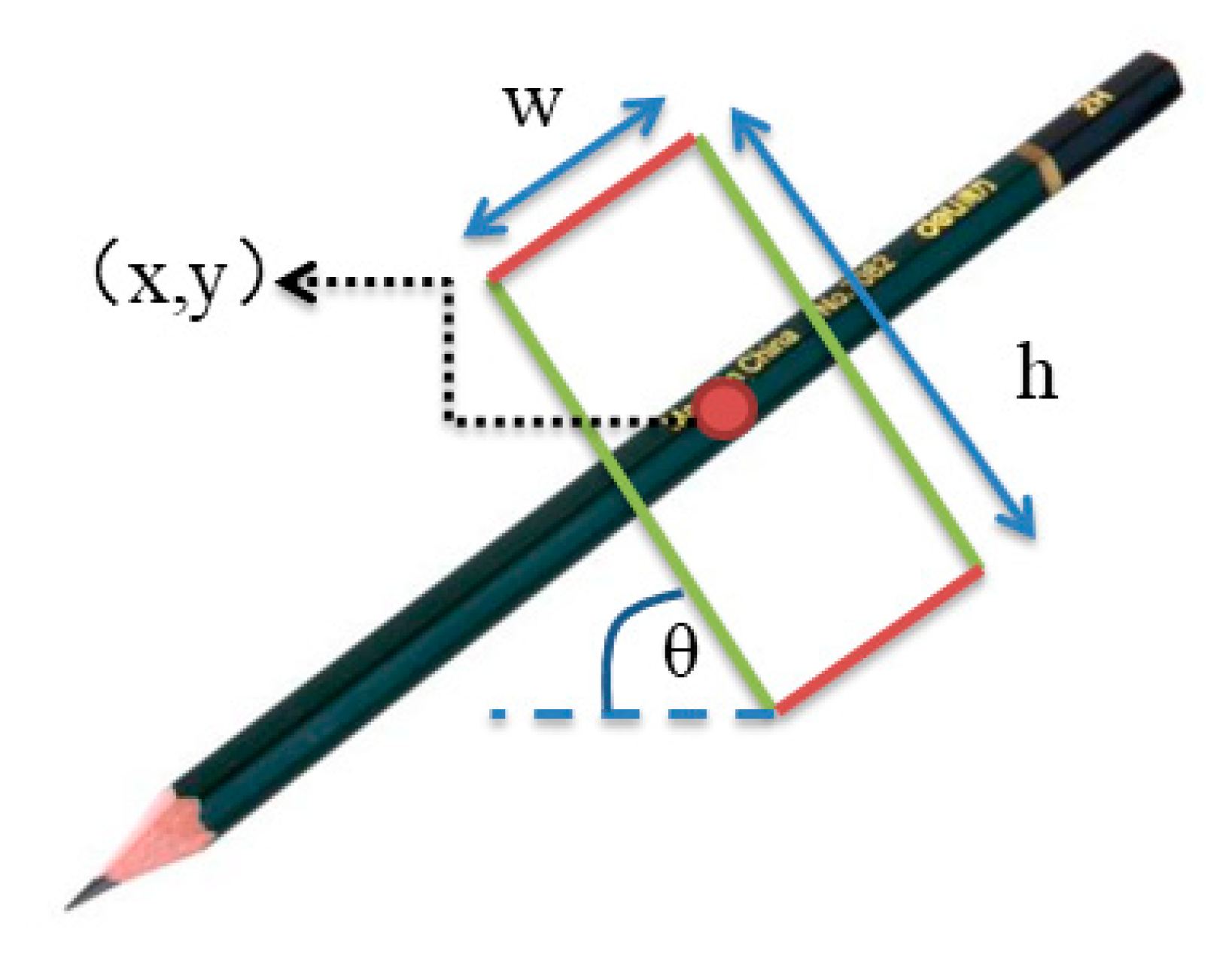
3.1. Problem Formulation
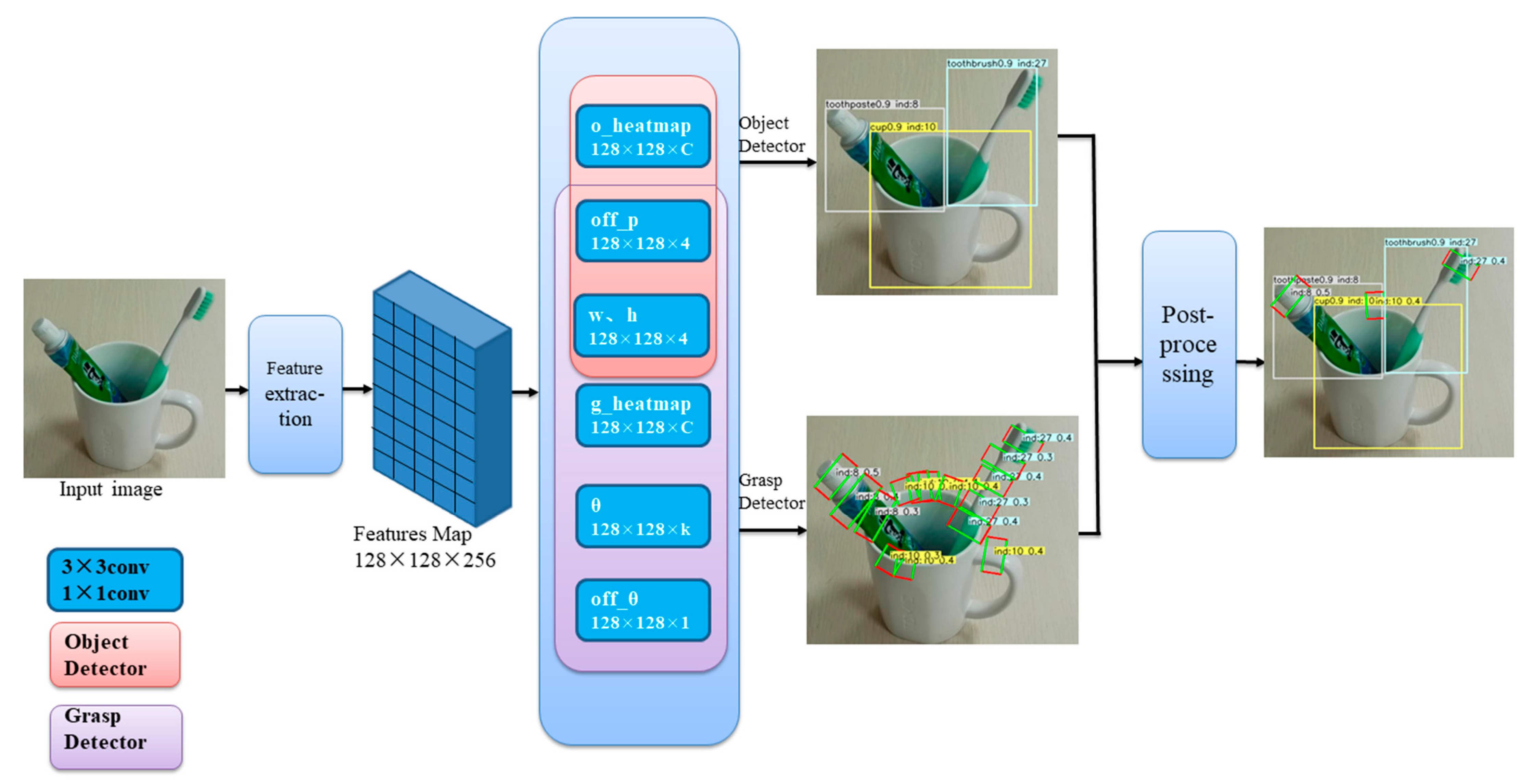
3.2. Network Architecture
3.3. Keypoint Estimate Mechanism for Training
3.4. Loss Function
3.5. Matching Strategy
4. Experiments
4.1. Dataset
- Image-wise split splits all the images of the dataset randomly into training set and validation set. This is to test the generalization ability of the network to detect new objects.
- Object-wise split splits the object instances randomly into train and validation set. The training and validation data sets do not have instances in the other’s dataset. That is, all pictures of the same instance are assigned to the same dataset. This is to test the generalization ability of the network to new instances.
4.2. Implementation Details
4.3. Metrics
- the difference between the predicted grasp rotation angle and the ground-truth grasp rotation angle is less than 30°.
- the Jaccard index of the predicted grasp and the ground-truth is more than 25%. The Jaccard index for a predicted rectangle and a ground-truth rectangle defined as:where is the area of predicted grasp rectangle and is the area of ground-truth grasp rectangle. is union of these two rectangles. is the intersection of these two rectangles.
- A detection (o, g) includes object detection result o = (Bo, Co) and top-1 grasp detection result g, where Bo is the position of the object predicted by the network and Co is the predicted category.
- The object o is detected correctly, which means that the predicted category Co is the same as ground-truth and the IOU between the predicted position Bo and ground-truth is greater than 0.5.
- The Top-1 grasp g is detected correctly, which means that the predicted Top-1 grasp has a rotation angle difference less than 30° and Jaccard Index more than 0.25 with at least one ground truth grasp rectangle belonging to the object.
5. Results
5.1. Validation Results on Cornell Dataset
5.2. Validation Results on VMRD Dataset
5.3. Robot Experiment
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Jiang, Y.; Moseson, S.; Saxena, A. Efficient grasping from RGBD images: Learning using a new rectangle representation. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3304–3311. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep Learning for Detecting Robotic Grasps. Int. J. Robot. Res. 2013, 34, 705–724. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 769–776. [Google Scholar]
- Guo, D.; Sun, F.; Liu, H.; Kong, T.; Fang, B.; Xi, N. A hybrid deep architecture for robotic grasp detection. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1609–1614. [Google Scholar]
- Zhou, X.; Lan, X.; Zhang, H.; Tian, Z.; Zhang, Y.; Zheng, N. Fully Convolutional Grasp Detection Network with Oriented Anchor Box. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7223–7230. [Google Scholar]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2016, 37, 421–436. [Google Scholar] [CrossRef]
- Gualtieri, M.; Pas, A.T.; Saenko, K.; Platt, R. High precision grasp pose detection in dense clutter. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 598–605. [Google Scholar]
- Jeffrey, M.; Ken, G. Learning deep policies for robot bin picking by simulating robust grasping sequences. In Proceedings of the 1st Annual Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; Volume 78, pp. 515–524. [Google Scholar]
- Mahler, J.; Matl, M.; Liu, X.; Li, A.; Gealy, D.; Goldberg, K. Dex-net 3.0: Computing robust robot suction grasp targets in point clouds using a new analytic model and deep learning. In Proceedings of the IEEE International Conference on Robotics and Automation, Exhibition Center, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Chu, F.-J.; Xu, R.; Vela, P.A. Real-World Multiobject, Multigrasp Detection. IEEE Robot. Autom. Lett. 2018, 3, 3355–3362. [Google Scholar] [CrossRef] [Green Version]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M. Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3750–3757. [Google Scholar]
- Zhang, H.; Lan, X.; Bai, S.; Zhou, X.; Tian, Z.; Zheng, N. ROI-based Robotic Grasp Detection for Object Overlapping Scenes. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macao, China, 4–8 November 2019; pp. 4768–4775. [Google Scholar]
- Zhang, H.; Lan, X.; Zhou, X.; Tian, Z.; Zhang, Y.; Zheng, N. Visual manipulation relationship network for autonomous robotics. In Proceedings of the 2018 IEEE-RAS 18th International Conference on Humanoid Robots (Humanoids), Beijing, China, 6–9 November 2018; pp. 118–125. [Google Scholar]
- AMiller, A.T.; Allen, P.K. Graspit! a versatile simulator for robotic grasping. Robot. Autom. Mag. IEEE 2004, 11, 110–122. [Google Scholar]
- Pelossof, R.; Miller, A.; Allen, P.; Jebara, T. An SVM learning approach to robotic grasping. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004; Volume 4, pp. 3512–3518. [Google Scholar]
- Bohg, J.; Morales, A.; Asfour, T.; Kragic, D. Data-driven grasp synthesis—A survey. IEEE Trans. Robot. 2014, 30, 289–309. [Google Scholar] [CrossRef] [Green Version]
- Saxena, A.; Driemeyer, J.; Ng, A.Y. Robotic grasping of novel objects using vision. Int. J. Robot. Res. 2008, 27, 157–173. [Google Scholar] [CrossRef] [Green Version]
- Le, Q.V.; Kamm, D.; Kara, A.F.; Ng, A.Y. Learning to grasp objects with multiple contact points. In Proceedings of the Robotics and Automation(ICRA) 2010 IEEE International Conference, Anchorage, Alaska, 3–8 May 2010; pp. 5062–5069. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Depierre, A.; Dellandréa, E.; Chen, L. Optimizing correlated graspability score and grasp regression for better grasp prediction. arXiv 2020, arXiv:2002.00872. [Google Scholar]
- Li, B.; Cao, H.; Qu, Z.; Hu, Y.; Wang, Z.; Liang, Z. Event-based Robotic Grasping Detection with Neuromorphic Vision Sensor and Event-Stream Dataset. arXiv 2020, arXiv:2002.00872. [Google Scholar]
- Guo, D.; Kong, T.; Sun, F.; Liu, H. Object discovery and grasp detection with a shared convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2038–2043. [Google Scholar]
- Vohra, M.; Prakash, R.; Behera, L. Real-time Grasp Pose Estimation for Novel Objects in Densely Cluttered Environment. arXiv 2020, arXiv:2001.02076. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep Layer Aggregation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2403–2412. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Real-time multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4903–4911. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster rcnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 2999–3007. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Algorithm | Accuracy (%) | |
|---|---|---|---|
| Image-Wise | Object-Wise | ||
| Jiang et al. [1] | Fast Search | 60.5 | 58.3 |
| Lenz et al. [2] | SAE, struct. reg. Two stage | 73.9 | 75.6 |
| Redmon et al. [3] | AlexNet, MultiGrasp | 88.0 | 87.1 |
| Kumra et al. [4] | ResNet-50 × 2, Multi-model Grasp Predictor | 89.21 | 88.96 |
| Guo et al. [5] | ZF-net, Hybrid network, 3 scales and 3 aspect ratios | 93.2 | 89.1 |
| Chu et al. [11] | VGG-16 model | 95.5 | 91.7 |
| ResNet-50 model | 96.0 | 96.1 | |
| Zhou et al. [6] | ResNet-50 FCGN | 97.7 | 94.9 |
| ResNet-101 FCGN | 97.7 | 96.6 | |
| the proposed scheme | keypoint-based scheme | 96.05 | 96.5 |
| k 1 | Loss | mAPg (%) 2 |
|---|---|---|
| 6 | Cross Entropy | 57.3 |
| 9 | Cross Entropy | 64.2 |
| 12 | Cross Entropy | 69.3 |
| 18 | Cross Entropy | 72.6 |
| 18 | Focal Loss | 74.3 |
| Approach | Algorithm | mAPg (%) |
|---|---|---|
| Zhou et al. [13] | Faster-RCNN [31] + FCGN [6] | 54.5 |
| Zhou et al. [13] | ROI-GD | 68.2 |
| the proposed scheme | keypoint-based scheme | 74.3 |
| Object | Single-Object Scenes | Multi-Object Scenes | ||
|---|---|---|---|---|
| Prediction | Grasping | Prediction | Grasping | |
| Knife | 8/10 | 8/10 | 7/10 | 7/10 |
| Bananas | 10/10 | 10/10 | 10/10 | 10/10 |
| Toothbrush | 10/10 | 9/10 | 10/10 | 8/10 |
| Toothpaste | 10/10 | 10/10 | 10/10 | 10/10 |
| Wrenches | 10/10 | 10/10 | 10/10 | 9/10 |
| Wrist developer | 10/10 | 10/10 | 8/10 | 7/10 |
| Screwdrivers | 10/10 | 8/10 | 10/10 | 10/10 |
| Apples | 10/10 | 10/10 | 10/10 | 9/10 |
| Pliers | 10/10 | 9/10 | 9/10 | 7/10 |
| Tape | 10/10 | 10/10 | 10/10 | 10/10 |
| Accuracy (%) | 98 | 94 | 94 | 87 |
| Approach | Algorithm | Accuracy (%) | |
|---|---|---|---|
| Single-Object Scenes | Multi-Object Scenes | ||
| Zhou et al. [13] | ROI-GD | 92.5 | 83.75 |
| the proposed scheme | keypoint-based scheme | 94 | 87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Wang, F.; Ru, C.; Jiang, Y.; Li, J. Keypoint-Based Robotic Grasp Detection Scheme in Multi-Object Scenes. Sensors 2021, 21, 2132. https://doi.org/10.3390/s21062132
Li T, Wang F, Ru C, Jiang Y, Li J. Keypoint-Based Robotic Grasp Detection Scheme in Multi-Object Scenes. Sensors. 2021; 21(6):2132. https://doi.org/10.3390/s21062132
Chicago/Turabian StyleLi, Tong, Fei Wang, Changlei Ru, Yong Jiang, and Jinghong Li. 2021. "Keypoint-Based Robotic Grasp Detection Scheme in Multi-Object Scenes" Sensors 21, no. 6: 2132. https://doi.org/10.3390/s21062132