
Deep Supervised Residual Dense Network for Underwater Image Enhancement


Abstract
:1. Introduction
- (1)
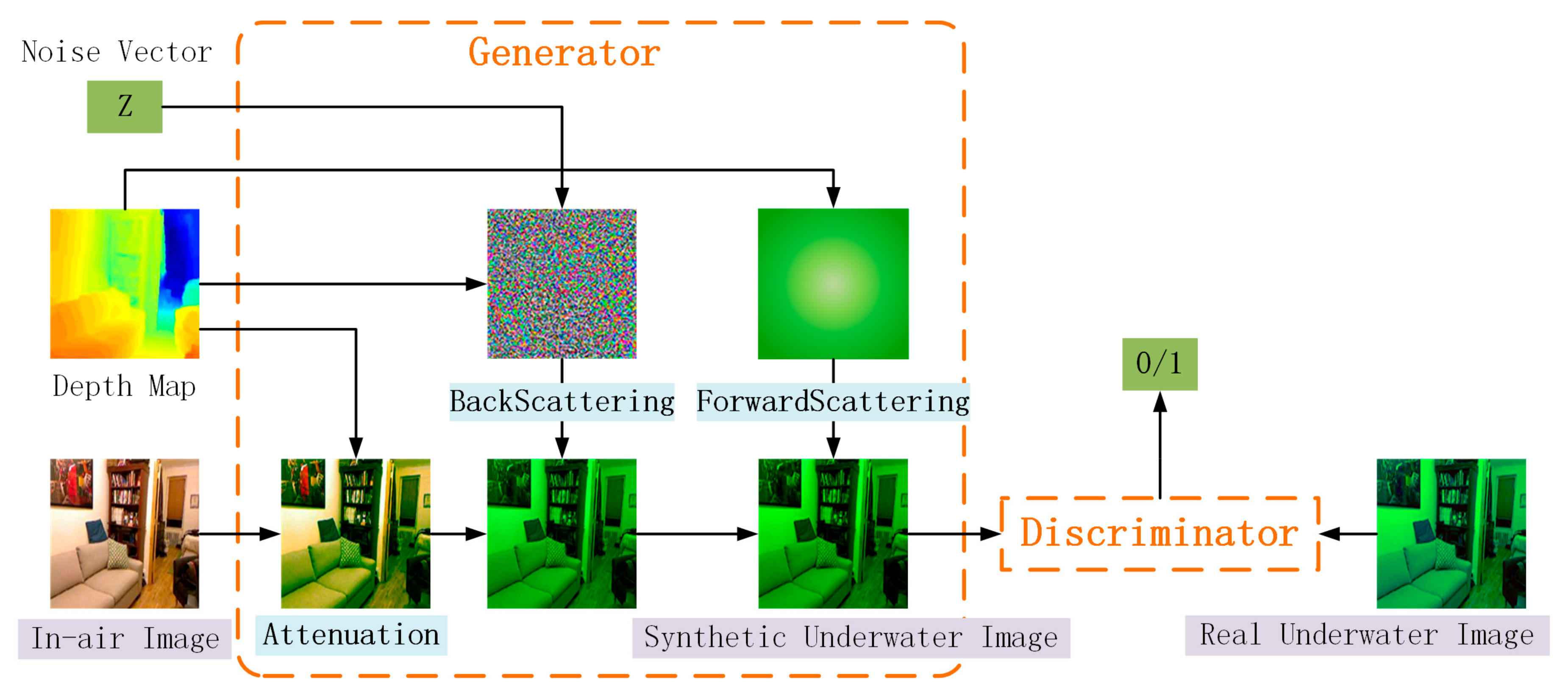
- Because it is difficult to obtain real clear underwater images, taking real underwater images, in-air images, and depth maps as input, we used UWGAN to generate a large training dataset of paired images by training generator and discriminator.
- (2)
- DS_RD_Net is proposed for underwater image detailed enhancement. Residual dense blocks are adopted to fully extract features of different levels and different scales in order to reduce the loss of details during feature propagation. Residual path blocks are added to the skip connection between the encoder and decoder, which balances the semantic differences between the low-level features and high-level features and reduces the loss of details in the down-sampling process.
- (3)
- A deep supervised mechanism is introduced to guide the DS_RD_Net training and improve the gradient propagation, thereby enhancing the robustness of the network and enabling the model to achieve a good enhancement effect on images with different degrees of degradation.
- (4)
- We executed extensive performance comparisons between DS_RD_Net and other underwater image enhancement methods and demonstrated the effectiveness of the proposed method quantitatively and qualitatively.
2. Synthesis Algorithm of Underwater Images
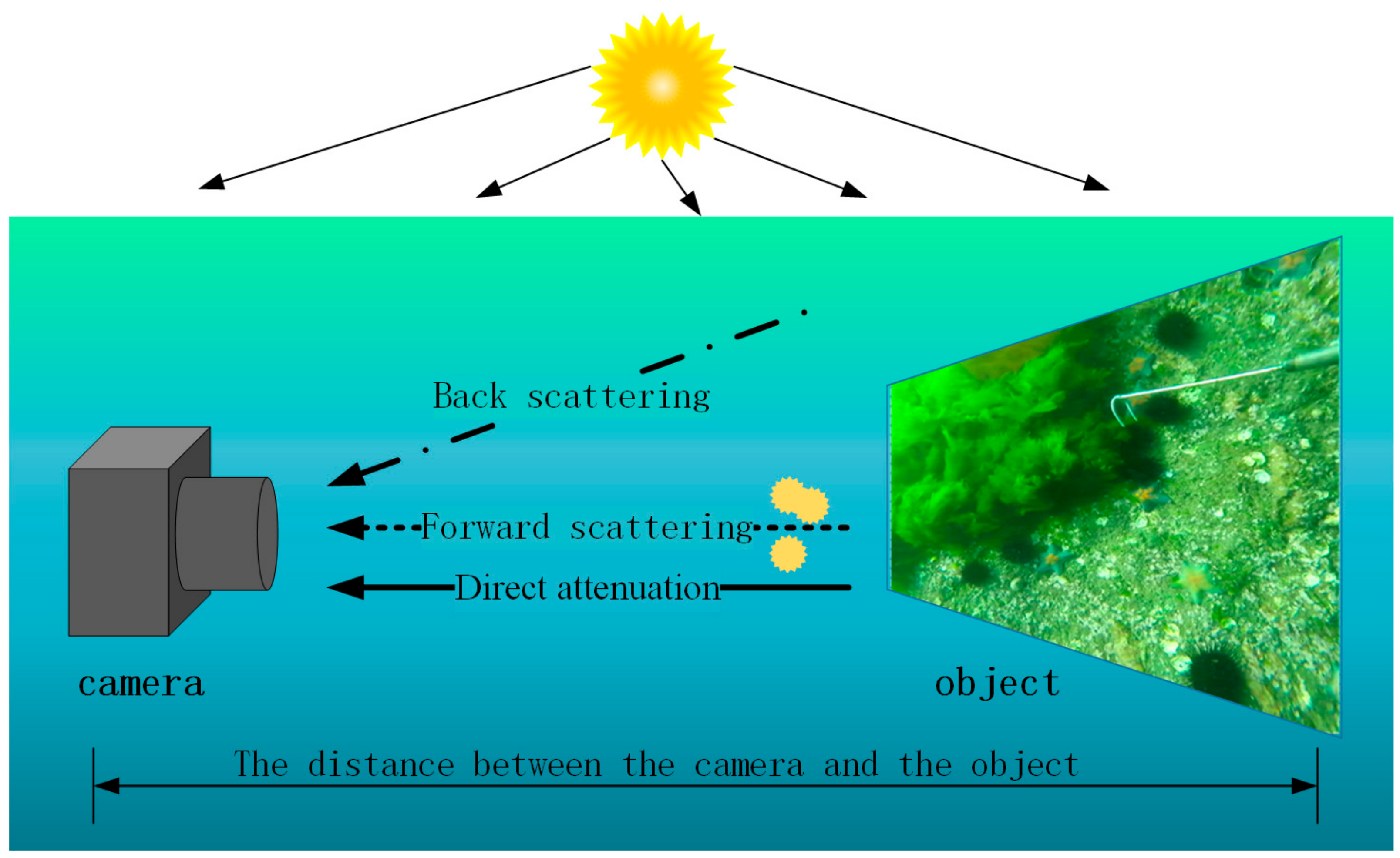
2.1. The Imaging Principle of Underwater Images
2.2. Synthetic Model of Underwater Images
3. Deep Supervised Residual Dense Network
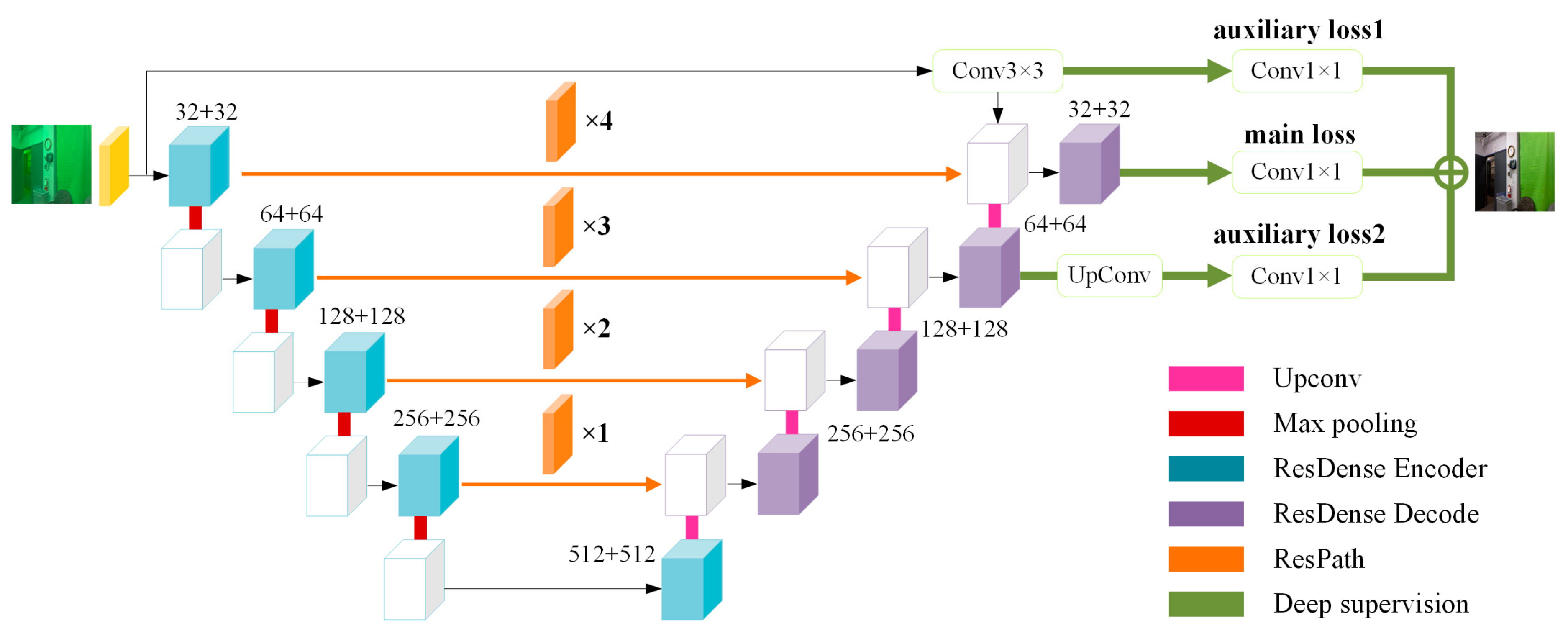
3.1. Residual Dense Blocks
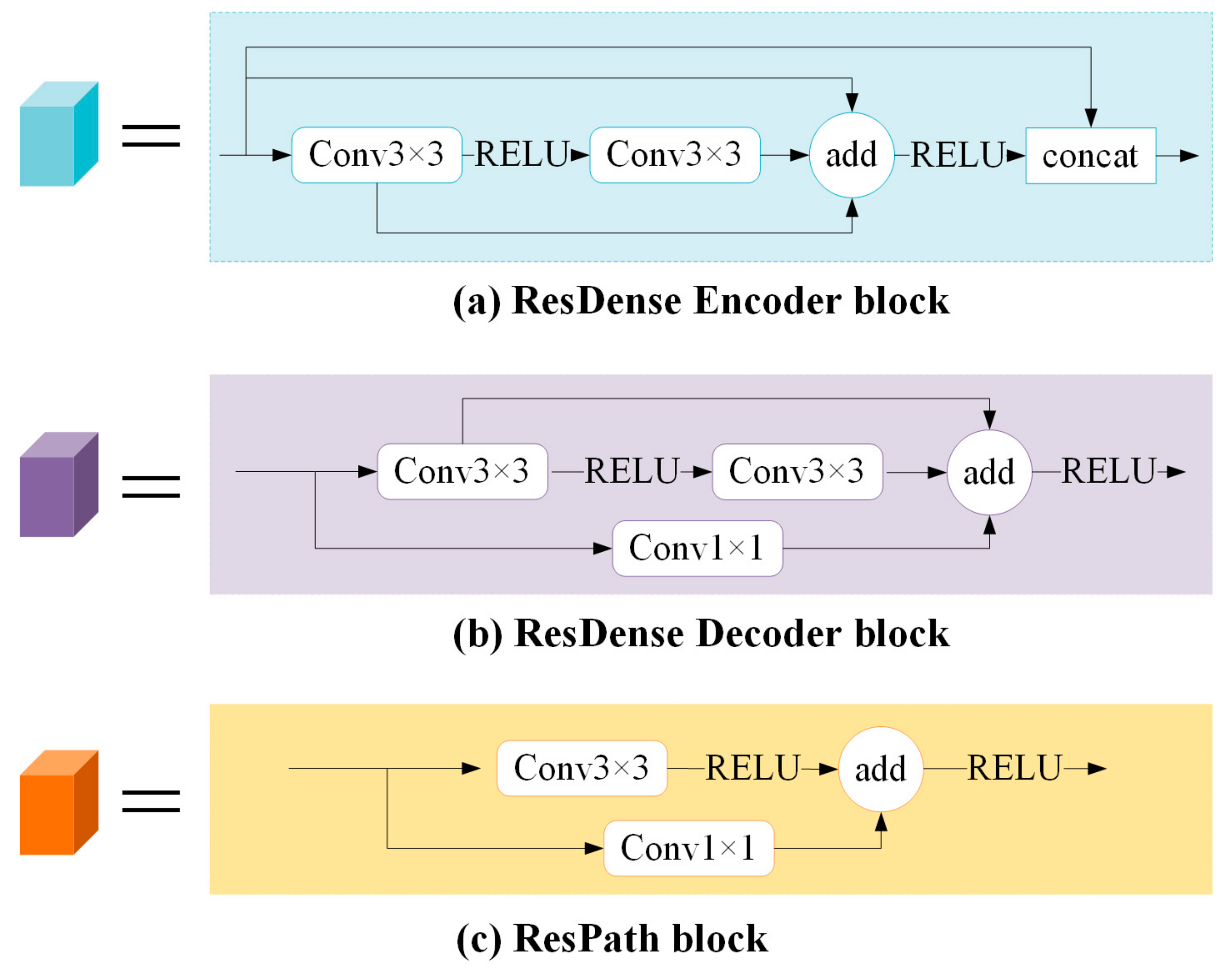
- The encoder: Firstly, similar to ResNet [15], the ResDense Encoder block (Figure 5a) contains two convolution-ReLU operations and allows the original input to be directly passed to the back of the second convolution so that the information integrity can be protected only by learning the difference between the input and output. It can alleviate the loss in the process of feature extraction and improve the problems of gradient vanishing and gradient explosion. Secondly, a connection is added between the output of the first convolution and the output of the last convolution, which allows the parameters to be updated in the first convolution even if the gradient in the second convolution is close to zero. At this time, the feature aggregation operation enables rich information to be combined for feature extraction in consecutive layers, which is sufficient to back propagate the gradient effectively. Thirdly, like DenseNet [16], the input and output of two convolution-ReLU are superimposed on the dimension, realizing feature reuse and maximize the information flow in the network. This densely connected mode can obtain rich features through fewer convolutions.
- The decoder: The ResDense Decoder block (Figure 5b) also contains two convolution-ReLU operations and adds a connection between the output of the first convolution and the output of the last convolution. The difference is that the original input is not directly passed to the back of the second convolution, but conv1×1 is added to the connection. More nonlinearity is introduced to enhance the expressive ability of the network.
3.2. Residual Path
3.3. Deep Supervision
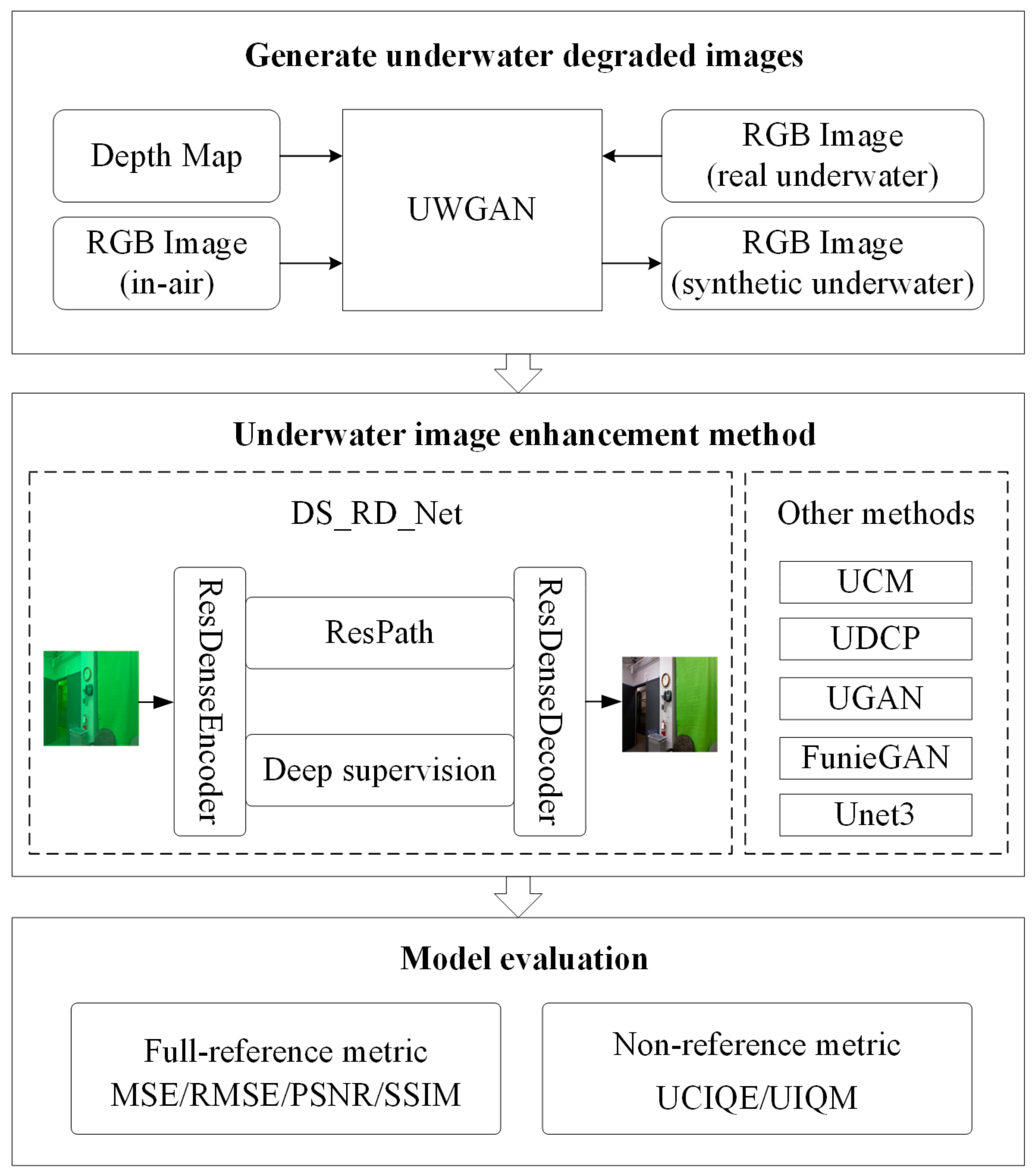
4. Experiments and Discussions
4.1. Dataset
4.2. Experimental Setup
4.3. Ablation Experiments and Analysis
4.4. Comparison Experiments and Analysis
4.4.1. Qualitative Evaluations
4.4.2. Quantitative Evaluations
4.5. Evaluation on Underwater Object Detection
5. Conclusions
- Considering that it is difficult to obtain many paired underwater datasets, UWGAN is used for modelling underwater images from in-air images and depths. The generative adversarial network incorporates the process of underwater image formation to generate underwater degraded output images. The synthetic underwater images will be used in the image enhancement network.
- In view of the loss of details in the process of underwater image enhancement, we proposed a deep supervised residual dense network. The network uses residual dense blocks to extract features of different levels and different scales, which can realize feature reuse and reduce loss during feature propagation; moreover, residual path blocks are added to the skip connection between encoder and decoder, which balances the semantic differences between low-level features and high-level features and reduces the loss of spatial information in the down-sampling process.
- A deep supervision mechanism is introduced to construct the accompanying objective function for the hidden layer output of the network, and it guides the network training process and improves the phenomenon that the gradient disappears during the backpropagation of the deep convolutional neural network. This improves the robustness of the network and enables the model to achieve a good enhancement effect on images with different degrees of degradation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| UCM | Unsupervised color correction method |
| UDCP | Underwater dark channel prior |
| UGAN | Underwater generative adversarial network |
| FunieGAN | Fully convolutional GAN for real-time underwater image enhancement |
| UWGAN | Underwater GAN for generating realistic underwater images. |
| Unet3 | Unet with three down-sampling |
| Unet4 | Unet with four down-sampling |
| RD-Unet | Add residual dense blocks based on Unet4 |
| RD_RP-Unet | Add residual path blocks based on RD-Unet |
| DS_RD_Net | Add a deep supervision based on RD_RP-Unet |
| MSE | Mean squared error |
| RMSE | Root-mean-squared error |
| PSNR | Peak signal to noise ratio |
| SSIM | Structural similarity index measure |
| UCIQE | Underwater color image quality evaluation |
| UIQM | Underwater image quality measurement |
References
- Iqbal, K.; Odetayo, M.; James, A.; Salam, R.A.; Talib, A.Z.H. Enhancing the low quality images using unsupervised colour correction method. In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1703–1709. [Google Scholar]
- Orujov, F.; Maskeliūnas, R.; Damaševičius, R.; Wei, W. Fuzzy based image edge detection algorithm for blood vessel detection in retinal images. Appl. Soft Comput. 2020, 94, 106452. [Google Scholar] [CrossRef]
- Versaci, M.; Morabito, F.C. Image edge detection: A new approach based on fuzzy entropy and fuzzy divergence. Int. J. Fuzzy Syst. 2021. [Google Scholar] [CrossRef]
- Khan, M.A.; Dharejo, F.A.; Deeba, F.; Ashraf, S.; Kim, J.; Kim, H. Toward developing tangling noise removal and blind inpainting mechanism based on total variation in image processing. Electron. Lett. 2021. [Google Scholar] [CrossRef]
- Gao, F.; Wang, K.; Yang, Z.; Wang, Y.; Zhang, Q. Underwater Image Enhancement Based on Local Contrast Correction and Multi-Scale Fusion. J. Mar. Sci. Eng. 2021, 9, 225. [Google Scholar] [CrossRef]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 825–830. [Google Scholar]
- Liu, K.; Liang, Y. Underwater image enhancement method based on adaptive attenuation-curve prior. Opt. Express 2021, 29, 10321–10345. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef] [Green Version]
- Wang, N.; Zhou, Y.; Han, F.; Zhu, H.; Zheng, Y. UWGAN: Underwater GAN for real-world underwater color restoration and dehazing. arXiv 2019, arXiv:1912.10269. [Google Scholar]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Yang, Y.; Qu, X.; Cao, D.; Li, K. A deep learning based image enhancement approach for autonomous driving at night. Knowl.-Based Syst. 2021, 213, 106617. [Google Scholar] [CrossRef]
- Jaffe, J.S. Computer modeling and the design of optimal underwater imaging systems. IEEE J. Ocean. Eng. 1990, 15, 101–111. [Google Scholar] [CrossRef]
- Jafari, M.; Auer, D.; Francis, S.; Garibaldi, J.; Chen, X. DRU-Net: An Efficient Deep Convolutional Neural Network for Medical Image Segmentation. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1144–1148. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Proceedings of the Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; pp. 562–570. [Google Scholar]
- Silberman, N.; Fergus, R. Indoor scene segmentation using a structured light sensor. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 601–608. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef] [PubMed]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Anwar, S.; Li, C. Diving deeper into underwater image enhancement: A survey. Signal Process. Image Commun. 2020, 89, 115978. [Google Scholar] [CrossRef]
- Uplavikar, P.M.; Wu, Z.; Wang, Z. All-in-One Underwater Image Enhancement Using Domain-Adversarial Learning. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 1–8. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MSE ↓ | RMSE ↓ | PSNR ↑ | SSIM ↑ |
|---|---|---|---|---|
| Unet3 [9] | 77.7151 | 8.5030 | 29.8178 | 0.9215 |
| Unet4 | 33.5260 | 5.4869 | 33.7995 | 0.9466 |
| RD-Unet | 29.8556 | 5.1630 | 34.3432 | 0.9526 |
| RD_RP-Unet | 23.0679 | 4.5872 | 35.2685 | 0.9605 |
| DS_RD_Net | 19.3452 | 4.1534 | 36.2106 | 0.9647 |
| Method | UCIQE ↑ | UIQM ↑ |
|---|---|---|
| Original images | 0.4055 | 2.0483 |
| Unet3 [9] | 0.5330 | 2.8504 |
| Unet4 | 0.5344 | 2.6782 |
| RD-Unet | 0.5298 | 2.6806 |
| RD_RP-Unet | 0.5376 | 2.6892 |
| DS_RD_Net | 0.5335 | 2.6653 |
| Method | MSE ↓ | RMSE ↓ | PSNR ↑ | SSIM ↑ |
|---|---|---|---|---|
| UCM [1] | 2268.064 | 45.1733 | 15.5250 | 0.7998 |
| UDCP [6] | 7252.162 | 82.5960 | 10.1175 | 0.4991 |
| UGAN [24] | 55.1747 | 7.1374 | 31.3839 | 0.9435 |
| FunieGAN [11] | 70.1131 | 7.6450 | 31.1095 | 0.9563 |
| Unet3 [9] | 77.7151 | 8.5030 | 29.8178 | 0.9215 |
| DS_RD_Net | 19.3452 | 4.1534 | 36.2106 | 0.9647 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Y.; Huang, L.; Hong, Z.; Cao, S.; Zhang, Y.; Wang, J. Deep Supervised Residual Dense Network for Underwater Image Enhancement. Sensors 2021, 21, 3289. https://doi.org/10.3390/s21093289
Han Y, Huang L, Hong Z, Cao S, Zhang Y, Wang J. Deep Supervised Residual Dense Network for Underwater Image Enhancement. Sensors. 2021; 21(9):3289. https://doi.org/10.3390/s21093289
Chicago/Turabian StyleHan, Yanling, Lihua Huang, Zhonghua Hong, Shouqi Cao, Yun Zhang, and Jing Wang. 2021. "Deep Supervised Residual Dense Network for Underwater Image Enhancement" Sensors 21, no. 9: 3289. https://doi.org/10.3390/s21093289