Facial Expression Recognition Based on Weighted-Cluster Loss and Deep Transfer Learning Using a Highly Imbalanced Dataset


Abstract
:1. Introduction
- First, the objective of this paper is to mitigate the overfitting problem caused by an insufficient amount of data and imbalanced data problem when building a FER model which recognizes eight common facial expressions on AffectNet dataset [5].
- Third, to alleviate the imbalanced-data problem, we propose a new loss function, named weighted-cluster loss, which gives weights to each emotion class’s loss terms based on their relative proportion of the total number of samples in the training dataset.
- Last, experiments are conducted to validate the effectiveness of the proposed method. The experimental results on AffectNet data show that our FER model outperforms its counterpart models in term of various evaluation metrics such as accuracy, F1-score, Cohen’s kappa score [26], Krippendorff’s alpha score [27], area under the receiver operating characteristic curve (AUC), and area under the precision-recall curve (AUC-PR).
2. Related Works
2.1. Facial Expression Recognition Approaches
2.2. Transfer Learning for Facial Expression Recognition
2.3. Data Re-Sampling and Augmentation
2.4. Weighted Loss and Auxiliary Loss
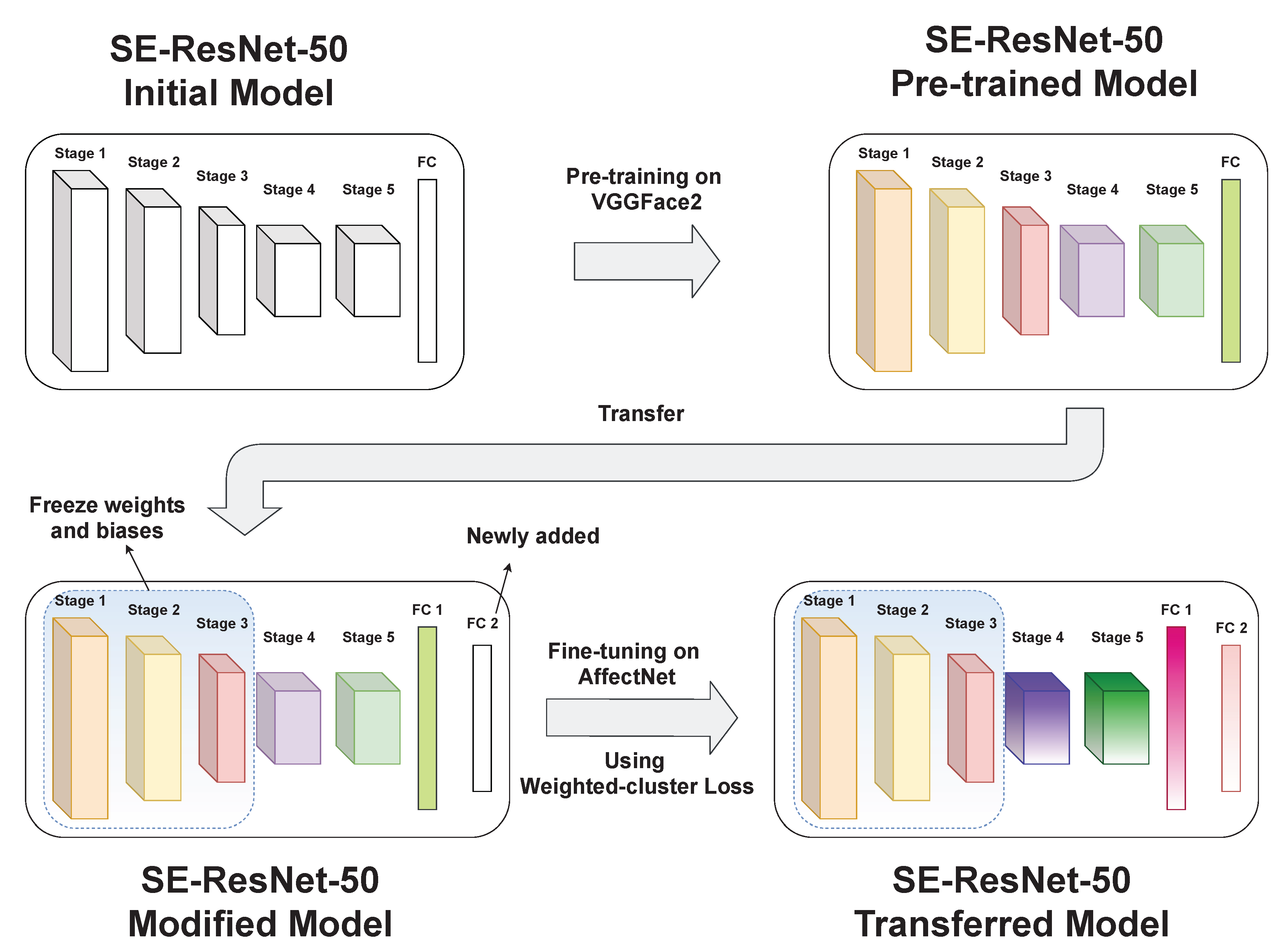
3. Methods
3.1. Base Model and Pre-Training
3.1.1. Base Models
3.1.2. Pre-Training
3.2. Fine-Tuning
3.3. Weighted-Cluster Loss
3.3.1. Review of Weighted-Softmax Loss
3.3.2. Review of Center Loss
3.3.3. The Proposed Weighted-Cluster Loss
| Algorithm 1 Learning algorithm of the FER model with the jointly loss functions |
Input: Training data , mini-batch size m, number of iterations T, learning rates and , and hyper-parameters
Output: Network layer parameters W |
4. Experiments
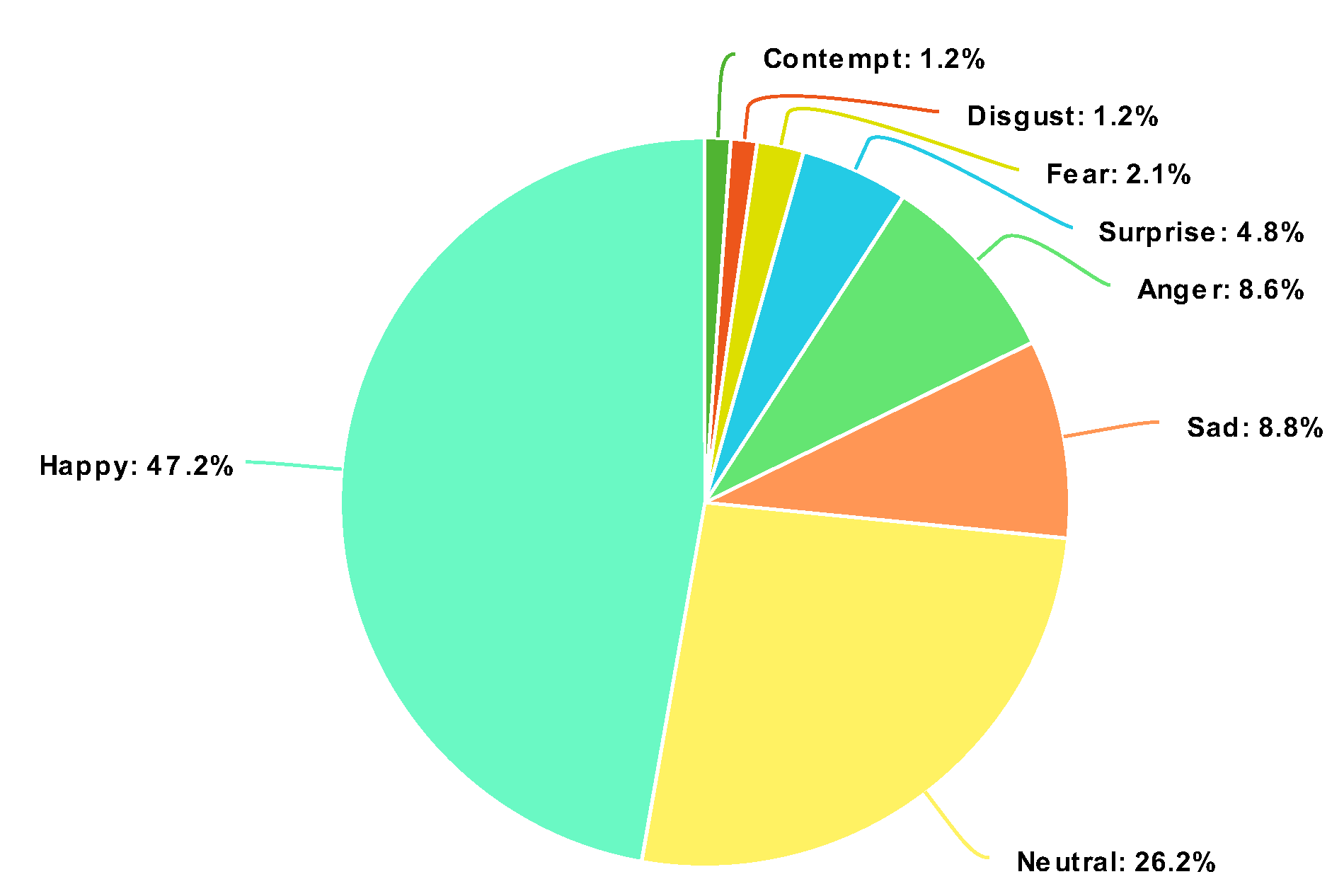
4.1. Experimental Datasets
4.1.1. AffectNet Dataset
4.1.2. VGGFace2 Dataset
4.2. Evaluation Metrics
4.3. Experiment Setups and Implementation Details
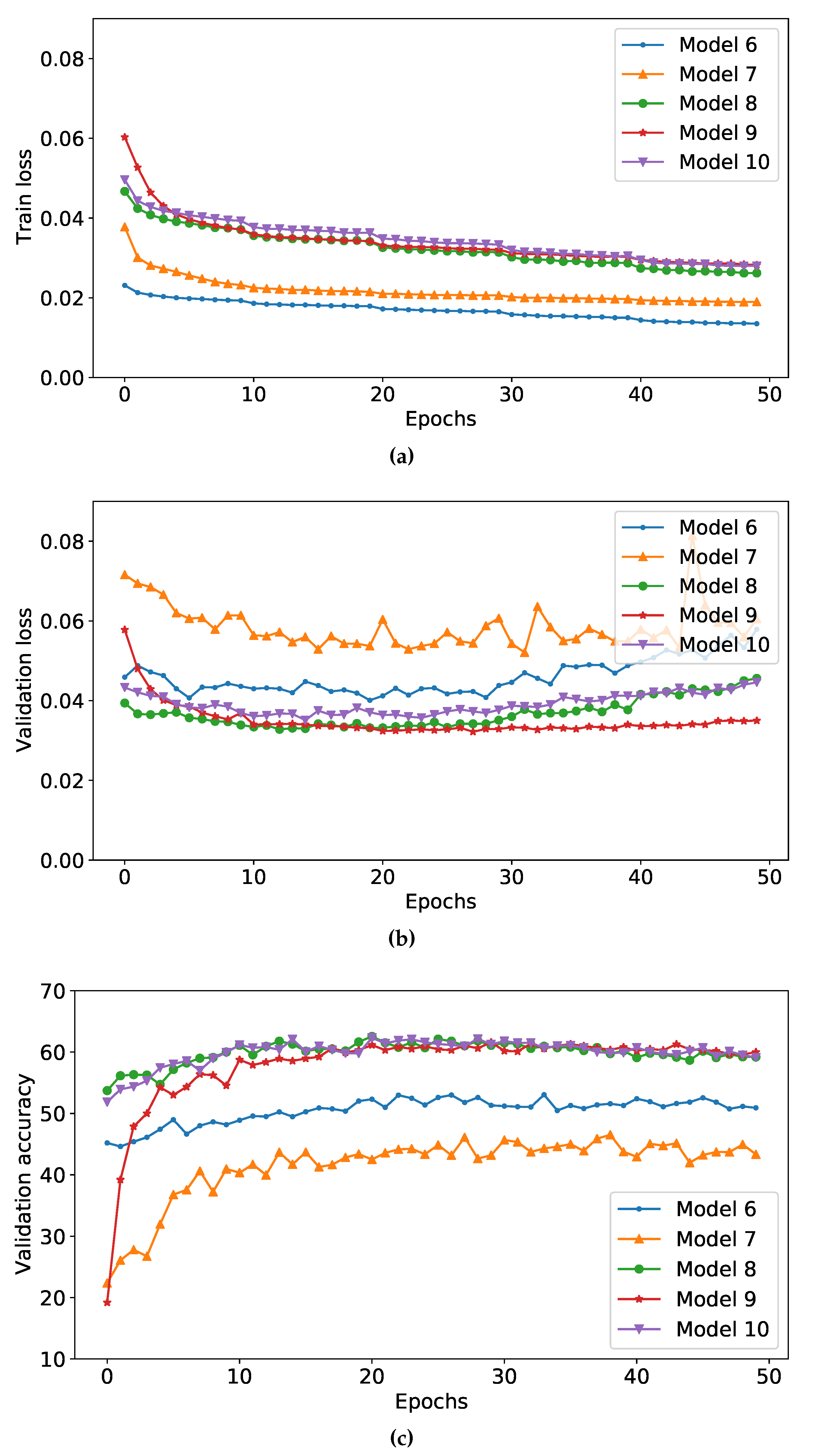
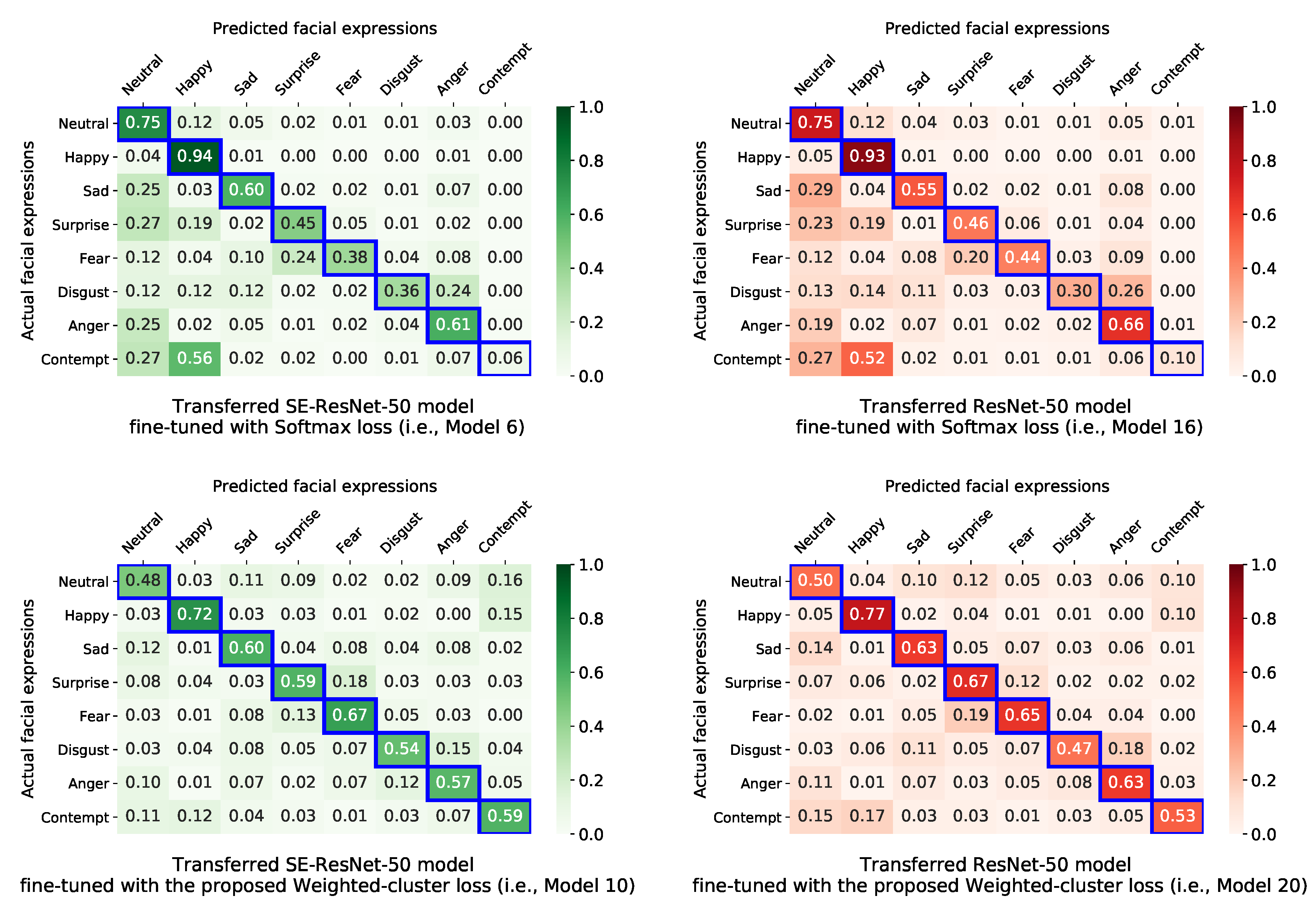
4.4. Results and Discussions
4.5. Threats to Validity
- Threat to internal validity: Threat to internal validity include errors when implementing the codes and conducting experiments. Although the implementations and experiments were carefully verified, errors are possible.
- Threat to external validity: Threats to external validity include the generalization to other datasets of the results in this paper. Applying the proposed methods in this paper to additional datasets will reduce this threat.
- Threats to construct validity: Threats to construct validity include the appropriateness of the benchmark algorithms and evaluation metrics. For the most part, the proposed FER model outperformed their counterparts on the same test dataset as expected. The evaluation metrics used for validating models (i.e., accuracy, F1-Score, Kappa score, AUC, and AUC-PR) are common in machine learning studies to evaluate the performance of classification models.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hickson, S.; Dufour, N.; Sud, A.; Kwatra, V.; Essa, I. Eyemotion: Classifying facial expressions in VR using eye-tracking cameras. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1626–1635. [Google Scholar]
- Chen, C.H.; Lee, I.J.; Lin, L.Y. Augmented reality-based self-facial modeling to promote the emotional expression and social skills of adolescents with autism spectrum disorders. Res. Dev. Disabilities 2015, 36, 396–403. [Google Scholar] [CrossRef] [PubMed]
- Dornaika, F.; Raducanu, B. Efficient facial expression recognition for human robot interaction. In Proceedings of the International Work-Conference on Artificial Neural Networks, San Sebastián, Spain, 20–22 June 2007; pp. 700–708. [Google Scholar]
- Zhan, C.; Li, W.; Ogunbona, P.; Safaei, F. A real-time facial expression recognition system for online games. Int. J. Comput. Games Technol. 2008, 2008, 10. [Google Scholar] [CrossRef] [Green Version]
- Mollahosseini, A.; Hasani, B.; Mahoor, M. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affective Comput. 2017. [Google Scholar] [CrossRef] [Green Version]
- AffectNet Database. Available online: http://mohammadmahoor.com/affectnet/ (accessed on 15 August 2019).
- Tian, Y.l.; Kanade, T.; Cohn, J.F. Evaluation of Gabor-wavelet-based facial action unit recognition in image sequences of increasing complexity. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Washington, DC, USA, 21 May 2002; pp. 229–234. [Google Scholar]
- Whitehill, J.; Omlin, C.W. Haar features for facs au recognition. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vision Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef] [Green Version]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dahmane, M.; Meunier, J. Emotion recognition using dynamic grid-based HoG features. In Proceedings of the Face and Gesture 2011, Santa Barbara, CA, USA, 21–25 March 2011. [Google Scholar]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. arXiv 2018, arXiv:1804.08348. [Google Scholar] [CrossRef] [Green Version]
- Ko, B. A brief review of facial emotion recognition based on visual information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimi Kahou, S.; Michalski, V.; Konda, K.; Memisevic, R.; Pal, C. Recurrent neural networks for emotion recognition in video. In Proceedings of the 17th ACM International Conference on Multimodal Interaction, Seattle, DC, USA, 9–13 November 2015; pp. 467–474. [Google Scholar]
- Walecki, R.; Rudovic, O.; Pavlovic, V.; Schuller, B.; Pantic, M. Deep structured learning for facial expression intensity estimation. Image Vis. Comput. 2017, 259, 143–154. [Google Scholar]
- Kim, D.H.; Baddar, W.J.; Jang, J.; Ro, Y.M. Multi-objective based spatio-temporal feature representation learning robust to expression intensity variations for facial expression recognition. IEEE Trans. Affective Comput. 2017, 10, 223–236. [Google Scholar] [CrossRef]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Visa, S.; Ralescu, A. Issues in mining imbalanced data sets-a review paper. In Proceedings of the Sixteen midwest artificial intelligence and cognitive science conference, Dayton, OH, USA, 22 February 2005. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 8–10 June 2015; pp. 815–823. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European conference on computer vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 499–515. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 7132–7141. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation. In Proceedings of the Australasian joint conference on artificial intelligence, Hobart, Australia, 4–8 December 2006; pp. 1015–1021. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd international conference on Machine learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Krippendorff, K. Estimating the reliability, systematic error and random error of interval data. Educ. Psychol. Meas. 1970, 30, 61–70. [Google Scholar] [CrossRef]
- Zhi, R.; Flierl, M.; Ruan, Q.; Kleijn, W.B. Graph-preserving sparse nonnegative matrix factorization with application to facial expression recognition. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2011, 41, 38–52. [Google Scholar]
- Hu, Y.; Zeng, Z.; Yin, L.; Wei, X.; Zhou, X.; Huang, T.S. Multi-view facial expression recognition. In Proceedings of the 8th IEEE International Conference on Automatic Face & Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–6. [Google Scholar]
- Zhong, L.; Liu, Q.; Yang, P.; Liu, B.; Huang, J.; Metaxas, D.N. Learning active facial patches for expression analysis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2562–2569. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013; pp. 117–124. [Google Scholar]
- Dhall, A.; Goecke, R.; Joshi, J.; Wagner, M.; Gedeon, T. Emotion recognition in the wild challenge 2013. In Proceedings of the 15th ACM International Conference on Multimodal Interaction, Sydney, Australia, 24–31 July 2013; pp. 509–516. [Google Scholar]
- Dhall, A.; Goecke, R.; Joshi, J.; Sikka, K.; Gedeon, T. Emotion recognition in the wild challenge 2014: Baseline, data and protocol. In Proceedings of the 16th ACM International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; pp. 461–466. [Google Scholar]
- Dhall, A.; Ramana Murthy, O.; Goecke, R.; Joshi, J.; Gedeon, T. Video and image based emotion recognition challenges in the wild: Emotiw 2015. In Proceedings of the 17th ACM International Conference on Multimodal Interactionn, Seattle, DC, USA, 9–13 November 2015; pp. 423–426. [Google Scholar]
- Dhall, A.; Goecke, R.; Joshi, J.; Hoey, J.; Gedeon, T. Emotiw 2016: Video and group-level emotion recognition challenges. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 427–432. [Google Scholar]
- Dhall, A.; Goecke, R.; Ghosh, S.; Joshi, J.; Hoey, J.; Gedeon, T. From individual to group-level emotion recognition: EmotiW 5.0. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, Scotland, 13–17 November 2017; pp. 524–528. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in neural information processing systems, Lake Tahoe, Nevada, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Tang, Y. Deep Learning Using Linear Support Vector Machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the 26th British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Do, N.T.; Kim, S.H. Affective Expression Analysis in-the-Wild Using Multi-Task Temporal Statistical Deep Learning Model. arXiv 2020, arXiv:2002.09120. [Google Scholar]
- Thai Ly, S.; Do, N.T.; Lee, G.S.; Kim, S.H.; Yang, H.J. Multimodal 2D and 3D for In-the-wild Facial Expression Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ngo, T.Q.; Yoon, S. Facial Expression Recognition on Static Images. In Proceedings of the International Conference on Future Data and Security Engineering, FDSE2019, Nha Trang, Vietnam, 27–29 November 2019; pp. 640–647. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Lai, Y.H.; Lai, S.H. Emotion-preserving representation learning via generative adversarial network for multi-view facial expression recognition. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 263–270. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep learning face representation by joint identification-verification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1988–1996. [Google Scholar]
- Liu, X.; Vijaya Kumar, B.; You, J.; Jia, P. Adaptive deep metric learning for identity-aware facial expression recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 20–29. [Google Scholar]
- Guo, Y.; Tao, D.; Yu, J.; Xiong, H.; Li, Y.; Tao, D. Deep neural networks with relativity learning for facial expression recognition. In Proceedings of the 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Cai, J.; Meng, Z.; Khan, A.S.; Li, Z.; O’Reilly, J.; Tong, Y. Island loss for learning discriminative features in facial expression recognition. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 302–309. [Google Scholar]
- VGGFace2—A Large Scale Image Dataset for Face Recognition. Available online: http://www.robots.ox.ac.uk/~vgg/data/vgg_face2/ (accessed on 15 August 2019).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Method | Human Resource | Computing Resource | Computational Complexity | Accuracy |
|---|---|---|---|---|---|
| Conventional | Gabor wavelets coefficients [7] | High | Low | Low | Medium |
| Haar features [8] | High | Low | Low | Medium | |
| Local binary pattern (LBP) [9] | High | Low | Low | Medium | |
| LBP on three orthogonal planes (LBP-TOP) [10] | High | Low | Low | Medium | |
| Scale-invariant feature transform (SIFT) [29] | High | Low | Low | Medium | |
| Histogram of gradient (HOG) [11] | High | Low | Low | Medium | |
| Deep learning-based | Convolutional neural network [40] | Low | High | High | High |
| Transfer learning-based CNN (Our approaches) | Low | Medium | Medium | High |
| Output Size | Kernel | Repeat | |
|---|---|---|---|
| Stage 1 (Freeze) | convolution | 1 | |
| Stage 2 (Freeze) | convolution block | 3 | |
| Stage 3 (Freeze) | convolution block | 4 | |
| Stage 4 | convolution block | 6 | |
| Stage 5 | convolution block | 3 | |
| global average pooling | |||
| Fully connected | Fully connected | ||
| Fully connected | Fully connected | ||
| Output layer | 8-d softmax | ||
| Emotion | Training | Validation | Test |
|---|---|---|---|
| Neutral | 74,374 | 500 | 500 |
| Happy | 133,915 | 500 | 500 |
| Sad | 24,959 | 500 | 500 |
| Surprise | 13,590 | 500 | 500 |
| Fear | 5878 | 500 | 500 |
| Disgust | 3303 | 500 | 500 |
| Anger | 24,382 | 500 | 500 |
| Contempt | 3250 | 500 | 500 |
| Total | 283,651 | 4000 | 4000 |
| Abbreviation | Meaning |
|---|---|
| ResNet | Residual neural network |
| SE-ResNet | ResNet-based squeeze and excitation neural network |
| Alpha | Krippendorff’s alpha score |
| Kappa | Cohen’s kappa score |
| AUC | Area under the receiver operating characteristic curve |
| AUC-PR | Area under precision recall curve |
| Base Model | Model No. | Pre-Trained | Loss Function | Accuracy | F1-Score | Kappa | Alpha | AUCPR | AUC |
|---|---|---|---|---|---|---|---|---|---|
| SE-ResNet-50 | 1 | No | Softmax | 50.65 | 46.87 | 43.60 | 42.60 | 62.87 | 90.67 |
| 2 | No | Center with softmax | 46.07 | 39.24 | 38.37 | 36.89 | 55.96 | 87.92 | |
| 3 | No | Weighted-softmax | 56.37 | 56.41 | 50.14 | 50.09 | 62.27 | 90.49 | |
| 4 | No | Center with weighted-softmax | 56.90 | 57.06 | 50.74 | 50.71 | 62.24 | 90.33 | |
| 5 | No | Weighted-cluster with weighted-softmax | 56.27 | 56.42 | 50.03 | 49.97 | 61.57 | 90.10 | |
| 6 | Yes | Softmax | 52.22 | 49.51 | 45.4 | 44.54 | 63.27 | 90.75 | |
| 7 | Yes | Center with softmax | 47.08 | 40.02 | 39.51 | 38.27 | 54.91 | 86.75 | |
| 8 | Yes | Weighted-softmax | 59.72 | 59.72 | 53.97 | 53.93 | 66.47 | 91.85 | |
| 9 | Yes | Center with weighted-softmax | 59.60 | 59.50 | 53.83 | 53.82 | 65.35 | 91.21 | |
| 10 | Yes | Weighted-cluster with weighted-softmax (proposed) | 60.70 | 60.49 | 55.09 | 55.06 | 66.55 | 91.82 |
| Base Model | Model No. | Pre-Trained | Loss Function | Accuracy | F1-score | Kappa | Alpha | AUCPR | AUC |
|---|---|---|---|---|---|---|---|---|---|
| ResNet-50 | 11 | No | Softmax | 49.85 | 46.67 | 42.69 | 41.46 | 62.80 | 90.63 |
| 12 | No | Center with softmax | 46.62 | 39.96 | 39.00 | 37.67 | 54.08 | 86.26 | |
| 13 | No | Weighted-softmax | 57.40 | 57.33 | 51.31 | 51.23 | 63.05 | 90.82 | |
| 14 | No | Center with weighted-softmax | 57.20 | 57.08 | 51.09 | 51.06 | 62.61 | 90.50 | |
| 15 | No | Weighted-cluster with weighted-softmax | 57.37 | 57.40 | 51.29 | 51.24 | 62.79 | 90.52 | |
| 16 | Yes | Softmax | 51.88 | 48.89 | 45.00 | 44.10 | 61.6 | 90.22 | |
| 17 | Yes | Center with softmax | 48.33 | 44.00 | 40.94 | 39.8 | 56.96 | 87.89 | |
| 18 | Yes | Weighted-softmax | 58.65 | 58.59 | 52.74 | 52.71 | 64.58 | 91.17 | |
| 19 | Yes | Center with weighted-softmax | 58.27 | 58.07 | 52.31 | 52.24 | 63.59 | 90.54 | |
| 20 | Yes | Weighted-cluster with weighted-softmax | 59.45 | 59.42 | 53.66 | 53.66 | 65.26 | 91.51 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngo, Q.T.; Yoon, S. Facial Expression Recognition Based on Weighted-Cluster Loss and Deep Transfer Learning Using a Highly Imbalanced Dataset. Sensors 2020, 20, 2639. https://doi.org/10.3390/s20092639
Ngo QT, Yoon S. Facial Expression Recognition Based on Weighted-Cluster Loss and Deep Transfer Learning Using a Highly Imbalanced Dataset. Sensors. 2020; 20(9):2639. https://doi.org/10.3390/s20092639
Chicago/Turabian StyleNgo, Quan T., and Seokhoon Yoon. 2020. "Facial Expression Recognition Based on Weighted-Cluster Loss and Deep Transfer Learning Using a Highly Imbalanced Dataset" Sensors 20, no. 9: 2639. https://doi.org/10.3390/s20092639