The uulmMAC Database—A Multimodal Affective Corpus for Affective Computing in Human-Computer Interaction

 and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants and Cohort Description
2.2. The Interaction Scheme
2.3. Experiment Structure
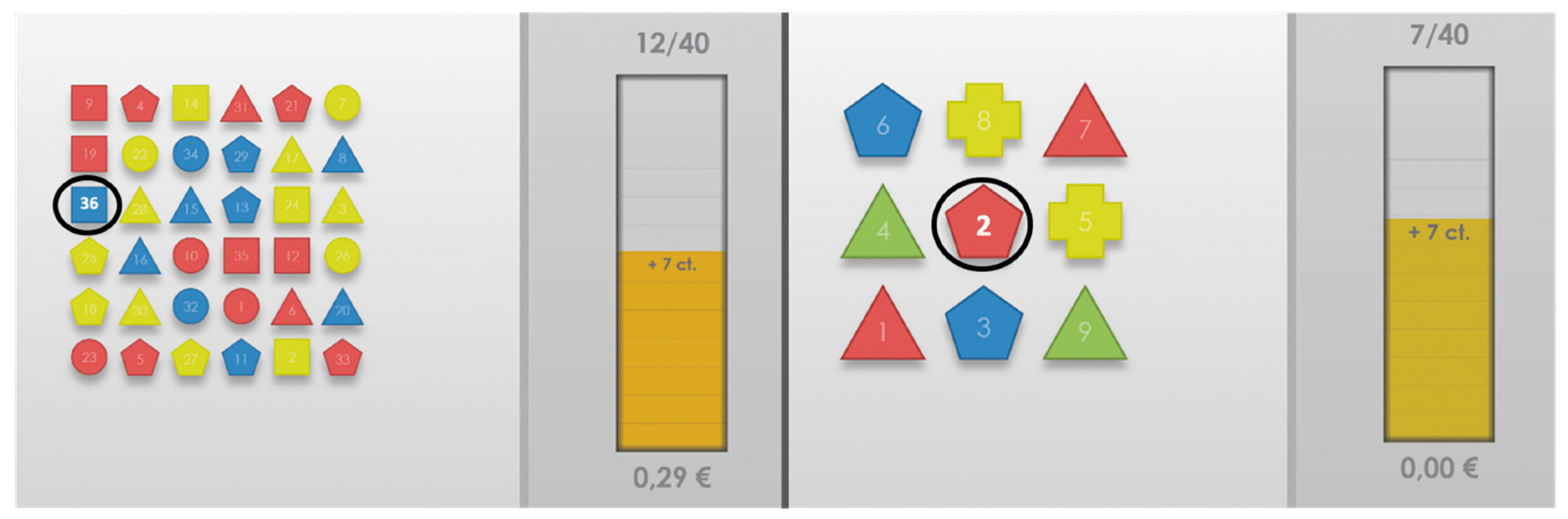
2.3.1. Induction Sequences
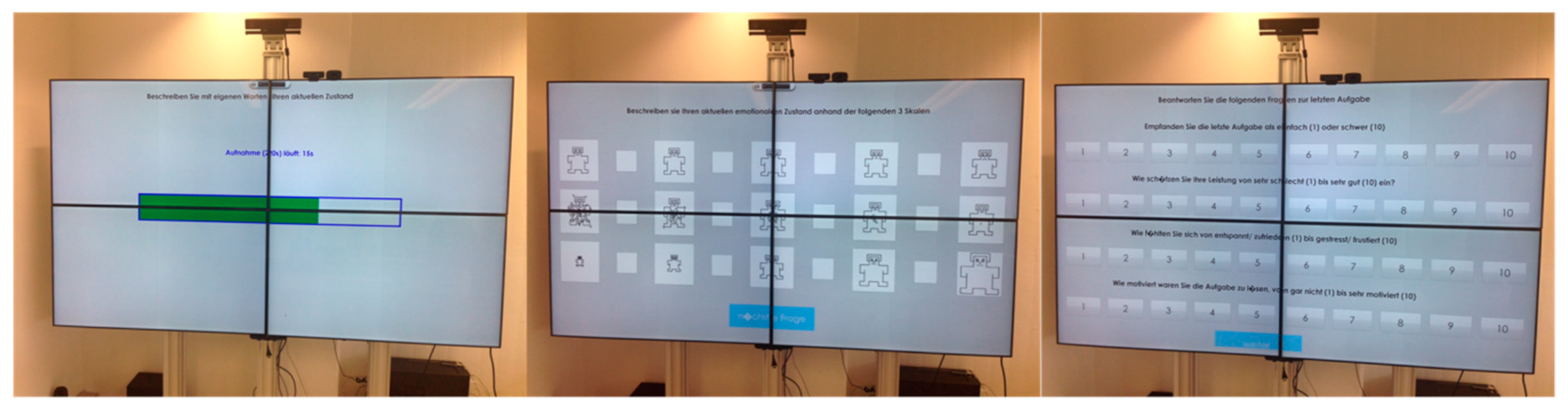
2.3.2. Subjective Feedback
2.3.3. Respiration Baseline and Results’ Summary
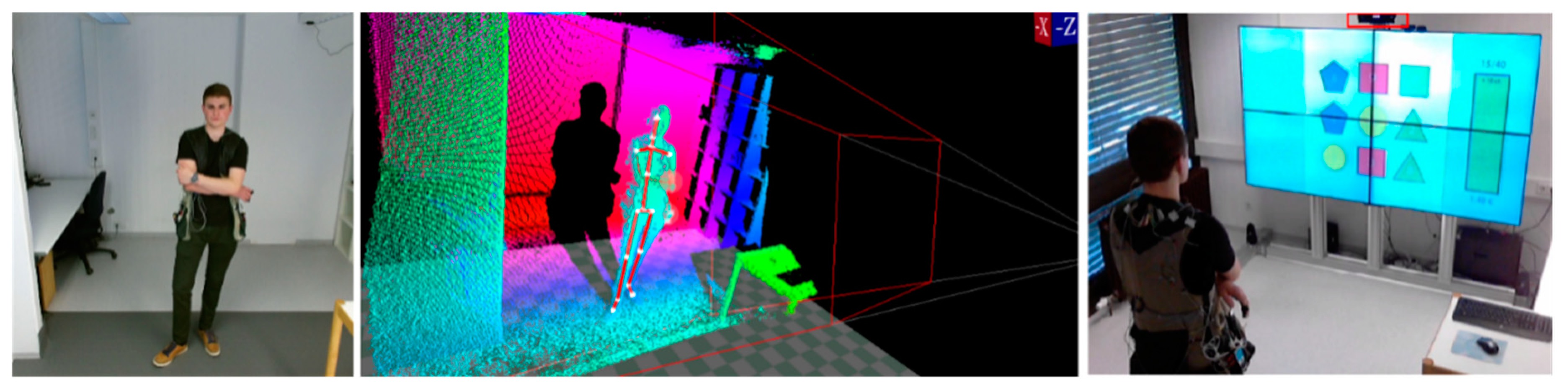
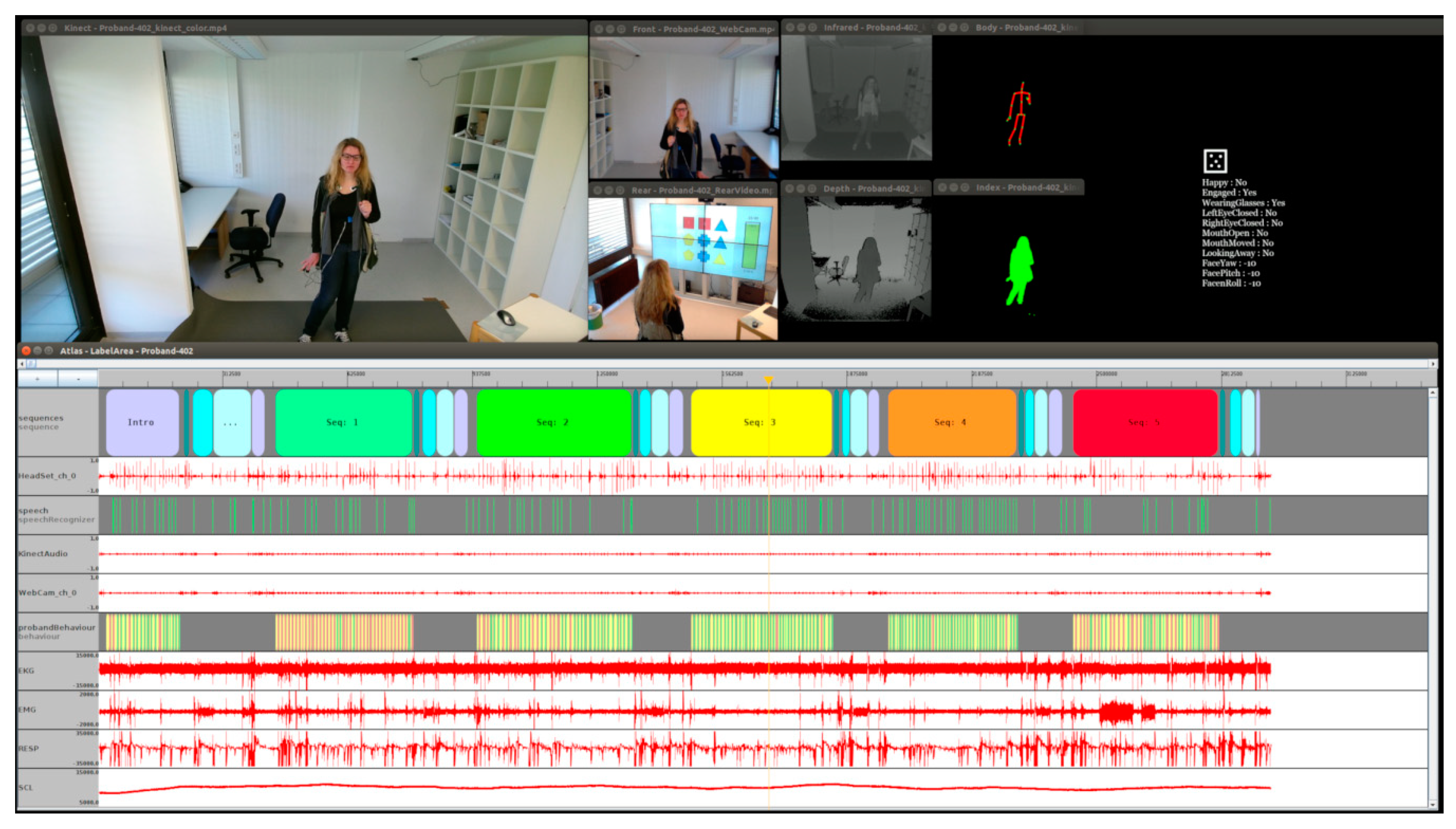
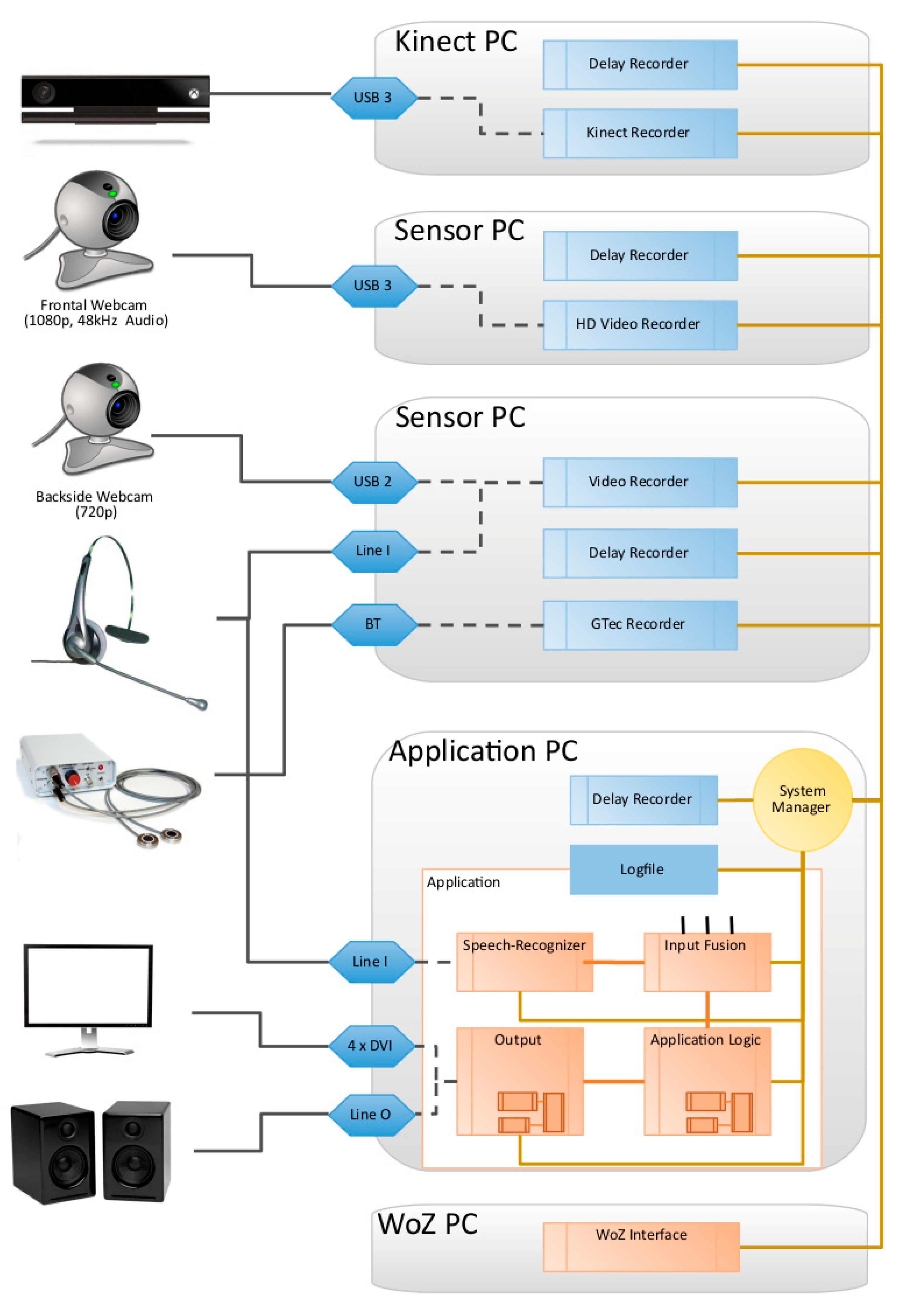
2.4. Technical Implementation
2.5. Multimodal Sensors for Data Acquisition
3. Results
3.1. The Database
- Group A involves 38 subjects from the first sample who underwent one single measurement. It consists of 38 recording sessions.
- Group B involves 19 subjects from the second sample who underwent three different measurements. It consists of 57 recording sessions. Group B includes three different subgroups: Group B1, Group B2, and Group B3 consisting of 19 recording sessions each and representing the first, second and third measurement time of the 19 subjects, respectively.
3.2. Evaluation via Questionnaires
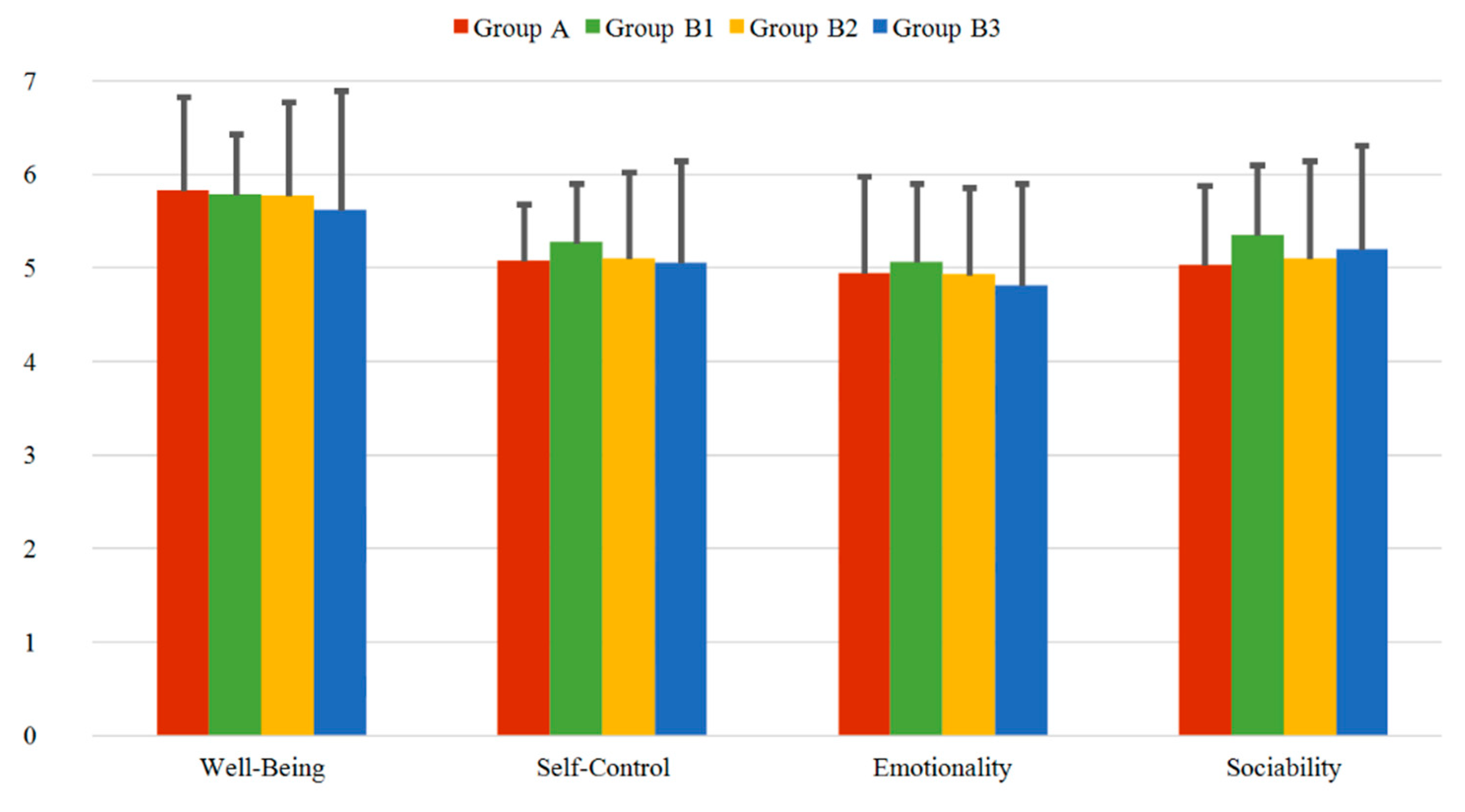
3.2.1. TEIQue-SF Questionnaire
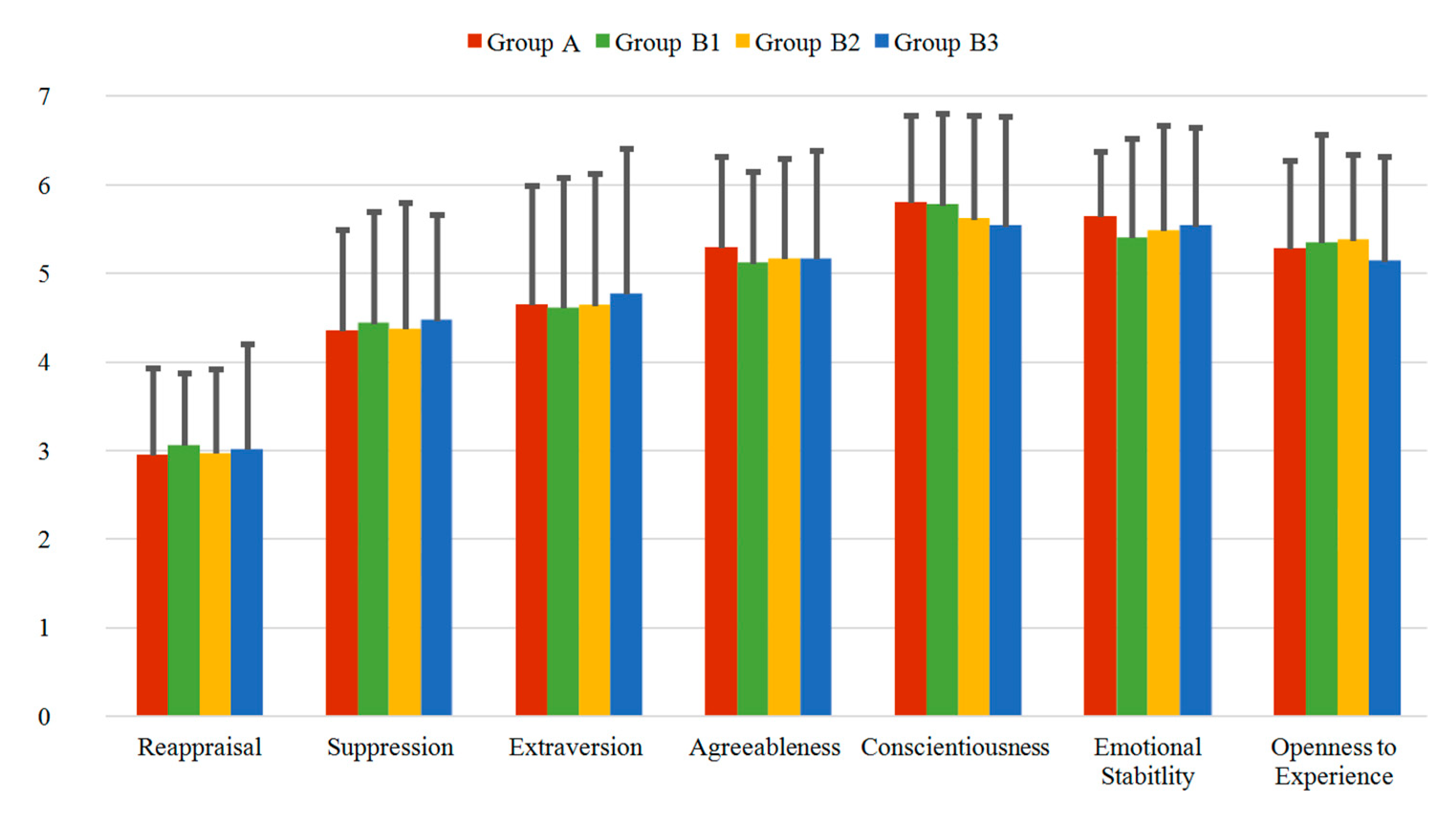
3.2.2. ERQ and TIPI Questionnaires
3.3. Validation via Subjective Feedback
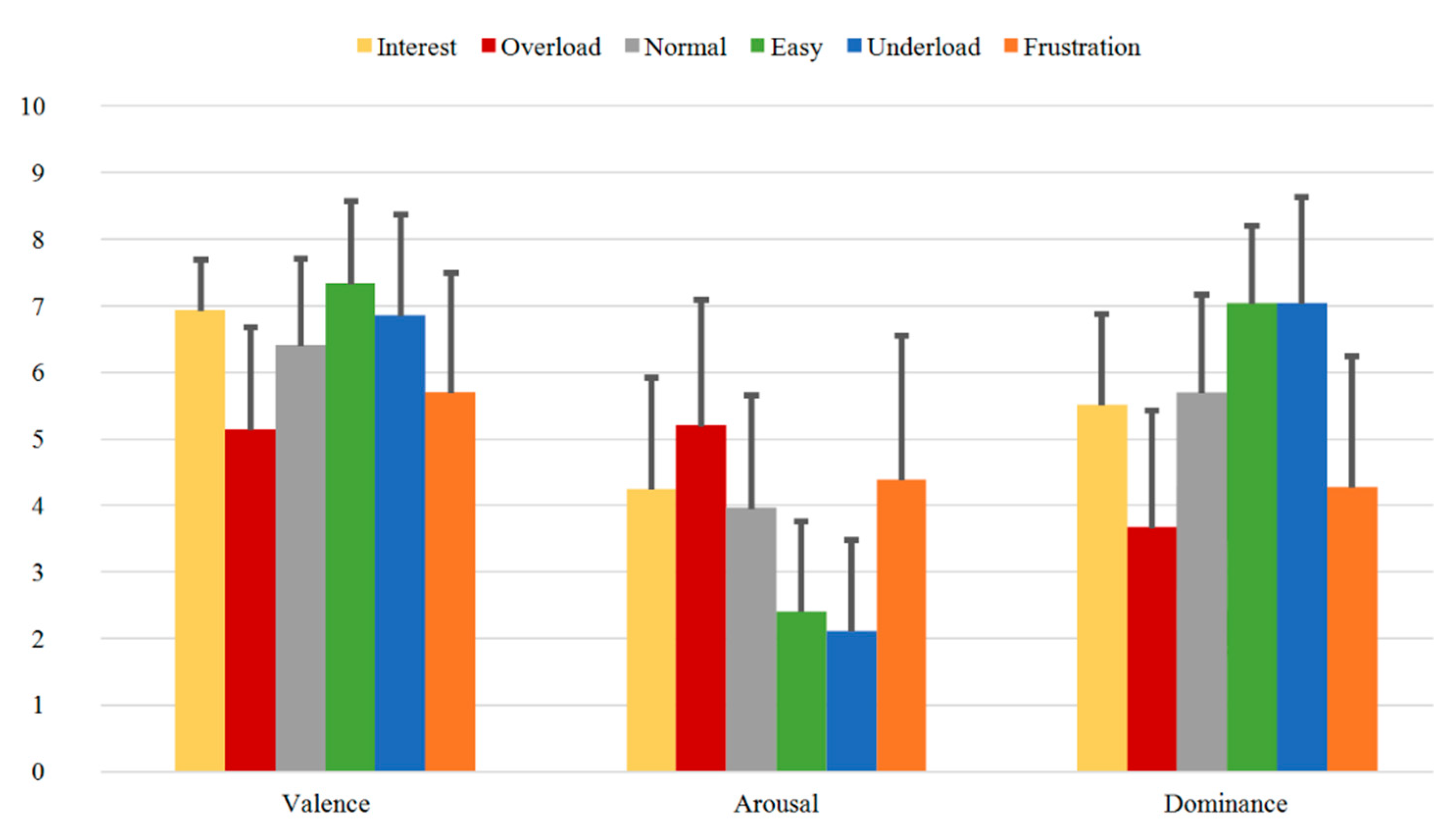
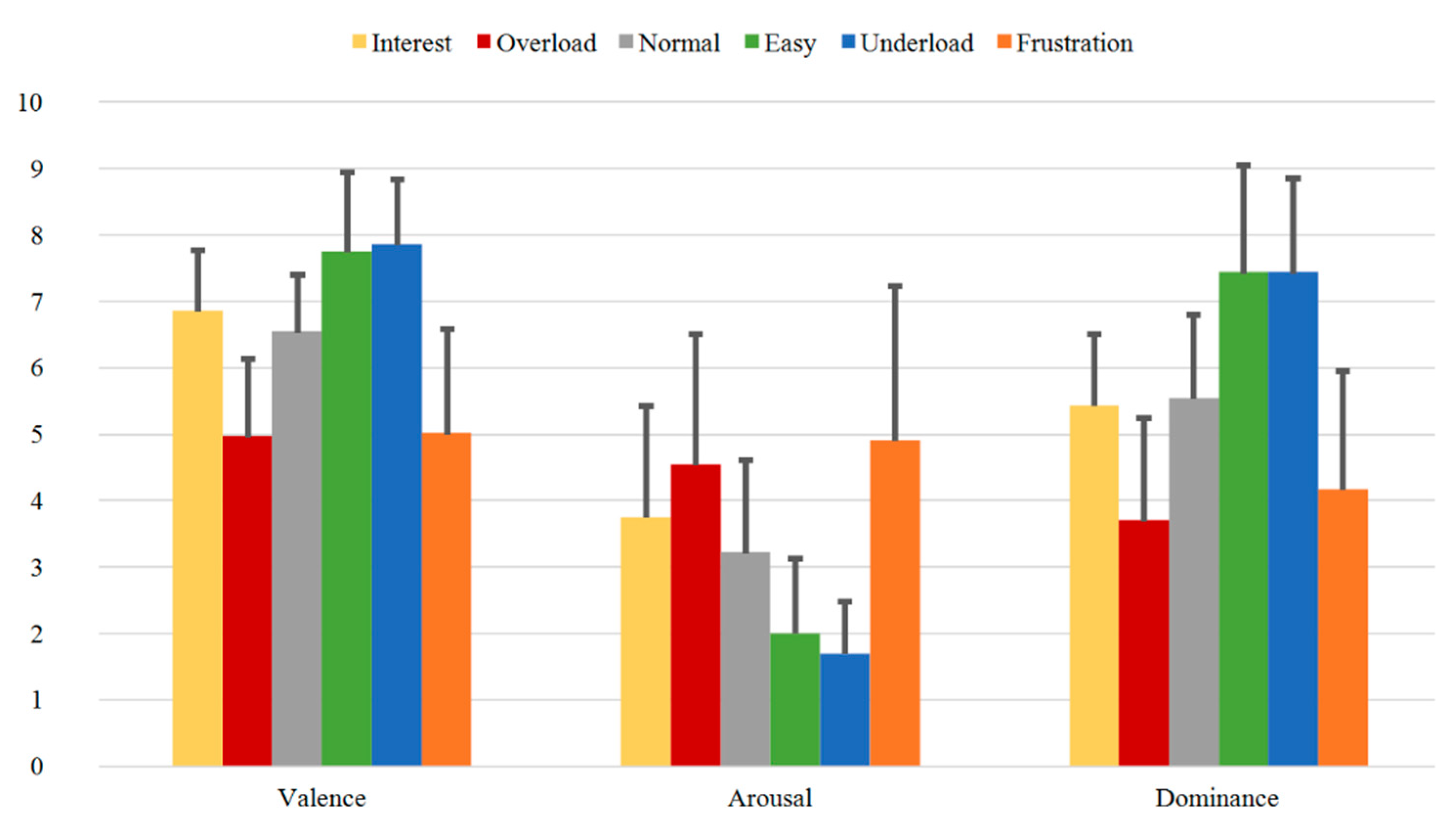
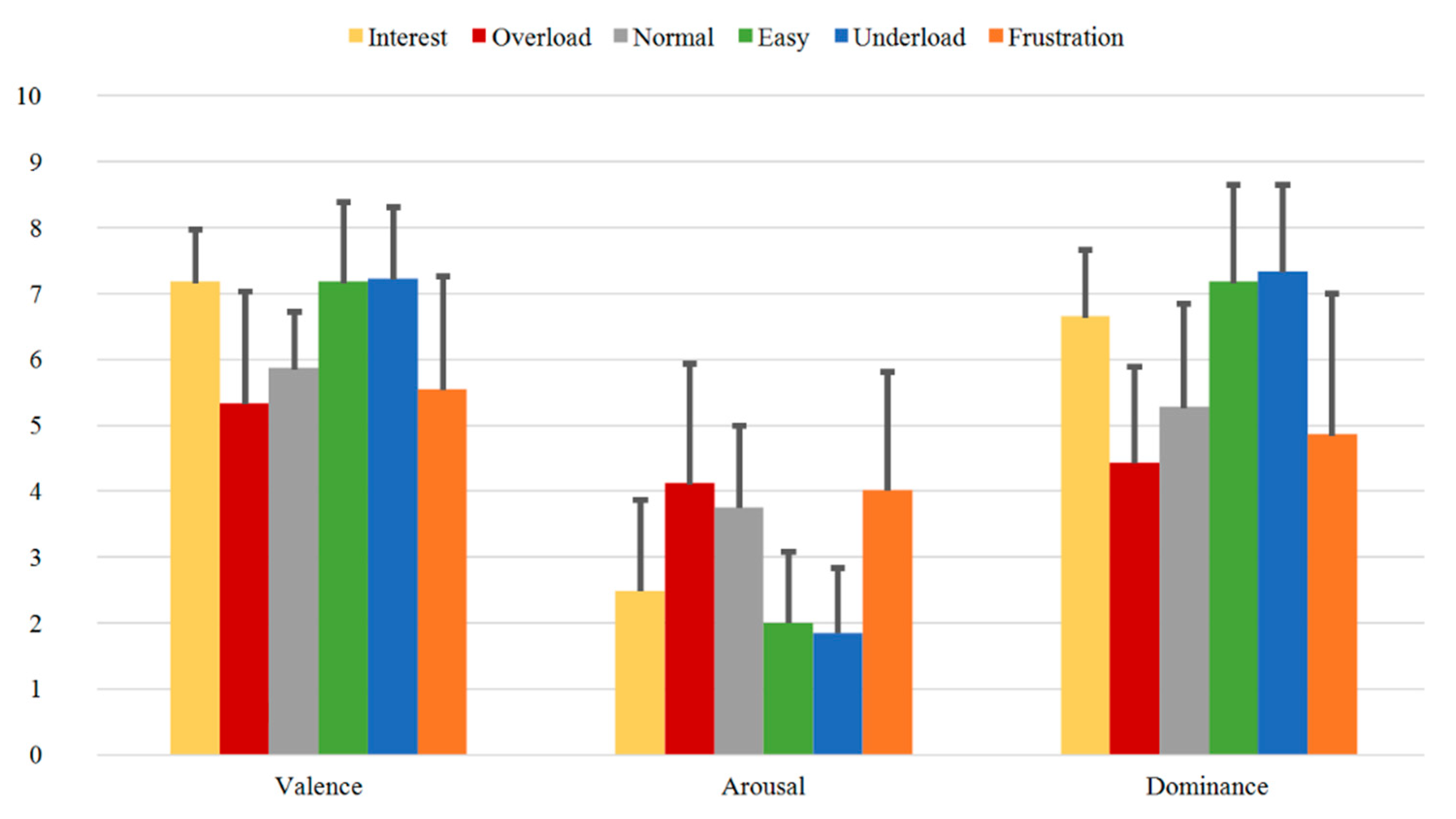
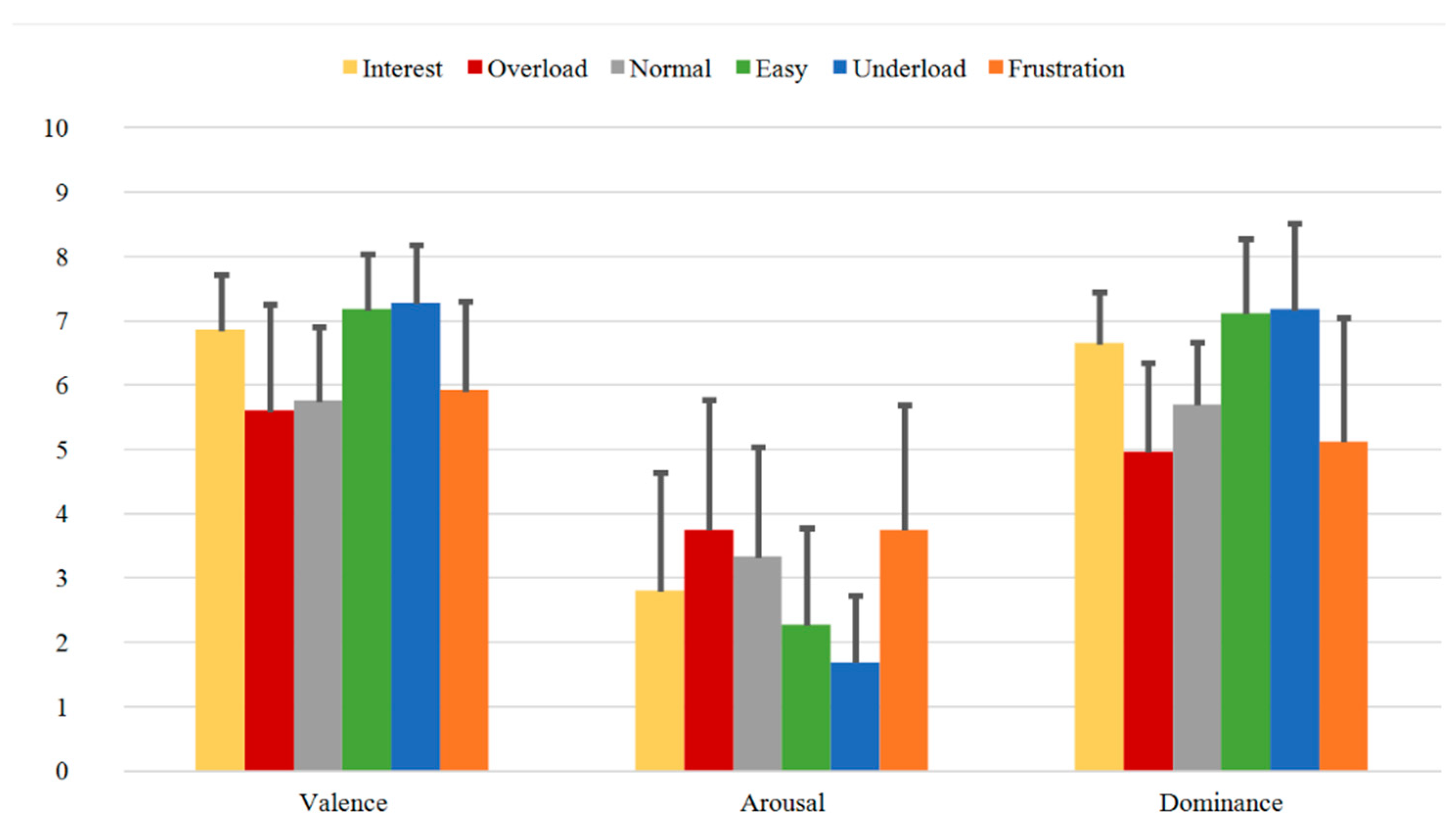
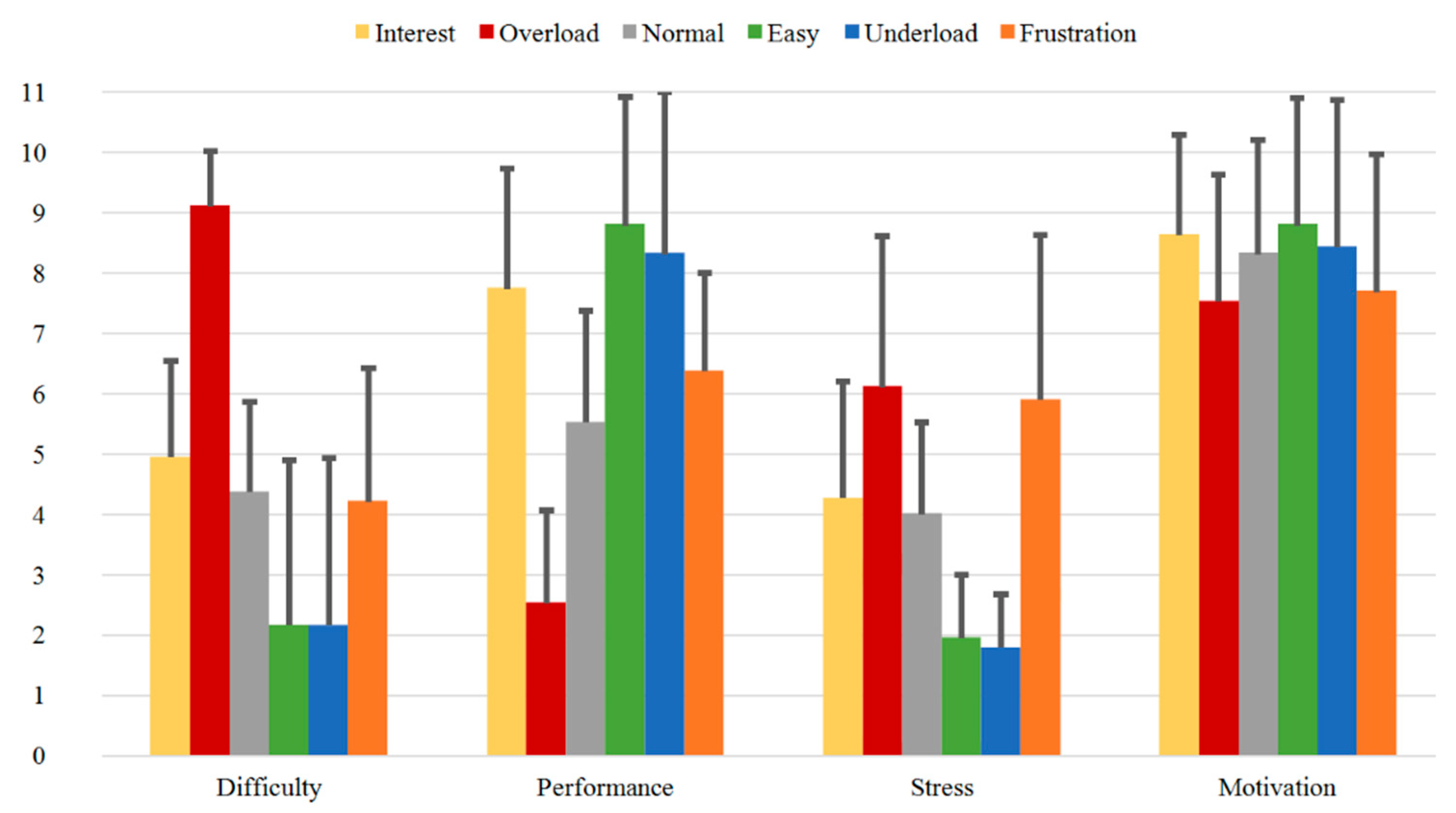
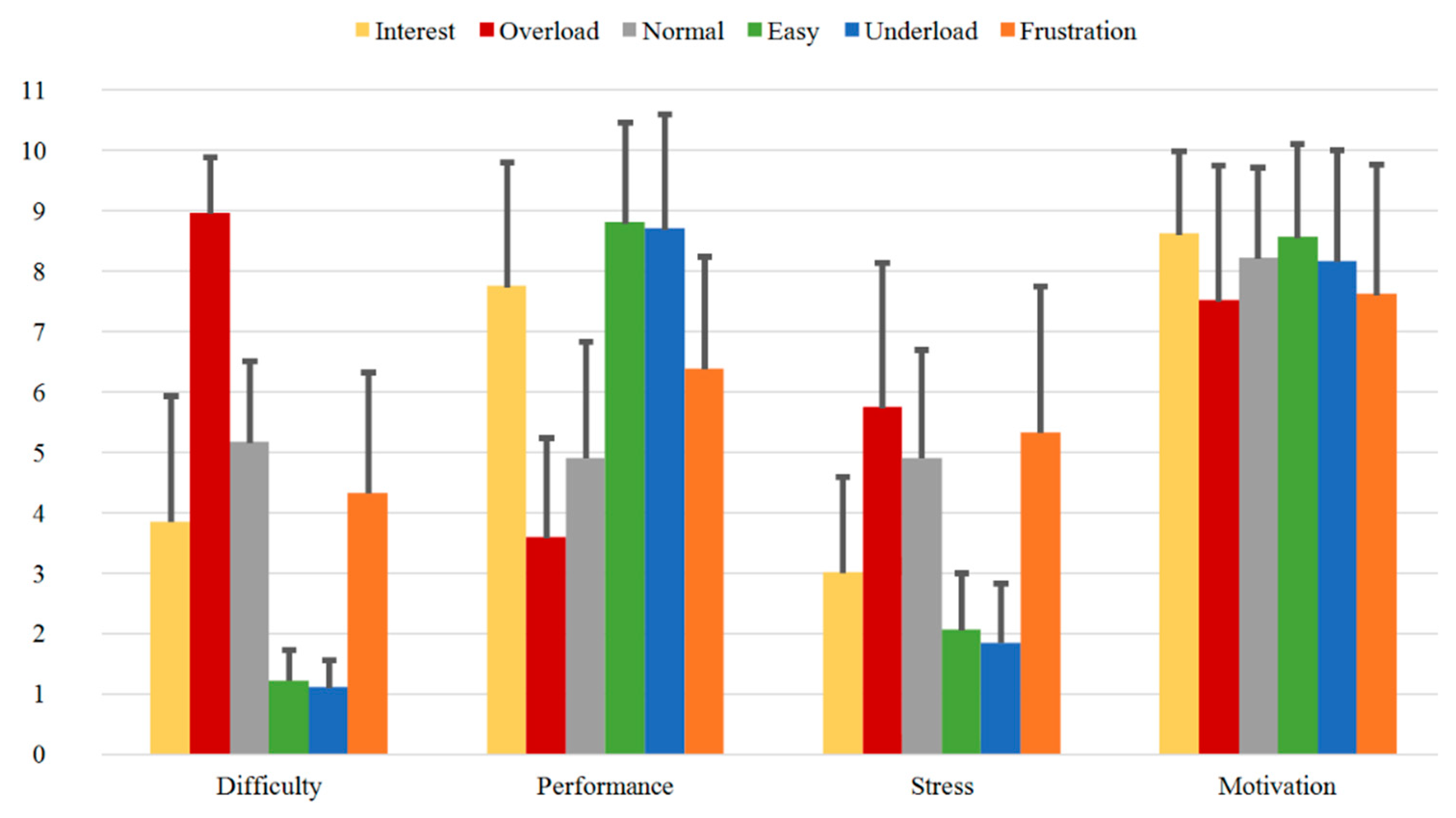
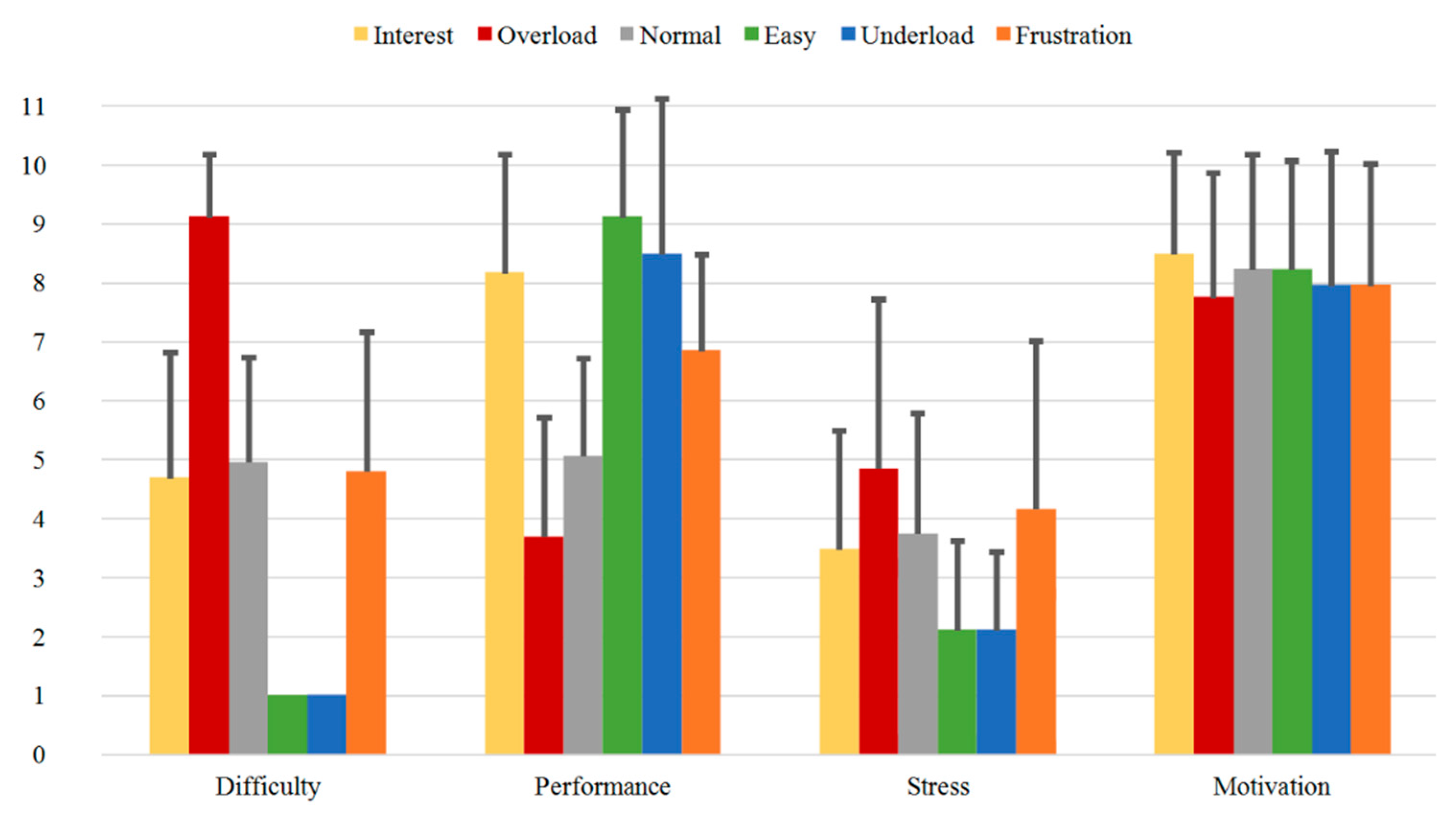
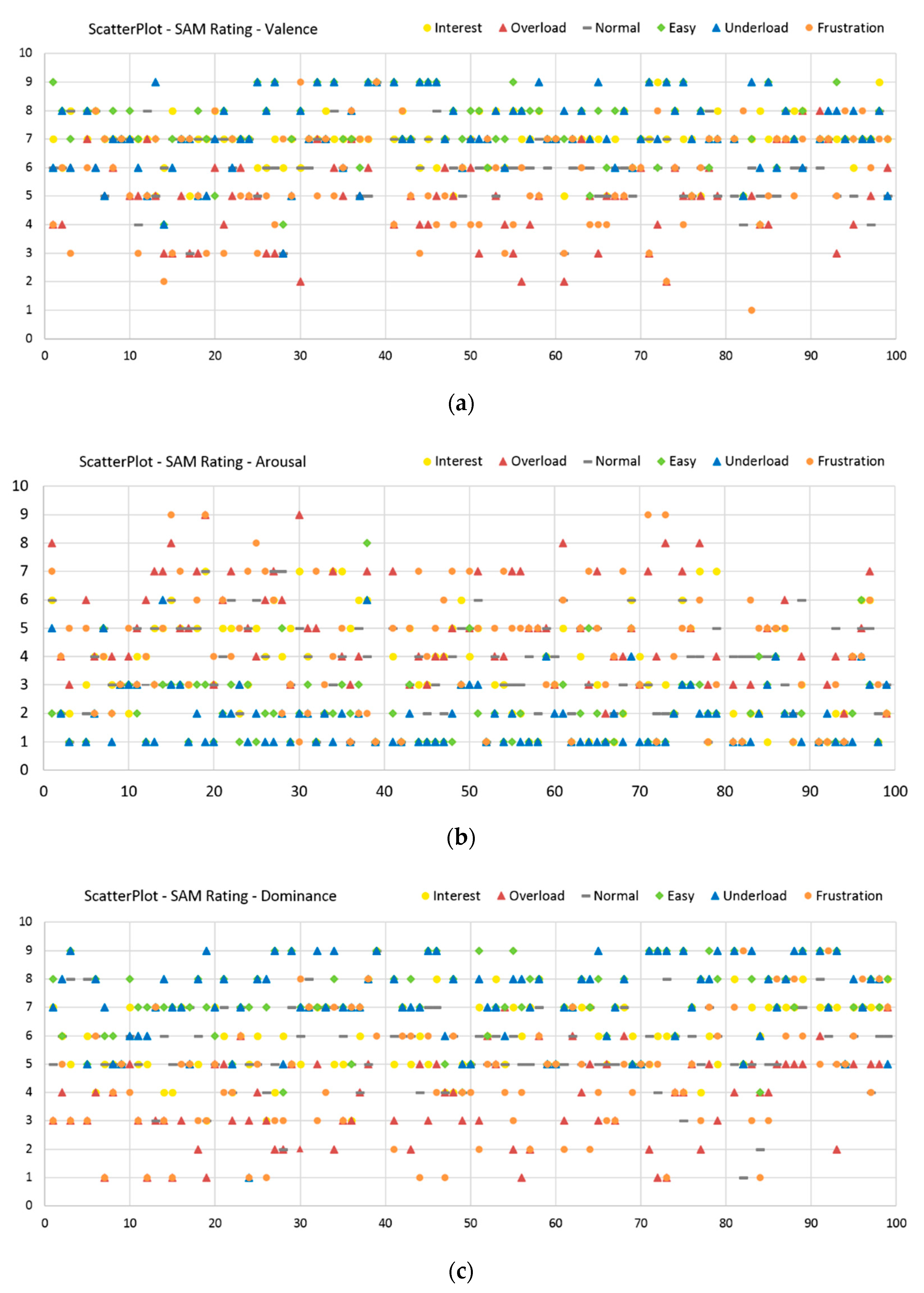
3.3.1. SAM Ratings
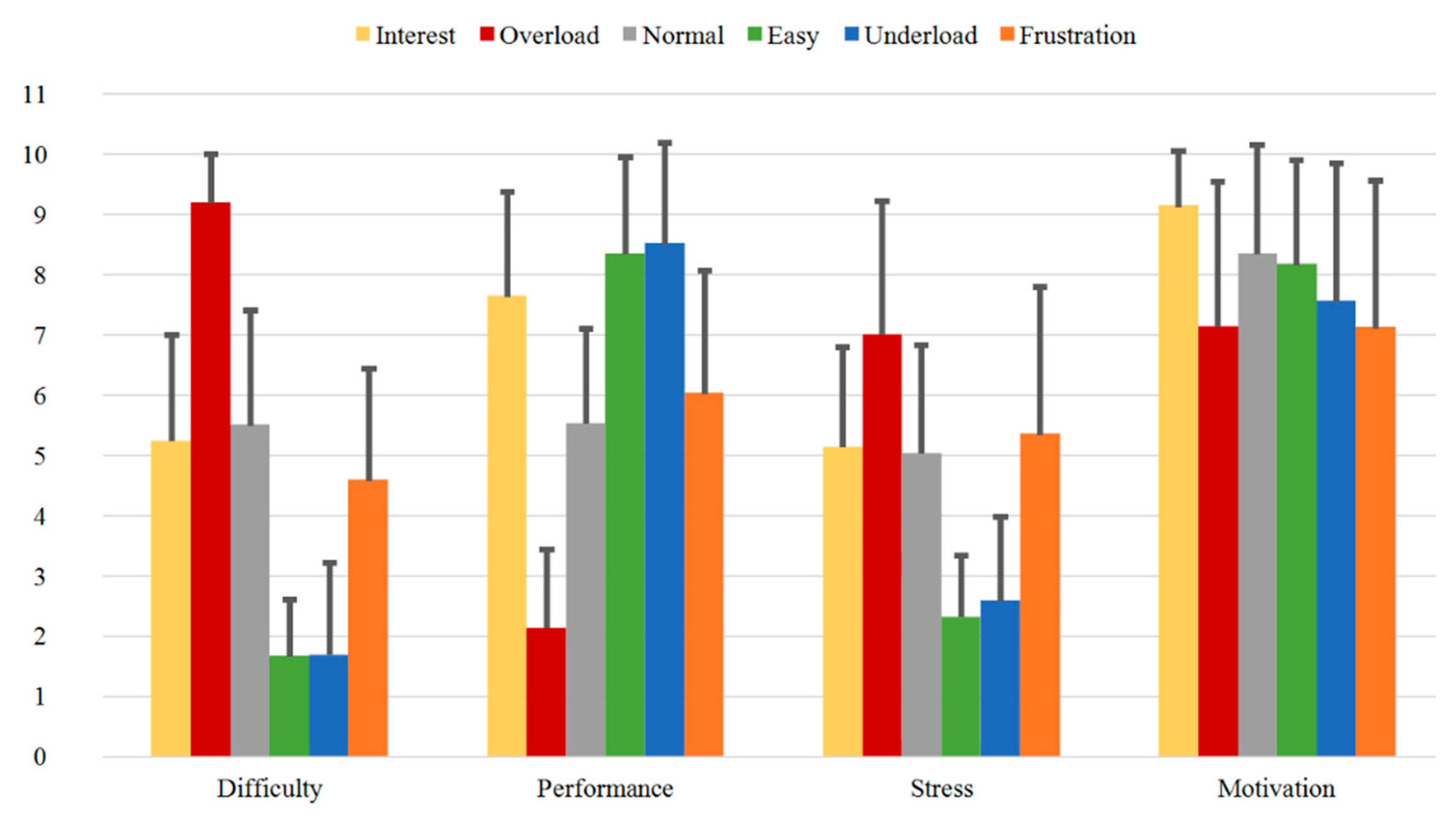
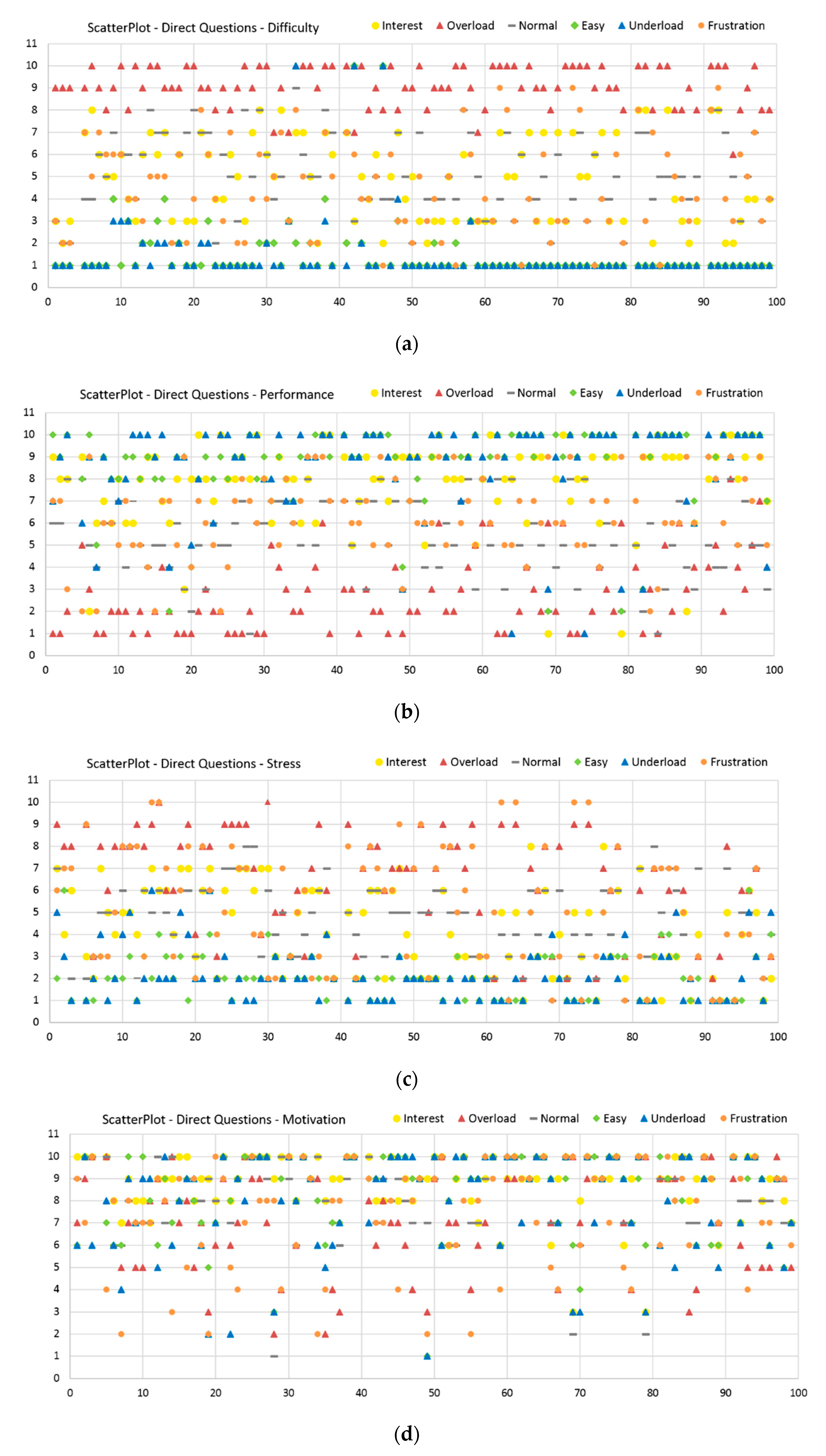
3.3.2. Direct Questions
3.4. Data Annotation
4. Discussion and Summary
- Dataset for affective computing research: We designed and implemented a HCI scenario and acquired the uulmMAC dataset for emotional and cognitive states recognition. The dataset consists of six different sequences, including the states Interest, Overload, Normal, Easy, Underload, and Frustration. The emotional-cognitive conditions were thereby induced by increasing the task field objects and colors as well as decreasing the available time of an interactive game paradigm.
- Multimodal mobile and interactive: It consists of highly multimodal (biosignals, videos, audios, Kinect), mobile (standing, walking, freely moving positions with wireless physiology sensors), and interactive (HCI via natural speech) emotional-cognitive HCI scenario.
- Large number of subjects/recording sessions: The original experiment includes 60 subjects and 100 recording sessions, from which 57 subjects and 95 recording sessions are left as part of the final dataset. Depending on the focus of the research question or modality, the recording sessions of 38 subjects or 19 subjects or all 57 subjects can be analyzed: For instance, when focusing on physiological reactions with no specific interest in facial EMG, all 57 subjects (Group A + Group B1) can be analyzed; while when focusing on facial expression from video data, 38 subjects (Group A) can be analyzed.
- Transtemporal analysis: Our dataset also allows transtemporal research and investigations of the changes and variations of the induction, reactions and recognition over time: This is possible with our second sample of 20 subjects who underwent three different measurements at three different times with one-week interval-time inbetween. The transtemporal part of the final dataset includes 19 subjects (Group B) out of the original 20 subjects, left after quality check. Further, the data analysis and evaluation of the subjective feedback and questionnaires show transtemporally stable and valid induction results.
- Validated dataset: The induction of the various emotional and cognitive load states via six different sequences is validated through evaluation of subjective feedback acquired during the experiment. These are used as ground truth for our paradigm. On one side, the reported SAM Ratings vary between the sequences and show significant differences between the relevant induced states (Table 3 and Table 4 or Table A1a and Table A1b). Additionally, the SAM Ratings results of Group B1 show a consistent course with the results of Group A (first measurements from both samples) with no statistically significant differences based on an ANOVA. On the other side, the results from the Direct Questions are compatible with the related induction state (i.e., the Overload and Frustration sequences have high “Stress” answers rates, while the Interest sequence has high “Motivation” answers rates etc.) and show significant differences between the relevant induced states (Table 5 and Table 6 or Table A2a and Table A2b). Additionally, the Direct Questions ratings of Group B1 present similar course as the results of Group A for all the four questions with no statistically significant differences based on an ANOVA. Finally, the evaluation and analysis of the various questionnaires, acquired from the subjects prior the experiment, also show stable results.
- High technical quality: The technical quality of the data and related signals is also checked and demonstrated via different preliminary classifications conducted on various subsets of the database including: the video data [63], the gesture data [65], the audio data [66], the biophysiological data [67], the speech and the biophysiological data [68], and the multimodal data [69].
Author Contributions
Funding
Conflicts of Interest
Appendix A



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VAD | V | V | V | V | V | V | A | A | A | A | A | A | D | D | D | D | D | D | |
| Seq. | I | O | N | E | U | F | I | O | N | E | U | F | I | O | N | E | U | F | |
| V | I | 0.000 | 0.272 | 0.655 | 0.817 | 0.003 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.002 | 0.758 | 0.949 | 0.000 | |
| V | O | 0.000 | 0.003 | 0.000 | 0.000 | 0.369 | 0.044 | 0.878 | 0.005 | 0.000 | 0.000 | 0.025 | 0.527 | 0.000 | 0.486 | 0.000 | 0.000 | 0.030 | |
| V | N | 0.272 | 0.003 | 0.076 | 0.190 | 0.094 | 0.000 | 0.004 | 0.000 | 0.000 | 0.000 | 0.000 | 0.044 | 0.000 | 0.038 | 0.250 | 0.345 | 0.000 | |
| V | E | 0.655 | 0.000 | 0.076 | 0.636 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.673 | 0.397 | 0.000 | |
| V | U | 0.817 | 0.000 | 0.190 | 0.636 | 0.004 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.002 | 0.852 | 0.949 | 0.000 | |
| V | F | 0.003 | 0.369 | 0.094 | 0.000 | 0.004 | 0.000 | 0.309 | 0.000 | 0.000 | 0.000 | 0.001 | 0.590 | 0.000 | 1.000 | 0.001 | 0.002 | 0.000 | |
| A | I | 0.000 | 0.044 | 0.000 | 0.000 | 0.000 | 0.000 | 0.044 | 0.397 | 0.000 | 0.000 | 0.921 | 0.003 | 0.207 | 0.001 | 0.000 | 0.000 | 0.939 | |
| A | O | 0.000 | 0.878 | 0.004 | 0.000 | 0.000 | 0.309 | 0.044 | 0.004 | 0.000 | 0.000 | 0.045 | 0.355 | 0.000 | 0.460 | 0.000 | 0.000 | 0.035 | |
| A | N | 0.000 | 0.005 | 0.000 | 0.000 | 0.000 | 0.000 | 0.397 | 0.004 | 0.000 | 0.000 | 0.606 | 0.000 | 0.397 | 0.000 | 0.000 | 0.000 | 0.625 | |
| A | E | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.397 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| A | U | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.397 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| A | F | 0.000 | 0.025 | 0.000 | 0.000 | 0.000 | 0.001 | 0.921 | 0.045 | 0.606 | 0.000 | 0.000 | 0.005 | 0.229 | 0.002 | 0.000 | 0.000 | 0.758 | |
| D | I | 0.000 | 0.527 | 0.044 | 0.000 | 0.001 | 0.590 | 0.003 | 0.355 | 0.000 | 0.000 | 0.000 | 0.005 | 0.000 | 0.852 | 0.000 | 0.000 | 0.003 | |
| D | O | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.207 | 0.000 | 0.397 | 0.000 | 0.000 | 0.229 | 0.000 | 0.000 | 0.000 | 0.000 | 0.287 | |
| D | N | 0.002 | 0.486 | 0.038 | 0.000 | 0.002 | 1.000 | 0.001 | 0.460 | 0.000 | 0.000 | 0.000 | 0.002 | 0.852 | 0.000 | 0.001 | 0.001 | 0.001 | |
| D | E | 0.758 | 0.000 | 0.250 | 0.673 | 0.852 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 1.000 | 0.000 | |
| D | U | 0.949 | 0.000 | 0.345 | 0.397 | 0.949 | 0.002 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 1.000 | 0.000 | |
| D | F | 0.000 | 0.030 | 0.000 | 0.000 | 0.000 | 0.000 | 0.939 | 0.035 | 0.625 | 0.000 | 0.000 | 0.758 | 0.003 | 0.287 | 0.001 | 0.000 | 0.000 |
| VAD | V | V | V | V | V | V | A | A | A | A | A | A | D | D | D | D | D | D | |
| Seq. | I | O | N | E | U | F | I | O | N | E | U | F | I | O | N | E | U | F | |
| V | I | 0.000 | 0.100 | 0.254 | 0.742 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.343 | 0.609 | 0.000 | |
| V | O | 0.000 | 0.000 | 0.000 | 0.000 | 0.164 | 0.003 | 0.704 | 0.000 | 0.000 | 0.000 | 0.139 | 0.313 | 0.000 | 0.179 | 0.000 | 0.000 | 0.013 | |
| V | N | 0.100 | 0.000 | 0.003 | 0.061 | 0.002 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.004 | 0.026 | 0.047 | 0.000 | |
| V | E | 0.254 | 0.000 | 0.003 | 0.311 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.705 | 0.529 | 0.000 | |
| V | U | 0.742 | 0.000 | 0.061 | 0.311 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.998 | 0.950 | 0.000 | |
| V | F | 0.000 | 0.164 | 0.002 | 0.000 | 0.000 | 0.000 | 0.179 | 0.000 | 0.000 | 0.000 | 0.006 | 0.950 | 0.000 | 0.802 | 0.000 | 0.000 | 0.000 | |
| A | I | 0.000 | 0.003 | 0.000 | 0.000 | 0.000 | 0.000 | 0.007 | 0.184 | 0.000 | 0.000 | 0.202 | 0.000 | 0.313 | 0.000 | 0.000 | 0.000 | 0.569 | |
| A | O | 0.000 | 0.704 | 0.000 | 0.000 | 0.000 | 0.179 | 0.007 | 0.000 | 0.000 | 0.000 | 0.129 | 0.257 | 0.000 | 0.114 | 0.000 | 0.000 | 0.022 | |
| A | N | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.184 | 0.000 | 0.000 | 0.000 | 0.013 | 0.000 | 0.899 | 0.000 | 0.000 | 0.000 | 0.139 | |
| A | E | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.282 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| A | U | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.282 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| A | F | 0.000 | 0.139 | 0.000 | 0.000 | 0.000 | 0.006 | 0.202 | 0.129 | 0.013 | 0.000 | 0.000 | 0.007 | 0.014 | 0.001 | 0.000 | 0.000 | 0.255 | |
| D | I | 0.000 | 0.313 | 0.001 | 0.000 | 0.000 | 0.950 | 0.000 | 0.257 | 0.000 | 0.000 | 0.000 | 0.007 | 0.000 | 0.569 | 0.000 | 0.000 | 0.000 | |
| D | O | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.313 | 0.000 | 0.899 | 0.000 | 0.000 | 0.014 | 0.000 | 0.000 | 0.000 | 0.000 | 0.179 | |
| D | N | 0.000 | 0.179 | 0.004 | 0.000 | 0.000 | 0.802 | 0.000 | 0.114 | 0.000 | 0.000 | 0.000 | 0.001 | 0.569 | 0.000 | 0.000 | 0.000 | 0.000 | |
| D | E | 0.343 | 0.000 | 0.026 | 0.705 | 0.998 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 | 0.000 | |
| D | U | 0.609 | 0.000 | 0.047 | 0.529 | 0.950 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 | 0.000 | |
| D | F | 0.000 | 0.013 | 0.000 | 0.000 | 0.000 | 0.000 | 0.569 | 0.022 | 0.139 | 0.000 | 0.000 | 0.255 | 0.000 | 0.179 | 0.000 | 0.000 | 0.000 |
| Quest. | Dif | Dif | Dif | Dif | Dif | Dif | Per | Per | Per | Per | Per | Per | Str | Str | Str | Str | Str | Str | Mot | Mot | Mot | Mot | Mot | Mot | |
| Seq. | I | O | N | E | U | F | I | O | N | E | U | F | I | O | N | E | U | F | I | O | N | E | U | F | |
| Dif | I | 0.000 | 0.742 | 0.000 | 0.000 | 0.254 | 0.000 | 0.000 | 0.850 | 0.000 | 0.000 | 0.176 | 0.768 | 0.000 | 0.826 | 0.000 | 0.000 | 0.768 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Dif | O | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.128 | 0.135 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.883 | 0.000 | 0.086 | 0.047 | 0.000 | 0.000 | |
| Dif | N | 0.742 | 0.000 | 0.000 | 0.000 | 0.103 | 0.000 | 0.000 | 0.941 | 0.000 | 0.000 | 0.304 | 0.731 | 0.000 | 0.675 | 0.000 | 0.000 | 0.659 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Dif | E | 0.000 | 0.000 | 0.000 | 0.941 | 0.000 | 0.000 | 0.381 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.254 | 0.075 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Dif | U | 0.000 | 0.000 | 0.000 | 0.941 | 0.000 | 0.000 | 0.211 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.181 | 0.059 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Dif | F | 0.254 | 0.000 | 0.103 | 0.000 | 0.000 | 0.000 | 0.000 | 0.111 | 0.000 | 0.000 | 0.001 | 0.269 | 0.000 | 0.211 | 0.000 | 0.000 | 0.205 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Per | I | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.115 | 0.107 | 0.000 | 0.000 | 0.393 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.341 | 0.192 | 0.141 | 0.825 | 0.454 | |
| Per | O | 0.000 | 0.000 | 0.000 | 0.381 | 0.211 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.606 | 0.423 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Per | N | 0.850 | 0.000 | 0.941 | 0.000 | 0.000 | 0.111 | 0.000 | 0.000 | 0.000 | 0.000 | 0.162 | 0.804 | 0.000 | 0.728 | 0.000 | 0.000 | 0.864 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Per | E | 0.000 | 0.128 | 0.000 | 0.000 | 0.000 | 0.000 | 0.115 | 0.000 | 0.000 | 0.898 | 0.000 | 0.000 | 0.003 | 0.000 | 0.000 | 0.000 | 0.000 | 0.121 | 0.006 | 1.000 | 0.606 | 0.121 | 0.007 | |
| Per | U | 0.000 | 0.135 | 0.000 | 0.000 | 0.000 | 0.000 | 0.107 | 0.000 | 0.000 | 0.898 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.077 | 0.002 | 0.659 | 0.774 | 0.085 | 0.002 | |
| Per | F | 0.176 | 0.000 | 0.304 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.162 | 0.000 | 0.000 | 0.123 | 0.006 | 0.076 | 0.000 | 0.000 | 0.222 | 0.000 | 0.011 | 0.000 | 0.000 | 0.000 | 0.007 | |
| Str | I | 0.768 | 0.000 | 0.731 | 0.000 | 0.000 | 0.269 | 0.000 | 0.000 | 0.804 | 0.000 | 0.000 | 0.123 | 0.000 | 0.768 | 0.000 | 0.000 | 0.826 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Str | O | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.393 | 0.000 | 0.000 | 0.003 | 0.001 | 0.006 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.928 | 0.004 | 0.015 | 0.410 | 0.768 | |
| Str | N | 0.826 | 0.000 | 0.675 | 0.000 | 0.000 | 0.211 | 0.000 | 0.000 | 0.728 | 0.000 | 0.000 | 0.076 | 0.768 | 0.000 | 0.000 | 0.000 | 0.813 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Str | E | 0.000 | 0.000 | 0.000 | 0.254 | 0.181 | 0.000 | 0.000 | 0.606 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.462 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Str | U | 0.000 | 0.000 | 0.000 | 0.075 | 0.059 | 0.000 | 0.000 | 0.423 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.462 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Str | F | 0.768 | 0.000 | 0.659 | 0.000 | 0.000 | 0.205 | 0.000 | 0.000 | 0.864 | 0.000 | 0.000 | 0.222 | 0.826 | 0.000 | 0.813 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Mot | I | 0.000 | 0.883 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.121 | 0.077 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.070 | 0.050 | 0.000 | 0.000 | |
| Mot | O | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.341 | 0.000 | 0.000 | 0.006 | 0.002 | 0.011 | 0.000 | 0.928 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.009 | 0.021 | 0.239 | 0.941 | |
| Mot | N | 0.000 | 0.086 | 0.000 | 0.000 | 0.000 | 0.000 | 0.192 | 0.000 | 0.000 | 1.000 | 0.659 | 0.000 | 0.000 | 0.004 | 0.000 | 0.000 | 0.000 | 0.000 | 0.070 | 0.009 | 0.864 | 0.176 | 0.010 | |
| Mot | E | 0.000 | 0.047 | 0.000 | 0.000 | 0.000 | 0.000 | 0.141 | 0.000 | 0.000 | 0.606 | 0.774 | 0.000 | 0.000 | 0.015 | 0.000 | 0.000 | 0.000 | 0.000 | 0.050 | 0.021 | 0.864 | 0.208 | 0.027 | |
| Mot | U | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.825 | 0.000 | 0.000 | 0.121 | 0.085 | 0.000 | 0.000 | 0.410 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.239 | 0.176 | 0.208 | 0.423 | |
| Mot | F | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.454 | 0.000 | 0.000 | 0.007 | 0.002 | 0.007 | 0.000 | 0.768 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.941 | 0.010 | 0.027 | 0.423 |
| Quest. | Dif | Dif | Dif | Dif | Dif | Dif | Per | Per | Per | Per | Per | Per | Str | Str | Str | Str | Str | Str | Mot | Mot | Mot | Mot | Mot | Mot | |
| Seq. | I | O | N | E | U | F | I | O | N | E | U | F | I | O | N | E | U | F | I | O | N | E | U | F | |
| Dif | I | 0.000 | 0.907 | 0.000 | 0.000 | 0.091 | 0.000 | 0.000 | 0.584 | 0.000 | 0.000 | 0.011 | 0.511 | 0.000 | 0.431 | 0.000 | 0.000 | 0.352 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Dif | O | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.091 | 0.106 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.485 | 0.000 | 0.043 | 0.030 | 0.000 | 0.000 | |
| Dif | N | 0.907 | 0.000 | 0.000 | 0.000 | 0.080 | 0.000 | 0.000 | 0.687 | 0.000 | 0.000 | 0.012 | 0.323 | 0.000 | 0.343 | 0.000 | 0.000 | 0.548 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Dif | E | 0.000 | 0.000 | 0.000 | 0.954 | 0.000 | 0.000 | 0.441 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.576 | 0.443 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Dif | U | 0.000 | 0.000 | 0.000 | 0.954 | 0.000 | 0.000 | 0.245 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.441 | 0.363 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Dif | F | 0.091 | 0.000 | 0.080 | 0.000 | 0.000 | 0.000 | 0.000 | 0.009 | 0.000 | 0.000 | 0.000 | 0.343 | 0.000 | 0.323 | 0.000 | 0.000 | 0.008 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Per | I | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.043 | 0.049 | 0.000 | 0.000 | 0.032 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.375 | 0.091 | 0.155 | 0.771 | 0.181 | |
| Per | O | 0.000 | 0.000 | 0.000 | 0.441 | 0.245 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.954 | 0.888 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Per | N | 0.584 | 0.000 | 0.687 | 0.000 | 0.000 | 0.009 | 0.000 | 0.000 | 0.000 | 0.000 | 0.036 | 0.223 | 0.000 | 0.124 | 0.000 | 0.000 | 0.954 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Per | E | 0.000 | 0.091 | 0.000 | 0.000 | 0.000 | 0.000 | 0.043 | 0.000 | 0.000 | 0.862 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.163 | 0.001 | 0.848 | 0.694 | 0.067 | 0.000 | |
| Per | U | 0.000 | 0.106 | 0.000 | 0.000 | 0.000 | 0.000 | 0.049 | 0.000 | 0.000 | 0.862 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.259 | 0.001 | 0.798 | 0.523 | 0.069 | 0.001 | |
| Per | F | 0.011 | 0.000 | 0.012 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.036 | 0.000 | 0.000 | 0.000 | 0.027 | 0.000 | 0.000 | 0.000 | 0.080 | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.002 | |
| Str | I | 0.511 | 0.000 | 0.323 | 0.000 | 0.000 | 0.343 | 0.000 | 0.000 | 0.223 | 0.000 | 0.000 | 0.000 | 0.000 | 0.684 | 0.000 | 0.000 | 0.175 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Str | O | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.032 | 0.000 | 0.000 | 0.000 | 0.000 | 0.027 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.163 | 0.000 | 0.000 | 0.021 | 0.343 | |
| Str | N | 0.431 | 0.000 | 0.343 | 0.000 | 0.000 | 0.323 | 0.000 | 0.000 | 0.124 | 0.000 | 0.000 | 0.000 | 0.684 | 0.000 | 0.000 | 0.000 | 0.104 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Str | E | 0.000 | 0.000 | 0.000 | 0.576 | 0.441 | 0.000 | 0.000 | 0.954 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.684 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Str | U | 0.000 | 0.000 | 0.000 | 0.443 | 0.363 | 0.000 | 0.000 | 0.888 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.684 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Str | F | 0.352 | 0.000 | 0.548 | 0.000 | 0.000 | 0.008 | 0.000 | 0.000 | 0.954 | 0.000 | 0.000 | 0.080 | 0.175 | 0.000 | 0.104 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Mot | I | 0.000 | 0.485 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.163 | 0.259 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.176 | 0.121 | 0.001 | 0.000 | |
| Mot | O | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.375 | 0.000 | 0.000 | 0.001 | 0.001 | 0.001 | 0.000 | 0.163 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.005 | 0.008 | 0.363 | 1.000 | |
| Mot | N | 0.000 | 0.043 | 0.000 | 0.000 | 0.000 | 0.000 | 0.091 | 0.000 | 0.000 | 0.848 | 0.798 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.176 | 0.005 | 1.000 | 0.072 | 0.003 | |
| Mot | E | 0.000 | 0.030 | 0.000 | 0.000 | 0.000 | 0.000 | 0.155 | 0.000 | 0.000 | 0.694 | 0.523 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.121 | 0.008 | 1.000 | 0.169 | 0.005 | |
| Mot | U | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.771 | 0.000 | 0.000 | 0.067 | 0.069 | 0.000 | 0.000 | 0.021 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.363 | 0.072 | 0.169 | 0.234 | |
| Mot | F | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.181 | 0.000 | 0.000 | 0.000 | 0.001 | 0.002 | 0.000 | 0.343 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 | 0.003 | 0.005 | 0.234 |
References
- Paas, F.; Tuovinen, J.E.; Tabbers, H.; Van Gerven, P.W.M. Cognitive load measurement as a means to advance cognitive load theory. Educ. Psychol. 2003, 38, 63–71. [Google Scholar] [CrossRef]
- Sweller, J.; Merrienboer, J.; Paas, F. Cognitive Architecture and Instructional Design. Educ. Psychol. Rev. 1998, 10, 251–296. [Google Scholar] [CrossRef]
- Sweller, J.; Ayres, P.; Kalyuga, S. Cognitive Load Theory; Springer: New York, NY, USA, 2011. [Google Scholar]
- Rösner, D.; Hazer-Rau, D.; Kohrs, C.; Bauer, T.; Günther, S.; Hoffmann, H.; Zhang, L.; Brechmann, A. Is there a Biological Basis for Success in Human Companion Interaction?—Results from a Transsituational Study. In Human-Computer Interaction—Theory, Design, Development and Practice; Kurosu, M., Ed.; Part I; Lecture Notes in Computer Science LNCS; Springer: Cham, Switzerland, 2016; Volume 9731, pp. 77–88. [Google Scholar] [CrossRef]
- Moos, D. Examining hypermedia learning: The role of cognitive load and self-regulated learning. J. Educ. Multimed. Hypermed. 2013, 22, 39–61. [Google Scholar]
- Creemers, B.; Kyriakides, L.; Panayiotis, A. Improvement of Teaching by Mastering Specific Competences: The Competency-Based Approach. In Teacher Professional Development for Improving Quality of Teaching; Springer: Berlin, Germany, 2013; pp. 13–28. [Google Scholar]
- Lini, S.; Bey, C.; Hourlier, S.; Vallespir, B.; Johnston, A.; Favier, P.A. Evaluating ASAP (Anticipation Support for Aeronautical Planning): A user-centered case study. In Proceedings of the 17th International Symposium on Aviation Psychology, Dayton, OH, USA, 6–9 May 2013. [Google Scholar]
- Taylor, T.; Pradhan, A.K.; Divekar, G.; Romoser, M.; Muttart, J.; Gomez, R.; Pollatsek, A.; Fisher, D.L. The view from the road: The contribution of on-road glance-monitoring technologies to understanding driver behavior. Accid. Anal. Prev. 2013, 58, 175–186. [Google Scholar] [CrossRef]
- Hirshfield, L.M.; Solovey, E.T.; Girouard, A.; Kebinger, J.; Jacob, R.J.K.; Sassaroli, A.; Fantini, S. Brain measurement for usability testing and adaptive interfaces: An example of uncovering syntactic workload with functional near infrared spectroscopy. In Proceedings of the 27th SIGCHI Conference on Human Factors in Computing Systems (CHI ‘09), Boston, MA, USA, 4–9 April 2009; pp. 2185–2194. [Google Scholar] [CrossRef]
- Greene, S.; Thapliyal, H.; Caban-Holt, A. A Survey of Affective Computing for Stress Detection: Evaluating technologies in stress detection for better health. IEEE Consum. Electron. Mag. 2016, 5, 44–56. [Google Scholar] [CrossRef]
- Wilson, G.F.; Schlegel, R.E. Operator Functional State Assessment; NATO RTO Publication RTO-TR-HF M-104; NATO Research and Technology Organization: Neuilly sur Seine, France, 2004. [Google Scholar]
- Hart, S.; Staveland, L. Development of the NASA-TLX (Task Load Index): Results of empirical and theoretical research. In Human Mental Workload; Hancock, P.A., Meshkati, N., Eds.; Elsevier Science Publishers, North Holland Press: Amsterdam, The Netherlands, 1988; pp. 139–183. [Google Scholar]
- O’Donnell, R.; Eggemeier, F. Workload assessment methodology. In Handbook of Perception and Human Performance. Cognitive Processes and Performance; Boff, K., Kaufman, L., Thomas, J., Eds.; Wiley: New York, NY, USA, 1986; pp. 1–49. [Google Scholar]
- Wierwille, W.W.; Eggemeier, F.T. Recommendations for mental workload measurement in a test and evaluation environment. Hum. Factors J. Hum. Factors Erg.Soc. 1993, 35, 263–281. [Google Scholar] [CrossRef]
- Gingell, R. Review of Workload Measurement, Analysis and Interpretation Methods. Eur. Organ. Saf. Air Navig. 2003, 33, 1–33. [Google Scholar]
- Fridman, L.; Reimer, B.; Mehler, B.; Freeman, W.T. Cognitive Load Estimation in the Wild. In Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI ‘18), Montreal, QC, Canada, 21–26 April 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Van Dille, L.F.; Heslenfeld, D.J.; Koole, S.L. Tuning down the emotional brain: An fMRI study of the effects of cognitive load on the processing of affective images. NeuroImage 2009, 45, 1212–1219. [Google Scholar] [CrossRef]
- Just, M.A.; Carpenter, P.A.; Miyake, A. Neuroindices of cognitive workload: Neuroimaging, pupillometric and event-related potential studies of brain work. Theor. Issues Ergon. Sci. 2003, 4, 56–88. [Google Scholar] [CrossRef]
- Jerčić, P.; Sennersten, C.; Lindley, C. Modeling cognitive load and physiological arousal through pupil diameter and heart rate. Multimed. Tools Appl. 2020, 79, 3145–3159. [Google Scholar] [CrossRef] [Green Version]
- Von Bauer, P. Cognitive State Classification Using Psychophysiological Measures. Master’s Thesis, Universität Konstanz, Konstanz, Germany, 2018. [Google Scholar]
- Luria, G.; Rosenblum, S. A computerized multidimensional measurement of mental workload via handwriting analysis. Behav. Res. Methods. 2012, 44, 575–586. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, K. Cognitive load examination via pen interactions. Ph.D. Thesis, The University of New South Wales, Sydney, Australia, 2015. Available online: http://unsworks.unsw.edu.au/fapi/datastream/unsworks:38410/SOURCE02?view=true (accessed on 14 February 2020).
- Su, J.; Luz, S. Predicting Cognitive Load Levels from Speech Data. In Recent Advances in Nonlinear Speech Processing; Esposito, A., Faundez-Zanuy, M., Esposito, A.M., Cordasco, G., Drugman, T., Solé-Casals, J., Morabito, F.C., Eds.; Springer: Berlin Heidelberg, Germany, 2016; pp. 255–263. [Google Scholar]
- Mattys, S.; Wiget, L. Effects of cognitive load on speech recognition. J. Mem. Langg. 2011, 65, 145–160. [Google Scholar] [CrossRef]
- Das, D.; Chatterjee, D.; Sinha, A. Unsupervised approach for measurement of cognitive load using EEG signals. In Proceedings of the 13th IEEE Conference on BioInformatics and BioEngineering, Chania, Greece, 10–13 November 2013; pp. 1–6. [Google Scholar]
- Bauer, R.; Gharabaghi, A. Estimating cognitive load during self-regulation of brain activity and neurofeedback with therapeutic brain-computer interfaces. Front. Behav. Neurosci. 2015, 9, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klingner, J.; Tversky, B.; Hanrahan, P. Effects of visual and verbal presentation on cognitive load in vigilance, memory and arithmetic tasks. J. Psychophys. 2011, 48, 323–332. [Google Scholar] [CrossRef] [PubMed]
- Hossain, G.; Yeasin, M. Understanding Effects of Cognitive Load from Pupillary Responses Using Hilbert Analytic Phase. In Proceedings of the IEEE on Computer Vision and Pattern Recognition Workshops 2014, Columbus, OH, USA, 23–28 June 2014; pp. 381–386. [Google Scholar]
- Chen, F.; Zhou, J.; Wang, Y.; Yu, K.; Arshad, S.Z.; Khawaji, A.; Conway, D. Robust Multimodal Cognitive Load Measurement; Human-Computer Interaction Series; Springer: Berlin, Germany, 2016. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A.; Epps, J.; Eyben, F.; Ringeval, F.; Marchi, E.; Zhang, Y. The Interspeech 2014 Computational Paralinguistics Challenge: Cognitive & Physical Load. In Proceedings of the 15th Annual Conference of the International Speech Communication Association (ISCA), Singapore, 14–18 September 2014; pp. 427–431. [Google Scholar]
- Liu, X.; Chen, T.; Xie, G.; Liu, G. Contact-Free Cognitive Load Recognition Based on Eye Movement. J. Electr. Comput. Eng. 2016, 2016. [Google Scholar] [CrossRef]
- Zhang, L.; Rukavina, S.; Gruss, S.; Traue, H.C.; Hazer, D. Classification analysis for the emotion recognition from psychobiological data. In Proceedings of the International Symposium on Companion-Technologies (ISCT’15), Ulm, Germany, 23–25 September 2015. [Google Scholar]
- Hamdi, H.; Richard, P.; Suteau, A.; Allain, P. Emotion assessment for affective computing based on physiological responses. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Lang, P.; Bradley, M.; Cuthbert, B. The International Affective Picture System (IAPS): Technical Manual and Affective Ratings; The Center for Research in Psychophysiology, University of Florida: Gainesville, FL, USA, 1999. [Google Scholar]
- Gross, J.; Levenson, R. Emotion elicitation using films. Cogn. Emot. 1995, 9, 87–108. [Google Scholar] [CrossRef]
- Soleymani, M.; Pantic, M.; Pun, T. Multimodal emotion recognition in response to videos. IEEE Trans. Affect. Comput. 2012, 3, 211–223. [Google Scholar] [CrossRef] [Green Version]
- Hazer, D.; Ma, X.Y.; Rukavina, S.; Gruss, S.; Walter, S.; Traue, H.C. Emotion Elicitation Using Film Clips: Effect of Age Groups on Movie Choice and Emotion Rating. In Human-Computer Interaction; Stephanidis, C., Ed.; HCI 2015, Communications in Computer and Information Science; Springer: Cham, Switzerland, 2015; Volume 528, pp. 110–116. [Google Scholar] [CrossRef]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A database for emotion analysis using physiological signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Chanel, G.; Rebetez, C.; Bétrancourt, M.; Pun, T. Emotion Assessment From Physiological Signals for Adaptation of Game Difficulty. IEEE Trans. Syst. Man Cybern. Part. A Syst. Hum. 2011, 41, 1052–1063. [Google Scholar] [CrossRef] [Green Version]
- Hudlicka, E. To feel or not to feel: The role of affect in human–computer interaction. Int. J. Hum.-Comput. Stud. 2003, 59, 1–32. [Google Scholar] [CrossRef]
- Brave, S.; Nass, C. Emotion in Human–Computer Interaction. In The Human-Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications; L. Erlbaum Associates Inc.: Mahwah, NJ, USA, 2003; pp. 81–96. [Google Scholar]
- Conati, C. Probabilistic assessment of user’s emotions in educational games. Appl. Ai. 2002, 16, 555–576. [Google Scholar] [CrossRef] [Green Version]
- Klein, J.; Moon, Y.; Picard, R.W. This computer responds to user frustration: Theory, design and results. Interact. Comput. 2002, 14, 119–140. [Google Scholar] [CrossRef]
- Taylor, B.; Dey, A.; Siewiorek, D.; Smailagic, A. Using Physiological Sensors to Detect Levels of User Frustration Induced by System Delays. In Proceedings of the International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp’15), Osaka, Japan, 7–11 September 2015; pp. 517–528. [Google Scholar] [CrossRef]
- Suhaib, A.; Zwart, N.; Gouweleeuw, K.; Verhoeven, G. Classification of Disappointment and Frustration Elicited by Human-Computer Interaction: Towards Affective HCI, 2019. Available online: https://www.researchgate.net/publication/335158621_Classification_of_Disappointment_and_Frustration_Elicited_by_Human-Computer_Interaction_Towards_Affective_HCI (accessed on 7 April 2020).
- Lisetti, C.; Nasoz, F. Using Noninvasive Wearable Computers to Recognize Human Emotions from Physiological Signals. Eurasip J. Adv. Signal. Process. 2004, 11, 1672–1687. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Rani, P.; Sarkar, N. An empirical study of machine learning techniques for affect recognition in human-robot interaction. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IEEE’RS), Edmonton, Canada, 2–6 August 2005; pp. 2662–2667. [Google Scholar] [CrossRef]
- Silvia, P.J. Interest—The curious emotion. Curr. Dir. Psychol. Sci. 2008, 17, 57–60. [Google Scholar] [CrossRef]
- Reeve, J.; Lee, W.; Won, S. Interest as Emotion, as Affect, and as Schema. In Interest in Mathematics and Science Learning; American Educational Research Association: Washington, DC, USA, 2015; Chapter 5; pp. 79–92. [Google Scholar] [CrossRef]
- Ellsworth, P.C. Some reasons to expect universal antecedents of emotion. In The Nature of Emotion: Fundamental Questions; Ekman, P., Davidson, R.J., Eds.; Oxford University Press: New York, NY, USA, 1994; pp. 150–154. [Google Scholar]
- Schüssel, F.; Honold, F.; Bubalo, N.; Huckauf, A.; Traue, H.C.; Hazer-Rau, D. In-depth analysis of multimodal interaction: An explorative paradigm. In Human-Computer Interaction—Interaction Platforms and Techniques; Kurosu, M., Ed.; Lecture Notes in Computer Science LNCS; Springer: Cham, Switzerland, 2016; Volume 9732, pp. 233–240. [Google Scholar] [CrossRef]
- Traue, H.C.; Ohl, F.; Limbrecht, K.; Scherer, S.; Kessler, H.; Schwenker, F.; Kozyba, M.; Brechmann, A.; Hoffmann, H.; Scheck, A.; et al. Framework for Emotions and Dispositions in Man-Companion Interaction. In Coverbal Synchrony in Human-Machine Interaction; Campbell, N., Rojc, M., Eds.; Science Publishers: Rawalpindi, Pakistan, 2013; pp. 99–140. [Google Scholar] [CrossRef]
- Gross, J.J.; John, O.P. Individual differences in two emotion regulation processes: Implications for affect, relationships, and well-being. J. Personal. Soc. Psychol. 2003, 85, 348–362. [Google Scholar] [CrossRef] [PubMed]
- Abler, B.; Kessler, H. Emotion Regulation Questionnaire—Eine deutschsprachige Fassung des ERQ von Gross und John (2003). Diagnostica 2009, 55, 144–152. [Google Scholar] [CrossRef]
- Cooper, A.; Petrides, K.V. A psychometric analysis of the Trait Emotional Intelligence Questionnaire-Short Form (TEIQue-SF) using item response theory. J. Personal. Assess. 2010, 92, 449–457. [Google Scholar] [CrossRef]
- Jacobs, I.; Sim, C.W.; Zimmermann, J. The German TEIQue-SF: Factorial structure and relations to agentic and communal traits and mental health. Pers. Individ. Differ. 2015, 72, 72–189. [Google Scholar] [CrossRef]
- Gosling, S.D.; Rentfrow, P.J.; Swann, W.B. A very brief measure of the big five personality domains. J. Res. Personal. 2003, 37, 504–528. [Google Scholar] [CrossRef]
- Muck, P.M.; Hell, B.; Gosling, S.D. Construct validation of a short five-factor model instrument: A self-peer study on the German adaptation of the Ten-Item Personality Inventory (TIPI-G). Eur. J. Psychol. Assess. 2007, 23, 23–166. [Google Scholar] [CrossRef] [Green Version]
- The Semaine Developer Website. Available online: http://semaine.opendfki.de (accessed on 27 September 2015).
- Meudt, S.; Bigalke, L.; Schwenker, F. ATLAS—Annotation tool using partially supervised learning and Multi-view Co-learning in Human-Computer-Interaction Scenarios. In Proceedings of the 11th International Conference on Information Science, Signal Processing and their Applications (ISSPA’12), Montreal, QC, Canada, 2–5 July 2012; pp. 1309–1312. [Google Scholar]
- Meudt, S.; Schwenker, F. ATLAS—Machine learning based annotation of multimodal data recorded in human-computer interaction scenarios. In Proceedings of the International Symposium on Companion Technology (ISCT’15), Ulm, Germany, 23–25 September 2015; pp. 181–186. [Google Scholar]
- Thiam, P.; Kächele, M.; Schwenker, F.; Palm, G. Ensembles of Support Vector Data Description for Active Learning Based Annotation of Affective Corpora. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015; pp. 1801–1807. [Google Scholar]
- Thiam, P.; Meudt, S.; Palm, G.; Schwenker, F. Temporal Dependency Based Multi-modal Active Learning Approach for Audiovisual Event Detection. Neural Process. Lett. 2018, 48, 709–732. [Google Scholar] [CrossRef]
- Thiam, P.; Meudt, S.; Kächele, M.; Schwenker, F.; Palm, G. Detection of Emotional Events Utilizing Support Vector Methods in an Active Learning HCI Scenario. In Proceedings of the Workshop on Emotion Representation and Modelling in Human-Computer-Interaction-Systems (ERM4HCI’14), Istanbul, Turkey, 16 November 2014; pp. 31–36. [Google Scholar] [CrossRef]
- Hihn, H.; Meudt, S.; Schwenker, F. Inferring Mental Overload based on Postural Behavior and Gestures. In Proceedings of the Emotion Recognition and Modeling for Companion Technology (ERM4CT’16), Tokyo, Japan, 16 November 201; pp. 1–8. [CrossRef]
- Thiam, P.; Meudt, S.; Schwenker, F.; Palm, G. Active Learning for Speech Event Detection in HCI. In Proceedings of the Artificial Neural Networks in Pattern Recognition (ANNPR’16), Ulm, Germany, 28–30 September 2016; pp. 285–297. [Google Scholar]
- Daucher, A.; Gruss, S.; Jerg-Bretzke, L.; Walter, S.; Hazer-Rau, D. Preliminary classification of cognitive load states in a human machine interaction scenario. In Proceedings of the International Conference on Companion Technology (ICCT’17), Ulm, Germany, 11–13 September 2017; pp. 1–5. [Google Scholar]
- Held, D.; Meudt, S.; Schwenker, F. Bimodal Recognition of Cognitive Load Based on Speech and Physiological Changes. In Multimodal Pattern Recognition of Social Signals in Human-Computer Interaction (MPRSS 2016); Schwenker, F., Scherer, S., Eds.; Lecture Notes in Computer Science LNCS; Springer: Cham, Switzerland, 2017; Volume 10183, pp. 12–23. [Google Scholar] [CrossRef]
- Kindsvater, D.; Meudt, S.; Schwenker, F. Fusion Architectures for Multimodal Cognitive Load Recognition. In Multimodal Pattern Recognition of Social Signals in Human-Computer-Interaction (MPRSS 2016); Schwenker, F., Scherer, S., Eds.; Lecture Notes in Computer Science LNCS; Springer: Cham, Switzerland, 2017; Volume 10183, pp. 12–23. [Google Scholar] [CrossRef]
- Kirschbaum, C.; Pirke, K.; Hellhammer, D. The Trier Social Stress Test—A Tool for Investigating Psychobiological Stress Responses in a Laboratory Setting. Neuropsychobiology 1993, 28, 76–81. [Google Scholar] [CrossRef] [PubMed]
- Stroop, R. Studies of interference in serial verbal reactions. J. Exp. Psychol. 1935, 18, 643–662. [Google Scholar] [CrossRef]
- Wijsman, J.; Grundlehner, B.; Liu, H.; Hermens, H. Wearable Physiological Sensors Reflect Mental Stress State in Office-Like Situations. In Proceedings of the Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 600–605. [Google Scholar]
- Koldijk, S.; Sappelli, M.; Verberne, S.; Neerincx, M.; Kraaij, W. The SWELL Knowledge Work Dataset for Stress and User Modeling Research. In Proceedings of the 16th International Conference on Multimodal Interaction (ICMI’14), Istanbul, Turkey, 12–16 November 2014; pp. 291–298. [Google Scholar]
- Choi, J.; Ahmed, B.; Gutierrez-Osuna, R. Development and Evaluation of an Ambulatory Stress Monitor based on wearable sensors. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 279–286. [Google Scholar] [CrossRef] [PubMed] [Green Version]















| Sequence Nr. | Induction of | Number of Tasks | Search Field | Time (s) to Answer |
|---|---|---|---|---|
| *Sequence 1 | Interest | 40 tasks | 3 × 3 and 4 × 4 items | 10 s/task |
| *Sequence 2 | Overload | 40 tasks | 6 × 6 items | 6 s/task |
| *Sequence 3 | Normal | 40 tasks | 4 × 4 items | 10 s/task |
| *Sequence 4 | Easy | 40 tasks | 3 × 3 items | 100 s/task |
| *Sequence 5 | Underload | 40 tasks | 3 × 3 items | 100 s/task |
| *Sequence 6 | Frustration | 40 tasks | 3 × 3 and 4 × 4 items | 10 s/task |
| Modality | Average Network Latency (ms) | Estimated Max. Delay (ms) |
|---|---|---|
| Kinect (Video / Depth / IR / Audio / Pose) | 5.61 | 1.35 |
| Front video | 4.95 | 1.27 |
| Rear video, atmosphere audio, headset audio, biosignals | 5.37 | 0.83 |
| User interface | 5.17 | 1.17 |
| WOZ interface | 5.52 | 1.17 |
| Average estimated synchronization error | 1.35 – 0.83 = 0.52 |
| SAM Ratings | Mean-Diff. Group A | p-Value Group A | Mean-Diff. Group A + Group B1 | p-Value Group A + Group B1 |
|---|---|---|---|---|
| V_Normal – V_Interest | –0.526 | 0.272 | –0.509 | 0.100 |
| V_Normal – V_Overload | 1.263 | 0.003** | 1.351 | 0.000*** |
| V_Normal – V_Easy | –0.921 | 0.076 | –1.053 | 0.003** |
| V_Normal – V_Underload | –0.447 | 0.190 | –0.772 | 0.061 |
| V_Normal – V_Frustration | 0.711 | 0.094 | 0.930 | 0.002** |
| A_Normal – A_Interest | –0.289 | 0.397 | –0.386 | 0.184 |
| A_Normal – A_Overload | –1.237 | 0.004** | –1.246 | 0.000*** |
| A_Normal – A_Easy | 1.553 | 0.000*** | 1.491 | 0.000*** |
| A_Normal – A_Underload | 1.842 | 0.000*** | 1.754 | 0.000*** |
| A_Normal – A_Frustration | –0.421 | 0.606 | –0.807 | 0.013* |
| D_Normal – D_Interest | 0.184 | 0.852 | 0.175 | 0.569 |
| D_Normal – D_Overload | 2.026 | 0.000*** | 2.018 | 0.000*** |
| D_Normal – D_Easy | –1.342 | 0.001** | –1.561 | 0.000*** |
| D_Normal – D_Underload | –1.342 | 0.001** | -1.579 | 0.000*** |
| D_Normal – D_Frustration | 1.421 | 0.001** | 1.404 | 0.000*** |
| SAM Ratings | Mean-Diff. Group A | p-Value Group A | Mean-Diff. Group A + Group B1 | p-Value Group A + Group B1 |
|---|---|---|---|---|
| V_Overload – V_Underload | –1.711 | 0.000*** | –2.123 | 0.000*** |
| V_Interest – V_Frustration | 1.237 | 0.003** | 1.439 | 0.000*** |
| A_Overload – A_Underload | 3.079 | 0.000*** | 3.000 | 0.000*** |
| A_Interest – A_Frustration | –0.132 | 0.921 | –0.421 | 0.202 |
| D_Overload – D_Underload | –3.368 | 0.000*** | –3.596 | 0.000*** |
| D_Interest – D_Frustration | 1.237 | 0.003** | 1.228 | 0.000*** |
| Direct Questions | Mean-Diff. Group A | p-Value Group A | Mean-Diff. Group A + Group B1 | p-Value Group A + Group B1 |
|---|---|---|---|---|
| Dif_Normal – Dif_Interest | 0.263 | 0.742 | –0.035 | 0.907 |
| Dif_Normal – Dif_Overload | –3.684 | 0.000*** | –3.965 | 0.000*** |
| Dif_Normal – Dif_Easy | 3.842 | 0.000*** | 3.351 | 0.000*** |
| Dif_Normal – Dif_Underload | 3.816 | 0.000*** | 3.333 | 0.000*** |
| Dif_Normal – Dif_Frustration | 0.921 | 0.103 | 0.719 | 0.080 |
| Per_Normal – Per_Interest | –2.105 | 0.000*** | –2.123 | 0.000*** |
| Per_Normal – Per_Overload | 3.395 | 0.000*** | 3.316 | 0.000*** |
| Per_Normal – Per_Easy | –2.816 | 0.000*** | –3.000 | 0.000*** |
| Per_Normal – Per_Underload | –2.974 | 0.000*** | –2.947 | 0.000*** |
| Per_Normal – Per_Frustration | –0.500 | 0.162 | –0.632 | 0.036* |
| Str_Normal – Str_Interest | –0.105 | 0.768 | –0.123 | 0.684 |
| Str_Normal – Str_Overload | –1.974 | 0.000*** | –2.053 | 0.000*** |
| Str_Normal – Str_Easy | 2.711 | 0.000*** | 2.544 | 0.000*** |
| Str_Normal – Str_Underload | 2.447 | 0.000*** | 2.421 | 0.000*** |
| Str_Normal – Str_Frustration | –0.316 | 0.813 | –0.737 | 0.104 |
| Mot_Normal – Mot_Interest | –0.789 | 0.070 | –0.667 | 0.176 |
| Mot_Normal – Mot_Overload | 1.211 | 0.009** | 1.035 | 0.005** |
| Mot_Normal – Mot_Easy | 0.184 | 0.864 | 0.000 | 1.000 |
| Mot_Normal – Mot_Underload | 0.789 | 0.176 | 0.544 | 0.072 |
| Mot_Normal – Mot_Frustration | 1.237 | 0.010* | 1.035 | 0.003** |
| Direct Questions | Mean-Diff. Group A | p-Value Group A | Mean-Diff. Group A + Group B1 | p-Value Group A + Group B1 |
|---|---|---|---|---|
| Dif_Overload – Dif_Underload | 7.500 | 0.000*** | 7.298 | 0.000*** |
| Dif_Interest – Dif_Frustration | 0.658 | 0.254 | 0.754 | 0.091 |
| Per_Overload – Per_Underload | –6.368 | 0.000*** | –6.263 | 0.000*** |
| Per_Interest – Per_Frustration | 1.605 | 0.000*** | 1.491 | 0.000*** |
| Str_Overload – Str_Underload | 4.421 | 0.000*** | 4.474 | 0.000*** |
| Str_Interest – Str_Frustration | –0.211 | 0.826 | –0.614 | 0.175 |
| Mot_Overload – Mot_Underload | –0.421 | 0.239 | –0.491 | 0.363 |
| Mot_ Interest – Mot_Frustration | 2.026 | 0.000*** | 1.702 | 0.000*** |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hazer-Rau, D.; Meudt, S.; Daucher, A.; Spohrs, J.; Hoffmann, H.; Schwenker, F.; Traue, H.C. The uulmMAC Database—A Multimodal Affective Corpus for Affective Computing in Human-Computer Interaction. Sensors 2020, 20, 2308. https://doi.org/10.3390/s20082308
Hazer-Rau D, Meudt S, Daucher A, Spohrs J, Hoffmann H, Schwenker F, Traue HC. The uulmMAC Database—A Multimodal Affective Corpus for Affective Computing in Human-Computer Interaction. Sensors. 2020; 20(8):2308. https://doi.org/10.3390/s20082308
Chicago/Turabian StyleHazer-Rau, Dilana, Sascha Meudt, Andreas Daucher, Jennifer Spohrs, Holger Hoffmann, Friedhelm Schwenker, and Harald C. Traue. 2020. "The uulmMAC Database—A Multimodal Affective Corpus for Affective Computing in Human-Computer Interaction" Sensors 20, no. 8: 2308. https://doi.org/10.3390/s20082308