1. Introduction
Economic growth, environmental protection, sustainable development, the global climate crisis, social inequality, and many other issues are all intertwined with complex systems [
1,
2]. Therefore, gaining a deep understanding of how complex systems operate, evolve, grow, stabilize, and collapse is of paramount importance. However, this task is exceptionally challenging due to the fact that complex systems consist of diverse and heterogeneous agents that interact through complex nonlinear relationships [
3]. Moreover, they all exhibit emergent phenomena, which are highly common in complex systems but carry a sense of mystery [
4].
How did the first living cell emerge from the collisions between various molecules in the Earth’s early environment [
5]? How does the cognitive concept of “I” emerge from the intricate interactions among countless neurons in our brain [
6]? How do large neural language models suddenly exhibit emergent abilities [
7]? These fundamental questions revolve around the concept of emergence in complex living, cognitive, and artificial systems. Emergence refers to the phenomenon where macroscopic properties and phenomena cannot be solely attributed to or explained by the properties of individual components [
4,
8,
9,
10]. This presents a formidable challenge to the traditional reductionist perspective while also shedding light on the underlying reasons for the enigmatic nature of emergent phenomena.
However, as elucidated by Bedau’s theory of weak emergence [
10], many emergent phenomena can be comprehended through the interactions among the individuals within the system [
4]. Complex systems, in fact, consist of extensive networks of interacting components [
11]. Within these networks, even a minor cause, such as a perturbation of a single unit, can propagate through the interconnected network, resulting in a collective effect. The phenomenon described is commonly known as the butterfly effect [
12], which provides an explanation for the occurrence of emergence. On the other hand, emergent properties, such as homeostasis [
13], can stabilize the system itself, thereby preserving the locality of causal effects and preventing the observation of macro-level effects. These phenomena demonstrate that complex systems achieve interactions through causal laws, where numerous local causal laws form interconnected causal networks as a whole. And this whole possesses unique causal characteristics.
Causality, or causation, refers to the connection between a cause and its resulting effect [
14,
15,
16]. It describes the phenomenon in which an event, known as the cause, leads to another event, known as the effect. Traditional studies of causality have typically focused on the causal relationship between two or a few variables. However, the unique characteristics of causality in complex systems present new challenges to classical causal science due to the vast number of variables involved and the presence of emergent phenomena. In complex systems, it is possible for one cause to have multiple effects, and conversely, one effect may be influenced by a multitude of causes. Furthermore, in complex systems, causality often exhibits cross-level properties, which are closely associated with emergence.
Emergence and causation interconnect with each other. On one hand, emergence is the causal effect of complex and nonlinear interactions between components in complex systems [
8,
9]. On the other hand, emergent properties may have causal effects on individuals in complex systems [
4,
17]. For example, the price of fossil fuel is the emerging result of the interactions between buyers and sellers in the market. At the same time, the price may also provide feedback to the market: it can affect the decision making of each individual.
Furthermore, we can understand emergence through the perspective of causation. What emergence means is that some phenomena and properties on the macroscopic level can not be attributed to the microscopic properties [
18]. Thus, emergent properties or phenomena lose their direct explanations as usual but may be attributed to the causes on the macro-level, as pointed out by [
19]. Therefore, new causalities can be observed on larger scales.
In conclusion, gaining a deep understanding of emergence is crucial in the field of complex system studies. Specifically, the development of a quantitative theory of emergence is on the verge of emerging. Such a theory holds the potential to address significant challenges, including the origins of life [
20], the emergence of novel capabilities in large neural network models [
7], and the potential for intelligence, consciousness, and free will to arise in artificial systems [
21]. Causality not only exhibits a profound connection with emergence but is also considered by many researchers as one of the most crucial perspectives for quantitatively comprehending emergence [
18,
19,
22,
23].
Two primary challenges take precedence in understanding emergence from a causal perspective. The first is establishing a quantitative definition of emergence, whereas the second involves identifying emergent behaviors or phenomena through data analysis.
To address the first challenge, two prominent quantitative theories of emergence have emerged in the past decade. The first is Erik Hoel et al.’s theory of causal emergence [
19], whereas the second is Fernando E. Rosas et al.’s theory of emergence based on partial information decomposition [
24].
Hoel et al.’s theory of causal emergence specifically addresses complex systems that are modeled using Markov chains. It employs the concept of effective information (EI) to quantify the extent of causal influence within Markov chains and enables comparisons of EI values across different scales [
19,
25]. Causal emergence is defined by the difference in the EI values between the macro-level and micro-level. Several examples of discrete Markov chains have been shown to exhibit causal emergence if their EI values of macro-level dynamics are larger than those of micro-level dynamics. Hoel and other researchers further extended the measures of effective information and causal emergence for dynamical systems with continuous variables [
26] and complex networks [
27]. Other measures are also possible for quantifying causal effects and, consequently, causal emergence. In [
28], Comolatti and Hoel systematically compared several causal effect measures and concluded that causal emergence is independent of the selection of the measure.
However, in Hoel’s theory of causal emergence, it is essential to establish a coarse-graining strategy beforehand. Alternatively, the strategy can be derived by maximizing the effective information (EI) [
19]. However, this task becomes challenging for large-scale systems due to the computational complexity involved. To address these problems, Rosas et al. introduced a new quantitative definition of causal emergence [
24] that does not depend on coarse-graining methods, drawing from partial information decomposition (PID)-related theory. PID is an approach developed by Williams et al., which seeks to decompose the mutual information between a target and source variables into non-overlapping information atoms: unique, redundant, and synergistic information [
29]. Based on this groundwork, Rosas further developed the concept and introduced a theory called
ID to decompose the mutual information between multiple target and source variables [
30]. This framework provides a quantitative definition of causal emergence by measuring the positive synergy information between the source and target variables based on the inherent characteristics of the system.
The second challenge pertains to the identification of emergence from data. In an effort to address this issue, Rosas et al. derived a numerical method [
24]. However, it is important to acknowledge that this method offers only a sufficient condition for emergence and is an approximate approach. Another limitation is that a coarse-grained macro-state variable should be given beforehand to apply this method. Hence, there is a need for the development of new methods.
Recently, artificial intelligence, propelled by the rapid advancements in machine learning and deep neural network technology, has witnessed significant progress. In the context of causal emergence, there are two key aspects to consider. Firstly, machine learning and neural network technology can be employed to address the challenge of identifying causal emergence. By leveraging these tools, we can develop approaches to effectively detect and analyze causal emergence phenomena. Secondly, the concepts and techniques from causal emergence can be introduced into machine learning to enhance the generalization capabilities of models. This integration can potentially improve the ability of machine learning algorithms to generalize well beyond the training data, leading to more robust and adaptable systems.
In a recent study by Zhang et al. [
31], a machine learning framework named the Neural Information Squeezer (NIS) was introduced to address the challenge of identifying causal emergence using Hoel et al.’s framework. Remarkably, the NIS neural network, functioning as a “machine observer” equipped with an internal model, exhibits a remarkable ability to identify causal emergence across various types of data. In the latest updated version of this work, the Neural Information Squeezer Plus (NIS+) has been developed to directly maximize the critical measure of causal emergence theory, namely effective information (EI) [
32]. Through extensive experiments conducted on both simulated data and real brain data, the NIS+ has demonstrated its ability to automatically find emergent macro-variables and macro-dynamics. Consequently, the NIS+ enables quantifying causal emergence in data with the learned macro-dynamics. The results of these experiments highlight the effectiveness and potential of the NIS+ in capturing and analyzing causal emergence phenomena.
Furthermore, the NIS+ showcases superior performance in terms of generalization ability by directly maximizing effective information (EI). This brings forth a second question: can we leverage the measure of causation, EI, in the context of causal emergence, to enhance the generalization capability of neural networks for out-of-distribution scenarios? This concept is referred to as causal emergence for machine learning. By exploring this idea, we aim to bridge the gap between causal emergence and machine learning, potentially unlocking new avenues for improving the generalization abilities of machine learning.
Finally, in
Section 5, we address several important and related issues. Firstly, we explore the similarities and differences between two emerging fields: causal emergence and causal representation learning [
33]. This comparison sheds light on the interplay between these two domains. Secondly, we delve into a philosophical problem concerning ontological or epistemological causality and emergence, providing insights into the underlying philosophical implications. Lastly, we discuss the potential applications of causal emergence in complex systems and how it contributes to our understanding of complex systems from a causal emergence perspective. These discussions broaden the scope of this paper and offer intriguing avenues for future research.
This paper aims to provide a comprehensive review of the latest research on the quantitative theory and applications of causal emergence and related works. It also explores the connections between causal emergence, machine learning, and complex systems. The subsequent section delves into the background of causal emergence, with a particular focus on the interplay between causation and emergence in complex systems. In
Section 3, various quantitative theoretical frameworks are introduced, including Crutchfield et al.’s computational mechanics [
22], Seth et al.’s Granger causal emergence [
23], Hoel et al.’s causal emergence theory, and Rosas et al.’s theory of emergence based on information decomposition. Additionally, related concepts such as the coarse-graining strategy, measures of effective information, and partial information decomposition are discussed, and a comparative analysis of these theories is presented.
Section 4 addresses the connection between causal emergence theory and machine learning. It explores the use of machine learning and neural network techniques for identifying causal emergence and extends the measure of effective information (EI) to machine learning problems. Finally, this paper delves into other important topics and potential applications in the fields of machine learning and complex systems.
3. Quantifying Emergence by Causality
Since causality and emergence have a strong connection and causality has multiple quantitative frameworks and measures, it becomes natural to use causality to quantify emergence. In this section, we review several frameworks used to quantify multi-scale causality and emergence.
3.1. Early Related Works
Before the theory of causal emergence was proposed by Hoel et al., some works introduced very similar ideas to causal emergence theory. For example, Crutchfield et al.’s computational mechanics theory considered causal states, which are the partitions of the state space and may have good predictions. Furthermore, Seth et al. proposed G-causality to quantify emergence using Granger’s causality. We discuss them in detail below.
3.2. Computational Mechanics
The theory of computational mechanics proposed by Crutchfield, Shalizi, and Feldman et al. tried to formulate this kind of emergent causation in a quantitative framework [
22]. In some sense, computational mechanics can be understood as the inverse of statistical mechanics. This is because statistical mechanics derives macro-level consequences from micro-dynamics, whereas the inverse process is performed by computational mechanics, which constructs a minimal causal model from the observations of a stochastic process that can generate the observed time series.
Let us assume that the stochastic process under consideration can be represented as . We can divide it into two segments beginning from time step t: the history before t, denoted as , and the future after t, denoted as . If the process is stationary, we can remove the denotation of t. Thus, all possible histories form a set, denoted as , and all futures form a set, denoted as .
We aim to establish a model that can reconstruct and predict observed random sequences, with a higher accuracy being desirable. However, the randomness of the sequences prevents us from achieving a perfect reconstruction unless we record every randomly occurring character. This would make the model excessively long. To preserve useful information as concisely as possible, we need a coarse-grained mapping that captures the ordered structure in the random sequences, known as patterns [
63]. We can partition
into mutually exclusive and jointly comprehensive subsets that form a set
. Any subset
is called a “state”. We define a function from histories to states as
. Thus,
is a method that can partition the history into mutually exclusive and jointly comprehensive subsets.
For a set of states
, we can measure its simplicity using a complexity metric. Intuitively, the larger the cardinality of
, the more complex it is. Additionally, we need to consider its distribution. For example, if one state occurs frequently while others occur rarely, it is less complex compared to a situation with a uniform distribution. Therefore, we can define the
statistical complexity of a set of states using Shannon entropy [
79]:
When constructing predictive models using a set of states, the statistical complexity refers to the size of the model.
What kind of state set can achieve the best balance between predictiveness and parsimony? We can introduce an equivalent relationship called
causal equivalence [
63]. Concretely, we say
and
are causally equivalent if and only if:
This equivalent relationship can partition all the histories into equivalent classes, and they are defined as causal states. We denote all the causal states of a history as , where is a function that can map a history to the causal state which is a subset of the histories.
For any two causal states
and
, we can define
causal transitions as a set of labeled probabilities
that represent the transition from the causal state
to the causal state
while emitting the symbol
[
63]:
where
is the current causal state,
is its successor, and
denotes all the sequences of length
, in which the first symbol emitted is
s (we use slightly different symbols from those in [
79]). Hence, by combining:
and
, we ensure that all subsequent causal states will have the identical initial emitted symbol
s. We denote the set
by
T. The definition of causal transitions leads to a direct conclusion:
, where
is read as the semi-infinite sequence obtained by concatenating the history
and the symbol
s [
79].
The -machine of a process is defined as the ordered pair , where is the causal state function (which can map a state s to the partition ), and T is the set of the transition matrices (the dynamics) for the states defined by .
Up until now, we have defined
-machine, which is a pattern discovery machine where the patterns are unraveled from the set of histories. The remaining task is to show that it is, in some sense, optimal. It has the important properties of being minimally predictive, maximally statistically complex, and minimally stochastic [
79].
We compare the causal state
to any state
to show that for the purpose of predicting the future, the causal states do a better job, i.e., they provide more information. This property can be formulated as a mathematical theorem, called
the maximal predictability theorem. It is stated as follows: if
is the causal state given by
, then for any other state
and all
, we have:
where
is the conditional entropy, and
is the
L-length sequences for future. Thus, the inequality shows that the uncertainty of
given the causal state
is less than all other states.
After achieving optimal predictiveness, the causal state set remains the one with minimal statistical complexity. We first introduce the notion of prescient rivals denoted as , which are the states that are as predictive as the causal states; viz., for all , .
Next, we present the
minimum statistical complexity theorem: for all prescient rivals
,
Next, we show that the causal states are
minimally stochastic. That is to say, compared with other competitors with the same ability to predict the future, the causal states and their transition dynamics have the least uncertainty. Then, we have the
minimal stochasticity theorem, which is expressed as follows: for all prescient rivals
,
where
and
are the next causal state of the process and the next state, respectively. This means that the causal state and
-machine provide the best intrinsic determinism.
Since the causal state set is considered the best, how can we compute the causal states and
-machine from the observed data? The authors of [
63] introduced a
hierarchical machine reconstruction algorithm; however, the details are not reiterated here.
Although this algorithm may not be applicable to all operational scenarios, the authors presented numerical computational results and corresponding machine reconstruction pathways for chaotic dynamics, hidden Markov models, and cellular automata as examples [
63,
79].
It is interesting to compare the theory of computational mechanics with causal emergence. Indeed, we can understand that all the histories are micro-level states, and all the states are macro-states. Thus the function that can map a history to a state R is a possible coarse-graining strategy.
It is worth pointing out that the causal state
is the special state that can have at least the same predictive power as the micro-state
, i.e., the full history. Therefore,
is similar to the notion in the effective coarse-graining strategy in [
31] (see
Section 3.6.5), and the causal transitions
T represent the corresponding effective macro-level dynamics. The feature of minimal stochasticity characterizes the deterministic property of the macro-dynamic. This property is characterized by effective information (EI) in causal emergence theory.
Although a clear definition and quantitative theory of emergence were not provided, the authors discussed the relationship between computational mechanics and emergence [
63,
80]. In [
63], the authors explained that emergence can be conceptualized as a dynamic process in which a pattern acquires the ability to predictably adapt to different environments, as observed by an external observer. Additionally, they differentiated intrinsic emergence from emergence itself, as intrinsic emergence goes beyond the mere production of patterns and encompasses the formation of an embedded observer within the system through these patterns.
3.3. G-Emergence Theory
G-emergence theory, proposed by Seth in 2008 [
23], is one of the earliest works on a quantitative measure of emergence. His basic idea is to use nonlinear Granger causality to measure weak emergence in complex systems.
Granger causality (G-causality) is formally defined as follows: Given two time series A and B, if the past values of B can help predict the future values of A, beyond what can be forecasted using the past values of A, then B is said to be “Granger-cause” of A. This implies the existence of Granger causality between A and B.
When applying a bivariate autoregressive model for predictions, residual terms are included in the equations of the two variables. Then, the residuals can be utilized to quantify the extent of the causal effect in G-causality. The degree of
B being the G-cause of
A is quantified by the logarithmic of the ratio of the two variances of residuals. One is the residual of the autoregression model of
A if all the terms of
B are omitted, and the other is the residual of the full prediction model, as shown in
Figure 3. In addition, in [
23], the author also defined G-autonomous as the ability of past values in a time series to predict its own future values. And the degree of G-autonomous can be measured in a similar way as G-causality.
With these two basic notions in G-causality, as shown in
Figure 4, the author defined G-emergence on macro-variables as follows: a macro-variable
M is G-emergent from a set of micro-variables
if and only if (i)
M is G-autonomous with respect to
, and (ii)
is G-cause of
M. The degree of G-emergence can also be quantitatively measured by multiplying the degree of G-autonomous of
M and the average of G-causes of
on
M.
The author tested the G-emergence theory on the Boid model. This model is a famous artificial life model that simulates the flocking behavior of birds using three simple rules: cohesion, alignment, and separation [
60]. These basic rules are realized by the virtual forces exerted on each bird, and the strength of each force can be controlled. The author found that by increasing the strength of cohesion, the G-emergence of the entire flock also increased. Here, the macro-variable is selected as the center of the flock (center of mass), and each bird is a micro-variable. The author also discovered a downward causality phenomenon in this simple model: the center of mass can be used to predict each individual bird. However, the author did not distinguish downward causation from other common causality in their work because Granger’s causality is not a real causal relationship.
Seth’s G-emergence theory was the first attempt to quantify the emergence phenomenon via a causality measure. However, the causality measure that the author used was Granger causality, which is not a strict causal measure, and it also depends on the regression method to be used. Furthermore, the measure is defined on variables but not dynamics, which means the result depends on the selection of variables.
3.4. Other Quantitative Theories of Emergence
There are alternative means of measuring emergence that do not require relying on causality. Two different methods have been discussed by the scholars. One is to understand emergence as a process from disorder to order, and the other is to understand emergence from the perspective that “the whole is greater than the sum of parts”.
For example, Moez Mnif and Christian Müller-Schloer used Shannon entropy [
81] to measure order and disorder. In a self-organized process, emergence occurs when there is an increase in order. This increase can be quantified by measuring the Shannon entropy difference between the initial state and the final state, denoted as
. However, this definition has two limitations. Firstly, the measurement of entropy, denoted as
H, is dependent on the abstract level of observation. Therefore, it is necessary to account for the entropy increase resulting from a change in the observer’s abstract level. Secondly, the choice of the initial condition of the system is arbitrary. To address this limitation, one approach is to measure the relative level of Shannon entropy compared to the maximum entropy distribution. Finally, emergence can be quantified by:
where
is the maximized entropy of the system. If no prior information is available, the maximum entropy, denoted as
, corresponds to the Shannon entropy of an equal probability distribution. On the other hand,
H represents the Shannon entropy of the system at the final moment of a self-organization process. Additionally,
represents the entropy increase during this process resulting from a change in the observer’s abstraction level. It should be noted that if the observer does not alter their abstraction level, this term would be zero. We can also normalize this quantity by dividing
such that different features can be compared by the normalized quality. For a multivariate system, the authors suggested employing a radar plot to visualize the emergence fingerprint of the dynamical process, which showcases the normalized emergence measure across various variables. Then, the authors applied this method to a simulated system of chickens. M. Tang and X. Mao applied this indicator to artificial society models [
82].
Inspired by Moez Mnif and Christian Müller-Schloer’s work, ref. [
83] suggested using the divergence measure between two probability distributions to better quantify emergence. They understood emergence as being
an unexpected or unpredictable change of the distribution underlying the observed samples. However, this method suffers from computational complexity and estimation accuracy. To address these problems, ref. [
84] further proposed an approximating method using the Gaussian mixture model to estimate the density and introduced Mahalanobis distance to characterize the divergence between data and Gaussian components, leading to better results. In [
85], the authors systematically compared the three aforementioned methods and applied them to a simple test example. Another Shannon entropy-based emergence measure was proposed by Holzer and de Meer et al. [
86,
87]. They considered a complex system as a self-organization process in which different individuals interact with communications. Emergence can then be measured based on a ratio between the Shannon entropy measure on all communications between agents and the total summation of the Shannon entropy for each communication as a separate source.
Unlike the aforementioned methods, refs. [
88,
89] proposed a method to quantify emergence based on the idea that “the whole is greater than the sum of its parts”, defining emergence from the interaction rules and states of agents instead of the overall statistical measure of the whole system. Specifically, this measure consists of two terms that are subtracted from each other. The first term characterizes the collective states of the entire system, whereas the second term represents the summation of the individual states of all its constituent parts. This measure emphasizes the emergence that arises from the interactions and collective behavior of the system. This method was then tested on the example of bird flock simulation.
3.5. Erik Hoel’s Causal Emergence Theory
3.5.1. Basic Idea
The first quantitative emergence theory based on Markov dynamics and causality measures through intervention was Erik Hoel’s causal emergence theory.
In this framework, system properties can be characterized at various levels, ranging from micro to macro. If a system exhibits stronger causality at the macro-level than at the micro-level, it demonstrates causal emergence. Causality is reflected between successive states during the system’s evolution. The strength of a system’s causality reveals the extent to which its future state is influenced by its current state. The basic idea of causal emergence is illustrated in
Figure 5.
For example, statistical mechanics is a typical theory of causal emergence. At the micro-level, a huge number of molecules collide and exhibit random behaviors such that probabilistic language must be used to describe them. However, if we coarse-grain the whole system into several thermodynamic physical variables like pressure, temperature, etc., we can use very concise and exact thermodynamic equations to describe their behaviors. Therefore, thermodynamic laws have a stronger causal effect than micro-level molecular dynamics.
Formal tools are used to describe the elements in Hoel’s causal emergence theory. Typically, it employs discrete Markov models to describe the micro-dynamics of systems, and the corresponding macro-level systems with different Markov dynamics can be derived by coarse-graining the micro-systems. Additionally, the inherent strength of the causal effect of the Markov model can be measured with effective information (EI), indicating how effectively a particular state influences the future state of a system.
EI is an intrinsic property of a system’s dynamics and can be quantified by the transitional probability matrix (TPM). A coarse-graining strategy is a function that maps a set of micro-states into a particular macro-state, allowing for the derivation of a new dynamical model described by TPM from the micro-level TPM. The effective information of the coarse-grained model can also be computed. The phenomenon of causal emergence implies that as we coarse-grain microscopic states, the amount of effective information transmitted from the current state to the next state can possibly increase. At a certain macroscopic scale of coarse-graining, the effective information reaches a maximum; this scale represents the point at which the system state has the maximum causal power to predict future states in the most reliable and effective way.
To illustrate causal emergence, let us look at a particular Markov chain model with four possible states, whose transition probability matrix (TPM) is:
In this model, if we take the first three states as group 1 and the last state as group 2, anyone in group 1 can transition to any of the three states in the same group with equal probability at the next moment. However, because there is only one state in group 2, so the fourth state will always stay in its position. Intuitively, we can conclude that the future states are not fully determined by the current states, and uncertainty mainly arises from group 1.
However, if we merge the first three states in group 1 into one new state and keep the fourth state in group 2 as it is, we obtain a coarse-grained Markov model with two states, represented by the following TPM:
Now, the future states of the new system can be fully determined by the current states. This shows that we can eliminate the uncertainty of a nondeterministic system by performing coarse-graining over the system states.
3.5.2. About Coarse-Graining
The example above illustrates how a system’s determinism can increase as it is coarse-grained. Coarse-graining is a process that simplifies the description of a system by grouping its components into larger, more slowly varying units. It is often used to identify the essential features of a system that determine its macroscopic behavior, without being burdened by the details of micro-scale interactions. Unlike dimension reduction techniques, such as PCA and SVD, coarse-graining takes into account the system’s features at different spatial and temporal scales. Coarse-graining also differs from renormalization. In physics, the renormalization group method was invented to eliminate infinities in integrals. It is also used to coarse-grain a system such that the Hamiltonian or partition functions are similar between micro- and macro-levels [
90,
91]. However, the coarse-graining method does not have this requirement in general. Although both techniques are designed to describe a system from a coarse-grained level, coarse-graining focuses more on the states of the system, whereas renormalization cares about dynamics, system rules, partition functions, etc. Renormalization is frequently used in physics and the study of phase transitions to explore critical phenomena and symmetry breaking. These are aspects that coarse-graining typically does not consider.
Given a transitional probability matrix (TPM), there are many ways to partition the state space for coarse-graining the system. What kind of coarse-graining strategies are more reasonable? In [
19,
25], the authors suggested selecting an appropriate coarse-graining method by maximizing the effective information of the coarse TPM. In the literature, there is another criterion for selecting a coarse-graining strategy called lumpability, where the lumpability of a TPM refers to the coarse-grained TPM exhibiting similar dynamics and observation statistics [
92]. Commutativity is another requirement that requires the operations of coarse-graining and state transitions to be commutative [
93]. There are also other discussions or reasonable model reductions of Markov or hidden Markov models [
94,
95,
96].
3.5.3. About Effective Information
In order to quantify emergence, a widely used method is to calculate the mutual information between the past states and future states of a system. This mutual information defines the upper limit of the information being transferred from the past to the future. If the mutual information is high, it suggests that a significant amount of information about the past is retained in the future.
One limitation of utilizing mutual information is that the resulting value may fluctuate in response to changes in the joint probability of data. This can make it difficult to obtain a consistent outcome if the system is exposed to different inputs.
Effective Information (EI)
To address this limitation, Hoel introduced the concept of effective information to measure the causal effect of the current state on the future state of a system. Effective information is a scoring metric based on mutual information and can be calculated from the system’s transition probability matrix (TPM), which is invariant to the input data.
By “intervening” in the current state distribution to follow the uniform distribution (the distribution of maximum entropy), denoted as
, the TPM enables the prediction of the future state distribution
at the next moment. The effective information (
) of the system is defined as the mutual information between
and
, which can be expressed as
The probability distribution of the random variable
, representing the initial state, is denoted as
, indicating that it follows a uniform distribution. Hoel adopted the notion of the “do” operator from Judea Pearl’s causal analysis framework [
25]. It is worth noting that in Pearl’s context, the do operator is typically used to assign a specific value to the intervened variable rather than applying a distribution [
16].
Another point that needs clarification is that the “do” operator used here is purely a mathematical construct that specifies the distribution of . It does not imply the need for actual intervention in the system. However, the imaginary “do” operation is equivalent to a real intervention in the context of this scenario, given that the dynamical mechanism (TPM) is provided. Consequently, we can perform any desired intervention on the system, just as in computer simulations.
The second issue pertains to why we apply the “do” operator to a uniform distribution. In [
19], Hoel et al. claimed that the distribution should be the maximum entropy distribution, which is the most reasonable selection for the input variable
if we have no prior information about the input variable [
97]. As we know, uniform distribution can be derived by maximizing entropy if there is no constraint.
The authors of this review believe that applying the “do” operator to a uniform distribution ensures that the objective measured by EI solely reflects the dynamical mechanism itself, i.e., the TPM, and is independent of any input data.
This point can be clearer if we re-express EI as a function of the TPM of the system (see
Appendix A for the detailed derivation):
where
represents the transitional probability of the system from the state
i to the state
j.
Therefore, effective information offers a solution to the aforementioned limitation of mutual information. Given that the TPM can capture the inherent nature of a system, EI is likewise an intrinsic property of the system.
However, if we apply the “do” operator to the system using different distributions, EI will depend on the chosen distribution, and certain transition probabilities of specific rows may carry greater weight in the average calculation. Consequently, deriving a simple expression solely based on the transitional probability matrix (TPM) may not be possible. Furthermore, if there is no “do” operator, the effects of the dynamical mechanism and the input distribution in EI would not be distinguishable or separated, as the mutual information is a function of the input distribution .
The Derived Measures of EI
Furthermore, we can calculate the EIs for the TPMs of both macro- and micro-dynamics, and their difference is defined as the measure of causal emergence, that is,
where
represents the TPM of macro-level dynamics, and
represents the TPM of micro-level dynamics.
measures the degree of causal emergence. If
, then causal emergence occurs; otherwise, it does not occur.
However, there is a limitation for EI and CE when comparing two dynamics that differ significantly in size. This is because the value of effective information relies on the number of possible states within the system, denoted as
N, with an upper bound of
. To facilitate comparisons between different coarse-graining strategies and scales, effective information is often normalized, resulting in a metric known as the effect coefficient
.
The value of the effect coefficient is always between 0 and 1, representing the proportion of effective information being transferred from current states to future states. If the information is fully transferred, the effect coefficient is 1.
In addition to characterizing causal emergence, the effect coefficient can be further broken down into two meaningful components: “
”, which represents the certainty of a current state evolving into a certain state or diverging into multiple states in the next moment, and “
”, which represents the possibility of multiple current states converging into one state in the next moment.
where both “
” and “
” can be defined in terms of the TPM (refer to Equations (
8) and (
10)):
It should be noted that the determinism of a system is always greater than its degeneracy, as the lower bound of the effect coefficient is 0. The following examples illustrate what determinism and degeneracy look like in systems with varying TPMs.
In
Figure 6, the square cells represent the elements of the TPM, and the grayscale areas represent the values of the TPM elements. Example (a) is a bijective system, meaning that all information from current states can be transferred to future states without loss. It is fully deterministic with zero degeneracy. Example (b) is an extreme case where all current states lead to only one future state, illustrating that high determinism does not necessarily imply a high effect coefficient. Systems (c) and (d) differ but have the same effect coefficients. Finally, system (e) is a coarse-grained version of either system (c) or (d), demonstrating two important points: first, different microscopic systems can be coarse-grained to the same macroscopic system, and second, causal emergence can be quantitatively captured from coarse-graining by the increased effect coefficient.
One limitation of EI is its global nature, as highlighted by the fact that the summation of additional terms encompasses the entire state space, as defined in Equation (
8). Therefore, ref. [
98] proposed the concept of flickering emergence, which decomposes EI into each term added in Equation (
8). This new feature can characterize the local properties of Markov dynamics.
Comparison with Other Measures of Causation
Hoel’s theory of causal emergence is based on effective information, however, is the selection of EI necessary for measuring causation? Is causal emergence a phenomenon that depends on the selection of the measure of causation? To address this problem, in Comolatti and Hoel’s work [
28], a systematic comparison was conducted between effective information (EI) and other measures of causation that are widely applied in various fields, ranging from philosophy to genetics.
The findings of this comparison revealed that causal emergence is not merely a peculiar phenomenon limited to a specific measure. Instead, it exhibits commonalities and shared characteristics across different measures and fields of study. EI is not the sole measure for capturing causal emergence; there are other measures of causation that can also reveal the phenomenon of causal emergence. This suggests that the concept of causal emergence has broader applicability and relevance. We introduce this work in detail below.
Firstly, Hoel highlighted that causation is not merely a singular relationship between a cause and an effect. Instead, it encompasses two fundamental dimensions known as causal primitives: sufficiency and necessity.
The sufficiency aspect of causation refers to the scenario where the occurrence of the cause guarantees the occurrence of the effect. In other words, whenever the cause happens, the effect is also observed. This sufficiency dimension, denoted as
, can be formally defined as the probability of the effect
e occurring given the condition that the cause
c has occurred:
In addition, a necessary (
) relation in causation refers to the absence of the effect implying the absence of the cause. In other words, when the effect does not occur, it indicates that the cause also does not occur. This can be understood as a kind of causal effect measure for the counterfactual. This necessary dimension, denoted as
, can be quantitatively defined as the probability that the effect
e does not occur when the condition that the cause
c has not occurred is given by:
where
represents the set of all possible causes in
C but with the particular cause
c being excluded. Therefore,
represents the probability that
e occurs if other causes except
c occur.
With these causal primitives defined, Hoel compared different measures of causation, including Hume’s constant conjunction [
40], Cheng’s causal attribution [
99], Eells’s measure of causation as probability raising [
41], Suppes’s measure of causation as probability raising [
42], and Judea Pearl’s measures of causation [
16]. The finding was that all of these measures can be expressed as the two causal primitives.
For example, Cheng’s causal attribution can be expressed as:
With this understanding, a natural question arises: Can effective information (EI) be expressed using causal primitives? The answer is affirmative. However, to clarify this point, two important distinctions need to be made. Firstly, in most measures of causation, the causal variables are binary, whereas EI is defined for variables with multiple values. Secondly, EI is an information-theoretic measure, whereas others are probabilistic measures. Despite these distinctions, EI can still be expressed using causal primitives.
To understand this, let us examine the equivalent measure of EI: normalized effective information (
) in Equation (
11). This measure contains two terms. The first term is
, and the second one is
. These two terms can be expressed as
and
:
where
is the Shannon entropy of the conditional probability
, which is
, and
is the distribution of all causes. In the definition of EI (Equation (
7)), this distribution is intervened as a uniform distribution such that equal weights are assigned to causes
. It is not hard to see that
is an information metric for
and is averaged for all causes. Furthermore, as
increases and approaches one, indicating the emergence of causal effect, the value of
H decreases, whereas determinism concurrently increases. Thus, the determinism term in EI plays a similar role to that of
in causal primitives.
Another term is
, which can be re-written as:
where
is also the Shannon entropy of the conditional probability
, which is calculated by averaging the causal effect for all elements in
C as
. The entropy
serves as a measure of the average causal effect for counterfactuals, as
can be interpreted as
. This is due to the approximation
when the number of elements in
C is significantly large, and
C certainly encompasses
. Consequently,
in
acts as the counterpart to
in causal primitives.
Therefore, EI or is a valuable measure of causation, particularly in cases where the cause and effect variables are not limited to binary values.
Comolatti and Hoel [
28] conducted additional experiments to investigate the phenomenon of causal emergence using various Markovian dynamics, employing different measures of causation, as discussed above. Their findings revealed the widespread occurrence of causal emergence, regardless of the specific measure of causation employed.
3.5.4. Examples of Causal Emergence
The example above demonstrates a coarse-graining strategy that is intuitive, as it involves aggregation at the state level. However, in reality, coarse-graining often occurs among variables, and the combination of these variables produces different states. Let us look at a more complicated example of a boolean network, given in [
19], and inspect the causal emergence when coarse-graining its state transition mechanism. A, B, C, and D are four binary variables whose state transition relations are shown in
Figure 7a.
In order to demonstrate how different coarse-graining strategies can impact effective information, we can combine two micro-states into a single macro-state. For example, we can define
and
as coarse-grained variables at the macro-level, where their values can be either ‘off’ or ‘on’. Using various aggregation strategies, as illustrated in (a)/(b) and (d)/(e) in
Figure 8, we can construct the TPMs for the resulting coarse-grained systems. The TPM and the corresponding metrics are presented in
Figure 8c,f, respectively.
The effective information values for the two macroscopic systems are
and
, respectively. It is evident that the effective information has increased in the first coarse-graining scenario (
), whereas it has decreased in the second case (
). Thus, causal emergence is observed in the first coarse-graining scenario. This implies that (1) proper coarse-graining can lead to causal emergence in a macroscopic system, and (2) not all coarse-graining approaches result in higher effective information. This example illustrates that coarse-graining can play an important role in emergence, and effective information is a well-defined quantification method. This gives us the opportunity to identify causal emergence in a given system. This raises the following question: What coarse-graining strategy can generate the maximum effective information? We address this question in
Section 4.
3.5.5. Extensions to Continuous Systems
Effective information and its associated metrics have been shown to be useful in quantifying causal emergence. However, there are some limitations to be aware of. First, the method is only applicable to discrete-state systems. Second, knowledge of the system’s transition probability matrix (TPM) is required to calculate the effective information metrics. Efforts have been made to apply or extend the concepts of effective information to continuous systems [
26,
31,
100].
Ordinal Partition Network
One approach to incorporating effective information in continuous systems is to transform the continuous variables into discrete ones using the ordinal partition network (OPN) method [
100]. The basic idea is to transform the time-series data generated by a continuous dynamical system into a sub-time series of dimensionality
d with discrete values and then establish a transition probability matrix (TPM) between these discrete series. This approach involves three steps: firstly, sampling the original time series with a specified time interval
to create sub-time series of dimensionality
d; secondly, ranking these sub-series based on their values; and finally, utilizing the
d-dimensional vectors of rank orders to represent the original sub-series. By employing rank orders, this method ensures that the values are restricted to integers within a certain range.
In [
100], the author applied the OPN method to the Rossler chaotic attractor system. By quantifying effective information, he noticed that effective information (such as determinism and degeneracy) was sensitive to the critical phase transition between period and chaos [
100].
Causal Geometry
Alternatively, Pavel Chvykov and Erik Hoel extended the causal emergence framework to continuous systems and proposed the concept of causal geometry [
26].
To understand the basic idea of this work, we suppose the continuous system considered is a continuous functional map and assume that the uncertainties are small disturbances added to this deterministic function, that is,
where
x is the input variable defined on the interval
,
L is a very large constant,
y is the output variable, and
is a Gaussian noise with a zero mean and standard deviation
. Then, an approximate form of the effective information for such a continuous system can be obtained using the Gaussian integral.
The reason we set the domain of
x to
is to guarantee that the Gaussian integral can be implemented and to simplify the definition of a uniform distribution on it.
This form can be easily generalized to a dynamical system with discrete time steps once we replace
x and
y with
and
, respectively. The formula can also be extended to higher dimensions, with
and
represented in bold. Suppose
and
, where
n and
m are positive integers. Equation (
19) can be generalized to the following form:
where
is the covariance matrix of the Gaussian noise
,
represents the uniform distribution on the hypercube
,
is the absolute value operation, and det is the determinant.
Note that the conditional distribution of
given
is a Gaussian distribution, that is,
. Thus, the term in the expectation in Equation (
20) can be written as:
and this corresponds to the determinant of the negative Fisher information metric for the distribution
:
which measures the sensitivity of the logarithmic
to changes in
, where
represents the partial derivative with respect to the
th component of
. Therefore, we have defined a distance metric for the Riemann manifold
on the parameter space
, encompassing all possible distributions of
. This is the origin of the term “geometry” in this framework.
Finally, we can obtain an expression for EI with the Fisher information metric:
This formula can be generalized to cases where
is a non-Gaussian distribution. Once the distribution function is known, we can obtain its Fisher information metric, and then EI can be calculated using Equation (
23). The reason behind this is that the whole manifold
for any
can be understood as a concatenation of local Gaussian distributions.
In [
26], the authors considered a more general case in which intervention noise is added to the input (intervention) variable
x in Equation (
19). The intervention noise is denoted as
, where
is the standard deviation of
. In contrast,
is called observational noise distinguishing it from
, and is added to the output (observational) variable
y according to Equation (
19). Finally, if two kinds of noise are both considered and if
and
, Equation (
19) becomes:
This is the formula for EI for the continuous mapping function (Equation (
18)) given by [
26]. Using this equation and a logistic function for
, the authors compared the EIs of a more continuous map (Equation (
18)) and a more discrete map with an adjustable parameter in the logistic function. They discovered that when the noise level is low, the continuous map can exhibit higher EI compared to the discrete map. However, as the noise level increases, discretizing the mapping function can lead to a model with higher EI. This phenomenon helps explain why digital circuits eventually outperform analog circuits in mitigating noise interference; the binarization and coarse-graining strategy of digital circuits suppresses the propagation and diffusion of noise.
To generalize the information geometry to the case with intervention noise and observational noise, let us introduce a new intermediate variable with dimensionality l such that we cannot control by directly intervening . Instead, we can intervene to influence and indirectly affect . Therefore, the three variables form a Markov chain: .
In this case, two manifolds can be obtained: the effect manifold with metric and the intervention manifold with metric , where and . These two manifolds together are called causal geometry.
Finally, the EI calculation formula for causal geometry is:
where we have set
and
to reduce the number of free parameters, and
is the identity matrix with size
n,
.
EI Calculation for Neural Networks
One of the application areas for continuous EI is neural networks. In [
101], the authors applied EI to analyze the causal effects for different layers of neural networks and compared the results with the information bottleneck theory. The method they used to calculate EI was to convert continuous variables into discrete ones by dividing the domains of the input and output variables into small regions. However, this method has high computational complexity and is challenging to extend to high dimensions.
In [
31], the authors proposed a new numeric method for calculating EI on neural networks. The basic idea behind this method is to understand a well-trained feed-forward neural network as a stochastic mapping, following:
where
is the input variable,
is the output variable, and
is the deterministic map of the neural network. Additionally,
is a Gaussian noise with a mean of zero and a covariance matrix
, where
is the mean square error on dimension
i across the entire training dataset. In this way, the neural network can be regarded as a Gaussian distribution
.
Therefore, Equation (
20) can be used on this neural network to calculate EI. In [
31], the authors used the Monte Carlo integration method to estimate the expectation in Equation (
20). This technique significantly reduces the computational complexity.
However, when the authors compared the results calculated using Equation (
20) for various neural networks with different dimensions, they obtained unreasonable results: EI increased with the number of dimensions. Thus, causal emergence was not always observed because micro-dynamics exhibited unreasonably larger EI. Another drawback of Equation (
20) is that the parameter
L always dominates the value of the expression and should be removed from the equation. One way to solve this issue is to use Eff instead of EI (see Equation (
10)). However, not all
Ls in Equation (
20) can be eliminated. Therefore, the authors introduced the notion of dimension-averaged EI, defined as
which simply divides EI by the dimension of the output variable
. By using dimension-averaged EI,
L can be removed when calculating dimension-averaged causal emergence for the neural networks
and
representing macro- and micro-dynamics, respectively, given by
where dCE is the dimension-averaged causal emergence measure. If we incorporate Equation (
20) into Equation (
28), we obtain:
in which
L is eliminated.
3.5.6. Causal Emergence in Complex Networks
Many complex systems can be represented by networks; therefore, applying the framework for causal emergence to networks is necessary. However, two problems should be solved in advance to apply Hoel’s framework: one is to assign dynamics to the studied network because networks are static structures without any dynamical properties and the other is to coarse-grain the network.
Klein and Hoel [
27] addressed the first problem by considering random walks on complex networks. Subsequently, the TPM of the system was defined based on the transfer probabilities between nodes of a large number of random walkers. Due to the good mathematical properties of the random walk dynamics on graphs, the authors established an explicit expression for EI on networks, and the final form only relied on the weighted normalized adjacency matrix
(
) of the network. The expression is as follows:
where
represents the Shannon entropy calculated from the distribution of the averaged out-weights across all nodes (
), which characterizes the determinism of the random walk dynamics;
is the average Shannon entropy for all nodes, which characterizes the degeneracy of the dynamics; and
is the uncertainty of node
i.
To address the second problem, in [
27], the greedy algorithm was used to group nodes to form a macro-network. It is worth noting that when merging micro-nodes into macro-nodes, the TPM of the resulting macro-network can be derived by merging the probabilities from the TPM of the micro-level. To ensure that the grouped macro-network maintains the same random walk dynamics as the original one, a dynamic consistency test is implemented.
In the experimental section, the aforementioned paper explored the application of a greedy search for identifying causal emergence in complex networks. Experiments were conducted on artificial networks as well as four types of real networks. In the case of ER random networks, the size of effective information was solely dependent on the connection probability p and converged to with the increase in network size. Additionally, a significant finding was the presence of a phase transition point, where the average degree of the network reached approximately . Beyond this point, the random network structure did not contain additional information with increasing size. In the case of preferential attachment (PA) networks, when ( represents the degree of preferential attachment), the effective information of the network increased as the network size expanded. Conversely, when , the opposite was observed. The scale-free network corresponding to represented the critical boundary of growth. Regarding real networks, the authors found that biological networks exhibited the lowest EI due to the presence of significant noise, which can be removed through effective coarse-graining, and causal emergence was the most significant compared to other types of networks. However, technical networks exhibited sparsity and non-degeneracy, resulting in higher average efficiency and more specific node relationships. Consequently, they exhibited the highest EIs among the studied networks.
The network coarse-graining method mentioned above is the greedy algorithm. However, when the network is very large, the efficiency of this method remains considerably low. Following that, Griebenow et al. [
102] introduced a spectral clustering-based approach for identifying causal emergence within networks. More specifically, the method involved performing eigenvalue decomposition of the TPM, followed by constructing a similarity matrix using the eigenvectors of the nodes. The OPTICS algorithm was employed to cluster the nodes, and nodes belonging to the same cluster were aggregated into a macro-node. Subsequently, the maximum value of EI was selected by utilizing the linear search distance hyperparameter
. In their paper, the authors additionally proposed a gradient descent algorithm based on deep learning. This approach encompassed several steps, beginning with the random initialization of a grouping matrix. Then, this matrix was used to construct a macro-network by combining the micro-networks. Finally, the grouping strategies were automatically learned through the process of maximizing effective information within the macro-network. However, this method often falls into the local optimal solution.
3.5.7. Other Applications
Once the method for quantifying causal emergence in complex systems is developed, it can be applied across various fields that possess abundant network data. The first type of network studied was biological networks.
As previously discussed, biological networks are full of noise, which poses challenges in comprehending their internal operating principles. On one hand, such noise arises from inherent fluctuations within the system itself, whereas on the other hand, it can be introduced through measurement or observation processes. Consequently, Klein et al. [
103] further explored the relationship between noise, degeneracy, and certainty in biological networks and their specific meanings. For instance, in gene expression networks, highly deterministic relationships indicate that the expression of one gene almost invariably leads to the expression of another gene. Simultaneously, degeneracy is a prevalent phenomenon in the evolutionary processes of biological systems. Due to these two factors, it remains unclear at which scale biological systems should be analyzed to gain a deeper understanding of their functions.
To address this, Klein et al. [
104] conducted an analysis of protein interaction networks across more than 1800 species. They employed EI as a measure for assessing the levels of noise and uncertainty in protein interactions. The findings revealed that the macro-scale network exhibited lower levels of noise and degeneracy. Additionally, the nodes within the macro-scale interaction group demonstrated greater resilience compared to the nodes that were not part of the macro-scale interaction group. Through robust analysis, the authors demonstrated that eukaryotes exhibited a stronger degree of causal emergence compared to archaea. Additionally, to address the ’deterministic paradox,’ the authors introduced the concepts of the neutral process and the selection process in biological evolution. The neutral process operates at the micro-scale, leveraging mutations to promote interactions and enhance species diversity. On the other hand, the selection process operates at the macro-scale, effectively eliminating noise that hampers system operation and efficiency. Therefore, in order to adapt to the demands of evolution, it becomes essential for evolved biological systems to function across multiple scales.
Hoel et al. [
43] conducted further research on the causal emergence within biological systems. The authors elaborated that macro- and micro-systems exist widely in biological systems. For example, the micro-scale of a group of cells can involve potential ion channel changes, whereas the macro-scale corresponds to the membrane potential changes of cells. Furthermore, the authors utilized EI to analyze gene regulatory networks, aiming to identify the most informative models for controlling mammalian heart development. By quantifying the causal emergence within the largest component of the gene network of Saccharomyces cerevisia, it was revealed that informative macro-scale structures were prevalent across biological systems. Additionally, the authors emphasized the importance of evolutionary systems operating at multiple scales due to the significant advantages they offer. Natural selection requires variation between populations, and degradation observed in biological systems serves as a crucial factor for evolution. Degradation provides the conditions for the evolutionary process. However, organisms also need to maintain predicted consistency in phenotype, behavior, and structure to ensure survival and reproduction. Consequently, evolved systems need to operate at multiple scales, and the function of multi-scale systems is malleable in changing environments.
Swain et al. [
105] conducted an investigation into the impact of ant colony interaction history on task assignment and task switching. They employed effective information to examine how noise information propagates among ants and explored the relationship between EI and the proportion of ants assigned to different tasks within ant colonies. The study revealed that the extent of historical interaction between ant colonies influenced task assignment. Additionally, the specific type of ant colony involved in an interaction determined the level of noise present within that interaction. For example, the interactions between foragers displayed significantly higher levels of noise when contrasted with interactions between nurses or cleaners. Furthermore, even when ants switched functional groups, the cohesion within ant colonies ensured the stability of the overall colony, and different functional ant colonies also played different roles in maintaining group cohesion.
The EI indicator and causal emergence theoretic framework can also be applied to artificial systems. For example, Marrow et al. [
101] quantified and monitored the changes in the causal structure of neural networks during training, in which EI was employed to evaluate the degree of causal influence of nodes and edges on downstream tasks at each layer. By observing the changes in EI, including determinism (sensitivity) and degeneracy, throughout model training, the generalization ability of the model could be determined, thus helping better understand and explain the working principle of neural networks.
Varley et al. [
100] attempted to apply the causal emergence framework to both discrete cellular automata and continuous Rossler systems. In the case of cellular automata systems, the authors select 88 unique rules corresponding to four types: static, periodic, chaotic, and complex. By considering each state as a node, where each state determines the subsequent state, a directed state transition graph is constructed. The analysis revealed that rules 1, 2, and 4 correspond to the strongest causal emergence of dynamics. Notably, the network constructed by these three rules exhibited a significant presence of star and spoke motifs. In addition, the authors also draw some quantitative conclusions, for example, among the 17 rules belonging to the third and fourth categories, 30% exist causal emergence, 70% show causal degradation, and the CE of cellular automata with the same rules remained relatively consistent across different sizes.
Furthermore, the authors employed the OPN algorithm to transform the continuous system into a discrete-state transition graph for comparative analysis (see
Section 3.5.5). They found that chaos dynamics demonstrated a correlation with low determinism, and the variations in the degeneracy and efficiency coefficients aligned with the changes observed in the determinism curve.
3.5.8. Critiques
In the extensive literature on causality and emergence, Hoel’s theory has attracted attention for linking emergence and causality through interventionism, introducing the concept of causal emergence in a quantitative manner. However, Dewhurst [
77] provided a philosophical clarification of Hoel’s theory, arguing that it was epistemological rather than metaphysical. This suggests that Hoel’s macroscopic causality is merely a causal explanation based on information theory, rather than involving “genuinely novel causal powers”. This also raises concerns about the assumption of a uniform distribution, as there is no empirical basis to favor it over other distributions.
The computation of Hoel’s effective information relies on two premises: (1) knowledge of the system’s microscopic dynamics, and (2) knowledge of the coarse-graining scheme. However, in practice, it is rare for both conditions to be simultaneously satisfied, especially in observational studies where both are unknown. This limitation hinders the practical applicability of Hoel’s theory.
It has been pointed out that Hoel’s theory neglects the constraints on coarse-graining methods, and certain coarse-graining methods can lead to ambiguity [
78]. Additionally, the combination of some coarse-graining operations over states and coarse-graining operations over time does not exhibit commutativity. For instance, by assuming
is a coarse-graining operation over states (merging
n states into
m states), and
is a coarse-graining operation over time (combining two time steps into one), the equation
does not always hold. This indicates that certain coarse-graining operations can result in a discrepancy between the evolution of macroscopic states and the coarse-grained states of the evolved microscopic systems. It implies the need for consistent constraints on coarse-graining strategies.
This means that solely maximizing EI may raise some problems, and further constraints must be added to the framework. We discuss this problem in
Section 4.1.1.
3.6. Fernando E. Rosas’s Quantification of Causal Emergence
3.6.1. Basic Idea
In Hoel’s framework, it is essential to find a coarse-graining strategy in order to determine the occurrence of causal emergence, and the outcome is influenced by the choice of the coarse-graining method. Although it has been suggested by Hoel [
19,
25] that an optimal strategy can be identified by maximizing EI, certain issues have been raised by Dewhurst [
77]. EI is a global measure because it requires the input variable
X to be a uniform distribution over the whole domain [
24]. However, many regions are not observable from the data. Consequently, there is a pressing need for an alternative theoretical framework for causal emergence that does not rely on a coarse-graining method.
In response, Fernando E. Rosas took an approach that did not require a coarse-graining strategy as a prerequisite, attempting to break down excess entropy—the mutual information between a system’s past and future states—into non-overlapping parts to identify the information components most relevant to causal emergence. To accomplish this, he relied on the partial information decomposition (PID) framework proposed by Williams and Beer, which provides a method for the non-overlapping decomposition of joint mutual information [
29]. Below, we introduce Williams and Beer’s theoretical framework.
3.6.2. Partial Information Decomposition
The partial information decomposition (PID) framework investigates the general informational relationship between source variables and a target variable. To simplify the problem description without sacrificing generality, let us consider a system with two input variables (, ) and one output variable (Y) as an example, as depicted in the Venn diagram below.
The mutual information between the target variable and individual source variables,
and
, as well as the mutual information between the target variable and the joint source variable,
, exhibits a complex relationship. Intuitively, one cannot be converted to another. Nonetheless, it is an intuitive notion that the overlapped circular plates of
and
divide the oval region of
into four adjacent non-overlapping regions, representing the three types of information components of
:
Specifically:
: Redundant information refers to the information held by both sources;
: Unique information refers to the information held by one source but not the other;
: Synergistic information is the information held by all sources together, but not any individual one.
If we can identify variable representations corresponding to these information components, the non-overlapping feature in the Venn diagram indicates their independence from one another.
For a more intuitive understanding, let us consider a few simple toy examples.
Case 1,
: This is a scenario in which a single source variable can predict the target variable, and the addition of another source variable does not enhance the prediction of the target variable. In this case, we have
, as depicted in
Figure 9b.
Case 2,
: In another scenario, neither of the source variables can predict the target variable individually, but together, they can predict the target variable synergistically. In this case,
, as depicted in
Figure 9c.
Case 3,
: In this scenario, the target variable can be predicted by one of the source variables but not the other, which implies
, as depicted in
Figure 9d.
For general cases, Williams and Beer presented a method for calculating redundant information, defined as
. This method reflects the concept of redundancy, identifying it as the shared information across all sources, which is equivalent to the minimum amount of information contributed by any single source:
Figure 9e presents an alternative way of visualizing the PID framework, known as the redundancy lattice [
29]. In this representation, {12} denotes synergistic information,
and
denote unique information, and
denotes redundant information. In the subsequent sections, we demonstrate that the
ID framework employs the notation of the redundancy lattice.
Although the PID framework remains compatible with scenarios involving more than two source variables, it should be noted that the corresponding Venn diagrams and redundancy lattices for these scenarios can become substantially more complicated and difficult to decipher, as discussed in [
29].
3.6.3. Integrated Information Decomposition
The PID framework provides a useful framework for analyzing the non-overlapping information composition in a multivariate system. However, its application to causal analysis of dynamic systems is limited by the fact that it only allows for a single target variable. This limitation prevents the framework from fully capturing the transitions of multiple states across time steps. To address this challenge, Fernando E. Rosas developed Integrated Information Decomposition (
ID) [
30], which takes its name from Integrated Information Theory (IIT) [
21]. This extension of PID provides a more comprehensive method for analyzing dynamic systems.
To introduce Rosas’s framework clearly, we consider a system with only two variables. All the definitions and calculations can be generalized to systems with more variables.
The objective of the ID framework is to decompose excess entropy into non-overlapping information components. In a two-variable Markovian system, excess entropy is given by , where and represent the current states, and , represent the future states. From a causation perspective, and represent causes, whereas and represent effects.
Rosas first noted that mathematically, the PID framework is symmetric with respect to the source and target variables. There are two viewpoints for analyzing the above Markovian system with PID. One viewpoint takes
and
together as the target variable (aiming to decompose the “cause” to elements), whereas the other viewpoint takes
and
together as the target variable (aiming to decompose the “effect” to elements). The redundancy lattices of these perspectives are illustrated in
Figure 10a,b, and respectively, are referred to as “forward PID” and “ PID”.
Next, Rosas introduced the
ID framework, consolidating forward PID and backward PID into a single framework. In this framework, the one-to-many relationship in PID was expanded to include many-to-many relationships. He built full connections between the elements of the redundancy lattices of forward PID and backward PID. This approach generates 16 relations between the source and target, as depicted by the colored lines in
Figure 11a (each color corresponds to a specific source element of
). These relations are referred to as “
ID atoms” and can be represented as vertices in a lattice, as shown in
Figure 11b. This more complex lattice is referred to as the double-redundancy lattice because it is a “product” of two redundancy lattices (of forward PID and backward PID).
In the double-redundancy lattice, each vertex is defined as a “
ID atom”, denoted as
, where
. For instance, the
ID atom of the vertice
is denoted as
. The
ID atom represents the broken-down information transmitted from the cause elements to the effect elements, and their cumulative sum amounts to the excess entropy of the entire system. Consequently, the formal definition of Integrated Information Decomposition (
ID) is:
The main advantage of ID is that it can provide a more fine-grained analysis of complex systems compared to PID by introducing the temporal dynamic. By decomposing the mutual information of the system at different times, ID provides another approach for the quantitative study of causal emergence.
3.6.4. Reconciling Emergences
Building upon the concept of synergistic information in the PID framework, Rosas introduced a quantitative definition of causal emergence using the ID framework to tackle the challenge of identifying an appropriate coarse-graining strategy. The definition includes two aspects: firstly, determining whether the system has the capacity to generate causal emergence, and secondly, assessing the occurrence of causal emergence given a specific macroscopic feature.
Regarding a system’s capacity to exhibit causal emergence, this definition establishes a connection between causal emergence and synergistic relationships among variables across different time points. Consequently, a system denoted as
is said to possess the capacity for causally emergent features if and only if:
In this context, causal emergence is understood as the synergistic effect between variables at preceding and subsequent moments within a Markovian dynamics system.
Then, Rosas further divided causal emergence into two parts in the ID framework, downward causality and causal decoupling, based on the distinct characteristics of the information atoms. Among the sixteen ID atoms obtained by decomposing the mutual information using ID, there are four information atoms corresponding to the synergistic effect, which is regarded as the composition of causal emergence. These atoms are denoted as , .
Downward causality is denoted as
, encapsulating the information atoms that exclusively manifest a synergistic effect in forward PID, as shown in
Figure 12 and
Figure 13:
While causal decoupling is denoted as
, pinpointing the specific information atom where both forward and backward PID exhibit synergy:
Since
ID is a non-overlapping decomposition of all information, this classification takes into account all cases of causal emergence, that is,
In addition to that, Rosas also provided an approach to quantify the causal emergence of a specific macro-variable, i.e., a coarse-graining strategy. If a system has the capacity to generate causal emergence, there can be some macroscopic features that exhibit causal emergence. A feature variable
V is said to be supervenient on the underlying system if it does not provide any predictive power for future states at times
when the complete state
X of the system at time
t is known with perfect precision. This is equivalent to
being statistically independent of
given
. Then, for a system described by
, a supervenient feature
is said to exhibit causal causation if:
For this definition, the system’s capacity of causal emergence is required, where
> 0, since
holds for any supervenient feature
. Corresponding to the classification of the system’s capacity, the downward causation (as indicated by the red dotted line in
Figure 13) of a feature variable
V exists when
and causal decoupling (as indicated by the blue dotted line in
Figure 13) exists when
which also depends on the capacity of the system. Furthermore,
is said to have pure causal decoupling if
and
. If all the emergent features exhibit pure causal decoupling, the system is said to be perfectly decoupled.
Although a rigorous quantitative definition for causal emergence was proposed, the mathematical formulations used in ID can be complex and computationally demanding, making it difficult to apply the method to real-world systems. Also, In addition, the inconsistency in PID calculation causes the definition of causal emergence to depend on a specific PID calculation. To address these problems, Rosas relaxed the calculation of causal emergence and established a identification criteria based one the sufficient conditions of causal decoupling and downward causation.
Specifically, to avoid exploring the specific quantitative methods of synergistic and redundant information, this criteria repeatedly subtracts redundant information, making the result a sufficient condition for causal emergence, which lose some of its generality but improves the reliability. The three indicators to be used are:
which measures the mutual information between macro-variables across two time steps minus the mutual information between each micro-state and macro-state.
which is the maximum of the difference between mutual information of
and
and the summation of the mutual information of
and
.
which is the maximum mutual information between
and
. For the above indicators,
V is a predefined macro-variable, but the specific method for finding such a macro-variable is not discussed in [
24].
The specific usage of the indicators are as follows: Firstly, is a sufficient condition for the causal emergence of . Secondly, is a sufficient condition for to show downward causation. Thirdly, and together constitute a sufficient condition for causal decoupling.
In summary, Rosas proposed an approach to quantitatively characterize and classified causal emergence based on ID by establishing the relationship between causal emergence and the synergistic effect of variables at different time points and further categorized causal emergence. The definition not only provides an objective assessment of a system’s capacity for causal emergence but also enables the measurement the causal emergence associated with a specific macro-feature. His significant contributions include bridging the gap between the study of causal emergence and quantitative empirical research, classifying the different types of causal emergence, and complementing philosophical discussions on the topic.
The PID and
ID frameworks hold the potential for explaining data in various applications. For instance, Luppi et al. recently employed the
ID method to analyze brain BOLD signals [
106], aiming to identify the synergistic core of the brain. Their findings revealed that synergistic information facilitates the integration of different brain regions, whereas redundancy contributes to robustness. This study offers valuable insights into understanding the underlying mechanisms of the brain.
The advancement of partial information decomposition techniques allows for further analysis of the mutual information between variables, enabling a deeper understanding of system properties from multiple perspectives. In a study by Varley et al. [
107], the authors applied partial information decomposition to decompose the mutual information of a system. They calculated an indicator of synergy bias to assess how synergistic information is distributed across different levels of the system using the method proposed by Williams and Beer [
29]. A higher synergy bias indicated a greater amount of partial information involved in synergistic relationships. Subsequently, the authors observed that in certain systems exhibiting causal emergence, when the system is simplified or reduced, the synergy bias increases. This suggests that as we coarse-grain the system, partial information undergoes a transformation from redundancy to synergy. The overall conclusion drawn was that emergence can be understood as a form of information conversion.
3.6.5. Causal Emergence Identification from Data
In the previous sections, we introduced several works on quantifying emergence through causality and other information-theoretic concepts. All of these works tried to propose quantitative measures, conceptual frameworks, and numeric examples based on Markovian dynamics for causal emergence. However, in practical applications, for a theoretical framework to be implemented, we need to automatically identify causal emergence from real data, especially time-series data of dynamic systems, and provide explanations for the results.
The first method for causal emergence identification was introduced in Rosas’s paper on causal emergence [
24] and involves the three indicators defined by Equations (
41)–(
43), as mentioned in
Section 3.6.4. The identification criteria were exemplified in three case studies, leading to the following conclusions: particle collisions emerge as a distinctive feature within Conway’s Game of Life, flock dynamics emerge as a characteristic feature in simulated bird behavior, and the representation of motor behavior in the cortex emerges from neural activity.
Although these three indicators avoid the problem of redundant information calculation, it is important to note that they serve as sufficient conditions, rather than as definitive proof of emergence. In other words, indicators greater than 0 can suggest the presence of emergence, but indicators less than 0 do not necessarily imply the absence of emergence. The construction of this indicator faces challenges in identifying emergence in systems with significant redundant information or a large number of variables, which is often the case in many real-world systems. Additionally, a limitation of this method is the requirement of a predetermined coarse-grained variable V, and different choices of this variable can significantly impact the results. As a result, the development of an automatic coarse-graining strategy based on data remains an unresolved issue.
As a result, the current theoretical frameworks for causal emergence lack a practical and effective identification algorithm. Although previous studies have proposed methods based on static network structures and approximations for information decomposition, there is still a need for a comprehensive approach that can be applied to general Markovian dynamic systems. One of the main challenges is the necessity to search for all possible functions of coarse-graining or decomposing subsets within the data to identify causal emergence in complex systems. However, conventional numerical methods are unable to handle the computational costs associated with such an extensive search in a vast functional space. Therefore, the development of new methods is imperative to address these issues.
In
Section 4, we explore the application of machine learning techniques to address the challenge of identifying causal emergence within time-series data.
3.6.6. Comparison with Hoel’s Framework
When comparing Hoel’s framework to Rosas’s quantification framework for causal emergence, several clear advantages can be observed in the latter. Firstly, Rosas’s theory does not require a predetermined coarse-graining method, making it more mathematically rigorous and formal. Secondly, it offers a detailed decomposition of causal emergence, specifically downward causation and causal decoupling. Lastly, it effectively avoids cases of fake causal emergence, where the macro-variable depends solely on unique or redundant information from the micro-variables.
However, there are also some disadvantages to consider. Firstly, in order to obtain the full information lattice, a systematic iteration of all variable compositions is required. Additionally, despite the use of Formula (
38), it is necessary to define a macro-variable. Unfortunately, the authors do not provide any method to identify such a variable. Secondly, all the mutual information and its decomposition are based on correlations rather than causality. It is crucial to discuss how to incorporate causal elements, such as intervention and counterfactuals, into the framework.
Finally, the issue of identifying whether causal emergence occurs in a system based on the given time-series data of its behaviors has not been addressed in the preceding discussion. To address this problem, the application of emerging technologies in machine learning and artificial intelligence is required. These technologies can provide valuable tools and techniques for detecting and analyzing causal emergence.
4. Causal Emergence and Machine Learning
Recently, newly emerging machine learning technologies have made significant breakthroughs in addressing a range of important and challenging problems [
108,
109,
110,
111,
112,
113,
114,
115,
116]. Examples include defeating human champions in complex games like Go [
108,
109], predicting the intricate structures of protein folding [
110], and generating human language using large language models [
117]. These achievements have been made possible through the application of machine learning methods, which leverage well-designed neural network architectures and automatic differentiation techniques.
However, there is a crucial limitation of conventional machine learning: it can only capture the information or associations within the data, without being able to uncover the underlying causal relationships. According to the theory of causal hierarchy by Judea Pearl [
15,
16,
118], causality is very different from association because the former always represents a more stable relationship that is invariant in different environments, whereas the latter may be more dependent on contexts and reflects the limitation of the data. Therefore, it is necessary to develop new machine learning frameworks to incorporate the consideration of causality [
33,
118,
119]. Numerous studies have provided evidence to show that incorporating aspects of causality can lead to improved performance in machine learning tasks, including out-of-distribution generalization, adaptation to diverse environments, and handling interventions [
118,
120,
121].
Machine learning and causal inference are also connected to causal emergence in two aspects, which we call “causal emergence with machine learning” and “causal emergence for machine learning”. On one hand, machine learning can be employed to address the challenge of identifying causal emergence from data, referred to as “causal emergence with machine learning”. On the other hand, causal emergence theory and effective information (EI) measures have potential applications in the field of machine learning, known as “causal emergence for machine learning”. However, the extension depends on a deeper understanding of how causal emergence theory is related to causality.
4.1. Causal Emergence with Machine Learning
In
Section 3.6.5, we discussed the challenge of identifying causal emergence. Although Rosas et al. presented a method to address this issue by calculating an approximate measure of causal emergence based on their theoretical framework (Equation (
41)), the method requires the availability of a macro-variable, denoted as
, which needs to be defined in advance. However, defining this variable in a general sense when confronted with data remains challenging. Hence, the question arises of whether we can leverage machine learning to automatically learn the macro-variable. In this section, we explore two recent approaches that utilize machine learning and neural network techniques to address the problem of causal emergence identification from the perspective of Heol et al.’s theoretical framework for EI maximization. These methods aim to learn the coarse-graining strategy, macro-variable, and macro-dynamics directly from the data, eliminating the need for explicit definitions. By leveraging the power of machine learning, we can potentially overcome the limitations of manual variable definition and enable a more automated and data-driven approach to identifying causal emergence.
4.1.1. Neural Information Squeezer (NIS)
The first work we introduce has just been published in this special issue. In this paper, the authors formulated the problem of causal emergence identification in continuous Markov dynamics. Suppose the time-series data
are generated by a stochastic dynamical system continuously, which can be described by a differential equation,
where
is a Gaussian noise. The time series
represents the observations of the micro-states of the system. The problem we confront is identifying whether causal emergence occurs for the original system. We also want to know the appropriate coarse-graining strategies, the macro-dynamics corresponding to the chosen coarse-graining method, and the dimension of the phase space at the macro-level when the causal emergence occurs.
To address this problem, the authors proposed a mathematical framework by converting the original issue into an optimization problem for functions. Specifically, the goal is to find the appropriate coarse-graining strategy
, defined on
, where
is the dimension of the macro-states. Additionally, the aim is to determine the macro-level Markov dynamics
f, defined on
with the random noise
, by maximizing
—the dimension-averaged EI of the macro-dynamics (see Equation (
27)). This is expressed as,
However, this problem has a trivial solution, e.g., is a constant map for all micro-states, and the macro-dynamic is an identity. Surprisingly, this solution has a large EI because the identity map has the largest determinism and lowest degeneracy among all q-dimensional functions. This is trivial because too much information has been abandoned by the coarse-graining strategy such that the macro-dynamic is useless.
To address the problem, the authors added a reasonable constraint to the original optimization framework, called the effectiveness requirement. A coarse-graining strategy and its corresponding macro-dynamics are considered effective if there exists another decoarse-graining function
such that the functions
,
f, and
can predict the micro-state, instead of the macro-state, in the next time step based on the state in the previous step. The constraint can be written as,
for all time steps
t, where
is a given constant. This way, an effective coarse-graining strategy and macro-dynamics not only maximize the EI but also reproduce the original micro-dynamics as much as possible.
This constraint is an important complement to the framework for EI maximization because the decoarse-graining function
can map macro-states back to micro-states, addressing the problem of the ambiguity of macro-states. This constraint also ensures commutativity. To demonstrate this, we can apply
to both sides of Equation (
46), resulting in
.
However, the problem is still hard to solve. In [
31], the authors proposed a two-stage method, which can minimize the prediction error under a given dimension
q of macro-states in the first step and maximize EI for different values of
q in the second step. The first step can be solved by training a neural network, and the second step converts the complex functional optimization problem into a line search in one-dimensional space.
To realize the abstract mathematical framework, the authors proposed an encoder-dynamics learner-decoder framework for neural networks, named the Neural Information Squeezer (NIS), vividly describing the basic working principle of the framework as depicted in
Figure 14.
In order to reduce the complexity of the encoder and decoder, corresponding to
and
, respectively, the authors used an invertible neural network to implement the encoder and inverted the input-output workflow of the same neural network to implement the decoder. Concretely, the encoding process was decomposed into two computation steps: information conversion with the invertible neural network
on a
p-dimensional input space, and information discarding with a simple projection operation. This is expressed as:
where
is the projection operator that projects a
-dimensional vector into a
q-dimensional vector, retaining dimensions from 1 to
q. The decoding process also consists of two stages: randomly sampling Gaussian noise to complete the details of macro-states, and information conversion but in an inverted way, that is,
where
is a
-dimensional standard Gaussian random vector, and ⨁ is the operation of vector concatenation.
The adoption of an invertible neural network in the framework serves two main purposes. Firstly, by inverting the workflow of the neural network to obtain the decoder , a significant reduction in the number of parameters is achieved. This reduction can lead to improved efficiency and computational benefits. Secondly, the use of invertible functions in the neural network provides favorable mathematical properties that facilitate the analysis of the entire framework in a tractable manner. These properties enable researchers to gain insights and understand the characteristics of the framework more easily.
This architectural design with an invertible neural network not only reduces the complexity of computation but also separates the input information from the micro-states into noise and EI for prediction. The authors proved a mathematical theorem stating that, as the neural network converges through training, the mutual information between adjacent macro-states tends to approach the mutual information of two adjacent-step micro-states in the data. This means that all the information discarded by the encoder is almost irrelevant to the prediction. All the useful information converges into the information bottleneck within the macro-level dynamics learner. Another theorem demonstrates that the degree of information compression for micro-states increases as we reduce the dimension of the macro-states. Thus, the macro-state dynamics learner, acting as a narrower information bottleneck, progressively discards more and more extraneous information from the original micro-state data.
To address the problem of causal emergence identification, we first optimize the neural networks, and the dimension-averaged EI,
, can be obtained for different
q. When
, the derived
is the dimension-averaged EI for the micro-dynamics. Finally, the calculation of
is the measure of dimension-averaged causal emergence (see Equation (
28)). If
, we can state that causal emergence occurs.
Numeric examples are provided to show the effectiveness of the whole framework. Interestingly, the Neural Information Squeezer can handle time-series data with discrete micro-states, even though the whole framework was initially designed for continuous dynamical systems. Particularly, the model determines the same coarse-graining strategy and macro-level dynamic as illustrated in the example of a boolean network with four nodes in Hoel’s original paper, although no information about node grouping and state mapping was provided in the framework.
It is also interesting to compare the NIS with the frameworks and models mentioned in previous sections. Compared to the theory of computational mechanics, the NIS can be treated as a kind of -machine because any encoded macro-states can be understood as states. When the whole framework is well trained, such that it can precisely predict future micro-states, the encoded macro-states converge to effective states, which can be treated as causal states in computational mechanics. However, the objective that maximizes the effective information (EI) in the NIS has no correspondence.
The NIS also shares a similarity with G-emergence because it adopts the ideas of Granger causality: the effective macro-state is optimized by predicting the micro-state in the next time step. However, there are several obvious differences between the two frameworks. In the theory of G-emergence, the macro-state must initially be selected manually, although it is optimized automatically. In addition, the NIS uses neural networks to predict future states, whereas G-emergence uses auto-regressive techniques to fit the data. Due to the universal approximate theorem (see [
122,
123]), neural networks are more advantageous.
The NIS provides a solution for causal emergence identification from data, and it is the first solution for addressing the problem of the automatic construction of the coarse-graining strategy and macro-dynamics from data for causal emergence identification.
Another important benefit of the NIS is that it essentially addresses a generalized causal emergence identification problem, extending beyond mere justification. This is because following training, the NIS not only identifies whether causal emergence occurs but also obtains a neural network for coarse-graining the data and another for simulating the macro-dynamics. This can provide us with richer information compared to a mere justification.
4.1.2. Neural Information Squeezer Plus (NIS+)
One of the biggest problems of the NIS is that it does not directly address the EI maximization problem by optimizing the neural networks (encoder, decoder, and dynamics learner). Instead, it searches for the optimal dimension of the macro-state space
q such that EI can be maximized. Therefore, for a given
q, the neural networks are optimal for reconstructing the micro-dynamics (minimizing Equation (
46)) but not for EI. In addition, the NIS cannot support complex computations such as coarse-graining functions involving multiple steps of information conversion and discarding.
To address these problems, the NIS+ was proposed, as discussed in [
32]. Mathematically, the problem of EI maximization can be transformed into a machine learning problem based on the definition of EI and the variational inequality and probability reweighting technique. After this conversion, the minimization problem can be solved by training three neural networks
and
with parameters
, and
, respectively. Formally, the minimization problem without constraints can be written as:
where
and
are the macro-states.
is a Lagrangian multiplier, which is regarded as a hyperparameter in experiments.
is the inverse probability weight, which is defined as:
where
is the new distribution of macro-states
after intervention for
, and
p is the natural distribution of the data. In practice,
is estimated through kernel density estimation (KDE) [
124]. The approximated distribution,
, is assumed to be a uniform distribution, which is characterized by a constant value. Consequently, the weight
w is computed as the ratio of these two distributions. Theorems have been proven to ensure the correctness of this conversion. The overall framework for the NIS+ is depicted in
Figure 15.
Additionally, to apply the NIS+ to data generated by complex systems like multi-agent systems and cellular automata, the structures of the encoder can be extended by defining two kinds of combinations: stacking the basic encoder and concatenating the basic encoder. Here, a basic encoder is the composition of an invertible neural network and a projection operation. By inverting the directions of all the basic encoders and supplementing empty inputs with Gaussian noise vectors, we can obtain the corresponding decoder.
Serious numerical experiments have demonstrated that the NIS+ can automatically learn emergent dynamics and the coarse-graining strategy from data and can integrate these results to identify causal emergence.
For instance, in experiments utilizing training data generated by introducing Gaussian noise to SIR dynamics, the NIS+ demonstrated superior performance compared to the NIS in recovering the vector field of derivatives that aligned with the actual macro-level SIR dynamics. To assess the ability of the NIS+ to learn emergent dynamics, the authors generated data based on macro-states using the SIR dynamics as the ground truth. However, the NIS+ cannot directly utilize this data; only micro-level noisy data can be employed. These micro-level data were generated by introducing Gaussian noise to the macro-states.
In the experiments conducted with the Boid model, training data were generated using the renowned Boid model, which simulates the herding behavior of birds. Both the NIS+ and NIS demonstrated the ability to automatically learn macro-level states and dynamics. In this simulation, the authors divided all artificial birds (boids) into two distinct groups. Interestingly, the learned macro-states could also be categorized into two groups. Within each group, the predicted trajectories generated by the learned macro-dynamics of this group accurately followed the center of the boid groups.
The ability to capture emergent patterns was verified through experiments conducted in the “Game of Life”. The NIS+ demonstrated the capability to automatically discover both static and dynamic patterns, such as the “glider”, within the learned latent space. Additionally, when clear emergent patterns appeared in the data, larger effective information (EI) was observed for the learned emergent macro-dynamics.
Across all the training data generated through simulations, the NIS+ outperformed comparative models, including the NIS, variational autoencoders, and feed-forward neural networks, in experiments testing the model on data distributions that differed from the training data.
The paper also presented results on real data. Two sets of real fMRI time-series data from human subjects were used. The first dataset, AOMIC ID1000 [
125], contained fMRI scanning data collected while subjects watched the same movie clip. As a comparison, another fMRI dataset, AOMIC PIOP2 [
125], containing resting-state data from 50 subjects, was also utilized. The primary training objective was to predict the fMRI signal at the next time step using the learned macro-dynamics and decoder while simultaneously maximizing the effective information (EI) of the macro-level dynamics. Ultimately, a one-dimensional macro-state was found to represent all 100-dimensional micro-state data. Through attribution analysis, the authors found that micro-level signals with larger weights contributing to the one-dimensional macro-state were located in areas associated with visual tasks. However, in the comparison dataset with resting-state data, seven-dimensional macro-states were found to represent the micro-states, and attribution experiments revealed that micro-states with larger weights were distributed across different brain areas.
After the macro-dynamics and coarse-graining strategy were learned, the EIs at both the macro-level and micro-level could be calculated so that causal emergence could be quantified. The experiments showed that the measure of causal emergence depends on different types of noise. If noise was added to the observational data (micro-state), the degree of causal emergence increased with the level of noise. In contrast, if the noise was from the dynamical mechanism, i.e., added to macro-states, the degree of causal emergence decreased with the level of noise. This implies that coarse-graining can learn to eliminate noise in raw data so that better macro-dynamics with larger EI can emerge. However, if the noise is from the internal dynamics, it cannot be removed through coarse-graining.
4.2. Why Is Causal Emergence “Causal”?
In the previous sections, we discussed two frameworks that utilize machine learning and neural network techniques to address the challenge of causal emergence identification. Both frameworks place significant emphasis on maximizing EI to learn the coarse-graining strategy and macro-dynamics. Notably, the NIS+ framework extends the NIS approach to achieve real EI maximization, whereas the NIS relies on adjusting the hyperparameter q to optimize EI.
Moreover, the NIS+ has demonstrated an additional capability to generalize data distributions that differ from the training data. This suggests that the NIS+ can learn an invariant causal mechanism that is independent of the input distribution shifts through EI maximization. However, before extending this method to other machine learning scenarios, an essential question needs to be addressed: Is there a genuine relationship between causal emergence, EI maximization, and causality itself?
In the previous sections, we introduced two theoretical frameworks of causal emergence: Hoel’s framework and Rosas’s framework. In both frameworks, the measurement of causal emergence heavily relies on mutual information. However, it is crucial to acknowledge that mutual information primarily quantifies correlation rather than causality. So why do the authors assert that their theories pertain to “causal” emergence?
The key point lies in the research objectives of these frameworks, which focus on a Markov dynamical system. In this context, the dynamical mechanism is assumed to be known, and confounding variables are not considered. Under this assumption, measures related to correlation can effectively indicate causality. While mutual information itself is not a direct measure of causality, it can serve as a proxy for causality when the underlying dynamics are well understood and confounding factors are absent. Therefore, in the context of these frameworks, the use of mutual information as a measure for causal emergence is justified because it captures the relationships between variables in a way that aligns with the assumed known dynamics of the system.
When comparing the two frameworks, Hoel’s framework can be considered more “causal” than Rosas’s framework. This is because Hoel’s framework introduces the do operator in the definition of effective information (EI), as expressed in Equation (
7). The do operator allows for interventions and represents a causal manipulation of variables, which strengthens the causal interpretation of the framework. Furthermore, the significance of EI lies in its deep connections with other measures of causation proposed in various fields [
28]. According to the information in
Section 3.5.3, these measures aim to quantify the causal impact of an intervention or treatment on an outcome. By incorporating the do operator, EI aligns with these causal effect measures and provides a valuable tool for assessing causal relationships.
Furthermore, let us delve into the application background of the NIS and NIS+ to understand why these frameworks, based on EI maximization, are considered causal. Firstly, the input data in both frameworks, denoted as
, are generated by a Markovian dynamical system, with no other confounding factors considered, apart from the system itself. As a result, the state of two consecutive time steps, represented as
and
, without loss of generality, can be modeled by a simple causal diagram
due to the Markovian property. This causal diagram naturally adheres to the exogeneity assumption in causal inference [
16], indicating the absence of any confounders between the two states. Consequently, the “do” operator in EI can be replaced with conditional probability, which can be estimated from observations.
Taking all these aspects into consideration, we conclude that the theoretical frameworks of causal emergence and the machine frameworks for causal emergence identification, namely the NIS and NIS+, are indeed related to causality. Moreover, they can be extended to other scenarios within the realm of machine learning. We further explore and discuss this point in the subsequent sections.
4.3. Causal Emergence for Machine Learning
In this sub-section, we introduce how causal emergence can enhance machine learning in out-of-distribution scenarios. It turns out that the do intervention introduced in EI captures the causal dependency from the data generation process and thus complements correlation-based machine learning algorithms.
4.3.1. Out-of-Distribution Generalization
As demonstrated in the previous subsection, the measurement of causal emergence by vanilla effective information [
19] is defined for stationary dynamics systems in a self-supervised fashion since the input (cause) space and the output (effect) space share the support. However, Hoel generalized effective information to general input-output systems [
26] (see
Section 3.5.5), where the cause and the effect space take arbitrary support, which could either be discrete or continuous. Empowered by the general notation of EI, causal emergence could be applied in supervised machine learning to evaluate the strength of causation between the feature space
(or its learned representation) and the target space
, thus enhancing the prediction from the cause (feature) to the effect (target). It is worth noting that a direct fitting from
to
on the observations suffices for common prediction tasks with an i.i.d. assumption, implying that the training and test data are independently and identically distributed.
However, if samples are drawn from outside the training distribution, it is essential to learn a representation space that generalizes from the training to the test environment, known as out-of-distribution (OOD) generalization. Due to the common belief that causal relations generalize better than statistical correlations [
126], causal emergence theory could serve as a criterion for the causation embedded in the representation space. The occurrence of causal emergence indicates the revelation of potential causal factors of the target, thus producing a robust representation space with regard to out-of-distribution generalization.
Introduction to OOD
Before the detailed discussion of the connection between causal emergence and OOD generalization, we begin with a brief introduction to the latter topic. Out-of-distribution generalization toward arbitrary distributional shifts is generally considered impossible [
127]. Therefore, it is commonly assumed that there exists an underlying causal mechanism governing the data generation process, which remains invariant to distributional shifts. Formally, according to Pearl’s Structural Equation Model [
16], which causally formulates data generation, the target
Y is supposed to be generated from a part of the feature
X, i.e.,
, where
represents the selected features or a representation of
X, and
is a random noise independent of
. Obviously,
is the true cause of the target, and the causal mechanism
f is presumed to be invariant across training and test environments. On the other hand, the raw feature
X might comprise a mixture of causal variables and non-causal variables. The latter could arise from confounding, selection bias, or anti-causal mechanisms, all of which introduce spurious correlations between the target and non-causal variables. The strength and direction of these spurious correlations vary across environments, resulting in distributional shifts that hamper the out-of-distribution performance of machine learning techniques. As a remedy, a prominent branch of OOD algorithms [
126,
128,
129,
130] learns an invariant representation space distilling the causal variables from the raw feature space. Typically, a metric of the representation is devised to verify the stability of the correlation between the learned representation space and the target and is adopted as a regularization for the optimization objective to encourage the representation learner to extract causal variables from features. The paradigm for invariant representation learning can be expressed as [
131]:
where
is the learned representation,
f is the learned predictor,
is the task-specific risk function, and
is the regularization.
Representation learning-based OOD algorithms are diversified in their constraints on the representation space characterized by the regularizers. Each metric of the representation fits a specific data generation pattern and does not guarantee to filter out the causal variables when the setting is violated. However, causal emergence potentially offers a united metric of representation for OOD generalization rooted in causality theory.
Before diving into the application of causal emergence, we first discuss the representative regularizers of representation learning and their limitations. Domain-invariant representation learning proposes an aligned feature space with the constraint
, where
denotes the environment index for training and test environments. The regularization is implemented by the metric of Maximum Mean Discrepancy (MMD) distance of representation across environments [
132] or an adversarial classifier for the environment index [
130]. However, the alignment constraint provides a generalization guarantee only for a covariate shift [
129], where the distribution shift is restricted to the features
X without perturbing
. On the other hand, invariant risk minimization [
126,
133] pursues an invariant conditional distribution
of the representation across environments, which translates to
. Invariant risk minimization has been proven to recover the causal variable in a data generation process where the non-causal variable is anti-causally generated by the target but is reported to fail under a covariate shift [
134]. Further, conditional invariant representation [
128,
132] is designed specifically for image classification where the target is modeled as the cause of the feature instead of the effect. The conditional independence
is enforced on the representation space.
It has been theoretically proven that any statistical independence regularization is valid for a subgroup of Structural Equation Models, and it does not generalize across all data generation processes [
135]. As a result, the metric of representation manages to capture the causation between the representation space and the target variable only if a specific causal graph of data generation is given, hindering the general applicability of invariant representation learning. Worse still, the existence of the environment index
in the independence regularizers introduces the necessity of multiple environments for training procedures, increasing the data collection and labeling expenses. To this end, there is active demand for a unified and general metric of representation for OOD generalization, for which causal emergence might be a good candidate.
Causal Emergence and OOD
The link between OOD generalization and causal emergence can be attributed to the do intervention of effective information. By definition [
16], intervening in the feature distribution with
modifies the structural equations of all the variables in the feature space to a constant value, whereas the equation for the target remains intact as
. On one hand, the assumption of the causal mechanism’s invariance to distributional shift is respected since the causal correlation between causal variables and the target is reserved. On the other hand, the spurious correlation between non-causal variables and the target is removed by the intervention. For example, a non-causal variable anti-causally correlated with the target leads to a structural equation as
, and
replaces the equation with
, where
, and
represents the maximum entropy distribution on the domain of
. As a result,
is no longer caused by
Y, and the spurious correlation vanishes. In another example, if a non-causal variable is correlated with the target by a confounder
E (probably in the feature space), the structural equation takes the form of
and
. Then, the do intervention would modify the equation to
and confounding ceases to exist. In summary, the intervention introduced by EI captures the causal correlation between features and the target while suppressing the spurious correlation. It renders EI an ideal metric to assess the causality contained in the representation space and, thus, the generalization of the induced algorithm.
Recall that an increment in effective information implies the occurrence of causal emergence. Therefore, we propose a conjecture that out-of-distribution generalization could be achieved simultaneously with maximizing EI (or normalized EI) for representation learning. Notably, Shannon’s mutual information holds the property that any representation has no gain of mutual information with the target over the raw feature space, i.e., , as per the data processing theorem. Thus, direct fitting inclines to absorb as much information with the target as possible into the representation space. In contrast, EI (or normalized EI) would possibly peak at a medium stage of abstraction of raw features, coinciding with the philosophy of OOD generalization that less could be more. Ideally, at the peak of EI (or normalized EI) where causal emergence occurs, all non-causal features are excluded, and the causal features are revealed, resulting in the most informative representation while remaining invariant to distributional shifts.
The removal of spurious correlations and recovery of causal mechanisms by manipulating feature distributions are principles shared by the reweighting technique widely adopted in the OOD literature. For instance, stable learning [
136,
137,
138] is designed for scenarios where collinearity exists in input variables, causing spurious correlations between non-causal variables and the target. It achieves this by reweighting training samples to decorrelate the features, thus reducing collinearity and eliminating spurious correlations. Similar to EI, stable learning is free of environment index labeling. Further, both sample reweighting and feature decorrelation share the philosophy of distribution intervention. In this sense, EI could be viewed as an information-theoretic abstraction of reweighting-based debiasing techniques for OOD generalization.
5. Discussion and Perspectives
We have presented several quantitative theoretical frameworks on causal emergence. However, there are numerous unexplored problems and implications that warrant further discussion. In this section, we address four key topics for future research: causal emergence and causal representation learning, ontological and epidemiological causality and emergence, potential applications in complex systems, and understanding complex systems from the perspective of causal emergence.
5.1. Causal Emergence and Causal Representation Learning
Causal representation learning (CRL) is an emerging field in artificial intelligence (AI) [
33] that combines two important fields in AI: representation learning and causal inference. Representation learning aims to extract important features (or representations) hidden in data to make predictions automatically [
139]. It can be regarded as a typical application of deep learning and has achieved remarkable success in various domains such as image classification [
111], face recognition [
112], language understanding [
113,
114,
115], and game playing [
109,
116]. However, conventional representation learning suffers from a critical limitation: it can only capture the information of associations within the data but not the underlying causal relationships. Therefore, it is important to consider causality in representation learning.
To address the problem, CRL tries to combine the advantages of the two sub-fields: representation learning and causal inference to extract the important features and the relationships with causation behind data automatically [
33].
A typical CRL scenario is depicted in
Figure 16. Suppose there is a set of variables and causal mechanisms (including causal graphs and structural equations) that describes how the world of robotic arms and colorful blocks works. However, these mechanisms are not directly observable for the agent undergoing causal representation learning. Instead, what the agent can observe is a set of images generated by robotic arms and blocks. The objective of a causal learning framework is to extract the causal variables and mechanisms from the observed images, and the variables and mechanisms can be used to implement other downstream tasks, for example, causal relationship discovery [
140] and predictions in different environments [
120] or domains [
118,
121].
When comparing
Figure 14 and
Figure 15 with
Figure 16, we found that as a framework for machine learning, Neural Information Squeezer Plus can be regarded as a kind of CRL framework. Thus, with the NIS and NIS+, we effectively employ CRL to address the problem of identifying causal emergence (CE). Both CE and CRL frameworks feature an encoder and decoder designed to represent raw data as causal variables. Latent causal mechanisms can be learned in both frameworks. In this section, we compare the similarities and differences between these two emerging fields.
5.1.1. Similarities
It is interesting to compare the tasks of causal emergence identification within the theoretical framework of Erik Hoel and causal representation learning. Actually, the task of causal emergence identification can be understood as a task of causal representation learning, where the macro-variables are the causal variables, the macro-dynamics are the causal mechanisms, and the coarse-graining strategy is an encoding process that transforms the original data into representations. Within this framework, EI can be understood as a measure of the strength of the causal effect on the mechanism. To identify causal emergence, we need to learn the appropriate causal variables to represent data and discover causal mechanisms at the macro-level (in the representational latent space) to ensure that the EI of the learned causal mechanism in the latent space is larger than that of the original data.
Table 1 shows a detailed comparison of causal emergence identification and causal representation learning.
With these similarities, the technologies and concepts from both fields can learn from each other. For example, the techniques of causal representation learning can be applied to discover causal emergence.
On the other hand, the learned abstract causal representations can be viewed as macro-states, which enhances the explainability of causal representation learning. This perspective suggests that CRL essentially uncovers hidden causal emergent features within the data.
Moreover, these similarities between emergent phenomena and CRL contribute to a deeper understanding of emergence itself. By applying CRL frameworks to data generated by dynamical systems exhibiting emergent phenomena, we can extract more profound causal structures. These profound causal structures may serve as the origins of the mysteries surrounding emergence. By delving into the depths of CRL and uncovering the hidden causal relationships within complex systems, we can gain insights into the mechanisms behind emergent phenomena. These causal structures may provide a foundation for understanding the emergence of novel properties and behaviors that arise from the interactions of simpler components.
5.1.2. Differences
However, there are several theoretical differences between CRL and causal emergence. The biggest difference is that CRL assumes that there is a real causal mechanism behind the data, and the data are generated by this causal mechanism [
33]. In contrast, for causal emergence identification, the emergent variables and mechanisms at the macro-level are just handy ways to observe and understand data, and “real causality” may not exist. The differences are illustrated in
Figure 17.
However, if an epistemological perspective is adopted, this difference disappears because both approaches extract meaningful information from observational data to obtain representations with stronger causal effects.
Another major difference is that the causal mechanism for macro-states in causal emergence is a dynamical system. Therefore, if the dynamics in the macro-state space are on a network, circular structures may exist because the state variables will be iterated in the dynamical system. As a result, feedback and circular indirect interactions are allowed in such a model. However, the causal mechanism is always represented by a structural causal model in CRL. Although these models are always directed acyclic graphs, loops or circular structures are not allowed. However, these differences are not important because Markovian dynamics can always be converted to causal models, as mentioned in
Section 2.1.
Finally, unknown co-founders are always ignored in causal emergence, whereas they play very important roles in causal structural models.
In summary, there are deep connections between causal emergence and CRL. On one hand, the machine learning framework for causal emergence identification exhibits similar structures to the frameworks for CRL. And even the concepts can establish one-to-one correspondence, as shown in
Table 1. Therefore, the ideas and techniques of both sides can learn from each other.
On the other hand, studies of causal emergence can provide new perspectives and insights for causal representation learning algorithms. For example, we can interpret the learned representations and causal mechanisms as emergent causal laws. The maximization of EI may improve the efficiency of learning the causalities for both CRL and reinforcement learning agents.
5.2. Ontological and Epistemological Causality and Emergence
Although machine learning techniques have facilitated the learning of causal structures and models, as well as the exploration of emergent properties and causation, it is important to consider whether the results obtained through machine learning reflect ontological causality and emergence or if they are merely epistemological phenomena.
Here, ontological causality refers to the causal relationships that exist in objective reality, independent of our knowledge or understanding. Ontological causality explores the fundamental mechanisms and interactions that give rise to causal effects in the world. Similarly, ontological emergence is concerned with the objective existence of emergent properties and their underlying mechanisms.
Epistemological causality, on the other hand, focuses on our knowledge and understanding of causality. It deals with how we perceive, model, and explain causal relationships based on our observations and experiences, but the causality may not exist in the real world. Epistemological emergence, akin to epistemological causality, focuses on our comprehension and elucidation of emergent phenomena. In other words, epistemological causality and emergence depend on an observer, and different observers may have distinct perspectives about causality and emergence for a particular objective phenomenon.
There has been a longstanding debate regarding the ontological and epistemological aspects of causality and emergence throughout history [
17,
22,
68,
76]. The authors of [
68] highlighted that the concept of “causation” in the literature is often vague and should be differentiated into “cause” and “reason”, aligning with ontological and epistemological causality. “Cause” means genuine cause that sufficiently causes the effects (causal closure principle [
141] and exclusion principle [
142]), whereas “reason” serves as a mere explanation for individuals to comprehend the effects. Reason may not possess the same level of rigor as genuine cause, but it does offer a certain degree of predictability that individuals find valuable in certain circumstances.
However, distinguishing between them, particularly when addressing specific phenomena, remains a challenging task. One such controversial concept is downward causation, which has sparked extensive discussions. The question of whether downward causation exists objectively or not remains open. In [
24], Rosas argued that downward causation not only exists independently of particular observers but also provides a characterization of the phenomenon through quantified measures using information decomposition. However, Yurchenko proposed that it is important to differentiate between two separate concepts: causality and reasoning. According to this perspective, downward causation falls under the category of “reason” rather than causation. In this context, causality and reasoning can be seen as representing ontological and epistemological causality, respectively.
Similarly, debates persist regarding the nature of causal emergence. The question arises as to whether causal emergence is a genuine phenomenon that exists independently of particular observers [
77]. In
Section 3.5.4, we highlighted that different coarse-graining strategies can lead to distinct macro-dynamic mechanisms with varying measures of EI. In essence, different coarse-graining strategies can be seen as representing different observers. However, Hoel’s theory proposes a criterion to differentiate between coarse-graining methods, namely EI maximization. Consequently, for a given set of Markovian dynamics, only the coarse-graining strategy and corresponding macro-dynamics that maximize the EI measure can be considered as an objective outcome. Nevertheless, a challenge arises when multiple solutions exist that maximize EI, introducing a degree of subjectivity [
77]. The authors of [
31,
32] addressed this issue by introducing constraints on prediction errors in micro-states, which partially alleviates the problem. However, the question of whether optimal results have unique solutions remains an open problem that requires further investigation.
Similarly, although the incorporation of machine learning cannot resolve debates surrounding ontological and epistemological causality and emergence, it can provide objective standards that help mitigate subjectivity. This is because machine learning algorithms strive to optimize objective functions. Thus, machine learning agents can be viewed as “objective” observers that make judgments on causality and emergence. This represents an additional advantage of incorporating machine learning. However, the issue of unique solutions is crucial in this approach and warrants further attention.
Are the machine learning results ontological or epistemological? The answer is that the results are epistemological and depend on machine learning algorithms. However, this does not mean that all the results of machine learning are meaningless since if the learning agents are well trained and the defined mathematical objectives are effectively optimized, the results can also be considered objective and independent of the algorithms.
It is intriguing to pose the same question regarding human cognition. Do all cognitive results in the human brain, encompassing causality, coarse-graining strategies, and macro-dynamics, reflect objective reality, or are they purely epistemological? Firstly, answering this question is exceedingly challenging. Secondly, the cognitive results specific to a particular human brain must objectively manifest within the neural network structures. Thus, for that brain, these results are ontological. Similar reasons hold for machine learning. The cognitive results of machine learning algorithms are recorded by the structures and parameters in neural networks. Therefore, studying these structures may reveal the properties of the original systems, and the nature of the interactions between the observer and the observed objects can be objectively reflected by machines.
Furthermore, the integration of machine learning can assist in establishing a theoretical framework for modeling observers and studying the interactions between the observer and the corresponding observed complex systems. This framework allows us not only to explore the hard problems regarding causality and emergence but also to understand the limitations and boundaries of the observer. One example of this research is the emergent classicality of quantum systems from the information bottleneck formed by machine learning algorithms [
143].
5.3. Potential Applications in Complex Systems
In
Section 4, we discussed the techniques related to causal emergence identification, machine learning, and causal inference. In this sub-section, we discuss the potential applications of these techniques in complex systems. Complex systems can be understood as a large network, with events connected by causal links. Automatically discovering the complex causal relationships from data is a challenging problem.
The research area of causal discovery has tried to address this problem in various ways [
144,
145,
146,
147,
148,
149]. However, additional challenges may arise when applying these causal discovery methods in complex systems because circular causal structures and cross-level causation may exist.
Circular causal structures widely exist in complex dynamical systems due to the feedback effect. That is, one variable may affect itself via a direct self-loop feedback or a long chain forming a circle. This circular causal structure may pose a challenge to existing methods of causality because most of these methods study directed acyclic causal graphs. However, recent progress has seen the development of some methods for discovering these circular structures in a data-driven manner, e.g., [
46,
47,
48,
49,
150,
151,
152,
153].
Another aspect is that higher-level or cross-level causation may exist if the ingredients of scale and coarse-graining are considered. For example, downward causation describes the causal effect between macro-level and micro-level variables. Thus, the causal connections may be cross-level. If causal emergence occurs in a complex system, some strong causality may be found between macro-variables. All of these factors in complex systems present new challenges. The machine learning methods discussed in
Section 4.1.1 can address the question of whether higher-level causality exists at the macro-level. However, it is important to note that this is a global property. It must be further developed and extended to find a local causal relationship between macro-variables or macro-variables and micro-variables [
98]. Moreover, existing methods of causal discovery must be extended to consider the method of grouping a set of variables or coarse-graining a system. For example, ref. [
154] proposed a coarse-to-fine causal discovery algorithm based on Granger causality and a graph neural network. The grouping process of variables is from coarse to fine, which can improve the efficiency of the algorithm. Other multi-level causal discovery methods were proposed and discussed in [
155,
156,
157].
Another interesting problem is emergence detection. In complex dynamical systems, various higher-level patterns, such as waves, periodic oscillations, and solitons, are ubiquitous. For instance, in the climate system, typhoons and tornadoes are emergent vortex structures. In urban areas, traffic jams also emerge as a result of interactions among a large number of cars. Social riots are another example of emergent events in higher levels of human society. Identifying these emergent patterns at an early stage is crucial and significant [
81,
158,
159,
160,
161,
162,
162]. Therefore, there is an urgent need for a method that can automatically detect these emergent patterns and even provide early warning signals.
In this review, we mainly focus on the emergence of causality; however, we are not limited to this specific type of emergence. More macroscopic or global-level properties could also be emergent, although causal emergence may be the most important one. For example, in [
163], the authors discussed the concept of emergent information closure, which refers to the idea that the encoded information within an agent can form a closed system that is not influenced by the external world. The authors then argued that this agent with information closure can be regarded as a kind of consciousness. Symmetry may be another interesting property within some complex systems, and it may be emergent. For example, any single trajectory of a large number of random walkers in a two-dimensional Euclidean space is random. Nevertheless, the Gaussian distribution surface describing how the number of walkers falling in each small region changes with different locations is isotropic. This kind of symmetry can only be found at the macro-level and, thus, it is emergent. It would be interesting and useful to deploy a method for automatically discovering this kind of emergent symmetry. The framework for the NIS can be extended to address the problem of emergent symmetry identification if the optimized objective, EI, is replaced with a measure of isotope or more general symmetry [
164]. Similarly, we can also find other emergent symmetries using this framework once their measurement and optimization are possible.
However, it is crucial to acknowledge the inherent limitations of applying machine learning techniques to causal discovery and emergence identification problems. For instance, in [
45], the authors highlighted the existence of ’statistically equivalent’ but causally distinct DAGs, implying that different causal structures can be constructed to account for the same dataset. Consequently, when utilizing machine learning techniques to uncover causality and emergent properties, similar challenges need to be addressed. Further research in this direction warrants significant attention to overcome these obstacles.
5.4. Understanding Complex Systems from Causal Emergence
A profound understanding of causal emergence and emergent causality can provide insights into understanding various mysterious phenomena in complex systems, including living systems, social systems, climate systems, ecosystems, and more. Significantly, fundamental questions, such as free will [
68], consciousness [
165], and life, are all intricately connected to emergent causation [
166]. For instance, free will can be viewed as an emergent form of downward causation [
68]. Social phenomena can be comprehended through the lens of causal emergence [
167]. Interestingly, both the EI and
ID frameworks for causal emergence have connections with one of the theories of consciousness, namely the integrated information theory [
168]. However, understanding these abstract concepts and phenomena in the context of causal emergence is merely an initial step.
For a specific system, there are three problems that should be addressed in future studies: (1) When does causal emergence occur? (2) How does emergent causality have functional effects on the system? (3) How does emergent causality change when the system is changed to adapt to the environment? We discuss these problems one by one.
We still do not know when causal emergence will occur and how the measure of causal emergence changes with some key parameters of a system. In [
32], the authors showed how the measure of causal emergence changes with different noises in the Boid model (see the relevant discussion in
Section 4.1.2). It is reasonable to expect that there is a phase transition of emergent causality within a complex system when some key parameter changes because the causality or strength of the causal effect is also a global property, and it may be dependent on some order parameters.
If causal emergence occurs in the system, how does the emergent causation affect the parts and the whole of the system? For example, the emergent “I” can be understood as an emergent macro-variable [
68]. How does “I” influence the part, say the foot, to move? This problem is non-trivial because it relates to the problem of mind–body interaction. It is important to study the information flows at both the macro-level and micro-level together to understand this phenomenon.
Finally, what is the relationship between adaptation and emergence [
4,
169,
170]? Sometimes, when we refer to a property as emergent, we essentially mean that this property can be developed through adaptation. Therefore, adaptation or evolution serves as a causal force for certain emergent properties. This concept also applies to emergent causality. For instance, downward causation, which is commonly found in complex systems, emerges as a result of adaptation and evolution. The next crucial question is, how can we evolve an emergent property or causation? This problem resembles the issue of designing emergence [
171,
172,
173]. However, our aim here is to seek an explanation rather than a design. We want to understand the specific environment and manner in which the observed emergent causation can be evolved through adaptation.
All these problems require further studies in the future. However, these problems are just a few of the more interesting problems that need to be addressed.

 ,
, 

















{kind=link}
{kind=link}
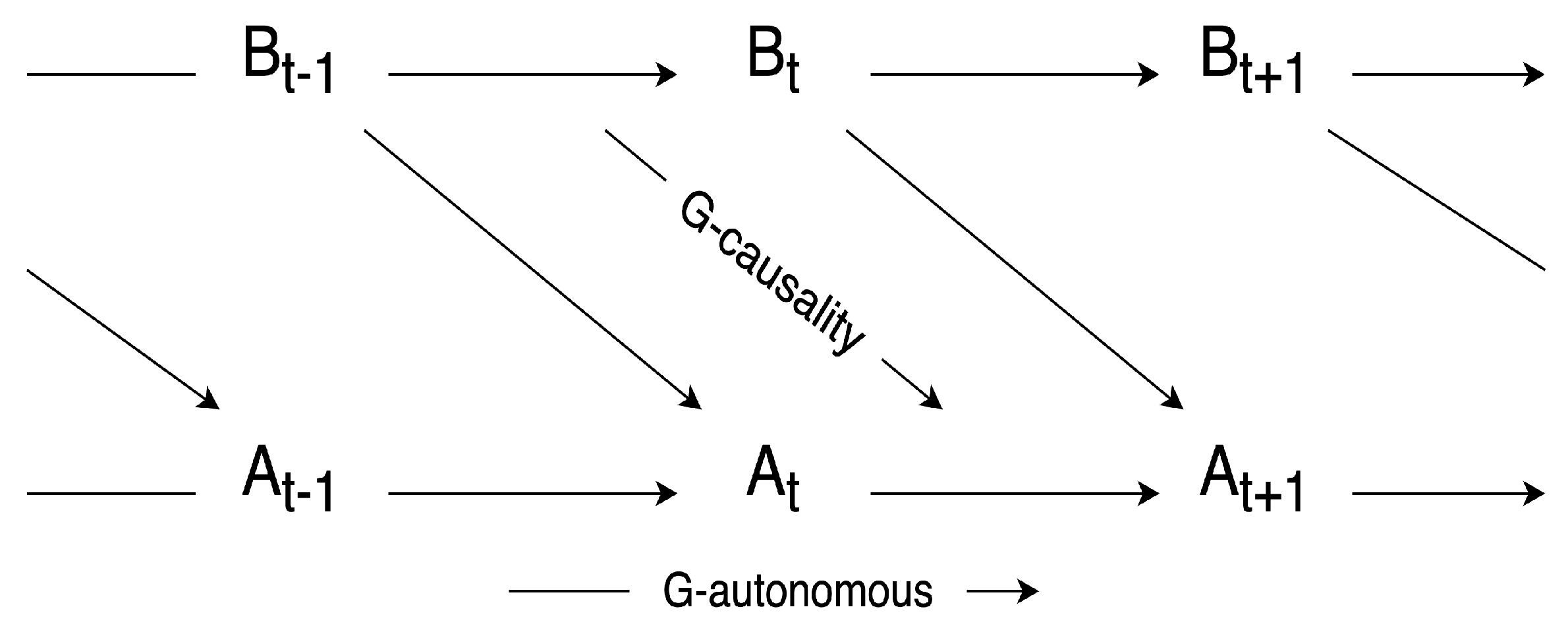{kind=link}
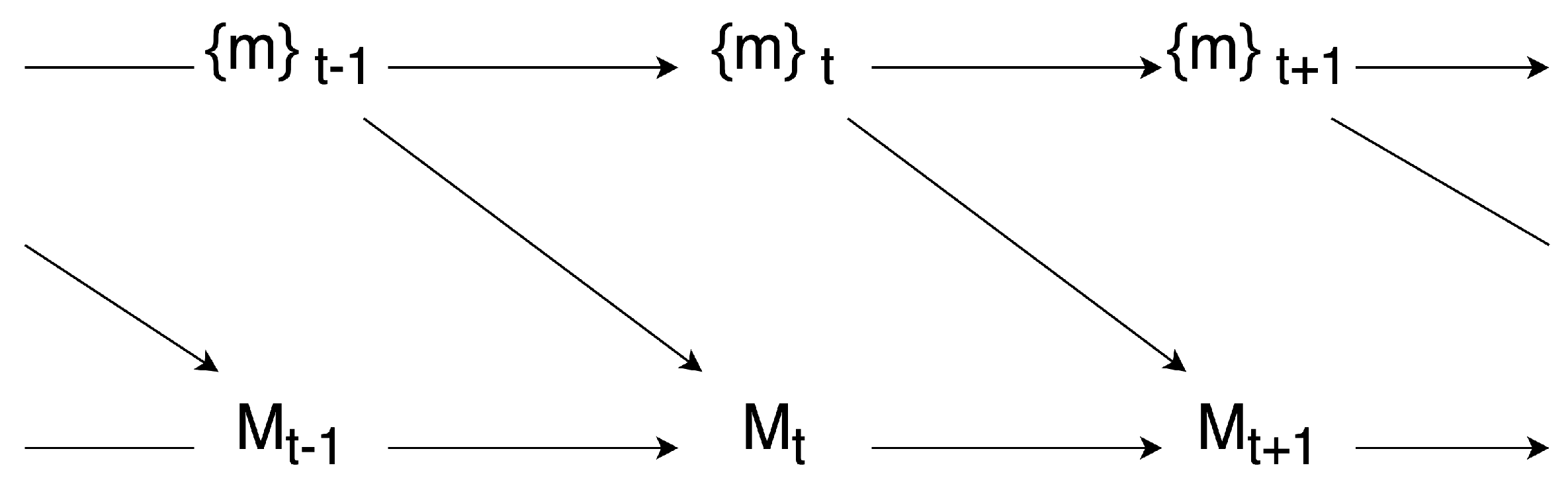{kind=link}
{kind=link}
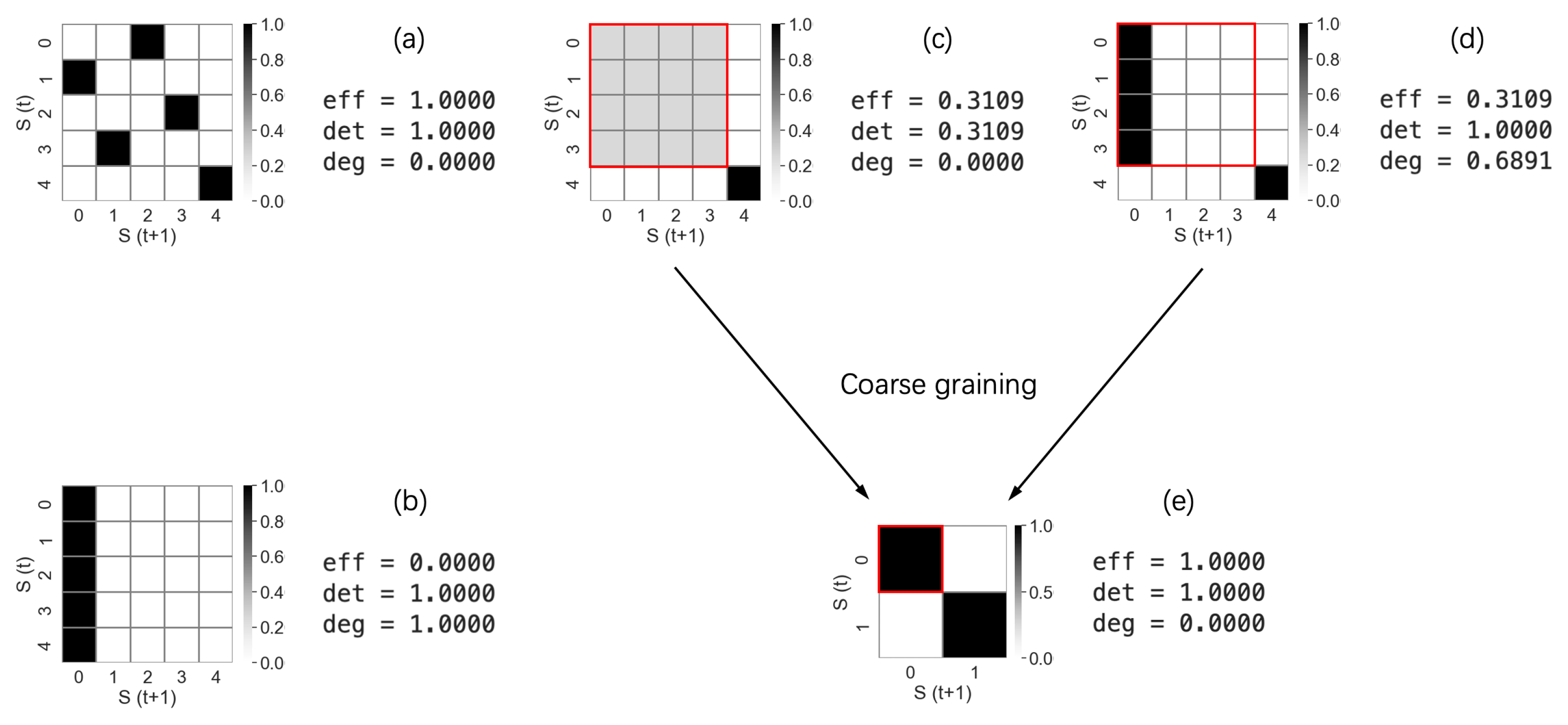{kind=link}
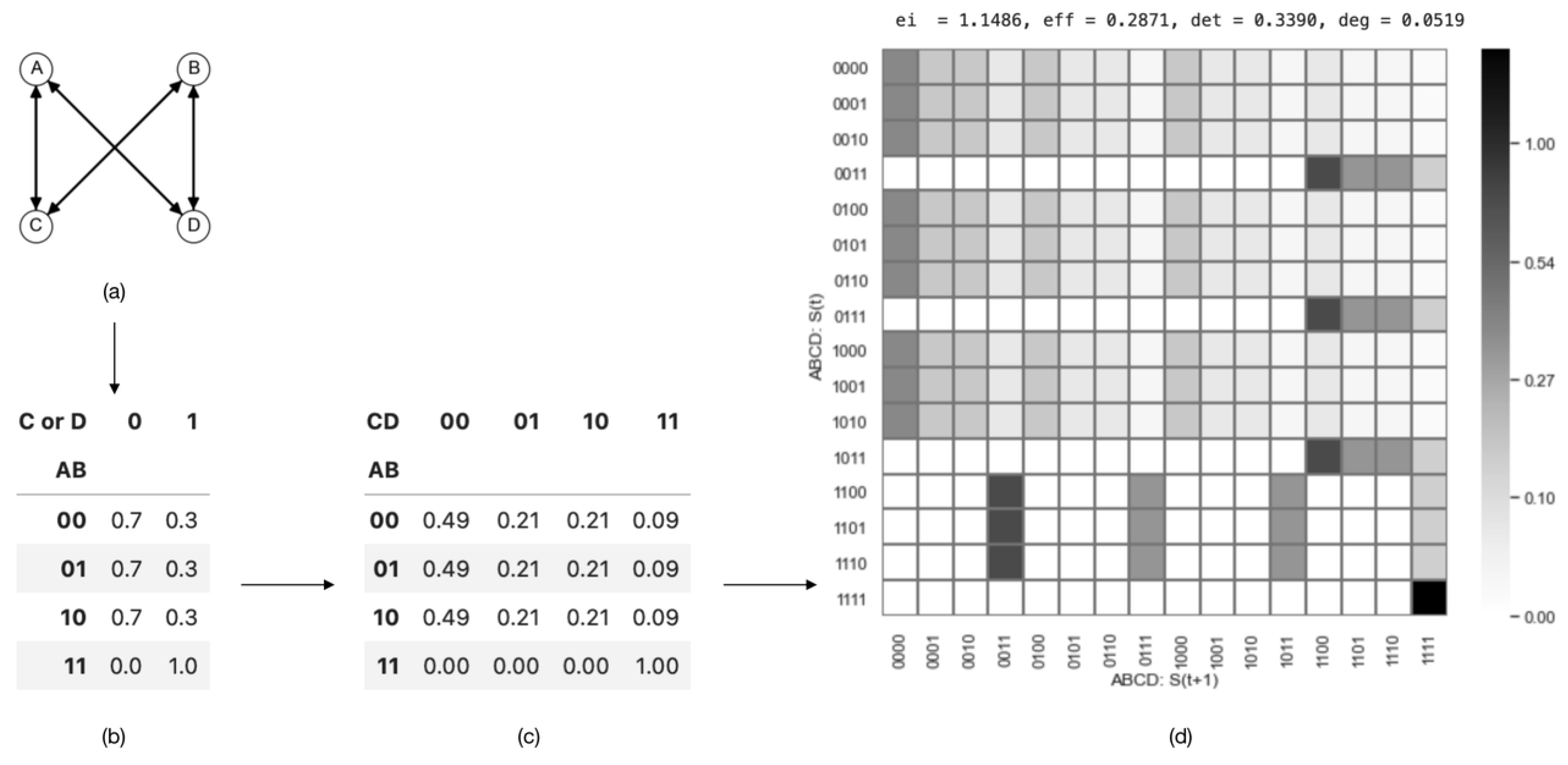{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
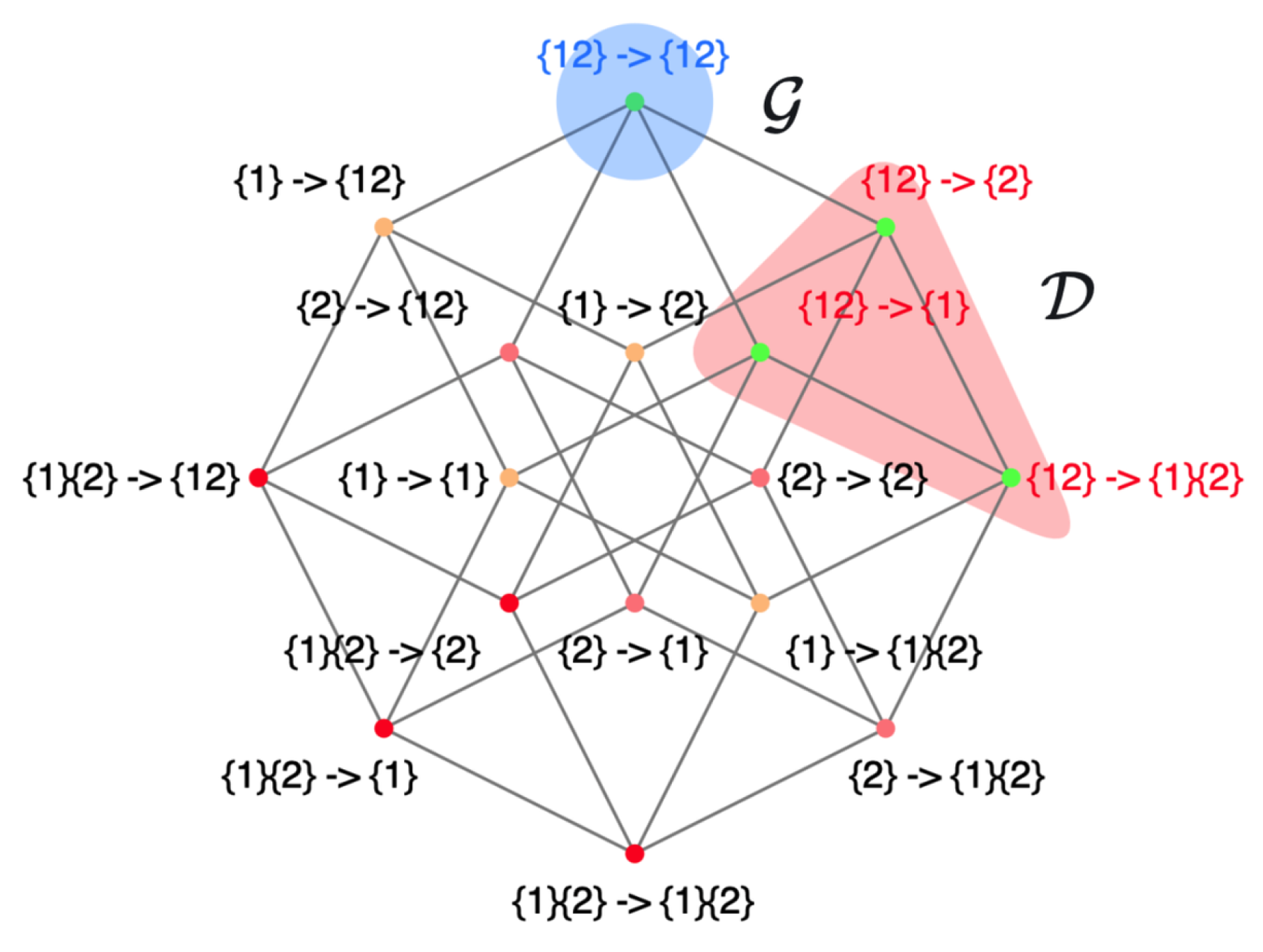{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}