
Neural Causal Information Extractor for Unobserved Causes

Abstract
:1. Introduction
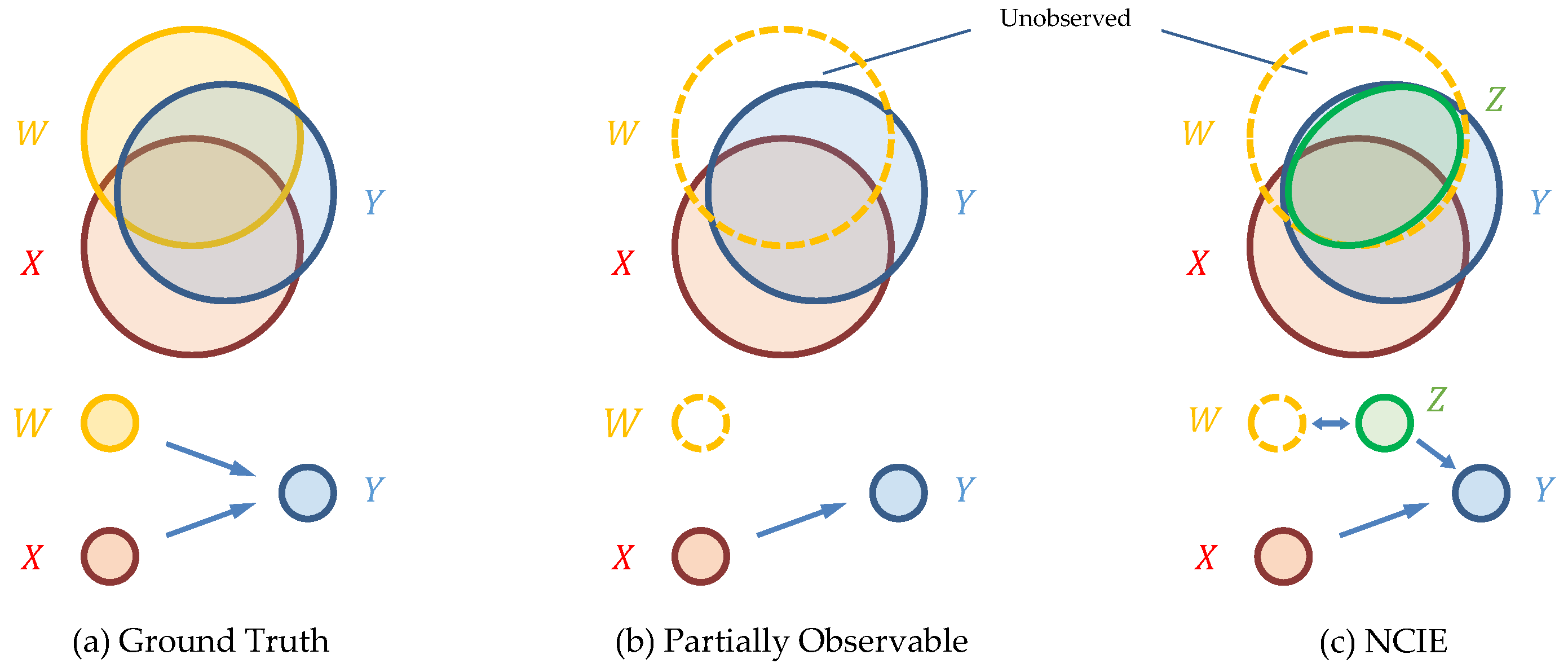
- We propose a generator–discriminator architecture that generates implicit variables to complement the unobserved causes in the causal structures while retaining the observed causes.
- The implicit variables we generate could carry information from the unobserved variables and reveal their dynamics.
- Time series prediction tasks show that the combination of observed and implicit variables helps improve the prediction of targets, verifying that they are better candidates for causal inference.
2. Literature Review
2.1. Causal Inference without Considering Unobserved Variables
2.2. Causal Inference Considering Unobserved Variables
2.3. Mutual Information Estimator
3. Problem Statement
- We focus on the unobserved variables that provide information to Y. Those without information of Y do not affect the distributions of Y.
- In the case of time series, we denote , as the explicit and implicit causes of to uphold the assumption of temporal priority [1], i.e., causal relationships only move from past variables to future variables in time series. For simplicity, we denote and as X and Z, and as Y.
- We assume , , and are in a closed system and there is a causal loop among them, i.e., and may induce , and and may induce .
- While we are generating , we do not necessarily obey temporal priority [1], which is a common practice in refs. [20,21,22,23,24,25,26,27,28,30]. Therefore, we employ and to generate . We note that we do not focus on finding the exact causes of Z here. Instead of finding causes of Z by applying the whole structures we use on Y, we just use a basic RNN to present Z from the explicit causes.
4. Methods
4.1. Neural Causal Information Extractor
4.1.1. Generator
4.1.2. Discriminator
4.1.3. NCIE: Maximizing Mutual Information
4.2. Verifying Causality from Z to Y by Time Series Prediction
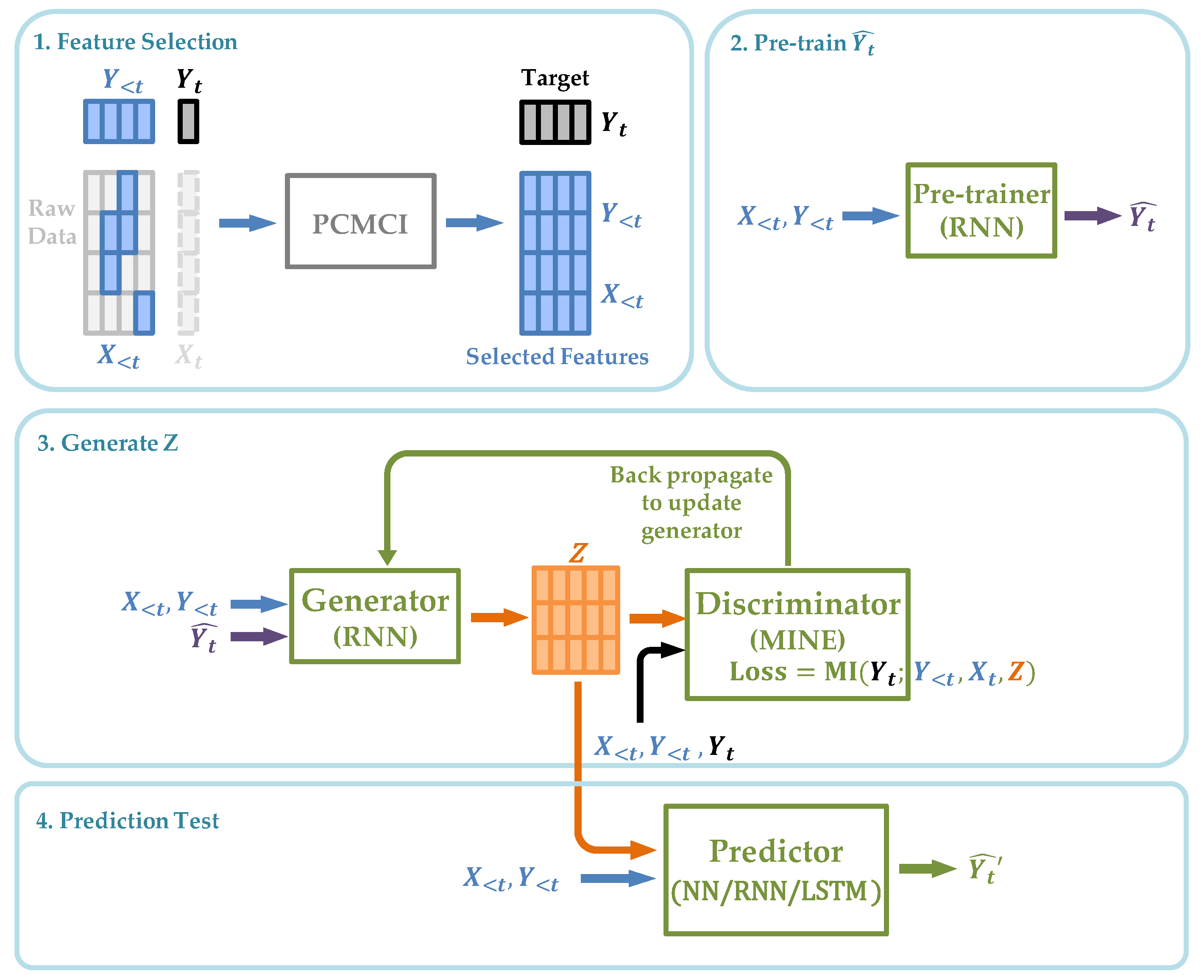
4.2.1. Motivation and Architecture
- We select the explicit causes X from the raw time series with a maximum lag of k using PCMCI [3], which is a framework that identifies the time-lagged causal relationship given the assumption of the completeness of the given data (no unobserved data). With its high precision, we assume the resulting X is the set of all the real causes of Y. Furthermore, we select the lagged from to as the autoregressive terms, together with X to be the set of observed causes;
- We train the pre-training module and generate to estimate ;
- After finishing training the previous module, we use output as the input of this modified NCIE module and train the generator and discriminator (Section 4.1) together to generate Z;
- We train neural network (Equation (27)) to generate , which is applied to examine the improvement of the prediction effect on Y given by Z.
4.2.2. Prediction
5. Experiments
5.1. Synthetic Data Experiments: Dynamics of Z
5.1.1. Case 1: A Linear System
5.1.2. Case 2: A Non-Linear System
5.1.3. Case 3: A Non-Linear System
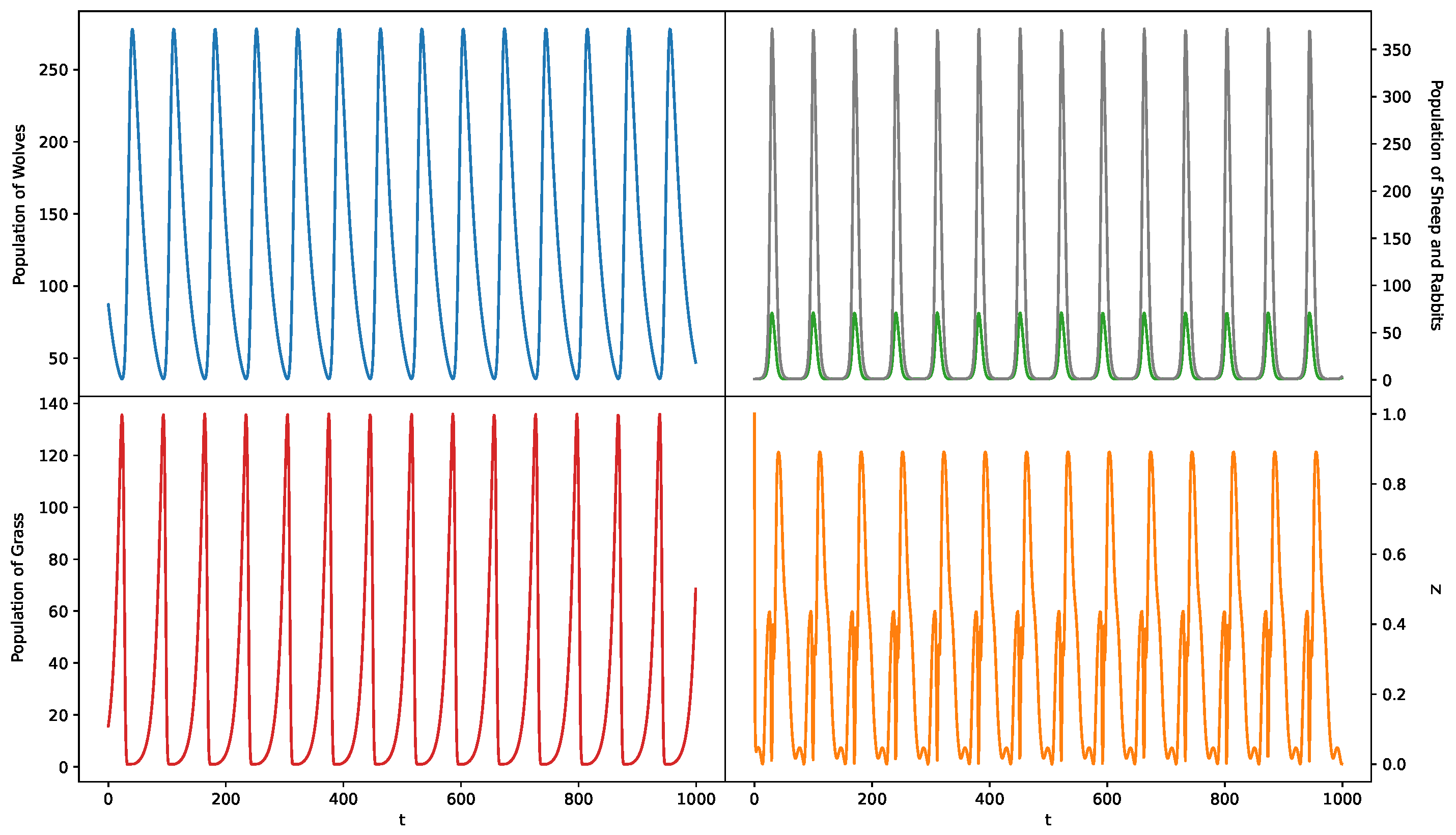
5.1.4. Case 4: 1—Predator 2—Prey Model Where Prey Share the Same Food
5.1.5. The Interpretation of Z
- , the unique information that could only be provided by W;
- , the unique information that could only be provided by ;
- , the synergistic information provided only when both and W are present;
- , the redundant information that could be provided by either or W.
5.2. Preformance Evaluation by Real-World Data Experiments
5.2.1. Information Recovery
- The Electricity Transformer (Oil) Temperature (ETT) [17], which includes four datasets sampled at different time intervals (1 min, 2 min, 1 h, and 2 h). The observed causes include useful and useless loads in different levels;
- The daily exchange rates [51] of eight countries, with one of them set as the target and the other seven as the observed causes for predicting the target;
- Minneapolis–St Paul interstate metro traffic volume [52], in which observed causes include temperature, weather, and holidays;
- The PM2.5 quantity in Beijing (https://www.kaggle.com/datasets/rupakroy/lstm-datasets-multivariate-univariate) (accessed on 6 November 2023), in which observed causes include dew, temperature, atmospheric pressure, weather, as well as wind direction and speed (all the codes and data are available at https://github.com/jh-liang/NeuralCausalInfoExtractor) (accessed on 6 November 2023).
5.2.2. Single-Step Time Series Forecasting
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gong, C.; Yao, D.; Zhang, C.; Li, W.; Bi, J. Causal discovery from temporal Data: An overview and new perspectives. arXiv 2023, arXiv:2303.10112. [Google Scholar]
- Spirtes, P.; Glymour, C.N.; Scheines, R. Causation, Prediction, and Search; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Runge, J.; Nowack, P.; Kretschmer, M.; Flaxman, S.; Sejdinovic, D. Detecting and quantifying causal associations in large nonlinear time series datasets. Sci. Adv. 2019, 5, eaau4996. [Google Scholar] [CrossRef]
- Heckerman, D.; Geiger, D.; Chickering, D.M. Learning Bayesian networks: The combination of knowledge and statistical data. Mach. Learn. 1995, 20, 197–243. [Google Scholar] [CrossRef]
- Kayaalp, M.; Cooper, G.F. A Bayesian network scoring metric that is based on globally uniform parameter priors. arXiv 2012, arXiv:1301.0576. [Google Scholar]
- Marcinkevičs, R.; Vogt, J.E. Interpretable models for Granger causality using self-explaining neural networks. arXiv 2021, arXiv:2101.07600. [Google Scholar]
- Jiang, P.; Kumar, P. Information transfer from causal history in complex system dynamics. Phys. Rev. E 2019, 99, 012306. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Convertino, M. Inferring ecosystem networks as information flows. Sci. Rep. 2021, 11, 7094. [Google Scholar] [CrossRef]
- Engelberg, J.E.; Parsons, C.A. The causal impact of media in financial markets. J. Financ. 2011, 66, 67–97. [Google Scholar] [CrossRef]
- Farag, H.; Cressy, R. Do unobservable factors explain the disposition effect in emerging stock markets? Appl. Financ. Econ. 2010, 20, 1173–1183. [Google Scholar] [CrossRef]
- Williams, B.K.; Brown, E.D. Partial observability and management of ecological systems. Ecol. Evol. 2022, 12, e9197. [Google Scholar] [CrossRef]
- Chadès, I.; Pascal, L.V.; Nicol, S.; Fletcher, C.S.; Ferrer-Mestres, J. A primer on partially observable Markov decision processes (POMDPs). Methods Ecol. Evol. 2021, 12, 2058–2072. [Google Scholar] [CrossRef]
- Singh, M.F.; Wang, A.; Braver, T.S.; Ching, S. Scalable surrogate deconvolution for identification of partially-observable systems and brain modeling. J. Neural Eng. 2020, 17, 046025. [Google Scholar] [CrossRef] [PubMed]
- Gupta, V.; Li, L.K.; Chen, S.; Wan, M. Model-free forecasting of partially observable spatiotemporally chaotic systems. Neural Netw. 2023, 160, 297–305. [Google Scholar] [CrossRef]
- Duan, C.; Jiang, Y.; Pu, H.; Luo, J.; Liu, F.; Tang, B. Health prediction of partially observable failing systems under varying environments. ISA Trans. 2023, 137, 379–392. [Google Scholar] [CrossRef] [PubMed]
- Geiger, P.; Zhang, K.; Schoelkopf, B.; Gong, M.; Janzing, D. Causal inference by identification of vector autoregressive processes with hidden components. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1917–1925. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Virtual, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Yao, W.; Sun, Y.; Ho, A.; Sun, C.; Zhang, K. Learning temporally causal latent processes from general temporal data. arXiv 2021, arXiv:2110.05428. [Google Scholar]
- Klindt, D.; Schott, L.; Sharma, Y.; Ustyuzhaninov, I.; Brendel, W.; Bethge, M.; Paiton, D. Towards nonlinear disentanglement in natural data with temporal sparse coding. arXiv 2020, arXiv:2007.10930. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Hyvärinen, A.; Shimizu, S.; Hoyer, P.O. Causal modelling combining instantaneous and lagged effects: An identifiable model based on non-Gaussianity. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 424–431. [Google Scholar]
- Hyvarinen, A.; Morioka, H. Nonlinear ICA of temporally dependent stationary sources. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics; Singh, A., Zhu, J., Eds.; MIT Press: Cambridge, MA, USA, 2017; Volume 54, pp. 460–469. [Google Scholar]
- Clark, D.; Livezey, J.; Bouchard, K. Unsupervised discovery of temporal structure in noisy data with dynamical components analysis. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Bai, J.; Wang, W.; Zhou, Y.; Xiong, C. Representation learning for sequence data with deep autoencoding predictive components. arXiv 2020, arXiv:2010.03135. [Google Scholar]
- Meng, R.; Luo, T.; Bouchard, K. Compressed predictive information coding. arXiv 2022, arXiv:2203.02051. [Google Scholar]
- Wu, H.; Gattami, A.; Flierl, M. Conditional mutual information-based contrastive loss for financial time series forecasting. In Proceedings of the First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 1–7. [Google Scholar]
- Granger, C.W. Investigating causal relations by econometric models and cross-spectral methods. Econom. J. Econom. Soc. 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Rosas, F.E.; Mediano, P.A.; Jensen, H.J.; Seth, A.K.; Barrett, A.B.; Carhart-Harris, R.L.; Bor, D. Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data. PLoS Comput. Biol. 2020, 16, e1008289. [Google Scholar] [CrossRef] [PubMed]
- Malinsky, D.; Spirtes, P. Causal structure learning from multivariate time series in settings with unmeasured confounding. In Proceedings of the 2018 ACM SIGKDD Workshop on Causal Discovery, London, UK, 20 August 2018; pp. 23–47. [Google Scholar]
- Gerhardus, A.; Runge, J. High-recall causal discovery for autocorrelated time series with latent confounders. Adv. Neural Inf. Process. Syst. 2020, 33, 12615–12625. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Louizos, C.; Shalit, U.; Mooij, J.M.; Sontag, D.; Zemel, R.; Welling, M. Causal effect inference with deep latent-variable models. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef]
- Xiu, Y.; Cao, K.; Ren, X.; Chen, B.; Chan, W.K. Self-similar growth and synergistic link prediction in technology-convergence networks: The case of intelligent transportation systems. Fractal Fract. 2023, 7, 109. [Google Scholar] [CrossRef]
- Belghazi, M.I.; Baratin, A.; Rajeswar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, R.D. Mine: Mutual information neural estimation. arXiv 2018, arXiv:1801.04062. [Google Scholar]
- Mukherjee, S.; Asnani, H.; Kannan, S. CCMI: Classifier based conditional mutual information estimation. In Proceedings of the Uncertainty in Artificial Intelligence, Virtual, 3–6 August 2020; pp. 1083–1093. [Google Scholar]
- Zhang, R.; Koyama, M.; Ishiguro, K. Learning structured latent factors from dependent data: A generative model framework from information-theoretic perspective. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 11141–11152. [Google Scholar]
- Zhu, H.; Wang, S. Learning fair models without sensitive attributes: A generative approach. arXiv 2022, arXiv:2203.16413. [Google Scholar] [CrossRef]
- Diz-Pita, É.; Otero-Espinar, M.V. Predator–prey models: A review of some recent advances. Mathematics 2021, 9, 1783. [Google Scholar] [CrossRef]
- Leeuwen, E.v.; Jansen, V.; Bright, P. How population dynamics shape the functional response in a one-predator–two-prey system. Ecology 2007, 88, 1571–1581. [Google Scholar] [CrossRef] [PubMed]
- Lotka, A.J. Elements of Physical Biology; Williams & Wilkins: Philadelphia, PA, USA, 1925. [Google Scholar]
- Volterra, V. Volume 2, Societá anonima tipografica “Leonardo da Vinci”. In Variazioni e Fluttuazioni del Numero d’Individui in Specie Animali Conviventi; Accademia Nazionale dei Lincei: Roma, Italy, 1927. [Google Scholar]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Kleinman, M.; Achille, A.; Soatto, S.; Kao, J.C. Redundant information neural estimation. Entropy 2021, 23, 922. [Google Scholar] [CrossRef]
- Quax, R.; Har-Shemesh, O.; Sloot, P.M. Quantifying synergistic information using intermediate stochastic variables. Entropy 2017, 19, 85. [Google Scholar] [CrossRef]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling long-and short-term temporal patterns with deep neural networks. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 95–104. [Google Scholar]
- Hogue, J. Metro Interstate Traffic Volume. Uci. Mach. Learn. Repos. 2019. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Explicit X | Explicit X + Implicit Z | Target Y |
|---|---|---|---|
| 1 | 0.646 | 5.46 | 5.52 |
| 2 | 0.679 | 4.11 | 5.35 |
| 3 | 1.44 | 3.47 | 5.29 |
| 4 | 2.84 | 3.48 | 5.36 |
| Datasets | Explicit | Explicit + Implicit Z | Target Y |
|---|---|---|---|
| ETTh1 | 2.78 | 5.54 | 6.75 |
| ETTh2 | 3.55 | 5.55 | 6.66 |
| ETTm1 | 3.12 | 5.46 | 6.33 |
| ETTm2 | 4.278 | 5.36 | 6.27 |
| ExcRat | 3.63 | 6.24 | 7.31 |
| Metro | 2.66 | 5.68 | 7.37 |
| PM2.5 | 1.80 | 4.59 | 5.52 |
| Datasets | NN | I-NN | RNN | I-RNN | LSTM | I-LSTM |
|---|---|---|---|---|---|---|
| ETTh1 | 1.97 × 10 | 1.89 × 10 | 1.65 × 10 | 1.77 × 10 | 2.05 × 10 | 2.01 × 10 |
| ETTh2 | 1.81 × 10 | 1.45 × 10 | 2.05 × 10 | 1.28 × 10 | 2.62 × 10 | 1.64 × 10 |
| ETTm1 | 4.19 × 10 | 4.16 × 10 | 4.35 × 10 | 4.24 × 10 | 7.57 × 10 | 5.12 × 10 |
| ETTm2 | 2.22 × 10 | 1.68 × 10 | 4.59 × 10 | 3.37 × 10 | 1.45 × 10 | 8.17 × 10 |
| ExcRat | 9.90 × 10 | 9.84 × 10 | 2.01 × 10 | 1.99 × 10 | 4.25 × 10 | 3.57 × 10 |
| Metro | 3.33 × 10 | 2.91 × 10 | 4.09 × 10 | 4.03 × 10 | 4.36 × 10 | 3.94 × 10 |
| PM2.5 | 5.50 × 10 | 5.46 × 10 | 5.87 × 10 | 5.78 × 10 | 5.87 × 10 | 5.70 × 10 |
| Datasets | Pre-Trained | Explicit | Explicit + Z | Y |
|---|---|---|---|---|
| ETTh1 | 1.46 | 3.59 | 3.60 | 6.31 |
| ETTh2 | 2.56 | 3.65 | 3.90 | 6.69 |
| ETTm1 | 2.51 | 3.05 | 2.94 | 5.58 |
| ETTm2 | 3.39 | 4.36 | 4.37 | 6.23 |
| ExcRat | 2.87 | 2.98 | 4.14 | 6.88 |
| Metro | 1.06 | 3.42 | 3.45 | 7.60 |
| PM2.5 | 0.96 | 2.32 | 2.34 | 6.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leong, K.-H.; Xiu, Y.; Chen, B.; Chan, W.K. Neural Causal Information Extractor for Unobserved Causes. Entropy 2024, 26, 46. https://doi.org/10.3390/e26010046
Leong K-H, Xiu Y, Chen B, Chan WK. Neural Causal Information Extractor for Unobserved Causes. Entropy. 2024; 26(1):46. https://doi.org/10.3390/e26010046
Chicago/Turabian StyleLeong, Keng-Hou, Yuxuan Xiu, Bokui Chen, and Wai Kin (Victor) Chan. 2024. "Neural Causal Information Extractor for Unobserved Causes" Entropy 26, no. 1: 46. https://doi.org/10.3390/e26010046