1. Introduction
An epidemic is a disease for which observation value exceeds the expected value. Once an epidemic affects a large population or spreads globally, it is called a pandemic [
1]. In recent decades, the incidence and mortality of emerging infectious diseases have increased worldwide, causing significant social, political, and economic damage [
2]. For example, several large-scale epidemics that have broken out in recent years include Severe Acute Respiratory Syndrome (SARS), H1N1 influenza, and the ebola virus, which have undoubtedly had a huge impact on the social, political, economic, and other aspects of the infected countries. In 2019, the initial outbreak of COVID-19 in Wuhan, Hubei Province, China, spread rapidly around the world, posing a major threat to global public health. According to the World Health Organization [
3], through 1 January 2023, more than 656 million confirmed cases of COVID-19 and more than 6.6 million deaths have been reported worldwide.
Mortality is an important epidemiological measurement, which is used to indicate the severity of the disease and measure the virulence of the disease. The World Health Organization has defined mortality as the ratio of the cumulative number of deaths to the cumulative number of confirmed cases. Mortality is used as an indicator to measure the severity of the disease [
4]. Yip et al. [
5] found that, in the early stage of the epidemic, because the infection was not over, few patients died of the disease, so the estimated fatality rate was low. With the development of the epidemic, more and more people died at the end of the disease, while more and more people were diagnosed, so the estimated rate was still low. Last [
6] argued that the simple estimator is not sensitive to changes in mortality during the epidemic and will only perform well at the end of the epidemic.
Lam et al. [
7] believed that the mortality of emerging epidemics may change over time, and the downward trend of mortality may reflect the effectiveness of government interventions and the improvement of medical resources. Ambreen et al. [
8] considered the impact of meteorological factors on COVID-19. Chen et al. [
9] also believed that pairing assistance is an effective way to curb COVID-19. During the outbreak of an epidemic, Lam et al. [
7] recommended using real-time fatality rate to measure the severity of the epidemic, rather than traditional mortality. The real-time fatality rate is defined as the probability of death based on the counting process method conditional on death or recovery. Compared with traditional mortality, the real-time fatality rate has been proven to be more sensitive to capturing changes in mortality during the course of an epidemic. Reich et al. [
10] defined the relative fatality rate as the ratio of the fatality rate of a group to that of another reference group and compared the fatality rate of a specific group using a generalized linear model framework. Chen et al. [
11] used the generalized linear model framework to estimate the fatality rate according to the maximal likelihood method. However, the assumptions about the real-time fatality rate in their methods are very strict and may be more suitable for chronic diseases than for emerging infectious diseases. In order to detect changes in the real-time fatality rate, Yip et al. [
12] proposed a competitive risk model implemented by the counting process to estimate the real-time fatality rate. Yip et al. [
5] considered the chain multinomial model to estimate the real-time fatality rate. Lam et al. [
7] developed a single-sample sequential test for the null hypothesis of constant fatality rate. Qu et al. [
13] developed a multi-sample sequential test for the null hypothesis of real-time fatality rate.
During the highly infectious epidemic outbreak, the government needs to formulate effective interventions as soon as possible to effectively curb the spread of the disease to reduce mortality, minimize the severity of the disease, and ensure the safety of people’s lives. Due to various reasons, it is difficult to collect complete and detailed data. However, it is relatively easy to obtain summary data on confirmed cases, deaths, and recoveries of COVID-19 from the official channels of health departments in various regions.
In order to solve the above problem, it is necessary to carry out relevant statistical tests and compare the severity of diseases between multiple groups according to a simple data structure. Inspired by Yip et al. [
12], we propose the analysis of variance using permutation test for real-time fatality rates among different groups over a fixed time period. With the accumulation of statistical evidence, the null hypothesis can be rejected. Under the proposed testing procedure, we can also test the differences in real-time fatality rate between different regions, different treatment groups, and different age groups, so as to provide information for the health sector. We recall that Zhao et al. [
14] tested the clinical symptoms of patients using Remdesivir and other therapeutic drugs through survival analysis of log-rank and found that the survival rate of patients using Remdesivir was significantly improved within 8 weeks. In essence, the potential use of multi-group trials is to compare the changes in the real-time fatality rate with Remdesivir and standard treatment. In the empirical analysis section, we compare the differences in real-time fatality rate among different regions. The results suggest that the effectiveness of interventions and medical resource assistance implemented by government departments during public health emergencies are useful and critical.
In
Section 2, the test statistic is put forward to study the asymptotic distribution. In
Section 3, the relevant knowledge of the permutation test is introduced. In
Section 4, simulation experiments are carried out to evaluate the effectiveness of the proposed test method in different scenarios. In
Section 5, the proposed test procedure is applied to the comparison of disease severity among three independent clusters during the outbreak: mainland China (excluding Hubei Province), Hubei Province (excluding Wuhan), and Wuhan. In
Section 6, we summarize the provided results.
2. Preliminaries
2.1. Test Statistic
In this paper, days are taken as the unit, and time 0 can be set as the day where observation is implemented for a particular group. Time is divided into T fixed intervals, the research objects are divided into k groups according to certain rules, and the sample size of each group is . Information about the number of cases, deaths, and recoveries in the group at the end of each interval is collected in order from . Denote the numbers of deaths, recoveries, and hospitalizations in the i-th group at the end of day t by , , and , respectively. We further denote the cumulative numbers of deaths and recoveries in the group at the end of day t by and .
Assuming that the number of confirmed cases in the
i-th group at the end of day
is
, they are independently and identically distributed for each confirmed patient and will be in one of the following three states on day
t: death, recovery, hospitalization. That is,
assuming that the probability of death is
, the probability of recovery is
, and the probability of hospitalization is
. According to the multinomial distribution proposed by Yip et al. [
5], we have
According to Yip et al. [
12], for group
i, death and recovery are regarded as two competing risks. To consider the real-time fatality rate on day
t, the real-time fatality rate is defined as
and the kernel function of the probability density function of Equation (
1) is
therefore the logarithmic likelihood function of Equation (
1) is
For
, set
,
, and
to derivation of
and
, respectively. We have
, that is,
so
Removing the redundancy term, we can regard
as a function of
, with derivations of
and
respectively on
, and obtain the following likelihood equation:
Let Equations (5) and (6) be equal to 0; their maximum likelihood estimation solution satisfies
and
, respectively. Since
, the maximum likelihood estimation value of
and
is
Therefore, the maximum likelihood estimator of
is defined by
With the passing of time, the severity of the epidemic will change, and the above-mentioned real-time fatality rate can be used to compare the changes in the severity of the epidemic among different groups. Therefore, the following hypothesis
is proposed by considering death and recovery as two competing risks. It is easy to see that the above hypothesis is equal to
when the null hypothesis holds true, and we expect that the two competing risks of death and recovery are similar during the observation period. Therefore, we propose the following expression of the sum of squares for factor (
) and the sum of squares for error (
); that is,
The following test statistic is obtained:
2.2. The Asymptotic Distribution of the Test Statistic
Assume that is a column vector of an n-dimensional normal random variable. Let A be an real symmetric matrix; then is called the quadratic form of A. Denote the rank of A by r. According to the knowledge of linear algebra, it can be seen that the rank of the quadratic is r, for short .
Suppose that the
n observation values
(
;
) in one-way analysis of variance are
n independent random variables and that
. Set
is the
n-order square matrix with all elements 1,
is the
n-order unit matrix, and
is a block diagonal matrix, where
; that is:
and
Based on the above assumptions, the following three basic quadratic forms are obtained through calculation:
Through the quadratic form in (10), Mao et al. [
15] proved that
,
, and the sum of squares for total (
) are quadratic forms of normal random vectors, whose ranks are equal to their respective degrees of freedom; therefore, we have
Under the null hypothesis, we also have
and
are independent, so
Here,
F is the probability distribution of the test statistic required for one-way analysis of variance. Then, for the given significance level
, it can be determined that the rejection region is
Since the data used in the analysis of variance need to satisfy the assumptions of normality, homogeneity of variance and independence are needed; however, since the data in this study do not satisfy these assumptions, we will use the permutation test for the variance analysis, which is introduced in detail in the next section.
3. Permutation Test
When the data do not satisfy the premise assumptions of normality, homogeneity of variance, or independence in the variance analysis, the variance analysis cannot be conducted [
16]. In this case, statistical methods based on randomization and resampling can be used for testing. We use a widely applicable statistical method from the idea of randomization, which is called a permutation test. Xue et al. [
17] pointed out that the permutation test has obvious advantages over traditional statistical methods because it does not need to make presuppositions about the distribution and is conducted solely based on the information contained in the observed samples.
The core problem to be solved by using the permutation test for variance analysis is how to estimate the probability distribution of the test statistic under the condition that the null hypothesis is established. The basic thought is that if the null hypothesis that states that there is no significant difference in the mean of the sample data from k groups is true, then the null hypothesis cannot be overturned by calculating the observation value (denoted as ) of its test statistics based on the observed k independent samples. At this time, if k samples are mixed and then randomly divided into k new samples, also known as permutation samples, the observed values of the test statistics are calculated again and tested, and the same inferred conclusion will be obtained.
Assuming that it is necessary to test whether there is any difference between the effect among
k groups, then set a total of
(
) experimental units, and divide these experimental units into
k parts. Each part contains
units, and
k different treatments are applied separately. The test results obtained from each treatment are recorded as
(
), and the effect value is
; then the assumption to be considered is
when assigning experimental units based on the principle of randomization. By arbitrarily lining up
n experimental units into a row and applying
k different treatments to
units in turn, the data
are randomly extracted from the effect
. If the following test statistic is used
then
is evaluated with the probability of
every time;
is arranged in a row and divided into
k parts, where the value of each part is
; and the value of
can be calculated according to (12). By repeating this process,
values of
can be obtained, denoted as
. Arrange all
into
according to size, and select an appropriate
(
) according to significance level
.
When
, reject the null hypothesis, believing that there is a significant difference in the effect among
k groups. The following is the rejection region of the permutation test:
Equation (
13) uses the quantile of the permutation distribution as the critical value to determine the rejection region. It can be seen that both the permutation method and the parameter method need to calculate the test statistic. The difference is that the permutation method does not compare the test statistic with the theoretical distribution but rather compares the test statistic with the empirical distribution obtained by the permutation sample and judges whether there is enough evidence to reject the null hypothesis according to the extremeness of the statistical value.
4. Simulation
A large-scale simulation is carried out to evaluate the performance of the proposed approach, generating simulated data for daily confirmed cases, with deaths and recoveries unknown. This simulates the real-world epidemiological data in which only aggregated counts are reported during an epidemic outbreak. We assume that the observation period is 50 days (), and it needs to take into account how real-time fatality rates changes over time in practice. Therefore, we assume that, during the 50-day observation period, when , the daily number of confirmed cases follows the Poisson distribution of parameter , and when , the daily number of confirmed cases follows the Poisson distribution of parameter . In addition, the simulation scenarios are based on the preassigned death probability and recovery probabilities on day t for group i. The daily number of deaths and recoveries are generated according to the multinomial setting in (1), and the real-time fatality rates are further calculated according to the generated simulation data. Finally, the permutation test is used for variance analysis to determine the differences in disease severity among k groups.
Under
, the performance of the proposed test is evaluated by considering various scenarios in which the real-time fatality rates are equal among three groups (group A, group B, group C). From the simulation results in
Table 1, we can see that the analysis of variance using the permutation test can sensitively capture the differences in real-time fatality rate among different groups, thus rejecting the null hypothesis of equal real-time fatality rate.
Figure 1 shows the multiple comparison tests of the first four scenarios at the confidence level
. The upper left corner shows that the confidence interval of the mean difference of each group in scenario 1 does not contain the 0 point. Therefore, we can judge that there is a significant difference in the real-time fatality rate among the three groups in scenario 1. The upper right corner shows the confidence interval of the mean difference of each group in scenario 2, and only the confidence interval of the mean difference between group A and group B contains the 0 point, which means that there is no significant difference in the real-time fatality rate between group A and group B. The lower left corner and the lower right corner respectively show the confidence interval of the mean difference of each group in scenarios 3 and 4. In these two figures, the confidence interval of mean difference of group B and group C contains the 0 point; that is, there is no significant difference in the real-time fatality rate between group B and group C under scenarios 3 and 4.
5. Empirical Analysis
COVID-19 is the most widespread global pandemic to hit humanity in the past century. It is a serious crisis for the whole world, posing a major threat to human life and health [
18,
19]. The first case of COVID-19 was found in Wuhan, Hubei Province, China, in December 2019. At present, China’s National Health Commission has renamed it as the Novel Coronavirus Infection. Kraemer et al. [
20] found that, despite restrictions on mobility imposed in Wuhan on 23 January 2020, it still could not stop the rapid spread of COVID-19 to other cities. According to the statistics of the National Health Commission [
21], as of 24:00 on 29 February 2020, a total of 79,824 confirmed cases had been reported in mainland China, including 2870 deaths; 66,907 confirmed cases and 2761 deaths had been reported in Hubei Province; and 49,122 confirmed cases and 2195 deaths had been reported in Wuhan. At first glance, the mortality in mainland China is about
, the mortality in Hubei Province is about
, and the mortality in Wuhan is about
. However, it is difficult to estimate the mortality of an epidemic, especially for the outbreak of COVID-19. Medical staff all over China have to make every effort to deal with this extremely infectious and terrible disease. Next, the proposed method is applied to analyze the differences in disease severity among different regions over time.
6. Data Description
Considering that the intervention measures implemented during the epidemic and availability of medical resources may have a potential impact on the fatality rate in the initial stage of COVID-19 in China, we have divided mainland China into three different clusters, namely mainland China excluding Hubei Province, Hubei Province excluding Wuhan, and Wuhan, and we use the real-time fatality rate to analyze the differences in disease severity among different clusters. The daily number of confirmed cases, daily deaths, and daily recoveries for each cluster from the official website of the National Health Commission (
http://www.nhc.gov.cn, accessed on 11 June 2020) were extracted and summarized from 31 January 2020 to 30 March 2020.
Figure 2 shows the real-time fatality rate estimator of the three independent clusters throughout the observation period. We can see that, in the initial stage of the COVID-19 epidemic, there are obvious differences in disease severity among different regions in mainland China. With the passage of time, the difference in the severity of the disease gradually decreases. In this regard, we provide some explanations to describe the observed phenomena.
In the initial stage of the epidemic, most of the confirmed cases were mainly concentrated in Hubei Province. Given the large number of patients and the lack of clinical experience with the disease, the local medical systems were overwhelmed. In Wuhan in particular, many patients were not treated in time, causing the highest mortality there, followed by Hubei Province (excluding Wuhan). On the other hand, the implementation of strict lockdown measures in Wuhan curbed the spread of the disease to a certain extent, providing valuable preparation time for other regions to prevent the epidemic. In the face of the unknown, sudden, and fierce natural disasters of the epidemic, the Chinese government decisively launched a battle of epidemic prevention and control and mobilized all necessary resources throughout the country to support virus control in Hubei Province and Wuhan. Leishenshan Hospital and Huoshenshan Hospital, which were used to focus on the treatment of COVID-19 patients, had 1500 beds and 100 beds, respectively. These two hospitals took only about ten days to realize the whole process, from the completion of the design plan to delivery. Cities in Hubei Province received paring assistance from other provinces [
9]. As of 14 February 2020, more than 25,000 medical professionals rushed to Wuhan. In addition, Wuhan successfully established 16 Fangcang shelter hospitals, which eased the great pressure on the medical system [
22]. Meanwhile, more than 40 designated hospitals were set up in Wuhan, mainly to treat severe COVID-19 patients [
23]. During the observation period, the real-time fatality rate in mainland China (excluding Hubei Province) was basically stable at a low level. With the continuous alleviation of the pressure of medical resources in Wuhan and Hubei Province, their real-time fatality rate generally showed a continuous downward trend. Finally, by late February 2020, the real-time fatality rates in the three regions were no longer significantly different, and the level remained relatively low in March 2020.
Empirical Analysis Result
In this section, the proposed permutation test is applied to the analysis of variance to test the degree of difference in real-time fatality rates over time among different clusters. The unit is a day, which means there are
time intervals, and the 0th day (
) is 31 January 2020. A three-sample test is conducted on
:
and we set the overall significance level
to 0.05.
Specifically, during the 60-day observation period, the test statistic
of the original sample is first calculated. Then, we mix the three original samples, randomly assign the original samples into three groups to obtain the permutation samples, calculate the test statistic
of the permutation samples, and repeat this
times. Finally,
is arranged in order, making the distribution of
the empirical distribution. The decision is made by comparing
with the empirical distribution. According to
Table 2, there are generally significant differences in the real-time fatality rates of the three regions during the 60-day observation period. The multiple comparison test results in
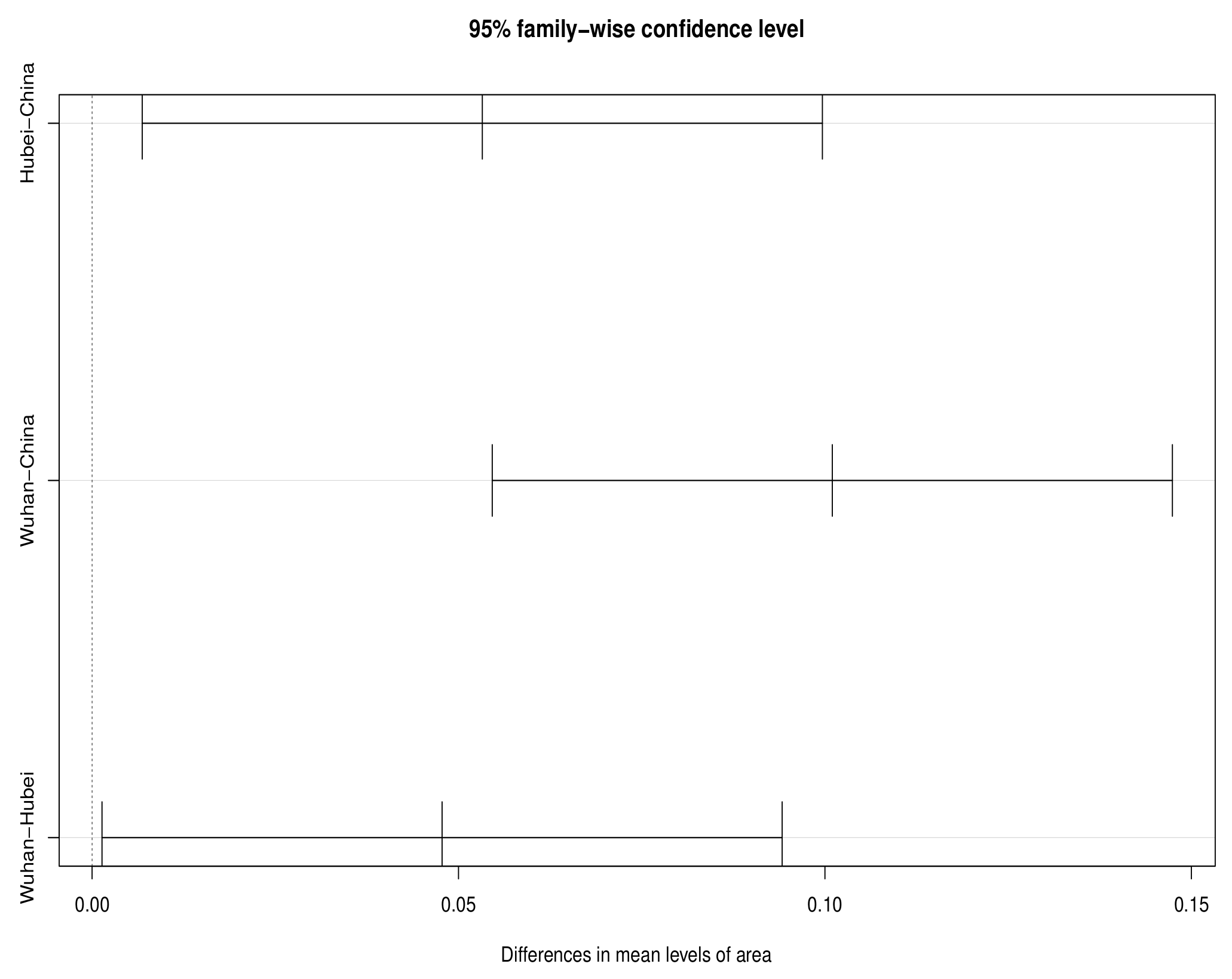
Figure 3 show that the confidence interval of the mean difference in real-time fatality rate between two or two of the three regions does not contain the 0 point, which shows significant difference in disease severity among the three regions during the whole observation period. According to
Table 3, we can see that the real-time fatality rate in Hubei is 0.0532 higher than in China on average, while the real-time fatality rate in Wuhan is 0.1010 higher than in China on average, and 0.0478 higher than in Hubei.
Further, in order to measure the effectiveness of the intervention measures implemented by the Chinese government and the impact of improved medical resources on disease severity, we conduct a temporal examination of the real-time fatality rates in Hubei and Wuhan before and after assistance. First, the proposed method is performed for the period from 31 January 2020 to 26 February 2020, when
. According to the results in
Figure 4, before the aid to Hubei and Wuhan and at the initial stage of the aid, the confidence interval of the mean difference of the real-time death rate between the three regions does not contain the 0 point, suggesting that there are still significant differences in the real-time fatality rate between the three regions.
In the late assistance period, the same inspection procedure is carried out from 27 February 2020 to 30 March 2020, when
. As shown in
Figure 5, during this period, the confidence interval of the mean difference in the real-time fatality rate in the three regions contains the 0 point, suggesting that there is no significant difference in the real-time fatality rate in the three regions. It can be considered that the accessibility of medical resources in different regions is roughly the same, and the intervention policies implemented by the Chinese government have effectively alleviated the disease severity. The result shown in
Figure 5 further confirms similar real-time fatality rates in the three regions from late February 2020 to late March 2020.
7. Conclusions
In this paper, a non-parametric test procedure is proposed. The non-parametric test method generally does not involve population parameters, and its assumptions are much less than those of a parametric test. Therefore, nonparametric tests are used to compare differences in real-time fatality rates among independent groups during epidemic outbreaks. Since implementing effective interventions can inhibit the spread of the disease to some extent, thereby reducing the disease severity and saving more lives, our approach can validate the effectiveness of interventions. The asymptotic distribution of the test statistic under the null hypothesis allows analysis of variance to be performed using the permutation test, and the null hypothesis can be rejected when there are significant differences in disease severity among groups. At the same time, our simulations show that the proposed test can accurately identify inter-group differences in disease severity for various scenarios. The test procedure proposed in this paper is applied to the data of the initial stage of the COVID-19 epidemic in mainland China to test the difference in the severity of the disease among the three independent clusters. The results show that there is a significant difference in the real-time fatality rate of the three clusters during the whole observation period. Through the discussion of time segments, we found that with the implementation of effective intervention measures and the improvement in medical resources, there is no significant difference in the real-time fatality rate of the three clusters in the later stage of observation. We can see that the severity of COVID-19 in mainland China may be related to the implementation of interventions and the availability of medical resources, which reflects the important role of effective interventions and medical resources in reducing the real-time fatality rate.
Our method can be applied to the case of k samples. In essence, this allows researchers to study more clinical questions in concrete real-life situations, such as investigating the extent of differences in the real-time fatality rate between multiple sex groups or age groups, which may help study other factors that influence the real-time fatality rate of diseases. It is important to note that different treatment regimens are used clinically for different groups, and investigating the extent to which mortality varies between treatment groups can help healthcare providers determine the most effective treatment regimens. The method proposed in this paper can be one of the important methods to evaluate the efficacy of different treatment regimens. The test procedure is based on the information contained in the observed sample and is not limited by the population distribution. Surveillance data from authorities during outbreaks is always incomplete, with some data such as gender and age being difficult to obtain, especially in areas with low awareness of protection and inadequate healthcare systems. Despite the post-pandemic period, detailed data on the COVID-19 are still difficult to obtain, and for most regions, only daily confirmed cases, deaths, and recoveries are recorded and aggregated. It is most important for the health department to use the simplest data structures to gain a deeper understanding of the disease so that rapid interventions can be taken to curb the spread of the disease early and reduce mortality.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}