
Topic Discovery and Hotspot Analysis of Sentiment Analysis of Chinese Text Using Information-Theoretic Method

Abstract
:1. Introduction
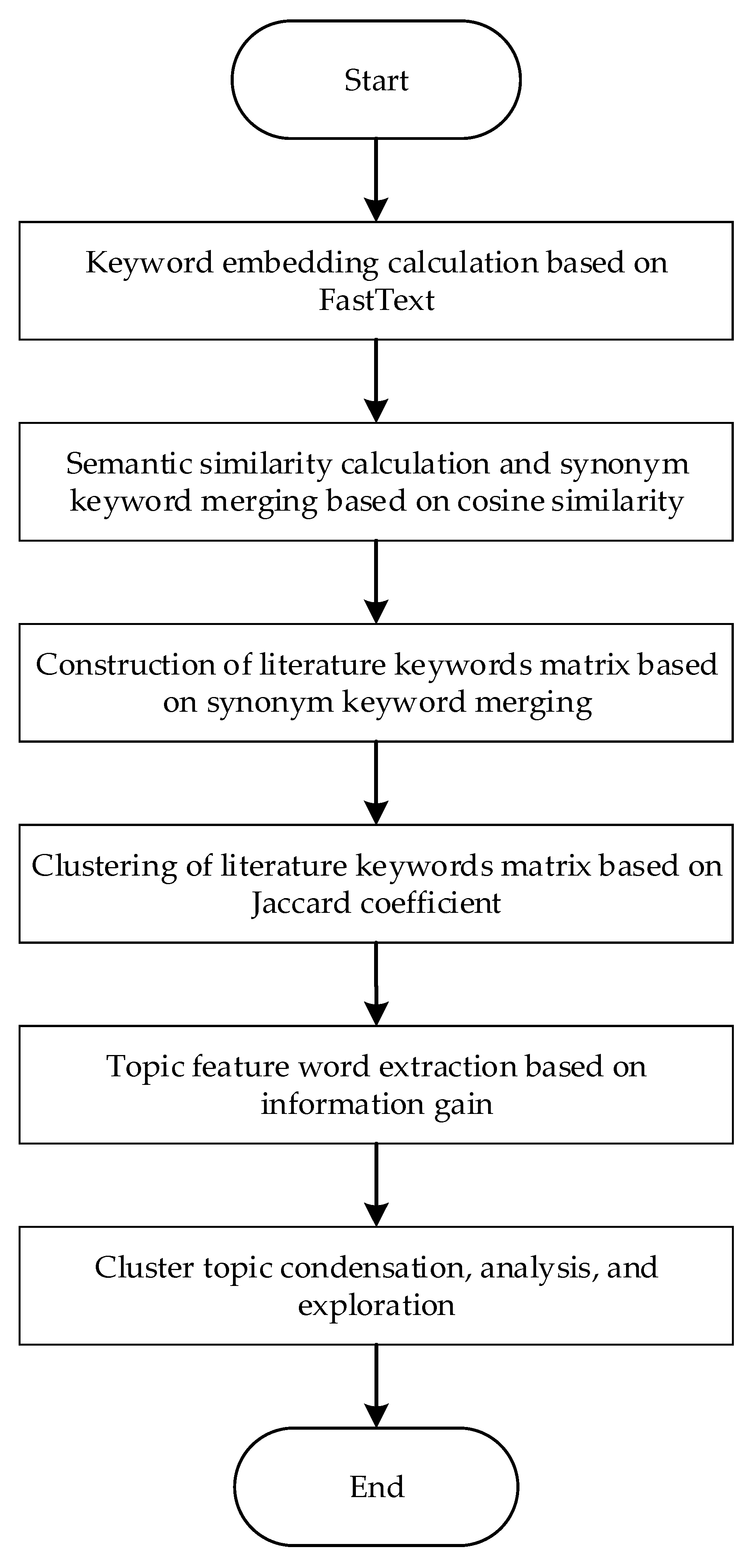
2. Construction of the Topic Discovery Model Using Information-Theoretic Method
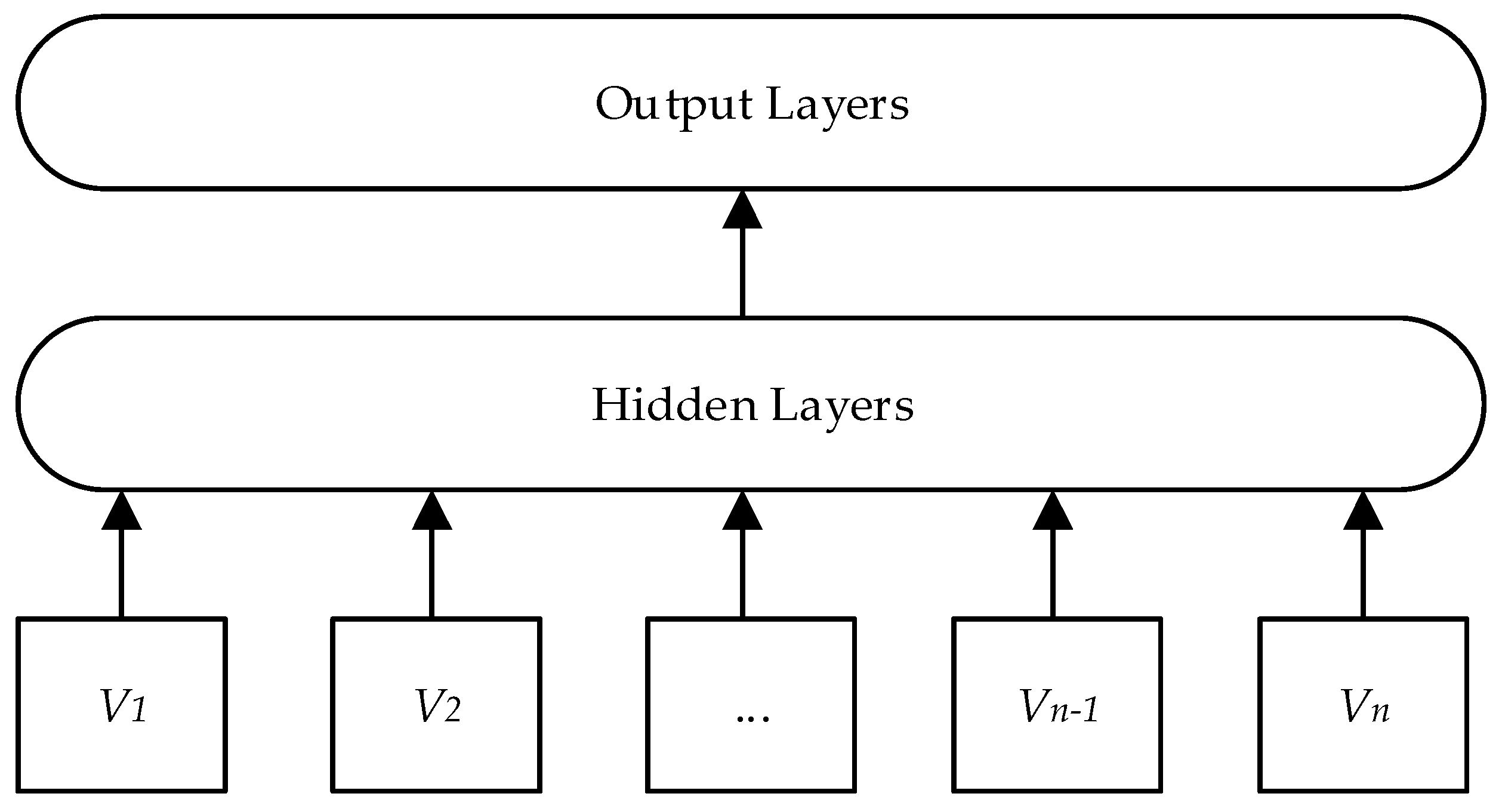
2.1. Synonymous Keyword Merging Based on FastText Model
2.2. Topic Clustering Based on Jaccard Coefficient
2.3. Topic Feature Word Extraction Based on Information Gain
3. Experiments and Results
3.1. Data Sources and Experimental Procedures
3.2. Experimental Results and Analysis
3.2.1. Keyword Semantic Similarity Calculation and Synonym Merging
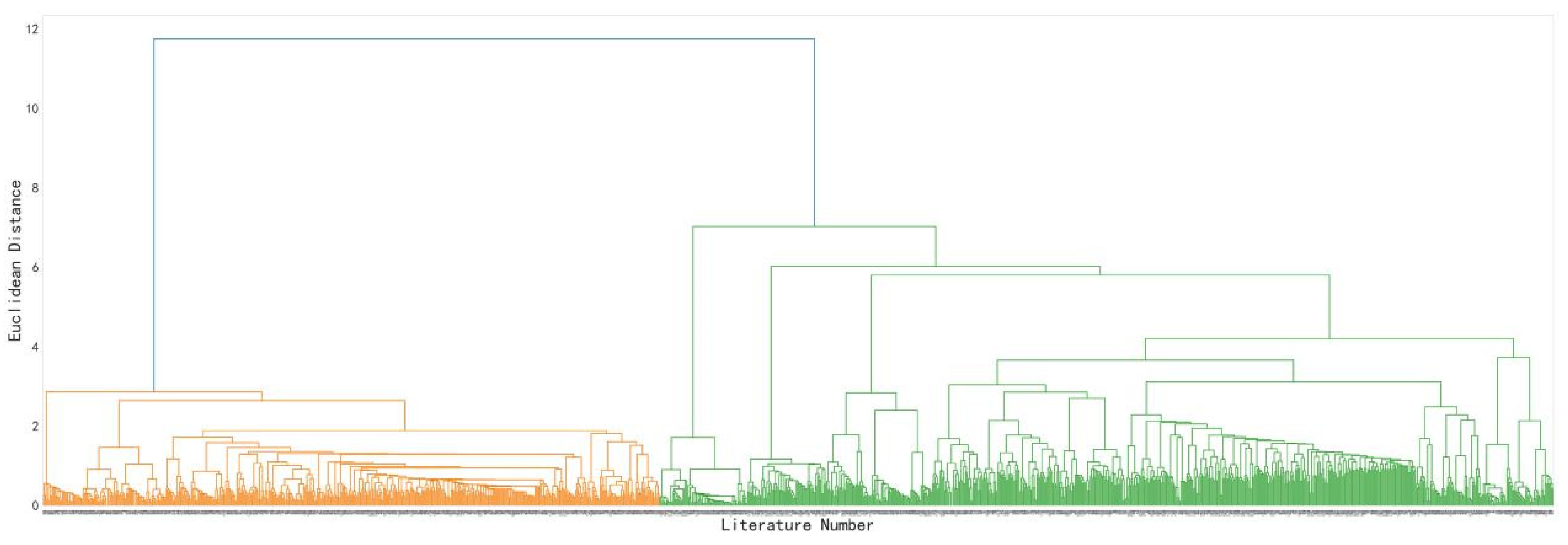
3.2.2. Topic Clustering Analysis Using Jaccard Coefficients
3.2.3. Key Feature Word Extraction Using Information Gain
3.3. Connotation Analysis of Each Topic
- (1)
- The first topic: Chinese Online Reviews
- (2)
- The second topic: Sentiment Analysis Tasks and Scenarios
- (3)
- The third topic: Microblog Public Opinion Analysis
- (4)
- The fourth topic: Sentiment Classification
- (5)
- The fifth topic: Sentiment Lexicon
- (6)
- The sixth topic: Convolutional Neural Network
- (7)
- The seventh topic: Big Data Mining
- (8)
- The eighth topic: Deep Learning
- (9)
- The ninth topic: Aspect-Based Sentiment Analysis
- (10)
- The tenth topic: Feature Extraction
- (11)
- The eleventh topic: Multimodal Sentiment Analysis
- (12)
- The twelfth topic: Word Embedding
3.4. Annual Distribution of Literature and Research Trend Analysis
3.4.1. Annual Distribution of Literature in Each Topic
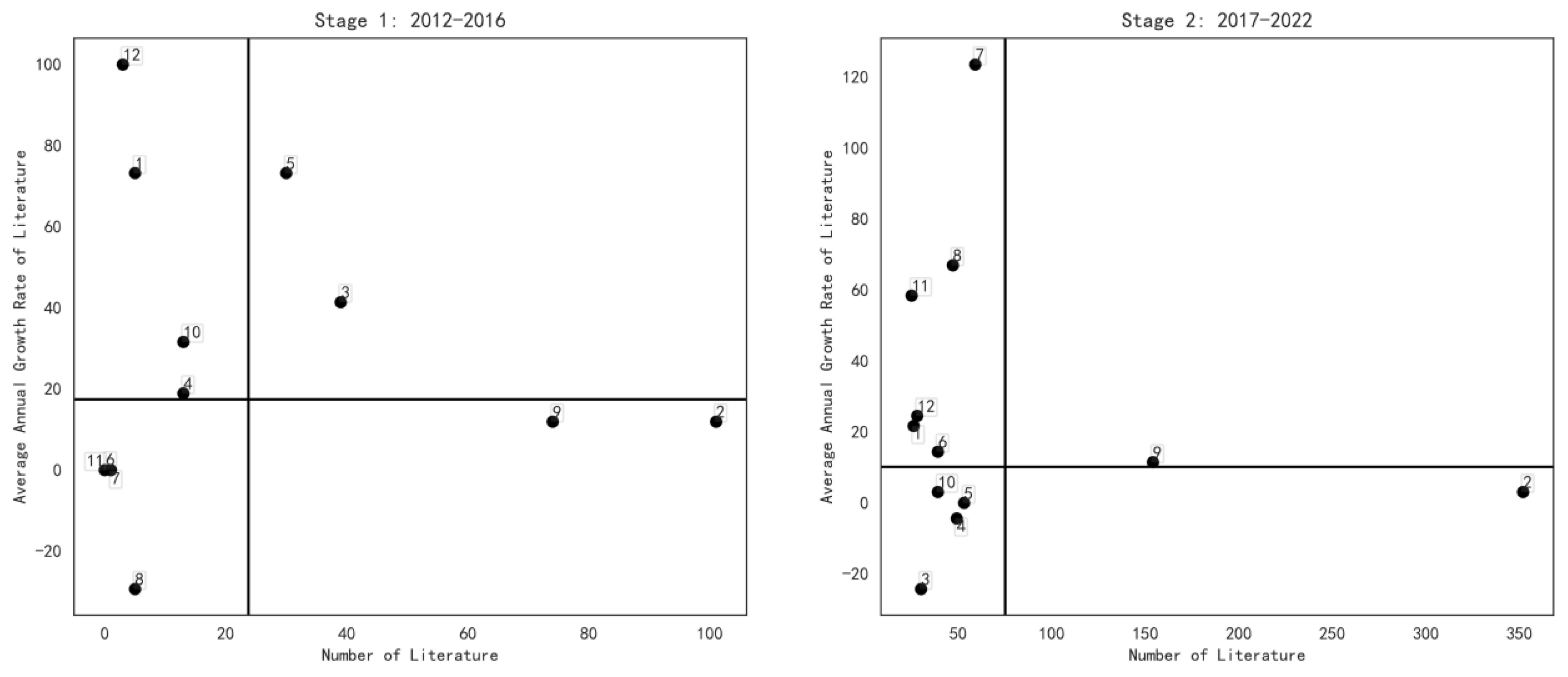
3.4.2. Topic Distribution Matrix and Research Trend Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhong, J.; Liu, W.; Wang, S.; Yang, H. Review of Methods and Applications of Text Sentiment Analysis. Data Anal. Knowl. Discov. 2021, 5, 1–13. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Assoc. Comput. Linguist. 2002, 10, 79–86. [Google Scholar]
- Alslaity, A.; Orji, R. Machine Learning Techniques for Emotion Detection and Sentiment Analysis: Current State, Challenges, and Future Directions. Behav. Inf. Technol. 2022, 1–26. [Google Scholar] [CrossRef]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Sciarretta, L.; Ursino, D.; Virgili, L. A Space-Time Framework for Sentiment Scope Analysis in Social Media. Big Data Cogn. Comput. 2022, 6, 130. [Google Scholar] [CrossRef]
- Almars, A.; Li, X.; Zhao, X. Modelling User Attitudes Using Hierarchical Sentiment-topic Model. Data Knowl. Eng. 2019, 119, 139–149. [Google Scholar] [CrossRef]
- Yin, R.; Wu, J.; Tian, R.; Gan, F. Topic Modeling and Sentiment Analysis of Chinese People’s Attitudes toward Volunteerism Amid the COVID-19 pandemic. Front. Psychol. 2022, 13, 1064372. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Rabbani, M.; Ahmadi, S.; Boukela, L.; Zhao, R.; Larik, R.S.A. A NLP Framework Based on Meaningful Latent-Topic Detection and Sentiment Analysis via Fuzzy Lattice Reasoning on Youtube Comments. Multimed. Tools Appl. 2021, 80, 4155–4181. [Google Scholar] [CrossRef]
- Hong, W.; Li, M. A Review: Text Sentiment Analysis Methods. Comput. Eng. Sci. 2019, 41, 750–757. [Google Scholar]
- Wang, R.; Meng, X. Review of lmage Sentiment Analysis. Rev. Image Sentim. Anal. 2020, 195, 119–127. [Google Scholar]
- Liu, J.; Zhang, P.; Liu, Y.; Zhang, W.; Fang, J. Summary of Multi-modal Sentiment Analysis Technology. J. Front. Comput. Sci. Technol. 2021, 15, 1165–1182. [Google Scholar]
- Xu, L.; Liu, X.; Yan, Y.; Yuan, W.; Lin, H. Survey of Russian Sentiment Analysis. Comput. Eng. Appl. 2022, 58, 13–22. [Google Scholar]
- Xu, Y.; Cao, H.; Wang, W.; Du, W.; Xu, C. Cross-Lingual Sentiment Analysis: A Survey. Data Anal. Knowl. Discov. 2023, 7, 1–21. [Google Scholar]
- Zhao, R.; Zhang, Y. Evolution Study of Sentiment Analysis Based on Bibliometrics of Time and Space Dimensions. Inf. Sci. 2018, 36, 171–177. [Google Scholar]
- Chen, H.; Wei, R.; Zhang, W.; Zhang, Y. Research on Domestic Text Sentiment Analysis Based on Co-word Analysis. J. Mod. Inf. 2019, 39, 91–101. [Google Scholar]
- Tan, K.; Yang, K. Research Hotspot and Trend of Public Opinion Emotion Analysis Based on Neural Network—Visual Analysis Based on CiteSpace. Intell. Comput. Appl. 2022, 12, 33–42. [Google Scholar]
- Zhang, C.; Zhang, J. Research Topic Mining, Hot Spot and Trend Analysis of Block Chain in China. J. Stat. Inf. 2021, 36, 119–128. [Google Scholar]
- Zhang, C.; Zhao, D.; Ni, Y. Topic Mining and Hot Spot Analysis of China’s Carbon Emission Peak and Carbon Neutrality. Price: Theory Pract. 2022, 5, 110–113. [Google Scholar]
- Bai, Z.; Zhou, Y.; Zhang, H. Short Text Classification Model of GM-FastText Multi-channel Word Vector. Comput. Syst. Appl. 2022, 31, 403–408. [Google Scholar]
- Yu, P. Jaccard Distance of Logical Formulas and Its Application. J. Front. Comput. Sci. Technol. 2020, 14, 1975–1980. [Google Scholar]
- Wang, R.; Song, J.; Chen, C. Application of Sentiment Analysis Based on Word2vec in Brand Awareness. Libr. Inf. Serv. 2017, 61, 6–12. [Google Scholar]
- Shi, L.; Lin, J.; Zhu, G. A Hybrid Neural Network for Product Feature Extraction and Customer Requirements Analysis on Chinese Online Reviews. Data Anal. Knowl. Discov. 2023, 1–11. Available online: http://kns.cnki.net/kcms/detail/10.1478.g2.20230216.1139.004.html (accessed on 21 May 2023).
- Li, Z.; Xu, H.; Duan, B. Research on Image Emotion Feature Extraction Based on Deep Learning CNN Model. Libr. Inf. Serv. 2019, 63, 96–107. [Google Scholar]
- Liu, J.; Zhang, S. Analysis of the Evolution of Hot Topics in Microblogs Based on Sentiment Analysis. China CIO News 2022, 348, 137–140. [Google Scholar]
- Xing, Y.; Wang, J.; Wei, Y.; Wang, D. Research on the Evolution of Online Public Opinion Users’ Sentiment under the New Media Environment—Based on the Theory of Emotional Polarity and Intensity. Intell. Sci. 2018, 36, 142–148. [Google Scholar]
- Alistair, K.; Diana, I. Sentiment Classification of Movie Reviews Using Contextual Valence Shifters. Comput. Intell. 2006, 22, 110–125. [Google Scholar]
- Lin, X.; Chen, Z.; Wang, Z. Aspect-level Sentiment Classification Based on Imbalanced Data and Ensemble Learning. Comput. Sci. 2022, 49, 144–149. [Google Scholar]
- Zhu, Q.; Liang, B.; Xu, R.; Liu, Y.; Chen, Y. Attention-based Recurrent Network Combined with Financial Lexicon for Aspect-level Sentiment Classification. J. Chin. Inf. Process. 2022, 36, 109–117. [Google Scholar]
- Wu, J.; Lu, K. Chinese Weibo Sentiment Analysis based on Multiple Sentiment Lexicons and Rule Sets. Comput. Appl. Softw. 2019, 36, 93–99. [Google Scholar]
- Wang, K.; Xia, R. A Survey on Automatical Construction Methods of Sentiment Lexicons. Acta Autom. Sin. 2016, 42, 495–511. [Google Scholar]
- Pan, L.; Zeng, C.; Zhang, H.; Wen, C.; Hao, R.; He, P. Text Sentiment Analysis Method Combining Generalized Autoregressive Pre-training Language Model and Recurrent Convolutional Neural Network. J. Comput. Appl. 2022, 42, 1108–1115. [Google Scholar]
- Lu, J.; Gong, Y. Text Sentiment Classification Model Based on Self-attention and Expanded Convolutional Neural Network. Comput. Eng. Des. 2020, 41, 1645–1651. [Google Scholar]
- Wang, Y.; Shen, Y.; Dai, Y. Sentiment Analysis of Texts Based on Fine-Grained Multi-Channel Convolutional Neural Network. Comput. Eng. 2020, 46, 102–108. [Google Scholar]
- Huang, Z.; Wu, Y. Text Emotion Analysis Based on BERT and CNN-BISRU. Comput. Appl. Softw. 2022, 39, 213–218. [Google Scholar]
- Li, A.; Zhang, Z.; Lin, Y.; Wang, Q.; Yang, J.; Meng, W.; Zhang, Y. Research on Emotion Monitoring of Public Based on Social Network Big Data. Big Data Res. 2022, 8, 105–126. [Google Scholar]
- Wang, N.; He, Y.; Liu, L. Research on the Construction and Effectiveness of Investor Sentiment Index—Based on Emotional Analysis Oriental Wealth Stock Bar Posts. Price: Theory Pract. 2022, 11, 146–151. [Google Scholar]
- Xu, X.; Zhu, Y. Data-driven Dynamic Collaborative Method of Public and Experts in Large-group Emergency Decision-making. Syst. Eng. Electron. 2023, 1–15. Available online: http://kns.cnki.net/kcms/detail/11.2422.tn.20230220.1113.010.html (accessed on 21 May 2023).
- Hu, Y.; Tong, T.; Zhang, X.; Peng, J. Self-attention-based BGRU and CNN for Sentiment Analysis. Comput. Sci. 2022, 49, 252–258. [Google Scholar]
- Yuan, J.; Ding, Y.; Pan, D.; Li, L. Chinese Implicit Sentiment Classification Model Based on Sequence and Contextual Features. J. Comput. Appl. 2021, 41, 2820–2828. [Google Scholar]
- Wu, S.; Ma, J. Multi-task Multimodal Sentiment Analysis Model Based on Aware Fusion. Data Anal. Knowl. Discov. 2022, 1–15. Available online: http://kns.cnki.net/kcms/detail/10.1478.G2.20221223.1401.001.html (accessed on 21 May 2023).
- Wang, J.; Liu, Z.; Liu, T.; Wang, Y.; Chai, Y. Multimodal Sentiment Analysis Based on Multilevel Feature Fusion Attention Network. J. Chin. Inf. Process. 2022, 36, 145–154. [Google Scholar]
- Zhang, J.; Jiang, L. Research on Irony Recognition of Travel Reviews Based on Multi-modal Deep Learning. Inf. Stud. Theory Appl. 2022, 45, 158–164. [Google Scholar]
- Du, H.; Xu, X.; Wu, D.; Liu, Y.; Yu, Z. A Sentiment Classification Method Based on Sentiment-Specific Word Embedding. J. Chin. Inf. Process. 2017, 31, 170–176. [Google Scholar]
- Gao, H.; Gong, M.; Liu, J. Sentiment Analysis of Online Healthcare Reviews Based on Feature Weighted Word Vector. J. Beijing Inst. Technol. 2021, 41, 999–1005. [Google Scholar]
- Cao, L.; Zhou, Y.; Wu, C.; Huang, Z. Mutual Learning Based Multiple Word Embeddings Fusion Framework for Sentiment Classification. J. Chin. Inf. Process. 2022, 36, 164–172. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keywords | ALBERT | Attention Mechanism | ...... | CRF Model | Attention-Highway |
|---|---|---|---|---|---|
| ALBERT | 1.000 | 0.991 | ...... | 0.954 | 0.884 |
| Attention Mechanism | 0.991 | 1.000 | ...... | 0.952 | 0.940 |
| ...... | ...... | ...... | ...... | ...... | ...... |
| CRF Model | 0.954 | 0.952 | ...... | 1.000 | 0.871 |
| Attention-Highway | 0.884 | 0.940 | ...... | 0.871 | 1.000 |
| Keywords | Similar Keywords and Similarities |
|---|---|
| Word Vector | Word Granularity Word Vector (0.997), Char-Word Representation (0.995), Word Vector Filling (0.996) |
| Context | Global Context (0.992), Context Enhancement (0.990), Context-Aware (0.990), Context Entropy (0.996), Contextual Constraints (0.993) |
| Aspect-Level Sentiment Analysis | Aspect-Based Sentiment Analysis (0.991), Multi-Aspect Sentiment Analysis (0.992), Attribute Sentiment Analysis (0.992), Attribute-Level Sentiment Analysis (0.997), Aspect-Level Sentiment Analysis (0.997) |
| Topic Probability Model | LDA Model (0.995), Theme-Emotion Mining Model (0.999), Topic Sentiment Model (0.995), Topic Sentiment Mixture (0.993), Time-Aware Sentiment-Topic Model (0.996), Probability Topic Model (0.993), Topic Model (0.996) |
| Attention Mechanism | Interaction Attention Mechanism (0.992), Positional Attention Mechanisms (0.995), Bidirectional Attention Mechanism (0.995), Dual-Way Attention Mechanism (0.998), Dual Attention Mechanism (0.996), Sentry Attention Mechanism (0.998), Multi-Head Attention (0.991), Multi-Attention Mechanism (0.998), Locality Sensitive Hashing Attention (0.993), Sparse Self-Attention Mechanism (0.993), Self-Attention Mechanism (0.997), Self-Attention (0.991) |
| Literature Number | 3D Convolutional Neural Networks | BILSTM | … | Thematic Sentiment Analysis | Interaction Attention Mechanism | Aspect-Level Sentiment Analysis |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | … | 0 | 1 | 0 |
| 2 | 0 | 1 | … | 0 | 0 | 0 |
| 3 | 0 | 0 | … | 1 | 1 | 1 |
| … | … | … | … | … | … | … |
| 1186 | 0 | 0 | … | 0 | 0 | 0 |
| Category Number | Number of Literature | Percentage (%) | Category Number | Number of Literature | Percentage (%) |
|---|---|---|---|---|---|
| 1 | 31 | 2.61 | 7 | 60 | 5.06 |
| 2 | 453 | 38.20 | 8 | 52 | 4.38 |
| 3 | 69 | 5.82 | 9 | 228 | 19.22 |
| 4 | 62 | 5.23 | 10 | 52 | 4.38 |
| 5 | 83 | 7.00 | 11 | 25 | 2.11 |
| 6 | 40 | 3.37 | 12 | 31 | 2.61 |
| Category Number | Keywords and Information Gain (×10−2) | Category Topic |
|---|---|---|
| 1 | Chinese Online Reviews (4.194), Multi-Attribute Online Review Decision Making (4.153), Online Review of Cigarette (4.115), Online Reviews Mining (4.077), Online Review Text (3.973) | Chinese Online Reviews |
| 2 | Sentiment Analysis Task (14.634), Analysis of Public Sentiment and Emotion (14.500), Image Sentiment Analysis (13.104), Thematic Sentiment Analysis (12.903), Text Sentiment Analysis (12.432) | Sentiment Analysis Tasks and Scenarios |
| 3 | Microblog (9.305), Emoticon (9.305), Microblog Data (9.181), Public Opinion on Microblog (9.181), Weibo Rumors (9.181) | Microblog Public Opinion Analysis |
| 4 | Sentiment Classification (6.375), Sentiment Classification Annotation (6.308), Sentiment Classification Model (6.276), Image Sentiment Classification (6.212), Text Sentiment Classification (6.151) | Sentiment Classification |
| 5 | Sentiment Lexicon (9.547), Financial Sentiment Lexicon (9.478), Sentiment Lexicon Construction (9.410), Highly Credible Lexicon (9.344), Semantic Lexicon Matching (9.280) | Sentiment Lexicon |
| 6 | 3D Convolutional Neural Networks (2.617), Convolutional Neural Networks Model (2.123), Bidirectional Sliced Gated Recurrent Unit (0.547), Bidirectional Gated Recurrent Neural Network (0.520), Deep Neural Network (0.485) | Convolutional Neural Network |
| 7 | Big Data Mining (1.988), Analysis of Public Sentiment and Emotion (1.795), Sentiment Analysis (1.782), Chinese Microblog Sentiment Analysis (1.767), Text Sentiment Analysis (1.414) | Big Data Mining |
| 8 | Deep Learning (2.252), Deep Learning Hybrid Model (2.190), Natural Language Processing (1.063), Natural Language Processing Technology (1.051), End-to-End (0.230) | Deep Learning |
| 9 | Aspect-Level Sentiment Analysis (7.247), Thematic Sentiment Analysis (6.462), Sentiment Analysis Task (6.388), Image Sentiment Analysis (5.970), Fine-Gained Sentiment Analysis (5.231) | Aspect-Based Sentiment Analysis |
| 10 | Feature Extractor (1.939), Local Feature Extraction (1.889), Text Feature Extraction (1.889), Customer Features Extraction (1.889), Sentiment Feature Extraction (1.651) | Feature Extraction |
| 11 | Multimodal Learning (4.439), Multimodal Application (4.090), Multimodal Fusion Architecture (4.090), Multimodal Network (3.990), Multimodal Data (3.886) | Multimodal Sentiment Analysis |
| 12 | Word Embedding Model (4.373), GloVe Word Vector (4.325), Sentiment Enhanced Word Vector (4.279), Feature Weighted Word Vector (4.115), Location-Weighted Word Vector (4.006) | Word Embedding |
| Category Number | Category Topic | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | Total | Average Annual Growth Rate (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Chinese Online Reviews | 0 | 0 | 1 | 1 | 3 | 3 | 3 | 4 | 4 | 4 | 8 | 31 | 29.68 |
| 2 | Sentiment Analysis Tasks and Scenarios | 14 | 15 | 21 | 29 | 22 | 48 | 46 | 64 | 73 | 65 | 56 | 453 | 14.87 |
| 3 | Microblog Public Opinion Analysis | 2 | 6 | 12 | 11 | 8 | 8 | 6 | 7 | 3 | 4 | 2 | 69 | 0.00 |
| 4 | Sentiment Classification | 2 | 1 | 4 | 2 | 4 | 5 | 9 | 7 | 13 | 11 | 4 | 62 | 7.18 |
| 5 | Sentiment Lexicon | 1 | 5 | 10 | 5 | 9 | 7 | 12 | 11 | 6 | 10 | 7 | 83 | 21.48 |
| 6 | Convolutional Neural Network | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 6 | 13 | 11 | 9 | 40 | 44.22 |
| 7 | Big Data Mining | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 3 | 9 | 21 | 25 | 60 | 43.00 |
| 8 | Deep Learning | 0 | 0 | 2 | 2 | 1 | 1 | 3 | 9 | 11 | 10 | 13 | 52 | 26.36 |
| 9 | Aspect-Based Sentiment Analysis | 14 | 9 | 11 | 18 | 22 | 18 | 27 | 24 | 30 | 24 | 31 | 228 | 8.27 |
| 10 | Feature Extraction | 2 | 0 | 2 | 3 | 6 | 6 | 7 | 4 | 8 | 7 | 7 | 52 | 13.35 |
| 11 | Multimodal Sentiment Analysis | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 3 | 9 | 10 | 25 | 58.49 |
| 12 | Word Embedding | 0 | 0 | 0 | 1 | 2 | 1 | 6 | 8 | 6 | 4 | 3 | 31 | 16.99 |
| Total | 35 | 37 | 63 | 72 | 78 | 98 | 120 | 149 | 179 | 180 | 175 | 1186 | 14.35 | |
| Time Interval | Number of Literature | Literature Volume Thresholds | Growth Rate Thresholds |
|---|---|---|---|
| stage 1: 2012~2016 | 285 | 23.75 | 17.38% |
| stage 2: 2017~2022 | 901 | 75.08 | 10.15% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Fan, H.; Zhang, J.; Yang, Q.; Tang, L. Topic Discovery and Hotspot Analysis of Sentiment Analysis of Chinese Text Using Information-Theoretic Method. Entropy 2023, 25, 935. https://doi.org/10.3390/e25060935
Zhang C, Fan H, Zhang J, Yang Q, Tang L. Topic Discovery and Hotspot Analysis of Sentiment Analysis of Chinese Text Using Information-Theoretic Method. Entropy. 2023; 25(6):935. https://doi.org/10.3390/e25060935
Chicago/Turabian StyleZhang, Changlu, Haojie Fan, Jian Zhang, Qiong Yang, and Liqian Tang. 2023. "Topic Discovery and Hotspot Analysis of Sentiment Analysis of Chinese Text Using Information-Theoretic Method" Entropy 25, no. 6: 935. https://doi.org/10.3390/e25060935