
Sentiment Analysis on Online Videos by Time-Sync Comments

Abstract
:1. Introduction
2. Related Work
2.1. Time-Sync Comments
2.2. Video Highlight Extraction
2.3. Sentiment Analysis
3. Problem Definition
3.1. Illustration of Time-Sync Comments
3.2. Formal Definition
3.3. Problem Statement
- (1)
- Problem of Sentiment Highlight Extraction:Given v and . For any , to find and to satisfy all the constraint conditions below,
- a.
- and ;
- b.
- For any , and have similar sentiment;
- c.
- and do not have similar sentiment;
- d.
- and do not have similar sentiment.
- (2)
- Problem of Sentiment Intensity calculation:Given , , and S. For any , find a vector that shows intensity distribution in for , where is the value of intensity in and .
4. Sentiment Highlight Extraction
4.1. Construct TSC Vectors
4.2. Generate Similarity Matrices
4.3. Calculate Feature Similarity
4.4. Finding Video Highlights
5. Sentiment Intensity Calculation
5.1. Word Groups Division for TSCs
5.2. Sentiment Intensity Calculation for Highlights
- (a)
- There is neither an adverb nor negative word in . The sentiment intensity of is the same as that of emotional word , which iswhere is the sentiment intensity of emotional word .
- (b)
- There is no adverb but there are negative words in . Since a negative word oppositely affects a emotional word, in Chinese grammar, the presence of an even number of negative words at the same time indicates a stronger positive meaning, while the simultaneous appearance of an odd number of negative words indicates a stronger negative meaning. Therefore, according to the number of negative words that appear, the sentiment intensity of is calculated aswhere is the sentiment intensity of emotional word .
- (c)
- There is no negative word but there is one adverb in . The sentiment intensity of is calculated aswhere is the weight of adverb D, and is the sentiment intensity of emotional word .
- (d)
- There are both adverbs and negative words in . As comments in are Chinese characters, according to Chinese linguistic features, if there is more than one adverb in word group , then we consider to be not grammatical, so we just consider that there is one adverb or less in . At the same time, an adverb written before or after a negative word affects the sentiment intensity of a word group differently. If the position of an adverb is before all negative words in , the sentiment intensity of is calculated aswhere is the weight of adverb D, and is the sentiment intensity of emotional word .If there are negative words before D, and negative words after D, the sentiment intensity of is calculated aswhere W is the parameter to weaken sentiment intensity, is the weight of adverb D, and is the sentiment intensity of emotional word .
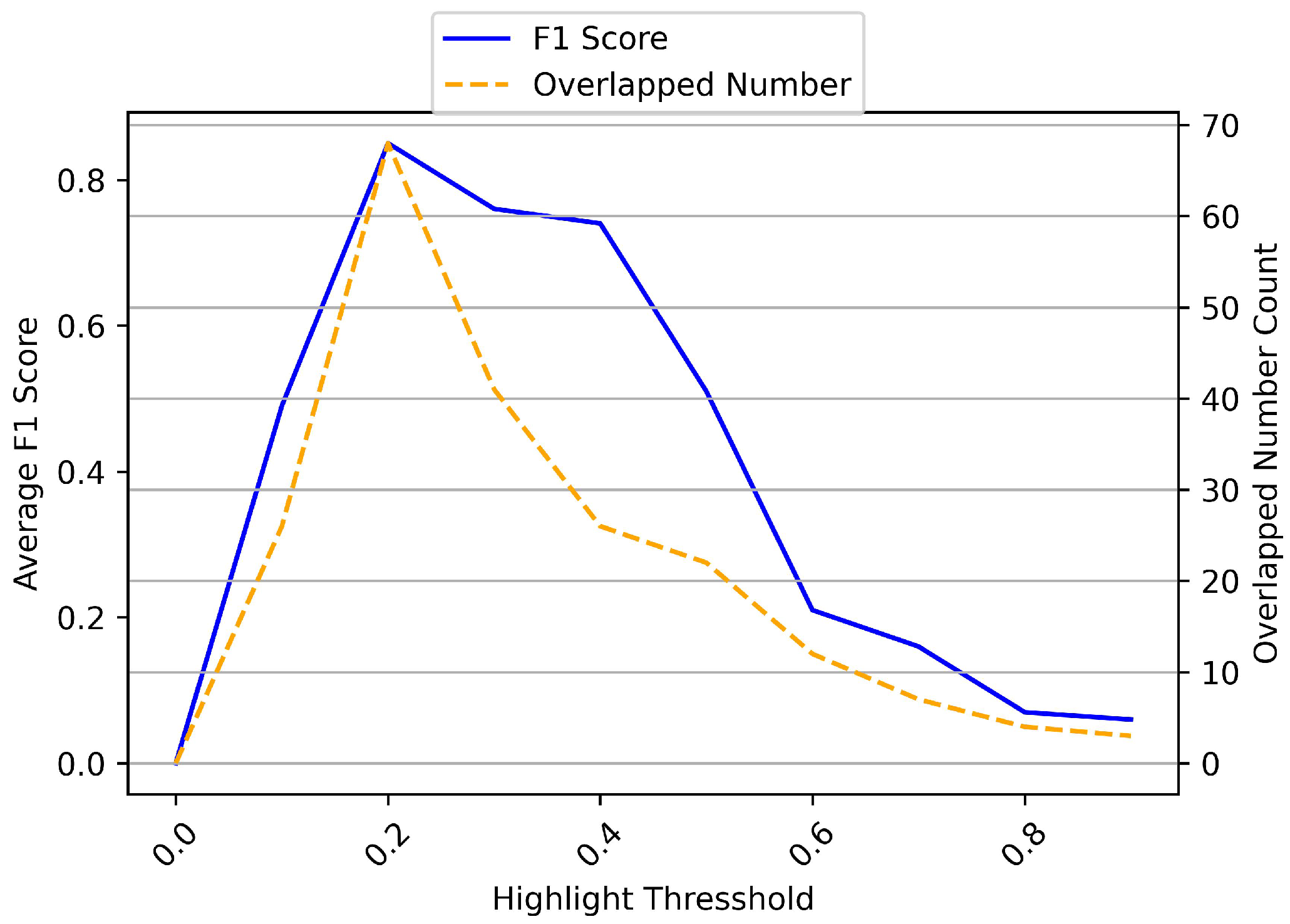
6. Evaluation
6.1. Experiment Setup
- (1)
- Sentiment highlight F1 score, calculated by equation
- (2)
- Overlapped number count, which is the number of overlapped fragments between highlights extracted by our proposed approach and the baseline highlights.
6.2. Evaluation of Sentiment Highlights Extraction
6.3. Evaluation of Sentiment Intensity Calculation
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, B.; Zhong, E.; Tan, B.; Horner, A.; Yang, Q. Crowdsourced Time-Sync Video Tagging Using Temporal and Personalized Topic Modeling. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; Association for Computing Machinery: New York, NY, USA, 2014. KDD ’14. pp. 721–730. [Google Scholar] [CrossRef]
- Liao, Z.; Xian, Y.; Yang, X.; Zhao, Q.; Zhang, C.; Li, J. TSCSet: A Crowdsourced Time-Sync Comment Dataset for Exploration of User Experience Improvement. In Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan, 7–11 March 2018; Association for Computing Machinery: New York, NY, USA, 2018. IUI ’18. pp. 641–652. [Google Scholar] [CrossRef]
- Hu, Z.; Cui, J.; Wang, W.H.; Lu, F.; Wang, B. Video Content Classification Using Time-Sync Comments and Titles. In Proceedings of the 2022 7th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, 22–24 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 252–258. [Google Scholar]
- Ping, Q.; Chen, C. Video highlights detection and summarization with lag-calibration based on concept-emotion mapping of crowd-sourced time-sync comments. arXiv 2017, arXiv:1708.02210. [Google Scholar]
- Pan, Z.; Li, X.; Cui, L.; Zhang, Z. Video clip recommendation model by sentiment analysis of time-sync comments. Multimed. Tools Appl. 2020, 79, 33449–33466. [Google Scholar] [CrossRef]
- Ping, Q. Video recommendation using crowdsourced time-sync comments. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, USA, 2 October 2018; pp. 568–572. [Google Scholar]
- Pan, J.; Wang, S.; Fang, L. Representation Learning through Multimodal Attention and Time-Sync Comments for Affective Video Content Analysis. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 42–50. [Google Scholar]
- Cao, W.; Zhang, K.; Wu, H.; Xu, T.; Chen, E.; Lv, G.; He, M. Video emotion analysis enhanced by recognizing emotion in video comments. Int. J. Data Sci. Anal. 2022, 14, 175–189. [Google Scholar] [CrossRef]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Terracina, G.; Ursino, D.; Virgili, L. Representation, detection and usage of the content semantics of comments in a social platform. J. Inf. Sci. 2022, 01655515221087663. [Google Scholar] [CrossRef]
- Harrando, I.; Reboud, A.; Lisena, P.; Troncy, R.; Laaksonen, J.; Virkkunen, A.; Kurimo, M. Using Fan-Made Content, Subtitles and Face Recognition for Character-Centric Video Summarization. In Proceedings of the International Workshop on Video Retrieval Evaluation, Gaithersburg, MD, USA, 17–19 November 2020. [Google Scholar]
- Rochan, M.; Ye, L.; Wang, Y. Video summarization using fully convolutional sequence networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 347–363. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 4690–4699. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Bao, J.; Ye, M. Head pose estimation based on robust convolutional neural network. Cybern. Inf. Technol. 2016, 16, 133–145. [Google Scholar] [CrossRef] [Green Version]
- Patacchiola, M.; Cangelosi, A. Head pose estimation in the wild using Convolutional Neural Networks and adaptive gradient methods. Pattern Recognit. 2017, 71, 132–143. [Google Scholar] [CrossRef] [Green Version]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Kocabas, M.; Karagoz, S.; Akbas, E. MultiPoseNet: Fast Multi-Person Pose Estimation using Pose Residual Network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, J.; Wang, C.; Zhu, H.; Mao, Y.; Fang, H.S.; Lu, C. Crowdpose: Efficient crowded scenes pose estimation and a new benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10863–10872. [Google Scholar]
- Zhang, Y.; Gao, J.; Yang, X.; Liu, C.; Li, Y.; Xu, C. Find Objects and Focus on Highlights: Mining Object Semantics for Video Highlight Detection via Graph Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12902–12909. [Google Scholar]
- Dai, B.; Fidler, S.; Urtasun, R.; Lin, D. Towards Diverse and Natural Image Descriptions via a Conditional GAN. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 2989–2998. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Chen, Z. Image Captioning with Visual-Semantic LSTM. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Washington, DC, USA, 2018. IJCAI’18. pp. 793–799. [Google Scholar]
- Vadicamo, L.; Carrara, F.; Cimino, A.; Cresci, S.; Dell’Orletta, F.; Falchi, F.; Tesconi, M. Cross-media learning for image sentiment analysis in the wild. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 308–317. [Google Scholar]
- Xu, J.; Li, Z.; Huang, F.; Li, C.; Philip, S.Y. Social Image Sentiment Analysis by Exploiting Multimodal Content and Heterogeneous Relations. IEEE Trans. Ind. Inform. 2020, 17, 2974–2982. [Google Scholar] [CrossRef]
- Zhang, K.; Zhu, Y.; Zhang, W.; Zhu, Y. Cross-modal image sentiment analysis via deep correlation of textual semantic. Knowl.-Based Syst. 2021, 216, 106803. [Google Scholar] [CrossRef]
- Yadav, V.; Ragot, N. Text extraction in document images: Highlight on using corner points. In Proceedings of the 2016 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 281–286. [Google Scholar]
- Song, K.; Yao, T.; Ling, Q.; Mei, T. Boosting image sentiment analysis with visual attention. Neurocomputing 2018, 312, 218–228. [Google Scholar] [CrossRef]
- Zheng, L.; Wang, H.; Gao, S. Sentimental feature selection for sentiment analysis of Chinese online reviews. Int. J. Mach. Learn. Cybern. 2018, 9, 75–84. [Google Scholar] [CrossRef]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Xue, W.; Li, T. Aspect Based Sentiment Analysis with Gated Convolutional Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 2514–2523. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Zhang, Y.; Vo, D.T. Gated neural networks for targeted sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Moholkar, K.; Rathod, K.; Rathod, K.; Tomar, M.; Rai, S. Sentiment Classification Using Recurrent Neural Network. In Proceedings of the Intelligent Communication Technologies and Virtual Mobile Networks, Tirunelveli, India, 14–15 February 2019; Springer: Cham, Switzerland, 2019; pp. 487–493. [Google Scholar]
- Elfaik, H.; Nfaoui, E.H. Deep Bidirectional LSTM Network Learning-Based Sentiment Analysis for Arabic Text. J. Intell. Syst. 2021, 30, 395–412. [Google Scholar] [CrossRef]
- Chen, J.; Yu, J.; Zhao, S.; Zhang, Y. User’s Review Habits Enhanced Hierarchical Neural Network for Document-Level Sentiment Classification. Neural Process. Lett. 2021, 53, 2095–2111. [Google Scholar] [CrossRef]
- Chakravarthi, B.R.; Priyadharshini, R.; Muralidaran, V.; Suryawanshi, S.; Jose, N.; Sherly, E.; McCrae, J.P. Overview of the track on sentiment analysis for dravidian languages in code-mixed text. In Proceedings of the Forum for Information Retrieval Evaluation, Hyderabad, India, 16–20 December 2020; pp. 21–24. [Google Scholar]
- Al-Smadi, M.; Talafha, B.; Al-Ayyoub, M.; Jararweh, Y. Using long short-term memory deep neural networks for aspect-based sentiment analysis of Arabic reviews. Int. J. Mach. Learn. Cybern. 2019, 10, 2163–2175. [Google Scholar] [CrossRef]
- Marstawi, A.; Sharef, N.M.; Aris, T.N.M.; Mustapha, A. Ontology-based aspect extraction for an improved sentiment analysis in summarization of product reviews. In Proceedings of the 8th International Conference on Computer Modeling and Simulation, Canberra Australia, 20–23 January 2017; pp. 100–104. [Google Scholar]
- Abdi, A.; Shamsuddin, S.M.; Hasan, S.; Piran, J. Automatic sentiment-oriented summarization of multi-documents using soft computing. Soft Comput. 2019, 23, 10551–10568. [Google Scholar] [CrossRef]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Sciarretta, L.; Ursino, D.; Virgili, L. A Space-Time Framework for Sentiment Scope Analysis in Social Media. Big Data Cogn. Comput. 2022, 6, 130. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| v | TSC commented video |
| Start time of video v | |
| Finish time of video v | |
| Video length (time duration) | |
| Set of fragments in video v | |
| The number of fragments in video v | |
| i-th fragment in video v | |
| Start time of fragment | |
| Finish time of fragment | |
| Length of fragment (time span) | |
| I | Interval between and |
| Set of highlights in video v | |
| The number of highlights in video v | |
| i-th highlight in video v | |
| S | Set of k-type sentiments |
| i-th type in sentiment set S | |
| Sentiment intensity of highlight | |
| Intensity value of sentiment type | |
| Set of TSCs in video v | |
| The number of TSC in the video v | |
| Set of TSC in fragment | |
| b | One TSC in TSC set |
| Comment of TSC b | |
| Time stamp of TSC b | |
| User who sends TSC b | |
| The number of users who send TSCs in video v |
| Movie Name | Movie Length | Movie Type |
|---|---|---|
| Spider-Man: Homecoming | 133 min 32 s | Action and Adventure |
| White Snake | 98 min 42 s | Action and Adventure |
| Inception | 148 min 8 s | Action and Adventure |
| Jurassic World Dominion | 147 min 12 s | Action and Adventure |
| Pacific Rim | 131 min 17 s | Action and Adventure |
| Transformers | 143 min 23 s | Action and Adventure |
| Ready Player One | 139 min 57 s | Action and Adventure |
| World War Z | 123 min 3 s | Action and Adventure |
| Green Book | 130 min 11 s | Comedy |
| Charlie Chaplin | 144 min 30 s | Comedy |
| Let the Bullets Fly | 126 min 38 s | Comedy |
| Johnny English | 87 min 25 s | Comedy |
| Modern Times | 86 min 43 s | Comedy |
| The Croods: A New Age | 95 min 20 s | Comedy |
| La La Land | 128 min 2 s | Comedy |
| The Truman Show | 102 min 57 s | Comedy |
| Harry Potter and the Philosopher’s Stone | 158 min 50 s | Fantasy |
| Fantastic Beasts and Where to Find Them | 132 min 52 s | Fantasy |
| Kong | 118 min 32 s | Fantasy |
| Triangle | 98 min 59 s | Fantasy |
| The Shawshank Redemption | 142 min 29 s | Crime |
| Catch Me If You Can | 140 min 44 s | Crime |
| Slumdog Millionaire | 120 min 38 s | Crime |
| Who Am I— Kein System ist sicher | 101 min 47 s | Crime |
| Escape Room: Tournament of Champions | 88 min 5 s | Horror |
| The Meg | 114 min 38 s | Horror |
| Blood Diamond | 143 min 21 s | Thriller |
| Shutter Island | 138 min 4 s | Thriller |
| Secret Superstar | 149 min 47 s | Music |
| Heidi | 96 min 24 s | Family |
| Duo Guan | 134 min 45 s | Sport |
| Saving Private Ryan | 169 min 26 s | War |
| Source Code | 93 min 18 s | Action |
| Dangal | 139 min 57 s | Action |
| Movie Name | Highlight No. | Highlight Playback Time | Movie Name | Highlight No. | Highlight Playback Time |
|---|---|---|---|---|---|
| Pacific Rim | 1 | 18:48–19:11 | Charlie Chaplin | 1 | 1:00–1:55 |
| 2 | 20:20–21:00 | 2 | 4:07–4:34 | ||
| 3 | 26:50–27:57 | 3 | 7:08–7:33 | ||
| 4 | 52:09–52:56 | 4 | 9:01–9:39 | ||
| 5 | 78:02–79:00 | 5 | 20:26–21:17 | ||
| 6 | 79:26–80:51 | 6 | 23:41–24:10 | ||
| 7 | 82:03–82:39 | 7 | 24:48–25:30 | ||
| 8 | 89:01–90:12 | 8 | 30:06–30:54 | ||
| 9 | 94:30–95:13 | 9 | 37:50–38:37 | ||
| 10 | 96:02–96:53 | 10 | 39:05–39:58 | ||
| 11 | 101:05–101:36 | 11 | 42:03–42:32 | ||
| 12 | 113:49–114:15 | 12 | 45:23–45:57 | ||
| 13 | 118:28–118:51 | 13 | 54:28–55:17 | ||
| 14 | 121:09–122:40 | 14 | 55:48–56:39 | ||
| 15 | 57:29–58:20 | ||||
| 16 | 94:49–95:33 | ||||
| 17 | 111:25–111:57 | ||||
| 18 | 118:01–118:50 | ||||
| 19 | 130:26–131:17 | ||||
| Harry Potter and the Philosopher’s Stone | 1 | 0:00–1:30 | Catch Me If You Can | 1 | 1:25–1:54 |
| 2 | 12:24–13:11 | 2 | 2:26–3:10 | ||
| 3 | 13:45–14:58 | 3 | 20:29–20:55 | ||
| 4 | 21:00–22:11 | 4 | 21:07–21:58 | ||
| 5 | 23:47–24:11 | 5 | 24:06–24:35 | ||
| 6 | 26:25–27:00 | 6 | 25:29–25:52 | ||
| 7 | 36:46–37:40 | 7 | 26:20–26:54 | ||
| 8 | 40:50–42:34 | 8 | 40:46–41:59 | ||
| 9 | 48:27–48:57 | 9 | 55:45–56:10 | ||
| 10 | 52:08–52:51 | 10 | 58:25–58:55 | ||
| 11 | 53:21–53:59 | 11 | 59:50–60:20 | ||
| 12 | 56:41–57:20 | 12 | 61:23–62:16 | ||
| 13 | 66:01–66:39 | 13 | 75:49–76:12 | ||
| 14 | 70:41–71:12 | 14 | 84:43–85:30 | ||
| 15 | 77:41–78:32 | 15 | 107:48–108:17 | ||
| 16 | 108:44–109:19 | 16 | 126:09–126:59 | ||
| 17 | 147:23–148:18 | 17 | 127:28–128:20 | ||
| 18 | 150:05–150:52 | 18 | 128:44–129:20 | ||
| 19 | 134:24–135:50 | ||||
| Blood Diamond | 1 | 6:40–7:20 | Secret Superstar | 1 | 53:45–54:35 |
| 2 | 24:45–25:10 | 2 | 60:08–61:12 | ||
| 3 | 49:23–49:59 | 3 | 66:41–67:12 | ||
| 4 | 55:46–56:11 | 4 | 67:24–67:59 | ||
| 5 | 60:23–61:30 | 5 | 72:21–72:53 | ||
| 6 | 68:20–69:00 | 6 | 79:30–79:50 | ||
| 7 | 72:10–73:16 | 7 | 81:26–81:51 | ||
| 8 | 80:43–81:34 | 8 | 93:28–93:54 | ||
| 9 | 91:27–92:19 | 9 | 96:00–97:10 | ||
| 10 | 96:47–97:19 | 10 | 97:40–98:14 | ||
| 11 | 108:04–108:57 | 11 | 102:41–103:35 | ||
| 12 | 109:29–109:50 | 12 | 110:23–111:33 | ||
| 13 | 110:45–111:10 | 13 | 132:05–132:50 | ||
| 14 | 115:44–116:18 | 14 | 134:21–135:18 | ||
| 15 | 128:10–129:12 | 15 | 138:30–139:12 | ||
| 16 | 131:42–132:16 | 16 | 139:42–140:36 | ||
| 17 | 132:47–133:11 | 17 | 144:28–144:59 | ||
| 18 | 134:05–135:35 | 18 | 145:29–145:53 | ||
| 19 | 146:01–146:32 |
| Movie Name | Random | MTER | PING | Our Method (without Find Highlights) | Our Method (with LDA) | Our Method (with BERT) |
|---|---|---|---|---|---|---|
| Spider-Man: Homecoming | 0.100 | 0.200 | 0.597 | 0.167 | 0.364 | 0.615 |
| White Snake | 0.300 | 0.091 | 0.824 | 0.267 | 0.824 | 0.828 |
| Inception | 0.083 | 0.267 | 0.650 | 0.200 | 0.400 | 0.588 |
| Jurassic World Dominion | 0.133 | 0.062 | 0.520 | 0.356 | 0.571 | 0.636 |
| Pacific Rim | 0.071 | 0.467 | 0.579 | 0.110 | 0.707 | 0.710 |
| Transformers | 0.409 | 0.472 | 0.609 | 0.312 | 0.733 | 0.661 |
| Ready Player One | 0.214 | 0.366 | 0.741 | 0.268 | 0.600 | 0.606 |
| World War Z | 0.200 | 0.375 | 0.686 | 0.320 | 0.730 | 0.733 |
| Green Book | 0.200 | 0.091 | 0.632 | 0.267 | 0.571 | 0.591 |
| Charlie Chaplin | 0.126 | 0.150 | 0.742 | 0.253 | 0.813 | 0.831 |
| Let the Bullets Fly | 0.214 | 0.067 | 0.649 | 0.245 | 0.586 | 0.545 |
| Johnny English | 0.231 | 0.315 | 0.429 | 0.154 | 0.497 | 0.770 |
| Modern Times | 0.200 | 0.462 | 0.655 | 0.286 | 0.656 | 0.750 |
| The Croods: A New Age | 0.167 | 0.100 | 0.500 | 0.370 | 0.686 | 0.717 |
| La La Land | 0.250 | 0.154 | 0.642 | 0.111 | 0.737 | 0.800 |
| The Truman Show | 0.296 | 0.402 | 0.623 | 0.320 | 0.709 | 0.714 |
| Harry Potter and the Philosopher’s Stone | 0.105 | 0.121 | 0.699 | 0.150 | 0.733 | 0.774 |
| Fantastic Beasts and Where to Find Them | 0.190 | 0.211 | 0.606 | 0.074 | 0.705 | 0.638 |
| Kong | 0.389 | 0.392 | 0.759 | 0.303 | 0.800 | 0.875 |
| Triangle | 0.100 | 0.125 | 0.500 | 0.286 | 0.533 | 0.625 |
| The Shawshank Redemption | 0.167 | 0.286 | 0.636 | 0.222 | 0.500 | 0.515 |
| Catch Me If You Can | 0.158 | 0.271 | 0.525 | 0.268 | 0.703 | 0.606 |
| Slumdog Millionaire | 0.143 | 0.333 | 0.299 | 0.165 | 0.707 | 0.652 |
| Who Am I - Kein System ist sicher | 0.083 | 0.267 | 0.612 | 0.200 | 0.573 | 0.575 |
| Escape Room: Tournament of Champions | 0.100 | 0.091 | 0.816 | 0.267 | 0.750 | 0.773 |
| The Meg | 0.154 | 0.214 | 0.422 | 0.185 | 0.700 | 0.742 |
| Blood Diamond | 0.056 | 0.211 | 0.747 | 0.222 | 0.654 | 0.701 |
| Shutter Island | 0.171 | 0.267 | 0.691 | 0.390 | 0.600 | 0.610 |
| Secret Superstar | 0.158 | 0.375 | 0.620 | 0.180 | 0.861 | 0.796 |
| Heidi | 0.250 | 0.378 | 0.677 | 0.214 | 0.636 | 0.653 |
| Duo Guan | 0.133 | 0.343 | 0.456 | 0.170 | 0.549 | 0.596 |
| Saving Private Ryan | 0.247 | 0.211 | 0.693 | 0.267 | 0.759 | 0.800 |
| Source Code | 0.143 | 0.200 | 0.692 | 0.190 | 0.807 | 0.923 |
| Dangal | 0.176 | 0.167 | 0.472 | 0.299 | 0.626 | 0.769 |
| Average | 0.180 | 0.250 | 0.618 | 0.237 | 0.658 | 0.697 |
| Random | MTER | PING | Our Method (without Find Highlights) | Our Method (with LDA) | Our Method (with BERT) | |
|---|---|---|---|---|---|---|
| Average overlapped number | 2.23 | 4.10 | 7.71 | 2.91 | 8.20 | 8.32 |
| Euclidean Distance | Pearson Correlation Coefficient | Manhattan Distance | Minkowski Distance | Cosine Similarity | |
|---|---|---|---|---|---|
| Average F1 Score | 0.660 | 0.685 | 0.619 | 0.669 | 0.697 |
| Average Overlapped Number | 7.66 | 8.21 | 6.94 | 7.73 | 8.32 |
| Pacific Rim | Charlie Chaplin | |||||
| Playback Time | 26:50–27:57 | 96:02–96:53 | 121:09–122:40 | 37:50–38:37 | 45:23–45:57 | 94:49–95:33 |
| Intensity Value | 0.03,0.62,0.0,0.0, 0.02,0.34,0.0 | 0.07,0.24,0.0,0.12, 0.05,0.45,0.06 | 0.10,0.61,0.0,0.0, 0.09,0.20,0.0 | 0.05,0.93,0.0,0.0, 0.02,0.0,0.0 | 0.04,0.80,0.0,0.12, 0.0,0.04,0.0 | 0.08,0.63,0.0,0.11, 0.0,0.18,0.0 |
| Intensity Figure |  |  |  |  |  |  |
| Film Plot |  |  |  |  |  |  |
| Harry Potter and the Philosopher’s Stone | Catch Me If You Can | |||||
| Playback Time | 40:50–42:34 | 77:41–78:32 | 147:23–148:18 | 40:46–41:59 | 61:23-62:16 | 126:09-126:59 |
| Intensity Value | 0.10,0.64,0.0,0.10, 0.11,0.05,0.0 | 0.07,0.39,0.0,0.05, 0.04,0.46,0.0 | 0.28,0.35,0.0,0.07, 0.0,0.30,0.0 | 0.0,0.61,0.0,0.07, 0.07,0.25,0.0 | 0.30,0.36,0.0,0.0, 0.0,0.34,0.0 | 0.29,0.44,0.0,0.0, 0.11,0.15,0.0 |
| Intensity Figure |  |  |  |  |  |  |
| Film Plot |  |  |  |  |  |  |
| Blood Diamond | Secret Superstar | |||||
| Playback Time | 60:23–61:30 | 72:10–73:16 | 108:04–108:57 | 96:00–97:10 | 110:23–111:33 | 134:21–135:18 |
| Intensity Value | 0.12,0.46,0.0,0.06, 0.04,0.32,0.0 | 0.15,0.51,0.0,0.0, 0.09,0.19,0.06 | 0.09,0.35,0.0,0.06, 0.0,0.49,0.0 | 0.20,0.34,0.0,0.14, 0.04,0.20,0.07 | 0.03,0.25,0.0,0.16, 0.04,0.53,0.0 | 0.26,0.42,0.0,0.03, 0.06,0.21,0.02 |
| Intensity Figure |  |  |  |  |  |  |
| Film Plot |  |  |  |  |  |  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Li, Z.; Ma, X.; Zhao, Q.; Zhang, C.; Yu, G. Sentiment Analysis on Online Videos by Time-Sync Comments. Entropy 2023, 25, 1016. https://doi.org/10.3390/e25071016
Li J, Li Z, Ma X, Zhao Q, Zhang C, Yu G. Sentiment Analysis on Online Videos by Time-Sync Comments. Entropy. 2023; 25(7):1016. https://doi.org/10.3390/e25071016
Chicago/Turabian StyleLi, Jiangfeng, Ziyu Li, Xiaofeng Ma, Qinpei Zhao, Chenxi Zhang, and Gang Yu. 2023. "Sentiment Analysis on Online Videos by Time-Sync Comments" Entropy 25, no. 7: 1016. https://doi.org/10.3390/e25071016