1. Introduction
Marine background noise (MBN) is an eternal sound field in the marine environment that contains information about environmental characteristics such as water body, seabed, and sea surfaces [
1,
2]. For sonar with acoustic waves as the main means of detection and communication, it is necessary to consider the complex sound field with marine environmental noise as the background. Therefore, the study of ocean background noise, especially the study of feature extraction, is of great significance to the development of underwater acoustic weapons [
3].
At present, traditional feature extraction methods mainly include frequency domain and time domain feature extraction methods [
4,
5,
6], which can only effectively extract linear and stationary signals. However, MBN is a classic underwater acoustic signal with nonlinear, nonstationary, and non-Gaussian characteristics [
7], and traditional feature extraction methods cannot effectively reflect its information [
8,
9]. While deep-learning-based methods also work well for feature extraction, they often require larger datasets and higher experimental configurations [
10,
11]. To address these shortcomings of the above methods, many scholars have studied a large number of nonlinear feature extraction methods, among which the mainstream methods are mainly based on two aspects of entropy and LZC [
12,
13]. This paper divides nonlinear dynamic features into two categories, entropy and Lempel–Ziv complexity (LZC), for comparative experimental analysis of MBN.
Entropy can be used to analyze signal complexity by virtue of its ability to characterize the degree of chaos in a time series [
14]. Since the Shannon entropy theorem was put forward in 1948 [
15], entropy has been widely used in various fields. In 1991, Pincus et al. first proposed approximate entropy (AE) [
16], which improves the dependence of previous entropy on the length of time series and has a strong general ability. Sample entropy (SE) was first proposed by Richman et al. in 2000 [
17]. Similar to AE, they are functions defined based on the unit step function, and SE can effectively reflect the information of signals with data loss. In 2007, Chen et al. proposed fuzzy entropy (FE) by combining the concepts of SE and fuzzy membership [
18], which is an improved AE algorithm that reduces the signal loss of AE and SE due to the characteristics of unit step function during signal calculation. Unlike AE, SE, and FE, PE was proposed by Bandt et al. in 2002 [
19], which is an improved entropy based on the Shannon entropy theorem; its calculation process is simple and has strong anti-noise ability. DE was proposed by Rostaghi et al. in 2016 [
20]; it not only has the advantage of fast calculation speed, but also can reflect the amplitude change of signal, which is one of the most widely used entropies at present.
LZC is a significant theory in nonlinear dynamics, similar to entropy, and it is often used to evaluate the disorder and irregularity of signals [
21]. The primary LZC algorithm was proposed by Lempel and Ziv in 1976 [
22]. Due to the binary conversion of sequences, LZC has the advantages of no parameter setting and high computational efficiency, but the converted 0-1 sequence loses a lot of the original information of the sequence [
23,
24]. For this reason, Bai et al. [
25] first combined LZC with entropy theory and proposed the permutation LZC (PLZC) by replacing the binary mapping with the permutation pattern in PE, which inherits the strong anti-noise ability of PE and improves the ability of LZC to characterize signals [
26]. In 2020, Mao et al. [
27] were inspired by the advantages of DE to effectively reflect amplitude information and integrated it into LZC to launch dispersion LZC (DLZC); the application of DLZC in various fields showed high stability and separability [
28]. Dispersion entropy-based Lempel–Ziv complexity (DELZC) is a newly proposed complexity measure [
29], which makes full use of the more effective dispersion pattern in DE to reflect more pattern information and further boosts the ability to capture the dynamic changes of signal.
The main contribution of this paper is the study of an MBN feature extraction method based on nonlinear dynamic features, where the entropy-based features include dispersion entropy (DE), permutation entropy (PE), fuzzy entropy (FE), and sample entropy (SE), and LZC-based features include LZC, dispersion LZC (DLZC), permutation LZC (PLZC), and dispersion entropy-based LZC (DELZC). Lastly, the separability of various types of features is compared by classification experiments of real MBNs. This paper is organized as follows:
Section 2 provides a brief review of common entropy and LZC and conducts simulation experiments on their ability to detect time series complexity. In
Section 3, we conducted the feature extraction method of MBN based on nonlinear dynamic features.
Section 4 and
Section 5 present the discussion and conclusions, respectively.
2. Nonlinear Dynamic Features
In this paper, nonlinear dynamic features are divided into two categories: entropy and Lempel–Ziv complexity (LZC). We introduce the relevant theories of entropy and LZC, respectively.
2.1. Entropy
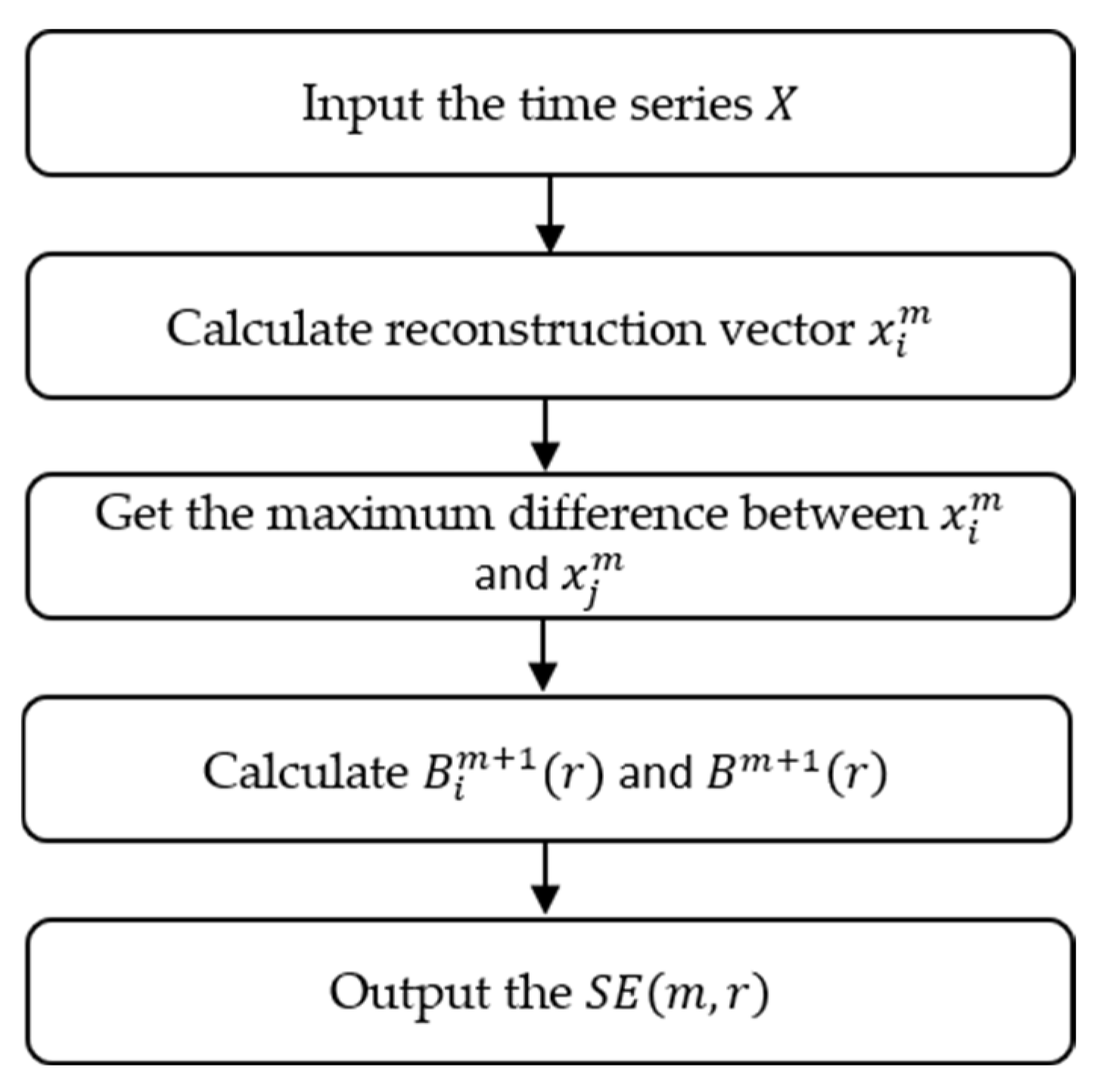
Entropy can reflect the complexity of time series, among which SE, FE, PE, and DE are four common entropies, and their steps are explained in this section. The physical meanings of SE and FE are similar; these can measure the probability of the occurrence of new patterns in a time series. The specific steps of SE are as follows:
- (1)
For a specific time series
, given an embedding dimension
, a set of vector sequences
can be obtained, where
can be expressed as:
- (2)
Define the absolute value of the maximum difference between the distance between vectors
and
:
where
.
- (3)
Given , record the standard deviation of as , count the number of with as , , and define .
- (4)
- (5)
Increase the embedding dimension to
, and repeat the above steps to obtain
and
. The final expression of
SE is:
where the calculation flow chart of
SE is shown in
Figure 1.
FE introduces fuzzy membership degree
based on
SE, which can be expressed as:
where
means embedding dimension, and
.
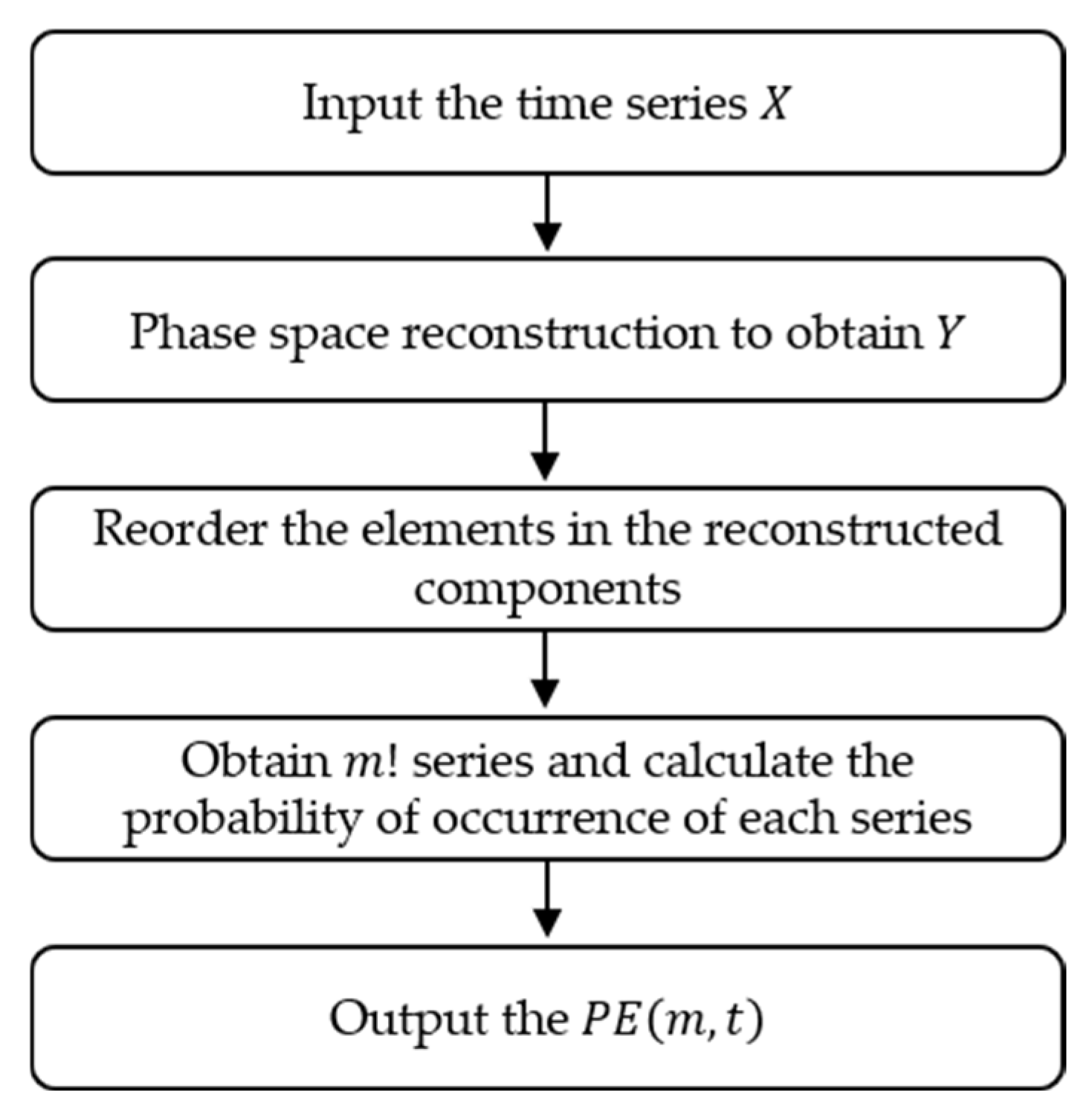
The PE and DE are both developed based on Shannon entropy, where PE can be defined as follows:
- (1)
For the given time series
, phase space reconstruction is performed to obtain
:
where
is the embedding dimension,
is the delay time, and
.
- (2)
Reorder the elements in each reconstructed component in ascending order to obtain:
If , then sort according to the size of , that is,
Finally, the new index of each group of elements is , in which there are different time series, and the probability of each series occurrence are .
- (3)
According to the Shannon entropy theorem, the expression of
PE can be expressed as:
where
Figure 2 displays the calculation flow chart of
PE.
DE is an improved algorithm of
PE, and its calculation formula is:
where
signifies the embedding dimension,
represents the number of categories, and
is the delay time.
2.2. Lempel–Ziv Complexity
Lempel–Ziv complexity is an important branch of nonlinear dynamics, among which LZC, PLZC, DLZC, and DELZC are the most representative ones. This section gives the calculation steps of these four LZC-based features.
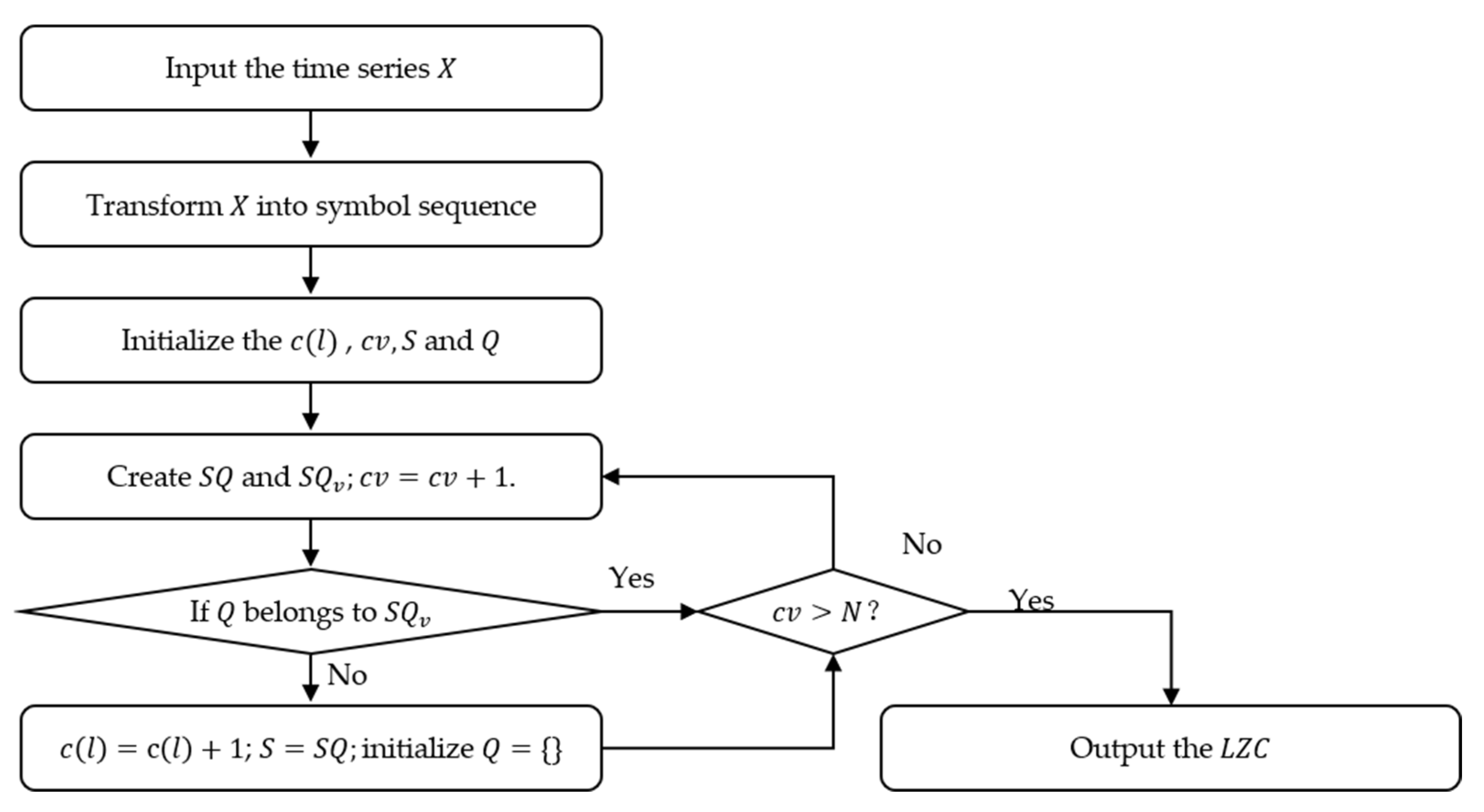
LZC is the primitive algorithm, which reflects the complexity of time series by counting the occurrence rate of new patterns in the sequence. The calculation flow chart of LZC is illustrated in
Figure 3, and specific steps are as follows:
- (1)
For time series
, each element is converted to 0 or 1 by the following formula:
where
is the mean value of sequence
, then the symbol sequence
is obtained.
- (2)
Initialize the complexity index and count value to 0 and 1, respectively, and let and denote the first and second elements in . By merging and into , is obtained by removing the last element of .
- (3)
Judge whether belongs to . If so, update by adding the next character. Otherwise, , , and initialize . For each judgment that is performed, the updated and updated are obtained in the same way as Step (2), and .
- (4)
Judge whether exceeds ; if not, return to Step (3); otherwise, the calculation of complexity is completed.
- (5)
The normalized result of
LZC can be expressed as:
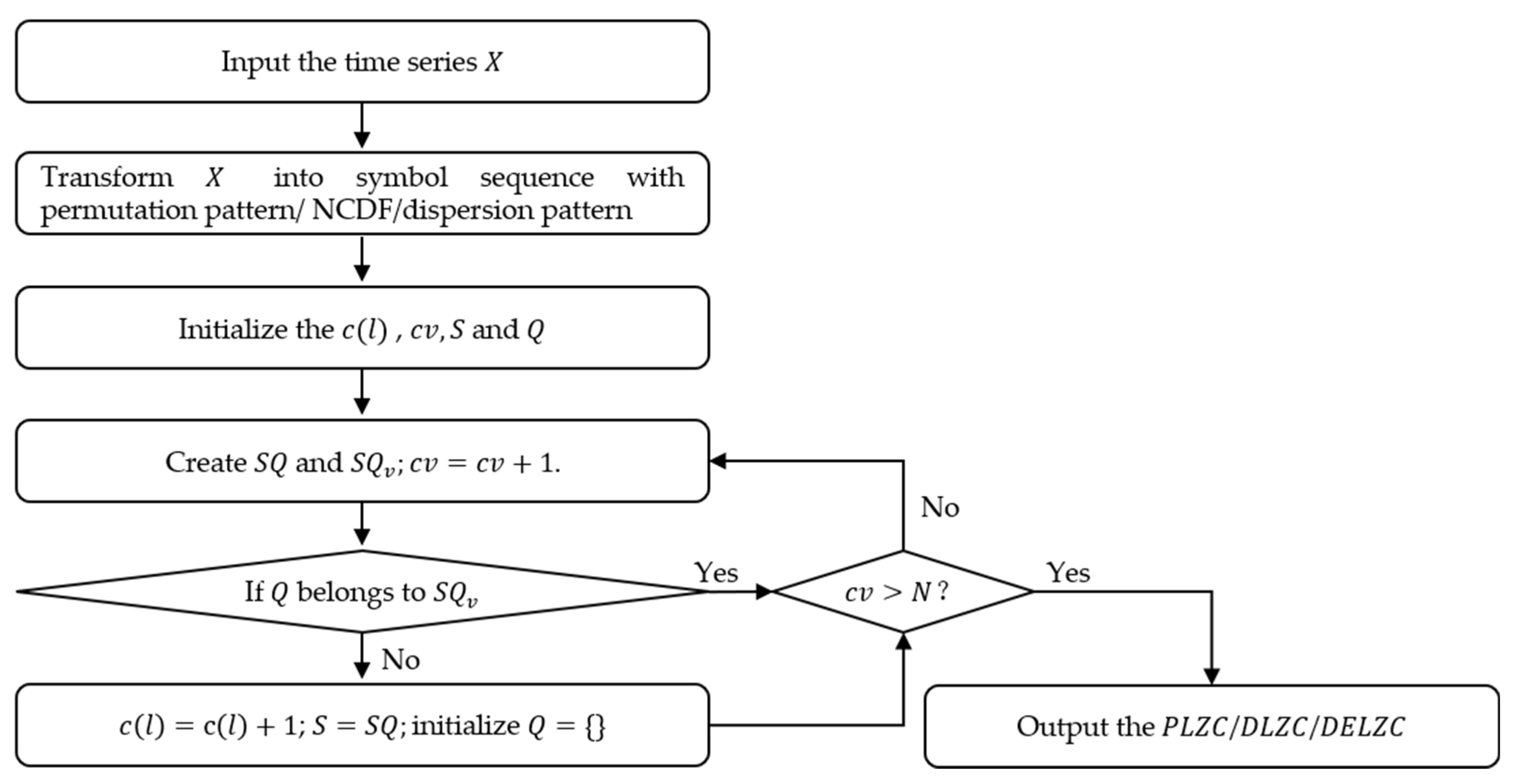
PLZC,
DLZC, and
DELZC are presented by improving the mapping of the original sequence in
LZC Step (1).
PLZC uses the permutation pattern in
PE to generate the symbol sequence for
LZC;
DLZC and
DELZC increase the number of categories in the symbol sequence by referring to different steps in
DE. The calculation flow chart of
PLZC,
DLZC, and
DELZC is shown in
Figure 4.
For
PLZC, the calculation process includes Step (1) and Step (2) of
PE in
Section 2.1, then we name the obtained permutation pattern according to the corresponding pattern category to obtain the symbol sequence; finally, the value of
PLZC is obtained according to
LZC Step (2) to Step (5). It is noteworthy that the calculation formula will also change as the number of element categories in the symbol sequence increases, and the specific formula is as follows:
where
is the embedding dimension.
For
DLZC and
DELZC, these two algorithms are proposed by introducing the normal cumulative distribution function (NCDF) and dispersion pattern in
DE into the original
LZC, respectively.
DLZC employs NCDF and a rounding function to convert the original sequence into a symbol sequence with
categories; in
DELZC, after the conversion of NCDF and rounding function, the phase space is reconstructed to obtain a variety of dispersion patterns, and then the symbol sequence is obtained in a similar way to
PLZC. Through the above processing, the calculation formulas of
DLZC and
DELZC are as follows:
where
is the number of categories and
is the embedding dimension.
2.3. Simulation Experiment Verification
For the nonlinear dynamics characterized in the previous section, the MIX signal is introduced as a reflection of their ability to detect changes in the degree of chaos of the time series. The MIX signal consists of a periodic signal
, a random signal
, and a controlling parameter
. By artificially changing the parameter
, we can control the randomness of the entire synthesized signal. The MIX signal can be defined as follows:
In the comparative experiments of this subsection,
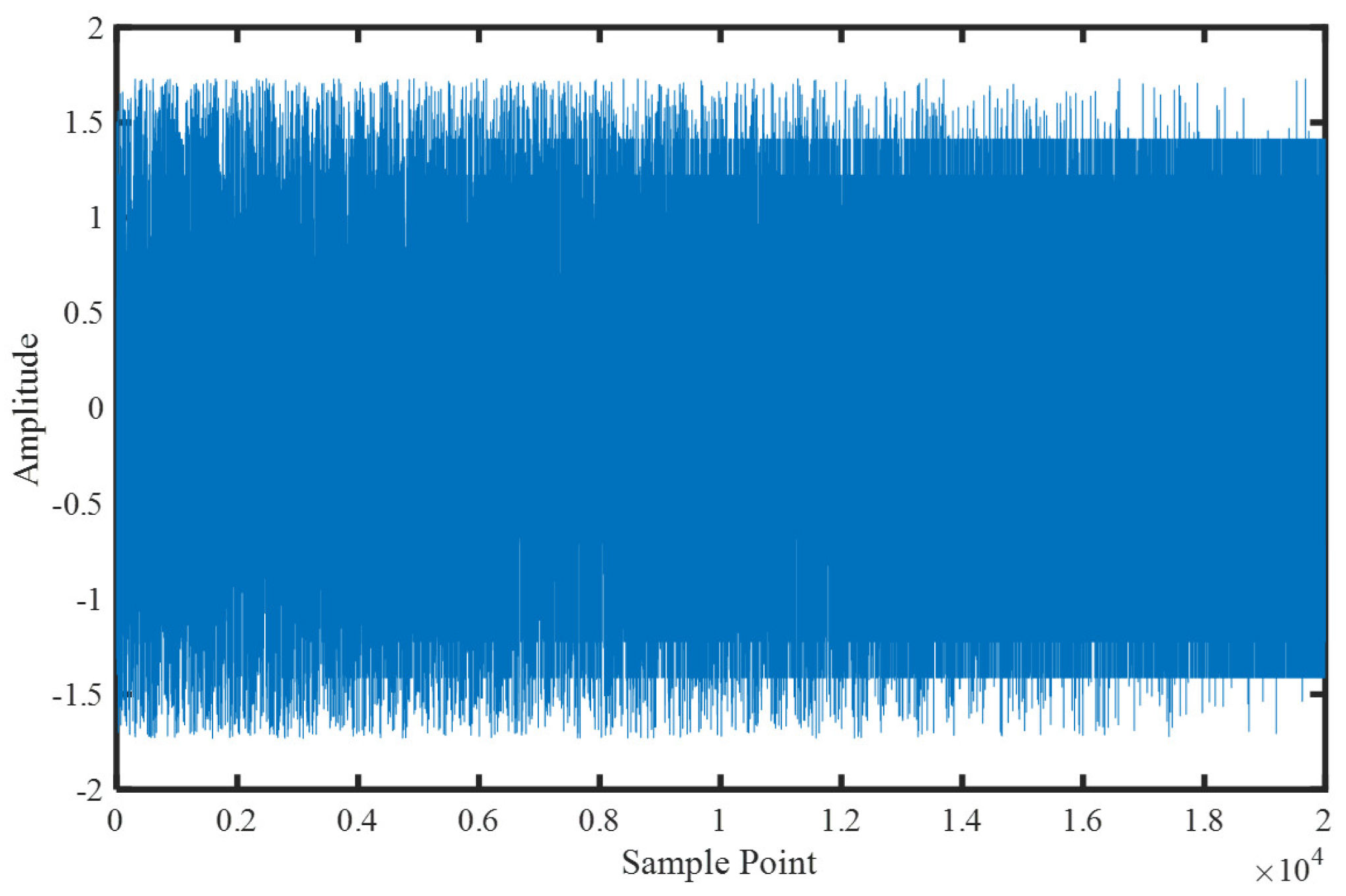
is linearly decreased from an initial value of 0.99 to a final value of 0.01. The sampling frequency is 1000 Hz, and the total length is 20 s. The time domain waveform of the MIX signal is shown in
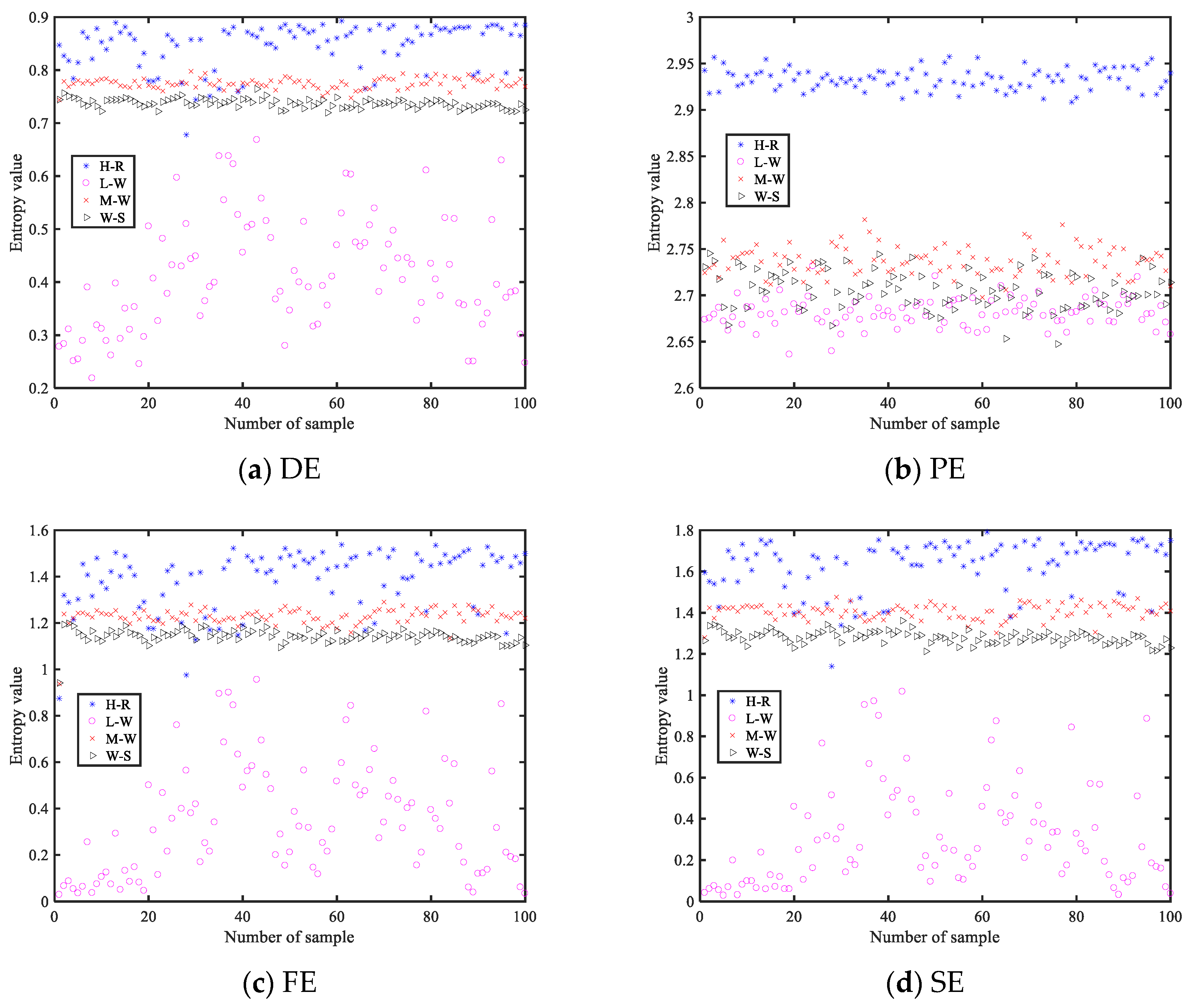
Figure 5, where it can be visually observed that the signal becomes increasingly stable. In this section, sliding windows with a length of 1 s and 90% overlap are used to extract sample signals, resulting in a total of 190 segments. By calculating various entropy values for each segment, the ability of each type of entropy to detect changes in the chaos of the time series is examined.
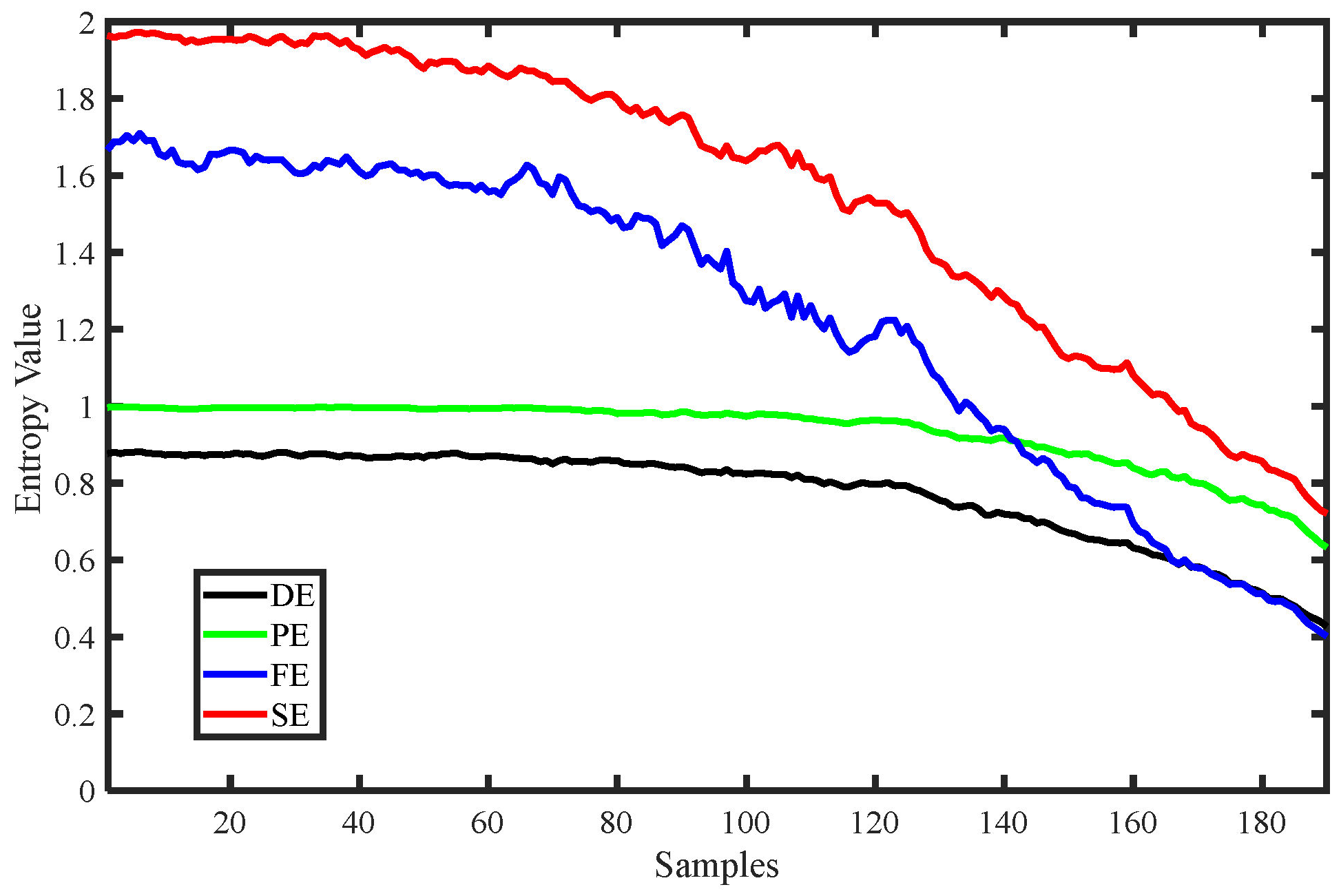
Various entropy change curves of the MIX signal are shown in
Figure 6, including DE, PE, SE, and FE, and
Table 1 shows the parameter settings of these four entropies. From
Figure 6, it can be seen that all the entropy value curves generally decrease as the complexity of the MIX signal decreases, indicating that various entropies can reflect changes in the degree of chaos in the time series. Among these, the curves of DE and PE are relatively stable, indicating strong stability of the entropy values, while FE and SE exhibit larger fluctuations but are able to more clearly reflect changes in the degree of chaos in the signal during the early stages. In conclusion, all four entropies can effectively reflect changes in the degree of chaos in the time series.
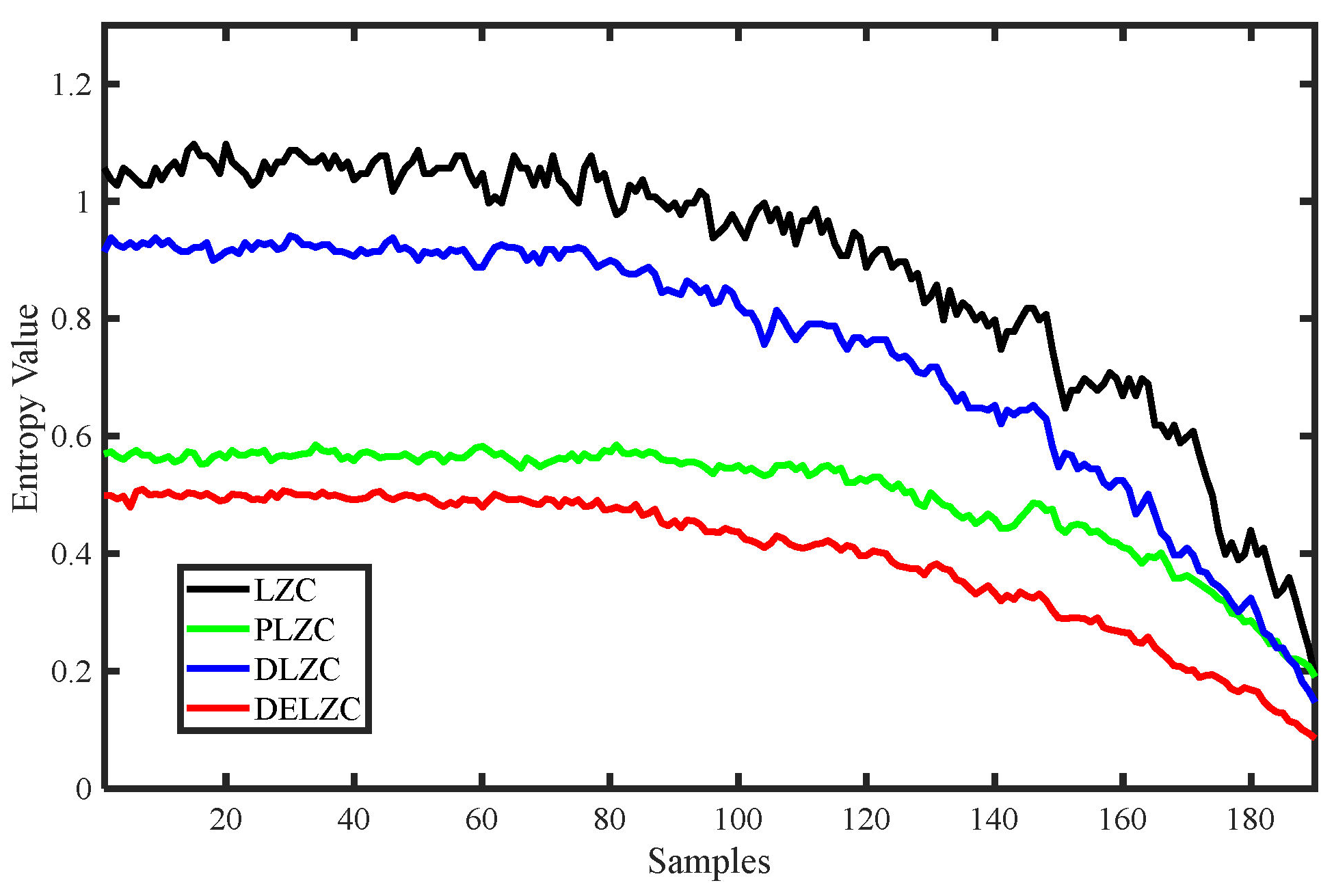
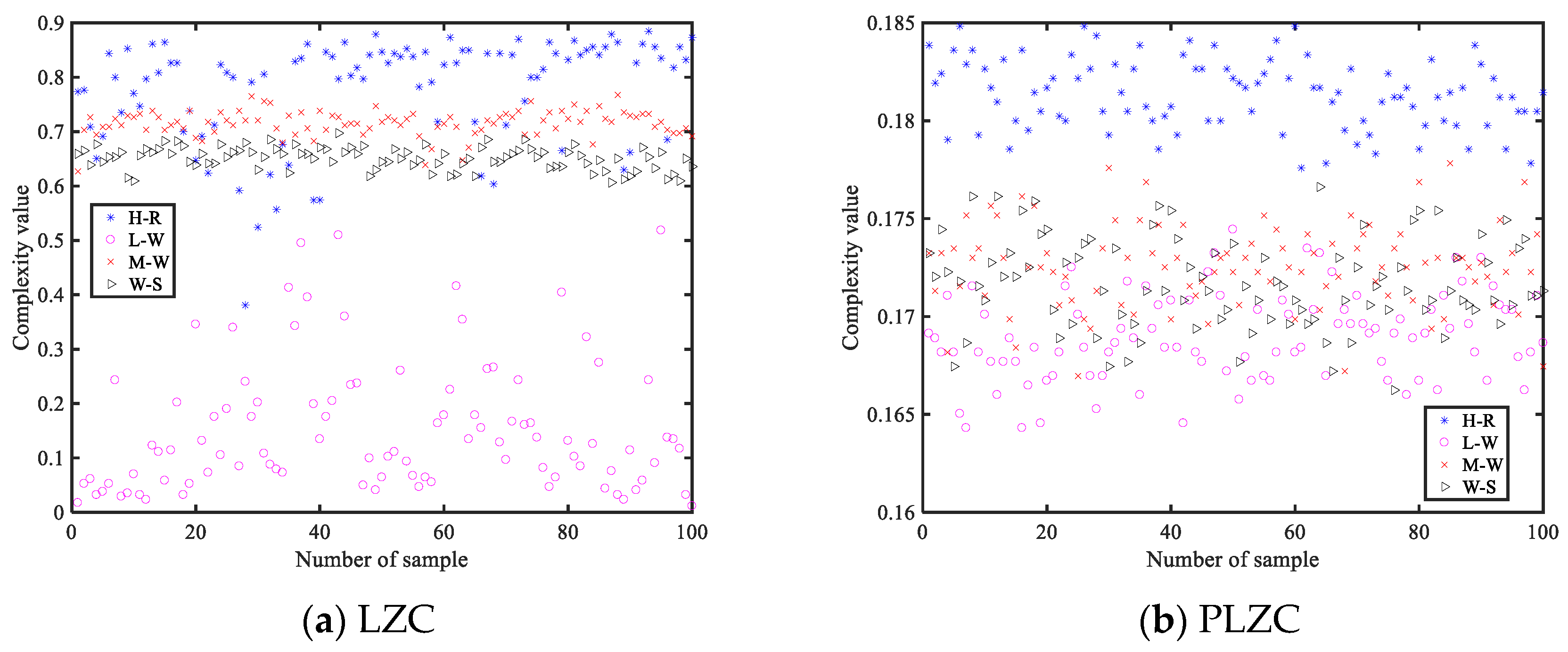
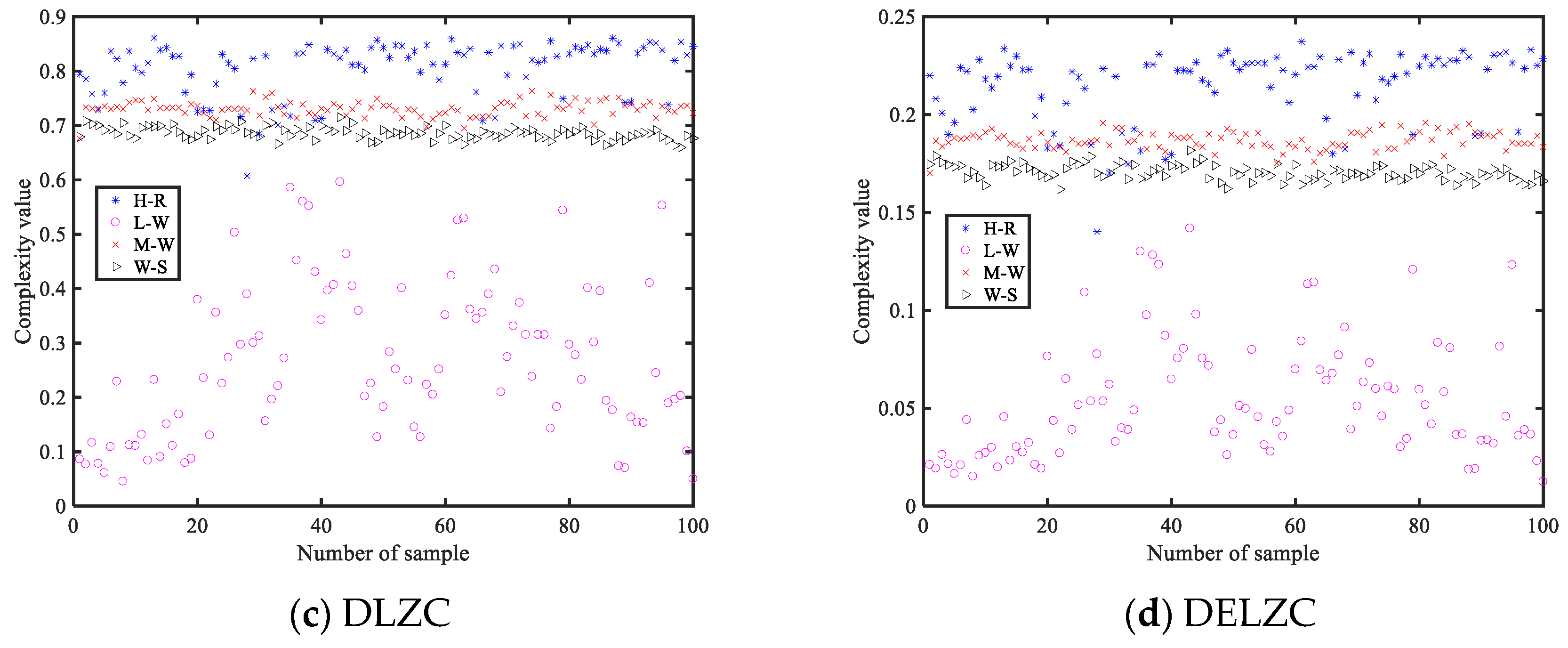
Similarly, we conducted the same experiments for four types of LZCs, including LZC, PLZC, DLZC, and DELZC; the obtained complexity value curves are shown in
Figure 7, and their parameters are also shown in
Table 2. From
Figure 7, it can be observed that as the complexity of the MIX signal continuously decreases, the change curves of all four LZCs also show a decreasing trend, while the remaining three complexities except LZC also show a strong stability in characterizing the degree of MIX signal confusion. Therefore, it can be concluded that all four complexities can also effectively reflect the change of the chaos degree of the time series.
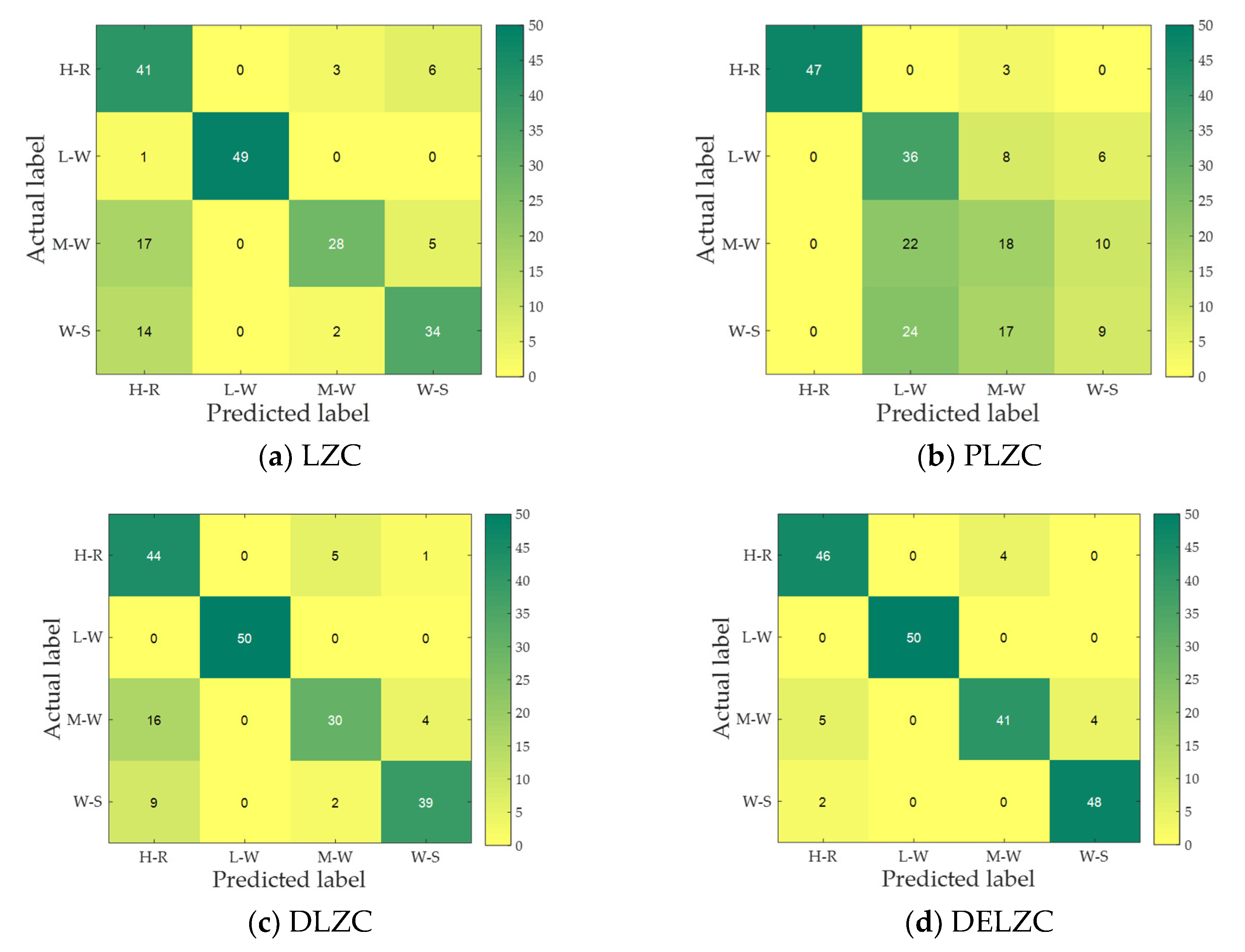
4. Discussion
In this paper, we carry out the experiments of MBN feature extraction based on entropy and LZC in the experimental part, in which the entropy of comparison includes DE, PE, FE, and SE, and the LZC of comparison includes LZC, PLZC, DLZC, and DELZC. Finally, the classification algorithm KNN is used to calculate recognition effects. In future research, we will use new deep-learning-based methods for classification and recognition [
31,
32]. To further compare the effect of different nonlinear dynamic features on feature extraction,
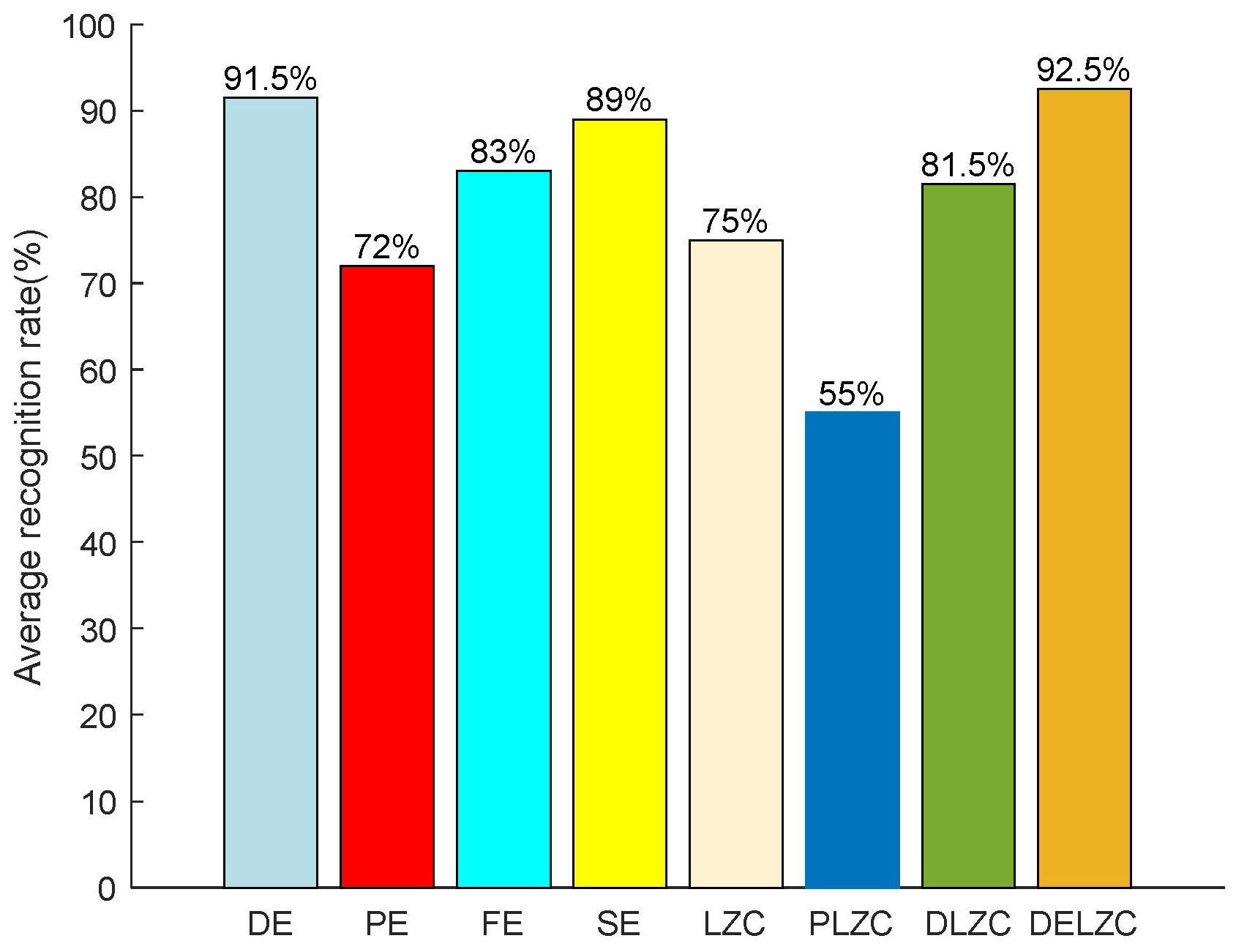
Figure 13 shows the average recognition rate of feature extraction methods based on eight nonlinear dynamic features for MBN.
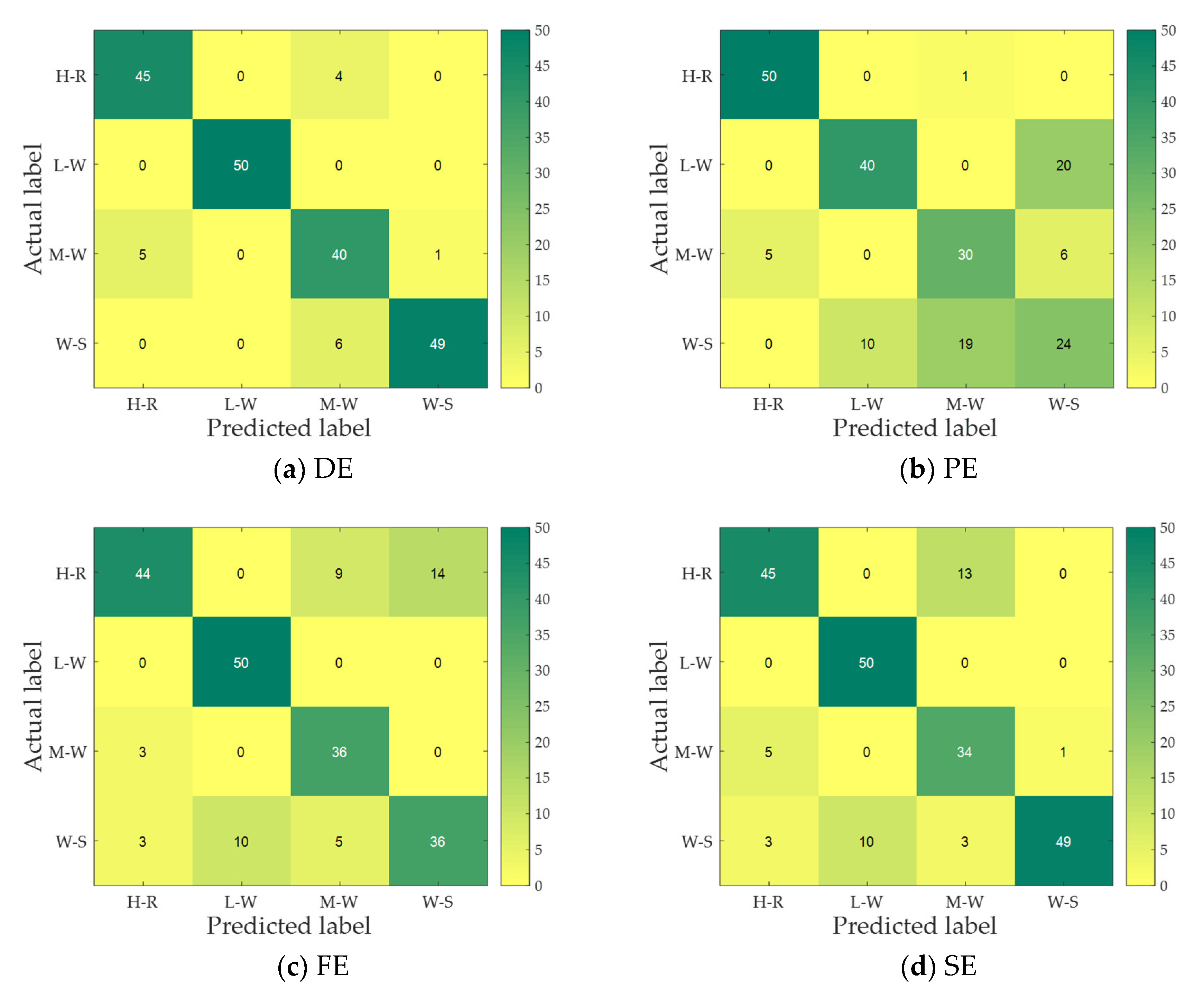
It can be seen from
Figure 13 that DELZC has the highest recognition rate of 92.5%, and PLZC has the lowest recognition rate of 55%; for the entropy-based feature extraction method, the recognition rate is higher than 70%, and DE has the highest average recognition rate; in addition, for the LZC-based feature extraction method, except for PLZC, the recognition rate based on other features is higher than 75%; last but not least, regardless of entropy-based feature extraction method or LZC-based feature extraction method, they both have their own advantages, and both show better feature extraction performance for marine background noise signals.
In addition, to further explore the effect of multiple feature extraction, we also conduct hybrid multiple feature extraction, i.e., mixing entropy and LZC together as the subjects of feature extraction at the same time.
Table 2 demonstrates the highest recognition rate for hybrid multiple feature extraction.
It is clear from
Table 7 that hybrid multiple feature extraction is significantly more effective than extracting only entropy or LZC, and the highest recognition rate can reach 98% when the number of extracted features is between two and six. As with the entropy-based and LZC-based multiple feature extraction experiments, the recognition rate does not always increase as the number of extracted features increases. The recognition rate stays the same at first, but eventually the recognition rate drops instead. The more features extracted, the higher the recognition rate, but it is not the case that the more features, the better. When a few features can obtain the highest accuracy, the more features are selected, the more redundant they are, resulting in a decrease in recognition rate. Therefore, there will be a phenomenon where the more features extracted, the lower the recognition rate.
5. Conclusions
This paper studies the feature extraction method of MBN based on nonlinear dynamic features, especially the feature extraction methods based on entropy or LZC and compares the different feature extraction methods through measured MBN. The main conclusions are as follows: (1) for entropy-based MBN single feature extraction methods, the feature extraction method based on dispersion entropy has the highest recognition rate of 91.5%, which is 19.5%, 8.5%, and 2.5% higher than the recognition rates of PE, FE, and SE, respectively; (2) for LZC-based MBN single feature extraction methods, the feature extraction method based on DELZC has the highest recognition rate of 92.5%, which is 17.5%, 37.5%, and 11% higher than the recognition rates of LZC, PLZC, and DELZC, respectively; (3) whether for entropy-based multiple feature extraction method or LZC-based multiple feature extraction method, they both significantly improve the recognition rate of single feature extraction methods; and (4) it is not the case that the higher the number of features extracted, the higher the recognition rate, and as the number of features continues to increase, the recognition rate may remain the same or even decrease.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}