


KNN-Based Machine Learning Classifier Used on Deep Learned Spatial Motion Features for Human Action Recognition

Abstract
:1. Introduction
- The fusion of spatial and temporal cues, represented by intensity and optical flow vectors, respectively.
- The proposal of a single-stream shallow network—HARNet Architecture—for extracting deep learned action features.
- The proposal of a KNN-based machine learning framework for classifying up to 101 human actions.
- Experimentation and comparison with SOTA (state-of-the-art techniques) on a benchmark dataset.
2. Related Work
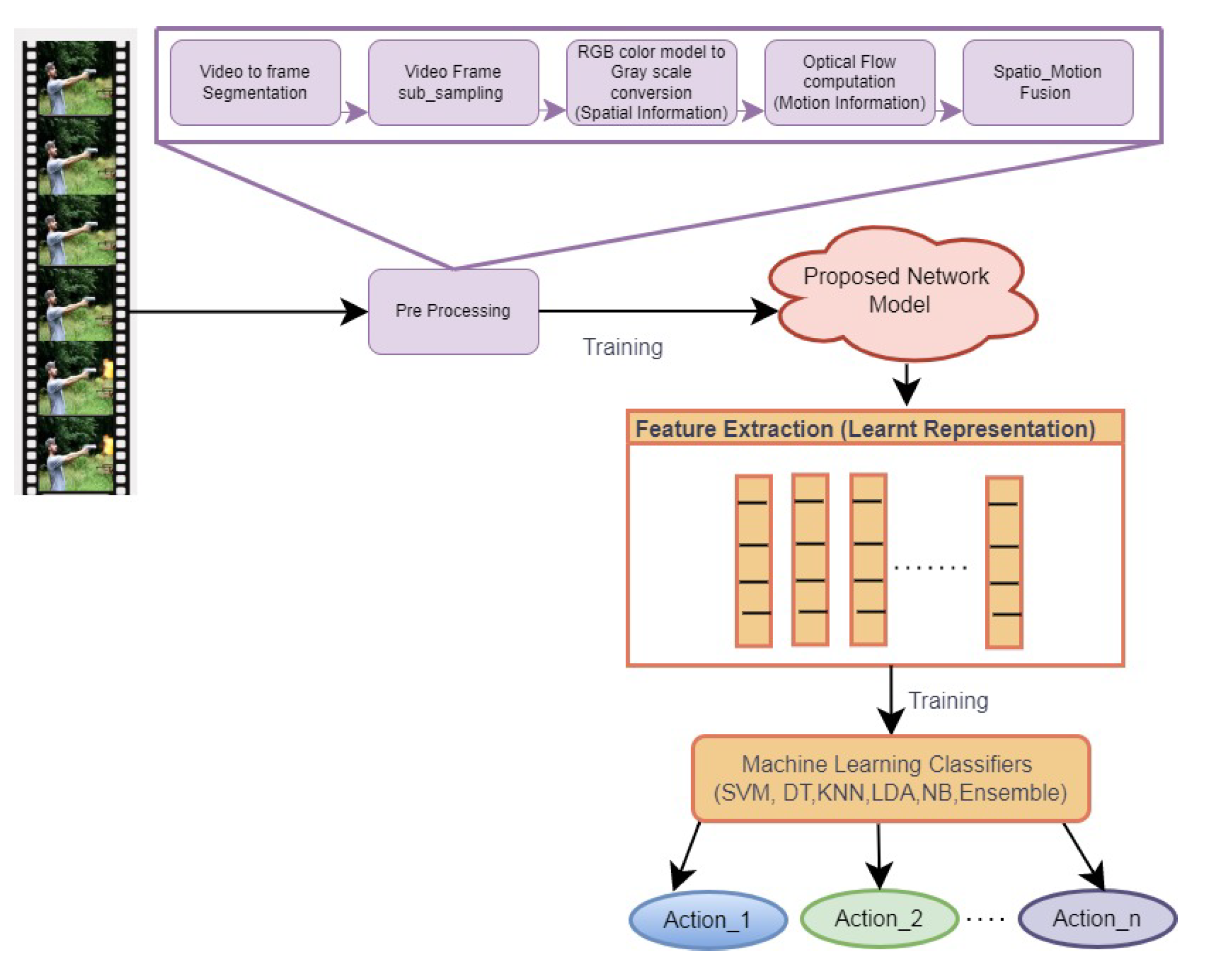
3. Proposed Spatial Motion Feature Learning Framework
3.1. Preprocessing
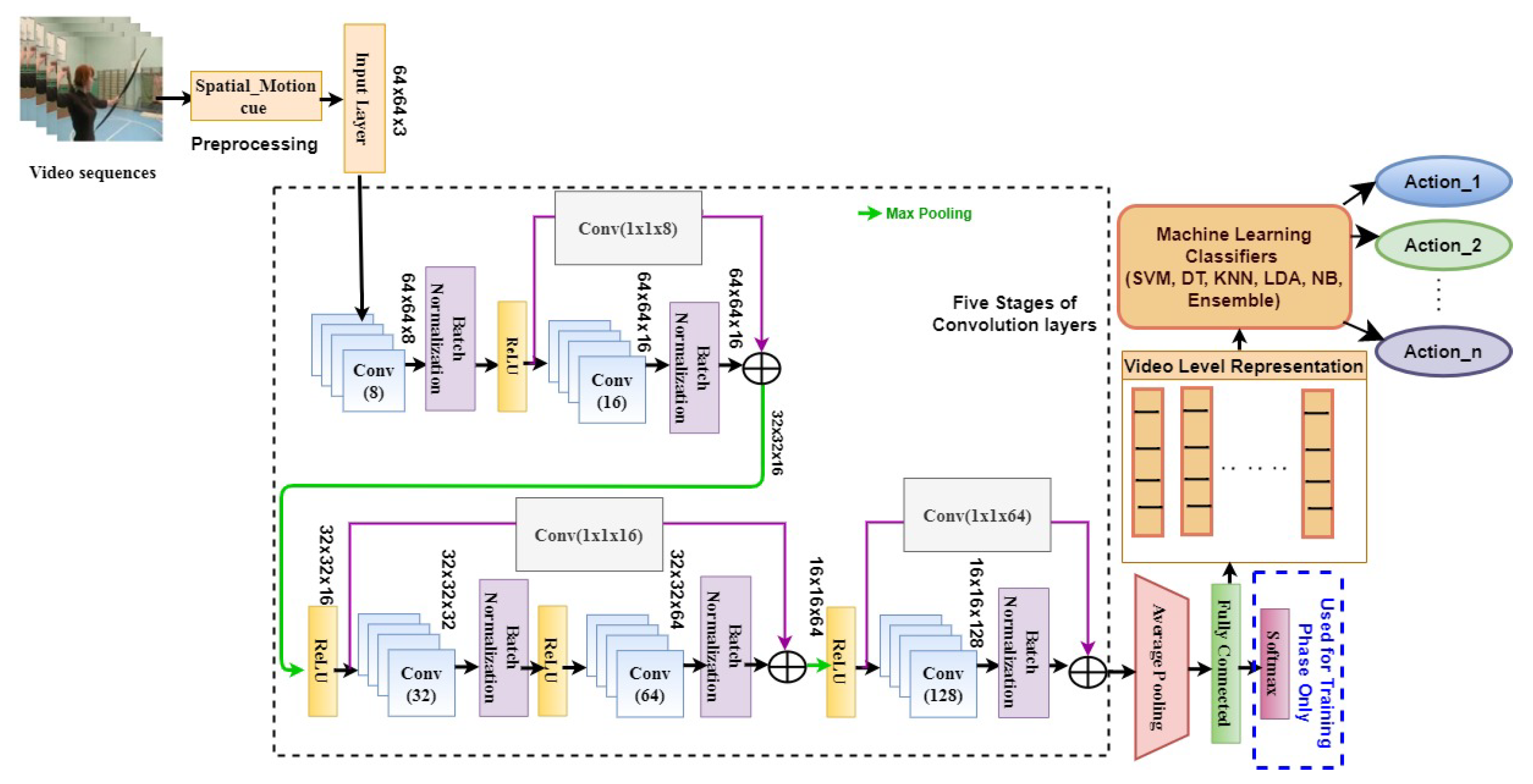
3.2. Design of Proposed Network Model
3.3. Information Bottleneck Principle
3.4. Classification
- k-Nearest Neighbor classifier: k-NN is practically applicable for recognizing patterns of human actions, as it is non-parametric, which means that it does not assume the distribution of data. Hence, it works well in our proposed approach. The k-NN classifier stores all cases of training data and tries to classify test data based on similarity measures. Euclidean distance is considered as a similarity measure for finding the neighbors in our experiment. The number of neighbors included for classifying the test sample is one.
- Support Vector Machine: Complex data transformation is performed by SVM based on the chosen kernel function. With the help of those transformations, the separation boundary between data is maximized.
- Decision Tree: The decision tree is a systematic approach used for multi-class classification problems. A set of queries in relation to the features of a dataset is posed by DT. It is visualized using a binary tree. Data on the root node are again split into two different records that have different attributes. The leaves represent the classes of the dataset.
- Naïve Bayes: Bayes theorem is the basis of the naïve Bayes classification method. The naïve Bayes method is used because of the assumption that there is independence between every pair of features in the data.
- Linear Discriminant Analysis: The linear discriminant analysis (LDA) classification method is used in our experiments. It assumes that data of different classes are based on different Gaussian distributions. LDA uses the estimated probability that a piece of test data belongs to a particular class for classifying it. The class with the highest probability is predicted as the output class of the given sample.
- Ensemble: The adaptive boosting multi-class classification method is used as an ensemble aggregation approach for our experimentation. The number of learning cycles used in our experiments is 100, with the same learning rate for shrinkage.
4. Experimental Details on Network Learning Setup
4.1. Datasets for HAR
4.2. Results and Discussion
4.2.1. Evaluation on UCF101
4.2.2. Evaluation on HMDB51
4.2.3. Evaluation on KTH Dataset
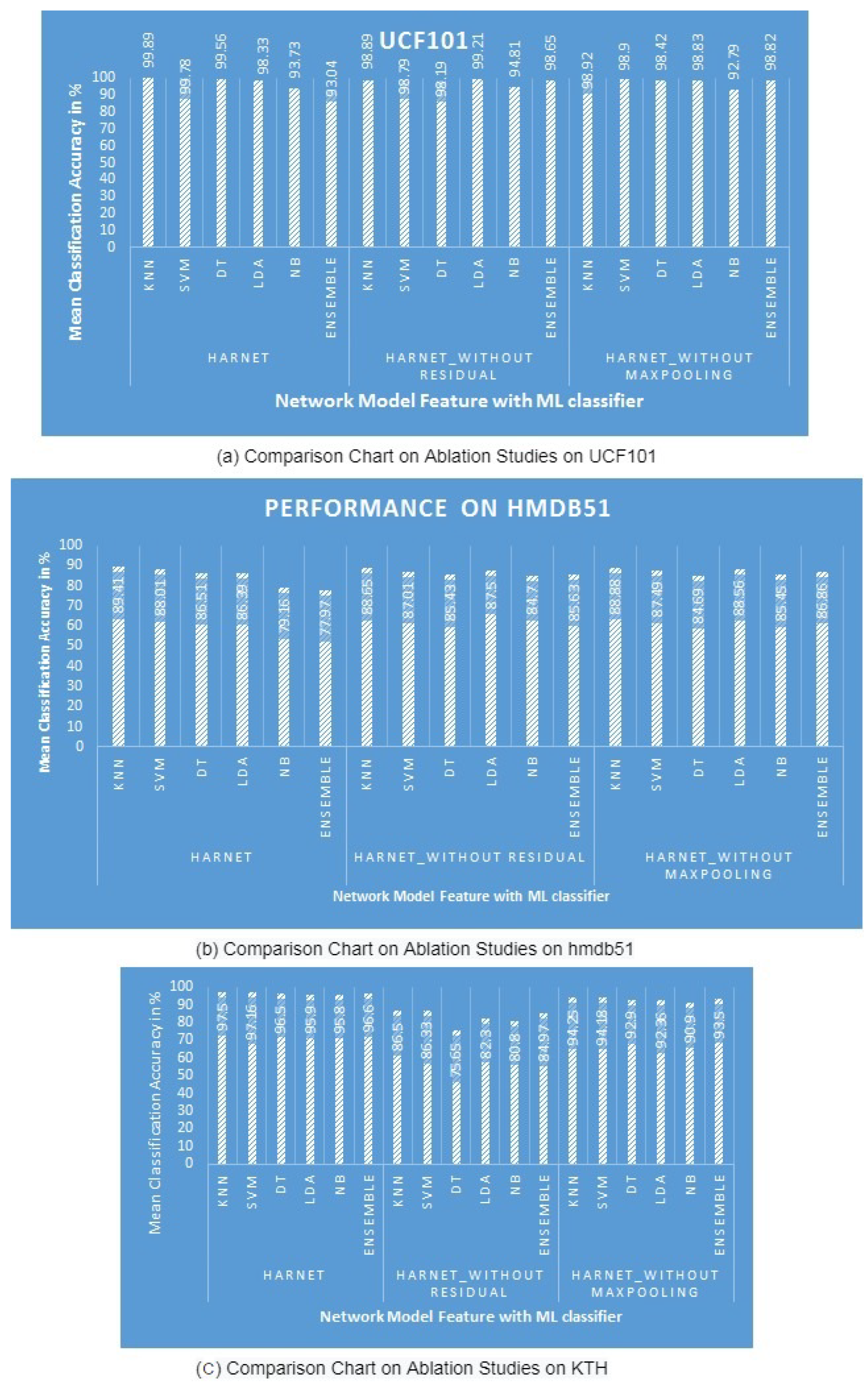
4.2.4. Results of the Ablation Study
4.3. Comparison with State-of-the-Art Methods
5. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Roshan, S.; Srivathsan, G.; Deepak, K. Violence Detection in Automated Video Surveillance: Recent Trends and Comparative Studies. In Intelligent Data-Centric Systems; Academic Press: Cambridge, MA, USA, 2020; pp. 157–171. [Google Scholar]
- Vosta, S.; Yow, K.C. A CNN-RNN Combined Structure for Real-World Violence Detection in Surveillance Cameras. Appl. Sci. 2022, 12, 1021. [Google Scholar] [CrossRef]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. A combined multiple action recognition and summarization for surveillance video sequences. Appl. Intell. 2021, 51, 690–712. [Google Scholar] [CrossRef]
- Berroukham, A.; Housni, K.; Lahraichi, M.; Boulfrifi, I. Deep learning-based methods for anomaly detection in video surveillance: A review. Bull. Electr. Eng. Inform. 2023, 12, 314–327. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Q.; Du, Z.; Wu, A. Human Action Recognition for Dynamic Scenes of Emergency Rescue Based on Spatial-Temporal Fusion Network. Electronics 2023, 12, 538. [Google Scholar] [CrossRef]
- Wen, R.; Tay, W.L.; Nguyen, B.P.; Chng, C.-B.; Chui, C.K. Hand gesture guided robot-assisted surgery based on a direct augmented reality interface. Comput. Methods Programs Biomed. 2014, 116, 68–80. [Google Scholar] [CrossRef]
- Zhu, H.; Xue, M.; Wang, Y.; Yuan, G.; Li, X. Fast Visual Tracking with Siamese Oriented Region Proposal Network. IEEE Signal Process. Lett. 2022, 29, 1437–1441. [Google Scholar] [CrossRef]
- Wen, R.; Nguyen, B.P.; Chng, C.-B.; Chui, C.K. In situ spatial AR surgical planning using projector-Kinect system. In Proceedings of the 4th Symposium on Information and Communication Technology, Da Nang, Vietnam, 5–6 December 2013. [Google Scholar]
- Lai, X.; Yang, B.; Ma, B.; Liu, M.; Yin, Z.; Yin, L.; Zheng, W. An Improved Stereo Matching Algorithm Based on Joint Similarity Measure and Adaptive Weights. Appl. Sci. 2023, 13, 514. [Google Scholar] [CrossRef]
- Yang, Q.; Lu, T.; Zhou, H. A Spatio-Temporal Motion Network for Action Recognition Based on Spatial Attention. Entropy 2022, 24, 368. [Google Scholar] [CrossRef]
- Tasnim, N.; Baek, J.H. Dynamic Edge Convolutional Neural Network for Skeleton-Based Human Action Recognition. Sensors 2023, 23, 778. [Google Scholar] [CrossRef]
- Joefrie, Y.Y.; Aono, M. Video Action Recognition Using Motion and Multi-View Excitation with Temporal Aggregation. Entropy 2022, 24, 1663. [Google Scholar] [CrossRef]
- Ahn, D.; Kim, S.; Hong, H.; Ko, B.C. STAR-Transformer: A Spatio-temporal Cross Attention Transformer for Human Action Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 3330–3339. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep Learning and the Information Bottleneck Principle. In Proceedings of the Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015. [Google Scholar]
- Cikel, K.; Arzamendia Lopez, M.; Gregor, D.; Gutiérrez, D.; Toral, S. Evaluation of a CNN + LSTM system for the classification of hand-washing steps. In Proceedings of the XIX Conference of the Spanish Association for Artificial Intelligence (CAEPIA), Malaga, Spain, 22–24 September 2021. [Google Scholar]
- Cao, Q.; Xu, F.; Li, H. User Authentication by Gait Data from Smartphone Sensors Using Hybrid Deep Learning Network. Mathematics 2022, 10, 2283. [Google Scholar] [CrossRef]
- Patalas-Maliszewska, J.; Halikowski, D. A Deep Learning-Based Model for the Automated Assessment of the Activity of a Single Worker. Sensors 2020, 20, 2571. [Google Scholar] [CrossRef]
- Mohan, C.S. Fine-grained action recognition using dynamic kernels. Pattern Recognit. 2022, 122, 108282. [Google Scholar]
- Wang, X.; Zheng, S.; Yang, R.; Zheng, A.; Chen, Z.; Tang, J.; Luo, B. Pedestrian attribute recognition: A survey. Pattern Recognit. 2022, 121, 108220. [Google Scholar] [CrossRef]
- Perez, M.; Liu, J.; Kot, A.C. Skeleton-based relational reasoning for group activity analysis. Pattern Recognit. 2022, 122, 108360. [Google Scholar] [CrossRef]
- Gedamu, K.; Ji, Y.; Yang, Y.; Gao, L.; Shen, H.T. Arbitrary-view human action recognition via novel-view action generation. Pattern Recognit. 2021, 118, 108043. [Google Scholar] [CrossRef]
- Yang, L.; Dong, K.; Ding, Y.; Brighton, J.; Zhan, Z.; Zhao, Y. Recognition of visual-related non-driving activities using a dual-camera monitoring system. Pattern Recognit. 2021, 116, 107955. [Google Scholar] [CrossRef]
- Zhu, L.; Wan, B.; Li, C.; Tian, G.; Hou, Y.; Yuan, K. Dyadic relational graph convolutional networks for skeleton-based human interaction recognition. Pattern Recognit. 2021, 115, 107920. [Google Scholar] [CrossRef]
- Ulhaq, A.; Akhtar, A.; Pogrebna, N.; Mian, G. Vision Transformers for Action Recognition: A Survey. arXiv 2022, arXiv:2209.05700. [Google Scholar]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action Transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognit. 2022, 124, 108487. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunk, B.G. Determining Optical Flow. Artif. Intell. 1981, 17, 185–204. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Stiefelhagen, R.; Serre Thomas, T. Hmdb51: A large video database for human motion recognition. In Transactions of the High Performance Computing Center, Stuttgart (HLRS); Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar] [CrossRef]
- Kthactiondataset. Available online: https://www.csc.kth.se/cvap/actions/ (accessed on 26 March 2023).
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; Le Cun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Nasir, I.M.; Raza, M.; Shah, J.H.; Khan, M.A.; Rehman, A. Human Action Recognition using Machine Learning in Uncontrolled Environment. In Proceedings of the 1st International Conference on Artificial Intelligence and Data Analytics, Riyadh, Saudi Arabia, 6–7 April 2021. [Google Scholar]
- Zhang, C.-Y.; Xiao, Y.-Y.; Lin, J.-C.; Chen, C.P.; Liu, W.; Tong, Y.H. 3-D Deconvolutional Networks for the Unsupervised Representation Learning of Human Motions. IEEE Trans. Cybern. 2020, 52, 398–410. [Google Scholar] [CrossRef]
- Wang, A.X.; Chukova, S.S.; Nguyen, B.P. Implementation and Analysis of Centroid Displacement-Based k-Nearest Neighbors. In Advanced Data Mining and Applications, Proceedings of the 18th International Conference—ADMA 2022, Brisbane, QLD, Australia, 28–30 November 2022; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar] [CrossRef]
- Wang, A.X.; Chukova, S.S.; Nguyen, B.P. Ensemble k-nearest neighbors based on centroid displacement. Inf. Sci. 2023, 629, 313–323. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 8–16. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, CA, USA, 8–13 December 2014; pp. 8–13. [Google Scholar]
- Du, T.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 11–18. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T.; Venice, I. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the 16th International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 22–29.
- Zhou, Y.; Sun, X.; Zha, Z.-J.; Zeng, W. MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 18–23. [Google Scholar]
- Tu, Z.; Li, H.; Zhang, D.; Dauwels, J.; Li, B.Y. Action-Stage Emphasized Spatiotemporal VLAD for Video Action Recognition. J. IEEE Trans. Image Process. 2019, 28, 2799–2812. [Google Scholar] [CrossRef]
- Li, X.; Xie, M.; Zhang, Y.; Ding, G.; Tong, W. Dual attention convolutional network for action recognition. IET Image Process. 2020, 14, 1059–1065. [Google Scholar] [CrossRef]
- Perrett, T.; Masullo, A.; Burghardt, T.; Mirmehdi, M.; Damen, D. Temporal-relational crosstransformers for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 475–484. [Google Scholar]
- Chen, B.; Meng, F.; Tang, H.; Tong, G. Two-Level Attention Module Based on Spurious-3D Residual Networks for Human Action Recognition. Sensors 2023, 23, 1707. [Google Scholar] [CrossRef]
- Omi, K.; Kimata, J.; Tamaki, T. Model-Agnostic Multi-Domain Learning with Domain-Specific Adapters for Action Recognition. IEICE Trans. Inf. Syst. 2022, 105, 2119–2126. [Google Scholar] [CrossRef]
- Bregonzio, M.; Xiang, T.; Gong, S. Fusing appearance and distribution information of interest points for action recognition. Pattern Recognit. 2012, 45, 1220–1234. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Cho, J.; Lee, M.; Chang, H.J. Robust action recognition using local motion and group sparsity. Pattern Recognit. 2014, 47, 1813–1825. [Google Scholar] [CrossRef]
- Yao, L.; Liu, Y.; Huang, S.J. Spatio-temporal information for human action recognition. Image Video Proc. 2016, 39. [Google Scholar] [CrossRef]
- Zhang, C.; Tian, Y.; Guo, X.; Daal, L. Deep activationbased Computer, attribute learning for action recognition in depth videos. Vis Image Underst. 2018, 167, 37–49. [Google Scholar] [CrossRef]
- Mishra, O.; Kavimandan, P.S.; Kapoor, R. Modal Frequencies Based Human Action Recognition Using Silhouettes and Simplicial Elements. IJE Trans. A Basics 2022, 35, 45–52. [Google Scholar]
- Wang, L.; Tong, Z.; Ji, B.; Wu, G. TDN: Temporal Difference Networks for Efficient Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 20–25 June 2021; pp. 19–25. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Model | Hyper Parameter Tuning | Accuracy (%) before Tuning | Accuracy (%) after Tuning | |||
|---|---|---|---|---|---|---|
| k-NN | Hyperparameter | K | Distance metric | 95.58 | 97.49 | |
| Tuning range | [1–100] | Euclidean, Cityblock, Minkowski, Chebychev, Hamming, Spearman, Cosine, Mahalanobis | ||||
| Tuned value | 1 | Euclidean | ||||
| SVM | Hyperparameter | Box constraint | Coding | Kernel scale | 95.93 | 97.16 |
| Tuning range | [0–1000] | 1-vs-1, 1-vs-all | [0–1000] | |||
| Tuned value | 1 | 1-vs-1 | 1 | |||
| DT | Hyperparameter | Minimum leaf size | 94.26 | 96.50 | ||
| Tuning range | [1–300] | |||||
| Tuned value | 1 | |||||
| LDA | Hyperparameter | Delta | Gamma | 93.78 | 95.93 | |
| Tuning range | [1 × 10−6, 1 × 10−3] | [0–1] | ||||
| Tuned value | 0 | 0.002 | ||||
| NB | Hyperparameter | Distribution | Width | 92.96 | 95.76 | |
| Tuning range | Normal, kernel | [0–10] | ||||
| Tuned value | Normal | - | ||||
| Ensemble | Hyperparameter | Number of learning cycles | Learning rate | 94.05 | 96.64 | |
| Tuning range | [1–400] | [0–1] | ||||
| Tuned value | 100 | 1 | ||||
| Model | Hyperparameter Tuning | |||
|---|---|---|---|---|
| HARNet | Hyperparameter | Momentum | Initial learning rate | Mini-batch size |
| Tuning range | [0–1] | [0.001–1] | [16–64] | |
| Tuned | 0.5 | 0.01 | 32 | |
| Dataset | Features | ||||
|---|---|---|---|---|---|
| Number of Video Clips | Frame Rate in Frames per Second | Number of Action Categories | Challenges | Variations in Data Capturing | |
| HMBD51 | 6849 | 30 | 51 | Camera movement | Camera view point, different video quality |
| UCF101 | 13320 | 25 | 101 | Cluttered background, camera movement | Pose and appearance of object in varying scale, different illumination conditions and view points |
| KTH | 2391 | 25 | 6 | Presence of shadow, low-quality video | Scale variation, subjects with different clothes, indoors, outdoors |
| ML Classifier | Accuracy | Precision | Recall | Specificity | F1-Score |
|---|---|---|---|---|---|
| LDA | 98.33 | 0.9826 | 0.9834 | 0.9998 | 0.9826 |
| NB | 93.73 | 0.9392 | 0.9390 | 0.9994 | 0.9361 |
| Ensemble | 93.04 | 0.9114 | 0.8934 | 0.9993 | 0.8906 |
| DT | 99.56 | 0.9953 | 0.9951 | 1 | 0.9951 |
| SVM | 99.98 | 0.9998 | 0.9998 | 1 | 0.9998 |
| KNN | 99.99 | 0.9999 | 0.9990 | 1 | 0.9999 |
| ML Classifier | Accuracy in % | Precision | Recall | Specificity | F1-Score |
|---|---|---|---|---|---|
| LDA | 86.39 | 0.8680 | 0.8573 | 0.8993 | 0.8620 |
| NB | 79.16 | 0.7911 | 0.7846 | 0.8978 | 0.7857 |
| Ensemble | 77.97 | 0.8260 | 0.7416 | 0.8975 | 0.7722 |
| SVM | 88.01 | 0.8819 | 0.8767 | 0.8996 | 0.8792 |
| DT | 86.51 | 0.8638 | 0.8596 | 0.8993 | 0.8615 |
| KNN | 89.41 | 0.8943 | 0.8933 | 0.8999 | 0.8938 |
| ML Classifier | Accuracy | Precision | Recall | Specificity | F1-Score |
|---|---|---|---|---|---|
| LDA | 95.93 | 0.9561 | 0.9372 | 0.9918 | 0.9450 |
| NB | 95.76 | 0.9468 | 0.9382 | 0.9916 | 0.9420 |
| Ensemble | 96.64 | 0.9564 | 0.9524 | 0.9934 | 0.9543 |
| DT | 96.50 | 0.9546 | 0.9505 | 0.9931 | 0.9525 |
| SVM | 97.16 | 0.9628 | 0.9586 | 0.9944 | 0.9606 |
| KNN | 97.49 | 0.9667 | 0.9623 | 0.9951 | 0.9644 |
| Model | ML Classifier | HMDB51 | UCF101 | KTH |
|---|---|---|---|---|
| HARNet | KNN | 89.41 | 99.89 | 97.50 |
| SVM | 88.01 | 99.78 | 97.16 | |
| DT | 86.51 | 99.56 | 96.50 | |
| LDA | 86.39 | 98.33 | 95.9 | |
| NB | 79.16 | 93.73 | 95.8 | |
| Ensemble | 77.97 | 93.04 | 96.6 | |
| HARNet_without Residual | KNN | 88.65 (0.86% ↓) | 98.89 (1% ↓) | 86.50 (11.28% ↓) |
| SVM | 87.01 | 98.79 | 86.33 | |
| DT | 85.43 | 98.19 | 75.65 | |
| LDA | 87.50 | 99.21 | 82.3% | |
| NB | 84.70 | 94.81 | 80.8% | |
| Ensemble | 85.63 | 98.65 | 84.97% | |
| HARNet_without Maxpooling | KNN | 88.88 (0.59% ↓) | 98.92 (0.97% ↓) | 94.25 (3.33% ↓) |
| SVM | 87.49 | 98.90 | 94.18 | |
| DT | 84.69 | 98.42 | 92.90 | |
| LDA | 88.56 | 98.83 | 92.36 | |
| NB | 85.45 | 92.79 | 90.9 | |
| Ensemble | 86.86 | 98.82 | 93.5 |
| Author | Method | Year | Accuracy (%) |
|---|---|---|---|
| Simonyan, K. and Zisserman, A. [37] | Two-stream (fusion by SVM) | 2014 | 88.00 |
| Du et al. [38] | C3D (Fine tuned from I380k) | 2015 | 85.20 |
| Wang, et al. [36] | TSN | 2016 | 94.2 |
| Qiu et al. [39] | Pseudo 3D | 2017 | 93.70 |
| Zhou et al. [40] | Mixed 3D/2D conv Tube (MiCT) | 2018 | 88.90 |
| Tran et al. [31] | R(2 + 1)D-RGB(Kinetics) | 2018 | 96.80 |
| Tran et al. [31] | R(2 + 1)D-TwoStream(Kinetics) | 2018 | 97.30 |
| Tu et al. [41] | ActionS-ST-VLAD | 2019 | 95.60 |
| Li et al. [42] | DANet | 2020 | 86.70 |
| Perrett et al. [43] | TRX | 2021 | 96.10 |
| Yongmei Zhang [5] | STFusionNet | 2022 | 93.20 |
| Chen [44] | 2L-Attention-s3DResNet | 2023 | 95.68 |
| Proposed | HARNet + KNN | - | 99.98 |
| Author | Method | Year | Accuracy (%) |
|---|---|---|---|
| Simonyan, K. and Zisserman, A. [37] | Two stream(fusion by SVM) | 2014 | 59.40 |
| Wang, et al. [36] | TSN | 2016 | 68.50 |
| Zhou et al. [40] | Mixed 3D/2D conv Tube (MiCT) | 2018 | 63.80 |
| Tran et al. [31] | R(2 + 1)D-RGB (Kinetics) | 2018 | 74.50 |
| Tran et al. [31] | R(2 + 1)D-TwoStream (Kinetics) | 2018 | 78.70 |
| Tu et al. [41] | ActionS-ST-VLAD | 2019 | 71.40 |
| Li et al. [42] | DANet-50 | 2020 | 54.30 |
| Rehman, Inzamam [32] | 3DCF+NFC | 2021 | 82.55 |
| Perrett et al. [43] | TRX | 2021 | 75.60 |
| Omi et al. [45] | Multi-Domain | 2022 | 75.62 |
| Chen [44] | 2L-Attention-s3DResNet | 2023 | 72.60 |
| Proposed | HARNet + KNN | - | 91.58 |
| Author | Method | Year | Accuracy (%) |
|---|---|---|---|
| Bregonzio et al. [46] | Appearance + distribution − MKL Fusion | 2012 | 94.33 |
| Shuiwang et al. [47] | 3DCNN | 2013 | 90.20 |
| Cho [48] | Local motion + full motion | 2014 | 89.70 |
| Yao [49] | STB + Pool | 2016 | 95.83 |
| Zhang et al. [50] | SIFT + BoW + SVM | 2018 | 94.69 |
| Zhang et al. [33] | 3D Deconvolution NN2 | 2020 | 97.40 |
| Mishra [51] | FEA + RBF-SVM | 2022 | 96.20 |
| Proposed | HARNet + KNN | - | 97.58 |
| Author | Method | Pretraining Dataset | Year | Parameters (M) |
|---|---|---|---|---|
| Simonyan, K. and Zisserman, A. [37] | Two stream | ImageNet | 2014 | 25 |
| Du et al. [38] | C3D | Kinetics400 | 2015 | 34.6 |
| Wang, et al. [36] | TSN | ImageNet | 2016 | 24.3 |
| Qiu et al. [39] | Pseudo 3D | ImageNet /Kinetics400 | 2017 | 25.4 |
| Zhou et al. [40] | Mixed 3D/2D conv Tube (MiCT) | Kinetics400 | 2018 | 50.2 |
| Li et al. [42] | DANet | - | 2020 | 36.26 |
| Wang [52] | TDN | Kinetics400 + ImageNet | 2021 | 52.3 |
| Omi et al. [45] | Multi-Domain | Kinetics400 | 2022 | 32.02 |
| Chen [44] | 2L-Attention-s3DResNet | Kinetics400 | 2023 | 3.08 |
| Proposed | HARNET | HMDB51 | - | 0.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paramasivam, K.; Sindha, M.M.R.; Balakrishnan, S.B. KNN-Based Machine Learning Classifier Used on Deep Learned Spatial Motion Features for Human Action Recognition. Entropy 2023, 25, 844. https://doi.org/10.3390/e25060844
Paramasivam K, Sindha MMR, Balakrishnan SB. KNN-Based Machine Learning Classifier Used on Deep Learned Spatial Motion Features for Human Action Recognition. Entropy. 2023; 25(6):844. https://doi.org/10.3390/e25060844
Chicago/Turabian StyleParamasivam, Kalaivani, Mohamed Mansoor Roomi Sindha, and Sathya Bama Balakrishnan. 2023. "KNN-Based Machine Learning Classifier Used on Deep Learned Spatial Motion Features for Human Action Recognition" Entropy 25, no. 6: 844. https://doi.org/10.3390/e25060844